Data Mining: Concepts and Techniques. Chapter 7 Jiawei Han. University of Illinois at Urbana-Champaign. Department of Computer Science
|
|
|
- Rosemary Riley
- 6 years ago
- Views:
Transcription
1 Data Mining: Concepts and Techniques Chapter 7 Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign 6 Jiawei Han and Micheline Kamber, All rights reserved
2 Chapter 7. Cluster Analysis. What is Cluster Analysis?. Types of Data in Cluster Analysis 3. A Categorization of Major Clustering Methods. Partitioning Methods 5. Hierarchical Methods 6. Density-Based Methods
3 What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters distance (or similarity) measures Cluster analysis Finding similarities between data according to the characteristics found in the data and grouping similar data objects into clusters Unsupervised learning: no predefined classes Typical applications As a stand-alone tool to get insight into data distribution As a preprocessing step for other algorithms 3
4 Examples of Clustering Applications Marketing: Help marketers discover distinct groups in their customer bases, and then use this knowledge to develop targeted marketing programs Land use: Identification of areas of similar land use in an earth observation database Insurance: Identifying groups of motor insurance policy holders with a high average claim cost City-planning: Identifying groups of houses according to their house type, value, and geographical location Earth-quake studies: Observed earth quake epicenters should be clustered along continent faults
5 Example clustering for ontology aligment 5
6 Requirements of Clustering in Data Mining Scalability Ability to deal with different types of attributes Discovery of clusters with arbitrary shape Minimal requirements for domain knowledge to determine input parameters Able to deal with noise and outliers Insensitive to order of input records High dimensionality Incorporation of user-specified constraints Interpretability and usability 6
7 Chapter 7. Cluster Analysis. What is Cluster Analysis?. Types of Data in Cluster Analysis 3. A Categorization of Major Clustering Methods. Partitioning Methods 5. Hierarchical Methods 6. Density-Based Methods 7
8 Data Structures Data matrix n objects, p attributes (two modes) One row represents one object x... x f... x p x... x... x i if ip x... x n... x nf np Dissimilarity matrix Distance table (one mode) d(,) d(3, ) d (3,) : d ( n :,) d ( n :,)
9 Type of data in clustering analysis Interval-scaled variables Continuous measurements (weight, temperature, ) Binary variables Variables with states (on/off, yes/no) Nominal variables A generalization of the binary variable in that it can take more than states (color/red,yellow,blue,green) Ordinal ranking is important (e.g. medals(gold,silver,bronze)) Ratio variables a positive measurement on a nonlinear scale (growth) Variables of mixed types 9
10 Interval-valued variables Sometimes we need to standardize the data Calculate the mean absolute deviation: s = (... f n x m + x m + + x m f f f f nf f ) where n m = (x + x x f f f nf ). Calculate the standardized measurement (z-score) z = x if if s f m f
11 Distances between objects Distances are normally used to measure the similarity or dissimilarity between two data objects Properties d(i,j) d(i,i) = d(i,j) = d(j,i) d(i,j) d(i,k) + d(k,j)
12 Euclidean distance: Manhattan distance: )... ( ), ( p p j x i x j x i x j x i x j i d = Distances between objects where i = (x i, x i,, x ip ) and j = (x j, x j,, x jp ) are two p-dimensional data objects,... ), ( p p j x i x j x i x j x i x j i d =
13 Minkowski distance: q is a positive integer q q p p q q j x i x j x i x j x i x j i d )... ( ), ( = Distances between objects 3 If q =, d is Manhattan distance If q =, d is Euclidean distance
14 Binary Variables symmetric binary variables: both states are equally important; / asymmetric binary variables: one state is more important than the other (e.g. outcome of disease test); is the important state, the other
15 Contingency tables for Binary Variables Object i Object j a b a + b c d sum a + c b + d sum c + d p a: number of attributes having for object i and for object j b: number of attributes having for object i and for object j c: number of attributes having for object i and for object j d: number of attributes having for object i and for object j p = a+b+c+d 5
16 Distance measure for symmetric binary variables p d b c a sum d c d c b a b a sum Object i Object j 6 d c b a c b j i d = ), (
17 Distance measure for asymmetric binary variables Object i Object j sum a b a + c d c + sum a + c b + d p b d Jaccard coefficient = - d(i,j) = d ( i, j ) = b a + + b c + c sim a a Jaccard ( i, j ) = + b + c 7
18 Dissimilarity between Binary Variables Example Name Gender Fever Cough Test- Test- Test-3 Test- Jack M Y N P N N N Mary F Y N P N P N Jim M Y P N N N N gender is a symmetric attribute the remaining attributes are asymmetric binary distance based on these let the values Y and P be set to, and the value N be set to d d ( ( jack jack d ( jim, mary,, mary jim ) ) ) = = = =.33 =.67 =.75 8
19 Nominal or Categorical Variables Method : Simple matching m: # of matches, p: total # of variables d ( i, j ) = p p m Method : use a large number of binary variables creating a new binary variable for each of the M nominal states 9
20 Ordinal Variables An ordinal variable can be discrete or continuous Order is important, e.g., rank Can be treated like interval-scaled replace x if by their rank r {,..., f M if f } map the range of each variable onto [, ] by replacing i-th object in the f-th variable by z = r if M if f compute the dissimilarity using methods for intervalscaled variables
21 Ratio-Scaled Variables Ratio-scaled variable: a positive measurement on a nonlinear scale, approximately at exponential scale, such as Ae Bt or Ae -Bt Methods: treat them like interval-scaled variables not a good choice! (why? the scale can be distorted) apply logarithmic transformation y if = log(x if ) treat them as continuous ordinal data, treat their rank as interval-scaled
22 Variables of Mixed Types A database may contain all the six types of variables symmetric binary, asymmetric binary, nominal, ordinal, interval and ratio One may use a weighted formula to combine their effects: f is binary or nominal: d (f) ij = if x if = x jf, or d (f) ij = otherwise f is interval-based: use the normalized distance f is ordinal or ratio-scaled compute ranks r if and and treat z if as interval-scaled d ( delta(i,j) = iff (i) x-value is missing or (ii) x-values are and f asymmetric binary attribute i, j ) = z if Σ = r M p ( f ) δ d f = ij p ( f Σ δ f = ij if f ( ij ) f )
23 Vector Objects Vector objects: keywords in documents, gene features in micro-arrays, etc. Broad applications: information retrieval, biologic taxonomy, etc. Cosine measure 3
24 Vector model for information retrieval (simplified) cloning Doc (,,) Doc (,,) Q(,,) (,,) adrenergic receptor sim(d,q) = d. q d x q
25 Chapter 7. Cluster Analysis. What is Cluster Analysis?. Types of Data in Cluster Analysis 3. A Categorization of Major Clustering Methods. Partitioning Methods 5. Hierarchical Methods 6. Density-Based Methods 5
