Programming Models MapReduce
|
|
|
- Marjory Cannon
- 5 years ago
- Views:
Transcription
1 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan /18-847b Advanced Cloud Computing Fall 2013 Sep 23,
2 MapReduce In a Nutshell MapReduce incorporates two phases Map Phase Reduce phase HDFS Split BLK 0 HDFS Split BLK 1 Dataset HDFS Split BLK 2 HDFS HDFS Split BLK 3 Map Task Map Task Map Task Map Task Map Phase Shuffle Stage Merge & Sort Stage Reduce Phase Reduce Task Reduce Task Reduce Task Reduce Stage To HDFS
3 Data Distribution In a MapReduce cluster, data is distributed to all the nodes of the cluster as it is being loaded An underlying distributed systems (e.g., GFS, HDFS) splits large data s into chunks which are managed by different nodes in the cluster Input data: A large Node 1 Chunk of input data Node 2 Chunk of input data Node 3 Chunk of input data Even though the chunks are distributed across several machines, they form a single namespace 7
4 MapReduce In MapReduce, splits are processed in isolation by tasks called Mappers The output from the mappers is denoted as intermediate output and brought into a second set of tasks called Reducers Map Phase splits mappers C0 C1 C2 C3 M0 M1 M2 M3 IO IO IO IO The process of reading intermediate output into a set of Reducers is known as shuffling The Reducers produce the final output Reduce Phase Shuffling Data Merge & Sort Reducers R0 R1 Overall, MapReduce breaks the data flow into two phases, map phase and reduce phase FO FO
5 Keys and Values The programmer in MapReduce has to specify two functions, the map function and the reduce function that implement the Mapper and the Reducer in a MapReduce program In MapReduce data elements are always structured as key-value (i.e., (K, V)) pairs The map and reduce functions receive and emit (K, V) pairs Input Splits Intermediate Output Final Output (K, V) Pairs Map Function (K, V ) Pairs Reduce Function (K, V ) Pairs
6 Splits A split can contain reference to one or more HDFS blocks Configurable parameter Each map task processes one split # of splits dictates the # of map tasks By default one split contains reference to one HDFS block Map tasks are scheduled in the vicinity of HDFS blocks to reduce network traffic
7 s Map tasks store intermediate output on local disk (not HDFS) A subset of intermediate key space is assigned to each Reducer hash(key) mod R These subsets are known as partitions Different colors represent different keys (potentially) from different Mappers s are the input to Reducers

8 Network Topology In MapReduce MapReduce assumes a tree style network topology Nodes are spread over different racks embraced in one or many data centers The bandwidth between two nodes is dependent on their relative locations in the network topology The assumption is that nodes that are on the same rack will have higher bandwidth between them as opposed to nodes that are off-rack
9 Hadoop MapReduce: A Closer Look Node 1 Node 2 Files loaded from local HDFS store Files loaded from local HDFS store InputFormat InputFormat Split Split Split Split Split Split RecordReaders RR RR RR RR RR RR RecordReaders Input (K, V) pairs Input (K, V) pairs Map Map Map Map Map Map Intermediate (K, V) pairs er Shuffling Process er Intermediate (K, V) pairs Sort Reduce Intermediate (K,V) pairs exchanged by all nodes Sort Reduce Final (K, V) pairs Final (K, V) pairs Writeback to local HDFS store OutputFormat OutputFormat Writeback to local HDFS store
10 Input Files Input s are where the data for a MapReduce task is initially stored The input s typically reside in a distributed system (e.g. HDFS) The format of input s is arbitrary Line-based log s Binary s Multi-line input records Or something else entirely 14
11 Input Splits An input split describes a unit of data that a single map task in a MapReduce program will process By dividing the into splits, we allow several map tasks to operate on a single in parallel Files loaded from local HDFS store If the is very large, this can improve performance significantly through parallelism Each map task corresponds to a single input split InputFormat Split Split Split
12 RecordReader The input split defines a slice of data but does not describe how to access it The RecordReader class actually loads data from its source and converts it into (K, V) pairs suitable for reading by Mappers The RecordReader is invoked repeatedly on the input until the entire split is consumed Files loaded from local HDFS store InputFormat Each invocation of the RecordReader leads to another call of the map function defined by the programmer Split Split Split RR RR RR
13 Mapper and Reducer The Mapper performs the user-defined work of the first phase of the MapReduce program Files loaded from local HDFS store A new instance of Mapper is created for each split InputFormat The Reducer performs the user-defined work of the second phase of the MapReduce program Split Split Split A new instance of Reducer is created for each partition For each key in the partition assigned to a Reducer, the Reducer is called once RR RR RR Map Map Map er Sort Reduce
14 er Each mapper may emit (K, V) pairs to any partition Files loaded from local HDFS store Therefore, the map nodes must all agree on where to send different pieces of intermediate data The partitioner class determines which partition a given (K,V) pair will go to The default partitioner computes a hash value for a given key and assigns it to a partition based on this result InputFormat Split Split Split RR RR RR Map Map Map er Sort Reduce
15 Sort Each Reducer is responsible for reducing the values associated with (several) intermediate keys Files loaded from local HDFS store InputFormat The set of intermediate keys on a single node is automatically sorted by MapReduce before they are presented to the Reducer Split Split Split RR RR RR Map Map Map er Sort Reduce
16 Combiner Functions MapReduce applications are limited by the bandwidth available on the cluster It pays to minimize the data shuffled between map and reduce tasks Hadoop allows the user to specify a combiner function (just like the reduce function) to be run on a map output (Y, T) R R N N N N MT MT MT MT MT MT RT MT Map output (1950, 0) (1950, 20) (1950, 10) LEGEND: Combiner output R = Rack N = Node MT = Map Task RT = Reduce Task Y = Year T = Temperature (1950, 20)
17 Job Scheduling in MapReduce In MapReduce, an application is represented as a job A job encompasses multiple map and reduce tasks Job schedulers in MapReduce are pluggable Hadoop MapReduce by default FIFO scheduler for jobs Schedules jobs in order of submission Starvation with long-running jobs No job preemption No evaluation of job priority or size 24
18 Multi-user Job Scheduling in MapReduce Fair scheduler (Facebook) Pools of jobs, each pool is assigned a set of shares Jobs get (on ave) equal share of slots over time Across pools, use Fair scheduler, within pool, FIFO or Fair scheduler Capacity scheduler (Yahoo!) Creates job queues Each queue is configured with # (capacity) of slots Within queue, scheduling is priority based
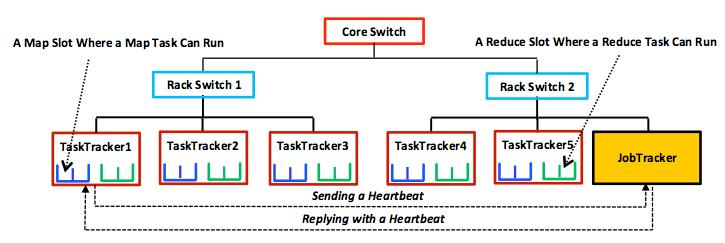
19 Task Scheduling in MapReduce MapReduce adopts a master-slave architecture The master node in MapReduce is referred to as Job Tracker (JT) Each slave node in MapReduce is referred to as Task Tracker (TT) MapReduce adopts a pull scheduling strategy rather than a push one JT Tasks Queue T0 T1 T2 TT Task Slots TT Task Slots I.e., JT does not push map and reduce tasks to TTs but rather TTs pull them by making pertaining requests 26
20 Map and Reduce Task Scheduling Every TT sends a heartbeat message periodically to JT encompassing a request for a map or a reduce task to run I. Map Task Scheduling: JT satisfies requests for map tasks via attempting to schedule mappers in the vicinity of their input splits (i.e., it considers locality) II. Reduce Task Scheduling: However, JT simply assigns the next yet-to-run reduce task to a requesting TT regardless of TT s network location and its implied effect on the reducer s shuffle time (i.e., it does not consider locality) 27
21 Task Scheduling
22 Fault Tolerance in Hadoop Data redundancy Achieved at the storage layer through replicas (default is 3) Stored a physically separate machines Can tolerate Corrupted s Faulty nodes HDFS: Computes checksums for all data written to it Verifies when reading Task Resiliency (task slowdown or failure) Monitor tasks to detect faulty or slow Replicate 31
