Approaches to Mining the Web
|
|
|
- May Dalton
- 5 years ago
- Views:
Transcription
1 Approaches to Mining the Web Olfa Nasraoui University of Louisville
2 Web Mining: Mining Web Data (3 Types) Structure Mining: extracting info from topology of the Web (links among pages) Hubs: pages pointing to many other pages Authorities: pages pointed to by many other pages Communities: pages forming islands Usage Mining: extracting info on how people visit the above pages, ex: which route through site leads to checkout? Content Mining: Extracting useful info from page content (text, images, other etc), used by search engines, agents, recommendation engines to help users find what they are looking for
3 The Web from the perspective of data mining WWW = pages connected by links A Web server provides access to the pages on a website A Web page may consist of several components/frames A pageview several frames From now on, page 1 frame
4 Idealized Data Representation Structure: Directed graph (nodes: pages, edges: links) Content: Index: string/word/phrase page Usage: Profile: Each profile summarizes sites, paths, queries, documents read, items purchased, etc relatively static/rigid compared to usage Not static: behavior of users OVER TIME
5 What can each type of mining do? Structure: organize, cluster, rank by authority, etc Content: Information retrieval Usage: personalization, Info retrieval Short time frame: single session Long time frame: repeat sessions/repeat visitors (need ID, ex: registered customer)
6 Type of data Ideal data Real life Applications Future trends Content: (Web crawlers collect this data, they can have global view) -Complete -Up-todate -Easy to obtain -Public -Unrestricted Information retrieval Structure: (Web crawlers collect this data, they can have global view) -Complete -Up-todate -Easy to obtain -Public -Unrestricted Information retrieval, social networks Usage: Web logs + App server logs + databases (external data: product, transaction, etc) -Complete -Up-todate -Hard to obtain -Private -Restricted -Scattered User profiling, personalizatio n Information retrieval
7 Part 1: Mining Structure: Global Structure Links reveal many things: Hubs & authorities popularity Islands can help disambiguate synonyms & organize by topic/community Web : directed graph Link analysis: branch of DM concerned w/ finding patterns in graphs & networks
8 Global Structure continued Counting citations: # of citations to an article = main evidence of its usefulness The more links leading to a site the more important it must be Yet, an accurate picture of Web links is difficult because the Web is not static. Static link: fixed URL Dynamic link: not fixed, ex: generated as response to a search/query.
9 Kleinberg s algorithm: Hubs & Authorities Hubs & authorities: measure of usefulness of a page Popular sites such as yahoo! Will be ranked higher than less popular but more authoritative subject-specific pages (because of the # links) Solution: rank not by total # of links, but # of subject-related links pointing to them Essential feature: pages based not only on content (root set), but also on link analysis: larger pool contains pages w/ in-links/out-links relative to the root set Larger pool contains more global structure can be mined to determine authoritative pages Content pages Links Other pages Larger pool Only d pages Candidate pages Sort by authority / hub score Ranked pages
10 Kleinberg s Algorithm Phase 1: Create root set Phase 2: Identify candidate set Phase 3: Rank Hubs and authorities Content pages Only d pages Sort by authority / hub score Links Other pages Larger pool Candidate pages Ranked pages
11 Phase 1: Creating the root set (Based on CONTENT ONLY!) Preprocess search string: Eliminate stop list words (the, a, for, etc) Stemming: reduce words to base root (going go, referral refer, dogs dog, etc) Search the Web index consisting of mapping between {words pages} Score each page based on terms it contains (TF.IDF): Term rarity in entire collection of pages (IDF) Term frequency within this page (TF) Sort and select top n (typically n = 200) NOTE: we will discuss TF, IDF when we talk about content mining or text mining
12 Phase 2: Identifying candidate set (content enriched w/ structure) Expand root set by including: Pages w/ links to each page in root set Pages w/ links from each page in root set Limit # of pages brought into candidate set by any single member of root set to parameter (d, typically d = 50) Typical size of candidate set = Possible refinement strategies: Filter out any links from within same website/domain as a page in root set (most purely navigational) Diversification: remove bias/redundancy by limiting # of pages from same website brought into candidate set by any single member of root set to parameter (m)
13 Phase 3: Ranking Hubs and authorities Divide candidate set into hubs & authorities Main assumption: hubs & authorities have mutually reinforcing relationship: A strong hub links to many authorities A strong authority is linked to by many hubs HITS algorithm (Hyperlink-Induced Topic Search): For each page p, a value a p in [0,1], measures its authority For each page p, a value h p in [0,1], measures its strength as a hub
14 HITS Algorithm (Hyperlink-Induced Topic Search) If page is pointed to by many good hubs, we update the value of a p for the page p, to be the sum of h q over all pages q that link to p: a p = h q, sum over all q such that q p If a page points to many good authorities, we increase its hub weight: h p = a q, sum over all q such that p q.
15 HITS Algorithm (Hyperlink-Induced Topic Search) Initialize a p and h p for all pages p in candidate set; REPEAT { a p = h q, sum over all q such that q p; Normalize a p by dividing by sum of squares; h p = a q, sum over all q such that p q; Normalize h p by dividing by sum of squares; } UNTIL Convergence
16 HITS Algorithm (continued ) Systems based on the HITS algorithm: Google: achieve better quality search results than those generated by purely content based {termindex} engines such as AltaVista and those based on directories created by human ontologists such as Yahoo! Difficulties from ignoring textual contexts: Topic Drift: when a hub contain multiple topics to unrelated subjects Topic hijacking: when many pages from a single Web site point to the same single popular site (even when unrelated to subject of search!)
17 Local Structure Sticky vs. slippery page on same website Stickiness: metric that measures how long visitors stay on same site Sticky Pages: should be Destination pages: Content! (information, products etc) Slippery pages: opposite of above: exist only to provide links to other pages: Navigational Pages In a way checkout pages should not be sticky or this may indicate a problem! Local structure of website largely depends on goals
18 Part 2: Mining Usage Patterns Even when main concern is content or structure, usage may be helpful! Ex: can measure popularity of a page by # of visitors Clickstream: lowest level data for web usage mining = series of requests for pages received by web server that hosts a site Hits: Record of every GIF, JPEG, and HTML file requested by the user s browser These hits can be aggregated into page views Page views can be further aggregated into sessions Can also link several sessions to an identified visitor for more effective market basket analysis Frame 1.html pageview Frame 2.html session pageview Image.gif 1 visitor session pageview session flash1.swf
19 Different Data Sources Web Logs: Low level Tracks individual items (even those that are embedded within a web page like graphics, etc) requested by a Web browser Application logs: Higher level In e-commerce architecture, page content constructed on the fly by an application server Same URL (in web log) may correspond to different web content (logged on app server) App servers know when customers check in and check out, items placed or removed from shopping cart, etc
20 Web Logs Web Logs: Low level data Tracks individual items (even those that are embedded within a web page like graphics, etc) requested by a Web browser (see next page) Often several servers involved: ad server (banners), web servers (text, images), app. Servers (content calculated on fly, ex: shopping cart data w/ prices etc) Hence: user clicks on 1 link turns into multiple hits in website these hits may be recorded across multiple logs on different servers
21 Excerpt from web log file Format: time stamp, originating IP address, method, requested URL, error status code 17:11: GET /people/faculty/halford/halford.html :11: GET /people/faculty/griffin/griffin.html :11: GET /graphics/schematics.jpg :11: GET /graphics/griffin.jpg :11: GET /people/faculty/nasraoui/nasraoui.html :11: GET /people/faculty/nasraoui/frame_content.html :11: GET /people/faculty/nasraoui/home1.html :11: GET /people/faculty/nasraoui/graphics/backgrounds/horizon.jpg :11: GET /people/faculty/nasraoui/graphics/smallmail.gif 200 Additional data possible: referrer address (the last page where the user was), size of data transferred, protocol (mainly HTTP on a web server), user agent (browser type)
22 Web Log Data Preparation Step 1: Filtering: remove all log entries representing requests for graphic files (jpeg, gif, png,,etc.) Step 2: Despidering: removing entries generated by requests from spiders/crawlers (ex: used by search engines to index Web pages) and other bots (ex: performance monitoring systems) Some spiders can be recognized by name (in agent field of log entry), also by their access patterns (heuristically)
23 Web Log Data Preparation continued Step 3: User identification: a prerequisite to sessionization: Identify requests made by same user during single visit User registration/login (only sure way) Alternatives based on heuristics: Combination of IP Address + Agent field (browser) Identify requests made by same user during multiple visits Return visitors are recognized either by registration mechanisms or by cookies Cookies: text strings issued by web server and stored by the browser on client computer. They uniquely identify a user session. In future, Web server requests o see if any of its past cookies is stored on user s computer to recognize user Assumptions: user has accepted to store cookie in old session, has not disabled or deleted cookies in new session, and is using same computer + browser
24 Web Log Data Preparation continued Step 4: Sessionization: identifying a series of pageviews as requested by same user during a single visit Heuristics: all requests from same user within a maximal time duration between consecutive requests Same user: recognized by cookie, or by modifying all URLs on currently requested page to include unique session identifier If user clicks on any link from this page, the web server will be able to track the session by simply parsing the requested URL to extract the user ID Web logs may be insufficient: hard to estimate how long a user was viewing a page
25 Web Log Data Preparation continued Step 5: Path completion: Web logs may be insufficient: caching may hide some requests: Browser keeps a cache of recently visited pages for days. When user requests this page, it is loaded locally without any request to server (unless reload page is selected) Caching can also occur at a different level: proxy server (handles requests in an intermediary fashion between the user and the destination server (ex: corporate proxy or Internet Service Provider proxy) Another proxy-caused problem: For different users that connect via the same proxy, IP address of proxy is the one that is logged in the Web log difficult to distinguish between different users
26 Web Log Data Preparation continued Path completion: Some solutions: Using referrer info (+ site structure) can approximately reconstruct a session Referrer info can be saved in Web log: records where user was (previous page) just before user requested a local page Good News for the caching problem: Dynamic web pages (created using Java Server Pages (JSP) or Microsoft s Active Server Pages (ASP) are not cached because each dynamically created page is unique.
27 Application logs Higher level type of data In e-commerce architecture, page content constructed on the fly by an application server Same URL (in Web log) may correspond to different web content (logged on app. server) Example: request for the price of a product may return different prices depending on the date, promotions, etc App servers know when customers check in and check out, when items are placed or removed from shopping cart, etc. Will discuss more in next chapter
28 Application: Usage Mining to Improve Site Usability Very common application of Web usage mining Treat user sessions consisting of page requests like market baskets consisting of items purchased Analyze data using association rule mining Discovered associations (A => B) may suggest additional links between unconnected pages This makes site easier to navigate, and allows users to find what they need faster Analyze data to group similar sessions into clusters Clusters may correspond to user profiles / modes of usage of the website Knowing user profiles may suggest improvements to web site design and even dynamic website design during same session
29 Web Usage Mining Tasks: Associations & Sequences Treat user sessions consisting of page requests like market baskets consisting of items purchased Analyze data using association rule mining Discovered associations (A => B) may suggest additional links between unconnected pages This makes site easier to navigate, and allows users to find what they need faster Suggest recommendations for associated products based on current basket (cross-sell) Sequential pattern discovery: extension of association rules mining that discovers patterns of co-occurrence incorporating the notion of time sequence. Pattern: a Web page or a set of pages accessed immediately after another set of pages. help to discover users trends, and make predictions about visit patterns
30 Web Usage Mining Tasks: Clustering, Collaborative Filtering Clustering: Analyze data to group similar sessions into clusters Clusters may correspond to user profiles / modes of usage of the website Knowing user profiles may suggest improvements to web site design dynamic website design during same session Design of several smaller websites or stores Collaborative Filtering Recommend products on a site with large # of products Lazy learning: no need for learning, based on examples of past usage Problems: sparse data: many more products/pages than customers/browsers, scaling up to huge # of visitors & # of items or pages
31 Example: Effect of Recommendation System on a home shopping group Avg Cross-Sell Value Cross Sell Success Rate With traditional methods With cross-sell realtime recommendation s $ % higher 9.8% 50% higher Source: J. Riedl, Why Does KDD Care About Personalization?
32 Mining Web Content Task most popularly performed by Web search engines Information Retrieval (IR): formal name for task performed by search engine to help users find what they look for. Web Content: HTML: Hypertext Markup Language: standard for describing the way document should be displayed using tags. XML: extensible Markup Language: extensible standard that allows community of users to agree on application-specific set of tags that help in understanding what document info means!
33 Content Mining continued Most current content mining Text mining Information retrieval: Find what user is looking for But without finding too much else!!! These two conflicting ideas are captured by 2 measures of IR: Precision: Of the pages returned, what proportion are correct? Recall: Of all the pages that are correct, what proportion are returned? Typically Perfect recall very low precision Perfect precision very low recall
34 Content based Classification Classification Very common application of data mining Assign a class label to a data record In Web content mining: Assign keywords to a Web page (to predict its topic) Assign a language to a Web page (ex: to restrict search results to a given language) Challenge: Most data mining methods for classification work w/ structured data However free text is unstructured! Traditionally, free text was transformed into structured data (in the form of keyword vectors) via feature (i.e. keyword) extraction
35 Automatic Classification of Web Documents Assign a class label to each document from a set of predefined topic categories Based on a set of examples of pre-classified documents Example: Use Yahoo!'s taxonomy and its associated documents as training and test sets Derive a Web document classification scheme Use the scheme to classify new Web documents Keyword-based document classification methods (mostly using vector space model of documents as a vector of keyword/term frequencies etc) Statistical models (ex: Naïve Bayes: models document classes as word probability distributions)
36 More Content based Classification Methods Genetic Algorithms can be used to evolve classifier of text documents Ex: classify customer comments/ s/web blogs as positive or negative? Memory based reasoning or K-Nearest neighbors based classification (K-NN): assign keywords to a web page Compare a new page to a set of pre-classified examples The k most similar pages are used to classify the new page using weighted voting Confidence in classification: related to degree of similarity to examples
37 Vector Space Model Vector Space Model: documents represented using keywords in text documents. Documents are vectors in this s-dimensional space. Mathematical model: mxs matrix where each row 1 document, each column 1 term or keyword t 1 t 2 t s d d d m Entries in matrix: If keyword # j occurs n times in document #i, then the content of [row i, col j] = n
38 Document Vector D={d 1,,d n } of documents and T={t 1,.,t s } of indexing/querying terms. Vector Space model: each document is represented as a vector of dimension s = the number of terms. di,..., =< w, i1 wi 2 wis w ij is weight of term t j in d i. Let f ij = freq of occurrence of term t j in d i w = ij N = # of documents f ij * log[ N / N j ] N j = # of documents in which term t j occurs at least once Inverted Document Frequency (IDF) = log (N/N j ) measures rarity of term w ij typically normalized: divide by Σ w ij, Σ w ij 2, or max {w ij }. >
39 Similarity Assessing similarity between two Web pages Similarity is inversely related to distance Euclidean distance is not appropriate for text data (huge dimensionality, asymmetrical attributes/words) Intuitively, similarity between two pages should depend on the # of words in common compared to total # of words in both pages Ex: Cosine similarity = #common words / (#words in page 1 X #words in page 2) s wij * wqj j= 1 SIM ( d, d ) = i q s j= 1 w 2 ij s j= 1 w 2 qj
40 Case Study: Classification of Customer omments as Compliment or Complaint Business context: customers comment on quality of service of airline company: s, fill comment forms on website, etc Data: free text + other (ex: flight #, service class, date, destination, etc) Preprocessing: Free text document vector + Add metadata about comment (size in bytes, # distinct words) Data Mining Task: Classification (class 0: compliment, class 1:complaint)
41 Case Study: Classification of Customer omments as Compliment or Complaint Data Mining Task: Classification (class 0: compliment, class 1:complaint) Genetic Programming is used to evolve prediction tree Solutions similar to single layer Neural Net Chromosome encodes a solution: each gene = attribute or operation word1 word2 feature3 Chromosomes compete based on fitness 85% classification accuracy Enough to speed up complaint processing! Important attributes: comment length complaint Σ Some words: baggage, courteous, experience score
42 Clustering Web Documents to Support Searching Search engine can help users find what they need by clustering search results into folders and sub-folders. Northern Light organizes the Web into custom search folders Folders are labeled by humans (hence semi-automatic) Accessible only by registration / subscription Newest version: Enterprise Search Engine (to be used inside a business Knowledge Management) Example: Vivissimo clusters search results on the fly without any labeling (see next slide ) Difference is in the use of a concept hierarchy! Most extreme use of such a hierarchy: yahoo! (entirely manual)
43 Discovered Clusters
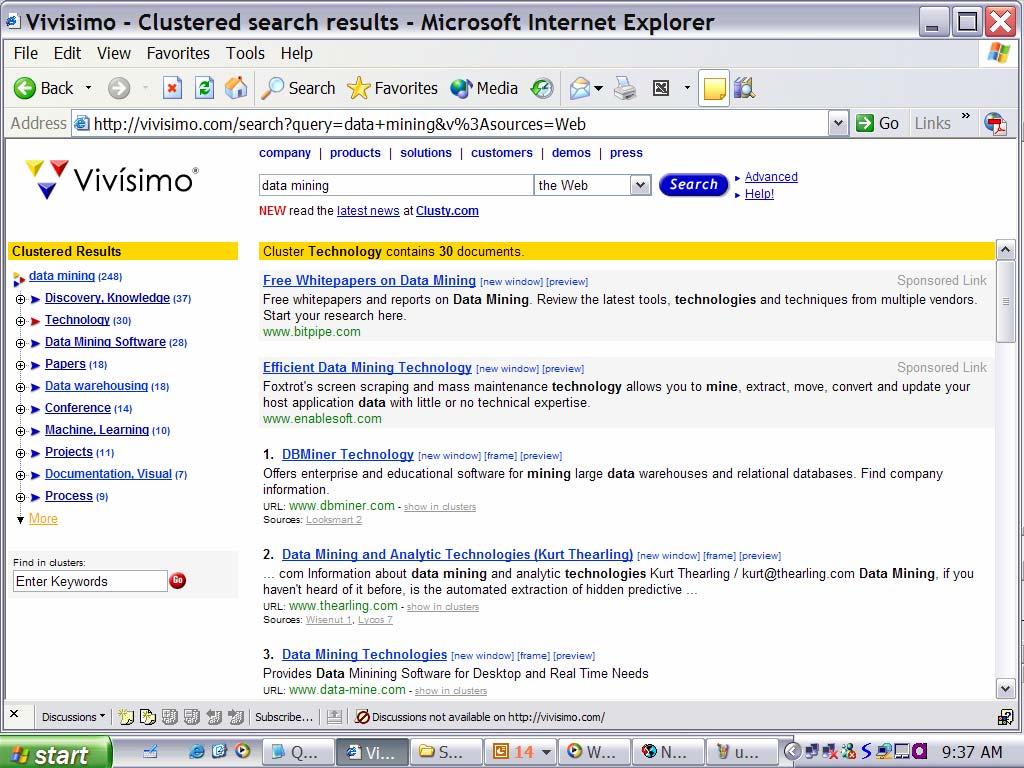
44 Cluster Technology
45 Cluster Discovery, Knowledge
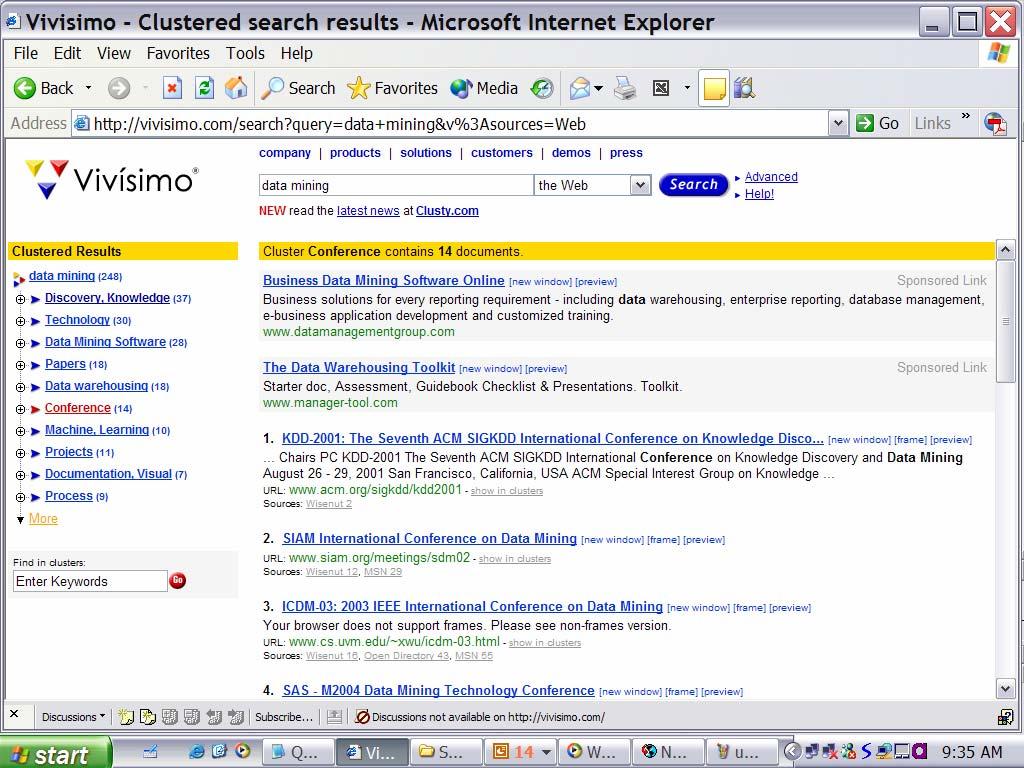
46 Cluster Conference

47 Search query = mining Discovered Clusters
48 Extracting Information from Free Text Free text (unstructured) Feature/Information Extraction Features (structured) Feature/Information extraction: important to extract specific data, ex: price, product attributes, vendors, etc Useful in e-commerce: comparison shopping This has been made easier by recent structuring of content using XML tags
49 Summary of Approaches for Mining the Web Structure Mining: analyzing links between pages Global vs. local structure Global structure identify hubs, authorities Local structure understand site s intended purpose, detect design problems Typically based on graph analysis HITS algorithm App: search engines (for global structure) Usage Mining: Analyzing user behavior over time Build user profiles of anonymous visitors Data mining tasks: association rule discovery, clustering App: personalization, marketing, etc Content Mining Extract info from web pages Data mining tasks: clustering, classification App: search engines
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
UNIT-V WEB MINING. 3/18/2012 Prof. Asha Ambhaikar, RCET Bhilai.
 UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
DATA MINING II - 1DL460. Spring 2014"
 DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Web Mining Team 11 Professor Anita Wasilewska CSE 634 : Data Mining Concepts and Techniques
 Web Mining Team 11 Professor Anita Wasilewska CSE 634 : Data Mining Concepts and Techniques Imgref: https://www.kdnuggets.com/2014/09/most-viewed-web-mining-lectures-videolectures.html Contents Introduction
Web Mining Team 11 Professor Anita Wasilewska CSE 634 : Data Mining Concepts and Techniques Imgref: https://www.kdnuggets.com/2014/09/most-viewed-web-mining-lectures-videolectures.html Contents Introduction
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Web Mining. Data Mining and Text Mining (UIC Politecnico di Milano) Daniele Loiacono
 Daniele Loiacono") Web Mining Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References q Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data Management
Web Mining Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References q Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data Management
Web Mining. Data Mining and Text Mining (UIC Politecnico di Milano) Daniele Loiacono
 Daniele Loiacono") Web Mining Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data Management
Web Mining Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data Management
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Link Analysis and Web Search
 Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
CHAPTER - 3 PREPROCESSING OF WEB USAGE DATA FOR LOG ANALYSIS
 CHAPTER - 3 PREPROCESSING OF WEB USAGE DATA FOR LOG ANALYSIS 48 3.1 Introduction The main aim of Web usage data processing is to extract the knowledge kept in the web log files of a Web server. By using
CHAPTER - 3 PREPROCESSING OF WEB USAGE DATA FOR LOG ANALYSIS 48 3.1 Introduction The main aim of Web usage data processing is to extract the knowledge kept in the web log files of a Web server. By using
Web Mining. Data Mining and Text Mining (UIC Politecnico di Milano) Daniele Loiacono
 Daniele Loiacono") Web Mining Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data Management
Web Mining Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data Management
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
Chapter 12: Web Usage Mining
 Chapter 12: Web Usage Mining - An introduction Chapter written by Bamshad Mobasher Many slides are from a tutorial given by B. Berendt, B. Mobasher, M. Spiliopoulou Introduction Web usage mining: automatic
Chapter 12: Web Usage Mining - An introduction Chapter written by Bamshad Mobasher Many slides are from a tutorial given by B. Berendt, B. Mobasher, M. Spiliopoulou Introduction Web usage mining: automatic
Web Usage Mining. Overview Session 1. This material is inspired from the WWW 16 tutorial entitled Analyzing Sequential User Behavior on the Web
 Web Usage Mining Overview Session 1 This material is inspired from the WWW 16 tutorial entitled Analyzing Sequential User Behavior on the Web 1 Outline 1. Introduction 2. Preprocessing 3. Analysis 2 Example
Web Usage Mining Overview Session 1 This material is inspired from the WWW 16 tutorial entitled Analyzing Sequential User Behavior on the Web 1 Outline 1. Introduction 2. Preprocessing 3. Analysis 2 Example
Web Usage Mining from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer Chapter written by Bamshad Mobasher
 Web Usage Mining from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer Chapter written by Bamshad Mobasher Many slides are from a tutorial given by B. Berendt, B. Mobasher,
Web Usage Mining from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer Chapter written by Bamshad Mobasher Many slides are from a tutorial given by B. Berendt, B. Mobasher,
Authoritative Sources in a Hyperlinked Environment
 Authoritative Sources in a Hyperlinked Environment Journal of the ACM 46(1999) Jon Kleinberg, Dept. of Computer Science, Cornell University Introduction Searching on the web is defined as the process of
Authoritative Sources in a Hyperlinked Environment Journal of the ACM 46(1999) Jon Kleinberg, Dept. of Computer Science, Cornell University Introduction Searching on the web is defined as the process of
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM
 CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES
 TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES Mu. Annalakshmi Research Scholar, Department of Computer Science, Alagappa University, Karaikudi. annalakshmi_mu@yahoo.co.in Dr. A.
TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES Mu. Annalakshmi Research Scholar, Department of Computer Science, Alagappa University, Karaikudi. annalakshmi_mu@yahoo.co.in Dr. A.
DATA MINING II - 1DL460. Spring 2017
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
User Profiling for Interest-focused Browsing History
 User Profiling for Interest-focused Browsing History Miha Grčar, Dunja Mladenič, Marko Grobelnik Jozef Stefan Institute, Jamova 39, 1000 Ljubljana, Slovenia {Miha.Grcar, Dunja.Mladenic, Marko.Grobelnik}@ijs.si
User Profiling for Interest-focused Browsing History Miha Grčar, Dunja Mladenič, Marko Grobelnik Jozef Stefan Institute, Jamova 39, 1000 Ljubljana, Slovenia {Miha.Grcar, Dunja.Mladenic, Marko.Grobelnik}@ijs.si
Overview of Web Mining Techniques and its Application towards Web
 Overview of Web Mining Techniques and its Application towards Web *Prof.Pooja Mehta Abstract The World Wide Web (WWW) acts as an interactive and popular way to transfer information. Due to the enormous
Overview of Web Mining Techniques and its Application towards Web *Prof.Pooja Mehta Abstract The World Wide Web (WWW) acts as an interactive and popular way to transfer information. Due to the enormous
Instructor: Stefan Savev
 LECTURE 2 What is indexing? Indexing is the process of extracting features (such as word counts) from the documents (in other words: preprocessing the documents). The process ends with putting the information
LECTURE 2 What is indexing? Indexing is the process of extracting features (such as word counts) from the documents (in other words: preprocessing the documents). The process ends with putting the information
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
An Introduction to Search Engines and Web Navigation
 An Introduction to Search Engines and Web Navigation MARK LEVENE ADDISON-WESLEY Ал imprint of Pearson Education Harlow, England London New York Boston San Francisco Toronto Sydney Tokyo Singapore Hong
An Introduction to Search Engines and Web Navigation MARK LEVENE ADDISON-WESLEY Ал imprint of Pearson Education Harlow, England London New York Boston San Francisco Toronto Sydney Tokyo Singapore Hong
Application of rough ensemble classifier to web services categorization and focused crawling
 With the expected growth of the number of Web services available on the web, the need for mechanisms that enable the automatic categorization to organize this vast amount of data, becomes important. A
With the expected growth of the number of Web services available on the web, the need for mechanisms that enable the automatic categorization to organize this vast amount of data, becomes important. A
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Path Analysis References: Ch.10, Data Mining Techniques By M.Berry, andg.linoff Dr Ahmed Rafea
 Path Analysis References: Ch.10, Data Mining Techniques By M.Berry, andg.linoff http://www9.org/w9cdrom/68/68.html Dr Ahmed Rafea Outline Introduction Link Analysis Path Analysis Using Markov Chains Applications
Path Analysis References: Ch.10, Data Mining Techniques By M.Berry, andg.linoff http://www9.org/w9cdrom/68/68.html Dr Ahmed Rafea Outline Introduction Link Analysis Path Analysis Using Markov Chains Applications
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Web Data mining-a Research area in Web usage mining
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 13, Issue 1 (Jul. - Aug. 2013), PP 22-26 Web Data mining-a Research area in Web usage mining 1 V.S.Thiyagarajan,
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 13, Issue 1 (Jul. - Aug. 2013), PP 22-26 Web Data mining-a Research area in Web usage mining 1 V.S.Thiyagarajan,
Keyword Extraction by KNN considering Similarity among Features
 64 Int'l Conf. on Advances in Big Data Analytics ABDA'15 Keyword Extraction by KNN considering Similarity among Features Taeho Jo Department of Computer and Information Engineering, Inha University, Incheon,
64 Int'l Conf. on Advances in Big Data Analytics ABDA'15 Keyword Extraction by KNN considering Similarity among Features Taeho Jo Department of Computer and Information Engineering, Inha University, Incheon,
Pattern Classification based on Web Usage Mining using Neural Network Technique
 International Journal of Computer Applications (975 8887) Pattern Classification based on Web Usage Mining using Neural Network Technique Er. Romil V Patel PIET, VADODARA Dheeraj Kumar Singh, PIET, VADODARA
International Journal of Computer Applications (975 8887) Pattern Classification based on Web Usage Mining using Neural Network Technique Er. Romil V Patel PIET, VADODARA Dheeraj Kumar Singh, PIET, VADODARA
12 Web Usage Mining. With Bamshad Mobasher and Olfa Nasraoui
 12 Web Usage Mining With Bamshad Mobasher and Olfa Nasraoui With the continued growth and proliferation of e-commerce, Web services, and Web-based information systems, the volumes of clickstream, transaction
12 Web Usage Mining With Bamshad Mobasher and Olfa Nasraoui With the continued growth and proliferation of e-commerce, Web services, and Web-based information systems, the volumes of clickstream, transaction
Web Structure Mining using Link Analysis Algorithms
 Web Structure Mining using Link Analysis Algorithms Ronak Jain Aditya Chavan Sindhu Nair Assistant Professor Abstract- The World Wide Web is a huge repository of data which includes audio, text and video.
Web Structure Mining using Link Analysis Algorithms Ronak Jain Aditya Chavan Sindhu Nair Assistant Professor Abstract- The World Wide Web is a huge repository of data which includes audio, text and video.
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. Springer
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Basic techniques. Text processing; term weighting; vector space model; inverted index; Web Search
 Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Information Retrieval. hussein suleman uct cs
 Information Management Information Retrieval hussein suleman uct cs 303 2004 Introduction Information retrieval is the process of locating the most relevant information to satisfy a specific information
Information Management Information Retrieval hussein suleman uct cs 303 2004 Introduction Information retrieval is the process of locating the most relevant information to satisfy a specific information
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER
 VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
String Vector based KNN for Text Categorization
 458 String Vector based KNN for Text Categorization Taeho Jo Department of Computer and Information Communication Engineering Hongik University Sejong, South Korea tjo018@hongik.ac.kr Abstract This research
458 String Vector based KNN for Text Categorization Taeho Jo Department of Computer and Information Communication Engineering Hongik University Sejong, South Korea tjo018@hongik.ac.kr Abstract This research
Automated Online News Classification with Personalization
 Automated Online News Classification with Personalization Chee-Hong Chan Aixin Sun Ee-Peng Lim Center for Advanced Information Systems, Nanyang Technological University Nanyang Avenue, Singapore, 639798
Automated Online News Classification with Personalization Chee-Hong Chan Aixin Sun Ee-Peng Lim Center for Advanced Information Systems, Nanyang Technological University Nanyang Avenue, Singapore, 639798
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval
 Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Chapter 3 Process of Web Usage Mining
 Chapter 3 Process of Web Usage Mining 3.1 Introduction Users interact frequently with different web sites and can access plenty of information on WWW. The World Wide Web is growing continuously and huge
Chapter 3 Process of Web Usage Mining 3.1 Introduction Users interact frequently with different web sites and can access plenty of information on WWW. The World Wide Web is growing continuously and huge
Web Usage Mining: A Research Area in Web Mining
 Web Usage Mining: A Research Area in Web Mining Rajni Pamnani, Pramila Chawan Department of computer technology, VJTI University, Mumbai Abstract Web usage mining is a main research area in Web mining
Web Usage Mining: A Research Area in Web Mining Rajni Pamnani, Pramila Chawan Department of computer technology, VJTI University, Mumbai Abstract Web usage mining is a main research area in Web mining
Web Search Ranking. (COSC 488) Nazli Goharian Evaluation of Web Search Engines: High Precision Search
 Nazli Goharian Evaluation of Web Search Engines: High Precision Search") Web Search Ranking (COSC 488) Nazli Goharian nazli@cs.georgetown.edu 1 Evaluation of Web Search Engines: High Precision Search Traditional IR systems are evaluated based on precision and recall. Web search
Web Search Ranking (COSC 488) Nazli Goharian nazli@cs.georgetown.edu 1 Evaluation of Web Search Engines: High Precision Search Traditional IR systems are evaluated based on precision and recall. Web search
Text Categorization (I)
") CS473 CS-473 Text Categorization (I) Luo Si Department of Computer Science Purdue University Text Categorization (I) Outline Introduction to the task of text categorization Manual v.s. automatic text categorization
CS473 CS-473 Text Categorization (I) Luo Si Department of Computer Science Purdue University Text Categorization (I) Outline Introduction to the task of text categorization Manual v.s. automatic text categorization
Bruno Martins. 1 st Semester 2012/2013
 Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
WEB PAGE RE-RANKING TECHNIQUE IN SEARCH ENGINE
 WEB PAGE RE-RANKING TECHNIQUE IN SEARCH ENGINE Ms.S.Muthukakshmi 1, R. Surya 2, M. Umira Taj 3 Assistant Professor, Department of Information Technology, Sri Krishna College of Technology, Kovaipudur,
WEB PAGE RE-RANKING TECHNIQUE IN SEARCH ENGINE Ms.S.Muthukakshmi 1, R. Surya 2, M. Umira Taj 3 Assistant Professor, Department of Information Technology, Sri Krishna College of Technology, Kovaipudur,
Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _
 COURSE DELIVERY PLAN - THEORY Page 1 of 6 Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _ LP: CS6007 Rev. No: 01 Date: 27/06/2017 Sub.
COURSE DELIVERY PLAN - THEORY Page 1 of 6 Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _ LP: CS6007 Rev. No: 01 Date: 27/06/2017 Sub.
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most
 In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
Opportunities and challenges in personalization of online hotel search
 Opportunities and challenges in personalization of online hotel search David Zibriczky Data Science & Analytics Lead, User Profiling Introduction 2 Introduction About Mission: Helping the travelers to
Opportunities and challenges in personalization of online hotel search David Zibriczky Data Science & Analytics Lead, User Profiling Introduction 2 Introduction About Mission: Helping the travelers to
Home Page. Title Page. Page 1 of 14. Go Back. Full Screen. Close. Quit
 Page 1 of 14 Retrieving Information from the Web Database and Information Retrieval (IR) Systems both manage data! The data of an IR system is a collection of documents (or pages) User tasks: Browsing
Page 1 of 14 Retrieving Information from the Web Database and Information Retrieval (IR) Systems both manage data! The data of an IR system is a collection of documents (or pages) User tasks: Browsing
Information Retrieval
 Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Personalized Information Retrieval
 Personalized Information Retrieval Shihn Yuarn Chen Traditional Information Retrieval Content based approaches Statistical and natural language techniques Results that contain a specific set of words or
Personalized Information Retrieval Shihn Yuarn Chen Traditional Information Retrieval Content based approaches Statistical and natural language techniques Results that contain a specific set of words or
A Survey on Web Information Retrieval Technologies
 A Survey on Web Information Retrieval Technologies Lan Huang Computer Science Department State University of New York, Stony Brook Presented by Kajal Miyan Michigan State University Overview Web Information
A Survey on Web Information Retrieval Technologies Lan Huang Computer Science Department State University of New York, Stony Brook Presented by Kajal Miyan Michigan State University Overview Web Information
Nitin Cyriac et al, Int.J.Computer Technology & Applications,Vol 5 (1), WEB PERSONALIZATION
, WEB PERSONALIZATION") WEB PERSONALIZATION Mrs. M.Kiruthika 1, Nitin Cyriac 2, Aditya Mandhare 3, Soniya Nemade 4 DEPARTMENT OF COMPUTER ENGINEERING Fr. CONCEICAO RODRIGUES INSTITUTE OF TECHNOLOGY,VASHI Email- 1 venkatr20032002@gmail.com,
WEB PERSONALIZATION Mrs. M.Kiruthika 1, Nitin Cyriac 2, Aditya Mandhare 3, Soniya Nemade 4 DEPARTMENT OF COMPUTER ENGINEERING Fr. CONCEICAO RODRIGUES INSTITUTE OF TECHNOLOGY,VASHI Email- 1 venkatr20032002@gmail.com,
Natural Language Processing
 Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Feature selection. LING 572 Fei Xia
 Feature selection LING 572 Fei Xia 1 Creating attribute-value table x 1 x 2 f 1 f 2 f K y Choose features: Define feature templates Instantiate the feature templates Dimensionality reduction: feature selection
Feature selection LING 572 Fei Xia 1 Creating attribute-value table x 1 x 2 f 1 f 2 f K y Choose features: Define feature templates Instantiate the feature templates Dimensionality reduction: feature selection
Survey Paper on Web Usage Mining for Web Personalization
 ISSN 2278 0211 (Online) Survey Paper on Web Usage Mining for Web Personalization Namdev Anwat Department of Computer Engineering Matoshri College of Engineering & Research Center, Eklahare, Nashik University
ISSN 2278 0211 (Online) Survey Paper on Web Usage Mining for Web Personalization Namdev Anwat Department of Computer Engineering Matoshri College of Engineering & Research Center, Eklahare, Nashik University
A Survey on Web Personalization of Web Usage Mining
 A Survey on Web Personalization of Web Usage Mining S.Jagan 1, Dr.S.P.Rajagopalan 2 1 Assistant Professor, Department of CSE, T.J. Institute of Technology, Tamilnadu, India 2 Professor, Department of CSE,
A Survey on Web Personalization of Web Usage Mining S.Jagan 1, Dr.S.P.Rajagopalan 2 1 Assistant Professor, Department of CSE, T.J. Institute of Technology, Tamilnadu, India 2 Professor, Department of CSE,
A Comparative study of Clustering Algorithms using MapReduce in Hadoop
 A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
LIST OF ACRONYMS & ABBREVIATIONS
 LIST OF ACRONYMS & ABBREVIATIONS ARPA CBFSE CBR CS CSE FiPRA GUI HITS HTML HTTP HyPRA NoRPRA ODP PR RBSE RS SE TF-IDF UI URI URL W3 W3C WePRA WP WWW Alpha Page Rank Algorithm Context based Focused Search
LIST OF ACRONYMS & ABBREVIATIONS ARPA CBFSE CBR CS CSE FiPRA GUI HITS HTML HTTP HyPRA NoRPRA ODP PR RBSE RS SE TF-IDF UI URI URL W3 W3C WePRA WP WWW Alpha Page Rank Algorithm Context based Focused Search
AN EFFICIENT COLLECTION METHOD OF OFFICIAL WEBSITES BY ROBOT PROGRAM
 AN EFFICIENT COLLECTION METHOD OF OFFICIAL WEBSITES BY ROBOT PROGRAM Masahito Yamamoto, Hidenori Kawamura and Azuma Ohuchi Graduate School of Information Science and Technology, Hokkaido University, Japan
AN EFFICIENT COLLECTION METHOD OF OFFICIAL WEBSITES BY ROBOT PROGRAM Masahito Yamamoto, Hidenori Kawamura and Azuma Ohuchi Graduate School of Information Science and Technology, Hokkaido University, Japan
Chapter 5: Summary and Conclusion CHAPTER 5 SUMMARY AND CONCLUSION. Chapter 1: Introduction
 CHAPTER 5 SUMMARY AND CONCLUSION Chapter 1: Introduction Data mining is used to extract the hidden, potential, useful and valuable information from very large amount of data. Data mining tools can handle
CHAPTER 5 SUMMARY AND CONCLUSION Chapter 1: Introduction Data mining is used to extract the hidden, potential, useful and valuable information from very large amount of data. Data mining tools can handle
CS377: Database Systems Text data and information. Li Xiong Department of Mathematics and Computer Science Emory University
 CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
Tag-based Social Interest Discovery
 Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Part 11: Collaborative Filtering. Francesco Ricci
 Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
F. Aiolli - Sistemi Informativi 2007/2008. Web Search before Google
 Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
AN OVERVIEW OF SEARCHING AND DISCOVERING WEB BASED INFORMATION RESOURCES
 Journal of Defense Resources Management No. 1 (1) / 2010 AN OVERVIEW OF SEARCHING AND DISCOVERING Cezar VASILESCU Regional Department of Defense Resources Management Studies Abstract: The Internet becomes
Journal of Defense Resources Management No. 1 (1) / 2010 AN OVERVIEW OF SEARCHING AND DISCOVERING Cezar VASILESCU Regional Department of Defense Resources Management Studies Abstract: The Internet becomes
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2
 A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Encoding Words into String Vectors for Word Categorization
 Int'l Conf. Artificial Intelligence ICAI'16 271 Encoding Words into String Vectors for Word Categorization Taeho Jo Department of Computer and Information Communication Engineering, Hongik University,
Int'l Conf. Artificial Intelligence ICAI'16 271 Encoding Words into String Vectors for Word Categorization Taeho Jo Department of Computer and Information Communication Engineering, Hongik University,
Lecture 9: I: Web Retrieval II: Webology. Johan Bollen Old Dominion University Department of Computer Science
 Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Chrome based Keyword Visualizer (under sparse text constraint) SANGHO SUH MOONSHIK KANG HOONHEE CHO
 SANGHO SUH MOONSHIK KANG HOONHEE CHO") Chrome based Keyword Visualizer (under sparse text constraint) SANGHO SUH MOONSHIK KANG HOONHEE CHO INDEX Proposal Recap Implementation Evaluation Future Works Proposal Recap Keyword Visualizer (chrome
Chrome based Keyword Visualizer (under sparse text constraint) SANGHO SUH MOONSHIK KANG HOONHEE CHO INDEX Proposal Recap Implementation Evaluation Future Works Proposal Recap Keyword Visualizer (chrome
Information Retrieval and Web Search
 Information Retrieval and Web Search Link analysis Instructor: Rada Mihalcea (Note: This slide set was adapted from an IR course taught by Prof. Chris Manning at Stanford U.) The Web as a Directed Graph
Information Retrieval and Web Search Link analysis Instructor: Rada Mihalcea (Note: This slide set was adapted from an IR course taught by Prof. Chris Manning at Stanford U.) The Web as a Directed Graph
The Application Research of Semantic Web Technology and Clickstream Data Mart in Tourism Electronic Commerce Website Bo Liu
 International Conference on Education Technology, Management and Humanities Science (ETMHS 2015) The Application Research of Semantic Web Technology and Clickstream Data Mart in Tourism Electronic Commerce
International Conference on Education Technology, Management and Humanities Science (ETMHS 2015) The Application Research of Semantic Web Technology and Clickstream Data Mart in Tourism Electronic Commerce
Link Analysis in Web Mining
 Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Session 10: Information Retrieval
 INFM 63: Information Technology and Organizational Context Session : Information Retrieval Jimmy Lin The ischool University of Maryland Thursday, November 7, 23 Information Retrieval What you search for!
INFM 63: Information Technology and Organizational Context Session : Information Retrieval Jimmy Lin The ischool University of Maryland Thursday, November 7, 23 Information Retrieval What you search for!
Information Retrieval
 Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Google Analytics. powerful simplicity, practical insight
 Google Analytics powerful simplicity, practical insight 1 Overview Google Analytics Improve your site and increase marketing ROI Free, hosted web analytics service View over 80+ reports online, for download,
Google Analytics powerful simplicity, practical insight 1 Overview Google Analytics Improve your site and increase marketing ROI Free, hosted web analytics service View over 80+ reports online, for download,
Chapter 28. Outline. Definitions of Data Mining. Data Mining Concepts
 Chapter 28 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms
Chapter 28 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms
Chapter 2 BACKGROUND OF WEB MINING
 Chapter 2 BACKGROUND OF WEB MINING Overview 2.1. Introduction to Data Mining Data mining is an important and fast developing area in web mining where already a lot of research has been done. Recently,
Chapter 2 BACKGROUND OF WEB MINING Overview 2.1. Introduction to Data Mining Data mining is an important and fast developing area in web mining where already a lot of research has been done. Recently,
COMP5331: Knowledge Discovery and Data Mining
 COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
CS 6320 Natural Language Processing
 CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
Optimizing Search Engines using Click-through Data
 Optimizing Search Engines using Click-through Data By Sameep - 100050003 Rahee - 100050028 Anil - 100050082 1 Overview Web Search Engines : Creating a good information retrieval system Previous Approaches
Optimizing Search Engines using Click-through Data By Sameep - 100050003 Rahee - 100050028 Anil - 100050082 1 Overview Web Search Engines : Creating a good information retrieval system Previous Approaches
Einführung in Web und Data Science Community Analysis. Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme
 Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
Measurement and evaluation: Web analytics and data mining. MGMT 230 Week 10
 Measurement and evaluation: Web analytics and data mining MGMT 230 Week 10 After today s class you will be able to: Explain the types of information routinely gathered by web servers Understand how analytics
Measurement and evaluation: Web analytics and data mining MGMT 230 Week 10 After today s class you will be able to: Explain the types of information routinely gathered by web servers Understand how analytics
Social Network Analysis
 Social Network Analysis Giri Iyengar Cornell University gi43@cornell.edu March 14, 2018 Giri Iyengar (Cornell Tech) Social Network Analysis March 14, 2018 1 / 24 Overview 1 Social Networks 2 HITS 3 Page
Social Network Analysis Giri Iyengar Cornell University gi43@cornell.edu March 14, 2018 Giri Iyengar (Cornell Tech) Social Network Analysis March 14, 2018 1 / 24 Overview 1 Social Networks 2 HITS 3 Page
INTRODUCTION. Chapter GENERAL
 Chapter 1 INTRODUCTION 1.1 GENERAL The World Wide Web (WWW) [1] is a system of interlinked hypertext documents accessed via the Internet. It is an interactive world of shared information through which
Chapter 1 INTRODUCTION 1.1 GENERAL The World Wide Web (WWW) [1] is a system of interlinked hypertext documents accessed via the Internet. It is an interactive world of shared information through which
Focused crawling: a new approach to topic-specific Web resource discovery. Authors
 Focused crawling: a new approach to topic-specific Web resource discovery Authors Soumen Chakrabarti Martin van den Berg Byron Dom Presented By: Mohamed Ali Soliman m2ali@cs.uwaterloo.ca Outline Why Focused
Focused crawling: a new approach to topic-specific Web resource discovery Authors Soumen Chakrabarti Martin van den Berg Byron Dom Presented By: Mohamed Ali Soliman m2ali@cs.uwaterloo.ca Outline Why Focused