Text mining tools for semantically enriching the scientific literature
|
|
|
- Stuart Chapman
- 5 years ago
- Views:
Transcription
1 Text mining tools for semantically enriching the scientific literature Sophia Ananiadou Director National Centre for Text Mining School of Computer Science University of Manchester
2 Need for enriching the literature Need for semantic search i.e. beyond keywords Need for technologies enabling focused semantic search via the creation of semantic metadata from literature The current scientific literature, were it to be presented in semantically accessible form, contains huge amounts of undiscovered science Peter Murray-Rust, Data-driven science: A Scientist s view. NSF/JISC Repositories Workshop, 2007
3 Impact of text mining Extraction of named entities (genes, proteins, metabolites, etc) Discovery of concepts allows semantic annotation of documents Improves information access by going beyond index terms, enabling semantic querying Improves clustering, classification of documents Visualisation based on semantic metadata derived from text mining results
4 Beyond named entities: facts Extraction of relationships, events (facts) for knowledge discovery Information extraction, more sophisticated annotation of texts (fact annotation) Enables even more advanced semantic querying
5 Enriched annotation Text Mining provides enriched annotation layers the user will be able to carry out an easily expressed semantic query which will deliver facts matching that semantic query rather than just sets of documents he has to read Information Extraction and not just Information Retrieval Fact extraction and not just sentence extraction
6 Annotations derived from Text Mining lexicon ontology text processing raw (unstructured) text part-of-speech tagging named entity recognition deep syntactic parsing annotated (structured) text Secretion of TNF was abolished by BHA in PMA-stimulated U937 cells. NP NP S VP VP PP PP PP NP Multi-layered annotations NN IN NN VBZ VBN IN NN IN JJ NN NNS. Secretion of TNF was abolished by BHA in PMA-stimulated U937 cells. protein_molecule organic_compound cell_line negative regulation
7 Mining associations from MEDLINE FACTA: Finding Associated Concepts with Text Analysis What diseases are related to a particular chemical? What proteins are related to a particular disease? etc. EBIMed PubMatrix : FACTA Quick and interactive
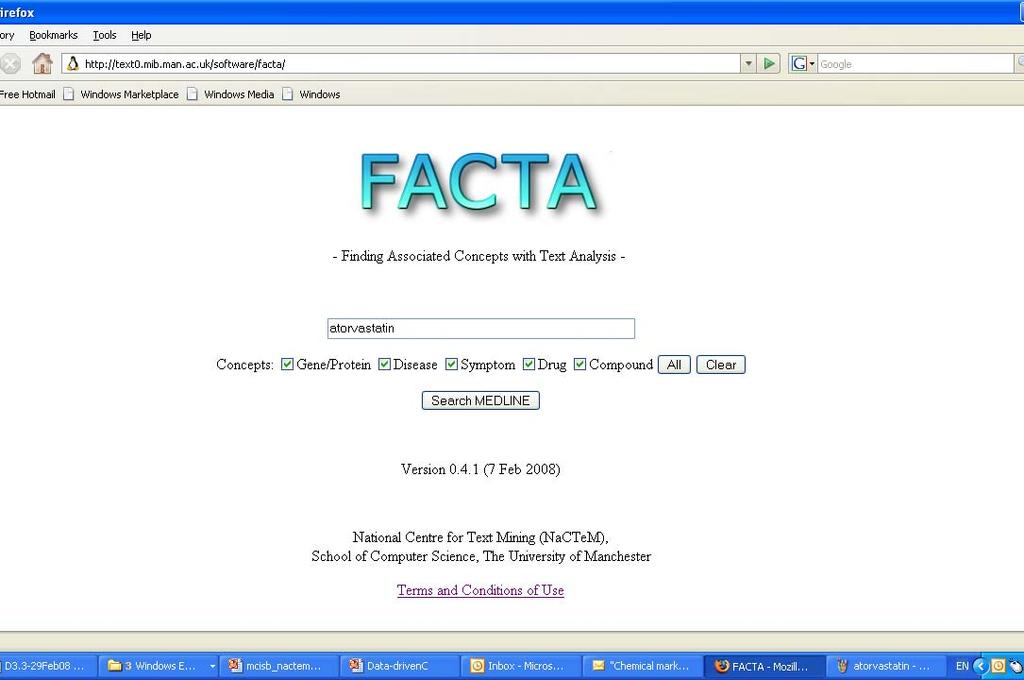
8 Query
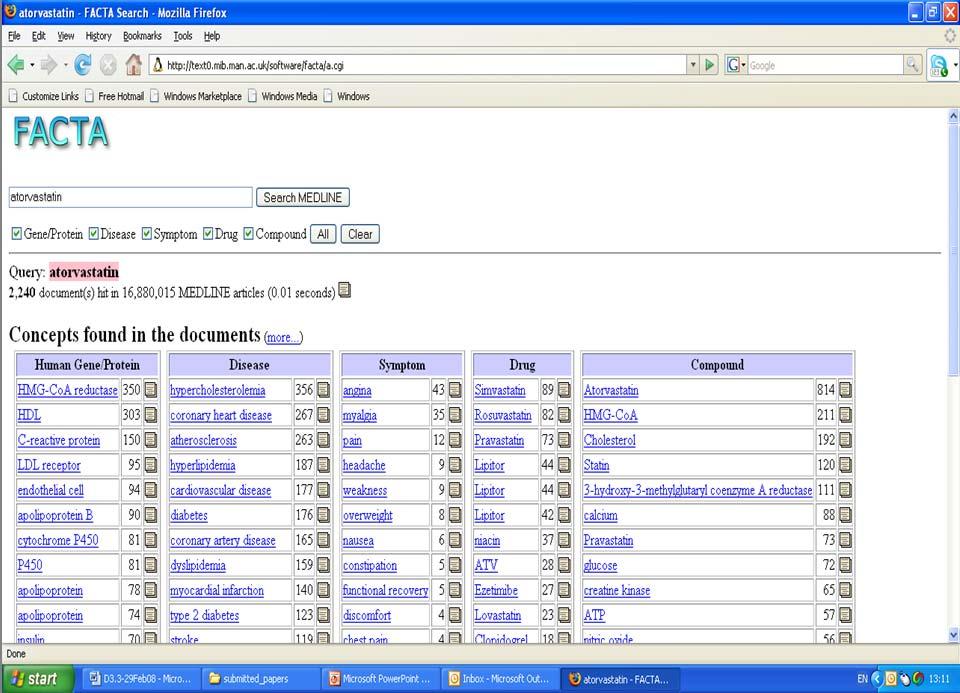
9 Click!
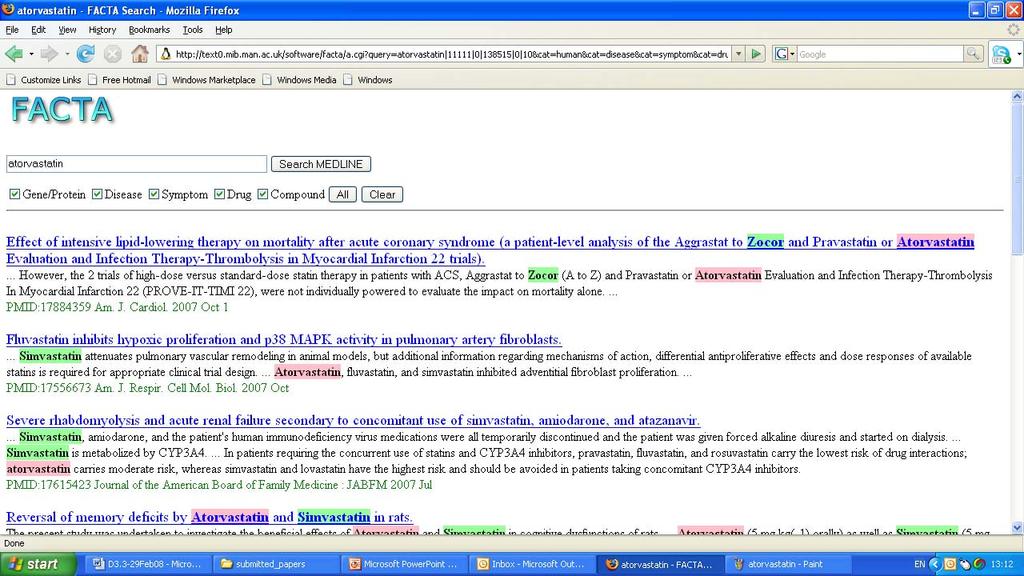
10
11 Innovative Technologies applied to: Term recognition Named entity recognition Fact extraction semantic mark-up improves search classifying, linking documents Semantic Mark-up knowledge discovery, hidden links, associations, hypothesis generation
12 Natural Language Processing technologies Part-of-speech tagging: GENIA Tuned to biomedical text: 97-99% precision Dictionary-based named-entity recognition Deep parsing Predicate argument relations (90%) Protein-protein interaction extraction Event / fact extraction

13 Automatic Term Recognition
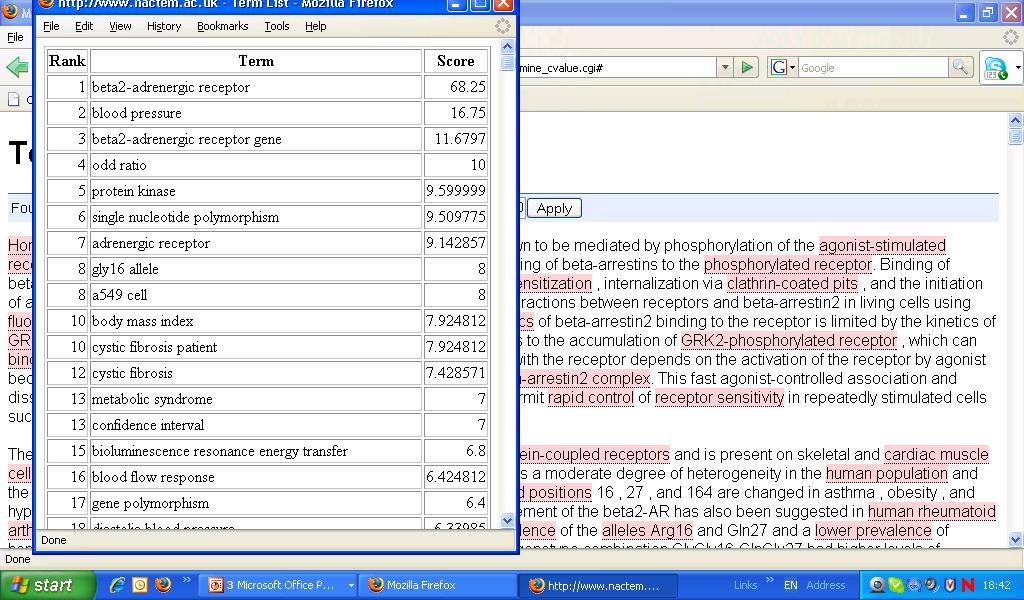
14
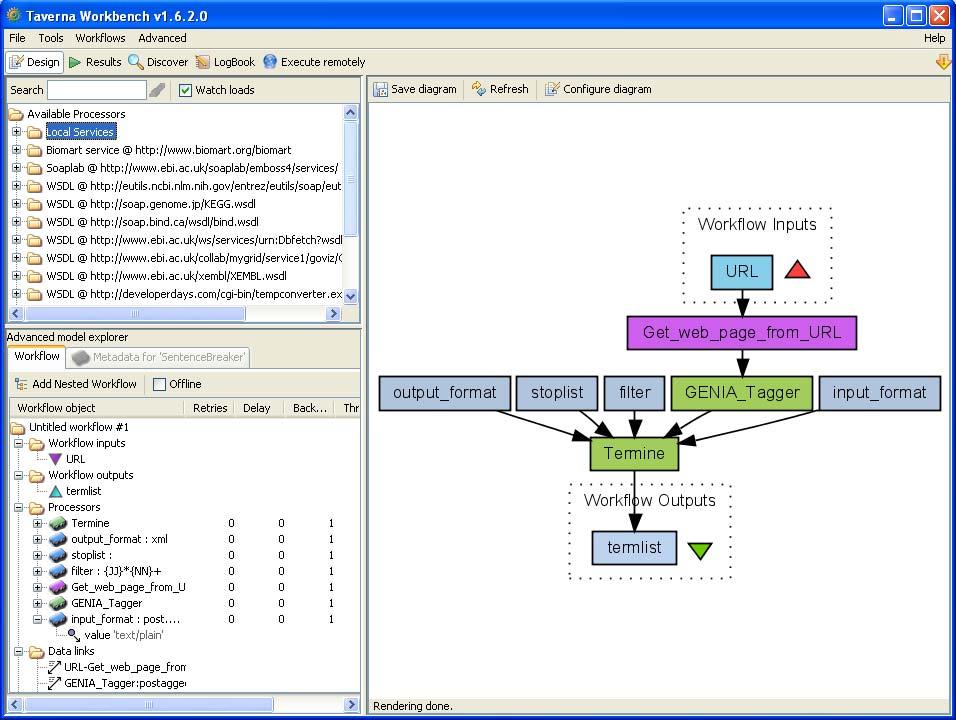
15

16 Recognising and Disambiguating Acronyms in Biomedical Literature
17 Named-entity recognition The peri-kappa B site mediates human immunodeficiency DNA virus virus type 2 enhancer activation in monocytes cell_type Entity types (defined by Ontologies) Genes/protein names Enzymes, substances, metabolites, etc GO ontology, KEGG, CheBI, etc
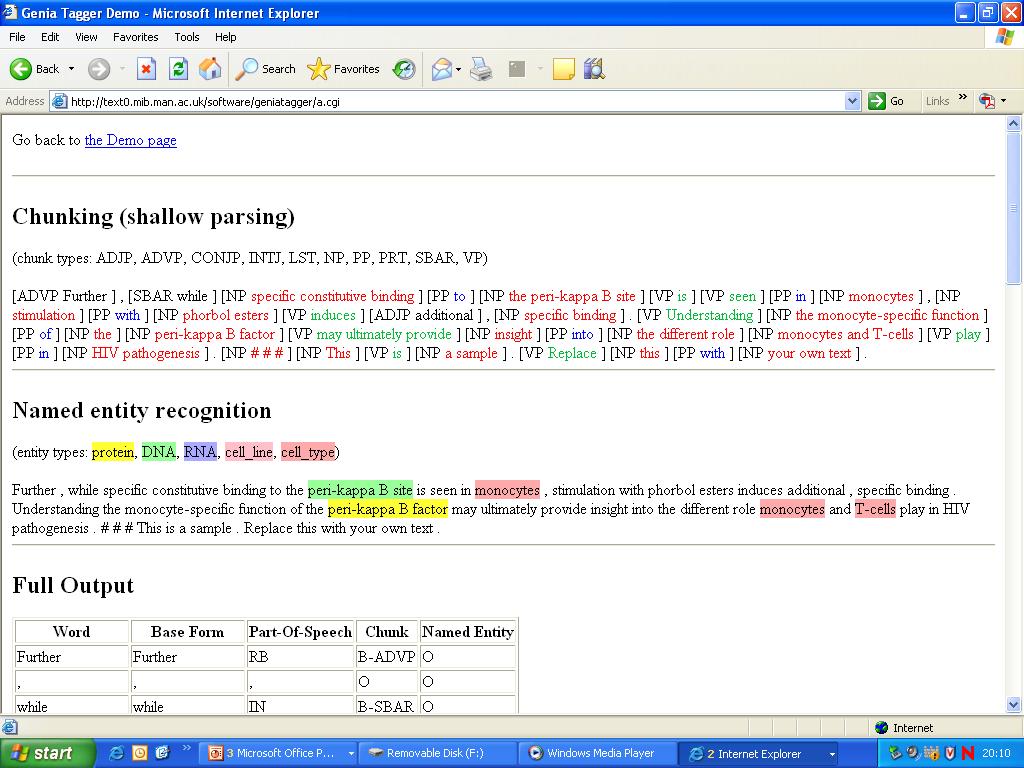
18
 BioLexicon Over 1.5M lexical entries for bio-text mining and growing.")
19 Leveraging resources Annotated texts (GENIA corpus, GENIA event corpus) Resources for bio-text mining resource-building NLP tools for text-based knowledge harvesting (NaCTeM) BioLexicon Over 1.5M lexical entries for bio-text mining and growing. Containing rich linguistic information for bio-text mining
20 Existing repositories Population Process chemical, disease, enzyme, species names Subclustering of term variants gene/protein names Medline abstracts new gene/protein names Named entity recognition Term mapping by normalization Bio-Lexicon Manual curation Verb subcategorization terminological verbs on-going verb subcategorization frames
21 Semantic search based on facts MEDIE: an interactive advanced IR system retrieving facts Performs a semantic search Core technology annotates texts GENIA tagger syntactic structures Enju (deep parser) facts Dictionary-based named entity recognition J. Tsujii
22 Medie system overview Off-line Input Textbase Deep parser Entity Recognizer Semanticallyannotated Textbase On-line RegionAlgebra Search engine Query Search results

23 Sentence Retrieval System Using Semantic Representation MEDIE
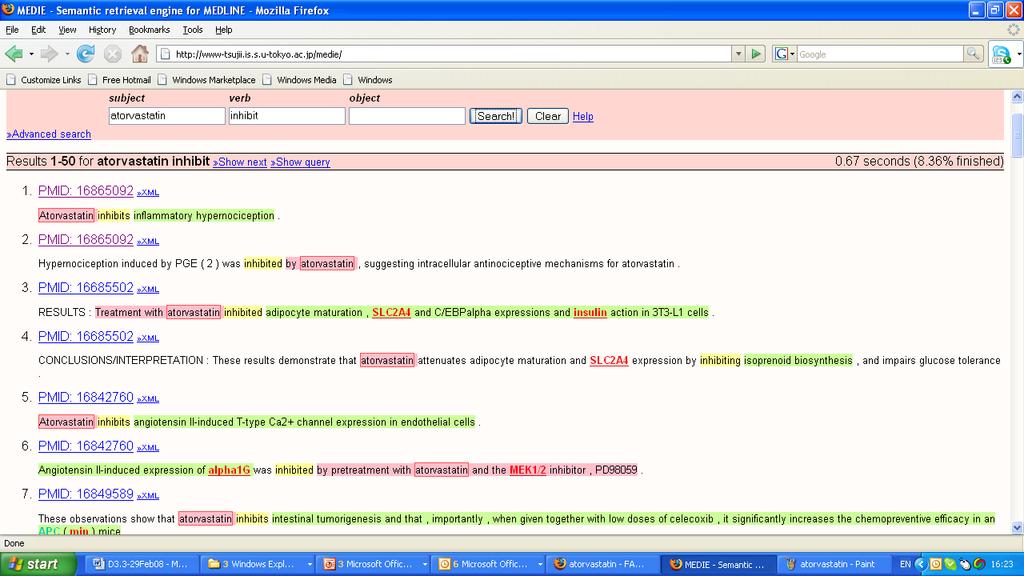
24
25 InfoPubMed An interactive Information Extraction system and an efficient PubMed search tool, helping users to find information about biomedical entities such as genes, proteins, and the interactions between them. System components Deep parsing technology Extraction of protein-protein interactions Multi-window interface on a browser

26 InfoPubMed Interactions and not just co-occurrences. Calculated using ML and deep semantics.
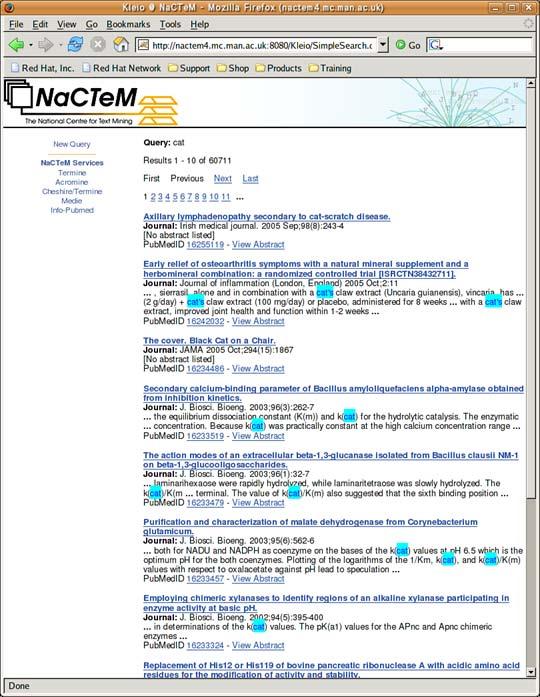
27 Semantic Information Retrieval KLEIO: a semantically enriched information retrieval system for biology Offers textual and metadata searches across MEDLINE Leverages terminology technologies Named entity recognition: gene, protein, metabolite, organ, disease, symptom







































28 KLEIO architecture
29

30 Fewer documents with more precise query
31 Linking and enriching pathways with text REFINE (BBSRC) MCISB and NaCTeM (Kell, Ananiadou, Tsujii) to integrate text mining techniques with visualisation technologies for better understanding of the evidence for biochemical and signalling pathways to enrich pathway models encoded in the Systems Biology Markup Language (SBML) with evidence derived from text mining
32 2 Steps for linking text with pathways Pathways IkB IkB P IkB U athway Construction Event Extraction Biological events IkB IkB IkB IkB P IkB U Literature Tsujii-lab, Tokyo IkappaB is phosphorylated Ikappa B ubiquitination degradation of IkB

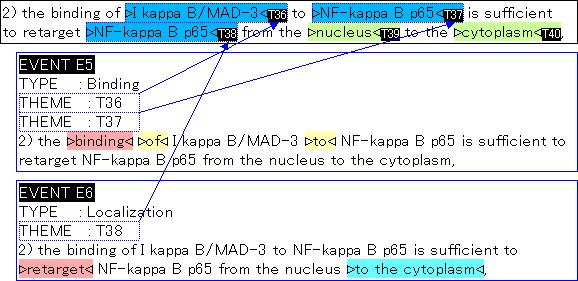
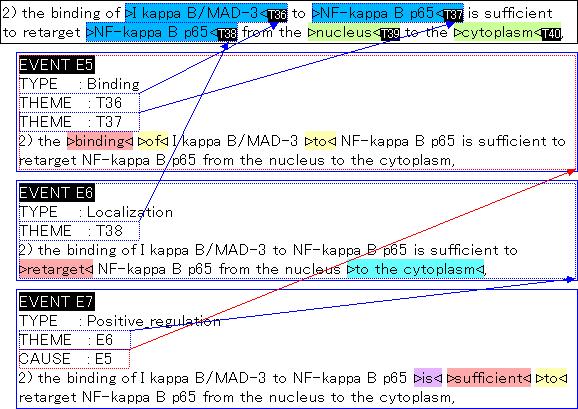
33 Event Annotation - Example
34 Statistics & References Statistics 36,114 events have been identified from and annotated to 1,000 Medline abstracts, which contain 9,372 sentences Kim, Jin-Dong, Tomoko Ohta and Jun'ichi Tsujii (2008) Corpus annotation for mining biomedical events from literature. BMC Bioinformatics
35 Acknowledgements Junichi Tsujii and his lab (University of Tokyo) MEDIE, InfoPubMed, event annotation Yoshimasa Tsuruoka (NER, FACTA, KLEIO, REFINE) Naoaki Okazaki (TerMine, AcroMine) Yutaka Sasaki (BioLexicon, NER, KLEIO) John McNaught (BioLexicon, BOOTStrep project) Chikashi Nobata (KLEIO) Douglas Kell (REFINE)
What is Text Mining? Sophia Ananiadou National Centre for Text Mining University of Manchester
 National Centre for Text Mining www.nactem.ac.uk University of Manchester Outline Aims of text mining Text Mining steps Text Mining uses Applications 2 Aims Extract and discover knowledge hidden in text
National Centre for Text Mining www.nactem.ac.uk University of Manchester Outline Aims of text mining Text Mining steps Text Mining uses Applications 2 Aims Extract and discover knowledge hidden in text
Connecting Text Mining and Pathways using the PathText Resource
 Connecting Text Mining and Pathways using the PathText Resource Sætre, Kemper, Oda, Okazaki a, Matsuoka b, Kikuchi c, Kitano d, Tsuruoka, Ananiadou, Tsujii e a Computer Science, University of Tokyo, Hongo
Connecting Text Mining and Pathways using the PathText Resource Sætre, Kemper, Oda, Okazaki a, Matsuoka b, Kikuchi c, Kitano d, Tsuruoka, Ananiadou, Tsujii e a Computer Science, University of Tokyo, Hongo
The GENIA corpus Linguistic and Semantic Annotation of Biomedical Literature. Jin-Dong Kim Tsujii Laboratory, University of Tokyo
 The GENIA corpus Linguistic and Semantic Annotation of Biomedical Literature Jin-Dong Kim Tsujii Laboratory, University of Tokyo Contents Ontology, Corpus and Annotation for IE Annotation and Information
The GENIA corpus Linguistic and Semantic Annotation of Biomedical Literature Jin-Dong Kim Tsujii Laboratory, University of Tokyo Contents Ontology, Corpus and Annotation for IE Annotation and Information
Customisable Curation Workflows in Argo
 Customisable Curation Workflows in Argo Rafal Rak*, Riza Batista-Navarro, Andrew Rowley, Jacob Carter and Sophia Ananiadou National Centre for Text Mining, University of Manchester, UK *Corresponding author:
Customisable Curation Workflows in Argo Rafal Rak*, Riza Batista-Navarro, Andrew Rowley, Jacob Carter and Sophia Ananiadou National Centre for Text Mining, University of Manchester, UK *Corresponding author:
UIMA-based Annotation Type System for a Text Mining Architecture
 UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
Information Retrieval, Information Extraction, and Text Mining Applications for Biology. Slides by Suleyman Cetintas & Luo Si
 Information Retrieval, Information Extraction, and Text Mining Applications for Biology Slides by Suleyman Cetintas & Luo Si 1 Outline Introduction Overview of Literature Data Sources PubMed, HighWire
Information Retrieval, Information Extraction, and Text Mining Applications for Biology Slides by Suleyman Cetintas & Luo Si 1 Outline Introduction Overview of Literature Data Sources PubMed, HighWire
@Note2 tutorial. Hugo Costa Ruben Rodrigues Miguel Rocha
 @Note2 tutorial Hugo Costa (hcosta@silicolife.com) Ruben Rodrigues (pg25227@alunos.uminho.pt) Miguel Rocha (mrocha@di.uminho.pt) 23-01-2018 The document presents a typical workflow using @Note2 platform
@Note2 tutorial Hugo Costa (hcosta@silicolife.com) Ruben Rodrigues (pg25227@alunos.uminho.pt) Miguel Rocha (mrocha@di.uminho.pt) 23-01-2018 The document presents a typical workflow using @Note2 platform
EVENT EXTRACTION WITH COMPLEX EVENT CLASSIFICATION USING RICH FEATURES
 Journal of Bioinformatics and Computational Biology Vol. 8, No. 1 (2010) 131 146 c 2010 The Authors DOI: 10.1142/S0219720010004586 EVENT EXTRACTION WITH COMPLEX EVENT CLASSIFICATION USING RICH FEATURES
Journal of Bioinformatics and Computational Biology Vol. 8, No. 1 (2010) 131 146 c 2010 The Authors DOI: 10.1142/S0219720010004586 EVENT EXTRACTION WITH COMPLEX EVENT CLASSIFICATION USING RICH FEATURES
An UIMA based Tool Suite for Semantic Text Processing
 An UIMA based Tool Suite for Semantic Text Processing Katrin Tomanek, Ekaterina Buyko, Udo Hahn Jena University Language & Information Engineering Lab StemNet Knowledge Management for Immunology in life
An UIMA based Tool Suite for Semantic Text Processing Katrin Tomanek, Ekaterina Buyko, Udo Hahn Jena University Language & Information Engineering Lab StemNet Knowledge Management for Immunology in life
Lecture11b: NLP (Introduction)
") Lecture11b: NLP (Introduction) CS540 4/10/18 Announcements Project #1 Group grades have been mailed out Individual grades are posted on canvas similar to group grades if teams didn t turn in columns, I
Lecture11b: NLP (Introduction) CS540 4/10/18 Announcements Project #1 Group grades have been mailed out Individual grades are posted on canvas similar to group grades if teams didn t turn in columns, I
A Framework for BioCuration (part II)
") A Framework for BioCuration (part II) Text Mining for the BioCuration Workflow Workshop, 3rd International Biocuration Conference Friday, April 17, 2009 (Berlin) Martin Krallinger Spanish National Cancer
A Framework for BioCuration (part II) Text Mining for the BioCuration Workflow Workshop, 3rd International Biocuration Conference Friday, April 17, 2009 (Berlin) Martin Krallinger Spanish National Cancer
Powering Knowledge Discovery. Insights from big data with Linguamatics I2E
 Powering Knowledge Discovery Insights from big data with Linguamatics I2E Gain actionable insights from unstructured data The world now generates an overwhelming amount of data, most of it written in natural
Powering Knowledge Discovery Insights from big data with Linguamatics I2E Gain actionable insights from unstructured data The world now generates an overwhelming amount of data, most of it written in natural
The CALBC RDF Triple store: retrieval over large literature content
 The CALBC RDF Triple store: retrieval over large literature content Samuel Croset, Christoph Grabmüller, Chen Li, Silverstras Kavaliauskas, Dietrich Rebholz-Schuhmann croset@ebi.ac.uk 10 th December 2010,
The CALBC RDF Triple store: retrieval over large literature content Samuel Croset, Christoph Grabmüller, Chen Li, Silverstras Kavaliauskas, Dietrich Rebholz-Schuhmann croset@ebi.ac.uk 10 th December 2010,
Australian Journal of Basic and Applied Sciences. Named Entity Recognition from Biomedical Abstracts An Information Extraction Task
 ISSN:1991-8178 Australian Journal of Basic and Applied Sciences Journal home page: www.ajbasweb.com Named Entity Recognition from Biomedical Abstracts An Information Extraction Task 1 N. Kanya and 2 Dr.
ISSN:1991-8178 Australian Journal of Basic and Applied Sciences Journal home page: www.ajbasweb.com Named Entity Recognition from Biomedical Abstracts An Information Extraction Task 1 N. Kanya and 2 Dr.
The GENIA Corpus: an Annotated Research Abstract Corpus in Molecular Biology Domain
 The GENIA Corpus: an Annotated Research Abstract Corpus in Molecular Biology Domain Tomoko Ohta University of okap@is.s.u-tokyo.ac.jp Yuka Tateisi CREST, JST yucca@is.s.u-tkyo.ac.jp Jin-Dong Kim CREST,
The GENIA Corpus: an Annotated Research Abstract Corpus in Molecular Biology Domain Tomoko Ohta University of okap@is.s.u-tokyo.ac.jp Yuka Tateisi CREST, JST yucca@is.s.u-tkyo.ac.jp Jin-Dong Kim CREST,
National Centre for Text Mining NaCTeM. e-science and data mining workshop
 National Centre for Text Mining NaCTeM e-science and data mining workshop John Keane Co-Director, NaCTeM john.keane@manchester.ac.uk School of Informatics, University of Manchester What is text mining?
National Centre for Text Mining NaCTeM e-science and data mining workshop John Keane Co-Director, NaCTeM john.keane@manchester.ac.uk School of Informatics, University of Manchester What is text mining?
Maximizing the Value of STM Content through Semantic Enrichment. Frank Stumpf December 1, 2009
 Maximizing the Value of STM Content through Semantic Enrichment Frank Stumpf December 1, 2009 What is Semantics and Semantic Processing? Content Knowledge Framework Technology Framework Search Text Images
Maximizing the Value of STM Content through Semantic Enrichment Frank Stumpf December 1, 2009 What is Semantics and Semantic Processing? Content Knowledge Framework Technology Framework Search Text Images
The Text Analytics Challenge BioCreative V - Extraction of causal network information in BEL
 The Text Analytics Challenge BioCreative V - Extraction of causal network information in BEL http://tinyurl.com/beltask Fabio Rinaldi Outline Biomedical text mining, motivation Competitive evaluations:
The Text Analytics Challenge BioCreative V - Extraction of causal network information in BEL http://tinyurl.com/beltask Fabio Rinaldi Outline Biomedical text mining, motivation Competitive evaluations:
Building trainable taggers in a web-based, UIMA-supported NLP workbench
 Building trainable taggers in a web-based, UIMA-supported NLP workbench Rafal Rak, BalaKrishna Kolluru and Sophia Ananiadou National Centre for Text Mining School of Computer Science, University of Manchester
Building trainable taggers in a web-based, UIMA-supported NLP workbench Rafal Rak, BalaKrishna Kolluru and Sophia Ananiadou National Centre for Text Mining School of Computer Science, University of Manchester
Incremental Information Extraction Using Dependency Parser
 Incremental Information Extraction Using Dependency Parser A.Carolin Arockia Mary 1 S.Abirami 2 A.Ajitha 3 PG Scholar, ME-Software PG Scholar, ME-Software Assistant Professor, Computer Engineering Engineering
Incremental Information Extraction Using Dependency Parser A.Carolin Arockia Mary 1 S.Abirami 2 A.Ajitha 3 PG Scholar, ME-Software PG Scholar, ME-Software Assistant Professor, Computer Engineering Engineering
Visualizing Semantic Metadata from Biological Publications
 Visualizing Semantic Metadata from Biological Publications Johannes Hellrich, Erik Faessler, Ekaterina Buyko and Udo Hahn Jena University Language and Information Engineering (JULIE) Lab Friedrich-Schiller-Universität
Visualizing Semantic Metadata from Biological Publications Johannes Hellrich, Erik Faessler, Ekaterina Buyko and Udo Hahn Jena University Language and Information Engineering (JULIE) Lab Friedrich-Schiller-Universität
Semantic Retrieval for the Accurate Identification of Relational Concepts in Massive Textbases
 Semantic Retrieval for the Accurate Identification of Relational Concepts in Massive Textbases Yusuke Miyao Tomoko Ohta Katsuya Masuda Yoshimasa Tsuruoka Kazuhiro Yoshida Takashi Ninomiya Jun ichi Tsujii
Semantic Retrieval for the Accurate Identification of Relational Concepts in Massive Textbases Yusuke Miyao Tomoko Ohta Katsuya Masuda Yoshimasa Tsuruoka Kazuhiro Yoshida Takashi Ninomiya Jun ichi Tsujii
Statistical Parsing for Text Mining from Scientific Articles
 Statistical Parsing for Text Mining from Scientific Articles Ted Briscoe Computer Laboratory University of Cambridge November 30, 2004 Contents 1 Text Mining 2 Statistical Parsing 3 The RASP System 4 The
Statistical Parsing for Text Mining from Scientific Articles Ted Briscoe Computer Laboratory University of Cambridge November 30, 2004 Contents 1 Text Mining 2 Statistical Parsing 3 The RASP System 4 The
Mining the Biomedical Research Literature. Ken Baclawski
 Mining the Biomedical Research Literature Ken Baclawski Data Formats Flat files Spreadsheets Relational databases Web sites XML Documents Flexible very popular text format Self-describing records XML Documents