23 Task Resiliency MapReduce can guide jobs toward a successful completion even when jobs are run on a large cluster where probability of failures increases The primary way that MapReduce achieves fault tolerance is through restarting tasks If a TT fails to communicate with JT for a period of time (by default, 1 minute in Hadoop), JT will assume that TT in question has crashed If the job is still in the map phase, JT asks another TT to re-execute all Mappers that previously ran at the failed TT If the job is in the reduce phase, JT asks another TT to re-execute all Reducers that were in progress on the failed TT 32
24 Speculative Execution A MapReduce job is dominated by the slowest task MapReduce attempts to locate slow tasks (stragglers) and run redundant (speculative) tasks that will optimistically commit before the corresponding stragglers This process is known as speculative execution Only one copy of a straggler is allowed to be speculated Whichever copy of a task commits first, it becomes the definitive copy, and the other copy is killed by JT
25 What Makes MapReduce Unique? MapReduce is characterized by: 1. Its simplified programming model which allows the user to quickly write and test distributed systems 2. Its efficient and automatic distribution of data and workload across machines 3. Its flat scalability curve. Specifically, after a Mapreduce program is written and functioning on 10 nodes, very little-if any- work is required for making that same program run on 1000 nodes 4. Its fault tolerance approach 36
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
2/26/2017. For instance, consider running Word Count across 20 splits
 Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
CCA-410. Cloudera. Cloudera Certified Administrator for Apache Hadoop (CCAH)
") Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
CS-2510 COMPUTER OPERATING SYSTEMS
 CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
MapReduce Algorithm Design
 MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
TP1-2: Analyzing Hadoop Logs
 TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Survey Paper on Traditional Hadoop and Pipelined Map Reduce
 International Journal of Computational Engineering Research Vol, 03 Issue, 12 Survey Paper on Traditional Hadoop and Pipelined Map Reduce Dhole Poonam B 1, Gunjal Baisa L 2 1 M.E.ComputerAVCOE, Sangamner,
International Journal of Computational Engineering Research Vol, 03 Issue, 12 Survey Paper on Traditional Hadoop and Pipelined Map Reduce Dhole Poonam B 1, Gunjal Baisa L 2 1 M.E.ComputerAVCOE, Sangamner,
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
A SURVEY ON SCHEDULING IN HADOOP FOR BIGDATA PROCESSING
 Journal homepage: www.mjret.in ISSN:2348-6953 A SURVEY ON SCHEDULING IN HADOOP FOR BIGDATA PROCESSING Bhavsar Nikhil, Bhavsar Riddhikesh,Patil Balu,Tad Mukesh Department of Computer Engineering JSPM s
Journal homepage: www.mjret.in ISSN:2348-6953 A SURVEY ON SCHEDULING IN HADOOP FOR BIGDATA PROCESSING Bhavsar Nikhil, Bhavsar Riddhikesh,Patil Balu,Tad Mukesh Department of Computer Engineering JSPM s
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Camdoop Exploiting In-network Aggregation for Big Data Applications Paolo Costa
 Camdoop Exploiting In-network Aggregation for Big Data Applications costa@imperial.ac.uk joint work with Austin Donnelly, Antony Rowstron, and Greg O Shea (MSR Cambridge) MapReduce Overview Input file
Camdoop Exploiting In-network Aggregation for Big Data Applications costa@imperial.ac.uk joint work with Austin Donnelly, Antony Rowstron, and Greg O Shea (MSR Cambridge) MapReduce Overview Input file
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Big Data for Engineers Spring Resource Management
 Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus
 UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Big Data 7. Resource Management
 Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
This material is covered in the textbook in Chapter 21.
 This material is covered in the textbook in Chapter 21. The Google File System paper, by S Ghemawat, H Gobioff, and S-T Leung, was published in the proceedings of the ACM Symposium on Operating Systems
This material is covered in the textbook in Chapter 21. The Google File System paper, by S Ghemawat, H Gobioff, and S-T Leung, was published in the proceedings of the ACM Symposium on Operating Systems
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Mitigating Data Skew Using Map Reduce Application
 Ms. Archana P.M Mitigating Data Skew Using Map Reduce Application Mr. Malathesh S.H 4 th sem, M.Tech (C.S.E) Associate Professor C.S.E Dept. M.S.E.C, V.T.U Bangalore, India archanaanil062@gmail.com M.S.E.C,
Ms. Archana P.M Mitigating Data Skew Using Map Reduce Application Mr. Malathesh S.H 4 th sem, M.Tech (C.S.E) Associate Professor C.S.E Dept. M.S.E.C, V.T.U Bangalore, India archanaanil062@gmail.com M.S.E.C,
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Introduction to MapReduce
 Introduction to MapReduce Jacqueline Chame CS503 Spring 2014 Slides based on: MapReduce: Simplified Data Processing on Large Clusters. Jeffrey Dean and Sanjay Ghemawat. OSDI 2004. MapReduce: The Programming
Introduction to MapReduce Jacqueline Chame CS503 Spring 2014 Slides based on: MapReduce: Simplified Data Processing on Large Clusters. Jeffrey Dean and Sanjay Ghemawat. OSDI 2004. MapReduce: The Programming
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
What Is Datacenter (Warehouse) Computing. Distributed and Parallel Technology. Datacenter Computing Architecture
 Computing. Distributed and Parallel Technology. Datacenter Computing Architecture") What Is Datacenter (Warehouse) Computing Distributed and Parallel Technology Datacenter, Warehouse and Cloud Computing Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University,
What Is Datacenter (Warehouse) Computing Distributed and Parallel Technology Datacenter, Warehouse and Cloud Computing Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University,
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
Survey on MapReduce Scheduling Algorithms
 Survey on MapReduce Scheduling Algorithms Liya Thomas, Mtech Student, Department of CSE, SCTCE,TVM Syama R, Assistant Professor Department of CSE, SCTCE,TVM ABSTRACT MapReduce is a programming model used
Survey on MapReduce Scheduling Algorithms Liya Thomas, Mtech Student, Department of CSE, SCTCE,TVM Syama R, Assistant Professor Department of CSE, SCTCE,TVM ABSTRACT MapReduce is a programming model used
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
L5-6:Runtime Platforms Hadoop and HDFS
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
MapReduce. Stony Brook University CSE545, Fall 2016
 MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
Introduction to Map/Reduce. Kostas Solomos Computer Science Department University of Crete, Greece
 Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Chisel++: Handling Partitioning Skew in MapReduce Framework Using Efficient Range Partitioning Technique
 Chisel++: Handling Partitioning Skew in MapReduce Framework Using Efficient Range Partitioning Technique Prateek Dhawalia Sriram Kailasam D. Janakiram Distributed and Object Systems Lab Dept. of Comp.
Chisel++: Handling Partitioning Skew in MapReduce Framework Using Efficient Range Partitioning Technique Prateek Dhawalia Sriram Kailasam D. Janakiram Distributed and Object Systems Lab Dept. of Comp.
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692)
") FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
Introduction to Distributed Data Systems
 Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements
![Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements](/thumbs/89/98108012.jpg "Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements") Tutorial Outline Map/Reduce Map/reduce Hadoop Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009
Tutorial Outline Map/Reduce Map/reduce Hadoop Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009
MapReduce & HyperDex. Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University
 MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
Locality Aware Fair Scheduling for Hammr
 Locality Aware Fair Scheduling for Hammr Li Jin January 12, 2012 Abstract Hammr is a distributed execution engine for data parallel applications modeled after Dryad. In this report, we present a locality
Locality Aware Fair Scheduling for Hammr Li Jin January 12, 2012 Abstract Hammr is a distributed execution engine for data parallel applications modeled after Dryad. In this report, we present a locality