Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
|
|
|
- Daniella Rose
- 5 years ago
- Views:
Transcription


1 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
2 Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha status Future directions
3 What Spark Is Not a wrapper around Hadoop Separate, fast, MapReduce- like engine In- memory data storage for very fast iterative queries Powerful optimization and scheduling Interactive use from Scala interpreter Compatible with Hadoop s storage APIs Can read/write to any Hadoop- supported system, including HDFS, HBase, SequenceFiles, etc
4 Project History Started in summer of 2009 Open sourced in early 2010 In use at UC Berkeley, UCSF, Princeton, Klout, Conviva, Quantifind, Yahoo! Research
5 Spark Programming Model Resilient distributed datasets (RDDs) Distributed collections of Scala objects Can be cached in memory across cluster nodes Manipulated like local Scala collections Automatically rebuilt on failure
 Transformed RDD RDD results errors = lines.filter(_.startswith( ERROR )) messages = errors.map(_.")

6 Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns Base lines = spark.textfile( hdfs://... ) Transformed RDD RDD results errors = lines.filter(_.startswith( ERROR )) messages = errors.map(_.split( \t )(2)) tasks Driver cachedmsgs = messages.cache() Worker Block 1 Cache 1 cachedmsgs.filter(_.contains( foo )).count cachedmsgs.filter(_.contains( bar )).count... Result: Result: full- text scaled search to 1 of TB Wikipedia data in 5-7 in <1 sec sec (vs (vs sec sec for for on- disk data) Action Cache 3 Worker Block 3 Worker Block 2 Cache 2
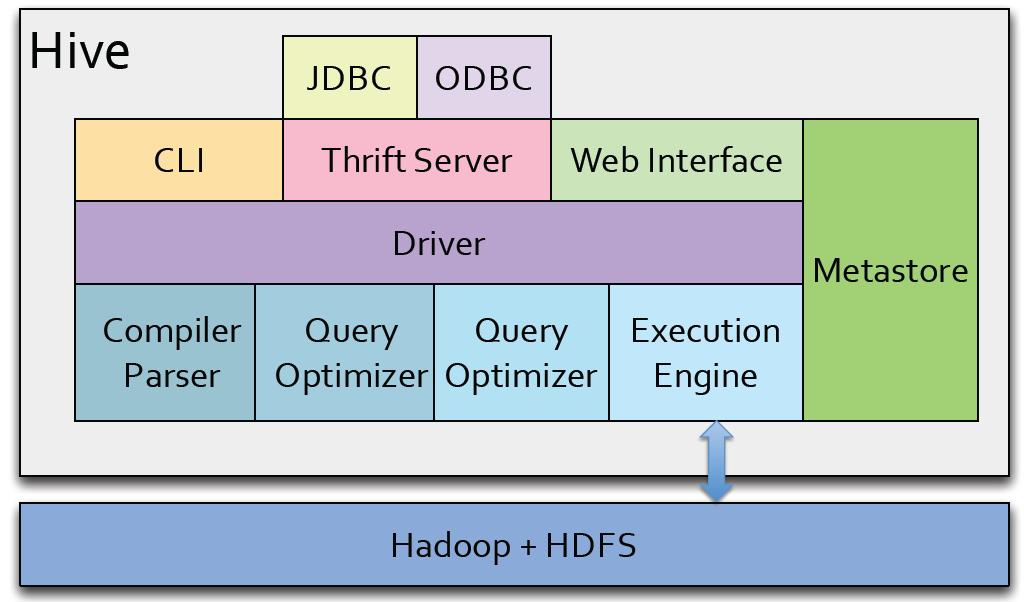
7 Apache Hive Data warehouse solution developed at Facebook SQL- like language called HiveQL to query structured data stored in HDFS Queries compile to Hadoop MapReduce jobs
8
9 Hive Principles SQL provides a familiar interface for users Extensible types, functions, and storage formats Horizontally scalable with high performance on large datasets
10 Hive Applications Reporting Ad hoc analysis ETL for machine learning
11 Hive Downsides Not interactive Hadoop startup latency is ~20 seconds, even for small jobs No query locality If queries operate on the same subset of data, they still run from scratch Reading data from disk is often bottleneck Requires separate machine learning dataflow
12 Shark Motivation Exploit temporal locality: working set of data can often fit in memory to be reused between queries Provide low latency on small queries Integrate distributed UDF s into SQL
13 Introducing Shark Shark = Spark + Hive Run HiveQL queries through Spark with Hive UDF, UDAF, SerDe Utilize Spark s in- memory RDD caching and flexible language capabilities










14 Shark in the AMP Stack Shark Bagel (Pregel on Spark) Spark Streaming Spark Debug Tools Hadoop MPI Mesos Private Cluster Amazon EC2
15 Shark Physical operators using Spark Rely on Spark s fast execution, fault tolerance, and in- memory RDD s Reuse as much Hive code as possible Convert logical query plan generated from Hive into Spark execution graph Compatible with Hive Run HiveQL queries on existing HDFS data using Hive metadata, without modifications

16
17 0.1 alpha: 84% Hive tests passing (575 out of 683)
18 0.1 alpha Experimental SQL/RDD integration User selected caching with CTAS Columnar RDD cache Some performance improvements
19 Caching User selected caching with CTAS CREATE TABLE mytable_cached AS SELECT * FROM mytable WHERE count > 10; mytable_cached becomes an in- memory materialized view that can be used to answer queries.
20 SQL/Spark Integration Allow users to implement sophisticated algorithms as UDFs in Spark Query processing UDFs are streamlined val rdd = sc.sql2rdd( "select foo, count(*) c from pokes group by foo") println(rdd.count) println(rdd.maprows(_.getint( c )).reduce(_+_))
21 Performance optimizations Hash- based shuffle (speeds up group- bys) Hadoop does sort- based shuffle which can be expensive. Limit push- down in order by select * from pokes order by foo limit 10 Columnar cache
22 Large Caches in JVM Java objects have large overhead (2-4x the actual data size) Boxing/Unboxing is slow GC is a bottleneck if we have many long- lived objects
23 Example: Caching Rows Int, Double, Boolean True = 64 bytes* Should be ~ 13 bytes *Estimated on 64 bit VM. Implementations may vary.
24 Possible Solutions 1. Store deserialized Java objects 2. Serialize objects to in- memory byte array 3. Use memory slab external to JVM 4. Store data in primitive arrays
25 Deserialized Java Objects + Fast (requires little CPU) (Up to 5X speedup) - Poor memory usage (3X worse) - Lots of Garbage Collection overhead
26 Serialize to Bytes + Best memory efficiency + Efficient GC - CPU usage to serialize/ deserialize each obj
27 Store in External Slab + Efficient memory + No GC - CPU usage to serialize/ deserialize each obj - More difficult to implement
28 Primitive Column Arrays + Efficient memory (similar to byte arrays) + Efficient GC + No extra CPU overhead
29 Column vs Row Storage Column Row john 4.1 john mike sally 2 mike sally 6.4
30 Columnar Benefits Better compression Fewer objects to track Only materialize necessary columns => Less CPU
31 Columnar in Shark Store all primitive columns in primitive arrays on each node Less deserialization overhead Space efficient and easier to garbage collect
32 Result Achieved efficient storage space without sacrificing performance
33 Limit Pushdown in Sort SELECT * FROM table ORDER BY key LIMIT 10;
34 Main Idea The limit can be applied before sorting all data to increase performance. Each mapper computes its Top K and then a single reducer merges these
35 Possible Implementations 1. PriorityQueue (Heap) to keep running top k in one traversal on each mapper. O(n logk)
36 Possible Implementations 2. QuickSelect algorithm. Essentially quicksort, but prunes elements on one side of pivot when possible. O(n)
37 Result We chose to use Google Guava s implementation of QuickSelect. We observed much better performance than Hive which applies the limit after sorting on each reducer.
38 Demo 3- node EC2 large cluster (2 virtual cores, 7GB of RAM) Synthetic TPC- H data (2x scale factor)
39 Some numbers while we wait for Hive to finish running Brown/Stonebraker benchmark 70GB1 Also used on Hive mailing list2 10 Amazon EC2 High Memory Nodes (30GB of RAM/node) Naively cache input tables Compare Shark to Hive vs- dbms/

40 Benchmarks: Query 1 30GB input table SELECT * FROM grep WHERE field LIKE %XYZ% ;

41 Benchmark: Query 2 5 GB input table SELECT pagerank, pageurl FROM rankings WHERE pagerank > 10;
42 Status Passing 575 Hive tests out of 683. You can help us decide what to implement next.
43 Unsupported Hive Features ADD FILE (use Hadoop distributed cache to distribute user- defined scripts) STREAMTABLE hint not supported Outer join with non- equi join filter Table statistics (piggyback file sink) Table with buckets ORDER BY with multiple reducers has a bug (will be fixed this week!) MapJoin has a serialization bug (will be fixed this week!)
44 Unsupported Hive Features Automatically convert joins to mapjoins Sort- merge mapjoins Partitions with different input formats Unique joins Writing to two or more tables in a single SELECT INSERT Archiving data virtual columns (INPUT FILE NAME, BLOCK OFFSET INSIDE FILE) Merge small files from output
45 What s coming up (in a month)? Performance improvements (groupbys, joins) Demo of Shark on a 100- node cluster in SIGMOD 2012 (May 22, Scottsdale, AZ) mining Wikipedia visit log data
46 What s coming up (a year)? Shark- specific query optimizer Automatic tuning of parameters (e.g. number of reducers) Off- heap caching (e.g. EhCache) Automatic caching based on query analysis Shared caching infrastructure
47 Conclusion Shark is a warehouse solution compatible with Apache Hive Can be orders of magnitude faster We are looking for people to try and we are happy to provide support
48 Thank you! Questions? (will be updated tonight)
Spark & Spark SQL. High- Speed In- Memory Analytics over Hadoop and Hive Data. Instructor: Duen Horng (Polo) Chau
 Chau") CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
Shark: SQL and Rich Analytics at Scale. Reynold Xin UC Berkeley
 Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 29, 2013 UC BERKELEY Stage 0:M ap-shuffle-reduce M apper(row ) { fields = row.split("\t") em it(fields[0],fields[1]); } Reducer(key,values)
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 29, 2013 UC BERKELEY Stage 0:M ap-shuffle-reduce M apper(row ) { fields = row.split("\t") em it(fields[0],fields[1]); } Reducer(key,values)
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Warehouse- Scale Computing and the BDAS Stack
 Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Big Data Infrastructures & Technologies Hadoop Streaming Revisit.
 Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Shark: Hive on Spark
 Optional Reading (additional material) Shark: Hive on Spark Prajakta Kalmegh Duke University 1 What is Shark? Port of Apache Hive to run on Spark Compatible with existing Hive data, metastores, and queries
Optional Reading (additional material) Shark: Hive on Spark Prajakta Kalmegh Duke University 1 What is Shark? Port of Apache Hive to run on Spark Compatible with existing Hive data, metastores, and queries
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Lightning Fast Cluster Computing. Michael Armbrust Reflections Projections 2015 Michast
 Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09. Presented by: Daniel Isaacs
 Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Spark and distributed data processing
 Stanford CS347 Guest Lecture Spark and distributed data processing Reynold Xin @rxin 2016-05-23 Who am I? Reynold Xin PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD),
Stanford CS347 Guest Lecture Spark and distributed data processing Reynold Xin @rxin 2016-05-23 Who am I? Reynold Xin PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD),
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Workload Characterization and Optimization of TPC-H Queries on Apache Spark
 Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Shark: SQL and Rich Analytics at Scale. Yash Thakkar ( ) Deeksha Singh ( )
 Deeksha Singh ( )") Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
The Datacenter Needs an Operating System
 UC BERKELEY The Datacenter Needs an Operating System Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter Needs an Operating System 3. Mesos,
UC BERKELEY The Datacenter Needs an Operating System Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter Needs an Operating System 3. Mesos,
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory
 Shark: Fast Data Analysis Using Coarse-grained Distributed Memory Clifford Engle Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2013-35
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory Clifford Engle Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2013-35
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models RCFile: A Fast and Space-efficient Data
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models RCFile: A Fast and Space-efficient Data
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
The Stratosphere Platform for Big Data Analytics
 The Stratosphere Platform for Big Data Analytics Hongyao Ma Franco Solleza April 20, 2015 Stratosphere Stratosphere Stratosphere Big Data Analytics BIG Data Heterogeneous datasets: structured / unstructured
The Stratosphere Platform for Big Data Analytics Hongyao Ma Franco Solleza April 20, 2015 Stratosphere Stratosphere Stratosphere Big Data Analytics BIG Data Heterogeneous datasets: structured / unstructured
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Sparrow. Distributed Low-Latency Spark Scheduling. Kay Ousterhout, Patrick Wendell, Matei Zaharia, Ion Stoica
 Sparrow Distributed Low-Latency Spark Scheduling Kay Ousterhout, Patrick Wendell, Matei Zaharia, Ion Stoica Outline The Spark scheduling bottleneck Sparrow s fully distributed, fault-tolerant technique
Sparrow Distributed Low-Latency Spark Scheduling Kay Ousterhout, Patrick Wendell, Matei Zaharia, Ion Stoica Outline The Spark scheduling bottleneck Sparrow s fully distributed, fault-tolerant technique
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
MapReduce review. Spark and distributed data processing. Who am I? Today s Talk. Reynold Xin
 Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
A Platform for Fine-Grained Resource Sharing in the Data Center
 Mesos A Platform for Fine-Grained Resource Sharing in the Data Center Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony Joseph, Randy Katz, Scott Shenker, Ion Stoica University of California,
Mesos A Platform for Fine-Grained Resource Sharing in the Data Center Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony Joseph, Randy Katz, Scott Shenker, Ion Stoica University of California,
Discretized Streams. An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters
 Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Accelerate Big Data Insights
 Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
DATA MINING II - 1DL460
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory
 Shark: Fast Data Analysis Using Coarse-grained Distributed Memory Clifford Engle Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2013-35
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory Clifford Engle Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2013-35
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
CDS. André Schaaff1, François-Xavier Pineau1, Gilles Landais1, Laurent Michel2 de Données astronomiques de Strasbourg, 2SSC-XMM-Newton
 Docker @ CDS André Schaaff1, François-Xavier Pineau1, Gilles Landais1, Laurent Michel2 1Centre de Données astronomiques de Strasbourg, 2SSC-XMM-Newton Paul Trehiou Université de technologie de Belfort-Montbéliard
Docker @ CDS André Schaaff1, François-Xavier Pineau1, Gilles Landais1, Laurent Michel2 1Centre de Données astronomiques de Strasbourg, 2SSC-XMM-Newton Paul Trehiou Université de technologie de Belfort-Montbéliard
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma
 Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Course Schedule Tuesday 10.3. Introduction and the Big Data Challenge Tuesday 17.3. MapReduce and Spark: Overview Tuesday
Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Course Schedule Tuesday 10.3. Introduction and the Big Data Challenge Tuesday 17.3. MapReduce and Spark: Overview Tuesday
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
CIS 601 Graduate Seminar. Dr. Sunnie S. Chung Dhruv Patel ( ) Kalpesh Sharma ( )
 Kalpesh Sharma ( )") Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Beyond MapReduce: Apache Spark Antonino Virgillito
 Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Homework 3: Wikipedia Clustering Cliff Engle & Antonio Lupher CS 294-1
 Introduction: Homework 3: Wikipedia Clustering Cliff Engle & Antonio Lupher CS 294-1 Clustering is an important machine learning task that tackles the problem of classifying data into distinct groups based
Introduction: Homework 3: Wikipedia Clustering Cliff Engle & Antonio Lupher CS 294-1 Clustering is an important machine learning task that tackles the problem of classifying data into distinct groups based
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Introduction to Hive Cloudera, Inc.
 Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Parallel Processing Spark and Spark SQL
 Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads
 HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi, Alexander Rasin and Avi Silberschatz Presented by
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi, Alexander Rasin and Avi Silberschatz Presented by
Stream Processing on IoT Devices using Calvin Framework
 Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
Today s Papers. Architectural Differences. EECS 262a Advanced Topics in Computer Systems Lecture 17
 EECS 262a Advanced Topics in Computer Systems Lecture 17 Comparison of Parallel DB, CS, MR and Jockey October 30 th, 2013 John Kubiatowicz and Anthony D. Joseph Electrical Engineering and Computer Sciences
EECS 262a Advanced Topics in Computer Systems Lecture 17 Comparison of Parallel DB, CS, MR and Jockey October 30 th, 2013 John Kubiatowicz and Anthony D. Joseph Electrical Engineering and Computer Sciences