Accelerating MATLAB with CUDA
|
|
|
- Randell Cox
- 6 years ago
- Views:
Transcription

1 Accelerating MATLAB with CUDA Massimiliano Fatica NVIDIA Won-Ki Jeong University of Utah
2 Overview MATLAB can be easily extended via MEX files to take advantage of the computational power offered by the latest NVIDIA GPUs (GeForce 8800, Quadro FX5600, Tesla). Programming the GPU for computational purposes was a very cumbersome task before CUDA. Using CUDA, it is now very easy to achieve impressive speed-up with minimal effort. This work is a proof of concept that shows the feasibility and benefits of using this approach.
3 MEX file Even though MATLAB is built on many well-optimized libraries, some functions can perform better when written in a compiled language (e.g. C and Fortran). MATLAB provides a convenient API for interfacing code written in C and FORTRAN to MATLAB functions with MEX files. MEX files could be used to exploit multi-core processors with OpenMP or threaded codes or like in this case to offload functions to the GPU.
4 NVMEX Native MATLAB script cannot parse CUDA code New MATLAB script nvmex.m compiles CUDA code (.cu) to create MATLAB function files Syntax similar to original mex script: >> nvmex f nvmexopts.bat filename.cu IC:\cuda\include LC:\cuda\lib -lcudart Available for Windows and Linux from:
5 Mex files for CUDA A typical mex file will perform the following steps: 1. Convert from double to single precision 2. Rearrange the data layout for complex data 3. Allocate memory on the GPU 4. Transfer the data from the host to the GPU 5. Perform computation on GPU (library, custom code) 6. Transfer results from the GPU to the host 7. Rearrange the data layout for complex data 8. Convert from single to double 9. Clean up memory and return results to MATLAB Some of these steps will go away with new versions of the library (2,7) and new hardware (1,8)
6 CUDA MEX example Additional code in MEX file to handle CUDA /*Parse input, convert to single precision and to interleaved complex format */.. /* Allocate array on the GPU */ cufftcomplex *rhs_complex_d; cudamalloc( (void **) &rhs_complex_d,sizeof(cufftcomplex)*n*m); /* Copy input array in interleaved format to the GPU */ cudamemcpy( rhs_complex_d, input_single, sizeof(cufftcomplex)*n*m, cudamemcpyhosttodevice); /* Create plan for CUDA FFT NB: transposing dimensions*/ cufftplan2d(&plan, N, M, CUFFT_C2C) ; /* Execute FFT on GPU */ cufftexecc2c(plan, rhs_complex_d, rhs_complex_d, CUFFT_INVERSE) ; /* Copy result back to host */ cudamemcpy( input_single, rhs_complex_d, sizeof(cufftcomplex)*n*m, cudamemcpydevicetohost); /* Clean up memory and plan on the GPU */ cufftdestroy(plan); cudafree(rhs_complex_d); /*Convert back to double precision and to split complex format */.
7 Initial study Focus on 2D FFTs. FFT-based methods are often used in single precision ( for example in image processing ) Mex files to overload MATLAB functions, no modification between the original MATLAB code and the accelerated one. Application selected for this study: solution of the Euler equations in vorticity form using a pseudo-spectral method.
8 Implementation details: Case A) FFT2.mex and IFFT2.mex Mex file in C with CUDA FFT functions. Standard mex script could be used. Overall effort: few hours Case B) Szeta.mex: Vorticity source term written in CUDA Mex file in CUDA with calls to CUDA FFT functions. Small modifications necessary to handle files with a.cu suffix Overall effort: ½ hour (starting from working mex file for 2D FFT)
9 Configuration Hardware: Software: AMD Opteron 250 with 4 GB of memory NVIDIA GeForce 8800 GTX Windows XP and Microsoft VC8 compiler RedHat Enterprise Linux 4 32 bit, gcc compiler MATLAB R2006b CUDA 1.0
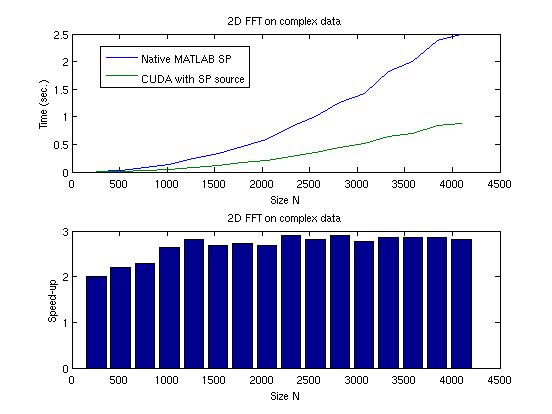
10 FFT2 performance
11 Vorticity source term function S = Szeta(zeta,k,nu4) % Pseudospectral calculation of vorticity source term % S = -(- psi_y*zeta_x + psi_x*zeta_y) + nu4*del^4 zeta % on a square periodic domain, where zeta = psi_xx + psi_yy is an NxN matrix % of vorticity and k is vector of Fourier wavenumbers in each direction. % Output is an NxN matrix of S at all pseudospectral gridpoints zetahat = fft2(zeta); [KX KY] = meshgrid(k,k); % Matrix of (x,y) wavenumbers corresponding % to Fourier mode (m,n) del2 = -(KX.^2 + KY.^2); del2(1,1) = 1; % Set to nonzero to avoid division by zero when inverting % Laplacian to get psi psihat = zetahat./del2; dpsidx = real(ifft2(1i*kx.*psihat)); dpsidy = real(ifft2(1i*ky.*psihat)); dzetadx = real(ifft2(1i*kx.*zetahat)); dzetady = real(ifft2(1i*ky.*zetahat)); diff4 = real(ifft2(del2.^2.*zetahat)); S = -(-dpsidy.*dzetadx + dpsidx.*dzetady) - nu4*diff4;
12 Caveats The current CUDA FFT library only supports interleaved format for complex data while MATLAB stores all the real data followed by the imaginary data. Complex to complex (C2C) transforms used The accelerated computations are not taking advantage of the symmetry of the transforms. The current GPU hardware only supports single precision (double precision will be available in the next generation GPU towards the end of the year). Conversion to/from single from/to double is consuming a significant portion of wall clock time.
13 Advection of an elliptic vortex 256x256 mesh, 512 RK4 steps, Linux, MATLAB file MATLAB 168 seconds MATLAB with CUDA (single precision FFTs) 14.9 seconds (11x)

14 Pseudo-spectral simulation of 2D Isotropic turbulence. 512x512 mesh, 400 RK4 steps, Windows XP, MATLAB file MATLAB 992 seconds MATLAB with CUDA (single precision FFTs) 93 seconds
15 Power spectrum of vorticity is very sensitive to fine scales. Result from original MATLAB run and CUDA accelerated one are in excellent agreement MATLAB run CUDA accelerated MATLAB run
16 Timing details 1024x1024 mesh, 400 RK4 steps on Windows, 2D isotropic turbulence Runtime Opteron 250 Speed up Runtime Opteron 2210 Speed up PCI-e Bandwidth: 1135 MB/s 1483 MB/s Host to/from device 1003 MB/s 1223 MB/s Standard MATLAB 8098 s 9525s Overload FFT2 and IFFT s 1.8x 4937s 1.9x Overload Szeta 735 s 11.x 789s 12.X Overload Szeta, FFT2 and IFFT2 577 s 14.x 605s 15.7x
17 Conclusion Integration of CUDA is straightforward as a MEX plug-in No need for users to leave MATLAB to run big simulations: high productivity Relevant speed-ups even for small size grids Plenty of opportunities for further optimizations
S05: High Performance Computing with CUDA. CUDA Libraries. Massimiliano Fatica, NVIDIA. CUBLAS: BLAS implementation CUFFT: FFT implementation
 CUDA Libraries Massimiliano Fatica, NVIDIA Outline CUDA libraries: CUBLAS: BLAS implementation CUFFT: FFT implementation Using CUFFT to solve a Poisson equation with spectral methods: How to use the profile
CUDA Libraries Massimiliano Fatica, NVIDIA Outline CUDA libraries: CUBLAS: BLAS implementation CUFFT: FFT implementation Using CUFFT to solve a Poisson equation with spectral methods: How to use the profile
Master Thesis Accelerating Image Registration on GPUs
 Master Thesis Accelerating Image Registration on GPUs A proof of concept migration of FAIR to CUDA Sunil Ramgopal Tatavarty Prof. Dr. Ulrich Rüde Dr.-Ing.Harald Köstler Lehrstuhl für Systemsimulation Universität
Master Thesis Accelerating Image Registration on GPUs A proof of concept migration of FAIR to CUDA Sunil Ramgopal Tatavarty Prof. Dr. Ulrich Rüde Dr.-Ing.Harald Köstler Lehrstuhl für Systemsimulation Universität
Using a GPU in InSAR processing to improve performance
 Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Georgia Institute of Technology Center for Signal and Image Processing Steve Conover February 2009
 Georgia Institute of Technology Center for Signal and Image Processing Steve Conover February 2009 Introduction CUDA is a tool to turn your graphics card into a small computing cluster. It s not always
Georgia Institute of Technology Center for Signal and Image Processing Steve Conover February 2009 Introduction CUDA is a tool to turn your graphics card into a small computing cluster. It s not always
RAPID MULTI-GPU PROGRAMMING WITH CUDA LIBRARIES. Nikolay Markovskiy
 RAPID MULTI-GPU PROGRAMMING WITH CUDA LIBRARIES Nikolay Markovskiy CUDA 6 cublas cufft 2. cublas-xt 3. cufft-xt 1. NVBLAS WHAT IS NVBLAS? Drop-in replacement of BLAS Built on top of cublas-xt BLAS Level
RAPID MULTI-GPU PROGRAMMING WITH CUDA LIBRARIES Nikolay Markovskiy CUDA 6 cublas cufft 2. cublas-xt 3. cufft-xt 1. NVBLAS WHAT IS NVBLAS? Drop-in replacement of BLAS Built on top of cublas-xt BLAS Level
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
JCudaMP: OpenMP/Java on CUDA
 JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
GPU ARCHITECTURE Chris Schultz, June 2017
 Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Using OpenACC With CUDA Libraries
 Using OpenACC With CUDA Libraries John Urbanic with NVIDIA Pittsburgh Supercomputing Center Copyright 2015 3 Ways to Accelerate Applications Applications Libraries Drop-in Acceleration CUDA Libraries are
Using OpenACC With CUDA Libraries John Urbanic with NVIDIA Pittsburgh Supercomputing Center Copyright 2015 3 Ways to Accelerate Applications Applications Libraries Drop-in Acceleration CUDA Libraries are
CUFFT Library PG _V1.0 June, 2007
 PG-00000-003_V1.0 June, 2007 PG-00000-003_V1.0 Confidential Information Published by Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Notice This source code is subject to ownership rights under
PG-00000-003_V1.0 June, 2007 PG-00000-003_V1.0 Confidential Information Published by Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Notice This source code is subject to ownership rights under
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Speed Up Your Codes Using GPU
 Speed Up Your Codes Using GPU Wu Di and Yeo Khoon Seng (Department of Mechanical Engineering) The use of Graphics Processing Units (GPU) for rendering is well known, but their power for general parallel
Speed Up Your Codes Using GPU Wu Di and Yeo Khoon Seng (Department of Mechanical Engineering) The use of Graphics Processing Units (GPU) for rendering is well known, but their power for general parallel
A Sampling of CUDA Libraries Michael Garland
 A Sampling of CUDA Libraries Michael Garland NVIDIA Research CUBLAS Implementation of BLAS (Basic Linear Algebra Subprograms) on top of CUDA driver Self-contained at the API level, no direct interaction
A Sampling of CUDA Libraries Michael Garland NVIDIA Research CUBLAS Implementation of BLAS (Basic Linear Algebra Subprograms) on top of CUDA driver Self-contained at the API level, no direct interaction
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels
 National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
GPU Computing: A Quick Start
 GPU Computing: A Quick Start Orest Shardt Department of Chemical and Materials Engineering University of Alberta August 25, 2011 Session Goals Get you started with highly parallel LBM Take a practical
GPU Computing: A Quick Start Orest Shardt Department of Chemical and Materials Engineering University of Alberta August 25, 2011 Session Goals Get you started with highly parallel LBM Take a practical
ATS-GPU Real Time Signal Processing Software
 Transfer A/D data to at high speed Up to 4 GB/s transfer rate for PCIe Gen 3 digitizer boards Supports CUDA compute capability 2.0+ Designed to work with AlazarTech PCI Express waveform digitizers Optional
Transfer A/D data to at high speed Up to 4 GB/s transfer rate for PCIe Gen 3 digitizer boards Supports CUDA compute capability 2.0+ Designed to work with AlazarTech PCI Express waveform digitizers Optional
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
GeoImaging Accelerator Pansharpen Test Results. Executive Summary
 Executive Summary After demonstrating the exceptional performance improvement in the orthorectification module (approximately fourteen-fold see GXL Ortho Performance Whitepaper), the same approach has
Executive Summary After demonstrating the exceptional performance improvement in the orthorectification module (approximately fourteen-fold see GXL Ortho Performance Whitepaper), the same approach has
High Performance and GPU Computing in MATLAB
 High Performance and GPU Computing in MATLAB Jan Houška houska@humusoft.cz http://www.humusoft.cz 1 About HUMUSOFT Company: Humusoft s.r.o. Founded: 1990 Number of employees: 18 Location: Praha 8, Pobřežní
High Performance and GPU Computing in MATLAB Jan Houška houska@humusoft.cz http://www.humusoft.cz 1 About HUMUSOFT Company: Humusoft s.r.o. Founded: 1990 Number of employees: 18 Location: Praha 8, Pobřežní
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
Using OpenACC With CUDA Libraries
 Using OpenACC With CUDA Libraries John Urbanic with NVIDIA Pittsburgh Supercomputing Center Copyright 2018 3 Ways to Accelerate Applications Applications Libraries Drop-in Acceleration CUDA Libraries are
Using OpenACC With CUDA Libraries John Urbanic with NVIDIA Pittsburgh Supercomputing Center Copyright 2018 3 Ways to Accelerate Applications Applications Libraries Drop-in Acceleration CUDA Libraries are
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
General Purpose GPU programming (GP-GPU) with Nvidia CUDA. Libby Shoop
 with Nvidia CUDA. Libby Shoop") General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
Supporting Data Parallelism in Matcloud: Final Report
 Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Deep learning in MATLAB From Concept to CUDA Code
 Deep learning in MATLAB From Concept to CUDA Code Roy Fahn Applications Engineer Systematics royf@systematics.co.il 03-7660111 Ram Kokku Principal Engineer MathWorks ram.kokku@mathworks.com 2017 The MathWorks,
Deep learning in MATLAB From Concept to CUDA Code Roy Fahn Applications Engineer Systematics royf@systematics.co.il 03-7660111 Ram Kokku Principal Engineer MathWorks ram.kokku@mathworks.com 2017 The MathWorks,
Introduction to GPU (Graphics Processing Unit) Architecture & Programming
 Architecture & Programming") Introduction to GU (Graphics rocessing Unit) Architecture & rogramming C240A. 2017 T. Yang ome of slides are from M. Hall of Utah C6235 Overview Hardware architecture rogramming model Example Historical
Introduction to GU (Graphics rocessing Unit) Architecture & rogramming C240A. 2017 T. Yang ome of slides are from M. Hall of Utah C6235 Overview Hardware architecture rogramming model Example Historical
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Getting Started with MATLAB Francesca Perino
 Getting Started with MATLAB Francesca Perino francesca.perino@mathworks.it 2014 The MathWorks, Inc. 1 Agenda MATLAB Intro Importazione ed esportazione Programmazione in MATLAB Tecniche per la velocizzazione
Getting Started with MATLAB Francesca Perino francesca.perino@mathworks.it 2014 The MathWorks, Inc. 1 Agenda MATLAB Intro Importazione ed esportazione Programmazione in MATLAB Tecniche per la velocizzazione
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
GPGPU. Alan Gray/James Perry EPCC The University of Edinburgh.
 GPGPU Alan Gray/James Perry EPCC The University of Edinburgh a.gray@ed.ac.uk Contents Introduction GPU Technology Programming GPUs GPU Performance Optimisation 2 Introduction 3 Introduction Central Processing
GPGPU Alan Gray/James Perry EPCC The University of Edinburgh a.gray@ed.ac.uk Contents Introduction GPU Technology Programming GPUs GPU Performance Optimisation 2 Introduction 3 Introduction Central Processing
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
CUDA-GDB: The NVIDIA CUDA Debugger
 CUDA-GDB: The NVIDIA CUDA Debugger User Manual Version 2.2 Beta 3/30/2009 ii CUDA Debugger User Manual Version 2.2 Beta Table of Contents Chapter 1. Introduction... 1 1.1 CUDA-GDB: The NVIDIA CUDA Debugger...1
CUDA-GDB: The NVIDIA CUDA Debugger User Manual Version 2.2 Beta 3/30/2009 ii CUDA Debugger User Manual Version 2.2 Beta Table of Contents Chapter 1. Introduction... 1 1.1 CUDA-GDB: The NVIDIA CUDA Debugger...1
GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran. G. Ruetsch, M. Fatica, E. Phillips, N.
 GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran G. Ruetsch, M. Fatica, E. Phillips, N. Juffa Outline WRF and RRTM Previous Work CUDA Fortran Features RRTM in CUDA
GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran G. Ruetsch, M. Fatica, E. Phillips, N. Juffa Outline WRF and RRTM Previous Work CUDA Fortran Features RRTM in CUDA
Parallel Computing: What has changed lately? David B. Kirk
 Parallel Computing: What has changed lately? David B. Kirk Supercomputing 2007 Future Science and Engineering Breakthroughs Hinge on Computing Computational Geoscience Computational Chemistry Computational
Parallel Computing: What has changed lately? David B. Kirk Supercomputing 2007 Future Science and Engineering Breakthroughs Hinge on Computing Computational Geoscience Computational Chemistry Computational
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
GPGPU, 4th Meeting Mordechai Butrashvily, CEO GASS Company for Advanced Supercomputing Solutions
 GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Don t reinvent the wheel. BLAS LAPACK Intel Math Kernel Library
 Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Unified Memory. Notes on GPU Data Transfers. Andreas Herten, Forschungszentrum Jülich, 24 April Member of the Helmholtz Association
 Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
INTRODUCTION TO GPU COMPUTING IN AALTO. Topi Siro
 INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 11.6.2014 PART I Introduction to GPUs Basics of CUDA (and OpenACC) Running GPU jobs on Triton Hands-on 1 PART II Optimizing CUDA codes Libraries Hands-on
INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 11.6.2014 PART I Introduction to GPUs Basics of CUDA (and OpenACC) Running GPU jobs on Triton Hands-on 1 PART II Optimizing CUDA codes Libraries Hands-on
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
GpuWrapper: A Portable API for Heterogeneous Programming at CGG
 GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
Predictive Runtime Code Scheduling for Heterogeneous Architectures
 Predictive Runtime Code Scheduling for Heterogeneous Architectures Víctor Jiménez, Lluís Vilanova, Isaac Gelado Marisa Gil, Grigori Fursin, Nacho Navarro HiPEAC 2009 January, 26th, 2009 1 Outline Motivation
Predictive Runtime Code Scheduling for Heterogeneous Architectures Víctor Jiménez, Lluís Vilanova, Isaac Gelado Marisa Gil, Grigori Fursin, Nacho Navarro HiPEAC 2009 January, 26th, 2009 1 Outline Motivation
[ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG.
![[ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG.](/thumbs/96/128486115.jpg "[ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG.") [ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG. Setting up Development Environment 1. O/S Platform is Windows. 2. Install the latest NVIDIA Driver. 11) 3.
[ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG. Setting up Development Environment 1. O/S Platform is Windows. 2. Install the latest NVIDIA Driver. 11) 3.
INTRODUCTION TO GPU COMPUTING IN AALTO. Topi Siro
 INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 12.6.2013 OUTLINE PART I Introduction to GPUs Basics of CUDA PART II Maximizing performance Coalesced memory access Optimizing memory transfers Occupancy
INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 12.6.2013 OUTLINE PART I Introduction to GPUs Basics of CUDA PART II Maximizing performance Coalesced memory access Optimizing memory transfers Occupancy
Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors
 Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron University of Virginia IPDPS 2009 Outline Leukocyte
Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron University of Virginia IPDPS 2009 Outline Leukocyte
NLSEmagic: Nonlinear Schrödinger Equation Multidimensional. Matlab-based GPU-accelerated Integrators using Compact High-order Schemes
 NLSEmagic: Nonlinear Schrödinger Equation Multidimensional Matlab-based GPU-accelerated Integrators using Compact High-order Schemes R. M. Caplan 1 Nonlinear Dynamical System Group 2, Computational Science
NLSEmagic: Nonlinear Schrödinger Equation Multidimensional Matlab-based GPU-accelerated Integrators using Compact High-order Schemes R. M. Caplan 1 Nonlinear Dynamical System Group 2, Computational Science
AES Cryptosystem Acceleration Using Graphics Processing Units. Ethan Willoner Supervisors: Dr. Ramon Lawrence, Scott Fazackerley
 AES Cryptosystem Acceleration Using Graphics Processing Units Ethan Willoner Supervisors: Dr. Ramon Lawrence, Scott Fazackerley Overview Introduction Compute Unified Device Architecture (CUDA) Advanced
AES Cryptosystem Acceleration Using Graphics Processing Units Ethan Willoner Supervisors: Dr. Ramon Lawrence, Scott Fazackerley Overview Introduction Compute Unified Device Architecture (CUDA) Advanced
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
compiler, CUBLAS and CUFFT (required for development) collection of examples and documentation
 collection of examples and documentation") CUDA Toolkit CUDA Driver: Toolkit: required component to run CUDA applications compiler, CUBLAS and CUFFT (required for development) SDK: collection of examples and documentation Support for Linux (32
CUDA Toolkit CUDA Driver: Toolkit: required component to run CUDA applications compiler, CUBLAS and CUFFT (required for development) SDK: collection of examples and documentation Support for Linux (32
PART IV. CUDA programming! code, libraries and tools. Dr. Christian Napoli, M.Sc.! Dpt. Mathematics and Informatics, University of Catania!
 Postgraduate course on Electronics and Informatics Engineering (M.Sc.) Training Course on Circuits Theory (prof. G. Capizzi) Workshop on High performance computing and GPGPU computing Postgraduate course
Postgraduate course on Electronics and Informatics Engineering (M.Sc.) Training Course on Circuits Theory (prof. G. Capizzi) Workshop on High performance computing and GPGPU computing Postgraduate course
Cuda C Programming Guide Appendix C Table C-
 Cuda C Programming Guide Appendix C Table C-4 Professional CUDA C Programming (1118739329) cover image into the powerful world of parallel GPU programming with this down-to-earth, practical guide Table
Cuda C Programming Guide Appendix C Table C-4 Professional CUDA C Programming (1118739329) cover image into the powerful world of parallel GPU programming with this down-to-earth, practical guide Table
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA
 CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures
 A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures E. Ayguade 1,2, R.M. Badia 2,4, D. Cabrera 2, A. Duran 2, M. Gonzalez 1,2, F. Igual 3, D. Jimenez 1, J. Labarta 1,2, X. Martorell
A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures E. Ayguade 1,2, R.M. Badia 2,4, D. Cabrera 2, A. Duran 2, M. Gonzalez 1,2, F. Igual 3, D. Jimenez 1, J. Labarta 1,2, X. Martorell
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
CUFFT LIBRARY USER'S GUIDE. DU _v7.5 September 2015
 CUFFT LIBRARY USER'S GUIDE DU-06707-001_v7.5 September 2015 TABLE OF CONTENTS Chapter 1. Introduction...1 Chapter 2. Using the cufft API... 3 2.1. Accessing cufft...4 2.2. Fourier Transform Setup...5 2.3.
CUFFT LIBRARY USER'S GUIDE DU-06707-001_v7.5 September 2015 TABLE OF CONTENTS Chapter 1. Introduction...1 Chapter 2. Using the cufft API... 3 2.1. Accessing cufft...4 2.2. Fourier Transform Setup...5 2.3.
CUDA Kenjiro Taura 1 / 36
 CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team
 Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
NVIDIA CUDA DEBUGGER CUDA-GDB. User Manual
 CUDA DEBUGGER CUDA-GDB User Manual PG-00000-004_V2.3 June, 2009 CUDA-GDB PG-00000-004_V2.3 Published by Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Notice ALL DESIGN SPECIFICATIONS, REFERENCE
CUDA DEBUGGER CUDA-GDB User Manual PG-00000-004_V2.3 June, 2009 CUDA-GDB PG-00000-004_V2.3 Published by Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Notice ALL DESIGN SPECIFICATIONS, REFERENCE
GPU 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives