Deterministic Shared Memory Multiprocessing
|
|
|
- Byron Fields
- 5 years ago
- Views:
Transcription
1 Deterministic Shared Memory Multiprocessing Luis Ceze, University of Washington joint work with Owen Anderson, Tom Bergan, Joe Devietti, Brandon Lucia, Karin Strauss, Dan Grossman, Mark Oskin. Safe MultiProcessing Architectures at the University of Washington
2 A multithreaded voting machine thread 0 thread 1 while (more_votes) { load t <- votes t++ store t -> votes } Non-determinism is evil. while (more_votes) { load t <- votes t++ store t -> votes } votes == 2 votes == 2 votes == 1 2

3 Shared Memory Parallel Programming is Hard sequential bugs concurrency bugs nondeterministic memory access interleavings hard to debug hard to test hard to replicate hard to leverage crash information 3
4 Record and Replay Systems What needs to be recorded? volume of data? practicalities? What problems does it solve? 4

5 Determinism Can Help Development no more heisenbugs! time-travel debugging test inputs, not interleavings Deployment reproduce bugs from field easy to synchronize replicas software behaves as tested Effectively, make parallel programs behave like sequential programs... Can we remove non-determinism in arbitrary parallel programs without removing performance? 5




6 DMP from 10,000 6 We only care about communicating instructions Deterministic serialization same communication but what about performance? Recover parallelism from non-communicating insns
7 Related Work on Determinism Helps with Record + Replay DMP debugging? testing? replicas? deployment? Needs hw? usually yes (for now) examples: FDR, ReRun, Capo Deterministic parallel programming languages (Jade, DPJ,...) 7
8 DMP Implementation Alternatives PERFORMANCE DMP Serial DMP SharingTable DMP TM DMP TMForward COMPLEXITY 8

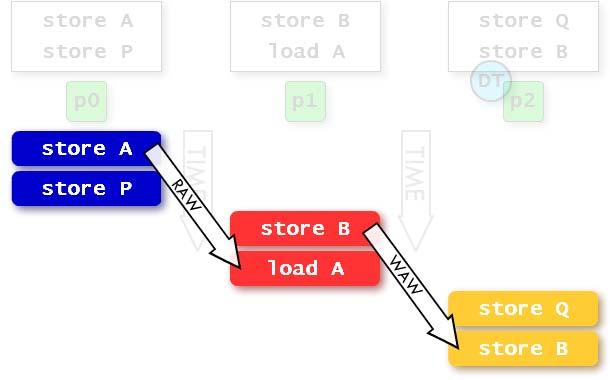
9 DMP-Serial Example 9
10 Can we do better? Only need to serialize communicating instructions Break each quantum into communication-free parallel prefix and communicative serial suffix 10
11 DMP-SharingTable Need to know when communication happens, to transition from parallel to serial mode Leverage existing cache coherence protocol When a line moves between processors, communication is (potentially) happening The Sharing Table tracks information about ownership State of Sharing Table must evolve deterministically Only allow updates during serial suffix 11



12 DMP-SharingTable Example 12


13 Quantum Rounds quantum P P P parallel prefix S S race! S serial suffix P P P 13
14 DMP-TM: Recovering Parallelism with Speculation DMP-SharingTable conservatively assumes that all changes in ownership are communication but most changes in ownership are not communication (within round) Use TM support to speculate that a quantum is not involved in communication If communication happens, rollback + re-execute Each quantum is an implicit transaction Commit quanta in-order (need DT to commit) 14



15 DMP-TM Example 15
16 DMP-TM-Forward: Speculative Value Forwarding DMP-TM eliminates WAW and WAR dependencies but cannot speculate past true (RAW) dependences Idea: speculatively forward values to future quanta coherence protocol + ordered transactions make it easy to decide when and where to forward rollback if a quantum s speculatively read data is updated before the quantum commits 16

17 DMP-TM-Forward Example 17
18 TM-Forward Rollback Deterministic Order store A add store A add load A sub add store A sub Need value from youngest older store 18
19 TM-Forward Recursive Rollback Deterministic Order store A add store A add load A store B add sub load B 19



20 Better Quantum Building Any deterministic policy will work We want quanta that are free of communication no communication no serialization, no rollbacks 20
21 Experimental Methodology PIN-based simulator Models serialization, quantum building, address conflicts and transaction rollbacks Assumes constant IPC with free commits SPLASH2 and PARSEC benchmark suites 21
22 DMP Performance Results!"#$%&'#(!%)*+,&-'.(' #(#-&.&!%+#+/$0'1)!)**&*'&2&0"$(#' DMP-Serial DMP-ShTab DMP-TM DMP-TMForward !&)-/' splash2 benchmark suite parsec 22
23 Supporting Debugging Instrumentation Need to allow instrumentation of programs and still keep the same original memory interleaving and behavior so the programmer can attach a debugger and inspect state This requires conveying to the system what was added to the original code P1 P2 P1 P2 23
24 Deploying Deterministic Execution Need to make it deterministic across machines too Same quantum formation Same order of deterministic token passing 24
25 If we have time... Software-only Sharing Table implementation Making execution deterministic across machines Dealing with nondeterminism from I/O and the OS Other interesting questions: Security implications? What does determinism mean in reactive (think DB server) applications? How do we expose some of the DMP mechanisms to the programmer? Determinism in race-free programs Determinism in relaxed memory models 25
26 Current/Future Work Deterministic Multiprocessing software-only implementation as a compiler+runtime (coming soon ;)) goal: preserve scalability, even if at the cost of higher absolute overhead lots of static analysis and aggressive runtime system evaluating impact in testing, dealing with butterfly effect system issues (I/O, OS, etc.) 26


27 ? Luis Ceze, University of Washington joint work with Owen Anderson, Tom Bergan, Joe Devietti, Brandon Lucia, Karin Strauss, Dan Grossman, Mark Oskin. Safe MultiProcessing Architectures at the University of Washington
DMP Deterministic Shared Memory Multiprocessing
 DMP Deterministic Shared Memory Multiprocessing University of Washington Joe Devietti, Brandon Lucia, Luis Ceze, Mark Oskin A multithreaded voting machine 2 thread 0 thread 1 while (more_votes) { load
DMP Deterministic Shared Memory Multiprocessing University of Washington Joe Devietti, Brandon Lucia, Luis Ceze, Mark Oskin A multithreaded voting machine 2 thread 0 thread 1 while (more_votes) { load
Explicitly Parallel Programming with Shared Memory is Insane: At Least Make it Deterministic!
 Explicitly Parallel Programming with Shared Memory is Insane: At Least Make it Deterministic! Joe Devietti, Brandon Lucia, Luis Ceze and Mark Oskin University of Washington Parallel Programming is Hard
Explicitly Parallel Programming with Shared Memory is Insane: At Least Make it Deterministic! Joe Devietti, Brandon Lucia, Luis Ceze and Mark Oskin University of Washington Parallel Programming is Hard
DMP: DETERMINISTIC SHARED- MEMORY MULTIPROCESSING
 ... DMP: DETERMINISTIC SHARED- MEMORY MULTIPROCESSING... SHARED-MEMORY MULTICORE AND MULTIPROCESSOR SYSTEMS ARE NONDETERMINISTIC, WHICH FRUSTRATES DEBUGGING AND COMPLICATES TESTING OF MULTITHREADED CODE,
... DMP: DETERMINISTIC SHARED- MEMORY MULTIPROCESSING... SHARED-MEMORY MULTICORE AND MULTIPROCESSOR SYSTEMS ARE NONDETERMINISTIC, WHICH FRUSTRATES DEBUGGING AND COMPLICATES TESTING OF MULTITHREADED CODE,
MELD: Merging Execution- and Language-level Determinism. Joe Devietti, Dan Grossman, Luis Ceze University of Washington
 MELD: Merging Execution- and Language-level Determinism Joe Devietti, Dan Grossman, Luis Ceze University of Washington CoreDet results overhead normalized to nondet 800% 600% 400% 200% 0% 2 4 8 2 4 8 2
MELD: Merging Execution- and Language-level Determinism Joe Devietti, Dan Grossman, Luis Ceze University of Washington CoreDet results overhead normalized to nondet 800% 600% 400% 200% 0% 2 4 8 2 4 8 2
A Case for System Support for Concurrency Exceptions
 A Case for System Support for Concurrency Exceptions Luis Ceze, Joseph Devietti, Brandon Lucia and Shaz Qadeer University of Washington {luisceze, devietti, blucia0a}@cs.washington.edu Microsoft Research
A Case for System Support for Concurrency Exceptions Luis Ceze, Joseph Devietti, Brandon Lucia and Shaz Qadeer University of Washington {luisceze, devietti, blucia0a}@cs.washington.edu Microsoft Research
Deterministic Process Groups in
 Deterministic Process Groups in Tom Bergan Nicholas Hunt, Luis Ceze, Steven D. Gribble University of Washington A Nondeterministic Program global x=0 Thread 1 Thread 2 t := x x := t + 1 t := x x := t +
Deterministic Process Groups in Tom Bergan Nicholas Hunt, Luis Ceze, Steven D. Gribble University of Washington A Nondeterministic Program global x=0 Thread 1 Thread 2 t := x x := t + 1 t := x x := t +
Explicitly Parallel Programming with Shared-Memory is Insane: At Least Make it Deterministic!
 Explicitly Parallel Programming with Shared-Memory is Insane: At Least Make it Deterministic! Joe Devietti, Brandon Lucia, Luis Ceze and Mark Oskin Department of Computer Science and Engineering University
Explicitly Parallel Programming with Shared-Memory is Insane: At Least Make it Deterministic! Joe Devietti, Brandon Lucia, Luis Ceze and Mark Oskin Department of Computer Science and Engineering University
Deterministic Scaling
 Deterministic Scaling Gabriel Southern Madan Das Jose Renau Dept. of Computer Engineering, University of California Santa Cruz {gsouther, madandas, renau}@soe.ucsc.edu http://masc.soe.ucsc.edu ABSTRACT
Deterministic Scaling Gabriel Southern Madan Das Jose Renau Dept. of Computer Engineering, University of California Santa Cruz {gsouther, madandas, renau}@soe.ucsc.edu http://masc.soe.ucsc.edu ABSTRACT
RCDC: A Relaxed Consistency Deterministic Computer
 RCDC: A Relaxed Consistency Deterministic Computer Joseph Devietti Jacob Nelson Tom Bergan Luis Ceze Dan Grossman University of Washington, Department of Computer Science & Engineering {devietti,nelson,tbergan,luisceze,djg}@cs.washington.edu
RCDC: A Relaxed Consistency Deterministic Computer Joseph Devietti Jacob Nelson Tom Bergan Luis Ceze Dan Grossman University of Washington, Department of Computer Science & Engineering {devietti,nelson,tbergan,luisceze,djg}@cs.washington.edu
Samsara: Efficient Deterministic Replay in Multiprocessor. Environments with Hardware Virtualization Extensions
 Samsara: Efficient Deterministic Replay in Multiprocessor Environments with Hardware Virtualization Extensions Shiru Ren, Le Tan, Chunqi Li, Zhen Xiao, and Weijia Song June 24, 2016 Table of Contents 1
Samsara: Efficient Deterministic Replay in Multiprocessor Environments with Hardware Virtualization Extensions Shiru Ren, Le Tan, Chunqi Li, Zhen Xiao, and Weijia Song June 24, 2016 Table of Contents 1
DeLorean: Recording and Deterministically Replaying Shared Memory Multiprocessor Execution Efficiently
 : Recording and Deterministically Replaying Shared Memory Multiprocessor Execution Efficiently, Luis Ceze* and Josep Torrellas Department of Computer Science University of Illinois at Urbana-Champaign
: Recording and Deterministically Replaying Shared Memory Multiprocessor Execution Efficiently, Luis Ceze* and Josep Torrellas Department of Computer Science University of Illinois at Urbana-Champaign
Deterministic Parallel Programming
 Deterministic Parallel Programming Concepts and Practices 04/2011 1 How hard is parallel programming What s the result of this program? What is data race? Should data races be allowed? Initially x = 0
Deterministic Parallel Programming Concepts and Practices 04/2011 1 How hard is parallel programming What s the result of this program? What is data race? Should data races be allowed? Initially x = 0
RelaxReplay: Record and Replay for Relaxed-Consistency Multiprocessors
 RelaxReplay: Record and Replay for Relaxed-Consistency Multiprocessors Nima Honarmand and Josep Torrellas University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu/ 1 RnR: Record and Deterministic
RelaxReplay: Record and Replay for Relaxed-Consistency Multiprocessors Nima Honarmand and Josep Torrellas University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu/ 1 RnR: Record and Deterministic
All about Eve: Execute-Verify Replication for Multi-Core Servers
 All about Eve: Execute-Verify Replication for Multi-Core Servers Manos Kapritsos, Yang Wang, Vivien Quema, Allen Clement, Lorenzo Alvisi, Mike Dahlin Dependability Multi-core Databases Key-value stores
All about Eve: Execute-Verify Replication for Multi-Core Servers Manos Kapritsos, Yang Wang, Vivien Quema, Allen Clement, Lorenzo Alvisi, Mike Dahlin Dependability Multi-core Databases Key-value stores
Vulcan: Hardware Support for Detecting Sequential Consistency Violations Dynamically
 Vulcan: Hardware Support for Detecting Sequential Consistency Violations Dynamically Abdullah Muzahid, Shanxiang Qi, and University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu MICRO December
Vulcan: Hardware Support for Detecting Sequential Consistency Violations Dynamically Abdullah Muzahid, Shanxiang Qi, and University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu MICRO December
Deterministic Replay and Data Race Detection for Multithreaded Programs
 Deterministic Replay and Data Race Detection for Multithreaded Programs Dongyoon Lee Computer Science Department - 1 - The Shift to Multicore Systems 100+ cores Desktop/Server 8+ cores Smartphones 2+ cores
Deterministic Replay and Data Race Detection for Multithreaded Programs Dongyoon Lee Computer Science Department - 1 - The Shift to Multicore Systems 100+ cores Desktop/Server 8+ cores Smartphones 2+ cores
Reproducible Simulation of Multi-Threaded Workloads for Architecture Design Exploration
 Reproducible Simulation of Multi-Threaded Workloads for Architecture Design Exploration Cristiano Pereira, Harish Patil, Brad Calder $ Computer Science and Engineering, University of California, San Diego
Reproducible Simulation of Multi-Threaded Workloads for Architecture Design Exploration Cristiano Pereira, Harish Patil, Brad Calder $ Computer Science and Engineering, University of California, San Diego
Abstraction: Distributed Ledger
 Bitcoin 2 Abstraction: Distributed Ledger 3 Implementation: Blockchain this happened this happened this happen hashes & signatures hashes & signatures hashes signatu 4 Implementation: Blockchain this happened
Bitcoin 2 Abstraction: Distributed Ledger 3 Implementation: Blockchain this happened this happened this happen hashes & signatures hashes & signatures hashes signatu 4 Implementation: Blockchain this happened
Efficient and highly portable deterministic multithreading (DetLock)
") Computing (2014) 96:1131 1147 DOI 10.1007/s00607-013-0370-9 Efficient and highly portable deterministic multithreading (DetLock) Hamid Mushtaq Zaid Al-Ars Koen Bertels Received: 22 March 2013 / Accepted:
Computing (2014) 96:1131 1147 DOI 10.1007/s00607-013-0370-9 Efficient and highly portable deterministic multithreading (DetLock) Hamid Mushtaq Zaid Al-Ars Koen Bertels Received: 22 March 2013 / Accepted:
Dataflow Architectures. Karin Strauss
 Dataflow Architectures Karin Strauss Introduction Dataflow machines: programmable computers with hardware optimized for fine grain data-driven parallel computation fine grain: at the instruction granularity
Dataflow Architectures Karin Strauss Introduction Dataflow machines: programmable computers with hardware optimized for fine grain data-driven parallel computation fine grain: at the instruction granularity
Do you have to reproduce the bug on the first replay attempt?
 Do you have to reproduce the bug on the first replay attempt? PRES: Probabilistic Replay with Execution Sketching on Multiprocessors Soyeon Park, Yuanyuan Zhou University of California, San Diego Weiwei
Do you have to reproduce the bug on the first replay attempt? PRES: Probabilistic Replay with Execution Sketching on Multiprocessors Soyeon Park, Yuanyuan Zhou University of California, San Diego Weiwei
High-Level Small-Step Operational Semantics for Software Transactions
 High-Level Small-Step Operational Semantics for Software Transactions Katherine F. Moore Dan Grossman The University of Washington Motivating Our Approach Operational Semantics Model key programming-language
High-Level Small-Step Operational Semantics for Software Transactions Katherine F. Moore Dan Grossman The University of Washington Motivating Our Approach Operational Semantics Model key programming-language
Speculative Synchronization
 Speculative Synchronization José F. Martínez Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu/martinez Problem 1: Conservative Parallelization No parallelization
Speculative Synchronization José F. Martínez Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu/martinez Problem 1: Conservative Parallelization No parallelization
740: Computer Architecture Memory Consistency. Prof. Onur Mutlu Carnegie Mellon University
 740: Computer Architecture Memory Consistency Prof. Onur Mutlu Carnegie Mellon University Readings: Memory Consistency Required Lamport, How to Make a Multiprocessor Computer That Correctly Executes Multiprocess
740: Computer Architecture Memory Consistency Prof. Onur Mutlu Carnegie Mellon University Readings: Memory Consistency Required Lamport, How to Make a Multiprocessor Computer That Correctly Executes Multiprocess
Summary: Open Questions:
 Summary: The paper proposes an new parallelization technique, which provides dynamic runtime parallelization of loops from binary single-thread programs with minimal architectural change. The realization
Summary: The paper proposes an new parallelization technique, which provides dynamic runtime parallelization of loops from binary single-thread programs with minimal architectural change. The realization
Universal Parallel Computing Research Center at Illinois
 Universal Parallel Computing Research Center at Illinois Making parallel programming synonymous with programming Marc Snir 08-09 The UPCRC@ Illinois Team BACKGROUND 3 Moore s Law Pre 2004 Number of transistors
Universal Parallel Computing Research Center at Illinois Making parallel programming synonymous with programming Marc Snir 08-09 The UPCRC@ Illinois Team BACKGROUND 3 Moore s Law Pre 2004 Number of transistors
Respec: Efficient Online Multiprocessor Replay via Speculation and External Determinism
 Respec: Efficient Online Multiprocessor Replay via Speculation and External Determinism Dongyoon Lee Benjamin Wester Kaushik Veeraraghavan Satish Narayanasamy Peter M. Chen Jason Flinn Dept. of EECS, University
Respec: Efficient Online Multiprocessor Replay via Speculation and External Determinism Dongyoon Lee Benjamin Wester Kaushik Veeraraghavan Satish Narayanasamy Peter M. Chen Jason Flinn Dept. of EECS, University
Efficient Deterministic Multithreading Without Global Barriers
 Efficient Deterministic Multithreading Without Global Barriers Kai Lu 1,2 Xu Zhou 1,2 Tom Bergan 3 Xiaoping Wang 1,2 1.Science and Technology on Parallel and Distributed Processing Laboratory, National
Efficient Deterministic Multithreading Without Global Barriers Kai Lu 1,2 Xu Zhou 1,2 Tom Bergan 3 Xiaoping Wang 1,2 1.Science and Technology on Parallel and Distributed Processing Laboratory, National
Respec: Efficient Online Multiprocessor Replay via Speculation and External Determinism
 Respec: Efficient Online Multiprocessor Replay via Speculation and External Determinism Dongyoon Lee Benjamin Wester Kaushik Veeraraghavan Satish Narayanasamy Peter M. Chen Jason Flinn Dept. of EECS, University
Respec: Efficient Online Multiprocessor Replay via Speculation and External Determinism Dongyoon Lee Benjamin Wester Kaushik Veeraraghavan Satish Narayanasamy Peter M. Chen Jason Flinn Dept. of EECS, University
POSH: A TLS Compiler that Exploits Program Structure
 POSH: A TLS Compiler that Exploits Program Structure Wei Liu, James Tuck, Luis Ceze, Wonsun Ahn, Karin Strauss, Jose Renau and Josep Torrellas Department of Computer Science University of Illinois at Urbana-Champaign
POSH: A TLS Compiler that Exploits Program Structure Wei Liu, James Tuck, Luis Ceze, Wonsun Ahn, Karin Strauss, Jose Renau and Josep Torrellas Department of Computer Science University of Illinois at Urbana-Champaign
Speculative Synchronization: Applying Thread Level Speculation to Parallel Applications. University of Illinois
 Speculative Synchronization: Applying Thread Level Speculation to Parallel Applications José éf. Martínez * and Josep Torrellas University of Illinois ASPLOS 2002 * Now at Cornell University Overview Allow
Speculative Synchronization: Applying Thread Level Speculation to Parallel Applications José éf. Martínez * and Josep Torrellas University of Illinois ASPLOS 2002 * Now at Cornell University Overview Allow
C++ Memory Model. Don t believe everything you read (from shared memory)
") C++ Memory Model Don t believe everything you read (from shared memory) The Plan Why multithreading is hard Warm-up example Sequential Consistency Races and fences The happens-before relation The DRF guarantee
C++ Memory Model Don t believe everything you read (from shared memory) The Plan Why multithreading is hard Warm-up example Sequential Consistency Races and fences The happens-before relation The DRF guarantee
The Java Memory Model
 The Java Memory Model The meaning of concurrency in Java Bartosz Milewski Plan of the talk Motivating example Sequential consistency Data races The DRF guarantee Causality Out-of-thin-air guarantee Implementation
The Java Memory Model The meaning of concurrency in Java Bartosz Milewski Plan of the talk Motivating example Sequential consistency Data races The DRF guarantee Causality Out-of-thin-air guarantee Implementation
Hardware Support for Software Debugging
 Hardware Support for Software Debugging Mohammad Amin Alipour Benjamin Depew Department of Computer Science Michigan Technological University Report Documentation Page Form Approved OMB No. 0704-0188 Public
Hardware Support for Software Debugging Mohammad Amin Alipour Benjamin Depew Department of Computer Science Michigan Technological University Report Documentation Page Form Approved OMB No. 0704-0188 Public
ECMon: Exposing Cache Events for Monitoring
 ECMon: Exposing Cache Events for Monitoring Vijay Nagarajan Rajiv Gupta University of California at Riverside, CSE Department, Riverside, CA 92521 {vijay,gupta}@cs.ucr.edu ABSTRACT The advent of multicores
ECMon: Exposing Cache Events for Monitoring Vijay Nagarajan Rajiv Gupta University of California at Riverside, CSE Department, Riverside, CA 92521 {vijay,gupta}@cs.ucr.edu ABSTRACT The advent of multicores
Thread-Level Speculation on Off-the-Shelf Hardware Transactional Memory
 Thread-Level Speculation on Off-the-Shelf Hardware Transactional Memory Rei Odaira Takuya Nakaike IBM Research Tokyo Thread-Level Speculation (TLS) [Franklin et al., 92] or Speculative Multithreading (SpMT)
Thread-Level Speculation on Off-the-Shelf Hardware Transactional Memory Rei Odaira Takuya Nakaike IBM Research Tokyo Thread-Level Speculation (TLS) [Franklin et al., 92] or Speculative Multithreading (SpMT)
TERN: Stable Deterministic Multithreading through Schedule Memoization
 TERN: Stable Deterministic Multithreading through Schedule Memoization Heming Cui, Jingyue Wu, Chia-che Tsai, Junfeng Yang Columbia University Appeared in OSDI 10 Nondeterministic Execution One input many
TERN: Stable Deterministic Multithreading through Schedule Memoization Heming Cui, Jingyue Wu, Chia-che Tsai, Junfeng Yang Columbia University Appeared in OSDI 10 Nondeterministic Execution One input many
Hybrid Static-Dynamic Analysis for Statically Bounded Region Serializability
 Hybrid Static-Dynamic Analysis for Statically Bounded Region Serializability Aritra Sengupta, Swarnendu Biswas, Minjia Zhang, Michael D. Bond and Milind Kulkarni ASPLOS 2015, ISTANBUL, TURKEY Programming
Hybrid Static-Dynamic Analysis for Statically Bounded Region Serializability Aritra Sengupta, Swarnendu Biswas, Minjia Zhang, Michael D. Bond and Milind Kulkarni ASPLOS 2015, ISTANBUL, TURKEY Programming
CSE 444: Database Internals. Section 9: 2-Phase Commit and Replication
 CSE 444: Database Internals Section 9: 2-Phase Commit and Replication 1 Today 2-Phase Commit Replication 2 Two-Phase Commit Protocol (2PC) One coordinator and many subordinates Phase 1: Prepare Phase 2:
CSE 444: Database Internals Section 9: 2-Phase Commit and Replication 1 Today 2-Phase Commit Replication 2 Two-Phase Commit Protocol (2PC) One coordinator and many subordinates Phase 1: Prepare Phase 2:
The Bulk Multicore Architecture for Programmability
 The Bulk Multicore Architecture for Programmability Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu Acknowledgments Key contributors: Luis Ceze Calin
The Bulk Multicore Architecture for Programmability Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu Acknowledgments Key contributors: Luis Ceze Calin
Fully Automatic and Precise Detection of Thread Safety Violations
 Fully Automatic and Precise Detection of Thread Safety Violations Michael Pradel and Thomas R. Gross Department of Computer Science ETH Zurich 1 Motivation Thread-safe classes: Building blocks for concurrent
Fully Automatic and Precise Detection of Thread Safety Violations Michael Pradel and Thomas R. Gross Department of Computer Science ETH Zurich 1 Motivation Thread-safe classes: Building blocks for concurrent
Chí Cao Minh 28 May 2008
 Chí Cao Minh 28 May 2008 Uniprocessor systems hitting limits Design complexity overwhelming Power consumption increasing dramatically Instruction-level parallelism exhausted Solution is multiprocessor
Chí Cao Minh 28 May 2008 Uniprocessor systems hitting limits Design complexity overwhelming Power consumption increasing dramatically Instruction-level parallelism exhausted Solution is multiprocessor
Scalable Shared Memory Programing
 Scalable Shared Memory Programing Marc Snir www.parallel.illinois.edu What is (my definition of) Shared Memory Global name space (global references) Implicit data movement Caching: User gets good memory
Scalable Shared Memory Programing Marc Snir www.parallel.illinois.edu What is (my definition of) Shared Memory Global name space (global references) Implicit data movement Caching: User gets good memory
Transactional Memory. Prof. Hsien-Hsin S. Lee School of Electrical and Computer Engineering Georgia Tech
 Transactional Memory Prof. Hsien-Hsin S. Lee School of Electrical and Computer Engineering Georgia Tech (Adapted from Stanford TCC group and MIT SuperTech Group) Motivation Uniprocessor Systems Frequency
Transactional Memory Prof. Hsien-Hsin S. Lee School of Electrical and Computer Engineering Georgia Tech (Adapted from Stanford TCC group and MIT SuperTech Group) Motivation Uniprocessor Systems Frequency
The Design Complexity of Program Undo Support in a General Purpose Processor. Radu Teodorescu and Josep Torrellas
 The Design Complexity of Program Undo Support in a General Purpose Processor Radu Teodorescu and Josep Torrellas University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu Processor with program
The Design Complexity of Program Undo Support in a General Purpose Processor Radu Teodorescu and Josep Torrellas University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu Processor with program
Yuxi Chen, Shu Wang, Shan Lu, and Karthikeyan Sankaralingam *
 Yuxi Chen, Shu Wang, Shan Lu, and Karthikeyan Sankaralingam * * 2 q Synchronization mistakes in multithreaded programs Thread 1 Thread 2 If(ptr){ tmp = *ptr; ptr = NULL; } Segfault q Common q Hard to diagnose
Yuxi Chen, Shu Wang, Shan Lu, and Karthikeyan Sankaralingam * * 2 q Synchronization mistakes in multithreaded programs Thread 1 Thread 2 If(ptr){ tmp = *ptr; ptr = NULL; } Segfault q Common q Hard to diagnose
Atomicity via Source-to-Source Translation
 Atomicity via Source-to-Source Translation Benjamin Hindman Dan Grossman University of Washington 22 October 2006 Atomic An easier-to-use and harder-to-implement primitive void deposit(int x){ synchronized(this){
Atomicity via Source-to-Source Translation Benjamin Hindman Dan Grossman University of Washington 22 October 2006 Atomic An easier-to-use and harder-to-implement primitive void deposit(int x){ synchronized(this){
Lecture 12: TM, Consistency Models. Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations
 Lecture 12: TM, Consistency Models Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations 1 Paper on TM Pathologies (ISCA 08) LL: lazy versioning, lazy conflict detection, committing
Lecture 12: TM, Consistency Models Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations 1 Paper on TM Pathologies (ISCA 08) LL: lazy versioning, lazy conflict detection, committing
Programming Models for Supercomputing in the Era of Multicore
 Programming Models for Supercomputing in the Era of Multicore Marc Snir MULTI-CORE CHALLENGES 1 Moore s Law Reinterpreted Number of cores per chip doubles every two years, while clock speed decreases Need
Programming Models for Supercomputing in the Era of Multicore Marc Snir MULTI-CORE CHALLENGES 1 Moore s Law Reinterpreted Number of cores per chip doubles every two years, while clock speed decreases Need
Introduction to Concurrency. Kenneth M. Anderson University of Colorado, Boulder CSCI 5828 Lecture 4 01/21/2010
 Introduction to Concurrency Kenneth M. Anderson University of Colorado, Boulder CSCI 5828 Lecture 4 01/21/2010 University of Colorado, 2010 1 Credit where Credit is Due 2 Some text and images for this
Introduction to Concurrency Kenneth M. Anderson University of Colorado, Boulder CSCI 5828 Lecture 4 01/21/2010 University of Colorado, 2010 1 Credit where Credit is Due 2 Some text and images for this
Embedded System Programming
 Embedded System Programming Multicore ES (Module 40) Yann-Hang Lee Arizona State University yhlee@asu.edu (480) 727-7507 Summer 2014 The Era of Multi-core Processors RTOS Single-Core processor SMP-ready
Embedded System Programming Multicore ES (Module 40) Yann-Hang Lee Arizona State University yhlee@asu.edu (480) 727-7507 Summer 2014 The Era of Multi-core Processors RTOS Single-Core processor SMP-ready
Concurrency Control In Distributed Main Memory Database Systems. Justin A. DeBrabant
 In Distributed Main Memory Database Systems Justin A. DeBrabant debrabant@cs.brown.edu Concurrency control Goal: maintain consistent state of data ensure query results are correct The Gold Standard: ACID
In Distributed Main Memory Database Systems Justin A. DeBrabant debrabant@cs.brown.edu Concurrency control Goal: maintain consistent state of data ensure query results are correct The Gold Standard: ACID
GautamAltekar and Ion Stoica University of California, Berkeley
 GautamAltekar and Ion Stoica University of California, Berkeley Debugging datacenter software is really hard Datacenter software? Large-scale, data-intensive, distributed apps Hard? Non-determinism Can
GautamAltekar and Ion Stoica University of California, Berkeley Debugging datacenter software is really hard Datacenter software? Large-scale, data-intensive, distributed apps Hard? Non-determinism Can
Mohamed M. Saad & Binoy Ravindran
 Mohamed M. Saad & Binoy Ravindran VT-MENA Program Electrical & Computer Engineering Department Virginia Polytechnic Institute and State University TRANSACT 11 San Jose, CA An operation (or set of operations)
Mohamed M. Saad & Binoy Ravindran VT-MENA Program Electrical & Computer Engineering Department Virginia Polytechnic Institute and State University TRANSACT 11 San Jose, CA An operation (or set of operations)
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Kendo: Efficient Deterministic Multithreading in Software
 Kendo: Efficient Deterministic Multithreading in Software Marek Olszewski Jason Ansel Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology mareko,
Kendo: Efficient Deterministic Multithreading in Software Marek Olszewski Jason Ansel Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology mareko,
Processor speed. Concurrency Structure and Interpretation of Computer Programs. Multiple processors. Processor speed. Mike Phillips <mpp>
 Processor speed 6.037 - Structure and Interpretation of Computer Programs Mike Phillips Massachusetts Institute of Technology http://en.wikipedia.org/wiki/file:transistor_count_and_moore%27s_law_-
Processor speed 6.037 - Structure and Interpretation of Computer Programs Mike Phillips Massachusetts Institute of Technology http://en.wikipedia.org/wiki/file:transistor_count_and_moore%27s_law_-
Lecture 24: Multiprocessing Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Potential violations of Serializability: Example 1
 CSCE 6610:Advanced Computer Architecture Review New Amdahl s law A possible idea for a term project Explore my idea about changing frequency based on serial fraction to maintain fixed energy or keep same
CSCE 6610:Advanced Computer Architecture Review New Amdahl s law A possible idea for a term project Explore my idea about changing frequency based on serial fraction to maintain fixed energy or keep same
Atom-Aid: Detecting and Surviving Atomicity Violations
 Atom-Aid: Detecting and Surviving Atomicity Violations Abstract Writing shared-memory parallel programs is an error-prone process. Atomicity violations are especially challenging concurrency errors. They
Atom-Aid: Detecting and Surviving Atomicity Violations Abstract Writing shared-memory parallel programs is an error-prone process. Atomicity violations are especially challenging concurrency errors. They
Chasing Away RAts: Semantics and Evaluation for Relaxed Atomics on Heterogeneous Systems
 Chasing Away RAts: Semantics and Evaluation for Relaxed Atomics on Heterogeneous Systems Matthew D. Sinclair, Johnathan Alsop, Sarita V. Adve University of Illinois @ Urbana-Champaign hetero@cs.illinois.edu
Chasing Away RAts: Semantics and Evaluation for Relaxed Atomics on Heterogeneous Systems Matthew D. Sinclair, Johnathan Alsop, Sarita V. Adve University of Illinois @ Urbana-Champaign hetero@cs.illinois.edu
Chimera: Hybrid Program Analysis for Determinism
 Chimera: Hybrid Program Analysis for Determinism Dongyoon Lee, Peter Chen, Jason Flinn, Satish Narayanasamy University of Michigan, Ann Arbor - 1 - * Chimera image from http://superpunch.blogspot.com/2009/02/chimera-sketch.html
Chimera: Hybrid Program Analysis for Determinism Dongyoon Lee, Peter Chen, Jason Flinn, Satish Narayanasamy University of Michigan, Ann Arbor - 1 - * Chimera image from http://superpunch.blogspot.com/2009/02/chimera-sketch.html
COREMU: a Portable and Scalable Parallel Full-system Emulator
 COREMU: a Portable and Scalable Parallel Full-system Emulator Haibo Chen Parallel Processing Institute Fudan University http://ppi.fudan.edu.cn/haibo_chen Full-System Emulator Useful tool for multicore
COREMU: a Portable and Scalable Parallel Full-system Emulator Haibo Chen Parallel Processing Institute Fudan University http://ppi.fudan.edu.cn/haibo_chen Full-System Emulator Useful tool for multicore
DBT Tool. DBT Framework
 Thread-Safe Dynamic Binary Translation using Transactional Memory JaeWoong Chung,, Michael Dalton, Hari Kannan, Christos Kozyrakis Computer Systems Laboratory Stanford University http://csl.stanford.edu
Thread-Safe Dynamic Binary Translation using Transactional Memory JaeWoong Chung,, Michael Dalton, Hari Kannan, Christos Kozyrakis Computer Systems Laboratory Stanford University http://csl.stanford.edu
UNIVERSITY OF CALIFORNIA RIVERSIDE. IMPRESS: Improving Multicore Performance and Reliability via Efficient Support for Software Monitoring
 UNIVERSITY OF CALIFORNIA RIVERSIDE IMPRESS: Improving Multicore Performance and Reliability via Efficient Support for Software Monitoring A Dissertation submitted in partial satisfaction of the requirements
UNIVERSITY OF CALIFORNIA RIVERSIDE IMPRESS: Improving Multicore Performance and Reliability via Efficient Support for Software Monitoring A Dissertation submitted in partial satisfaction of the requirements
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP)
 in the Stanford Hydra Chip Multiprocessor (CMP)") Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) A 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) A 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Lightweight Fault Detection in Parallelized Programs
 Lightweight Fault Detection in Parallelized Programs Li Tan UC Riverside Min Feng NEC Labs Rajiv Gupta UC Riverside CGO 13, Shenzhen, China Feb. 25, 2013 Program Parallelization Parallelism can be achieved
Lightweight Fault Detection in Parallelized Programs Li Tan UC Riverside Min Feng NEC Labs Rajiv Gupta UC Riverside CGO 13, Shenzhen, China Feb. 25, 2013 Program Parallelization Parallelism can be achieved
Lock Prediction. Brandon Lucia Joseph Devietti Tom Bergan Luis Ceze Dan Grossman
 Lock Prediction Brandon Lucia Joseph Devietti Tom Bergan Luis Ceze Dan Grossman University of Washington, Computer Science and Engineering http://sampa.cs.washington.edu Abstract This paper makes the case
Lock Prediction Brandon Lucia Joseph Devietti Tom Bergan Luis Ceze Dan Grossman University of Washington, Computer Science and Engineering http://sampa.cs.washington.edu Abstract This paper makes the case
Improving the Practicality of Transactional Memory
 Improving the Practicality of Transactional Memory Woongki Baek Electrical Engineering Stanford University Programming Multiprocessors Multiprocessor systems are now everywhere From embedded to datacenter
Improving the Practicality of Transactional Memory Woongki Baek Electrical Engineering Stanford University Programming Multiprocessors Multiprocessor systems are now everywhere From embedded to datacenter
TIME TRAVELING HARDWARE AND SOFTWARE SYSTEMS. Xiangyao Yu, Srini Devadas CSAIL, MIT
 TIME TRAVELING HARDWARE AND SOFTWARE SYSTEMS Xiangyao Yu, Srini Devadas CSAIL, MIT FOR FIFTY YEARS, WE HAVE RIDDEN MOORE S LAW Moore s Law and the scaling of clock frequency = printing press for the currency
TIME TRAVELING HARDWARE AND SOFTWARE SYSTEMS Xiangyao Yu, Srini Devadas CSAIL, MIT FOR FIFTY YEARS, WE HAVE RIDDEN MOORE S LAW Moore s Law and the scaling of clock frequency = printing press for the currency
1. Introduction to Concurrent Programming
 1. Introduction to Concurrent Programming A concurrent program contains two or more threads that execute concurrently and work together to perform some task. When a program is executed, the operating system
1. Introduction to Concurrent Programming A concurrent program contains two or more threads that execute concurrently and work together to perform some task. When a program is executed, the operating system
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
QuickRec: Prototyping an Intel Architecture Extension for Record and Replay of Multithreaded Programs
 QuickRec: Prototyping an Intel Architecture Extension for Record and Replay of Multithreaded Programs Intel: Gilles Pokam, Klaus Danne, Cristiano Pereira, Rolf Kassa, Tim Kranich, Shiliang Hu, Justin Gottschlich
QuickRec: Prototyping an Intel Architecture Extension for Record and Replay of Multithreaded Programs Intel: Gilles Pokam, Klaus Danne, Cristiano Pereira, Rolf Kassa, Tim Kranich, Shiliang Hu, Justin Gottschlich
Predicting Data Races from Program Traces
 Predicting Data Races from Program Traces Luis M. Carril IPD Tichy Lehrstuhl für Programmiersysteme KIT die Kooperation von Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH) Concurrency &
Predicting Data Races from Program Traces Luis M. Carril IPD Tichy Lehrstuhl für Programmiersysteme KIT die Kooperation von Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH) Concurrency &
NDSeq: Runtime Checking for Nondeterministic Sequential Specs of Parallel Correctness
 EECS Electrical Engineering and Computer Sciences P A R A L L E L C O M P U T I N G L A B O R A T O R Y NDSeq: Runtime Checking for Nondeterministic Sequential Specs of Parallel Correctness Jacob Burnim,
EECS Electrical Engineering and Computer Sciences P A R A L L E L C O M P U T I N G L A B O R A T O R Y NDSeq: Runtime Checking for Nondeterministic Sequential Specs of Parallel Correctness Jacob Burnim,
Life, Death, and the Critical Transition: Finding Liveness Bugs in System Code
 Life, Death, and the Critical Transition: Finding Liveness Bugs in System Code Charles Killian, James W. Anderson, Ranjit Jhala, and Amin Vahdat Presented by Nick Sumner 25 March 2008 Background We already
Life, Death, and the Critical Transition: Finding Liveness Bugs in System Code Charles Killian, James W. Anderson, Ranjit Jhala, and Amin Vahdat Presented by Nick Sumner 25 March 2008 Background We already
Deterministic OpenMP for Race-Free Parallelism
 Deterministic OpenMP for Race-Free Parallelism Amittai Aviram and Bryan Ford Yale University {amittai.aviram, bryan.ford}@yale.edu Recent deterministic parallel programming models show promise for their
Deterministic OpenMP for Race-Free Parallelism Amittai Aviram and Bryan Ford Yale University {amittai.aviram, bryan.ford}@yale.edu Recent deterministic parallel programming models show promise for their
Simplifying the Development and Debug of 8572-Based SMP Embedded Systems. Wind River Workbench Development Tools
 Simplifying the Development and Debug of 8572-Based SMP Embedded Systems Wind River Workbench Development Tools Agenda Introducing multicore systems Debugging challenges of multicore systems Development
Simplifying the Development and Debug of 8572-Based SMP Embedded Systems Wind River Workbench Development Tools Agenda Introducing multicore systems Debugging challenges of multicore systems Development
Consistency. CS 475, Spring 2018 Concurrent & Distributed Systems
 Consistency CS 475, Spring 2018 Concurrent & Distributed Systems Review: 2PC, Timeouts when Coordinator crashes What if the bank doesn t hear back from coordinator? If bank voted no, it s OK to abort If
Consistency CS 475, Spring 2018 Concurrent & Distributed Systems Review: 2PC, Timeouts when Coordinator crashes What if the bank doesn t hear back from coordinator? If bank voted no, it s OK to abort If
Record and Replay of Multithreaded Applications
 Record and Replay of Multithreaded Applications Aliaksandra Sankova aliaksandra.sankova@ist.utl.pt Instituto Superior Técnico (Advisor: Professor Luís Rodrigues) Abstract. With the advent of multi-core
Record and Replay of Multithreaded Applications Aliaksandra Sankova aliaksandra.sankova@ist.utl.pt Instituto Superior Técnico (Advisor: Professor Luís Rodrigues) Abstract. With the advent of multi-core
Parallelization of Spider Planner
 Parallelization of Spider Planner Morten Smedsrud, SINTEF 1 SPIDER - A Generic VRP Solver Designed to be widely applicable Based on generic, rich model Predictive route planning Plan repair, reactive planning
Parallelization of Spider Planner Morten Smedsrud, SINTEF 1 SPIDER - A Generic VRP Solver Designed to be widely applicable Based on generic, rich model Predictive route planning Plan repair, reactive planning
LogSI-HTM: Log Based Snapshot Isolation in Hardware Transactional Memory
 LogSI-HTM: Log Based Snapshot Isolation in Hardware Transactional Memory Lois Orosa and Rodolfo zevedo Institute of Computing, University of Campinas (UNICMP) {lois.orosa,rodolfo}@ic.unicamp.br bstract
LogSI-HTM: Log Based Snapshot Isolation in Hardware Transactional Memory Lois Orosa and Rodolfo zevedo Institute of Computing, University of Campinas (UNICMP) {lois.orosa,rodolfo}@ic.unicamp.br bstract
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Runtime Support for Scalable Task-parallel Programs
 Runtime Support for Scalable Task-parallel Programs Pacific Northwest National Lab xsig workshop May 2018 http://hpc.pnl.gov/people/sriram/ Single Program Multiple Data int main () {... } 2 Task Parallelism
Runtime Support for Scalable Task-parallel Programs Pacific Northwest National Lab xsig workshop May 2018 http://hpc.pnl.gov/people/sriram/ Single Program Multiple Data int main () {... } 2 Task Parallelism
Intel Parallel Studio 2011
 THE ULTIMATE ALL-IN-ONE PERFORMANCE TOOLKIT Studio 2011 Product Brief Studio 2011 Accelerate Development of Reliable, High-Performance Serial and Threaded Applications for Multicore Studio 2011 is a comprehensive
THE ULTIMATE ALL-IN-ONE PERFORMANCE TOOLKIT Studio 2011 Product Brief Studio 2011 Accelerate Development of Reliable, High-Performance Serial and Threaded Applications for Multicore Studio 2011 is a comprehensive
Production-Run Software Failure Diagnosis via Hardware Performance Counters. Joy Arulraj, Po-Chun Chang, Guoliang Jin and Shan Lu
 Production-Run Software Failure Diagnosis via Hardware Performance Counters Joy Arulraj, Po-Chun Chang, Guoliang Jin and Shan Lu Motivation Software inevitably fails on production machines These failures
Production-Run Software Failure Diagnosis via Hardware Performance Counters Joy Arulraj, Po-Chun Chang, Guoliang Jin and Shan Lu Motivation Software inevitably fails on production machines These failures
Outline. Exploiting Program Parallelism. The Hydra Approach. Data Speculation Support for a Chip Multiprocessor (Hydra CMP) HYDRA
 HYDRA") CS 258 Parallel Computer Architecture Data Speculation Support for a Chip Multiprocessor (Hydra CMP) Lance Hammond, Mark Willey and Kunle Olukotun Presented: May 7 th, 2008 Ankit Jain Outline The Hydra
CS 258 Parallel Computer Architecture Data Speculation Support for a Chip Multiprocessor (Hydra CMP) Lance Hammond, Mark Willey and Kunle Olukotun Presented: May 7 th, 2008 Ankit Jain Outline The Hydra
Foundations of the C++ Concurrency Memory Model
 Foundations of the C++ Concurrency Memory Model John Mellor-Crummey and Karthik Murthy Department of Computer Science Rice University johnmc@rice.edu COMP 522 27 September 2016 Before C++ Memory Model
Foundations of the C++ Concurrency Memory Model John Mellor-Crummey and Karthik Murthy Department of Computer Science Rice University johnmc@rice.edu COMP 522 27 September 2016 Before C++ Memory Model
DoublePlay: Parallelizing Sequential Logging and Replay
 oubleplay: Parallelizing Sequential Logging and Replay Kaushik Veeraraghavan ongyoon Lee enjamin Wester Jessica Ouyang Peter M. hen Jason Flinn Satish Narayanasamy University of Michigan {kaushikv,dongyoon,bwester,jouyang,pmchen,jflinn,nsatish}@umich.edu
oubleplay: Parallelizing Sequential Logging and Replay Kaushik Veeraraghavan ongyoon Lee enjamin Wester Jessica Ouyang Peter M. hen Jason Flinn Satish Narayanasamy University of Michigan {kaushikv,dongyoon,bwester,jouyang,pmchen,jflinn,nsatish}@umich.edu
EECS 452 Lecture 9 TLP Thread-Level Parallelism
 EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS
 ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS DANIEL SANCHEZ MIT CHRISTOS KOZYRAKIS STANFORD ISCA-40 JUNE 27, 2013 Introduction 2 Current detailed simulators are slow (~200
ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS DANIEL SANCHEZ MIT CHRISTOS KOZYRAKIS STANFORD ISCA-40 JUNE 27, 2013 Introduction 2 Current detailed simulators are slow (~200
Fall 2012 Parallel Computer Architecture Lecture 16: Speculation II. Prof. Onur Mutlu Carnegie Mellon University 10/12/2012
 18-742 Fall 2012 Parallel Computer Architecture Lecture 16: Speculation II Prof. Onur Mutlu Carnegie Mellon University 10/12/2012 Past Due: Review Assignments Was Due: Tuesday, October 9, 11:59pm. Sohi
18-742 Fall 2012 Parallel Computer Architecture Lecture 16: Speculation II Prof. Onur Mutlu Carnegie Mellon University 10/12/2012 Past Due: Review Assignments Was Due: Tuesday, October 9, 11:59pm. Sohi
Operating System. Chapter 4. Threads. Lynn Choi School of Electrical Engineering
 Operating System Chapter 4. Threads Lynn Choi School of Electrical Engineering Process Characteristics Resource ownership Includes a virtual address space (process image) Ownership of resources including
Operating System Chapter 4. Threads Lynn Choi School of Electrical Engineering Process Characteristics Resource ownership Includes a virtual address space (process image) Ownership of resources including
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP)
 in the Stanford Hydra Chip Multiprocessor (CMP)") Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) Hydra ia a 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) Hydra ia a 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
c Copyright 2014 Benjamin P. Wood
 c Copyright 2014 Benjamin P. Wood Software and Hardware Support for Data-Race Exceptions Benjamin P. Wood A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of
c Copyright 2014 Benjamin P. Wood Software and Hardware Support for Data-Race Exceptions Benjamin P. Wood A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of
Curriculum 2013 Knowledge Units Pertaining to PDC
 Curriculum 2013 Knowledge Units Pertaining to C KA KU Tier Level NumC Learning Outcome Assembly level machine Describe how an instruction is executed in a classical von Neumann machine, with organization
Curriculum 2013 Knowledge Units Pertaining to C KA KU Tier Level NumC Learning Outcome Assembly level machine Describe how an instruction is executed in a classical von Neumann machine, with organization
ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS
 ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS DANIEL SANCHEZ MIT CHRISTOS KOZYRAKIS STANFORD ISCA-40 JUNE 27, 2013 Introduction 2 Current detailed simulators are slow (~200
ZSIM: FAST AND ACCURATE MICROARCHITECTURAL SIMULATION OF THOUSAND-CORE SYSTEMS DANIEL SANCHEZ MIT CHRISTOS KOZYRAKIS STANFORD ISCA-40 JUNE 27, 2013 Introduction 2 Current detailed simulators are slow (~200
Tasks with Effects. A Model for Disciplined Concurrent Programming. Abstract. 1. Motivation
 Tasks with Effects A Model for Disciplined Concurrent Programming Stephen Heumann Vikram Adve University of Illinois at Urbana-Champaign {heumann1,vadve}@illinois.edu Abstract Today s widely-used concurrent
Tasks with Effects A Model for Disciplined Concurrent Programming Stephen Heumann Vikram Adve University of Illinois at Urbana-Champaign {heumann1,vadve}@illinois.edu Abstract Today s widely-used concurrent
Parallelizing SPECjbb2000 with Transactional Memory
 Parallelizing SPECjbb2000 with Transactional Memory JaeWoong Chung, Chi Cao Minh,, Brian D. Carlstrom, Christos Kozyrakis Picture comes here Computer Systems Lab Stanford University http://tcc.stanford.edu
Parallelizing SPECjbb2000 with Transactional Memory JaeWoong Chung, Chi Cao Minh,, Brian D. Carlstrom, Christos Kozyrakis Picture comes here Computer Systems Lab Stanford University http://tcc.stanford.edu