INF5820/INF9820 LANGUAGE TECHNOLOGICAL APPLICATIONS. Jan Tore Lønning, Lecture 8, 12 Oct
|
|
|
- Osborn Cameron
- 5 years ago
- Views:
Transcription
1 1 INF5820/INF9820 LANGUAGE TECHNOLOGICAL APPLICATIONS Jan Tore Lønning, Lecture 8, 12 Oct
2 Today 2 Preparing bitext Parameter tuning Reranking Some linguistic issues
3 STMT so far 3 We have seen all the main elements of a phrasebased STMT-system: The model How to train it Decoding For actually building a system, we will use some tools implementing this model, e.g. Moses Remains some details at both ends Start: Preprocessing End: Tuning
4 Preprocessing 4 (Exercise 4.1) Which preparations must be done to a training corpus to make it suitable for training an SMT system? Clean up text Character encoding Mark-up (XML, html) Tokenization Why?
5 Preprocessing: casing 5 Case folding (downcasing) or not? The city is large. the city is large. Washington is large. washington is large. Why not? Mary met Smith and Browne mary met smith and browne Adding ambiguity Translating proper names wrongly
6 Alternative: true casing 6 What The city is large. the city is large. Washington is large. Washington is large. How? Read through corpus, count occurrences which are not sentence initial model Use model on corpus Remaining problem: beginning of sentence Browne met Smith? Green men entered the room Cannot always do right. But true casing is best alternative.
7 Sentence align the source and target 7 Assume two parallel texts which are split into sentences E: e1, e2,, en F: f1, f2,, fm Not necessarily equally many Task: organize E and F into equally many segments E: E1, E2,, Ek F: F1, F2,, Fk Where Ei corresponds to Fi Ei consists of some consecutive sentences: e j, e j+1,, e j+s Similarly for Fi: f k, fk +1,, f k+u Ei and Fi are minimal: There is no sub segment Ei of Ei and Fi of Fi such that Ei and Fi correspond and Ei =/=Ei or Fi =/=Fi
8 Sentence alignment continued 8 Sentence pairs: x many sentences in Ei, y many sentences in Fi Then call Ei-Fi an x-y pair 1-1pair: Good for training 1-0 pair or 0 1 pair: Ignore for training 1 2 or 2 1 pairs. Might be considered for training. How to identify sentences? Sentence length Word pairs from dictionary
9 Today 9 Preparing bitext Parameter tuning Reranking Some linguistic issues
10 The generative SMT-model 10 Adding weights: Koehn, lecture 5, Slide 17-21
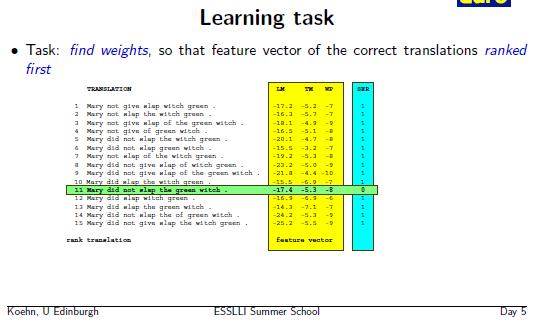
11 How to tune weights? Make an original system, S0, using a parallel corpus, C1, for the phrase table. 2. Use a distinct small parallel corpus, C2. (dev set) 3. Produce several S0-translations for each f-sentence in C2. n-best list (n=100, 1000, 10000) 4. Use a method for scoring the candidate translations in C2. (typically modified BLEU-score). 5. Try to adjust the weights to bring the best candidates in (4) towards top of list. 6. Make new system with adjusted weights. 7. Repeat from 3 towards convergence.
12 12
13 13
14 How to? (sec. 9.3) Try to adjust the weights to bring the best candidates in (4) towards top of list. No analytic solution We can t differentiate a function and find zero values Take 1: try systematically, say λ LM =.1,.2,.3,,.9 λ φ =.1,.2,,.9- λ LM = λ_lm λ D = =.1,.2,, 1- (λ LM + λ φ ) Too many values to try out Small changes in λs, large effect on result: The steps are too large
15 Take 2: Powell search 15 Optimize one λ, say λ LM, keeping the other fixed. With this value for λ LM, optimize the next λ, etc. A method for searching for the best value for each λ
16 Take 3: 16 (alternative) Simplex algorithm Variants of hill climbing Read sec 9.3 Not the details of Finding threshold points Combining threshold points in sec Not Simplex
17 17 Will the solutions be global?
18 Today 18 Preparing bitext Parameter tuning Reranking Some linguistic issues

19 Reranking model for SMT 19 Translation in two steps 1. Use a STMT-system as we have seen so far Output: A set of translation candidates 2. Use the reranker to rank the outputs and select between them Discriminative model
20 Statistical models 20 Generative model Discriminative model Construct solutions and assign them probabilities Examples PCFG: Assign trees Probabilities to the trees HMM-tagger Produce tag-sequences w/probabilities The translation models, both IBM and phrasebased Starts with a set of solutions Select between them on the basis of a statistical score Example: Malt parser
21 The reranker 21 Consider it as a classification problem Supervised learning Training material: A set of sentences in source language One or more reference translations of these Output of the STMT-system for these sentences Choose learning goal: (A way to evaluate the output sentences) Typically modified BLEU (or NIST) score
22 The reranker - learning 22 Choose features Choose a learning strategy: Naïve Bayes Maximum entropy (INF5830) Skip here Etc. The result is a ranker which - if we have succeeded -will return a reordered list where the top element has a better score than the top element before reranking Observe: This is machine learning The resulting reranker will not always improve the results
23 Reranking vs Tuning 23 What is the difference between Tuning and Reranking?
24 Reranking vs Tuning 24 Tuning is part of the training of the original STMTsystem. Tuning is applied to make an optimal translation system Reranking is part of a full MT-pipeline.. It is part of the decoding. It is applied to each sentence after the beam decoder has made an n-best list.
25 Today 25 Preparing bitext Parameter tuning Reranking Some linguistic issues
26 SMT + Linguistic Information Transliteration Compounds Names Morphology Word order and syntax
27 Translating numbers 27 How should a STMT system translate 12356? Most likely: It hasn t seen the number before. But since it translates into itself: one possible solution: Remove the number before translation, replace it by some dummy (say NNNN) Insert the number after translation (A default of not translating unseen tokens would give the same result)
28 Transliteration Norwegian, German 12, or English or 12,500 But the numbers are not exactly the same even in closely related languages Solution: Specific modules Translate specific phenomena Taken out of the regular SMT
29 Transliteration - names How should names in Japanese or Russian be spelled in English? The book describes recipes for doing this statistically(sec. 10.1) We will not consider this
30 Compounds German, Norwegian samhandlingsreform snøskredfare English word segmentation cruising speed Phrase-based SMT better than word-based New compounds/sparse data still a challenge Compound splitting in source language may help But how to put Humpty Dumpty together again? (when going to German or Norwegian)
31 Compounds in LOGON A set of possible templates: N 1 N 2 Ad 1 N 2 N 1 N 2 N 2 of N 1 etc. Generate all possible transfer rules from basic transfer rules for N 1 and N 2 from dictionary (order of n*n) Filter against monolingual target corpus Possible improvement: Turn into a probabilistic model
32 Translating names Which names should be translated and which not? How? Oslofjorden Rondane Statens lånekasse for utdanning Sognefjellesveien Sognefjellsveien the Sognefjellsveien Sognefjell Road the Sognefjell Road Sogn Mountain Road the Sogn Mountain Road the Parish Mountain Road
33 Translating names 33 Difficult to specify a recipe that fits all.
Tuning. Philipp Koehn presented by Gaurav Kumar. 28 September 2017
 Tuning Philipp Koehn presented by Gaurav Kumar 28 September 2017 The Story so Far: Generative Models 1 The definition of translation probability follows a mathematical derivation argmax e p(e f) = argmax
Tuning Philipp Koehn presented by Gaurav Kumar 28 September 2017 The Story so Far: Generative Models 1 The definition of translation probability follows a mathematical derivation argmax e p(e f) = argmax
NTT SMT System for IWSLT Katsuhito Sudoh, Taro Watanabe, Jun Suzuki, Hajime Tsukada, and Hideki Isozaki NTT Communication Science Labs.
 NTT SMT System for IWSLT 2008 Katsuhito Sudoh, Taro Watanabe, Jun Suzuki, Hajime Tsukada, and Hideki Isozaki NTT Communication Science Labs., Japan Overview 2-stage translation system k-best translation
NTT SMT System for IWSLT 2008 Katsuhito Sudoh, Taro Watanabe, Jun Suzuki, Hajime Tsukada, and Hideki Isozaki NTT Communication Science Labs., Japan Overview 2-stage translation system k-best translation
Discriminative Training for Phrase-Based Machine Translation
 Discriminative Training for Phrase-Based Machine Translation Abhishek Arun 19 April 2007 Overview 1 Evolution from generative to discriminative models Discriminative training Model Learning schemes Featured
Discriminative Training for Phrase-Based Machine Translation Abhishek Arun 19 April 2007 Overview 1 Evolution from generative to discriminative models Discriminative training Model Learning schemes Featured
Statistical Machine Translation Part IV Log-Linear Models
 Statistical Machine Translation art IV Log-Linear Models Alexander Fraser Institute for Natural Language rocessing University of Stuttgart 2011.11.25 Seminar: Statistical MT Where we have been We have
Statistical Machine Translation art IV Log-Linear Models Alexander Fraser Institute for Natural Language rocessing University of Stuttgart 2011.11.25 Seminar: Statistical MT Where we have been We have
Sparse Feature Learning
 Sparse Feature Learning Philipp Koehn 1 March 2016 Multiple Component Models 1 Translation Model Language Model Reordering Model Component Weights 2 Language Model.05 Translation Model.26.04.19.1 Reordering
Sparse Feature Learning Philipp Koehn 1 March 2016 Multiple Component Models 1 Translation Model Language Model Reordering Model Component Weights 2 Language Model.05 Translation Model.26.04.19.1 Reordering
Outline GIZA++ Moses. Demo. Steps Output files. Training pipeline Decoder
 GIZA++ and Moses Outline GIZA++ Steps Output files Moses Training pipeline Decoder Demo GIZA++ A statistical machine translation toolkit used to train IBM Models 1-5 (moses only uses output of IBM Model-1)
GIZA++ and Moses Outline GIZA++ Steps Output files Moses Training pipeline Decoder Demo GIZA++ A statistical machine translation toolkit used to train IBM Models 1-5 (moses only uses output of IBM Model-1)
Experimenting in MT: Moses Toolkit and Eman
 Experimenting in MT: Moses Toolkit and Eman Aleš Tamchyna, Ondřej Bojar Institute of Formal and Applied Linguistics Faculty of Mathematics and Physics Charles University, Prague Tue Sept 8, 2015 1 / 30
Experimenting in MT: Moses Toolkit and Eman Aleš Tamchyna, Ondřej Bojar Institute of Formal and Applied Linguistics Faculty of Mathematics and Physics Charles University, Prague Tue Sept 8, 2015 1 / 30
NLP in practice, an example: Semantic Role Labeling
 NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
The HDU Discriminative SMT System for Constrained Data PatentMT at NTCIR10
 The HDU Discriminative SMT System for Constrained Data PatentMT at NTCIR10 Patrick Simianer, Gesa Stupperich, Laura Jehl, Katharina Wäschle, Artem Sokolov, Stefan Riezler Institute for Computational Linguistics,
The HDU Discriminative SMT System for Constrained Data PatentMT at NTCIR10 Patrick Simianer, Gesa Stupperich, Laura Jehl, Katharina Wäschle, Artem Sokolov, Stefan Riezler Institute for Computational Linguistics,
Tokenization and Sentence Segmentation. Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017
 Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Marcello Federico MMT Srl / FBK Trento, Italy
 Marcello Federico MMT Srl / FBK Trento, Italy Proceedings for AMTA 2018 Workshop: Translation Quality Estimation and Automatic Post-Editing Boston, March 21, 2018 Page 207 Symbiotic Human and Machine Translation
Marcello Federico MMT Srl / FBK Trento, Italy Proceedings for AMTA 2018 Workshop: Translation Quality Estimation and Automatic Post-Editing Boston, March 21, 2018 Page 207 Symbiotic Human and Machine Translation
Homework 1. Leaderboard. Read through, submit the default output. Time for questions on Tuesday
 Homework 1 Leaderboard Read through, submit the default output Time for questions on Tuesday Agenda Focus on Homework 1 Review IBM Models 1 & 2 Inference (compute best alignment from a corpus given model
Homework 1 Leaderboard Read through, submit the default output Time for questions on Tuesday Agenda Focus on Homework 1 Review IBM Models 1 & 2 Inference (compute best alignment from a corpus given model
A Space-Efficient Phrase Table Implementation Using Minimal Perfect Hash Functions
 A Space-Efficient Phrase Table Implementation Using Minimal Perfect Hash Functions Marcin Junczys-Dowmunt Faculty of Mathematics and Computer Science Adam Mickiewicz University ul. Umultowska 87, 61-614
A Space-Efficient Phrase Table Implementation Using Minimal Perfect Hash Functions Marcin Junczys-Dowmunt Faculty of Mathematics and Computer Science Adam Mickiewicz University ul. Umultowska 87, 61-614
Corpus Acquisition from the Internet
 Corpus Acquisition from the Internet Philipp Koehn partially based on slides from Christian Buck 26 October 2017 Big Data 1 For many language pairs, lots of text available. Text you read in your lifetime
Corpus Acquisition from the Internet Philipp Koehn partially based on slides from Christian Buck 26 October 2017 Big Data 1 For many language pairs, lots of text available. Text you read in your lifetime
Statistical parsing. Fei Xia Feb 27, 2009 CSE 590A
 Statistical parsing Fei Xia Feb 27, 2009 CSE 590A Statistical parsing History-based models (1995-2000) Recent development (2000-present): Supervised learning: reranking and label splitting Semi-supervised
Statistical parsing Fei Xia Feb 27, 2009 CSE 590A Statistical parsing History-based models (1995-2000) Recent development (2000-present): Supervised learning: reranking and label splitting Semi-supervised
Machine Translation Zoo
 Machine Translation Zoo Tree-to-tree transfer and Discriminative learning Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague May 5th 2013, Seminar of Formal Linguistics,
Machine Translation Zoo Tree-to-tree transfer and Discriminative learning Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague May 5th 2013, Seminar of Formal Linguistics,
Discriminative Training with Perceptron Algorithm for POS Tagging Task
 Discriminative Training with Perceptron Algorithm for POS Tagging Task Mahsa Yarmohammadi Center for Spoken Language Understanding Oregon Health & Science University Portland, Oregon yarmoham@ohsu.edu
Discriminative Training with Perceptron Algorithm for POS Tagging Task Mahsa Yarmohammadi Center for Spoken Language Understanding Oregon Health & Science University Portland, Oregon yarmoham@ohsu.edu
AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands
 AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands Svetlana Stoyanchev, Hyuckchul Jung, John Chen, Srinivas Bangalore AT&T Labs Research 1 AT&T Way Bedminster NJ 07921 {sveta,hjung,jchen,srini}@research.att.com
AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands Svetlana Stoyanchev, Hyuckchul Jung, John Chen, Srinivas Bangalore AT&T Labs Research 1 AT&T Way Bedminster NJ 07921 {sveta,hjung,jchen,srini}@research.att.com
EXPERIMENTAL SETUP: MOSES
 EXPERIMENTAL SETUP: MOSES Moses is a statistical machine translation system that allows us to automatically train translation models for any language pair. All we need is a collection of translated texts
EXPERIMENTAL SETUP: MOSES Moses is a statistical machine translation system that allows us to automatically train translation models for any language pair. All we need is a collection of translated texts
INF FALL NATURAL LANGUAGE PROCESSING. Jan Tore Lønning, Lecture 4, 10.9
 1 INF5830 2015 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning, Lecture 4, 10.9 2 Working with texts From bits to meaningful units Today: 3 Reading in texts Character encodings and Unicode Word tokenization
1 INF5830 2015 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning, Lecture 4, 10.9 2 Working with texts From bits to meaningful units Today: 3 Reading in texts Character encodings and Unicode Word tokenization
Better translations with user collaboration - Integrated MT at Microsoft
 Better s with user collaboration - Integrated MT at Microsoft Chris Wendt Microsoft Research One Microsoft Way Redmond, WA 98052 christw@microsoft.com Abstract This paper outlines the methodologies Microsoft
Better s with user collaboration - Integrated MT at Microsoft Chris Wendt Microsoft Research One Microsoft Way Redmond, WA 98052 christw@microsoft.com Abstract This paper outlines the methodologies Microsoft
Machine Learning for Deep-syntactic MT
 Machine Learning for Deep-syntactic MT Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 11, 2015 Seminar on the 35th Anniversary of the Cooperation
Machine Learning for Deep-syntactic MT Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 11, 2015 Seminar on the 35th Anniversary of the Cooperation
The QCN System for Egyptian Arabic to English Machine Translation. Presenter: Hassan Sajjad
 The QCN System for Egyptian Arabic to English Machine Translation Presenter: Hassan Sajjad QCN Collaboration Ahmed El Kholy Wael Salloum Nizar Habash Ahmed Abdelali Nadir Durrani Francisco Guzmán Preslav
The QCN System for Egyptian Arabic to English Machine Translation Presenter: Hassan Sajjad QCN Collaboration Ahmed El Kholy Wael Salloum Nizar Habash Ahmed Abdelali Nadir Durrani Francisco Guzmán Preslav
A General-Purpose Rule Extractor for SCFG-Based Machine Translation
 A General-Purpose Rule Extractor for SCFG-Based Machine Translation Greg Hanneman, Michelle Burroughs, and Alon Lavie Language Technologies Institute Carnegie Mellon University Fifth Workshop on Syntax
A General-Purpose Rule Extractor for SCFG-Based Machine Translation Greg Hanneman, Michelle Burroughs, and Alon Lavie Language Technologies Institute Carnegie Mellon University Fifth Workshop on Syntax
A Weighted Finite State Transducer Implementation of the Alignment Template Model for Statistical Machine Translation.
 A Weighted Finite State Transducer Implementation of the Alignment Template Model for Statistical Machine Translation May 29, 2003 Shankar Kumar and Bill Byrne Center for Language and Speech Processing
A Weighted Finite State Transducer Implementation of the Alignment Template Model for Statistical Machine Translation May 29, 2003 Shankar Kumar and Bill Byrne Center for Language and Speech Processing
CMU-UKA Syntax Augmented Machine Translation
 Outline CMU-UKA Syntax Augmented Machine Translation Ashish Venugopal, Andreas Zollmann, Stephan Vogel, Alex Waibel InterACT, LTI, Carnegie Mellon University Pittsburgh, PA Outline Outline 1 2 3 4 Issues
Outline CMU-UKA Syntax Augmented Machine Translation Ashish Venugopal, Andreas Zollmann, Stephan Vogel, Alex Waibel InterACT, LTI, Carnegie Mellon University Pittsburgh, PA Outline Outline 1 2 3 4 Issues
Discriminative Reranking for Machine Translation
 Discriminative Reranking for Machine Translation Libin Shen Dept. of Comp. & Info. Science Univ. of Pennsylvania Philadelphia, PA 19104 libin@seas.upenn.edu Anoop Sarkar School of Comp. Science Simon Fraser
Discriminative Reranking for Machine Translation Libin Shen Dept. of Comp. & Info. Science Univ. of Pennsylvania Philadelphia, PA 19104 libin@seas.upenn.edu Anoop Sarkar School of Comp. Science Simon Fraser
TectoMT: Modular NLP Framework
 : Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
: Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
Treex: Modular NLP Framework
 : Modular NLP Framework Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 2015, Prague, MT Marathon Outline Motivation, vs. architecture internals Future
: Modular NLP Framework Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 2015, Prague, MT Marathon Outline Motivation, vs. architecture internals Future
THE CUED NIST 2009 ARABIC-ENGLISH SMT SYSTEM
 THE CUED NIST 2009 ARABIC-ENGLISH SMT SYSTEM Adrià de Gispert, Gonzalo Iglesias, Graeme Blackwood, Jamie Brunning, Bill Byrne NIST Open MT 2009 Evaluation Workshop Ottawa, The CUED SMT system Lattice-based
THE CUED NIST 2009 ARABIC-ENGLISH SMT SYSTEM Adrià de Gispert, Gonzalo Iglesias, Graeme Blackwood, Jamie Brunning, Bill Byrne NIST Open MT 2009 Evaluation Workshop Ottawa, The CUED SMT system Lattice-based
RLAT Rapid Language Adaptation Toolkit
 RLAT Rapid Language Adaptation Toolkit Tim Schlippe May 15, 2012 RLAT Rapid Language Adaptation Toolkit - 2 RLAT Rapid Language Adaptation Toolkit RLAT Rapid Language Adaptation Toolkit - 3 Outline Introduction
RLAT Rapid Language Adaptation Toolkit Tim Schlippe May 15, 2012 RLAT Rapid Language Adaptation Toolkit - 2 RLAT Rapid Language Adaptation Toolkit RLAT Rapid Language Adaptation Toolkit - 3 Outline Introduction
Parsing tree matching based question answering
 Parsing tree matching based question answering Ping Chen Dept. of Computer and Math Sciences University of Houston-Downtown chenp@uhd.edu Wei Ding Dept. of Computer Science University of Massachusetts
Parsing tree matching based question answering Ping Chen Dept. of Computer and Math Sciences University of Houston-Downtown chenp@uhd.edu Wei Ding Dept. of Computer Science University of Massachusetts
Machine Translation and Discriminative Models
 Machine Translation and Discriminative Models Tree-to-tree transfer and Discriminative learning Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague March 23rd 2015,
Machine Translation and Discriminative Models Tree-to-tree transfer and Discriminative learning Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague March 23rd 2015,
Local Phrase Reordering Models for Statistical Machine Translation
 Local Phrase Reordering Models for Statistical Machine Translation Shankar Kumar, William Byrne Center for Language and Speech Processing, Johns Hopkins University, 3400 North Charles Street, Baltimore,
Local Phrase Reordering Models for Statistical Machine Translation Shankar Kumar, William Byrne Center for Language and Speech Processing, Johns Hopkins University, 3400 North Charles Street, Baltimore,
TALP: Xgram-based Spoken Language Translation System Adrià de Gispert José B. Mariño
 TALP: Xgram-based Spoken Language Translation System Adrià de Gispert José B. Mariño Outline Overview Outline Translation generation Training IWSLT'04 Chinese-English supplied task results Conclusion and
TALP: Xgram-based Spoken Language Translation System Adrià de Gispert José B. Mariño Outline Overview Outline Translation generation Training IWSLT'04 Chinese-English supplied task results Conclusion and
Arabic Preprocessing Schemes for Statistical Machine Translation *
 National Research Council Canada Institute for Information Technology Conseil national de recherches Canada Institut de technologie de l'information Arabic Preprocessing Schemes for Statistical Machine
National Research Council Canada Institute for Information Technology Conseil national de recherches Canada Institut de technologie de l'information Arabic Preprocessing Schemes for Statistical Machine
Power Mean Based Algorithm for Combining Multiple Alignment Tables
 Power Mean Based Algorithm for Combining Multiple Alignment Tables Sameer Maskey, Steven J. Rennie, Bowen Zhou IBM T.J. Watson Research Center {smaskey, sjrennie, zhou}@us.ibm.com Abstract Alignment combination
Power Mean Based Algorithm for Combining Multiple Alignment Tables Sameer Maskey, Steven J. Rennie, Bowen Zhou IBM T.J. Watson Research Center {smaskey, sjrennie, zhou}@us.ibm.com Abstract Alignment combination
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Topics for Today. The Last (i.e. Final) Class. Weakly Supervised Approaches. Weakly supervised learning algorithms (for NP coreference resolution)
 Class. Weakly Supervised Approaches. Weakly supervised learning algorithms (for NP coreference resolution)") Topics for Today The Last (i.e. Final) Class Weakly supervised learning algorithms (for NP coreference resolution) Co-training Self-training A look at the semester and related courses Submit the teaching
Topics for Today The Last (i.e. Final) Class Weakly supervised learning algorithms (for NP coreference resolution) Co-training Self-training A look at the semester and related courses Submit the teaching
Improving the quality of a customized SMT system using shared training data. August 28, 2009
 Improving the quality of a customized SMT system using shared training data Chris.Wendt@microsoft.com Will.Lewis@microsoft.com August 28, 2009 1 Overview Engine and Customization Basics Experiment Objective
Improving the quality of a customized SMT system using shared training data Chris.Wendt@microsoft.com Will.Lewis@microsoft.com August 28, 2009 1 Overview Engine and Customization Basics Experiment Objective
K-best Parsing Algorithms
 K-best Parsing Algorithms Liang Huang University of Pennsylvania joint work with David Chiang (USC Information Sciences Institute) k-best Parsing Liang Huang (Penn) k-best parsing 2 k-best Parsing I saw
K-best Parsing Algorithms Liang Huang University of Pennsylvania joint work with David Chiang (USC Information Sciences Institute) k-best Parsing Liang Huang (Penn) k-best parsing 2 k-best Parsing I saw
Workshop on statistical machine translation for curious translators. Víctor M. Sánchez-Cartagena Prompsit Language Engineering, S.L.
 Workshop on statistical machine translation for curious translators Víctor M. Sánchez-Cartagena Prompsit Language Engineering, S.L. Outline 1) Introduction to machine translation 2) 3)Acquisition of parallel
Workshop on statistical machine translation for curious translators Víctor M. Sánchez-Cartagena Prompsit Language Engineering, S.L. Outline 1) Introduction to machine translation 2) 3)Acquisition of parallel
An Unsupervised Model for Joint Phrase Alignment and Extraction
 An Unsupervised Model for Joint Phrase Alignment and Extraction Graham Neubig 1,2, Taro Watanabe 2, Eiichiro Sumita 2, Shinsuke Mori 1, Tatsuya Kawahara 1 1 Graduate School of Informatics, Kyoto University
An Unsupervised Model for Joint Phrase Alignment and Extraction Graham Neubig 1,2, Taro Watanabe 2, Eiichiro Sumita 2, Shinsuke Mori 1, Tatsuya Kawahara 1 1 Graduate School of Informatics, Kyoto University
Parts of Speech, Named Entity Recognizer
 Parts of Speech, Named Entity Recognizer Artificial Intelligence @ Allegheny College Janyl Jumadinova November 8, 2018 Janyl Jumadinova Parts of Speech, Named Entity Recognizer November 8, 2018 1 / 25
Parts of Speech, Named Entity Recognizer Artificial Intelligence @ Allegheny College Janyl Jumadinova November 8, 2018 Janyl Jumadinova Parts of Speech, Named Entity Recognizer November 8, 2018 1 / 25
More on indexing CE-324: Modern Information Retrieval Sharif University of Technology
 More on indexing CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Plan
More on indexing CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Plan
1 Implement EM training of IBM model 1
 INF5820, fall 2016 Assignment 2: Alignment for Stat. MT Deadline 21 Oct. at 6 pm, to be delivered in Devilry In this set we will familiarize ourselves with the first steps in the construction of a statistical
INF5820, fall 2016 Assignment 2: Alignment for Stat. MT Deadline 21 Oct. at 6 pm, to be delivered in Devilry In this set we will familiarize ourselves with the first steps in the construction of a statistical
Unsupervised Keyword Extraction from Single Document. Swagata Duari Aditya Gupta Vasudha Bhatnagar
 Unsupervised Keyword Extraction from Single Document Swagata Duari Aditya Gupta Vasudha Bhatnagar Presentation Outline Introduction and Motivation Statistical Methods for Automatic Keyword Extraction Graph-based
Unsupervised Keyword Extraction from Single Document Swagata Duari Aditya Gupta Vasudha Bhatnagar Presentation Outline Introduction and Motivation Statistical Methods for Automatic Keyword Extraction Graph-based
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most
 In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Homework 2: HMM, Viterbi, CRF/Perceptron
 Homework 2: HMM, Viterbi, CRF/Perceptron CS 585, UMass Amherst, Fall 2015 Version: Oct5 Overview Due Tuesday, Oct 13 at midnight. Get starter code from the course website s schedule page. You should submit
Homework 2: HMM, Viterbi, CRF/Perceptron CS 585, UMass Amherst, Fall 2015 Version: Oct5 Overview Due Tuesday, Oct 13 at midnight. Get starter code from the course website s schedule page. You should submit
Learning to find transliteration on the Web
 Learning to find transliteration on the Web Chien-Cheng Wu Department of Computer Science National Tsing Hua University 101 Kuang Fu Road, Hsin chu, Taiwan d9283228@cs.nthu.edu.tw Jason S. Chang Department
Learning to find transliteration on the Web Chien-Cheng Wu Department of Computer Science National Tsing Hua University 101 Kuang Fu Road, Hsin chu, Taiwan d9283228@cs.nthu.edu.tw Jason S. Chang Department
A CASE STUDY: Structure learning for Part-of-Speech Tagging. Danilo Croce WMR 2011/2012
 A CAS STUDY: Structure learning for Part-of-Speech Tagging Danilo Croce WM 2011/2012 27 gennaio 2012 TASK definition One of the tasks of VALITA 2009 VALITA is an initiative devoted to the evaluation of
A CAS STUDY: Structure learning for Part-of-Speech Tagging Danilo Croce WM 2011/2012 27 gennaio 2012 TASK definition One of the tasks of VALITA 2009 VALITA is an initiative devoted to the evaluation of
Random Restarts in Minimum Error Rate Training for Statistical Machine Translation
 Random Restarts in Minimum Error Rate Training for Statistical Machine Translation Robert C. Moore and Chris Quirk Microsoft Research Redmond, WA 98052, USA bobmoore@microsoft.com, chrisq@microsoft.com
Random Restarts in Minimum Error Rate Training for Statistical Machine Translation Robert C. Moore and Chris Quirk Microsoft Research Redmond, WA 98052, USA bobmoore@microsoft.com, chrisq@microsoft.com
Information Retrieval and Organisation
 Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2016/17 IR Chapter 02 The Term Vocabulary and Postings Lists Constructing Inverted Indexes The major steps in constructing
Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2016/17 IR Chapter 02 The Term Vocabulary and Postings Lists Constructing Inverted Indexes The major steps in constructing
Classification. 1 o Semestre 2007/2008
 Classification Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 Single-Class
Classification Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 Single-Class
Taming Text. How to Find, Organize, and Manipulate It MANNING GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS. Shelter Island
 Taming Text How to Find, Organize, and Manipulate It GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS 11 MANNING Shelter Island contents foreword xiii preface xiv acknowledgments xvii about this book
Taming Text How to Find, Organize, and Manipulate It GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS 11 MANNING Shelter Island contents foreword xiii preface xiv acknowledgments xvii about this book
IBM Model 1 and Machine Translation
 IBM Model 1 and Machine Translation Recap 2 Expectation Maximization (EM) 0. Assume some value for your parameters Two step, iterative algorithm 1. E-step: count under uncertainty, assuming these parameters
IBM Model 1 and Machine Translation Recap 2 Expectation Maximization (EM) 0. Assume some value for your parameters Two step, iterative algorithm 1. E-step: count under uncertainty, assuming these parameters
Moses version 2.1 Release Notes
 Moses version 2.1 Release Notes Overview The document is the release notes for the Moses SMT toolkit, version 2.1. It describes the changes to toolkit since version 1.0 from January 2013. The aim during
Moses version 2.1 Release Notes Overview The document is the release notes for the Moses SMT toolkit, version 2.1. It describes the changes to toolkit since version 1.0 from January 2013. The aim during
Digital Libraries: Language Technologies
 Digital Libraries: Language Technologies RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Recall: Inverted Index..........................................
Digital Libraries: Language Technologies RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Recall: Inverted Index..........................................
Start downloading our playground for SMT: wget
 Before we start... Start downloading Moses: wget http://ufal.mff.cuni.cz/~tamchyna/mosesgiza.64bit.tar.gz Start downloading our playground for SMT: wget http://ufal.mff.cuni.cz/eman/download/playground.tar
Before we start... Start downloading Moses: wget http://ufal.mff.cuni.cz/~tamchyna/mosesgiza.64bit.tar.gz Start downloading our playground for SMT: wget http://ufal.mff.cuni.cz/eman/download/playground.tar
The Prague Bulletin of Mathematical Linguistics NUMBER 91 JANUARY
 The Prague Bulletin of Mathematical Linguistics NUMBER 9 JANUARY 009 79 88 Z-MERT: A Fully Configurable Open Source Tool for Minimum Error Rate Training of Machine Translation Systems Omar F. Zaidan Abstract
The Prague Bulletin of Mathematical Linguistics NUMBER 9 JANUARY 009 79 88 Z-MERT: A Fully Configurable Open Source Tool for Minimum Error Rate Training of Machine Translation Systems Omar F. Zaidan Abstract
Incremental Integer Linear Programming for Non-projective Dependency Parsing
 Incremental Integer Linear Programming for Non-projective Dependency Parsing Sebastian Riedel James Clarke ICCS, University of Edinburgh 22. July 2006 EMNLP 2006 S. Riedel, J. Clarke (ICCS, Edinburgh)
Incremental Integer Linear Programming for Non-projective Dependency Parsing Sebastian Riedel James Clarke ICCS, University of Edinburgh 22. July 2006 EMNLP 2006 S. Riedel, J. Clarke (ICCS, Edinburgh)
PBML. logo. The Prague Bulletin of Mathematical Linguistics NUMBER??? FEBRUARY Improved Minimum Error Rate Training in Moses
 PBML logo The Prague Bulletin of Mathematical Linguistics NUMBER??? FEBRUARY 2009 1 11 Improved Minimum Error Rate Training in Moses Nicola Bertoldi, Barry Haddow, Jean-Baptiste Fouet Abstract We describe
PBML logo The Prague Bulletin of Mathematical Linguistics NUMBER??? FEBRUARY 2009 1 11 Improved Minimum Error Rate Training in Moses Nicola Bertoldi, Barry Haddow, Jean-Baptiste Fouet Abstract We describe
MOSES. Statistical Machine Translation System. User Manual and Code Guide. Philipp Koehn University of Edinburgh
 MOSES Statistical Machine Translation System User Manual and Code Guide Philipp Koehn pkoehn@inf.ed.ac.uk University of Edinburgh Abstract This document serves as user manual and code guide for the Moses
MOSES Statistical Machine Translation System User Manual and Code Guide Philipp Koehn pkoehn@inf.ed.ac.uk University of Edinburgh Abstract This document serves as user manual and code guide for the Moses
Comment Extraction from Blog Posts and Its Applications to Opinion Mining
 Comment Extraction from Blog Posts and Its Applications to Opinion Mining Huan-An Kao, Hsin-Hsi Chen Department of Computer Science and Information Engineering National Taiwan University, Taipei, Taiwan
Comment Extraction from Blog Posts and Its Applications to Opinion Mining Huan-An Kao, Hsin-Hsi Chen Department of Computer Science and Information Engineering National Taiwan University, Taipei, Taiwan
Algorithms for NLP. Machine Translation. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Machine Translation Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Machine Translation Machine Translation: Examples Levels of Transfer Word-Level MT: Examples la politique
Algorithms for NLP Machine Translation Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Machine Translation Machine Translation: Examples Levels of Transfer Word-Level MT: Examples la politique
Exam Marco Kuhlmann. This exam consists of three parts:
 TDDE09, 729A27 Natural Language Processing (2017) Exam 2017-03-13 Marco Kuhlmann This exam consists of three parts: 1. Part A consists of 5 items, each worth 3 points. These items test your understanding
TDDE09, 729A27 Natural Language Processing (2017) Exam 2017-03-13 Marco Kuhlmann This exam consists of three parts: 1. Part A consists of 5 items, each worth 3 points. These items test your understanding
Thot Toolkit for Statistical Machine Translation. User Manual. Daniel Ortiz Martínez Webinterpret
 Thot Toolkit for Statistical Machine Translation User Manual Daniel Ortiz Martínez daniel.o@webinterpret.com Webinterpret January 2018 CONTENTS 1 Introduction 1 1.1 Statistical Foundations.............................
Thot Toolkit for Statistical Machine Translation User Manual Daniel Ortiz Martínez daniel.o@webinterpret.com Webinterpret January 2018 CONTENTS 1 Introduction 1 1.1 Statistical Foundations.............................
The Prague Bulletin of Mathematical Linguistics NUMBER 94 SEPTEMBER An Experimental Management System. Philipp Koehn
 The Prague Bulletin of Mathematical Linguistics NUMBER 94 SEPTEMBER 2010 87 96 An Experimental Management System Philipp Koehn University of Edinburgh Abstract We describe Experiment.perl, an experimental
The Prague Bulletin of Mathematical Linguistics NUMBER 94 SEPTEMBER 2010 87 96 An Experimental Management System Philipp Koehn University of Edinburgh Abstract We describe Experiment.perl, an experimental
MMT Modern Machine Translation. First Evaluation Plan
 This project has received funding from the European Union s Horizon 2020 research and innovation programme under grant agreement No 645487. MMT Modern Machine Translation First Evaluation Plan Author(s):
This project has received funding from the European Union s Horizon 2020 research and innovation programme under grant agreement No 645487. MMT Modern Machine Translation First Evaluation Plan Author(s):
A Semi-supervised Word Alignment Algorithm with Partial Manual Alignments
 A Semi-supervised Word Alignment Algorithm with Partial Manual Alignments Qin Gao, Nguyen Bach and Stephan Vogel Language Technologies Institute Carnegie Mellon University 000 Forbes Avenue, Pittsburgh
A Semi-supervised Word Alignment Algorithm with Partial Manual Alignments Qin Gao, Nguyen Bach and Stephan Vogel Language Technologies Institute Carnegie Mellon University 000 Forbes Avenue, Pittsburgh
A Bambara Tonalization System for Word Sense Disambiguation Using Differential Coding, Segmentation and Edit Operation Filtering
 A Bambara Tonalization System for Word Sense Disambiguation Using Differential Coding, Segmentation and Edit Operation Filtering Luigi (Y.-C.) Liu Damien Nouvel ER-TIM, INALCO, 2 rue de Lille, Paris, France
A Bambara Tonalization System for Word Sense Disambiguation Using Differential Coding, Segmentation and Edit Operation Filtering Luigi (Y.-C.) Liu Damien Nouvel ER-TIM, INALCO, 2 rue de Lille, Paris, France
An efficient and user-friendly tool for machine translation quality estimation
 An efficient and user-friendly tool for machine translation quality estimation Kashif Shah, Marco Turchi, Lucia Specia Department of Computer Science, University of Sheffield, UK {kashif.shah,l.specia}@sheffield.ac.uk
An efficient and user-friendly tool for machine translation quality estimation Kashif Shah, Marco Turchi, Lucia Specia Department of Computer Science, University of Sheffield, UK {kashif.shah,l.specia}@sheffield.ac.uk
Dynamic Feature Selection for Dependency Parsing
 Dynamic Feature Selection for Dependency Parsing He He, Hal Daumé III and Jason Eisner EMNLP 2013, Seattle Structured Prediction in NLP Part-of-Speech Tagging Parsing N N V Det N Fruit flies like a banana
Dynamic Feature Selection for Dependency Parsing He He, Hal Daumé III and Jason Eisner EMNLP 2013, Seattle Structured Prediction in NLP Part-of-Speech Tagging Parsing N N V Det N Fruit flies like a banana
Computer Science February Homework Assignment #2 Due: Friday, 9 March 2018 at 19h00 (7 PM),
,") Computer Science 401 13 February 2018 St. George Campus University of Toronto Homework Assignment #2 Due: Friday, 9 March 2018 at 19h00 (7 PM), Statistical Machine Translation TA: Mohamed Abdalla (mohamed.abdalla@mail.utoronto.ca);
Computer Science 401 13 February 2018 St. George Campus University of Toronto Homework Assignment #2 Due: Friday, 9 March 2018 at 19h00 (7 PM), Statistical Machine Translation TA: Mohamed Abdalla (mohamed.abdalla@mail.utoronto.ca);
Modeling Sequence Data
 Modeling Sequence Data CS4780/5780 Machine Learning Fall 2011 Thorsten Joachims Cornell University Reading: Manning/Schuetze, Sections 9.1-9.3 (except 9.3.1) Leeds Online HMM Tutorial (except Forward and
Modeling Sequence Data CS4780/5780 Machine Learning Fall 2011 Thorsten Joachims Cornell University Reading: Manning/Schuetze, Sections 9.1-9.3 (except 9.3.1) Leeds Online HMM Tutorial (except Forward and
Indexing. UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze
 Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Recap of the previous lecture. This lecture. A naïve dictionary. Introduction to Information Retrieval. Dictionary data structures Tolerant retrieval
 Ch. 2 Recap of the previous lecture Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval The type/token distinction Terms are normalized types put in the dictionary Tokenization
Ch. 2 Recap of the previous lecture Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval The type/token distinction Terms are normalized types put in the dictionary Tokenization
Reassessment of the Role of Phrase Extraction in PBSMT
 Reassessment of the Role of Phrase Extraction in PBSMT Francisco Guzman Centro de Sistemas Inteligentes Tecnológico de Monterrey Monterrey, N.L., Mexico guzmanhe@gmail.com Qin Gao and Stephan Vogel Language
Reassessment of the Role of Phrase Extraction in PBSMT Francisco Guzman Centro de Sistemas Inteligentes Tecnológico de Monterrey Monterrey, N.L., Mexico guzmanhe@gmail.com Qin Gao and Stephan Vogel Language
Improved Models of Distortion Cost for Statistical Machine Translation
 Improved Models of Distortion Cost for Statistical Machine Translation Spence Green, Michel Galley, and Christopher D. Manning Computer Science Department Stanford University Stanford, CA 9435 {spenceg,mgalley,manning}@stanford.edu
Improved Models of Distortion Cost for Statistical Machine Translation Spence Green, Michel Galley, and Christopher D. Manning Computer Science Department Stanford University Stanford, CA 9435 {spenceg,mgalley,manning}@stanford.edu
UNIVERSITY OF EDINBURGH COLLEGE OF SCIENCE AND ENGINEERING SCHOOL OF INFORMATICS INFR08008 INFORMATICS 2A: PROCESSING FORMAL AND NATURAL LANGUAGES
 UNIVERSITY OF EDINBURGH COLLEGE OF SCIENCE AND ENGINEERING SCHOOL OF INFORMATICS INFR08008 INFORMATICS 2A: PROCESSING FORMAL AND NATURAL LANGUAGES Saturday 10 th December 2016 09:30 to 11:30 INSTRUCTIONS
UNIVERSITY OF EDINBURGH COLLEGE OF SCIENCE AND ENGINEERING SCHOOL OF INFORMATICS INFR08008 INFORMATICS 2A: PROCESSING FORMAL AND NATURAL LANGUAGES Saturday 10 th December 2016 09:30 to 11:30 INSTRUCTIONS
Training a Super Model Look-Alike:Featuring Edit Distance, N-Gram Occurrence,and One Reference Translation p.1/40
 Training a Super Model Look-Alike: Featuring Edit Distance, N-Gram Occurrence, and One Reference Translation Eva Forsbom, Uppsala University evafo@stp.ling.uu.se MT Summit IX Workshop on Machine Translation
Training a Super Model Look-Alike: Featuring Edit Distance, N-Gram Occurrence, and One Reference Translation Eva Forsbom, Uppsala University evafo@stp.ling.uu.se MT Summit IX Workshop on Machine Translation
Large Scale Parallel Document Mining for Machine Translation
 Large Scale Parallel Document Mining for Machine Translation Jakob Uszkoreit Jay M. Ponte Ashok C. Popat Moshe Dubiner Google, Inc. {uszkoreit,ponte,popat,moshe}@google.com Abstract A distributed system
Large Scale Parallel Document Mining for Machine Translation Jakob Uszkoreit Jay M. Ponte Ashok C. Popat Moshe Dubiner Google, Inc. {uszkoreit,ponte,popat,moshe}@google.com Abstract A distributed system
Statistical Machine Translation with Word- and Sentence-Aligned Parallel Corpora
 Statistical Machine Translation with Word- and Sentence-Aligned Parallel Corpora Chris Callison-Burch David Talbot Miles Osborne School on nformatics University of Edinburgh 2 Buccleuch Place Edinburgh
Statistical Machine Translation with Word- and Sentence-Aligned Parallel Corpora Chris Callison-Burch David Talbot Miles Osborne School on nformatics University of Edinburgh 2 Buccleuch Place Edinburgh
slide courtesy of D. Yarowsky Splitting Words a.k.a. Word Sense Disambiguation Intro to NLP - J. Eisner 1
 Splitting Words a.k.a. Word Sense Disambiguation 600.465 - Intro to NLP - J. Eisner Representing Word as Vector Could average over many occurrences of the word... Each word type has a different vector
Splitting Words a.k.a. Word Sense Disambiguation 600.465 - Intro to NLP - J. Eisner Representing Word as Vector Could average over many occurrences of the word... Each word type has a different vector
Finding parallel texts on the web using cross-language information retrieval
 Finding parallel texts on the web using cross-language information retrieval Achim Ruopp University of Washington, Seattle, WA 98195, USA achimr@u.washington.edu Fei Xia University of Washington Seattle,
Finding parallel texts on the web using cross-language information retrieval Achim Ruopp University of Washington, Seattle, WA 98195, USA achimr@u.washington.edu Fei Xia University of Washington Seattle,
CS6200 Information Retrieval. David Smith College of Computer and Information Science Northeastern University
 CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University Indexing Process!2 Indexes Storing document information for faster queries Indexes Index Compression
CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University Indexing Process!2 Indexes Storing document information for faster queries Indexes Index Compression
Assignment 4 CSE 517: Natural Language Processing
 Assignment 4 CSE 517: Natural Language Processing University of Washington Winter 2016 Due: March 2, 2016, 1:30 pm 1 HMMs and PCFGs Here s the definition of a PCFG given in class on 2/17: A finite set
Assignment 4 CSE 517: Natural Language Processing University of Washington Winter 2016 Due: March 2, 2016, 1:30 pm 1 HMMs and PCFGs Here s the definition of a PCFG given in class on 2/17: A finite set
Stabilizing Minimum Error Rate Training
 Stabilizing Minimum Error Rate Training George Foster and Roland Kuhn National Research Council Canada first.last@nrc.gc.ca Abstract The most commonly used method for training feature weights in statistical
Stabilizing Minimum Error Rate Training George Foster and Roland Kuhn National Research Council Canada first.last@nrc.gc.ca Abstract The most commonly used method for training feature weights in statistical
Language Support, Linguistics, and Text Analytics in Solr
 Boston Apache Lucene and Solr Meetup Language Support, Linguistics, and Text Analytics in Solr Carl Steve W. Kearns Hoffman Product Manager Basis Technology Founder & CEO www.basistech.com Agenda About
Boston Apache Lucene and Solr Meetup Language Support, Linguistics, and Text Analytics in Solr Carl Steve W. Kearns Hoffman Product Manager Basis Technology Founder & CEO www.basistech.com Agenda About
Shallow Parsing Swapnil Chaudhari 11305R011 Ankur Aher Raj Dabre 11305R001
 Shallow Parsing Swapnil Chaudhari 11305R011 Ankur Aher - 113059006 Raj Dabre 11305R001 Purpose of the Seminar To emphasize on the need for Shallow Parsing. To impart basic information about techniques
Shallow Parsing Swapnil Chaudhari 11305R011 Ankur Aher - 113059006 Raj Dabre 11305R001 Purpose of the Seminar To emphasize on the need for Shallow Parsing. To impart basic information about techniques
Reassessment of the Role of Phrase Extraction in PBSMT
 Reassessment of the Role of Phrase Extraction in Francisco Guzmán CCIR-ITESM guzmanhe@gmail.com Qin Gao LTI-CMU qing@cs.cmu.edu Stephan Vogel LTI-CMU stephan.vogel@cs.cmu.edu Presented by: Nguyen Bach
Reassessment of the Role of Phrase Extraction in Francisco Guzmán CCIR-ITESM guzmanhe@gmail.com Qin Gao LTI-CMU qing@cs.cmu.edu Stephan Vogel LTI-CMU stephan.vogel@cs.cmu.edu Presented by: Nguyen Bach
CS 6320 Natural Language Processing
 CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
Question of the Day. Machine Translation. Statistical Word Alignment. Centauri/Arcturan (Knight, 1997) Centauri/Arcturan (Knight, 1997)
 Centauri/Arcturan (Knight, 1997)") Question of the Day Is it possible to learn to translate from plain example translations? Machine Translation Statistical Word Alignment Based on slides by Philipp Koehn and Kevin Knight Word Alignment
Question of the Day Is it possible to learn to translate from plain example translations? Machine Translation Statistical Word Alignment Based on slides by Philipp Koehn and Kevin Knight Word Alignment
Question Answering Systems
 Question Answering Systems An Introduction Potsdam, Germany, 14 July 2011 Saeedeh Momtazi Information Systems Group Outline 2 1 Introduction Outline 2 1 Introduction 2 History Outline 2 1 Introduction
Question Answering Systems An Introduction Potsdam, Germany, 14 July 2011 Saeedeh Momtazi Information Systems Group Outline 2 1 Introduction Outline 2 1 Introduction 2 History Outline 2 1 Introduction
Conditional Random Fields - A probabilistic graphical model. Yen-Chin Lee 指導老師 : 鮑興國
 Conditional Random Fields - A probabilistic graphical model Yen-Chin Lee 指導老師 : 鮑興國 Outline Labeling sequence data problem Introduction conditional random field (CRF) Different views on building a conditional
Conditional Random Fields - A probabilistic graphical model Yen-Chin Lee 指導老師 : 鮑興國 Outline Labeling sequence data problem Introduction conditional random field (CRF) Different views on building a conditional
Orange3-Textable Documentation
 Orange3-Textable Documentation Release 3.0a1 LangTech Sarl Dec 19, 2017 Contents 1 Getting Started 3 1.1 Orange Textable............................................. 3 1.2 Description................................................
Orange3-Textable Documentation Release 3.0a1 LangTech Sarl Dec 19, 2017 Contents 1 Getting Started 3 1.1 Orange Textable............................................. 3 1.2 Description................................................
Natural Language Processing SoSe Question Answering. (based on the slides of Dr. Saeedeh Momtazi)
") Natural Language Processing SoSe 2015 Question Answering Dr. Mariana Neves July 6th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Introduction History QA Architecture Outline 3 Introduction
Natural Language Processing SoSe 2015 Question Answering Dr. Mariana Neves July 6th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Introduction History QA Architecture Outline 3 Introduction
Midterm Examination CS540-2: Introduction to Artificial Intelligence
 Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
Machine Learning in GATE
 Machine Learning in GATE Angus Roberts, Horacio Saggion, Genevieve Gorrell Recap Previous two days looked at knowledge engineered IE This session looks at machine learned IE Supervised learning Effort
Machine Learning in GATE Angus Roberts, Horacio Saggion, Genevieve Gorrell Recap Previous two days looked at knowledge engineered IE This session looks at machine learned IE Supervised learning Effort