Self-supervised CNN for Unconstrained 3D Facial Performance Capture from an RGB-D Camera
|
|
|
- Merilyn Jackson
- 5 years ago
- Views:
Transcription
1 1 Self-supervised CNN for Unconstrained 3D Facial Performance Capture from an RGB-D Camera Yudong Guo, Juyong Zhang, Lin Cai, Jianfei Cai and Jianmin Zheng arxiv: v2 [cs.cv] 17 Aug 2018 Abstract We present a novel method for real-time 3D facial performance capture with consumer-level RGB-D sensors. Our capturing system is targeted at robust and stable 3D face capturing in the wild, in which the RGB-D facial data contain noise, imperfection and occlusion, and often exhibit high variability in motion, pose, expression and lighting conditions, thus posing great challenges. The technical contribution is a self-supervised deep learning framework, which is trained directly from raw RGB-D data. The key novelties include: (1) learning both the core tensor and the parameters for refining our parametric face model; (2) using vertex displacement and UV map for learning surface detail; (3) designing the loss function by incorporating temporal coherence and same identity constraints based on pairs of RGB-D images and utilizing sparse norms, in addition to the conventional terms for photo-consistency, feature similarity, regularization as well as geometry consistency; and (4) augmenting the training data set in new ways. The method is demonstrated in a live setup that runs in real-time on a smartphone and an RGB-D sensor. Extensive experiments show that our method is robust to severe occlusion, fast motion, large rotation, exaggerated facial expressions and diverse lighting. Index Terms facial performance capture, self-supervised learning, convolutional neural networks I. INTRODUCTION This paper considers the problem of real-time, high-quality 3D facial performance capture in unconstrained environment using a consumer-level RGB-D sensor. Note that 3D face capture from RGB videos has been well studied [54], [17], [11], [10], but real-time RGB based methods still have difficulty to achieve high-quality and robust facial performance capture due to limited information from the input RGB images (see Fig. 8). RGB-D sensors, on the other hand, provide not only appearance information but also depth information that is robust to illumination changes and occlusions. Hence RGB-D based capturing has recently received increasing attention, especially with consumer-grade depth cameras becoming popular. For example, some newly released smart phones like Apple s iphone X are equipped with an RGB-D camera, which stimulates the call for more efficient and pragmatic RGB- D face capturing solutions on mobile devices. While smart phones require minimal hardware setup, their acquisition is likely in unconstrained environment and their computation power is limited, which pose technical challenges. Therefore the problem of developing real-time, high-quality 3D face capture in unconstrained environment is of great interest and its Yudong Guo, Juyong Zhang and Lin Cai are with School of Mathematical Sciences, University of Science and Technology of China. Jianfei Cai and Jianmin Zheng are with School of Computer Science and Engineering, Nanyang Technological University. Corresponding author. juyong@ustc.edu.cn. solution will facilitate various applications such as personalized gaming, make-up apps, social media and telepresence at the consumer-level. Since Weise et al. [58] presented a seminal work for realtime facial performance capture based on RGB-D camera, several enhancements have been proposed [7], [32], [13], [53]. However, a few limitations exist in these works. First, the tracking and reconstruction is formulated as a non-linear optimization problem and consequently real time performance can only be achieved on PC, but not on mobile devices, as pointed out in [53]. Second, a parametric model defined based on a fixed PCA (Principal Component Analysis) basis is used for either identity [58], [7], [32] or both identity and expression [53]. Such a parametric model may not match the test 3D face well. Thus personalized blendshape is built to better represent the test 3D face, which requires user-specific calibration or manual assistance. Third, since the low rank representations only capture the basic shape of the face, the reconstructed face usually lacks facial detail such as wrinkles. Our work is inspired by the great success of deep learning technology, particularly convolution neural networks (CNN), which has caused paradigm-shift in many research fields due to its powerfulness in data-driven modelling. Deep learning is very suitable for applications that involve complex optimization but require fast processing speed, since learning based solutions can shift complex optimization to the offline training stage while the online inference stage can be very fast. Recently, deep learning based methods have been proposed for 3D face reconstruction based on RGB inputs. [41] and [20] propose a coarse-to-fine network architecture where a coarse-scale CNN is trained to regress the parameters of a parametric face model and a fine-scale CNN is trained to recover the face detail. [52] proposes an unsupervised CNN structure including a CNN encoder and a fixed rendering module as decoder and trains the structure end-to-end for 3D face reconstruction from RGB input. [51] further improves the reconstruction accuracy by learning the corrective basis from sparsely labeled in-the-wild images. Despite the great progress, learning based RGB methods still inherit the limitations from traditional optimization based RGB methods. For example, RGB-based methods only have appearance information and they cannot perform well or even fail in dark environment, while RGB-D based methods can still work as shown in Fig. 8. With the help of additional depth information, RGB-D based methods could achieve better and more robust performance, compared to RGB-based methods. Motivated by these observations, we aim to introduce a CNN based solution with RGB-D data.






2 2 Figure 1: Left: A snapshot of our developed real-time RGB-D 3D face capture system in a live setup; Right: several 3D face reconstruction results with RGB-D data under unconstrained environment. Our method is the first deep learning based 3D face capture work on RGB-D inputs. Our trained model can quickly regress the face shape, albedo, lighting and pose information from the input RGB-D image, which achieves more than 25 fps on Huawei Kirin 970 processor, while none of the existing RGB-D methods can run in real-time on mobile devices. It is however non-trivial to either convert existing optimization based RGB-D methods to learning-based approaches or extend existing deep learning based RGB face capture methods to RGB-D scenarios. For example, [20] requires to synthesize a large number of photo-realistic face images with corresponding 3D geometry information based on inverse rendering in order to train their coarse-scale CNN and fine-scale CNN in a fully supervised manner. Nevertheless, synthesizing another large set of RGB-D photo-realistic face images with high-quality 3D geometry information would be too time-consuming. In this paper, we propose a CNN framework for real-time RGB-D based 3D face capture. The framework follows the coarse-to-fine network architecture and consists of a mediumscale CNN to regress a medium-scale face model and a finescale CNN to recover the surface details. Both CNN models are trained in a completely self-supervised manner in that the face shape and details are automatically learned from large-scale unlabelled RGB-D data. Different from existing methods which use a fixed PCA basis for the parametric model, our method learns both the basis and the parameters during training. This novel approach greatly improves the reconstruction accuracy. To make the tracking process stable, our medium-scale CNN incorporates optical flow between two adjacent frames and the same identity constraint for any frame pairs of the same person during training for temporal coherence. To improve the robustness, we augment the input training data with scaling, occlusions, etc, while the images used in the loss function are still the original RGB-D images. In this way, our trained model is robust to fast moving, large poses, different expressions, different lighting conditions, and large occlusions. For the fine-scale CNN, we represent surface details as per-vertex displacements along the normal direction instead of per-pixel depth displacements in [41], which is more effective for the final 3D mesh representation, and use the UV map to facilitate the CNN-based surface detail refinement. Moreover, we adopt the second-order SH to model lighting in our unsupervised learning, which can reconstruct more accurate geometry details. To sum up, the paper has the following major contributions: We propose a self-supervised CNN learning framework for real-time 3D face capture. To the best of our knowledge, this is the first deep learning based method for 3D face capture with RGB-D data. We collect a large RGB-D dataset from a variety of identities with different facial expressions, poses, and lighting conditions. This dataset facilitates CNN learning in the field 1. Different from existing works that represent the parametric face model with a fixed basis derived from 3DMM or FaceWareHouse, we propose to learn both the basis (or core tensor) and the coefficient parameters from the large scale training data set. In this way, the refined parametric face model can better capture the target 3D face shape. Moreover, we extend our framework to the scenario with RGB inputs, where our novel idea is to use both RGB and depth during training while only using RGB during testing for facial performance capture. Specifically, during training we utilize the captured depth data as an additional supervision information at the output. Experiments show that such additional supervision from depth greatly improves 3D face reconstruction performance from RGB inputs. Apart from the geometry consistency, photo-consistency and regularization, our training process also takes into account other factors including temporal coherence and same identity constraints, the use of sparse norms such as l 2,1 norm and l 1 norm, and vertex displacement for modeling surface details, which lead to robust and highquality tracking and reconstruction. We have demonstrated our method in a live setup where the hardware includes a Huawei Mate 10 smartphone and an RGB- D camera as shown in Fig. 1. The experiments were conducted with different subjects, diverse lighting conditions, challenging head motions, exaggerated expressions and severe occlusions. For all these test examples, our medium-scale reconstruction can run on mobile devices with half-precision float in real time. 1 We will release the dataset after clearance of copyright issues.
3 3 The quantitative comparison with the state-of-the-art shows that our method performs better. II. RELATED WORK Facial performance capture is a fundamental topic in computer graphics and animation. It is well-established in the film industry for animation production. There is rich literature in this field. A nice overview of fundamental techniques for performance-driven facial animation is given in [39], [63]. Traditional film and game production uses controlled studio conditions for high-quality capturing. Facial makers [18], [5] or calibrated camera arrays [8], [3] are also used for producing robust features or high-quality data. Recently many methods that are easily adaptable and suitable for consumerlevel applications are developed. This section briefly reviews those techniques that are related to our work. Facial Performance Capture from RGB Inputs. Monocular RGB images or video can be easily obtained and many methods have been proposed to reconstruct faces from monocular RGB video. A popular way is to fit the input images using a parametric face model such as the 3D Morphable Model (3DMM) [6]. The reconstructed model can be further refined by recovering 3D shape from shading variation [28], [27]. For instance, in [16], a template is deformed to a 3D model created by a binocular stereo approach. In [56], a blendshape model is built and fitted to a monocular video off-line, and then the surface detail is added by shading-based shape refinement under general lighting conditions. [46] uses a similar approach and refines the results by iteratively optimizing the large-scale facial geometry and the fine-scale facial detail. [22] proposes to create fully rigged, personalized 3D facial avatars from hand-held video. The method performs the tracking and reconstruction computation on PC though the input images are captured by mobile devices. [17] fits a 3D face using a multi-layer approach and extracts a high-fidelity parameterized 3D face rig that contains a generative wrinkle formation model capturing the person-specific idiosyncrasies. As the low-rank parametric face model limits its expressiveness and ability to capture fine details, [49] proposes to derive a person-specific face model from all available images, and each frame of the video is recontructed by a novel 3D optical flow approach coupled with shading cues. In general, these methods work off-line and are not suitable for real-time 3D facial performance capture. To achieve real-time capturing, [11] presents a learning-based regression approach to fit a generic identity and expression model to an RGB face video on the fly. [59] extends it to run on mobile devices at real-time frame rates by directly regressing the head poses and expression coefficients in one-step. The approach is also extended to include the learning of fine-scale facial wrinkles [10]. [54] presents a method to jointly fit a parametric model for identity, expression and skin reflectance to the input color, which achieves real-time 3D face tracking and facial reenactment while most of previous methods for facial reenactment work offline [14], [15]. CNN-based 3D Face Reconstruction from RGB Inputs. Due to the powerfulness of convolution neural networks, various deep learning methods have been developed for 3D face reconstruction, face alignment, face recognition and dense facial correspondences from RGB images. Examples are [26], [4], [62], [29], [34], [55], [25], [19], [60]. In these methods, 3D Morphable Model (3DMM) [6], [42] is used to represent 3D faces and CNN is applied to learn the 3DMM and pose parameters. For unconstrained real-time 3D facial performance capture, [44] presents a method through explicit semantic segmentation in the RGB input. By a regression-based facial tracking with segmented face images as training, uninterrupted facial performance capture can be achieved. [40], [41] present methods for 3D face reconstruction from an RGB image by training a coarse-scale CNN in a fully supervised manner using synthetic data to learn the 3DMM parameters and training a finescale CNN in an unsupervised manner to regress per-pixel depth displacement for detailed geometry with the first-order spherical harmonics lighting model. [31] proposes to directly learn the vertex positions from RGB images by building an initial PCA basis. [20] proposes a fully supervised deep learning framework for reconstructing a detailed 3D face from monocular RGB video in real time. Unsupervised training has been proposed by [52] using an analysis-by-synthesis energy function. [23] proposes to directly regress volumes with CNN for a single face image. While these CNN-based methods for 3D face reconstruction from RGB images can achieve impressive realtime performance, they have inherent limitations due to the RGB inputs: easily affected by illumination; unable to handle images captured in dark environment. Facial Performance Capture from RGB-D Inputs. Compared to RGB inputs, RGB-D inputs provide additional depth information that benifits more robust facial performance capture with better quality. In fact, Weise et al. [58] developed a facial performance capture system that combines 3D and 2D non-rigid registration in optimization and achieves realtime robust 3D face tracking. This system however needs to build an accurate 3D expression blendshape by scanning and processing a predefined set of facial expressions in advance. [32] describes a system that only requires pre-building a neutral face model, generates initial blendshapes using deformation transfer [48], and then trains PCA-based correctives for the blendshapes during tracking with examples obtained from pervertex Laplacian deformations. [7] introduces a calibrationfree system that requires no user-specific preprocessing by jointly solving for a detailed 3D expression model of the user and the corresponding dynamic tracking parameters via an optimization procedure. [13] proposes an approach that incrementally deforms a 3D template mesh model to best match the input RGB-D data and facial landmarks detected from the single RGB-D image. [21] presents a realtime facial tracking system in unconstrained settings using a consumerlevel RGB-D sensor. The system personalizes the tracking model on-the-fly by progressively refining the user s identity, expressions, and texture with reliable samples and temporal filtering. To generate high quality 3D face models from RGB-D data, [33] proposes an approach consisting of two stages: offline construction of personalized wrinkled blendshape and online 3D facial performance capturing. [53] presents a method that reconstructs high-quality facial performance of each actor by
4 4 jointly optimizing the unknown head pose, identity parameters, facial expression parameters, face albedo values, and the illumination. The method focuses on photo-realistic capture and re-rendering of facial templates to achieve expression transfer between real actors. Different from fitting the RGB-D data to the parametric model, [35] proposes to divide the input depth frame into several semantic regions and search for the best matching shape for each region in database. The reconstructed 3D mesh is constructed by combining the input depth frame with the matched shapes in the database. [37] proposes a direct approach that reconstructs and tracks the 3D face without templates or prior models. Compared to existing real-time RGB-D based methods, which can only reconstruct a smooth 3D face in real time on PC [53] due to complex optimization, our deep learning based solution can achieve a similar quality reconstruction in real time on mobile device or a fine-scale 3D face reconstruction with geometry detail in real time on PC. This mainly owes to deep learning paradigm, which shifts the complexity to offline training while testing can be very fast. In addition, the newly embedded NPU (Neural Processing Unit) chips at mobile devices also greatly empower the computational capability of mobile devices for deep learning. Compared to existing realtime RGB based methods, our approach makes use of the captured depth information for better self-supervision during training, and can support both RGB-D and RGB inputs during testing, which leads to more reliable and accurate 3D face reconstruction. III. FACE REPRESENTATION AND RENDERING This section describes 3D face representation and the rendering process used in our work. A. Face Representation The face is basically represented as a vector p = [p T 1, p T 2,, p T n ] T R 3n via a mesh of n vertices v i (i = 1, 2,..., n) with fixed connectivity, where p i denotes the position of vertex v i. A parametric face model is used to specify the connectivity and geometry of the mesh, which gives a low rank representation. Fine-scale facial geometry is further added to refine the positions of vertices of the mesh. Parametric Face Model. While many previous works use 3DMM as the parametric face model to encode 3D face geometry and albedo, we encode facial identity and expression with a bilinear face model based on FaceWareHouse [12] similar to [11], which is shown to better represent 3D face expressions. We collect the vertex coordinates of all face meshes in FaceWarehouse into a third-order data tensor and perform 2-mode SVD reduction along the identity mode and the expression mode to derive a bilinear face model that approximates the original dataset. Specifically, the facial geometry is represented as: p = A r 2 α id 3 α exp, (1) where A r is the reduced core tensor computed from the SVD reduction and α id R 50, α exp R 47 are identity and expression coefficients that control the face shape. Following [6], the facial albedo b is represented with PCA: b = b + A alb α alb, (2) where b denotes average face albedo, A alb denotes the principal axes extracted from a set of textured 3D meshes, and α alb is the albedo coefficient vector. To obtain the albedo basis, we transfer the albedo basis from Basel Face Model (BFM) [38] to the mesh representation of FaceWarehouse [12] by nonrigid registration. Fine-Scale Facial Geometry. While the parametric representation captures global shape information of individuals, it has difficulty in handling fine-level face details such as wrinkles and folds. To alleviate this issue, we further encode fine-level facial details by per-vertex displacements along vertex normals, similar to the approach in [17]. B. Rendering Process The rendering process of a face image depends on several factors: face geometry, albedo, pose, lighting and camera parameters. To generate a realistic synthetic image of a face, we render the facial imagery using a standard perspective pinhole camera, which can be parameterized as follows: q i = Π(Rp i + t) (3) where p i and q i are the locations of vertex v i in the world coordinate system and in the image plane, respectively, R is the rotation matrix constructed from Euler angles pitch, yaw, roll, t is the translation vector and Π : R 3 R 2 is a perspective projection. To model the lighting condition, we approximate the globe illumination using the spherical harmonics (SH) basis functions [36]. Furthermore, we assume that a face is a Lambertian surface. Under this assumption, the irradiance of a vertex v i is determined by vertex normal n i and scalar albedo b i : 2 B I(n i, b i γ) = b i γ k φ k (n i ) = b i φ(n i ) γ (4) k=1 where φ(n i ) = [φ 1 (n i ),..., φ B 2(n i )] T is the SH basis computed with normal n i, and γ = [γ 1,..., γ B 2] T is the SH coefficients. In this paper, we use the first three bands (B = 3) of SHs for the illumination computation. IV. PROPOSED CNN LEARNING FRAMEWORK FOR RGB-D 3D FACE CAPTURE The overall pipeline of the proposed CNN learning framework is shown in Fig. 2. The framework consists of two CNNs: medium-scale CNN and fine-scale CNN. The medium-scale CNN is to regress the medium-scale facial representation from an input RGB-D frame and the fine-scale CNN is to regress per-vertex displacements along vertex normals from the current medium-scale reconstruction.







 and poses under different lighting")




















5 5 Figure 2: The pipeline of our proposed CNN learning based method for RGB-D 3D Face Capture. The medium-scale CNN regresses the parametric face model and the parameters including shape, pose, lighting and albedo. The fine-scale CNN directly regresses a displacement for every vertex along the vertex normal direction in the UV map domain. A. Training Data Preparation To train the medium-scale CNN, we capture RGB-D videos of about 200 people with PrimeSense and about 400 people with iphone X. The average number of frames in each video is around 500 and the total number of RGB-D training frames is about 300K. The male-to-female ratio of our training data is 1:1. About 60% are Chinese, 20% are Pakistanis/Bengalese, and 20% are Europeans. The ages of people in training data are mainly from 10 to 60. In each video, we capture the same person with different expressions (smile, frown, mouth open, etc) and poses under different lighting conditions (morning, afternoon and evening). Fig. 3 shows samples of the captured data. To train the fine-scale CNN, we only use the RGB-D videos captured with iphonex because of its high-quality color images, which are needed for shading-based surface detail recovery. The input RGB-D images fed to CNN need to be cropped by the detected facial bounding boxes. Since both the crop operation and the perspective projection (relative to camera intrinsic parameters) are linear transformation, we adjust the perspective projection to match the crop operation by changing the known camera intrinsic parameters (focal length and principle point). This is analogous to the process of training images captured by different depth cameras (with different intrinsic parameters) at the same time. For depth information input, a straightforward way is to directly feed the depth map to CNN. This, nevertheless, may make CNN difficult to learn translation due to the lack of camera intrinsic parameters. Another approach is to explicitly feed both the depth map and camera intrinsic parameters to CNN, by which the results are getting better, but they are not good enough. Our approach is to convert the depth value at every pixel to 3-channel point coordinates in the camera space with the camera intrinsic parameters, before feeding it to CNN. In this way, the network can directly infer Euler angles and the translation vector from the 3-channel point coordinates. Our experiments show that it achieves better results than the two straightforward approaches. For RGB images, we scale each color channel with a randomly generated scalar s (0.5, 1.5) for data augmentation of varying lighting conditions. We also randomly disturb the Figure 3: Samples of the captured training data. We capture each person with different poses and expressions under different lighting conditions. The left two columns are RGB-D data captured by PrimeSense camera, and the right two columns are RGB-D data captured by iphonex. Original Crop Scaling Flip Occlusion Figure 4: Samples of different data augmentation results. The first column is the original RGB-D data, and the remainings are the augmentation images by random cropping, scaling, flipping and occlusion separately. crop operation of RGB-D images for robust and efficient tracking, considering that for the sake of speedup a facial bounding box is determined based on the regressed facial parameters of the last frame rather than doing face detection at each frame. To handle occluded faces, we capture 2000 RGB-D hand images. During training process, we randomly simulate faces occluded by hands by translating the hands in front of faces. This could be easily done since we have the depth information. We then feed the simulated data into the network for training. Note that although the input are occluded faces, we use original RGB-D images as supervision when computing the loss functions. Fig. 4 shows samples of the proposed data augmentation. B. Medium-Scale CNN The medium-scale CNN is targeted at the mediumscale geometry. That is, given an RGB-D image as input, our medium-scale modeling network regresses

 = w pp E pp (χ) + w ps E ps (χ) (6) Figure 5: An overview of our medium-scale network training")
6 6 parameters are between any two frames from the same video, respectively, and w col, w lan, w reg, w flow and w same are tuning weights compensating for scaling of the terms. During training, we sample both pairs of adjacent frames and pairs of nonadjacent frames, where E flow is only applied to adjacent frames to ensure temporal smoothness and E same is applied to all pairs of frames so as to ensure identity consistency even across a long time span. In the following, we formulate each term of (5) in detail. Geometry Terms. We use two terms to measure how well the reconstructed mesh matches the input depth frame: E geo (χ) = w pp E pp (χ) + w ps E ps (χ) (6) Figure 5: An overview of our medium-scale network training architecture. The network is always trained on a pair of RGB-D frames to enforce temporal coherence and identity consistency. For each RGB-D frame, the RGB features and XYZ features are concatenated after the third inception module. The loss function includes both the Single Loss and the Pair Loss defined in Eq. (5). the reduced core tensor A r and the parameter set χ = {α id, α exp, α alb, pitch, yaw, roll, t, r}, where r = (γ T r, γ T g, γ T b )T denotes the SH illumination coefficients of RGB channels. The medium-scale network training architecture is shown in Fig. 5. Our training architecture has two characteristics. The first one is that we always use a pair of RGB-D frames to train the network. This enforces temporal coherence and identity consistency across individual frames. Though it seems that there are two streams in the network training architecture for each of the two RGB-D frames respectively, the two streams are actually sharing the same network. The second characteristic is that for each RGB-D frame, the RGB channels and the 3-channel point coordinates (converted from depth) go through different networks first and their features are later concatenated for the parameter regression. Such RGB-D learning structure has been proven better than directly concatenating RGB-D data at the input [57]. Our overall loss function for training can be written as E loss = E geo + w col E col + w lan E lan + w reg E reg }{{} Single Loss + w flow E flow + w same E }{{ same } Pair Loss where the first four terms are to measure how well the regressed parameters explain the input RGB-D observations from each frame, the last two terms E flow and E same are to measure how well the parameters of two adjacent frames match the optical flow between them and how close the identity and albedo (5) where w pp and w ps are tuning weights. The first term in (6) is the point-to-point distances of back-projected 3D points between the real depth map and the rendered depth map: E pp (χ) = 1 F p syn (m) p real (m ) 2, (7) m F where 2 is the l 2,1 norm, F is the set of all visible pixels, p syn (m) and p real (m ) are the back-projected locations of pixel m in the rendered depth map and pixel m in the real depth map, respectively, where m is the pixel in the real depth map whose back-projected location is closest to m s. For computational efficiency, we search for m in a [ 5, 5] [ 5, 5] neighbor region of m. To get the set of all visible pixels F, we do rasterization with the current geometry and pose. The second term in (6) evaluates the point-to-surface distance: E ps (χ) = 1 F n T real(m )(p syn (m) p real (m )), (8) m F where n real (m ) is the normal of pixel m computed based on the neighboring pixels in the real depth map. It is worth pointing out that (7) and (8) are formulated in l 2,1 norm and l 1 norm respectively, which improve the resistance to noise and outliers that often exist in the captured depth maps. Note that the optimization of the geometry term is actually a non-rigid sparse ICP procedure. Based on the correspondence between the current 3D face mesh and the input point cloud, we update the rigid (rotation and translation) and non-rigid (identity and expression parameters) in backpropagation during training. This process is iterated until convergence. Color Term. The color term evaluates how well the rendered face image based on the regressed parameters matches the input RGB image: E col (χ) = 1 F I syn (m) I real (m) 2, (9) m F where I syn (m) and I real (m) are the synthetic color and the real color at pixel m, respectively. We also use the l 2,1 norm for robustness since we do not account for specular reflection and person-specific albedo, which are considered as outliers in our model. Landmark Term. The landmark term measures how close the projected vertices are to the corresponding landmarks in the input image. Moreover, for better handling expressions with eye movement, we add a term measuring the change of
7 7 the distance between upper and lower eyelids. Specifically, the landmark term is formulated as: E lan (χ) = 1 L q i Π(Rp i + t) 2 i L (q i q j ) (Π(Rp i + t) Π(Rp j + t)) 2, + 1 LP (i,j) LP (10) where L is the set of landmarks, q i is a detected landmark position in the input image, p i is the corresponding vertex location in the 3D mesh, (i, j) is a pair of points on the upper and lower eyelids, and LP is the set of all the eyelid pairs. We adopt the method proposed in [9] to detect facial landmarks and then manually refine the landmarks along the contour of mouth and eyes. During training, half of the contour landmark points are discarded according to the currently regressed yaw angle since the key points on the left (right) contour are invisible when people turn left (right). Regularization Term. The regularization term aims to ensure that the parameters of the regressed parametric face model are plausible: 50 ( ) 2 αid,i 50 ( ) 2 αalb,i 47 ( ) 2 αexp,i E reg (χ) = + +, i=1 σ id,i i=1 σ alb,i i=1 σ exp,i (11) where σs are the standard deviations of the corresponding principal directions. In this work, we use 50 principal components for albedo, 50 for identity and 47 for expression. Temporal Coherence Term. Note that the above four terms are frame-to-frame independent. To account for temporal coherence between frames for stable tracking, additional terms are needed. To this end, we introduce a temporal coherence term that measures how well the moving flow of the projected mesh matches the optical flow between two adjacent RGB frames: E flow (χ n, χ n 1 ) = 1 (P r n (p) P r n 1 (p)) f(m) 2 F 2, m F (12) where χ n and χ n 1 are the regressed parameters for the current frame and the previous frame respectively, p is the corresponding position on the 3D mesh for pixel m by barycentric interpolation of the three vertices of the underlying triangle, P r n (p) and P r n 1 (p) are the projections of p on the image plane for the current frame and the previous frame respectively, and f(m) is the optical flow at pixel m. We compute the dense optical flow using the method of [61]. Note that we compute optical flow before data augmentation, and thus we can obtain accurate optical flow for the augmented dark facial images. Same Identity Term. When tracking the same person, identical identity and albedo parameters for different frames are expected. However, since identity and expression are not totally independent in the parametric face model, the identity parameters of the same person at different frames might vary during the tracking process. To alleviate this problem, we include an identity term to ensure the consistency of the identity and albedo parameters of the same person: where n 1 and n 2 are any two frames of the same person, including non-adjacent frames. Learning Bilinear Face Model. Note that the bilinear face model A r defined in (1) is constructed by performing 2-mode SVD reduction from the FaceWareHouse dataset [12]. Although the SVD reduction is a good way to extract the low-dimensional facial model, it is not necessarily optimal. Moreover, it may not work well for faces that do not belong to the types included in the FaceWareHouse dataset. For this reason, we propose not to fix the reduced core tensor, but to further refine it with our collected large-scale training dataset. Our strategy is to use a dictionary learning process [1], where estimating the parameters of the parametric face model is a coding step and refining the core tensor is a dictionary update step. Specifically, we denote by A r the refined core tensor that is assumed to better represent the middle-level geometry, and add the following term to (5): E rega (A r) = w Areg A r A r 2 +w Asmo (A r A r ) 2, (14) where (A r A r ) is the Laplacian computed on a mesh of dimensions, and w Areg and w Asmo are tuning weights. In particular, we create a geometry layer before the loss layer, where we set A r as the weights (learnable parameters), identity and expression parameters as the input and the output is the reconstructed 3D geometry. When learning A r from the amended (5), we keep parameters χ fixed (set learning rate to zero for convolutional layers) and update A r using Stochastic Gradient Descent (SGD). Remarks: We would like to point out that the first four terms in (5) are in principle similar to those used in the optimizationbased method [53]. However, there are a few fundamental differences. First, we use either l 2,1 norm or l 1 norm for the first two terms in (5), while [53] uses l 2 norm in order to achieve the real-time requirement. Using l 2,1 norm and l 1 norm makes our method more robust to the input depth noise and the imperfection of the parametric facial model. Second, although [53] jointly optimizes facial identity and reflectance on a short control sequence, the temporal coherence between adjacent two frames (e.g. optical flow) is not considered. We add the temporal coherence constraint via the pair loss which helps to improve the tracking stability. The last but most important one is that we refine the core tensor during CNN training in addition to regressing the model parameters, which greatly improves the reconstruction accuracy. Moreover, the key insight here is that our solution is a learning based approach, which can afford to use more sophisticated loss terms during offline training without affecting the real-time performance during online inference. In contrast, the existing optimizationbased real-time RGB-D solutions can only use simple terms and less constraints in order to achieve the real-time requirement, not to mention that they do not reconstruct fine-scale 3D facial details. C. Fine-Scale CNN E same (χ n1, χ n2 ) = ( The purpose of the fine-scale CNN is to refine the surface α id,n1 α id,n α alb,n1 α alb,n2 2 2), details of the medium-scale face mesh obtained from the (13) medium-scale CNN. [31] proposes a CNN framework to

![In addition, using a fully connected layer to regress all vertex positions in [31] is neither efficient nor reasonable, considering that there is a large number of vertices (say, 47954 vertices) and](/docs-images/93/112853819/images/8-1.jpg "each vertex is only dependent of its neighbor vertices.")
![[41] and [20] regress a per-pixel depth displacement map in an unsupervised and supervised manner, respectively, to refine facial surface details.](/docs-images/93/112853819/images/8-2.jpg "Although the representation of the perpixel depth displacement map is quite convenient for CNN learning, it does not align with the 3D face mesh representation and it only refines the geometry of a")


![[47], and regress the displacements in the UV map domain.](/docs-images/93/112853819/images/8-5.jpg "Specifically, the input to the fine-scale CNN is a four-dimensional map in the UV domain, where each UV pixel contains the intensity value and the XYZ coordinates of the corresponding 3D point on the")


, a regularization term E sm (d) and a temporal coherence term E cl (d n, d n-1 ), each of which is explained below. Shading Term.")
8 8 directly learn vertex positions from RGB images, but the method needs ground-truth vertex positions for fully supervised learning and a per-user calibration for building an initial PCA basis, which needs to be retrained for each new identity. In addition, using a fully connected layer to regress all vertex positions in [31] is neither efficient nor reasonable, considering that there is a large number of vertices (say, vertices) and each vertex is only dependent of its neighbor vertices. [41] and [20] regress a per-pixel depth displacement map in an unsupervised and supervised manner, respectively, to refine facial surface details. Although the representation of the perpixel depth displacement map is quite convenient for CNN learning, it does not align with the 3D face mesh representation and it only refines the geometry of a particular view. In this work, we make use of shading information, which is related to the surface normal whose variance intrinsically reflects the local high-frequency shape changes, to learn a displacement for every vertex along the vertex normal direction for fine-scale face modeling. Considering that the conventional CNN learning prefers inputs and outputs in a regular grid, we parameterize the 3D face mesh to a UV map, which is done by minimizing the symmetric Dirichlet energy [47], and regress the displacements in the UV map domain. Specifically, the input to the fine-scale CNN is a four-dimensional map in the UV domain, where each UV pixel contains the intensity value and the XYZ coordinates of the corresponding 3D point on the reconstructed medium-level 3D face mesh. The output to the fine-scale CNN is another UV map, where each UV pixel contains one scalar value representing the predicted normaldirection displacement for the corresponding 3D point on the face mesh. In this way, we can use a pixel-to-pixel network structure, which is more efficient and better preserves local information. Fig. 6 gives examples of the input intensity image and the XYZ image parameterized on the UV domain, where the resolution of UV map is We denote by d the output UV map containing the displacements of all pixels and we define our loss function for fine-scale CNN based on shape from shading. The function is a sum of a shading term E sh (d), a regularization term E sm (d) and a temporal coherence term E cl (d n, d n-1 ), each of which is explained below. Shading Term. Considering that in a triangular mesh a face has well-defined normal compared to vertices, we define our shading term based on faces rather than vertices: E sh (d) = w face i T I(n i b i, γ) c i 2 +w edge i j E (I(n i b i, γ) I(n j b j, γ)) (c i c j ) 2, (15) where w face, w edge are tuning weights, T is the set of all triangles in the 3D face mesh, E is the set of all edges, c i is the intensity value at the center of triangle i sampled by projecting the 3D face mesh onto the image plane and bilinearly interpolating neighbor pixels, and I(n i b i, γ) is the predicted intensity with the current normal n i given the obtained albedo b i and the SH lighting coefficients γ. Note that n i is indirectly affected by the UV displacement map d. That is, given the fine-scale CNN output d, we update the vertex positions of the 3D face mesh accordingly, based on which we then update Figure 6: Examples of the input intensity image and the XYZ image parameterized in the UV domain for fine-scale CNN. From top to bottom: original face images, parameterized intensity images and parameterized XYZ images. triangle normals n i and compute (15). Regularization Term. We regularize the face mesh to be smooth and close to the reconstructed mesh in medium-scale level by minimizing the l 2,1 norm of Laplacian vectors and the l 2 norm of d respectively: E sm (d) = w sm p i 2 + w mi d 2 2, (16) v i V where w sm and w mi are tuning weights, V is the set of all vertices, and p i is the position of vertex v i. Temporal Coherence Term. Similar to the medium-scale face modeling, we also add a temporal coherence term that measures the difference of triangle normals between two adjacent frames: E cl (d n, d n-1 ) = w cl n n,i n n 1,i 2 2, (17) i T where w cl is a tuning weight, and n n,i and n n 1,i are the unit normals of triangle i in the current frame and the previous frame, respectively. D. Extensions to RGB Based Facial Performance Capture It is worth pointing out that our CNN framework is very flexible. Though it is designed for facial performance capture with an RGB-D camera, we can easily extend it to facial performance capture with only RGB input. The novel idea here is that to use both RGB and depth data during training while using only RGB data during testing. Specifically, during training, we use RGB data as input to match the testing scenario while using the additional depth information as supervision at the output, i.e. keeping similar RGB-D terms in the loss function. This is very different from the existing deep learning based 3D face reconstruction methods from RGB images, where only RGB images are used in both training and testing. Our
9 9 experiments show that the addition supervision from depth during training delivers better reconstruction results. Particularly, we train a model with only RGB images as input but still keep the depth related terms in the loss function to guide the CNN model. Our initial attempt is to adopt the same loss function as that in the scenario with RGB-D input. However, the loss of the geometry terms cannot converge since it is not easy to accurately estimate the real-world translation through CNN with only RGB image input. Therefore, rather than using the point-to-point distance and the point-to-surface distance in (6), we use the normal-to-normal distance between the real depth map and the rendered depth map, which is defined as: E n (χ) = 1 F n syn (m) n real (m ) 2, (18) m F where 2 is the l 2,1 norm, F is the set of all visible pixels, m is the pixel in the real depth map whose back-projected location is closest to m, and n syn (m) and n real (m ) are the unit normals of the rendered depth map at pixel m and the real depth map at pixel m, respectively. V. RESULTS In this section, we first evaluate the performance of our learning based 3D face capture method in different aspects, and then compare it with state-of-the-art methods. Implementation. We train our CNNs based on Caffe [24]. For training the medium-scale neural network, we first use the landmark term and the regularization term to do an initial alignment, and then add other terms for a dense alignment. When feeding the input image into the network, we crop the face region to with bilinear interpolation. In the testing process, the face region of the first frame is generated by face detection, and the bounding box of any other frame is automatically obtained according to the predicted landmarks by projecting the reconstructed 3D mesh of the previous frame. For the medium-scale CNN, we use GoogLenet [50] structure and concatenate the RGB features and XYZ features after the third inception module. For the fine-scale CNN, we use U- Net [43] structure. We train our networks using Adam solver with the mini-batch size of 50 for both networks. We train the medium-scale CNN by iteratively updating the convolutional layers with 20K iterations and the parametric model A r with 20K iterations, and the total number of iterations is 200K. The fine-scale CNN is trained with 30K iterations. The weights for loss functions including w pp, w ps, w col, w lan, w reg, w flow, w same, w Areg, w Asmo. w face,w edge, w sm, w mi and w cl are empirically set to 2, 2, 1, 0.5, 0.5, 0.5, , 1000, 2000, 0.1, 1, 0.1, 0.02 and 0.01, respectively. Our CNN based 3D face reconstruction and tracking are implemented in C++ and tested on various RGB-D sequences. We conduct experiments on a desktop PC with a quad-core Intel CPU i7, 4GB RAM and NVIDIA GTX 1070 GPU. Besides, we also export our trained medium-scale CNN to HUAWEI Mate 10 mobile device, which is with Kirin 970 NPU (FP TFLOP) and Octa-core CPU (4x2.4 GHz Cortex-A73 & 4x1.8 GHz Cortex-A53). As for the running time for each frame, on the PC, it takes 9ms for medium-scale CNN and 14ms for fine-scale CNN. On HUAWEI Mate 10 smartphone, on average our medium-scale CNN takes around 33 ms for one frame with half-precision float. Note that our fine-scale CNN cannot achieve real-time computation on the smartphone, but on the common PC we demonstrate that the combination of both medium-scale CNN and fine-scale CNN can be run in real time. Since this paper focuses on real-time 3D face reconstruction and tracking on mobile devices, in the following without specification the results of our method refer to the results of our medium-scale CNN, which can be run on mobile devices in real time. A. Evaluation of Our Method Robustness. Fig. 7 shows the reconstructed 3D faces of our medium-scale CNN model on sampled RGB-D frames with large poses, different expressions, motion blur, different lighting conditions and occlusions. The accompanying video shows the tracking results of the complete sequences. With the additional depth information, our method is more robust than the RGB based methods. As shown in Fig. 8, the state-of-theart RGB-based methods cannot perform well or even fail to reconstruct the 3D face with the RGB images captured in dark environment, while our method with RGB-D input can still reconstruct the 3D face shape well thanks to the additional depth information. The reconstruction result comparison between with and without occlusion data agumentation is shown in Fig. 9, and it shows that the mouth part is distored if the training data set does not include occlusions, while our method could achieve better results. From these experiments, we can observe that our method is robust to these challenging scenarios, which is mainly due to a diversity of identities, poses, expressions and lighting conditions contained in our large-scale training data set. To further improve the robustness, we also do data augmentation including random cropping and scaling, flipping and occlusion simulation during training. With these diverse data and our carefully designed training strategies, we successfully train a powerful and robust model offline, which can then be run in real time during the inference stage. Note that Thies et al. [53] cannot handle very fast head motion and dark environments, as pointed out in their paper. Generalization Ability. Although our medium-scale CNN model is trained with the RGB-D data captured by PrimeSense camera and iphonex, it can be applied to other RGB-D cameras. We test our trained medium-scale CNN model with different depth cameras including Kinect (V1), PrimeSene, Intel RealSense F200, and iphone-x. Fig. 10 shows the 3D reconstruction results with different sensors on the same person. It can be observed that the reconstruction results across different sensors are consistent. Temporal Coherence. We demonstrate the advantage of the temporal coherence term in (12) in the medium-scale CNN training by comparing the tracking results between the models trained with and without the temporal coherence term. We apply both methods on an RGB-D sequence containing 100 frames of a face (kept as static as possible) and evaluate the

![RGB-based methods [23],](/docs-images/93/112853819/images/10-1.jpg "[45] on the inputs")
















































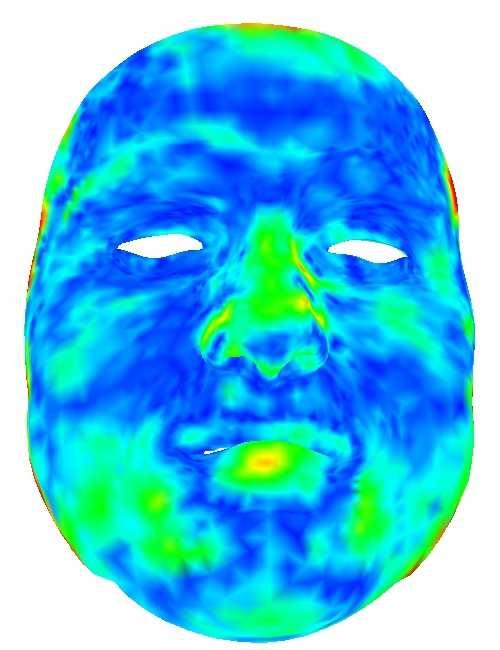
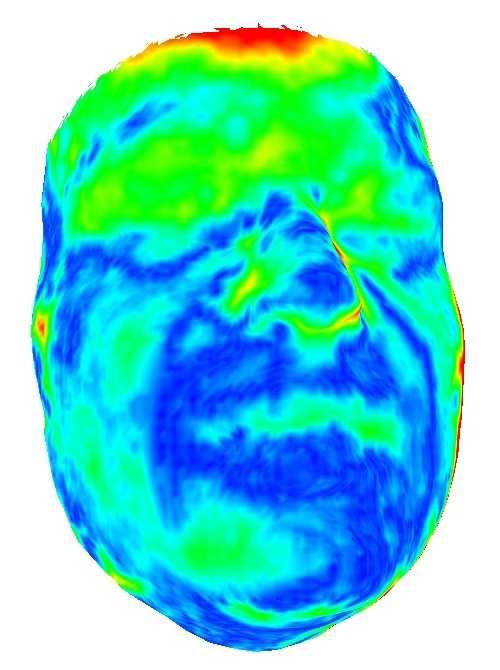
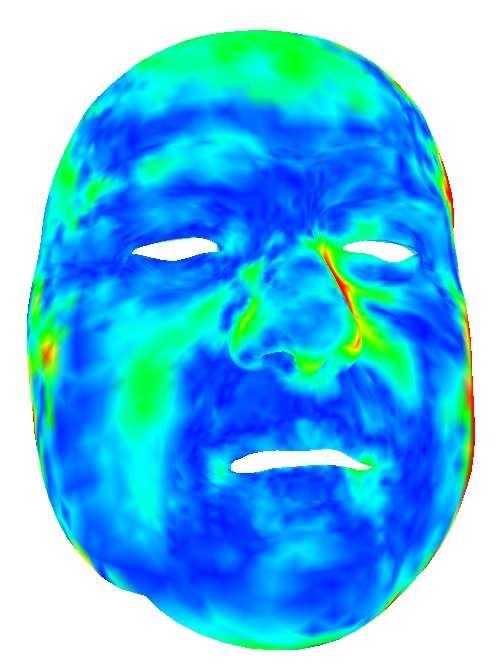
10 10 Figure 8: Comparisons with the RGB-based methods [23], [45] on the inputs captured in dark environment. Note that the input to [23], [45] is an RGB image, and the input of our method here includes a pair of RGB and depth images. Figure 9: Reconstruction results of our medium-scale CNN model trained without and with occlusion data augmentation. On the top are input RGB images and depth clouds, on the bottom are the results without (left) and with (right) occlusion data augmentation. Figure 7: Reconstruction results of our medium-scale CNN model on sampled RGB-D frames with large poses, different expressions, motion blur, different lighting conditions and occlusions. For every three rows from top to bottom: input face images, reconstructed 3D meshes overlayed with input point clouds, reconstructed 3D meshes overlayed with input images. vertex displacements of the reconstructed 3D face of each frame w.r.t the mean 3D face averaged over all the reconstructions. The average vertex displacements of each frame are shown in Fig. 11. It can be observed that the reconstruction results with the temporal coherence term are more stable than those without the temporal coherence term. Reconstruction Quality of Medium-scale CNN. Fig. 12 gives a few examples of the reconstructed 3D meshes and the corresponding geometry fitting errors. Geometry fitting error is defined as the point-to-point distance between the reconstructed 3D mesh and the input point cloud. Here, we show the fitting results of not only our medium-scale CNN model but also a trained model that is almost the same as the medium-scale CNN model except that it does not optimize the tensor A0r. We test our method on an RGB-D sequence including 150 frames, and the mean and standard deviation values of the geometry fitting errors are 2.33 mm / 0.45 mm and 1.91 mm / 0.23 mm for the models without and with optimizing A0r, respectively. Fig. 12 shows three frames of the RGB-D sequence, and we can observe that the geometry fitting errors are reduced significantly with the help of A0r. We also evaluate our method on a large-scale test set including 152 people and RGB-D images, and the mean and standard deviation values of the geometry fitting errors between our reconstructed results and the input point clouds are 1.83mm / 0.74mm. Our method also works well for subtle expressions like mouth and eye movements, as shown in Fig. 13. This is due to









 between the models trained with and")
")
: mean 0.28 and std 0.12. Without (12): mean 0.")










11 11 Kinect V1 PrimeSense RealSense F200 iphonex Figure 10: Our trained medium-scale CNN model works well for different types of depth cameras. Figure 12: Comparisons of the 3D reconstruction and tracking results without and with optimizing A0r. From top to bottom: input color image and point cloud, reconstructed 3D meshes and geometry fitting errors. Left: results without optimizing A0r. Right: results with optimizing A0r. Mean and standard deviations of the geometry fitting errors are 2.33 mm / 0.45 mm without optimizing A0r and 1.91 mm / 0.23 mm with optimizing A0r. The mean and standard deviation values are computed on 150 models, and here we show three examples Figure 11: Comparison of the average vertex displacement results (w.r.t the mean 3D face averaged over all the reconstructions) between the models trained with and without the temporal coherence term. We can see that the temporal coherence term (12) leads to more stable tracking results. With (12): mean 0.28 and std Without (12): mean 0.39 and std Figure 13: Reconstruction results for subtle expressions like mouth and eye movements. to the mesh vertices via regressing the displacements along each vertex normal according to shape-from-shading with the second-order SH lighting model. two reasons. First, we learn to refine the bilinear face tensor to better fit the scanned RGB-D data, which significantly improves the expression ability. Second, we add the distance constraint B. Comparisons with State-of-the-Art Approaches in Eq. 10 to improve the shape on the eye parts. In this subsection, we compare our trained medium-scale Reconstruction Quality of Fine-scale CNN. Fig. 14 com- CNN model with the following state-of-the-art approaches pares the 3D reconstruction results of our medium-scale model which can also reconstruct 3D faces from an RGB-D camera and our fine-scale model. It can be seen that compared to in real time. the medium-scale CNN, the fine-scale CNN recovers more [53]. - This method achieves the state-of-the-art performance fine geometric details such as wrinkles. This is because our on real-time 3D face reconstruction and tracking from a single fine-scale CNN is able to directly add the geometry details RGB-D camera. It basically recovers 3D face geometry, albedo
![12 Ours [53] [11] Figure 14: Comparisons of the 3D reconstruction results of our medium-scale model and our fine-scale model.](/docs-images/93/112853819/images/12-0.jpg "From top to bottom: input images, results of our medium-scale CNN, and results of our fine-scale CNN. The geometric details recovered by our fine-scale model are more obviously observed.")

![Our results are comparable to them, while our method can run on mobile device in real time. Note that we only have the video sequence used in [53], but not the reconstructed 3D meshes.](/docs-images/93/112853819/images/12-2.jpg "Thus we cannot compare the geometry fitting errors with [53].")

![We compare our method with it on the test examples used in [53].](/docs-images/93/112853819/images/12-4.jpg "While our method takes as input the RGB-D data and the camera parameters, the method of [11] only uses the RGB data to regress the shape parameters and the camera parameter. As shown in Fig.")


, results of [53] (RGB-D input), and our result (RGB-D input).")
12 12 Ours [53] [11] Figure 14: Comparisons of the 3D reconstruction results of our medium-scale model and our fine-scale model. From top to bottom: input images, results of our medium-scale CNN, and results of our fine-scale CNN. The geometric details recovered by our fine-scale model are more obviously observed. and lighting from an RGB-D sequence simultaneously by solving an optimization problem. It achieves real-time tracking on a desktop PC with the help of GPU computing. Fig. 15 shows some reconstruction results, and the full comparisons on all the video frames are given in the accompanying video. Our results are comparable to them, while our method can run on mobile device in real time. Note that we only have the video sequence used in [53], but not the reconstructed 3D meshes. Thus we cannot compare the geometry fitting errors with [53]. For the video sequence of 600 frames (see the supplementary video), our method achieves the geometry fitting errors with mean / standard deviation of 2.29 mm/0.20 mm, which are comparable to the final results of 2.26 mm/0.27 mm reported in [53]. [11]. - This method learns the 3D face shape parameters from a single RGB video stream. We compare our method with it on the test examples used in [53]. While our method takes as input the RGB-D data and the camera parameters, the method of [11] only uses the RGB data to regress the shape parameters and the camera parameter. As shown in Fig. 15, our method outputs better shapes especially for the frames with expressions. ARKit. - Apple Inc recently released ARKit [2], which has the feature of capturing a user s 3D face with iphone X smartphone. We compare our reconstruction results with those obtained by the Face Mesh tool in MeasureKit 2, where all face data comes directly from ARKit. Both methods take the RGB-D data scanned by iphone X as input. We quantitatively evaluate the geometry accuracy of both methods, which is defined as the point-to-point distance between a reconstruction mesh and the corresponding ground-truth geometry captured 2 Figure 15: Comparisons with [11] and [53]. From top to bottom: input color sequence, results of [11] (RGB input), results of [53] (RGB-D input), and our result (RGB-D input). by Range 7 3D Scanner [30]. Note that we only compare the facial part since the laser scanner fails to capture hair. To align the reconstructed 3D face model with the ground-truth 3D point cloud, we first manually label several landmarks to do rigid registration and then apply dense ICP for dense registration. From Fig. 16, we can see that the geometry produced by our method is visually comparable or better than ARKit. The fitting errors in mean and standard deviation of our method and ARKit against the ground-truth geometry are also given for the examples in Fig. 16, where our method obtains smaller fitting errors than ARKit. We also compare our method with ARKit for the scenario with only RGB input during testing, where we call ARKit on iphone-x with only RGB information by disabling the depth camera, and apply it on the same examples in Fig. 16. Our method with RGB inputs gives fitting errors in mean/standard deviation: 1.72/1.46 mm, 1.83/1.89 mm and 2.02/1.58 mm respectively for the three examples in Fig. 16, while ARKit with RGB inputs gives errors: 1.81/1.69 mm, 2.32/2.12 mm and 2.27/2.17 mm. Other RGB-based methods. - We also compare our method with the state-of-the-art RGB-based methods [23], [45] by using the source codes provided by the authors. These RGBbased methods only use RGB information, while our method takes the additional depth information, which is used only in training but not in testing, for better self-supervised learning. We compute the fitting error by aligning the reconstructed meshes with the scanned point cloud. It can be observed from Fig. 17 that our method achieves the best reconstruction quality due to the additional depth supervision. These example demonstrates that even rough depth data captured by consumergrade depth cameras can significantly improve the face capture performance.
![[23] 13 1.52/1.45 1.72/1.46 4.](/docs-images/93/112853819/images/13-0.jpg "57/3.04mm 3.37/2.73mm 4.16/3.")

![38mm 1.48/1.32 [45] 1.81/1.69 4.](/docs-images/93/112853819/images/13-2.jpg "52/3.46mm 10mm 2.32/2.12 1.42/1.")



![[23], [45].](/docs-images/93/112853819/images/13-6.jpg "From top to bottom: input")

![results of [23], results of](/docs-images/93/112853819/images/13-8.jpg "ours (RGB) and results of ours")


![Note that [23], [45] use only](/docs-images/93/112853819/images/13-11.jpg "RGB information while our")






















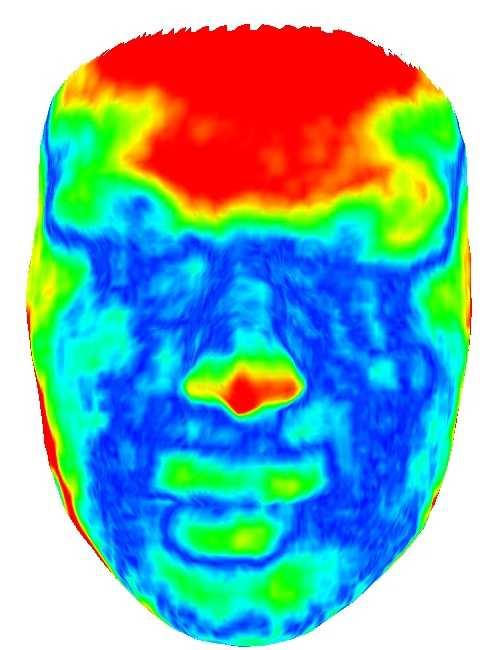

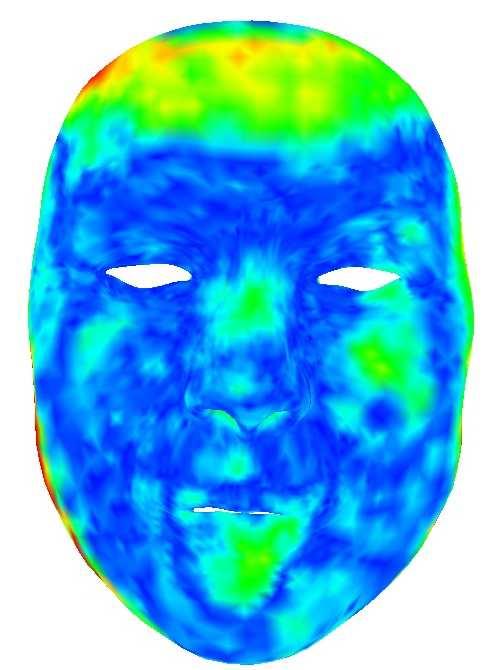



















13 [23] / / /3.04mm 3.37/2.73mm 4.16/3.01mm 5.81/3.29mm 3.65/2.64mm 2.28/1.97mm 3.16/2.22mm 3.27/2.38mm 1.48/1.32 [45] 1.81/ /3.46mm 10mm 2.32/ / / / /1.93mm 10mm 0mm 2.27/ / / / /1.84mm 2.25/2.06mm 0mm Figure 17: Comparisons with the RGB-based methods [23], [45]. From top to bottom: input facial images and scanned point clouds, results of [45], results of [23], results of ours (RGB) and results of ours (RGB-D input). The mean/std error to scanned point clouds is show on the bottom of each error map. Note that [23], [45] use only RGB information while our method (RGB) also uses depth information in training although not in testing. Figure 16: Comparisons with ARKit. 1st column: groundtruth geometry captured by Range 7 3D Scanner and input images. 2nd column: results of ARKit with only RGB input and geometry accuracy (w.r.t. ground-truth geometry). 3rd column: results of ARKit with RGB-D input. 4th column: results of our networks. Experiments show that our method is suitable for method with RGB input. 5th column: results of our method consumer-level RGB-D sensors and capturing 3D faces in the with RGB-D input. The error map images show the fitting wild, which is of great practical value. While ARKit [2] can real-time construct 3D face models error between the reconstructed models and the groundtruth models. The mean / standard deviations of errors (mm) are from RGB-D data captured by iphone X smartphone, its underlying technique has not been made public. Most previous listed at the bottom. work has difficulty to achieve accurate and robust real-time 3D facial capture from RGB-D data on mobile phones. Our work VI. D ISCUSSION &C ONCLUSION suggests that using RGB-D data and deep learning techniques We have presented an RGB-D deep learning method for provides a promising solution, especially noticing that some 3D facial performance capture, which is able to run on newly-released smartphones are equipped with advanced chip mobile devices and achieves high-quality, robust, and real- (for example, Huawei s Kirin 970 NPU) supporting deep time performance even under the scenarios with large poses, learning. different facial expressions, motion blur and diverse lighting One limitation of our current work is that while our conditions. The underlying technique is a self-supervised medium-scale CNN can achieve real time facial performance CNN framework that trains a medium-scale CNN and a capture on mobile devices, our fine-scale network still cannot fine-scale CNN directly from RGB-D raw face data. The due to its complexity. Optimizing the implementation and framework is flexible to support facial performance capture smartly modeling the surface fine detail will help speed up. with RGB-D or RGB input during testing. The key technical Another limitation of our work is that we assume Lambertian novelties lie in the training of the parametric face model, surface reflectance and smoothly varying illumination, which which learns both the core tensor and the model parameters, may introduce artifacts in general environments (e.g., with the use of UV map and vertex displacement for CNN-based strong subsurface scattering, high frequency or self-shadowing). surface detail refinement, and the elaborately-designed loss Though our sparse approximation to the color information function. In particular, considerable efforts have been put into could alleviate these artifacts to a certain extent, it is worth devising the terms for the loss functions and integrating various investigating more powerful formulation to handle general components to achieve efficient and robust training of the reflectance and illumination.
3DFaceNet: Real-time Dense Face Reconstruction via Synthesizing Photo-realistic Face Images
 1 3DFaceNet: Real-time Dense Face Reconstruction via Synthesizing Photo-realistic Face Images Yudong Guo, Juyong Zhang, Jianfei Cai, Boyi Jiang and Jianmin Zheng arxiv:1708.00980v2 [cs.cv] 11 Sep 2017
1 3DFaceNet: Real-time Dense Face Reconstruction via Synthesizing Photo-realistic Face Images Yudong Guo, Juyong Zhang, Jianfei Cai, Boyi Jiang and Jianmin Zheng arxiv:1708.00980v2 [cs.cv] 11 Sep 2017
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Synthesizing Realistic Facial Expressions from Photographs
 Synthesizing Realistic Facial Expressions from Photographs 1998 F. Pighin, J Hecker, D. Lischinskiy, R. Szeliskiz and D. H. Salesin University of Washington, The Hebrew University Microsoft Research 1
Synthesizing Realistic Facial Expressions from Photographs 1998 F. Pighin, J Hecker, D. Lischinskiy, R. Szeliskiz and D. H. Salesin University of Washington, The Hebrew University Microsoft Research 1
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
 MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Face Alignment Across Large Poses: A 3D Solution
 Face Alignment Across Large Poses: A 3D Solution Outline Face Alignment Related Works 3D Morphable Model Projected Normalized Coordinate Code Network Structure 3D Image Rotation Performance on Datasets
Face Alignment Across Large Poses: A 3D Solution Outline Face Alignment Related Works 3D Morphable Model Projected Normalized Coordinate Code Network Structure 3D Image Rotation Performance on Datasets
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA
 TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi 1, Francois de Sorbier 1 and Hideo Saito 1 1 Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi,
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi 1, Francois de Sorbier 1 and Hideo Saito 1 1 Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi,
Dense 3D Modelling and Monocular Reconstruction of Deformable Objects
 Dense 3D Modelling and Monocular Reconstruction of Deformable Objects Anastasios (Tassos) Roussos Lecturer in Computer Science, University of Exeter Research Associate, Imperial College London Overview
Dense 3D Modelling and Monocular Reconstruction of Deformable Objects Anastasios (Tassos) Roussos Lecturer in Computer Science, University of Exeter Research Associate, Imperial College London Overview
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/93/113542646.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
A Morphable Model for the Synthesis of 3D Faces
 A Morphable Model for the Synthesis of 3D Faces Marco Nef Volker Blanz, Thomas Vetter SIGGRAPH 99, Los Angeles Presentation overview Motivation Introduction Database Morphable 3D Face Model Matching a
A Morphable Model for the Synthesis of 3D Faces Marco Nef Volker Blanz, Thomas Vetter SIGGRAPH 99, Los Angeles Presentation overview Motivation Introduction Database Morphable 3D Face Model Matching a
From processing to learning on graphs
 From processing to learning on graphs Patrick Pérez Maths and Images in Paris IHP, 2 March 2017 Signals on graphs Natural graph: mesh, network, etc., related to a real structure, various signals can live
From processing to learning on graphs Patrick Pérez Maths and Images in Paris IHP, 2 March 2017 Signals on graphs Natural graph: mesh, network, etc., related to a real structure, various signals can live
Depth. Common Classification Tasks. Example: AlexNet. Another Example: Inception. Another Example: Inception. Depth
 Common Classification Tasks Recognition of individual objects/faces Analyze object-specific features (e.g., key points) Train with images from different viewing angles Recognition of object classes Analyze
Common Classification Tasks Recognition of individual objects/faces Analyze object-specific features (e.g., key points) Train with images from different viewing angles Recognition of object classes Analyze
AAM Based Facial Feature Tracking with Kinect
 BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 15, No 3 Sofia 2015 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2015-0046 AAM Based Facial Feature Tracking
BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 15, No 3 Sofia 2015 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2015-0046 AAM Based Facial Feature Tracking
Face Re-Lighting from a Single Image under Harsh Lighting Conditions
 Face Re-Lighting from a Single Image under Harsh Lighting Conditions Yang Wang 1, Zicheng Liu 2, Gang Hua 3, Zhen Wen 4, Zhengyou Zhang 2, Dimitris Samaras 5 1 The Robotics Institute, Carnegie Mellon University,
Face Re-Lighting from a Single Image under Harsh Lighting Conditions Yang Wang 1, Zicheng Liu 2, Gang Hua 3, Zhen Wen 4, Zhengyou Zhang 2, Dimitris Samaras 5 1 The Robotics Institute, Carnegie Mellon University,
Multiple Model Estimation : The EM Algorithm & Applications
 Multiple Model Estimation : The EM Algorithm & Applications Princeton University COS 429 Lecture Nov. 13, 2007 Harpreet S. Sawhney hsawhney@sarnoff.com Recapitulation Problem of motion estimation Parametric
Multiple Model Estimation : The EM Algorithm & Applications Princeton University COS 429 Lecture Nov. 13, 2007 Harpreet S. Sawhney hsawhney@sarnoff.com Recapitulation Problem of motion estimation Parametric
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA
 TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi, Francois de Sorbier and Hideo Saito Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi, Kohoku-ku,
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi, Francois de Sorbier and Hideo Saito Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi, Kohoku-ku,
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference
 Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference Minh Dao 1, Xiang Xiang 1, Bulent Ayhan 2, Chiman Kwan 2, Trac D. Tran 1 Johns Hopkins Univeristy, 3400
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference Minh Dao 1, Xiang Xiang 1, Bulent Ayhan 2, Chiman Kwan 2, Trac D. Tran 1 Johns Hopkins Univeristy, 3400
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
3D Editing System for Captured Real Scenes
 3D Editing System for Captured Real Scenes Inwoo Ha, Yong Beom Lee and James D.K. Kim Samsung Advanced Institute of Technology, Youngin, South Korea E-mail: {iw.ha, leey, jamesdk.kim}@samsung.com Tel:
3D Editing System for Captured Real Scenes Inwoo Ha, Yong Beom Lee and James D.K. Kim Samsung Advanced Institute of Technology, Youngin, South Korea E-mail: {iw.ha, leey, jamesdk.kim}@samsung.com Tel:
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Processing 3D Surface Data
 Processing 3D Surface Data Computer Animation and Visualisation Lecture 12 Institute for Perception, Action & Behaviour School of Informatics 3D Surfaces 1 3D surface data... where from? Iso-surfacing
Processing 3D Surface Data Computer Animation and Visualisation Lecture 12 Institute for Perception, Action & Behaviour School of Informatics 3D Surfaces 1 3D surface data... where from? Iso-surfacing
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
A Non-Linear Image Registration Scheme for Real-Time Liver Ultrasound Tracking using Normalized Gradient Fields
 A Non-Linear Image Registration Scheme for Real-Time Liver Ultrasound Tracking using Normalized Gradient Fields Lars König, Till Kipshagen and Jan Rühaak Fraunhofer MEVIS Project Group Image Registration,
A Non-Linear Image Registration Scheme for Real-Time Liver Ultrasound Tracking using Normalized Gradient Fields Lars König, Till Kipshagen and Jan Rühaak Fraunhofer MEVIS Project Group Image Registration,
A Survey of Light Source Detection Methods
 A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
Processing 3D Surface Data
 Processing 3D Surface Data Computer Animation and Visualisation Lecture 17 Institute for Perception, Action & Behaviour School of Informatics 3D Surfaces 1 3D surface data... where from? Iso-surfacing
Processing 3D Surface Data Computer Animation and Visualisation Lecture 17 Institute for Perception, Action & Behaviour School of Informatics 3D Surfaces 1 3D surface data... where from? Iso-surfacing
Bilevel Sparse Coding
 Adobe Research 345 Park Ave, San Jose, CA Mar 15, 2013 Outline 1 2 The learning model The learning algorithm 3 4 Sparse Modeling Many types of sensory data, e.g., images and audio, are in high-dimensional
Adobe Research 345 Park Ave, San Jose, CA Mar 15, 2013 Outline 1 2 The learning model The learning algorithm 3 4 Sparse Modeling Many types of sensory data, e.g., images and audio, are in high-dimensional
BIL Computer Vision Apr 16, 2014
 BIL 719 - Computer Vision Apr 16, 2014 Binocular Stereo (cont d.), Structure from Motion Aykut Erdem Dept. of Computer Engineering Hacettepe University Slide credit: S. Lazebnik Basic stereo matching algorithm
BIL 719 - Computer Vision Apr 16, 2014 Binocular Stereo (cont d.), Structure from Motion Aykut Erdem Dept. of Computer Engineering Hacettepe University Slide credit: S. Lazebnik Basic stereo matching algorithm
CHAPTER 3 DISPARITY AND DEPTH MAP COMPUTATION
 CHAPTER 3 DISPARITY AND DEPTH MAP COMPUTATION In this chapter we will discuss the process of disparity computation. It plays an important role in our caricature system because all 3D coordinates of nodes
CHAPTER 3 DISPARITY AND DEPTH MAP COMPUTATION In this chapter we will discuss the process of disparity computation. It plays an important role in our caricature system because all 3D coordinates of nodes
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Unsupervised learning in Vision
 Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Motion Estimation. There are three main types (or applications) of motion estimation:
 of motion estimation:") Members: D91922016 朱威達 R93922010 林聖凱 R93922044 謝俊瑋 Motion Estimation There are three main types (or applications) of motion estimation: Parametric motion (image alignment) The main idea of parametric motion
Members: D91922016 朱威達 R93922010 林聖凱 R93922044 謝俊瑋 Motion Estimation There are three main types (or applications) of motion estimation: Parametric motion (image alignment) The main idea of parametric motion
Face Hallucination Based on Eigentransformation Learning
 Advanced Science and Technology etters, pp.32-37 http://dx.doi.org/10.14257/astl.2016. Face allucination Based on Eigentransformation earning Guohua Zou School of software, East China University of Technology,
Advanced Science and Technology etters, pp.32-37 http://dx.doi.org/10.14257/astl.2016. Face allucination Based on Eigentransformation earning Guohua Zou School of software, East China University of Technology,
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Deep Learning: Image Registration. Steven Chen and Ty Nguyen
 Deep Learning: Image Registration Steven Chen and Ty Nguyen Lecture Outline 1. Brief Introduction to Deep Learning 2. Case Study 1: Unsupervised Deep Homography 3. Case Study 2: Deep LucasKanade What is
Deep Learning: Image Registration Steven Chen and Ty Nguyen Lecture Outline 1. Brief Introduction to Deep Learning 2. Case Study 1: Unsupervised Deep Homography 3. Case Study 2: Deep LucasKanade What is
Stereo. 11/02/2012 CS129, Brown James Hays. Slides by Kristen Grauman
 Stereo 11/02/2012 CS129, Brown James Hays Slides by Kristen Grauman Multiple views Multi-view geometry, matching, invariant features, stereo vision Lowe Hartley and Zisserman Why multiple views? Structure
Stereo 11/02/2012 CS129, Brown James Hays Slides by Kristen Grauman Multiple views Multi-view geometry, matching, invariant features, stereo vision Lowe Hartley and Zisserman Why multiple views? Structure
Flexible Calibration of a Portable Structured Light System through Surface Plane
 Vol. 34, No. 11 ACTA AUTOMATICA SINICA November, 2008 Flexible Calibration of a Portable Structured Light System through Surface Plane GAO Wei 1 WANG Liang 1 HU Zhan-Yi 1 Abstract For a portable structured
Vol. 34, No. 11 ACTA AUTOMATICA SINICA November, 2008 Flexible Calibration of a Portable Structured Light System through Surface Plane GAO Wei 1 WANG Liang 1 HU Zhan-Yi 1 Abstract For a portable structured
Learning a generic 3D face model from 2D image databases using incremental structure from motion
 Learning a generic 3D face model from 2D image databases using incremental structure from motion Jose Gonzalez-Mora 1,, Fernando De la Torre b, Nicolas Guil 1,, Emilio L. Zapata 1 a Department of Computer
Learning a generic 3D face model from 2D image databases using incremental structure from motion Jose Gonzalez-Mora 1,, Fernando De la Torre b, Nicolas Guil 1,, Emilio L. Zapata 1 a Department of Computer
CHAPTER 3. Single-view Geometry. 1. Consequences of Projection
 CHAPTER 3 Single-view Geometry When we open an eye or take a photograph, we see only a flattened, two-dimensional projection of the physical underlying scene. The consequences are numerous and startling.
CHAPTER 3 Single-view Geometry When we open an eye or take a photograph, we see only a flattened, two-dimensional projection of the physical underlying scene. The consequences are numerous and startling.
Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction
 Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali University of Louisville Louisville, KY {hmrara01,syelha01,amali003}@louisville.edu Mike Miller,
Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali University of Louisville Louisville, KY {hmrara01,syelha01,amali003}@louisville.edu Mike Miller,
Multiple Model Estimation : The EM Algorithm & Applications
 Multiple Model Estimation : The EM Algorithm & Applications Princeton University COS 429 Lecture Dec. 4, 2008 Harpreet S. Sawhney hsawhney@sarnoff.com Plan IBR / Rendering applications of motion / pose
Multiple Model Estimation : The EM Algorithm & Applications Princeton University COS 429 Lecture Dec. 4, 2008 Harpreet S. Sawhney hsawhney@sarnoff.com Plan IBR / Rendering applications of motion / pose
Face Tracking. Synonyms. Definition. Main Body Text. Amit K. Roy-Chowdhury and Yilei Xu. Facial Motion Estimation
 Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Deep Learning for Virtual Shopping. Dr. Jürgen Sturm Group Leader RGB-D
 Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
Motion Tracking and Event Understanding in Video Sequences
 Motion Tracking and Event Understanding in Video Sequences Isaac Cohen Elaine Kang, Jinman Kang Institute for Robotics and Intelligent Systems University of Southern California Los Angeles, CA Objectives!
Motion Tracking and Event Understanding in Video Sequences Isaac Cohen Elaine Kang, Jinman Kang Institute for Robotics and Intelligent Systems University of Southern California Los Angeles, CA Objectives!
Registration of Dynamic Range Images
 Registration of Dynamic Range Images Tan-Chi Ho 1,2 Jung-Hong Chuang 1 Wen-Wei Lin 2 Song-Sun Lin 2 1 Department of Computer Science National Chiao-Tung University 2 Department of Applied Mathematics National
Registration of Dynamic Range Images Tan-Chi Ho 1,2 Jung-Hong Chuang 1 Wen-Wei Lin 2 Song-Sun Lin 2 1 Department of Computer Science National Chiao-Tung University 2 Department of Applied Mathematics National
ACQUIRING 3D models of deforming objects in real-life is
 IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS 1 Robust Non-rigid Motion Tracking and Surface Reconstruction Using L 0 Regularization Kaiwen Guo, Feng Xu, Yangang Wang, Yebin Liu, Member, IEEE
IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS 1 Robust Non-rigid Motion Tracking and Surface Reconstruction Using L 0 Regularization Kaiwen Guo, Feng Xu, Yangang Wang, Yebin Liu, Member, IEEE
Flow Estimation. Min Bai. February 8, University of Toronto. Min Bai (UofT) Flow Estimation February 8, / 47
 Flow Estimation February 8, / 47") Flow Estimation Min Bai University of Toronto February 8, 2016 Min Bai (UofT) Flow Estimation February 8, 2016 1 / 47 Outline Optical Flow - Continued Min Bai (UofT) Flow Estimation February 8, 2016 2
Flow Estimation Min Bai University of Toronto February 8, 2016 Min Bai (UofT) Flow Estimation February 8, 2016 1 / 47 Outline Optical Flow - Continued Min Bai (UofT) Flow Estimation February 8, 2016 2
Registration of Expressions Data using a 3D Morphable Model
 Registration of Expressions Data using a 3D Morphable Model Curzio Basso, Pascal Paysan, Thomas Vetter Computer Science Department, University of Basel {curzio.basso,pascal.paysan,thomas.vetter}@unibas.ch
Registration of Expressions Data using a 3D Morphable Model Curzio Basso, Pascal Paysan, Thomas Vetter Computer Science Department, University of Basel {curzio.basso,pascal.paysan,thomas.vetter}@unibas.ch
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE. Nan Hu. Stanford University Electrical Engineering
 STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
Speech Driven Synthesis of Talking Head Sequences
 3D Image Analysis and Synthesis, pp. 5-56, Erlangen, November 997. Speech Driven Synthesis of Talking Head Sequences Peter Eisert, Subhasis Chaudhuri,andBerndGirod Telecommunications Laboratory, University
3D Image Analysis and Synthesis, pp. 5-56, Erlangen, November 997. Speech Driven Synthesis of Talking Head Sequences Peter Eisert, Subhasis Chaudhuri,andBerndGirod Telecommunications Laboratory, University
Robust Articulated ICP for Real-Time Hand Tracking
 Robust Articulated-ICP for Real-Time Hand Tracking Andrea Tagliasacchi* Sofien Bouaziz Matthias Schröder* Mario Botsch Anastasia Tkach Mark Pauly * equal contribution 1/36 Real-Time Tracking Setup Data
Robust Articulated-ICP for Real-Time Hand Tracking Andrea Tagliasacchi* Sofien Bouaziz Matthias Schröder* Mario Botsch Anastasia Tkach Mark Pauly * equal contribution 1/36 Real-Time Tracking Setup Data
Modeling pigeon behaviour using a Conditional Restricted Boltzmann Machine
 Modeling pigeon behaviour using a Conditional Restricted Boltzmann Machine Matthew D. Zeiler 1,GrahamW.Taylor 1, Nikolaus F. Troje 2 and Geoffrey E. Hinton 1 1- University of Toronto - Dept. of Computer
Modeling pigeon behaviour using a Conditional Restricted Boltzmann Machine Matthew D. Zeiler 1,GrahamW.Taylor 1, Nikolaus F. Troje 2 and Geoffrey E. Hinton 1 1- University of Toronto - Dept. of Computer
Structured light 3D reconstruction
 Structured light 3D reconstruction Reconstruction pipeline and industrial applications rodola@dsi.unive.it 11/05/2010 3D Reconstruction 3D reconstruction is the process of capturing the shape and appearance
Structured light 3D reconstruction Reconstruction pipeline and industrial applications rodola@dsi.unive.it 11/05/2010 3D Reconstruction 3D reconstruction is the process of capturing the shape and appearance
Animation. CS 465 Lecture 22
 Animation CS 465 Lecture 22 Animation Industry production process leading up to animation What animation is How animation works (very generally) Artistic process of animation Further topics in how it works
Animation CS 465 Lecture 22 Animation Industry production process leading up to animation What animation is How animation works (very generally) Artistic process of animation Further topics in how it works
2D vs. 3D Deformable Face Models: Representational Power, Construction, and Real-Time Fitting
 2D vs. 3D Deformable Face Models: Representational Power, Construction, and Real-Time Fitting Iain Matthews, Jing Xiao, and Simon Baker The Robotics Institute, Carnegie Mellon University Epsom PAL, Epsom
2D vs. 3D Deformable Face Models: Representational Power, Construction, and Real-Time Fitting Iain Matthews, Jing Xiao, and Simon Baker The Robotics Institute, Carnegie Mellon University Epsom PAL, Epsom
Chapter 7. Conclusions and Future Work
 Chapter 7 Conclusions and Future Work In this dissertation, we have presented a new way of analyzing a basic building block in computer graphics rendering algorithms the computational interaction between
Chapter 7 Conclusions and Future Work In this dissertation, we have presented a new way of analyzing a basic building block in computer graphics rendering algorithms the computational interaction between
WARP BASED NEAR REGULAR TEXTURE ANALYSIS FOR IMAGE BASED TEXTURE OVERLAY
 WARP BASED NEAR REGULAR TEXTURE ANALYSIS FOR IMAGE BASED TEXTURE OVERLAY Anna Hilsmann 1,2 David C. Schneider 1,2 Peter Eisert 1,2 1 Fraunhofer Heinrich Hertz Institute Berlin, Germany 2 Humboldt University
WARP BASED NEAR REGULAR TEXTURE ANALYSIS FOR IMAGE BASED TEXTURE OVERLAY Anna Hilsmann 1,2 David C. Schneider 1,2 Peter Eisert 1,2 1 Fraunhofer Heinrich Hertz Institute Berlin, Germany 2 Humboldt University
Modeling Facial Expressions in 3D Avatars from 2D Images
 Modeling Facial Expressions in 3D Avatars from 2D Images Emma Sax Division of Science and Mathematics University of Minnesota, Morris Morris, Minnesota, USA 12 November, 2016 Morris, MN Sax (U of Minn,
Modeling Facial Expressions in 3D Avatars from 2D Images Emma Sax Division of Science and Mathematics University of Minnesota, Morris Morris, Minnesota, USA 12 November, 2016 Morris, MN Sax (U of Minn,
Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. Presented by: Karen Lucknavalai and Alexandr Kuznetsov
 Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization Presented by: Karen Lucknavalai and Alexandr Kuznetsov Example Style Content Result Motivation Transforming content of an image
Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization Presented by: Karen Lucknavalai and Alexandr Kuznetsov Example Style Content Result Motivation Transforming content of an image
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Human Shape from Silhouettes using Generative HKS Descriptors and Cross-Modal Neural Networks
 Human Shape from Silhouettes using Generative HKS Descriptors and Cross-Modal Neural Networks Endri Dibra 1, Himanshu Jain 1, Cengiz Öztireli 1, Remo Ziegler 2, Markus Gross 1 1 Department of Computer
Human Shape from Silhouettes using Generative HKS Descriptors and Cross-Modal Neural Networks Endri Dibra 1, Himanshu Jain 1, Cengiz Öztireli 1, Remo Ziegler 2, Markus Gross 1 1 Department of Computer
Computer Vision Lecture 17
 Computer Vision Lecture 17 Epipolar Geometry & Stereo Basics 13.01.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar in the summer semester
Computer Vision Lecture 17 Epipolar Geometry & Stereo Basics 13.01.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar in the summer semester
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Translation Symmetry Detection: A Repetitive Pattern Analysis Approach
 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops Translation Symmetry Detection: A Repetitive Pattern Analysis Approach Yunliang Cai and George Baciu GAMA Lab, Department of Computing
2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops Translation Symmetry Detection: A Repetitive Pattern Analysis Approach Yunliang Cai and George Baciu GAMA Lab, Department of Computing
Prof. Fanny Ficuciello Robotics for Bioengineering Visual Servoing
 Visual servoing vision allows a robotic system to obtain geometrical and qualitative information on the surrounding environment high level control motion planning (look-and-move visual grasping) low level
Visual servoing vision allows a robotic system to obtain geometrical and qualitative information on the surrounding environment high level control motion planning (look-and-move visual grasping) low level
3D Active Appearance Model for Aligning Faces in 2D Images
 3D Active Appearance Model for Aligning Faces in 2D Images Chun-Wei Chen and Chieh-Chih Wang Abstract Perceiving human faces is one of the most important functions for human robot interaction. The active
3D Active Appearance Model for Aligning Faces in 2D Images Chun-Wei Chen and Chieh-Chih Wang Abstract Perceiving human faces is one of the most important functions for human robot interaction. The active
Ping Tan. Simon Fraser University
 Ping Tan Simon Fraser University Photos vs. Videos (live photos) A good photo tells a story Stories are better told in videos Videos in the Mobile Era (mobile & share) More videos are captured by mobile
Ping Tan Simon Fraser University Photos vs. Videos (live photos) A good photo tells a story Stories are better told in videos Videos in the Mobile Era (mobile & share) More videos are captured by mobile
Computer Vision Lecture 17
 Announcements Computer Vision Lecture 17 Epipolar Geometry & Stereo Basics Seminar in the summer semester Current Topics in Computer Vision and Machine Learning Block seminar, presentations in 1 st week
Announcements Computer Vision Lecture 17 Epipolar Geometry & Stereo Basics Seminar in the summer semester Current Topics in Computer Vision and Machine Learning Block seminar, presentations in 1 st week
Stereo: Disparity and Matching
 CS 4495 Computer Vision Aaron Bobick School of Interactive Computing Administrivia PS2 is out. But I was late. So we pushed the due date to Wed Sept 24 th, 11:55pm. There is still *no* grace period. To
CS 4495 Computer Vision Aaron Bobick School of Interactive Computing Administrivia PS2 is out. But I was late. So we pushed the due date to Wed Sept 24 th, 11:55pm. There is still *no* grace period. To
PERFORMANCE CAPTURE FROM SPARSE MULTI-VIEW VIDEO
 Stefan Krauß, Juliane Hüttl SE, SoSe 2011, HU-Berlin PERFORMANCE CAPTURE FROM SPARSE MULTI-VIEW VIDEO 1 Uses of Motion/Performance Capture movies games, virtual environments biomechanics, sports science,
Stefan Krauß, Juliane Hüttl SE, SoSe 2011, HU-Berlin PERFORMANCE CAPTURE FROM SPARSE MULTI-VIEW VIDEO 1 Uses of Motion/Performance Capture movies games, virtual environments biomechanics, sports science,
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction
 Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Accurate and Dense Wide-Baseline Stereo Matching Using SW-POC
 Accurate and Dense Wide-Baseline Stereo Matching Using SW-POC Shuji Sakai, Koichi Ito, Takafumi Aoki Graduate School of Information Sciences, Tohoku University, Sendai, 980 8579, Japan Email: sakai@aoki.ecei.tohoku.ac.jp
Accurate and Dense Wide-Baseline Stereo Matching Using SW-POC Shuji Sakai, Koichi Ito, Takafumi Aoki Graduate School of Information Sciences, Tohoku University, Sendai, 980 8579, Japan Email: sakai@aoki.ecei.tohoku.ac.jp
Point based global illumination is now a standard tool for film quality renderers. Since it started out as a real time technique it is only natural
 1 Point based global illumination is now a standard tool for film quality renderers. Since it started out as a real time technique it is only natural to consider using it in video games too. 2 I hope that
1 Point based global illumination is now a standard tool for film quality renderers. Since it started out as a real time technique it is only natural to consider using it in video games too. 2 I hope that
Speed up a Machine-Learning-based Image Super-Resolution Algorithm on GPGPU
 Speed up a Machine-Learning-based Image Super-Resolution Algorithm on GPGPU Ke Ma 1, and Yao Song 2 1 Department of Computer Sciences 2 Department of Electrical and Computer Engineering University of Wisconsin-Madison
Speed up a Machine-Learning-based Image Super-Resolution Algorithm on GPGPU Ke Ma 1, and Yao Song 2 1 Department of Computer Sciences 2 Department of Electrical and Computer Engineering University of Wisconsin-Madison
Lecture 19: Depth Cameras. Visual Computing Systems CMU , Fall 2013
 Lecture 19: Depth Cameras Visual Computing Systems Continuing theme: computational photography Cameras capture light, then extensive processing produces the desired image Today: - Capturing scene depth
Lecture 19: Depth Cameras Visual Computing Systems Continuing theme: computational photography Cameras capture light, then extensive processing produces the desired image Today: - Capturing scene depth
Multi-View Stereo for Static and Dynamic Scenes
 Multi-View Stereo for Static and Dynamic Scenes Wolfgang Burgard Jan 6, 2010 Main references Yasutaka Furukawa and Jean Ponce, Accurate, Dense and Robust Multi-View Stereopsis, 2007 C.L. Zitnick, S.B.
Multi-View Stereo for Static and Dynamic Scenes Wolfgang Burgard Jan 6, 2010 Main references Yasutaka Furukawa and Jean Ponce, Accurate, Dense and Robust Multi-View Stereopsis, 2007 C.L. Zitnick, S.B.
Fundamentals of Stereo Vision Michael Bleyer LVA Stereo Vision
 Fundamentals of Stereo Vision Michael Bleyer LVA Stereo Vision What Happened Last Time? Human 3D perception (3D cinema) Computational stereo Intuitive explanation of what is meant by disparity Stereo matching
Fundamentals of Stereo Vision Michael Bleyer LVA Stereo Vision What Happened Last Time? Human 3D perception (3D cinema) Computational stereo Intuitive explanation of what is meant by disparity Stereo matching
ELEC Dr Reji Mathew Electrical Engineering UNSW
 ELEC 4622 Dr Reji Mathew Electrical Engineering UNSW Review of Motion Modelling and Estimation Introduction to Motion Modelling & Estimation Forward Motion Backward Motion Block Motion Estimation Motion
ELEC 4622 Dr Reji Mathew Electrical Engineering UNSW Review of Motion Modelling and Estimation Introduction to Motion Modelling & Estimation Forward Motion Backward Motion Block Motion Estimation Motion
Camera model and multiple view geometry
 Chapter Camera model and multiple view geometry Before discussing how D information can be obtained from images it is important to know how images are formed First the camera model is introduced and then
Chapter Camera model and multiple view geometry Before discussing how D information can be obtained from images it is important to know how images are formed First the camera model is introduced and then
Occluded Facial Expression Tracking
 Occluded Facial Expression Tracking Hugo Mercier 1, Julien Peyras 2, and Patrice Dalle 1 1 Institut de Recherche en Informatique de Toulouse 118, route de Narbonne, F-31062 Toulouse Cedex 9 2 Dipartimento
Occluded Facial Expression Tracking Hugo Mercier 1, Julien Peyras 2, and Patrice Dalle 1 1 Institut de Recherche en Informatique de Toulouse 118, route de Narbonne, F-31062 Toulouse Cedex 9 2 Dipartimento
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images
 Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
Learning visual odometry with a convolutional network
 Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
FAST REGISTRATION OF TERRESTRIAL LIDAR POINT CLOUD AND SEQUENCE IMAGES
 FAST REGISTRATION OF TERRESTRIAL LIDAR POINT CLOUD AND SEQUENCE IMAGES Jie Shao a, Wuming Zhang a, Yaqiao Zhu b, Aojie Shen a a State Key Laboratory of Remote Sensing Science, Institute of Remote Sensing
FAST REGISTRATION OF TERRESTRIAL LIDAR POINT CLOUD AND SEQUENCE IMAGES Jie Shao a, Wuming Zhang a, Yaqiao Zhu b, Aojie Shen a a State Key Laboratory of Remote Sensing Science, Institute of Remote Sensing
Occlusion Robust Multi-Camera Face Tracking
 Occlusion Robust Multi-Camera Face Tracking Josh Harguess, Changbo Hu, J. K. Aggarwal Computer & Vision Research Center / Department of ECE The University of Texas at Austin harguess@utexas.edu, changbo.hu@gmail.com,
Occlusion Robust Multi-Camera Face Tracking Josh Harguess, Changbo Hu, J. K. Aggarwal Computer & Vision Research Center / Department of ECE The University of Texas at Austin harguess@utexas.edu, changbo.hu@gmail.com,
calibrated coordinates Linear transformation pixel coordinates
 1 calibrated coordinates Linear transformation pixel coordinates 2 Calibration with a rig Uncalibrated epipolar geometry Ambiguities in image formation Stratified reconstruction Autocalibration with partial
1 calibrated coordinates Linear transformation pixel coordinates 2 Calibration with a rig Uncalibrated epipolar geometry Ambiguities in image formation Stratified reconstruction Autocalibration with partial
Unsupervised Learning of Spatiotemporally Coherent Metrics
 Unsupervised Learning of Spatiotemporally Coherent Metrics Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, Yann LeCun arxiv 2015. Presented by Jackie Chu Contributions Insight between slow feature
Unsupervised Learning of Spatiotemporally Coherent Metrics Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, Yann LeCun arxiv 2015. Presented by Jackie Chu Contributions Insight between slow feature
On-line and Off-line 3D Reconstruction for Crisis Management Applications
 On-line and Off-line 3D Reconstruction for Crisis Management Applications Geert De Cubber Royal Military Academy, Department of Mechanical Engineering (MSTA) Av. de la Renaissance 30, 1000 Brussels geert.de.cubber@rma.ac.be
On-line and Off-line 3D Reconstruction for Crisis Management Applications Geert De Cubber Royal Military Academy, Department of Mechanical Engineering (MSTA) Av. de la Renaissance 30, 1000 Brussels geert.de.cubber@rma.ac.be
CMSC427 Advanced shading getting global illumination by local methods. Credit: slides Prof. Zwicker
 CMSC427 Advanced shading getting global illumination by local methods Credit: slides Prof. Zwicker Topics Shadows Environment maps Reflection mapping Irradiance environment maps Ambient occlusion Reflection
CMSC427 Advanced shading getting global illumination by local methods Credit: slides Prof. Zwicker Topics Shadows Environment maps Reflection mapping Irradiance environment maps Ambient occlusion Reflection
Face Recognition Markus Storer, 2007
 Face Recognition Markus Storer, 2007 Agenda Face recognition by humans 3D morphable models pose and illumination model creation model fitting results Face recognition vendor test 2006 Face Recognition
Face Recognition Markus Storer, 2007 Agenda Face recognition by humans 3D morphable models pose and illumination model creation model fitting results Face recognition vendor test 2006 Face Recognition
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Self-calibration of a pair of stereo cameras in general position
 Self-calibration of a pair of stereo cameras in general position Raúl Rojas Institut für Informatik Freie Universität Berlin Takustr. 9, 14195 Berlin, Germany Abstract. This paper shows that it is possible
Self-calibration of a pair of stereo cameras in general position Raúl Rojas Institut für Informatik Freie Universität Berlin Takustr. 9, 14195 Berlin, Germany Abstract. This paper shows that it is possible
Miniature faking. In close-up photo, the depth of field is limited.
 Miniature faking In close-up photo, the depth of field is limited. http://en.wikipedia.org/wiki/file:jodhpur_tilt_shift.jpg Miniature faking Miniature faking http://en.wikipedia.org/wiki/file:oregon_state_beavers_tilt-shift_miniature_greg_keene.jpg
Miniature faking In close-up photo, the depth of field is limited. http://en.wikipedia.org/wiki/file:jodhpur_tilt_shift.jpg Miniature faking Miniature faking http://en.wikipedia.org/wiki/file:oregon_state_beavers_tilt-shift_miniature_greg_keene.jpg
DISTANCE MAPS: A ROBUST ILLUMINATION PREPROCESSING FOR ACTIVE APPEARANCE MODELS
 DISTANCE MAPS: A ROBUST ILLUMINATION PREPROCESSING FOR ACTIVE APPEARANCE MODELS Sylvain Le Gallou*, Gaspard Breton*, Christophe Garcia*, Renaud Séguier** * France Telecom R&D - TECH/IRIS 4 rue du clos
DISTANCE MAPS: A ROBUST ILLUMINATION PREPROCESSING FOR ACTIVE APPEARANCE MODELS Sylvain Le Gallou*, Gaspard Breton*, Christophe Garcia*, Renaud Séguier** * France Telecom R&D - TECH/IRIS 4 rue du clos
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
CS 4495 Computer Vision A. Bobick. Motion and Optic Flow. Stereo Matching
 Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza
 Davide Scaramuzza") Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time, ICRA 14, by Pizzoli, Forster, Scaramuzza [M. Pizzoli, C. Forster,
Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time, ICRA 14, by Pizzoli, Forster, Scaramuzza [M. Pizzoli, C. Forster,
cse 252c Fall 2004 Project Report: A Model of Perpendicular Texture for Determining Surface Geometry
 cse 252c Fall 2004 Project Report: A Model of Perpendicular Texture for Determining Surface Geometry Steven Scher December 2, 2004 Steven Scher SteveScher@alumni.princeton.edu Abstract Three-dimensional
cse 252c Fall 2004 Project Report: A Model of Perpendicular Texture for Determining Surface Geometry Steven Scher December 2, 2004 Steven Scher SteveScher@alumni.princeton.edu Abstract Three-dimensional