Asynchronous OpenCL/MPI numerical simulations of conservation laws
|
|
|
- Roderick Stevens
- 5 years ago
- Views:
Transcription

1 Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford
2 Conservation laws Many equations in physics are systems of conservation i F i (W )=0. i=1 I W = W (x, t) 2 R m :vectorofconservedquantities,f i (W ): flux vector. I x =(x 1...x d ):spacevariable,d: spacedimension,t: time; Applications: fluid mechanics, electromagnetics,... Outlines: 1. 2D structured grids, synchronous OpenCL/MPI based numerical simulations. 2. 3D unstructured grids, asynchronous OpenCL/MPI based numerical simulations.
3 1) Structured grid First simple approach: discretization of a 2D equation (d = 2) on a structured grid I W 1 F 1 2 F 2 (W )=0. I We compute samples W n i,j of W (x, t) at grid points x =(i x, j x) and time t = n t. I Finite Difference (FD) method: W i,j W n+1 i,j W n i,j t t W i,j + F 1,n i+1/2,j F 1,n i 1/2,j x + F 2,n i,j+1/2 F 2,n i,j 1/2 x = 0, = 0.
4 OpenCL implementation The data are arranged in a (i, j) matrix. 1 work-item = 1 cell (i, j). 1 work-group = 1 row i. For each time step n: I compute the fluxes balance in the x 1 -direction for each cell of each row of the grid. I transpose the matrix (exchange i and j) in a coalescent way. I compute the fluxes balance in the x 2 -direction for each row of the transposed grid. I transpose again the matrix.
5 OpenCL + synchronous MPI I Use of several GPUs; L I Subdomain decomposition; I 1 GPU = 1 subdomain = 1 MPI node; I MPI for exchanging data between GPUs (greyed cells layers). 0 L GPU 0 GPU 1 GPU 2 GPU 3 MPI 0 MPI 1 MPI 2 MPI 3
6 Comparisons On large grids (> ). We compare: I an optimized OpenMP implementation of the FD scheme on 2x6-core CPUs; I the OpenCL implementation running on 2x6-core CPUs, NVidia or AMD GPU; I the OpenCL+MPI implementation running on 4 GPUs. Implementation Time Speedup OpenMP (CPU Intel 2x6 cores) 717 s 1 OpenCL (CPU Intel 2x6 cores) 996 s 0.7 OpenCL (NVidia Tesla K20) 45 s 16 OpenCL (AMD Radeon HD 7970) 38 s 19 OpenCL + MPI (4 x NVIDIA K20) 12 s 58
7 Shock-bubble interaction I Simulation of a compressible two-fluid flow: interaction of a shock wave in a liquid with a gas bubble I Coarse mesh OpenCL simulation on an AMD HD 5850 I OpenGL/OpenCL interop + video capture.

8 Very fine mesh I Very fine mesh OpenCL + MPI simulation, 40,000x20,000 grid. 4 billions unknowns per time step I 10xNVIDIA K20 GPUs, 30 hours I Red=high density (compressed liquid); blue=low density (gas).
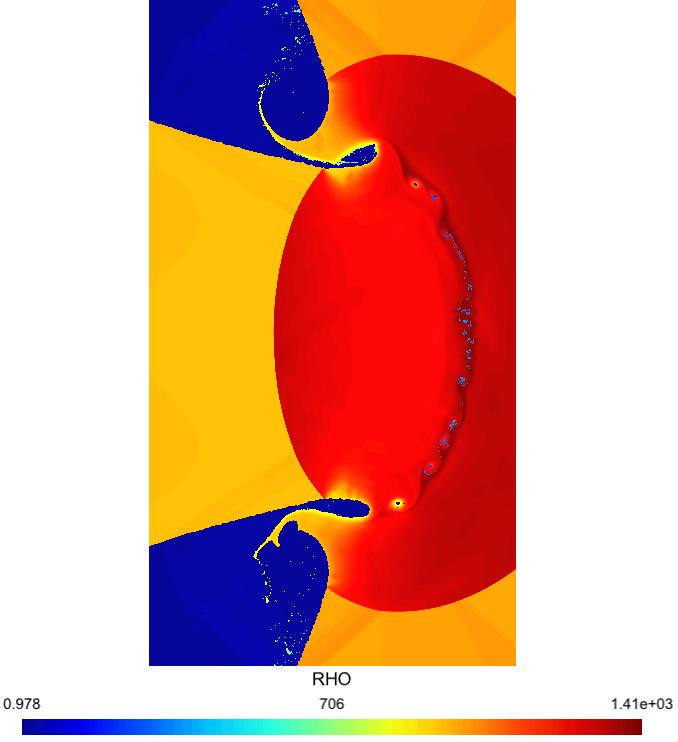
9 Zoom 1
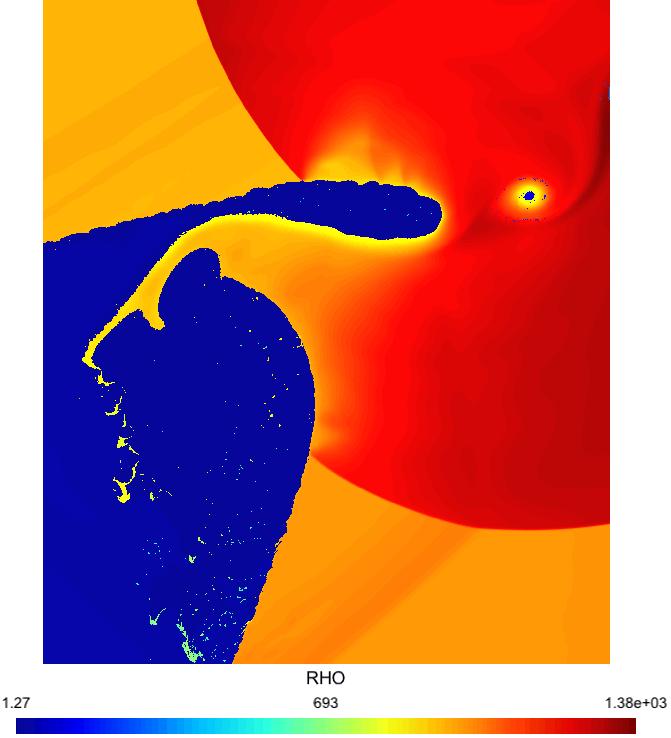

10 Zoom 2
11 2) Unstructured grid I Unstructured hexahedrons mesh for representing complex geometries. I Subdomain decomposition. 1 domain = 1 MPI node = 1 OpenCL device. I Zone decomposition. Each subdomain is split into volume zones and interface zones. I Non-conformity between zones is allowed.

12 Mesh example Anon-conformingmeshwithtwosubdomains,threevolumezones and three interface zones. I Subdomain 1: only one big refined volume zone. Two interface zones. I Subdomain 2: two small volume zones (coarse and refined). Three interface zones.
13 Mesh structure Subdomain 1 Volume zone 1 Interface zone 1 Interface zone 1 0 Volume zone 2 Interface zone 2 Interface zone 2 0 Volume zone 3 Subdomain 2 Interface zone 3
14 Discontinuous Galerkin (DG) approximation Generalization of the FD method: DG method in a 3D space. In each cell L of the mesh, the conserved quantities are expanded on Lagrange polynomial basis functions I L is a (possibly stretched) hexahedron W (x, t) =W j L (t) L j (x), x 2 L. I W is determined by its values at the blue points I W is discontinuous at green points.
15 DG formulation The numerical solution satisfies the DG approximation scheme ˆ ˆ ˆ 8L, t W i L F (W, W, r i L )+ F (W L, W R, n LR ) i L = 0. L I R denotes the neighbor cells I n LR is the unit normal vector oriented from L to R. I F (W L, W R, n): numerical flux. I F (W, W, n) =F k (W )n L n LR Time integration of a system of ordinary differential equations. R
16 OpenCL + asynchronous MPI advantages of the DG formulation: I new possibilities: varying polynomial order, mesh refinement, complex geometries. I local stencil. I high polynomial order ) high amount of uniform local parallel computations. I many optimizations for hexahedrons meshes. I natural MIMD/SIMD parallelism: subdomains (MPI), elementary computations (OpenCL). possible issues: I memory access (unstructured mesh) at interfaces between cells! hard to avoid... I branch tests in GPU kernels! compile a customized kernel for each zone. I MPI communications imply GPU/Host memory transfers! overlap transfers and computations.
17 Task graph
18 Task graph
19 MPI/OpenCL events management Problem: how to express the dependency between MPI and OpenCL operations? I We decided to rely only on the OpenCL events management. I The beginning of a task depends on the completions of a list of OpenCL events. The task is itself associated to an OpenCL event. I At an interface zone between two subdomains, an extraction task contains a GPU to host memory transfer, a MPI send/receive communication and a host to GPU transfer. I we create an OpenCL user event, and launch a MPI blocking sendrecv in a thread. At the end of the communication, in the thread, the OpenCL event is marked as completed. Using threads avoids blocking the main program flow.
20 Results Big mesh, polynomial order D = 3, NVIDIA K20 GPUs, infiniband network. 1 GPU 2 GPUs 4 GPUs 8 GPUs Sync. TFLOPS/s ASync. TFLOPS/s We achieve ' 30% of the peak performance.
: mesh of the interior and exterior of the aircraft.")
21 Application I Electromagnetic wave interaction with an aircraft (Maxwell equations). I Aircraft geometry described with 3, 337, 875 hexaedrons ('1 billion unknowns per time step): mesh of the interior and exterior of the aircraft. I We use 8 GPUs to perform the computation. The simulation does not fit into a single GPU memory.

22 Conclusion I Many physical models are conservation laws. Among them: two-fluid flows, electromagnetics. I Efficient OpenCL/MPI computing requires adapted data structures. I OpenCL allows driving asynchronous computations and MPI communications. I Work in progress: optimizing unstructured memory access, more sophisticated runtime, new physical models. For more details and a bibliography see:
A generic Discontinuous Galerkin solver based on OpenCL task graph. Application to electromagnetic compatibility.
 A generic Discontinuous Galerkin solver based on OpenCL task graph. Application to electromagnetic compatibility. Philippe HELLUY 1,2 1 IRMA, Université de Strasbourg, 2 Inria Tonus, France CEMRACS, July
A generic Discontinuous Galerkin solver based on OpenCL task graph. Application to electromagnetic compatibility. Philippe HELLUY 1,2 1 IRMA, Université de Strasbourg, 2 Inria Tonus, France CEMRACS, July
Shallow Water Simulations on Graphics Hardware
 Shallow Water Simulations on Graphics Hardware Ph.D. Thesis Presentation 2014-06-27 Martin Lilleeng Sætra Outline Introduction Parallel Computing and the GPU Simulating Shallow Water Flow Topics of Thesis
Shallow Water Simulations on Graphics Hardware Ph.D. Thesis Presentation 2014-06-27 Martin Lilleeng Sætra Outline Introduction Parallel Computing and the GPU Simulating Shallow Water Flow Topics of Thesis
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Advective and conservative semi-lagrangian schemes on uniform and non-uniform grids
 Advective and conservative semi-lagrangian schemes on uniform and non-uniform grids M. Mehrenberger Université de Strasbourg and Max-Planck Institut für Plasmaphysik 5 September 2013 M. Mehrenberger (UDS
Advective and conservative semi-lagrangian schemes on uniform and non-uniform grids M. Mehrenberger Université de Strasbourg and Max-Planck Institut für Plasmaphysik 5 September 2013 M. Mehrenberger (UDS
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
Adaptive Mesh Astrophysical Fluid Simulations on GPU. San Jose 10/2/2009 Peng Wang, NVIDIA
 Adaptive Mesh Astrophysical Fluid Simulations on GPU San Jose 10/2/2009 Peng Wang, NVIDIA Overview Astrophysical motivation & the Enzo code Finite volume method and adaptive mesh refinement (AMR) CUDA
Adaptive Mesh Astrophysical Fluid Simulations on GPU San Jose 10/2/2009 Peng Wang, NVIDIA Overview Astrophysical motivation & the Enzo code Finite volume method and adaptive mesh refinement (AMR) CUDA
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids
 A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics
 Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla
 Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla SIAM PP 2016, April 13 th 2016 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer,
Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla SIAM PP 2016, April 13 th 2016 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer,
RAMSES on the GPU: An OpenACC-Based Approach
 RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
1.2 Numerical Solutions of Flow Problems
 1.2 Numerical Solutions of Flow Problems DIFFERENTIAL EQUATIONS OF MOTION FOR A SIMPLIFIED FLOW PROBLEM Continuity equation for incompressible flow: 0 Momentum (Navier-Stokes) equations for a Newtonian
1.2 Numerical Solutions of Flow Problems DIFFERENTIAL EQUATIONS OF MOTION FOR A SIMPLIFIED FLOW PROBLEM Continuity equation for incompressible flow: 0 Momentum (Navier-Stokes) equations for a Newtonian
Radial Basis Function-Generated Finite Differences (RBF-FD): New Opportunities for Applications in Scientific Computing
: New Opportunities for Applications in Scientific Computing") Radial Basis Function-Generated Finite Differences (RBF-FD): New Opportunities for Applications in Scientific Computing Natasha Flyer National Center for Atmospheric Research Boulder, CO Meshes vs. Mesh-free
Radial Basis Function-Generated Finite Differences (RBF-FD): New Opportunities for Applications in Scientific Computing Natasha Flyer National Center for Atmospheric Research Boulder, CO Meshes vs. Mesh-free
A portable implementation of the radix sort algorithm in OpenCL
 A portable implementation of the radix sort algorithm in OpenCL Philippe Helluy To cite this version: Philippe Helluy. A portable implementation of the radix sort algorithm in OpenCL. 2011.
A portable implementation of the radix sort algorithm in OpenCL Philippe Helluy To cite this version: Philippe Helluy. A portable implementation of the radix sort algorithm in OpenCL. 2011.
Parallel Algorithms: Adaptive Mesh Refinement (AMR) method and its implementation
 method and its implementation") Parallel Algorithms: Adaptive Mesh Refinement (AMR) method and its implementation Massimiliano Guarrasi m.guarrasi@cineca.it Super Computing Applications and Innovation Department AMR - Introduction Solving
Parallel Algorithms: Adaptive Mesh Refinement (AMR) method and its implementation Massimiliano Guarrasi m.guarrasi@cineca.it Super Computing Applications and Innovation Department AMR - Introduction Solving
Unstructured Grid Numbering Schemes for GPU Coalescing Requirements
 Unstructured Grid Numbering Schemes for GPU Coalescing Requirements Andrew Corrigan 1 and Johann Dahm 2 Laboratories for Computational Physics and Fluid Dynamics Naval Research Laboratory 1 Department
Unstructured Grid Numbering Schemes for GPU Coalescing Requirements Andrew Corrigan 1 and Johann Dahm 2 Laboratories for Computational Physics and Fluid Dynamics Naval Research Laboratory 1 Department
Efficiency of adaptive mesh algorithms
 Efficiency of adaptive mesh algorithms 23.11.2012 Jörn Behrens KlimaCampus, Universität Hamburg http://www.katrina.noaa.gov/satellite/images/katrina-08-28-2005-1545z.jpg Model for adaptive efficiency 10
Efficiency of adaptive mesh algorithms 23.11.2012 Jörn Behrens KlimaCampus, Universität Hamburg http://www.katrina.noaa.gov/satellite/images/katrina-08-28-2005-1545z.jpg Model for adaptive efficiency 10
Intro to Parallel Computing
 Outline Intro to Parallel Computing Remi Lehe Lawrence Berkeley National Laboratory Modern parallel architectures Parallelization between nodes: MPI Parallelization within one node: OpenMP Why use parallel
Outline Intro to Parallel Computing Remi Lehe Lawrence Berkeley National Laboratory Modern parallel architectures Parallelization between nodes: MPI Parallelization within one node: OpenMP Why use parallel
GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES TAKAHIRO HARADA, AMD DESTRUCTION FOR GAMES ERWIN COUMANS, AMD
 GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES TAKAHIRO HARADA, AMD DESTRUCTION FOR GAMES ERWIN COUMANS, AMD GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES Jason Yang, Takahiro Harada AMD HYBRID CPU-GPU
GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES TAKAHIRO HARADA, AMD DESTRUCTION FOR GAMES ERWIN COUMANS, AMD GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES Jason Yang, Takahiro Harada AMD HYBRID CPU-GPU
GAMER : a GPU-accelerated Adaptive-MEsh-Refinement Code for Astrophysics GPU 與自適性網格於天文模擬之應用與效能
 GAMER : a GPU-accelerated Adaptive-MEsh-Refinement Code for Astrophysics GPU 與自適性網格於天文模擬之應用與效能 Hsi-Yu Schive ( 薛熙于 ), Tzihong Chiueh ( 闕志鴻 ), Yu-Chih Tsai ( 蔡御之 ), Ui-Han Zhang ( 張瑋瀚 ) Graduate Institute
GAMER : a GPU-accelerated Adaptive-MEsh-Refinement Code for Astrophysics GPU 與自適性網格於天文模擬之應用與效能 Hsi-Yu Schive ( 薛熙于 ), Tzihong Chiueh ( 闕志鴻 ), Yu-Chih Tsai ( 蔡御之 ), Ui-Han Zhang ( 張瑋瀚 ) Graduate Institute
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Introducing OpenMP Tasks into the HYDRO Benchmark
 Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Introducing OpenMP Tasks into the HYDRO Benchmark Jérémie Gaidamour a, Dimitri Lecas a, Pierre-François Lavallée a a 506,
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Introducing OpenMP Tasks into the HYDRO Benchmark Jérémie Gaidamour a, Dimitri Lecas a, Pierre-François Lavallée a a 506,
Continuum-Microscopic Models
 Scientific Computing and Numerical Analysis Seminar October 1, 2010 Outline Heterogeneous Multiscale Method Adaptive Mesh ad Algorithm Refinement Equation-Free Method Incorporates two scales (length, time
Scientific Computing and Numerical Analysis Seminar October 1, 2010 Outline Heterogeneous Multiscale Method Adaptive Mesh ad Algorithm Refinement Equation-Free Method Incorporates two scales (length, time
Adaptive Refinement Tree (ART) code. N-Body: Parallelization using OpenMP and MPI
 code. N-Body: Parallelization using OpenMP and MPI") Adaptive Refinement Tree (ART) code N-Body: Parallelization using OpenMP and MPI 1 Family of codes N-body: OpenMp N-body: MPI+OpenMP N-body+hydro+cooling+SF: OpenMP N-body+hydro+cooling+SF: MPI 2 History:
Adaptive Refinement Tree (ART) code N-Body: Parallelization using OpenMP and MPI 1 Family of codes N-body: OpenMp N-body: MPI+OpenMP N-body+hydro+cooling+SF: OpenMP N-body+hydro+cooling+SF: MPI 2 History:
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
PhD Student. Associate Professor, Co-Director, Center for Computational Earth and Environmental Science. Abdulrahman Manea.
 Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
New formulations of the semi-lagrangian method for Vlasov-type equations
 New formulations of the semi-lagrangian method for Vlasov-type equations Eric Sonnendrücker IRMA Université Louis Pasteur, Strasbourg projet CALVI INRIA Nancy Grand Est 17 September 2008 In collaboration
New formulations of the semi-lagrangian method for Vlasov-type equations Eric Sonnendrücker IRMA Université Louis Pasteur, Strasbourg projet CALVI INRIA Nancy Grand Est 17 September 2008 In collaboration
PROGRAMMING OF MULTIGRID METHODS
 PROGRAMMING OF MULTIGRID METHODS LONG CHEN In this note, we explain the implementation detail of multigrid methods. We will use the approach by space decomposition and subspace correction method; see Chapter:
PROGRAMMING OF MULTIGRID METHODS LONG CHEN In this note, we explain the implementation detail of multigrid methods. We will use the approach by space decomposition and subspace correction method; see Chapter:
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Large-scale Gas Turbine Simulations on GPU clusters
 Large-scale Gas Turbine Simulations on GPU clusters Tobias Brandvik and Graham Pullan Whittle Laboratory University of Cambridge A large-scale simulation Overview PART I: Turbomachinery PART II: Stencil-based
Large-scale Gas Turbine Simulations on GPU clusters Tobias Brandvik and Graham Pullan Whittle Laboratory University of Cambridge A large-scale simulation Overview PART I: Turbomachinery PART II: Stencil-based
Final Report. Discontinuous Galerkin Compressible Euler Equation Solver. May 14, Andrey Andreyev. Adviser: Dr. James Baeder
 Final Report Discontinuous Galerkin Compressible Euler Equation Solver May 14, 2013 Andrey Andreyev Adviser: Dr. James Baeder Abstract: In this work a Discontinuous Galerkin Method is developed for compressible
Final Report Discontinuous Galerkin Compressible Euler Equation Solver May 14, 2013 Andrey Andreyev Adviser: Dr. James Baeder Abstract: In this work a Discontinuous Galerkin Method is developed for compressible
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU
 Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU Lifan Xu Wei Wang Marco A. Alvarez John Cavazos Dongping Zhang Department of Computer and Information Science University of Delaware
Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU Lifan Xu Wei Wang Marco A. Alvarez John Cavazos Dongping Zhang Department of Computer and Information Science University of Delaware
Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP
 Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP Zhe Weng and Peter Strazdins*, Computer Systems Group, Research School of Computer Science, The Australian National University
Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP Zhe Weng and Peter Strazdins*, Computer Systems Group, Research School of Computer Science, The Australian National University
arxiv: v1 [cs.ms] 8 Aug 2018
![arxiv: v1 [cs.ms] 8 Aug 2018](/thumbs/83/87599411.jpg "arxiv: v1 [cs.ms] 8 Aug 2018") ACCELERATING WAVE-PROPAGATION ALGORITHMS WITH ADAPTIVE MESH REFINEMENT USING THE GRAPHICS PROCESSING UNIT (GPU) XINSHENG QIN, RANDALL LEVEQUE, AND MICHAEL MOTLEY arxiv:1808.02638v1 [cs.ms] 8 Aug 2018 Abstract.
ACCELERATING WAVE-PROPAGATION ALGORITHMS WITH ADAPTIVE MESH REFINEMENT USING THE GRAPHICS PROCESSING UNIT (GPU) XINSHENG QIN, RANDALL LEVEQUE, AND MICHAEL MOTLEY arxiv:1808.02638v1 [cs.ms] 8 Aug 2018 Abstract.
3D Finite Difference Time-Domain Modeling of Acoustic Wave Propagation based on Domain Decomposition
 3D Finite Difference Time-Domain Modeling of Acoustic Wave Propagation based on Domain Decomposition UMR Géosciences Azur CNRS-IRD-UNSA-OCA Villefranche-sur-mer Supervised by: Dr. Stéphane Operto Jade
3D Finite Difference Time-Domain Modeling of Acoustic Wave Propagation based on Domain Decomposition UMR Géosciences Azur CNRS-IRD-UNSA-OCA Villefranche-sur-mer Supervised by: Dr. Stéphane Operto Jade
Recent results with elsa on multi-cores
 Michel Gazaix (ONERA) Steeve Champagneux (AIRBUS) October 15th, 2009 Outline Short introduction to elsa elsa benchmark on HPC platforms Detailed performance evaluation IBM Power5, AMD Opteron, INTEL Nehalem
Michel Gazaix (ONERA) Steeve Champagneux (AIRBUS) October 15th, 2009 Outline Short introduction to elsa elsa benchmark on HPC platforms Detailed performance evaluation IBM Power5, AMD Opteron, INTEL Nehalem
Simulating tsunami propagation on parallel computers using a hybrid software framework
 Simulating tsunami propagation on parallel computers using a hybrid software framework Xing Simula Research Laboratory, Norway Department of Informatics, University of Oslo March 12, 2007 Outline Intro
Simulating tsunami propagation on parallel computers using a hybrid software framework Xing Simula Research Laboratory, Norway Department of Informatics, University of Oslo March 12, 2007 Outline Intro
Efficient AMG on Hybrid GPU Clusters. ScicomP Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann. Fraunhofer SCAI
 Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Acknowledgements. Prof. Dan Negrut Prof. Darryl Thelen Prof. Michael Zinn. SBEL Colleagues: Hammad Mazar, Toby Heyn, Manoj Kumar
 Philipp Hahn Acknowledgements Prof. Dan Negrut Prof. Darryl Thelen Prof. Michael Zinn SBEL Colleagues: Hammad Mazar, Toby Heyn, Manoj Kumar 2 Outline Motivation Lumped Mass Model Model properties Simulation
Philipp Hahn Acknowledgements Prof. Dan Negrut Prof. Darryl Thelen Prof. Michael Zinn SBEL Colleagues: Hammad Mazar, Toby Heyn, Manoj Kumar 2 Outline Motivation Lumped Mass Model Model properties Simulation
Nonoscillatory Central Schemes on Unstructured Triangulations for Hyperbolic Systems of Conservation Laws
 Nonoscillatory Central Schemes on Unstructured Triangulations for Hyperbolic Systems of Conservation Laws Ivan Christov Bojan Popov Department of Mathematics, Texas A&M University, College Station, Texas
Nonoscillatory Central Schemes on Unstructured Triangulations for Hyperbolic Systems of Conservation Laws Ivan Christov Bojan Popov Department of Mathematics, Texas A&M University, College Station, Texas
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
How to Optimize Geometric Multigrid Methods on GPUs
 How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede
 Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Liszt, a language for PDE solvers
 Liszt, a language for PDE solvers Zachary DeVito, Niels Joubert, Francisco Palacios, Stephen Oakley, Montserrat Medina, Mike Barrientos, Erich Elsen, Frank Ham, Alex Aiken, Karthik Duraisamy, Eric Darve,
Liszt, a language for PDE solvers Zachary DeVito, Niels Joubert, Francisco Palacios, Stephen Oakley, Montserrat Medina, Mike Barrientos, Erich Elsen, Frank Ham, Alex Aiken, Karthik Duraisamy, Eric Darve,
Towards Exascale Computing with the Atmospheric Model NUMA
 Towards Exascale Computing with the Atmospheric Model NUMA Andreas Müller, Daniel S. Abdi, Michal Kopera, Lucas Wilcox, Francis X. Giraldo Department of Applied Mathematics Naval Postgraduate School, Monterey
Towards Exascale Computing with the Atmospheric Model NUMA Andreas Müller, Daniel S. Abdi, Michal Kopera, Lucas Wilcox, Francis X. Giraldo Department of Applied Mathematics Naval Postgraduate School, Monterey
Efficient Imaging Algorithms on Many-Core Platforms
 Efficient Imaging Algorithms on Many-Core Platforms H. Köstler Dagstuhl, 22.11.2011 Contents Imaging Applications HDR Compression performance of PDE-based models Image Denoising performance of patch-based
Efficient Imaging Algorithms on Many-Core Platforms H. Köstler Dagstuhl, 22.11.2011 Contents Imaging Applications HDR Compression performance of PDE-based models Image Denoising performance of patch-based
Nonoscillatory Central Schemes on Unstructured Triangular Grids for Hyperbolic Systems of Conservation Laws
 Nonoscillatory Central Schemes on Unstructured Triangular Grids for Hyperbolic Systems of Conservation Laws Ivan Christov 1,* Bojan Popov 1 Peter Popov 2 1 Department of Mathematics, 2 Institute for Scientific
Nonoscillatory Central Schemes on Unstructured Triangular Grids for Hyperbolic Systems of Conservation Laws Ivan Christov 1,* Bojan Popov 1 Peter Popov 2 1 Department of Mathematics, 2 Institute for Scientific
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters
 SIAM PP 2014 High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters C. Riesinger, A. Bakhtiari, M. Schreiber Technische Universität München February 20, 2014
SIAM PP 2014 High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters C. Riesinger, A. Bakhtiari, M. Schreiber Technische Universität München February 20, 2014
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs
 Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Evaluating the Potential of Graphics Processors for High Performance Embedded Computing
 Evaluating the Potential of Graphics Processors for High Performance Embedded Computing Shuai Mu, Chenxi Wang, Ming Liu, Yangdong Deng Department of Micro-/Nano-electronics Tsinghua University Outline
Evaluating the Potential of Graphics Processors for High Performance Embedded Computing Shuai Mu, Chenxi Wang, Ming Liu, Yangdong Deng Department of Micro-/Nano-electronics Tsinghua University Outline
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS
 S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
PyFR: Heterogeneous Computing on Mixed Unstructured Grids with Python. F.D. Witherden, M. Klemm, P.E. Vincent
 PyFR: Heterogeneous Computing on Mixed Unstructured Grids with Python F.D. Witherden, M. Klemm, P.E. Vincent 1 Overview Motivation. Accelerators and Modern Hardware Python and PyFR. Summary. Motivation
PyFR: Heterogeneous Computing on Mixed Unstructured Grids with Python F.D. Witherden, M. Klemm, P.E. Vincent 1 Overview Motivation. Accelerators and Modern Hardware Python and PyFR. Summary. Motivation
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Designing Parallel Programs. This review was developed from Introduction to Parallel Computing
 Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Available online at ScienceDirect. Parallel Computational Fluid Dynamics Conference (ParCFD2013)
") Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 61 ( 2013 ) 81 86 Parallel Computational Fluid Dynamics Conference (ParCFD2013) An OpenCL-based parallel CFD code for simulations
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 61 ( 2013 ) 81 86 Parallel Computational Fluid Dynamics Conference (ParCFD2013) An OpenCL-based parallel CFD code for simulations
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
A4. Intro to Parallel Computing
 Self-Consistent Simulations of Beam and Plasma Systems Steven M. Lund, Jean-Luc Vay, Rémi Lehe and Daniel Winklehner Colorado State U., Ft. Collins, CO, 13-17 June, 2016 A4. Intro to Parallel Computing
Self-Consistent Simulations of Beam and Plasma Systems Steven M. Lund, Jean-Luc Vay, Rémi Lehe and Daniel Winklehner Colorado State U., Ft. Collins, CO, 13-17 June, 2016 A4. Intro to Parallel Computing
Scalable, Hybrid-Parallel Multiscale Methods using DUNE
 MÜNSTER Scalable Hybrid-Parallel Multiscale Methods using DUNE R. Milk S. Kaulmann M. Ohlberger December 1st 2014 Outline MÜNSTER Scalable Hybrid-Parallel Multiscale Methods using DUNE 2 /28 Abstraction
MÜNSTER Scalable Hybrid-Parallel Multiscale Methods using DUNE R. Milk S. Kaulmann M. Ohlberger December 1st 2014 Outline MÜNSTER Scalable Hybrid-Parallel Multiscale Methods using DUNE 2 /28 Abstraction
Multigrid Solvers in CFD. David Emerson. Scientific Computing Department STFC Daresbury Laboratory Daresbury, Warrington, WA4 4AD, UK
 Multigrid Solvers in CFD David Emerson Scientific Computing Department STFC Daresbury Laboratory Daresbury, Warrington, WA4 4AD, UK david.emerson@stfc.ac.uk 1 Outline Multigrid: general comments Incompressible
Multigrid Solvers in CFD David Emerson Scientific Computing Department STFC Daresbury Laboratory Daresbury, Warrington, WA4 4AD, UK david.emerson@stfc.ac.uk 1 Outline Multigrid: general comments Incompressible
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers
 Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Literature Report. Daniël Pols. 23 May 2018
 Literature Report Daniël Pols 23 May 2018 Applications Two-phase flow model The evolution of the momentum field in a two phase flow problem is given by the Navier-Stokes equations: u t + u u = 1 ρ p +
Literature Report Daniël Pols 23 May 2018 Applications Two-phase flow model The evolution of the momentum field in a two phase flow problem is given by the Navier-Stokes equations: u t + u u = 1 ρ p +
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory
 Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Introduction à OpenCL
 1 1 UDS/IRMA Journée GPU Strasbourg, février 2010 Sommaire 1 OpenCL 2 3 GPU architecture A modern Graphics Processing Unit (GPU) is made of: Global memory (typically 1 Gb) Compute units (typically 27)
1 1 UDS/IRMA Journée GPU Strasbourg, février 2010 Sommaire 1 OpenCL 2 3 GPU architecture A modern Graphics Processing Unit (GPU) is made of: Global memory (typically 1 Gb) Compute units (typically 27)
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
COURTESY A. KLOECKNER
 GPU Metaprogramming applied to High Order DG and Loop Generation Division of Applied Mathematics Brown University August 19, 2009 Thanks Jan Hesthaven (Brown) Tim Warburton (Rice) Akil Narayan (Brown)
GPU Metaprogramming applied to High Order DG and Loop Generation Division of Applied Mathematics Brown University August 19, 2009 Thanks Jan Hesthaven (Brown) Tim Warburton (Rice) Akil Narayan (Brown)
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU. Robert Strzodka NVAMG Project Lead
 Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
From Physics Model to Results: An Optimizing Framework for Cross-Architecture Code Generation
 From Physics Model to Results: An Optimizing Framework for Cross-Architecture Code Generation Erik Schnetter, Perimeter Institute with M. Blazewicz, I. Hinder, D. Koppelman, S. Brandt, M. Ciznicki, M.
From Physics Model to Results: An Optimizing Framework for Cross-Architecture Code Generation Erik Schnetter, Perimeter Institute with M. Blazewicz, I. Hinder, D. Koppelman, S. Brandt, M. Ciznicki, M.
simulation framework for piecewise regular grids
 WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
Higher Order Multigrid Algorithms for a 2D and 3D RANS-kω DG-Solver
 www.dlr.de Folie 1 > HONOM 2013 > Marcel Wallraff, Tobias Leicht 21. 03. 2013 Higher Order Multigrid Algorithms for a 2D and 3D RANS-kω DG-Solver Marcel Wallraff, Tobias Leicht DLR Braunschweig (AS - C
www.dlr.de Folie 1 > HONOM 2013 > Marcel Wallraff, Tobias Leicht 21. 03. 2013 Higher Order Multigrid Algorithms for a 2D and 3D RANS-kω DG-Solver Marcel Wallraff, Tobias Leicht DLR Braunschweig (AS - C
High-order methods for the next generation of computational engineering software
 High-order methods for the next generation of computational engineering software Rubén Sevilla Zienkiewicz Centre for Computational Engineering College of Engineering Swansea University Swansea Wales,
High-order methods for the next generation of computational engineering software Rubén Sevilla Zienkiewicz Centre for Computational Engineering College of Engineering Swansea University Swansea Wales,
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Semi-Lagrangian kinetic and gyrokinetic simulations
 Semi-Lagrangian kinetic and gyrokinetic simulations M. Mehrenberger IRMA, University of Strasbourg and TONUS project (INRIA) Marseille, Equations cinétiques, 11.11.2014 Collaborators : B. Afeyan, A. Back,
Semi-Lagrangian kinetic and gyrokinetic simulations M. Mehrenberger IRMA, University of Strasbourg and TONUS project (INRIA) Marseille, Equations cinétiques, 11.11.2014 Collaborators : B. Afeyan, A. Back,
Center for Computational Science
 Center for Computational Science Toward GPU-accelerated meshfree fluids simulation using the fast multipole method Lorena A Barba Boston University Department of Mechanical Engineering with: Felipe Cruz,
Center for Computational Science Toward GPU-accelerated meshfree fluids simulation using the fast multipole method Lorena A Barba Boston University Department of Mechanical Engineering with: Felipe Cruz,
Introduction à OpenCL et applications
 Philippe Helluy 1, Anaïs Crestetto 1 1 Université de Strasbourg - IRMA Lyon, journées groupe calcul, 10 novembre 2010 Sommaire OpenCL 1 OpenCL 2 3 4 OpenCL GPU architecture A modern Graphics Processing
Philippe Helluy 1, Anaïs Crestetto 1 1 Université de Strasbourg - IRMA Lyon, journées groupe calcul, 10 novembre 2010 Sommaire OpenCL 1 OpenCL 2 3 4 OpenCL GPU architecture A modern Graphics Processing
Splotch: High Performance Visualization using MPI, OpenMP and CUDA
 Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
Session S0069: GPU Computing Advances in 3D Electromagnetic Simulation
 Session S0069: GPU Computing Advances in 3D Electromagnetic Simulation Andreas Buhr, Alexander Langwost, Fabrizio Zanella CST (Computer Simulation Technology) Abstract Computer Simulation Technology (CST)
Session S0069: GPU Computing Advances in 3D Electromagnetic Simulation Andreas Buhr, Alexander Langwost, Fabrizio Zanella CST (Computer Simulation Technology) Abstract Computer Simulation Technology (CST)
Introduction to C omputational F luid Dynamics. D. Murrin
 Introduction to C omputational F luid Dynamics D. Murrin Computational fluid dynamics (CFD) is the science of predicting fluid flow, heat transfer, mass transfer, chemical reactions, and related phenomena
Introduction to C omputational F luid Dynamics D. Murrin Computational fluid dynamics (CFD) is the science of predicting fluid flow, heat transfer, mass transfer, chemical reactions, and related phenomena
About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS.
 About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS. Phoenix FD core SIMULATION & RENDERING. SIMULATION CORE - GRID-BASED
About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS. Phoenix FD core SIMULATION & RENDERING. SIMULATION CORE - GRID-BASED
Implementation of an integrated efficient parallel multiblock Flow solver
 Implementation of an integrated efficient parallel multiblock Flow solver Thomas Bönisch, Panagiotis Adamidis and Roland Rühle adamidis@hlrs.de Outline Introduction to URANUS Why using Multiblock meshes
Implementation of an integrated efficient parallel multiblock Flow solver Thomas Bönisch, Panagiotis Adamidis and Roland Rühle adamidis@hlrs.de Outline Introduction to URANUS Why using Multiblock meshes