Hands On: Multimedia Methods for Large Scale Video Analysis (Lecture) Dr. Gerald Friedland,
|
|
|
- Albert Maxwell
- 5 years ago
- Views:
Transcription
1 Hands On: Multimedia Methods for Large Scale Video Analysis (Lecture) Dr. Gerald Friedland, 1
2 Today Recap: Some more Machine Learning Multimedia Systems An example Multimedia System 2
3 Recap: Architecture of Content Analysis Algorithms 3
4 Recap: Some More Machine Learning k-nearest Neighbors Neural Networks SVMs HMMs 4

5 k-nearest Neighbors 5
6 Another Magic Duo Histograms are the most practically used image models Nearest Neighbors (with Euclidean Distance) is the most used technique for visual features are comparison 6
7 Neural Networks (MLPs) 7
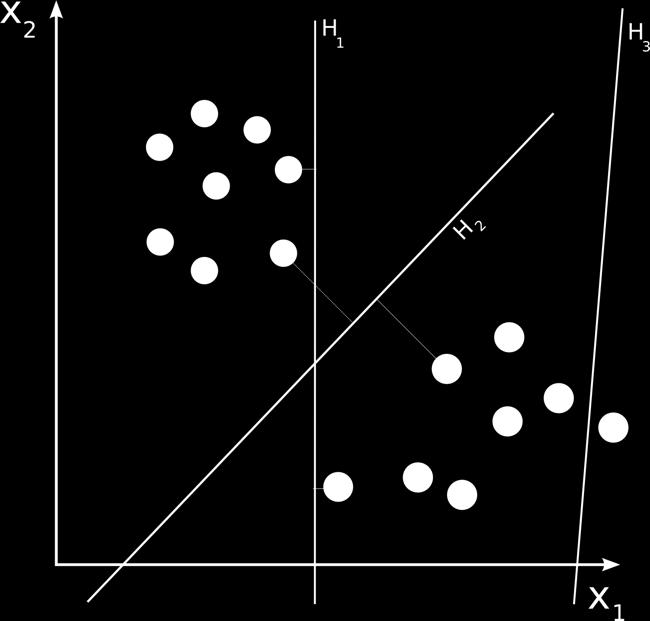
8 Linear Separation 8
9 Support Vector Machines 9
10 Hidden Markov Models a s: State transitions b s: Likelihood observations 10
11 Hidden Markov Models 11
12 Multimedia: Definition Entry: multimedia Function: noun plural but singular or plural in construction Date: 1950 A technique (as the combining of sound, video, and text) for expressing ideas (as in communication, entertainment, or art) in which several media are employed; also: something (as software) using or facilitating such a technique. (Merriam-Webster online dictionary) 12
13 Multimedia Content Analysis Automatic analysis of the content (semantics) contained in data directly encoded for human perception (audio, images, video, touch) and its associated meta data (natural text, computerencoded data). 13
14 Multimodal Integration 14
15 Multimodal Integration... is a field of cognitive psychology. 14
16 Multimodal Integration... is a field of cognitive psychology. Before 1960: Unimodal approach 14
17 Multimodal Integration... is a field of cognitive psychology. Before 1960: Unimodal approach Initial results in the 1960 s, recently hyped again (2003+) 14
18 Multimodal Integration... is a field of cognitive psychology. Before 1960: Unimodal approach Initial results in the 1960 s, recently hyped again (2003+) 14
19 Multimodal Integration Human psychology suggests: 15
20 Multimodal Integration Human psychology suggests: Multiple sensory inputs increase the speed of the output (Hershenson 1962) 15
21 Multimodal Integration Human psychology suggests: Multiple sensory inputs increase the speed of the output (Hershenson 1962) Uncertainty in sensory domains results in increased dependency of multisensory integration (Alais & Burr 2004) 15
22 Multimodal Integration In computer science: 16
23 Multimodal Integration In computer science: How to create systems that benefit from multimodal integration in similar ways the brain does, i.e. they are 16
24 Multimodal Integration In computer science: How to create systems that benefit from multimodal integration in similar ways the brain does, i.e. they are more accurate, robust, and/or faster than unimodal state of the art and/or 16
25 Multimodal Integration In computer science: How to create systems that benefit from multimodal integration in similar ways the brain does, i.e. they are more accurate, robust, and/or faster than unimodal state of the art and/or offer qualitative improvements over unimodal approaches 16
26 Recap: Architecture of Content Analysis Algorithms 17
27 Generic Scheme of a Classification Algorithm Signal reduce dimensions Some signal is observed and reduced... Features build abstraction...to the essentials relevant to the problem,... Models generate score Decision output decision...statistical models are used to compute a score (e.g. probabilities) for the given observations, so that a decision function can decide on the classification. Result 18
28 Feature-Level Integration Signal 1 reduce dimensions Features Signal 2 reduce dimensions Features + build abstraction Models generate score Decision output decision Result Features are integrated before the model layer using a function +. For example concatenation: n-dimensional vector + m- dimensional vector = n+mdimensional vector 19
29 Model-Level Integration Signal 1 reduce dimensions Features build abstraction Signal 2 reduce dimensions Features build abstraction Models generate scores Models generate scores + combined score Decision output decision Output scores are integrated using a function +. For example weighted combined log-likelihoods. Result 20
30 Decision-Level Integration Signal 1 reduce dimensions Features build abstraction Signal 2 reduce dimensions Features build abstraction Models generate score Models generate score Decision output decision Decision output decision Output decision are fused using a function +. For example majority voting. + output decision Result WARNING: Meta-data fusion in general is a difficult research problem. 21
31 Remarks Signal-level integration is unlikely because of intractable data dimensionality. Multi-Level integration is also possible. In reality, a classification algorithm is more complicated than this scheme (eg. feedback loops) The integration function + may also be learned automatically. 22
32 Example System Dialocalization: Acoustic Speaker Diarization and Visual Localization as Joint Optimization Problem G. Friedland, C. Yeo., H. Hung: Dialocalizaton: Acoustic Speaker Diarization and Visual Localization as Joint Optimization Problem, ACM Transactions on Multimedia Computing, Communications, and Applications, Vol. 6, No. 4, Article 27, November

33 Current Common Sense Localization (Computer Vision Task) Localization in space. Speaker Diarization (Speech Processing Task)
34 Example: Speaker Diarization Audiotrack: Speaker localization on timeline: who spoke when. 25
35 Example: Speaker Diarization Audiotrack: Speaker localization on timeline: who spoke when. 25
36 Example: Speaker Diarization Audiotrack: Segmentation: Speaker localization on timeline: who spoke when. 25
37 Example: Speaker Diarization Audiotrack: Segmentation: Clustering: Speaker localization on timeline: who spoke when. 25
38 Example: Speaker Diarization Audiotrack: Segmentation: Clustering: Speaker localization on timeline: who spoke when. 25
39 Speaker Diarization... tries to answer the question: who spoke when? using a single microphone input without prior knowledge of anything (#speakers, language, text, etc...) 26
40 Single Audio Stream Audio Signal Feature Extraction MFCC Speech Only Segmentation Diarization Engine Metadata Speech/Non- Speech Detector Clustering 27
 Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging")
41 Bottom-Up Algorithm Cluster1 Cluster2 Cluster3 Cluster1 Cluster2 Cluster3 Cluster2 Cluster1 Cluster2 Cluster3 Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
42 Bottom-Up Algorithm Initialization Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
43 Bottom-Up Algorithm Initialization Cluster1 Cluster2 Cluster3 Cluster1 Cluster2 Cluster3 Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
44 Bottom-Up Algorithm Initialization Cluster1 Cluster2 Cluster3 Cluster1 Cluster2 Cluster3 (Re-)Training Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
45 Bottom-Up Algorithm Initialization Cluster1 Cluster2 Cluster3 Cluster1 Cluster2 Cluster3 (Re-)Training Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
46 Bottom-Up Algorithm Initialization Cluster1 Cluster2 Cluster3 Cluster1 Cluster2 Cluster3 (Re-)Training (Re-)Alignment Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
47 Bottom-Up Algorithm Initialization Cluster1 Cluster2 Cluster3 Cluster1 Cluster2 Cluster3 (Re-)Training (Re-)Alignment Cluster2 Cluster1 Cluster2 Cluster3 Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
48 Bottom-Up Algorithm Initialization Cluster1 Cluster2 Cluster3 Cluster1 Cluster2 Cluster3 (Re-)Training Yes Merge two Clusters? (Re-)Alignment Cluster2 Cluster1 Cluster2 Cluster3 Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
49 Bottom-Up Algorithm Initialization Cluster2 Cluster1 Cluster2 Cluster2 (Re-)Training Yes Merge two Clusters? (Re-)Alignment Cluster2 Cluster1 Cluster2 Cluster3 Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
50 Bottom-Up Algorithm Initialization Cluster2 Cluster1 Cluster2 Cluster2 (Re-)Training Yes Merge two Clusters? (Re-)Alignment Cluster2 Cluster1 Cluster2 Cluster3 Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
51 Bottom-Up Algorithm Initialization Cluster2 Cluster1 Cluster2 Cluster2 (Re-)Training Yes Merge two Clusters? (Re-)Alignment Cluster1 Cluster2 Cluster1 Cluster2 Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
52 Bottom-Up Algorithm Initialization Cluster2 Cluster1 Cluster2 Cluster2 (Re-)Training Yes No Merge two Clusters? End (Re-)Alignment Cluster1 Cluster2 Cluster1 Cluster2 Start with too many clusters (initialized randomly) Purify clusters by comparing and merging similar clusters Resegment and repeat until no more merging needed 28
53 Current Accuracy Single-Stream System ICSI Devset 07 Eval07 VACE (AMI) Speech/Non Speech Error 6.4% 6.8% 12.2% Speaker Error 11.3% 14.9% 19.89% Diarization Error Rate 17.57% 21.24% 32.09% ICSI Speaker Diarization Engine as participated in NIST RT07. 29
54 Goals 30
55 Goals Improve Robustness while... 30
56 Goals Improve Robustness while......increasing or at least keeping the speed. 30
57 Goals Improve Robustness while......increasing or at least keeping the speed. Need to identify speakers, eg by association with face. 30
58 Goals Improve Robustness while......increasing or at least keeping the speed. Need to identify speakers, eg by association with face. 30
59 Goals Improve Robustness while......increasing or at least keeping the speed. Need to identify speakers, eg by association with face. Idea: Multimodality could help 30
60 Multimodal Speaker tries to answer the question: who spoke when? using a single microphone and single camera input without prior knowledge of anything (#speakers, language, text, etc...) 31
61 AMI Meeting Room Setup 32

62 AMI Meetings: Real- World Problems Close-view still not good enough for face detection People lean back and forward, stand up, walk around, leave the room, etc... 33

63 Even more Problems: Single Camera View Very low resolution per participant Partial occlusions 34
64 Audio/Visual Correlation Assumptions Camera captures all participants, most of the time. Speaker locations have limited spatial variance. Speakers have more visual activity than non-speakers. 35
65 Multimodal Diarization Audio Signal Feature Extraction MFCC Speech/Non- Speech Detector MFCC (only Speech) Segmentation Diarization Engine "Who spoke when" Events Feature Extraction Video Activity (only Speech Regions) Clustering Video Signal 36

66 Video Feature Extraction MPEG-4 Video Detect Skin Blocks Avg. Motion Vectors Divide Frames into n Regions n-dimensional activity vector Windowsize: 400ms 37
67 Model-Level Integration Audio Video MFCC Activity GMMs likelihoods GMMs likelihoods + Decision Result 38

68 Multimodal Diarization Results 12 Meetings from AMI corpus VACE Meetings 39
69 Multimodal vs Unimodal Video features alone perform poorly! Error/System Four Cameras Random Speaker Error 68.80% 75.00% 40
70 Multimodal vs Unimodal Video features alone perform poorly! Error/System Four Cameras Random Speaker Error 68.80% 75.00% Warning: Designing multimodal algorithms may require integrated thinking. Blackbox combination of unimodal approaches may not work. 40
71 Agglomerative Clustering + Video activities in each region Cepstral audio features Models containing MFCC and video activity vectors 41

72 Who Spoke When?? + Video activities in each region Cepstral audio Features Which model fits best? Speaker X 42
73 Where is the Speaker? Speaker X +? Speaker from Diarization all possible activity locations for speakers Which activity location fits best? 43
74 Speaker Localization Audio Signal Feature Extraction Segmentation MFCC Speech/Non- Speech Detector MFCC (only Speech) Diarization Engine Clustering "who spoke when" Events Video Activity (only Speech Regions) Feature Extraction Invert Visual Models "where the speaker was" Video Signal 44

75 Speaker Localization and Diarization 45
76 Conclusion I Speaker Diarization = Speaker Localization No need to treat as separate problem! 46
77 Conclusion II 47
78 Conclusion II Multimodal diarization with video results in: 47
79 Conclusion II Multimodal diarization with video results in: higher accuracy at low computational overhead 47
80 Conclusion II Multimodal diarization with video results in: higher accuracy at low computational overhead speaker localisation as a by-product = Multimodal Synergy 47
81 Conclusion III 48
82 Conclusion III It is possible to create a machine learning system that benefits from multimodal integration such that 48
83 Conclusion III It is possible to create a machine learning system that benefits from multimodal integration such that it is more accurate than the unimodal state of the art and it 48
84 Conclusion III It is possible to create a machine learning system that benefits from multimodal integration such that it is more accurate than the unimodal state of the art and it offers qualitative improvements over unimodal approaches (here: more semantic output) 48
85 Next Week (Project Meeting) Benjamin Elizalde on ICSIs TRECVID MED 2012 System
86 Next Week (Lecture) How to estimate computational needs 50
Hands On: Multimedia Methods for Large Scale Video Analysis (Lecture) Dr. Gerald Friedland,
 Dr. Gerald Friedland,") Hands On: Multimedia Methods for Large Scale Video Analysis (Lecture) Dr. Gerald Friedland, fractor@icsi.berkeley.edu 1 Today Answers to Questions How to estimate resources for large data projects - Some
Hands On: Multimedia Methods for Large Scale Video Analysis (Lecture) Dr. Gerald Friedland, fractor@icsi.berkeley.edu 1 Today Answers to Questions How to estimate resources for large data projects - Some
Multimedia Event Detection for Large Scale Video. Benjamin Elizalde
 Multimedia Event Detection for Large Scale Video Benjamin Elizalde Outline Motivation TrecVID task Related work Our approach (System, TF/IDF) Results & Processing time Conclusion & Future work Agenda 2
Multimedia Event Detection for Large Scale Video Benjamin Elizalde Outline Motivation TrecVID task Related work Our approach (System, TF/IDF) Results & Processing time Conclusion & Future work Agenda 2
Towards Audio-Visual On-line Diarization Of Participants In Group Meetings
 Towards Audio-Visual On-line Diarization Of Participants In Group Meetings Hayley Hung 1 and Gerald Friedland 2 1 IDIAP Research Institute, Martigny, Switzerland 2 International Computer Science Institute
Towards Audio-Visual On-line Diarization Of Participants In Group Meetings Hayley Hung 1 and Gerald Friedland 2 1 IDIAP Research Institute, Martigny, Switzerland 2 International Computer Science Institute
Automatic Enhancement of Correspondence Detection in an Object Tracking System
 Automatic Enhancement of Correspondence Detection in an Object Tracking System Denis Schulze 1, Sven Wachsmuth 1 and Katharina J. Rohlfing 2 1- University of Bielefeld - Applied Informatics Universitätsstr.
Automatic Enhancement of Correspondence Detection in an Object Tracking System Denis Schulze 1, Sven Wachsmuth 1 and Katharina J. Rohlfing 2 1- University of Bielefeld - Applied Informatics Universitätsstr.
The Stanford/Technicolor/Fraunhofer HHI Video Semantic Indexing System
 The Stanford/Technicolor/Fraunhofer HHI Video Semantic Indexing System Our first participation on the TRECVID workshop A. F. de Araujo 1, F. Silveira 2, H. Lakshman 3, J. Zepeda 2, A. Sheth 2, P. Perez
The Stanford/Technicolor/Fraunhofer HHI Video Semantic Indexing System Our first participation on the TRECVID workshop A. F. de Araujo 1, F. Silveira 2, H. Lakshman 3, J. Zepeda 2, A. Sheth 2, P. Perez
Dynamic Time Warping
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Dynamic Time Warping Dr Philip Jackson Acoustic features Distance measures Pattern matching Distortion penalties DTW
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Dynamic Time Warping Dr Philip Jackson Acoustic features Distance measures Pattern matching Distortion penalties DTW
Tracking. Hao Guan( 管皓 ) School of Computer Science Fudan University
 School of Computer Science Fudan University") Tracking Hao Guan( 管皓 ) School of Computer Science Fudan University 2014-09-29 Multimedia Video Audio Use your eyes Video Tracking Use your ears Audio Tracking Tracking Video Tracking Definition Given
Tracking Hao Guan( 管皓 ) School of Computer Science Fudan University 2014-09-29 Multimedia Video Audio Use your eyes Video Tracking Use your ears Audio Tracking Tracking Video Tracking Definition Given
Keyword Extraction by KNN considering Similarity among Features
 64 Int'l Conf. on Advances in Big Data Analytics ABDA'15 Keyword Extraction by KNN considering Similarity among Features Taeho Jo Department of Computer and Information Engineering, Inha University, Incheon,
64 Int'l Conf. on Advances in Big Data Analytics ABDA'15 Keyword Extraction by KNN considering Similarity among Features Taeho Jo Department of Computer and Information Engineering, Inha University, Incheon,
There is No Data Like Less Data: Percepts for Video Concept Detection on Consumer-Produced Media
 There is No Data Like Less Data: Percepts for Video Concept Detection on Consumer-Produced Media Benjamin Elizalde Gerald Friedland International Computer International Computer Science Institute Science
There is No Data Like Less Data: Percepts for Video Concept Detection on Consumer-Produced Media Benjamin Elizalde Gerald Friedland International Computer International Computer Science Institute Science
Baseball Game Highlight & Event Detection
 Baseball Game Highlight & Event Detection Student: Harry Chao Course Adviser: Winston Hu 1 Outline 1. Goal 2. Previous methods 3. My flowchart 4. My methods 5. Experimental result 6. Conclusion & Future
Baseball Game Highlight & Event Detection Student: Harry Chao Course Adviser: Winston Hu 1 Outline 1. Goal 2. Previous methods 3. My flowchart 4. My methods 5. Experimental result 6. Conclusion & Future
An Introduction to Pattern Recognition
 An Introduction to Pattern Recognition Speaker : Wei lun Chao Advisor : Prof. Jian-jiun Ding DISP Lab Graduate Institute of Communication Engineering 1 Abstract Not a new research field Wide range included
An Introduction to Pattern Recognition Speaker : Wei lun Chao Advisor : Prof. Jian-jiun Ding DISP Lab Graduate Institute of Communication Engineering 1 Abstract Not a new research field Wide range included
A ROBUST SPEAKER CLUSTERING ALGORITHM
 A ROBUST SPEAKER CLUSTERING ALGORITHM J. Ajmera IDIAP P.O. Box 592 CH-1920 Martigny, Switzerland jitendra@idiap.ch C. Wooters ICSI 1947 Center St., Suite 600 Berkeley, CA 94704, USA wooters@icsi.berkeley.edu
A ROBUST SPEAKER CLUSTERING ALGORITHM J. Ajmera IDIAP P.O. Box 592 CH-1920 Martigny, Switzerland jitendra@idiap.ch C. Wooters ICSI 1947 Center St., Suite 600 Berkeley, CA 94704, USA wooters@icsi.berkeley.edu
Experimental Design for Machine Learning on Multimedia Data See:
 Experimental Design for Machine Learning on Multimedia Data See: http://www.icsi.berkeley.edu/~fractor/spring2019/ Dr. Gerald Friedland, fractor@eecs.berkeley.edu 1 was: Hands On: Multimedia Methods for
Experimental Design for Machine Learning on Multimedia Data See: http://www.icsi.berkeley.edu/~fractor/spring2019/ Dr. Gerald Friedland, fractor@eecs.berkeley.edu 1 was: Hands On: Multimedia Methods for
Semantic Video Indexing
 Semantic Video Indexing T-61.6030 Multimedia Retrieval Stevan Keraudy stevan.keraudy@tkk.fi Helsinki University of Technology March 14, 2008 What is it? Query by keyword or tag is common Semantic Video
Semantic Video Indexing T-61.6030 Multimedia Retrieval Stevan Keraudy stevan.keraudy@tkk.fi Helsinki University of Technology March 14, 2008 What is it? Query by keyword or tag is common Semantic Video
Hands On: Multimedia Methods for Large Scale Video Analysis (Project Meeting) Dr. Gerald Friedland,
 Dr. Gerald Friedland,") Hands On: Multimedia Methods for Large Scale Video Analysis (Project Meeting) Dr. Gerald Friedland, fractor@icsi.berkeley.edu 1 Today Today Project Requirements Today Project Requirements Data available
Hands On: Multimedia Methods for Large Scale Video Analysis (Project Meeting) Dr. Gerald Friedland, fractor@icsi.berkeley.edu 1 Today Today Project Requirements Today Project Requirements Data available
Short Survey on Static Hand Gesture Recognition
 Short Survey on Static Hand Gesture Recognition Huu-Hung Huynh University of Science and Technology The University of Danang, Vietnam Duc-Hoang Vo University of Science and Technology The University of
Short Survey on Static Hand Gesture Recognition Huu-Hung Huynh University of Science and Technology The University of Danang, Vietnam Duc-Hoang Vo University of Science and Technology The University of
Real-time Monitoring of Participants Interaction in a Meeting using Audio-Visual sensors
 Real-time Monitoring of Participants Interaction in a Meeting using Audio-Visual sensors Carlos Busso, Panayiotis G. Georgiou, and Shrikanth S. Narayanan Speech Analysis and Interpretation Laboratory (SAIL)
Real-time Monitoring of Participants Interaction in a Meeting using Audio-Visual sensors Carlos Busso, Panayiotis G. Georgiou, and Shrikanth S. Narayanan Speech Analysis and Interpretation Laboratory (SAIL)
Content-based Video Genre Classification Using Multiple Cues
 Content-based Video Genre Classification Using Multiple Cues Hazım Kemal Ekenel Institute for Anthropomatics Karlsruhe Institute of Technology (KIT) 76131 Karlsruhe, Germany ekenel@kit.edu Tomas Semela
Content-based Video Genre Classification Using Multiple Cues Hazım Kemal Ekenel Institute for Anthropomatics Karlsruhe Institute of Technology (KIT) 76131 Karlsruhe, Germany ekenel@kit.edu Tomas Semela
Production of Video Images by Computer Controlled Cameras and Its Application to TV Conference System
 Proc. of IEEE Conference on Computer Vision and Pattern Recognition, vol.2, II-131 II-137, Dec. 2001. Production of Video Images by Computer Controlled Cameras and Its Application to TV Conference System
Proc. of IEEE Conference on Computer Vision and Pattern Recognition, vol.2, II-131 II-137, Dec. 2001. Production of Video Images by Computer Controlled Cameras and Its Application to TV Conference System
TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION. Prateek Verma, Yang-Kai Lin, Li-Fan Yu. Stanford University
 TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION Prateek Verma, Yang-Kai Lin, Li-Fan Yu Stanford University ABSTRACT Structural segmentation involves finding hoogeneous sections appearing
TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION Prateek Verma, Yang-Kai Lin, Li-Fan Yu Stanford University ABSTRACT Structural segmentation involves finding hoogeneous sections appearing
K-Nearest Neighbor Classification Approach for Face and Fingerprint at Feature Level Fusion
 K-Nearest Neighbor Classification Approach for Face and Fingerprint at Feature Level Fusion Dhriti PEC University of Technology Chandigarh India Manvjeet Kaur PEC University of Technology Chandigarh India
K-Nearest Neighbor Classification Approach for Face and Fingerprint at Feature Level Fusion Dhriti PEC University of Technology Chandigarh India Manvjeet Kaur PEC University of Technology Chandigarh India
Dr Andrew Abel University of Stirling, Scotland
 Dr Andrew Abel University of Stirling, Scotland University of Stirling - Scotland Cognitive Signal Image and Control Processing Research (COSIPRA) Cognitive Computation neurobiology, cognitive psychology
Dr Andrew Abel University of Stirling, Scotland University of Stirling - Scotland Cognitive Signal Image and Control Processing Research (COSIPRA) Cognitive Computation neurobiology, cognitive psychology
MACHINE LEARNING: CLUSTERING, AND CLASSIFICATION. Steve Tjoa June 25, 2014
 MACHINE LEARNING: CLUSTERING, AND CLASSIFICATION Steve Tjoa kiemyang@gmail.com June 25, 2014 Review from Day 2 Supervised vs. Unsupervised Unsupervised - clustering Supervised binary classifiers (2 classes)
MACHINE LEARNING: CLUSTERING, AND CLASSIFICATION Steve Tjoa kiemyang@gmail.com June 25, 2014 Review from Day 2 Supervised vs. Unsupervised Unsupervised - clustering Supervised binary classifiers (2 classes)
Browsing News and TAlk Video on a Consumer Electronics Platform Using face Detection
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Browsing News and TAlk Video on a Consumer Electronics Platform Using face Detection Kadir A. Peker, Ajay Divakaran, Tom Lanning TR2005-155
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Browsing News and TAlk Video on a Consumer Electronics Platform Using face Detection Kadir A. Peker, Ajay Divakaran, Tom Lanning TR2005-155
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
Multiple Kernel Learning for Emotion Recognition in the Wild
 Multiple Kernel Learning for Emotion Recognition in the Wild Karan Sikka, Karmen Dykstra, Suchitra Sathyanarayana, Gwen Littlewort and Marian S. Bartlett Machine Perception Laboratory UCSD EmotiW Challenge,
Multiple Kernel Learning for Emotion Recognition in the Wild Karan Sikka, Karmen Dykstra, Suchitra Sathyanarayana, Gwen Littlewort and Marian S. Bartlett Machine Perception Laboratory UCSD EmotiW Challenge,
Deep Learning. Volker Tresp Summer 2014
 Deep Learning Volker Tresp Summer 2014 1 Neural Network Winter and Revival While Machine Learning was flourishing, there was a Neural Network winter (late 1990 s until late 2000 s) Around 2010 there
Deep Learning Volker Tresp Summer 2014 1 Neural Network Winter and Revival While Machine Learning was flourishing, there was a Neural Network winter (late 1990 s until late 2000 s) Around 2010 there
Encoding Words into String Vectors for Word Categorization
 Int'l Conf. Artificial Intelligence ICAI'16 271 Encoding Words into String Vectors for Word Categorization Taeho Jo Department of Computer and Information Communication Engineering, Hongik University,
Int'l Conf. Artificial Intelligence ICAI'16 271 Encoding Words into String Vectors for Word Categorization Taeho Jo Department of Computer and Information Communication Engineering, Hongik University,
Unsupervised Learning
 Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Multimedia Databases. Wolf-Tilo Balke Younès Ghammad Institut für Informationssysteme Technische Universität Braunschweig
 Multimedia Databases Wolf-Tilo Balke Younès Ghammad Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Previous Lecture Audio Retrieval - Query by Humming
Multimedia Databases Wolf-Tilo Balke Younès Ghammad Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Previous Lecture Audio Retrieval - Query by Humming
String Vector based KNN for Text Categorization
 458 String Vector based KNN for Text Categorization Taeho Jo Department of Computer and Information Communication Engineering Hongik University Sejong, South Korea tjo018@hongik.ac.kr Abstract This research
458 String Vector based KNN for Text Categorization Taeho Jo Department of Computer and Information Communication Engineering Hongik University Sejong, South Korea tjo018@hongik.ac.kr Abstract This research
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
Multimedia Databases. 9 Video Retrieval. 9.1 Hidden Markov Model. 9.1 Hidden Markov Model. 9.1 Evaluation. 9.1 HMM Example 12/18/2009
 9 Video Retrieval Multimedia Databases 9 Video Retrieval 9.1 Hidden Markov Models (continued from last lecture) 9.2 Introduction into Video Retrieval Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme
9 Video Retrieval Multimedia Databases 9 Video Retrieval 9.1 Hidden Markov Models (continued from last lecture) 9.2 Introduction into Video Retrieval Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme
Columbia University High-Level Feature Detection: Parts-based Concept Detectors
 TRECVID 2005 Workshop Columbia University High-Level Feature Detection: Parts-based Concept Detectors Dong-Qing Zhang, Shih-Fu Chang, Winston Hsu, Lexin Xie, Eric Zavesky Digital Video and Multimedia Lab
TRECVID 2005 Workshop Columbia University High-Level Feature Detection: Parts-based Concept Detectors Dong-Qing Zhang, Shih-Fu Chang, Winston Hsu, Lexin Xie, Eric Zavesky Digital Video and Multimedia Lab
Multimedia Information Retrieval The case of video
 Multimedia Information Retrieval The case of video Outline Overview Problems Solutions Trends and Directions Multimedia Information Retrieval Motivation With the explosive growth of digital media data,
Multimedia Information Retrieval The case of video Outline Overview Problems Solutions Trends and Directions Multimedia Information Retrieval Motivation With the explosive growth of digital media data,
Maximum Likelihood Beamforming for Robust Automatic Speech Recognition
 Maximum Likelihood Beamforming for Robust Automatic Speech Recognition Barbara Rauch barbara@lsv.uni-saarland.de IGK Colloquium, Saarbrücken, 16 February 2006 Agenda Background: Standard ASR Robust ASR
Maximum Likelihood Beamforming for Robust Automatic Speech Recognition Barbara Rauch barbara@lsv.uni-saarland.de IGK Colloquium, Saarbrücken, 16 February 2006 Agenda Background: Standard ASR Robust ASR
Joint design of data analysis algorithms and user interface for video applications
 Joint design of data analysis algorithms and user interface for video applications Nebojsa Jojic Microsoft Research Sumit Basu Microsoft Research Nemanja Petrovic University of Illinois Brendan Frey University
Joint design of data analysis algorithms and user interface for video applications Nebojsa Jojic Microsoft Research Sumit Basu Microsoft Research Nemanja Petrovic University of Illinois Brendan Frey University
Research Article Image and Video Indexing Using Networks of Operators
 Hindawi Publishing Corporation EURASIP Journal on Image and Video Processing Volume 2007, Article ID 56928, 13 pages doi:10.1155/2007/56928 Research Article Image and Video Indexing Using Networks of Operators
Hindawi Publishing Corporation EURASIP Journal on Image and Video Processing Volume 2007, Article ID 56928, 13 pages doi:10.1155/2007/56928 Research Article Image and Video Indexing Using Networks of Operators
SRE08 system. Nir Krause Ran Gazit Gennady Karvitsky. Leave Impersonators, fraudsters and identity thieves speechless
 Leave Impersonators, fraudsters and identity thieves speechless SRE08 system Nir Krause Ran Gazit Gennady Karvitsky Copyright 2008 PerSay Inc. All Rights Reserved Focus: Multilingual telephone speech and
Leave Impersonators, fraudsters and identity thieves speechless SRE08 system Nir Krause Ran Gazit Gennady Karvitsky Copyright 2008 PerSay Inc. All Rights Reserved Focus: Multilingual telephone speech and
Object Recognition. Lecture 11, April 21 st, Lexing Xie. EE4830 Digital Image Processing
 Object Recognition Lecture 11, April 21 st, 2008 Lexing Xie EE4830 Digital Image Processing http://www.ee.columbia.edu/~xlx/ee4830/ 1 Announcements 2 HW#5 due today HW#6 last HW of the semester Due May
Object Recognition Lecture 11, April 21 st, 2008 Lexing Xie EE4830 Digital Image Processing http://www.ee.columbia.edu/~xlx/ee4830/ 1 Announcements 2 HW#5 due today HW#6 last HW of the semester Due May
FaceNet. Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana
 FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
MULTIMODAL PERSON IDENTIFICATION IN A SMART ROOM. J.Luque, R.Morros, J.Anguita, M.Farrus, D.Macho, F.Marqués, C.Martínez, V.Vilaplana, J.
 MULTIMODAL PERSON IDENTIFICATION IN A SMART ROOM JLuque, RMorros, JAnguita, MFarrus, DMacho, FMarqués, CMartínez, VVilaplana, J Hernando Technical University of Catalonia (UPC) Jordi Girona, 1-3 D5, 08034
MULTIMODAL PERSON IDENTIFICATION IN A SMART ROOM JLuque, RMorros, JAnguita, MFarrus, DMacho, FMarqués, CMartínez, VVilaplana, J Hernando Technical University of Catalonia (UPC) Jordi Girona, 1-3 D5, 08034
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
EE 6882 Statistical Methods for Video Indexing and Analysis
 EE 6882 Statistical Methods for Video Indexing and Analysis Fall 2004 Prof. ShihFu Chang http://www.ee.columbia.edu/~sfchang Lecture 1 part A (9/8/04) 1 EE E6882 SVIA Lecture #1 Part I Introduction Course
EE 6882 Statistical Methods for Video Indexing and Analysis Fall 2004 Prof. ShihFu Chang http://www.ee.columbia.edu/~sfchang Lecture 1 part A (9/8/04) 1 EE E6882 SVIA Lecture #1 Part I Introduction Course
Multimodal Sparse Coding for Event Detection
 Multimodal Sparse Coding for Event Detection Youngjune Gwon William M. Campbell Kevin Brady Douglas Sturim MIT Lincoln Laboratory, Lexington, M 02420, US Miriam Cha H. T. Kung Harvard University, Cambridge,
Multimodal Sparse Coding for Event Detection Youngjune Gwon William M. Campbell Kevin Brady Douglas Sturim MIT Lincoln Laboratory, Lexington, M 02420, US Miriam Cha H. T. Kung Harvard University, Cambridge,
CSE 6242 A / CX 4242 DVA. March 6, Dimension Reduction. Guest Lecturer: Jaegul Choo
 CSE 6242 A / CX 4242 DVA March 6, 2014 Dimension Reduction Guest Lecturer: Jaegul Choo Data is Too Big To Analyze! Limited memory size! Data may not be fitted to the memory of your machine! Slow computation!
CSE 6242 A / CX 4242 DVA March 6, 2014 Dimension Reduction Guest Lecturer: Jaegul Choo Data is Too Big To Analyze! Limited memory size! Data may not be fitted to the memory of your machine! Slow computation!
Advanced Multimodal Machine Learning
 Advanced Multimodal Machine Learning Lecture 1.2: Challenges and applications Louis-Philippe Morency Tadas Baltrušaitis 1 Objectives Identify the 5 technical challenges in multimodal machine learning Identify
Advanced Multimodal Machine Learning Lecture 1.2: Challenges and applications Louis-Philippe Morency Tadas Baltrušaitis 1 Objectives Identify the 5 technical challenges in multimodal machine learning Identify
Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach
 Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach Abstract Automatic linguistic indexing of pictures is an important but highly challenging problem for researchers in content-based
Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach Abstract Automatic linguistic indexing of pictures is an important but highly challenging problem for researchers in content-based
Analysis of Local Appearance-based Face Recognition on FRGC 2.0 Database
 Analysis of Local Appearance-based Face Recognition on FRGC 2.0 Database HAZIM KEMAL EKENEL (ISL),, Germany e- mail: ekenel@ira.uka.de web: http://isl.ira.uka.de/~ekenel/ http://isl.ira.uka.de/face_recognition/
Analysis of Local Appearance-based Face Recognition on FRGC 2.0 Database HAZIM KEMAL EKENEL (ISL),, Germany e- mail: ekenel@ira.uka.de web: http://isl.ira.uka.de/~ekenel/ http://isl.ira.uka.de/face_recognition/
CS6670: Computer Vision
 CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
SOUND EVENT DETECTION AND CONTEXT RECOGNITION 1 INTRODUCTION. Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2
 Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2 1 Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 33720, Tampere, Finland toni.heittola@tut.fi,
Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2 1 Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 33720, Tampere, Finland toni.heittola@tut.fi,
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Hello, I am from the State University of Library Studies and Information Technologies, Bulgaria
 Hello, My name is Svetla Boytcheva, I am from the State University of Library Studies and Information Technologies, Bulgaria I am goingto present you work in progress for a research project aiming development
Hello, My name is Svetla Boytcheva, I am from the State University of Library Studies and Information Technologies, Bulgaria I am goingto present you work in progress for a research project aiming development
Xing Fan, Carlos Busso and John H.L. Hansen
 Xing Fan, Carlos Busso and John H.L. Hansen Center for Robust Speech Systems (CRSS) Erik Jonsson School of Engineering & Computer Science Department of Electrical Engineering University of Texas at Dallas
Xing Fan, Carlos Busso and John H.L. Hansen Center for Robust Speech Systems (CRSS) Erik Jonsson School of Engineering & Computer Science Department of Electrical Engineering University of Texas at Dallas
Semantic Word Embedding Neural Network Language Models for Automatic Speech Recognition
 Semantic Word Embedding Neural Network Language Models for Automatic Speech Recognition Kartik Audhkhasi, Abhinav Sethy Bhuvana Ramabhadran Watson Multimodal Group IBM T. J. Watson Research Center Motivation
Semantic Word Embedding Neural Network Language Models for Automatic Speech Recognition Kartik Audhkhasi, Abhinav Sethy Bhuvana Ramabhadran Watson Multimodal Group IBM T. J. Watson Research Center Motivation
Multimodal Cue Detection Engine for Orchestrated Entertainment
 Multimodal Cue Detection Engine for Orchestrated Entertainment Danil Korchagin, Stefan Duffner, Petr Motlicek, and Carl Scheffler Idiap Research Institute, Martigny, Switzerland Abstract. In this paper,
Multimodal Cue Detection Engine for Orchestrated Entertainment Danil Korchagin, Stefan Duffner, Petr Motlicek, and Carl Scheffler Idiap Research Institute, Martigny, Switzerland Abstract. In this paper,
2. Basic Task of Pattern Classification
 2. Basic Task of Pattern Classification Definition of the Task Informal Definition: Telling things apart 3 Definition: http://www.webopedia.com/term/p/pattern_recognition.html pattern recognition Last
2. Basic Task of Pattern Classification Definition of the Task Informal Definition: Telling things apart 3 Definition: http://www.webopedia.com/term/p/pattern_recognition.html pattern recognition Last
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Static Gesture Recognition with Restricted Boltzmann Machines
 Static Gesture Recognition with Restricted Boltzmann Machines Peter O Donovan Department of Computer Science, University of Toronto 6 Kings College Rd, M5S 3G4, Canada odonovan@dgp.toronto.edu Abstract
Static Gesture Recognition with Restricted Boltzmann Machines Peter O Donovan Department of Computer Science, University of Toronto 6 Kings College Rd, M5S 3G4, Canada odonovan@dgp.toronto.edu Abstract
Moving Object Segmentation Method Based on Motion Information Classification by X-means and Spatial Region Segmentation
 IJCSNS International Journal of Computer Science and Network Security, VOL.13 No.11, November 2013 1 Moving Object Segmentation Method Based on Motion Information Classification by X-means and Spatial
IJCSNS International Journal of Computer Science and Network Security, VOL.13 No.11, November 2013 1 Moving Object Segmentation Method Based on Motion Information Classification by X-means and Spatial
Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing
 Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing Samer Al Moubayed Center for Speech Technology, Department of Speech, Music, and Hearing, KTH, Sweden. sameram@kth.se
Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing Samer Al Moubayed Center for Speech Technology, Department of Speech, Music, and Hearing, KTH, Sweden. sameram@kth.se
Multimodal Video Indexing: A Review of the State-of-the-art
 Multimedia Tools and Applications, 25, 5 35, 2005 c 2005 Springer Science + Business Media, Inc. Manufactured in The Netherlands. Multimodal Video Indexing: A Review of the State-of-the-art CEES G.M. SNOEK
Multimedia Tools and Applications, 25, 5 35, 2005 c 2005 Springer Science + Business Media, Inc. Manufactured in The Netherlands. Multimodal Video Indexing: A Review of the State-of-the-art CEES G.M. SNOEK
Combining Audio and Video for Detection of Spontaneous Emotions
 Combining Audio and Video for Detection of Spontaneous Emotions Rok Gajšek, Vitomir Štruc, Simon Dobrišek, Janez Žibert, France Mihelič, and Nikola Pavešić Faculty of Electrical Engineering, University
Combining Audio and Video for Detection of Spontaneous Emotions Rok Gajšek, Vitomir Štruc, Simon Dobrišek, Janez Žibert, France Mihelič, and Nikola Pavešić Faculty of Electrical Engineering, University
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda
 Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Optimizing feature representation for speaker diarization using PCA and LDA
 Optimizing feature representation for speaker diarization using PCA and LDA itsikv@netvision.net.il Jean-Francois Bonastre jean-francois.bonastre@univ-avignon.fr Outline Speaker Diarization what is it?
Optimizing feature representation for speaker diarization using PCA and LDA itsikv@netvision.net.il Jean-Francois Bonastre jean-francois.bonastre@univ-avignon.fr Outline Speaker Diarization what is it?
Event-Based Modeling and Processing of Digital Media
 Event-Based Modeling and Processing of Digital Media Rahul Singh Zhao Li Pilho Kim Derik Pack Ramesh Jain Experiential Systems Group Georgia Institute of Technology Ubiquity of Media Surveillance, biometrics,
Event-Based Modeling and Processing of Digital Media Rahul Singh Zhao Li Pilho Kim Derik Pack Ramesh Jain Experiential Systems Group Georgia Institute of Technology Ubiquity of Media Surveillance, biometrics,
Lecture Video Indexing and Retrieval Using Topic Keywords
 Lecture Video Indexing and Retrieval Using Topic Keywords B. J. Sandesh, Saurabha Jirgi, S. Vidya, Prakash Eljer, Gowri Srinivasa International Science Index, Computer and Information Engineering waset.org/publication/10007915
Lecture Video Indexing and Retrieval Using Topic Keywords B. J. Sandesh, Saurabha Jirgi, S. Vidya, Prakash Eljer, Gowri Srinivasa International Science Index, Computer and Information Engineering waset.org/publication/10007915
Video Key-Frame Extraction using Entropy value as Global and Local Feature
 Video Key-Frame Extraction using Entropy value as Global and Local Feature Siddu. P Algur #1, Vivek. R *2 # Department of Information Science Engineering, B.V. Bhoomraddi College of Engineering and Technology
Video Key-Frame Extraction using Entropy value as Global and Local Feature Siddu. P Algur #1, Vivek. R *2 # Department of Information Science Engineering, B.V. Bhoomraddi College of Engineering and Technology
of Manchester The University COMP14112 Markov Chains, HMMs and Speech Revision
 COMP14112 Lecture 11 Markov Chains, HMMs and Speech Revision 1 What have we covered in the speech lectures? Extracting features from raw speech data Classification and the naive Bayes classifier Training
COMP14112 Lecture 11 Markov Chains, HMMs and Speech Revision 1 What have we covered in the speech lectures? Extracting features from raw speech data Classification and the naive Bayes classifier Training
Machine Learning Practice and Theory
 Machine Learning Practice and Theory Day 9 - Feature Extraction Govind Gopakumar IIT Kanpur 1 Prelude 2 Announcements Programming Tutorial on Ensemble methods, PCA up Lecture slides for usage of Neural
Machine Learning Practice and Theory Day 9 - Feature Extraction Govind Gopakumar IIT Kanpur 1 Prelude 2 Announcements Programming Tutorial on Ensemble methods, PCA up Lecture slides for usage of Neural
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Knowledge Acquisition from Multimedia Content using an Evolution Framework
 Knowledge Acquisition from Multimedia Content using an Evolution Framework D. Kosmopoulos, S. Petridis, I. Pratikakis, V. Gatos, S. Perantonis, V. Karkaletsis, G. Paliouras Computational Intelligence Laboratory,
Knowledge Acquisition from Multimedia Content using an Evolution Framework D. Kosmopoulos, S. Petridis, I. Pratikakis, V. Gatos, S. Perantonis, V. Karkaletsis, G. Paliouras Computational Intelligence Laboratory,
Generation of Sports Highlights Using a Combination of Supervised & Unsupervised Learning in Audio Domain
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Generation of Sports Highlights Using a Combination of Supervised & Unsupervised Learning in Audio Domain Radhakrishan, R.; Xiong, Z.; Divakaran,
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Generation of Sports Highlights Using a Combination of Supervised & Unsupervised Learning in Audio Domain Radhakrishan, R.; Xiong, Z.; Divakaran,
Video Event Detection Using Motion Relativity and Feature Selection
 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. XX, NO. XX, XX 1 Video Event Detection Using Motion Relativity and Feature Selection Feng Wang, Zhanhu Sun, Yu-Gang Jiang, and Chong-Wah Ngo Abstract Event detection
IEEE TRANSACTIONS ON MULTIMEDIA, VOL. XX, NO. XX, XX 1 Video Event Detection Using Motion Relativity and Feature Selection Feng Wang, Zhanhu Sun, Yu-Gang Jiang, and Chong-Wah Ngo Abstract Event detection
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
Lecture 12: Video Representation, Summarisation, and Query
 Lecture 12: Video Representation, Summarisation, and Query Dr Jing Chen NICTA & CSE UNSW CS9519 Multimedia Systems S2 2006 jchen@cse.unsw.edu.au Last week Structure of video Frame Shot Scene Story Why
Lecture 12: Video Representation, Summarisation, and Query Dr Jing Chen NICTA & CSE UNSW CS9519 Multimedia Systems S2 2006 jchen@cse.unsw.edu.au Last week Structure of video Frame Shot Scene Story Why
Audio-visual interaction in sparse representation features for noise robust audio-visual speech recognition
 ISCA Archive http://www.isca-speech.org/archive Auditory-Visual Speech Processing (AVSP) 2013 Annecy, France August 29 - September 1, 2013 Audio-visual interaction in sparse representation features for
ISCA Archive http://www.isca-speech.org/archive Auditory-Visual Speech Processing (AVSP) 2013 Annecy, France August 29 - September 1, 2013 Audio-visual interaction in sparse representation features for
Content-based image and video analysis. Machine learning
 Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
MATRIX BASED SEQUENTIAL INDEXING TECHNIQUE FOR VIDEO DATA MINING
 MATRIX BASED SEQUENTIAL INDEXING TECHNIQUE FOR VIDEO DATA MINING 1 D.SARAVANAN 2 V.SOMASUNDARAM Assistant Professor, Faculty of Computing, Sathyabama University Chennai 600 119, Tamil Nadu, India Email
MATRIX BASED SEQUENTIAL INDEXING TECHNIQUE FOR VIDEO DATA MINING 1 D.SARAVANAN 2 V.SOMASUNDARAM Assistant Professor, Faculty of Computing, Sathyabama University Chennai 600 119, Tamil Nadu, India Email
FACIAL MOVEMENT BASED PERSON AUTHENTICATION
 FACIAL MOVEMENT BASED PERSON AUTHENTICATION Pengqing Xie Yang Liu (Presenter) Yong Guan Iowa State University Department of Electrical and Computer Engineering OUTLINE Introduction Literature Review Methodology
FACIAL MOVEMENT BASED PERSON AUTHENTICATION Pengqing Xie Yang Liu (Presenter) Yong Guan Iowa State University Department of Electrical and Computer Engineering OUTLINE Introduction Literature Review Methodology
CONTENT BASED VIDEO RETRIEVAL SYSTEM
 CONTENT BASED RETRIEVAL SYSTEM Madhav Gitte 1, Harshal Bawaskar 2, Sourabh Sethi 3, Ajinkya Shinde 4 1 B.E. Scholar, Department of Information Technology, Sinhgad College of Engineering Pune-41, University
CONTENT BASED RETRIEVAL SYSTEM Madhav Gitte 1, Harshal Bawaskar 2, Sourabh Sethi 3, Ajinkya Shinde 4 1 B.E. Scholar, Department of Information Technology, Sinhgad College of Engineering Pune-41, University
Multifactor Fusion for Audio-Visual Speaker Recognition
 Proceedings of the 7th WSEAS International Conference on Signal, Speech and Image Processing, Beijing, China, September 15-17, 2007 70 Multifactor Fusion for Audio-Visual Speaker Recognition GIRIJA CHETTY
Proceedings of the 7th WSEAS International Conference on Signal, Speech and Image Processing, Beijing, China, September 15-17, 2007 70 Multifactor Fusion for Audio-Visual Speaker Recognition GIRIJA CHETTY
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
The Kinect Sensor. Luís Carriço FCUL 2014/15
 Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
TRECVid 2012 Experiments at Dublin City University
 TRECVid 2012 Experiments at Dublin City University Jinlin Guo, Zhenxing Zhang, David Scott, Frank Hopfgartner, Rami Albatal, Cathal Gurrin, and Alan F. Smeaton CLARITY: Centre for Sensor Web Technologies
TRECVid 2012 Experiments at Dublin City University Jinlin Guo, Zhenxing Zhang, David Scott, Frank Hopfgartner, Rami Albatal, Cathal Gurrin, and Alan F. Smeaton CLARITY: Centre for Sensor Web Technologies
Available online Journal of Scientific and Engineering Research, 2016, 3(4): Research Article
: Research Article") Available online www.jsaer.com, 2016, 3(4):417-422 Research Article ISSN: 2394-2630 CODEN(USA): JSERBR Automatic Indexing of Multimedia Documents by Neural Networks Dabbabi Turkia 1, Lamia Bouafif 2, Ellouze
Available online www.jsaer.com, 2016, 3(4):417-422 Research Article ISSN: 2394-2630 CODEN(USA): JSERBR Automatic Indexing of Multimedia Documents by Neural Networks Dabbabi Turkia 1, Lamia Bouafif 2, Ellouze
Chapter 10. Conclusion Discussion
 Chapter 10 Conclusion 10.1 Discussion Question 1: Usually a dynamic system has delays and feedback. Can OMEGA handle systems with infinite delays, and with elastic delays? OMEGA handles those systems with
Chapter 10 Conclusion 10.1 Discussion Question 1: Usually a dynamic system has delays and feedback. Can OMEGA handle systems with infinite delays, and with elastic delays? OMEGA handles those systems with
Detection of Acoustic Events in Meeting-Room Environment
 11/Dec/2008 Detection of Acoustic Events in Meeting-Room Environment Presented by Andriy Temko Department of Electrical and Electronic Engineering Page 2 of 34 Content Introduction State of the Art Acoustic
11/Dec/2008 Detection of Acoustic Events in Meeting-Room Environment Presented by Andriy Temko Department of Electrical and Electronic Engineering Page 2 of 34 Content Introduction State of the Art Acoustic
Digital Newsletter. Editorial. Second Review Meeting in Brussels
 Editorial The aim of this newsletter is to inform scientists, industry as well as older people in general about the achievements reached within the HERMES project. The newsletter appears approximately
Editorial The aim of this newsletter is to inform scientists, industry as well as older people in general about the achievements reached within the HERMES project. The newsletter appears approximately
CHAPTER 8 Multimedia Information Retrieval
 CHAPTER 8 Multimedia Information Retrieval Introduction Text has been the predominant medium for the communication of information. With the availability of better computing capabilities such as availability
CHAPTER 8 Multimedia Information Retrieval Introduction Text has been the predominant medium for the communication of information. With the availability of better computing capabilities such as availability
Efficient Indexing and Searching Framework for Unstructured Data
 Efficient Indexing and Searching Framework for Unstructured Data Kyar Nyo Aye, Ni Lar Thein University of Computer Studies, Yangon kyarnyoaye@gmail.com, nilarthein@gmail.com ABSTRACT The proliferation
Efficient Indexing and Searching Framework for Unstructured Data Kyar Nyo Aye, Ni Lar Thein University of Computer Studies, Yangon kyarnyoaye@gmail.com, nilarthein@gmail.com ABSTRACT The proliferation
Supervised Multi-Modal Action Classification
 Supervised Multi-Modal Action Classification Robert W.H. Fisher Machine Learning Department Carnegie Mellon University Pittsburgh, PA 15213 Andrew ID: rwfisher rwfisher@cs.cmu.edu Prashant P. Reddy Machine
Supervised Multi-Modal Action Classification Robert W.H. Fisher Machine Learning Department Carnegie Mellon University Pittsburgh, PA 15213 Andrew ID: rwfisher rwfisher@cs.cmu.edu Prashant P. Reddy Machine
Detection of Mouth Movements and Its Applications to Cross-Modal Analysis of Planning Meetings
 2009 International Conference on Multimedia Information Networking and Security Detection of Mouth Movements and Its Applications to Cross-Modal Analysis of Planning Meetings Yingen Xiong Nokia Research
2009 International Conference on Multimedia Information Networking and Security Detection of Mouth Movements and Its Applications to Cross-Modal Analysis of Planning Meetings Yingen Xiong Nokia Research
DATA and signal modeling for images and video sequences. Region-Based Representations of Image and Video: Segmentation Tools for Multimedia Services
 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 9, NO. 8, DECEMBER 1999 1147 Region-Based Representations of Image and Video: Segmentation Tools for Multimedia Services P. Salembier,
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 9, NO. 8, DECEMBER 1999 1147 Region-Based Representations of Image and Video: Segmentation Tools for Multimedia Services P. Salembier,
3D Environment Reconstruction
 3D Environment Reconstruction Using Modified Color ICP Algorithm by Fusion of a Camera and a 3D Laser Range Finder The 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems October 11-15,
3D Environment Reconstruction Using Modified Color ICP Algorithm by Fusion of a Camera and a 3D Laser Range Finder The 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems October 11-15,
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach
 Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach Outline Objective Approach Experiment Conclusion and Future work Objective Automatically establish linguistic indexing of pictures
Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach Outline Objective Approach Experiment Conclusion and Future work Objective Automatically establish linguistic indexing of pictures
Multimedia Systems. Lehrstuhl für Informatik IV RWTH Aachen. Prof. Dr. Otto Spaniol Dr. rer. nat. Dirk Thißen
 Multimedia Systems Lehrstuhl für Informatik IV RWTH Aachen Prof. Dr. Otto Spaniol Dr. rer. nat. Dirk Thißen Page 1 Organization Lehrstuhl für Informatik 4 Lecture Lecture takes place on Thursday, 10:00
Multimedia Systems Lehrstuhl für Informatik IV RWTH Aachen Prof. Dr. Otto Spaniol Dr. rer. nat. Dirk Thißen Page 1 Organization Lehrstuhl für Informatik 4 Lecture Lecture takes place on Thursday, 10:00