Clustering analysis of gene expression data
|
|
|
- Benjamin Powell
- 5 years ago
- Views:
Transcription
1 Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition)

2 Human T cell expression data The matrix contains 47 expression samples from Lukk et al, Nature Biotechnology 2010 All samples are from T cells in different individuals Only the top 3000 genes with the largest variability were used The value is log2 of gene s expression level in a given sample as measured by the microarray technology T cells a T cell


3 How to interpret the expression data if you still have many genes and many samples?
4 Clustering to the rescue!
5 Clustering is a part of Machine Learning Supervised Learning: A machine learning technique whereby a system uses a set of training examples to learn how to correctly perform a task Example: a bunch of cancer expression samples each annotated with cancer type/tissue. Goal: predict cancer type based on expression pattern Unsupervised Learning (including clustering): In machine learning, unsupervised learning is a class of problems in which one seeks to determine how the data are organized. One only has unlabeled examples. Example: a bunch of breast cancer expression samples. Identify several different (yet unknown) subtypes with different likely outcomes
6 What is clustering? The goal of clustering is to group data points that are close (or similar) to each other Usually we need to identify such groups (or clusters) in an unsupervised manner Sometimes we take into account prior information (Bayesian methods) Need to define distance d ij between objects i and j In our case objects could be either genes or samples Easy in 2 dimensions but hard in 3000 dimensions Need to somehow reduce dimensionality x x x x x x x x x
7 How to define distance? Correlation coefficient distance d( X, Y) 1 ( X, Y) 1 Cov( X, Y ) ( Var( X ) Var( Y )
8 Reminder: Principal Component Analysis

9 Multivariable statistics and Principal Component Analysis (PCA) A table of n observations in which p variables were measured p x p symmetric matrix R of corr. coefficients PCA: Diagonalize matrix R
10 Trick: Rotate Coordinate Axes Suppose we have a population measured on p random variables X 1,,X p. Note that these random variables represent the p-axes of the Cartesian coordinate system in which the population resides. Our goal is to develop a new set of p axes (linear combinations of the original p axes) in the directions of greatest variability: X 2 X 1 This is accomplished by rotating the axes. Adapted from slides by Prof. S. Narasimhan, Computer Vision course at CMU
11 Principle Component Analysis (PCA) p x p symmetric matrix R of corr. coefficients R=n 1 Z *Z is a square of the matrix Z of standardized r.v.: all eigenvalues of R are non negative Diagonal elements=1 tr(r)=p Can be diagonalized: R=V*D*V where D is the diagonal matrix d(1,1) largest eig. value, d(p,p) the smallest one The meaning of V(i,k) contribution of the data type i to the k th eigenvector tr(d)=p, the largest eigenvalue d(1,1) absorbs a fraction =d(1,1)/p of all correlations can be ~100% Scores: Y=Z*V: n x p matrix. Meaning of Y(,k) participation of the sample # in the k th eigenvector
12 Back to clustering
 Fine needle")

13 Let s work with real cancer data! Data from Wolberg, Street, and Mangasarian (1994) Fine needle aspirates = biopsy for breast cancer Black dots cell nuclei. Irregular shapes/sizes may mean cancer 212 cancer patients and 357 healthy (column 1) 30 other properties (see table)
14 Common types of clustering algorithms Hierarchical if don t know in advance # of clusters Agglomerative: start: N clusters, merge into 1 cluster Divisive: start with 1 cluster and breaks it up into N Non hierarchical algorithms Principal Component Analysis (PCA) plot pairs of top eigenvectors of the covariance matrix Cov(X i, X j ) and uses visual information to group K means clustering: Iteratively apply the following two steps: Calculate the centroid (center of mass) of each cluster Assign each to the cluster to the nearest centroi
15 Credit: XKCD comics
16 UPGMA algorithm Hierarchical agglomerative clustering algorithm UPGMA = Unweighted Pair Group Method with Arithmetic mean Iterative algorithm: Start with a pair with the smallest d(x,y) Cluster these two together and replace it with their arithmetic mean (X+Y)/2 Recalculate all distances to this new cluster node Repeat until all nodes are merged

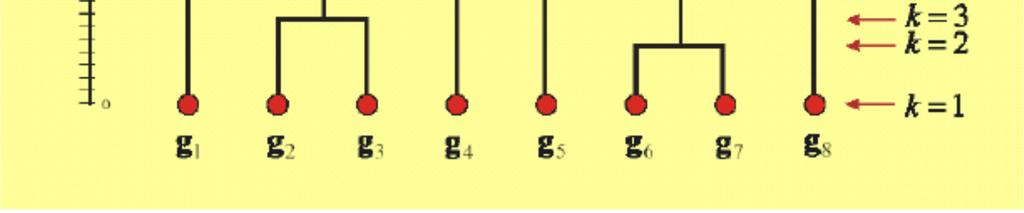
17 Output of UPGMA algorithm
18
19 Matlab demo
20 Human T cell expression data The matrix contains 47 expression samples from Lukk et al, Nature Biotechnology 2010 All samples are from T cells in different individuals Only the top 3000 genes with the largest variability were used The value is log2 of gene s expression level in a given sample as measured by the microarray technology T cells a T cell

21 Choices of distance metrics in clustergram( RowPDistValue, ColumnPDistValue,)
22 Choices of hierarchical clustering algorithm in clustergram( linkage, )
23 Clustering group exercise Each group will analyze a cluster of genes identified in the T cell expression table Analyze the table of top 100 genes by variance in 47 samples Cluster them using: Group 1: UPGMA = linkage, average, RowPDistValue, euclidian, Group 2: linkage, single, RowPDistValue, cityblock, Group 3: linkage, average, RowPDistValue, correlation, Group 4: UPGMA = linkage, single, RowPDistValue, euclidian, Use clustergram(, 'Standardize','Row', linkage, as specified for your group, RowPDistValue as specified for your group, 'RowLabels',gene_names1,'ColumnLabels, array_names)
24 Matlab code load expression_table.mat gene_variation=std(exp_t')'; [a,b]=sort(gene_variation,'descend'); ngenes=100; exp_t1=exp_t(b(1:ngenes),:); gene_names1=gene_names(b(1:ngenes)); %%% for group 1 CGobj1 = clustergram(exp_t1, 'Standardize','Row', 'RowLabels', gene_names1,'columnlabels',array_names) set(cgobj1,'rowlabels',gene_names1,'columnlabels', array_names,'linkage', 'average','rowpdist','euclidean');
25 Cluster analysis group exercise Which biological functions are overrepresented in different clusters? Pick a cluster: Select a node on the tree of rows, Right click Choose export group info into the workspace Name it gene_list Run the following two Matlab commands to display genes g1=gene_list.rownodenames; for m=1:length(g1); disp(g1{m}); end;
26 Search for shared biological functions copy the list of displayed genes go to "Start Analysis" on paste gene list into the box in the left panel select ENSEMBL_GENE_ID select gene list radio button pick "Functional Annotation Clustering" for gene list broken into multiple groups (clusters) each with related biological functions Select "Functional Annotation Clustering" rectangular button below to display annotation results Write down the # of genes in the cluster and the top functions in two most interesting clusters
27 Before clustering
28 UPGMA hierarchical clustering, Euclidian distance

29 UPGMA hierarchical clustering, correlation distance
30 Credit: XKCD comics
31 Basic concepts of network analysis
32 Degree of a node its # of neighbors 2 Degree K 2 =2 1 Degree K 1 =4
33 Directed networks have in and out degrees In degree K in =2 Out degree K out =5
34 How to find important nodes? By their degree Hubs = important Degree centrality Google tweaked it in 1990s Hubs pointed by other hubs = more important 2?? 1?
35 How Google PageRank algorithm works? Too many hits to a typical query: need to rank One could rank the importance of webpages by K in, but: Too democratic: It doesn t take into account importance of webpages sending links it s easy to trick and artificially boost the rank Google s solution: simulate the behavior of many random surfers and then count the number of hits for every webpage Popular pages send more surfers your way the Google weight is proportional to K in weighted by popularity
36 Mathematics of the Google Google solves a self consistent Eq.: G i ~ j T ij G j find the principal eigenvector T ij = A ij /K out (j) Problem: surfers trapped infinite loops with one entry and no exit Model with random jumps: G i ~ (1 ) j T ij G j + j G j =0.15 meaning that an average web surfer (circa 1995) on average jumped around 1/ 6 webpages before going somewhere else
37 How to find important nodes? By their degree Hubs = important Degree centrality By their connectivity Connectors = important Betweenness centrality
38 Betweenness centrality: definition Take a node i There are (N 1)*(N 2)/2 pairs of other nodes For each pair find the shortest path on the network If more than one shortest path, sample them equally Betweenness centrality C(I = the probability that a randomly selected pair has shortest path going through i
39 Clustering coefficient: Are my friends also friends with each other
40 Clustering coefficient: what fraction of your neighbors are connected to each other? For the entire network: C=mean(C i )=Σ i C i /N Network Science: Graph Theory 2012
41 Why it matters for expression data analysis?

42 T cell expression data The matrix contains 47 expression samples from Lukk et al, Nature Biotechnology 2011 All samples are normal T cells from different individuals Only the top 3000 genes with the largest variability were used The value is log2 of gene s expression level in a given sample as measured by microarray technology
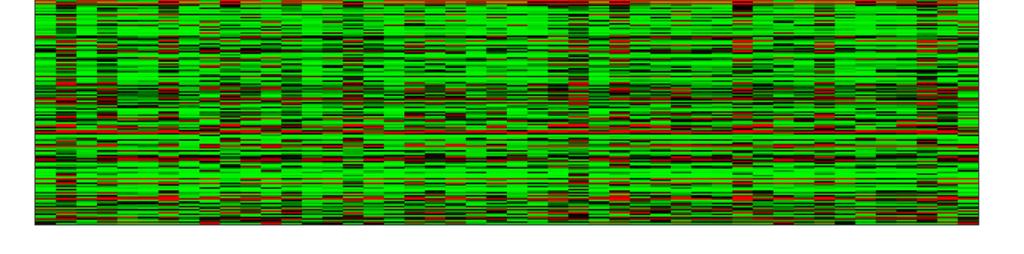
43 Before clustering

44 UPGMA hierarchical clustering, Euclidian distance
45 Another way to analyze expression data: Co expression networks
: for our T cell data N=3000, K=47 For each")
. Now you have a weighted network.")
46 How to construct a co-expression network? A co-expression network Samples Start with a matrix of log2 of expression levels of N genes in K samples (conditions): for our T cell data N=3000, K=47 For each of N(N 1)/2 pairs of genes i and j calculate the correlation coefficient ρ ij =σ ij /σ i σ j of gene levels across K samples Put a threshold, e.g. ρ ij >0.85, or otherwise select the most correlated pairs of genes (~4500 in our case). Now you have a weighted network. Identify densely interconnected functional modules in this network. Modules can be used to infer unknown functions of genes via Guilt by Association principle. Functional modules
47 Co expression network analysis exercise Start Gephi and open coexpression_network_random_start.gephi Run Layout Fruchterman Reingold Speed 10.0 Run Average degree, Network diameter, Modularity in the Statistics tab in the right panel. Color nodes by modularity class : Appearance Nodes Attribute Palette Icon Size nodes first by degree. Appearance Nodes Attribute Circles Icon Nodes in large tightly connected clusters have large degree Then size nodes by betweenness centrality Appearance Nodes Attribute Circles Icon These are coordinator nodes connecting different clusters to each other. Potentially biologically interesting


48 Credit: XKCD comics
Dimension reduction : PCA and Clustering
 Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
9/29/13. Outline Data mining tasks. Clustering algorithms. Applications of clustering in biology
 9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Dimension Reduction CS534
 Dimension Reduction CS534 Why dimension reduction? High dimensionality large number of features E.g., documents represented by thousands of words, millions of bigrams Images represented by thousands of
Dimension Reduction CS534 Why dimension reduction? High dimensionality large number of features E.g., documents represented by thousands of words, millions of bigrams Images represented by thousands of
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
Extracting Information from Complex Networks
 Extracting Information from Complex Networks 1 Complex Networks Networks that arise from modeling complex systems: relationships Social networks Biological networks Distinguish from random networks uniform
Extracting Information from Complex Networks 1 Complex Networks Networks that arise from modeling complex systems: relationships Social networks Biological networks Distinguish from random networks uniform
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
CS325 Artificial Intelligence Ch. 20 Unsupervised Machine Learning
 CS325 Artificial Intelligence Cengiz Spring 2013 Unsupervised Learning Missing teacher No labels, y Just input data, x What can you learn with it? Unsupervised Learning Missing teacher No labels, y Just
CS325 Artificial Intelligence Cengiz Spring 2013 Unsupervised Learning Missing teacher No labels, y Just input data, x What can you learn with it? Unsupervised Learning Missing teacher No labels, y Just
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Feature Extractors. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. The Perceptron Update Rule.
 CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
Basics of Network Analysis
 Basics of Network Analysis Hiroki Sayama sayama@binghamton.edu Graph = Network G(V, E): graph (network) V: vertices (nodes), E: edges (links) 1 Nodes = 1, 2, 3, 4, 5 2 3 Links = 12, 13, 15, 23,
Basics of Network Analysis Hiroki Sayama sayama@binghamton.edu Graph = Network G(V, E): graph (network) V: vertices (nodes), E: edges (links) 1 Nodes = 1, 2, 3, 4, 5 2 3 Links = 12, 13, 15, 23,
CLUSTERING IN BIOINFORMATICS
 CLUSTERING IN BIOINFORMATICS CSE/BIMM/BENG 8 MAY 4, 0 OVERVIEW Define the clustering problem Motivation: gene expression and microarrays Types of clustering Clustering algorithms Other applications of
CLUSTERING IN BIOINFORMATICS CSE/BIMM/BENG 8 MAY 4, 0 OVERVIEW Define the clustering problem Motivation: gene expression and microarrays Types of clustering Clustering algorithms Other applications of
Statistical Analysis of Metabolomics Data. Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte
 Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Hierarchical clustering
 Hierarchical clustering Rebecca C. Steorts, Duke University STA 325, Chapter 10 ISL 1 / 63 Agenda K-means versus Hierarchical clustering Agglomerative vs divisive clustering Dendogram (tree) Hierarchical
Hierarchical clustering Rebecca C. Steorts, Duke University STA 325, Chapter 10 ISL 1 / 63 Agenda K-means versus Hierarchical clustering Agglomerative vs divisive clustering Dendogram (tree) Hierarchical
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Kernels and Clustering Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Kernels and Clustering Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
May 1, CODY, Error Backpropagation, Bischop 5.3, and Support Vector Machines (SVM) Bishop Ch 7. May 3, Class HW SVM, PCA, and K-means, Bishop Ch
 Bishop Ch 7. May 3, Class HW SVM, PCA, and K-means, Bishop Ch") May 1, CODY, Error Backpropagation, Bischop 5.3, and Support Vector Machines (SVM) Bishop Ch 7. May 3, Class HW SVM, PCA, and K-means, Bishop Ch 12.1, 9.1 May 8, CODY Machine Learning for finding oil,
May 1, CODY, Error Backpropagation, Bischop 5.3, and Support Vector Machines (SVM) Bishop Ch 7. May 3, Class HW SVM, PCA, and K-means, Bishop Ch 12.1, 9.1 May 8, CODY Machine Learning for finding oil,
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Kernels and Clustering
 Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Clustering and Dimensionality Reduction. Stony Brook University CSE545, Fall 2017
 Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
CSE 40171: Artificial Intelligence. Learning from Data: Unsupervised Learning
 CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
Information Networks: PageRank
 Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Gene expression & Clustering (Chapter 10)
") Gene expression & Clustering (Chapter 10) Determining gene function Sequence comparison tells us if a gene is similar to another gene, e.g., in a new species Dynamic programming Approximate pattern matching
Gene expression & Clustering (Chapter 10) Determining gene function Sequence comparison tells us if a gene is similar to another gene, e.g., in a new species Dynamic programming Approximate pattern matching
Statistical Methods for Data Mining
 Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning
Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Clustering. Lecture 6, 1/24/03 ECS289A
 Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Clustering K-means. Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, Carlos Guestrin
 Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
CSE 255 Lecture 5. Data Mining and Predictive Analytics. Dimensionality Reduction
 CSE 255 Lecture 5 Data Mining and Predictive Analytics Dimensionality Reduction Course outline Week 4: I ll cover homework 1, and get started on Recommender Systems Week 5: I ll cover homework 2 (at the
CSE 255 Lecture 5 Data Mining and Predictive Analytics Dimensionality Reduction Course outline Week 4: I ll cover homework 1, and get started on Recommender Systems Week 5: I ll cover homework 2 (at the
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
CSE 547: Machine Learning for Big Data Spring Problem Set 2. Please read the homework submission policies.
 CSE 547: Machine Learning for Big Data Spring 2019 Problem Set 2 Please read the homework submission policies. 1 Principal Component Analysis and Reconstruction (25 points) Let s do PCA and reconstruct
CSE 547: Machine Learning for Big Data Spring 2019 Problem Set 2 Please read the homework submission policies. 1 Principal Component Analysis and Reconstruction (25 points) Let s do PCA and reconstruct
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
CSE 258 Lecture 5. Web Mining and Recommender Systems. Dimensionality Reduction
 CSE 258 Lecture 5 Web Mining and Recommender Systems Dimensionality Reduction This week How can we build low dimensional representations of high dimensional data? e.g. how might we (compactly!) represent
CSE 258 Lecture 5 Web Mining and Recommender Systems Dimensionality Reduction This week How can we build low dimensional representations of high dimensional data? e.g. how might we (compactly!) represent
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
Mining Social Network Graphs
 Mining Social Network Graphs Analysis of Large Graphs: Community Detection Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com Note to other teachers and users of these slides: We would be
Mining Social Network Graphs Analysis of Large Graphs: Community Detection Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com Note to other teachers and users of these slides: We would be
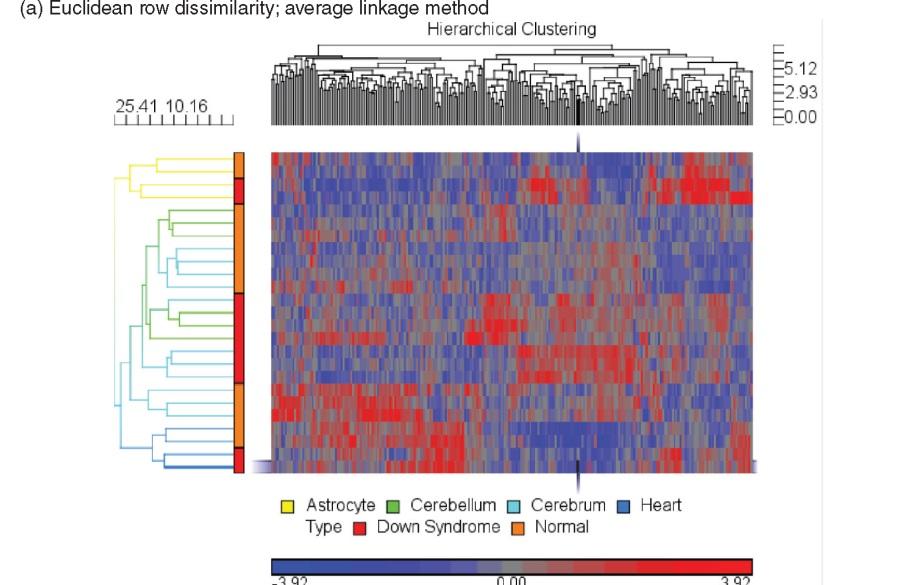
Comparisons and validation of statistical clustering techniques for microarray gene expression data. Outline. Microarrays.
 Comparisons and validation of statistical clustering techniques for microarray gene expression data Susmita Datta and Somnath Datta Presented by: Jenni Dietrich Assisted by: Jeffrey Kidd and Kristin Wheeler
Comparisons and validation of statistical clustering techniques for microarray gene expression data Susmita Datta and Somnath Datta Presented by: Jenni Dietrich Assisted by: Jeffrey Kidd and Kristin Wheeler
Introduction to Pattern Recognition Part II. Selim Aksoy Bilkent University Department of Computer Engineering
 Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
What is clustering. Organizing data into clusters such that there is high intra- cluster similarity low inter- cluster similarity
 Clustering What is clustering Organizing data into clusters such that there is high intra- cluster similarity low inter- cluster similarity Informally, finding natural groupings among objects. High dimensional
Clustering What is clustering Organizing data into clusters such that there is high intra- cluster similarity low inter- cluster similarity Informally, finding natural groupings among objects. High dimensional
Spectral Classification
 Spectral Classification Spectral Classification Supervised versus Unsupervised Classification n Unsupervised Classes are determined by the computer. Also referred to as clustering n Supervised Classes
Spectral Classification Spectral Classification Supervised versus Unsupervised Classification n Unsupervised Classes are determined by the computer. Also referred to as clustering n Supervised Classes
ECS 234: Data Analysis: Clustering ECS 234
 : Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
: Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Unsupervised Learning
 Unsupervised Learning Fabio G. Cozman - fgcozman@usp.br November 16, 2018 What can we do? We just have a dataset with features (no labels, no response). We want to understand the data... no easy to define
Unsupervised Learning Fabio G. Cozman - fgcozman@usp.br November 16, 2018 What can we do? We just have a dataset with features (no labels, no response). We want to understand the data... no easy to define
Giri Narasimhan. CAP 5510: Introduction to Bioinformatics. ECS 254; Phone: x3748
 CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 3/3/08 CAP5510 1 Gene g Probe 1 Probe 2 Probe N 3/3/08 CAP5510
CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 3/3/08 CAP5510 1 Gene g Probe 1 Probe 2 Probe N 3/3/08 CAP5510
Unsupervised Learning
 Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Clustering and Dimensionality Reduction
 Clustering and Dimensionality Reduction Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: Data Mining Automatically extracting meaning from
Clustering and Dimensionality Reduction Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: Data Mining Automatically extracting meaning from
SGN (4 cr) Chapter 11
 Chapter 11") SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
Unsupervised learning in Vision
 Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Unsupervised Learning
 Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
General Instructions. Questions
 CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
Unsupervised Learning and Data Mining
 Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Unsupervised Learning. Pantelis P. Analytis. Introduction. Finding structure in graphs. Clustering analysis. Dimensionality reduction.
 March 19, 2018 1 / 40 1 2 3 4 2 / 40 What s unsupervised learning? Most of the data available on the internet do not have labels. How can we make sense of it? 3 / 40 4 / 40 5 / 40 Organizing the web First
March 19, 2018 1 / 40 1 2 3 4 2 / 40 What s unsupervised learning? Most of the data available on the internet do not have labels. How can we make sense of it? 3 / 40 4 / 40 5 / 40 Organizing the web First
Centralities (4) By: Ralucca Gera, NPS. Excellence Through Knowledge
 By: Ralucca Gera, NPS. Excellence Through Knowledge") Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
Outline. Multivariate analysis: Least-squares linear regression Curve fitting
 DATA ANALYSIS Outline Multivariate analysis: principal component analysis (PCA) visualization of high-dimensional data clustering Least-squares linear regression Curve fitting e.g. for time-course data
DATA ANALYSIS Outline Multivariate analysis: principal component analysis (PCA) visualization of high-dimensional data clustering Least-squares linear regression Curve fitting e.g. for time-course data
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
PROMO 2017a - Tutorial
 PROMO 2017a - Tutorial Introduction... 2 Installing PROMO... 2 Step 1 - Importing data... 2 Step 2 - Preprocessing... 6 Step 3 Data Exploration... 9 Step 4 Clustering... 13 Step 5 Analysis of sample clusters...
PROMO 2017a - Tutorial Introduction... 2 Installing PROMO... 2 Step 1 - Importing data... 2 Step 2 - Preprocessing... 6 Step 3 Data Exploration... 9 Step 4 Clustering... 13 Step 5 Analysis of sample clusters...
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms
 Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]
![CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]](/thumbs/89/100746783.jpg "CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]") CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, 2015. 11:59pm, PDF to Canvas [100 points] Instructions. Please write up your responses to the following problems clearly and concisely.
CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, 2015. 11:59pm, PDF to Canvas [100 points] Instructions. Please write up your responses to the following problems clearly and concisely.
Multivariate Methods
 Multivariate Methods Cluster Analysis http://www.isrec.isb-sib.ch/~darlene/embnet/ Classification Historically, objects are classified into groups periodic table of the elements (chemistry) taxonomy (zoology,
Multivariate Methods Cluster Analysis http://www.isrec.isb-sib.ch/~darlene/embnet/ Classification Historically, objects are classified into groups periodic table of the elements (chemistry) taxonomy (zoology,
Linear and Non-linear Dimentionality Reduction Applied to Gene Expression Data of Cancer Tissue Samples
 Linear and Non-linear Dimentionality Reduction Applied to Gene Expression Data of Cancer Tissue Samples Franck Olivier Ndjakou Njeunje Applied Mathematics, Statistics, and Scientific Computation University
Linear and Non-linear Dimentionality Reduction Applied to Gene Expression Data of Cancer Tissue Samples Franck Olivier Ndjakou Njeunje Applied Mathematics, Statistics, and Scientific Computation University
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Bioinformatics - Lecture 07
 Bioinformatics - Lecture 07 Bioinformatics Clusters and networks Martin Saturka http://www.bioplexity.org/lectures/ EBI version 0.4 Creative Commons Attribution-Share Alike 2.5 License Learning on profiles
Bioinformatics - Lecture 07 Bioinformatics Clusters and networks Martin Saturka http://www.bioplexity.org/lectures/ EBI version 0.4 Creative Commons Attribution-Share Alike 2.5 License Learning on profiles
Week 7 Picturing Network. Vahe and Bethany
 Week 7 Picturing Network Vahe and Bethany Freeman (2005) - Graphic Techniques for Exploring Social Network Data The two main goals of analyzing social network data are identification of cohesive groups
Week 7 Picturing Network Vahe and Bethany Freeman (2005) - Graphic Techniques for Exploring Social Network Data The two main goals of analyzing social network data are identification of cohesive groups
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
How do microarrays work
 Lecture 3 (continued) Alvis Brazma European Bioinformatics Institute How do microarrays work condition mrna cdna hybridise to microarray condition Sample RNA extract labelled acid acid acid nucleic acid
Lecture 3 (continued) Alvis Brazma European Bioinformatics Institute How do microarrays work condition mrna cdna hybridise to microarray condition Sample RNA extract labelled acid acid acid nucleic acid
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Step-by-Step Guide to Advanced Genetic Analysis
 Step-by-Step Guide to Advanced Genetic Analysis Page 1 Introduction In the previous document, 1 we covered the standard genetic analyses available in JMP Genomics. Here, we cover the more advanced options
Step-by-Step Guide to Advanced Genetic Analysis Page 1 Introduction In the previous document, 1 we covered the standard genetic analyses available in JMP Genomics. Here, we cover the more advanced options
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Lecture Topic Projects
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, basic tasks, data types 3 Introduction to D3, basic vis techniques for non-spatial data Project #1 out 4 Data
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, basic tasks, data types 3 Introduction to D3, basic vis techniques for non-spatial data Project #1 out 4 Data
Segmentation Computer Vision Spring 2018, Lecture 27
 Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Forestry Applied Multivariate Statistics. Cluster Analysis
 1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
Types of general clustering methods. Clustering Algorithms for general similarity measures. Similarity between clusters
 Types of general clustering methods Clustering Algorithms for general similarity measures agglomerative versus divisive algorithms agglomerative = bottom-up build up clusters from single objects divisive
Types of general clustering methods Clustering Algorithms for general similarity measures agglomerative versus divisive algorithms agglomerative = bottom-up build up clusters from single objects divisive
Collaborative filtering based on a random walk model on a graph
 Collaborative filtering based on a random walk model on a graph Marco Saerens, Francois Fouss, Alain Pirotte, Luh Yen, Pierre Dupont (UCL) Jean-Michel Renders (Xerox Research Europe) Some recent methods:
Collaborative filtering based on a random walk model on a graph Marco Saerens, Francois Fouss, Alain Pirotte, Luh Yen, Pierre Dupont (UCL) Jean-Michel Renders (Xerox Research Europe) Some recent methods:
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions
 Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
k-nn Disgnosing Breast Cancer
 k-nn Disgnosing Breast Cancer Prof. Eric A. Suess February 4, 2019 Example Breast cancer screening allows the disease to be diagnosed and treated prior to it causing noticeable symptoms. The process of
k-nn Disgnosing Breast Cancer Prof. Eric A. Suess February 4, 2019 Example Breast cancer screening allows the disease to be diagnosed and treated prior to it causing noticeable symptoms. The process of
EECS730: Introduction to Bioinformatics
 EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS
 FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS") AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS H.S Behera Department of Computer Science and Engineering, Veer Surendra Sai University
AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS H.S Behera Department of Computer Science and Engineering, Veer Surendra Sai University
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie
 Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
K-means Clustering & PCA
 K-means Clustering & PCA Andreas C. Kapourani (Credit: Hiroshi Shimodaira) 02 February 2018 1 Introduction In this lab session we will focus on K-means clustering and Principal Component Analysis (PCA).
K-means Clustering & PCA Andreas C. Kapourani (Credit: Hiroshi Shimodaira) 02 February 2018 1 Introduction In this lab session we will focus on K-means clustering and Principal Component Analysis (PCA).
Chapter 1. Using the Cluster Analysis. Background Information
 Chapter 1 Using the Cluster Analysis Background Information Cluster analysis is the name of a multivariate technique used to identify similar characteristics in a group of observations. In cluster analysis,
Chapter 1 Using the Cluster Analysis Background Information Cluster analysis is the name of a multivariate technique used to identify similar characteristics in a group of observations. In cluster analysis,
Clustering k-mean clustering
 Clustering k-mean clustering Genome 373 Genomic Informatics Elhanan Borenstein The clustering problem: partition genes into distinct sets with high homogeneity and high separation Clustering (unsupervised)
Clustering k-mean clustering Genome 373 Genomic Informatics Elhanan Borenstein The clustering problem: partition genes into distinct sets with high homogeneity and high separation Clustering (unsupervised)
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group