26 Major Clustering Approaches (I) Partitioning approach: Construct various partitions and then evaluate them by some criterion, e.g., minimizing the sum of square errors Typical methods: k-means, k-medoids, CLARANS Hierarchical approach: Create a hierarchical decomposition of the set of data (or objects) using some criterion Typical methods: Diana, Agnes, BIRCH, ROCK, CAMELEON Density-based approach: Based on connectivity and density functions Typical methods: DBSCAN, OPTICS, DenClue 6
27 Major Clustering Approaches (II) Grid-based approach: based on a multiple-level granularity structure Typical methods: STING, WaveCluster, CLIQUE Model-based: A model is hypothesized for each of the clusters and tries to find the best fit of that model to each other Typical methods: EM, SOM, COBWEB Frequent pattern-based: Based on the analysis of frequent patterns Typical methods: pcluster User-guided or constraint-based: Clustering by considering user-specified or application-specific constraints Typical methods: COD (obstacles), constrained clustering 7
28 Typical Alternatives to Calculate the Distance between Clusters Single link: smallest distance between an element in one cluster and an element in the other, i.e., dis(k i, K j ) = min(t ip, t jq ) Complete link: largest distance between an element in one cluster and an element in the other, i.e., dis(k i, K j ) = max(t ip, t jq ) Average: di t b t l t i l t d Average: avg distance between an element in one cluster and an element in the other, i.e., dis(k i, K j ) = avg(t ip, t jq ) Centroid: distance between the centroids of two clusters, i.e., dis(k i, K j ) = dis(c i, C j ) Medoid: distance between the medoids of two clusters, i.e., dis(k i, K j ) = dis(m i, M j ) Medoid: one chosen, centrally located object in the cluster 8
29 Centroid, Radius and Diameter of a Cluster (for numerical data sets) Centroid: the middle of a cluster Σ C m = N = N ( t i ip ) Radius: square root of average distance from any point of the cluster to its centroid Σ N R i = m = ( t ip N c m ) Diameter: square root of average mean squared distance between all pairs of points in the cluster D m = Σ N i = Σ N i = N ( ( N t ip ) t iq ) 9
30 Chapter 7. Cluster Analysis. What is Cluster Analysis?. Types of Data in Cluster Analysis 3. A Categorization of Major Clustering Methods. Partitioning Methods 5. Hierarchical Methods 6. Density-Based Methods 3
31 Partitioning Algorithms: Basic Concept Partitioning method: Construct a partition of a database D of n objects into a set of k clusters, s.t., min sum of squared distance k Σ m = Σ t mi Km ( C m t mi ) Given a k, find a partition of k clusters that optimizes the chosen partitioning criterion Global optimal: exhaustively enumerate all partitions Heuristic methods: k-means and k-medoids algorithms k-means (MacQueen 67): Each cluster is represented by the center of the cluster k-medoids or PAM (Partition around medoids) (Kaufman & Rousseeuw 87): Each cluster is represented by one of the objects in the cluster 3
32 The K-Means Clustering Method Given k, data D. arbitrarily choose k objects as initial cluster centers. Repeat Assign each object to the cluster to which the object is most similar based on mean values of the objects in the cluster Update cluster means (calculate mean value of the objects for each cluster) Until no change 3
33 The K-Means Clustering Method Example Assign each object to most similar center reassign Update the cluster means reassign K= Arbitrarily choose K objects as initial cluster centers Update the cluster means
34 Comments on the K-Means Method Strength: Relatively efficient: O(tkn), where n is # objects, k is # clusters, and t is # iterations. Normally, k, t << n. Comparing: PAM: O(k(n-k) ), CLARA: O(ks + k(n-k)) Comment: Often terminates at a local optimum. The global optimum may be found using techniques such as: deterministic annealing and genetic algorithms Weakness Applicable only when mean is defined, then what about categorical data? Need to specify k, the number of clusters, in advance Unable to handle noisy data and outliers Not suitable to discover clusters with non-convex shapes 3
35 What Is the Problem of the K-Means Method? The k-means algorithm is sensitive to outliers! Since an object with an extremely large value may substantially distort the distribution of the data. K-Medoids: Instead of taking the mean value of the object in a cluster as a reference point, medoids can be used, which is the most centrally located object in a cluster
36 The K-Medoids Clustering Method Find representative objects, called medoids, in clusters PAM (Partitioning Around Medoids, 987) starts from an initial set of medoids and iteratively replaces one of the medoids by one of the non-medoids if it improves the total distance of the resulting clustering PAM works effectively for small data sets, but does not scale well for large data sets CLARA (Kaufmann & Rousseeuw, 99) CLARANS (Ng & Han, 99): Randomized sampling 36
37 A Typical K-Medoids Algorithm (PAM) - idea Total Cost = K= Arbitrary choose k objects as initial medoids Total Cost = 6 Assign each remaining object to nearest medoids Randomly select a nonmedoid object,o ramdom Do loop Until no change Swapping O and O ramdom If quality is improved Compute total cost of swapping
38 PAM (Partitioning Around Medoids) (987) PAM (Kaufman and Rousseeuw, 987) Algorithm Select k representative objects arbitrarily For each pair of non-selected object h and selected object i, calculate the total swapping cost TC ih Select a pair i and h, which corresponds to the minimum swapping cost If TC ih <, i is replaced by h Then assign each non-selected object to the most similar representative object repeat steps -3 until there is no change 38
39 PAM Clustering: Total swapping cost TC ih = j C jih t j i h t j h i Cjih = d(j, h) - d(j, i) Cjih = j h i t i h j t Cjih = d(j, t) - d(j, i) Cjih = d(j, h) - d(j, t) 39
40 What Is the Problem with PAM? Pam is more robust than k-means in the presence of noise and outliers because a medoid is less influenced by outliers or other extreme values than a mean Pam works efficiently for small data sets but does not scale well for large data sets. O(k(n-k) ) for each iteration where n is # of data,k is # of clusters Sampling based method, CLARA(Clustering LARge Applications)
41 CLARA (Clustering Large Applications) (99) CLARA (Kaufmann and Rousseeuw in 99) Built in statistical analysis packages, such as S+ It draws multiple samples of the data set, applies PAM on each sample, and gives the best clustering as the output Strength: deals with larger data sets than PAM Weakness: Efficiency depends on the sample size A good clustering based on samples will not necessarily represent a good clustering of the whole data set if the sample is biased
42 CLARA (Clustering Large Applications) (99) Algorithm (n=5, s = +k) Repeat n times: Draw sample of s objects from the entire data set and perform PAM to find k mediods of the sample assign each non-selected object in the entire data set to the most similar mediod Calculate average dissimilarity of the clustering. If the value is smaller than the current minimum, use this value as current minimum and retain the k medoids as best so far.
43 Graph abstraction Node represents k objects (medoids), a potential solution for the clustering. Nodes are neighbors if the sets of objects differ by one object. Each node has k(n-k) neighbors. Cost differential between two neighbors is TCih (with Oi and Oh are the differing nodes in the mediod sets) 3
44 Graph Abstraction PAM searches for node in the graph with minimum cost CLARA searches in smaller graphs (as it uses PAM on samples of the entire data set) CLARANS Searches in the original graph Searches part of the graph Uses the neighbors to guide the search
45 CLARANS ( Randomized CLARA) (99) CLARANS (A Clustering Algorithm based on Randomized Search) (Ng and Han 9) It is more efficient and scalable than both PAM and CLARA 5
46 CLARANS ( Randomized CLARA) (99) Algorithm Numlocal: number of local minima to be found Maxneighbor: maximum number of neighbors to compare Repeat numlocal times: (find local minimum) Take arbitrary node in the graph Consider random neighbor S of the current node and calculate the cost differential. If S has lower cost, then set S to current and repeat this step. If S does not have lower cost, repeat this step (check at most Maxneighbor neighbors) Compare the cost of current node with minimum cost so far. If the cost is lower, set minumum cost to cost of the current node, and bestnode to the current node. 6
47 Chapter 7. Cluster Analysis. What is Cluster Analysis?. Types of Data in Cluster Analysis 3. A Categorization of Major Clustering Methods. Partitioning Methods 5. Hierarchical Methods 6. Density-Based Methods 7
48 Hierarchical Clustering Use distance matrix as clustering criteria. This method does not require the number of clusters k as an input, but needs a termination condition Step Step Step Step 3 Step a b c d e a b d e c d e a b c d e Step Step 3 Step Step Step agglomerative (AGNES) divisive (DIANA) 8
49 (,) 5 3 (,) Complete-link Clustering Example 9 9 max{9,8} }, max{ max{,9} }, max{ 6 max{6,3} }, max{,5,5 (,),5,, (,),,3,3 (,),3 = = = = = = = = = d d d d d d d d d 3 5
50 (,) 5 3 (,) 7 6 (,5) 3 (,) (,5) 3 (,) Complete-link Clustering Example 5 7 max{7,5} }, max{ max{,9} }, max{ 3,5 3, 3,(,5) (,),5 (,), (,),(,5) = = = = = = d d d d d d 3 5
51 (,) 5 3 (,) 7 6 (,5) 3 (,) (,5) 3 (,) Complete-link Clustering Example 5 }, max{ ) 3,(,5 (,),(,5),,3),(,5) ( = = d d d th=9 th=
52 AGNES (Agglomerative Nesting) Introduced in Kaufmann and Rousseeuw (99) Implemented in statistical analysis packages, e.g., Splus Use the Single-Link method and the dissimilarity matrix. Merge nodes that have the least dissimilarity Go on in a non-descending fashion Eventually all nodes belong to the same cluster 5
53 AGNES (Agglomerative Nesting)
54 Dendrogram: Shows How the Clusters are Merged Decompose data objects into a several levels of nested partitioning (tree of clusters), called a dendrogram. A clustering of the data objects is obtained by cutting the dendrogram d at the desired dlevel, l then each connected td component forms a cluster. 5
55 DIANA (Divisive Analysis) Introduced in Kaufmann and Rousseeuw (99) Implemented in statistical analysis packages, e.g., Splus Inverse order of AGNES Eventually each node forms a cluster on its own
56 Recent Hierarchical Clustering Methods Major weakness of agglomerative clustering methods do not scale well: time complexity of at least O(n ), where n is the number of total objects can never undo what was done previously Integration of hierarchical with distance-based clustering BIRCH (996): uses CF-tree and incrementally adjusts the quality of sub-clusters ROCK (999): clustering categorical data by neighbor and link analysis CHAMELEON (999): hierarchical clustering using dynamic modeling 56
57 BIRCH (996) Birch: Balanced Iterative Reducing and Clustering using Hierarchies (Zhang, Ramakrishnan & Livny, SIGMOD 96) Incrementally construct a CF (Clustering Feature) tree, a hierarchical data structure for multiphase clustering Phase : scan DB to build an initial in-memory CF tree (a multi-level compression of the data that tries to preserve the inherent clustering structure of the data) Phase : use an arbitrary clustering algorithm to cluster the leaf nodes of the CF-tree Scales linearly: finds a good clustering with a single scan and improves the quality with a few additional scans Weakness: handles only numeric data, and sensitive to the order of the data record, not always natural clusters. 57
58 Clustering Feature Vector in BIRCH Clustering Feature: CF = (N, LS, SS) N: Number of data points LS: N i==x i SS: N i= =X i CF = (5, (6,3),(5,9)) (3,) (,6) (,5) (,7) (3,8) 58
59 CF-Tree in BIRCH Clustering feature: summary of the statistics for a given subcluster: the -th, st and nd moments of the subcluster from the statistical point of view. registers crucial measurements for computing cluster and utilizes storage efficiently A CF tree is a height-balanced tree that stores the clustering features for a hierarchical clustering A nonleaf node in a tree has children and stores the sums of the CFs of their children A nonleaf node represents a cluster made of the subclusters represented by its children A leaf node represents a cluster made of the subclusters represented by its entries A CF tree has two parameters Branching factor: specify the maximum number of children. threshold: max diameter of sub-clusters stored at the leaf nodes 59
60 The CF Tree Structure Root B = 6 T = 7 CF CF child CF 3 child 3 child CF 6 child 6 Non-leaf node CF CF CF CF child CF 3 child 3 child CF 5 child 5 Leaf node Leaf node prev CF a CF b CF k next prev CF l CF m CF q next 6
61 ROCK: Clustering Categorical Data ROCK: RObust Clustering using links S. Guha, R. Rastogi & K. Shim, ICDE 99 Major ideas Use links to measure similarity/proximity maximize the sum of the number of links between points within a cluster, minimize the sum of the number of links for points in different clusters Computational complexity: On ( + nmm + n log n) m a 6
62 Similarity Measure in ROCK Traditional measures for categorical data may not work well, e.g., Jaccard coefficient Example: Two groups (clusters) of transactions C. <a, b, c, d, e>: {a, b, c}, {a, b, d}, {a, b, e}, {a, c, d}, {a, c, e}, {a, d, e}, {b, c, d}, {b, c, e}, {b, d, e}, {c, d, e} C. <a, b, f, g>: {a, b, f}, {a, b, g}, {a, f, g}, {b, f, g} Jaccard coefficient may lead to wrong clustering result C :. ({a, b, c}, {b, d, e}} to.5 ({a, b, c}, {a, b, d}) C & C : could be as high as.5 ({a, b, c}, {a, b, f}) Jaccard coefficient-based similarity function: Sim ( T, T ) Ex. Let T = {a, b, c}, T = {c, d, e} Sim { c }, T ) = = = { a, b, c, d, e } 5 ( T. = T T T T 6
63 Link Measure in ROCK Neighbor: p and p are neighbors iff sim(p,p) >= t (sim and t between and ) Link(pi,pj) pj) is the number of common neighbors between pi and pj 63
64 Link Measure in ROCK Links: # of common neighbors C <a, b, c, d, e>: {a, b, c}, {a, b, d}, {a, b, e}, {a, c, d}, {a, c, e}, {a, d, e}, {b, c, d}, {b, c, e}, {b, d, e}, {c, d, e} C <a, b, f, g>: {a, b, f}, {a, b, g}, {a, f, g}, {b, f, g} Let T = {a, b, c}, T = {c, d, e}, T 3 ={a {a, b, f} and sim the Jaccard coefficient similarity and t=.5 link(t, T ) =, since they have common neighbors {a, c, d}, {a, c, e}, {b, c, d}, {b, c, e} link(t, T 3 ) = 5, since they have 5 common neighbors {a, b, d}, {a, b, e}, {a, b, g}, {a, b, c}, {a, b, f} 6
65 Link Measure in ROCK Link(Ci,Cj) = the number of cross links between clusters Ci and Cj G(Ci,Cj) = goodness measure for merging g Ci and Cj = Link(Ci,Cj) divided by the expected number of cross links 65
66 The ROCK Algorithm Algorithm: sampling-based clustering Draw random sample Hierarchical clustering with links using goodness measure of merging Label data in disk: a point is assigned to the cluster for which it has the most neighbors after normalization 66
67 CHAMELEON: Hierarchical Clustering Using Dynamic Modeling (999) CHAMELEON: by G. Karypis, E.H. Han, and V. Kumar 99 Measures the similarity based on a dynamic model Two clusters are merged only if the interconnectivity and closeness (proximity) between two clusters are high relative to the internal interconnectivity of the clusters and closeness of items within the clusters A two-phase algorithm. Use a graph partitioning algorithm: cluster objects into a large number of relatively small sub-clusters. Use an agglomerative hierarchical clustering algorithm: find the genuine clusters by repeatedly combining these sub-clusters 67
68 Data Set Overall Framework of CHAMELEON Construct Sparse Graph Partition the Graph Merge Partition Final Clusters 68
69 CHAMELEON: Hierarchical Clustering Using Dynamic Modeling (999) A two-phase algorithm. Use a graph partitioning algorithm: cluster objects into a large number of relatively small sub-clusters. Based on k-nearest neighbor graph Edge between two nodes if points corresponding to either of the nodes are among the k-most similar points of the point corresponding to the other node Edge weight is density of the region Dynamic notion of neighborhood: in regions with high density, a neighborhood radius is small, while in sparse regions the neighborhood radius is large 69
70 CHAMELEON: Hierarchical Clustering Using Dynamic Modeling (999) A two-phase algorithm.. Use an agglomerative hierarchical clustering algorithm: find the genuine clusters by repeatedly combining these sub-clusters Interconnectivity between clusters Ci and Cj: normalized sum of the weights of the edges that connect nodes in Ci and Cj Closeness of clusters Ci and Cj: average similarity between points in Ci that are connected to points in Cj Merge if both measures are above user-defined thresholds 7
71 CHAMELEON (Clustering Complex Objects) 7
72 Chapter 7. Cluster Analysis. What is Cluster Analysis?. Types of Data in Cluster Analysis 3. A Categorization of Major Clustering Methods. Partitioning Methods 5. Hierarchical Methods 6. Density-Based Methods 7
73 Density-Based Clustering Methods Clustering based on density (local cluster criterion), such as density-connected points Major features: Discover clusters of arbitrary shape Handle noise One scan Need density parameters as termination condition Several interesting studies: DBSCAN: Ester, et al. (KDD 96) OPTICS: Ankerst, et al (SIGMOD 99). DENCLUE: Hinneburg & D. Keim (KDD 98) CLIQUE: Agrawal, et al. (SIGMOD 98) (more grid-based) 73
74 Density-Based Clustering: Basic Concepts Two parameters: Eps: Maximum radius of the neighborhood MinPts: Minimum number of points in an Epsneighborhood of that point N Eps (p): {q belongs to D dist(p,q) <= Eps} Directly density-reachable: A point p is directly densityreachable from a point q w.r.t. Eps, MinPts if p belongs to N Eps (q) p core point condition: q N Eps (q) >= MinPts MinPts = 5 Eps = cm 7
75 Density-Reachable and Density-Connected Density-reachable: A point p is density-reachable from a point q w.r.t. Eps, MinPts if there is a chain of points p,, p n, p = q, p n = p such that p i+ is directly density-reachable from p i q p p Density-connected A point p is density-connected to a point q w.r.t. Eps, MinPts if there is a point o such that both, p and q are density-reachable from o w.r.t. Eps and MinPts p q o 75
76 DBSCAN: Density Based Spatial Clustering of Applications with Noise Relies on a density-based notion of cluster: A cluster is defined as a maximal set of density-connected points Discovers clusters of arbitrary shape in spatial databases with noise Outlier Border Core Eps = cm MinPts = 5 76
77 DBSCAN: The Algorithm Arbitrary select a point p Retrieve all points density-reachable from p w.r.t. Eps and MinPts. If p is a core point, a cluster is formed. If p is a border point, no points are density-reachable from p and DBSCAN visits the next point of the database. Continue the process until all of the points have been processed. 77


78 DBSCAN: Sensitive to Parameters 78


79 CHAMELEON (Clustering Complex Objects) 79
80 OPTICS: A Cluster-Ordering Method (999) OPTICS: Ordering Points To Identify the Clustering Structure Ankerst, Breunig, Kriegel, and Sander (SIGMOD 99) Produces a special order of the database wrt its density-based clustering structure This cluster-ordering contains info equivalent to the density-based clusterings corresponding to a broad range of parameter settings Good for both automatic and interactive cluster analysis, including finding intrinsic clustering structure Can be represented graphically or using visualization techniques 8
81 OPTICS: Some Extension from DBSCAN Core Distance of p wrt MinPts: smallest distance eps between p and an object in its eps-neighborhood such that p would be a core object for eps and MinPts. Otherwise, undefined. Reachability Distance of p wrt o: Max (core-distance (o), d (o, p)) if o is core object. Undefined d otherwise p p o Max (core-distance (o), d (o, p)) r(p, o) =.5cm. r(p,o) = cm MinPts = 5 ε = 3 cm 8
82 OPTICS () Select non-processed object o () Find neighbors (eps-neighborhood) Compute core distance for o Write object o to ordered file and mark o as processed If o is not a core object, restart at () (o is a core object ) Put neighbors of o in Seedlist and order If neighbor n is not yet in SeedList then add (n, reachability from o) else if reachability from o < current reachability, then update reachability + order SeedList wrt reachability Take new object from Seedlist with smallest reachability and restart at () 8
83 Reachability -distance undefined ε ε ε Cluster-order of the objects 83
84 DENCLUE: Using Statistical Density Functions DENsity-based CLUstEring by Hinneburg & Keim (KDD 98) Using statistical density functions Major features Solid mathematical foundation Good for data sets with large amounts of noise Allows a compact mathematical description of arbitrarily shaped clusters in high-dimensional data sets Significant faster than existing algorithm (e.g., DBSCAN) But needs a large number of parameters 8
85 Denclue: Technical Essence Uses grid cells but only keeps information about grid cells that do actually contain data points and manages these cells in a tree-based access structure Influence function: describes the impact of a data point within its neighborhood f ( x, y ) = e Gaussian = dxy (, ) σ Overall density of the data space can be calculated as the sum of the influence function of all data points f D Gaussian d ( x, x N σ ( x ) = i = e i ) Clusters can be determined mathematically by identifying density attractors. Density attractors are local maxima of the overall density function f D Gaussian d ( x, x N σ ( x, x i ) = = ( x i i x ) e i ) 85


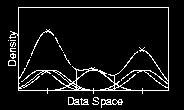
86 Density Attractor 86
87 Denclue: Technical Essence Significant density attractor for threshold k: density attractor with density larger than or equal to k Set of significant density attractors X for threshold k: for each pair of density attractors x, x in X there is a path from x to x such that each point on the path has density larger than or equal to k Center-defined cluster for a significant density attractor x for threshold k: points that are density attracted by x Points that are attracted to a density attractor with density less than k are called outliers Arbitrary-shape cluster for a set of significant density attractors X for threshold k: points that are density attracted to some density attractor in X 87

88 Center-Defined and Arbitrary 88
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Lecture 7 Cluster Analysis: Part A
 Lecture 7 Cluster Analysis: Part A Zhou Shuigeng May 7, 2007 2007-6-23 Data Mining: Tech. & Appl. 1 Outline What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering
Lecture 7 Cluster Analysis: Part A Zhou Shuigeng May 7, 2007 2007-6-23 Data Mining: Tech. & Appl. 1 Outline What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
Cluster Analysis. CSE634 Data Mining
 Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Clustering Techniques
 Clustering Techniques Marco BOTTA Dipartimento di Informatica Università di Torino botta@di.unito.it www.di.unito.it/~botta/didattica/clustering.html Data Clustering Outline What is cluster analysis? What
Clustering Techniques Marco BOTTA Dipartimento di Informatica Università di Torino botta@di.unito.it www.di.unito.it/~botta/didattica/clustering.html Data Clustering Outline What is cluster analysis? What
UNIT V CLUSTERING, APPLICATIONS AND TRENDS IN DATA MINING. Clustering is unsupervised classification: no predefined classes
 UNIT V CLUSTERING, APPLICATIONS AND TRENDS IN DATA MINING What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other
UNIT V CLUSTERING, APPLICATIONS AND TRENDS IN DATA MINING What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other
Lecture 3 Clustering. January 21, 2003 Data Mining: Concepts and Techniques 1
 Lecture 3 Clustering January 21, 2003 Data Mining: Concepts and Techniques 1 What is Cluster Analysis? Cluster: a collection of data objects High intra-class similarity Low inter-class similarity How to
Lecture 3 Clustering January 21, 2003 Data Mining: Concepts and Techniques 1 What is Cluster Analysis? Cluster: a collection of data objects High intra-class similarity Low inter-class similarity How to
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 09: Vector Data: Clustering Basics Instructor: Yizhou Sun yzsun@cs.ucla.edu October 27, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification
CS145: INTRODUCTION TO DATA MINING 09: Vector Data: Clustering Basics Instructor: Yizhou Sun yzsun@cs.ucla.edu October 27, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification
CS Data Mining Techniques Instructor: Abdullah Mueen
 CS 591.03 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 6: BASIC CLUSTERING Chapter 10. Cluster Analysis: Basic Concepts and Methods Cluster Analysis: Basic Concepts Partitioning Methods Hierarchical
CS 591.03 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 6: BASIC CLUSTERING Chapter 10. Cluster Analysis: Basic Concepts and Methods Cluster Analysis: Basic Concepts Partitioning Methods Hierarchical
CS490D: Introduction to Data Mining Prof. Chris Clifton. Cluster Analysis
 CS490D: Introduction to Data Mining Prof. Chris Clifton February, 004 Clustering Cluster Analysis What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods
CS490D: Introduction to Data Mining Prof. Chris Clifton February, 004 Clustering Cluster Analysis What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods
Lezione 21 CLUSTER ANALYSIS
 Lezione 21 CLUSTER ANALYSIS 1 Cluster Analysis What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods Density-Based
Lezione 21 CLUSTER ANALYSIS 1 Cluster Analysis What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods Density-Based
Cluster Analysis. Outline. Motivation. Examples Applications. Han and Kamber, ch 8
 Outline Cluster Analysis Han and Kamber, ch Partitioning Methods Hierarchical Methods Density-Based Methods Grid-Based Methods Model-Based Methods CS by Rattikorn Hewett Texas Tech University Motivation
Outline Cluster Analysis Han and Kamber, ch Partitioning Methods Hierarchical Methods Density-Based Methods Grid-Based Methods Model-Based Methods CS by Rattikorn Hewett Texas Tech University Motivation
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Community Detection. Jian Pei: CMPT 741/459 Clustering (1) 2
 2") Clustering Community Detection http://image.slidesharecdn.com/communitydetectionitilecturejune0-0609559-phpapp0/95/community-detection-in-social-media--78.jpg?cb=3087368 Jian Pei: CMPT 74/459 Clustering
Clustering Community Detection http://image.slidesharecdn.com/communitydetectionitilecturejune0-0609559-phpapp0/95/community-detection-in-social-media--78.jpg?cb=3087368 Jian Pei: CMPT 74/459 Clustering
! Introduction. ! Partitioning methods. ! Hierarchical methods. ! Model-based methods. ! Density-based methods. ! Scalability
 Preview Lecture Clustering! Introduction! Partitioning methods! Hierarchical methods! Model-based methods! Densit-based methods What is Clustering?! Cluster: a collection of data objects! Similar to one
Preview Lecture Clustering! Introduction! Partitioning methods! Hierarchical methods! Model-based methods! Densit-based methods What is Clustering?! Cluster: a collection of data objects! Similar to one
COMP5331: Knowledge Discovery and Data Mining
 COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Jiawei Han, Micheline Kamber, and Jian Pei 2012 Han, Kamber & Pei. All rights
COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified by Dr. Lei Chen based on the slides provided by Jiawei Han, Micheline Kamber, and Jian Pei 2012 Han, Kamber & Pei. All rights
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Vector Data: Clustering: Part I Instructor: Yizhou Sun yzsun@cs.ucla.edu April 26, 2017 Methods to Learn Classification Clustering Vector Data Text Data Recommender System Decision
CS249: ADVANCED DATA MINING Vector Data: Clustering: Part I Instructor: Yizhou Sun yzsun@cs.ucla.edu April 26, 2017 Methods to Learn Classification Clustering Vector Data Text Data Recommender System Decision
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 1 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 30, 2013 Announcement Homework 1 due next Monday (10/14) Course project proposal due next
CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 1 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 30, 2013 Announcement Homework 1 due next Monday (10/14) Course project proposal due next
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Chapter 10: Cluster Analysis: Basic Concepts and Methods Instructor: Yizhou Sun yzsun@ccs.neu.edu April 2, 2013 Chapter 10. Cluster Analysis: Basic Concepts and Methods Cluster
CS6220: DATA MINING TECHNIQUES Chapter 10: Cluster Analysis: Basic Concepts and Methods Instructor: Yizhou Sun yzsun@ccs.neu.edu April 2, 2013 Chapter 10. Cluster Analysis: Basic Concepts and Methods Cluster
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
d(2,1) d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......
 d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......") Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Cluster Analysis Reading: Chapter 10.4, 10.6, 11.1.3 Han, Chapter 8.4,8.5,9.2.2, 9.3 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber &
CS570: Introduction to Data Mining Cluster Analysis Reading: Chapter 10.4, 10.6, 11.1.3 Han, Chapter 8.4,8.5,9.2.2, 9.3 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber &
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
COMP 465: Data Mining Still More on Clustering
 3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 1 Instructor: Yizhou Sun yzsun@ccs.neu.edu February 10, 2016 Announcements Homework 1 grades out Re-grading policy: If you have doubts in your
CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 1 Instructor: Yizhou Sun yzsun@ccs.neu.edu February 10, 2016 Announcements Homework 1 grades out Re-grading policy: If you have doubts in your
Unsupervised Learning Hierarchical Methods
 Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 10
 Chapter 10") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 10 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 10 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
DBSCAN. Presented by: Garrett Poppe
 DBSCAN Presented by: Garrett Poppe A density-based algorithm for discovering clusters in large spatial databases with noise by Martin Ester, Hans-peter Kriegel, Jörg S, Xiaowei Xu Slides adapted from resources
DBSCAN Presented by: Garrett Poppe A density-based algorithm for discovering clusters in large spatial databases with noise by Martin Ester, Hans-peter Kriegel, Jörg S, Xiaowei Xu Slides adapted from resources
Hierarchy. No or very little supervision Some heuristic quality guidances on the quality of the hierarchy. Jian Pei: CMPT 459/741 Clustering (2) 1
 1") Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Clustering Analysis Basics
 Clustering Analysis Basics Ke Chen Reading: [Ch. 7, EA], [5., KPM] Outline Introduction Data Types and Representations Distance Measures Major Clustering Methodologies Summary Introduction Cluster: A collection/group
Clustering Analysis Basics Ke Chen Reading: [Ch. 7, EA], [5., KPM] Outline Introduction Data Types and Representations Distance Measures Major Clustering Methodologies Summary Introduction Cluster: A collection/group
Metodologie per Sistemi Intelligenti. Clustering. Prof. Pier Luca Lanzi Laurea in Ingegneria Informatica Politecnico di Milano Polo di Milano Leonardo
 Metodologie per Sistemi Intelligenti Clustering Prof. Pier Luca Lanzi Laurea in Ingegneria Informatica Politecnico di Milano Polo di Milano Leonardo Outline What is clustering? What are the major issues?
Metodologie per Sistemi Intelligenti Clustering Prof. Pier Luca Lanzi Laurea in Ingegneria Informatica Politecnico di Milano Polo di Milano Leonardo Outline What is clustering? What are the major issues?
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Distance-based Methods: Drawbacks
 Distance-based Methods: Drawbacks Hard to find clusters with irregular shapes Hard to specify the number of clusters Heuristic: a cluster must be dense Jian Pei: CMPT 459/741 Clustering (3) 1 How to Find
Distance-based Methods: Drawbacks Hard to find clusters with irregular shapes Hard to specify the number of clusters Heuristic: a cluster must be dense Jian Pei: CMPT 459/741 Clustering (3) 1 How to Find
Data Mining: Concepts and Techniques. Chapter 7. Cluster Analysis. Examples of Clustering Applications. What is Cluster Analysis?
 Data Mining: Concepts an Techniques Chapter Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.eu/~hanj Jiawei Han an Micheline Kamber, All rights reserve
Data Mining: Concepts an Techniques Chapter Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.eu/~hanj Jiawei Han an Micheline Kamber, All rights reserve
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Course Content. What is Classification? Chapter 6 Objectives
 Principles of Knowledge Discovery in Data Fall 007 Chapter 6: Data Clustering Dr. Osmar R. Zaïane University of Alberta Course Content Introduction to Data Mining Association Analysis Sequential Pattern
Principles of Knowledge Discovery in Data Fall 007 Chapter 6: Data Clustering Dr. Osmar R. Zaïane University of Alberta Course Content Introduction to Data Mining Association Analysis Sequential Pattern
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Data Mining 4. Cluster Analysis
 Data Mining 4. Cluster Analysis 4.5 Spring 2010 Instructor: Dr. Masoud Yaghini Introduction DBSCAN Algorithm OPTICS Algorithm DENCLUE Algorithm References Outline Introduction Introduction Density-based
Data Mining 4. Cluster Analysis 4.5 Spring 2010 Instructor: Dr. Masoud Yaghini Introduction DBSCAN Algorithm OPTICS Algorithm DENCLUE Algorithm References Outline Introduction Introduction Density-based
Course Content. Classification = Learning a Model. What is Classification?
 Lecture 6 Week 0 (May ) and Week (May 9) 459-0 Principles of Knowledge Discovery in Data Clustering Analysis: Agglomerative,, and other approaches Lecture by: Dr. Osmar R. Zaïane Course Content Introduction
Lecture 6 Week 0 (May ) and Week (May 9) 459-0 Principles of Knowledge Discovery in Data Clustering Analysis: Agglomerative,, and other approaches Lecture by: Dr. Osmar R. Zaïane Course Content Introduction
A Comparative Study of Various Clustering Algorithms in Data Mining
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Analysis and Extensions of Popular Clustering Algorithms
 Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Clustering in Ratemaking: Applications in Territories Clustering
 Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
CS 412 Intro. to Data Mining Chapter 10. Cluster Analysis: Basic Concepts and Methods
 CS 412 Intro. to Data Mining Chapter 10. Cluster Analysis: Basic Concepts and Methods Jiawei Han, Computer Science, Univ. Illinois at Urbana -Champaign, 2017 1 2 Chapter 10. Cluster Analysis: Basic Concepts
CS 412 Intro. to Data Mining Chapter 10. Cluster Analysis: Basic Concepts and Methods Jiawei Han, Computer Science, Univ. Illinois at Urbana -Champaign, 2017 1 2 Chapter 10. Cluster Analysis: Basic Concepts
7.1 Euclidean and Manhattan distances between two objects The k-means partitioning algorithm... 21
 Contents 7 Cluster Analysis 7 7.1 What Is Cluster Analysis?......................................... 7 7.2 Types of Data in Cluster Analysis.................................... 9 7.2.1 Interval-Scaled
Contents 7 Cluster Analysis 7 7.1 What Is Cluster Analysis?......................................... 7 7.2 Types of Data in Cluster Analysis.................................... 9 7.2.1 Interval-Scaled
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
CS412 Homework #3 Answer Set
 CS41 Homework #3 Answer Set December 1, 006 Q1. (6 points) (1) (3 points) Suppose that a transaction datase DB is partitioned into DB 1,..., DB p. The outline of a distributed algorithm is as follows.
CS41 Homework #3 Answer Set December 1, 006 Q1. (6 points) (1) (3 points) Suppose that a transaction datase DB is partitioned into DB 1,..., DB p. The outline of a distributed algorithm is as follows.
CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES
 CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES 7.1. Abstract Hierarchical clustering methods have attracted much attention by giving the user a maximum amount of
CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES 7.1. Abstract Hierarchical clustering methods have attracted much attention by giving the user a maximum amount of
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Sponsored by AIAT.or.th and KINDML, SIIT
 CC: BY NC ND Table of Contents Chapter 4. Clustering and Association Analysis... 171 4.1. Cluster Analysis or Clustering... 171 4.1.1. Distance and similarity measurement... 173 4.1.2. Clustering Methods...
CC: BY NC ND Table of Contents Chapter 4. Clustering and Association Analysis... 171 4.1. Cluster Analysis or Clustering... 171 4.1.1. Distance and similarity measurement... 173 4.1.2. Clustering Methods...
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Efficient and Effective Clustering Methods for Spatial Data Mining. Raymond T. Ng, Jiawei Han
 Efficient and Effective Clustering Methods for Spatial Data Mining Raymond T. Ng, Jiawei Han 1 Overview Spatial Data Mining Clustering techniques CLARANS Spatial and Non-Spatial dominant CLARANS Observations
Efficient and Effective Clustering Methods for Spatial Data Mining Raymond T. Ng, Jiawei Han 1 Overview Spatial Data Mining Clustering techniques CLARANS Spatial and Non-Spatial dominant CLARANS Observations
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Descriptive Modeling. Based in part on Chapter 9 of Hand, Manilla, & Smyth And Section 14.3 of HTF David Madigan
 Descriptive Modeling Based in part on Chapter 9 of Hand, Manilla, & Smyth And Section 14.3 of HTF David Madigan Data Mining Algorithms A data mining algorithm is a well-defined procedure that takes data
Descriptive Modeling Based in part on Chapter 9 of Hand, Manilla, & Smyth And Section 14.3 of HTF David Madigan Data Mining Algorithms A data mining algorithm is a well-defined procedure that takes data
Big Data Analytics! Special Topics for Computer Science CSE CSE Feb 9
 Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Clustering Algorithms for Spatial Databases: A Survey
 Clustering Algorithms for Spatial Databases: A Survey Erica Kolatch Department of Computer Science University of Maryland, College Park CMSC 725 3/25/01 kolatch@cs.umd.edu 1. Introduction Spatial Database
Clustering Algorithms for Spatial Databases: A Survey Erica Kolatch Department of Computer Science University of Maryland, College Park CMSC 725 3/25/01 kolatch@cs.umd.edu 1. Introduction Spatial Database
Clustering from Data Streams
 Clustering from Data Streams João Gama LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting
Clustering from Data Streams João Gama LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting
Clustering Algorithms for Data Stream
 Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
On Clustering Validation Techniques
 On Clustering Validation Techniques Maria Halkidi, Yannis Batistakis, Michalis Vazirgiannis Department of Informatics, Athens University of Economics & Business, Patision 76, 0434, Athens, Greece (Hellas)
On Clustering Validation Techniques Maria Halkidi, Yannis Batistakis, Michalis Vazirgiannis Department of Informatics, Athens University of Economics & Business, Patision 76, 0434, Athens, Greece (Hellas)
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
EECS 730 Introduction to Bioinformatics Microarray. Luke Huan Electrical Engineering and Computer Science
 EECS 730 Introduction to Bioinformatics Microarray Luke Huan Electrical Engineering and Computer Science http://people.eecs.ku.edu/~jhuan/ GeneChip 2011/11/29 EECS 730 2 Hybridization to the Chip 2011/11/29
EECS 730 Introduction to Bioinformatics Microarray Luke Huan Electrical Engineering and Computer Science http://people.eecs.ku.edu/~jhuan/ GeneChip 2011/11/29 EECS 730 2 Hybridization to the Chip 2011/11/29
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
COMPARISON OF DENSITY-BASED CLUSTERING ALGORITHMS
 COMPARISON OF DENSITY-BASED CLUSTERING ALGORITHMS Mariam Rehman Lahore College for Women University Lahore, Pakistan mariam.rehman321@gmail.com Syed Atif Mehdi University of Management and Technology Lahore,
COMPARISON OF DENSITY-BASED CLUSTERING ALGORITHMS Mariam Rehman Lahore College for Women University Lahore, Pakistan mariam.rehman321@gmail.com Syed Atif Mehdi University of Management and Technology Lahore,
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Clustering: Model, Grid, and Constraintbased Methods Reading: Chapters 10.5, 11.1 Han, Chapter 9.2 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han,
CS570: Introduction to Data Mining Clustering: Model, Grid, and Constraintbased Methods Reading: Chapters 10.5, 11.1 Han, Chapter 9.2 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han,
A Technical Insight into Clustering Algorithms & Applications
 A Technical Insight into Clustering Algorithms & Applications Nandita Yambem 1, and Dr A.N.Nandakumar 2 1 Research Scholar,Department of CSE, Jain University,Bangalore, India 2 Professor,Department of
A Technical Insight into Clustering Algorithms & Applications Nandita Yambem 1, and Dr A.N.Nandakumar 2 1 Research Scholar,Department of CSE, Jain University,Bangalore, India 2 Professor,Department of
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Faster Clustering with DBSCAN
 Faster Clustering with DBSCAN Marzena Kryszkiewicz and Lukasz Skonieczny Institute of Computer Science, Warsaw University of Technology, Nowowiejska 15/19, 00-665 Warsaw, Poland Abstract. Grouping data
Faster Clustering with DBSCAN Marzena Kryszkiewicz and Lukasz Skonieczny Institute of Computer Science, Warsaw University of Technology, Nowowiejska 15/19, 00-665 Warsaw, Poland Abstract. Grouping data
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme
 Entscheidungsunterstützungssysteme") Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Cluster Analysis: Basic Concepts and Methods
 HAN 17-ch10-443-496-9780123814791 2011/6/1 3:44 Page 443 #1 10 Cluster Analysis: Basic Concepts and Methods Imagine that you are the Director of Customer Relationships at AllElectronics, and you have five
HAN 17-ch10-443-496-9780123814791 2011/6/1 3:44 Page 443 #1 10 Cluster Analysis: Basic Concepts and Methods Imagine that you are the Director of Customer Relationships at AllElectronics, and you have five
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,