Last lecture. Some misc. stuff An older real processor Class review/overview.
|
|
|
- Myles Pope
- 5 years ago
- Views:
Transcription
1 Last lecture Some misc. stuff An older real processor Class review/overview.
2 HW5 Misc. Status issues Answers posted Returned on Wednesday (next week) Project presentation signup at Locations are all over (see link) Need to be there for whole time slot. Exam review etc. Q&A session 1-2:45pm on Wednesday 2/23 Office hours see calendar.
3 Stuff still to do Oral report Don t forget to be there for the whole hour PowerPoint or other slides Either bring portable or USB stick Written report Due 9pm Tuesday via . Exam 4/25 1:30-3:30pm This room (1670 BBB)
4 AMD 64-bit core Most taken from
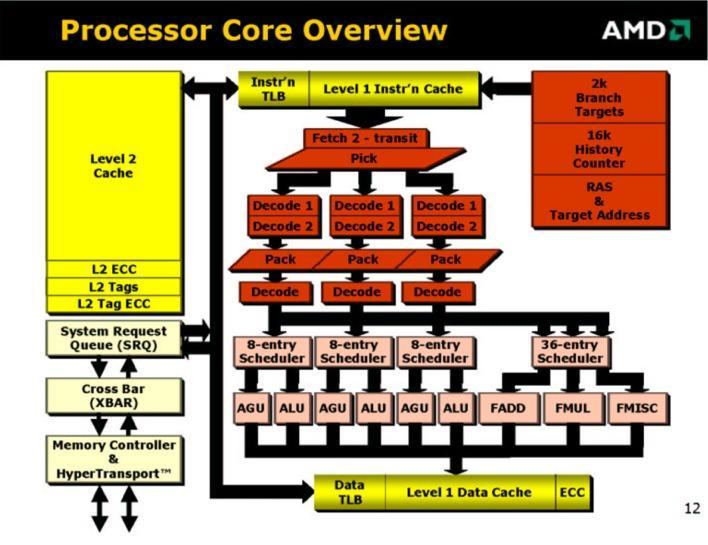
5

6

7 Bit-interleaved busses running North-South

8
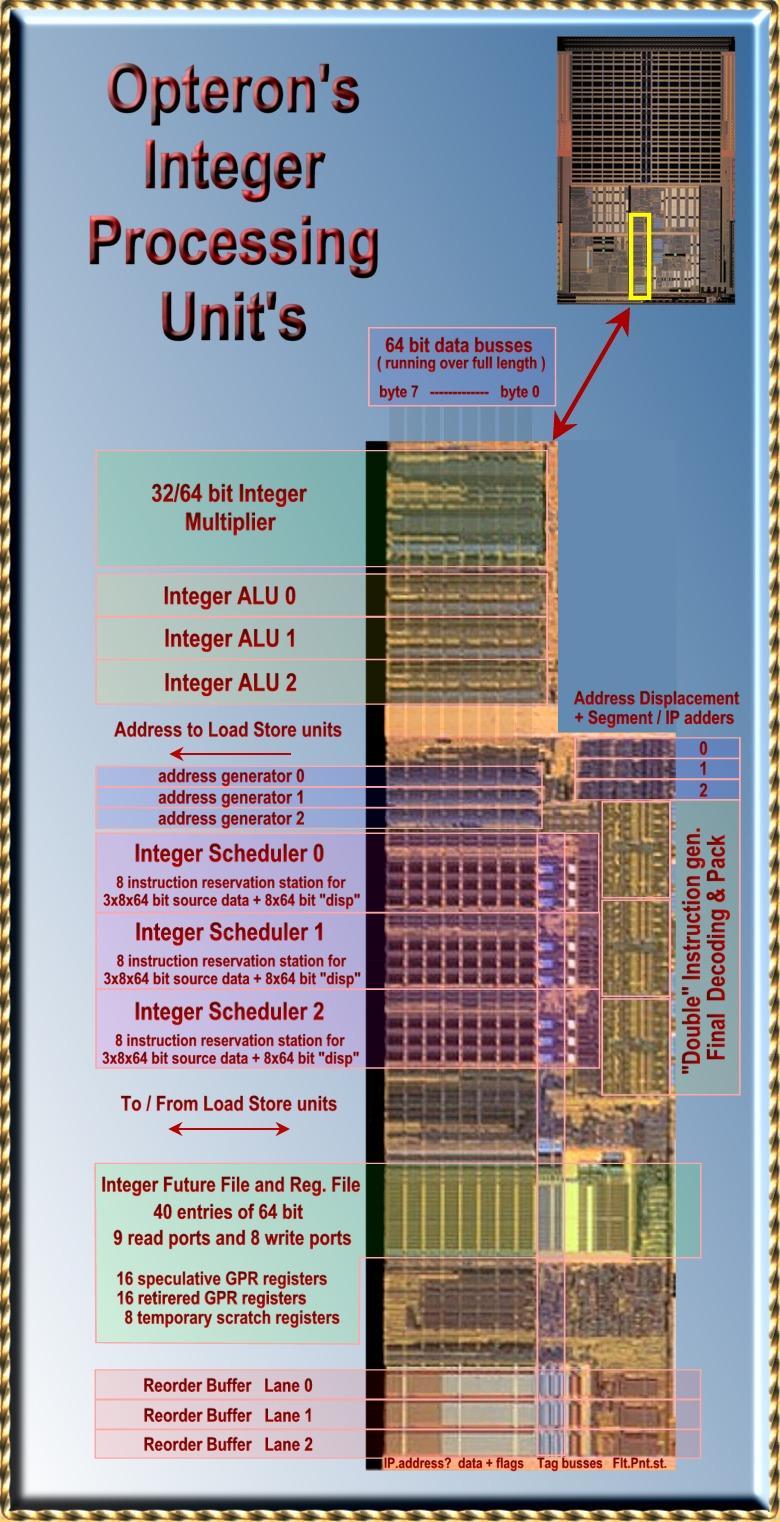
9
10 3 types of instructions Direct path RISC-like Vector path Integer Decode/Dispatch Broken into smaller instructions via micro code. Double 128-bit instructions which can be broken into 2 64-bit independent instructions are (called Double) Others are done via microcode Most 128-bit SSE and SSE2 are made into doubles.
11 RS Each cycle an instruction is issued into one of 3 lanes. Each lane has 8 RSs 1 ALU 1 AGU (Address Generation Unit) Each RS sees broadcasts from all ALUs, AGUs, L/S units etc.
12 Rename Break the physical register file into 2 parts (sort of like P6 scheme with ARF/RoB) 72 in-flight instructions are kept in the RoB The other structure is the IFFRF: Integer Future File and Register File 16 registers of committed state 16 future registers 8 scratch-pad registers
13 Future file In the P6 scheme we had to look 3 places for the data The PRF The RoB The CDB (later) Here we look in the FF or the CDB-like-things later. The FF holds the speculative value if it is known. At execution complete instructions check to see if they were the last thing to dispatch that writes to a given physical register. This is done by tagging the FF with the RoB number. If they were the last to have that AR as a destination, they update the FF.
14 How do we use the FF? At issue we: Check the FF for source operands Reserve a spot in the RoB Place our tag (RoB number) in the FF Mark the FF entry as invalid At EX complete we: Send RoB number and data to the CDB Send data to the RoB Update FF if tag matches At retire update ARF value (from RoB) At mispredict Copy ARF value into FF.
15 What did the FF buy us? P6-like advantages No free-list for PRF Can just clear the RAT on mis-predict. But no need to access the RoB looking for data RoB data only written once (EX complete) and only read once (Commit) Some pain Early branch resolution looks hard
16 ROB: An 8-bit descriptor for 72 entries Re-Order-Buffer Tag definition wrap bit Instruction In Flight Number re-order buffer index sub-index 0..2 bit 7 bit 6 bit 5 bit 4 bit 3 bit 2 bit 1 bit 0 1) A sub-index 0,1 or 2 which identifies from which of the three lanes the instruction was dispatched. 2) A value that identifies the cycle" in which the instruction was dispatched. The "cycle counter" wraps to 0 after reaching 23. 3) A wrap bit. When two instructions have different wrap bits then the cycle counter has wrapped between the dispatches.
17 More on the RoB What is basically happening is that we have three RoBs Each one size 24 We cycle through each one so that none get ahead of the other. Reduces read/write ports!
18 Mispredictions It looks like they wait until retirement to resolve all exceptions. Mispredictions are treated as exceptions! They just clear everything and have the retired registers overwrite the speculative ones in the IFFRF
19 More details. Each x86 instruction can launch both an ALU and an AGU operation Because x86 has lots of memory operations this makes sense. ALUs broadcast result tag one cycle early So RS can launch data to the ALU before data arrives.
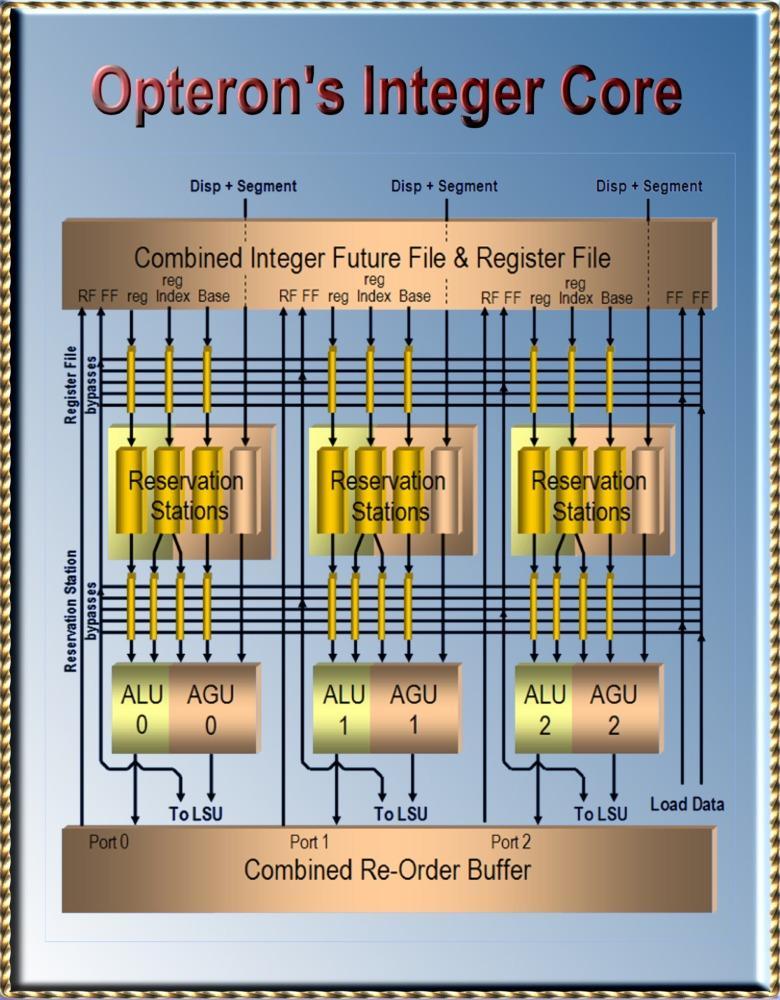
20 8 Lane
21 Class summary Major topics ILP in hardware (Out-of-order processors) How they work AND why we use them Caches and Virtual Memory Multi-processor ILP in software (Complier, IA-64) Power Less major topics Memory disambiguation Branch prediction Direction and target Advanced OoO issues Superscalar, instruction scheduling, multi-threading, etc.
22 The big questions What is computer architecture? What are the metrics of performance? What are the techniques we use to maximize these metrics?
23 ILP in hardware (1/2) ILP definitions Hazards vs dependencies Data, Name and Control dependencies What ILP means and finding it. Dynamic Scheduling Tomasulo s (three versions!) You can be promised a question on this! Branch Prediction Local, global, hybrid/correlating Tournament and gshare BTBs
24 ILP in hardware (2/2) Multiple Issue Static Static Superscalar VLIW Dynamic superscalar Speculation Branch, data ILP limit studies
25 ILP in hardware: Questions True or False 1. The original T-algorithm only allows reordering within basic blocks 2. In P6, if it weren t for precise interrupts, it would be okay to retire instructions out-of-order as long as they had finished executing and a branch isn t skipped over. 3. ILP in hardware is limited in scope due to the instruction window which is basically the size of the RS.
26 Quick idea: SMT One processor, two threads.
27 Caching (1/2) There is a huge amount of stuff associated with caching. The important stuff Locality Temporal/Spatial 3 Cs model Stack distance model Nuts-and-bolts Replacement policies (LRU, pseudo-lru) Performance (hit rate, T hit ; T miss, average access time) Write back/write thru Block size Basic improvement Multi-level cache Critical word first Write buffers
28 Caching (2/2) Non-standard caches Hash Victim Skew Misc. Virtual addresses and caching Impact of prefetching Latency hiding with OO execution
29 Cache: Questions (1/2) Changing has an impact on compulsory misses. A victim cache is more likely to help with than though it can help both (3 Cs) At least bits are required to keep exact track of LRU in a 5-way associative cache.
30 Cache question (2/2) A cache has a number of sets equal to the number of lines in the cache. A fully-associative cache with N lines will miss an access that has a stack distance of (state the largest range you can).
31 Multi-processor Amdahl s law as it applies to MP. Bus-based multi-processor Snooping MESI Bus transaction types (BRL etc.) Distributed-shared Directory schemes Synchronization Critical sections Spin-locks
32 Multi-processor: Question Under the MESI protocol what is the advantage of having a distinct clean and dirty exclusive state?
33 Software techniques for ILP (1/2) Pipeline scheduling Reordering instructions in a basic block to remove pipe stalls Loop unrolling Static information passed to processor Static branch prediction Static dependence information Loop issues Detecting loop dependencies Software pipelining
34 Software techniques for ILP (2/2) Global code scheduling Predicated instruction and CMOV Memory reference speculation Issues with preserving exception behavior IA-64 as a case study of hardware support for software ILP techniques Speculative loads Advanced loads Software pipelining optimizations
35 Software techniques for ILP: Questions What is the most significant disadvantage of loop unrolling? Using CMOV re-write the following code snippet, removing the branch. Don t change exception behavior and assume DIV only causes an exception if R3=0 BNE R1 R2 skip skip: nop R1=R2/R3
36 Power Understand why it s important Power vs. Energy How it s related to the existence of multicore Understand voltage scaling issues
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
EECS 470 Midterm Exam Winter 2008 answers
 EECS 470 Midterm Exam Winter 2008 answers Name: KEY unique name: KEY Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: #Page Points 2 /10
EECS 470 Midterm Exam Winter 2008 answers Name: KEY unique name: KEY Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: #Page Points 2 /10
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Reorder Buffer Implementation (Pentium Pro) Reorder Buffer Implementation (Pentium Pro)
 Reorder Buffer Implementation (Pentium Pro)") Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
EECS 470 Lecture 7. Branches: Address prediction and recovery (And interrupt recovery too.)
") EECS 470 Lecture 7 Branches: Address prediction and recovery (And interrupt recovery too.) Warning: Crazy times coming Project handout and group formation today Help me to end class 12 minutes early P3
EECS 470 Lecture 7 Branches: Address prediction and recovery (And interrupt recovery too.) Warning: Crazy times coming Project handout and group formation today Help me to end class 12 minutes early P3
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
EECS 470 Final Exam Fall 2013
 EECS 470 Final Exam Fall 2013 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: Page# Points 2 /21 3 /8 4 /12 5 /10 6
EECS 470 Final Exam Fall 2013 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: Page# Points 2 /21 3 /8 4 /12 5 /10 6
Tutorial 11. Final Exam Review
 Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
EECS 470. Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 7 Winter 2018
 Lecture 7 Winter 2018") EECS 470 Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 7 Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen,
EECS 470 Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 7 Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen,
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
EECS 470 Lecture 6. Branches: Address prediction and recovery (And interrupt recovery too.)
") EECS 470 Lecture 6 Branches: Address prediction and recovery (And interrupt recovery too.) Announcements: P3 posted, due a week from Sunday HW2 due Monday Reading Book: 3.1, 3.3-3.6, 3.8 Combining Branch
EECS 470 Lecture 6 Branches: Address prediction and recovery (And interrupt recovery too.) Announcements: P3 posted, due a week from Sunday HW2 due Monday Reading Book: 3.1, 3.3-3.6, 3.8 Combining Branch
CMSC Computer Architecture Lecture 18: Exam 2 Review Session. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 18: Exam 2 Review Session Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Due: 11:59pm, Dec. 1 st, Thursday " Two late days with
CMSC 22200 Computer Architecture Lecture 18: Exam 2 Review Session Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Due: 11:59pm, Dec. 1 st, Thursday " Two late days with
Keywords and Review Questions
 Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
CS433 Midterm. Prof Josep Torrellas. October 19, Time: 1 hour + 15 minutes
 CS433 Midterm Prof Josep Torrellas October 19, 2017 Time: 1 hour + 15 minutes Name: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your time.
CS433 Midterm Prof Josep Torrellas October 19, 2017 Time: 1 hour + 15 minutes Name: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your time.
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Lecture 8: Branch Prediction, Dynamic ILP. Topics: static speculation and branch prediction (Sections )
") Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
EECS 470 Final Exam Fall 2015
 EECS 470 Final Exam Fall 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: Page # Points 2 /17 3 /11 4 /13 5 /10
EECS 470 Final Exam Fall 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: Page # Points 2 /17 3 /11 4 /13 5 /10
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Lecture 9: More ILP. Today: limits of ILP, case studies, boosting ILP (Sections )
") Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
EECS 470. Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 6 Winter 2018
 Lecture 6 Winter 2018") EECS 470 Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 6 Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen,
EECS 470 Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 6 Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen,
CS252 Graduate Computer Architecture Lecture 6. Recall: Software Pipelining Example
 CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
ILP: Instruction Level Parallelism
 ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
RECAP. B649 Parallel Architectures and Programming
 RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
Performance of Computer Systems. CSE 586 Computer Architecture. Review. ISA s (RISC, CISC, EPIC) Basic Pipeline Model.
 Basic Pipeline Model.") Performance of Computer Systems CSE 586 Computer Architecture Review Jean-Loup Baer http://www.cs.washington.edu/education/courses/586/00sp Performance metrics Use (weighted) arithmetic means for execution
Performance of Computer Systems CSE 586 Computer Architecture Review Jean-Loup Baer http://www.cs.washington.edu/education/courses/586/00sp Performance metrics Use (weighted) arithmetic means for execution
Advanced Computer Architecture
 Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
CS146 Computer Architecture. Fall Midterm Exam
 CS146 Computer Architecture Fall 2002 Midterm Exam This exam is worth a total of 100 points. Note the point breakdown below and budget your time wisely. To maximize partial credit, show your work and state
CS146 Computer Architecture Fall 2002 Midterm Exam This exam is worth a total of 100 points. Note the point breakdown below and budget your time wisely. To maximize partial credit, show your work and state
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Computer Systems Architecture I. CSE 560M Lecture 10 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING
 DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson,
DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson,
Superscalar Processors
 Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
CS252 Graduate Computer Architecture Midterm 1 Solutions
 CS252 Graduate Computer Architecture Midterm 1 Solutions Part A: Branch Prediction (22 Points) Consider a fetch pipeline based on the UltraSparc-III processor (as seen in Lecture 5). In this part, we evaluate
CS252 Graduate Computer Architecture Midterm 1 Solutions Part A: Branch Prediction (22 Points) Consider a fetch pipeline based on the UltraSparc-III processor (as seen in Lecture 5). In this part, we evaluate
CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution. Prof. Yanjing Li University of Chicago
 CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution Prof. Yanjing Li University of Chicago Administrative Stuff! Lab2 due tomorrow " 2 free late days! Lab3 is out " Start early!! My office
CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution Prof. Yanjing Li University of Chicago Administrative Stuff! Lab2 due tomorrow " 2 free late days! Lab3 is out " Start early!! My office
ECE 552 / CPS 550 Advanced Computer Architecture I. Lecture 15 Very Long Instruction Word Machines
 ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 15 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 15 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
Lecture: Out-of-order Processors. Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ
 Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Dynamic Issue & HW Speculation. Raising the IPC Ceiling
 Dynamic Issue & HW Speculation Today s topics: Superscalar pipelines Dynamic Issue Scoreboarding: control centric approach Tomasulo: data centric approach 1 CS6810 Raising the IPC Ceiling w/ single-issue
Dynamic Issue & HW Speculation Today s topics: Superscalar pipelines Dynamic Issue Scoreboarding: control centric approach Tomasulo: data centric approach 1 CS6810 Raising the IPC Ceiling w/ single-issue
Page 1. Raising the IPC Ceiling. Dynamic Issue & HW Speculation. Fix OOO Completion Problem First. Reorder Buffer In Action
 Raising the IPC Ceiling Dynamic Issue & HW Speculation Today s topics: Superscalar pipelines Dynamic Issue Scoreboarding: control centric approach Tomasulo: data centric approach w/ single-issue IPC max
Raising the IPC Ceiling Dynamic Issue & HW Speculation Today s topics: Superscalar pipelines Dynamic Issue Scoreboarding: control centric approach Tomasulo: data centric approach w/ single-issue IPC max
Computer Architecture and Engineering CS152 Quiz #3 March 22nd, 2012 Professor Krste Asanović
 Computer Architecture and Engineering CS52 Quiz #3 March 22nd, 202 Professor Krste Asanović Name: This is a closed book, closed notes exam. 80 Minutes 0 Pages Notes: Not all questions are
Computer Architecture and Engineering CS52 Quiz #3 March 22nd, 202 Professor Krste Asanović Name: This is a closed book, closed notes exam. 80 Minutes 0 Pages Notes: Not all questions are
EECS 470 Final Exam Winter 2012
 EECS 470 Final Exam Winter 2012 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Page 2 /11 Page 3 /13 Page
EECS 470 Final Exam Winter 2012 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Page 2 /11 Page 3 /13 Page
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
CS 2410 Mid term (fall 2015) Indicate which of the following statements is true and which is false.
 Indicate which of the following statements is true and which is false.") CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
EECS 470 Midterm Exam Answer Key Fall 2004
 EECS 470 Midterm Exam Answer Key Fall 2004 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Part I /23 Part
EECS 470 Midterm Exam Answer Key Fall 2004 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Part I /23 Part
EECS 470 Midterm Exam
 EECS 470 Midterm Exam Winter 2014 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: NOTES: # Points Page 2 /12 Page 3
EECS 470 Midterm Exam Winter 2014 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: NOTES: # Points Page 2 /12 Page 3
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Course on Advanced Computer Architectures
 Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
EE382A Lecture 7: Dynamic Scheduling. Department of Electrical Engineering Stanford University
 EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
Lecture: Out-of-order Processors
 Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
Complex Pipelining COE 501. Computer Architecture Prof. Muhamed Mudawar
 Complex Pipelining COE 501 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Diversified Pipeline Detecting
Complex Pipelining COE 501 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Diversified Pipeline Detecting
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 14: Speculation II Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CS 246, Harvard University] Tomasulo+ROB Add
Computer Architecture Spring 2016 Lecture 14: Speculation II Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CS 246, Harvard University] Tomasulo+ROB Add
Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar, VLIW. CPE 631 Session 19 Exploiting ILP with SW Approaches
 Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
EECS 470 Midterm Exam Fall 2006
 EECS 40 Midterm Exam Fall 2 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Page 2 /18 Page 3 /13 Page 4 /15
EECS 40 Midterm Exam Fall 2 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Page 2 /18 Page 3 /13 Page 4 /15
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW
: Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW") Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW 1 Review from Last Lecture Leverage Implicit
Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW 1 Review from Last Lecture Leverage Implicit
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation. Types of dependences
 and its exploitation. Types of dependences") Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling)
") 18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
Review: Compiler techniques for parallelism Loop unrolling Ÿ Multiple iterations of loop in software:
 CS152 Computer Architecture and Engineering Lecture 17 Dynamic Scheduling: Tomasulo March 20, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
CS152 Computer Architecture and Engineering Lecture 17 Dynamic Scheduling: Tomasulo March 20, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
Superscalar Processors Ch 14
 Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processing (5) Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?
 Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?") Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
ECE 252 / CPS 220 Advanced Computer Architecture I. Lecture 14 Very Long Instruction Word Machines
 ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 14 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 14 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Computer Architecture Lecture 15: Load/Store Handling and Data Flow. Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/21/2014
 18-447 Computer Architecture Lecture 15: Load/Store Handling and Data Flow Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/21/2014 Lab 4 Heads Up Lab 4a out Branch handling and branch predictors
18-447 Computer Architecture Lecture 15: Load/Store Handling and Data Flow Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/21/2014 Lab 4 Heads Up Lab 4a out Branch handling and branch predictors
Computer Architecture: Out-of-Order Execution II. Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Out-of-Order Execution II Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 15 Video
Computer Architecture: Out-of-Order Execution II Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 15 Video
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University. P & H Chapter 4.10, 1.7, 1.8, 5.10, 6
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
CPE 631 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Multithreading Processors and Static Optimization Review. Adapted from Bhuyan, Patterson, Eggers, probably others
 Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Wide Instruction Fetch
 Wide Instruction Fetch Fall 2007 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs470 edu/courses/eecs470 block_ids Trace Table pre-collapse trace_id History Br. Hash hist. Rename Fill Table
Wide Instruction Fetch Fall 2007 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs470 edu/courses/eecs470 block_ids Trace Table pre-collapse trace_id History Br. Hash hist. Rename Fill Table
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,
 Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,") Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 9: Dynamic ILP. Topics: out-of-order processors (Sections )
") Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
EECS 470 Final Exam Fall 2005
 EECS 470 Final Exam Fall 2005 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Section 1 /30 Section 2 /30
EECS 470 Final Exam Fall 2005 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Section 1 /30 Section 2 /30
Lecture 16: Checkpointed Processors. Department of Electrical Engineering Stanford University
 Lecture 16: Checkpointed Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 18-1 Announcements Reading for today: class notes Your main focus:
Lecture 16: Checkpointed Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 18-1 Announcements Reading for today: class notes Your main focus:
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
 ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
EEC 581 Computer Architecture. Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW)
") 1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
Case Study IBM PowerPC 620
 Case Study IBM PowerPC 620 year shipped: 1995 allowing out-of-order execution (dynamic scheduling) and in-order commit (hardware speculation). using a reorder buffer to track when instruction can commit,
Case Study IBM PowerPC 620 year shipped: 1995 allowing out-of-order execution (dynamic scheduling) and in-order commit (hardware speculation). using a reorder buffer to track when instruction can commit,
 1 cycle per instruction I
1 cycle per instruction I Control Hazards. Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Website for Students VTU NOTES QUESTION PAPERS NEWS RESULTS
 Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
CS 1013 Advance Computer Architecture UNIT I
 CS 1013 Advance Computer Architecture UNIT I 1. What are embedded computers? List their characteristics. Embedded computers are computers that are lodged into other devices where the presence of the computer
CS 1013 Advance Computer Architecture UNIT I 1. What are embedded computers? List their characteristics. Embedded computers are computers that are lodged into other devices where the presence of the computer
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design
 EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
Dynamic Control Hazard Avoidance
 Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
EEC 581 Computer Architecture. Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW)
") EEC 581 Computer Architecture Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University
EEC 581 Computer Architecture Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University
References EE457. Out of Order (OoO) Execution. Instruction Scheduling (Re-ordering of instructions)
 Execution. Instruction Scheduling (Re-ordering of instructions)") EE457 Out of Order (OoO) Execution Introduction to Dynamic Scheduling of Instructions (The Tomasulo Algorithm) By Gandhi Puvvada References EE557 Textbook Prof Dubois EE557 Classnotes Prof Annavaram s
EE457 Out of Order (OoO) Execution Introduction to Dynamic Scheduling of Instructions (The Tomasulo Algorithm) By Gandhi Puvvada References EE557 Textbook Prof Dubois EE557 Classnotes Prof Annavaram s