Cluster Analysis. Summer School on Geocomputation. 27 June July 2011 Vysoké Pole
|
|
|
- Amber Morton
- 5 years ago
- Views:
Transcription
1 Cluster Analysis Summer School on Geocomputation 27 June July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University, Bratislava, Slovakia
2 Structure of cluster analyses Cluster analyses Nonhierarchical Hierarchical Model-based K-means K-medoids Agglomerative Divisive
3 Nonhierarchical clustering Finds a decomposition of objects 1,...,n into k disjoint clusters C 1,...,C k of similar objects: C... C =, 1 k { 1,..., n} i j C C = The objects are (mostly) characterized by vectors of features i j x1,..., x n R p p=2 k=3 n= C 1 = { 1,3,7,9 } { 2,5,8} C = 2 C 3 = { 4,6} C = 4 1 C = 2 3 C = 3 2 How do we understand decomposition into clusters of similar objects? How is this decomposition calculated? Many different approaches: k-means, k-medoids, model-based clustering,...
4 ρ k i= 1 r C i 2 ρ K-means clustering The target function to be minimized with respect to the selection of clusters: ( x, c ) is the Euclidean distance: where ( t), ( t) r i c i = 1 C i r C i x where is the centroid of C i. ρ( x, y) = r p ( x( t) y( t) ) x y are the t th components of the vectors x, y. t= 1 2 Bad Good
5 K-means clustering It is a difficult problem to find the clustering that minimizes the target function of the k-means problem. There are many efficient heuristics that find a good, although not always optimal solution. Example: Lloyd s Algorithm Create a random initial clustering C 1,..., C k. Until a maximum prescribed number of iterations is reached, or no reassignment of objects occurs do: Calculate the centroids c 1,..., c k of clusters. For every i=1,...,k : Form the new cluster C i from all the points that are closer to c i than to any other centroid.
6 Illustration of the k-means algorithm p=2 k=3 n=11 Choose an initial clustering
7 Illustration of the k-means algorithm p=2 k=3 n=11 Calculate the centroids of clusters
8 Illustration of the k-means algorithm p=2 k=3 n=11 Assign the points to the closest centroids
9 Illustration of the k-means algorithm p=2 k=3 n=11 Create the new clustering
10 Illustration of the k-means algorithm p=2 k=3 n=11 Create the new clustering
11 Illustration of the k-means algorithm p=2 k=3 n=11 Calculate the new centroids of clusters
12 Illustration of the k-means algorithm p=2 k=3 n=11 Assign the points to the closest centroids
13 Illustration of the k-means algorithm p=2 k=3 n=11 Create the new clustering
14 Illustration of the k-means algorithm p=2 k=3 n=11 Create the new clustering
15 Illustration of the k-means algorithm p=2 k=3 n=11 Calculate the new centroids of clusters
16 Illustration of the k-means algorithm p=2 k=3 n=11 Assign the points to the closest centroids
17 Illustration of the k-means algorithm p=2 k=3 n=11 Create the new clustering
18 Illustration of the k-means algorithm p=2 k=3 n=11 Create the new clustering The clustering is the same as in the previous step, therefore STOP.
19 Properties of the k-means algorithm Advantages: Simple to understand and implement. Fast and convergent in a finite number of steps. Disadvantages: Different initial clusterings can lead to different final clusterings. It is thus advisable to run the procedure several times with different (random) initial clusterings. The resulting clustering depends on the units of measurement. If the variables are of different nature or are very different with respect to their magnitude, then it is advisable to standardize them. Not suitable for finding clusters with nonconvex shapes. The variables must be euclidean (real) vectors, so that we can calculate centroids and measure the distance from centroids; it is not enough to have only the matrix of pairwise distances or dissimilarities.
20 Computational issues of k-means Complexity: Linear in the number of objects, provided that we bound the number of iterations. In R (library stats): kmeans(x, centers, iter.max, nstart, algorithm) Dataframe of real vectors of features The number of clusters Maximum number of iterations The method used ("Hartigan-Wong", "Lloyd", "Forgy", "MacQueen" ) Number of restarts
 ( k) = ρ ( x c ) i= 1 r C ( k ) i r i C c ( k ) 1,..., ( k ) 1,.")
