Recommender Systems. Francesco Ricci Database and Information Systems Free University of Bozen, Italy
|
|
|
- Madeline Peters
- 5 years ago
- Views:
Transcription
1 Recommender Systems Francesco Ricci Database and Information Systems Free University of Bozen, Italy
2 Content Example of Recommender System The basic idea of collaborative-based filtering Collaborative-based filtering: technical details Content-based filtering Knowledge-based recommender systems Evaluating recommender systems Challenges 2

3 Jeff Bezos If I have 3 million customers on the Web, I should have 3 million stores on the Web Jeff Bezos, CEO of Amazon.com Degree in Computer Science $4.3 billion, ranked no. 47 in the Forbes list of the World's Wealthiest People 3 [Person of the Year-999]






4 What movie should I see? 4 The Internet Movie Database (IMDb) provides information about actors, films, television shows, television stars, video games and production crew personnel. Owned by Amazon.com since 998, as of June 2, 2006 IMDb featured 796,328 titles and 2,27,37 people.

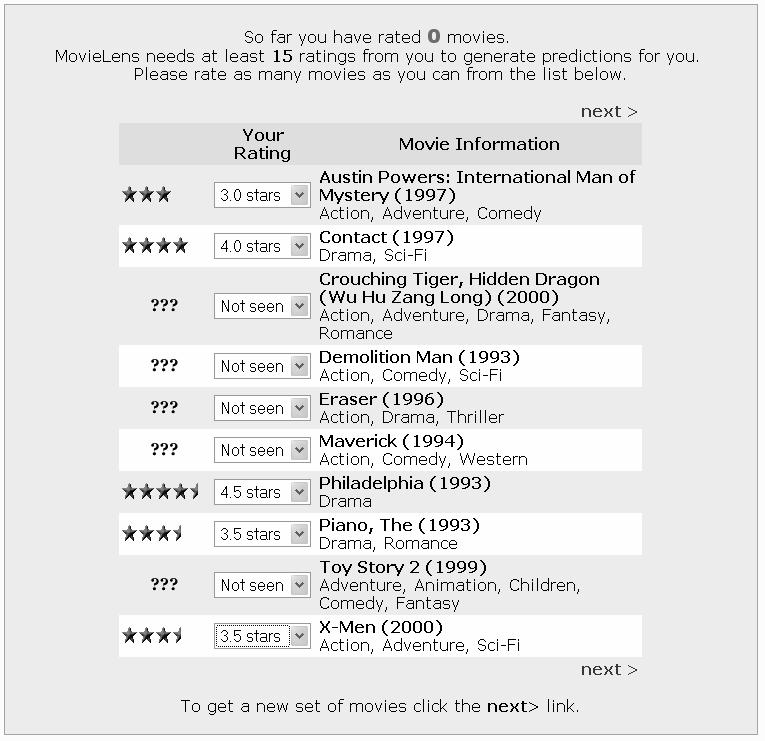
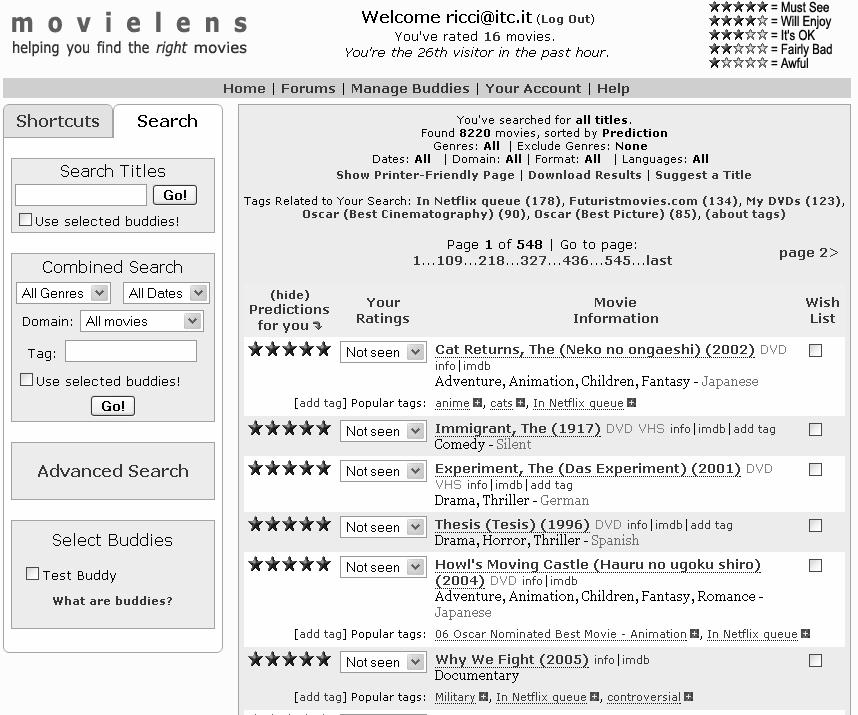
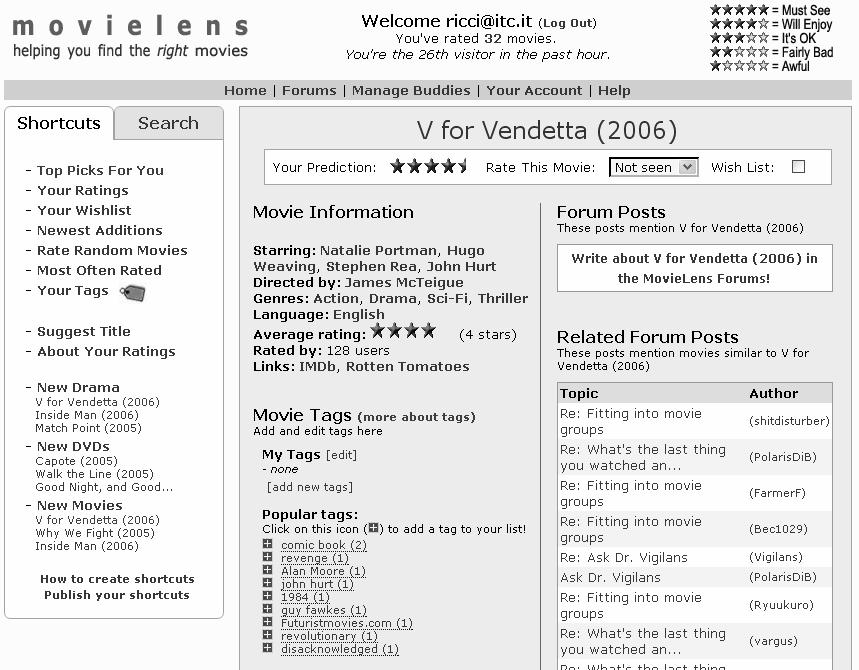
5 Movie Lens 5
6 Movielens Approach You rate/ evaluate some movies on a ( Awful ) to 5 ( Must to see ) scale The system stores your ratings and build your user model You ask for recommendations, i.e., movies that you would like and you have not seen yet The system exploits your user model and the user model of other similar users to compute some predictions, i.e., it guess what will be your rating for some movies and displays those movies having higher predicted ratings You browse the list of recommendations and eventually decide to watch one of these recommended movies. 6
7 7
8 8
9 9

10 What travel should I do? I would like to escape from this ugly an tedious work life and relax for two weeks in a sunny place. I am fed up with these crowded and noisy places just the sand and the sea and some adventure. I would like to bring my wife and my children on a holiday it should not be to expensive. I prefer mountainous places not to far from home. Children parks, easy paths and good cuisine are a must. I want to experience the contact with a completely different culture. I would like to be fascinated by the people and learn to look at my life in a totally different way. 0

11 What book should I buy?
12 Example: Book recommendation Ephemeral I m taking two weeks off Novel I m interested in a Polish writer Should be a travel book I d like to reflect on the meaning of life User Long Term Dostoievsky Stendhal Checov Musil Pessoa Sedaris Auster Mann 2 Recommendation Joseph Conrad, Hearth of darkness

13 What news should I read? 3
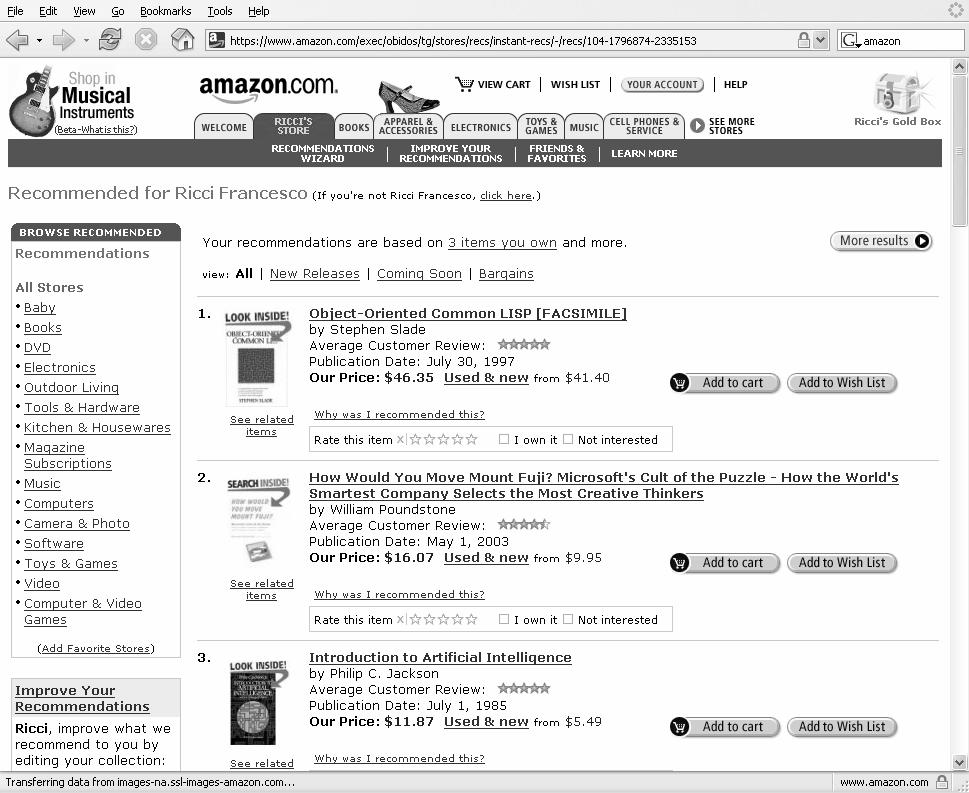
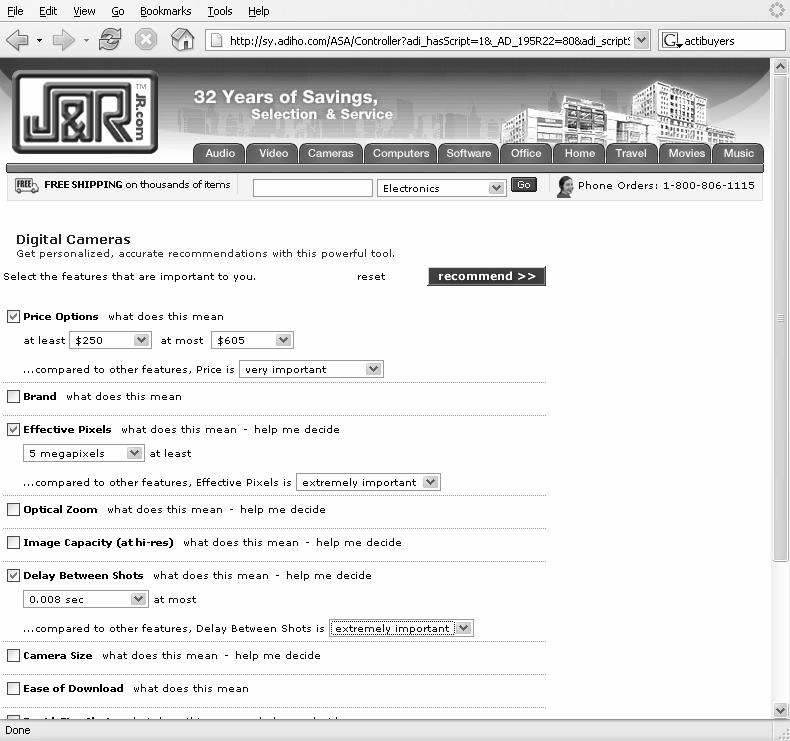
14 Examples Some examples found in the Web:. Amazon.com looks in the user past buying history, and recommends product bought by a user with similar buying behavior 2. Tripadvisor.com - Quoting product reviews of a community of users 3. Activebuyersguide.com make questions about searched benefits to reduce the number of candidate products 4. Trip.com make questions and exploits to constraint the search (exploit standardized profiles) 4 5. Smarter Kids self selection of a user profile classification of products in user profiles.
15 The Problem 5
16 A Solution??????? 6
17 Original Definition of RS In everyday life we rely on recommendations from other people either by word of mouth, recommendation letters, movie and book reviews printed in newspapers In a typical recommender system people provide recommendations as inputs, which the system then aggregates and directs to appropriate recipients Aggregation of recommendations 7 Match the recommendations with those searching for recommendations [Resnick and Varian, 997]
18 Social Filtering??? 8
19 Recommender Systems A recommender system helps to make choices without sufficient personal experience of the alternatives To suggest products to their customers To provide consumers with information to help them decide which products to purchase They are based on a number of technologies: information filtering: search engines machine learning: classification learning adaptive and personalized system: adaptive hypermedia user modeling 9
20 Information Overload Internet = information overload, i.e., the state of having too much information to make a decision or remain informed about a topic: Too much mails, too much news, to much papers, Information retrieval technologies (a search engine like Google) can assist a user to locate content if the user knows exactly what he is looking for (with some difficulties!) The user must be able to say yes this is what I need when presented with the right result But in many information search task, e.g., product selection, the user is not aware of the range of available options may not know what to search if presented with some results may not be able to choose. 20
21 Ratings 2
22 Collaborative Filtering Positive rating Negative rating? 22
23 Collaborative-Based Filtering The collaborative based filtering recommendation techniques proceeds in these steps:. For a target/active user (the user to whom a recommendation has to be produced) the set of his ratings is identified 2. The users more similar to the target/active user (according to a similarity function) are identified (neighbor formation) 3. The products bought by these similar users are identified 4. For each one of these products a prediction - of the rating that would be given by the target user to the product - is generated 5. Based on this predicted rating a set of top N products are recommended. 23
24 Nearest Neighbor Collaborative-Based Filtering 0 Dislike Like? Unknown User Model = interaction history Current User? st item rate 4 th item rate Users Items 24 Hamming distance Nearest Neighbor
25 -Nearest Neighbor can be easily wrong 25 0 Dislike Like? Unknown User Model = interaction history Current User? st item rate This is the only user having a positive rating on this 4 th item rate product Hamming distance Users Nearest Neighbor Items

26 Matrix of ratings Items Users 26
27 Collaborative-Based Filtering 27 A collection of user u i, i=, n and a collection of products p j, j=,, m A n m matrix of ratings v ij, with v ij =? if user i did not rate product j Prediction for user i and product j is computed as: v* ij = v i + K ( v u? ik vkj v k kj Where, v i is the average rating of user i, K is a normalization factor such that the sum of u ik is, and u ik = j ( v ( v ij v v ) i )( v v v 2 j ij i j kj k Where the sum (and averages) is over j s.t. v ij and v kj are not?. [Breese et al., 998] kj ( v k ) ) 2 ) Similarity of users i and k
28 Example v 5j p j v* ij u 5 4 v 5 = 4 u i? v = 3.2 i u 8 3 v 8 = 3.5 u 9 5 v 9 = 3 Users similarities: u i5 = 0.5, u i8 = 0.5, u i9 = 0.8 v* ij = v i + K ( v u? ik vkj vk kj ) v* ij = /( ) * [0.5 (4-4) (3-3.5) (5-3) = /.8 * [ ] = =
29 Proximity Measure: Cosine Correlation can be replaced with a typical Information Retrieval similarity measure (u i and u j are two users, with ratings v ik and v jk, k=,, m) cos( u i, u j ) = k = m m k = v v 2 ik ik v m jk k = v 2 jk This has been shown to provide worse results by someone [Breese et al., 998] But many uses cosine [Sarwar et al., 2000] and somebody reports that it performs better [Anand and Mobasher, 2005] 29
30 Evaluating Recommender Systems The majority focused on system s accuracy in supporting the find good items user s task Assumption: if a user could examine all items available, he could place them in a ordering of preference. Measure how good is the system in predicting the exact rating value (value comparison) 2. Measure how well the system can predict whether the item is relevant or not (relevant vs. not relevant) 3. Measure how close the predicted ranking of items is to the user s true ranking (ordering comparison). 30
31 How Accuracy Has Been Measured Split the available data (so you need to collect data first!), i.e., the user-item ratings into two sets: training and test Build a model on the training data For instance, in a nearest neighbor (memory-based) CF simply put the ratings in the training in a separate set Compare the predicted rating on each test item (user-item combination) with the actual rating stored in the test set You need a metric to compare the predicted and true rating 3
32 Accuracy: Comparing Values Measure how close the recommender system s predicted ratings are to the true user ratings (for all the ratings in the test set). Predictive accuracy (rating): Mean Absolute Error (MAE), p i is the predicted rating and r i is the true one: MAE N i = = p N i r i Variation : mean squared error (take the square of the differences), or root mean squared error (and then take the square root). These emphasize large errors. Variation 2: Normalized MAE MAE divided by the range of possible ratings allowing comparing results on different data sets, having different rating scales. 32
33 Precision and Recall The rating scale must be binary or one must transform it into a binary scale (e.g. items rated above 4 vs. those rated below) Precision is the ratio of relevant items selected by the recommender to the number of items selected (N rs /N s ) Recall is the ratio of relevant items selected to the number of relevant (N rs /N r ) Precision and recall are the most popular metrics for evaluating information retrieval systems. 33
34 Precision and Recall selected not selected Precision = N rs / (N r s +N is ) Recall = N rs / (N rs + N rn ) N rn N rs N in relevant not relevant N is To improve both P and R you need to bring the lines closer together - i.e. better determination of relevance. 34
35 Example Complete Knowledge We assume to know the relevance of all the items in the catalogue for a given user The orange portion is that recommended by the system Precision=4/7=0.57 Recall=4/9= Selected 35
36 Example Incomplete Knowledge 36 We do not know the relevance of all the items in the catalogue for a given user The orange portion is that recommended by the system Precision=4/7=0.57 As before Recall=4/? 4/0 <= R <= 4/7 4/0 if all unknown are relevant 4/7 if all unknown are irrelevant ??? Selected
37 Precision vs. Recall A typical precision and recall curve 37
38 F Combinations of Recall and Precision such as F Typically systems with high recall have low precision and vice versa F PR = 2 P+ R Selected P=4/7=0.57 R=4/9=0.44 F =
39 Problems with Precision and Recall To compute them we must know what items are relevant and what are not relevant Difficult to know what is relevant for a user in a recommender system that manages thousands/millions of products May be easier for some tasks where, given the user or the context, the number of recommendable products is small only a small portion could fit Recall is more difficult to estimate (knowledge of all the relevant products) Precision is a bit easier you must know what part of the selected products are relevant (you can ask to the user after the recommendation but has not been done in this way not many evaluations did involve real users). 39
40 Example of Evaluation of a Collaborative Filtering Recommender System Movie data: 3500 users, 3000 movies, random selection of 00,000 ratings obtained a matrix of 943 users and 682 movies Sparsity = 00,000 / 943*682 = ) On average there are /943 = 06 ratings per user E-Commerce data: 6,502 customers, 23,554 products and 97,045 purchase records Sparsity = On average 4.9 ratings per user Sparsity is the proportion of missing ratings over all the possible ratings (#missing-ratings/#all-possible-ratings). 40 [Sarwar et al., 2000] All the possible ratings
41 Evaluation Procedure They evaluate top-n recommendation (0 recommendations for each user) Separate ratings in training and test sets (80% - 20%) Use the training to make the prediction Compare (precision and recall) the items in the test set of a user with the top N recommendations for that user Hit set is the intersection of the top N with the test (selected-relevant) Precision = size of the hit set / size of the top-n set Recall = size of the hit set / size of the test set (they assume that all the items not rated are not relevant optimistic assumption) They used the cosine metric in the CF prediction method. 4
42 Generation of recommendations Instead of using the average v* ij = v i + K ( v u? ik vkj v k kj ) They used the most-frequent item recommendation method Looks in the neighbors (users similar to the target user) scanning the purchase data Compute a frequency count of the products (the frequency of a product in the neighbors purchases) Sort the products according to the frequency Returns the N most frequent products 42

43 Comparison with Association Rules 43 Lo and Hi means low (=20) and original dimensionality for the products dimension achieved with LSI (Latent Semantic Indexing)

44 Comparison with Association Rules 44 Lo and Hi means low (=20) and original dimensionality for the products dimension achieved with LSI (Latent Semantic Indexing)
45 Core Recommendation Techniques U is a set of users I is a set of items/products [Burke, 2002] 45
46 Content-Based Recommender Has its root in Information Retrieval (IR) It is mainly used for recommending text-based products (web pages, usenet news messages) products for which you can find a textual description The items to recommend are described by their associated features (e.g. keywords) The User Model can be structured in a similar way as the content: for instance the features/keywords more likely to occur in the preferred documents Then, for instance, text documents can be recommended based on a comparison between their content (words appearing in the text) and a user model (a set of preferred words) The user model can also be a classifier based on whatever technique (e.g., Neural Networks, Naive Bayes, C4.5 ). 46


47 Syskill & Webert User Interface The user indicated interest in The user indicated no interest in System Prediction 47
48 Content Model: Syskill & Webert 48 A document (HTML page) is described as a set of Boolean features (a word is present or not) A feature is considered important for the prediction task if the Information Gain is high Information Gain: G(S,W) = E(S) [P((W is present)*e(s W is present ) + P(W is absent)*e(s W is absent )] E( S) = { E(S) is the Entropy of a labeled collection (how randomly the two labels are distributed) W is a word a Boolean feature (present/not-present) S is a set of documents, S hot is the subset of interesting documents They have used the 28 most informative words (highest information gain). } c hot, cold p( S c )log ( p( S 2 c ))
49 Learning They used a Bayesian classifier (one for each user), where the probability that a document w =v,, w n =v n (e.g. car=, story=0,, price=) belongs to a class (cold or hot) is P( C = hot w = v, K, w n = v n ) P( C = hot) P( wj = vj C = hot) j Both P(w j = v j C=hot) (i.e., the probability that in the set of the documents liked by a user the word w j is present or not) and P(C=hot) is estimated from the training data After training on 30/40 examples it can predict hot/cold with an accuracy between 70% and 80%. 49
50 A Better Model for the Document TF-IDF means Term Frequency Inverse Document Frequency The less frequent the word is in the corpus the greater is this The greater the frequency of the word the greater is this term tf i is the number of times word t i appears in document d (the term frequency), df i is the number of documents in the corpus which contain t i (the document frequency), n is the number of documents in the corpus and tf max is the maximum term frequency over all words in d. 50
51 Computing TF-IDF -- An Example Given a document D containing terms (a, b, and c) with given frequencies: freq(a,d)=3, freq(b,d)=2, freq(c,d)= Assume collection contains 0,000 documents and the term total frequencies of these terms are: N a =50, N b =300, N c =250 Then: a: tf = 3/3; idf = log(0.000/50) = 5.3; tf-idf = 5.3 b: tf = 2/3; idf = log(0.000/300) = 2.0; tf-idf =.3 c: tf = /3; idf = log(0.000/250) = 3.7; tf-idf =.2 5
52 Using TF-IDF One can build a classifier (e.g. Bayesian) as before, where instead of using a Boolean array for representing a document, the array now contains the tf-idf values of the selected words (a bit more complex because features are not Boolean anymore) But can also build a User Model by (Rocchio, 97) Average of the tf-idf representations of interesting documents of a user (Centroid) Subtracting a fraction of the average of the not interesting documents (0.25 in [Pazzani & Billsus, 997] Then new documents close (cosine distance) to this user model are recommended. 52
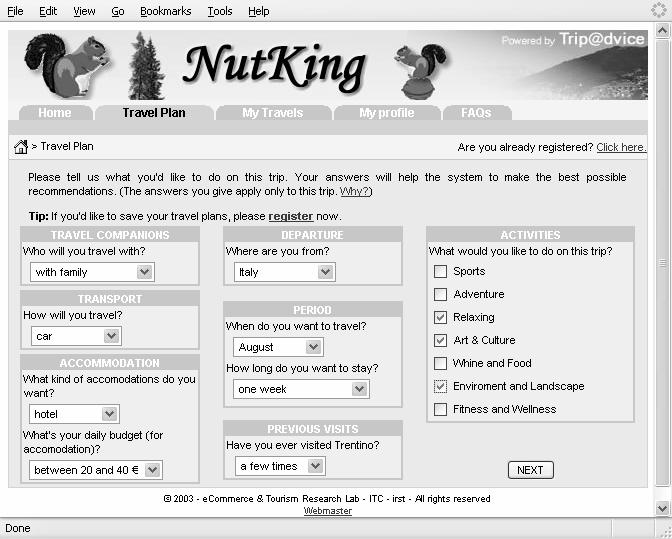
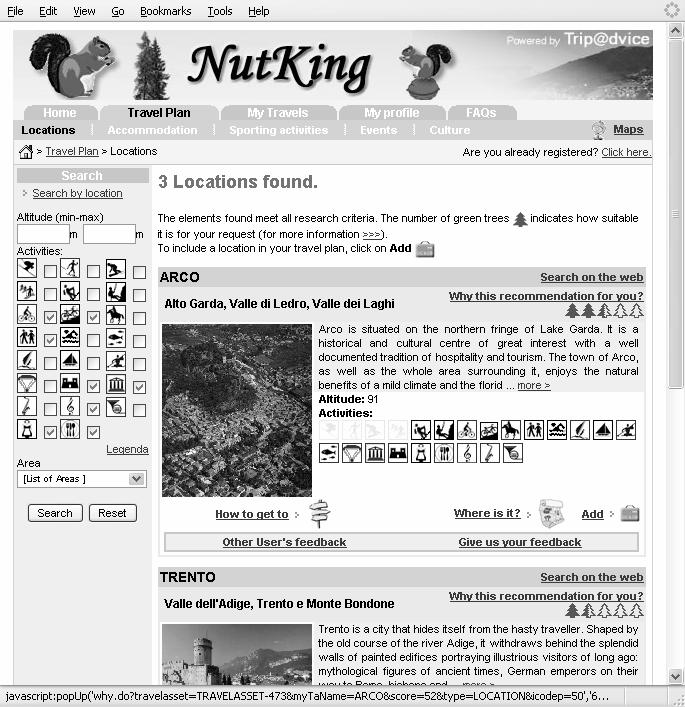
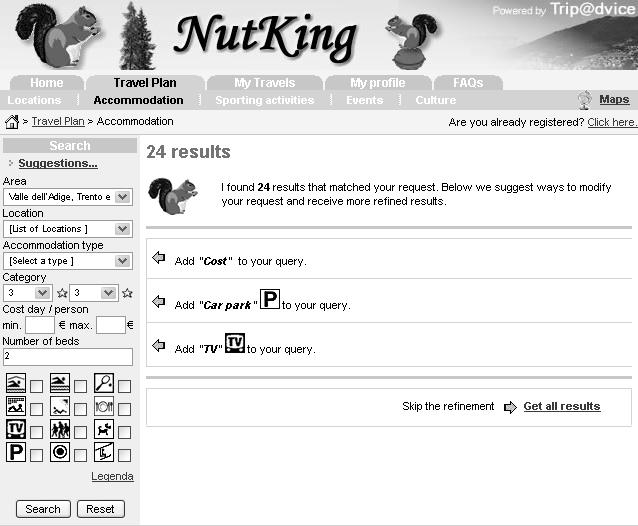
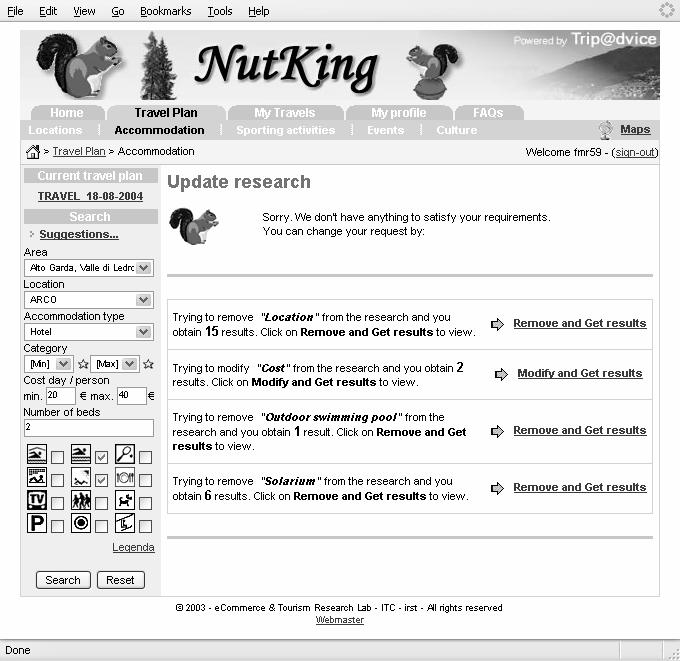
53 Example Not interesting Documents Interesting Documents Centroid Doc2 User Model Doc 53 Doc is estimated more interesting than Doc2
54 Problems of Content-Based Recommenders A very shallow analysis of certain kinds of content can be supplied Some kind of items are not amenable to any feature extraction methods with current technologies (e.g. movies, music) Even for texts (as web pages) the IR techniques cannot consider multimedia information, aesthetic qualities, download time (any ideas about to use them?) Hence if you rate positively a page it could be not related to the presence of certain keywords! 54
55 Problems of Content-Based Recommenders (2) Over-specialization: the system can only recommend items scoring high against a user s profile the user is recommended with items similar to those already rated Requires user feed-backs: the pure content-based approach (similarly to CF) requires user feedback on items in order to provide meaningful recommendations It tends to recommend expected items this tends to increase trust but could make the recommendation not much useful (no serendipity) Works better in those situations where the products are generated dynamically (news, , events, etc.) and there is the need to check if these items are relevant or not. 55
56 Knowledge Based Recommender Suggests products based on inferences about a user s needs and preferences Functional knowledge: about how a particular item meets a particular user need The user model can be any knowledge structure that supports this inference A query A case (in a case-based reasoning system) An adapted similarity metric (for matching) A part of an ontology There is a large use of domain knowledge encoded in a knowledge representation language/approach. 56
57 ActiveBuyersGuide 57

58 58

59 Entrée: Case-Based Recommender Entree is a restaurant recommender system it finds restaurants:. in a new city similar to restaurants the user knows and likes 2. or those matching some user goals (case features). 59

60 Partial Match In general, only a subset of the preferences will be matched in the recommended restaurant. 60
61 6
62 62
63 Query Tightening 63
64 64

![, 2002]](/docs-images/96/126861999/images/65-1.jpg)
65 65 [Ricci et al., 2002]
 34 National Tourism Organizations Project started 2004")
66 Major European Tourism Destination Portal of the European Travel Commission (ETC) 34 National Tourism Organizations Project started 2004 Consortium: EC3, TIScover, ITC-irst, Siemens, Lixto On line since April page views/month visitors/month 66
67 Evaluation of RS There are many criteria for evaluating RS User satisfaction/usability User effort (e.g. time or rec. cycles required) Accuracy of the prediction Success of the prediction (the product is bought after the recommendation) Coverage (recall) Confidence in the recommendation (trust) Understandability of the recommendation Degree of novelty brought by the recommendation (serendipity) Transparency Quantity Diversity Risk minimization Cost effective (the cheapest product having the required features) 67 Robustness of the method (e.g. against an attack) Scalability
68 Challenges Generic user models (multiple products and tasks) Generic recommender systems (multiple products and tasks) Distributed recommender system (users and products data are distributed) Portable recommender systems (user data stored at user side) (user) Configurable recommender systems Multi strategy adapted to the user Privacy protecting RS Context dependent RS Emotional and values aware RS Trust and recommendations Persuasion technologies Easily deployable RS 68 Group recommendations
69 Challenges (2) Interactive Recommendations sequential decision making Hybrid recommendation technologies Consumer Behavior and Recommender Systems Complex Products recommendations Mobile Recommendations Business Models for Recommender Systems High risk and value recommender systems Recommendation and negotiation Recommendation and information search Recommendation and configuration Listening customers 69 Recommender systems and ontologies
70 Summing up At the beginning user recommendations (ratings/evaluations) are used to build new recommendations collaborative or social filtering The recommender system is a machine that burns recommendations to build new recommendations The expansion many new methods are introduced (content-based, hybrid, clustering, ) the aim is to tackle information overload and improve the behavior of CF methods (considering context and product descriptions) 70
71 Summing up (2) Decision support recommender systems are tools for helping users to take decision (what product to buy or what news to read) The gain in utility (personalized) without and with recommendation is the metric; Information search and processing cannot be separated from the RS research; The recommendation process becomes an important factor Conversational systems are introduced More adaptive and flexible conversations should be supported 7
72 Conclusions A recommender system main task is helping to choose products that are potentially more interesting to the user from a large set of options Recommender systems personalize the humancomputer interaction make the interaction adapted to the specific needs and characteristics of the user Personalization is a complex topic: many factors and there is no single theory that explain all. 72

73 It s all about You 73
74 74 Questions?
75 75
76 76
77 77

78 Trip.com 78

79 Trip.com 79

80 Trip.com 80

81 8

82 82
Part 11: Collaborative Filtering. Francesco Ricci
 Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Recommendations in Context
 Recommendations in Context Francesco Ricci Free University of Bolzano/Bozen fricci@unibz.it What movie should I see? 2 1 What book should I buy? 3 What news should I read? 4 2 What paper should I read?
Recommendations in Context Francesco Ricci Free University of Bolzano/Bozen fricci@unibz.it What movie should I see? 2 1 What book should I buy? 3 What news should I read? 4 2 What paper should I read?
Part 11: Collaborative Filtering. Francesco Ricci
 Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Content-Based Filtering and Hybrid Systems. Francesco Ricci
 Content-Based Filtering and Hybrid Systems Francesco Ricci Content Typologies of recommender systems Content-based recommenders Naive Bayes classifiers and content-based filtering Content representation
Content-Based Filtering and Hybrid Systems Francesco Ricci Content Typologies of recommender systems Content-based recommenders Naive Bayes classifiers and content-based filtering Content representation
Part 12: Advanced Topics in Collaborative Filtering. Francesco Ricci
 Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Collaborative Filtering and Evaluation of Recommender Systems
 Collaborative Filtering and Evaluation of Recommender Systems Francesco Ricci ecommerce and Tourism Research Laboratory Automated Reasoning Systems Division ITC-irst Trento Italy ricci@itc.it http://ectrl.itc.it
Collaborative Filtering and Evaluation of Recommender Systems Francesco Ricci ecommerce and Tourism Research Laboratory Automated Reasoning Systems Division ITC-irst Trento Italy ricci@itc.it http://ectrl.itc.it
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman
 Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Recommender Systems (RSs)
") Recommender Systems Recommender Systems (RSs) RSs are software tools providing suggestions for items to be of use to users, such as what items to buy, what music to listen to, or what online news to read
Recommender Systems Recommender Systems (RSs) RSs are software tools providing suggestions for items to be of use to users, such as what items to buy, what music to listen to, or what online news to read
Hybrid Recommendation System Using Clustering and Collaborative Filtering
 Hybrid Recommendation System Using Clustering and Collaborative Filtering Roshni Padate Assistant Professor roshni@frcrce.ac.in Priyanka Bane B.E. Student priyankabane56@gmail.com Jayesh Kudase B.E. Student
Hybrid Recommendation System Using Clustering and Collaborative Filtering Roshni Padate Assistant Professor roshni@frcrce.ac.in Priyanka Bane B.E. Student priyankabane56@gmail.com Jayesh Kudase B.E. Student
Recommender Systems. Collaborative Filtering & Content-Based Recommending
 Recommender Systems Collaborative Filtering & Content-Based Recommending 1 Recommender Systems Systems for recommending items (e.g. books, movies, CD s, web pages, newsgroup messages) to users based on
Recommender Systems Collaborative Filtering & Content-Based Recommending 1 Recommender Systems Systems for recommending items (e.g. books, movies, CD s, web pages, newsgroup messages) to users based on
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University Infinite data. Filtering data streams
 /9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
/9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
Diversity in Recommender Systems Week 2: The Problems. Toni Mikkola, Andy Valjakka, Heng Gui, Wilson Poon
 Diversity in Recommender Systems Week 2: The Problems Toni Mikkola, Andy Valjakka, Heng Gui, Wilson Poon Review diversification happens by searching from further away balancing diversity and relevance
Diversity in Recommender Systems Week 2: The Problems Toni Mikkola, Andy Valjakka, Heng Gui, Wilson Poon Review diversification happens by searching from further away balancing diversity and relevance
Introduction to Data Mining
 Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Content-based Dimensionality Reduction for Recommender Systems
 Content-based Dimensionality Reduction for Recommender Systems Panagiotis Symeonidis Aristotle University, Department of Informatics, Thessaloniki 54124, Greece symeon@csd.auth.gr Abstract. Recommender
Content-based Dimensionality Reduction for Recommender Systems Panagiotis Symeonidis Aristotle University, Department of Informatics, Thessaloniki 54124, Greece symeon@csd.auth.gr Abstract. Recommender
Recommender Systems: Practical Aspects, Case Studies. Radek Pelánek
 Recommender Systems: Practical Aspects, Case Studies Radek Pelánek 2017 This Lecture practical aspects : attacks, context, shared accounts,... case studies, illustrations of application illustration of
Recommender Systems: Practical Aspects, Case Studies Radek Pelánek 2017 This Lecture practical aspects : attacks, context, shared accounts,... case studies, illustrations of application illustration of
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Recommender Systems 6CCS3WSN-7CCSMWAL
 Recommender Systems 6CCS3WSN-7CCSMWAL http://insidebigdata.com/wp-content/uploads/2014/06/humorrecommender.jpg Some basic methods of recommendation Recommend popular items Collaborative Filtering Item-to-Item:
Recommender Systems 6CCS3WSN-7CCSMWAL http://insidebigdata.com/wp-content/uploads/2014/06/humorrecommender.jpg Some basic methods of recommendation Recommend popular items Collaborative Filtering Item-to-Item:
Project Report. An Introduction to Collaborative Filtering
 Project Report An Introduction to Collaborative Filtering Siobhán Grayson 12254530 COMP30030 School of Computer Science and Informatics College of Engineering, Mathematical & Physical Sciences University
Project Report An Introduction to Collaborative Filtering Siobhán Grayson 12254530 COMP30030 School of Computer Science and Informatics College of Engineering, Mathematical & Physical Sciences University
Information Retrieval. CS630 Representing and Accessing Digital Information. What is a Retrieval Model? Basic IR Processes
 CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
Improving Results and Performance of Collaborative Filtering-based Recommender Systems using Cuckoo Optimization Algorithm
 Improving Results and Performance of Collaborative Filtering-based Recommender Systems using Cuckoo Optimization Algorithm Majid Hatami Faculty of Electrical and Computer Engineering University of Tabriz,
Improving Results and Performance of Collaborative Filtering-based Recommender Systems using Cuckoo Optimization Algorithm Majid Hatami Faculty of Electrical and Computer Engineering University of Tabriz,
Relevance Feedback and Query Reformulation. Lecture 10 CS 510 Information Retrieval on the Internet Thanks to Susan Price. Outline
 Relevance Feedback and Query Reformulation Lecture 10 CS 510 Information Retrieval on the Internet Thanks to Susan Price IR on the Internet, Spring 2010 1 Outline Query reformulation Sources of relevance
Relevance Feedback and Query Reformulation Lecture 10 CS 510 Information Retrieval on the Internet Thanks to Susan Price IR on the Internet, Spring 2010 1 Outline Query reformulation Sources of relevance
Recommender Systems. Nivio Ziviani. Junho de Departamento de Ciência da Computação da UFMG
 Recommender Systems Nivio Ziviani Departamento de Ciência da Computação da UFMG Junho de 2012 1 Introduction Chapter 1 of Recommender Systems Handbook Ricci, Rokach, Shapira and Kantor (editors), 2011.
Recommender Systems Nivio Ziviani Departamento de Ciência da Computação da UFMG Junho de 2012 1 Introduction Chapter 1 of Recommender Systems Handbook Ricci, Rokach, Shapira and Kantor (editors), 2011.
Part 15: Knowledge-Based Recommender Systems. Francesco Ricci
 Part 15: Knowledge-Based Recommender Systems Francesco Ricci Content p Knowledge-based recommenders: definition and examples p Case-Based Reasoning p Instance-Based Learning p A recommender system exploiting
Part 15: Knowledge-Based Recommender Systems Francesco Ricci Content p Knowledge-based recommenders: definition and examples p Case-Based Reasoning p Instance-Based Learning p A recommender system exploiting
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most
 In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
Preference Learning in Recommender Systems
 Preference Learning in Recommender Systems M. de Gemmis L. Iaquinta P. Lops C. Musto F. Narducci G. Semeraro Department of Computer Science University of Bari, Italy ECML/PKDD workshop on Preference Learning,
Preference Learning in Recommender Systems M. de Gemmis L. Iaquinta P. Lops C. Musto F. Narducci G. Semeraro Department of Computer Science University of Bari, Italy ECML/PKDD workshop on Preference Learning,
A Recommender System Based on Improvised K- Means Clustering Algorithm
 A Recommender System Based on Improvised K- Means Clustering Algorithm Shivani Sharma Department of Computer Science and Applications, Kurukshetra University, Kurukshetra Shivanigaur83@yahoo.com Abstract:
A Recommender System Based on Improvised K- Means Clustering Algorithm Shivani Sharma Department of Computer Science and Applications, Kurukshetra University, Kurukshetra Shivanigaur83@yahoo.com Abstract:
Orange3 Data Fusion Documentation. Biolab
 Biolab Mar 07, 2018 Widgets 1 IMDb Actors 1 2 Chaining 5 3 Completion Scoring 9 4 Fusion Graph 13 5 Latent Factors 17 6 Matrix Sampler 21 7 Mean Fuser 25 8 Movie Genres 29 9 Movie Ratings 33 10 Table
Biolab Mar 07, 2018 Widgets 1 IMDb Actors 1 2 Chaining 5 3 Completion Scoring 9 4 Fusion Graph 13 5 Latent Factors 17 6 Matrix Sampler 21 7 Mean Fuser 25 8 Movie Genres 29 9 Movie Ratings 33 10 Table
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Outline. Possible solutions. The basic problem. How? How? Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity
 Outline Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity Lecture 10 CS 410/510 Information Retrieval on the Internet Query reformulation Sources of relevance for feedback Using
Outline Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity Lecture 10 CS 410/510 Information Retrieval on the Internet Query reformulation Sources of relevance for feedback Using
CS 6320 Natural Language Processing
 CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
Information Retrieval. Information Retrieval and Web Search
 Information Retrieval and Web Search Introduction to IR models and methods Information Retrieval The indexing and retrieval of textual documents. Searching for pages on the World Wide Web is the most recent
Information Retrieval and Web Search Introduction to IR models and methods Information Retrieval The indexing and retrieval of textual documents. Searching for pages on the World Wide Web is the most recent
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Predicting User Ratings Using Status Models on Amazon.com
 Predicting User Ratings Using Status Models on Amazon.com Borui Wang Stanford University borui@stanford.edu Guan (Bell) Wang Stanford University guanw@stanford.edu Group 19 Zhemin Li Stanford University
Predicting User Ratings Using Status Models on Amazon.com Borui Wang Stanford University borui@stanford.edu Guan (Bell) Wang Stanford University guanw@stanford.edu Group 19 Zhemin Li Stanford University
Information Retrieval: Retrieval Models
 CS473: Web Information Retrieval & Management CS-473 Web Information Retrieval & Management Information Retrieval: Retrieval Models Luo Si Department of Computer Science Purdue University Retrieval Models
CS473: Web Information Retrieval & Management CS-473 Web Information Retrieval & Management Information Retrieval: Retrieval Models Luo Si Department of Computer Science Purdue University Retrieval Models
Recommender Systems - Content, Collaborative, Hybrid
 BOBBY B. LYLE SCHOOL OF ENGINEERING Department of Engineering Management, Information and Systems EMIS 8331 Advanced Data Mining Recommender Systems - Content, Collaborative, Hybrid Scott F Eisenhart 1
BOBBY B. LYLE SCHOOL OF ENGINEERING Department of Engineering Management, Information and Systems EMIS 8331 Advanced Data Mining Recommender Systems - Content, Collaborative, Hybrid Scott F Eisenhart 1
Information Retrieval and Web Search
 Information Retrieval and Web Search Introduction to IR models and methods Rada Mihalcea (Some of the slides in this slide set come from IR courses taught at UT Austin and Stanford) Information Retrieval
Information Retrieval and Web Search Introduction to IR models and methods Rada Mihalcea (Some of the slides in this slide set come from IR courses taught at UT Austin and Stanford) Information Retrieval
A probabilistic model to resolve diversity-accuracy challenge of recommendation systems
 A probabilistic model to resolve diversity-accuracy challenge of recommendation systems AMIN JAVARI MAHDI JALILI 1 Received: 17 Mar 2013 / Revised: 19 May 2014 / Accepted: 30 Jun 2014 Recommendation systems
A probabilistic model to resolve diversity-accuracy challenge of recommendation systems AMIN JAVARI MAHDI JALILI 1 Received: 17 Mar 2013 / Revised: 19 May 2014 / Accepted: 30 Jun 2014 Recommendation systems
BBS654 Data Mining. Pinar Duygulu
 BBS6 Data Mining Pinar Duygulu Slides are adapted from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org Mustafa Ozdal Example: Recommender Systems Customer X Buys Metallica
BBS6 Data Mining Pinar Duygulu Slides are adapted from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org Mustafa Ozdal Example: Recommender Systems Customer X Buys Metallica
TriRank: Review-aware Explainable Recommendation by Modeling Aspects
 TriRank: Review-aware Explainable Recommendation by Modeling Aspects Xiangnan He, Tao Chen, Min-Yen Kan, Xiao Chen National University of Singapore Presented by Xiangnan He CIKM 15, Melbourne, Australia
TriRank: Review-aware Explainable Recommendation by Modeling Aspects Xiangnan He, Tao Chen, Min-Yen Kan, Xiao Chen National University of Singapore Presented by Xiangnan He CIKM 15, Melbourne, Australia
International Journal of Advance Engineering and Research Development. A Facebook Profile Based TV Shows and Movies Recommendation System
 Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 3, March -2017 A Facebook Profile Based TV Shows and Movies Recommendation
Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 3, March -2017 A Facebook Profile Based TV Shows and Movies Recommendation
Ranking Algorithms For Digital Forensic String Search Hits
 DIGITAL FORENSIC RESEARCH CONFERENCE Ranking Algorithms For Digital Forensic String Search Hits By Nicole Beebe and Lishu Liu Presented At The Digital Forensic Research Conference DFRWS 2014 USA Denver,
DIGITAL FORENSIC RESEARCH CONFERENCE Ranking Algorithms For Digital Forensic String Search Hits By Nicole Beebe and Lishu Liu Presented At The Digital Forensic Research Conference DFRWS 2014 USA Denver,
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
CSE 258. Web Mining and Recommender Systems. Advanced Recommender Systems
 CSE 258 Web Mining and Recommender Systems Advanced Recommender Systems This week Methodological papers Bayesian Personalized Ranking Factorizing Personalized Markov Chains Personalized Ranking Metric
CSE 258 Web Mining and Recommender Systems Advanced Recommender Systems This week Methodological papers Bayesian Personalized Ranking Factorizing Personalized Markov Chains Personalized Ranking Metric
CS435 Introduction to Big Data Spring 2018 Colorado State University. 3/21/2018 Week 10-B Sangmi Lee Pallickara. FAQs. Collaborative filtering
 W10.B.0.0 CS435 Introduction to Big Data W10.B.1 FAQs Term project 5:00PM March 29, 2018 PA2 Recitation: Friday PART 1. LARGE SCALE DATA AALYTICS 4. RECOMMEDATIO SYSTEMS 5. EVALUATIO AD VALIDATIO TECHIQUES
W10.B.0.0 CS435 Introduction to Big Data W10.B.1 FAQs Term project 5:00PM March 29, 2018 PA2 Recitation: Friday PART 1. LARGE SCALE DATA AALYTICS 4. RECOMMEDATIO SYSTEMS 5. EVALUATIO AD VALIDATIO TECHIQUES
COMP6237 Data Mining Making Recommendations. Jonathon Hare
 COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
Chapter 8. Evaluating Search Engine
 Chapter 8 Evaluating Search Engine Evaluation Evaluation is key to building effective and efficient search engines Measurement usually carried out in controlled laboratory experiments Online testing can
Chapter 8 Evaluating Search Engine Evaluation Evaluation is key to building effective and efficient search engines Measurement usually carried out in controlled laboratory experiments Online testing can
Final Report - Smart and Fast Sorting
 Final Report - Smart and Fast Email Sorting Antonin Bas - Clement Mennesson 1 Project s Description Some people receive hundreds of emails a week and sorting all of them into different categories (e.g.
Final Report - Smart and Fast Email Sorting Antonin Bas - Clement Mennesson 1 Project s Description Some people receive hundreds of emails a week and sorting all of them into different categories (e.g.
Available online at ScienceDirect. Procedia Technology 17 (2014 )
") Available online at www.sciencedirect.com ScienceDirect Procedia Technology 17 (2014 ) 528 533 Conference on Electronics, Telecommunications and Computers CETC 2013 Social Network and Device Aware Personalized
Available online at www.sciencedirect.com ScienceDirect Procedia Technology 17 (2014 ) 528 533 Conference on Electronics, Telecommunications and Computers CETC 2013 Social Network and Device Aware Personalized
Movie Recommender System - Hybrid Filtering Approach
 Chapter 7 Movie Recommender System - Hybrid Filtering Approach Recommender System can be built using approaches like: (i) Collaborative Filtering (ii) Content Based Filtering and (iii) Hybrid Filtering.
Chapter 7 Movie Recommender System - Hybrid Filtering Approach Recommender System can be built using approaches like: (i) Collaborative Filtering (ii) Content Based Filtering and (iii) Hybrid Filtering.
vector space retrieval many slides courtesy James Amherst
 vector space retrieval many slides courtesy James Allan@umass Amherst 1 what is a retrieval model? Model is an idealization or abstraction of an actual process Mathematical models are used to study the
vector space retrieval many slides courtesy James Allan@umass Amherst 1 what is a retrieval model? Model is an idealization or abstraction of an actual process Mathematical models are used to study the
James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence!
 James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence! (301) 219-4649 james.mayfield@jhuapl.edu What is Information Retrieval? Evaluation
James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence! (301) 219-4649 james.mayfield@jhuapl.edu What is Information Retrieval? Evaluation
Home Page. Title Page. Page 1 of 14. Go Back. Full Screen. Close. Quit
 Page 1 of 14 Retrieving Information from the Web Database and Information Retrieval (IR) Systems both manage data! The data of an IR system is a collection of documents (or pages) User tasks: Browsing
Page 1 of 14 Retrieving Information from the Web Database and Information Retrieval (IR) Systems both manage data! The data of an IR system is a collection of documents (or pages) User tasks: Browsing
Multi-domain Predictive AI. Correlated Cross-Occurrence with Apache Mahout and GPUs
 Multi-domain Predictive AI Correlated Cross-Occurrence with Apache Mahout and GPUs Pat Ferrel ActionML, Chief Consultant Apache Mahout, PMC & Committer Apache PredictionIO, PMC & Committer pat@apache.org
Multi-domain Predictive AI Correlated Cross-Occurrence with Apache Mahout and GPUs Pat Ferrel ActionML, Chief Consultant Apache Mahout, PMC & Committer Apache PredictionIO, PMC & Committer pat@apache.org
Recommendation Algorithms: Collaborative Filtering. CSE 6111 Presentation Advanced Algorithms Fall Presented by: Farzana Yasmeen
 Recommendation Algorithms: Collaborative Filtering CSE 6111 Presentation Advanced Algorithms Fall. 2013 Presented by: Farzana Yasmeen 2013.11.29 Contents What are recommendation algorithms? Recommendations
Recommendation Algorithms: Collaborative Filtering CSE 6111 Presentation Advanced Algorithms Fall. 2013 Presented by: Farzana Yasmeen 2013.11.29 Contents What are recommendation algorithms? Recommendations
Information Retrieval CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Boolean Retrieval vs. Ranked Retrieval Many users (professionals) prefer
Information Retrieval CS 6900 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Boolean Retrieval vs. Ranked Retrieval Many users (professionals) prefer
Web Personalisation and Recommender Systems
 Web Personalisation and Recommender Systems Shlomo Berkovsky and Jill Freyne DIGITAL PRODUCTIVITY FLAGSHIP Outline Part 1: Information Overload and User Modelling Part 2: Web Personalisation and Recommender
Web Personalisation and Recommender Systems Shlomo Berkovsky and Jill Freyne DIGITAL PRODUCTIVITY FLAGSHIP Outline Part 1: Information Overload and User Modelling Part 2: Web Personalisation and Recommender
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Tag-based Social Interest Discovery
 Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
A PROPOSED HYBRID BOOK RECOMMENDER SYSTEM
 A PROPOSED HYBRID BOOK RECOMMENDER SYSTEM SUHAS PATIL [M.Tech Scholar, Department Of Computer Science &Engineering, RKDF IST, Bhopal, RGPV University, India] Dr.Varsha Namdeo [Assistant Professor, Department
A PROPOSED HYBRID BOOK RECOMMENDER SYSTEM SUHAS PATIL [M.Tech Scholar, Department Of Computer Science &Engineering, RKDF IST, Bhopal, RGPV University, India] Dr.Varsha Namdeo [Assistant Professor, Department
Keyword Extraction by KNN considering Similarity among Features
 64 Int'l Conf. on Advances in Big Data Analytics ABDA'15 Keyword Extraction by KNN considering Similarity among Features Taeho Jo Department of Computer and Information Engineering, Inha University, Incheon,
64 Int'l Conf. on Advances in Big Data Analytics ABDA'15 Keyword Extraction by KNN considering Similarity among Features Taeho Jo Department of Computer and Information Engineering, Inha University, Incheon,
Reading group on Ontologies and NLP:
 Reading group on Ontologies and NLP: Machine Learning27th infebruary Automated 2014 1 / 25 Te Reading group on Ontologies and NLP: Machine Learning in Automated Text Categorization, by Fabrizio Sebastianini.
Reading group on Ontologies and NLP: Machine Learning27th infebruary Automated 2014 1 / 25 Te Reading group on Ontologies and NLP: Machine Learning in Automated Text Categorization, by Fabrizio Sebastianini.
Task Description: Finding Similar Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Task Description: Finding Similar Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 11, 2017 Sham Kakade 2017 1 Document
Case Study 2: Document Retrieval Task Description: Finding Similar Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 11, 2017 Sham Kakade 2017 1 Document
Data Mining Lecture 2: Recommender Systems
 Data Mining Lecture 2: Recommender Systems Jo Houghton ECS Southampton February 19, 2019 1 / 32 Recommender Systems - Introduction Making recommendations: Big Money 35% of Amazons income from recommendations
Data Mining Lecture 2: Recommender Systems Jo Houghton ECS Southampton February 19, 2019 1 / 32 Recommender Systems - Introduction Making recommendations: Big Money 35% of Amazons income from recommendations
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology
 Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Information Retrieval
 Introduction to Information Retrieval SCCS414: Information Storage and Retrieval Christopher Manning and Prabhakar Raghavan Lecture 10: Text Classification; Vector Space Classification (Rocchio) Relevance
Introduction to Information Retrieval SCCS414: Information Storage and Retrieval Christopher Manning and Prabhakar Raghavan Lecture 10: Text Classification; Vector Space Classification (Rocchio) Relevance
Introduction to Information Retrieval
 Introduction to Information Retrieval (Supplementary Material) Zhou Shuigeng March 23, 2007 Advanced Distributed Computing 1 Text Databases and IR Text databases (document databases) Large collections
Introduction to Information Retrieval (Supplementary Material) Zhou Shuigeng March 23, 2007 Advanced Distributed Computing 1 Text Databases and IR Text databases (document databases) Large collections
LECTURE 12. Web-Technology
 LECTURE 12 Web-Technology Household issues Course evaluation on Caracal o https://caracal.uu.nl o Between 3-4-2018 and 29-4-2018 Assignment 3 deadline extension No lecture/practice on Friday 30/03/18 2
LECTURE 12 Web-Technology Household issues Course evaluation on Caracal o https://caracal.uu.nl o Between 3-4-2018 and 29-4-2018 Assignment 3 deadline extension No lecture/practice on Friday 30/03/18 2
Web Personalization & Recommender Systems
 Web Personalization & Recommender Systems COSC 488 Slides are based on: - Bamshad Mobasher, Depaul University - Recent publications: see the last page (Reference section) Web Personalization & Recommender
Web Personalization & Recommender Systems COSC 488 Slides are based on: - Bamshad Mobasher, Depaul University - Recent publications: see the last page (Reference section) Web Personalization & Recommender
Property1 Property2. by Elvir Sabic. Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14
 Property1 Property2 by Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14 Content-Based Introduction Pros and cons Introduction Concept 1/30 Property1 Property2 2/30 Based on item
Property1 Property2 by Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14 Content-Based Introduction Pros and cons Introduction Concept 1/30 Property1 Property2 2/30 Based on item
Recommender Systems - Introduction. Data Mining Lecture 2: Recommender Systems
 Recommender Systems - Introduction Making recommendations: Big Money 35% of amazons income from recommendations Netflix recommendation engine worth $ Billion per year And yet, Amazon seems to be able to
Recommender Systems - Introduction Making recommendations: Big Money 35% of amazons income from recommendations Netflix recommendation engine worth $ Billion per year And yet, Amazon seems to be able to
Information Retrieval
 Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
INFSCI 2480 Adaptive Information Systems Adaptive [Web] Search. Peter Brusilovsky.
![INFSCI 2480 Adaptive Information Systems Adaptive [Web] Search. Peter Brusilovsky.](/thumbs/71/65930731.jpg "INFSCI 2480 Adaptive Information Systems Adaptive [Web] Search. Peter Brusilovsky.") INFSCI 2480 Adaptive Information Systems Adaptive [Web] Search Peter Brusilovsky http://www.sis.pitt.edu/~peterb/ Where we are? Search Navigation Recommendation Content-based Semantics / Metadata Social
INFSCI 2480 Adaptive Information Systems Adaptive [Web] Search Peter Brusilovsky http://www.sis.pitt.edu/~peterb/ Where we are? Search Navigation Recommendation Content-based Semantics / Metadata Social
User Profiling for Interest-focused Browsing History
 User Profiling for Interest-focused Browsing History Miha Grčar, Dunja Mladenič, Marko Grobelnik Jozef Stefan Institute, Jamova 39, 1000 Ljubljana, Slovenia {Miha.Grcar, Dunja.Mladenic, Marko.Grobelnik}@ijs.si
User Profiling for Interest-focused Browsing History Miha Grčar, Dunja Mladenič, Marko Grobelnik Jozef Stefan Institute, Jamova 39, 1000 Ljubljana, Slovenia {Miha.Grcar, Dunja.Mladenic, Marko.Grobelnik}@ijs.si
Predictive Analysis: Evaluation and Experimentation. Heejun Kim
 Predictive Analysis: Evaluation and Experimentation Heejun Kim June 19, 2018 Evaluation and Experimentation Evaluation Metrics Cross-Validation Significance Tests Evaluation Predictive analysis: training
Predictive Analysis: Evaluation and Experimentation Heejun Kim June 19, 2018 Evaluation and Experimentation Evaluation Metrics Cross-Validation Significance Tests Evaluation Predictive analysis: training
Social Search Networks of People and Search Engines. CS6200 Information Retrieval
 Social Search Networks of People and Search Engines CS6200 Information Retrieval Social Search Social search Communities of users actively participating in the search process Goes beyond classical search
Social Search Networks of People and Search Engines CS6200 Information Retrieval Social Search Social search Communities of users actively participating in the search process Goes beyond classical search
Natural Language Processing
 Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
The influence of social filtering in recommender systems
 The influence of social filtering in recommender systems 1 Introduction Nick Dekkers 3693406 Recommender systems have become more and more intertwined in our everyday usage of the web. Think about the
The influence of social filtering in recommender systems 1 Introduction Nick Dekkers 3693406 Recommender systems have become more and more intertwined in our everyday usage of the web. Think about the
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
AI Dining Suggestion App. CS 297 Report Bao Pham ( ) Advisor: Dr. Chris Pollett
 Advisor: Dr. Chris Pollett") AI Dining Suggestion App CS 297 Report Bao Pham (009621001) Advisor: Dr. Chris Pollett Abstract Trying to decide what to eat can be challenging and time-consuming. Google or Yelp are two popular search
AI Dining Suggestion App CS 297 Report Bao Pham (009621001) Advisor: Dr. Chris Pollett Abstract Trying to decide what to eat can be challenging and time-consuming. Google or Yelp are two popular search
CS54701: Information Retrieval
 CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
Collaborative Filtering based on User Trends
 Collaborative Filtering based on User Trends Panagiotis Symeonidis, Alexandros Nanopoulos, Apostolos Papadopoulos, and Yannis Manolopoulos Aristotle University, Department of Informatics, Thessalonii 54124,
Collaborative Filtering based on User Trends Panagiotis Symeonidis, Alexandros Nanopoulos, Apostolos Papadopoulos, and Yannis Manolopoulos Aristotle University, Department of Informatics, Thessalonii 54124,
What is Learning? CS 343: Artificial Intelligence Machine Learning. Raymond J. Mooney. Problem Solving / Planning / Control.
 What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
- Content-based Recommendation -
 - Content-based Recommendation - Institute for Software Technology Inffeldgasse 16b/2 A-8010 Graz Austria 1 Content-based recommendation While CF methods do not require any information about the items,
- Content-based Recommendation - Institute for Software Technology Inffeldgasse 16b/2 A-8010 Graz Austria 1 Content-based recommendation While CF methods do not require any information about the items,
Clustering (COSC 416) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Semantic Extensions to Syntactic Analysis of Queries Ben Handy, Rohini Rajaraman
 Semantic Extensions to Syntactic Analysis of Queries Ben Handy, Rohini Rajaraman Abstract We intend to show that leveraging semantic features can improve precision and recall of query results in information
Semantic Extensions to Syntactic Analysis of Queries Ben Handy, Rohini Rajaraman Abstract We intend to show that leveraging semantic features can improve precision and recall of query results in information
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Michele Gorgoglione Politecnico di Bari Viale Japigia, Bari (Italy)
") Does the recommendation task affect a CARS performance? Umberto Panniello Politecnico di Bari Viale Japigia, 82 726 Bari (Italy) +3985962765 m.gorgoglione@poliba.it Michele Gorgoglione Politecnico di Bari
Does the recommendation task affect a CARS performance? Umberto Panniello Politecnico di Bari Viale Japigia, 82 726 Bari (Italy) +3985962765 m.gorgoglione@poliba.it Michele Gorgoglione Politecnico di Bari
Recommender System. What is it? How to build it? Challenges. R package: recommenderlab
 Recommender System What is it? How to build it? Challenges R package: recommenderlab 1 What is a recommender system Wiki definition: A recommender system or a recommendation system (sometimes replacing
Recommender System What is it? How to build it? Challenges R package: recommenderlab 1 What is a recommender system Wiki definition: A recommender system or a recommendation system (sometimes replacing
In the recent past, the World Wide Web has been witnessing an. explosive growth. All the leading web search engines, namely, Google,
 1 1.1 Introduction In the recent past, the World Wide Web has been witnessing an explosive growth. All the leading web search engines, namely, Google, Yahoo, Askjeeves, etc. are vying with each other to
1 1.1 Introduction In the recent past, the World Wide Web has been witnessing an explosive growth. All the leading web search engines, namely, Google, Yahoo, Askjeeves, etc. are vying with each other to
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
amount of available information and the number of visitors to Web sites in recent years
 Collaboration Filtering using K-Mean Algorithm Smrity Gupta Smrity_0501@yahoo.co.in Department of computer Science and Engineering University of RAJIV GANDHI PROUDYOGIKI SHWAVIDYALAYA, BHOPAL Abstract:
Collaboration Filtering using K-Mean Algorithm Smrity Gupta Smrity_0501@yahoo.co.in Department of computer Science and Engineering University of RAJIV GANDHI PROUDYOGIKI SHWAVIDYALAYA, BHOPAL Abstract:
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.