Information Retrieval II
|
|
|
- Derek Percival Simon
- 6 years ago
- Views:
Transcription
1 Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU
2 Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning 40 parameters at the London School of Economics Coffee Break Web SearchEngineering Field Work: how do Web search engines really work? Stretch Break Discussion: Other IR problems for machine learning Historical context
3 The Web Search Scene (Sep 10) 1. Google 2. Yahoo! 3. BING - Bing Is Not Google These have the vast majority of the market in the USA but they re not alone.

4 Baidu - leader in China

5 Naver - leader in Korea

6 Yandex - leader in Russia
7 Google revenue: US$23.65B in 2009! Let s get a share of all this money! Let s build a Search Engine.
8 *** IMAGE ***
9 My design parameters for new Web SE 500 million queries/day - say peak of per second. Average page revisit frequency - once per month 50 billion Web pages Average page size is 25KB (2008) Average URL length is approx 100 characters (5 terabytes!) 1.25 petabyte of data (Plus, at least 100% network overhead) 2.5 million gigabytes of network traffic per crawl. hundreds of millions of distinct words 25 trillion word occurrences
10 *** IMAGE ***
11 Design issues for the spider Data bandwidth = 9.6 gigabits/sec. better not focus the spider on one server (or one country)! need a huge degree of parallelism a major load balancing problem Cache needs 5 terabytes to store just URLs! need very efficient lookup methods
12 Parallel approach to Indexing and Query Processing Divide the data across a cluster of PCs Node = 2.8 GHz i7 PC, 8 gb RAM, 2 x 1 tb disk, $2k per year to lease and operate Replicate clusters and use load-balancing network front-end NOW PC PC PC PC PC PC PC PC PC PC Docs Docs Docs Docs Docs Docs Docs Docs Docs Docs
13 Query processing Each node is responsible for 50 million documents (1 tb) Therefore need 1000 nodes to handle full collection, If each node can process 10 queries/sec Need queries/sec, therefore 1000 clusters. Need 1000 x 1000 = 1,000,000 PCs $2.0B/year lease cost. Say query result page is 25kB long queries/sec gigabits/sec
14 *** IMAGE *** (Thanks to Wei-Ying Ma (MSRA) and Mark Sanderson, Sheffield University)
15 Electricity Say each node consumes 250Watts of electricity. Total power draw for 1,001,000 machines = 250 megawatts Plus airconditioning at 1:3 = 83 megawatts Total power = 333 megawatts
16 Index structure Postings (uncompressed). (2,3)(7,1)(11,2)(17,1)(22,6) Term count postings aaaaa 1 Index oboe 5 oblong 3 zzzzz 2 Term Dictionary Score DocID Length QIE Snippet doc doc Arist... doc doc doc doc Acc.s Document Table
17 Data structure sizes (per node) Term Dictionary each entry: 12 byte string, 4 byte count, 4 byte offset total size: 10M x 20 = 200 MB Doc Table each entry: 50 byte string (name), 4 byte length, 4 byte score, 100 byte string (snippet) total size: 50M x 158 = 8.0 gb Inverted File each entry: 4-byte docno, 4-byte count total size: 6.5B x 8 = 53 gb Compressed text for document summaries 100GB? It fits easily. What about link, anchor text and user behaviour indexes? UK-2007 (115M pages) has 4.1 billion links!
18 Indexing - Use one cluster Index 50M pages in about 2.5 days. Dirt cheap
19 Two ways of query processing: TAAT and DAAT Query: lpg vehicle subsidy 1. [lpg; 27,000] - (2,7) (2,9) (2,100) (173,5) (2005, 19) (2005,178) (9999, 1) [vehicle; 112,000] - (13,31) (18,25) (173,6) (5006,88) (9999, 18) [subsidy; 11,000] - (99,108) (173,7) (173,99) (7798,13) (9999,205)... TAAT (Term at a time) Process all postings for lpg, then all for vehicle, then subsidy. Non-zero scores for every doc containing one or more of the terms DAAT (Document at a time) Scan three postings lists in parallel Only count matches which meet a criterion. e.g. AND or WAND (Broder et al, CIKM, 2003) (Use skipping)
20 DAAT Ranking Fewer results to sort (full matches only) Can stop when we have required number of matches (or so) Assign document numbers in order of descending static score. Compression techniques relying on doc-number diffs still work Ensure that unscanned matches are not likely to be good. Use limited document accumulators (better memory residency) Can apply local ranking heuristics to candidate set. Terms in proximity, terms in headings etc.
21 ClueWeb09 Demo
22 Cutting costs Answer Caching Pre-compute answers to popular queries (manually if nec.) Top X queries account for 30% of query load One PC can serve answers for all X queries. Save 300 clusters, $600M per year! Process Queries on Partial Data, eg. document titles, anchor text. Shorten results page Make spidering adaptive, continuous Avoid crawling spam and low value content Make query processing more efficient more data per node less time per query (but 10 queries/sec is already good going)
23 General Efficiency Observations Two types of efficiency technique: A. No loss of effectiveness fast algorithms B. Trade-off efficiency/effectiveness use heuristics to reduce work Memory management is critical Can reduce memory demand by careful design/layout of data structures compression Disk accesses very slow = 5M instructions Avoid as much as possible Disk transfers negligible except for very common terms compression pays off in reduced transfer costs
24 Hardware Issues 1. Choose cheap, low-heat-output, reliable servers 2. Build in fault tolerance. Can t allow a whole cluster to be down because one node has failed! 3. Efficient fault diagnosis and repair procedures.
25 Speeding up query processing 1. Use a limited number of score accumulators 2. Process term lists in parallel, not sequentially 3. Assign document numbers according to descending value 4. Stop early 5. Seek perfect load balance across clusters. The cluster is as slow as the slowest node.
26 Result Presentation For each top-ranked doc, print DOCID, snippet etc. How to generate summaries Canned summaries - query independent Query biased summaries - quite a computational challenge
27 Other Issues Privacy David Hawking Smith St, Nowhere 2586 Masses of query and click data what can we use it for? Search quality tuning machine learning Ranking evidence Spelling corrections. Query suggestions Legal issues with advertisers, copyright owners,...
28 Doing More with Queries Maintaining Quality - Are we really Better?
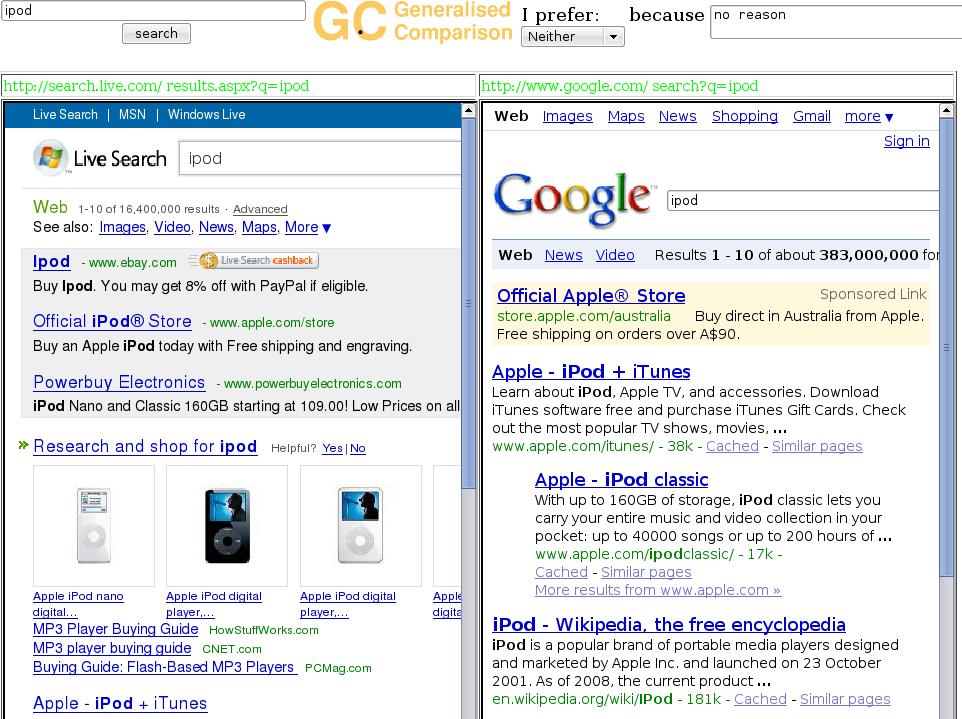
29 Side-by-side comparisons

30

31

32
33 Summary of this Section The Web search engine business model is very risky Starting a new Web search engine requires: Lots of hardware (intelligently chosen and operated.) Huge capital Very large bandwidth network connections Clever engineering (CE) save huge amounts of network traffic during spidering save vast amounts of query processing hardware CE during QP relies on caching / pre-computation clever parallelism memory residency / avoidance of disk accesses smart algorithms
34 BTW - What s the role of a Chief Scientist?

35
Information Retrieval I
 Information Retrieval I David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
Information Retrieval I David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
Crawler. Crawler. Crawler. Crawler. Anchors. URL Resolver Indexer. Barrels. Doc Index Sorter. Sorter. URL Server
 Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Distributed Systems. 05r. Case study: Google Cluster Architecture. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Review: AltaVista. BigTable. Index Stream Readers (ISRs) Advanced Search
 Advanced Search") CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
The Anatomy of a Large-Scale Hypertextual Web Search Engine
 The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards This time: Spell correction Soundex Index construction Index
Introduction to Information Retrieval Lecture 4: Index Construction Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards This time: Spell correction Soundex Index construction Index
Efficiency. Efficiency: Indexing. Indexing. Efficiency Techniques. Inverted Index. Inverted Index (COSC 488)
") Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Analyzing the performance of top-k retrieval algorithms. Marcus Fontoura Google, Inc
 Analyzing the performance of top-k retrieval algorithms Marcus Fontoura Google, Inc This talk Largely based on the paper Evaluation Strategies for Top-k Queries over Memory-Resident Inverted Indices, VLDB
Analyzing the performance of top-k retrieval algorithms Marcus Fontoura Google, Inc This talk Largely based on the paper Evaluation Strategies for Top-k Queries over Memory-Resident Inverted Indices, VLDB
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
THE WEB SEARCH ENGINE
 International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
Using Graphics Processors for High Performance IR Query Processing
 Using Graphics Processors for High Performance IR Query Processing Shuai Ding Jinru He Hao Yan Torsten Suel Polytechnic Inst. of NYU Polytechnic Inst. of NYU Polytechnic Inst. of NYU Yahoo! Research Brooklyn,
Using Graphics Processors for High Performance IR Query Processing Shuai Ding Jinru He Hao Yan Torsten Suel Polytechnic Inst. of NYU Polytechnic Inst. of NYU Polytechnic Inst. of NYU Yahoo! Research Brooklyn,
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
CS6200 Information Retrieval. David Smith College of Computer and Information Science Northeastern University
 CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University Indexing Process!2 Indexes Storing document information for faster queries Indexes Index Compression
CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University Indexing Process!2 Indexes Storing document information for faster queries Indexes Index Compression
Query Evaluation Strategies
 Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Labs (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa Research
Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Labs (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa Research
DATA MINING II - 1DL460. Spring 2014"
 DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
COMP Parallel Computing. Lecture 22 November 29, Datacenters and Large Scale Data Processing
 - Parallel Computing Lecture 22 November 29, 2018 Datacenters and Large Scale Data Processing Topics Parallel memory hierarchy extend to include disk storage Google web search Large parallel application
- Parallel Computing Lecture 22 November 29, 2018 Datacenters and Large Scale Data Processing Topics Parallel memory hierarchy extend to include disk storage Google web search Large parallel application
Indexing. UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze
 Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
A Combined Semi-Pipelined Query Processing Architecture For Distributed Full-Text Retrieval
 A Combined Semi-Pipelined Query Processing Architecture For Distributed Full-Text Retrieval Simon Jonassen and Svein Erik Bratsberg Department of Computer and Information Science Norwegian University of
A Combined Semi-Pipelined Query Processing Architecture For Distributed Full-Text Retrieval Simon Jonassen and Svein Erik Bratsberg Department of Computer and Information Science Norwegian University of
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Engineering Goals. Scalability Availability. Transactional behavior Security EAI... CS530 S05
 Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Around the Web in Six Weeks: Documenting a Large-Scale Crawl
 Around the Web in Six Weeks: Documenting a Large-Scale Crawl Sarker Tanzir Ahmed, Clint Sparkman, Hsin- Tsang Lee, and Dmitri Loguinov Internet Research Lab Department of Computer Science and Engineering
Around the Web in Six Weeks: Documenting a Large-Scale Crawl Sarker Tanzir Ahmed, Clint Sparkman, Hsin- Tsang Lee, and Dmitri Loguinov Internet Research Lab Department of Computer Science and Engineering
Optimized Top-K Processing with Global Page Scores on Block-Max Indexes
 Optimized Top-K Processing with Global Page Scores on Block-Max Indexes Dongdong Shan 1 Shuai Ding 2 Jing He 1 Hongfei Yan 1 Xiaoming Li 1 Peking University, Beijing, China 1 Polytechnic Institute of NYU,
Optimized Top-K Processing with Global Page Scores on Block-Max Indexes Dongdong Shan 1 Shuai Ding 2 Jing He 1 Hongfei Yan 1 Xiaoming Li 1 Peking University, Beijing, China 1 Polytechnic Institute of NYU,
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Information Retrieval and Organisation
 Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2015/16 IR Chapter 04 Index Construction Hardware In this chapter we will look at how to construct an inverted index Many
Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2015/16 IR Chapter 04 Index Construction Hardware In this chapter we will look at how to construct an inverted index Many
Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
High-Performance Distributed DBMS for Analytics
 1 High-Performance Distributed DBMS for Analytics 2 About me Developer, hardware engineering background Head of Analytic Products Department in Yandex jkee@yandex-team.ru 3 About Yandex One of the largest
1 High-Performance Distributed DBMS for Analytics 2 About me Developer, hardware engineering background Head of Analytic Products Department in Yandex jkee@yandex-team.ru 3 About Yandex One of the largest
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Dremel: Interactive Analysis of Web-Scale Database
 Dremel: Interactive Analysis of Web-Scale Database Presented by Jian Fang Most parts of these slides are stolen from here: http://bit.ly/hipzeg What is Dremel Trillion-record, multi-terabyte datasets at
Dremel: Interactive Analysis of Web-Scale Database Presented by Jian Fang Most parts of these slides are stolen from here: http://bit.ly/hipzeg What is Dremel Trillion-record, multi-terabyte datasets at
Warehouse-Scale Computing
 ecture 31 Computer Science 61C Spring 2017 April 7th, 2017 Warehouse-Scale Computing 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned to computer
ecture 31 Computer Science 61C Spring 2017 April 7th, 2017 Warehouse-Scale Computing 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned to computer
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Design of Alta Vista. Course Overview. Google System Anatomy
 CSE 454 - Case Studies Indexing & Retrieval in Google Slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Design of Alta Vista Based on a talk by Mike Burrows Group Meetings Starting Tomorrow
CSE 454 - Case Studies Indexing & Retrieval in Google Slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Design of Alta Vista Based on a talk by Mike Burrows Group Meetings Starting Tomorrow
Seek and Ye shall Find
 Seek and Ye shall Find The continuum of computer intelligence COS 116, Spring 2010 Adam Finkelstein Final tally: Computer $77,147, Ken Jennings $24,000, Brad Rutter $21,600. Jennings: I, for one, welcome
Seek and Ye shall Find The continuum of computer intelligence COS 116, Spring 2010 Adam Finkelstein Final tally: Computer $77,147, Ken Jennings $24,000, Brad Rutter $21,600. Jennings: I, for one, welcome
Google: A Computer Scientist s Playground
 Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground
 Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
index construct Overview Overview Recap How to construct index? Introduction Index construction Introduction to Recap
 to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
3-2. Index construction. Most slides were adapted from Stanford CS 276 course and University of Munich IR course.
 3-2. Index construction Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Ch. 4 Index construction How do we construct an index? What strategies can we use with
3-2. Index construction Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Ch. 4 Index construction How do we construct an index? What strategies can we use with
Desktop Crawls. Document Feeds. Document Feeds. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Search Engine Architecture II
 Search Engine Architecture II Primary Goals of Search Engines Effectiveness (quality): to retrieve the most relevant set of documents for a query Process text and store text statistics to improve relevance
Search Engine Architecture II Primary Goals of Search Engines Effectiveness (quality): to retrieve the most relevant set of documents for a query Process text and store text statistics to improve relevance
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December ISSN Web Search Engine
 International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
The anatomy of a large-scale l small search engine: Efficient index organization and query processing
 The anatomy of a large-scale l small search engine: Efficient index organization and query processing Simon Jonassen Department of Computer and Information Science Norwegian University it of Science and
The anatomy of a large-scale l small search engine: Efficient index organization and query processing Simon Jonassen Department of Computer and Information Science Norwegian University it of Science and
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Query Evaluation Strategies
 Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Research (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa
Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Research (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa
Searching the Web for Information
 Search Xin Liu Searching the Web for Information How a Search Engine Works Basic parts: 1. Crawler: Visits sites on the Internet, discovering Web pages 2. Indexer: building an index to the Web's content
Search Xin Liu Searching the Web for Information How a Search Engine Works Basic parts: 1. Crawler: Visits sites on the Internet, discovering Web pages 2. Indexer: building an index to the Web's content
CSE 124: Networked Services Lecture-17
 Fall 2010 CSE 124: Networked Services Lecture-17 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/30/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-17 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/30/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Information Retrieval and Organisation
 Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2016/17 IR Chapter 01 Boolean Retrieval Example IR Problem Let s look at a simple IR problem Suppose you own a copy of Shakespeare
Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2016/17 IR Chapter 01 Boolean Retrieval Example IR Problem Let s look at a simple IR problem Suppose you own a copy of Shakespeare
Introduction to Information Retrieval (Manning, Raghavan, Schutze)
") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling
 EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project progress report
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project progress report
HashCache: Cache Storage for the Next Billion
 HashCache: Cache Storage for the Next Billion Anirudh Badam KyoungSoo Park Vivek S. Pai Larry L. Peterson Princeton University 1 Next Billion Internet Users 2 Next Billion Internet Users Schools, urban
HashCache: Cache Storage for the Next Billion Anirudh Badam KyoungSoo Park Vivek S. Pai Larry L. Peterson Princeton University 1 Next Billion Internet Users 2 Next Billion Internet Users Schools, urban
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Seek and Ye shall Find
 Seek and Ye shall Find The continuum of computer intelligence COS 116, Spring 2012 Adam Finkelstein Recap: Binary Representation Powers of 2 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2 7 2 8 2 9 2 10 1 2 4 8 16 32 64
Seek and Ye shall Find The continuum of computer intelligence COS 116, Spring 2012 Adam Finkelstein Recap: Binary Representation Powers of 2 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2 7 2 8 2 9 2 10 1 2 4 8 16 32 64
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
CS54701: Information Retrieval
 CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
Search Quality. Jan Pedersen 10 September 2007
 Search Quality Jan Pedersen 10 September 2007 Outline The Search Landscape A Framework for Quality RCFP Search Engine Architecture Detailed Issues 2 Search Landscape 2007 Source: Search Engine Watch: US
Search Quality Jan Pedersen 10 September 2007 Outline The Search Landscape A Framework for Quality RCFP Search Engine Architecture Detailed Issues 2 Search Landscape 2007 Source: Search Engine Watch: US
MapReduce & BigTable
 CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
Mining data streams. Irene Finocchi. finocchi/ Intro Puzzles
 Intro Puzzles Mining data streams Irene Finocchi finocchi@di.uniroma1.it http://www.dsi.uniroma1.it/ finocchi/ 1 / 33 Irene Finocchi Mining data streams Intro Puzzles Stream sources Data stream model Storing
Intro Puzzles Mining data streams Irene Finocchi finocchi@di.uniroma1.it http://www.dsi.uniroma1.it/ finocchi/ 1 / 33 Irene Finocchi Mining data streams Intro Puzzles Stream sources Data stream model Storing
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Administrative. Distributed indexing. Index Compression! What I did last summer lunch talks today. Master. Tasks
 Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Warehouse-Scale Computing
 Warehouse-Scale Computing") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Warehouse-Scale Computing Instructors: Nicholas Weaver & Vladimir Stojanovic http://inst.eecs.berkeley.edu/~cs61c/ Coherency Tracked by
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Warehouse-Scale Computing Instructors: Nicholas Weaver & Vladimir Stojanovic http://inst.eecs.berkeley.edu/~cs61c/ Coherency Tracked by
UNIT-V WEB MINING. 3/18/2012 Prof. Asha Ambhaikar, RCET Bhilai.
 UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
FAWN. A Fast Array of Wimpy Nodes. David Andersen, Jason Franklin, Michael Kaminsky*, Amar Phanishayee, Lawrence Tan, Vijay Vasudevan
 FAWN A Fast Array of Wimpy Nodes David Andersen, Jason Franklin, Michael Kaminsky*, Amar Phanishayee, Lawrence Tan, Vijay Vasudevan Carnegie Mellon University *Intel Labs Pittsburgh Energy in computing
FAWN A Fast Array of Wimpy Nodes David Andersen, Jason Franklin, Michael Kaminsky*, Amar Phanishayee, Lawrence Tan, Vijay Vasudevan Carnegie Mellon University *Intel Labs Pittsburgh Energy in computing
Search & Google. Melissa Winstanley
 Search & Google Melissa Winstanley mwinst@cs.washington.edu The size of data Byte: a single character Kilobyte: a short story, a simple web html file Megabyte: a photo, a short song Gigabyte: a movie,
Search & Google Melissa Winstanley mwinst@cs.washington.edu The size of data Byte: a single character Kilobyte: a short story, a simple web html file Megabyte: a photo, a short song Gigabyte: a movie,
Full-Text Indexing For Heritrix
 Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Index Construction. Dictionary, postings, scalable indexing, dynamic indexing. Web Search
 Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
Processing a Trillion Cells per Mouse Click
 Processing a Trillion Cells per Mouse Click Common Sense 13/01 21.3.2013 Alex Hall, Google Zurich Olaf Bachmann, Robert Buessow, Silviu Ganceanu, Marc Nunkesser Outline of the Talk AdSpam team at Google
Processing a Trillion Cells per Mouse Click Common Sense 13/01 21.3.2013 Alex Hall, Google Zurich Olaf Bachmann, Robert Buessow, Silviu Ganceanu, Marc Nunkesser Outline of the Talk AdSpam team at Google
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Anatomy of a search engine. Design criteria of a search engine Architecture Data structures
 Anatomy of a search engine Design criteria of a search engine Architecture Data structures Step-1: Crawling the web Google has a fast distributed crawling system Each crawler keeps roughly 300 connection
Anatomy of a search engine Design criteria of a search engine Architecture Data structures Step-1: Crawling the web Google has a fast distributed crawling system Each crawler keeps roughly 300 connection
COMP 273 Winter physical vs. virtual mem Mar. 15, 2012
 Virtual Memory The model of MIPS Memory that we have been working with is as follows. There is your MIPS program, including various functions and data used by this program, and there are some kernel programs
Virtual Memory The model of MIPS Memory that we have been working with is as follows. There is your MIPS program, including various functions and data used by this program, and there are some kernel programs
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX
 Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
Engineering at Scale. Paul Baecke
 Engineering at Scale THE CHALLENGES OF PREDICTING QUERIES IN WEB SEARCH ENGINES Paul Baecke Introduction How is what we do Extreme Computing? What is the product Complexity online Complexity offline
Engineering at Scale THE CHALLENGES OF PREDICTING QUERIES IN WEB SEARCH ENGINES Paul Baecke Introduction How is what we do Extreme Computing? What is the product Complexity online Complexity offline
Query Answering Using Inverted Indexes
 Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
An Overview of Search Engine. Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia
 An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
Lecture S3: File system data layout, naming
 Lecture S3: File system data layout, naming Review -- 1 min Intro to I/O Performance model: Log Disk physical characteristics/desired abstractions Physical reality Desired abstraction disks are slow fast
Lecture S3: File system data layout, naming Review -- 1 min Intro to I/O Performance model: Log Disk physical characteristics/desired abstractions Physical reality Desired abstraction disks are slow fast
Elementary IR: Scalable Boolean Text Search. (Compare with R & G )
") Elementary IR: Scalable Boolean Text Search (Compare with R & G 27.1-3) Information Retrieval: History A research field traditionally separate from Databases Hans P. Luhn, IBM, 1959: Keyword in Context
Elementary IR: Scalable Boolean Text Search (Compare with R & G 27.1-3) Information Retrieval: History A research field traditionally separate from Databases Hans P. Luhn, IBM, 1959: Keyword in Context
Information Retrieval. Danushka Bollegala
 Information Retrieval Danushka Bollegala Anatomy of a Search Engine Document Indexing Query Processing Search Index Results Ranking 2 Document Processing Format detection Plain text, PDF, PPT, Text extraction
Information Retrieval Danushka Bollegala Anatomy of a Search Engine Document Indexing Query Processing Search Index Results Ranking 2 Document Processing Format detection Plain text, PDF, PPT, Text extraction
Storage Systems. Storage Systems
 Storage Systems Storage Systems We already know about four levels of storage: Registers Cache Memory Disk But we've been a little vague on how these devices are interconnected In this unit, we study Input/output
Storage Systems Storage Systems We already know about four levels of storage: Registers Cache Memory Disk But we've been a little vague on how these devices are interconnected In this unit, we study Input/output
SEARCH ENGINE INSIDE OUT
 SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-05-03 1/ 36 Take-away
Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-05-03 1/ 36 Take-away
Part 2: Boolean Retrieval Francesco Ricci
 Part 2: Boolean Retrieval Francesco Ricci Most of these slides comes from the course: Information Retrieval and Web Search, Christopher Manning and Prabhakar Raghavan Content p Term document matrix p Information
Part 2: Boolean Retrieval Francesco Ricci Most of these slides comes from the course: Information Retrieval and Web Search, Christopher Manning and Prabhakar Raghavan Content p Term document matrix p Information
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
DELL EMC DATA DOMAIN SISL SCALING ARCHITECTURE
 WHITEPAPER DELL EMC DATA DOMAIN SISL SCALING ARCHITECTURE A Detailed Review ABSTRACT While tape has been the dominant storage medium for data protection for decades because of its low cost, it is steadily
WHITEPAPER DELL EMC DATA DOMAIN SISL SCALING ARCHITECTURE A Detailed Review ABSTRACT While tape has been the dominant storage medium for data protection for decades because of its low cost, it is steadily
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
MG4J: Managing Gigabytes for Java. MG4J - intro 1
 MG4J: Managing Gigabytes for Java MG4J - intro 1 Managing Gigabytes for Java Schedule: 1. Introduction to MG4J framework. 2. Exercitation: try to set up a search engine on a particular collection of documents.
MG4J: Managing Gigabytes for Java MG4J - intro 1 Managing Gigabytes for Java Schedule: 1. Introduction to MG4J framework. 2. Exercitation: try to set up a search engine on a particular collection of documents.
Corso di Biblioteche Digitali
 Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto