IBM BigInsights V IBM Corporation
|
|
|
- Leon Conley
- 6 years ago
- Views:
Transcription
1 IBM BigInsights V4


2 Solution for Big Data Rest Data: Data to analyze are already stored (structured and unstructured) Examples: logs, facebook, twitter, etc. Solution: Hadoop (open source) / IBM BigInsights (Enterprise Hadoop ) Data in motion: Data are analyzed in real time, just in the moment they are generated. They are analyzed with any previous storage Examples: Sensors, RFID, CDR, etc. 2 Solution: IBM Infosphere Streams

3 3

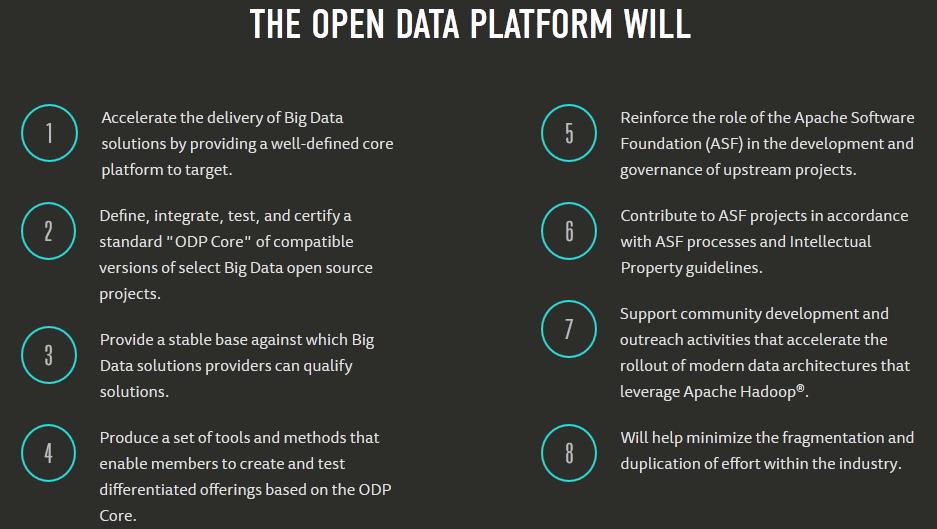
4 Open Data Platform Initiative Why is IBM involved? Strong history of leadership in open source & standards Supports our commitment to open source currency in all future releases Accelerates our innovation within Hadoop & surrounding applications Open Data Platform (ODP) and Apache Software Foundation (ASF) ODP supports the ASF mission ASF provides a governance model around individual projects without looking at ecosystem ODP aims to provide a vendor-led consistent packaging model for core Apache components as an ecosystem All Standard Apache Open Source Components HDFS MapReduce Spark Hive HCatalog Pig YARN Ambari HBase Flume Sqoop Solr/Lucene ODP 4
5 Overview of BigInsights IBM BigInsights Analyst Industry standard SQL (Big SQL) Spreadsheet-style tool (BigSheets) IBM BigInsights Data Scientist Text Analytics Machine Learning on Big R Big R (R support) Big SQL BigSheets... Free Quick Start (non production): IBM Open Platform BigInsights Analyst, Data Scientist features Community support IBM BigInsights Enterprise Management POSIX Distributed Filesystem Multi-workload, multi-tenant scheduling IBM Open Platform with Apache Hadoop (HDFS, YARN, MapReduce, Ambari, Hbase, Hive, Oozie, Parquet, Parquet Format, Pig, Snappy, Solr, Spark, Sqoop, Zookeeper, Open JDK, Knox, Slider) 5
6 What is Ambari? Apache Ambari is the open source operational platform to provision, manage and monitor Hadoop clusters Install and Manage Hadoop cluster Web based user Interface Monitoring and Alerting Cluster Expansion and Node Management Comprehensive REST API 6
7 Open Source frameworks I Avro: A data serialization system that includes a schema within each file. A schema defines the data types that are contained within a file, and is validated as the data is written to the file using the Avro APIs. Users can include primary data types and complex type definitions within a schema. Flume: A distributed, reliable, and highly available service for efficiently moving large amounts of data in a Hadoop cluster HBase: A column-oriented database management system that runs on top of HDFS and is often used for sparse data sets. Unlike relational database systems, HBase does not support a structured query language like SQL. HBase applications are written in Java, much like a typical MapReduce application. HBase allows many attributes to be grouped into column families so that the elements of a column family are all stored together. This approach is different from a row-oriented relational database, where all columns of a row are stored together 7
8 Open Source frameworks II Hive: A data warehouse infrastructure that facilitates data extract-transform-load (ETL) operations, in addition to analyzing large data sets that are stored in the Hadoop Distributed File System (HDFS). SQL developers write statements in HQL, which are broken down by the Hive service into MapReduce jobs, and then run across a Hadoop cluster. InfoSphere BigInsights includes a JDBC driver (BigSQL) that is used for programming with Hive and for connecting with Cognos Business Intelligence software (HCatalog: A table and storage management service for Hadoop data that presents a table abstraction so that you do not need to know where or how your data is stored. You can change how you write data, while still supporting existing data in older formats. HCatalog wraps additional layers around the Hive metadata store to provide an enhanced metadata service that includes functions for both MapReduce and Pig) Knox: Apache Knox gateway is a system that provides a single point of authentication and access for Apache Hadoop services in a cluster.the Knox gateway simplifies Hadoop security for users that access the cluster data and execute jobs and operators that control access and manage the cluster. The gateway runs as a server, or a cluster of servers, providing centralized access to one or more Hadoop clusters. Lucene: A high-performance text search engine library that is written entirely in Java. When you search within a collection of text, Lucene breaks the documents into text fields and builds an index from them. The index is the key component of Lucene that forms the basis of rapid text search capabilities. You use the searching methods within the Lucene libraries to find text components. / Solr: Solr is an enterprise search tool from the Apache Lucene project that offers powerful search tools, including faceted search, fielded search, hit highlighting, as well as indexing capabilities, reliability and scalability, a central configuration system, and failover and recovery. 8
9 Open Source frameworks III Oozie: A management application that simplifies workflow and coordination between MapReduce jobs. Oozie provides users with the ability to define actions and dependencies between actions. Oozie then schedules actions to run when the required dependencies are met. Workflows can be scheduled to start based on a given time or based on the arrival of specific data in the file system. Parquet : mr contains multiple sub-modules, which implement the core components of reading and writing a nested, column-oriented data stream, map this core onto the parquet format, and provide Hadoop Input/Output Formats, Pig loaders, and other java-based utilities for interacting with Parquet. format: It's a project that contains format specifications and Thrift definitions of metadata required to properly read Parquet files. R: A Project for Statistical Computing Slider: Apache Slider allows you to deploy existing distributed applications on YARN, monitor them, and make them larger or smaller, as desired. Slider HBase support allows you to run HBase instances as long-running applications on YARN. The Slider HBase App Package provides this support Spark: Apache Spark is a fast and general-purpose cluster computing system based on memory execution. It provides high-level APIs in Java, Scala and Python, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLLib for machine learning, GraphX for combined data-parallel and graph-parallel computations, and Spark Streaming for streaming data processing. 9
10 Open Source frameworks IV Sqoop: A tool designed to easily import information from structured databases (such as SQL) and related Hadoop systems (such as Hive and HBase) into your Hadoop cluster. You can also use Sqoop to extract data from Hadoop and export it to relational databases and enterprise data warehouses. YARN: Yarn decouples resource management (ResourceManager) from workload management (NodeManagers). The ResourceManager ensures that the cluster capacity is not exceeded by keeping track of the scheduled containers and queueing requests when resources are busy. NodeManagers spawn containers scheduled by the ResourceManager and monitor that they do not go beyond the expected resource utilization. Containers that use more memory or CPU than allocated are terminated. Zookeeper: A centralized infrastructure and set of services that enable synchronization across a cluster. ZooKeeper maintains common objects that are needed in large cluster environments, such as configuration information, distributed synchronization, and group services. 10
11 Overview of BigInsights IBM BigInsights Analyst Industry standard SQL (Big SQL) Spreadsheet-style tool (BigSheets) IBM BigInsights Data Scientist Text Analytics Machine Learning on Big R Big R (R support) Big SQL BigSheets... Free Quick Start (non production): IBM Open Platform BigInsights Analyst, Data Scientist features Community support IBM BigInsights Enterprise Management POSIX Distributed Filesystem Multi-workload, multi-tenant scheduling IBM Open Platform with Apache Hadoop (HDFS, YARN, MapReduce, Ambari, Hbase, Hive, Oozie, Parquet, Parquet Format, Pig, Snappy, Solr, Spark, Sqoop, Zookeeper, Open JDK, Knox, Slider) 11

12 IBM GPFS: HDFS alternative Drop-in replacement for HDFS No need for dedicated analytics infrastructure Cost savings No need to move data in and out of an analytics dedicated silo Software defined infrastructure for multi-tenancy Fast parallel file system POSIX & HDFS semantics Hadoop & non-hadoop apps Built-in high availability HDFS Compute Cluster GPFS-FPO 12
13 POSIX makes it easier! Example: Make a file available to Hadoop HDFS: hadoop fs copyfromlocal /local/source/path /hdfs/target/path GPFS/UNIX: cp /source/path /target/path Any system, including non-hadoop aware systems, can make a file visible to hadoop 13
14 POSIX makes it easier! Example: current working directory There is no concept of current working directory HDFS: hadoop fs mv /always/absolute/path/to/file/that/can/be/really/long/ /always/absolute/path/to/file/that/can/be/also/really/long/ GPFS/regular UNIX: mv path1/ path2/ 14 Relative paths, current working directories.
15 POSIX makes it easier! Example: Comparing two files HDFS: diff < (hadoop fs -cat /path/to/file) < (hadoop fs -cat /path/to/file2) GPFS/regular UNIX: diff path/to/file1 path/to/file2 Let s hope these aren t big files that we re streaming from HDFS to UNIX 15
16 POSIX makes it easier! Hadoop processed output for other systems (and keep a copy in Hadoop) Hadoop jobs write copy copy Raw data ext4 HDFS ext4 Copies in both HDFS and ext4 Traditional applications Raw data Application writes direct to Hadoop path GPFS-FPO direct-read Traditional applications 16 direct read, one version
17 Platform Symphony Multiple users, applications and lines of business on a shared, heterogeneous, multi-tenant grid A B C D Third Party Trading & Risk Platforms In-house Applications BigInsights Workload Manager C C C C C C B B A A A A A A A A C C C C C C B B A A A A A A A A C C C C C C B D D D D D D B B B B B B B B B B D D D D D D B B B Resource Orchestration 17
18 A Quick Comparison: Scheduling Capability Capability Capacity Scheduler Fair Scheduler Hierarchical Queues Y Y Y Capacity Guarantees Y Y Y Queue level ACLs Y Y Y Memory based allocations Y Y Y Guaranteed minimum resources Y Y Y CPU based allocations N Y* Y Task pre-emption (with grace period) N Y Y Time-of-day based strategy N N Y Platform Symphony *partial: utilizes dominant resource fairness calculation 18
19 Platform Symphony performance features Other Grid Server Each engine polls broker ~5 times per second (configurable) Client Broker Engines Send work when engine ready Network transport (client to broker) Wait for engine to poll broker Network transport (broker to engine) Compute Result Post result back to broker Serialize input data Broker Compute time De-serialize Input data Serialize result Time Platform Symphony Network transpor t Serialize input SSM Compute time & logging De-serialize Network transport (SSM to engine) Compute result No wait time due to polling, faster serialization/de-serialization, More network efficient protocol Serialize Time Network transport (engine to SSM) Platform Symphony advantages: Efficient C language routines use CDR (common data representation) and IOCP rather than slow, heavy-weight XML data encoding) Network transit time is reduced by avoiding text based HTTP protocol and encoding data in more compact CDR binary format Processing time for all Symphony services is reduced by using a native HPC C/C++ implementation for system services rather than Java Platform Symphony has a more efficient push model that avoids entirely the architectural problems with polling 19
20 Comparison with HDFS GPFS-FPO HDFS Robust No single point of failure NameNode vulnerability Data Integrity High Evidence of data loss Scale Thousands of nodes Thousands of nodes POSIX Compliance Full supports a wide range of applications Limited Data Management Security, Backup, Replication Limited MapReduce Performance Good Medium Workload Isolation Supports disk isolation Not Support High performance support for traditional applications Good Poor 20
21 Overview of BigInsights IBM BigInsights Analyst Industry standard SQL (Big SQL) Spreadsheet-style tool (BigSheets) IBM BigInsights Data Scientist Text Analytics Machine Learning on Big R Big R (R support) Big SQL BigSheets... Free Quick Start (non production): IBM Open Platform BigInsights Analyst, Data Scientist features Community support IBM BigInsights Enterprise Management POSIX Distributed Filesystem Multi-workload, multi-tenant scheduling IBM Open Platform with Apache Hadoop (HDFS, YARN, MapReduce, Ambari, Hbase, Hive, Oozie, Parquet, Parquet Format, Pig, Snappy, Solr, Spark, Sqoop, Zookeeper, Open JDK, Knox, Slider) 21


 Export results of analysis Create custom plug-ins Add /")
22 Spreadsheet-style analysis (BigSheets) Web-based analysis and visualization. Helps nonprogrammers to work with Hadoop cluster. Spreadsheet-like interface Explore, manipulate data without writing code Add / delete columns Filter data Invoke pre-built functions Generate charts (Pie charts, bar charts, tag clouds, maps...) Export results of analysis Create custom plug-ins Add / delete columns... 22
23 Working with BigSheets Create workbook for data in DFS Customize workbook through graphical editor and built-in functions Filter data Apply functions / macros / formulas Combine data from multiple workbooks Statistical functions added: median, K top elements, variance, mode... Run workbook: apply work to full data set Builder Model Front End Evaluation Service PIG Model w/ Data Results Explore results in spreadsheet format and/or create charts Simulation Optionally, export your data Full Execution 23

24 New geospatial capabilities in BigSheets Topological functions determine if regions contain, overlap, touch and more. Metric functions measure area, distance and length Constructor and transformation functions convert data into different formats Helper functions validate data and count points, geometries and so forth 24
25 Overview of BigInsights IBM BigInsights Analyst Industry standard SQL (Big SQL) Spreadsheet-style tool (BigSheets) IBM BigInsights Data Scientist Text Analytics Machine Learning on Big R Big R (R support) Big SQL BigSheets... Free Quick Start (non production): IBM Open Platform BigInsights Analyst, Data Scientist features Community support IBM BigInsights Enterprise Management POSIX Distributed Filesystem Multi-workload, multi-tenant scheduling IBM Open Platform with Apache Hadoop (HDFS, YARN, MapReduce, Ambari, Hbase, Hive, Oozie, Parquet, Parquet Format, Pig, Snappy, Solr, Spark, Sqoop, Zookeeper, Open JDK, Knox, Slider) 25
26 What is Big SQL? Big SQL brings robust SQL support to the Hadoop ecosystem Scalable server architecture Comprehensive SQL'2011 ansi support Standards compliant client drivers (JDBC & ODBC). IBM Data Server client driver Wide variety of data sources (Hive and Hbase) and file formats Open source interoperability DB2 compatible SQL PL support SQL bodied functions SQL bodied stored procedures Robust error handling Application logic/security encapsulation Flow of control logic Our driving design goals Existing queries should run with no or few modifications Existing JDBC and ODBC compliant tools should continue to function Queries should be executed as efficiently as the chosen storage mechanisms allow 26
27 IBM Big SQL Embraces Open Source HDFS file formats Big SQL applies SQL to your existing Hadoop data No propriety storage format Support Parquet, ORC, SEQ, delimited, Avro... A "table" is simply a view on your Hadoop data All data is Hadoop data Hive Big SQL In files in HDFS Pig Hive APIs Sqoop Table definitions shared with Hive Hive APIs Hive Metastore Hive APIs The Hive Metastore catalogs table definitions Reading/writing data logic is shared with Hive Definitions can be shared across the Hadoop ecosystem Hadoop Cluster Data stored in Hive immediately query-able 27
28 Architected for Performance Architected from the ground up for low latency and high throughput MapReduce replaced with a modern MPP architecture Compiler and runtime are native code (not java) Big SQL worker daemons live directly on cluster Continuously running (no startup latency) Processing happens locally at the data Message passing allows data to flow directly between nodes Operations occur in memory with the ability to spill to disk Supports aggregations and sorts larger than available RAM SQL-based Application IBM Data Server Client Big SQL SQL MPP Runtime Data Sources Parquet CSV Seq RC Avro ORC JSON Custom InfoSphere BigInsights 28

29 About Big SQL performance: Hadoop-DS benchmark TPC (Transaction Processing Performance Council) Formed August 1988 Widely recognized as most credible, vendor-independent SQL benchmarks TPC-H and TPC-DS are the most relevant to SQL over Hadoop R/W nature of workload not suitable for HDFS Hadoop-DS benchmark: BigInsights, Hive, Cloudera Run by IBM & reviewed by TPC certified auditor Based on TPC-DS. Key deviations No data maintenance, persistence phases (not supported across all vendors).or ACID property validation as these are not feasible with HDFS Common set of queries across all solutions Subset that all vendors can successfully execute at scale factor Queries are not cherry picked Most complete TPC-DS like benchmark executed so far Analogous to porting a relational workload to SQL on Hadoop Visit Hadoop Dev ( and search on hadoop-ds 29


30 IBM Big SQL Runs 100% of the TPC-DS queries Competitive environments require significant effort Key points With competing solutions, many queries needed to be re-written, some significantly Owing to various restrictions, some queries could not be rewritten or failed at run-time Re-writing queries in a benchmark scenario where results are known is one thing doing this against real databases in production is another 30
31 IBM Big SQL Leading performance 3.6x faster than Impala, 5.4x faster than Hive 2:55:36 4:25:49 Big SQL significantly outperforms both Impala and Hive 3.6x faster than Impala in an audited result 48:28 Big SQL is the only solution able to run all queries at 10TB and 30TB scale Letter of attestation available from InfoSizing, TPC certified auditors 31
 When we need to talk about the previous version, it will be called \"Big SQL 1.0\" The 1.")
32 Big SQL 1.0 & Naming Big SQL 1.0 is used generically to refer to the previous Big SQL In documentation "Big SQL" is always the latest version (3.0) When we need to talk about the previous version, it will be called "Big SQL 1.0" The 1.0 to try to make it unambiguous that it is the "old" version Big SQL shares catalogs with Hive via the Hive metastore Each can query the others tables SQL engine analyzes incoming queries Separates portion(s) to execute at the server vs. portion(s) to execute on the cluster Re-writes query if necessary for improved performance Determines appropriate storage handler for data Produces execution plan Executes and coordinates query Big SQL 3.0 Clients Big SQL 3.0 Master Node Hive Metastore Big SQL 1.0 Big SQL 1.0 Clients Management Node Mgmt Node Mgmt Node Big SQL 3.0 Worker HDFS Data Node MRTask Tracker Other Service Big SQL 3.0 Worker HDFS Data Node MRTask Tracker Other Service 32 Data Node Data Node
33 Features At a Glance Application Portability & Integration Data shared with Hadoop ecosystem Comprehensive file format support Superior enablement of IBM software Enhanced by Third Party software Federation Rich SQL Comprehensive SQL Support IBM SQL PL compatibility Performance Modern MPP runtime Powerful SQL query rewriter Cost based optimizer Optimized for concurrent user throughput Results not constrained by memory HDFS Caching Enterprise Features Distributed requests to multiple data sources within a single SQL statement Main data sources supported: DB2 LUW, Teradata, Oracle, Netezza, SQL Server 2014, Informix Advanced security/auditing Resource and workload management Self tuning memory management Comprehensive monitoring 33
34 SQL Support Provides robust SQL support including Nested subquery support In SELECT, FROM, WHERE and HAVING clauses Correlated and uncorrelated Equality, non-equality subqueries EXISTS, NOT EXISTS, IN, ANY, SOME, etc. Windowed aggregates (rank, first_value, ntile...) Standard join syntax, ansi join syntax, cross join and non-equijoin support Union, intersect, except Top N/Limit Row constructors Overlaps, like_regex, is distinct from, with,nth_value, limit offset etc. The same SQL you use on your data warehouse should run with few or no modifications 34
35 Analytic Capabilities Extensive analytic capabilities Grouping sets with CUBE and ROLLUP In-database analytics (e.g. K-Means, Decision Tree) Standard OLAP operations LEAD LAG RANK DENSE_RANK ROW_NUMBER RATIO_TO_REPORT FIRST_VALUE LAST_VALUE Analytic aggregates CORRELATION COVARIANCE STDDEV VARIANCE REGR_AVGX REGR_AVGY REGR_COUNT REGR_INTERCEPT REGR_ICPT REGR_R2 REGR_SLOPE REGR_XXX REGR_SXY REGR_XYY WIDTH_BUCKET VAR_SAMP VAR_POP STDDEV_POP STDDEV_SAMP COVAR_SAMP COVAR_POP NTILE 35
36 Overview of BigInsights IBM BigInsights Analyst Industry standard SQL (Big SQL) Spreadsheet-style tool (BigSheets) IBM BigInsights Data Scientist Text Analytics Machine Learning on Big R Big R (R support) Big SQL BigSheets Free Quick Start (non production): IBM Open Platform BigInsights Analyst, Data Scientist features Community support IBM BigInsights Enterprise Management POSIX Distributed Filesystem Multi-workload, multi-tenant scheduling IBM Open Platform with Apache Hadoop* (HDFS, YARN, MapReduce, Ambari, Hbase, Hive, Oozie, Parquet, Parquet Format, Pig, Snappy, Solr, Spark, Sqoop, Zookeeper, Open JDK, Knox, Slider) 36
 deriving patterns within the structured data, and finally evaluation and interpretation of the output.")
37 What is Text Analytics? Text analytics usually involves the process of structuring the input text (usually parsing) deriving patterns within the structured data, and finally evaluation and interpretation of the output. Typical text mining tasks include text categorization, concept/entity extraction, production of granular taxonomies, sentiment analysis, document summarization, and entity relation modeling (i.e.,relations between named entities). Context has to be take into account. Text analysis involves information retrieval, lexical analysis to study word frequency distributions, pattern recognition, tagging/annotation, information extraction, data mining techniques including link and association analysis, visualization, and predictive analytics. Text Analytics Parsing Facts Deep understanding of text 37
38 Extracting information from text Text Single column or document Text preparation Classified words / attributes Classified words / attributes via lexical analysis Recognize Information Extraction (IE) via deep linguistic analysis language detection verb-centric abstraction sentence noun-centric segmentation abstraction tokenization shallow parsing part-of-speech tagging extraction operations span operations join operations consolidations Tagged syntax Describe via extractors Entity Recognition Machine Data Primitives Sentiment Analyze Entity Analytics Preventative Maintenance Customer Segmentation Sentiment Affinity 38

39 Text analytics tooling Web-based tool to define rules to extract data and derive information from unstructured text Graphical interface to describe structure of various textual formats from log file data to natural language 39


40 Pre-built text extractors The extractor library contains a rich set of pre-built extractors Finance actions Named Entities Generic Machine Data Sentiment Analysis You can control output properties Output columns and names Row filters Some pre-built extractors can be customized Add / remove dictionary terms 40
41 Annotator Query Language (AQL) Language to create rules for Text Analytics. SQL Like Language. Fully declarative text analytics language. Once compiled produced an AOG plan to work in the data. No black boxes or modules that can t be customized. Tooling for easy customization because you are abstracted from the programmatic details. Competing solutions make use of locked up black-box modules that cannot be customized, which restricts flexibility and are difficult to optimize for performance create view AmountWithUnit as extract pattern <N.match> <U.match> as match from Number N, Unit U; create dictionary UnitDict as ('million','billion'); create view Unit as extract dictionary 'UnitDict' on D.text as match from Document D; 41 create view Number as extract regex /\d+(\.\d+)?/ on D.text as match from Document D;
42 Text Analytics Simple Example Extract information from unstructured sources for business insight Customer: I m calling because I received an incorrect bill. I just paid my bill two days ago, and my payment is not reflected Agent: Sorry for the inconvenience. May I have your Account Number, please? Customer: wait I meant Agent: For verification purposes, can I get your name and birth date? Customer: Marge Simpson, Nov 23, 1975 and the account is under my Husband s name, Homer Agent: Thank you for that information. Per our system, you did pay your bill Aug. 12th <call _center_record trans_id=132436> <cust_id> </cust_id> <account_holder> Homer Simpson </account_holder> <caller_birthdate> </caller_birthdate> <inquiry>balance</inqury> <balance>0</balance> <sentiment>positive</sentiment> <pmt_date> </pmt_date>.... </call_center_record> 42
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
BigInsights Version 4 Overview
 BigInsights Version 4 Overview KANG Changsung (Kangcs@kr.ibm.com), Lab Services, KLAB, IBM Korea Outline The Open Data Platform consortium What it is Competitive response IBM s strategy BigInsights packaging
BigInsights Version 4 Overview KANG Changsung (Kangcs@kr.ibm.com), Lab Services, KLAB, IBM Korea Outline The Open Data Platform consortium What it is Competitive response IBM s strategy BigInsights packaging
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Getting Started with Hadoop and BigInsights
 Getting Started with Hadoop and BigInsights Alan Fischer e Silva Hadoop Sales Engineer Nov 2015 Agenda! Intro! Q&A! Break! Hands on Lab 2 Hadoop Timeline 3 In a Big Data World. The Technology exists now
Getting Started with Hadoop and BigInsights Alan Fischer e Silva Hadoop Sales Engineer Nov 2015 Agenda! Intro! Q&A! Break! Hands on Lab 2 Hadoop Timeline 3 In a Big Data World. The Technology exists now
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
BigInsights and Cognos Stefan Hubertus, Principal Solution Specialist Cognos Wilfried Hoge, IT Architect Big Data IBM Corporation
 BigInsights and Cognos Stefan Hubertus, Principal Solution Specialist Cognos Wilfried Hoge, IT Architect Big Data 2013 IBM Corporation A Big Data architecture evolves from a traditional BI architecture
BigInsights and Cognos Stefan Hubertus, Principal Solution Specialist Cognos Wilfried Hoge, IT Architect Big Data 2013 IBM Corporation A Big Data architecture evolves from a traditional BI architecture
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Big! SQL 3.0. Analyzing SQL on Hadoop. Uday Kale Big SQL Development, IBM InfoSphere BigInsights. 18-Sep IBM Corporation
 Big! SQL 3.0 Analyzing SQL on Hadoop Uday Kale (udayk@us.ibm.com) Big SQL Development, IBM InfoSphere BigInsights 18-Sep-2014 2014 IBM Corporation Please Note IBM s statements regarding its plans, directions,
Big! SQL 3.0 Analyzing SQL on Hadoop Uday Kale (udayk@us.ibm.com) Big SQL Development, IBM InfoSphere BigInsights 18-Sep-2014 2014 IBM Corporation Please Note IBM s statements regarding its plans, directions,
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
IBM BigInsights on Cloud
 Service Description IBM BigInsights on Cloud This Service Description describes the Cloud Service IBM provides to Client. Client means the company and its authorized users and recipients of the Cloud Service.
Service Description IBM BigInsights on Cloud This Service Description describes the Cloud Service IBM provides to Client. Client means the company and its authorized users and recipients of the Cloud Service.
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED DATA PLATFORM
 CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Oracle GoldenGate for Big Data
 Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
docs.hortonworks.com
 docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Apache HAWQ (incubating)
") HADOOP NATIVE SQL What is HAWQ? Apache HAWQ (incubating) Is an elastic parallel processing SQL engine that runs native in Apache Hadoop to directly access data for advanced analytics. Why HAWQ? Hadoop
HADOOP NATIVE SQL What is HAWQ? Apache HAWQ (incubating) Is an elastic parallel processing SQL engine that runs native in Apache Hadoop to directly access data for advanced analytics. Why HAWQ? Hadoop
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015)
") 4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015) Benchmark Testing for Transwarp Inceptor A big data analysis system based on in-memory computing Mingang Chen1,2,a,
4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015) Benchmark Testing for Transwarp Inceptor A big data analysis system based on in-memory computing Mingang Chen1,2,a,
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
HDP Security Overview
 3 HDP Security Overview Date of Publish: 2018-07-15 http://docs.hortonworks.com Contents HDP Security Overview...3 Understanding Data Lake Security... 3 What's New in This Release: Knox... 5 What's New
3 HDP Security Overview Date of Publish: 2018-07-15 http://docs.hortonworks.com Contents HDP Security Overview...3 Understanding Data Lake Security... 3 What's New in This Release: Knox... 5 What's New
HDP Security Overview
 3 HDP Security Overview Date of Publish: 2018-07-15 http://docs.hortonworks.com Contents HDP Security Overview...3 Understanding Data Lake Security... 3 What's New in This Release: Knox... 5 What's New
3 HDP Security Overview Date of Publish: 2018-07-15 http://docs.hortonworks.com Contents HDP Security Overview...3 Understanding Data Lake Security... 3 What's New in This Release: Knox... 5 What's New
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Querying Microsoft SQL Server 2008/2012
 Querying Microsoft SQL Server 2008/2012 Course 10774A 5 Days Instructor-led, Hands-on Introduction This 5-day instructor led course provides students with the technical skills required to write basic Transact-SQL
Querying Microsoft SQL Server 2008/2012 Course 10774A 5 Days Instructor-led, Hands-on Introduction This 5-day instructor led course provides students with the technical skills required to write basic Transact-SQL
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem. Janusz Szwabiński
 Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Impala. A Modern, Open Source SQL Engine for Hadoop. Yogesh Chockalingam
 Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
IBM Big SQL Partner Application Verification Quick Guide
 IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Querying Microsoft SQL Server
 Querying Microsoft SQL Server Course 20461D 5 Days Instructor-led, Hands-on Course Description This 5-day instructor led course is designed for customers who are interested in learning SQL Server 2012,
Querying Microsoft SQL Server Course 20461D 5 Days Instructor-led, Hands-on Course Description This 5-day instructor led course is designed for customers who are interested in learning SQL Server 2012,
Benchmarks Prove the Value of an Analytical Database for Big Data
 White Paper Vertica Benchmarks Prove the Value of an Analytical Database for Big Data Table of Contents page The Test... 1 Stage One: Performing Complex Analytics... 3 Stage Two: Achieving Top Speed...
White Paper Vertica Benchmarks Prove the Value of an Analytical Database for Big Data Table of Contents page The Test... 1 Stage One: Performing Complex Analytics... 3 Stage Two: Achieving Top Speed...
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
DB2 SQL Class Outline
 DB2 SQL Class Outline The Basics of SQL Introduction Finding Your Current Schema Setting Your Default SCHEMA SELECT * (All Columns) in a Table SELECT Specific Columns in a Table Commas in the Front or
DB2 SQL Class Outline The Basics of SQL Introduction Finding Your Current Schema Setting Your Default SCHEMA SELECT * (All Columns) in a Table SELECT Specific Columns in a Table Commas in the Front or
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
IBM BigInsights on Cloud
 Service Description IBM BigInsights on Cloud This Service Description describes the Cloud Service IBM provides to Client. Client means the company and its authorized users and recipients of the Cloud Service.
Service Description IBM BigInsights on Cloud This Service Description describes the Cloud Service IBM provides to Client. Client means the company and its authorized users and recipients of the Cloud Service.
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
Oracle Big Data Fundamentals Ed 1
 Oracle University Contact Us: +0097143909050 Oracle Big Data Fundamentals Ed 1 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big Data
Oracle University Contact Us: +0097143909050 Oracle Big Data Fundamentals Ed 1 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big Data
20461: Querying Microsoft SQL Server 2014 Databases
 Course Outline 20461: Querying Microsoft SQL Server 2014 Databases Module 1: Introduction to Microsoft SQL Server 2014 This module introduces the SQL Server platform and major tools. It discusses editions,
Course Outline 20461: Querying Microsoft SQL Server 2014 Databases Module 1: Introduction to Microsoft SQL Server 2014 This module introduces the SQL Server platform and major tools. It discusses editions,
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Trafodion Enterprise-Class Transactional SQL-on-HBase
 Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
Hadoop Overview. Lars George Director EMEA Services
 Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hortonworks and The Internet of Things
 Hortonworks and The Internet of Things Dr. Bernhard Walter Solutions Engineer About Hortonworks Customer Momentum ~700 customers (as of November 4, 2015) 152 customers added in Q3 2015 Publicly traded
Hortonworks and The Internet of Things Dr. Bernhard Walter Solutions Engineer About Hortonworks Customer Momentum ~700 customers (as of November 4, 2015) 152 customers added in Q3 2015 Publicly traded
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Apache Hadoop 3. Balazs Gaspar Sales Engineer CEE & CIS Cloudera, Inc. All rights reserved.
 Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
EsgynDB Enterprise 2.0 Platform Reference Architecture
 EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
AVANTUS TRAINING PTE LTD
 [MS20461]: Querying Microsoft SQL Server 2014 Length : 5 Days Audience(s) : IT Professionals Level : 300 Technology : SQL Server Delivery Method : Instructor-led (Classroom) Course Overview This 5-day
[MS20461]: Querying Microsoft SQL Server 2014 Length : 5 Days Audience(s) : IT Professionals Level : 300 Technology : SQL Server Delivery Method : Instructor-led (Classroom) Course Overview This 5-day
Hadoop: The Definitive Guide
 THIRD EDITION Hadoop: The Definitive Guide Tom White Q'REILLY Beijing Cambridge Farnham Köln Sebastopol Tokyo labte of Contents Foreword Preface xv xvii 1. Meet Hadoop 1 Daw! 1 Data Storage and Analysis
THIRD EDITION Hadoop: The Definitive Guide Tom White Q'REILLY Beijing Cambridge Farnham Köln Sebastopol Tokyo labte of Contents Foreword Preface xv xvii 1. Meet Hadoop 1 Daw! 1 Data Storage and Analysis
Stinger Initiative. Making Hive 100X Faster. Page 1. Hortonworks Inc. 2013
 Stinger Initiative Making Hive 100X Faster Page 1 HDP: Enterprise Hadoop Distribution OPERATIONAL SERVICES Manage AMBARI & Operate at Scale OOZIE HADOOP CORE FLUME SQOOP DATA SERVICES PIG Store, HIVE Process
Stinger Initiative Making Hive 100X Faster Page 1 HDP: Enterprise Hadoop Distribution OPERATIONAL SERVICES Manage AMBARI & Operate at Scale OOZIE HADOOP CORE FLUME SQOOP DATA SERVICES PIG Store, HIVE Process
Fluentd + MongoDB + Spark = Awesome Sauce
 Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
SOLUTION TRACK Finding the Needle in a Big Data Innovator & Problem Solver Cloudera
 SOLUTION TRACK Finding the Needle in a Big Data Haystack @EvaAndreasson, Innovator & Problem Solver Cloudera Agenda Problem (Solving) Apache Solr + Apache Hadoop et al Real-world examples Q&A Problem Solving
SOLUTION TRACK Finding the Needle in a Big Data Haystack @EvaAndreasson, Innovator & Problem Solver Cloudera Agenda Problem (Solving) Apache Solr + Apache Hadoop et al Real-world examples Q&A Problem Solving
Configuring Ports for Big Data Management, Data Integration Hub, Enterprise Information Catalog, and Intelligent Data Lake 10.2
 Configuring s for Big Data Management, Data Integration Hub, Enterprise Information Catalog, and Intelligent Data Lake 10.2 Copyright Informatica LLC 2016, 2017. Informatica, the Informatica logo, Big
Configuring s for Big Data Management, Data Integration Hub, Enterprise Information Catalog, and Intelligent Data Lake 10.2 Copyright Informatica LLC 2016, 2017. Informatica, the Informatica logo, Big
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI
 DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
Security and Performance advances with Oracle Big Data SQL
 Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Information empowerment for your evolving data ecosystem
 Information empowerment for your evolving data ecosystem Highlights Enables better results for critical projects and key analytics initiatives Ensures the information is trusted, consistent and governed
Information empowerment for your evolving data ecosystem Highlights Enables better results for critical projects and key analytics initiatives Ensures the information is trusted, consistent and governed
Hive SQL over Hadoop
 Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Oracle Big Data. A NA LYT ICS A ND MA NAG E MENT.
 Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Gain Insights From Unstructured Data Using Pivotal HD. Copyright 2013 EMC Corporation. All rights reserved.
 Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Technical White Paper
 Issue 01 Date 2017-07-30 HUAWEI TECHNOLOGIES CO., LTD. 2017. All rights reserved. No part of this document may be reproduced or transmitted in any form or by any means without prior written consent of
Issue 01 Date 2017-07-30 HUAWEI TECHNOLOGIES CO., LTD. 2017. All rights reserved. No part of this document may be reproduced or transmitted in any form or by any means without prior written consent of
Big Data Analytics. Description:
 Big Data Analytics Description: With the advance of IT storage, pcoressing, computation, and sensing technologies, Big Data has become a novel norm of life. Only until recently, computers are able to capture
Big Data Analytics Description: With the advance of IT storage, pcoressing, computation, and sensing technologies, Big Data has become a novel norm of life. Only until recently, computers are able to capture
Going beyond MapReduce
 Going beyond MapReduce MapReduce provides a simple abstraction to write distributed programs running on large-scale systems on large amounts of data MapReduce is not suitable for everyone MapReduce abstraction
Going beyond MapReduce MapReduce provides a simple abstraction to write distributed programs running on large-scale systems on large amounts of data MapReduce is not suitable for everyone MapReduce abstraction