May 1, CODY, Error Backpropagation, Bischop 5.3, and Support Vector Machines (SVM) Bishop Ch 7. May 3, Class HW SVM, PCA, and K-means, Bishop Ch
|
|
|
- Tamsyn Daniel
- 5 years ago
- Views:
Transcription
1 May 1, CODY, Error Backpropagation, Bischop 5.3, and Support Vector Machines (SVM) Bishop Ch 7. May 3, Class HW SVM, PCA, and K-means, Bishop Ch 12.1, 9.1 May 8, CODY Machine Learning for finding oil, focusing on 1) robust seismic denoising/interpolation using structured matrix approximation 2) seismic image clustering and classification, using t-sne(t-distributed stochastic neighbor embedding) and CNN. Weichang Li, Goup Leader Aramco, Houston. May 10, Class HW First distribution of final projects. Bishop Ch 9 May 15, CODY Seismology and Machine Learning, Daniel Trugman (half class), ch 9 May 17, Class HW Ocean acoustic source tracking. Final projects. The main goal in the last 3 weeks is the Final project. ch 9 May 22, Dictionary learning, Mike Bianco (half class), Graphical models Bishop Ch 8 May 24, Graphical models Bishop Ch 8 May 31, No Class Workshop, Big Data and The Earth Sciences: Grand Challenges Workshop June 5, Discuss workshop. Spiess Hall open for project discussion 11am-. June 7, Workshop report. No class June 12 Spiess Hall open for project discussion 9-11:30am and 2-7pm June 16 Final report delivered. Beer time
2 SVMs are Perceptrons! SVM s use each training case, x, to define a feature K(x,.) where K is user chosen. So the user designs the features. SVM do feature selection by picking support vectors, and learn feature weighting from a big optimization problem. So an SVM is a clever way to train a standard perceptron. All that a perceptron cannot do, cannot be done by SVM s (but it s a long time since 1969 so people have forgotten this). SVM DOES: Margin maximization Kernel trick Sparse
3 SVM summarized--- Only kernels Minimize with respect to w, w 0 C ( ) ζ n + + w 2 (Bishop 7.21), Solution found in dual domain with Lagrange multipliers a n, n = 1 N and This gives the support vectors S w4 = ) 6 a n t n φ(xn) (Bishop 7.8) Used for predictions y= = w 0 + w > φ x = w 0 +? a n ) 6 t n φ x n T φ x = w 0 +? a n t n k x n, x (Bishop 7.13) ) 6
; % predict [predict_label,~, ~] = svmpredict(rand([length(y),1]), X, model,'-q'); >> modelmodel = struct with fields: Parameters: [5 1 double] nr_class: 2 totalsv: 36")
4 case 'Classify' % train SVM Code for classification model = svmtrain(y, X,['-c g ' gamma ' -q ' kernel]); % predict [predict_label,~, ~] = svmpredict(rand([length(y),1]), X, model,'-q'); >> modelmodel = struct with fields: Parameters: [5 1 double] nr_class: 2 totalsv: 36 rho: Label: [2 1 double] sv_indices: [36 1 double] ProbA: [] ProbB: [] nsv: [2 1 double] sv_coef: [36 1 double] SVs: [36 2 double]
5 Can be inner product in infinite dimensional space Assume x R 1 and γ > 0. e γ x i x j 2 = e γ(x i x j ) 2 = e γx i 2+2γx ix j γxj 2 ( 2γx i x j 1+ + (2γx ix j ) 2 =e γx 2 i γx 2 j =e γx 2 i γx 2 j where + + (2γx ix j ) 3 + ) 1! 2! 3! ( 2γ 2γ (2γ) ! x i 1! x 2 (2γ) j + xi 2 2 2! 2! (2γ) 3 (2γ) xi 3 3 xj 3 + ) = φ(x i ) T φ(x j ), 3! 3! φ(x) =e γx 2 [1, 2γ 1! x, (2γ) 2 (2γ) x 2 3 T, x 3, ]. 2! 3! x 2 j
6 Finding the Decision Function w: maybe infinite variables The dual problem min α subject to 1 2 αt Qα e T α 0 α i C, i =1,...,l y T α =0, where Q ij = y i y j φ(x i ) T φ(x j )ande = [1,...,1] T At optimum Corresponds to (Bishop 7.32) With y=t w = l i=1 α iy i φ(x i ) A finite problem: #variables = #training data Using these results to eliminate w, b, and {ξ n } from the Lagrangian, we obtain the dual Lagrangian in the form L(a) = N a n 1 2 n=1 N N a n a m t n t m k(x n, x m ) (7.32) n=1 m=1 which is identical to the separable case, except that the constraints are somewhat
7 2 Linear Kernel 2 Sigmoid Function Kernel 1 1 x Polynomial Kernel Radial Basis Function Kernel 2 1 x x x1
8 Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning methods such as regression and classification. In that setting we observe both a set of features X 1,X 2,...,X p for each object, as well as a response or outcome variable Y. The goal is then to predict Y using X 1,X 2,...,X p. Here we instead focus on unsupervised learning, we where observe only the features X 1,X 2,...,X p. We are not interested in prediction, because we do not have an associated response variable Y.
9 The Goals of Unsupervised Learning The goal is to discover interesting things about the measurements: is there an informative way to visualize the data? Can we discover subgroups among the variables or among the observations? We discuss two methods: principal components analysis, a tool used for data visualization or data pre-processing before supervised techniques are applied, and clustering, a broad class of methods for discovering unknown subgroups in data. 2/50
10 Challenge of unsupervised learning Unsupervised learning is more subjective than supervised learning, as there is no simple goal for the analysis, such as prediction of a response. But techniques for unsupervised learning are of growing importance in a number of fields: subgroups of breast cancer patients grouped by their gene expression measurements, groups of shoppers characterized by their browsing and purchase histories, movies grouped by the ratings assigned by movie viewers. However, it is often easier to work with unlabeled data. Think of the movie rating Past science history
11 Principal Components Analysis Dimensionality reduction Data-compression less storage and easy learning Data visualization PCA produces a low-dimensional representation of a dataset. It finds a sequence of linear combinations of the variables that have maximal variance, and are mutually uncorrelated. Apart from producing derived variables for use in supervised learning problems, PCA also serves as a tool for data visualization.

12 PCA don t work well for classification
13 Principal Components Analysis: details The first principal component of a set of features X 1,X 2,...,X p is the normalized linear combination of the features Z 1 = 11 X X p1 X p that P has the largest variance. By normalized, we mean that p 2 j=1 j1 = 1. We refer to the elements 11,..., p1 as the loadings of the first principal component; together, the loadings make up the principal component loading vector, 1 =( p1) T. We constrain the loadings so that their sum of squares is equal to one, since otherwise setting these elements to be arbitrarily large in absolute value could result in an arbitrarily large variance.
14
15 Computation of Principal Components Suppose we have a n p data set X. Since we are only interested in variance, we assume that each of the variables in X has been centered to have mean zero (that is, the column means of X are zero). We then look for the linear combination of the sample feature values of the form z i1 = 11 x i x i p1 x ip (1) for i = 1,...,n that has largest sample variance, subject to the constraint that P p 2 j=1 j1 = 1. Since each of the x ij has mean zero, then so does z i1 (for any values of j1). Hence the sample variance of the z i1 can be written as 1 P n n i=1 z2 i1.
16 Computation: continued Plugging in (1) the first principal component loading vector solves the optimization problem maximize 11,..., p1 1 n 0 i=1 px j=1 j1x ij 1 A 2 subject to px j=1 2 j1 =1. This problem can be solved via a singular-value decomposition of the matrix X, a standard technique in linear algebra. We refer to Z 1 as the first principal component, with realized values z 11,...,z n1
17 Further principal components The second principal component is the linear combination of X 1,...,X p that has maximal variance among all linear combinations that are uncorrelated with Z 1. The second principal component scores z 12,z 22,...,z n2 take the form z i2 = 12 x i x i p2 x ip, where 2 is the second principal component loading vector, with elements 12, 22,..., p2.
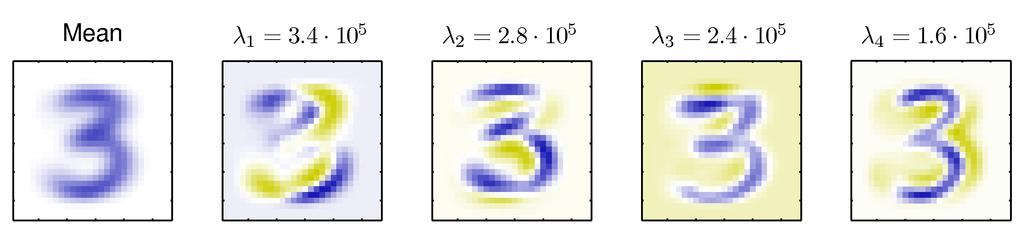
18 Test Data
19

20 PCA VS Regression PCA vs Fisher PCA looks for a low-dimensional representation of the observations that explains a good fraction of the variance. Clustering looks for homogeneous subgroups among the observations.
21 Proportion Variance Explained To understand the strength of each component, we are interested in knowing the proportion of variance explained (PVE) by each one. The total variance present in a data set (assuming that the variables have been centered to have mean zero) is defined as px px 1 nx Var(X j )= x 2 n ij, j=1 j=1 i=1 and the variance explained by the mth principal component is Var(Z m )= 1 nx z 2 n im. i=1 It can be shown that P p j=1 Var(X j)= P M m=1 Var(Z m), with M =min(n 1,p).
22 Proportion Variance Explained: continued Therefore, the PVE of the mth principal component is given by the positive quantity between 0 and 1 P n P i=1 z2 im p P n j=1 i=1 x2 ij. The PVEs sum to one. We sometimes display the cumulative PVEs. Prop. Variance Explained Cumulative Prop. Variance Explained Principal Component Principal Component
23 How many principal components should we use? If we use principal components as a summary of our data, how many components are su cient? No simple answer to this question, as cross-validation is not available for this purpose. Why not? When could we use cross-validation to select the number of components? the scree plot on the previous slide can be used as a guide: we look for an elbow.
24 Clustering Clustering refers to a very broad set of techniques for finding subgroups, or clusters, in a data set. We seek a partition of the data into distinct groups so that the observations within each group are quite similar to each other, It make this concrete, we must define what it means for two or more observations to be similar or di erent. Indeed, this is often a domain-specific consideration that must be made based on knowledge of the data being studied.
25 Two clustering methods In K-means clustering, we seek to partition the observations into a pre-specified number of clusters. In hierarchical clustering, we do not know in advance how many clusters we want; in fact, we end up with a tree-like visual representation of the observations, called a dendrogram, that allows us to view at once the clusterings obtained for each possible number of clusters, from 1 to n.
26 N K J = r nk x n µ k 2 (9.1) n=1 k=1 K-means m of the squares of the distances of each data point to its Solving for r nk r nk = { { 1 if k = arg minj x n µ j 2 0 otherwise. (9.2) Differentiating for μ k er the optimization of the with the held fixed. The objective N 2 r nk (x n µ k )=0 (9.3) n=1 which we can easily solve for µ k to give µ k = n r nkx n n r nk. (9.4) The denominator in this expression is equal to the number of points assigned to
27 K-means
28 K-means clustering K=2 K=3 K=4 A simulated data set with 150 observations in 2-dimensional space. Panels show the results of applying K-means clustering with di erent values of K, the number of clusters. The color of each observation indicates the cluster to which it was assigned using the K-means clustering algorithm. Note that there is no ordering of the clusters, so the cluster coloring is arbitrary. These cluster labels were not used in clustering; instead, they are the outputs of the clustering procedure.
29 K-Means Clustering Algorithm 1. Randomly assign a number, from 1 to K, to each of the observations. These serve as initial cluster assignments for the observations. 2. Iterate until the cluster assignments stop changing: 2.1 For each of the K clusters, compute the cluster centroid. The kth cluster centroid is the vector of the p feature means for the observations in the kth cluster. 2.2 Assign each observation to the cluster whose centroid is closest (where closest is defined using Euclidean distance).
30 Properties of the Algorithm This algorithm is guaranteed to decrease the value of the objective (4) at each step. Why? Note that 1 C k X i,i 0 2C k where x kj = 1 cluster C k. C k px (x ij x i 0 j) 2 =2 X j=1 i2c k px (x ij x kj ) 2, j=1 P i2c k x ij is the mean for feature j in however it is not guaranteed to give the global minimum. Why not?
31 Data Step 1 Iteration 1, Step 2a Iteration 1, Step 2b Iteration 2, Step 2a Final Results Example Details of Previous Figure The progress of the K-means algorithm with K=3. Top left: The observations are shown. Top center: In Step 1 of the algorithm, each observation is randomly assigned to a cluster. Top right: In Step 2(a), the cluster centroids are computed. These are shown as large colored disks. Initially the centroids are almost completely overlapping because the initial cluster assignments were chosen at random. Bottom left: In Step 2(b), each observation is assigned to the nearest centroid. Bottom center: Step 2(a) is once again performed, leading to new cluster centroids. Bottom right: The results obtained after 10 iterations. 33 / / 50
32 Details of Previous Figure Different starting values K-means clustering performed six times on the data from previous figure with K = 3, each time with a di erent random assignment of the observations in Step 1 of the K-means algorithm. Above each plot is the value of the objective (4). Three di erent local optima were obtained, one of which resulted in a smaller value of the objective and provides better separation between the clusters. Those labeled in red all achieved the same best solution, with an objective value of / 50
33 Hierarchical Clustering K-means clustering requires us to pre-specify the number of clusters K. This can be a disadvantage (later we discuss strategies for choosing K) Hierarchical clustering is an alternative approach which does not require that we commit to a particular choice of K. In this section, we describe bottom-up or agglomerative clustering. This is the most common type of hierarchical clustering, and refers to the fact that a dendrogram is built starting from the leaves and combining clusters up to the trunk.
34 Hierarchical Clustering Algorithm The approach in words: Start with each point in its own cluster. Identify the closest two clusters and merge them. Repeat. Ends when all points are in a single cluster. Dendrogram A C B D E D E B A C
35 An Example X observations generated in 2-dimensional space. In reality there are three distinct classes, shown in separate colors. However, we will treat these class labels as unknown and will seek to cluster the observations in order to discover the classes from the data. X 1
36 Example X X 1 45 observations generated in 2-dimensional space. In reality there are three distinct classes, shown in separate colors. However, we will treat these class labels as unknown and will seek to cluster the observations in order to discover the classes from the data Left: Dendrogram obtained from hierarchically clustering the data from previous slide, with complete linkage and Euclidean distance. Center: The dendrogram from the left-hand panel, cut at a height of 9 (indicated by the dashed line). This cut results in two distinct clusters, shown in di erent colors. Right: The dendrogram from the left-hand panel, now cut at a height of 5. This cut results in three distinct clusters, shown in di erent colors. Note that the colors were not used in clustering, but are simply used for display purposes in this figure
37 NOT USED
Statistical Methods for Data Mining
 Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning
Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning
Workshop report 1. Daniels report is on website 2. Don t expect to write it based on listening to one project (we had 6 only 2 was sufficient
 Workshop report 1. Daniels report is on website 2. Don t expect to write it based on listening to one project (we had 6 only 2 was sufficient quality) 3. I suggest writing it on one presentation. 4. Include
Workshop report 1. Daniels report is on website 2. Don t expect to write it based on listening to one project (we had 6 only 2 was sufficient quality) 3. I suggest writing it on one presentation. 4. Include
Statistical Methods for Data Mining
 Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning
Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning
Unsupervised Learning
 Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
SUPPORT VECTOR MACHINES
 SUPPORT VECTOR MACHINES Today Reading AIMA 8.9 (SVMs) Goals Finish Backpropagation Support vector machines Backpropagation. Begin with randomly initialized weights 2. Apply the neural network to each training
SUPPORT VECTOR MACHINES Today Reading AIMA 8.9 (SVMs) Goals Finish Backpropagation Support vector machines Backpropagation. Begin with randomly initialized weights 2. Apply the neural network to each training
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
SUPPORT VECTOR MACHINES
 SUPPORT VECTOR MACHINES Today Reading AIMA 18.9 Goals (Naïve Bayes classifiers) Support vector machines 1 Support Vector Machines (SVMs) SVMs are probably the most popular off-the-shelf classifier! Software
SUPPORT VECTOR MACHINES Today Reading AIMA 18.9 Goals (Naïve Bayes classifiers) Support vector machines 1 Support Vector Machines (SVMs) SVMs are probably the most popular off-the-shelf classifier! Software
Clustering. Mihaela van der Schaar. January 27, Department of Engineering Science University of Oxford
 Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
An Introduction to Machine Learning
 TRIPODS Summer Boorcamp: Topology and Machine Learning August 6, 2018 General Set-up Introduction Set-up and Goal Suppose we have X 1,X 2,...,X n data samples. Can we predict properites about any given
TRIPODS Summer Boorcamp: Topology and Machine Learning August 6, 2018 General Set-up Introduction Set-up and Goal Suppose we have X 1,X 2,...,X n data samples. Can we predict properites about any given
Content-based image and video analysis. Machine learning
 Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
A Dendrogram. Bioinformatics (Lec 17)
") A Dendrogram 3/15/05 1 Hierarchical Clustering [Johnson, SC, 1967] Given n points in R d, compute the distance between every pair of points While (not done) Pick closest pair of points s i and s j and
A Dendrogram 3/15/05 1 Hierarchical Clustering [Johnson, SC, 1967] Given n points in R d, compute the distance between every pair of points While (not done) Pick closest pair of points s i and s j and
Hierarchical clustering
 Hierarchical clustering Rebecca C. Steorts, Duke University STA 325, Chapter 10 ISL 1 / 63 Agenda K-means versus Hierarchical clustering Agglomerative vs divisive clustering Dendogram (tree) Hierarchical
Hierarchical clustering Rebecca C. Steorts, Duke University STA 325, Chapter 10 ISL 1 / 63 Agenda K-means versus Hierarchical clustering Agglomerative vs divisive clustering Dendogram (tree) Hierarchical
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
DM6 Support Vector Machines
 DM6 Support Vector Machines Outline Large margin linear classifier Linear separable Nonlinear separable Creating nonlinear classifiers: kernel trick Discussion on SVM Conclusion SVM: LARGE MARGIN LINEAR
DM6 Support Vector Machines Outline Large margin linear classifier Linear separable Nonlinear separable Creating nonlinear classifiers: kernel trick Discussion on SVM Conclusion SVM: LARGE MARGIN LINEAR
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
Clustering and Dimensionality Reduction. Stony Brook University CSE545, Fall 2017
 Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Machine Learning: Think Big and Parallel
 Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Support Vector Machines.
 Support Vector Machines srihari@buffalo.edu SVM Discussion Overview 1. Overview of SVMs 2. Margin Geometry 3. SVM Optimization 4. Overlapping Distributions 5. Relationship to Logistic Regression 6. Dealing
Support Vector Machines srihari@buffalo.edu SVM Discussion Overview 1. Overview of SVMs 2. Margin Geometry 3. SVM Optimization 4. Overlapping Distributions 5. Relationship to Logistic Regression 6. Dealing
Lecture 27: Review. Reading: All chapters in ISLR. STATS 202: Data mining and analysis. December 6, 2017
 Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
CSE 255 Lecture 6. Data Mining and Predictive Analytics. Community Detection
 CSE 255 Lecture 6 Data Mining and Predictive Analytics Community Detection Dimensionality reduction Goal: take high-dimensional data, and describe it compactly using a small number of dimensions Assumption:
CSE 255 Lecture 6 Data Mining and Predictive Analytics Community Detection Dimensionality reduction Goal: take high-dimensional data, and describe it compactly using a small number of dimensions Assumption:
Clustering and The Expectation-Maximization Algorithm
 Clustering and The Expectation-Maximization Algorithm Unsupervised Learning Marek Petrik 3/7 Some of the figures in this presentation are taken from An Introduction to Statistical Learning, with applications
Clustering and The Expectation-Maximization Algorithm Unsupervised Learning Marek Petrik 3/7 Some of the figures in this presentation are taken from An Introduction to Statistical Learning, with applications
All lecture slides will be available at CSC2515_Winter15.html
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 9: Support Vector Machines All lecture slides will be available at http://www.cs.toronto.edu/~urtasun/courses/csc2515/ CSC2515_Winter15.html Many
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 9: Support Vector Machines All lecture slides will be available at http://www.cs.toronto.edu/~urtasun/courses/csc2515/ CSC2515_Winter15.html Many
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Kernels + K-Means Introduction to Machine Learning. Matt Gormley Lecture 29 April 25, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Kernels + K-Means Matt Gormley Lecture 29 April 25, 2018 1 Reminders Homework 8:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Kernels + K-Means Matt Gormley Lecture 29 April 25, 2018 1 Reminders Homework 8:
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
CSE 40171: Artificial Intelligence. Learning from Data: Unsupervised Learning
 CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Support Vector Machines (a brief introduction) Adrian Bevan.
 Adrian Bevan.") Support Vector Machines (a brief introduction) Adrian Bevan email: a.j.bevan@qmul.ac.uk Outline! Overview:! Introduce the problem and review the various aspects that underpin the SVM concept.! Hard margin
Support Vector Machines (a brief introduction) Adrian Bevan email: a.j.bevan@qmul.ac.uk Outline! Overview:! Introduce the problem and review the various aspects that underpin the SVM concept.! Hard margin
Data Mining: Concepts and Techniques. Chapter 9 Classification: Support Vector Machines. Support Vector Machines (SVMs)
") Data Mining: Concepts and Techniques Chapter 9 Classification: Support Vector Machines 1 Support Vector Machines (SVMs) SVMs are a set of related supervised learning methods used for classification Based
Data Mining: Concepts and Techniques Chapter 9 Classification: Support Vector Machines 1 Support Vector Machines (SVMs) SVMs are a set of related supervised learning methods used for classification Based
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
CSE 258 Lecture 5. Web Mining and Recommender Systems. Dimensionality Reduction
 CSE 258 Lecture 5 Web Mining and Recommender Systems Dimensionality Reduction This week How can we build low dimensional representations of high dimensional data? e.g. how might we (compactly!) represent
CSE 258 Lecture 5 Web Mining and Recommender Systems Dimensionality Reduction This week How can we build low dimensional representations of high dimensional data? e.g. how might we (compactly!) represent
Support Vector Machines
 Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
CSE 255 Lecture 5. Data Mining and Predictive Analytics. Dimensionality Reduction
 CSE 255 Lecture 5 Data Mining and Predictive Analytics Dimensionality Reduction Course outline Week 4: I ll cover homework 1, and get started on Recommender Systems Week 5: I ll cover homework 2 (at the
CSE 255 Lecture 5 Data Mining and Predictive Analytics Dimensionality Reduction Course outline Week 4: I ll cover homework 1, and get started on Recommender Systems Week 5: I ll cover homework 2 (at the
Machine Learning for OR & FE
 Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
Feature Extractors. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. The Perceptron Update Rule.
 CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Linear methods for supervised learning
 Linear methods for supervised learning LDA Logistic regression Naïve Bayes PLA Maximum margin hyperplanes Soft-margin hyperplanes Least squares resgression Ridge regression Nonlinear feature maps Sometimes
Linear methods for supervised learning LDA Logistic regression Naïve Bayes PLA Maximum margin hyperplanes Soft-margin hyperplanes Least squares resgression Ridge regression Nonlinear feature maps Sometimes
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Clustering COMS 4771
 Clustering COMS 4771 1. Clustering Unsupervised classification / clustering Unsupervised classification Input: x 1,..., x n R d, target cardinality k N. Output: function f : R d {1,..., k} =: [k]. Typical
Clustering COMS 4771 1. Clustering Unsupervised classification / clustering Unsupervised classification Input: x 1,..., x n R d, target cardinality k N. Output: function f : R d {1,..., k} =: [k]. Typical
Kernels and Clustering
 Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Clustering K-means. Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, Carlos Guestrin
 Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
Optimal Separating Hyperplane and the Support Vector Machine. Volker Tresp Summer 2018
 Optimal Separating Hyperplane and the Support Vector Machine Volker Tresp Summer 2018 1 (Vapnik s) Optimal Separating Hyperplane Let s consider a linear classifier with y i { 1, 1} If classes are linearly
Optimal Separating Hyperplane and the Support Vector Machine Volker Tresp Summer 2018 1 (Vapnik s) Optimal Separating Hyperplane Let s consider a linear classifier with y i { 1, 1} If classes are linearly
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Classification by Support Vector Machines
 Classification by Support Vector Machines Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Practical DNA Microarray Analysis 2003 1 Overview I II III
Classification by Support Vector Machines Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Practical DNA Microarray Analysis 2003 1 Overview I II III
CSE 158. Web Mining and Recommender Systems. Midterm recap
 CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
9/29/13. Outline Data mining tasks. Clustering algorithms. Applications of clustering in biology
 9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
Lab 2: Support vector machines
 Artificial neural networks, advanced course, 2D1433 Lab 2: Support vector machines Martin Rehn For the course given in 2006 All files referenced below may be found in the following directory: /info/annfk06/labs/lab2
Artificial neural networks, advanced course, 2D1433 Lab 2: Support vector machines Martin Rehn For the course given in 2006 All files referenced below may be found in the following directory: /info/annfk06/labs/lab2
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
1 Case study of SVM (Rob)
") DRAFT a final version will be posted shortly COS 424: Interacting with Data Lecturer: Rob Schapire and David Blei Lecture # 8 Scribe: Indraneel Mukherjee March 1, 2007 In the previous lecture we saw how
DRAFT a final version will be posted shortly COS 424: Interacting with Data Lecturer: Rob Schapire and David Blei Lecture # 8 Scribe: Indraneel Mukherjee March 1, 2007 In the previous lecture we saw how
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
5 Learning hypothesis classes (16 points)
") 5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
Chapter 6: Cluster Analysis
 Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Classification by Support Vector Machines
 Classification by Support Vector Machines Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Practical DNA Microarray Analysis 2003 1 Overview I II III
Classification by Support Vector Machines Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Practical DNA Microarray Analysis 2003 1 Overview I II III
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Kernels and Clustering Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Kernels and Clustering Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
A Course in Machine Learning
 A Course in Machine Learning Hal Daumé III 13 UNSUPERVISED LEARNING If you have access to labeled training data, you know what to do. This is the supervised setting, in which you have a teacher telling
A Course in Machine Learning Hal Daumé III 13 UNSUPERVISED LEARNING If you have access to labeled training data, you know what to do. This is the supervised setting, in which you have a teacher telling
CPSC 340: Machine Learning and Data Mining. Principal Component Analysis Fall 2016
 CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
Chakra Chennubhotla and David Koes
 MSCBIO/CMPBIO 2065: Support Vector Machines Chakra Chennubhotla and David Koes Nov 15, 2017 Sources mmds.org chapter 12 Bishop s book Ch. 7 Notes from Toronto, Mark Schmidt (UBC) 2 SVM SVMs and Logistic
MSCBIO/CMPBIO 2065: Support Vector Machines Chakra Chennubhotla and David Koes Nov 15, 2017 Sources mmds.org chapter 12 Bishop s book Ch. 7 Notes from Toronto, Mark Schmidt (UBC) 2 SVM SVMs and Logistic
Homework 4: Clustering, Recommenders, Dim. Reduction, ML and Graph Mining (due November 19 th, 2014, 2:30pm, in class hard-copy please)
") Virginia Tech. Computer Science CS 5614 (Big) Data Management Systems Fall 2014, Prakash Homework 4: Clustering, Recommenders, Dim. Reduction, ML and Graph Mining (due November 19 th, 2014, 2:30pm, in
Virginia Tech. Computer Science CS 5614 (Big) Data Management Systems Fall 2014, Prakash Homework 4: Clustering, Recommenders, Dim. Reduction, ML and Graph Mining (due November 19 th, 2014, 2:30pm, in
Support Vector Machines
 Support Vector Machines About the Name... A Support Vector A training sample used to define classification boundaries in SVMs located near class boundaries Support Vector Machines Binary classifiers whose
Support Vector Machines About the Name... A Support Vector A training sample used to define classification boundaries in SVMs located near class boundaries Support Vector Machines Binary classifiers whose
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms
 Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
Data Analysis 3. Support Vector Machines. Jan Platoš October 30, 2017
 Data Analysis 3 Support Vector Machines Jan Platoš October 30, 2017 Department of Computer Science Faculty of Electrical Engineering and Computer Science VŠB - Technical University of Ostrava Table of
Data Analysis 3 Support Vector Machines Jan Platoš October 30, 2017 Department of Computer Science Faculty of Electrical Engineering and Computer Science VŠB - Technical University of Ostrava Table of
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
CSE 158 Lecture 6. Web Mining and Recommender Systems. Community Detection
 CSE 158 Lecture 6 Web Mining and Recommender Systems Community Detection Dimensionality reduction Goal: take high-dimensional data, and describe it compactly using a small number of dimensions Assumption:
CSE 158 Lecture 6 Web Mining and Recommender Systems Community Detection Dimensionality reduction Goal: take high-dimensional data, and describe it compactly using a small number of dimensions Assumption:
Lecture 9: Support Vector Machines
 Lecture 9: Support Vector Machines William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 8 What we ll learn in this lecture Support Vector Machines (SVMs) a highly robust and
Lecture 9: Support Vector Machines William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 8 What we ll learn in this lecture Support Vector Machines (SVMs) a highly robust and
Unsupervised Learning
 Unsupervised Learning Fabio G. Cozman - fgcozman@usp.br November 16, 2018 What can we do? We just have a dataset with features (no labels, no response). We want to understand the data... no easy to define
Unsupervised Learning Fabio G. Cozman - fgcozman@usp.br November 16, 2018 What can we do? We just have a dataset with features (no labels, no response). We want to understand the data... no easy to define
CPSC 340: Machine Learning and Data Mining. Kernel Trick Fall 2017
 CPSC 340: Machine Learning and Data Mining Kernel Trick Fall 2017 Admin Assignment 3: Due Friday. Midterm: Can view your exam during instructor office hours or after class this week. Digression: the other
CPSC 340: Machine Learning and Data Mining Kernel Trick Fall 2017 Admin Assignment 3: Due Friday. Midterm: Can view your exam during instructor office hours or after class this week. Digression: the other
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Category Representation 013-014 Jakob Verbeek, December 13+0, 013 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.13.14
Generative and discriminative classification techniques Machine Learning and Category Representation 013-014 Jakob Verbeek, December 13+0, 013 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.13.14
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Support vector machines
 Support vector machines Cavan Reilly October 24, 2018 Table of contents K-nearest neighbor classification Support vector machines K-nearest neighbor classification Suppose we have a collection of measurements
Support vector machines Cavan Reilly October 24, 2018 Table of contents K-nearest neighbor classification Support vector machines K-nearest neighbor classification Suppose we have a collection of measurements
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Constrained optimization
 Constrained optimization A general constrained optimization problem has the form where The Lagrangian function is given by Primal and dual optimization problems Primal: Dual: Weak duality: Strong duality:
Constrained optimization A general constrained optimization problem has the form where The Lagrangian function is given by Primal and dual optimization problems Primal: Dual: Weak duality: Strong duality:
Feature scaling in support vector data description
 Feature scaling in support vector data description P. Juszczak, D.M.J. Tax, R.P.W. Duin Pattern Recognition Group, Department of Applied Physics, Faculty of Applied Sciences, Delft University of Technology,
Feature scaling in support vector data description P. Juszczak, D.M.J. Tax, R.P.W. Duin Pattern Recognition Group, Department of Applied Physics, Faculty of Applied Sciences, Delft University of Technology,
Machine Learning Classifiers and Boosting
 Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Lecture 10: SVM Lecture Overview Support Vector Machines The binary classification problem
 Computational Learning Theory Fall Semester, 2012/13 Lecture 10: SVM Lecturer: Yishay Mansour Scribe: Gitit Kehat, Yogev Vaknin and Ezra Levin 1 10.1 Lecture Overview In this lecture we present in detail
Computational Learning Theory Fall Semester, 2012/13 Lecture 10: SVM Lecturer: Yishay Mansour Scribe: Gitit Kehat, Yogev Vaknin and Ezra Levin 1 10.1 Lecture Overview In this lecture we present in detail
732A54/TDDE31 Big Data Analytics
 732A54/TDDE31 Big Data Analytics Lecture 10: Machine Learning with MapReduce Jose M. Peña IDA, Linköping University, Sweden 1/27 Contents MapReduce Framework Machine Learning with MapReduce Neural Networks
732A54/TDDE31 Big Data Analytics Lecture 10: Machine Learning with MapReduce Jose M. Peña IDA, Linköping University, Sweden 1/27 Contents MapReduce Framework Machine Learning with MapReduce Neural Networks
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2015
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest
Chap.12 Kernel methods [Book, Chap.7]
![Chap.12 Kernel methods [Book, Chap.7]](/thumbs/83/87786394.jpg "Chap.12 Kernel methods [Book, Chap.7]") Chap.12 Kernel methods [Book, Chap.7] Neural network methods became popular in the mid to late 1980s, but by the mid to late 1990s, kernel methods have also become popular in machine learning. The first
Chap.12 Kernel methods [Book, Chap.7] Neural network methods became popular in the mid to late 1980s, but by the mid to late 1990s, kernel methods have also become popular in machine learning. The first
Unsupervised Learning: Clustering
 Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Clustering analysis of gene expression data
 Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition) Human T cell expression data The matrix contains
Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition) Human T cell expression data The matrix contains
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Support Vector Machines
 Support Vector Machines . Importance of SVM SVM is a discriminative method that brings together:. computational learning theory. previously known methods in linear discriminant functions 3. optimization
Support Vector Machines . Importance of SVM SVM is a discriminative method that brings together:. computational learning theory. previously known methods in linear discriminant functions 3. optimization
Unsupervised learning in Vision
 Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning