Dr Andrew Abel University of Stirling, Scotland
|
|
|
- Amelia Booker
- 5 years ago
- Views:
Transcription


1 Dr Andrew Abel University of Stirling, Scotland




2 University of Stirling - Scotland
3 Cognitive Signal Image and Control Processing Research (COSIPRA) Cognitive Computation neurobiology, cognitive psychology and artificial intelligence Moving beyond traditional Machine Learning Considering the world Inspired by the brain, machines that can think and take decisions in response to stimuli Develop a deeper & more comprehensive unified understanding of brain s cognitive capabilities: perception, action, and attention; Learning and memory; decision making and reasoning; language processing and communication; problem solving and consciousness
4 Promote a more comprehensive and unified understanding of diverse topics perception, action, and attention; learning and memory; decision making and reasoning; Language processing and communication; problem solving and consciousness aspects of cognition. Increasing calls for the creation of cognitive machines, with cognitive powers similar to those of ourselves: are able to think for themselves; are flexible, adaptive and able to learn from both their own previous experience and that of others around them
5 Multimodal speech processing cognitively-inspired multimodal speech communication capabilities Multimodal Sentiment analysis realise emotional cognitive machines for more natural and affective interaction & language processing capabilities in cognitive machine Cognitive Control of Autonomous Systems realise action-selection and learning capabilities of our envisaged multi-modal cognitive machines Decision support Provide intelligent analysis and estimation of cancer care patient support Fraud detection Analyse words and meanings to seek truth and honesty
6 Developing new and different approaches to speech filtering Consider more than just audio Make use of other modalities Move away from traditional hearing aids Cognitive Inspiration Will give overview Demonstration of results Discuss potential component improvements

7 Sound pressure waves Causes fluid vibration in inner ear Hair cells send electrical impulses to brain Represent different frequencies
8 Hearing aids aim to compensate limitations in hearing auditory nerve hair cell inner ear damage Adjust frequencies to compensate Amplify certain frequencies Added sophistication over time 8
9 Noise cancellation algorithms Designed mainly to remove non-speech Effective on broadband sound Directional Microphones Only pick up sounds from set directions Frequency compression Programming to adjust settings Buttons or automatic Detectors to determine filtering Wind detectors Level detectors etc. Two-stage approaches Combining different methods Directional microphones and noise cancellation 9
10 Many users do not use full range of potential settings Dislike of directional microphones Limitations of effectiveness of noise cancellation Improved results in lab conditions not matched by reality Industry research very advanced, looks for incremental improvements in audio only algorithms Linking hearing aids Improved array microphones Rapid polarity changes
11 Hearing is not just mechanical, but is also cognitive Multimodal nature of perception and production of speech There is a relationship between the acoustic and visible properties of speech production. Established since Sumby and Pollack in 1954 Lip reading improves intelligibility of speech in noise Large gains reported Speech sounds louder when the listener looks directly at the speaker Audio threshold to detect speech lower (1-2dB) if audio accompanied with lip gesture Visual information can improve speech detection Audiovisual link seen in infants Infants as young as two months can associate between audio and visual
12 Initially combines audio-only beamforming with visually derived filtering Adds a lipreading component to an audioonly system
13 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 13
14 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 14
15 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 15


16 Simulated Room Environment Speech located at one location in room Noise at a different location Microphones then read simulated noisy convolved speech mixture Four microphone array used Produces four noisy speech signals Each signal windowed into 25ms frames Fourier Transform used to produce 128 dim power spectrum and phase of each signal
17 Audio Feature Extraction Visual Feature Extraction Visual Filtering Audio Beamforming Fuzzy Logic Controller 17


18 Video Recordings Viola-Jones Lip Detector Used to locate ROI Tracks each image automatically to get corner points of chosen ROI We are using lips as the ROI We extract DCT of mouth region from ROI of each frame Automatic lip tracking used to track ROI in sequence DCT extracted Interpolated to match audio frames 18
19

20
21 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 21

22 Wiener filtering W(f) = Est(f) / Noi(f) Estimation of noise free / noisy signal Carry out in frequency domain Calculated power spectrum and phase of noisy Estimated noise free power spectrum from visual data Want to modify power spectrum to produced enhanced value Noiseless log FB Estimation Uses GMM-GMR originally used for robot arm training Uses training data from GRID corpus 400 sentences chosen from four speakers Each sentence contains joint audiovisual vectors 22
23 Noiseless log FB Estimation Uses GMM-GMR Originally used for robot arm training Gaussian Mixture Models Gaussian Mixture Regression 8 components currently used K-means clustering to initialise EM Clustering to train Uses training data from GRID corpus 400 sentences chosen from four speakers Each sentence contains joint audiovisual vectors Allows us to estimate audio frames, given visual 23
24 Visual DCT vector input for each speech frame GMM GMR produces a smoothed estimate of equivalent audio Attempts to predict speech fb vectors from visual information Power Spectrum Interpolation 23 dim Log filterbank vector interpolated with Pchip To create 128 dim PS estimate of noise free system This can be used as part of a wiener filtering approach Currently still Early stage Errors in estimation Results in distorted speech Result of using simple model and interpolation 24
25 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 25
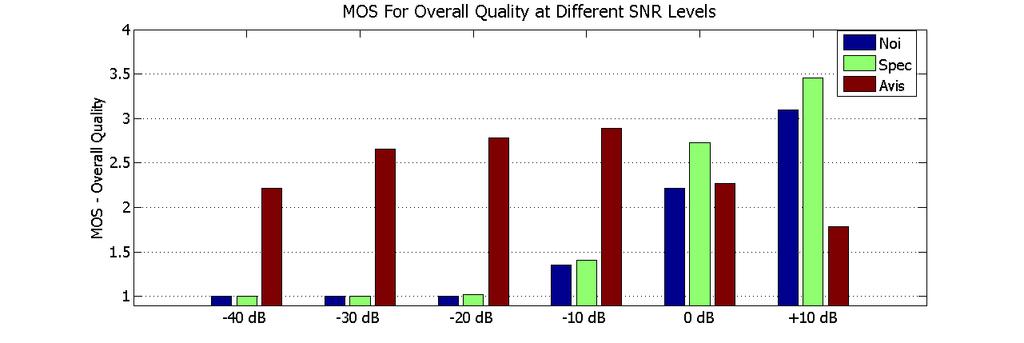
26 Composite objective measures Combination of several measures (PESQ, SegSNR) Compare to noisy speech and audio-only spectral subtraction Consider in very noisy environments SNR from -40dB to +10dB Test Data 20 sentences from the GRID Audiovisual Corpus, taken from four speakers Aircraft cockpit noise added to speech sentences Comparison Three versions of each sentence considered Noisy speech with no processing (Noi) An audio only spectral subtraction approach (Spec) Our audiovisual system (Avis)
27 27
28 Significant improvement found at very low SNR levels (- 40dB to -10dB) Unfiltered speech and spectral subtraction produce very poor results Audiovisual filtering produces much better results Higher SNR levels ( 0dB, +10dB) Audiovisual filtering continues to outperform other measures Overall, Audiovisual the strongest performer Particularly at low SNR levels This improvement less prominent when the noise level is lower At +10dB, objective overall score almost identical for noisy, audiovisual, and spectral subtraction Suggests that our system is best at very low SNR levels Environments where conventional approaches might struggle
29 Primary aim of this work is to enhance speech for human listeners Therefore, listening tests using volunteers to score speech subjectively carried out Assess value of objective measures Criteria follows procedures proposed by ITU-T International Telecoms Union Recommendation P.835 Listener Evaluation Listener listens to each sentence Scored from 1 to 5 Results of this assessment used to produce a Mean Opinion Score (MOS) for each criteria Listeners listened to each sentence and scored them Same dataset as objective tests Mean Opinion Scores found 29
30 30
31 At very low SNR levels Spectral Subtraction ineffective Audiovisual results strongly preferred by listeners Performs very well Big improvement seen in terms of preference In less noisy environments Audiovisual filtering performs very poorly Significant speech distortion introduced Reflected in very low listener scores Very strong overall scores at low SNR levels Our system shows a big improvement in these environments Outperforms audio only measure significantly Less strong at high SNR levels Primary problem is the level of speech distortion introduced Audiovisual performs very poorly Other limitations identified 31
 Often, a third phoneme is heard For example, a visual /ga/ combined with an audio /ba/ is often")
32 As stated, more than just lipreading When visual cues used without accurate lip data (dubbing similar audio over lips) Gain in speech intelligibility reported Also demonstrated by the well-known McGurk effect Audiovisual illusion (demonstrated by dubbing a phoneme video with a different sound) Often, a third phoneme is heard For example, a visual /ga/ combined with an audio /ba/ is often heard as /da/. People do not stare at lips all the time Focus on eye region predominantly More use of lips in noisy conditions Similar experiments on primates gaze focused on eye region, focus on lip region during speech
33 Audiovisual Filtering can process a noisy signal using lip information Only effective in certain conditions Other times, may introduce additional distortion or not be needed Other situations, audio only best Quite noisy, Stable source No visual information available Sometimes, unfiltered speech produces better results 33
34 Fuzzy Logic - Rule based system No human control, all controlled by the system inputs Able to adapt to changing audio and visual environment In real world, noise and environmental factors can change Three approaches suited to different environments Two stage filtering Audio Beamforming only No additional processing 34
35 35
36 36
37 As used in hearing aids Considers level audio power (i.e. how much activity) is in a frame
38 Level of detail in each cropped ROI Absolute value of 4th DCT coefficient Value varies image to image, but 4 th coefficient value consistent Compared to moving average of up to 10 previous good values (takes account of drift) Poor quality result in greater difference from mean than good quality Could be wrong ROI, or no ROI detected
39 Previous frame Takes output decision of previous frame Limits oscillation between frames
40 40
41 Fairly common sense If very noisy, use visual information But only if good quality visual information is available If less noise then use audio-only filtering No need for visual information If very low noise, no processing at all Keep background cues Why fuzzy? Can be adjusted and tweaked Not always clear which single rule is applicable Thresholds may vary between users
42 42
43 Several Rules may fire E.g. could be threshold of audio and audiovisual Fuzzy, so not part of crisp set Defuzzifying picks one final output for each frame Audiovisual (high), audio (medium), none (low)
44 Defuzzifying picks one final output for each frame Each frame is then filtered Fuzzy output at each frame used
45 Corpora in literature not sufficient Limited quantity of bad data Generally shot in clean environment Consistent audio and visual noise Custom corpus recorded Scottish volunteers Mix of reading and conversation tasks Emotional speech Audio and video files available
46


47 Speech and noise mixed in a simulated room environment Two noise types tested, broadband and transient Assume good quality visual information at all times
48
49 When the same audio and visual speech information is combined with different types of noise, the fuzzy decision is different. What about intermittent visual data? It isn t always good quality! Difficult to find in common corpora Test a number of sentences with the same noise level

50
51
52
53

54 The system will only use visual information if it is available If the visual information is not good enough, then it has to rely on audio only The switching works What about different levels of noise? Changing the SNR Mixing speech and the same noise at different levels Expect different outputs Use of less visual information when less noisy
55 Mainly audiovisual information when noisy

56 Less noise, less use of visual information
57 Audio only or unfiltered Mirroring human processing
58 Currently limited Limitations with audiovisual model Requires training with new corpus Beamforming artificially good Currently using a broadband noise at a static source Simulated room designed for the beamformer Other improvements also needed
59
60 Currently limited Limitations with audiovisual model Requires training with new corpus Beamforming artificially good Currently using a broadband noise at a static source Simulated room designed for the beamformer Other improvements also needed Shows that fuzzy switching works as expected Uses avis in very noisy environments Audio only in less noisy Not identical though
61 Possible to build a multimodal fuzzy logic based Speech Enhancement System A more flexible system Cognitively inspired use of visual information Can solve problems with individual audio and visual filtering Versatile with regard to different environments Can overcome limitations of individual techniques Can work with wider range of input data Use knowledge about the world Currently limited audio results 61
62 Not a finished proposal... Individual components have been tested General framework is satisfactory Limitations with results due to early stage of implementation Audio results of fuzzy logic limited due to audiovisual model used Fuzzy logic results depend on limited knowledge of environment Beamforming depends on simulated room mixing Much opportunity to upgrade individual components within the single framework
63 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 63
64 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 64
65 Speech segmentation algorithm developed Biologically inspired based on offsets and onsets Taken from AN spikes Tested separately successfully Awaiting integration Improved use of modalities Consider use of AN spikes as input Implemented in other work, can integrate
66 Audio Feature Extraction Visual Feature Extraction Visual Filtering Audio Beamforming Fuzzy Logic Controller 66
67 Alternative Visual Processing options Optical flow DCT of optical flow Shape models Additional visual modalities Eye region (eyebrows etc.) Body language Temporal element to processing Sequence of frames 67
68 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 68
69 This model is very basic Is in urgent need of improvement Currently single gaussian model Try Phoneme specific model Segment specific model Improved machine learning approach Neural network, HMM, Genetic Algorithm? Have audiovisual data, overall framework Need time and expertise... Different approach to filtering speech Comparison of approaches 69
70 Audio Feature Extraction Visual Feature Extraction Visually Derived Filtering Audio Beamforming Fuzzy Logic Controller 70

71 Improve to more state of the art model Adjust programming to use with real room rather than simulated room Use visual information for directional filtering Knowledge of source 71
72 Fuzzy Logic - Rule based system No human control, all controlled by the system inputs Able to adapt to changing audio and visual environment In real world, noise and environmental factors can change Three approaches suited to different environments Two stage filtering Audio Beamforming only No additional processing 72
73 Concept functions well Chosen detectors work Results are satisfactory Additional detectors and rules could be used Take account of any additional segmentation/modalities Consider more information about environment and sources More than just fuzzy logic? Make use of more modalities and outputs in a blackboard system
74 More than lipreading Hearing and listening depend on many factors Knowledge of language Understanding of accents Context of conversation Prediction of next words based on previous content Overall mood Body language Emotion, gestures, facial movements, volume
75 Cognitively inspired Hearsay system Blackboard
76 Cognitively inspired filtering aims to design hearing systems that function in a manner inspired by humans Take account of the environment when filtering Combine multiple modalities Switch between processing as appropriate Ignore information when not useful A different direction to current hearing aid development Overall grant in preparation Framework has been presented and tested Much potential for upgrades of individual components within this framework
77 Thank you all for listening Questions? Contact Details Dr Andrew Abel (Speech filtering research)
Principles of Audio Coding
 Principles of Audio Coding Topics today Introduction VOCODERS Psychoacoustics Equal-Loudness Curve Frequency Masking Temporal Masking (CSIT 410) 2 Introduction Speech compression algorithm focuses on exploiting
Principles of Audio Coding Topics today Introduction VOCODERS Psychoacoustics Equal-Loudness Curve Frequency Masking Temporal Masking (CSIT 410) 2 Introduction Speech compression algorithm focuses on exploiting
Towards Audiovisual TTS
 Towards Audiovisual TTS in Estonian Einar MEISTER a, SaschaFAGEL b and RainerMETSVAHI a a Institute of Cybernetics at Tallinn University of Technology, Estonia b zoobemessageentertainmentgmbh, Berlin,
Towards Audiovisual TTS in Estonian Einar MEISTER a, SaschaFAGEL b and RainerMETSVAHI a a Institute of Cybernetics at Tallinn University of Technology, Estonia b zoobemessageentertainmentgmbh, Berlin,
Audio-coding standards
 Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
Introducing Audio Signal Processing & Audio Coding. Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd
 Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd Overview Audio Signal Processing Applications @ Dolby Audio Signal Processing Basics
Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd Overview Audio Signal Processing Applications @ Dolby Audio Signal Processing Basics
Two-Layered Audio-Visual Speech Recognition for Robots in Noisy Environments
 The 2 IEEE/RSJ International Conference on Intelligent Robots and Systems October 8-22, 2, Taipei, Taiwan Two-Layered Audio-Visual Speech Recognition for Robots in Noisy Environments Takami Yoshida, Kazuhiro
The 2 IEEE/RSJ International Conference on Intelligent Robots and Systems October 8-22, 2, Taipei, Taiwan Two-Layered Audio-Visual Speech Recognition for Robots in Noisy Environments Takami Yoshida, Kazuhiro
Bb Collaborate. Virtual Classroom and Web Conferencing
 Bb Collaborate Virtual Classroom and Web Conferencing Bb Collaborate Participant Interface and Basic Moderator Controls The Blackboard Collaborate participant interface has 4 main areas. 1. Audio & Video
Bb Collaborate Virtual Classroom and Web Conferencing Bb Collaborate Participant Interface and Basic Moderator Controls The Blackboard Collaborate participant interface has 4 main areas. 1. Audio & Video
Perspectives on Multimedia Quality Prediction Methodologies for Advanced Mobile and IP-based Telephony
 Perspectives on Multimedia Quality Prediction Methodologies for Advanced Mobile and IP-based Telephony Nobuhiko Kitawaki University of Tsukuba 1-1-1, Tennoudai, Tsukuba-shi, 305-8573 Japan. E-mail: kitawaki@cs.tsukuba.ac.jp
Perspectives on Multimedia Quality Prediction Methodologies for Advanced Mobile and IP-based Telephony Nobuhiko Kitawaki University of Tsukuba 1-1-1, Tennoudai, Tsukuba-shi, 305-8573 Japan. E-mail: kitawaki@cs.tsukuba.ac.jp
Introducing Audio Signal Processing & Audio Coding. Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd
 Dolby Australia Pty Ltd") Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd Introducing Audio Signal Processing & Audio Coding 2013 Dolby Laboratories,
Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd Introducing Audio Signal Processing & Audio Coding 2013 Dolby Laboratories,
Detection of Mouth Movements and Its Applications to Cross-Modal Analysis of Planning Meetings
 2009 International Conference on Multimedia Information Networking and Security Detection of Mouth Movements and Its Applications to Cross-Modal Analysis of Planning Meetings Yingen Xiong Nokia Research
2009 International Conference on Multimedia Information Networking and Security Detection of Mouth Movements and Its Applications to Cross-Modal Analysis of Planning Meetings Yingen Xiong Nokia Research
Hands On: Multimedia Methods for Large Scale Video Analysis (Lecture) Dr. Gerald Friedland,
 Dr. Gerald Friedland,") Hands On: Multimedia Methods for Large Scale Video Analysis (Lecture) Dr. Gerald Friedland, fractor@icsi.berkeley.edu 1 Today Recap: Some more Machine Learning Multimedia Systems An example Multimedia
Hands On: Multimedia Methods for Large Scale Video Analysis (Lecture) Dr. Gerald Friedland, fractor@icsi.berkeley.edu 1 Today Recap: Some more Machine Learning Multimedia Systems An example Multimedia
System Identification Related Problems at SMN
 Ericsson research SeRvices, MulTimedia and Network Features System Identification Related Problems at SMN Erlendur Karlsson SysId Related Problems @ ER/SMN Ericsson External 2016-05-09 Page 1 Outline Research
Ericsson research SeRvices, MulTimedia and Network Features System Identification Related Problems at SMN Erlendur Karlsson SysId Related Problems @ ER/SMN Ericsson External 2016-05-09 Page 1 Outline Research
System Identification Related Problems at
 media Technologies @ Ericsson research (New organization Taking Form) System Identification Related Problems at MT@ER Erlendur Karlsson, PhD 1 Outline Ericsson Publications and Blogs System Identification
media Technologies @ Ericsson research (New organization Taking Form) System Identification Related Problems at MT@ER Erlendur Karlsson, PhD 1 Outline Ericsson Publications and Blogs System Identification
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 213 http://acousticalsociety.org/ ICA 213 Montreal Montreal, Canada 2-7 June 213 Engineering Acoustics Session 2pEAb: Controlling Sound Quality 2pEAb1. Subjective
Proceedings of Meetings on Acoustics Volume 19, 213 http://acousticalsociety.org/ ICA 213 Montreal Montreal, Canada 2-7 June 213 Engineering Acoustics Session 2pEAb: Controlling Sound Quality 2pEAb1. Subjective
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 13 Audio Signal Processing 14/04/01 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 13 Audio Signal Processing 14/04/01 http://www.ee.unlv.edu/~b1morris/ee482/
AUDIO SIGNAL PROCESSING FOR NEXT- GENERATION MULTIMEDIA COMMUNI CATION SYSTEMS
 AUDIO SIGNAL PROCESSING FOR NEXT- GENERATION MULTIMEDIA COMMUNI CATION SYSTEMS Edited by YITENG (ARDEN) HUANG Bell Laboratories, Lucent Technologies JACOB BENESTY Universite du Quebec, INRS-EMT Kluwer
AUDIO SIGNAL PROCESSING FOR NEXT- GENERATION MULTIMEDIA COMMUNI CATION SYSTEMS Edited by YITENG (ARDEN) HUANG Bell Laboratories, Lucent Technologies JACOB BENESTY Universite du Quebec, INRS-EMT Kluwer
Interference Reduction in Reverberant Speech Separation With Visual Voice Activity Detection
 1610 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 16, NO. 6, OCTOBER 2014 Interference Reduction in Reverberant Speech Separation With Visual Voice Activity Detection Qingju Liu, Andrew J. Aubrey, Member, IEEE,
1610 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 16, NO. 6, OCTOBER 2014 Interference Reduction in Reverberant Speech Separation With Visual Voice Activity Detection Qingju Liu, Andrew J. Aubrey, Member, IEEE,
Automatic Enhancement of Correspondence Detection in an Object Tracking System
 Automatic Enhancement of Correspondence Detection in an Object Tracking System Denis Schulze 1, Sven Wachsmuth 1 and Katharina J. Rohlfing 2 1- University of Bielefeld - Applied Informatics Universitätsstr.
Automatic Enhancement of Correspondence Detection in an Object Tracking System Denis Schulze 1, Sven Wachsmuth 1 and Katharina J. Rohlfing 2 1- University of Bielefeld - Applied Informatics Universitätsstr.
3G Services Present New Challenges For Network Performance Evaluation
 3G Services Present New Challenges For Network Performance Evaluation 2004-29-09 1 Outline Synopsis of speech, audio, and video quality evaluation metrics Performance evaluation challenges related to 3G
3G Services Present New Challenges For Network Performance Evaluation 2004-29-09 1 Outline Synopsis of speech, audio, and video quality evaluation metrics Performance evaluation challenges related to 3G
Andrea PureAudio BT-200 Noise Canceling Bluetooth Headset Performance Comparative Testing
 Andrea Audio Test Labs Andrea PureAudio BT-200 Noise Canceling Bluetooth Headset August 28 th 2008 Rev A Andrea Electronics Corporation 65 Orville Drive Suite One Bohemia NY 11716 (631)-719-1800 www.andreaelectronics.com
Andrea Audio Test Labs Andrea PureAudio BT-200 Noise Canceling Bluetooth Headset August 28 th 2008 Rev A Andrea Electronics Corporation 65 Orville Drive Suite One Bohemia NY 11716 (631)-719-1800 www.andreaelectronics.com
Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing
 Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing Samer Al Moubayed Center for Speech Technology, Department of Speech, Music, and Hearing, KTH, Sweden. sameram@kth.se
Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing Samer Al Moubayed Center for Speech Technology, Department of Speech, Music, and Hearing, KTH, Sweden. sameram@kth.se
Audio-coding standards
 Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
Synopsis of Basic VoIP Concepts
 APPENDIX B The Catalyst 4224 Access Gateway Switch (Catalyst 4224) provides Voice over IP (VoIP) gateway applications for a micro branch office. This chapter introduces some basic VoIP concepts. This chapter
APPENDIX B The Catalyst 4224 Access Gateway Switch (Catalyst 4224) provides Voice over IP (VoIP) gateway applications for a micro branch office. This chapter introduces some basic VoIP concepts. This chapter
Multifactor Fusion for Audio-Visual Speaker Recognition
 Proceedings of the 7th WSEAS International Conference on Signal, Speech and Image Processing, Beijing, China, September 15-17, 2007 70 Multifactor Fusion for Audio-Visual Speaker Recognition GIRIJA CHETTY
Proceedings of the 7th WSEAS International Conference on Signal, Speech and Image Processing, Beijing, China, September 15-17, 2007 70 Multifactor Fusion for Audio-Visual Speaker Recognition GIRIJA CHETTY
2-2-2, Hikaridai, Seika-cho, Soraku-gun, Kyoto , Japan 2 Graduate School of Information Science, Nara Institute of Science and Technology
 ISCA Archive STREAM WEIGHT OPTIMIZATION OF SPEECH AND LIP IMAGE SEQUENCE FOR AUDIO-VISUAL SPEECH RECOGNITION Satoshi Nakamura 1 Hidetoshi Ito 2 Kiyohiro Shikano 2 1 ATR Spoken Language Translation Research
ISCA Archive STREAM WEIGHT OPTIMIZATION OF SPEECH AND LIP IMAGE SEQUENCE FOR AUDIO-VISUAL SPEECH RECOGNITION Satoshi Nakamura 1 Hidetoshi Ito 2 Kiyohiro Shikano 2 1 ATR Spoken Language Translation Research
Data-Driven Face Modeling and Animation
 1. Research Team Data-Driven Face Modeling and Animation Project Leader: Post Doc(s): Graduate Students: Undergraduate Students: Prof. Ulrich Neumann, IMSC and Computer Science John P. Lewis Zhigang Deng,
1. Research Team Data-Driven Face Modeling and Animation Project Leader: Post Doc(s): Graduate Students: Undergraduate Students: Prof. Ulrich Neumann, IMSC and Computer Science John P. Lewis Zhigang Deng,
Getting Started with Crazy Talk 6
 Getting Started with Crazy Talk 6 Crazy Talk 6 is an application that generates talking characters from an image or photo, as well as facial animation for video. Importing an Image Launch Crazy Talk and
Getting Started with Crazy Talk 6 Crazy Talk 6 is an application that generates talking characters from an image or photo, as well as facial animation for video. Importing an Image Launch Crazy Talk and
AUDIOVISUAL COMMUNICATION
 AUDIOVISUAL COMMUNICATION Laboratory Session: Audio Processing and Coding The objective of this lab session is to get the students familiar with audio processing and coding, notably psychoacoustic analysis
AUDIOVISUAL COMMUNICATION Laboratory Session: Audio Processing and Coding The objective of this lab session is to get the students familiar with audio processing and coding, notably psychoacoustic analysis
Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008.
 Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008. Introduction There is much that is unknown regarding
Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008. Introduction There is much that is unknown regarding
Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information
 Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information Mustafa Berkay Yilmaz, Hakan Erdogan, Mustafa Unel Sabanci University, Faculty of Engineering and Natural
Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information Mustafa Berkay Yilmaz, Hakan Erdogan, Mustafa Unel Sabanci University, Faculty of Engineering and Natural
1 Audio quality determination based on perceptual measurement techniques 1 John G. Beerends
 Contents List of Figures List of Tables Contributing Authors xiii xxi xxiii Introduction Karlheinz Brandenburg and Mark Kahrs xxix 1 Audio quality determination based on perceptual measurement techniques
Contents List of Figures List of Tables Contributing Authors xiii xxi xxiii Introduction Karlheinz Brandenburg and Mark Kahrs xxix 1 Audio quality determination based on perceptual measurement techniques
Headphones: technologies, devices, and applications Workshop presented by CIRMMT RA-1: Instruments, devices, and systems April 19, h30-16h30
 Headphones: technologies, devices, and applications Workshop presented by CIRMMT RA-1: Instruments, devices, and systems April 19, 2017 13h30-16h30 13h30-14h00: D. Quiroz Smyth realiser: virtual surround
Headphones: technologies, devices, and applications Workshop presented by CIRMMT RA-1: Instruments, devices, and systems April 19, 2017 13h30-16h30 13h30-14h00: D. Quiroz Smyth realiser: virtual surround
Bo#leneck Features from SNR- Adap9ve Denoising Deep Classifier for Speaker Iden9fica9on
 Bo#leneck Features from SNR- Adap9ve Denoising Deep Classifier for Speaker Iden9fica9on TAN Zhili & MAK Man-Wai APSIPA 2015 Department of Electronic and Informa2on Engineering The Hong Kong Polytechnic
Bo#leneck Features from SNR- Adap9ve Denoising Deep Classifier for Speaker Iden9fica9on TAN Zhili & MAK Man-Wai APSIPA 2015 Department of Electronic and Informa2on Engineering The Hong Kong Polytechnic
Multimedia Communications. Audio coding
 Multimedia Communications Audio coding Introduction Lossy compression schemes can be based on source model (e.g., speech compression) or user model (audio coding) Unlike speech, audio signals can be generated
Multimedia Communications Audio coding Introduction Lossy compression schemes can be based on source model (e.g., speech compression) or user model (audio coding) Unlike speech, audio signals can be generated
Subjective Audiovisual Quality in Mobile Environment
 Vienna University of Technology Faculty of Electrical Engineering and Information Technology Institute of Communications and Radio-Frequency Engineering Master of Science Thesis Subjective Audiovisual
Vienna University of Technology Faculty of Electrical Engineering and Information Technology Institute of Communications and Radio-Frequency Engineering Master of Science Thesis Subjective Audiovisual
AUDIOVISUAL COMMUNICATION
 AUDIOVISUAL COMMUNICATION Laboratory Session: Audio Processing and Coding The objective of this lab session is to get the students familiar with audio processing and coding, notably psychoacoustic analysis
AUDIOVISUAL COMMUNICATION Laboratory Session: Audio Processing and Coding The objective of this lab session is to get the students familiar with audio processing and coding, notably psychoacoustic analysis
CT516 Advanced Digital Communications Lecture 7: Speech Encoder
 CT516 Advanced Digital Communications Lecture 7: Speech Encoder Yash M. Vasavada Associate Professor, DA-IICT, Gandhinagar 2nd February 2017 Yash M. Vasavada (DA-IICT) CT516: Adv. Digital Comm. 2nd February
CT516 Advanced Digital Communications Lecture 7: Speech Encoder Yash M. Vasavada Associate Professor, DA-IICT, Gandhinagar 2nd February 2017 Yash M. Vasavada (DA-IICT) CT516: Adv. Digital Comm. 2nd February
Topics for thesis. Automatic Speech-based Emotion Recognition
 Topics for thesis Bachelor: Automatic Speech-based Emotion Recognition Emotion recognition is an important part of Human-Computer Interaction (HCI). It has various applications in industrial and commercial
Topics for thesis Bachelor: Automatic Speech-based Emotion Recognition Emotion recognition is an important part of Human-Computer Interaction (HCI). It has various applications in industrial and commercial
5: Music Compression. Music Coding. Mark Handley
 5: Music Compression Mark Handley Music Coding LPC-based codecs model the sound source to achieve good compression. Works well for voice. Terrible for music. What if you can t model the source? Model the
5: Music Compression Mark Handley Music Coding LPC-based codecs model the sound source to achieve good compression. Works well for voice. Terrible for music. What if you can t model the source? Model the
End-to-end speech and audio quality evaluation of networks using AQuA - competitive alternative for PESQ (P.862) Endre Domiczi Sevana Oy
 Endre Domiczi Sevana Oy") End-to-end speech and audio quality evaluation of networks using AQuA - competitive alternative for PESQ (P.862) Endre Domiczi Sevana Oy Overview Significance of speech and audio quality Problems with
End-to-end speech and audio quality evaluation of networks using AQuA - competitive alternative for PESQ (P.862) Endre Domiczi Sevana Oy Overview Significance of speech and audio quality Problems with
Video Processing for Judicial Applications
 Video Processing for Judicial Applications Konstantinos Avgerinakis, Alexia Briassouli, Ioannis Kompatsiaris Informatics and Telematics Institute, Centre for Research and Technology, Hellas Thessaloniki,
Video Processing for Judicial Applications Konstantinos Avgerinakis, Alexia Briassouli, Ioannis Kompatsiaris Informatics and Telematics Institute, Centre for Research and Technology, Hellas Thessaloniki,
Confusability of Phonemes Grouped According to their Viseme Classes in Noisy Environments
 PAGE 265 Confusability of Phonemes Grouped According to their Viseme Classes in Noisy Environments Patrick Lucey, Terrence Martin and Sridha Sridharan Speech and Audio Research Laboratory Queensland University
PAGE 265 Confusability of Phonemes Grouped According to their Viseme Classes in Noisy Environments Patrick Lucey, Terrence Martin and Sridha Sridharan Speech and Audio Research Laboratory Queensland University
Maximum Likelihood Beamforming for Robust Automatic Speech Recognition
 Maximum Likelihood Beamforming for Robust Automatic Speech Recognition Barbara Rauch barbara@lsv.uni-saarland.de IGK Colloquium, Saarbrücken, 16 February 2006 Agenda Background: Standard ASR Robust ASR
Maximum Likelihood Beamforming for Robust Automatic Speech Recognition Barbara Rauch barbara@lsv.uni-saarland.de IGK Colloquium, Saarbrücken, 16 February 2006 Agenda Background: Standard ASR Robust ASR
GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS. Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1)
, Gabi Nakibly (2) and Dan Boneh (1)") GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1) (1) Stanford University (2) National Research and Simulation Center, Rafael Ltd. 0 MICROPHONE
GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1) (1) Stanford University (2) National Research and Simulation Center, Rafael Ltd. 0 MICROPHONE
Distributed Signal Processing for Binaural Hearing Aids
 Distributed Signal Processing for Binaural Hearing Aids Olivier Roy LCAV - I&C - EPFL Joint work with Martin Vetterli July 24, 2008 Outline 1 Motivations 2 Information-theoretic Analysis 3 Example: Distributed
Distributed Signal Processing for Binaural Hearing Aids Olivier Roy LCAV - I&C - EPFL Joint work with Martin Vetterli July 24, 2008 Outline 1 Motivations 2 Information-theoretic Analysis 3 Example: Distributed
SPEECH FEATURE EXTRACTION USING WEIGHTED HIGHER-ORDER LOCAL AUTO-CORRELATION
 Far East Journal of Electronics and Communications Volume 3, Number 2, 2009, Pages 125-140 Published Online: September 14, 2009 This paper is available online at http://www.pphmj.com 2009 Pushpa Publishing
Far East Journal of Electronics and Communications Volume 3, Number 2, 2009, Pages 125-140 Published Online: September 14, 2009 This paper is available online at http://www.pphmj.com 2009 Pushpa Publishing
Conference IAFPA 2007 Plymouth, UK
 Conference IAFPA 2007 Plymouth, UK Increasing Speech Intelligibility by DeNoising: What can be achieved? Jan Rademacher, Jörg Bitzer, Jörg Houpert University of Oldenburg, Medical Physics, Oldenburg, Germany
Conference IAFPA 2007 Plymouth, UK Increasing Speech Intelligibility by DeNoising: What can be achieved? Jan Rademacher, Jörg Bitzer, Jörg Houpert University of Oldenburg, Medical Physics, Oldenburg, Germany
TOWARDS A HIGH QUALITY FINNISH TALKING HEAD
 TOWARDS A HIGH QUALITY FINNISH TALKING HEAD Jean-Luc Oliv&s, Mikko Sam, Janne Kulju and Otto Seppala Helsinki University of Technology Laboratory of Computational Engineering, P.O. Box 9400, Fin-02015
TOWARDS A HIGH QUALITY FINNISH TALKING HEAD Jean-Luc Oliv&s, Mikko Sam, Janne Kulju and Otto Seppala Helsinki University of Technology Laboratory of Computational Engineering, P.O. Box 9400, Fin-02015
The Jabra Evolve Series A range of professional headsets to enhance productivity in the open office.
 The Jabra Evolve Series A range of professional headsets to enhance productivity in the open office. Enhance concentration and productivity in the open office with the Jabra Evolve Series. Easy to use
The Jabra Evolve Series A range of professional headsets to enhance productivity in the open office. Enhance concentration and productivity in the open office with the Jabra Evolve Series. Easy to use
COPYRIGHTED MATERIAL. Introduction. 1.1 Introduction
 1 Introduction 1.1 Introduction One of the most fascinating characteristics of humans is their capability to communicate ideas by means of speech. This capability is undoubtedly one of the facts that has
1 Introduction 1.1 Introduction One of the most fascinating characteristics of humans is their capability to communicate ideas by means of speech. This capability is undoubtedly one of the facts that has
Perceptual Coding. Lossless vs. lossy compression Perceptual models Selecting info to eliminate Quantization and entropy encoding
 Perceptual Coding Lossless vs. lossy compression Perceptual models Selecting info to eliminate Quantization and entropy encoding Part II wrap up 6.082 Fall 2006 Perceptual Coding, Slide 1 Lossless vs.
Perceptual Coding Lossless vs. lossy compression Perceptual models Selecting info to eliminate Quantization and entropy encoding Part II wrap up 6.082 Fall 2006 Perceptual Coding, Slide 1 Lossless vs.
LIP ACTIVITY DETECTION FOR TALKING FACES CLASSIFICATION IN TV-CONTENT
 LIP ACTIVITY DETECTION FOR TALKING FACES CLASSIFICATION IN TV-CONTENT Meriem Bendris 1,2, Delphine Charlet 1, Gérard Chollet 2 1 France Télécom R&D - Orange Labs, France 2 CNRS LTCI, TELECOM-ParisTech,
LIP ACTIVITY DETECTION FOR TALKING FACES CLASSIFICATION IN TV-CONTENT Meriem Bendris 1,2, Delphine Charlet 1, Gérard Chollet 2 1 France Télécom R&D - Orange Labs, France 2 CNRS LTCI, TELECOM-ParisTech,
INTERNATIONAL TELECOMMUNICATION UNION
 INTERNATIONAL TELECOMMUNICATION UNION ITU-T TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU P.862.1 (11/2003) SERIES P: TELEPHONE TRANSMISSION QUALITY, TELEPHONE INSTALLATIONS, LOCAL LINE NETWORKS Methods
INTERNATIONAL TELECOMMUNICATION UNION ITU-T TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU P.862.1 (11/2003) SERIES P: TELEPHONE TRANSMISSION QUALITY, TELEPHONE INSTALLATIONS, LOCAL LINE NETWORKS Methods
Agenda. ! Efficient Coding Hypothesis. ! Response Function and Optimal Stimulus Ensemble. ! Firing-Rate Code. ! Spike-Timing Code
 1 Agenda! Efficient Coding Hypothesis! Response Function and Optimal Stimulus Ensemble! Firing-Rate Code! Spike-Timing Code! OSE vs Natural Stimuli! Conclusion 2 Efficient Coding Hypothesis! [Sensory systems]
1 Agenda! Efficient Coding Hypothesis! Response Function and Optimal Stimulus Ensemble! Firing-Rate Code! Spike-Timing Code! OSE vs Natural Stimuli! Conclusion 2 Efficient Coding Hypothesis! [Sensory systems]
Neetha Das Prof. Andy Khong
 Neetha Das Prof. Andy Khong Contents Introduction and aim Current system at IMI Proposed new classification model Support Vector Machines Initial audio data collection and processing Features and their
Neetha Das Prof. Andy Khong Contents Introduction and aim Current system at IMI Proposed new classification model Support Vector Machines Initial audio data collection and processing Features and their
Chapter 14 MPEG Audio Compression
 Chapter 14 MPEG Audio Compression 14.1 Psychoacoustics 14.2 MPEG Audio 14.3 Other Commercial Audio Codecs 14.4 The Future: MPEG-7 and MPEG-21 14.5 Further Exploration 1 Li & Drew c Prentice Hall 2003 14.1
Chapter 14 MPEG Audio Compression 14.1 Psychoacoustics 14.2 MPEG Audio 14.3 Other Commercial Audio Codecs 14.4 The Future: MPEG-7 and MPEG-21 14.5 Further Exploration 1 Li & Drew c Prentice Hall 2003 14.1
Reservoir Computing with Emphasis on Liquid State Machines
 Reservoir Computing with Emphasis on Liquid State Machines Alex Klibisz University of Tennessee aklibisz@gmail.com November 28, 2016 Context and Motivation Traditional ANNs are useful for non-linear problems,
Reservoir Computing with Emphasis on Liquid State Machines Alex Klibisz University of Tennessee aklibisz@gmail.com November 28, 2016 Context and Motivation Traditional ANNs are useful for non-linear problems,
Call for Proposals Media Technology HIRP OPEN 2017
 Call for Proposals HIRP OPEN 2017 1 Copyright Huawei Technologies Co., Ltd. 2015-2016. All rights reserved. No part of this document may be reproduced or transmitted in any form or by any means without
Call for Proposals HIRP OPEN 2017 1 Copyright Huawei Technologies Co., Ltd. 2015-2016. All rights reserved. No part of this document may be reproduced or transmitted in any form or by any means without
Advanced Image Reconstruction Methods for Photoacoustic Tomography
 Advanced Image Reconstruction Methods for Photoacoustic Tomography Mark A. Anastasio, Kun Wang, and Robert Schoonover Department of Biomedical Engineering Washington University in St. Louis 1 Outline Photoacoustic/thermoacoustic
Advanced Image Reconstruction Methods for Photoacoustic Tomography Mark A. Anastasio, Kun Wang, and Robert Schoonover Department of Biomedical Engineering Washington University in St. Louis 1 Outline Photoacoustic/thermoacoustic
ijdsp Interactive Illustrations of Speech/Audio Processing Concepts
 ijdsp Interactive Illustrations of Speech/Audio Processing Concepts NSF Phase 3 Workshop, UCy Presentation of an Independent Study By Girish Kalyanasundaram, MS by Thesis in EE Advisor: Dr. Andreas Spanias,
ijdsp Interactive Illustrations of Speech/Audio Processing Concepts NSF Phase 3 Workshop, UCy Presentation of an Independent Study By Girish Kalyanasundaram, MS by Thesis in EE Advisor: Dr. Andreas Spanias,
Principles of MPEG audio compression
 Principles of MPEG audio compression Principy komprese hudebního signálu metodou MPEG Petr Kubíček Abstract The article describes briefly audio data compression. Focus of the article is a MPEG standard,
Principles of MPEG audio compression Principy komprese hudebního signálu metodou MPEG Petr Kubíček Abstract The article describes briefly audio data compression. Focus of the article is a MPEG standard,
BINAURAL SOUND LOCALIZATION FOR UNTRAINED DIRECTIONS BASED ON A GAUSSIAN MIXTURE MODEL
 BINAURAL SOUND LOCALIZATION FOR UNTRAINED DIRECTIONS BASED ON A GAUSSIAN MIXTURE MODEL Takanori Nishino and Kazuya Takeda Center for Information Media Studies, Nagoya University Furo-cho, Chikusa-ku, Nagoya,
BINAURAL SOUND LOCALIZATION FOR UNTRAINED DIRECTIONS BASED ON A GAUSSIAN MIXTURE MODEL Takanori Nishino and Kazuya Takeda Center for Information Media Studies, Nagoya University Furo-cho, Chikusa-ku, Nagoya,
2.4 Audio Compression
 2.4 Audio Compression 2.4.1 Pulse Code Modulation Audio signals are analog waves. The acoustic perception is determined by the frequency (pitch) and the amplitude (loudness). For storage, processing and
2.4 Audio Compression 2.4.1 Pulse Code Modulation Audio signals are analog waves. The acoustic perception is determined by the frequency (pitch) and the amplitude (loudness). For storage, processing and
Evaluation of VoIP Speech Quality Using Neural Network
 Journal of Communication and Computer 12 (2015) 237-243 doi: 10.17265/1548-7709/2015.05.003 D DAVID PUBLISHING Evaluation of VoIP Speech Quality Using Neural Network Angel Garabitov and Aleksandar Tsenov
Journal of Communication and Computer 12 (2015) 237-243 doi: 10.17265/1548-7709/2015.05.003 D DAVID PUBLISHING Evaluation of VoIP Speech Quality Using Neural Network Angel Garabitov and Aleksandar Tsenov
FACIAL MOVEMENT BASED PERSON AUTHENTICATION
 FACIAL MOVEMENT BASED PERSON AUTHENTICATION Pengqing Xie Yang Liu (Presenter) Yong Guan Iowa State University Department of Electrical and Computer Engineering OUTLINE Introduction Literature Review Methodology
FACIAL MOVEMENT BASED PERSON AUTHENTICATION Pengqing Xie Yang Liu (Presenter) Yong Guan Iowa State University Department of Electrical and Computer Engineering OUTLINE Introduction Literature Review Methodology
New Results in Low Bit Rate Speech Coding and Bandwidth Extension
 Audio Engineering Society Convention Paper Presented at the 121st Convention 2006 October 5 8 San Francisco, CA, USA This convention paper has been reproduced from the author's advance manuscript, without
Audio Engineering Society Convention Paper Presented at the 121st Convention 2006 October 5 8 San Francisco, CA, USA This convention paper has been reproduced from the author's advance manuscript, without
M I RA Lab. Speech Animation. Where do we stand today? Speech Animation : Hierarchy. What are the technologies?
 MIRALab Where Research means Creativity Where do we stand today? M I RA Lab Nadia Magnenat-Thalmann MIRALab, University of Geneva thalmann@miralab.unige.ch Video Input (face) Audio Input (speech) FAP Extraction
MIRALab Where Research means Creativity Where do we stand today? M I RA Lab Nadia Magnenat-Thalmann MIRALab, University of Geneva thalmann@miralab.unige.ch Video Input (face) Audio Input (speech) FAP Extraction
Spectral modeling of musical sounds
 Spectral modeling of musical sounds Xavier Serra Audiovisual Institute, Pompeu Fabra University http://www.iua.upf.es xserra@iua.upf.es 1. Introduction Spectral based analysis/synthesis techniques offer
Spectral modeling of musical sounds Xavier Serra Audiovisual Institute, Pompeu Fabra University http://www.iua.upf.es xserra@iua.upf.es 1. Introduction Spectral based analysis/synthesis techniques offer
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Lecture #9: Image Resizing and Segmentation
 Lecture #9: Image Resizing and Segmentation Mason Swofford, Rachel Gardner, Yue Zhang, Shawn Fenerin Department of Computer Science Stanford University Stanford, CA 94305 {mswoff, rachel0, yzhang16, sfenerin}@cs.stanford.edu
Lecture #9: Image Resizing and Segmentation Mason Swofford, Rachel Gardner, Yue Zhang, Shawn Fenerin Department of Computer Science Stanford University Stanford, CA 94305 {mswoff, rachel0, yzhang16, sfenerin}@cs.stanford.edu
Multi-pose lipreading and audio-visual speech recognition
 RESEARCH Open Access Multi-pose lipreading and audio-visual speech recognition Virginia Estellers * and Jean-Philippe Thiran Abstract In this article, we study the adaptation of visual and audio-visual
RESEARCH Open Access Multi-pose lipreading and audio-visual speech recognition Virginia Estellers * and Jean-Philippe Thiran Abstract In this article, we study the adaptation of visual and audio-visual
Chapter 5.5 Audio Programming
 Chapter 5.5 Audio Programming Audio Programming Audio in games is more important than ever before 2 Programming Basic Audio Most gaming hardware has similar capabilities (on similar platforms) Mostly programming
Chapter 5.5 Audio Programming Audio Programming Audio in games is more important than ever before 2 Programming Basic Audio Most gaming hardware has similar capabilities (on similar platforms) Mostly programming
Making an on-device personal assistant a reality
 June 2018 @qualcomm_tech Making an on-device personal assistant a reality Qualcomm Technologies, Inc. AI brings human-like understanding and behaviors to the machines Perception Hear, see, and observe
June 2018 @qualcomm_tech Making an on-device personal assistant a reality Qualcomm Technologies, Inc. AI brings human-like understanding and behaviors to the machines Perception Hear, see, and observe
Real-time Talking Head Driven by Voice and its Application to Communication and Entertainment
 ISCA Archive Real-time Talking Head Driven by Voice and its Application to Communication and Entertainment Shigeo MORISHIMA Seikei University ABSTRACT Recently computer can make cyberspace to walk through
ISCA Archive Real-time Talking Head Driven by Voice and its Application to Communication and Entertainment Shigeo MORISHIMA Seikei University ABSTRACT Recently computer can make cyberspace to walk through
Instructional Sequence for Electromagnetic Waves & Technology
 Grade Level: 7 Content and Performance Expectations Essential Question Disciplinary Core Ideas Cross Cutting Concepts Performance Expectation for Assessment Instructional Sequence for Electromagnetic Waves
Grade Level: 7 Content and Performance Expectations Essential Question Disciplinary Core Ideas Cross Cutting Concepts Performance Expectation for Assessment Instructional Sequence for Electromagnetic Waves
HuddlePod Air Big Audio
 HuddlePod Air Big Audio WIRELESS AUDIO POD and EXTERNAL AUDIO SYSTEM ADAPTER INSTALLATION & OPERATION MANUAL Please check HUDDLECAMHD.com for the most up to date version of this document Product Overview.
HuddlePod Air Big Audio WIRELESS AUDIO POD and EXTERNAL AUDIO SYSTEM ADAPTER INSTALLATION & OPERATION MANUAL Please check HUDDLECAMHD.com for the most up to date version of this document Product Overview.
LOW-DIMENSIONAL MOTION FEATURES FOR AUDIO-VISUAL SPEECH RECOGNITION
 LOW-DIMENSIONAL MOTION FEATURES FOR AUDIO-VISUAL SPEECH Andrés Vallés Carboneras, Mihai Gurban +, and Jean-Philippe Thiran + + Signal Processing Institute, E.T.S.I. de Telecomunicación Ecole Polytechnique
LOW-DIMENSIONAL MOTION FEATURES FOR AUDIO-VISUAL SPEECH Andrés Vallés Carboneras, Mihai Gurban +, and Jean-Philippe Thiran + + Signal Processing Institute, E.T.S.I. de Telecomunicación Ecole Polytechnique
Human Face Classification using Genetic Algorithm
 Human Face Classification using Genetic Algorithm Tania Akter Setu Dept. of Computer Science and Engineering Jatiya Kabi Kazi Nazrul Islam University Trishal, Mymenshing, Bangladesh Dr. Md. Mijanur Rahman
Human Face Classification using Genetic Algorithm Tania Akter Setu Dept. of Computer Science and Engineering Jatiya Kabi Kazi Nazrul Islam University Trishal, Mymenshing, Bangladesh Dr. Md. Mijanur Rahman
University of Huddersfield Repository
 University of Huddersfield Repository Wood, R. and Olszewska, Joanna Isabelle Lighting Variable AdaBoost Based On System for Robust Face Detection Original Citation Wood, R. and Olszewska, Joanna Isabelle
University of Huddersfield Repository Wood, R. and Olszewska, Joanna Isabelle Lighting Variable AdaBoost Based On System for Robust Face Detection Original Citation Wood, R. and Olszewska, Joanna Isabelle
Minimal-Impact Personal Audio Archives
 Minimal-Impact Personal Audio Archives Dan Ellis, Keansub Lee, Jim Ogle Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu
Minimal-Impact Personal Audio Archives Dan Ellis, Keansub Lee, Jim Ogle Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu
BIG DATA-DRIVEN FAST REDUCING THE VISUAL BLOCK ARTIFACTS OF DCT COMPRESSED IMAGES FOR URBAN SURVEILLANCE SYSTEMS
 BIG DATA-DRIVEN FAST REDUCING THE VISUAL BLOCK ARTIFACTS OF DCT COMPRESSED IMAGES FOR URBAN SURVEILLANCE SYSTEMS Ling Hu and Qiang Ni School of Computing and Communications, Lancaster University, LA1 4WA,
BIG DATA-DRIVEN FAST REDUCING THE VISUAL BLOCK ARTIFACTS OF DCT COMPRESSED IMAGES FOR URBAN SURVEILLANCE SYSTEMS Ling Hu and Qiang Ni School of Computing and Communications, Lancaster University, LA1 4WA,
Artificial Visual Speech Synchronized with a Speech Synthesis System
 Artificial Visual Speech Synchronized with a Speech Synthesis System H.H. Bothe und E.A. Wieden Department of Electronics, Technical University Berlin Einsteinufer 17, D-10587 Berlin, Germany Abstract:
Artificial Visual Speech Synchronized with a Speech Synthesis System H.H. Bothe und E.A. Wieden Department of Electronics, Technical University Berlin Einsteinufer 17, D-10587 Berlin, Germany Abstract:
Artificial Neuron Modelling Based on Wave Shape
 Artificial Neuron Modelling Based on Wave Shape Kieran Greer, Distributed Computing Systems, Belfast, UK. http://distributedcomputingsystems.co.uk Version 1.2 Abstract This paper describes a new model
Artificial Neuron Modelling Based on Wave Shape Kieran Greer, Distributed Computing Systems, Belfast, UK. http://distributedcomputingsystems.co.uk Version 1.2 Abstract This paper describes a new model
Parametric Coding of Spatial Audio
 Parametric Coding of Spatial Audio Ph.D. Thesis Christof Faller, September 24, 2004 Thesis advisor: Prof. Martin Vetterli Audiovisual Communications Laboratory, EPFL Lausanne Parametric Coding of Spatial
Parametric Coding of Spatial Audio Ph.D. Thesis Christof Faller, September 24, 2004 Thesis advisor: Prof. Martin Vetterli Audiovisual Communications Laboratory, EPFL Lausanne Parametric Coding of Spatial
CREATE A CONCENTRATION ZONE TO BOOST FOCUS AND PRODUCTIVITY.
 CREATE A CONCENTRATION ZONE TO BOOST FOCUS AND PRODUCTIVITY. MEET THE JABRA EVOLVE 40 PROFESSIONAL SOUND FOR GROWING BUSINESSES. Small and Medium Enterprises (SMEs) need the tools to be fast, flexible
CREATE A CONCENTRATION ZONE TO BOOST FOCUS AND PRODUCTIVITY. MEET THE JABRA EVOLVE 40 PROFESSIONAL SOUND FOR GROWING BUSINESSES. Small and Medium Enterprises (SMEs) need the tools to be fast, flexible
RECOMMENDATION ITU-R BS Procedure for the performance test of automated query-by-humming systems
 Rec. ITU-R BS.1693 1 RECOMMENDATION ITU-R BS.1693 Procedure for the performance test of automated query-by-humming systems (Question ITU-R 8/6) (2004) The ITU Radiocommunication Assembly, considering a)
Rec. ITU-R BS.1693 1 RECOMMENDATION ITU-R BS.1693 Procedure for the performance test of automated query-by-humming systems (Question ITU-R 8/6) (2004) The ITU Radiocommunication Assembly, considering a)
How Many Humans Does it Take to Judge Video Quality?
 How Many Humans Does it Take to Judge Video Quality? Bill Reckwerdt, CTO Video Clarity, Inc. Version 1.0 A Video Clarity Case Study page 1 of 5 Abstract for Subjective Video Quality Assessment In order
How Many Humans Does it Take to Judge Video Quality? Bill Reckwerdt, CTO Video Clarity, Inc. Version 1.0 A Video Clarity Case Study page 1 of 5 Abstract for Subjective Video Quality Assessment In order
Image Processing Pipeline for Facial Expression Recognition under Variable Lighting
 Image Processing Pipeline for Facial Expression Recognition under Variable Lighting Ralph Ma, Amr Mohamed ralphma@stanford.edu, amr1@stanford.edu Abstract Much research has been done in the field of automated
Image Processing Pipeline for Facial Expression Recognition under Variable Lighting Ralph Ma, Amr Mohamed ralphma@stanford.edu, amr1@stanford.edu Abstract Much research has been done in the field of automated
Presentational aids should be used for the right reasons in the right ways
 MPS Chap. 14 Using Presentational Aids Presentational aids should be used for the right reasons in the right ways In a way, they are an extension of delivery extending your media of presentation beyond
MPS Chap. 14 Using Presentational Aids Presentational aids should be used for the right reasons in the right ways In a way, they are an extension of delivery extending your media of presentation beyond
Coordinate Mapping Between an Acoustic and Visual Sensor Network in the Shape Domain for a Joint Self-Calibrating Speaker Tracking
 Coordinate Mapping Between an Acoustic and Visual Sensor Network in the Shape Domain for a Joint Self-Calibrating Speaker Tracking Florian Jacob and Reinhold Haeb-Umbach Department of Communications Engineering
Coordinate Mapping Between an Acoustic and Visual Sensor Network in the Shape Domain for a Joint Self-Calibrating Speaker Tracking Florian Jacob and Reinhold Haeb-Umbach Department of Communications Engineering
Filtering, scale, orientation, localization, and texture. Nuno Vasconcelos ECE Department, UCSD (with thanks to David Forsyth)
") Filtering, scale, orientation, localization, and texture Nuno Vasconcelos ECE Department, UCSD (with thanks to David Forsyth) Beyond edges we have talked a lot about edges while they are important, it
Filtering, scale, orientation, localization, and texture Nuno Vasconcelos ECE Department, UCSD (with thanks to David Forsyth) Beyond edges we have talked a lot about edges while they are important, it
THE SAVOX RADIO ACCESSORIES BUYING GUIDE 3 STEPS. For Choosing the Right Radio Accessories
 THE SAVOX RADIO ACCESSORIES BUYING GUIDE 3 STEPS For Choosing the Right Radio Accessories THE SAVOX RADIO ACCESSORIES BUYING GUIDE / 2 THIS BUYING GUIDE HAS BEEN DEVELOPED TO HELP YOU EVALUATE, COMPARE
THE SAVOX RADIO ACCESSORIES BUYING GUIDE 3 STEPS For Choosing the Right Radio Accessories THE SAVOX RADIO ACCESSORIES BUYING GUIDE / 2 THIS BUYING GUIDE HAS BEEN DEVELOPED TO HELP YOU EVALUATE, COMPARE
Optimization of Observation Membership Function By Particle Swarm Method for Enhancing Performances of Speaker Identification
 Proceedings of the 6th WSEAS International Conference on SIGNAL PROCESSING, Dallas, Texas, USA, March 22-24, 2007 52 Optimization of Observation Membership Function By Particle Swarm Method for Enhancing
Proceedings of the 6th WSEAS International Conference on SIGNAL PROCESSING, Dallas, Texas, USA, March 22-24, 2007 52 Optimization of Observation Membership Function By Particle Swarm Method for Enhancing
White Paper Voice Quality Sound design is an art form at Snom and is at the core of our development utilising some of the world's most advance voice
 White Paper Voice Quality Sound design is an art form at and is at the core of our development utilising some of the world's most advance voice quality engineering tools White Paper - Audio Quality Table
White Paper Voice Quality Sound design is an art form at and is at the core of our development utilising some of the world's most advance voice quality engineering tools White Paper - Audio Quality Table
Multi-Modal Human- Computer Interaction
 Multi-Modal Human- Computer Interaction Attila Fazekas University of Debrecen, Hungary Road Map Multi-modal interactions and systems (main categories, examples, benefits) Face detection, facial gestures
Multi-Modal Human- Computer Interaction Attila Fazekas University of Debrecen, Hungary Road Map Multi-modal interactions and systems (main categories, examples, benefits) Face detection, facial gestures
MULTIMODE TREE CODING OF SPEECH WITH PERCEPTUAL PRE-WEIGHTING AND POST-WEIGHTING
 MULTIMODE TREE CODING OF SPEECH WITH PERCEPTUAL PRE-WEIGHTING AND POST-WEIGHTING Pravin Ramadas, Ying-Yi Li, and Jerry D. Gibson Department of Electrical and Computer Engineering, University of California,
MULTIMODE TREE CODING OF SPEECH WITH PERCEPTUAL PRE-WEIGHTING AND POST-WEIGHTING Pravin Ramadas, Ying-Yi Li, and Jerry D. Gibson Department of Electrical and Computer Engineering, University of California,
Analyzing keyboard noises
 08/17 Introduction 1 Recording keyboard noises 2 3 Sound pressure level vs. time analysis 3 Loudness vs. time 4 Sharpness vs. time 4 Sound design by means of Playback Filters 5 Summary 7 Note 7 Introduction
08/17 Introduction 1 Recording keyboard noises 2 3 Sound pressure level vs. time analysis 3 Loudness vs. time 4 Sharpness vs. time 4 Sound design by means of Playback Filters 5 Summary 7 Note 7 Introduction
Appendix 4. Audio coding algorithms
 Appendix 4. Audio coding algorithms 1 Introduction The main application of audio compression systems is to obtain compact digital representations of high-quality (CD-quality) wideband audio signals. Typically
Appendix 4. Audio coding algorithms 1 Introduction The main application of audio compression systems is to obtain compact digital representations of high-quality (CD-quality) wideband audio signals. Typically
2014, IJARCSSE All Rights Reserved Page 461
 Volume 4, Issue 1, January 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Real Time Speech
Volume 4, Issue 1, January 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Real Time Speech
A Neural Network for Real-Time Signal Processing
 248 MalkofT A Neural Network for Real-Time Signal Processing Donald B. Malkoff General Electric / Advanced Technology Laboratories Moorestown Corporate Center Building 145-2, Route 38 Moorestown, NJ 08057
248 MalkofT A Neural Network for Real-Time Signal Processing Donald B. Malkoff General Electric / Advanced Technology Laboratories Moorestown Corporate Center Building 145-2, Route 38 Moorestown, NJ 08057
An Introduction to a Unique Safeguard Technology for Headset Users
 An Introduction to a Unique Safeguard Technology for Headset Users MWN March 2004 Sennheiser Communications A/S 6 Langager, 2680 Solrød Strand, Denmark Phone: +45 56180000, Fax: +45 56180099 www.sennheisercommunications.com
An Introduction to a Unique Safeguard Technology for Headset Users MWN March 2004 Sennheiser Communications A/S 6 Langager, 2680 Solrød Strand, Denmark Phone: +45 56180000, Fax: +45 56180099 www.sennheisercommunications.com