Dr. Gengbin Zheng and Ehsan Totoni. Parallel Programming Laboratory University of Illinois at Urbana-Champaign
|
|
|
- Frederick Sutton
- 5 years ago
- Views:
Transcription


1 Dr. Gengbin Zheng and Ehsan Totoni Parallel Programming Laboratory University of Illinois at Urbana-Champaign April 18, 2011


2 A function level simulator for parallel applications on peta scale machine An emulator runs applications at full scale A simulator predicts performance by simulating message passing 2
3 Improved simulation framework from these aspects Even larger/faster emulation and simulation More accurate prediction of sequential performance Apply BigSim to predict Blue Waters machine 3
4 Using existing (possibly different) clusters for emulation Applied memory reduction techniques For example, we achieved for NAMD: Emulate 10M atom benchmark on 256K cores using only 4K cores of Ranger (2GB/core) Emulate 100M atom benchmark on 1.2M cores using only 48K cores of Jaguar (1.3GB/core) 4


5 Predicting parallel applications can be challenging Accurate prediction of sequential execution blocks Network performance This paper explores techniques to use statistical models for sequential execution blocks Gengbin Zheng, Gagan Gupta, Eric Bohm, Isaac Dooley, and Laxmikant V. Kale, "Simulating Large Scale Parallel Applications using Statistical Models for Sequential Execution Blocks", in the Proceedings of the 16th International Conference on Parallel and Distributed Systems (ICPADS 2010) 5
6 6
7 CPU scaling Take execution on one machine to predict another not accurate Hardware simulator Cycle accurate timing However it is slow Performance counters Very hard, and platform specific An efficient and accurate prediction method? 7
8 Identify parameters that characterize the execution time of an SEB: x 1,x 2,, x n With machine learning, build statistical model of the execution time: T=f(x 1,x 2,,x n ) Run SEBs in realistic scenario and collect data points X 11,x 21,,x n1 => T1 X 12,x 22,,x n2 => T2 8
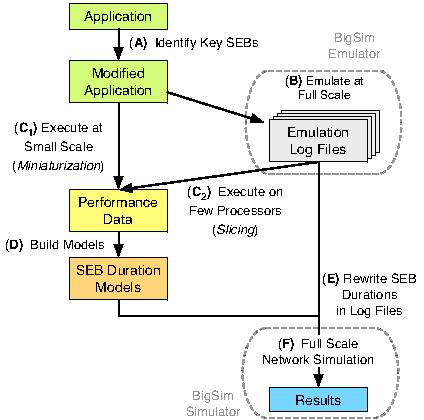
9 9
10 Slicing (C 2 ) Record and replay any processor Instrument exact parameters Require binary compatible architecture Miniaturization (C 1 ) Scaled down execution (smaller dataset, smaller number of processors) Not all application can scale down 10
11 Machine learning techniques Linear Regression Least median squared linear regression SVMreg Use machine learning software like weka As an example: T(N) = 0.036N N

12 Use Abe to predict Ranger NAS BT Benchmark BT.D.1024 emulate 64 core Abe, recording 8 target cores replay on Ranger to predict 12
13 NAMD STMV 1M atom benchmark 4096 core prediction Using 512 core of BG/P 13

14 Native Prediction 14
15 Will be here soon More than 300K POWER7 Cores PERCS Network Unique network not similar to any other! No theory or legacy for it Applications and runtimes tuned for other networks NSF Acceptance: Sustained petaflops for real applications Tuning applications typically takes months to years after machines become online

16 Two level fully connected Supernodes with 32 nodes 24 GB/s LLocal (LL) link, 5 GB/s LRemote (LR) link, 10 GB/s D link, 192 GB/s to IBM HUB Chip Node Node Node Node... Node Supernode Supernode Supernode Node... Supernode
17 Detailed packet level network model developed for Blue Waters Validated against MERCURY and IH Drawer Ping Pong within 1.1% of MERCURY Alltoall within 10% of drawer Optimizations for that scale Different outputs (link statistics, projections ) Some example studies: (E. Totoni et al., submitted to SC11) Topology aware mapping System noise Collective optimization
18 Apply different mappings in simulation Evaluate using output tools (Link Utilization )
19 Example: Mapping of 3D stencil Default mapping: rank ordered mapping of MPI tasks to cores of nodes Drawer mapping: 3D cuboids on nodes and drawers Supernode mapping: 3D cuboids on supernodes also; 80% communication decrease, 20% overall time
20 BigSim s noise injection support Captured noise of a node with the same architecture Replicate on all the target machines nodes with random offsets (not synchronized) Artificial periodic noise patterns for each core of a node With periodicity, amplitude and offset (phase) Replicate on all nodes with random offsets Increases length of computations appropriately
21 Applications: NAMD: 10 Million atom system on 256K cores MILC: su3_rmd on 4K cores K Neighbor with Allreduce 1 ms sequential computation, 2.4 ms total iteration time K Neighbor without Allreduce Inspecting with different noise frequencies and amplitudes
22 NAMD is tolerant, but jumps around certain frequencies MILC is sensitive even in small jobs (4K cores), almost as much affected as large jobs
23 Simple models are not enough In high frequencies there is chance that small MPI calls for collectives get affected Delaying execution significantly Combining noise patterns:
24 Optimized Alltoall for large messages in SN BigSim s link utilization output gives the idea: Outgoing links of a node are not used effectively at all times during Alltoall Shifted usage of different links
25 New algorithm: each core send to different node Use all 31 outgoing links Link utilization now looks better
26 Up to 5 times faster than existing Pairwise Exchange scheme Much closer to theoretical peak bandwidth of links



27
c 2011 by Ehsan Totoni. All rights reserved.
 c 2011 by Ehsan Totoni. All rights reserved. SIMULATION-BASED PERFORMANCE ANALYSIS AND TUNING FOR FUTURE SUPERCOMPUTERS BY EHSAN TOTONI THESIS Submitted in partial fulfillment of the requirements for the
c 2011 by Ehsan Totoni. All rights reserved. SIMULATION-BASED PERFORMANCE ANALYSIS AND TUNING FOR FUTURE SUPERCOMPUTERS BY EHSAN TOTONI THESIS Submitted in partial fulfillment of the requirements for the
Toward Runtime Power Management of Exascale Networks by On/Off Control of Links
 Toward Runtime Power Management of Exascale Networks by On/Off Control of Links, Nikhil Jain, Laxmikant Kale University of Illinois at Urbana-Champaign HPPAC May 20, 2013 1 Power challenge Power is a major
Toward Runtime Power Management of Exascale Networks by On/Off Control of Links, Nikhil Jain, Laxmikant Kale University of Illinois at Urbana-Champaign HPPAC May 20, 2013 1 Power challenge Power is a major
Using BigSim to Estimate Application Performance
 October 19, 2010 Using BigSim to Estimate Application Performance Ryan Mokos Parallel Programming Laboratory University of Illinois at Urbana-Champaign Outline Overview BigSim Emulator BigSim Simulator
October 19, 2010 Using BigSim to Estimate Application Performance Ryan Mokos Parallel Programming Laboratory University of Illinois at Urbana-Champaign Outline Overview BigSim Emulator BigSim Simulator
A CASE STUDY OF COMMUNICATION OPTIMIZATIONS ON 3D MESH INTERCONNECTS
 A CASE STUDY OF COMMUNICATION OPTIMIZATIONS ON 3D MESH INTERCONNECTS Abhinav Bhatele, Eric Bohm, Laxmikant V. Kale Parallel Programming Laboratory Euro-Par 2009 University of Illinois at Urbana-Champaign
A CASE STUDY OF COMMUNICATION OPTIMIZATIONS ON 3D MESH INTERCONNECTS Abhinav Bhatele, Eric Bohm, Laxmikant V. Kale Parallel Programming Laboratory Euro-Par 2009 University of Illinois at Urbana-Champaign
Charm++ for Productivity and Performance
 Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
PREDICTING COMMUNICATION PERFORMANCE
 PREDICTING COMMUNICATION PERFORMANCE Nikhil Jain CASC Seminar, LLNL This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
PREDICTING COMMUNICATION PERFORMANCE Nikhil Jain CASC Seminar, LLNL This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers
 IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers Abhinav S Bhatele and Laxmikant V Kale ACM Research Competition, SC 08 Outline Why should we consider topology
IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers Abhinav S Bhatele and Laxmikant V Kale ACM Research Competition, SC 08 Outline Why should we consider topology
Scalable Fault Tolerance Schemes using Adaptive Runtime Support
 Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications
 PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications Yanhua Sun, Laxmikant V. Kalé University of Illinois at Urbana-Champaign sun51@illinois.edu November 26,
PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications Yanhua Sun, Laxmikant V. Kalé University of Illinois at Urbana-Champaign sun51@illinois.edu November 26,
Strong Scaling for Molecular Dynamics Applications
 Strong Scaling for Molecular Dynamics Applications Scaling and Molecular Dynamics Strong Scaling How does solution time vary with the number of processors for a fixed problem size Classical Molecular Dynamics
Strong Scaling for Molecular Dynamics Applications Scaling and Molecular Dynamics Strong Scaling How does solution time vary with the number of processors for a fixed problem size Classical Molecular Dynamics
TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks
 TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks Bilge Acun, PhD Candidate Department of Computer Science University of Illinois at Urbana- Champaign *Contributors: Nikhil Jain,
TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks Bilge Acun, PhD Candidate Department of Computer Science University of Illinois at Urbana- Champaign *Contributors: Nikhil Jain,
A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé
 A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé Parallel Programming Laboratory Department of Computer Science University
A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé Parallel Programming Laboratory Department of Computer Science University
NAMD GPU Performance Benchmark. March 2011
 NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
Automated Mapping of Regular Communication Graphs on Mesh Interconnects
 Automated Mapping of Regular Communication Graphs on Mesh Interconnects Abhinav Bhatele, Gagan Gupta, Laxmikant V. Kale and I-Hsin Chung Motivation Running a parallel application on a linear array of processors:
Automated Mapping of Regular Communication Graphs on Mesh Interconnects Abhinav Bhatele, Gagan Gupta, Laxmikant V. Kale and I-Hsin Chung Motivation Running a parallel application on a linear array of processors:
NAMD Performance Benchmark and Profiling. February 2012
 NAMD Performance Benchmark and Profiling February 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
NAMD Performance Benchmark and Profiling February 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
Preliminary Evaluation of a Parallel Trace Replay Tool for HPC Network Simulations
 Preliminary Evaluation of a Parallel Trace Replay Tool for HPC Network Simulations Bilge Acun 1, Nikhil Jain 1, Abhinav Bhatele 2, Misbah Mubarak 3, Christopher D. Carothers 4, and Laxmikant V. Kale 1
Preliminary Evaluation of a Parallel Trace Replay Tool for HPC Network Simulations Bilge Acun 1, Nikhil Jain 1, Abhinav Bhatele 2, Misbah Mubarak 3, Christopher D. Carothers 4, and Laxmikant V. Kale 1
Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center
 Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center Motivation: Contention Experiments Bhatele, A., Kale, L. V. 2008 An Evaluation
Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center Motivation: Contention Experiments Bhatele, A., Kale, L. V. 2008 An Evaluation
Noise Injection Techniques to Expose Subtle and Unintended Message Races
 Noise Injection Techniques to Expose Subtle and Unintended Message Races PPoPP2017 February 6th, 2017 Kento Sato, Dong H. Ahn, Ignacio Laguna, Gregory L. Lee, Martin Schulz and Christopher M. Chambreau
Noise Injection Techniques to Expose Subtle and Unintended Message Races PPoPP2017 February 6th, 2017 Kento Sato, Dong H. Ahn, Ignacio Laguna, Gregory L. Lee, Martin Schulz and Christopher M. Chambreau
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance
 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance Jonathan Lifflander*, Esteban Meneses, Harshitha Menon*, Phil Miller*, Sriram Krishnamoorthy, Laxmikant V. Kale* jliffl2@illinois.edu,
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance Jonathan Lifflander*, Esteban Meneses, Harshitha Menon*, Phil Miller*, Sriram Krishnamoorthy, Laxmikant V. Kale* jliffl2@illinois.edu,
Scalable In-memory Checkpoint with Automatic Restart on Failures
 Scalable In-memory Checkpoint with Automatic Restart on Failures Xiang Ni, Esteban Meneses, Laxmikant V. Kalé Parallel Programming Laboratory University of Illinois at Urbana-Champaign November, 2012 8th
Scalable In-memory Checkpoint with Automatic Restart on Failures Xiang Ni, Esteban Meneses, Laxmikant V. Kalé Parallel Programming Laboratory University of Illinois at Urbana-Champaign November, 2012 8th
Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs
 Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs Isaac Dooley, Laxmikant V. Kale Department of Computer Science University of Illinois idooley2@illinois.edu kale@illinois.edu
Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs Isaac Dooley, Laxmikant V. Kale Department of Computer Science University of Illinois idooley2@illinois.edu kale@illinois.edu
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications
 for Bio-Science Applications") Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
NAMD Performance Benchmark and Profiling. November 2010
 NAMD Performance Benchmark and Profiling November 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox Compute resource - HPC Advisory
NAMD Performance Benchmark and Profiling November 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox Compute resource - HPC Advisory
Scalable Topology Aware Object Mapping for Large Supercomputers
 Scalable Topology Aware Object Mapping for Large Supercomputers Abhinav Bhatele (bhatele@illinois.edu) Department of Computer Science, University of Illinois at Urbana-Champaign Advisor: Laxmikant V. Kale
Scalable Topology Aware Object Mapping for Large Supercomputers Abhinav Bhatele (bhatele@illinois.edu) Department of Computer Science, University of Illinois at Urbana-Champaign Advisor: Laxmikant V. Kale
Maximizing Throughput on a Dragonfly Network
 Maximizing Throughput on a Dragonfly Network Nikhil Jain, Abhinav Bhatele, Xiang Ni, Nicholas J. Wright, Laxmikant V. Kale Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana,
Maximizing Throughput on a Dragonfly Network Nikhil Jain, Abhinav Bhatele, Xiang Ni, Nicholas J. Wright, Laxmikant V. Kale Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana,
xsim The Extreme-Scale Simulator
 www.bsc.es xsim The Extreme-Scale Simulator Janko Strassburg Severo Ochoa Seminar @ BSC, 28 Feb 2014 Motivation Future exascale systems are predicted to have hundreds of thousands of nodes, thousands of
www.bsc.es xsim The Extreme-Scale Simulator Janko Strassburg Severo Ochoa Seminar @ BSC, 28 Feb 2014 Motivation Future exascale systems are predicted to have hundreds of thousands of nodes, thousands of
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, Ranger and Jaguar
 Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, and Jaguar Abhinav Bhatelé, Lukasz Wesolowski, Eric Bohm, Edgar Solomonik and Laxmikant V. Kalé Department
Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, and Jaguar Abhinav Bhatelé, Lukasz Wesolowski, Eric Bohm, Edgar Solomonik and Laxmikant V. Kalé Department
Adaptive Runtime Support
 Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Tutorial: Application MPI Task Placement
 Tutorial: Application MPI Task Placement Juan Galvez Nikhil Jain Palash Sharma PPL, University of Illinois at Urbana-Champaign Tutorial Outline Why Task Mapping on Blue Waters? When to do mapping? How
Tutorial: Application MPI Task Placement Juan Galvez Nikhil Jain Palash Sharma PPL, University of Illinois at Urbana-Champaign Tutorial Outline Why Task Mapping on Blue Waters? When to do mapping? How
Analyses and Modeling of Applications Used to Demonstrate Sustained Petascale Performance on Blue Waters
 Analyses and Modeling of Applications Used to Demonstrate Sustained Petascale Performance on Blue Waters Torsten Hoefler With lots of help from the AUS Team and Bill Kramer at NCSA! All used images belong
Analyses and Modeling of Applications Used to Demonstrate Sustained Petascale Performance on Blue Waters Torsten Hoefler With lots of help from the AUS Team and Bill Kramer at NCSA! All used images belong
Interactive Analysis of Large Distributed Systems with Scalable Topology-based Visualization
 Interactive Analysis of Large Distributed Systems with Scalable Topology-based Visualization Lucas M. Schnorr, Arnaud Legrand, and Jean-Marc Vincent e-mail : Firstname.Lastname@imag.fr Laboratoire d Informatique
Interactive Analysis of Large Distributed Systems with Scalable Topology-based Visualization Lucas M. Schnorr, Arnaud Legrand, and Jean-Marc Vincent e-mail : Firstname.Lastname@imag.fr Laboratoire d Informatique
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Performance Modeling for Systematic Performance Tuning
 Performance Modeling for Systematic Performance Tuning Torsten Hoefler with inputs from William Gropp, Marc Snir, Bill Kramer Invited Talk RWTH Aachen University March 30 th, Aachen, Germany All used images
Performance Modeling for Systematic Performance Tuning Torsten Hoefler with inputs from William Gropp, Marc Snir, Bill Kramer Invited Talk RWTH Aachen University March 30 th, Aachen, Germany All used images
Lecture 20: Distributed Memory Parallelism. William Gropp
 Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
Scalable Interaction with Parallel Applications
 Scalable Interaction with Parallel Applications Filippo Gioachin Chee Wai Lee Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign Outline Overview Case Studies Charm++
Scalable Interaction with Parallel Applications Filippo Gioachin Chee Wai Lee Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign Outline Overview Case Studies Charm++
Reducing Communication Costs Associated with Parallel Algebraic Multigrid
 Reducing Communication Costs Associated with Parallel Algebraic Multigrid Amanda Bienz, Luke Olson (Advisor) University of Illinois at Urbana-Champaign Urbana, IL 11 I. PROBLEM AND MOTIVATION Algebraic
Reducing Communication Costs Associated with Parallel Algebraic Multigrid Amanda Bienz, Luke Olson (Advisor) University of Illinois at Urbana-Champaign Urbana, IL 11 I. PROBLEM AND MOTIVATION Algebraic
PRIMEHPC FX10: Advanced Software
 PRIMEHPC FX10: Advanced Software Koh Hotta Fujitsu Limited System Software supports --- Stable/Robust & Low Overhead Execution of Large Scale Programs Operating System File System Program Development for
PRIMEHPC FX10: Advanced Software Koh Hotta Fujitsu Limited System Software supports --- Stable/Robust & Low Overhead Execution of Large Scale Programs Operating System File System Program Development for
NAMD Serial and Parallel Performance
 NAMD Serial and Parallel Performance Jim Phillips Theoretical Biophysics Group Serial performance basics Main factors affecting serial performance: Molecular system size and composition. Cutoff distance
NAMD Serial and Parallel Performance Jim Phillips Theoretical Biophysics Group Serial performance basics Main factors affecting serial performance: Molecular system size and composition. Cutoff distance
Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning
 5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
CS 431/531 Introduction to Performance Measurement, Modeling, and Analysis Winter 2019
 CS 431/531 Introduction to Performance Measurement, Modeling, and Analysis Winter 2019 Prof. Karen L. Karavanic karavan@pdx.edu web.cecs.pdx.edu/~karavan Today s Agenda Why Study Performance? Why Study
CS 431/531 Introduction to Performance Measurement, Modeling, and Analysis Winter 2019 Prof. Karen L. Karavanic karavan@pdx.edu web.cecs.pdx.edu/~karavan Today s Agenda Why Study Performance? Why Study
Multi-threaded, discrete event simulation of distributed computing systems
 Multi-threaded, discrete event simulation of distributed computing systems Iosif C. Legrand California Institute of Technology, Pasadena, CA, U.S.A Abstract The LHC experiments have envisaged computing
Multi-threaded, discrete event simulation of distributed computing systems Iosif C. Legrand California Institute of Technology, Pasadena, CA, U.S.A Abstract The LHC experiments have envisaged computing
NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems
 NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems Carl Pearson 1, I-Hsin Chung 2, Zehra Sura 2, Wen-Mei Hwu 1, and Jinjun Xiong 2 1 University of Illinois Urbana-Champaign, Urbana
NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems Carl Pearson 1, I-Hsin Chung 2, Zehra Sura 2, Wen-Mei Hwu 1, and Jinjun Xiong 2 1 University of Illinois Urbana-Champaign, Urbana
Optimized Non-contiguous MPI Datatype Communication for GPU Clusters: Design, Implementation and Evaluation with MVAPICH2
 Optimized Non-contiguous MPI Datatype Communication for GPU Clusters: Design, Implementation and Evaluation with MVAPICH2 H. Wang, S. Potluri, M. Luo, A. K. Singh, X. Ouyang, S. Sur, D. K. Panda Network-Based
Optimized Non-contiguous MPI Datatype Communication for GPU Clusters: Design, Implementation and Evaluation with MVAPICH2 H. Wang, S. Potluri, M. Luo, A. K. Singh, X. Ouyang, S. Sur, D. K. Panda Network-Based
Recent Advances in Heterogeneous Computing using Charm++
 Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
BigSim: A Parallel Simulator for Performance Prediction of Extremely Large Parallel Machines
 BigSim: A Parallel Simulator for Performance Prediction of Extremely Large Parallel Machines Gengbin Zheng, Gunavardhan Kakulapati, Laxmikant V. Kalé Dept. of Computer Science University of Illinois at
BigSim: A Parallel Simulator for Performance Prediction of Extremely Large Parallel Machines Gengbin Zheng, Gunavardhan Kakulapati, Laxmikant V. Kalé Dept. of Computer Science University of Illinois at
Philip C. Roth. Computer Science and Mathematics Division Oak Ridge National Laboratory
 Philip C. Roth Computer Science and Mathematics Division Oak Ridge National Laboratory A Tree-Based Overlay Network (TBON) like MRNet provides scalable infrastructure for tools and applications MRNet's
Philip C. Roth Computer Science and Mathematics Division Oak Ridge National Laboratory A Tree-Based Overlay Network (TBON) like MRNet provides scalable infrastructure for tools and applications MRNet's
Aggregation of Real-Time System Monitoring Data for Analyzing Large-Scale Parallel and Distributed Computing Environments
 Aggregation of Real-Time System Monitoring Data for Analyzing Large-Scale Parallel and Distributed Computing Environments Swen Böhm 1,2, Christian Engelmann 2, and Stephen L. Scott 2 1 Department of Computer
Aggregation of Real-Time System Monitoring Data for Analyzing Large-Scale Parallel and Distributed Computing Environments Swen Böhm 1,2, Christian Engelmann 2, and Stephen L. Scott 2 1 Department of Computer
HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY
 HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY Presenters: Harshitha Menon, Seonmyeong Bak PPL Group Phil Miller, Sam White, Nitin Bhat, Tom Quinn, Jim Phillips, Laxmikant Kale MOTIVATION INTEGRATED
HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY Presenters: Harshitha Menon, Seonmyeong Bak PPL Group Phil Miller, Sam White, Nitin Bhat, Tom Quinn, Jim Phillips, Laxmikant Kale MOTIVATION INTEGRATED
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
FINAL REPORT. Milestone/Deliverable Description: Final implementation and final report
 FINAL REPORT PRAC Topic: Petascale simulations of complex biological behavior in fluctuating environments NSF Award ID: 0941360 Principal Investigator: Ilias Tagkopoulos, UC Davis Milestone/Deliverable
FINAL REPORT PRAC Topic: Petascale simulations of complex biological behavior in fluctuating environments NSF Award ID: 0941360 Principal Investigator: Ilias Tagkopoulos, UC Davis Milestone/Deliverable
Highly Scalable Parallel Sorting. Edgar Solomonik and Laxmikant Kale University of Illinois at Urbana-Champaign April 20, 2010
 Highly Scalable Parallel Sorting Edgar Solomonik and Laxmikant Kale University of Illinois at Urbana-Champaign April 20, 2010 1 Outline Parallel sorting background Histogram Sort overview Histogram Sort
Highly Scalable Parallel Sorting Edgar Solomonik and Laxmikant Kale University of Illinois at Urbana-Champaign April 20, 2010 1 Outline Parallel sorting background Histogram Sort overview Histogram Sort
CS 498 Hot Topics in High Performance Computing. Networks and Fault Tolerance. 10. Routing and Flow Control
 CS 498 Hot Topics in High Performance Computing Networks and Fault Tolerance 10. Routing and Flow Control Intro What did we learn in the last lecture Some more topologies Routing (schemes and metrics)
CS 498 Hot Topics in High Performance Computing Networks and Fault Tolerance 10. Routing and Flow Control Intro What did we learn in the last lecture Some more topologies Routing (schemes and metrics)
Ehsan Totoni Babak Behzad Swapnil Ghike Josep Torrellas
 Ehsan Totoni Babak Behzad Swapnil Ghike Josep Torrellas 2 Increasing number of transistors on chip Power and energy limited Single- thread performance limited => parallelism Many opeons: heavy mulecore,
Ehsan Totoni Babak Behzad Swapnil Ghike Josep Torrellas 2 Increasing number of transistors on chip Power and energy limited Single- thread performance limited => parallelism Many opeons: heavy mulecore,
Advanced Software for the Supercomputer PRIMEHPC FX10. Copyright 2011 FUJITSU LIMITED
 Advanced Software for the Supercomputer PRIMEHPC FX10 System Configuration of PRIMEHPC FX10 nodes Login Compilation Job submission 6D mesh/torus Interconnect Local file system (Temporary area occupied
Advanced Software for the Supercomputer PRIMEHPC FX10 System Configuration of PRIMEHPC FX10 nodes Login Compilation Job submission 6D mesh/torus Interconnect Local file system (Temporary area occupied
Linux Performance on IBM System z Enterprise
 Linux Performance on IBM System z Enterprise Christian Ehrhardt IBM Research and Development Germany 11 th August 2011 Session 10016 Agenda zenterprise 196 design Linux performance comparison z196 and
Linux Performance on IBM System z Enterprise Christian Ehrhardt IBM Research and Development Germany 11 th August 2011 Session 10016 Agenda zenterprise 196 design Linux performance comparison z196 and
PARALLEL ID3. Jeremy Dominijanni CSE633, Dr. Russ Miller
 PARALLEL ID3 Jeremy Dominijanni CSE633, Dr. Russ Miller 1 ID3 and the Sequential Case 2 ID3 Decision tree classifier Works on k-ary categorical data Goal of ID3 is to maximize information gain at each
PARALLEL ID3 Jeremy Dominijanni CSE633, Dr. Russ Miller 1 ID3 and the Sequential Case 2 ID3 Decision tree classifier Works on k-ary categorical data Goal of ID3 is to maximize information gain at each
The Tofu Interconnect 2
 The Tofu Interconnect 2 Yuichiro Ajima, Tomohiro Inoue, Shinya Hiramoto, Shun Ando, Masahiro Maeda, Takahide Yoshikawa, Koji Hosoe, and Toshiyuki Shimizu Fujitsu Limited Introduction Tofu interconnect
The Tofu Interconnect 2 Yuichiro Ajima, Tomohiro Inoue, Shinya Hiramoto, Shun Ando, Masahiro Maeda, Takahide Yoshikawa, Koji Hosoe, and Toshiyuki Shimizu Fujitsu Limited Introduction Tofu interconnect
A Case for High Performance Computing with Virtual Machines
 A Case for High Performance Computing with Virtual Machines Wei Huang*, Jiuxing Liu +, Bulent Abali +, and Dhabaleswar K. Panda* *The Ohio State University +IBM T. J. Waston Research Center Presentation
A Case for High Performance Computing with Virtual Machines Wei Huang*, Jiuxing Liu +, Bulent Abali +, and Dhabaleswar K. Panda* *The Ohio State University +IBM T. J. Waston Research Center Presentation
Communication Characteristics in the NAS Parallel Benchmarks
 Communication Characteristics in the NAS Parallel Benchmarks Ahmad Faraj Xin Yuan Department of Computer Science, Florida State University, Tallahassee, FL 32306 {faraj, xyuan}@cs.fsu.edu Abstract In this
Communication Characteristics in the NAS Parallel Benchmarks Ahmad Faraj Xin Yuan Department of Computer Science, Florida State University, Tallahassee, FL 32306 {faraj, xyuan}@cs.fsu.edu Abstract In this
BlueGene/L (No. 4 in the Latest Top500 List)
") BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
c 2014 by Ehsan Totoni. All rights reserved.
 c 2014 by Ehsan Totoni. All rights reserved. POWER AND ENERGY MANAGEMENT OF MODERN ARCHITECTURES IN ADAPTIVE HPC RUNTIME SYSTEMS BY EHSAN TOTONI DISSERTATION Submitted in partial fulfillment of the requirements
c 2014 by Ehsan Totoni. All rights reserved. POWER AND ENERGY MANAGEMENT OF MODERN ARCHITECTURES IN ADAPTIVE HPC RUNTIME SYSTEMS BY EHSAN TOTONI DISSERTATION Submitted in partial fulfillment of the requirements
MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA
 MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA Gilad Shainer 1, Tong Liu 1, Pak Lui 1, Todd Wilde 1 1 Mellanox Technologies Abstract From concept to engineering, and from design to
MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA Gilad Shainer 1, Tong Liu 1, Pak Lui 1, Todd Wilde 1 1 Mellanox Technologies Abstract From concept to engineering, and from design to
NAMD at Extreme Scale. Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale
 NAMD at Extreme Scale Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale Overview NAMD description Power7 Tuning Support for
NAMD at Extreme Scale Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale Overview NAMD description Power7 Tuning Support for
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods
 Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods Aaron K. Becker (abecker3@illinois.edu) Robert B. Haber Laxmikant V. Kalé University of Illinois, Urbana-Champaign Parallel
Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods Aaron K. Becker (abecker3@illinois.edu) Robert B. Haber Laxmikant V. Kalé University of Illinois, Urbana-Champaign Parallel
Molecular Dynamics and Quantum Mechanics Applications
 Understanding the Performance of Molecular Dynamics and Quantum Mechanics Applications on Dell HPC Clusters High-performance computing (HPC) clusters are proving to be suitable environments for running
Understanding the Performance of Molecular Dynamics and Quantum Mechanics Applications on Dell HPC Clusters High-performance computing (HPC) clusters are proving to be suitable environments for running
Flexible Hardware Mapping for Finite Element Simulations on Hybrid CPU/GPU Clusters
 Flexible Hardware Mapping for Finite Element Simulations on Hybrid /GPU Clusters Aaron Becker (abecker3@illinois.edu) Isaac Dooley Laxmikant Kale SAAHPC, July 30 2009 Champaign-Urbana, IL Target Application
Flexible Hardware Mapping for Finite Element Simulations on Hybrid /GPU Clusters Aaron Becker (abecker3@illinois.edu) Isaac Dooley Laxmikant Kale SAAHPC, July 30 2009 Champaign-Urbana, IL Target Application
Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters
 Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters Hari Subramoni, Ping Lai, Sayantan Sur and Dhabhaleswar. K. Panda Department of
Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters Hari Subramoni, Ping Lai, Sayantan Sur and Dhabhaleswar. K. Panda Department of
UNDERSTANDING THE IMPACT OF MULTI-CORE ARCHITECTURE IN CLUSTER COMPUTING: A CASE STUDY WITH INTEL DUAL-CORE SYSTEM
 UNDERSTANDING THE IMPACT OF MULTI-CORE ARCHITECTURE IN CLUSTER COMPUTING: A CASE STUDY WITH INTEL DUAL-CORE SYSTEM Sweety Sen, Sonali Samanta B.Tech, Information Technology, Dronacharya College of Engineering,
UNDERSTANDING THE IMPACT OF MULTI-CORE ARCHITECTURE IN CLUSTER COMPUTING: A CASE STUDY WITH INTEL DUAL-CORE SYSTEM Sweety Sen, Sonali Samanta B.Tech, Information Technology, Dronacharya College of Engineering,
Engineering Performance for Multiphysics Applications. William Gropp
 Engineering Performance for Multiphysics Applications William Gropp www.cs.illinois.edu/~wgropp Performance, then Productivity Note the then not instead of For easier problems, it is correct to invert
Engineering Performance for Multiphysics Applications William Gropp www.cs.illinois.edu/~wgropp Performance, then Productivity Note the then not instead of For easier problems, it is correct to invert
Characterizing the Influence of System Noise on Large-Scale Applications by Simulation Torsten Hoefler, Timo Schneider, Andrew Lumsdaine
 Characterizing the Influence of System Noise on Large-Scale Applications by Simulation Torsten Hoefler, Timo Schneider, Andrew Lumsdaine System Noise Introduction and History CPUs are time-shared Deamons,
Characterizing the Influence of System Noise on Large-Scale Applications by Simulation Torsten Hoefler, Timo Schneider, Andrew Lumsdaine System Noise Introduction and History CPUs are time-shared Deamons,
Technical Computing Suite supporting the hybrid system
 Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Performance Modeling as the Key to Extreme Scale Computing. William Gropp
 Performance Modeling as the Key to Extreme Scale Computing William Gropp www.cs.illinois.edu/~wgropp Performance is Key Parallelism is (usually) used to get more performance How do you know if you are
Performance Modeling as the Key to Extreme Scale Computing William Gropp www.cs.illinois.edu/~wgropp Performance is Key Parallelism is (usually) used to get more performance How do you know if you are
Runtime Algorithm Selection of Collective Communication with RMA-based Monitoring Mechanism
 1 Runtime Algorithm Selection of Collective Communication with RMA-based Monitoring Mechanism Takeshi Nanri (Kyushu Univ. and JST CREST, Japan) 16 Aug, 2016 4th Annual MVAPICH Users Group Meeting 2 Background
1 Runtime Algorithm Selection of Collective Communication with RMA-based Monitoring Mechanism Takeshi Nanri (Kyushu Univ. and JST CREST, Japan) 16 Aug, 2016 4th Annual MVAPICH Users Group Meeting 2 Background
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Installation and Test of Molecular Dynamics Simulation Packages on SGI Altix and Hydra-Cluster at JKU Linz
 Installation and Test of Molecular Dynamics Simulation Packages on SGI Altix and Hydra-Cluster at JKU Linz Rene Kobler May 25, 25 Contents 1 Abstract 2 2 Status 2 3 Changelog 2 4 Installation Notes 3 4.1
Installation and Test of Molecular Dynamics Simulation Packages on SGI Altix and Hydra-Cluster at JKU Linz Rene Kobler May 25, 25 Contents 1 Abstract 2 2 Status 2 3 Changelog 2 4 Installation Notes 3 4.1
The Tofu Interconnect D
 The Tofu Interconnect D 11 September 2018 Yuichiro Ajima, Takahiro Kawashima, Takayuki Okamoto, Naoyuki Shida, Kouichi Hirai, Toshiyuki Shimizu, Shinya Hiramoto, Yoshiro Ikeda, Takahide Yoshikawa, Kenji
The Tofu Interconnect D 11 September 2018 Yuichiro Ajima, Takahiro Kawashima, Takayuki Okamoto, Naoyuki Shida, Kouichi Hirai, Toshiyuki Shimizu, Shinya Hiramoto, Yoshiro Ikeda, Takahide Yoshikawa, Kenji
Charm++ on the Cell Processor
 Charm++ on the Cell Processor David Kunzman, Gengbin Zheng, Eric Bohm, Laxmikant V. Kale 1 Motivation Cell Processor (CBEA) is powerful (peak-flops) Allow Charm++ applications utilize the Cell processor
Charm++ on the Cell Processor David Kunzman, Gengbin Zheng, Eric Bohm, Laxmikant V. Kale 1 Motivation Cell Processor (CBEA) is powerful (peak-flops) Allow Charm++ applications utilize the Cell processor
c Copyright by Sameer Kumar, 2005
 c Copyright by Sameer Kumar, 2005 OPTIMIZING COMMUNICATION FOR MASSIVELY PARALLEL PROCESSING BY SAMEER KUMAR B. Tech., Indian Institute Of Technology Madras, 1999 M.S., University of Illinois at Urbana-Champaign,
c Copyright by Sameer Kumar, 2005 OPTIMIZING COMMUNICATION FOR MASSIVELY PARALLEL PROCESSING BY SAMEER KUMAR B. Tech., Indian Institute Of Technology Madras, 1999 M.S., University of Illinois at Urbana-Champaign,
Accelerating Molecular Modeling Applications with Graphics Processors
 Accelerating Molecular Modeling Applications with Graphics Processors John Stone Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign Research/gpu/ SIAM Conference
Accelerating Molecular Modeling Applications with Graphics Processors John Stone Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign Research/gpu/ SIAM Conference
Project Kickoff CS/EE 217. GPU Architecture and Parallel Programming
 CS/EE 217 GPU Architecture and Parallel Programming Project Kickoff David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2012 University of Illinois, Urbana-Champaign! 1 Two flavors Application Implement/optimize
CS/EE 217 GPU Architecture and Parallel Programming Project Kickoff David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2012 University of Illinois, Urbana-Champaign! 1 Two flavors Application Implement/optimize
Topology Awareness in the Tofu Interconnect Series
 Topology Awareness in the Tofu Interconnect Series Yuichiro Ajima Senior Architect Next Generation Technical Computing Unit Fujitsu Limited June 23rd, 2016, ExaComm2016 Workshop 0 Introduction Networks
Topology Awareness in the Tofu Interconnect Series Yuichiro Ajima Senior Architect Next Generation Technical Computing Unit Fujitsu Limited June 23rd, 2016, ExaComm2016 Workshop 0 Introduction Networks
Programming for Fujitsu Supercomputers
 Programming for Fujitsu Supercomputers Koh Hotta The Next Generation Technical Computing Fujitsu Limited To Programmers who are busy on their own research, Fujitsu provides environments for Parallel Programming
Programming for Fujitsu Supercomputers Koh Hotta The Next Generation Technical Computing Fujitsu Limited To Programmers who are busy on their own research, Fujitsu provides environments for Parallel Programming
Ultra-Fast NoC Emulation on a Single FPGA
 The 25 th International Conference on Field-Programmable Logic and Applications (FPL 2015) September 3, 2015 Ultra-Fast NoC Emulation on a Single FPGA Thiem Van Chu, Shimpei Sato, and Kenji Kise Tokyo
The 25 th International Conference on Field-Programmable Logic and Applications (FPL 2015) September 3, 2015 Ultra-Fast NoC Emulation on a Single FPGA Thiem Van Chu, Shimpei Sato, and Kenji Kise Tokyo
Introduction to FREE National Resources for Scientific Computing. Dana Brunson. Jeff Pummill
 Introduction to FREE National Resources for Scientific Computing Dana Brunson Oklahoma State University High Performance Computing Center Jeff Pummill University of Arkansas High Peformance Computing Center
Introduction to FREE National Resources for Scientific Computing Dana Brunson Oklahoma State University High Performance Computing Center Jeff Pummill University of Arkansas High Peformance Computing Center
Automated Load Balancing Invocation based on Application Characteristics
 Automated Load Balancing Invocation based on Application Characteristics Harshitha Menon, Nikhil Jain, Gengbin Zheng and Laxmikant Kalé Department of Computer Science University of Illinois at Urbana-Champaign,
Automated Load Balancing Invocation based on Application Characteristics Harshitha Menon, Nikhil Jain, Gengbin Zheng and Laxmikant Kalé Department of Computer Science University of Illinois at Urbana-Champaign,
Mapping Strategies for the PERCS Architecture
 Mapping Strategies for the PERCS Architecture Venkatesan T. Chakaravarthy, Monu Kedia, Yogish Sabharwal IBM Research - India {vechakra,mokedia1,ysabharwal}@in.ibm.com Naga Praveen Kumar Katta Princeton
Mapping Strategies for the PERCS Architecture Venkatesan T. Chakaravarthy, Monu Kedia, Yogish Sabharwal IBM Research - India {vechakra,mokedia1,ysabharwal}@in.ibm.com Naga Praveen Kumar Katta Princeton
Camdoop Exploiting In-network Aggregation for Big Data Applications Paolo Costa
 Camdoop Exploiting In-network Aggregation for Big Data Applications costa@imperial.ac.uk joint work with Austin Donnelly, Antony Rowstron, and Greg O Shea (MSR Cambridge) MapReduce Overview Input file
Camdoop Exploiting In-network Aggregation for Big Data Applications costa@imperial.ac.uk joint work with Austin Donnelly, Antony Rowstron, and Greg O Shea (MSR Cambridge) MapReduce Overview Input file
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Computer Comparisons Using HPCC. Nathan Wichmann Benchmark Engineer
 Computer Comparisons Using HPCC Nathan Wichmann Benchmark Engineer Outline Comparisons using HPCC HPCC test used Methods used to compare machines using HPCC Normalize scores Weighted averages Comparing
Computer Comparisons Using HPCC Nathan Wichmann Benchmark Engineer Outline Comparisons using HPCC HPCC test used Methods used to compare machines using HPCC Normalize scores Weighted averages Comparing
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox, Altair Compute
High Performance MPI on IBM 12x InfiniBand Architecture
 High Performance MPI on IBM 12x InfiniBand Architecture Abhinav Vishnu, Brad Benton 1 and Dhabaleswar K. Panda {vishnu, panda} @ cse.ohio-state.edu {brad.benton}@us.ibm.com 1 1 Presentation Road-Map Introduction
High Performance MPI on IBM 12x InfiniBand Architecture Abhinav Vishnu, Brad Benton 1 and Dhabaleswar K. Panda {vishnu, panda} @ cse.ohio-state.edu {brad.benton}@us.ibm.com 1 1 Presentation Road-Map Introduction
CSE5351: Parallel Processing Part III
 CSE5351: Parallel Processing Part III -1- Performance Metrics and Benchmarks How should one characterize the performance of applications and systems? What are user s requirements in performance and cost?
CSE5351: Parallel Processing Part III -1- Performance Metrics and Benchmarks How should one characterize the performance of applications and systems? What are user s requirements in performance and cost?
LAPI on HPS Evaluating Federation
 LAPI on HPS Evaluating Federation Adrian Jackson August 23, 2004 Abstract LAPI is an IBM-specific communication library that performs single-sided operation. This library was well profiled on Phase 1 of
LAPI on HPS Evaluating Federation Adrian Jackson August 23, 2004 Abstract LAPI is an IBM-specific communication library that performs single-sided operation. This library was well profiled on Phase 1 of
MPI+X on The Way to Exascale. William Gropp
 MPI+X on The Way to Exascale William Gropp http://wgropp.cs.illinois.edu Some Likely Exascale Architectures Figure 1: Core Group for Node (Low Capacity, High Bandwidth) 3D Stacked Memory (High Capacity,
MPI+X on The Way to Exascale William Gropp http://wgropp.cs.illinois.edu Some Likely Exascale Architectures Figure 1: Core Group for Node (Low Capacity, High Bandwidth) 3D Stacked Memory (High Capacity,
Interconnection Network for Tightly Coupled Accelerators Architecture
 Interconnection Network for Tightly Coupled Accelerators Architecture Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato Center for Computational Sciences University of Tsukuba, Japan 1 What
Interconnection Network for Tightly Coupled Accelerators Architecture Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato Center for Computational Sciences University of Tsukuba, Japan 1 What
c Copyright by Gengbin Zheng, 2005
 c Copyright by Gengbin Zheng, 2005 ACHIEVING HIGH PERFORMANCE ON EXTREMELY LARGE PARALLEL MACHINES: PERFORMANCE PREDICTION AND LOAD BALANCING BY GENGBIN ZHENG B.S., Beijing University, China, 1995 M.S.,
c Copyright by Gengbin Zheng, 2005 ACHIEVING HIGH PERFORMANCE ON EXTREMELY LARGE PARALLEL MACHINES: PERFORMANCE PREDICTION AND LOAD BALANCING BY GENGBIN ZHENG B.S., Beijing University, China, 1995 M.S.,
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing