Deep Learning as a Polyhedral Compiler's Killer App
|
|
|
- Sharlene Davidson
- 5 years ago
- Views:
Transcription
1 Deep Learning as a Polyhedral Compiler's Killer App From Research to Industry Transfer and Back and Again Albert Cohen - Inria and Facebook (work in progress)

2 Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zach DeVito, William S. Moses, Sven Verdoolaege, Andrew Adams, Albert Cohen









3
 frameworks")
4 Programming Language & Systems Research for Deep Learning? Deep learning has become massively popular over the last 10 years Machine Learning (ML) frameworks are all over the place Is this good enough?

5 Programming Language & Systems Research for Deep Learning?
6 Writing Good Neural Network Layers Tedious experience out of reach from Machine Learning (ML) users and researchers Existing layers: already in vendor libraries from Intel, Nvidia, etc. Can reach really great performance, 95%+ efciency on a few, almost ideal kernels But the practice is often far from machine peak New layer or neural net architecture performance bottleneck Heavy engineering burden to port across ML frameworks HPC library coders are scarce, not all genius, don t scale, tune by hand Goal: capture the ML expert s idea, concisely, automate the rest
7 Our Approach Don t write programs, synthesize them Derive ML-specifc techniques from software synthesis and compilers A mini-language, close to the mathematics and easy to manage by automatic tools A compiler for algebraic/algorithmic optimization and automatic diferentiation A compiler for polyhedral scheduling and mapping Generates efcient kernel implementations, e.g., for GPU acceleration Just-in-time specialization of the model (hyper)parameters, automatic tuning Works transparently: A New Op for machine learning and applications Integrated with industry-standard frameworks (currently Cafe2, PyTorch)
8 Abstraction without regret To make development efcient, we need abstractions that provide productivity without sacrifcing performance Given the enormous number of potential kernels, suggests a dynamic-codegeneration approach
9 Prior work Direct generation such as active library [2] or built-to-order (BTO) [3] provide usability, but miss optimization DSLs such as Halide [4] provide usability, and permit scheduling transformations, though manually specify. Compilers like XLA [5] or Latte [6] optimize and fuse operators, though performance lacking as the language can t represent complex schedules crucial to GPU/others. [2] Run-time code generation in C++ as a foundation for domain-specifc optimization, 2003 [3] Automating the generation of composed linear algebra kernels, 2009 [4] Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines, 2013 [5] Xla:domain-specifc compiler for linear algebra to optimizes tensorfow computations, 2017 [6] Latte: A language, compiler, and runtime for elegant and efcient deep neural networks, 2016

10 Our Approach

11 Our Approach
12 Synthesize From Mathematical Model Tight mathematical model, emits 1000s optimized lines of code Goup Convolution Kronecker Recurrent Units (KRU) algorithmic exploration of storage/recompute tradeofs
13 Synthesize From Mathematical Model Tight mathematical model, emits 1000s optimized lines of code


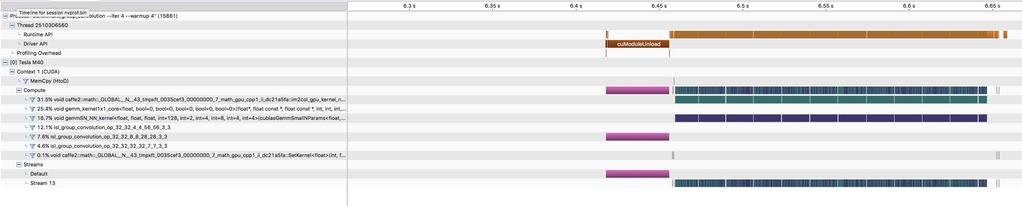
14 Rather Than Write Accelerator Code

15 Our Approach

16 Our Approach
17 Heard That Before? 30 years of parallelizing and optimizing compiler research wrapped into a robust, automated tool, w/ much ML specialization with modern C++ interface and tight ML framework integration Embed the most complex compositions of loop nest and tensor optimizations

18 Heard That Before? 30 years of parallelizing and optimizing compiler research wrapped into a robust, automated tool, w/ much ML specialization with modern C++ interface and tight ML framework integration

19 Algorithmic Contributions
20 Memory Promotion O[l+Idx[i][j]][k] => shared_o[l][i][j][k] Cache indirectly accessed arrays Only done when O and Idx are only read (not written) Promote directly accesses if tile of fxed size, elements reused, and >= 1 access without memory coalescing Promote indirectly accessed arrays in same way (ignore coalescing)

21 Performance?

22 Performance?

23 Algorithmic Exploration


24 Recurrent Networks? Courtesy Chris Olah, Google Brain

25 Simple RNN


26 Long Short Term Memory (LSTM)
27 Recurrent Networks? Work in progress Inspiration from functional languages with combinators, reactive and datafow synchronous languages Related to the modeling of fnite state machines on infnite streams with Kahn semantics in Lucid Synchrone / Esterel Technologies Scade 6 Challenge: combining data fow on init/last value with storage of tensor slices into higher dimensional tensors Good news: natural modeling of nested loops, space and time, in a polyhedral framework

28

29 Where From? Polly Labs Initiative Mathematical core isl : parametric linear optimization, Presburger arithmetic Industry transfer lab founded in February 2015 Building on 12 years of collaboration with AMD (Austin, Bangalore) and IISc (CSA, Bangalore) INRIA-CEFIPRA Associate Team with IISc Google Summer of Code(s) with IITH Partners IIT Hyderabad IISc ETH Zürich Qualcomm Xilinx Facebook
, Xilinx, Facebook (FAIR) Focus on LLVM ecosystem: http://llvm.")
30 Research and Industry Transfer - Virtual Lab Bilateral contract between INRIA and ARM, in cooperation with Qualcomm (QuIC), Xilinx, Facebook (FAIR) Focus on LLVM ecosystem: exploitation & developer community Mutualization of core polyhedral compilation infrastructure Contributing to domain-specific deep learning, image processing, solvers, linear algebra and research compilers Training and tutorials 30
31 Timeline isl started in 2008, licensed under LGPLv2.1 Used by GCC as its polyhedral library since 5.0 virtually every smartphone runs code generated using our algorithms : Relicensed under MIT, through CARP EU project Used by LLVM through the Polly project 2014: Triggered ARM to release tools to generate linear algebra kernels 2014: Qualcomm, then ARM, push for Polly Labs 2015: Qualcomm Snapdragon LLVM uses Polly, compiles Android OSP 2016: Xilinx starts an isl-based project within Vivado HLS 2017: Facebook works on a deep learning compiler using isl 2018: Safran, Morphing Machines (IISc spin-off), CEFIPRA project to work on correct-by-construction signal processing and data analytics 31
32 Context: economic challenge Funding a sustainable software tool development Mutualize investments by large and not-so-large users Leverage many different research funding instruments Build a sustainable ecosystem of tool vendors 32
33 Polly Labs experience so far: importance of both upstream and application-driven, cross-domain research, open source, distributed teams and world-class recruitment, advanced prototyping of software artifacts for successful industry transfer but very hard to work out labor law and inflexible rules of academic institutions... We are OPEN, HIRING and Looking for COLLABORATIONS
Neural Network Exchange Format
 Copyright Khronos Group 2017 - Page 1 Neural Network Exchange Format Deploying Trained Networks to Inference Engines Viktor Gyenes, specification editor Copyright Khronos Group 2017 - Page 2 Outlook The
Copyright Khronos Group 2017 - Page 1 Neural Network Exchange Format Deploying Trained Networks to Inference Engines Viktor Gyenes, specification editor Copyright Khronos Group 2017 - Page 2 Outlook The
NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS
 TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Compilers and Compiler-based Tools for HPC
 Compilers and Compiler-based Tools for HPC John Mellor-Crummey Department of Computer Science Rice University http://lacsi.rice.edu/review/2004/slides/compilers-tools.pdf High Performance Computing Algorithms
Compilers and Compiler-based Tools for HPC John Mellor-Crummey Department of Computer Science Rice University http://lacsi.rice.edu/review/2004/slides/compilers-tools.pdf High Performance Computing Algorithms
Analyses, Hardware/Software Compilation, Code Optimization for Complex Dataflow HPC Applications
 Analyses, Hardware/Software Compilation, Code Optimization for Complex Dataflow HPC Applications CASH team proposal (Compilation and Analyses for Software and Hardware) Matthieu Moy and Christophe Alias
Analyses, Hardware/Software Compilation, Code Optimization for Complex Dataflow HPC Applications CASH team proposal (Compilation and Analyses for Software and Hardware) Matthieu Moy and Christophe Alias
Shrinath Shanbhag Senior Software Engineer Microsoft Corporation
 Accelerating GPU inferencing with DirectML and DirectX 12 Shrinath Shanbhag Senior Software Engineer Microsoft Corporation Machine Learning Machine learning has become immensely popular over the last decade
Accelerating GPU inferencing with DirectML and DirectX 12 Shrinath Shanbhag Senior Software Engineer Microsoft Corporation Machine Learning Machine learning has become immensely popular over the last decade
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
TensorFlow: A System for Learning-Scale Machine Learning. Google Brain
 TensorFlow: A System for Learning-Scale Machine Learning Google Brain The Problem Machine learning is everywhere This is in large part due to: 1. Invention of more sophisticated machine learning models
TensorFlow: A System for Learning-Scale Machine Learning Google Brain The Problem Machine learning is everywhere This is in large part due to: 1. Invention of more sophisticated machine learning models
Red Hat's vision on Telco/NFV/IOT
 Red Hat's vision on Telco/NFV/IOT Guy Carmin guy@redhat.com whoami Guy Carmin RHCE, RHCI, RHCVA, RHCSA, 4 RHCP Senior Solution Architect whoami Click to add text Cloud Management Infra The FitBit raffle
Red Hat's vision on Telco/NFV/IOT Guy Carmin guy@redhat.com whoami Guy Carmin RHCE, RHCI, RHCVA, RHCSA, 4 RHCP Senior Solution Architect whoami Click to add text Cloud Management Infra The FitBit raffle
SDACCEL DEVELOPMENT ENVIRONMENT. The Xilinx SDAccel Development Environment. Bringing The Best Performance/Watt to the Data Center
 SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI
 NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
Unified Deep Learning with CPU, GPU, and FPGA Technologies
 Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Dynamic Cuda with F# HPC GPU & F# Meetup. March 19. San Jose, California
 Dynamic Cuda with F# HPC GPU & F# Meetup March 19 San Jose, California Dr. Daniel Egloff daniel.egloff@quantalea.net +41 44 520 01 17 +41 79 430 03 61 About Us! Software development and consulting company!
Dynamic Cuda with F# HPC GPU & F# Meetup March 19 San Jose, California Dr. Daniel Egloff daniel.egloff@quantalea.net +41 44 520 01 17 +41 79 430 03 61 About Us! Software development and consulting company!
Porting Scientific Applications to OpenPOWER
 Porting Scientific Applications to OpenPOWER Dirk Pleiter Forschungszentrum Jülich / JSC #OpenPOWERSummit Join the conversation at #OpenPOWERSummit 1 JSC s HPC Strategy IBM Power 6 JUMP, 9 TFlop/s Intel
Porting Scientific Applications to OpenPOWER Dirk Pleiter Forschungszentrum Jülich / JSC #OpenPOWERSummit Join the conversation at #OpenPOWERSummit 1 JSC s HPC Strategy IBM Power 6 JUMP, 9 TFlop/s Intel
Scheduling Image Processing Pipelines
 Lecture 14: Scheduling Image Processing Pipelines Visual Computing Systems Simple image processing kernel int WIDTH = 1024; int HEIGHT = 1024; float input[width * HEIGHT]; float output[width * HEIGHT];
Lecture 14: Scheduling Image Processing Pipelines Visual Computing Systems Simple image processing kernel int WIDTH = 1024; int HEIGHT = 1024; float input[width * HEIGHT]; float output[width * HEIGHT];
High-Performance Data Loading and Augmentation for Deep Neural Network Training
 High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
March 14, / 27. The isl Scheduler. Sven Verdoolaege. KU Leuven and Polly Labs. March 14, 2018
 March 14, 2018 1 / 27 The isl Scheduler Sven Verdoolaege KU Leuven and Polly Labs March 14, 2018 March 14, 2018 2 / 27 Outline 1 isl Overview 2 The isl Scheduler Input/Output Algorithms Issues isl Overview
March 14, 2018 1 / 27 The isl Scheduler Sven Verdoolaege KU Leuven and Polly Labs March 14, 2018 March 14, 2018 2 / 27 Outline 1 isl Overview 2 The isl Scheduler Input/Output Algorithms Issues isl Overview
Open Standards for Vision and AI Peter McGuinness NNEF WG Chair CEO, Highwai, Inc May 2018
 Copyright Khronos Group 2018 - Page 1 Open Standards for Vision and AI Peter McGuinness NNEF WG Chair CEO, Highwai, Inc peter.mcguinness@gobrach.com May 2018 Khronos Mission E.g. OpenGL ES provides 3D
Copyright Khronos Group 2018 - Page 1 Open Standards for Vision and AI Peter McGuinness NNEF WG Chair CEO, Highwai, Inc peter.mcguinness@gobrach.com May 2018 Khronos Mission E.g. OpenGL ES provides 3D
Arm s First-Generation Machine Learning Processor
 Arm s First-Generation Machine Learning Processor Ian Bratt 2018 Arm Limited Introducing the Arm Machine Learning (ML) Processor Optimized ground-up architecture for machine learning processing Massive
Arm s First-Generation Machine Learning Processor Ian Bratt 2018 Arm Limited Introducing the Arm Machine Learning (ML) Processor Optimized ground-up architecture for machine learning processing Massive
Enabling a Richer Multimedia Experience with GPU Compute. Roberto Mijat Visual Computing Marketing Manager
 Enabling a Richer Multimedia Experience with GPU Compute Roberto Mijat Visual Computing Marketing Manager 1 What is GPU Compute Operating System and most application processing continue to reside on the
Enabling a Richer Multimedia Experience with GPU Compute Roberto Mijat Visual Computing Marketing Manager 1 What is GPU Compute Operating System and most application processing continue to reside on the
Analyses, Hardware/Software Compilation, Code Optimization for Complex Dataflow HPC Applications
 Analyses, Hardware/Software Compilation, Code Optimization for Complex Dataflow HPC Applications CASH team proposal (Compilation and Analyses for Software and Hardware) Matthieu Moy and Christophe Alias
Analyses, Hardware/Software Compilation, Code Optimization for Complex Dataflow HPC Applications CASH team proposal (Compilation and Analyses for Software and Hardware) Matthieu Moy and Christophe Alias
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell 05/12/2015 IWOCL 2015 SYCL Tutorial Khronos OpenCL SYCL committee
 trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell Khronos OpenCL SYCL committee 05/12/2015 IWOCL 2015 SYCL Tutorial OpenCL SYCL committee work... Weekly telephone meeting Define
trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell Khronos OpenCL SYCL committee 05/12/2015 IWOCL 2015 SYCL Tutorial OpenCL SYCL committee work... Weekly telephone meeting Define
Progress Report on QDP-JIT
 Progress Report on QDP-JIT F. T. Winter Thomas Jefferson National Accelerator Facility USQCD Software Meeting 14 April 16-17, 14 at Jefferson Lab F. Winter (Jefferson Lab) QDP-JIT USQCD-Software 14 1 /
Progress Report on QDP-JIT F. T. Winter Thomas Jefferson National Accelerator Facility USQCD Software Meeting 14 April 16-17, 14 at Jefferson Lab F. Winter (Jefferson Lab) QDP-JIT USQCD-Software 14 1 /
Scheduling Image Processing Pipelines
 Lecture 15: Scheduling Image Processing Pipelines Visual Computing Systems Simple image processing kernel int WIDTH = 1024; int HEIGHT = 1024; float input[width * HEIGHT]; float output[width * HEIGHT];
Lecture 15: Scheduling Image Processing Pipelines Visual Computing Systems Simple image processing kernel int WIDTH = 1024; int HEIGHT = 1024; float input[width * HEIGHT]; float output[width * HEIGHT];
Beyond Hardware IP An overview of Arm development solutions
 Beyond Hardware IP An overview of Arm development solutions 2018 Arm Limited Arm Technical Symposia 2018 Advanced first design cost (US$ million) IC design complexity and cost aren t slowing down 542.2
Beyond Hardware IP An overview of Arm development solutions 2018 Arm Limited Arm Technical Symposia 2018 Advanced first design cost (US$ million) IC design complexity and cost aren t slowing down 542.2
THOMAS LATOZA SWE 621 FALL 2018 DESIGN ECOSYSTEMS
 THOMAS LATOZA SWE 621 FALL 2018 DESIGN ECOSYSTEMS LOGISTICS HW5 due today Project presentation on 12/6 Review for final on 12/6 2 EXAMPLE: NPM https://twitter.com/garybernhardt/status/1067111872225136640
THOMAS LATOZA SWE 621 FALL 2018 DESIGN ECOSYSTEMS LOGISTICS HW5 due today Project presentation on 12/6 Review for final on 12/6 2 EXAMPLE: NPM https://twitter.com/garybernhardt/status/1067111872225136640
Profiling and Debugging OpenCL Applications with ARM Development Tools. October 2014
 Profiling and Debugging OpenCL Applications with ARM Development Tools October 2014 1 Agenda 1. Introduction to GPU Compute 2. ARM Development Solutions 3. Mali GPU Architecture 4. Using ARM DS-5 Streamline
Profiling and Debugging OpenCL Applications with ARM Development Tools October 2014 1 Agenda 1. Introduction to GPU Compute 2. ARM Development Solutions 3. Mali GPU Architecture 4. Using ARM DS-5 Streamline
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening. Alberto Magni, Christophe Dubach, Michael O'Boyle
 A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
A Perspective on the Role of Open-Source IP In Government Electronic Systems
 A Perspective on the Role of Open-Source IP In Government Electronic Systems Linton G. Salmon Program Manager DARPA/MTO RISC-V Workshop November 29, 2017 Distribution Statement A (Approved for Public Release,
A Perspective on the Role of Open-Source IP In Government Electronic Systems Linton G. Salmon Program Manager DARPA/MTO RISC-V Workshop November 29, 2017 Distribution Statement A (Approved for Public Release,
HIRP OPEN 2018 Compiler & Programming Language. An Efficient Framework for Optimizing Tensors
 An Efficient Framework for Optimizing Tensors 1 Theme: 2 Subject: Compiler Technology List of Abbreviations NA 3 Background Tensor computation arises frequently in machine learning, graph analytics and
An Efficient Framework for Optimizing Tensors 1 Theme: 2 Subject: Compiler Technology List of Abbreviations NA 3 Background Tensor computation arises frequently in machine learning, graph analytics and
D-TEC DSL Technology for Exascale Computing
 D-TEC DSL Technology for Exascale Computing Progress Report: March 2013 DOE Office of Science Program: Office of Advanced Scientific Computing Research ASCR Program Manager: Dr. Sonia Sachs 1 Introduction
D-TEC DSL Technology for Exascale Computing Progress Report: March 2013 DOE Office of Science Program: Office of Advanced Scientific Computing Research ASCR Program Manager: Dr. Sonia Sachs 1 Introduction
An introduction to Halide. Jonathan Ragan-Kelley (Stanford) Andrew Adams (Google) Dillon Sharlet (Google)
 Andrew Adams (Google) Dillon Sharlet (Google)") An introduction to Halide Jonathan Ragan-Kelley (Stanford) Andrew Adams (Google) Dillon Sharlet (Google) Today s agenda Now: the big ideas in Halide Later: writing & optimizing real code Hello world (brightness)
An introduction to Halide Jonathan Ragan-Kelley (Stanford) Andrew Adams (Google) Dillon Sharlet (Google) Today s agenda Now: the big ideas in Halide Later: writing & optimizing real code Hello world (brightness)
Oracle Developer Studio 12.6
 Oracle Developer Studio 12.6 Oracle Developer Studio is the #1 development environment for building C, C++, Fortran and Java applications for Oracle Solaris and Linux operating systems running on premises
Oracle Developer Studio 12.6 Oracle Developer Studio is the #1 development environment for building C, C++, Fortran and Java applications for Oracle Solaris and Linux operating systems running on premises
End to End Optimization Stack for Deep Learning
 End to End Optimization Stack for Deep Learning Presenter: Tianqi Chen Paul G. Allen School of Computer Science & Engineering University of Washington Collaborators University of Washington AWS AI Team
End to End Optimization Stack for Deep Learning Presenter: Tianqi Chen Paul G. Allen School of Computer Science & Engineering University of Washington Collaborators University of Washington AWS AI Team
An Advanced Graph Processor Prototype
 An Advanced Graph Processor Prototype Vitaliy Gleyzer GraphEx 2016 DISTRIBUTION STATEMENT A. Approved for public release: distribution unlimited. This material is based upon work supported by the Assistant
An Advanced Graph Processor Prototype Vitaliy Gleyzer GraphEx 2016 DISTRIBUTION STATEMENT A. Approved for public release: distribution unlimited. This material is based upon work supported by the Assistant
Adam Paszke, Sam Gross, Soumith Chintala, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia
 Adam Paszke, Sam Gross, Soumith Chintala, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Alban Desmaison, Andreas Kopf, Edward Yang, Zach Devito,
Adam Paszke, Sam Gross, Soumith Chintala, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Alban Desmaison, Andreas Kopf, Edward Yang, Zach Devito,
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Fast Image Processing using Halide
 Fast Image Processing using Halide Andrew Adams (Google) Jonathan Ragan-Kelley (Berkeley) Zalman Stern (Google) Steven Johnson (Google) Dillon Sharlet (Google) Patricia Suriana (Google) 1 This talk The
Fast Image Processing using Halide Andrew Adams (Google) Jonathan Ragan-Kelley (Berkeley) Zalman Stern (Google) Steven Johnson (Google) Dillon Sharlet (Google) Patricia Suriana (Google) 1 This talk The
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Scaling Deep Learning. Bryan
 Scaling Deep Learning @ctnzr What do we want AI to do? Guide us to content Keep us organized Help us find things Help us communicate 帮助我们沟通 Drive us to work Serve drinks? Image Q&A Baidu IDL Sample questions
Scaling Deep Learning @ctnzr What do we want AI to do? Guide us to content Keep us organized Help us find things Help us communicate 帮助我们沟通 Drive us to work Serve drinks? Image Q&A Baidu IDL Sample questions
Inference Optimization Using TensorRT with Use Cases. Jack Han / 한재근 Solutions Architect NVIDIA
 Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Introduction. CS 2210 Compiler Design Wonsun Ahn
 Introduction CS 2210 Compiler Design Wonsun Ahn What is a Compiler? Compiler: A program that translates source code written in one language to a target code written in another language Source code: Input
Introduction CS 2210 Compiler Design Wonsun Ahn What is a Compiler? Compiler: A program that translates source code written in one language to a target code written in another language Source code: Input
A low memory footprint OpenCL simulation of short-range particle interactions
 A low memory footprint OpenCL simulation of short-range particle interactions Raymond Namyst STORM INRIA Group With Samuel Pitoiset, Inria and Emmanuel Cieren, Laurent Colombet, Laurent Soulard, CEA/DAM/DPTA
A low memory footprint OpenCL simulation of short-range particle interactions Raymond Namyst STORM INRIA Group With Samuel Pitoiset, Inria and Emmanuel Cieren, Laurent Colombet, Laurent Soulard, CEA/DAM/DPTA
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Fast Hardware For AI
 Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
An Efficient Stream Buffer Mechanism for Dataflow Execution on Heterogeneous Platforms with GPUs
 An Efficient Stream Buffer Mechanism for Dataflow Execution on Heterogeneous Platforms with GPUs Ana Balevic Leiden Institute of Advanced Computer Science University of Leiden Leiden, The Netherlands balevic@liacs.nl
An Efficient Stream Buffer Mechanism for Dataflow Execution on Heterogeneous Platforms with GPUs Ana Balevic Leiden Institute of Advanced Computer Science University of Leiden Leiden, The Netherlands balevic@liacs.nl
VTA: Open & Flexible DL Acceleration. Thierry Moreau TVM Conference, Dec 12th 2018
 VTA: Open & Flexible DL Acceleration Thierry Moreau TVM Conference, Dec 12th 2018 TVM Stack High-Level Differentiable IR Tensor Expression IR LLVM CUDA Metal TVM Stack High-Level Differentiable IR Tensor
VTA: Open & Flexible DL Acceleration Thierry Moreau TVM Conference, Dec 12th 2018 TVM Stack High-Level Differentiable IR Tensor Expression IR LLVM CUDA Metal TVM Stack High-Level Differentiable IR Tensor
Executive Brief: The CompassIntel A-List Index A-List in Artificial Intelligence Chipset
 Executive Brief: The CompassIntel A-List Index A-List in Artificial Intelligence Chipset Prepared by: Nadine Manjaro nadine@beyondm2mcommunication.com @NadineManjaro @compassintel The Team Stephanie Atkinson
Executive Brief: The CompassIntel A-List Index A-List in Artificial Intelligence Chipset Prepared by: Nadine Manjaro nadine@beyondm2mcommunication.com @NadineManjaro @compassintel The Team Stephanie Atkinson
Relay: a high level differentiable IR. Jared Roesch TVMConf December 12th, 2018
 Relay: a high level differentiable IR Jared Roesch TVMConf December 12th, 2018!1 This represents months of joint work with lots of great folks:!2 TVM Stack Optimization Relay High-Level Differentiable
Relay: a high level differentiable IR Jared Roesch TVMConf December 12th, 2018!1 This represents months of joint work with lots of great folks:!2 TVM Stack Optimization Relay High-Level Differentiable
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory
 Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Accelerating Convolutional Neural Nets. Yunming Zhang
 Accelerating Convolutional Neural Nets Yunming Zhang Focus Convolutional Neural Nets is the state of the art in classifying the images The models take days to train Difficult for the programmers to tune
Accelerating Convolutional Neural Nets Yunming Zhang Focus Convolutional Neural Nets is the state of the art in classifying the images The models take days to train Difficult for the programmers to tune
The OpenVX Computer Vision and Neural Network Inference
 The OpenVX Computer and Neural Network Inference Standard for Portable, Efficient Code Radhakrishna Giduthuri Editor, OpenVX Khronos Group radha.giduthuri@amd.com @RadhaGiduthuri Copyright 2018 Khronos
The OpenVX Computer and Neural Network Inference Standard for Portable, Efficient Code Radhakrishna Giduthuri Editor, OpenVX Khronos Group radha.giduthuri@amd.com @RadhaGiduthuri Copyright 2018 Khronos
KernelGen a toolchain for automatic GPU-centric applications porting. Nicolas Lihogrud Dmitry Mikushin Andrew Adinets
 P A R A L L E L C O M P U T A T I O N A L T E C H N O L O G I E S ' 2 0 1 2 KernelGen a toolchain for automatic GPU-centric applications porting Nicolas Lihogrud Dmitry Mikushin Andrew Adinets Contents
P A R A L L E L C O M P U T A T I O N A L T E C H N O L O G I E S ' 2 0 1 2 KernelGen a toolchain for automatic GPU-centric applications porting Nicolas Lihogrud Dmitry Mikushin Andrew Adinets Contents
Techniques to improve the scalability of Checkpoint-Restart
 Techniques to improve the scalability of Checkpoint-Restart Bogdan Nicolae Exascale Systems Group IBM Research Ireland 1 Outline A few words about the lab and team Challenges of Exascale A case for Checkpoint-Restart
Techniques to improve the scalability of Checkpoint-Restart Bogdan Nicolae Exascale Systems Group IBM Research Ireland 1 Outline A few words about the lab and team Challenges of Exascale A case for Checkpoint-Restart
Applying OpenCL. IWOCL, May Andrew Richards
 Applying OpenCL IWOCL, May 2017 Andrew Richards The next generation of software will not be built on CPUs 2 On a 100 millimetre-squared chip, Google needs something like 50 teraflops of performance - Daniel
Applying OpenCL IWOCL, May 2017 Andrew Richards The next generation of software will not be built on CPUs 2 On a 100 millimetre-squared chip, Google needs something like 50 teraflops of performance - Daniel
webmethods EntireX for ESB: Leveraging Platform and Application Flexibility While Optimizing Service Reuse
 December 2008 webmethods EntireX for ESB: Leveraging Platform and Application Flexibility While Optimizing Service Reuse By Chris Pottinger, Sr. Manager Product Development, and Juergen Lind, Sr. Product
December 2008 webmethods EntireX for ESB: Leveraging Platform and Application Flexibility While Optimizing Service Reuse By Chris Pottinger, Sr. Manager Product Development, and Juergen Lind, Sr. Product
A Breakthrough in Non-Volatile Memory Technology FUJITSU LIMITED
 A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
EGI-InSPIRE. Cloud Services. Steven Newhouse, EGI.eu Director. 23/05/2011 Cloud Services - ASPIRE - May EGI-InSPIRE RI
 EGI-InSPIRE Cloud Services Steven Newhouse, EGI.eu Director 23/05/2011 Cloud Services - ASPIRE - May 2011 1 Definition of the cloud Cloud computing is a model for enabling convenient, on-demand network
EGI-InSPIRE Cloud Services Steven Newhouse, EGI.eu Director 23/05/2011 Cloud Services - ASPIRE - May 2011 1 Definition of the cloud Cloud computing is a model for enabling convenient, on-demand network
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
 TVM: An Automated End-to-End Optimizing Compiler for Deep Learning Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos
LLVM An Introduction. Linux Collaboration Summit, April 7, 2011 David Kipping, Qualcomm Incorporated
 LLVM An Introduction Linux Collaboration Summit, April 7, 2011 David Kipping, Qualcomm Incorporated 2 LLVM An Introduction LLVM Vision and Approach Primary mission: build a set of modular compiler components:
LLVM An Introduction Linux Collaboration Summit, April 7, 2011 David Kipping, Qualcomm Incorporated 2 LLVM An Introduction LLVM Vision and Approach Primary mission: build a set of modular compiler components:
Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 2017 Codeplay Software Ltd.
, Ruyman Reyes, Mehdi Goli (Codeplay Software) 2017 Codeplay Software Ltd.") SYCL-BLAS: LeveragingSYCL-BLAS Expression Trees for Linear Algebra Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 1 About me... Phd in Compilers and Parallel
SYCL-BLAS: LeveragingSYCL-BLAS Expression Trees for Linear Algebra Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 1 About me... Phd in Compilers and Parallel
Optimization Space Pruning without Regrets
 Optimization Space Pruning without Regrets Ulysse Beaugnon Antoine Pouille Marc Pouzet ENS, France name.surname@ens.fr Jacques Pienaar Google, USA jpienaar@google.com Albert Cohen INRIA, France albert.cohen@inria.fr
Optimization Space Pruning without Regrets Ulysse Beaugnon Antoine Pouille Marc Pouzet ENS, France name.surname@ens.fr Jacques Pienaar Google, USA jpienaar@google.com Albert Cohen INRIA, France albert.cohen@inria.fr
How icims Supports. Your Readiness for the European Union General Data Protection Regulation
 How icims Supports Your Readiness for the European Union General Data Protection Regulation The GDPR is the EU s next generation of data protection law. Aiming to strengthen the security and protection
How icims Supports Your Readiness for the European Union General Data Protection Regulation The GDPR is the EU s next generation of data protection law. Aiming to strengthen the security and protection
Recurrent Neural Networks. Deep neural networks have enabled major advances in machine learning and AI. Convolutional Neural Networks
 Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Exploiting High-Performance Heterogeneous Hardware for Java Programs using Graal
 Exploiting High-Performance Heterogeneous Hardware for Java Programs using Graal James Clarkson ±, Juan Fumero, Michalis Papadimitriou, Foivos S. Zakkak, Christos Kotselidis and Mikel Luján ± Dyson, The
Exploiting High-Performance Heterogeneous Hardware for Java Programs using Graal James Clarkson ±, Juan Fumero, Michalis Papadimitriou, Foivos S. Zakkak, Christos Kotselidis and Mikel Luján ± Dyson, The
Introduction to Deep Learning in Signal Processing & Communications with MATLAB
 Introduction to Deep Learning in Signal Processing & Communications with MATLAB Dr. Amod Anandkumar Pallavi Kar Application Engineering Group, Mathworks India 2019 The MathWorks, Inc. 1 Different Types
Introduction to Deep Learning in Signal Processing & Communications with MATLAB Dr. Amod Anandkumar Pallavi Kar Application Engineering Group, Mathworks India 2019 The MathWorks, Inc. 1 Different Types
Versal: AI Engine & Programming Environment
 Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
RFNoC Neural-Network Library using Vivado HLS (rfnoc-hls-neuralnet) EJ Kreinar Team E to the J Omega
 EJ Kreinar Team E to the J Omega") RFNoC Neural-Network Library using Vivado HLS (rfnoc-hls-neuralnet) EJ Kreinar Team E to the J Omega Overview An RFNoC out-of-tree module that can be used to simulate, synthesize, and run a neural network
RFNoC Neural-Network Library using Vivado HLS (rfnoc-hls-neuralnet) EJ Kreinar Team E to the J Omega Overview An RFNoC out-of-tree module that can be used to simulate, synthesize, and run a neural network
Xilinx ML Suite Overview
 Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
MICROSOFT AND SAUCE LABS FOR MODERN SOFTWARE DELIVERY
 SOLUTIONS BRIEF MICROSOFT AND SAUCE LABS FOR MODERN SOFTWARE DELIVERY AUTOMATE TESTING WITH VISUAL STUDIO TEAM SERVICES (VSTS) AND TEAM FOUNDATION SERVER (TFS) The key to efficient software delivery is
SOLUTIONS BRIEF MICROSOFT AND SAUCE LABS FOR MODERN SOFTWARE DELIVERY AUTOMATE TESTING WITH VISUAL STUDIO TEAM SERVICES (VSTS) AND TEAM FOUNDATION SERVER (TFS) The key to efficient software delivery is
High-Level Synthesis: Accelerating Alignment Algorithm using SDSoC
 High-Level Synthesis: Accelerating Alignment Algorithm using SDSoC Steven Derrien & Simon Rokicki The objective of this lab is to present how High-Level Synthesis (HLS) can be used to accelerate a given
High-Level Synthesis: Accelerating Alignment Algorithm using SDSoC Steven Derrien & Simon Rokicki The objective of this lab is to present how High-Level Synthesis (HLS) can be used to accelerate a given
OpenMP Device Offloading to FPGA Accelerators. Lukas Sommer, Jens Korinth, Andreas Koch
 OpenMP Device Offloading to FPGA Accelerators Lukas Sommer, Jens Korinth, Andreas Koch Motivation Increasing use of heterogeneous systems to overcome CPU power limitations 2017-07-12 OpenMP FPGA Device
OpenMP Device Offloading to FPGA Accelerators Lukas Sommer, Jens Korinth, Andreas Koch Motivation Increasing use of heterogeneous systems to overcome CPU power limitations 2017-07-12 OpenMP FPGA Device
FCUDA-SoC: Platform Integration for Field-Programmable SoC with the CUDAto-FPGA
 1 FCUDA-SoC: Platform Integration for Field-Programmable SoC with the CUDAto-FPGA Compiler Tan Nguyen 1, Swathi Gurumani 1, Kyle Rupnow 1, Deming Chen 2 1 Advanced Digital Sciences Center, Singapore {tan.nguyen,
1 FCUDA-SoC: Platform Integration for Field-Programmable SoC with the CUDAto-FPGA Compiler Tan Nguyen 1, Swathi Gurumani 1, Kyle Rupnow 1, Deming Chen 2 1 Advanced Digital Sciences Center, Singapore {tan.nguyen,
Wu Zhiwen.
 Wu Zhiwen zhiwen.wu@intel.com Agenda Background information OpenCV DNN module OpenCL acceleration Vulkan backend Sample 2 What is OpenCV? Open Source Compute Vision (OpenCV) library 2500+ Optimized algorithms
Wu Zhiwen zhiwen.wu@intel.com Agenda Background information OpenCV DNN module OpenCL acceleration Vulkan backend Sample 2 What is OpenCV? Open Source Compute Vision (OpenCV) library 2500+ Optimized algorithms
Automatic Code Generation TVM Stack
 Automatic Code Generation TVM Stack CSE 599W Spring TVM stack is an active project by saml.cs.washington.edu and many partners in the open source community The Gap between Framework and Hardware Frameworks
Automatic Code Generation TVM Stack CSE 599W Spring TVM stack is an active project by saml.cs.washington.edu and many partners in the open source community The Gap between Framework and Hardware Frameworks
Identifying Working Data Set of Particular Loop Iterations for Dynamic Performance Tuning
 Identifying Working Data Set of Particular Loop Iterations for Dynamic Performance Tuning Yukinori Sato (JAIST / JST CREST) Hiroko Midorikawa (Seikei Univ. / JST CREST) Toshio Endo (TITECH / JST CREST)
Identifying Working Data Set of Particular Loop Iterations for Dynamic Performance Tuning Yukinori Sato (JAIST / JST CREST) Hiroko Midorikawa (Seikei Univ. / JST CREST) Toshio Endo (TITECH / JST CREST)
SUSE Linux Entreprise Server for ARM
 FUT89013 SUSE Linux Entreprise Server for ARM Trends and Roadmap Jay Kruemcke Product Manager jayk@suse.com @mr_sles ARM Overview ARM is a Reduced Instruction Set (RISC) processor family British company,
FUT89013 SUSE Linux Entreprise Server for ARM Trends and Roadmap Jay Kruemcke Product Manager jayk@suse.com @mr_sles ARM Overview ARM is a Reduced Instruction Set (RISC) processor family British company,
CLICK TO EDIT MASTER TITLE STYLE. Click to edit Master text styles. Second level Third level Fourth level Fifth level
 CLICK TO EDIT MASTER TITLE STYLE Second level THE HETEROGENEOUS SYSTEM ARCHITECTURE ITS (NOT) ALL ABOUT THE GPU PAUL BLINZER, FELLOW, HSA SYSTEM SOFTWARE, AMD SYSTEM ARCHITECTURE WORKGROUP CHAIR, HSA FOUNDATION
CLICK TO EDIT MASTER TITLE STYLE Second level THE HETEROGENEOUS SYSTEM ARCHITECTURE ITS (NOT) ALL ABOUT THE GPU PAUL BLINZER, FELLOW, HSA SYSTEM SOFTWARE, AMD SYSTEM ARCHITECTURE WORKGROUP CHAIR, HSA FOUNDATION
Lubuntu Linux Virtual Machine
 Lubuntu Linux 18.04 Virtual Machine About Us Slide / 01 Founded in 2015, Sourcery Institute is a California nonprofit public-benefit corporation engaged in research, education, and advisory services in
Lubuntu Linux 18.04 Virtual Machine About Us Slide / 01 Founded in 2015, Sourcery Institute is a California nonprofit public-benefit corporation engaged in research, education, and advisory services in
Polly Polyhedral Optimizations for LLVM
 Polly Polyhedral Optimizations for LLVM Tobias Grosser - Hongbin Zheng - Raghesh Aloor Andreas Simbürger - Armin Grösslinger - Louis-Noël Pouchet April 03, 2011 Polly - Polyhedral Optimizations for LLVM
Polly Polyhedral Optimizations for LLVM Tobias Grosser - Hongbin Zheng - Raghesh Aloor Andreas Simbürger - Armin Grösslinger - Louis-Noël Pouchet April 03, 2011 Polly - Polyhedral Optimizations for LLVM
Parallelism in Spiral
 Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Weld: A Common Runtime for Data Analytics
 Weld: A Common Runtime for Data Analytics Shoumik Palkar, James Thomas, Anil Shanbhag*, Deepak Narayanan, Malte Schwarzkopf*, Holger Pirk*, Saman Amarasinghe*, Matei Zaharia Stanford InfoLab, *MIT CSAIL
Weld: A Common Runtime for Data Analytics Shoumik Palkar, James Thomas, Anil Shanbhag*, Deepak Narayanan, Malte Schwarzkopf*, Holger Pirk*, Saman Amarasinghe*, Matei Zaharia Stanford InfoLab, *MIT CSAIL
Chapter Outline. Chapter 2 Distributed Information Systems Architecture. Distributed transactions (quick refresh) Layers of an information system
 Layers of an information system") Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 2 Distributed Information Systems Architecture Chapter Outline
Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 2 Distributed Information Systems Architecture Chapter Outline
Practical Methodology. Lecture slides for Chapter 11 of Deep Learning Ian Goodfellow
 Practical Methodology Lecture slides for Chapter 11 of Deep Learning www.deeplearningbook.org Ian Goodfellow 2016-09-26 What drives success in ML? Arcane knowledge of dozens of obscure algorithms? Mountains
Practical Methodology Lecture slides for Chapter 11 of Deep Learning www.deeplearningbook.org Ian Goodfellow 2016-09-26 What drives success in ML? Arcane knowledge of dozens of obscure algorithms? Mountains
Creating outstanding digital cockpits with Qt Automotive Suite
 Creating outstanding digital cockpits with Qt Automotive Suite Get your digital cockpit first the finish line with Qt. Embedded World 2017 Trends in cockpit digitalization require a new approach to user
Creating outstanding digital cockpits with Qt Automotive Suite Get your digital cockpit first the finish line with Qt. Embedded World 2017 Trends in cockpit digitalization require a new approach to user
Deep Learning Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD.
 Asan Agibetov, PhD.") Deep Learning 861.061 Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD asan.agibetov@meduniwien.ac.at Medical University of Vienna Center for Medical Statistics,
Deep Learning 861.061 Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD asan.agibetov@meduniwien.ac.at Medical University of Vienna Center for Medical Statistics,
F# for Industrial Applications Worth a Try?
 F# for Industrial Applications Worth a Try? Jazoon TechDays 2015 Dr. Daniel Egloff Managing Director Microsoft MVP daniel.egloff@quantalea.net October 23, 2015 Who are we Software and solution provider
F# for Industrial Applications Worth a Try? Jazoon TechDays 2015 Dr. Daniel Egloff Managing Director Microsoft MVP daniel.egloff@quantalea.net October 23, 2015 Who are we Software and solution provider
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Analyzing the Disruptive Impact of a Silicon Compiler
 THE ELECTRONICS RESURGENCE INITIATIVE Analyzing the Disruptive Impact of a Silicon Compiler Andreas Olofsson 1947 Source: Wikipedia, Computer Museum 2017 Source: AMD Defense Advanced Research Project Agency
THE ELECTRONICS RESURGENCE INITIATIVE Analyzing the Disruptive Impact of a Silicon Compiler Andreas Olofsson 1947 Source: Wikipedia, Computer Museum 2017 Source: AMD Defense Advanced Research Project Agency
DataSToRM: Data Science and Technology Research Environment
 The Future of Advanced (Secure) Computing DataSToRM: Data Science and Technology Research Environment This material is based upon work supported by the Assistant Secretary of Defense for Research and Engineering
The Future of Advanced (Secure) Computing DataSToRM: Data Science and Technology Research Environment This material is based upon work supported by the Assistant Secretary of Defense for Research and Engineering
Small is the New Big: Data Analytics on the Edge
 Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
Ch 1: The Architecture Business Cycle
 Ch 1: The Architecture Business Cycle For decades, software designers have been taught to build systems based exclusively on the technical requirements. Software architecture encompasses the structures
Ch 1: The Architecture Business Cycle For decades, software designers have been taught to build systems based exclusively on the technical requirements. Software architecture encompasses the structures
ReconOS: An RTOS Supporting Hardware and Software Threads
 ReconOS: An RTOS Supporting Hardware and Software Threads Enno Lübbers and Marco Platzner Computer Engineering Group University of Paderborn marco.platzner@computer.org Overview the ReconOS project programming
ReconOS: An RTOS Supporting Hardware and Software Threads Enno Lübbers and Marco Platzner Computer Engineering Group University of Paderborn marco.platzner@computer.org Overview the ReconOS project programming
Operator Vectorization Library A TensorFlow Plugin
 Operator Vectorization Library A TensorFlow Plugin Matthew Pickett, Karen Brems, Florian Raudies Hewlett Packard Labs HPE-2016-94 Keyword(s): Machine learning; GPU acceleration; TensorFlow Abstract: TensorFlow
Operator Vectorization Library A TensorFlow Plugin Matthew Pickett, Karen Brems, Florian Raudies Hewlett Packard Labs HPE-2016-94 Keyword(s): Machine learning; GPU acceleration; TensorFlow Abstract: TensorFlow
Chapter Outline. Chapter 2 Distributed Information Systems Architecture. Layers of an information system. Design strategies.
 Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 2 Distributed Information Systems Architecture Chapter Outline
Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 2 Distributed Information Systems Architecture Chapter Outline