NERD workshop. Luca ALMAnaCH - Inria Paris. Berlin, 18/09/2017
|
|
|
- Aileen Wilson
- 5 years ago
- Views:
Transcription

1 NERD workshop Luca ALMAnaCH - Inria Paris Berlin, 18/09/2017
2 Agenda Introducing the (N)ERD service NERD REST API Usages and use cases
3 Entities Rigid textual expressions corresponding to certain pre-defined categories Taking advantage of semi-normalized, nomenclature-based expressions Examples: person: individual, function locations: country, place, etc. time: dates, time range, period,... organization: institution events: military, political, but also measures, substance, biotech entities, websites, etc.
4 Example Identification Unfortunately for the Allies, the pro-german King Constantine I dismissed the pro-allied government of E. Venizelos before the Allied expeditionary force could arrive. Categorization Unfortunately for the Allies, the pro-german King Constantine I dismissed the pro-allied government of E. Venizelos before the Allied expeditionary force could arrive. Normalization King title Resolution Constantine forename I suffix PERSON PERSON E forename King Constantine 1 > Wikidata: Q152099, Wikipedia: Venizelos last name E. Venizelos: Eleftherios Venizelos: Wikidata: Q205545, Wikipedia:

5 Example (2) [..] After marching through Belgium, Luxembourg and the Ardennes, the German Army advanced, in the latter half of August, into northern France where they met both the French army, under Joseph Joffre, and the initial six divisions of the British Expeditionary Force, under Sir John French. [..]
6 entity-fishing! NERD is a standard name this specific (N)ERD has a name: entity-fishing as we fish entities from the large ocean of knowledge within wikipedia/wikidata and more but don t worry, in this presentation I will keep calling it (N)ERD
7 (N)ERD service Full entity processing: the service is not limited to the recognition of entity mentions but also covers the disambiguation and the resolution of entities against standard knowledge bases (Wikipedia, Wikidata). Independence from a particular framework and usage scenario for maximum reuse State-of-the-art: we target state-of-the-art performances in term of accuracy, coverage (entity variety), speed and exploitation of the context. REST API service: the service is completely decoupled from the implementation details, thus independent from a particular platform, infrastructure and architecture, easier to integrate, to scale and to monitor.
8 (N)ERD service No requirement for expertise in knowledge engineering. Knowledge workers are not knowledge engineers and we cannot expect a good adhesion to a tool which would require sophisticated preliminary human effort (rules, lexicon, ontologies, etc.). The default usage mode of the service is thus automatic, relying on existing large scale knowledge bases and the ability to identified and normalise entities never seen before. Customisable: Offering to the user the possibility to customise easily the generic NERD to different historical topics without the need of knowledge engineering skills and the dependence to a particular framework (e.g. rules, formal ontology/logics, semantic web, etc.) Multilingual support: designed for several languages, exploiting the well implemented translation in Wikidata
9 document online process offline process language identification mention recognition wikipedia labels NER trainer corpus merging CONLL Reuters, Wikipedia, etc entity resolution candidate generation Entity attributes aggregator wikidata dump wikipedia dump disambiguation selection Random Forest Random Forest trainer trainer corpus selected articles from wikipedia corpus entities description
10 Mention recognition online process language identification mention recognition wikipedia labels merging entity resolution candidate generation disambiguation NER Entity attributes Random Forest two steps: Mention class tagging Identification of each mention and tag using wikipedia labels Use another open source tool (Grobid-NER) based on CRF machine learning model - total 27 classes as of today, supporting FR and EN Additional domain specific Named entities recognition can be applied (Chemistry, biology, etc.) Merging selection Random Forest merging wikipedia label identified mentions and recognised Named Entities
11 Entity resolution online process language identification mention recognition wikipedia labels merging NER Knowledge bases: Wikipedia (4 M entities) and Wikidata (27 M entities) Three steps: Candidate generation: the selection in the knowledge base of the entity candidates for an entity mention identified previously in the text. We exploit large standard datasets to create mention/entity statistical profiles. entity resolution candidate generation disambiguation selection Entity attributes Random Forest Random Forest Disambiguation: the association of a score to each candidate entity estimating how well the entity describes the mention in the context of the input text. Considering the other entities appearing at the same moment. Selection: decision to select or not an entity for a given mention
12 Entity resolution Approach using Machine Learning The statistical model is Random Forest and benefit from the several fine features generated by the rich information contained in the knowledge base The training data are obtained from the knowledge base itself as each mention in wikipedia is already resolved to the correct real entity (e.g. the mention Washington is pointing already to the correct page)
13 Demo
14 REST API REST API which is decoupled from the implementation Currently input and output is driven by a Query Language in JSON format
15 REST API Text: disambiguation of the paragraph of plain text (as provided in the query) or PDF (provided separately) short text: corresponding to several search terms used together and which can possibly be disambiguated when associated weighted terms: each term will be disambiguated, when possible, in the context of the complete vector Input Options and parameters
16 REST API language: provided language by the client, if none provided the language will be recognised on the fly onlyner: return only the recognised named entities without disambiguate them nbest: return the n disambiguated results (by default only the first one) Selected customisation
17 REST API entities: if entities in the text are already known, they can be provided in the query sentence: if used, it s segmenting the text using an internal segmenter sentences: return the n disambiguated results (by default only the first one)
18 REST API text processing Short text (< 5 words), use the shorttext option. Long text (> 500 word): the service is designed, trained and scaled for paragraphs: - process the PDF version of the text (if possible) - process the text by paragraphs providing the disambiguated entities from the previous paragraph at each query (see later) - process XML-TEI version of the text (soon available, the text will be handled server-side)
19 processsentence: trigger the NERD only on the selected sentence REST API sentences: provides the segmentation boundaries entities: if entities in the text are already known, they can be provided in the query
20 Process long text We assume the client should know better their own text and how to segment it. We also assume the client doesn t have natural paragraphs : call the segmenter with the long text process the first n sentences (10 < n < 20) process the following n sentences by providing the previously recognised entities and so on and so forth
21 Customisation API The customisation is a way to specialise the entity recognition, disambiguation and resolution for a particular domain. The context will be build based on Wikipedia articles and raw texts, which are all optional.

22 Example: WW2 customisation In the context of WW2, term like German Army or Vichy have different related wikipedia articles. wikipedia entity corresponding to the page Vichy France wikipedia entity corresponding to the page German army - Wehrmacht Each customisation is saved using a name, which can be selected in the query. Propriety customisation.
23 Demo
24 Usage and use cases The (N)ERD, initially based on Wikipedia and Freebase (discontinued in favour of Wikidata) is now moving toward Wikidata Better, cleaner and more structured data than DBPedia Once obtained the disambiguated entities, the Wikidata attributes contains a huge amount of information that can be exploited
25 Wikidata Generic knowledge base: 35M entities, 154M statements Licence CC0 (freely usable, modifiable, redistributable, etc) Knowledge base collaborative human+machines (88% of the editing are automatic) Wikidata has recently reached the 561,378,122 edits operation (18000 distinct human have collaborated, only 6 staff members, it's the largest collaborative DB in the world by far)
26 Wikidata model The Wikidata data model provides a meta-model or ontology for describing real world entities. Such descriptions are concrete models for real world entities. Wikidata s motto: verifiability, not truth : statements are supported by references. Contradictions can be verified. We do not say that Berlin has a population of 3,5 M, we say that there is this statement about Berlin's population being 3,5 M as of 2011 according to the German statistical office.
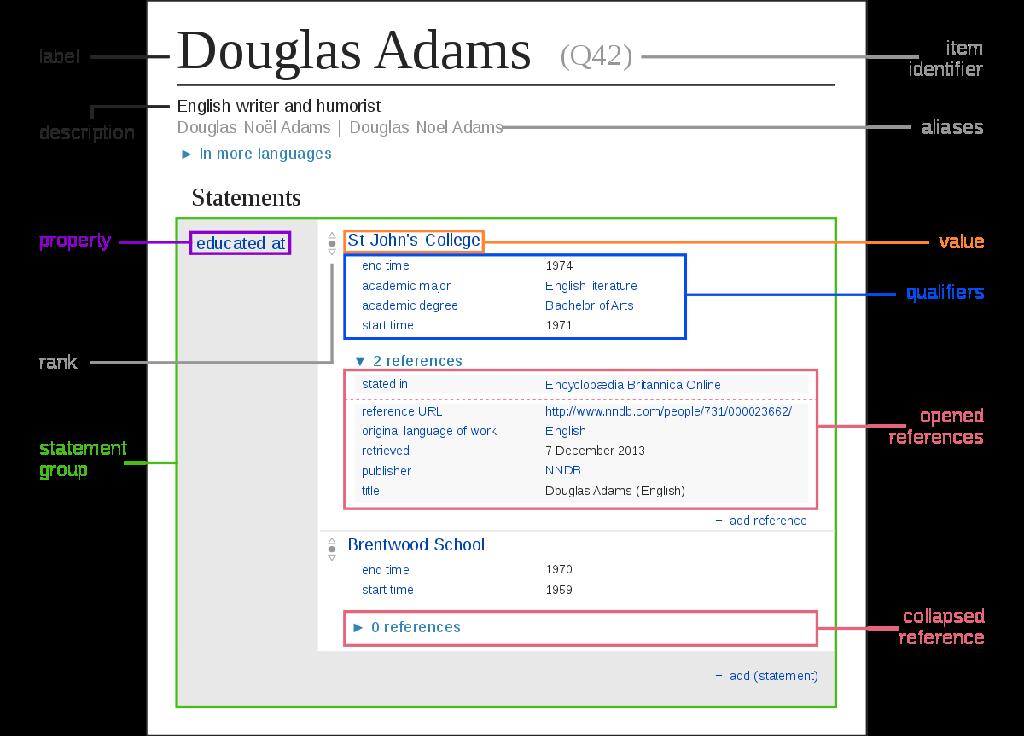

27
28 Wikidata model Wikidata is becoming progressively a scientific knowledge base of reference (genetic, chemistry, ecology, animal species, etc) e.g. Thanks to the amazing work of the Wikidata community, every human gene (according to the United States National Center for Biotechnology Information) now has a representative entity on Wikidata. (Ref: Example: (Rice) (Moon)
29 Demo
30 Questions?
31 Thank you
Linked Data Evolving the Web into a Global Data Space
 Linked Data Evolving the Web into a Global Data Space Anja Jentzsch, Freie Universität Berlin 05 October 2011 EuropeanaTech 2011, Vienna 1 Architecture of the classic Web Single global document space Web
Linked Data Evolving the Web into a Global Data Space Anja Jentzsch, Freie Universität Berlin 05 October 2011 EuropeanaTech 2011, Vienna 1 Architecture of the classic Web Single global document space Web
ANNUAL REPORT Visit us at project.eu Supported by. Mission
 Mission ANNUAL REPORT 2011 The Web has proved to be an unprecedented success for facilitating the publication, use and exchange of information, at planetary scale, on virtually every topic, and representing
Mission ANNUAL REPORT 2011 The Web has proved to be an unprecedented success for facilitating the publication, use and exchange of information, at planetary scale, on virtually every topic, and representing
DBpedia Spotlight at the MSM2013 Challenge
 DBpedia Spotlight at the MSM2013 Challenge Pablo N. Mendes 1, Dirk Weissenborn 2, and Chris Hokamp 3 1 Kno.e.sis Center, CSE Dept., Wright State University 2 Dept. of Comp. Sci., Dresden Univ. of Tech.
DBpedia Spotlight at the MSM2013 Challenge Pablo N. Mendes 1, Dirk Weissenborn 2, and Chris Hokamp 3 1 Kno.e.sis Center, CSE Dept., Wright State University 2 Dept. of Comp. Sci., Dresden Univ. of Tech.
Semantic Web Company. PoolParty - Server. PoolParty - Technical White Paper.
 Semantic Web Company PoolParty - Server PoolParty - Technical White Paper http://www.poolparty.biz Table of Contents Introduction... 3 PoolParty Technical Overview... 3 PoolParty Components Overview...
Semantic Web Company PoolParty - Server PoolParty - Technical White Paper http://www.poolparty.biz Table of Contents Introduction... 3 PoolParty Technical Overview... 3 PoolParty Components Overview...
CORE: Improving access and enabling re-use of open access content using aggregations
 CORE: Improving access and enabling re-use of open access content using aggregations Petr Knoth CORE (Connecting REpositories) Knowledge Media institute The Open University @petrknoth 1/39 Outline 1. The
CORE: Improving access and enabling re-use of open access content using aggregations Petr Knoth CORE (Connecting REpositories) Knowledge Media institute The Open University @petrknoth 1/39 Outline 1. The
Customisable Curation Workflows in Argo
 Customisable Curation Workflows in Argo Rafal Rak*, Riza Batista-Navarro, Andrew Rowley, Jacob Carter and Sophia Ananiadou National Centre for Text Mining, University of Manchester, UK *Corresponding author:
Customisable Curation Workflows in Argo Rafal Rak*, Riza Batista-Navarro, Andrew Rowley, Jacob Carter and Sophia Ananiadou National Centre for Text Mining, University of Manchester, UK *Corresponding author:
COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE
 COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE Project Acronym: CENDARI Project Grant No.: 284432 Theme: FP7-INFRASTRUCTURES-2011-1 Project Start Date: 01 February 2012 Project End Date: 31 January
COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE Project Acronym: CENDARI Project Grant No.: 284432 Theme: FP7-INFRASTRUCTURES-2011-1 Project Start Date: 01 February 2012 Project End Date: 31 January
Master Project. Various Aspects of Recommender Systems. Prof. Dr. Georg Lausen Dr. Michael Färber Anas Alzoghbi Victor Anthony Arrascue Ayala
 Master Project Various Aspects of Recommender Systems May 2nd, 2017 Master project SS17 Albert-Ludwigs-Universität Freiburg Prof. Dr. Georg Lausen Dr. Michael Färber Anas Alzoghbi Victor Anthony Arrascue
Master Project Various Aspects of Recommender Systems May 2nd, 2017 Master project SS17 Albert-Ludwigs-Universität Freiburg Prof. Dr. Georg Lausen Dr. Michael Färber Anas Alzoghbi Victor Anthony Arrascue
A Semantic Web-Based Approach for Harvesting Multilingual Textual. definitions from Wikipedia to support ICD-11 revision
 A Semantic Web-Based Approach for Harvesting Multilingual Textual Definitions from Wikipedia to Support ICD-11 Revision Guoqian Jiang 1,* Harold R. Solbrig 1 and Christopher G. Chute 1 1 Department of
A Semantic Web-Based Approach for Harvesting Multilingual Textual Definitions from Wikipedia to Support ICD-11 Revision Guoqian Jiang 1,* Harold R. Solbrig 1 and Christopher G. Chute 1 1 Department of
Text Mining. Representation of Text Documents
 Data Mining is typically concerned with the detection of patterns in numeric data, but very often important (e.g., critical to business) information is stored in the form of text. Unlike numeric data,
Data Mining is typically concerned with the detection of patterns in numeric data, but very often important (e.g., critical to business) information is stored in the form of text. Unlike numeric data,
Lightweight Transformation of Tabular Open Data to RDF
 Proceedings of the I-SEMANTICS 2012 Posters & Demonstrations Track, pp. 38-42, 2012. Copyright 2012 for the individual papers by the papers' authors. Copying permitted only for private and academic purposes.
Proceedings of the I-SEMANTICS 2012 Posters & Demonstrations Track, pp. 38-42, 2012. Copyright 2012 for the individual papers by the papers' authors. Copying permitted only for private and academic purposes.
Towards Summarizing the Web of Entities
 Towards Summarizing the Web of Entities contributors: August 15, 2012 Thomas Hofmann Director of Engineering Search Ads Quality Zurich, Google Switzerland thofmann@google.com Enrique Alfonseca Yasemin
Towards Summarizing the Web of Entities contributors: August 15, 2012 Thomas Hofmann Director of Engineering Search Ads Quality Zurich, Google Switzerland thofmann@google.com Enrique Alfonseca Yasemin
CACAO PROJECT AT THE 2009 TASK
 CACAO PROJECT AT THE TEL@CLEF 2009 TASK Alessio Bosca, Luca Dini Celi s.r.l. - 10131 Torino - C. Moncalieri, 21 alessio.bosca, dini@celi.it Abstract This paper presents the participation of the CACAO prototype
CACAO PROJECT AT THE TEL@CLEF 2009 TASK Alessio Bosca, Luca Dini Celi s.r.l. - 10131 Torino - C. Moncalieri, 21 alessio.bosca, dini@celi.it Abstract This paper presents the participation of the CACAO prototype
Named Entity Detection and Entity Linking in the Context of Semantic Web
 [1/52] Concordia Seminar - December 2012 Named Entity Detection and in the Context of Semantic Web Exploring the ambiguity question. Eric Charton, Ph.D. [2/52] Concordia Seminar - December 2012 Challenge
[1/52] Concordia Seminar - December 2012 Named Entity Detection and in the Context of Semantic Web Exploring the ambiguity question. Eric Charton, Ph.D. [2/52] Concordia Seminar - December 2012 Challenge
Text mining tools for semantically enriching the scientific literature
 Text mining tools for semantically enriching the scientific literature Sophia Ananiadou Director National Centre for Text Mining School of Computer Science University of Manchester Need for enriching the
Text mining tools for semantically enriching the scientific literature Sophia Ananiadou Director National Centre for Text Mining School of Computer Science University of Manchester Need for enriching the
Tulip: Lightweight Entity Recognition and Disambiguation Using Wikipedia-Based Topic Centroids. Marek Lipczak Arash Koushkestani Evangelos Milios
 Tulip: Lightweight Entity Recognition and Disambiguation Using Wikipedia-Based Topic Centroids Marek Lipczak Arash Koushkestani Evangelos Milios Problem definition The goal of Entity Recognition and Disambiguation
Tulip: Lightweight Entity Recognition and Disambiguation Using Wikipedia-Based Topic Centroids Marek Lipczak Arash Koushkestani Evangelos Milios Problem definition The goal of Entity Recognition and Disambiguation
Proposal for Implementing Linked Open Data on Libraries Catalogue
 Submitted on: 16.07.2018 Proposal for Implementing Linked Open Data on Libraries Catalogue Esraa Elsayed Abdelaziz Computer Science, Arab Academy for Science and Technology, Alexandria, Egypt. E-mail address:
Submitted on: 16.07.2018 Proposal for Implementing Linked Open Data on Libraries Catalogue Esraa Elsayed Abdelaziz Computer Science, Arab Academy for Science and Technology, Alexandria, Egypt. E-mail address:
Linked Data and cultural heritage data: an overview of the approaches from Europeana and The European Library
 Linked Data and cultural heritage data: an overview of the approaches from Europeana and The European Library Nuno Freire Chief data officer The European Library Pacific Neighbourhood Consortium 2014 Annual
Linked Data and cultural heritage data: an overview of the approaches from Europeana and The European Library Nuno Freire Chief data officer The European Library Pacific Neighbourhood Consortium 2014 Annual
BIODIVERSITY INFORMATION
 BIODIVERSITY INFORMATION RETRIEVAL ACROSS NETWORKED DATA SETS By Dr Sarinder Kaur ISKO UK Conference 2009 B I I A L Institute of Biological Sciences Faculty of Science University of Malaya, Kuala Lumpur
BIODIVERSITY INFORMATION RETRIEVAL ACROSS NETWORKED DATA SETS By Dr Sarinder Kaur ISKO UK Conference 2009 B I I A L Institute of Biological Sciences Faculty of Science University of Malaya, Kuala Lumpur
Presented by: Dimitri Galmanovich. Petros Venetis, Alon Halevy, Jayant Madhavan, Marius Paşca, Warren Shen, Gengxin Miao, Chung Wu
 Presented by: Dimitri Galmanovich Petros Venetis, Alon Halevy, Jayant Madhavan, Marius Paşca, Warren Shen, Gengxin Miao, Chung Wu 1 When looking for Unstructured data 2 Millions of such queries every day
Presented by: Dimitri Galmanovich Petros Venetis, Alon Halevy, Jayant Madhavan, Marius Paşca, Warren Shen, Gengxin Miao, Chung Wu 1 When looking for Unstructured data 2 Millions of such queries every day
Created with CMB AutoDoc - Server licence for ID Data
 Overview This presentation will be answering these main questions about AutoDoc: What does it do? What is it? How does it do it? Starting from the finish this is the most effective way to explain AutoDoc.
Overview This presentation will be answering these main questions about AutoDoc: What does it do? What is it? How does it do it? Starting from the finish this is the most effective way to explain AutoDoc.
Pig for Natural Language Processing. Max Jakob
 Pig for Natural Language Processing Max Jakob Agenda 1 2 3 Introduction (speaker, affiliation, project) Named Entities pignlproc Speaker: Max Jakob MSc in Computational Linguistics Software Developer at
Pig for Natural Language Processing Max Jakob Agenda 1 2 3 Introduction (speaker, affiliation, project) Named Entities pignlproc Speaker: Max Jakob MSc in Computational Linguistics Software Developer at
Programming Technologies for Web Resource Mining
 Programming Technologies for Web Resource Mining SoftLang Team, University of Koblenz-Landau Prof. Dr. Ralf Lämmel Msc. Johannes Härtel Msc. Marcel Heinz Motivation What are interesting web resources??
Programming Technologies for Web Resource Mining SoftLang Team, University of Koblenz-Landau Prof. Dr. Ralf Lämmel Msc. Johannes Härtel Msc. Marcel Heinz Motivation What are interesting web resources??
A fully-automatic approach to answer geographic queries: GIRSA-WP at GikiP
 A fully-automatic approach to answer geographic queries: at GikiP Johannes Leveling Sven Hartrumpf Intelligent Information and Communication Systems (IICS) University of Hagen (FernUniversität in Hagen)
A fully-automatic approach to answer geographic queries: at GikiP Johannes Leveling Sven Hartrumpf Intelligent Information and Communication Systems (IICS) University of Hagen (FernUniversität in Hagen)
iknow Use Cases Michael Br ands Senior Product Manager
 iknow Use Cases Michael Br ands Senior Product Manager Agenda iknow in the InterSystems offering Breakthrough Characteristics Steps in Deployment New Features Use Cases The InterSystems Technology Unlock
iknow Use Cases Michael Br ands Senior Product Manager Agenda iknow in the InterSystems offering Breakthrough Characteristics Steps in Deployment New Features Use Cases The InterSystems Technology Unlock
Query Difficulty Prediction for Contextual Image Retrieval
 Query Difficulty Prediction for Contextual Image Retrieval Xing Xing 1, Yi Zhang 1, and Mei Han 2 1 School of Engineering, UC Santa Cruz, Santa Cruz, CA 95064 2 Google Inc., Mountain View, CA 94043 Abstract.
Query Difficulty Prediction for Contextual Image Retrieval Xing Xing 1, Yi Zhang 1, and Mei Han 2 1 School of Engineering, UC Santa Cruz, Santa Cruz, CA 95064 2 Google Inc., Mountain View, CA 94043 Abstract.
NetMapper User Guide
 NetMapper User Guide Eric Malloy and Kathleen M. Carley March 2018 NetMapper is a tool that supports extracting networks from texts and assigning sentiment at the context level. Each text is processed
NetMapper User Guide Eric Malloy and Kathleen M. Carley March 2018 NetMapper is a tool that supports extracting networks from texts and assigning sentiment at the context level. Each text is processed
Putting ontologies to work in NLP
 Putting ontologies to work in NLP The lemon model and its future John P. McCrae National University of Ireland, Galway Introduction In natural language processing we are doing three main things Understanding
Putting ontologies to work in NLP The lemon model and its future John P. McCrae National University of Ireland, Galway Introduction In natural language processing we are doing three main things Understanding
Ontology Extraction from Heterogeneous Documents
 Vol.3, Issue.2, March-April. 2013 pp-985-989 ISSN: 2249-6645 Ontology Extraction from Heterogeneous Documents Kirankumar Kataraki, 1 Sumana M 2 1 IV sem M.Tech/ Department of Information Science & Engg
Vol.3, Issue.2, March-April. 2013 pp-985-989 ISSN: 2249-6645 Ontology Extraction from Heterogeneous Documents Kirankumar Kataraki, 1 Sumana M 2 1 IV sem M.Tech/ Department of Information Science & Engg
Natural Language Processing with PoolParty
 Natural Language Processing with PoolParty Table of Content Introduction to PoolParty 2 Resolving Language Problems 4 Key Features 5 Entity Extraction and Term Extraction 5 Shadow Concepts 6 Word Sense
Natural Language Processing with PoolParty Table of Content Introduction to PoolParty 2 Resolving Language Problems 4 Key Features 5 Entity Extraction and Term Extraction 5 Shadow Concepts 6 Word Sense
Enabling Semantic Search in Large Open Source Communities
 Enabling Semantic Search in Large Open Source Communities Gregor Leban, Lorand Dali, Inna Novalija Jožef Stefan Institute, Jamova cesta 39, 1000 Ljubljana {gregor.leban, lorand.dali, inna.koval}@ijs.si
Enabling Semantic Search in Large Open Source Communities Gregor Leban, Lorand Dali, Inna Novalija Jožef Stefan Institute, Jamova cesta 39, 1000 Ljubljana {gregor.leban, lorand.dali, inna.koval}@ijs.si
CMS - HLT Configuration Management System
 Journal of Physics: Conference Series PAPER OPEN ACCESS CMS - HLT Configuration Management System To cite this article: Vincenzo Daponte and Andrea Bocci 2015 J. Phys.: Conf. Ser. 664 082008 View the article
Journal of Physics: Conference Series PAPER OPEN ACCESS CMS - HLT Configuration Management System To cite this article: Vincenzo Daponte and Andrea Bocci 2015 J. Phys.: Conf. Ser. 664 082008 View the article
clarin:el an infrastructure for documenting, sharing and processing language data
 clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
CIRGDISCO at RepLab2012 Filtering Task: A Two-Pass Approach for Company Name Disambiguation in Tweets
 CIRGDISCO at RepLab2012 Filtering Task: A Two-Pass Approach for Company Name Disambiguation in Tweets Arjumand Younus 1,2, Colm O Riordan 1, and Gabriella Pasi 2 1 Computational Intelligence Research Group,
CIRGDISCO at RepLab2012 Filtering Task: A Two-Pass Approach for Company Name Disambiguation in Tweets Arjumand Younus 1,2, Colm O Riordan 1, and Gabriella Pasi 2 1 Computational Intelligence Research Group,
Enhanced retrieval using semantic technologies:
 Enhanced retrieval using semantic technologies: Ontology based retrieval as a new search paradigm? - Considerations based on new projects at the Bavarian State Library Dr. Berthold Gillitzer 28. Mai 2008
Enhanced retrieval using semantic technologies: Ontology based retrieval as a new search paradigm? - Considerations based on new projects at the Bavarian State Library Dr. Berthold Gillitzer 28. Mai 2008
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2
 A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
NOMAD Metadata for all
 EMMC Workshop on Interoperability NOMAD Metadata for all Cambridge, 8 Nov 2017 Fawzi Mohamed FHI Berlin NOMAD Center of excellence goals 200,000 materials known to exist basic properties for very few highly
EMMC Workshop on Interoperability NOMAD Metadata for all Cambridge, 8 Nov 2017 Fawzi Mohamed FHI Berlin NOMAD Center of excellence goals 200,000 materials known to exist basic properties for very few highly
D4.6 Data Value Chain Database v2
 D4.6 Data Value Chain Database v2 Coordinator: Fabrizio Orlandi (Fraunhofer) With contributions from: Isaiah Mulang Onando (Fraunhofer), Luis-Daniel Ibáñez (SOTON) Reviewer: Ryan Goodman (ODI) Deliverable
D4.6 Data Value Chain Database v2 Coordinator: Fabrizio Orlandi (Fraunhofer) With contributions from: Isaiah Mulang Onando (Fraunhofer), Luis-Daniel Ibáñez (SOTON) Reviewer: Ryan Goodman (ODI) Deliverable
Links, languages and semantics: linked data approaches in The European Library and Europeana. Valentine Charles, Nuno Freire & Antoine Isaac
 Links, languages and semantics: linked data approaches in The European Library and Europeana. Valentine Charles, Nuno Freire & Antoine Isaac 14 th August 2014, IFLA2014 satellite meeting, Paris The European
Links, languages and semantics: linked data approaches in The European Library and Europeana. Valentine Charles, Nuno Freire & Antoine Isaac 14 th August 2014, IFLA2014 satellite meeting, Paris The European
3 Publishing Technique
 Publishing Tool 32 3 Publishing Technique As discussed in Chapter 2, annotations can be extracted from audio, text, and visual features. The extraction of text features from the audio layer is the approach
Publishing Tool 32 3 Publishing Technique As discussed in Chapter 2, annotations can be extracted from audio, text, and visual features. The extraction of text features from the audio layer is the approach
Designing a System Engineering Environment in a structured way
 Designing a System Engineering Environment in a structured way Anna Todino Ivo Viglietti Bruno Tranchero Leonardo-Finmeccanica Aircraft Division Torino, Italy Copyright held by the authors. Rubén de Juan
Designing a System Engineering Environment in a structured way Anna Todino Ivo Viglietti Bruno Tranchero Leonardo-Finmeccanica Aircraft Division Torino, Italy Copyright held by the authors. Rubén de Juan
Building the Multilingual Web of Data. Integrating NLP with Linked Data and RDF using the NLP Interchange Format
 Building the Multilingual Web of Data Integrating NLP with Linked Data and RDF using the NLP Interchange Format Presenter name 1 Outline 1. Introduction 2. NIF Basics 3. NIF corpora 4. NIF tools & services
Building the Multilingual Web of Data Integrating NLP with Linked Data and RDF using the NLP Interchange Format Presenter name 1 Outline 1. Introduction 2. NIF Basics 3. NIF corpora 4. NIF tools & services
RPI INSIDE DEEPQA INTRODUCTION QUESTION ANALYSIS 11/26/2013. Watson is. IBM Watson. Inside Watson RPI WATSON RPI WATSON ??? ??? ???
 @ INSIDE DEEPQA Managing complex unstructured data with UIMA Simon Ellis INTRODUCTION 22 nd November, 2013 WAT SON TECHNOLOGIES AND OPEN ARCHIT ECT URE QUEST ION ANSWERING PROFESSOR JIM HENDLER S IMON
@ INSIDE DEEPQA Managing complex unstructured data with UIMA Simon Ellis INTRODUCTION 22 nd November, 2013 WAT SON TECHNOLOGIES AND OPEN ARCHIT ECT URE QUEST ION ANSWERING PROFESSOR JIM HENDLER S IMON
Computer-assisted Ontology Construction System: Focus on Bootstrapping Capabilities
 Computer-assisted Ontology Construction System: Focus on Bootstrapping Capabilities Omar Qawasmeh 1, Maxime Lefranois 2, Antoine Zimmermann 2, Pierre Maret 1 1 Univ. Lyon, CNRS, Lab. Hubert Curien UMR
Computer-assisted Ontology Construction System: Focus on Bootstrapping Capabilities Omar Qawasmeh 1, Maxime Lefranois 2, Antoine Zimmermann 2, Pierre Maret 1 1 Univ. Lyon, CNRS, Lab. Hubert Curien UMR
QAKiS: an Open Domain QA System based on Relational Patterns
 QAKiS: an Open Domain QA System based on Relational Patterns Elena Cabrio, Julien Cojan, Alessio Palmero Aprosio, Bernardo Magnini, Alberto Lavelli, Fabien Gandon To cite this version: Elena Cabrio, Julien
QAKiS: an Open Domain QA System based on Relational Patterns Elena Cabrio, Julien Cojan, Alessio Palmero Aprosio, Bernardo Magnini, Alberto Lavelli, Fabien Gandon To cite this version: Elena Cabrio, Julien
Technische Universität Dresden Fakultät Informatik. Wikidata. A Free Collaborative Knowledge Base. Markus Krötzsch TU Dresden.
 Technische Universität Dresden Fakultät Informatik Wikidata A Free Collaborative Knowledge Base Markus Krötzsch TU Dresden IBM June 2015 Where is Wikipedia Going? Wikipedia in 2015: A project that has
Technische Universität Dresden Fakultät Informatik Wikidata A Free Collaborative Knowledge Base Markus Krötzsch TU Dresden IBM June 2015 Where is Wikipedia Going? Wikipedia in 2015: A project that has
Exploring and Using the Semantic Web
 Exploring and Using the Semantic Web Mathieu d Aquin KMi, The Open University m.daquin@open.ac.uk What?? Exploring the Semantic Web Vocabularies Ontologies Linked Data RDF documents Example: Exploring
Exploring and Using the Semantic Web Mathieu d Aquin KMi, The Open University m.daquin@open.ac.uk What?? Exploring the Semantic Web Vocabularies Ontologies Linked Data RDF documents Example: Exploring
TIB AV-Portal. Margret Plank 19th of January 2015 TACC Meeting
 TIB AV-Portal Margret Plank 19th of January 2015 TACC Meeting German National Library of Science and Technology (TIB) German National Library of Science and Technology for all areas of engineering as well
TIB AV-Portal Margret Plank 19th of January 2015 TACC Meeting German National Library of Science and Technology (TIB) German National Library of Science and Technology for all areas of engineering as well
A Korean Knowledge Extraction System for Enriching a KBox
 A Korean Knowledge Extraction System for Enriching a KBox Sangha Nam, Eun-kyung Kim, Jiho Kim, Yoosung Jung, Kijong Han, Key-Sun Choi KAIST / The Republic of Korea {nam.sangha, kekeeo, hogajiho, wjd1004109,
A Korean Knowledge Extraction System for Enriching a KBox Sangha Nam, Eun-kyung Kim, Jiho Kim, Yoosung Jung, Kijong Han, Key-Sun Choi KAIST / The Republic of Korea {nam.sangha, kekeeo, hogajiho, wjd1004109,
The Luxembourg BabelNet Workshop
 The Luxembourg BabelNet Workshop 2 March 2016: Session 3 Tech session Disambiguating text with Babelfy. The Babelfy API Claudio Delli Bovi Outline Multilingual disambiguation with Babelfy Using Babelfy
The Luxembourg BabelNet Workshop 2 March 2016: Session 3 Tech session Disambiguating text with Babelfy. The Babelfy API Claudio Delli Bovi Outline Multilingual disambiguation with Babelfy Using Babelfy
Linking library data: contributions and role of subject data. Nuno Freire The European Library
 Linking library data: contributions and role of subject data Nuno Freire The European Library Outline Introduction to The European Library Motivation for Linked Library Data The European Library Open Dataset
Linking library data: contributions and role of subject data Nuno Freire The European Library Outline Introduction to The European Library Motivation for Linked Library Data The European Library Open Dataset
Building a National SGCN Dataset
 Building a National SGCN Dataset Moving form 56 Disparate Plans to One Integrated Product U.S. Department of the Interior U.S. Geological Survey Presentation Overview NBII Species Mashup LIVE DEMO Species
Building a National SGCN Dataset Moving form 56 Disparate Plans to One Integrated Product U.S. Department of the Interior U.S. Geological Survey Presentation Overview NBII Species Mashup LIVE DEMO Species
Module 3: GATE and Social Media. Part 4. Named entities
 Module 3: GATE and Social Media Part 4. Named entities The 1995-2018 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs Licence Named Entity Recognition Texts frequently
Module 3: GATE and Social Media Part 4. Named entities The 1995-2018 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs Licence Named Entity Recognition Texts frequently
INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA. Ernesto William De Luca
 INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA Ernesto William De Luca Overview 2 Motivation EuroWordNet RDF/OWL EuroWordNet RDF/OWL LexiRes Tool Conclusions Overview 3 Motivation EuroWordNet
INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA Ernesto William De Luca Overview 2 Motivation EuroWordNet RDF/OWL EuroWordNet RDF/OWL LexiRes Tool Conclusions Overview 3 Motivation EuroWordNet
Projects Tools BLAH proposal Conclusion. OntoGene/BioMeXT
 OntoGene/BioMeXT The Bio Term Hub and OGER Lenz Furrer, Nico Colic, Fabio Rinaldi University of Zurich and Swiss Institute of Bioinformatics January 10, 2018 Outline Projects Tools BLAH proposal Conclusion
OntoGene/BioMeXT The Bio Term Hub and OGER Lenz Furrer, Nico Colic, Fabio Rinaldi University of Zurich and Swiss Institute of Bioinformatics January 10, 2018 Outline Projects Tools BLAH proposal Conclusion
Development of guidelines for publishing statistical data as linked open data
 Development of guidelines for publishing statistical data as linked open data MERGING STATISTICS A ND GEOSPATIAL INFORMATION IN M E M B E R S TATE S POLAND Mirosław Migacz INSPIRE Conference 2016 Barcelona,
Development of guidelines for publishing statistical data as linked open data MERGING STATISTICS A ND GEOSPATIAL INFORMATION IN M E M B E R S TATE S POLAND Mirosław Migacz INSPIRE Conference 2016 Barcelona,
Integration and Evaluation. Bas Boom
 Integration and Evaluation Bas Boom Objectives nothing O5.1: Define component and datastructure that allows quick integration O5.2: Evaluation that targets both Research and Marine Biology perspectives
Integration and Evaluation Bas Boom Objectives nothing O5.1: Define component and datastructure that allows quick integration O5.2: Evaluation that targets both Research and Marine Biology perspectives
<is web> Information Systems & Semantic Web University of Koblenz Landau, Germany
 Information Systems & University of Koblenz Landau, Germany Semantic Search examples: Swoogle and Watson Steffen Staad credit: Tim Finin (swoogle), Mathieu d Aquin (watson) and their groups 2009-07-17
Information Systems & University of Koblenz Landau, Germany Semantic Search examples: Swoogle and Watson Steffen Staad credit: Tim Finin (swoogle), Mathieu d Aquin (watson) and their groups 2009-07-17
ELCO3: Entity Linking with Corpus Coherence Combining Open Source Annotators
 ELCO3: Entity Linking with Corpus Coherence Combining Open Source Annotators Pablo Ruiz, Thierry Poibeau and Frédérique Mélanie Laboratoire LATTICE CNRS, École Normale Supérieure, U Paris 3 Sorbonne Nouvelle
ELCO3: Entity Linking with Corpus Coherence Combining Open Source Annotators Pablo Ruiz, Thierry Poibeau and Frédérique Mélanie Laboratoire LATTICE CNRS, École Normale Supérieure, U Paris 3 Sorbonne Nouvelle
Riga Summit 2015 MultilingualWeb. Building a Multilingual Website with No Translation Resources. Thibault Grouas April
 Riga Summit 2015 MultilingualWeb Building a Multilingual Website with No Translation Resources Thibault Grouas April 29 2015 1. Technology and digital policies for languages in France Delegation for french
Riga Summit 2015 MultilingualWeb Building a Multilingual Website with No Translation Resources Thibault Grouas April 29 2015 1. Technology and digital policies for languages in France Delegation for french
Semantic Technologies in a Chemical Context
 Semantic Technologies in a Chemical Context Quick wins and the long-term game Dr. Heinz-Gerd Kneip BASF SE The International Conference on Trends for Scientific Information Professionals ICIC 2010, 24.-27.10.2010,
Semantic Technologies in a Chemical Context Quick wins and the long-term game Dr. Heinz-Gerd Kneip BASF SE The International Conference on Trends for Scientific Information Professionals ICIC 2010, 24.-27.10.2010,
The Edinburgh Geoparser
 The Edinburgh Geoparser A Tool to Geoparse Text Beatrice Alex balex@inf.ed.ac.uk, @bea_alex Projects UK Connectivity DEEP Palimpsest LitLong GAP/GapVis The developers Claire Grover, Richard Tobin, Kate
The Edinburgh Geoparser A Tool to Geoparse Text Beatrice Alex balex@inf.ed.ac.uk, @bea_alex Projects UK Connectivity DEEP Palimpsest LitLong GAP/GapVis The developers Claire Grover, Richard Tobin, Kate
The Wikipedia XML Corpus
 INEX REPORT The Wikipedia XML Corpus Ludovic Denoyer, Patrick Gallinari Laboratoire d Informatique de Paris 6 8 rue du capitaine Scott 75015 Paris http://www-connex.lip6.fr/denoyer/wikipediaxml {ludovic.denoyer,
INEX REPORT The Wikipedia XML Corpus Ludovic Denoyer, Patrick Gallinari Laboratoire d Informatique de Paris 6 8 rue du capitaine Scott 75015 Paris http://www-connex.lip6.fr/denoyer/wikipediaxml {ludovic.denoyer,
Ontology-driven content extraction using interlingual annotation of texts in the OMNIA project
 Ontology-driven content extraction using interlingual annotation of texts in the OMNIA project A. Falaise / D. Rouquet / D. Schwab / C. Boitet / H. Blanchon Falaise/Rouquet/Schwab/Boitet/Blanchon () OMNIA
Ontology-driven content extraction using interlingual annotation of texts in the OMNIA project A. Falaise / D. Rouquet / D. Schwab / C. Boitet / H. Blanchon Falaise/Rouquet/Schwab/Boitet/Blanchon () OMNIA
COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE
 COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE Project Acronym: CENDARI Project Grant No.: 284432 Theme: FP7-INFRASTRUCTURES-2011-1 Project Start Date: 01 February 2012 Project End Date: 31 January
COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE Project Acronym: CENDARI Project Grant No.: 284432 Theme: FP7-INFRASTRUCTURES-2011-1 Project Start Date: 01 February 2012 Project End Date: 31 January
Mining Wikipedia s Snippets Graph: First Step to Build A New Knowledge Base
 Mining Wikipedia s Snippets Graph: First Step to Build A New Knowledge Base Andias Wira-Alam and Brigitte Mathiak GESIS - Leibniz-Institute for the Social Sciences Unter Sachsenhausen 6-8, 50667 Köln,
Mining Wikipedia s Snippets Graph: First Step to Build A New Knowledge Base Andias Wira-Alam and Brigitte Mathiak GESIS - Leibniz-Institute for the Social Sciences Unter Sachsenhausen 6-8, 50667 Köln,
Using Linked Data to Reduce Learning Latency for e-book Readers
 Using Linked Data to Reduce Learning Latency for e-book Readers Julien Robinson, Johann Stan, and Myriam Ribière Alcatel-Lucent Bell Labs France, 91620 Nozay, France, Julien.Robinson@alcatel-lucent.com
Using Linked Data to Reduce Learning Latency for e-book Readers Julien Robinson, Johann Stan, and Myriam Ribière Alcatel-Lucent Bell Labs France, 91620 Nozay, France, Julien.Robinson@alcatel-lucent.com
RESEARCH ANALYTICS From Web of Science to InCites. September 20 th, 2010 Marta Plebani
 RESEARCH ANALYTICS From Web of Science to InCites September 20 th, 2010 Marta Plebani marta.plebani@thomsonreuters.com Web Of Science: main purposes Find high-impact articles and conference proceedings.
RESEARCH ANALYTICS From Web of Science to InCites September 20 th, 2010 Marta Plebani marta.plebani@thomsonreuters.com Web Of Science: main purposes Find high-impact articles and conference proceedings.
Semantic Retrieval of the TIB AV-Portal. Dr. Sven Strobel IATUL 2015 July 9, 2015; Hannover
 Semantic Retrieval of the TIB AV-Portal Dr. Sven Strobel IATUL 2015 July 9, 2015; Hannover Semantic Retrieval of the TIB AV-Portal Contents 1. TIB AV-Portal 2. Automatic Video Analysis 3. Named-Entity
Semantic Retrieval of the TIB AV-Portal Dr. Sven Strobel IATUL 2015 July 9, 2015; Hannover Semantic Retrieval of the TIB AV-Portal Contents 1. TIB AV-Portal 2. Automatic Video Analysis 3. Named-Entity
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda
 Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Untangling the semantic web:
 Untangling the semantic web: what does it mean for scholarly publications? In this presentation Louise Tutton will decode the meaning of the Semantic Web and its ultimate benefits within the publishing
Untangling the semantic web: what does it mean for scholarly publications? In this presentation Louise Tutton will decode the meaning of the Semantic Web and its ultimate benefits within the publishing
TIC: A Topic-based Intelligent Crawler
 2011 International Conference on Information and Intelligent Computing IPCSIT vol.18 (2011) (2011) IACSIT Press, Singapore TIC: A Topic-based Intelligent Crawler Hossein Shahsavand Baghdadi and Bali Ranaivo-Malançon
2011 International Conference on Information and Intelligent Computing IPCSIT vol.18 (2011) (2011) IACSIT Press, Singapore TIC: A Topic-based Intelligent Crawler Hossein Shahsavand Baghdadi and Bali Ranaivo-Malançon
Automatically Annotating Text with Linked Open Data
 Automatically Annotating Text with Linked Open Data Delia Rusu, Blaž Fortuna, Dunja Mladenić Jožef Stefan Institute Motivation: Annotating Text with LOD Open Cyc DBpedia WordNet Overview Related work Algorithms
Automatically Annotating Text with Linked Open Data Delia Rusu, Blaž Fortuna, Dunja Mladenić Jožef Stefan Institute Motivation: Annotating Text with LOD Open Cyc DBpedia WordNet Overview Related work Algorithms
Visual Concept Detection and Linked Open Data at the TIB AV- Portal. Felix Saurbier, Matthias Springstein Hamburg, November 6 SWIB 2017
 Visual Concept Detection and Linked Open Data at the TIB AV- Portal Felix Saurbier, Matthias Springstein Hamburg, November 6 SWIB 2017 Agenda 1. TIB and TIB AV-Portal 2. Automated Video Analysis 3. Visual
Visual Concept Detection and Linked Open Data at the TIB AV- Portal Felix Saurbier, Matthias Springstein Hamburg, November 6 SWIB 2017 Agenda 1. TIB and TIB AV-Portal 2. Automated Video Analysis 3. Visual
Taxonomy Tools: Collaboration, Creation & Integration. Dow Jones & Company
 Taxonomy Tools: Collaboration, Creation & Integration Dave Clarke Global Taxonomy Director dave.clarke@dowjones.com Dow Jones & Company Introduction Software Tools for Taxonomy 1. Collaboration 2. Creation
Taxonomy Tools: Collaboration, Creation & Integration Dave Clarke Global Taxonomy Director dave.clarke@dowjones.com Dow Jones & Company Introduction Software Tools for Taxonomy 1. Collaboration 2. Creation
Wikipedia Retrieval Task ImageCLEF 2011
 Wikipedia Retrieval Task ImageCLEF 2011 Theodora Tsikrika University of Applied Sciences Western Switzerland, Switzerland Jana Kludas University of Geneva, Switzerland Adrian Popescu CEA LIST, France Outline
Wikipedia Retrieval Task ImageCLEF 2011 Theodora Tsikrika University of Applied Sciences Western Switzerland, Switzerland Jana Kludas University of Geneva, Switzerland Adrian Popescu CEA LIST, France Outline
Tools and Infrastructure for Supporting Enterprise Knowledge Graphs
 Tools and Infrastructure for Supporting Enterprise Knowledge Graphs Sumit Bhatia, Nidhi Rajshree, Anshu Jain, and Nitish Aggarwal IBM Research sumitbhatia@in.ibm.com, {nidhi.rajshree,anshu.n.jain}@us.ibm.com,nitish.aggarwal@ibm.com
Tools and Infrastructure for Supporting Enterprise Knowledge Graphs Sumit Bhatia, Nidhi Rajshree, Anshu Jain, and Nitish Aggarwal IBM Research sumitbhatia@in.ibm.com, {nidhi.rajshree,anshu.n.jain}@us.ibm.com,nitish.aggarwal@ibm.com
Building a Linked Open Data Knowledge Graph Henning Schoenenberger Michele Pasin. Frankfurt Book Fair 2017 October 11, 2017
 Building a Linked Open Data Knowledge Graph Henning Schoenenberger Michele Pasin Frankfurt Book Fair 2017 October 11, 2017 1 Springer Nature s Metadata Mission Statement We understand metadata as the gateway
Building a Linked Open Data Knowledge Graph Henning Schoenenberger Michele Pasin Frankfurt Book Fair 2017 October 11, 2017 1 Springer Nature s Metadata Mission Statement We understand metadata as the gateway
QUARK AUTHOR THE SMART CONTENT TOOL. INFO SHEET Quark Author
 QUARK AUTHOR THE SMART CONTENT TOOL Quark Author is Web-based software that, together with Quark Publishing Platform, enables business and IT leaders to streamline and automate high-value customer communications
QUARK AUTHOR THE SMART CONTENT TOOL Quark Author is Web-based software that, together with Quark Publishing Platform, enables business and IT leaders to streamline and automate high-value customer communications
Text Mining: A Burgeoning technology for knowledge extraction
 Text Mining: A Burgeoning technology for knowledge extraction 1 Anshika Singh, 2 Dr. Udayan Ghosh 1 HCL Technologies Ltd., Noida, 2 University School of Information &Communication Technology, Dwarka, Delhi.
Text Mining: A Burgeoning technology for knowledge extraction 1 Anshika Singh, 2 Dr. Udayan Ghosh 1 HCL Technologies Ltd., Noida, 2 University School of Information &Communication Technology, Dwarka, Delhi.
Form Identifying. Figure 1 A typical HTML form
 Table of Contents Form Identifying... 2 1. Introduction... 2 2. Related work... 2 3. Basic elements in an HTML from... 3 4. Logic structure of an HTML form... 4 5. Implementation of Form Identifying...
Table of Contents Form Identifying... 2 1. Introduction... 2 2. Related work... 2 3. Basic elements in an HTML from... 3 4. Logic structure of an HTML form... 4 5. Implementation of Form Identifying...
Linked Data in Translation-Kits
 Linked Data in Translation-Kits FEISGILTT Dublin June 2014 Yves Savourel ENLASO Corporation Slides and code are available at: https://copy.com/ngbco13l9yls This presentation was made possible by The main
Linked Data in Translation-Kits FEISGILTT Dublin June 2014 Yves Savourel ENLASO Corporation Slides and code are available at: https://copy.com/ngbco13l9yls This presentation was made possible by The main
Introduction to Compendium Tutorial
 Instructors Simon Buckingham Shum, Anna De Liddo, Michelle Bachler Knowledge Media Institute, Open University UK Tutorial Contents http://compendium.open.ac.uk/institute 1 Course Introduction... 1 2 Compendium
Instructors Simon Buckingham Shum, Anna De Liddo, Michelle Bachler Knowledge Media Institute, Open University UK Tutorial Contents http://compendium.open.ac.uk/institute 1 Course Introduction... 1 2 Compendium
A cocktail approach to the VideoCLEF 09 linking task
 A cocktail approach to the VideoCLEF 09 linking task Stephan Raaijmakers Corné Versloot Joost de Wit TNO Information and Communication Technology Delft, The Netherlands {stephan.raaijmakers,corne.versloot,
A cocktail approach to the VideoCLEF 09 linking task Stephan Raaijmakers Corné Versloot Joost de Wit TNO Information and Communication Technology Delft, The Netherlands {stephan.raaijmakers,corne.versloot,
The Multilingual Language Library
 The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
Linked Open Data Cloud. John P. McCrae, Thierry Declerck
 Linked Open Data Cloud John P. McCrae, Thierry Declerck Hitchhiker s guide to the Linked Open Data Cloud DBpedia Largest node in the linked open data cloud Nucleus for a web of open data Most data is
Linked Open Data Cloud John P. McCrae, Thierry Declerck Hitchhiker s guide to the Linked Open Data Cloud DBpedia Largest node in the linked open data cloud Nucleus for a web of open data Most data is
A Comparison between Users free-text queries and RILM index terms. Shuheng Wu Queens College, CUNY Yun F. Henshaw RILM
 A Comparison between Users free-text queries and RILM index Shuheng Wu Queens College, CUNY Yun F. Henshaw RILM 1 Introduction Research questions Study design Agenda Data analysis results & suggestions
A Comparison between Users free-text queries and RILM index Shuheng Wu Queens College, CUNY Yun F. Henshaw RILM 1 Introduction Research questions Study design Agenda Data analysis results & suggestions
Advanced Searching of CAB Abstracts on CAB Direct
 Advanced Searching of CAB Abstracts on CAB Direct In the Simple Searching session, we looked at single and multi-word searching of CAB Direct using the Free-Text index. However, in a typical CAB ABSTRACTS
Advanced Searching of CAB Abstracts on CAB Direct In the Simple Searching session, we looked at single and multi-word searching of CAB Direct using the Free-Text index. However, in a typical CAB ABSTRACTS
DATA COLLECTION. Slides by WESLEY WILLETT 13 FEB 2014
 DATA COLLECTION Slides by WESLEY WILLETT INFO VISUAL 340 ANALYTICS D 13 FEB 2014 WHERE DOES DATA COME FROM? We tend to think of data as a thing in a database somewhere WHY DO YOU NEED DATA? (HINT: Usually,
DATA COLLECTION Slides by WESLEY WILLETT INFO VISUAL 340 ANALYTICS D 13 FEB 2014 WHERE DOES DATA COME FROM? We tend to think of data as a thing in a database somewhere WHY DO YOU NEED DATA? (HINT: Usually,
UBC Entity Discovery and Linking & Diagnostic Entity Linking at TAC-KBP 2014
 UBC Entity Discovery and Linking & Diagnostic Entity Linking at TAC-KBP 2014 Ander Barrena, Eneko Agirre, Aitor Soroa IXA NLP Group / University of the Basque Country, Donostia, Basque Country ander.barrena@ehu.es,
UBC Entity Discovery and Linking & Diagnostic Entity Linking at TAC-KBP 2014 Ander Barrena, Eneko Agirre, Aitor Soroa IXA NLP Group / University of the Basque Country, Donostia, Basque Country ander.barrena@ehu.es,
Managing Learning Objects in Large Scale Courseware Authoring Studio 1
 Managing Learning Objects in Large Scale Courseware Authoring Studio 1 Ivo Marinchev, Ivo Hristov Institute of Information Technologies Bulgarian Academy of Sciences, Acad. G. Bonchev Str. Block 29A, Sofia
Managing Learning Objects in Large Scale Courseware Authoring Studio 1 Ivo Marinchev, Ivo Hristov Institute of Information Technologies Bulgarian Academy of Sciences, Acad. G. Bonchev Str. Block 29A, Sofia
Handling Place References in Text
 Handling Place References in Text Introduction Most (geographic) information is available in the form of textual documents Place reference resolution involves two-subtasks: Recognition : Delimiting occurrences
Handling Place References in Text Introduction Most (geographic) information is available in the form of textual documents Place reference resolution involves two-subtasks: Recognition : Delimiting occurrences
Web 2.0, AJAX and RIAs
 Web 2.0, AJAX and RIAs Asynchronous JavaScript and XML Rich Internet Applications Markus Angermeier November, 2005 - some of the themes of Web 2.0, with example-sites and services Web 2.0 Common usage
Web 2.0, AJAX and RIAs Asynchronous JavaScript and XML Rich Internet Applications Markus Angermeier November, 2005 - some of the themes of Web 2.0, with example-sites and services Web 2.0 Common usage
Improving Interoperability of Text Mining Tools with BioC
 Improving Interoperability of Text Mining Tools with BioC Ritu Khare, Chih-Hsuan Wei, Yuqing Mao, Robert Leaman, Zhiyong Lu * National Center for Biotechnology Information, 8600 Rockville Pike, Bethesda,
Improving Interoperability of Text Mining Tools with BioC Ritu Khare, Chih-Hsuan Wei, Yuqing Mao, Robert Leaman, Zhiyong Lu * National Center for Biotechnology Information, 8600 Rockville Pike, Bethesda,
Fueling Time Machine: Information Extraction from Retro-Digitised Address Directories
 Fueling Time Machine: Information Extraction from Retro-Digitised Address Directories Mohamed Khemakhem, Carmen Brando, Laurent Romary, Frédérique Mélanie-Becquet, Jean-Luc Pinol To cite this version:
Fueling Time Machine: Information Extraction from Retro-Digitised Address Directories Mohamed Khemakhem, Carmen Brando, Laurent Romary, Frédérique Mélanie-Becquet, Jean-Luc Pinol To cite this version:
Markus Kaindl Senior Manager Semantic Data Business Owner SN SciGraph
 Analytics Building business tools for the scholarly publishing domain using LOD and the ELK stack SEMANTiCS Vienna 2018 Markus Kaindl Senior Manager Semantic Data Business Owner SN SciGraph 1 Agenda (25
Analytics Building business tools for the scholarly publishing domain using LOD and the ELK stack SEMANTiCS Vienna 2018 Markus Kaindl Senior Manager Semantic Data Business Owner SN SciGraph 1 Agenda (25
Scholarly Big Data: Leverage for Science
 Scholarly Big Data: Leverage for Science C. Lee Giles The Pennsylvania State University University Park, PA, USA giles@ist.psu.edu http://clgiles.ist.psu.edu Funded in part by NSF, Allen Institute for
Scholarly Big Data: Leverage for Science C. Lee Giles The Pennsylvania State University University Park, PA, USA giles@ist.psu.edu http://clgiles.ist.psu.edu Funded in part by NSF, Allen Institute for
CSC 5930/9010: Text Mining GATE Developer Overview
 1 CSC 5930/9010: Text Mining GATE Developer Overview Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 GATE Components 2 We will deal primarily with GATE Developer:
1 CSC 5930/9010: Text Mining GATE Developer Overview Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 GATE Components 2 We will deal primarily with GATE Developer:
SAPIENT Automation project
 Dr Maria Liakata Leverhulme Trust Early Career fellow Department of Computer Science, Aberystwyth University Visitor at EBI, Cambridge mal@aber.ac.uk 25 May 2010, London Motivation SAPIENT Automation Project
Dr Maria Liakata Leverhulme Trust Early Career fellow Department of Computer Science, Aberystwyth University Visitor at EBI, Cambridge mal@aber.ac.uk 25 May 2010, London Motivation SAPIENT Automation Project
3.4 Data-Centric workflow
 3.4 Data-Centric workflow One of the most important activities in a S-DWH environment is represented by data integration of different and heterogeneous sources. The process of extract, transform, and load
3.4 Data-Centric workflow One of the most important activities in a S-DWH environment is represented by data integration of different and heterogeneous sources. The process of extract, transform, and load