Mining the Biomedical Research Literature Ken Baclawski Data Formats Flat files Spreadsheets Relational databases Web sites XML Documents Flexible very popular text format Self-describing records XML Documents
Text Mining. Representation of Text Documents
 Data Mining is typically concerned with the detection of patterns in numeric data, but very often important (e.g., critical to business) information is stored in the form of text. Unlike numeric data,
Data Mining is typically concerned with the detection of patterns in numeric data, but very often important (e.g., critical to business) information is stored in the form of text. Unlike numeric data,
Original article Argo: an integrative, interactive, text mining-based workbench supporting curation
 Original article Argo: an integrative, interactive, text mining-based workbench supporting curation Rafal Rak*, Andrew Rowley, William Black and Sophia Ananiadou National Centre for Text Mining and School
Original article Argo: an integrative, interactive, text mining-based workbench supporting curation Rafal Rak*, Andrew Rowley, William Black and Sophia Ananiadou National Centre for Text Mining and School
PPI Finder: A Mining Tool for Human Protein-Protein Interactions
 PPI Finder: A Mining Tool for Human Protein-Protein Interactions Min He 1,2., Yi Wang 1., Wei Li 1 * 1 Key Laboratory of Molecular and Developmental Biology, Institute of Genetics and Developmental Biology,
PPI Finder: A Mining Tool for Human Protein-Protein Interactions Min He 1,2., Yi Wang 1., Wei Li 1 * 1 Key Laboratory of Molecular and Developmental Biology, Institute of Genetics and Developmental Biology,
A Comparative Study of Syntactic Parsers for Event Extraction
 A Comparative Study of Syntactic Parsers for Event Extraction Makoto Miwa 1 Sampo Pyysalo 1 Tadayoshi Hara 1 Jun ichi Tsujii 1,2,3 1 Department of Computer Science, the University of Tokyo, Japan Hongo
A Comparative Study of Syntactic Parsers for Event Extraction Makoto Miwa 1 Sampo Pyysalo 1 Tadayoshi Hara 1 Jun ichi Tsujii 1,2,3 1 Department of Computer Science, the University of Tokyo, Japan Hongo
Exploring the Generation and Integration of Publishable Scientific Facts Using the Concept of Nano-publications
 Exploring the Generation and Integration of Publishable Scientific Facts Using the Concept of Nano-publications Amanda Clare 1,3, Samuel Croset 2,3 (croset@ebi.ac.uk), Christoph Grabmueller 2,3, Senay
Exploring the Generation and Integration of Publishable Scientific Facts Using the Concept of Nano-publications Amanda Clare 1,3, Samuel Croset 2,3 (croset@ebi.ac.uk), Christoph Grabmueller 2,3, Senay
Domain Independent Knowledge Base Population From Structured and Unstructured Data Sources
 Domain Independent Knowledge Base Population From Structured and Unstructured Data Sources Michelle Gregory, Liam McGrath, Eric Bell, Kelly O Hara, and Kelly Domico Pacific Northwest National Laboratory
Domain Independent Knowledge Base Population From Structured and Unstructured Data Sources Michelle Gregory, Liam McGrath, Eric Bell, Kelly O Hara, and Kelly Domico Pacific Northwest National Laboratory
Integrated NLP Evaluation System for Pluggable Evaluation Metrics with Extensive Interoperable Toolkit
 Integrated NLP Evaluation System for Pluggable Evaluation Metrics with Extensive Interoperable Toolkit Yoshinobu Kano 1 Luke McCrohon 1 Sophia Ananiadou 2 Jun ichi Tsujii 1,2 1 Department of Computer Science,
Integrated NLP Evaluation System for Pluggable Evaluation Metrics with Extensive Interoperable Toolkit Yoshinobu Kano 1 Luke McCrohon 1 Sophia Ananiadou 2 Jun ichi Tsujii 1,2 1 Department of Computer Science,
Improving Interoperability of Text Mining Tools with BioC
 Improving Interoperability of Text Mining Tools with BioC Ritu Khare, Chih-Hsuan Wei, Yuqing Mao, Robert Leaman, Zhiyong Lu * National Center for Biotechnology Information, 8600 Rockville Pike, Bethesda,
Improving Interoperability of Text Mining Tools with BioC Ritu Khare, Chih-Hsuan Wei, Yuqing Mao, Robert Leaman, Zhiyong Lu * National Center for Biotechnology Information, 8600 Rockville Pike, Bethesda,
Discovering Biomedical Relations Utilizing the World-Wide Web. Sougata Mukherjea and Saurav Sahay. Pacific Symposium on Biocomputing 11: (2006)
") Discovering Biomedical Relations Utilizing the World-Wide Web Sougata Mukherjea and Saurav Sahay Pacific Symposium on Biocomputing 11:164-175(2006) DISCOVERING BIOMEDICAL RELATIONS UTILIZING THE WORLD-WIDE
Discovering Biomedical Relations Utilizing the World-Wide Web Sougata Mukherjea and Saurav Sahay Pacific Symposium on Biocomputing 11:164-175(2006) DISCOVERING BIOMEDICAL RELATIONS UTILIZING THE WORLD-WIDE
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
Collaborative Development and Evaluation of Text-processing Workflows in a UIMA-supported Web-based Workbench
 Collaborative Development and Evaluation of Text-processing Workflows in a UIMA-supported Web-based Workbench Rafal Rak, Andrew Rowley, Sophia Ananiadou National Centre for Text Mining and School of Computer
Collaborative Development and Evaluation of Text-processing Workflows in a UIMA-supported Web-based Workbench Rafal Rak, Andrew Rowley, Sophia Ananiadou National Centre for Text Mining and School of Computer
Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus
 Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus Donald C. Comeau *, Haibin Liu, Rezarta Islamaj Doğan and W. John Wilbur National Center
Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus Donald C. Comeau *, Haibin Liu, Rezarta Islamaj Doğan and W. John Wilbur National Center
Developing a hybrid dictionary-based bio-entity recognition technique
 RESEARCH ARTICLE Open Access Developing a hybrid dictionary-based bio-entity recognition technique Min Song 1, Hwanjo Yu 2, Wook-Shin Han 2,3* From ACM Eighth International Workshop on Data and Text Mining
RESEARCH ARTICLE Open Access Developing a hybrid dictionary-based bio-entity recognition technique Min Song 1, Hwanjo Yu 2, Wook-Shin Han 2,3* From ACM Eighth International Workshop on Data and Text Mining
Historical Text Mining:
 Historical Text Mining Historical Text Mining, and Historical Text Mining: Challenges and Opportunities Dr. Robert Sanderson Dept. of Computer Science University of Liverpool azaroth@liv.ac.uk http://www.csc.liv.ac.uk/~azaroth/
Historical Text Mining Historical Text Mining, and Historical Text Mining: Challenges and Opportunities Dr. Robert Sanderson Dept. of Computer Science University of Liverpool azaroth@liv.ac.uk http://www.csc.liv.ac.uk/~azaroth/
GRO Task: Populating the Gene Regulation Ontology with events and relations
 GRO Task: Populating the Gene Regulation Ontology with events and relations Jung-jae Kim, Xu Han School of Computer Engineering Nanyang Technological University Nanyang Avenue, Singapore jungjae.kim@ntu.edu.sg,
GRO Task: Populating the Gene Regulation Ontology with events and relations Jung-jae Kim, Xu Han School of Computer Engineering Nanyang Technological University Nanyang Avenue, Singapore jungjae.kim@ntu.edu.sg,
Turning Text into Insight: Text Mining in the Life Sciences WHITEPAPER
 Turning Text into Insight: Text Mining in the Life Sciences WHITEPAPER According to The STM Report (2015), 2.5 million peer-reviewed articles are published in scholarly journals each year. 1 PubMed contains
Turning Text into Insight: Text Mining in the Life Sciences WHITEPAPER According to The STM Report (2015), 2.5 million peer-reviewed articles are published in scholarly journals each year. 1 PubMed contains
Extraction of biomedical events using case-based reasoning
 Extraction of biomedical events using case-based reasoning Mariana L. Neves Biocomputing Unit Centro Nacional de Biotecnología - CSIC C/ Darwin 3, Campus de Cantoblanco, 28049, Madrid, Spain mlara@cnb.csic.es
Extraction of biomedical events using case-based reasoning Mariana L. Neves Biocomputing Unit Centro Nacional de Biotecnología - CSIC C/ Darwin 3, Campus de Cantoblanco, 28049, Madrid, Spain mlara@cnb.csic.es
clarin:el an infrastructure for documenting, sharing and processing language data
 clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
Integrated Access to Biological Data. A use case
 Integrated Access to Biological Data. A use case Marta González Fundación ROBOTIKER, Parque Tecnológico Edif 202 48970 Zamudio, Vizcaya Spain marta@robotiker.es Abstract. This use case reflects the research
Integrated Access to Biological Data. A use case Marta González Fundación ROBOTIKER, Parque Tecnológico Edif 202 48970 Zamudio, Vizcaya Spain marta@robotiker.es Abstract. This use case reflects the research
STEPP Tagger 1. BASIC INFORMATION 2. TECHNICAL INFORMATION. Tool name. STEPP Tagger. Overview and purpose of the tool
 1. BASIC INFORMATION Tool name STEPP Tagger Overview and purpose of the tool STEPP Tagger Part-of-speech tagger tuned to biomedical text. Given plain text, sentences and tokens are identified, and tokens
1. BASIC INFORMATION Tool name STEPP Tagger Overview and purpose of the tool STEPP Tagger Part-of-speech tagger tuned to biomedical text. Given plain text, sentences and tokens are identified, and tokens
Unstructured Text in Big Data The Elephant in the Room
 Unstructured Text in Big Data The Elephant in the Room David Milward ICIC, October 2013 Click Unstructured to to edit edit Master Master Big title Data style title style Big Data Volume, Variety, Velocity
Unstructured Text in Big Data The Elephant in the Room David Milward ICIC, October 2013 Click Unstructured to to edit edit Master Master Big title Data style title style Big Data Volume, Variety, Velocity
A curation pipeline and web-services for PDF documents
 A curation pipeline and web-services for PDF documents André Santos 1, Sérgio Matos 1, David Campos 2 and José Luís Oliveira 1 1 DETI/IEETA, University of Aveiro, 3810-193 Aveiro, Portugal {aleixomatos,andre.jeronimo,jlo}@ua.pt
A curation pipeline and web-services for PDF documents André Santos 1, Sérgio Matos 1, David Campos 2 and José Luís Oliveira 1 1 DETI/IEETA, University of Aveiro, 3810-193 Aveiro, Portugal {aleixomatos,andre.jeronimo,jlo}@ua.pt
About the Edinburgh Pathway Editor:
 About the Edinburgh Pathway Editor: EPE is a visual editor designed for annotation, visualisation and presentation of wide variety of biological networks, including metabolic, genetic and signal transduction
About the Edinburgh Pathway Editor: EPE is a visual editor designed for annotation, visualisation and presentation of wide variety of biological networks, including metabolic, genetic and signal transduction
Introduction to Text Mining. Hongning Wang
 Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Automated Key Generation of Incremental Information Extraction Using Relational Database System & PTQL
 Automated Key Generation of Incremental Information Extraction Using Relational Database System & PTQL Gayatri Naik, Research Scholar, Singhania University, Rajasthan, India Dr. Praveen Kumar, Singhania
Automated Key Generation of Incremental Information Extraction Using Relational Database System & PTQL Gayatri Naik, Research Scholar, Singhania University, Rajasthan, India Dr. Praveen Kumar, Singhania
Revealing the Modern History of Japanese Philosophy Using Digitization, Natural Language Processing, and Visualization
 Revealing the Modern History of Japanese Philosophy Using Digitization, Natural Language Katsuya Masuda *, Makoto Tanji **, and Hideki Mima *** Abstract This study proposes a framework to access to the
Revealing the Modern History of Japanese Philosophy Using Digitization, Natural Language Katsuya Masuda *, Makoto Tanji **, and Hideki Mima *** Abstract This study proposes a framework to access to the
Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger. Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight
 Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight Origin and Outcomes Currently funded through a Wellcome Trust Seed award Collaboration
Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight Origin and Outcomes Currently funded through a Wellcome Trust Seed award Collaboration
A new methodology for gene normalization using a mix of taggers, global alignment matching and document similarity disambiguation
 A new methodology for gene normalization using a mix of taggers, global alignment matching and document similarity disambiguation Mariana Neves 1, Monica Chagoyen 1, José M Carazo 1, Alberto Pascual-Montano
A new methodology for gene normalization using a mix of taggers, global alignment matching and document similarity disambiguation Mariana Neves 1, Monica Chagoyen 1, José M Carazo 1, Alberto Pascual-Montano
The KNIME Text Processing Plugin
 The KNIME Text Processing Plugin Kilian Thiel Nycomed Chair for Bioinformatics and Information Mining, University of Konstanz, 78457 Konstanz, Deutschland, Kilian.Thiel@uni-konstanz.de Abstract. This document
The KNIME Text Processing Plugin Kilian Thiel Nycomed Chair for Bioinformatics and Information Mining, University of Konstanz, 78457 Konstanz, Deutschland, Kilian.Thiel@uni-konstanz.de Abstract. This document
Text-mining-assisted biocuration workflows in Argo
 Database, 2014, 1 14 doi: 10.1093/database/bau070 Original article Original article Text-mining-assisted biocuration workflows in Argo Rafal Rak 1, *, Riza Theresa Batista-Navarro 1,2, Andrew Rowley 1,
Database, 2014, 1 14 doi: 10.1093/database/bau070 Original article Original article Text-mining-assisted biocuration workflows in Argo Rafal Rak 1, *, Riza Theresa Batista-Navarro 1,2, Andrew Rowley 1,
Chemical name recognition with harmonized feature-rich conditional random fields
 Chemical name recognition with harmonized feature-rich conditional random fields David Campos, Sérgio Matos, and José Luís Oliveira IEETA/DETI, University of Aveiro, Campus Universitrio de Santiago, 3810-193
Chemical name recognition with harmonized feature-rich conditional random fields David Campos, Sérgio Matos, and José Luís Oliveira IEETA/DETI, University of Aveiro, Campus Universitrio de Santiago, 3810-193
Measuring inter-annotator agreement in GO annotations
 Measuring inter-annotator agreement in GO annotations Camon EB, Barrell DG, Dimmer EC, Lee V, Magrane M, Maslen J, Binns ns D, Apweiler R. An evaluation of GO annotation retrieval for BioCreAtIvE and GOA.
Measuring inter-annotator agreement in GO annotations Camon EB, Barrell DG, Dimmer EC, Lee V, Magrane M, Maslen J, Binns ns D, Apweiler R. An evaluation of GO annotation retrieval for BioCreAtIvE and GOA.
Parmenides. Semi-automatic. Ontology. construction and maintenance. Ontology. Document convertor/basic processing. Linguistic. Background knowledge
 Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
SEMINAR: RECENT ADVANCES IN PARSING TECHNOLOGY. Parser Evaluation Approaches
 SEMINAR: RECENT ADVANCES IN PARSING TECHNOLOGY Parser Evaluation Approaches NATURE OF PARSER EVALUATION Return accurate syntactic structure of sentence. Which representation? Robustness of parsing. Quick
SEMINAR: RECENT ADVANCES IN PARSING TECHNOLOGY Parser Evaluation Approaches NATURE OF PARSER EVALUATION Return accurate syntactic structure of sentence. Which representation? Robustness of parsing. Quick
Enabling Open Science: Data Discoverability, Access and Use. Jo McEntyre Head of Literature Services
 Enabling Open Science: Data Discoverability, Access and Use Jo McEntyre Head of Literature Services www.ebi.ac.uk About EMBL-EBI Part of the European Molecular Biology Laboratory International, non-profit
Enabling Open Science: Data Discoverability, Access and Use Jo McEntyre Head of Literature Services www.ebi.ac.uk About EMBL-EBI Part of the European Molecular Biology Laboratory International, non-profit
Update: MIRIAM Registry and SBO
 Update: MIRIAM Registry and SBO Nick Juty, EMBL-EBI 3rd Sept, 2011 Overview MIRIAM Registry MIRIAM Guidelines.. MIRIAM Registry content URIs (URN form), example Summary/current developments SBO Purpose
Update: MIRIAM Registry and SBO Nick Juty, EMBL-EBI 3rd Sept, 2011 Overview MIRIAM Registry MIRIAM Guidelines.. MIRIAM Registry content URIs (URN form), example Summary/current developments SBO Purpose
Natural Language Processing. SoSe Question Answering
 Natural Language Processing SoSe 2017 Question Answering Dr. Mariana Neves July 5th, 2017 Motivation Find small segments of text which answer users questions (http://start.csail.mit.edu/) 2 3 Motivation
Natural Language Processing SoSe 2017 Question Answering Dr. Mariana Neves July 5th, 2017 Motivation Find small segments of text which answer users questions (http://start.csail.mit.edu/) 2 3 Motivation
Deliverable D1.4 Report Describing Integration Strategies and Experiments
 DEEPTHOUGHT Hybrid Deep and Shallow Methods for Knowledge-Intensive Information Extraction Deliverable D1.4 Report Describing Integration Strategies and Experiments The Consortium October 2004 Report Describing
DEEPTHOUGHT Hybrid Deep and Shallow Methods for Knowledge-Intensive Information Extraction Deliverable D1.4 Report Describing Integration Strategies and Experiments The Consortium October 2004 Report Describing
A RapidMiner framework for protein interaction extraction
 A RapidMiner framework for protein interaction extraction Timur Fayruzov 1, George Dittmar 2, Nicolas Spence 2, Martine De Cock 1, Ankur Teredesai 2 1 Ghent University, Ghent, Belgium 2 University of Washington,
A RapidMiner framework for protein interaction extraction Timur Fayruzov 1, George Dittmar 2, Nicolas Spence 2, Martine De Cock 1, Ankur Teredesai 2 1 Ghent University, Ghent, Belgium 2 University of Washington,
Extending the Facets concept by applying NLP tools to catalog records of scientific literature
 Extending the Facets concept by applying NLP tools to catalog records of scientific literature *E. Picchi, *M. Sassi, **S. Biagioni, **S. Giannini *Institute of Computational Linguistics **Institute of
Extending the Facets concept by applying NLP tools to catalog records of scientific literature *E. Picchi, *M. Sassi, **S. Biagioni, **S. Giannini *Institute of Computational Linguistics **Institute of
A Survey on Approaches to Text Mining using Information Extraction
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727 PP 27-31 www.iosrjournals.org A Survey on Approaches to Text Mining using Information Extraction Mrs. Rashmi Dukhi 1,
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727 PP 27-31 www.iosrjournals.org A Survey on Approaches to Text Mining using Information Extraction Mrs. Rashmi Dukhi 1,
{Ontology: Resource} x {Matching : Mapping} x {Schema : Instance} :: Components of the Same Challenge
 Wright State University CORE Scholar Kno.e.sis Publications The Ohio Center of Excellence in Knowledge- Enabled Computing (Kno.e.sis) 11-5-2006 {Ontology: Resource} x {Matching : Mapping} x {Schema : Instance}
Wright State University CORE Scholar Kno.e.sis Publications The Ohio Center of Excellence in Knowledge- Enabled Computing (Kno.e.sis) 11-5-2006 {Ontology: Resource} x {Matching : Mapping} x {Schema : Instance}
Knowledge Engineering with Semantic Web Technologies
 This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
I Know Your Name: Named Entity Recognition and Structural Parsing
 I Know Your Name: Named Entity Recognition and Structural Parsing David Philipson and Nikil Viswanathan {pdavid2, nikil}@stanford.edu CS224N Fall 2011 Introduction In this project, we explore a Maximum
I Know Your Name: Named Entity Recognition and Structural Parsing David Philipson and Nikil Viswanathan {pdavid2, nikil}@stanford.edu CS224N Fall 2011 Introduction In this project, we explore a Maximum
Acquiring Experience with Ontology and Vocabularies
 Acquiring Experience with Ontology and Vocabularies Walt Melo Risa Mayan Jean Stanford The author's affiliation with The MITRE Corporation is provided for identification purposes only, and is not intended
Acquiring Experience with Ontology and Vocabularies Walt Melo Risa Mayan Jean Stanford The author's affiliation with The MITRE Corporation is provided for identification purposes only, and is not intended
NCIBI Literature Mining Behind the Scenes, Web-Based Access
 NCIBI Literature Mining Behind the Scenes, Web-Based Access Alex Ade National Center for Integrative Biomedical Informatics University of Michigan 30 July, 2009 Introduction NCIBI Biomedical Literature
NCIBI Literature Mining Behind the Scenes, Web-Based Access Alex Ade National Center for Integrative Biomedical Informatics University of Michigan 30 July, 2009 Introduction NCIBI Biomedical Literature
Text Mining for Software Engineering
 Text Mining for Software Engineering Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe (TH), Germany Department of Computer Science and Software
Text Mining for Software Engineering Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe (TH), Germany Department of Computer Science and Software
Extracting reproducible simulation studies from model repositories using the CombineArchive Toolkit
 Extracting reproducible simulation studies from model repositories using the CombineArchive Toolkit Martin Scharm, Dagmar Waltemath Department of Systems Biology and Bioinformatics University of Rostock
Extracting reproducible simulation studies from model repositories using the CombineArchive Toolkit Martin Scharm, Dagmar Waltemath Department of Systems Biology and Bioinformatics University of Rostock
Knowledge Retrieval. Franz J. Kurfess. Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A.
 Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics
 Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics Media Intelligence Business intelligence (BI) Uses data mining techniques and tools for the transformation of raw data into meaningful
Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics Media Intelligence Business intelligence (BI) Uses data mining techniques and tools for the transformation of raw data into meaningful
MedLingMap: A growing resource mapping the Bio-Medical NLP field
 MedLingMap: A growing resource mapping the Bio-Medical NLP field Marie Meteer, Bensiin Borukhov, Michael Crivaro, Michael Shafir, Attapol Thamrongrattanarit {mmeteer, bborukhov, mcrivaro, mshafir, tet}@brandeis.edu
MedLingMap: A growing resource mapping the Bio-Medical NLP field Marie Meteer, Bensiin Borukhov, Michael Crivaro, Michael Shafir, Attapol Thamrongrattanarit {mmeteer, bborukhov, mcrivaro, mshafir, tet}@brandeis.edu
Medical Event Extraction using the Swedish FrameNet, a pilot study
 Medical Event Extraction using the Swedish FrameNet, a pilot study DIMITRIOS KOKKINAKIS Centre for Language Technology University of Gothenburg Sweden dimitrios.kokkinakis@svenska.gu.se Overview From entities
Medical Event Extraction using the Swedish FrameNet, a pilot study DIMITRIOS KOKKINAKIS Centre for Language Technology University of Gothenburg Sweden dimitrios.kokkinakis@svenska.gu.se Overview From entities
A Framework for Schema-Driven Relationship Discovery from Unstructured Text
 Wright State University CORE Scholar Kno.e.sis Publications The Ohio Center of Excellence in Knowledge- Enabled Computing (Kno.e.sis) 11-2006 A Framework for Schema-Driven Relationship Discovery from Unstructured
Wright State University CORE Scholar Kno.e.sis Publications The Ohio Center of Excellence in Knowledge- Enabled Computing (Kno.e.sis) 11-2006 A Framework for Schema-Driven Relationship Discovery from Unstructured
Digital repositories as research infrastructure: a UK perspective
 Digital repositories as research infrastructure: a UK perspective Dr Liz Lyon Director This work is licensed under a Creative Commons Licence Attribution-ShareAlike 2.0 UKOLN is supported by: Presentation
Digital repositories as research infrastructure: a UK perspective Dr Liz Lyon Director This work is licensed under a Creative Commons Licence Attribution-ShareAlike 2.0 UKOLN is supported by: Presentation
CHAPTER 5 SEARCH ENGINE USING SEMANTIC CONCEPTS
 82 CHAPTER 5 SEARCH ENGINE USING SEMANTIC CONCEPTS In recent years, everybody is in thirst of getting information from the internet. Search engines are used to fulfill the need of them. Even though the
82 CHAPTER 5 SEARCH ENGINE USING SEMANTIC CONCEPTS In recent years, everybody is in thirst of getting information from the internet. Search engines are used to fulfill the need of them. Even though the
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2
 A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
e-scider: A tool to retrieve, prioritize and analyze the articles from PubMed database Sujit R. Tangadpalliwar 1, Rakesh Nimbalkar 2, Prabha Garg* 3
 e-scider: A tool to retrieve, prioritize and analyze the articles from PubMed database Sujit R. Tangadpalliwar 1, Rakesh Nimbalkar 2, Prabha Garg* 3 1 National Institute of Pharmaceutical Education and
e-scider: A tool to retrieve, prioritize and analyze the articles from PubMed database Sujit R. Tangadpalliwar 1, Rakesh Nimbalkar 2, Prabha Garg* 3 1 National Institute of Pharmaceutical Education and
Diagnosticating and Propagating Health Maintenance Information Using Machine Learning Based Methodology
 Diagnosticating and Propagating Health Maintenance Information Using Machine Learning Based Methodology P.Deepa, M.Baskar Abstract:-The Machine Learning field has gained its thrust in almost any domain
Diagnosticating and Propagating Health Maintenance Information Using Machine Learning Based Methodology P.Deepa, M.Baskar Abstract:-The Machine Learning field has gained its thrust in almost any domain
TURNING TEXT INTO INSIGHT: TEXT MINING IN THE LIFE SCIENCES
 TURNING TEXT INTO INSIGHT: TEXT MINING IN THE LIFE SCIENCES According to The STM Report (2015), 2.5 million peer-reviewed articles are published in scholarly journals each year. 1 PubMed contains more
TURNING TEXT INTO INSIGHT: TEXT MINING IN THE LIFE SCIENCES According to The STM Report (2015), 2.5 million peer-reviewed articles are published in scholarly journals each year. 1 PubMed contains more
SciMiner User s Manual
 SciMiner User s Manual Copyright 2008 Junguk Hur. All rights reserved. Bioinformatics Program University of Michigan Ann Arbor, MI 48109, USA Email: juhur@umich.edu Homepage: http://jdrf.neurology.med.umich.edu/sciminer/
SciMiner User s Manual Copyright 2008 Junguk Hur. All rights reserved. Bioinformatics Program University of Michigan Ann Arbor, MI 48109, USA Email: juhur@umich.edu Homepage: http://jdrf.neurology.med.umich.edu/sciminer/
SBML to BioPAX. MIRIAM Annotations in use. Camille Laibe
 SBML to BioPAX MIRIAM Annotations in use Camille Laibe CellML Workshop, New Zealand, April 2009 TALK OUTLINE MIRIAM SBML to BioPAX conversion MIRIAM Minimum Information Requested In the Annotation of (biochemical)
SBML to BioPAX MIRIAM Annotations in use Camille Laibe CellML Workshop, New Zealand, April 2009 TALK OUTLINE MIRIAM SBML to BioPAX conversion MIRIAM Minimum Information Requested In the Annotation of (biochemical)
BioEve: User Interface Framework Bridging IE and IR. Pradeep Kanwar
 BioEve: User Interface Framework Bridging IE and IR by Pradeep Kanwar A Thesis Presented in Partial Fulfillment of the Requirements for the Degree Master of Science Approved October 2010 by the Graduate
BioEve: User Interface Framework Bridging IE and IR by Pradeep Kanwar A Thesis Presented in Partial Fulfillment of the Requirements for the Degree Master of Science Approved October 2010 by the Graduate
Semi-Supervised Abstraction-Augmented String Kernel for bio-relationship Extraction
 Semi-Supervised Abstraction-Augmented String Kernel for bio-relationship Extraction Pavel P. Kuksa, Rutgers University Yanjun Qi, Bing Bai, Ronan Collobert, NEC Labs Jason Weston, Google Research NY Vladimir
Semi-Supervised Abstraction-Augmented String Kernel for bio-relationship Extraction Pavel P. Kuksa, Rutgers University Yanjun Qi, Bing Bai, Ronan Collobert, NEC Labs Jason Weston, Google Research NY Vladimir
NERD workshop. Luca ALMAnaCH - Inria Paris. Berlin, 18/09/2017
 NERD workshop Luca Foppiano @ ALMAnaCH - Inria Paris Berlin, 18/09/2017 Agenda Introducing the (N)ERD service NERD REST API Usages and use cases Entities Rigid textual expressions corresponding to certain
NERD workshop Luca Foppiano @ ALMAnaCH - Inria Paris Berlin, 18/09/2017 Agenda Introducing the (N)ERD service NERD REST API Usages and use cases Entities Rigid textual expressions corresponding to certain
SAPIENT Automation project
 Dr Maria Liakata Leverhulme Trust Early Career fellow Department of Computer Science, Aberystwyth University Visitor at EBI, Cambridge mal@aber.ac.uk 25 May 2010, London Motivation SAPIENT Automation Project
Dr Maria Liakata Leverhulme Trust Early Career fellow Department of Computer Science, Aberystwyth University Visitor at EBI, Cambridge mal@aber.ac.uk 25 May 2010, London Motivation SAPIENT Automation Project
SELF-SERVICE SEMANTIC DATA FEDERATION
 SELF-SERVICE SEMANTIC DATA FEDERATION WE LL MAKE YOU A DATA SCIENTIST Contact: IPSNP Computing Inc. Chris Baker, CEO Chris.Baker@ipsnp.com (506) 721 8241 BIG VISION: SELF-SERVICE DATA FEDERATION Biomedical
SELF-SERVICE SEMANTIC DATA FEDERATION WE LL MAKE YOU A DATA SCIENTIST Contact: IPSNP Computing Inc. Chris Baker, CEO Chris.Baker@ipsnp.com (506) 721 8241 BIG VISION: SELF-SERVICE DATA FEDERATION Biomedical
SEEK User Manual. Introduction
 SEEK User Manual Introduction SEEK is a computational gene co-expression search engine. It utilizes a vast human gene expression compendium to deliver fast, integrative, cross-platform co-expression analyses.
SEEK User Manual Introduction SEEK is a computational gene co-expression search engine. It utilizes a vast human gene expression compendium to deliver fast, integrative, cross-platform co-expression analyses.
Genescene: Biomedical Text and Data Mining
 Claremont Colleges Scholarship @ Claremont CGU Faculty Publications and Research CGU Faculty Scholarship 5-1-2003 Genescene: Biomedical Text and Data Mining Gondy Leroy Claremont Graduate University Hsinchun
Claremont Colleges Scholarship @ Claremont CGU Faculty Publications and Research CGU Faculty Scholarship 5-1-2003 Genescene: Biomedical Text and Data Mining Gondy Leroy Claremont Graduate University Hsinchun
Fast and Effective System for Name Entity Recognition on Big Data
 International Journal of Computer Sciences and Engineering Open Access Research Paper Volume-3, Issue-2 E-ISSN: 2347-2693 Fast and Effective System for Name Entity Recognition on Big Data Jigyasa Nigam
International Journal of Computer Sciences and Engineering Open Access Research Paper Volume-3, Issue-2 E-ISSN: 2347-2693 Fast and Effective System for Name Entity Recognition on Big Data Jigyasa Nigam
A Linguistic Approach for Semantic Web Service Discovery
 A Linguistic Approach for Semantic Web Service Discovery Jordy Sangers 307370js jordysangers@hotmail.com Bachelor Thesis Economics and Informatics Erasmus School of Economics Erasmus University Rotterdam
A Linguistic Approach for Semantic Web Service Discovery Jordy Sangers 307370js jordysangers@hotmail.com Bachelor Thesis Economics and Informatics Erasmus School of Economics Erasmus University Rotterdam
RLIMS-P Website Help Document
 RLIMS-P Website Help Document Table of Contents Introduction... 1 RLIMS-P architecture... 2 RLIMS-P interface... 2 Login...2 Input page...3 Results Page...4 Text Evidence/Curation Page...9 URL: http://annotation.dbi.udel.edu/text_mining/rlimsp2/
RLIMS-P Website Help Document Table of Contents Introduction... 1 RLIMS-P architecture... 2 RLIMS-P interface... 2 Login...2 Input page...3 Results Page...4 Text Evidence/Curation Page...9 URL: http://annotation.dbi.udel.edu/text_mining/rlimsp2/
Corpus Linguistics: corpus annotation
 Corpus Linguistics: corpus annotation Karën Fort karen.fort@inist.fr November 30, 2010 Introduction Methodology Annotation Issues Annotation Formats From Formats to Schemes Sources Most of this course
Corpus Linguistics: corpus annotation Karën Fort karen.fort@inist.fr November 30, 2010 Introduction Methodology Annotation Issues Annotation Formats From Formats to Schemes Sources Most of this course
Natural Language Processing Tutorial May 26 & 27, 2011
 Cognitive Computation Group Natural Language Processing Tutorial May 26 & 27, 2011 http://cogcomp.cs.illinois.edu So why aren t words enough? Depends on the application more advanced task may require more
Cognitive Computation Group Natural Language Processing Tutorial May 26 & 27, 2011 http://cogcomp.cs.illinois.edu So why aren t words enough? Depends on the application more advanced task may require more
efip online Help Document
 efip online Help Document University of Delaware Computer and Information Sciences & Center for Bioinformatics and Computational Biology Newark, DE, USA December 2013 K K S I K K Table of Contents INTRODUCTION...
efip online Help Document University of Delaware Computer and Information Sciences & Center for Bioinformatics and Computational Biology Newark, DE, USA December 2013 K K S I K K Table of Contents INTRODUCTION...
Exam Marco Kuhlmann. This exam consists of three parts:
 TDDE09, 729A27 Natural Language Processing (2017) Exam 2017-03-13 Marco Kuhlmann This exam consists of three parts: 1. Part A consists of 5 items, each worth 3 points. These items test your understanding
TDDE09, 729A27 Natural Language Processing (2017) Exam 2017-03-13 Marco Kuhlmann This exam consists of three parts: 1. Part A consists of 5 items, each worth 3 points. These items test your understanding
Data Mining in Bioinformatics: Study & Survey
 Data Mining in Bioinformatics: Study & Survey Saliha V S St. Joseph s college Irinjalakuda Abstract--Large amounts of data are generated in medical research. A biological database consists of a collection
Data Mining in Bioinformatics: Study & Survey Saliha V S St. Joseph s college Irinjalakuda Abstract--Large amounts of data are generated in medical research. A biological database consists of a collection