21 α The elbow method Selecting k the number of clusters is frequently a problem. Often done by graphical heuristics, such as the elbow method. k 2 ( k ) ( k) = ρ ( x c ) i= 1 r C ( k ) i r i C c ( k ) 1,..., ( k ) 1,..., C c ( k ) k ( k ) k optimal clustering obtained by assuming k clusters corresponding centroids elbow
22 k i= 1 r C i d K-medoids clustering Instead of centroids uses medoids the most central objects (the best representatives ) of each cluster. This allows using only dissimilarities d(r,s) of all pairs (r,s) of the objects. The aim is to find the clusters C 1,...,C k that minimize the target function: ( r, mi ) where for each i the medoid m i minimizes r C i d ( r, ) m i Bad Good
23 K-medoids algorithm Similarly as for k-means, it is a difficult problem to find the clustering that minimizes the target function of the k-medoids problem. There are many efficient heuristics that find a good, although not always optimal solution. Example: Algorithm Partitioning around medoids (PAM) Randomly select k objects m 1,...,m k as initial medoids. Until the maximum number of iterations is reached or no improvement of the target function has been found do: Calculate the clustering based on m 1,...,m k by associating each point to the nearest medoid and calculate the value of the target function. For all pairs (m i, x s ), where x s is a non-medoid point, try to improve the target function by taking x s to be a new medoid point and m i to be a non-medoid point.
24 Disadvantages: Properties of the k-medoids algorithm Advantages: Simple to understand and implement. Fast and convergent in a finite number of steps. Usually less sensitive to outliers than k-means. Allows using general dissimilarities of objects. Different initial sets of medoids can lead to different final clusterings. It is thus advisable to run the procedure several times with different initial sets of medoids. The resulting clustering depends on the units of measurement. If the variables are of different nature or are very different with respect to their magnitude, then it is advisable to standardize them.
25 Computational issues of k-medoids Complexity: At least quadratic, depending on the actual implementation. In R (library cluster): pam(x, k, diss, metric, medoids, stand, ) Dataframe of real vectors of features or a matrix of dissimilarities The number of clusters Is x a dissimilarity matrix? (TRUE, FALSE) Metrics used (euclidean, manhattan) Vector of initial medoids Standardize data? (TRUE, FALSE)
26 The silhouette a(r) the average dissimilarity of the object r and the objects of the same cluster b (r) the average dissimilarity of the object r and the objects of the neighboring cluster Silhouette of the object r the measure of how well is r clustered b( r) a( r) s( r) = [ 1,1] max ( b( r), a( r) ) s(r) close to 1 the object r is well clustered close to 0 the object r is at the boundary of clusters less than 0 the object r is probably placed in a wrong cluster
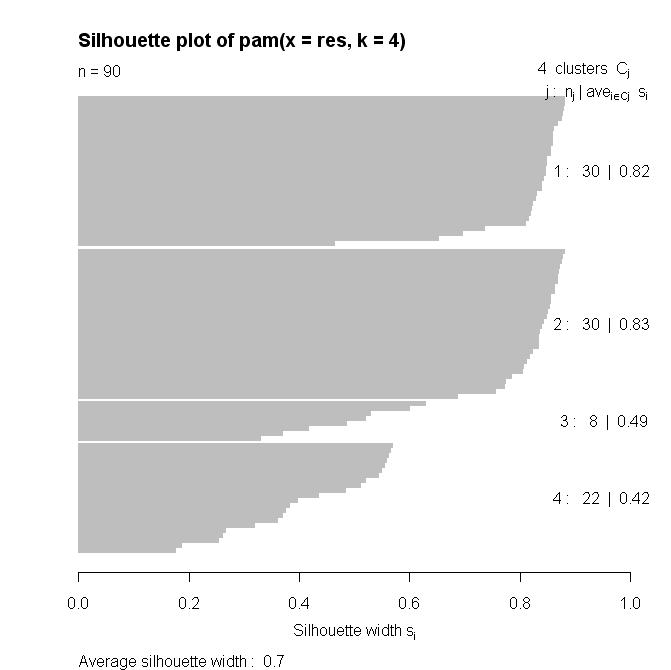
27 The silhouette
28 Model-based clustering We assume that the vectors of features of objects from the j-th cluster follow a multivariate normal distribution N p (µ j, Σ j ). The method of calculating the clustering is based on maximization of a (mathematically complicated) likelihood function. Idea: Find the most probable (most likely ) assignment of objects to clusters (and, simultaneously, the most likely positions of the centers µ j of the clusters and their covariance matricesσ j representing the shape of the clusters). Unlikely Likely
29 Model-based clustering Disadvantages compared to k-means and k-medoids More difficult to understand properly. Computationally more complex to solve. Cannot use only dissimilarities (disadvantage compared to k-medoids). Advantages over k-means and k-medoids Can find elliptic clusters with very high eccentricity, while k-means and k- medoids tend to form spherical clusters. The result is not dependent on the scale of variables (no standardization is necessary). Can find hidden clusters inside other more dispersed clusters. Allows a formal testing of the most appropriate number of clusters.
30 Computational issues of the model based clustering Complexity: Computationally a very hard problem, solved iteratively. We can use the so-called EM-algorithm, or algorithms of stochastic optimization. Modern computers can deal with problems with hundreds of variables and thousands of objects in a reasonable time. In R (library mclust): Mclust(data, modelnames,...) Dataframe of real vectors of features Model used (EII, VII, EEI, VEI, EVI, VVI, EEE, EEV, VEV, VVV)
31 Comparison of nonhierarchical clustering methods on artificial 2D data k-means model-based
32 Comparison of nonhierarchical clustering methods on artificial 2D data k-means model-based
33 Comparison of nonhierarchical clustering methods on artificial 2D data k-means model-based
34 Comparison of nonhierarchical clustering methods on the Landsat data p=36 dimensional measurements of color intensity of n=4435 areas k-means model-based
35 Hierarchical clustering Creates a hierarchy of objects represented by a tree of similarities called dendrogram. Most appropriate to cluster objects that were formed by a process of merging, splitting, or varying, such as countries, animals, commercial products, languages, fields of science etc. Advantages: For most methods, it is enough to have the dissimilarity matrix D between objects: D ij =d(r,s) is the dissimilarity between objects r and s. Does not require the knowledge of the number of clusters. Disadvantages: Depends on the scale of data. Computationally complex for large datasets. Different methods sometimes lead to very different dendrograms.
36 Example of a dendrogram height objects The dendrogram is created either: bottom-up (aglomerative, or ascending, clustering), or top-down (divisive, or descending, clustering).
37 Agglomerative clustering Algorithm: Create the set of clusters formed by individual objects (each object forms an individual cluster). While there are more than one top-level clusters do: Find the two top level clusters with the smallest mutual distance and join them into a new top level cluster. Different measures of distance between clusters provide different variants: Single linkage, Complete linkage, Average linkage, Ward s distance
38 Single linkage in agglomerative clustering The distance of two clusters is the dissimilarity of the least dissimilar objects of the clusters: D S ( C, C ) = min d( r, s) i j r C, s i C j Dendrogram
39 Average linkage in agglomerative clustering The distance of two clusters is the average of mutual dissimilarities of the objects in the clusters: 1 ( Ci, C j ) = D A d( r, s) C C i j r C i s C j Dendrogram
40 Other methods of measuring a distance of clusters in agglomerative clustering Complete linkage: the distance of clusters is the dissimilarity of the most dissimilar objects: ( ) + = j i j i C s j s C r i r C C m ij m j i W c x c x c x C C D ), ( ), ( ), (, ρ ρ ρ ( ) ), ( max,, s r d C C D i C j s C r j i C = Ward s distance: Requires that for each object r we have the real vector of features x r. (The matrix of dissimilarities is not enough.) It is the difference between an extension of the two clusters combined and the sum of the extensions of the two individual clusters....,, j i ij c c c the centroids of j i j i C C C C,,... ρ the distance between vectors
41 Computational issues of agglomerative clustering Complexity: At least quadratic complexity with respect to the number of objects (depending on implementation). In R (library cluster): agnes(x, diss, metric, stand, method, ) Dataframe of real vectors of features or a matrix of dissimilarities Is x a dissimilarity matrix? (TRUE, FALSE) Metrics used (euclidean, manhattan) Standardize data? (TRUE, FALSE) Method of measuring the distance of clusters (single, average, complete, Ward)
42 Divisive clustering Algorithm: Form a single cluster consisting of all objects. For each bottom level cluster containing at least two objects: Find the most eccentric object that initiates a splinter group. (The object that has maximal average dissimilarity to other objects.) Find all objects in the cluster that are more similar to the most eccentric object than to the rest of the objects. (For instance, the objects that have higher average dissimilarity to the eccentric object than to the rest of the objects.) Divide the cluster into two subclusters accordingly. Continue until all bottom level clusters consist of a single object.
43 Illustration of the divisive clustering
44 Illustration of the divisive clustering
45 Illustration of the divisive clustering
46 Illustration of the divisive clustering
47 Illustration of the divisive clustering
48 Illustration of the divisive clustering
49 Illustration of the divisive clustering
50 Illustration of the divisive clustering
51 Illustration of the divisive clustering Dendrogram
52 Computational issues of divisive clustering Complexity: At least linear with respect to the number of objects (depending on implementation and a on the kind of the splitting subroutine ). In R (library cluster): diana(x, diss, metric, stand, ) Dataframe of real vectors of features or a matrix of dissimilarities Is x a dissimilarity matrix? (TRUE, FALSE) Metrics used (euclidean, manhattan) Standardize data? (TRUE, FALSE)
53 Comparison of hierarchical clustering methods n=25 objects - European countries (Albania, Austria, Belgium, Bulgaria, Czechoslovakia, Denmark, EGermany, Finland, France, Greece, Hungary, Ireland, Italy, Netherlands, Norway, Poland, Portugal, Romania, Spain, Sweden, Switzerland, UK, USSR, WGermany, Yugoslavia) p=9 dimensional vectors of features - consumption of various kinds of food (Red Meat, White Meat, Eggs, Milk, Fish, Cereals, Starchy foods, Nuts, Fruits/Vegetables)
54 Agglomerative - single linkage
55 Agglomerative - complete linkage
56 Agglomerative - average linkage
57 Divisive clustering
58 Thank you for attention
MATH5745 Multivariate Methods Lecture 13
 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 1 / 33 Cluster analysis. Example: Fisher iris data Fisher (1936) 1 iris data consists of
MATH5745 Multivariate Methods Lecture 13 April 24, 2018 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 1 / 33 Cluster analysis. Example: Fisher iris data Fisher (1936) 1 iris data consists of
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Chapter 6 Continued: Partitioning Methods
 Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
STATS306B STATS306B. Clustering. Jonathan Taylor Department of Statistics Stanford University. June 3, 2010
 STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Clustering in R d. Clustering. Widely-used clustering methods. The k-means optimization problem CSE 250B
 Clustering in R d Clustering CSE 250B Two common uses of clustering: Vector quantization Find a finite set of representatives that provides good coverage of a complex, possibly infinite, high-dimensional
Clustering in R d Clustering CSE 250B Two common uses of clustering: Vector quantization Find a finite set of representatives that provides good coverage of a complex, possibly infinite, high-dimensional
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Clustering in Ratemaking: Applications in Territories Clustering
 Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Chapter 6: Cluster Analysis
 Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
Finding Clusters 1 / 60
 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Cluster analysis formalism, algorithms. Department of Cybernetics, Czech Technical University in Prague.
 Cluster analysis formalism, algorithms Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz poutline motivation why clustering? applications, clustering as
Cluster analysis formalism, algorithms Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz poutline motivation why clustering? applications, clustering as
Measure of Distance. We wish to define the distance between two objects Distance metric between points:
 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Introduction to Computer Science
 DM534 Introduction to Computer Science Clustering and Feature Spaces Richard Roettger: About Me Computer Science (Technical University of Munich and thesis at the ICSI at the University of California at
DM534 Introduction to Computer Science Clustering and Feature Spaces Richard Roettger: About Me Computer Science (Technical University of Munich and thesis at the ICSI at the University of California at
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Machine Learning. B. Unsupervised Learning B.1 Cluster Analysis. Lars Schmidt-Thieme
 Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
11/2/2017 MIST.6060 Business Intelligence and Data Mining 1. Clustering. Two widely used distance metrics to measure the distance between two records
 11/2/2017 MIST.6060 Business Intelligence and Data Mining 1 An Example Clustering X 2 X 1 Objective of Clustering The objective of clustering is to group the data into clusters such that the records within
11/2/2017 MIST.6060 Business Intelligence and Data Mining 1 An Example Clustering X 2 X 1 Objective of Clustering The objective of clustering is to group the data into clusters such that the records within
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
Summer School in Statistics for Astronomers & Physicists June 15-17, Cluster Analysis
 Summer School in Statistics for Astronomers & Physicists June 15-17, 2005 Session on Computational Algorithms for Astrostatistics Cluster Analysis Max Buot Department of Statistics Carnegie-Mellon University
Summer School in Statistics for Astronomers & Physicists June 15-17, 2005 Session on Computational Algorithms for Astrostatistics Cluster Analysis Max Buot Department of Statistics Carnegie-Mellon University
Service withdrawal: Selected IBM ServicePac offerings
 Announcement ZS09-0086, dated April 21, 2009 Service withdrawal: Selected IBM offerings Table of contents 1 Overview 9 Announcement countries 8 Withdrawal date Overview Effective April 21, 2009, IBM will
Announcement ZS09-0086, dated April 21, 2009 Service withdrawal: Selected IBM offerings Table of contents 1 Overview 9 Announcement countries 8 Withdrawal date Overview Effective April 21, 2009, IBM will
Unsupervised Learning. Clustering and the EM Algorithm. Unsupervised Learning is Model Learning
 Unsupervised Learning Clustering and the EM Algorithm Susanna Ricco Supervised Learning Given data in the form < x, y >, y is the target to learn. Good news: Easy to tell if our algorithm is giving the
Unsupervised Learning Clustering and the EM Algorithm Susanna Ricco Supervised Learning Given data in the form < x, y >, y is the target to learn. Good news: Easy to tell if our algorithm is giving the
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
were generated by a model and tries to model that we recover from the data then to clusters.
 Model Based Clustering Model based clustering Model based clustering assumes that thedata were generated by a model and tries to recover the original model from the data. The model that we recover from
Model Based Clustering Model based clustering Model based clustering assumes that thedata were generated by a model and tries to recover the original model from the data. The model that we recover from
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Algorithms In R/Clustering/K-Means
 1 / 7 Data Mining Algorithms In R/Clustering/K-Means Contents 1 Introduction 2 Technique to be discussed 2.1 Algorithm 2.2 Implementation 2.3 View 2.4 Case Study 2.4.1 Scenario 2.4.2 Input data 2.4.3 Execution
1 / 7 Data Mining Algorithms In R/Clustering/K-Means Contents 1 Introduction 2 Technique to be discussed 2.1 Algorithm 2.2 Implementation 2.3 View 2.4 Case Study 2.4.1 Scenario 2.4.2 Input data 2.4.3 Execution
Clust Clus e t ring 2 Nov
 Clustering 2 Nov 3 2008 HAC Algorithm Start t with all objects in their own cluster. Until there is only one cluster: Among the current clusters, determine the two clusters, c i and c j, that are most
Clustering 2 Nov 3 2008 HAC Algorithm Start t with all objects in their own cluster. Until there is only one cluster: Among the current clusters, determine the two clusters, c i and c j, that are most
Hierarchical clustering
 Aprendizagem Automática Hierarchical clustering Ludwig Krippahl Hierarchical clustering Summary Hierarchical Clustering Agglomerative Clustering Divisive Clustering Clustering Features 1 Aprendizagem Automática
Aprendizagem Automática Hierarchical clustering Ludwig Krippahl Hierarchical clustering Summary Hierarchical Clustering Agglomerative Clustering Divisive Clustering Clustering Features 1 Aprendizagem Automática
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions
 Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
An Introduction to Cluster Analysis. Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs
 An Introduction to Cluster Analysis Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs zhaoxia@ics.uci.edu 1 What can you say about the figure? signal C 0.0 0.5 1.0 1500 subjects Two
An Introduction to Cluster Analysis Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs zhaoxia@ics.uci.edu 1 What can you say about the figure? signal C 0.0 0.5 1.0 1500 subjects Two
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
10. MLSP intro. (Clustering: K-means, EM, GMM, etc.)
") 10. MLSP intro. (Clustering: K-means, EM, GMM, etc.) Rahil Mahdian 01.04.2016 LSV Lab, Saarland University, Germany What is clustering? Clustering is the classification of objects into different groups,
10. MLSP intro. (Clustering: K-means, EM, GMM, etc.) Rahil Mahdian 01.04.2016 LSV Lab, Saarland University, Germany What is clustering? Clustering is the classification of objects into different groups,
DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Machine learning - HT Clustering
 Machine learning - HT 2016 10. Clustering Varun Kanade University of Oxford March 4, 2016 Announcements Practical Next Week - No submission Final Exam: Pick up on Monday Material covered next week is not
Machine learning - HT 2016 10. Clustering Varun Kanade University of Oxford March 4, 2016 Announcements Practical Next Week - No submission Final Exam: Pick up on Monday Material covered next week is not
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC
 Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
What is clustering. Organizing data into clusters such that there is high intra- cluster similarity low inter- cluster similarity
 Clustering What is clustering Organizing data into clusters such that there is high intra- cluster similarity low inter- cluster similarity Informally, finding natural groupings among objects. High dimensional
Clustering What is clustering Organizing data into clusters such that there is high intra- cluster similarity low inter- cluster similarity Informally, finding natural groupings among objects. High dimensional
Tree Models of Similarity and Association. Clustering and Classification Lecture 5
 Tree Models of Similarity and Association Clustering and Lecture 5 Today s Class Tree models. Hierarchical clustering methods. Fun with ultrametrics. 2 Preliminaries Today s lecture is based on the monograph
Tree Models of Similarity and Association Clustering and Lecture 5 Today s Class Tree models. Hierarchical clustering methods. Fun with ultrametrics. 2 Preliminaries Today s lecture is based on the monograph
Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University
 Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University Kinds of Clustering Sequential Fast Cost Optimization Fixed number of clusters Hierarchical
Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University Kinds of Clustering Sequential Fast Cost Optimization Fixed number of clusters Hierarchical
CS 2750: Machine Learning. Clustering. Prof. Adriana Kovashka University of Pittsburgh January 17, 2017
 CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
Today s lecture. Clustering and unsupervised learning. Hierarchical clustering. K-means, K-medoids, VQ
 Clustering CS498 Today s lecture Clustering and unsupervised learning Hierarchical clustering K-means, K-medoids, VQ Unsupervised learning Supervised learning Use labeled data to do something smart What
Clustering CS498 Today s lecture Clustering and unsupervised learning Hierarchical clustering K-means, K-medoids, VQ Unsupervised learning Supervised learning Use labeled data to do something smart What
Multivariate analyses in ecology. Cluster (part 2) Ordination (part 1 & 2)
 Ordination (part 1 & 2)") Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster