Data Informatics. Seon Ho Kim, Ph.D.
|
|
|
- Whitney Boone
- 6 years ago
- Views:
Transcription
1 Data Informatics Seon Ho Kim, Ph.D.
2 HBase
3 HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate on top of the Hadoop distributed file system (HDFS) Distributed storage Table-like in data structure High scalability High availability High performance


4 HBase: Part of Hadoop s Ecosystem HBase is built on top of HDFS HBase files are internally stored in HDFS
5 HBase vs. HDFS Both are distributed systems that scale to hundreds or thousands of nodes HDFS is good for batch processing (scans over big files) Not good for record lookup Not good for incremental addition of small batches Not good for updates
6 HBase vs. HDFS (Cont d) HBase is designed to efficiently address the above points Fast record lookup Support for record-level insertion Support for updates (not in place) HBase updates are done by creating new versions of values
 If application has neither")
7 HBase vs. HDFS (Cont d) If application has neither random reads or writes è Stick to HDFS
8 HBase Is Not Tables have one primary index, the row key. No join operators. Scans and queries can select a subset of available columns, perhaps by using a wildcard. There are three types of lookups: Fast lookup using row key and optional timestamp. Full table scan Range scan from region start to end.
9 HBase Is Not (2) Limited atomicity and transaction support. HBase supports multiple batched mutations of single rows only. Data is unstructured and untyped. Not accessed or manipulated via SQL. Programmatic access via Java, REST, or Thrift APIs. Scripting via JRuby.
10 Why HBase? It is open source It has a good community and promise for the future It is developed on top of Hadoop and has good integration for the Hadoop platform, if you are using Hadoop already. It has a Cascading connector. Cascading is a software abstraction layer for Apache Hadoop. Cascading is used to create and execute complex data processing workflows on a Hadoop cluster using any JVM-based language (Java, JRuby, Clojure, etc.), hiding the underlying complexity of MapReduce jobs.
11 HBase benefits than RDBMS Automatic partitioning Scale linearly and automatically with new nodes Commodity hardware Fault tolerance Batch processing Who are using Hbase? Tech companies like: Facebook, Yahoo, Ebay, etc. Analytics companies like: RocketFuel, Flurry, etc.
12 HBase Data Model


13 HBase Data Model HBase is based on Google s Bigtable model: key-value pairs

14 HBase: Keys and Column Families Each row has a Key Each record is divided into Column Families Each column family consists of one or more Columns

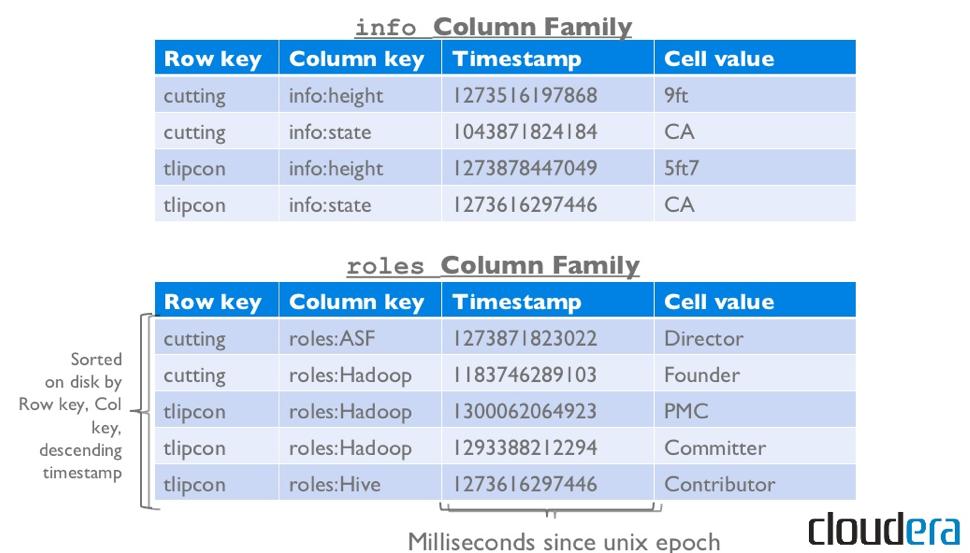
15 Column family named anchor Column family named Contents Key Byte array Serves as the primary key for the table Indexed far fast lookup Column Family Has a name (string) Contains one or more related columns Column Belongs to one column family Included inside the row familyname:columnname Row key com.apac he.ww w com.cnn.w ww Time Stamp t12 t11 t10 t15 t13 t6 t5 Column content s: <html> <html> <html> <html> Column anchor: Column named apache.com anchor:apache.com anchor:cnnsi.co m anchor:my.look. ca APACH E CNN CNN.co m t3 <html>
16 Version number for each row Version Number Row key Time Stamp Column content s: Column anchor: Unique within each key By defaultà System s timestamp com.apac he.ww w t12 t11 t10 <html> <html> anchor:apache.com value APACH E Data type is Long Value (Cell) t15 t13 anchor:cnnsi.co m anchor:my.look. ca CNN CNN.co m Byte array com.cnn.w ww t6 <html> t5 <html> t3 <html>

17 Notes on Data Model HBase schema consists of several Tables Each table consists of a set of Column Families Columns are not part of the schema HBase has Dynamic Columns Because column names are encoded inside the cells Different cells can have different columns Roles column family has different columns in different cells

18 Notes on Data Model (Cont d) The version number can be user-supplied Even does not have to be inserted in increasing order Version number are unique within each key Table can be very sparse Many cells are empty Keys are indexed as the primary key Has two columns [cnnsi.com & my.look.ca]
19 HBase Physical Model




20 HBase Physical Model Each column family is stored in a separate file (called HTables) Key & Version numbers are replicated with each column family Empty cells are not stored HBase maintains a multi-level index on values: <key, column family, column name, timestamp>
21 Example
22 HBase Architecture
23 Three Major Components The HBaseMaster One master The HRegionServer Many region servers The HBase client
24 Members Region A subset of a table s rows, like horizontal range partitioning Master Responsible for monitoring & coordinating region servers Load balancing for regions RegionServer slaves Serving requests (Write/Read/Scan) of Client Send HeartBeat to Master Throughput and Region numbers are scalable by region servers
25 HBase Components Region A subset of a table s rows, like horizontal range partitioning Automatically done RegionServer (many slaves) Manages data regions Serves data for reads and writes (using a log) Master Responsible for coordinating the slaves Assigns regions, detects failures Admin functions

26 Architecture

27 ZooKeeper HBase depends on ZooKeeper ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. By default HBase manages the ZooKeeper instance E.g., starts and stops ZooKeeper Master and RegionServers register themselves with ZooKeeper

28 HBase Tables

29

30
31
32
33
34
35
36 Key Design HBase has two fundamental key structures Row key Column key Both can be used to convey meaning Because they store particularly meaningful data Because their sorting order is important
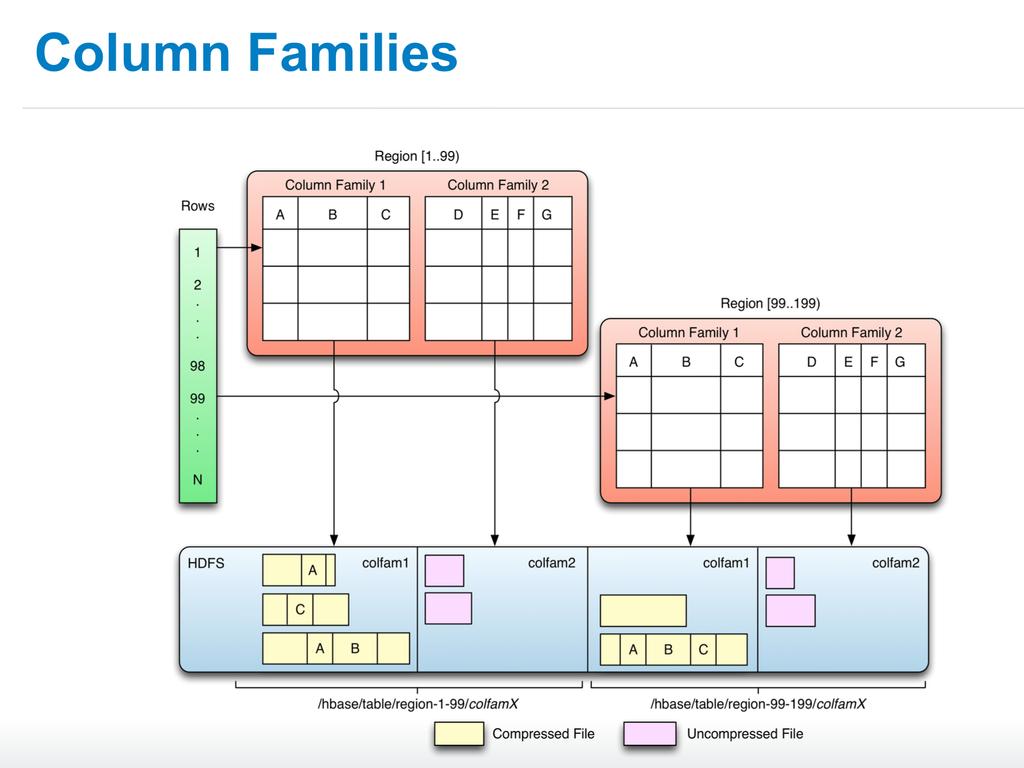
37 Logical vs. On-disk Layout of a Table Main unit of separation within a table is the column family The actual columns (as opposed to other columnoriented DB) are not used to separate data Although cells are stored logically in a table format, rows are stored as linear sets of the cells Cells contain all the vital information inside them

38
39 Logical Layout (Top-Left) Table consists of rows and columns Columns are the combination of a column family name and a column qualifier <cf name: qualifier> is the column key Rows have a row key to address all columns of a single logical row Folding the Logical Layout (Top-Right) The cells of each row are stored one after the other Each column family are stored separately On disk all cells of one family reside on an individual StoreFile HBase does not store unset cells Row and column key is required to address every cell
40 Versioning Multiple versions of the same cell stored consecutively, together with the timestamp Cells are sorted in descending order of timestamp Newest value first KeyValue object The entire cell, with all the structural information, is a KeyValue object Contains: row key, <column family: qualifier> column key, timestamp and value Sorted by row key first, then by column key
41 Physical Layout (Lower-Right) Select data by row key This reduces the amount of data to scan for a row or a range of rows Select data by row key and column key This focuses the system on an individual storage file Select data by column qualifier Exact lookups, including filters to omit useless data
42 Tall-Narrow vs. Flat-Wide Tables Tall-Narrow Tables Few columns Many rows Flat-Wide Tables Many columns Few rows Given the query granularity explained before Store parts of the cell data in the row key Furthermore, HBase splits at row boundaries It is recommended to go for Tall-Narrow Tables
43 Tall-Narrow vs. Flat-Wide Tables Example: data - version 1 You have all s of a user in a single row (e.g. userid is the row key) There will be some outliers with orders of magnitude more s than others A single row could outgrow the maximum file/region size and work against split facility
44 Tall-Narrow vs. Flat-Wide Tables Example: data - version 2 Each of a user is stored in a separate row (e.g. userid:messageid is the row key) On disk this makes no difference (see the disk layout figure) If the messageid is in the column qualifier or the row key, each cell still contains a single message The table can be split easily and the query granularity is more fine-grained
45 Partial Key Scans Partial Key Scans reinforce the concept of Tall-Narrow Tables From the example: assume you have a separate row per message, across all users If you don t have an exact combination of user and message ID you cannot access a particular message Partial Key Scan solves the problems Specify a start and end key The start key is set to the exact userid only, with the end key set at userid+1 This triggers the internal lexicographic comparison mechanism Since the table does not have an exact match, it positions the scan at: <userid>:<lowest-messageid> The scan will then iterate over all the messages of an exact user, parse the row key and get the messageid
46 Partial Key Scans Composite keys and atomicity Following the example: a single user inbox now spans many rows It is no longer possible to modify a single user inbox in one atomic operation If this is acceptable or not, depends on the application at hand

47
48
49
50
HBase: Overview. HBase is a distributed column-oriented data store built on top of HDFS
 HBase 1 HBase: Overview HBase is a distributed column-oriented data store built on top of HDFS HBase is an Apache open source project whose goal is to provide storage for the Hadoop Distributed Computing
HBase 1 HBase: Overview HBase is a distributed column-oriented data store built on top of HDFS HBase is an Apache open source project whose goal is to provide storage for the Hadoop Distributed Computing
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis
 Slides adapted by Tyler Davis") BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب
 Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
ADVANCED HBASE. Architecture and Schema Design GeeCON, May Lars George Director EMEA Services
 ADVANCED HBASE Architecture and Schema Design GeeCON, May 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer
ADVANCED HBASE Architecture and Schema Design GeeCON, May 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer
Ghislain Fourny. Big Data 5. Column stores
 Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
A Glimpse of the Hadoop Echosystem
 A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
Typical size of data you deal with on a daily basis
 Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
HBASE INTERVIEW QUESTIONS
 HBASE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hbase/hbase_interview_questions.htm Copyright tutorialspoint.com Dear readers, these HBase Interview Questions have been designed specially to get
HBASE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hbase/hbase_interview_questions.htm Copyright tutorialspoint.com Dear readers, these HBase Interview Questions have been designed specially to get
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Rails on HBase. Zachary Pinter and Tony Hillerson RailsConf 2011
 Rails on HBase Zachary Pinter and Tony Hillerson RailsConf 2011 What we will cover What is it? What are the tradeoffs that HBase makes? Why HBase is probably the wrong choice for your app Why HBase might
Rails on HBase Zachary Pinter and Tony Hillerson RailsConf 2011 What we will cover What is it? What are the tradeoffs that HBase makes? Why HBase is probably the wrong choice for your app Why HBase might
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Scaling Up HBase. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
Advanced HBase Schema Design. Berlin Buzzwords, June 2012 Lars George
 Advanced HBase Schema Design Berlin Buzzwords, June 2012 Lars George lars@cloudera.com About Me SoluDons Architect @ Cloudera Apache HBase & Whirr CommiIer Author of HBase The Defini.ve Guide Working with
Advanced HBase Schema Design Berlin Buzzwords, June 2012 Lars George lars@cloudera.com About Me SoluDons Architect @ Cloudera Apache HBase & Whirr CommiIer Author of HBase The Defini.ve Guide Working with
COSC 6339 Big Data Analytics. NoSQL (II) HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables
 HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables") COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
HBase... And Lewis Carroll! Twi:er,
 HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
10 Million Smart Meter Data with Apache HBase
 10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
MapReduce & BigTable
 CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
Projected by: LUKA CECXLADZE BEQA CHELIDZE Superviser : Nodar Momtsemlidze
 Projected by: LUKA CECXLADZE BEQA CHELIDZE Superviser : Nodar Momtsemlidze About HBase HBase is a column-oriented database management system that runs on top of HDFS. It is well suited for sparse data
Projected by: LUKA CECXLADZE BEQA CHELIDZE Superviser : Nodar Momtsemlidze About HBase HBase is a column-oriented database management system that runs on top of HDFS. It is well suited for sparse data
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Column-Family Databases Cassandra and HBase
 Column-Family Databases Cassandra and HBase Kevin Swingler Google Big Table Google invented BigTableto store the massive amounts of semi-structured data it was generating Basic model stores items indexed
Column-Family Databases Cassandra and HBase Kevin Swingler Google Big Table Google invented BigTableto store the massive amounts of semi-structured data it was generating Basic model stores items indexed
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
HBase vs Neo4j. Technical overview. Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon
 Ecolé Normale Superiuere de Lyon") HBase vs Neo4j Technical overview Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon 12th October 2017 1 Contents 1 Introduction 3 2 Overview of HBase and Neo4j
HBase vs Neo4j Technical overview Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon 12th October 2017 1 Contents 1 Introduction 3 2 Overview of HBase and Neo4j
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
NoSQL Databases. Amir H. Payberah. Swedish Institute of Computer Science. April 10, 2014
 NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
HBase. Леонид Налчаджи
 HBase Леонид Налчаджи leonid.nalchadzhi@gmail.com HBase Overview Table layout Architecture Client API Key design 2 Overview 3 Overview NoSQL Column oriented Versioned 4 Overview All rows ordered by row
HBase Леонид Налчаджи leonid.nalchadzhi@gmail.com HBase Overview Table layout Architecture Client API Key design 2 Overview 3 Overview NoSQL Column oriented Versioned 4 Overview All rows ordered by row
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Big Data Processing Technologies. Chentao Wu Associate Professor Dept. of Computer Science and Engineering
 Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Performance Analysis of Hbase
 Performance Analysis of Hbase Neseeba P.B, Dr. Zahid Ansari Department of Computer Science & Engineering, P. A. College of Engineering, Mangalore, 574153, India Abstract Hbase is a distributed column-oriented
Performance Analysis of Hbase Neseeba P.B, Dr. Zahid Ansari Department of Computer Science & Engineering, P. A. College of Engineering, Mangalore, 574153, India Abstract Hbase is a distributed column-oriented
Distributed Systems [Fall 2012]
![Distributed Systems [Fall 2012]](/thumbs/75/71557798.jpg "Distributed Systems [Fall 2012]") Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
Presented by Sunnie S Chung CIS 612
 By Yasin N. Silva, Arizona State University Presented by Sunnie S Chung CIS 612 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. See http://creativecommons.org/licenses/by-nc-sa/4.0/
By Yasin N. Silva, Arizona State University Presented by Sunnie S Chung CIS 612 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. See http://creativecommons.org/licenses/by-nc-sa/4.0/
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Column Stores and HBase. Rui LIU, Maksim Hrytsenia
 Column Stores and HBase Rui LIU, Maksim Hrytsenia December 2017 Contents 1 Hadoop 2 1.1 Creation................................ 2 2 HBase 3 2.1 Column Store Database....................... 3 2.2 HBase
Column Stores and HBase Rui LIU, Maksim Hrytsenia December 2017 Contents 1 Hadoop 2 1.1 Creation................................ 2 2 HBase 3 2.1 Column Store Database....................... 3 2.2 HBase
A Fast and High Throughput SQL Query System for Big Data
 A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
A Survey on Big Data
 A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Design & Implementation of Cloud Big table
 Design & Implementation of Cloud Big table M.Swathi 1,A.Sujitha 2, G.Sai Sudha 3, T.Swathi 4 M.Swathi Assistant Professor in Department of CSE Sri indu College of Engineering &Technolohy,Sheriguda,Ibrahimptnam
Design & Implementation of Cloud Big table M.Swathi 1,A.Sujitha 2, G.Sai Sudha 3, T.Swathi 4 M.Swathi Assistant Professor in Department of CSE Sri indu College of Engineering &Technolohy,Sheriguda,Ibrahimptnam
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores
 YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
Cassandra, MongoDB, and HBase. Cassandra, MongoDB, and HBase. I have chosen these three due to their recent
 Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Programming model and implementation for processing and. Programs can be automatically parallelized and executed on a large cluster of machines
 A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
Hadoop ecosystem. Nikos Parlavantzas
 1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora
 Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora Team Renato Marroquín! PhD student: Interested in: Information retrieval. Distributed and scalable data management. Apache Gora:
Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora Team Renato Marroquín! PhD student: Interested in: Information retrieval. Distributed and scalable data management. Apache Gora:
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
8/24/2017 Week 1-B Instructor: Sangmi Lee Pallickara
 Week 1-B-0 Week 1-B-1 CS535 BIG DATA FAQs Slides are available on the course web Wait list Term project topics PART 0. INTRODUCTION 2. DATA PROCESSING PARADIGMS FOR BIG DATA Sangmi Lee Pallickara Computer
Week 1-B-0 Week 1-B-1 CS535 BIG DATA FAQs Slides are available on the course web Wait list Term project topics PART 0. INTRODUCTION 2. DATA PROCESSING PARADIGMS FOR BIG DATA Sangmi Lee Pallickara Computer
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
W b b 2.0. = = Data Ex E pl p o l s o io i n
 Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Facebook. The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook. March 11, 2011
 Kannan Muthukkaruppan Software Engineer, Facebook. March 11, 2011") HBase @ Facebook The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook March 11, 2011 Talk Outline the new Facebook Messages, and how we got started with HBase quick
HBase @ Facebook The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook March 11, 2011 Talk Outline the new Facebook Messages, and how we got started with HBase quick
This is a brief tutorial that explains how to make use of Sqoop in Hadoop ecosystem.
 About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Cmprssd Intrduction To
 Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor