Exploratory Data Analysis using Self-Organizing Maps. Madhumanti Ray
|
|
|
- Clement Ross
- 5 years ago
- Views:
Transcription
1 Exploratory Data Analysis using Self-Organizing Maps Madhumanti Ray
2 Content Introduction Data Analysis methods Self-Organizing Maps Conclusion
3 Visualization of high-dimensional data items Exploratory data analysis finds structures in a given data set. Many methods exist deal with low dimensional data Eg: Andrews curve, Chernoff' faces Drawback? Difficult to visualize high-dimensional data, do not reduce amount of data
4 Data Exploration Techniques Clustering Projection
5 Clustering Reduces amount of data by grouping similar items together. Hierarchical Partitioning Partitioning : divide the data set into disjoint data clusters
6 K- means Algorithm Find Euclidean distance between each input and centroid of a cluster Assign input to nearest cluster Do above steps iteratively till value does not change significantly
7 Projection Methods Represents high-dimensional data in a lower-dimensional space Properties of the structure of data set is preserved Linear Projection methods Non-linear projection methods
8 Linear Projection Principal component analysis: Data sets with linear structures Original variables mapped to few variable, PC, retain key features of data set Projection Pursuit: Data projection deviating most from normally distribute data is picked for removal
9 Non-linear Projection methods Multidimensional Scaling: Topology preserving Distance between representations in lowerdimensional space close to original distance Objective function: Σ [d(k,l) d'(k,l)] 2 Rank order of distances maintained for comparison maintained by non-metric MDS better measure
10 Sammon's : MDS function normalized by original distance Principal curves: points on curve is average of all data points projecting to it.
11 Self Organizing Maps Unsupervised learning, non-parametric Can do both clustering and projection Preserves topology Implements competitive learning with cooperation
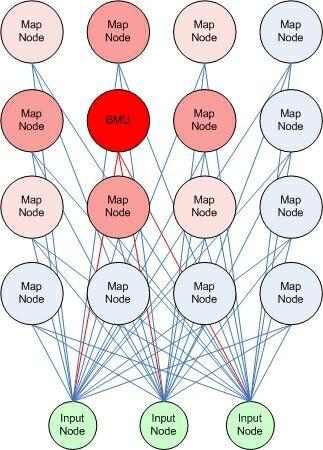
12
13 Self Organizing Maps Winning unit on lattice has reference vector closest to input: c = c(x) = arg min{ x-m i 2 } euclidean distance to find winning unit
14 Self Organizing Maps The learning is shared by neighbouring units - they orient their vectors towards input Governed by neighbourhood kernel h decreasing function m i (t + 1) = m i (t) + h ci (t)[x(t) m i (t)] h is wide at first, reduces over learning
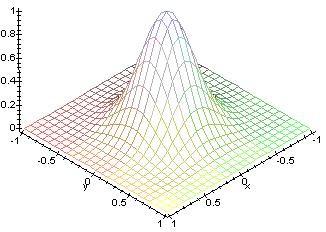
15
16 Features of SOM useful in exploring data Ordered display: neighbouring units on the map will represent inputs that are similar Visualization of clusters: distance between reference vectors gives density of cluster used for gray level values. Missing data : reference vectors compared to input using features present in input Outliers: affect only one unit and neighbours.
17 Using SOM Preprocessing: Feature extraction that represent the variations of data best. Ordering/scaling among feature components. Computation of maps: Initialize reference vectors, choose wide h Neighbourhood kernel h reduces in phase one Phase two, reaches final state of map
18 Using SOM Choosing best map: Teach set of maps with each size of maps and h Pick map that minimizes cost function best from each set Apply goodness measure for final pick Interpretation of map: Subjective to data set and problem SOM maps focused on local relations of data items Evaluation: Many methods, eg. Classification accuracy Generalizability
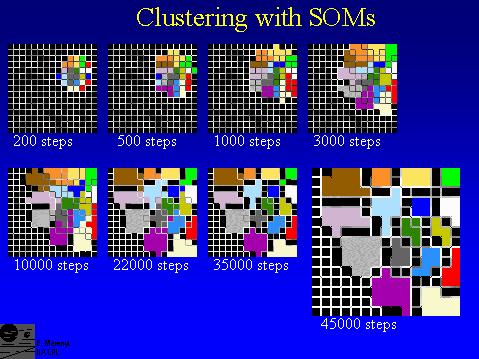
19
20 Difference with other MDS With MDS: Topology preserving, not distance i.e. similar inputs mapped to nearby locations Computational complexity depends on map units k. Each learning step is O(k) computations No local minima. Start with wide h, shrink to narrow form
21 Conclusion SOM: Viable alternative to other data exploration methods One method to implement clustering and projection Robust to handle continuous, discrete values, sparse data etc.
22 Questions?
CIE L*a*b* color model
 CIE L*a*b* color model To further strengthen the correlation between the color model and human perception, we apply the following non-linear transformation: with where (X n,y n,z n ) are the tristimulus
CIE L*a*b* color model To further strengthen the correlation between the color model and human perception, we apply the following non-linear transformation: with where (X n,y n,z n ) are the tristimulus
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Chapter 7: Competitive learning, clustering, and self-organizing maps
 Chapter 7: Competitive learning, clustering, and self-organizing maps António R. C. Paiva EEL 6814 Spring 2008 Outline Competitive learning Clustering Self-Organizing Maps What is competition in neural
Chapter 7: Competitive learning, clustering, and self-organizing maps António R. C. Paiva EEL 6814 Spring 2008 Outline Competitive learning Clustering Self-Organizing Maps What is competition in neural
arxiv: v1 [physics.data-an] 27 Sep 2007
![arxiv: v1 [physics.data-an] 27 Sep 2007](/thumbs/95/126120556.jpg "arxiv: v1 [physics.data-an] 27 Sep 2007") Classification of Interest Rate Curves Using Self-Organising Maps arxiv:0709.4401v1 [physics.data-an] 27 Sep 2007 M.Kanevski a,, M.Maignan b, V.Timonin a,1, A.Pozdnoukhov a,1 a Institute of Geomatics and
Classification of Interest Rate Curves Using Self-Organising Maps arxiv:0709.4401v1 [physics.data-an] 27 Sep 2007 M.Kanevski a,, M.Maignan b, V.Timonin a,1, A.Pozdnoukhov a,1 a Institute of Geomatics and
10/14/2017. Dejan Sarka. Anomaly Detection. Sponsors
 Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Learning
 Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
CHAPTER FOUR NEURAL NETWORK SELF- ORGANIZING MAP
 96 CHAPTER FOUR NEURAL NETWORK SELF- ORGANIZING MAP 97 4.1 INTRODUCTION Neural networks have been successfully applied by many authors in solving pattern recognition problems. Unsupervised classification
96 CHAPTER FOUR NEURAL NETWORK SELF- ORGANIZING MAP 97 4.1 INTRODUCTION Neural networks have been successfully applied by many authors in solving pattern recognition problems. Unsupervised classification
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Data Preprocessing. Javier Béjar. URL - Spring 2018 CS - MAI 1/78 BY: $\
 Data Preprocessing Javier Béjar BY: $\ URL - Spring 2018 C CS - MAI 1/78 Introduction Data representation Unstructured datasets: Examples described by a flat set of attributes: attribute-value matrix Structured
Data Preprocessing Javier Béjar BY: $\ URL - Spring 2018 C CS - MAI 1/78 Introduction Data representation Unstructured datasets: Examples described by a flat set of attributes: attribute-value matrix Structured
Artificial Neural Networks Unsupervised learning: SOM
 Artificial Neural Networks Unsupervised learning: SOM 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001
Artificial Neural Networks Unsupervised learning: SOM 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001
Function approximation using RBF network. 10 basis functions and 25 data points.
 1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Topic 6 Representation and Description
 Topic 6 Representation and Description Background Segmentation divides the image into regions Each region should be represented and described in a form suitable for further processing/decision-making Representation
Topic 6 Representation and Description Background Segmentation divides the image into regions Each region should be represented and described in a form suitable for further processing/decision-making Representation
Machine Learning Methods in Visualisation for Big Data 2018
 Machine Learning Methods in Visualisation for Big Data 2018 Daniel Archambault1 Ian Nabney2 Jaakko Peltonen3 1 Swansea University 2 University of Bristol 3 University of Tampere, Aalto University Evaluating
Machine Learning Methods in Visualisation for Big Data 2018 Daniel Archambault1 Ian Nabney2 Jaakko Peltonen3 1 Swansea University 2 University of Bristol 3 University of Tampere, Aalto University Evaluating
Methods for Intelligent Systems
 Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard eynard@elet.polimi.it Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering
Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard eynard@elet.polimi.it Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
COMBINED METHOD TO VISUALISE AND REDUCE DIMENSIONALITY OF THE FINANCIAL DATA SETS
 COMBINED METHOD TO VISUALISE AND REDUCE DIMENSIONALITY OF THE FINANCIAL DATA SETS Toomas Kirt Supervisor: Leo Võhandu Tallinn Technical University Toomas.Kirt@mail.ee Abstract: Key words: For the visualisation
COMBINED METHOD TO VISUALISE AND REDUCE DIMENSIONALITY OF THE FINANCIAL DATA SETS Toomas Kirt Supervisor: Leo Võhandu Tallinn Technical University Toomas.Kirt@mail.ee Abstract: Key words: For the visualisation
Clustering. Mihaela van der Schaar. January 27, Department of Engineering Science University of Oxford
 Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Unsupervised Learning
 Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Machine Learning for OR & FE
 Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
Unsupervised Learning
 Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
9/17/2009. Wenyan Li (Emily Li) Sep. 15, Introduction to Clustering Analysis
 Sep. 15, Introduction to Clustering Analysis") Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
Data Preprocessing. Javier Béjar AMLT /2017 CS - MAI. (CS - MAI) Data Preprocessing AMLT / / 71 BY: $\
 Data Preprocessing AMLT / / 71 BY: $\") Data Preprocessing S - MAI AMLT - 2016/2017 (S - MAI) Data Preprocessing AMLT - 2016/2017 1 / 71 Outline 1 Introduction Data Representation 2 Data Preprocessing Outliers Missing Values Normalization Discretization
Data Preprocessing S - MAI AMLT - 2016/2017 (S - MAI) Data Preprocessing AMLT - 2016/2017 1 / 71 Outline 1 Introduction Data Representation 2 Data Preprocessing Outliers Missing Values Normalization Discretization
Segmentation Computer Vision Spring 2018, Lecture 27
 Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Forestry Applied Multivariate Statistics. Cluster Analysis
 1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
ADVANCED MACHINE LEARNING MACHINE LEARNING. Kernel for Clustering kernel K-Means
 1 MACHINE LEARNING Kernel for Clustering ernel K-Means Outline of Today s Lecture 1. Review principle and steps of K-Means algorithm. Derive ernel version of K-means 3. Exercise: Discuss the geometrical
1 MACHINE LEARNING Kernel for Clustering ernel K-Means Outline of Today s Lecture 1. Review principle and steps of K-Means algorithm. Derive ernel version of K-means 3. Exercise: Discuss the geometrical
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Data Warehousing and Machine Learning
 Data Warehousing and Machine Learning Preprocessing Thomas D. Nielsen Aalborg University Department of Computer Science Spring 2008 DWML Spring 2008 1 / 35 Preprocessing Before you can start on the actual
Data Warehousing and Machine Learning Preprocessing Thomas D. Nielsen Aalborg University Department of Computer Science Spring 2008 DWML Spring 2008 1 / 35 Preprocessing Before you can start on the actual
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Intelligent Agent Technology in Modern Production and Trade Management
 20 Intelligent Agent Technology in Modern Production and Trade Management Serge Parshutin, Arnis Kirshners Institute of Information Technology, Riga Technical University Riga, Latvia 1. Introduction The
20 Intelligent Agent Technology in Modern Production and Trade Management Serge Parshutin, Arnis Kirshners Institute of Information Technology, Riga Technical University Riga, Latvia 1. Introduction The
k-means Clustering Todd W. Neller Gettysburg College
 k-means Clustering Todd W. Neller Gettysburg College Outline Unsupervised versus Supervised Learning Clustering Problem k-means Clustering Algorithm Visual Example Worked Example Initialization Methods
k-means Clustering Todd W. Neller Gettysburg College Outline Unsupervised versus Supervised Learning Clustering Problem k-means Clustering Algorithm Visual Example Worked Example Initialization Methods
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering
 Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Statistical Analysis of Metabolomics Data. Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte
 Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
A Dendrogram. Bioinformatics (Lec 17)
") A Dendrogram 3/15/05 1 Hierarchical Clustering [Johnson, SC, 1967] Given n points in R d, compute the distance between every pair of points While (not done) Pick closest pair of points s i and s j and
A Dendrogram 3/15/05 1 Hierarchical Clustering [Johnson, SC, 1967] Given n points in R d, compute the distance between every pair of points While (not done) Pick closest pair of points s i and s j and
Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions
 Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551,
Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551,
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
Preprocessing DWML, /33
 Preprocessing DWML, 2007 1/33 Preprocessing Before you can start on the actual data mining, the data may require some preprocessing: Attributes may be redundant. Values may be missing. The data contains
Preprocessing DWML, 2007 1/33 Preprocessing Before you can start on the actual data mining, the data may require some preprocessing: Attributes may be redundant. Values may be missing. The data contains
An Introduction to Cluster Analysis. Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs
 An Introduction to Cluster Analysis Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs zhaoxia@ics.uci.edu 1 What can you say about the figure? signal C 0.0 0.5 1.0 1500 subjects Two
An Introduction to Cluster Analysis Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs zhaoxia@ics.uci.edu 1 What can you say about the figure? signal C 0.0 0.5 1.0 1500 subjects Two
Automatic Group-Outlier Detection
 Automatic Group-Outlier Detection Amine Chaibi and Mustapha Lebbah and Hanane Azzag LIPN-UMR 7030 Université Paris 13 - CNRS 99, av. J-B Clément - F-93430 Villetaneuse {firstname.secondname}@lipn.univ-paris13.fr
Automatic Group-Outlier Detection Amine Chaibi and Mustapha Lebbah and Hanane Azzag LIPN-UMR 7030 Université Paris 13 - CNRS 99, av. J-B Clément - F-93430 Villetaneuse {firstname.secondname}@lipn.univ-paris13.fr
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Chapter 6: Cluster Analysis
 Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
IBL and clustering. Relationship of IBL with CBR
 IBL and clustering Distance based methods IBL and knn Clustering Distance based and hierarchical Probability-based Expectation Maximization (EM) Relationship of IBL with CBR + uses previously processed
IBL and clustering Distance based methods IBL and knn Clustering Distance based and hierarchical Probability-based Expectation Maximization (EM) Relationship of IBL with CBR + uses previously processed
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Multivariate Analysis (slides 9)
") Multivariate Analysis (slides 9) Today we consider k-means clustering. We will address the question of selecting the appropriate number of clusters. Properties and limitations of the algorithm will be
Multivariate Analysis (slides 9) Today we consider k-means clustering. We will address the question of selecting the appropriate number of clusters. Properties and limitations of the algorithm will be
Clustering COMS 4771
 Clustering COMS 4771 1. Clustering Unsupervised classification / clustering Unsupervised classification Input: x 1,..., x n R d, target cardinality k N. Output: function f : R d {1,..., k} =: [k]. Typical
Clustering COMS 4771 1. Clustering Unsupervised classification / clustering Unsupervised classification Input: x 1,..., x n R d, target cardinality k N. Output: function f : R d {1,..., k} =: [k]. Typical
Clustering & Classification (chapter 15)
") Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE
 BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE") APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE Sundari NallamReddy, Samarandra Behera, Sanjeev Karadagi, Dr. Anantha Desik ABSTRACT: Tata
APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE Sundari NallamReddy, Samarandra Behera, Sanjeev Karadagi, Dr. Anantha Desik ABSTRACT: Tata
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Unsupervised Learning
 Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised learning
 Unsupervised learning Enrique Muñoz Ballester Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy enrique.munoz@unimi.it Enrique Muñoz Ballester 2017 1 Download slides data and scripts:
Unsupervised learning Enrique Muñoz Ballester Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy enrique.munoz@unimi.it Enrique Muñoz Ballester 2017 1 Download slides data and scripts:
Lecture 3 January 22
 EE 38V: Large cale Learning pring 203 Lecture 3 January 22 Lecturer: Caramanis & anghavi cribe: ubhashini Krishsamy 3. Clustering In the last lecture, we saw Locality ensitive Hashing (LH) which uses hash
EE 38V: Large cale Learning pring 203 Lecture 3 January 22 Lecturer: Caramanis & anghavi cribe: ubhashini Krishsamy 3. Clustering In the last lecture, we saw Locality ensitive Hashing (LH) which uses hash
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
5.6 Self-organizing maps (SOM) [Book, Sect. 10.3]
![5.6 Self-organizing maps (SOM) [Book, Sect. 10.3]](/thumbs/88/116484380.jpg "5.6 Self-organizing maps (SOM) [Book, Sect. 10.3]") Ch.5 Classification and Clustering 5.6 Self-organizing maps (SOM) [Book, Sect. 10.3] The self-organizing map (SOM) method, introduced by Kohonen (1982, 2001), approximates a dataset in multidimensional
Ch.5 Classification and Clustering 5.6 Self-organizing maps (SOM) [Book, Sect. 10.3] The self-organizing map (SOM) method, introduced by Kohonen (1982, 2001), approximates a dataset in multidimensional
Dimension reduction : PCA and Clustering
 Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
L9: Hierarchical Clustering
 L9: Hierarchical Clustering This marks the beginning of the clustering section. The basic idea is to take a set X of items and somehow partition X into subsets, so each subset has similar items. Obviously,
L9: Hierarchical Clustering This marks the beginning of the clustering section. The basic idea is to take a set X of items and somehow partition X into subsets, so each subset has similar items. Obviously,
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Data Preprocessing Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Data Preprocessing Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation
K-means Clustering of Proportional Data Using L1 Distance
 K-means Clustering of Proportional Data Using L1 Distance Hisashi Kashima IBM Research, Tokyo Research Laboratory Jianying Hu Bonnie Ray Moninder Singh IBM Research, T.J. Watson Research Center Copyright
K-means Clustering of Proportional Data Using L1 Distance Hisashi Kashima IBM Research, Tokyo Research Laboratory Jianying Hu Bonnie Ray Moninder Singh IBM Research, T.J. Watson Research Center Copyright
Supervised vs.unsupervised Learning
 Supervised vs.unsupervised Learning In supervised learning we train algorithms with predefined concepts and functions based on labeled data D = { ( x, y ) x X, y {yes,no}. In unsupervised learning we are
Supervised vs.unsupervised Learning In supervised learning we train algorithms with predefined concepts and functions based on labeled data D = { ( x, y ) x X, y {yes,no}. In unsupervised learning we are
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
Kernels and Clustering
 Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Preface to the Second Edition. Preface to the First Edition. 1 Introduction 1
 Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
CPSC 340: Machine Learning and Data Mining. Multi-Dimensional Scaling Fall 2017
 CPSC 340: Machine Learning and Data Mining Multi-Dimensional Scaling Fall 2017 Assignment 4: Admin 1 late day for tonight, 2 late days for Wednesday. Assignment 5: Due Monday of next week. Final: Details
CPSC 340: Machine Learning and Data Mining Multi-Dimensional Scaling Fall 2017 Assignment 4: Admin 1 late day for tonight, 2 late days for Wednesday. Assignment 5: Due Monday of next week. Final: Details
Color Image Segmentation Using a Spatial K-Means Clustering Algorithm
 Color Image Segmentation Using a Spatial K-Means Clustering Algorithm Dana Elena Ilea and Paul F. Whelan Vision Systems Group School of Electronic Engineering Dublin City University Dublin 9, Ireland danailea@eeng.dcu.ie
Color Image Segmentation Using a Spatial K-Means Clustering Algorithm Dana Elena Ilea and Paul F. Whelan Vision Systems Group School of Electronic Engineering Dublin City University Dublin 9, Ireland danailea@eeng.dcu.ie
CSE 6242 A / CS 4803 DVA. Feb 12, Dimension Reduction. Guest Lecturer: Jaegul Choo
 CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo Data is Too Big To Do Something..
CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo Data is Too Big To Do Something..
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Giri Narasimhan. CAP 5510: Introduction to Bioinformatics. ECS 254; Phone: x3748
 CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 3/3/08 CAP5510 1 Gene g Probe 1 Probe 2 Probe N 3/3/08 CAP5510
CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 3/3/08 CAP5510 1 Gene g Probe 1 Probe 2 Probe N 3/3/08 CAP5510
Figure (5) Kohonen Self-Organized Map
 Kohonen Self-Organized Map") 2- KOHONEN SELF-ORGANIZING MAPS (SOM) - The self-organizing neural networks assume a topological structure among the cluster units. - There are m cluster units, arranged in a one- or two-dimensional array;
2- KOHONEN SELF-ORGANIZING MAPS (SOM) - The self-organizing neural networks assume a topological structure among the cluster units. - There are m cluster units, arranged in a one- or two-dimensional array;
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
CSE 40171: Artificial Intelligence. Learning from Data: Unsupervised Learning
 CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
Clustering Algorithms. Margareta Ackerman
 Clustering Algorithms Margareta Ackerman A sea of algorithms As we discussed last class, there are MANY clustering algorithms, and new ones are proposed all the time. They are very different from each
Clustering Algorithms Margareta Ackerman A sea of algorithms As we discussed last class, there are MANY clustering algorithms, and new ones are proposed all the time. They are very different from each
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
k-means Clustering Todd W. Neller Gettysburg College Laura E. Brown Michigan Technological University
 k-means Clustering Todd W. Neller Gettysburg College Laura E. Brown Michigan Technological University Outline Unsupervised versus Supervised Learning Clustering Problem k-means Clustering Algorithm Visual
k-means Clustering Todd W. Neller Gettysburg College Laura E. Brown Michigan Technological University Outline Unsupervised versus Supervised Learning Clustering Problem k-means Clustering Algorithm Visual