A CASE STUDY OF COMMUNICATION OPTIMIZATIONS ON 3D MESH INTERCONNECTS
|
|
|
- Emery Reed
- 5 years ago
- Views:
Transcription
1 A CASE STUDY OF COMMUNICATION OPTIMIZATIONS ON 3D MESH INTERCONNECTS Abhinav Bhatele, Eric Bohm, Laxmikant V. Kale Parallel Programming Laboratory Euro-Par 2009 University of Illinois at Urbana-Champaign
2 Outline 2 Motivation Solution: Mapping of OpenAtom Performance Benefits Bigger Picture: Resources Needed Heuristic Solutions Automatic Mapping


3 OpenAtom 3 Ab-Initio Molecular Dynamics code Consider electrostatic interactions between the nuclei and electrons Calculate different energy terms Divided into different phases with lot of communication
4 OpenAtom on Blue Gene/L 4 Time per step (secs) No. of cores w32 = 32 water molecules with 70 Ry cutoff w32 Default Runs on Blue Gene/L at IBM T J Watson Research Center, CO mode
")
5 The problem lies in 5 Performance Analysis and Visualization Tool: Projections (part of Charm++) Timeline View
6 Solution 6 Topology Aware Mapping


7 Processor Virtualization 7 Programmer: Decomposes the computation into objects Runtime: Maps the computation on to the processors User View System View
8 Benefits of Charm++ 8 Computation is divided into objects/chares/virtual processors (VPs) Separates decomposition from mapping VPs can be flexibly mapped to actual physical processors (PEs)
9 Topology Manager API 9 The application needs information such as Dimensions of the partition Rank to physical co-ordinates and vice-versa TopoManager: a uniform API On BG/L and BG/P: provides a wrapper for system calls On XT3/4/5, there are no such system calls Provides a clean and uniform interface to the application


10 Parallelization using Charm++ 10 Eric Bohm, Glenn J. Martyna, Abhinav Bhatele, Sameer Kumar, Laxmikant V. Kale, John A. Gunnels, and Mark E. Tuckerman. Fine Grained Parallelization of the Car-Parrinello ab initio MD Method on Blue Gene/L. IBM J. of R. and D.: Applications of Massively Parallel Systems, 52(1/2): , 2008.
11 Mapping Challenge 11 Load Balancing: Multiple VPs per PE Multiple groups of communicating objects Intra-group communication Inter-group communication Conflicting communication requirements

12 Topology Mapping of Chare Arrays 12 RealSpace and GSpace have state-wise communication Paircalculator and GSpace have plane-wise communication
13 Performance Improvements on BG/L 13 Time per step (secs) w32 = 32 water molecules with 70 Ry cutoff w32 Default w32 Topology No. of cores Runs on Blue Gene/L at IBM T J Watson Research Center, CO mode, Year: 2006

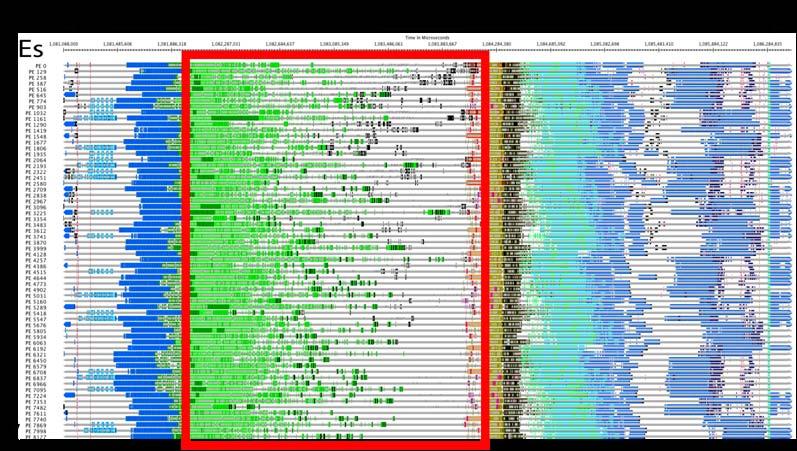
14 Improved Timeline Views 14
15 Results on Blue Gene/L 15 Time per step (secs) GST_BIG = 64 Ge, 128 Sb and 256 Te molecules with 20 Ry cutoff w256 Default w256 Topology GST_BIG Default GST_BIG Topology No. of cores Runs on Blue Gene/L at IBM T J Watson Research Center, CO mode
16 Results on Blue Gene/P Time per step (secs) w256 = 256 water molecules with 70 Ry cutoff w256 Default w256 Topology No. of cores Runs on Blue Gene/P at Argonne National Laboratory, VN mode
17 Results on Cray XT3 17 Time per step (secs) No. of cores w256 Default w256 Topology GST_BIG Default GST_BIG Topology Runs on Cray XT3 (Bigben) at Pittsburgh Supercomputing Center, VN mode (with system reservation to obtain complete 3d mesh shapes)
18 Performance Analysis 18 Idle Time (secs) w256m_70ry on Blue Gene/L Default Topology No. of cores Performance Analysis and Visualization Tool: Projections Idle time added across all processors
19 Reduction in Communication Volume 19 Bandwidth (GB) w256m_70ry on Blue Gene/P Default Topology No. of cores Data obtained from Blue Gene/P s Uniform Performance Counters
20 Relative Performance Improvement w256m_70ry % Improvement Cray XT3 Blue Gene/L Blue Gene/P No. of cores
21 Bigger picture 21 Different kinds of applications: Computation bound Communication bound Latency tolerant Latency sensitive Technique: Obtain processor topology and application communication graph Heuristic Techniques for mapping
22 Why does distance affect message latencies? 22 Consider a 3D mesh/torus interconnect Message latencies can be modeled by (L f /B) x D + L/B L f = length of flit, B = bandwidth, D = hops, L = message size When (L f * D) << L, first term is negligible But in presence of contention

23 Automatic Topology Aware Mapping 23 Many MPI applications exhibit a simple twodimensional near-neighbor communication pattern Examples: MILC, WRF, POP, Stencil,
24 Acknowledgements: Shawn Brown and Chad Vizino (PSC) Glenn Martyna, Sameer Kumar, Fred Mintzer (IBM) Teragrid for running time on Bigben (XT3) ANL for running time on Blue Gene/P Webpage: Funding DOE Grant B (CSAR), DOE Grant DE-FG05-08OR23332 (ORNL LCF) and NSF Grant ITR
IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers
 IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers Abhinav S Bhatele and Laxmikant V Kale ACM Research Competition, SC 08 Outline Why should we consider topology
IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers Abhinav S Bhatele and Laxmikant V Kale ACM Research Competition, SC 08 Outline Why should we consider topology
A Case Study of Communication Optimizations on 3D Mesh Interconnects
 A Case Study of Communication Optimizations on 3D Mesh Interconnects Abhinav Bhatelé, Eric Bohm, and Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign, Urbana,
A Case Study of Communication Optimizations on 3D Mesh Interconnects Abhinav Bhatelé, Eric Bohm, and Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign, Urbana,
Optimizing communication for Charm++ applications by reducing network contention
 CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 2009; 00:1 7 [Version: 2002/09/19 v2.02] Optimizing communication for Charm++ applications by reducing network
CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 2009; 00:1 7 [Version: 2002/09/19 v2.02] Optimizing communication for Charm++ applications by reducing network
Scalable Topology Aware Object Mapping for Large Supercomputers
 Scalable Topology Aware Object Mapping for Large Supercomputers Abhinav Bhatele (bhatele@illinois.edu) Department of Computer Science, University of Illinois at Urbana-Champaign Advisor: Laxmikant V. Kale
Scalable Topology Aware Object Mapping for Large Supercomputers Abhinav Bhatele (bhatele@illinois.edu) Department of Computer Science, University of Illinois at Urbana-Champaign Advisor: Laxmikant V. Kale
Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center
 Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center Motivation: Contention Experiments Bhatele, A., Kale, L. V. 2008 An Evaluation
Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center Motivation: Contention Experiments Bhatele, A., Kale, L. V. 2008 An Evaluation
Automated Mapping of Regular Communication Graphs on Mesh Interconnects
 Automated Mapping of Regular Communication Graphs on Mesh Interconnects Abhinav Bhatele, Gagan Gupta, Laxmikant V. Kale and I-Hsin Chung Motivation Running a parallel application on a linear array of processors:
Automated Mapping of Regular Communication Graphs on Mesh Interconnects Abhinav Bhatele, Gagan Gupta, Laxmikant V. Kale and I-Hsin Chung Motivation Running a parallel application on a linear array of processors:
Enabling Contiguous Node Scheduling on the Cray XT3
 Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino vizino@psc.edu Pittsburgh Supercomputing Center ABSTRACT: The Pittsburgh Supercomputing Center has enabled contiguous node scheduling to
Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino vizino@psc.edu Pittsburgh Supercomputing Center ABSTRACT: The Pittsburgh Supercomputing Center has enabled contiguous node scheduling to
QUANTIFYING NETWORK CONTENTION ON LARGE PARALLEL MACHINES
 Parallel Processing Letters c World Scientific Publishing Company QUANTIFYING NETWORK CONTENTION ON LARGE PARALLEL MACHINES Abhinav Bhatelé Department of Computer Science University of Illinois at Urbana-Champaign
Parallel Processing Letters c World Scientific Publishing Company QUANTIFYING NETWORK CONTENTION ON LARGE PARALLEL MACHINES Abhinav Bhatelé Department of Computer Science University of Illinois at Urbana-Champaign
Enabling Contiguous Node Scheduling on the Cray XT3
 Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino Pittsburgh Supercomputing Center Cray User Group Helsinki, Finland May 2008 With acknowledgements to Deborah Weisser, Jared Yanovich, Derek
Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino Pittsburgh Supercomputing Center Cray User Group Helsinki, Finland May 2008 With acknowledgements to Deborah Weisser, Jared Yanovich, Derek
Charm++ for Productivity and Performance
 Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
Charm++: An Asynchronous Parallel Programming Model with an Intelligent Adaptive Runtime System
 Charm++: An Asynchronous Parallel Programming Model with an Intelligent Adaptive Runtime System Laxmikant (Sanjay) Kale http://charm.cs.illinois.edu Parallel Programming Laboratory Department of Computer
Charm++: An Asynchronous Parallel Programming Model with an Intelligent Adaptive Runtime System Laxmikant (Sanjay) Kale http://charm.cs.illinois.edu Parallel Programming Laboratory Department of Computer
Dr. Gengbin Zheng and Ehsan Totoni. Parallel Programming Laboratory University of Illinois at Urbana-Champaign
 Dr. Gengbin Zheng and Ehsan Totoni Parallel Programming Laboratory University of Illinois at Urbana-Champaign April 18, 2011 A function level simulator for parallel applications on peta scale machine An
Dr. Gengbin Zheng and Ehsan Totoni Parallel Programming Laboratory University of Illinois at Urbana-Champaign April 18, 2011 A function level simulator for parallel applications on peta scale machine An
Toward Runtime Power Management of Exascale Networks by On/Off Control of Links
 Toward Runtime Power Management of Exascale Networks by On/Off Control of Links, Nikhil Jain, Laxmikant Kale University of Illinois at Urbana-Champaign HPPAC May 20, 2013 1 Power challenge Power is a major
Toward Runtime Power Management of Exascale Networks by On/Off Control of Links, Nikhil Jain, Laxmikant Kale University of Illinois at Urbana-Champaign HPPAC May 20, 2013 1 Power challenge Power is a major
OpenAtom: Scalable Ab-Initio Molecular Dynamics with Diverse Capabilities
 OpenAtom: Scalable Ab-Initio Molecular Dynamics with Diverse Capabilities Nikhil Jain, Eric Bohm, Eric Mikida, Subhasish Mandal, Minjung Kim, Prateek Jindal, Qi Li, Sohrab Ismail-Beigi, Glenn J. Martyna,
OpenAtom: Scalable Ab-Initio Molecular Dynamics with Diverse Capabilities Nikhil Jain, Eric Bohm, Eric Mikida, Subhasish Mandal, Minjung Kim, Prateek Jindal, Qi Li, Sohrab Ismail-Beigi, Glenn J. Martyna,
Overcoming Scaling Challenges in Biomolecular Simulations across Multiple Platforms
 Overcoming Scaling Challenges in Biomolecular Simulations across Multiple Platforms Abhinav Bhatelé, Sameer Kumar, Chao Mei, James C. Phillips, Gengbin Zheng, Laxmikant V. Kalé Department of Computer Science
Overcoming Scaling Challenges in Biomolecular Simulations across Multiple Platforms Abhinav Bhatelé, Sameer Kumar, Chao Mei, James C. Phillips, Gengbin Zheng, Laxmikant V. Kalé Department of Computer Science
HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY
 HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY Presenters: Harshitha Menon, Seonmyeong Bak PPL Group Phil Miller, Sam White, Nitin Bhat, Tom Quinn, Jim Phillips, Laxmikant Kale MOTIVATION INTEGRATED
HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY Presenters: Harshitha Menon, Seonmyeong Bak PPL Group Phil Miller, Sam White, Nitin Bhat, Tom Quinn, Jim Phillips, Laxmikant Kale MOTIVATION INTEGRATED
CkDirect: Unsynchronized One-Sided Communication in a Message-Driven Paradigm
 CkDirect: Unsynchronized One-Sided Communication in a Message-Driven Paradigm Eric Bohm, Sayantan Chakravorty, Pritish Jetley, Abhinav Bhatelé, Laxmikant V. Kalé Department of Computer Science, University
CkDirect: Unsynchronized One-Sided Communication in a Message-Driven Paradigm Eric Bohm, Sayantan Chakravorty, Pritish Jetley, Abhinav Bhatelé, Laxmikant V. Kalé Department of Computer Science, University
PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications
 PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications Yanhua Sun, Laxmikant V. Kalé University of Illinois at Urbana-Champaign sun51@illinois.edu November 26,
PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications Yanhua Sun, Laxmikant V. Kalé University of Illinois at Urbana-Champaign sun51@illinois.edu November 26,
Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods
 Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods Aaron K. Becker (abecker3@illinois.edu) Robert B. Haber Laxmikant V. Kalé University of Illinois, Urbana-Champaign Parallel
Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods Aaron K. Becker (abecker3@illinois.edu) Robert B. Haber Laxmikant V. Kalé University of Illinois, Urbana-Champaign Parallel
Heuristic-based techniques for mapping irregular communication graphs to mesh topologies
 Heuristic-based techniques for mapping irregular communication graphs to mesh topologies Abhinav Bhatele and Laxmikant V. Kale University of Illinois at Urbana-Champaign LLNL-PRES-495871, P. O. Box 808,
Heuristic-based techniques for mapping irregular communication graphs to mesh topologies Abhinav Bhatele and Laxmikant V. Kale University of Illinois at Urbana-Champaign LLNL-PRES-495871, P. O. Box 808,
A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé
 A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé Parallel Programming Laboratory Department of Computer Science University
A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé Parallel Programming Laboratory Department of Computer Science University
Scalable Interaction with Parallel Applications
 Scalable Interaction with Parallel Applications Filippo Gioachin Chee Wai Lee Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign Outline Overview Case Studies Charm++
Scalable Interaction with Parallel Applications Filippo Gioachin Chee Wai Lee Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign Outline Overview Case Studies Charm++
Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, Ranger and Jaguar
 Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, and Jaguar Abhinav Bhatelé, Lukasz Wesolowski, Eric Bohm, Edgar Solomonik and Laxmikant V. Kalé Department
Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, and Jaguar Abhinav Bhatelé, Lukasz Wesolowski, Eric Bohm, Edgar Solomonik and Laxmikant V. Kalé Department
 5 th Annual Workshop on Charm++ and Applications Welcome and Introduction State of Charm++ Laxmikant Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University
5 th Annual Workshop on Charm++ and Applications Welcome and Introduction State of Charm++ Laxmikant Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University
Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs
 Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs Laércio Lima Pilla llpilla@inf.ufrgs.br LIG Laboratory INRIA Grenoble University Grenoble, France Institute of Informatics
Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs Laércio Lima Pilla llpilla@inf.ufrgs.br LIG Laboratory INRIA Grenoble University Grenoble, France Institute of Informatics
PREDICTING COMMUNICATION PERFORMANCE
 PREDICTING COMMUNICATION PERFORMANCE Nikhil Jain CASC Seminar, LLNL This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
PREDICTING COMMUNICATION PERFORMANCE Nikhil Jain CASC Seminar, LLNL This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
Memory Tagging in Charm++
 Memory Tagging in Charm++ Filippo Gioachin Department of Computer Science University of Illinois at Urbana-Champaign gioachin@uiuc.edu Laxmikant V. Kalé Department of Computer Science University of Illinois
Memory Tagging in Charm++ Filippo Gioachin Department of Computer Science University of Illinois at Urbana-Champaign gioachin@uiuc.edu Laxmikant V. Kalé Department of Computer Science University of Illinois
OPTIMIZATION OF FFT COMMUNICATION ON 3-D TORUS AND MESH SUPERCOMPUTER NETWORKS ANSHU ARYA THESIS
 OPTIMIZATION OF FFT COMMUNICATION ON 3-D TORUS AND MESH SUPERCOMPUTER NETWORKS BY ANSHU ARYA THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer
OPTIMIZATION OF FFT COMMUNICATION ON 3-D TORUS AND MESH SUPERCOMPUTER NETWORKS BY ANSHU ARYA THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer
Memory Tagging in Charm++
 Memory Tagging in Charm++ Filippo Gioachin Department of Computer Science University of Illinois at Urbana-Champaign gioachin@uiuc.edu Laxmikant V. Kalé Department of Computer Science University of Illinois
Memory Tagging in Charm++ Filippo Gioachin Department of Computer Science University of Illinois at Urbana-Champaign gioachin@uiuc.edu Laxmikant V. Kalé Department of Computer Science University of Illinois
Dynamic Load Balancing for Weather Models via AMPI
 Dynamic Load Balancing for Eduardo R. Rodrigues IBM Research Brazil edrodri@br.ibm.com Celso L. Mendes University of Illinois USA cmendes@ncsa.illinois.edu Laxmikant Kale University of Illinois USA kale@cs.illinois.edu
Dynamic Load Balancing for Eduardo R. Rodrigues IBM Research Brazil edrodri@br.ibm.com Celso L. Mendes University of Illinois USA cmendes@ncsa.illinois.edu Laxmikant Kale University of Illinois USA kale@cs.illinois.edu
Scalable Fault Tolerance Schemes using Adaptive Runtime Support
 Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Tutorial: Application MPI Task Placement
 Tutorial: Application MPI Task Placement Juan Galvez Nikhil Jain Palash Sharma PPL, University of Illinois at Urbana-Champaign Tutorial Outline Why Task Mapping on Blue Waters? When to do mapping? How
Tutorial: Application MPI Task Placement Juan Galvez Nikhil Jain Palash Sharma PPL, University of Illinois at Urbana-Champaign Tutorial Outline Why Task Mapping on Blue Waters? When to do mapping? How
Automated Mapping of Regular Communication Graphs on Mesh Interconnects
 Automated Mapping of Regular Communication Graphs on Mesh Interconnects Abhinav Bhatelé, Gagan Raj Gupta, Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign Urbana,
Automated Mapping of Regular Communication Graphs on Mesh Interconnects Abhinav Bhatelé, Gagan Raj Gupta, Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign Urbana,
Highly Scalable Parallel Sorting. Edgar Solomonik and Laxmikant Kale University of Illinois at Urbana-Champaign April 20, 2010
 Highly Scalable Parallel Sorting Edgar Solomonik and Laxmikant Kale University of Illinois at Urbana-Champaign April 20, 2010 1 Outline Parallel sorting background Histogram Sort overview Histogram Sort
Highly Scalable Parallel Sorting Edgar Solomonik and Laxmikant Kale University of Illinois at Urbana-Champaign April 20, 2010 1 Outline Parallel sorting background Histogram Sort overview Histogram Sort
NAMD: A Portable and Highly Scalable Program for Biomolecular Simulations
 NAMD: A Portable and Highly Scalable Program for Biomolecular Simulations Abhinav Bhatele 1, Sameer Kumar 3, Chao Mei 1, James C. Phillips 2, Gengbin Zheng 1, Laxmikant V. Kalé 1 1 Department of Computer
NAMD: A Portable and Highly Scalable Program for Biomolecular Simulations Abhinav Bhatele 1, Sameer Kumar 3, Chao Mei 1, James C. Phillips 2, Gengbin Zheng 1, Laxmikant V. Kalé 1 1 Department of Computer
Automated Mapping of Structured Communication Graphs onto Mesh Interconnects
 Automated Mapping of Structured Communication Graphs onto Mesh Interconnects Abhinav Bhatelé, I-Hsin Chung and Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign,
Automated Mapping of Structured Communication Graphs onto Mesh Interconnects Abhinav Bhatelé, I-Hsin Chung and Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign,
NAMD at Extreme Scale. Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale
 NAMD at Extreme Scale Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale Overview NAMD description Power7 Tuning Support for
NAMD at Extreme Scale Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale Overview NAMD description Power7 Tuning Support for
Reducing Communication Costs Associated with Parallel Algebraic Multigrid
 Reducing Communication Costs Associated with Parallel Algebraic Multigrid Amanda Bienz, Luke Olson (Advisor) University of Illinois at Urbana-Champaign Urbana, IL 11 I. PROBLEM AND MOTIVATION Algebraic
Reducing Communication Costs Associated with Parallel Algebraic Multigrid Amanda Bienz, Luke Olson (Advisor) University of Illinois at Urbana-Champaign Urbana, IL 11 I. PROBLEM AND MOTIVATION Algebraic
High Performance Components with Charm++ and OpenAtom (Work in Progress)
") High Performance Components with Charm++ and OpenAtom (Work in Progress) Christian Perez Graal/Avalon INRIA EPI LIP, ENS Lyon, France Joint Laboratory for Petascale Computing University of Illinois at
High Performance Components with Charm++ and OpenAtom (Work in Progress) Christian Perez Graal/Avalon INRIA EPI LIP, ENS Lyon, France Joint Laboratory for Petascale Computing University of Illinois at
Welcome to the 2017 Charm++ Workshop!
 Welcome to the 2017 Charm++ Workshop! Laxmikant (Sanjay) Kale http://charm.cs.illinois.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at Urbana Champaign 2017
Welcome to the 2017 Charm++ Workshop! Laxmikant (Sanjay) Kale http://charm.cs.illinois.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at Urbana Champaign 2017
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Enzo-P / Cello. Formation of the First Galaxies. San Diego Supercomputer Center. Department of Physics and Astronomy
 Enzo-P / Cello Formation of the First Galaxies James Bordner 1 Michael L. Norman 1 Brian O Shea 2 1 University of California, San Diego San Diego Supercomputer Center 2 Michigan State University Department
Enzo-P / Cello Formation of the First Galaxies James Bordner 1 Michael L. Norman 1 Brian O Shea 2 1 University of California, San Diego San Diego Supercomputer Center 2 Michigan State University Department
Adaptive Runtime Support
 Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Topology and affinity aware hierarchical and distributed load-balancing in Charm++
 Topology and affinity aware hierarchical and distributed load-balancing in Charm++ Emmanuel Jeannot, Guillaume Mercier, François Tessier Inria - IPB - LaBRI - University of Bordeaux - Argonne National
Topology and affinity aware hierarchical and distributed load-balancing in Charm++ Emmanuel Jeannot, Guillaume Mercier, François Tessier Inria - IPB - LaBRI - University of Bordeaux - Argonne National
A Scalable Adaptive Mesh Refinement Framework For Parallel Astrophysics Applications
 A Scalable Adaptive Mesh Refinement Framework For Parallel Astrophysics Applications James Bordner, Michael L. Norman San Diego Supercomputer Center University of California, San Diego 15th SIAM Conference
A Scalable Adaptive Mesh Refinement Framework For Parallel Astrophysics Applications James Bordner, Michael L. Norman San Diego Supercomputer Center University of California, San Diego 15th SIAM Conference
Optimization of the Hop-Byte Metric for Effective Topology Aware Mapping
 Optimization of the Hop-Byte Metric for Effective Topology Aware Mapping C. D. Sudheer Department of Mathematics and Computer Science Sri Sathya Sai Institute of Higher Learning, India Email: cdsudheerkumar@sssihl.edu.in
Optimization of the Hop-Byte Metric for Effective Topology Aware Mapping C. D. Sudheer Department of Mathematics and Computer Science Sri Sathya Sai Institute of Higher Learning, India Email: cdsudheerkumar@sssihl.edu.in
c Copyright by Sameer Kumar, 2005
 c Copyright by Sameer Kumar, 2005 OPTIMIZING COMMUNICATION FOR MASSIVELY PARALLEL PROCESSING BY SAMEER KUMAR B. Tech., Indian Institute Of Technology Madras, 1999 M.S., University of Illinois at Urbana-Champaign,
c Copyright by Sameer Kumar, 2005 OPTIMIZING COMMUNICATION FOR MASSIVELY PARALLEL PROCESSING BY SAMEER KUMAR B. Tech., Indian Institute Of Technology Madras, 1999 M.S., University of Illinois at Urbana-Champaign,
Mapping to Irregular Torus Topologies and Other Techniques for Petascale Biomolecular Simulation
 SC14: International Conference for High Performance Computing, Networking, Storage and Analysis Mapping to Irregular Torus Topologies and Other Techniques for Petascale Biomolecular Simulation James C.
SC14: International Conference for High Performance Computing, Networking, Storage and Analysis Mapping to Irregular Torus Topologies and Other Techniques for Petascale Biomolecular Simulation James C.
Charm++ Workshop 2010
 Charm++ Workshop 2010 Eduardo R. Rodrigues Institute of Informatics Federal University of Rio Grande do Sul - Brazil ( visiting scholar at CS-UIUC ) errodrigues@inf.ufrgs.br Supported by Brazilian Ministry
Charm++ Workshop 2010 Eduardo R. Rodrigues Institute of Informatics Federal University of Rio Grande do Sul - Brazil ( visiting scholar at CS-UIUC ) errodrigues@inf.ufrgs.br Supported by Brazilian Ministry
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance
 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance Jonathan Lifflander*, Esteban Meneses, Harshitha Menon*, Phil Miller*, Sriram Krishnamoorthy, Laxmikant V. Kale* jliffl2@illinois.edu,
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance Jonathan Lifflander*, Esteban Meneses, Harshitha Menon*, Phil Miller*, Sriram Krishnamoorthy, Laxmikant V. Kale* jliffl2@illinois.edu,
Integrated Performance Views in Charm++: Projections Meets TAU
 1 Integrated Performance Views in Charm++: Projections Meets TAU Scott Biersdorff, Allen D. Malony Performance Research Laboratory Department of Computer Science University of Oregon, Eugene, OR, USA email:
1 Integrated Performance Views in Charm++: Projections Meets TAU Scott Biersdorff, Allen D. Malony Performance Research Laboratory Department of Computer Science University of Oregon, Eugene, OR, USA email:
Hierarchical task mapping for parallel applications on supercomputers
 J Supercomput DOI 10.1007/s11227-014-1324-5 Hierarchical task mapping for parallel applications on supercomputers Jingjin Wu Xuanxing Xiong Zhiling Lan Springer Science+Business Media New York 2014 Abstract
J Supercomput DOI 10.1007/s11227-014-1324-5 Hierarchical task mapping for parallel applications on supercomputers Jingjin Wu Xuanxing Xiong Zhiling Lan Springer Science+Business Media New York 2014 Abstract
Matrix multiplication on multidimensional torus networks
 Matrix multiplication on multidimensional torus networks Edgar Solomonik James Demmel Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2012-28
Matrix multiplication on multidimensional torus networks Edgar Solomonik James Demmel Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2012-28
Resource allocation and utilization in the Blue Gene/L supercomputer
 Resource allocation and utilization in the Blue Gene/L supercomputer Tamar Domany, Y Aridor, O Goldshmidt, Y Kliteynik, EShmueli, U Silbershtein IBM Labs in Haifa Agenda Blue Gene/L Background Blue Gene/L
Resource allocation and utilization in the Blue Gene/L supercomputer Tamar Domany, Y Aridor, O Goldshmidt, Y Kliteynik, EShmueli, U Silbershtein IBM Labs in Haifa Agenda Blue Gene/L Background Blue Gene/L
Preliminary Evaluation of a Parallel Trace Replay Tool for HPC Network Simulations
 Preliminary Evaluation of a Parallel Trace Replay Tool for HPC Network Simulations Bilge Acun 1, Nikhil Jain 1, Abhinav Bhatele 2, Misbah Mubarak 3, Christopher D. Carothers 4, and Laxmikant V. Kale 1
Preliminary Evaluation of a Parallel Trace Replay Tool for HPC Network Simulations Bilge Acun 1, Nikhil Jain 1, Abhinav Bhatele 2, Misbah Mubarak 3, Christopher D. Carothers 4, and Laxmikant V. Kale 1
Scalable Dynamic Adaptive Simulations with ParFUM
 Scalable Dynamic Adaptive Simulations with ParFUM Terry L. Wilmarth Center for Simulation of Advanced Rockets and Parallel Programming Laboratory University of Illinois at Urbana-Champaign The Big Picture
Scalable Dynamic Adaptive Simulations with ParFUM Terry L. Wilmarth Center for Simulation of Advanced Rockets and Parallel Programming Laboratory University of Illinois at Urbana-Champaign The Big Picture
Dynamic High-Level Scripting in Parallel Applications
 Dynamic High-Level Scripting in Parallel Applications Filippo Gioachin, Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign gioachin@uiuc.edu, kale@cs.uiuc.edu Abstract
Dynamic High-Level Scripting in Parallel Applications Filippo Gioachin, Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign gioachin@uiuc.edu, kale@cs.uiuc.edu Abstract
Using BigSim to Estimate Application Performance
 October 19, 2010 Using BigSim to Estimate Application Performance Ryan Mokos Parallel Programming Laboratory University of Illinois at Urbana-Champaign Outline Overview BigSim Emulator BigSim Simulator
October 19, 2010 Using BigSim to Estimate Application Performance Ryan Mokos Parallel Programming Laboratory University of Illinois at Urbana-Champaign Outline Overview BigSim Emulator BigSim Simulator
A Framework for Collective Personalized Communication
 A Framework for Collective Personalized Communication Laxmikant V. Kalé, Sameer Kumar Department of Computer Science University of Illinois at Urbana-Champaign {kale,skumar2}@cs.uiuc.edu Krishnan Varadarajan
A Framework for Collective Personalized Communication Laxmikant V. Kalé, Sameer Kumar Department of Computer Science University of Illinois at Urbana-Champaign {kale,skumar2}@cs.uiuc.edu Krishnan Varadarajan
Topology-aware task mapping for reducing communication contention on large parallel machines
 Topology-aware task mapping for reducing communication contention on large parallel machines Tarun Agarwal, Amit Sharma, Laxmikant V. Kalé Dept. of Computer Science University of Illinois at Urbana-Champaign
Topology-aware task mapping for reducing communication contention on large parallel machines Tarun Agarwal, Amit Sharma, Laxmikant V. Kalé Dept. of Computer Science University of Illinois at Urbana-Champaign
TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks
 TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks Bilge Acun, PhD Candidate Department of Computer Science University of Illinois at Urbana- Champaign *Contributors: Nikhil Jain,
TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks Bilge Acun, PhD Candidate Department of Computer Science University of Illinois at Urbana- Champaign *Contributors: Nikhil Jain,
c 2011 by Ehsan Totoni. All rights reserved.
 c 2011 by Ehsan Totoni. All rights reserved. SIMULATION-BASED PERFORMANCE ANALYSIS AND TUNING FOR FUTURE SUPERCOMPUTERS BY EHSAN TOTONI THESIS Submitted in partial fulfillment of the requirements for the
c 2011 by Ehsan Totoni. All rights reserved. SIMULATION-BASED PERFORMANCE ANALYSIS AND TUNING FOR FUTURE SUPERCOMPUTERS BY EHSAN TOTONI THESIS Submitted in partial fulfillment of the requirements for the
Technical Computing Suite supporting the hybrid system
 Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
NAMD Serial and Parallel Performance
 NAMD Serial and Parallel Performance Jim Phillips Theoretical Biophysics Group Serial performance basics Main factors affecting serial performance: Molecular system size and composition. Cutoff distance
NAMD Serial and Parallel Performance Jim Phillips Theoretical Biophysics Group Serial performance basics Main factors affecting serial performance: Molecular system size and composition. Cutoff distance
Introduction to FREE National Resources for Scientific Computing. Dana Brunson. Jeff Pummill
 Introduction to FREE National Resources for Scientific Computing Dana Brunson Oklahoma State University High Performance Computing Center Jeff Pummill University of Arkansas High Peformance Computing Center
Introduction to FREE National Resources for Scientific Computing Dana Brunson Oklahoma State University High Performance Computing Center Jeff Pummill University of Arkansas High Peformance Computing Center
NUMA Support for Charm++
 NUMA Support for Charm++ Christiane Pousa Ribeiro (INRIA) Filippo Gioachin (UIUC) Chao Mei (UIUC) Jean-François Méhaut (INRIA) Gengbin Zheng(UIUC) Laxmikant Kalé (UIUC) Outline Introduction Motivation
NUMA Support for Charm++ Christiane Pousa Ribeiro (INRIA) Filippo Gioachin (UIUC) Chao Mei (UIUC) Jean-François Méhaut (INRIA) Gengbin Zheng(UIUC) Laxmikant Kalé (UIUC) Outline Introduction Motivation
Maximizing Throughput on a Dragonfly Network
 Maximizing Throughput on a Dragonfly Network Nikhil Jain, Abhinav Bhatele, Xiang Ni, Nicholas J. Wright, Laxmikant V. Kale Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana,
Maximizing Throughput on a Dragonfly Network Nikhil Jain, Abhinav Bhatele, Xiang Ni, Nicholas J. Wright, Laxmikant V. Kale Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana,
c Copyright by Gengbin Zheng, 2005
 c Copyright by Gengbin Zheng, 2005 ACHIEVING HIGH PERFORMANCE ON EXTREMELY LARGE PARALLEL MACHINES: PERFORMANCE PREDICTION AND LOAD BALANCING BY GENGBIN ZHENG B.S., Beijing University, China, 1995 M.S.,
c Copyright by Gengbin Zheng, 2005 ACHIEVING HIGH PERFORMANCE ON EXTREMELY LARGE PARALLEL MACHINES: PERFORMANCE PREDICTION AND LOAD BALANCING BY GENGBIN ZHENG B.S., Beijing University, China, 1995 M.S.,
BigSim: A Parallel Simulator for Performance Prediction of Extremely Large Parallel Machines
 BigSim: A Parallel Simulator for Performance Prediction of Extremely Large Parallel Machines Gengbin Zheng, Gunavardhan Kakulapati, Laxmikant V. Kalé Dept. of Computer Science University of Illinois at
BigSim: A Parallel Simulator for Performance Prediction of Extremely Large Parallel Machines Gengbin Zheng, Gunavardhan Kakulapati, Laxmikant V. Kalé Dept. of Computer Science University of Illinois at
Towards Large Scale Predictive Flow Simulations
 Towards Large Scale Predictive Flow Simulations using ITAPS Tools and Services Onkar Sahni a a Present address: Center for Predictive Engineering and Computational Sciences (PECOS), ICES, UT Austin ollaborators:
Towards Large Scale Predictive Flow Simulations using ITAPS Tools and Services Onkar Sahni a a Present address: Center for Predictive Engineering and Computational Sciences (PECOS), ICES, UT Austin ollaborators:
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
The Red Storm System: Architecture, System Update and Performance Analysis
 The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
Optimizing a Parallel Runtime System for Multicore Clusters: A Case Study
 Optimizing a Parallel Runtime System for Multicore Clusters: A Case Study Chao Mei Department of Computing Science University of Illinois at Urbana-Champaign chaomei2@illinois.edu Gengbin Zheng Department
Optimizing a Parallel Runtime System for Multicore Clusters: A Case Study Chao Mei Department of Computing Science University of Illinois at Urbana-Champaign chaomei2@illinois.edu Gengbin Zheng Department
Topology Awareness in the Tofu Interconnect Series
 Topology Awareness in the Tofu Interconnect Series Yuichiro Ajima Senior Architect Next Generation Technical Computing Unit Fujitsu Limited June 23rd, 2016, ExaComm2016 Workshop 0 Introduction Networks
Topology Awareness in the Tofu Interconnect Series Yuichiro Ajima Senior Architect Next Generation Technical Computing Unit Fujitsu Limited June 23rd, 2016, ExaComm2016 Workshop 0 Introduction Networks
Enzo-P / Cello. Scalable Adaptive Mesh Refinement for Astrophysics and Cosmology. San Diego Supercomputer Center. Department of Physics and Astronomy
 Enzo-P / Cello Scalable Adaptive Mesh Refinement for Astrophysics and Cosmology James Bordner 1 Michael L. Norman 1 Brian O Shea 2 1 University of California, San Diego San Diego Supercomputer Center 2
Enzo-P / Cello Scalable Adaptive Mesh Refinement for Astrophysics and Cosmology James Bordner 1 Michael L. Norman 1 Brian O Shea 2 1 University of California, San Diego San Diego Supercomputer Center 2
Development Environments for HPC: The View from NCSA
 Development Environments for HPC: The View from NCSA Jay Alameda National Center for Supercomputing Applications, University of Illinois at Urbana-Champaign DEHPC 15 San Francisco, CA 18 October 2015 Acknowledgements
Development Environments for HPC: The View from NCSA Jay Alameda National Center for Supercomputing Applications, University of Illinois at Urbana-Champaign DEHPC 15 San Francisco, CA 18 October 2015 Acknowledgements
Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs
 Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs Isaac Dooley, Laxmikant V. Kale Department of Computer Science University of Illinois idooley2@illinois.edu kale@illinois.edu
Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs Isaac Dooley, Laxmikant V. Kale Department of Computer Science University of Illinois idooley2@illinois.edu kale@illinois.edu
Flexible Hardware Mapping for Finite Element Simulations on Hybrid CPU/GPU Clusters
 Flexible Hardware Mapping for Finite Element Simulations on Hybrid /GPU Clusters Aaron Becker (abecker3@illinois.edu) Isaac Dooley Laxmikant Kale SAAHPC, July 30 2009 Champaign-Urbana, IL Target Application
Flexible Hardware Mapping for Finite Element Simulations on Hybrid /GPU Clusters Aaron Becker (abecker3@illinois.edu) Isaac Dooley Laxmikant Kale SAAHPC, July 30 2009 Champaign-Urbana, IL Target Application
Petascale Multiscale Simulations of Biomolecular Systems. John Grime Voth Group Argonne National Laboratory / University of Chicago
 Petascale Multiscale Simulations of Biomolecular Systems John Grime Voth Group Argonne National Laboratory / University of Chicago About me Background: experimental guy in grad school (LSCM, drug delivery)
Petascale Multiscale Simulations of Biomolecular Systems John Grime Voth Group Argonne National Laboratory / University of Chicago About me Background: experimental guy in grad school (LSCM, drug delivery)
Applying Graph Partitioning Methods in Measurement-based Dynamic Load Balancing
 Applying Graph Partitioning Methods in Measurement-based Dynamic Load Balancing HARSHITHA MENON, University of Illinois at Urbana-Champaign ABHINAV BHATELE, Lawrence Livermore National Laboratory SÉBASTIEN
Applying Graph Partitioning Methods in Measurement-based Dynamic Load Balancing HARSHITHA MENON, University of Illinois at Urbana-Champaign ABHINAV BHATELE, Lawrence Livermore National Laboratory SÉBASTIEN
Strong Scaling for Molecular Dynamics Applications
 Strong Scaling for Molecular Dynamics Applications Scaling and Molecular Dynamics Strong Scaling How does solution time vary with the number of processors for a fixed problem size Classical Molecular Dynamics
Strong Scaling for Molecular Dynamics Applications Scaling and Molecular Dynamics Strong Scaling How does solution time vary with the number of processors for a fixed problem size Classical Molecular Dynamics
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Installation and Test of Molecular Dynamics Simulation Packages on SGI Altix and Hydra-Cluster at JKU Linz
 Installation and Test of Molecular Dynamics Simulation Packages on SGI Altix and Hydra-Cluster at JKU Linz Rene Kobler May 25, 25 Contents 1 Abstract 2 2 Status 2 3 Changelog 2 4 Installation Notes 3 4.1
Installation and Test of Molecular Dynamics Simulation Packages on SGI Altix and Hydra-Cluster at JKU Linz Rene Kobler May 25, 25 Contents 1 Abstract 2 2 Status 2 3 Changelog 2 4 Installation Notes 3 4.1
Adaptive MPI. Chao Huang, Orion Lawlor, L. V. Kalé
 Adaptive MPI Chao Huang, Orion Lawlor, L. V. Kalé chuang10@uiuc.edu, olawlor@acm.org, l-kale1@uiuc.edu Parallel Programming Laboratory University of Illinois at Urbana-Champaign Abstract. Processor virtualization
Adaptive MPI Chao Huang, Orion Lawlor, L. V. Kalé chuang10@uiuc.edu, olawlor@acm.org, l-kale1@uiuc.edu Parallel Programming Laboratory University of Illinois at Urbana-Champaign Abstract. Processor virtualization
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
Scaling All-to-All Multicast on Fat-tree Networks
 Scaling All-to-All Multicast on Fat-tree Networks Sameer Kumar, Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign {skumar, kale}@cs.uiuc.edu Abstract In this paper,
Scaling All-to-All Multicast on Fat-tree Networks Sameer Kumar, Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign {skumar, kale}@cs.uiuc.edu Abstract In this paper,
c 2012 Harshitha Menon Gopalakrishnan Menon
 c 2012 Harshitha Menon Gopalakrishnan Menon META-BALANCER: AUTOMATED LOAD BALANCING BASED ON APPLICATION BEHAVIOR BY HARSHITHA MENON GOPALAKRISHNAN MENON THESIS Submitted in partial fulfillment of the
c 2012 Harshitha Menon Gopalakrishnan Menon META-BALANCER: AUTOMATED LOAD BALANCING BASED ON APPLICATION BEHAVIOR BY HARSHITHA MENON GOPALAKRISHNAN MENON THESIS Submitted in partial fulfillment of the
Advanced Software for the Supercomputer PRIMEHPC FX10. Copyright 2011 FUJITSU LIMITED
 Advanced Software for the Supercomputer PRIMEHPC FX10 System Configuration of PRIMEHPC FX10 nodes Login Compilation Job submission 6D mesh/torus Interconnect Local file system (Temporary area occupied
Advanced Software for the Supercomputer PRIMEHPC FX10 System Configuration of PRIMEHPC FX10 nodes Login Compilation Job submission 6D mesh/torus Interconnect Local file system (Temporary area occupied
Generic Topology Mapping Strategies for Large-scale Parallel Architectures
 Generic Topology Mapping Strategies for Large-scale Parallel Architectures Torsten Hoefler and Marc Snir Scientific talk at ICS 11, Tucson, AZ, USA, June 1 st 2011, Hierarchical Sparse Networks are Ubiquitous
Generic Topology Mapping Strategies for Large-scale Parallel Architectures Torsten Hoefler and Marc Snir Scientific talk at ICS 11, Tucson, AZ, USA, June 1 st 2011, Hierarchical Sparse Networks are Ubiquitous
TECHNIQUES IN SCALABLE AND EFFECTIVE PARALLEL PERFORMANCE ANALYSIS CHEE WAI LEE DISSERTATION
 TECHNIQUES IN SCALABLE AND EFFECTIVE PARALLEL PERFORMANCE ANALYSIS BY CHEE WAI LEE DISSERTATION Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science
TECHNIQUES IN SCALABLE AND EFFECTIVE PARALLEL PERFORMANCE ANALYSIS BY CHEE WAI LEE DISSERTATION Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science
Memory Tagging in Charm++
 Memory Tagging in Charm++ Filippo Gioachin Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana Champaign Outline Overview Memory tagging Charm++ RTS CharmDebug Charm++ memory
Memory Tagging in Charm++ Filippo Gioachin Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana Champaign Outline Overview Memory tagging Charm++ RTS CharmDebug Charm++ memory
c Copyright by Tarun Agarwal, 2005
 c Copyright by Tarun Agarwal, 2005 STRATEGIES FOR TOPOLOGY-AWARE TASK MAPPING AND FOR REBALANCING WITH BOUNDED MIGRATIONS BY TARUN AGARWAL B.Tech., Indian Institute of Technology, Delhi, 2003 THESIS Submitted
c Copyright by Tarun Agarwal, 2005 STRATEGIES FOR TOPOLOGY-AWARE TASK MAPPING AND FOR REBALANCING WITH BOUNDED MIGRATIONS BY TARUN AGARWAL B.Tech., Indian Institute of Technology, Delhi, 2003 THESIS Submitted
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
An Orchestration Language for Parallel Objects
 An Orchestration Language for Parallel Objects Laxmikant V. Kalé Department of Computer Science University of Illinois kale@cs.uiuc.edu Mark Hills Department of Computer Science University of Illinois
An Orchestration Language for Parallel Objects Laxmikant V. Kalé Department of Computer Science University of Illinois kale@cs.uiuc.edu Mark Hills Department of Computer Science University of Illinois
Basic Low Level Concepts
 Course Outline Basic Low Level Concepts Case Studies Operation through multiple switches: Topologies & Routing v Direct, indirect, regular, irregular Formal models and analysis for deadlock and livelock
Course Outline Basic Low Level Concepts Case Studies Operation through multiple switches: Topologies & Routing v Direct, indirect, regular, irregular Formal models and analysis for deadlock and livelock
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Optimizing the performance of parallel applications on a 5D torus via task mapping
 Optimizing the performance of parallel applications on a D torus via task mapping Abhinav Bhatele, Nikhil Jain,, Katherine E. Isaacs,, Ronak Buch, Todd Gamblin, Steven H. Langer, Laxmikant V. Kale Lawrence
Optimizing the performance of parallel applications on a D torus via task mapping Abhinav Bhatele, Nikhil Jain,, Katherine E. Isaacs,, Ronak Buch, Todd Gamblin, Steven H. Langer, Laxmikant V. Kale Lawrence
Scalable In-memory Checkpoint with Automatic Restart on Failures
 Scalable In-memory Checkpoint with Automatic Restart on Failures Xiang Ni, Esteban Meneses, Laxmikant V. Kalé Parallel Programming Laboratory University of Illinois at Urbana-Champaign November, 2012 8th
Scalable In-memory Checkpoint with Automatic Restart on Failures Xiang Ni, Esteban Meneses, Laxmikant V. Kalé Parallel Programming Laboratory University of Illinois at Urbana-Champaign November, 2012 8th
Performance of HPC Applications over InfiniBand, 10 Gb and 1 Gb Ethernet. Swamy N. Kandadai and Xinghong He and
 Performance of HPC Applications over InfiniBand, 10 Gb and 1 Gb Ethernet Swamy N. Kandadai and Xinghong He swamy@us.ibm.com and xinghong@us.ibm.com ABSTRACT: We compare the performance of several applications
Performance of HPC Applications over InfiniBand, 10 Gb and 1 Gb Ethernet Swamy N. Kandadai and Xinghong He swamy@us.ibm.com and xinghong@us.ibm.com ABSTRACT: We compare the performance of several applications
NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems
 NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems Carl Pearson 1, I-Hsin Chung 2, Zehra Sura 2, Wen-Mei Hwu 1, and Jinjun Xiong 2 1 University of Illinois Urbana-Champaign, Urbana
NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems Carl Pearson 1, I-Hsin Chung 2, Zehra Sura 2, Wen-Mei Hwu 1, and Jinjun Xiong 2 1 University of Illinois Urbana-Champaign, Urbana