arxiv: v1 [cs.cv] 15 Apr 2016
|
|
|
- Gary Boyd
- 5 years ago
- Views:
Transcription
1 arxiv:0.09v [cs.cv] Apr 0 Long-term Temporal Convolutions for Action Recognition Gül Varol, Ivan Laptev Cordelia Schmid Inria Abstract. Typical human actions last several seconds and exhibit characteristic spatio-temporal structure. Recent methods attempt to capture this structure and learn action representations with convolutional neural networks. Such representations, however, are typically learned at the level of a few video frames failing to model actions at their full temporal extent. In this work we learn video representations using neural networks with long-term temporal convolutions (LTC). We demonstrate that LTC-CNN models with increased temporal extents improve the accuracy of action recognition. We also study the impact of different lowlevel representations, such as raw values of video pixels and optical flow vector fields and demonstrate the importance of high-quality optical flow estimation for learning accurate action models. We report state-of-theart results on two challenging benchmarks for human action recognition UCF0 (9.%) and HMDB (.%). Keywords: action recognition, video analysis, representation learning, spatio-temporal convolutions, neural networks. Introduction Human actions and events can be seen as spatio-temporal objects. Such a view finds support both in psychology [] and in computer vision approaches to action recognition in video [,,, ]. Successful methods for action recognition, indeed, share similar techniques with object recognition and represent actions by statistical models of local video descriptors. Differently to objects, however, actions are characterized by the temporal evolution of appearance governed by motion. Consistently with this fact, motion-based video descriptors such as HOF and MBH [, ] as well as recent CNN-based motion representations [] have shown most gains for action recognition in practice. The recent rise of convolutional neural networks (CNNs) convincingly demonstrates the power of learning visual representations []. Equipped with large-scale training datasets [8, 9], CNNs have quickly taken over the majority of still-image WILLOW project-team, Département d Informatique de l École Normale Supérieure, ENS/Inria/CNRS UMR 88, Paris, France. Thoth project-team, Inria Grenoble Rhône-Alpes, Laboratoire Jean Kuntzmann, France.
,(c): Actions often contain characteristic, class-specific space-time patterns that last for several seconds.")
 learns video representations over extended periods of time. recognition tasks such as object, scene and face recognition [9, 0, ].")
![Extensions of CNNs to action recognition in video have been proposed in several recent works [,, ].](/docs-images/83/88699560/images/2-2.jpg "Such methods, however, currently show only moderate improvements over earlier methods using hand-crafted video features [].")
![Current CNN methods for action recognition often extend CNN architectures for static images [] and learn action representations for short video intervals ranging from to frames [,,].](/docs-images/83/88699560/images/2-3.jpg "Yet, typical human actions such as handshaking and drinking, as well as cycles of repetitive actions such as walking and swimming often last several seconds and span tens or hundreds of video frames.")
2 Varol, Laptev, Schmid Breast stroke Front crawl 00f 0f 0f 0f 0f 0f (a) (b) (c) (d) 00f 0f 0f 0f 0f 0f Fig.. Video patches for two classes of swimming actions. (a),(c): Actions often contain characteristic, class-specific space-time patterns that last for several seconds. (b),(d): Splitting videos into short temporal intervals is likely to destroy such patterns making recognition more difficult. Our neural network with Long-term Temporal Convolutions (LTC) learns video representations over extended periods of time. recognition tasks such as object, scene and face recognition [9, 0, ]. Extensions of CNNs to action recognition in video have been proposed in several recent works [,, ]. Such methods, however, currently show only moderate improvements over earlier methods using hand-crafted video features []. Current CNN methods for action recognition often extend CNN architectures for static images [] and learn action representations for short video intervals ranging from to frames [,,]. Yet, typical human actions such as handshaking and drinking, as well as cycles of repetitive actions such as walking and swimming often last several seconds and span tens or hundreds of video frames. As illustrated in Figure (a),(c), actions often contain characteristic patterns with specific spatial as well as long-term temporal structure. Breaking this structure into short clips (see Figure (b),(d)) and aggregating video-level information by the simple average of clip scores [, ] or more sophisticated schemes such as as LSTMs [] is likely to be suboptimal. In this work, we investigate the learning of long-term video representations. We consider space-time convolutional neural networks [,, ] and study architectures with Long-term Temporal Convolutions (LTC), see Figure. To keep the complexity of networks tractable, we increase the temporal extent of representations by the cost of decreased spatial resolution. We also study the impact of different low-level representations, such as raw values of video pixels and optical flow vector fields. Our experiments confirm the advantage of motion-based representations and highlight the importance of good quality motion estimation for learning efficient representations for human action recognition. We report stateof-the-art performance on two recent and challenging human action benchmarks UCF0 and HMDB. The contributions of this work are are twofold. We demonstrate (i) the advantages of long-term temporal convolutions and (ii) the importance of high-quality optical flow estimation for learning accurate video representations for human action recognition. In the remaining part of the paper we discuss related work in Section, describe space-time CNN architectures in Section and present

3 Long-term Temporal Convolutions Fig.. Network architecture. Spatio-temporal convolutions with xx filters are applied in the first layers of the network. Max pooling and ReLU are applied in between all convolutional layers. Network input channels C...Ck are defined for different temporal resolutions T = 0, 0, 0, 80, 00 and either two-channel motion (flow-x, flow-y) or three-channel appearance (R,G,B). The spatio-temporal resolution of convolution layers decreases with the pooling operations. an extensive experimental study of our method in Section. Our implementation and pre-trained CNN models (compatible with Torch) are available on the project web page []. Related Work Action recognition in the last decade has been dominated by local video features [,, ] aggregated with Bag-of-Features histograms [8] or Fisher Vector representations [9]. While typical pipelines resemble earlier methods for object recognition, the use of local motion features and, in particular, Motion Boundary Histograms (MBH) [] has been found important for action recognition in practice. Explicit representations of the temporal structure of actions have rarely beed used with some exceptions such as the recent work [0]. Learning visual representations with Convolutional Neural Networks [, ] has shown clear advantages over hand-crafted features for many recognition tasks in static images [9, 0, ]. Extensions of CNN representations to action recognition in video have been proposed in several recent works [,,,,,,, ]. Some of these methods encode single video frames with static CNN features [,,]. Extensions to short video clips where video frames are treated as multi-channel inputs to D CNNs have also been investigated in [,, ]. Learning CNN representations for action recognition has been addressed for raw pixel inputs and for pre-computed optical flow features. Consistently with previous results obtained with hand-crafted representations, motion-based CNNs typically outperform CNN representations learned for RGB inputs [,]. In this work we investigate multi-resolution representations of motion and appearance where for motion-based CNNs we demonstrate the importance of high-quality optical flow estimation.
4 Varol, Laptev, Schmid Most of the current CNN methods use architectures with D convolutions, enabling shift-invariant representations in the image plane. Meanwhile, the invariance to translations in time is also important for action recognition since the beginning and the end of actions is unknown in general. CNNs with D spatio-temporal convolutions address this issue and provide a natural extension of D CNNs to video. D CNNs have been investigated for action recognition in [,,, ]. All of these methods, however, learn video representations for RGB input. Moreover, they typically consider very short video intervals, for example, -frame video clips are used in [] and,, frames in [,,] respectively. In this work we extend D CNNs to significantly longer temporal convolutions that enable action representation at their full temporal scale. We also explore the impact of optical flow input. Both of these extensions show clear advantages in our experimental comparison to previous methods. Long-term Temporal Convolutions In this section we first present the network architecture. We, then, specify the different inputs to networks used in this work. We finally provide details on the learning and testing procedure.. Network architecture Our network architecture with long-term temporal convolutions is illustrated in Figure. The network has space-time convolutional layers with, 8,, and filter response maps, followed by fully connected layers of sizes 08, 08 and number of classes. Following [] we use spacetime filters for all convolutional layers. Each convolutional layer is followed by a rectified linear unit (ReLU) and a space-time max pooling layer. Max pooling filters are of size except in the first layer, where it is. The size of convolution output is kept constant by padding pixel in all three dimensions. Filter stride for all dimensions is for convolution and for pooling operations. We use dropout for the first two fully connected layers. Fully connected layers are followed by ReLU layers and a softmax at the end of the network, which outputs class scores.. Network input To investigate the impact of long-term temporal convolutions, we here study network inputs with different temporal extents. We depart from the recent CD work [] and first compare inputs of frames (f) and 0 frames (0f). We then systematically analyze implications of the increased temporal and spatial resolutions for input signals in terms of motion and appearance. For the - frame network we crop input patches of size from videos with spatial resolution 8 pixels. We choose this baseline architecture to enable direct comparison with []. For the 0-frames networks we decrease spatial
![Long-term Temporal Convolutions RGB MPEG flow [] Farneback [] Brox [] Input Clip Video RGB.0 9.9 MPEG flow 8..8 Farneback.. Brox.8 9. Fig.](/docs-images/83/88699560/images/5-0.jpg ". Illustration of the three optical flow methods and comparison of corresponding recognition performance. From left to right: original image, MPEG, Farneback and Brox optical flow.")
.")


5 Long-term Temporal Convolutions RGB MPEG flow [] Farneback [] Brox [] Input Clip Video RGB MPEG flow 8..8 Farneback.. Brox.8 9. Fig.. Illustration of the three optical flow methods and comparison of corresponding recognition performance. From left to right: original image, MPEG, Farneback and Brox optical flow. The color coding indicates the orientation of the flow. The table on the right presents accuracy of action recognition in UCF0 (split ) dataset for different inputs. Results are obtained with 0f networks and training from scratch (see text for more details). resolution to preserve network complexity and use input patches of size randomly cropped from videos rescaled to 89 spatial resolution. As illustrated in Figure, the temporal resolution in our 0f network corresponds to 0, 0,, and frames for each of the five convolutional layers. In comparison, the temporal resolution of the f network is reduced more drastically to, 8,, and frame at each convolutional layer. We believe that preserving the temporal resolution at higher convolutional layers should enable learning more complex temporal patterns. The space-time resolution for the outputs of the fifth convolutional layers is and for the f and 0f networks respectively. The two networks have the same number of parameters in all layers with the exception of fc layer, where it is comparable. For a systematic study of networks with different input resolutions we also evaluate the effect of increased temporal resolution T = {0, 0, 0, 80, 00} and varying spatial resolution of {8 8, } pixels. In addition to the input size, we experiment with different types of input modalities. First, as in [], we use raw RGB values from video frames as input. To explicitly learn motion representations, we also use flow fields in x and y directions as input to our networks. Flow is computed for original videos. To maintain correct flow values for network inputs with reduced spatial resolution, the magnitude of the flow is scaled by the factor of spatial subsampling. In other words, if a point moves pixels in a 0 0 video frame, it s motion will be pixel when the frame is resized to 0 0 resolution. We found such a rescaling to be important when using original videos of varying spatial resolution. Moreover, to center the input data, we follow [] and subtract the mean flow vector for each frame. To investigate the dependency of action recognition on the quality of motion estimation, we experiment with three types of flow inputs obtained either directly from the video encoding, referred to as MPEG flow, or from two optical flow estimators, namely Farneback [] and Brox []. Figure shows results for the three flow algorithms. MPEG flow is a fast substitute for optical flow which can be obtained directly from video compression []. Such flow, however, has low
6 Varol, Laptev, Schmid spatial resolution and is not defined for all video frames. Farneback flow is also relatively fast and obtains rather noisy flow estimates. The approach of Brox is the most sophisticated of the three and is known to perform well in various flow estimation benchmarks. Furthermore, the available GPU implementation makes its extraction relatively fast.. Learning We train our networks on the training set of each split independently for both UCF0 and HMDB datasets, which contain 9.K and.k videos, respectively. We use stochastic gradient descent applied to mini-batches with negative log likelihood criterion. For f networks we use a mini-batch size of 0 video clips. We reduce the batch size to video clips for 0f networks, and 0 clips for 00f networks due to limitations of our GPUs. The initial learning rate for networks learned from scratch is 0 and 0 for networks fine-tuned from pre-trained models. For UCF0, the learning rate is decreased twice with a factor of 0. For f networks, the first decrease is after 80K iterations and the second one after K additional iterations. The optimization is completed after 0K more iterations. Convergence is faster for HMDB, so the learning rate is decreased once after 0K iterations and completed after 0K more iterations. These numbers are doubled for 0f networks and tripled for 00f networks, since their batch sizes are twice and three times smaller compared to f nets. The above schedule is used together with 0.9 dropout ratio. Our experimental setups with 0. dropout ratio have less iterations due to faster convergence. The momentum is set to 0.9 and weight decay is initialized with 0 and reduced by a factor of 0 at every decrease of the learning rate. Inspired by the random spatial cropping during training, we apply the corresponding augmentation to the temporal dimension as in [], which we call random clipping. During training, given an input video, we randomly select a point (x, y, t) to sample a video clip of fixed size. A common alternative is to preprocess the data by using a sliding window approach to have pre-segmented clips of fixed size; however, this approach limits the amount of data when the windows are not overlapped as in []. Another data augmentation method that we evaluate is to have a multiscale cropping similar to []. For this, we randomly select a coefficient for width and height separately from (.0, 0.8, 0., 0.) and resize the cropped region to the size of the network input. Finally, we horizontally flip the input with 0% probability. At test time, a video is divided into T -frame clips with a temporal stride of frames. Each clip is further tested with 0 crops, namely the corners and the center, together with their horizontal flips. The video score is obtained by averaging over clip scores and crop scores. If the number of frames in a video is less than the clip size, we pad the input by repeating the last frames of the video to fill the missing volume.
7 Long-term Temporal Convolutions Experiments We perform experiments on two widely used and challenging benchmarks for action recognition UCF0 and HMDB (Sec..). We first examine the effect of network parameters (Sec..). We then compare to the state of the art (Sec..) and present a visual analysis of the spatio-temporal filters (Sec..).. Datasets and evaluation metrics UCF0. UCF0 [] is a widely-used benchmark for action recognition with K clips from YouTube videos lasting sec. on average. The total number of frames is.m distributed among 0 categories. Videos have spatial resolution of 0 0 pixels and fps frame rate. HMDB. The HMDB dataset [8] consists of K videos of actions. The videos have 0 0 pixels spatial resolution and 0 fps frame rate. Although this dataset has been considered a large-scale benchmark for action recognition for the past few years, the amount of data for learning deep networks is limited. Evaluation metrics. We rely on two evaluation metrics. The first one measures per-clip accuracy, i.e. we assign each clip the class label with the maximum softmax output and measure the number of correctly assigned labels over all clips. The second metric measures video accuracy, i.e. the standard evaluation protocol. To obtain a video score we average the per-clip softmax scores and take the maximum value of this average as class label. We average over all videos to obtain video accuracy. We report our final results according to the standard evaluation protocol, which is the mean video accuracy across the three test splits. To evaluate the network parameters we use the first split.. Evaluation of LTC network parameters In the following we first examine the impact of optical flow and data augmentation. We then evaluate gains provided by long-term temporal convolutions for the best flow and data augmentation techniques by comparing f and 0f networks. We also investigate the advantage of pre-training on one dataset (UCF0) and fine-tuning on a smaller dataset (HMDB). Furthermore, we study the effect of systematically increased temporal resolution for flow and RGB inputs as well as the combination of networks. Optical flow. The impact of the flow quality on action recognition and a comparison to RGB is shown in Figure for UCF0 (split ). The network is trained from scratch and with a 0-frame video volume as input. We first observe that even the low-quality MPEG flow outperforms RGB. The increased quality of optical flow leads to further improvements. The use of Brox flow allows nearly 0%
8 8 Varol, Laptev, Schmid increase in performance. The improvements are consistent when classifying individual clips and full videos. This demonstrates that action recognition is easier to learn from motion information compared to raw pixel values. We also conclude that the high accuracy of optical flow estimation is critical to learn competitive video representations for action recognition. Given the results in Figure, we choose Brox flow for all remaining experiments in this paper. While results in Figure were obtained for 0f networks, the same holds for f networks (see Table ). Data augmentation. Table demonstrates the contribution of data augmentation when training a large CNN with limited amount of data. Our baseline uses sliding window clips with % overlap and a dropout of 0. during training. We gain.% with random clipping,.% with multiscale cropping and % with higher dropout ratio. When combined, the data augmentation and a higher dropout results in a % gain for video classification on UCF0 split. High dropout, multiscale cropping and random clipping are used in the remaining experiments, unless stated otherwise. Random Multiscale Dropout Clip acc. (%) Video acc. (%) clipping cropping Table. Data augmentations on UCF0 (split ). All results are with 0-frame Brox flow and training from scratch. All three modifications (random clipping, multiscale cropping and high dropout) give an improvement when used alone, the best performance is obtained when combined. Comparison of f and 0f networks. Our -frame and 0-frame networks have similar complexity in terms of input sizes and the number of network parameters (see Section ). Moreover, the -frame network resembles the CD architecture and enables direct comparison with []. We therefore study the gains provided by the 0-frame inputs before analyzing performance with systematically increasing temporal resolution (from 0 to 00 frames by steps of 0) in the next paragraph. Table compares the performance of f and 0f networks for RGB and flow inputs as well as for different data augmentation and dropout ratios for UCF0 split. We observe consistent and significant improvement of long-term temporal convolutions in 0f networks for all tested setups, when measured in terms of clip and video accuracies. Our 0f architecture significantly improves for both RGB
9 Long-term Temporal Convolutions 9 Input Multiscale Clip acc. (%) Video acc. (%) Dropout cropping f 0f gain f 0f gain RGB Flow Flow Table. Results for networks with different temporal resolutions and under variation of data augmentation and dropout for UCF0 (split ), trained from scratch. Random clipping is used in all experiments. Results are evaluated for individual clips and for full videos. Pre-training Clip acc. (%) Video acc. (%) on UCF0 f 0f gain f 0f gain Two-stream [] Table. Results for networks with different temporal resolutions for HMDB (split ). Flow input, random clipping, multiscale cropping and 0.9 dropout are used in all experiments. Results are shown for networks with and without pre-training on UCF0. and flow-based networks. As expected, the improvement is more prominent for clips since video evaluation aggregates information over the whole video. We repeat similar experiments for the split of HMDB dataset and report results in Table. Similarly to UCF0, flow-based networks with long-term temporal convolutions lead to significant improvements over the f network, in terms of clip and video accuracies. Given the small size of HMDB, we follow [] and also fine-tune networks that have been pre-trained on UCF0. As illustrated in the nd row of Table, such pre-training gives significant improvement. Moreover, our 0f flow networks significantly outperform results of the Temporal ConvNet ( [], Table ) evaluated in a comparable setup, both with and without pre-training. Varying temporal and spatial resolutions. Given the benefits of long-term temporal convolutions above, it is interesting to study networks for increasing temporal extents and varying spatial resolutions systematically. In particular, we investigate if accuracy saturates for networks with larger temporal extents, if higher spatial resolution impacts the performance of long-term temporal convolutions and if LTC is equally beneficial for flow and RGB networks. We also examine the combination of multiple temporal resolutions. To study these questions we evaluate RGB and flow networks for inputs with monotonically increasing temporal extent T = {0, 0, 0, 80, 00} and two spatial resolutions {8 8, }. For flow-based networks we follow our previous architecture defined in Figure modifying its spatial resolution for -pixel inputs. We also investigate combinations of flow and RGB obtained by averaging scores of flow and RGB networks.
10 0 Varol, Laptev, Schmid overall clip accuracy overall video accuracy per-action clip accuracy (%) 90 (%) PushUps (8) JavelinThrow (0) FloorGymnastics () YoYo (8) ShavingBeard () Shotput (90) H Flow+RGB RGB Flow #frames L 0 H Flow+RGB RGB Flow #frames L #frames Fig.. Results for the split of UCF0 dataset using LTC networks of (i) varying temporal extents T, (ii) varying spatial resolutions [high (H), low (L)] and (iii) different input modalities (RGB pre-trained on Sports-M, flow trained from scratch). For faster convergence all networks were trained using 0. dropout and a fixed batch size of 0. Classification results are shown for clips (left) and videos (middle) computed over all classes and presented for a subset of individual classes for flow input of low spatial resolution (right). The average number of frames in the training set for a class is denoted in parenthesis. For flow input, we train our networks from scratch. For RGB input, learning appears to be difficult from scratch. Even if we extend the temporal extent from 0 frames (see Table ) to 00 frames, we obtain.% on UCF0 split, which is still below frame-based D convolution methods fine-tuned from ImageNet pre-training []. Although longer temporal extent boosts the performance with significant margin, we conclude that one needs to pre-train RGB network on larger data. Given the large improvements provided by the pre-training of CD RGB network on the large-scale Sports-M dataset in [], we use this -frame pretrained network and extend it to longer temporal convolutions in steps. The first step is fine-tuning the -frame CD network. A randomly initialized fullyconnected layer of size 0 (number of classes) is added at the end of the network. Only the fully-connected layers are fine-tuned by freezing the convolutional layers. We start with a learning rate of 0 and decrease it to 0 after 0K iterations for K more iterations. In the second step, we input longer clips to the network and fine-tune all the layers. Convolutional layers are applied to longer video clips of T frames. This results in outputs from conv layer with T/ We have also tried to pre-train our flow-based networks on Sports-M but did not obtain significant improvements.







,")













11 Long-term Temporal Convolutions temporal resolution. To re-cycle pre-trained fully-connected layers of CD, we max-pool conv outputs over time and pass results to fc. We use a subset of the fc weights for inputs of lower spatial resolution. For this phase, we run for same number of iterations, but we decrease the learning rate from 0 to 0. We keep dropout ratio 0. as in the pre-trained network. Figure illustrates results of networks with varying temporal and spatial resolutions for clips and videos of UCF0, split. We observe significant improvements over T for LTC networks using flow (trained from scratch), RGB (with pre-training on Sports-M), as well as combination of both modalities. Networks with higher spatial resolutions give better results for lower values of T, however, the gain of increased spatial resolution is lower for networks with long temporal extents. Given the large number of parameters in high-resolution networks, such behavior can be explained by the overfitting due to the insufficient amount of training data in the UCF0 dataset. We believe that larger training sets could lead to further improvements. Moreover, flow benefits more from the averaging of clip scores than RGB. This could be an indication of static RGB information over different time intervals of the video, whereas flow is dynamic. The right plot of Figure shows results of LTC for a few individual classes. With exception to a few classes, most of the classes benefit from larger temporal extents. We can observe that two classes with large improvements for LTC are JavelinThrow FloorGymnastics time frames 0 frames Fig.. The highest improvement of long-term temporal convolutions in terms of class accuracy is for JavelinThrow. For -frame network, it is mostly confused with the FloorGymnastics class. Here, we visualize sample videos with frames extracted at every 8 frames. The intuitive explanation is that both classes start by running for a few seconds and then the actual action takes place. LTC can capture this interval, whereas -frame networks fail to recognize such long-term activities.

12 Varol, Laptev, Schmid JavelinThrow and FloorGymnastics. Both actions are composed of running followed by throwing a javelin or the actual gymnastics action. Short-term networks, thus, easily confuse the two actions, while LTC can capture such long and complex actions. Figure illustrates sample frames from these two classes. For both classes, we provide snapshots at every 8 frame. It is clear that, one needs to look at more than frames to recognize that it is the JavelinThrow action. Combination of networks of varying temporal resolutions. Finally we evaluate combinations of different networks. For final results on flow, 8 8 spatial resolution and 0.9 dropout are used for both UCF0 and HMDB datasets. The flow networks are learned from scratch for UCF0 and fine-tuned for HMDB. For final results on UCF0 with RGB input, we use spatial resolution networks fine-tuned from CD network []. However, we do not further fine-tune it for HMDB because of overfitting, and use CD network as a feature extractor in combination with SVM for obtaining RGB scores. Our implementation of CD as a feature extractor and a SVM classifier got 80.% and 9.% average performance on splits of UCF0 and HMDB, respectively. We get similar result when fine-tuning CD on -frames (80.% on UCF0). Figure (left) shows results for combining outputs of flow networks with different temporal extents. The combination is performed by averaging video-level class scores produced by each network. We observe that combinations of two networks with different temporal extents provides significant improvement for flow. The gains of combining more than two resolutions appear to be marginal. For final results, we report combining 0f and 00f networks for both flow and RGB, with the exception of HMDB RGB scores for which we use a SVM classifier on f feature extractor. Figure (right) shows results for combining multiscale networks of different modalities together with the IDT+FV baseline classifier [] on split of both datasets. We observe complementarity of different networks and IDT+FV where the best result is obtained by combining all classifiers. UCF0 HMDB LTC F low (00f) 8.. LTC F low (0f+00f) LTC RGB (00f) LTC RGB (0f+00f) 8. - LTC F low+rgb 9.0. LTC F low+rgb+idt 9.8. Fig.. Results for network combinations. (Left): Combination of LTC flow networks with different temporal extents on UCF0-split. (Right): Combination of flow and RGB networks together with IDT feature classifier on UCF0-split and HMDB- split. For UCF0, flow is trained from scratch and RGB is pre-trained on Sports-M. For HMDB, flow is pre-trained on UCF0 and RGB scores are obtained using CD feature extractor.
13 Method Long-term Temporal Convolutions UCF0 HMDB [] IDT+FV 8.9. Hand- [9] IDT+HSV 8.9. crafted [0] IDT+MIFS 89.. [] IDT+SFV -.8 [] Slow fusion (from scratch). - [] CD (from scratch) - [] Slow fusion. - CNN [] Spatial stream.0 0. (RGB) [] CD ( net) 8. - LTC RGB 8. - [] CD ( nets) 8. - CNN [] Temporal str. 8.. (Flow) LTC F low [] Two-stream (avg. fusion) [] Two-stream (SVM fusion) [] Convolutional pooling [] LSTM Fusion [] TDD 90.. [] CD+IDT [] TDD+IDT 9..9 [] Transformations 9..0 LTC F low+rgb 9..8 LTC F low+rgb +IDT 9.. Table. Comparison with the state-of-the-art on UCF0 and HMDB (mean accuracy across splits). LTC F low on UCF0 is able to get 8.%, which is above any deep approaches trained from scratch. When combined with RGB and IDT, it outperforms all the baselines on both datasets. This number is read from the plot in figure [] and is clip-based, therefore not directly comparable. These results are obtained with multi-task learning on both datasets.. Comparison with the state of the art In Table, we compare to the state-of-the-art on HMDB and UCF0 datasets. Note that the numbers do not directly match with previous tables and figures, which are reported only on first splits. Different methods are grouped together according to being hand-crafted, using only RGB input to CNNs, using only optical flow input to CNNs and combining any of these. Trajectory features perform already well, especially with higher-order encodings. CNNs on RGB perform very poor if trained from scratch, but strongly benefits from static image pre-training such as ImageNet. Recently [] trained space-time filters from a large collection of videos; however, their method is not end-to-end, given that one has to train a SVM on top of the CNN features. Although we fine-tune LTC RGB based on a network learned with a short temporal span and that we reduce the spatial resolution, we are able to improve by.% on UCF0 (80.% versus 8.%) with extending the pre-trained network to 00 frames.
14 Varol, Laptev, Schmid We observe that LTC outperforms D convolutions on both datasets. Moreover, LTC F low outperforms LTC RGB despite no pre-training. Our results using LTC F low+rgb with average fusion significantly outperform the Two-stream average fusion baseline [] by.8% and.8% on UCF0 and HMDB datasets, respectively. Moreover, the SVM fusion baseline in [] is still significantly below LTC F low+rgb. Overall, the combination of our best networks LTC F low+rgb together with the IDT method provides best results on both UCF0 (9.%) and HMDB (.%) datasets. Notably both of these results outperform all previously published results on these datasets.. Analysis of the D spatio-temporal filters Fig.. Spatio-temporal filters from the first layer of the network learned with - channel, Brox optical flow and 0 frames on UCF0. 0 out of filters are presented. Each cell in the grid represents two filters for -channel flow input (one for x and one for y). x and y intensities are converted into vectors in D. Third dimension (time) is denoted by putting vectors one after the other in different colors for better visualization (t= blue, t= red, t= green). We see that LTC is able to learn complex motion patterns for video representation. Better viewed in color. First layer weights. In order to have an intuition of what an LTC network learns, we visualize the first layer space-time convolutional filters in the vectorfield form. Filters learned on -channel optical flow vectors have dimension in terms of channels, width, height and time. For each filter, we take the two channels in each volume and visualize them as vectors using x- and y-components. Figure shows 0 example filters out of the from a network learned on UCF0 with 0 frames flow input. Since our filters are spatio-temporal, they have a third dimension in time. We find it convenient to show them as vectors concatenated one after the other with regard to the time steps. We denote each time step with different colors and see that the filters learned by long-term temporal convolutions are able to represent complex motions in local neighborhoods, which enables to incorporate even more complex patterns in later stages of the network. Our implementation of IDT+FV [] obtained 8.% and.% for UCF0 and HMDB, respectively.
15 Long-term Temporal Convolutions High-layer filter activations. We further investigate filters from higher convolutional layers by examining their highest activations. For a given layer and a chosen filter, we record the maximum activation value for all test videos for that filter. We then sort test videos according to the activation values and select the top videos. This procedure is similar to []. We can expect that a filter should be activated by similar action classes especially at the higher network layers. Given longer video clips available to the LTC networks, we also expect better grouping of actions from the same class by filter activations of LTC. We illustrate action classes for 0 filters (x-axis) and their top activations (y-axis) for the 00f and f networks in Figure 8(a). Each action class is represented by a unique color. The filters are sorted by their purity, i.e. the frequency of the dominating class. We assign each video the color of its ground truth class label. We see that the clustering of videos from the same class becomes more clear in higher layers in the network for both f and 00f networks. However, it is evident that 00f filters have more purity than f even in L and L. Note that f network is trained with high resolution ( ) flow and 00f network with low resolution (8 8) flow. Example frames from top-scoring videos for a set of selected filters f are shown in Figure 8(b) for f and 00f flow networks. We also provide a video on our project web page [] to show which videos activate for these filters. We can observe that for filters f maximizing the homogeneity of returned class labels, the top activations for filters of the 00f network result in videos with similar action classes. The grouping of videos by classes is less prominent for activations of the f network. This result indicates that the LTC networks have higher level of abstraction at corresponding convolution layers when compared to networks with smaller temporal extents. Conclusions This paper introduces and evaluates long-term temporal convolutions (LTC) and shows that they can significantly improve the performance. Using spacetime convolutions over a large number of video frames, we obtain state of the art performance on two action recognition datasets UCF0 and HMDB. We also demonstrate the impact of the optical flow quality. In the presence of limited training data, using flow improves over RGB and the quality of the flow impacts the results significantly. Acknowledgements This work was supported by the MSR-Inria joint lab, Google and Facebook Research Awards, the ERC starting grant ACTIVIA and the ERC advanced grant ALLEGRO. UCF0 videos are obtained by clipping different parts (video) from a longer video (group). We take one video per group assuming that videos from the same group would have similar activations and would avoid a proper analysis. In total, there are test groups per class; therefore there can be at most videos belonging to a class.







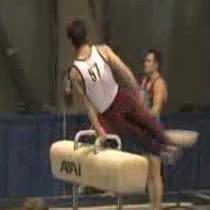




































16 Varol, Laptev, Schmid 00f f L L L L L (a) Top activations of filters at all (conv-conv) layers. Each row is another layer, indicated by L-L. Left is for 00 frames and right is for frames networks. Colors indicate different action classes. Each color plot illustrates distribution of classes for seven top activations of 0 selected filters. Rows are maximum responding test videos and columns are filters. (best viewed in color) 00f f F F F F Layer Layer (b) Frames corresponding to videos with top activations at conv and conv layers. Circles indicate the spatial location of the maximum response. The visualized frames correspond to the maximum response in time. Fig. 8. Comparison of 00f and f networks by looking at the top activations of filters.
17 Long-term Temporal Convolutions References. Tversky, B., Morrison, J., Zacks, J.: On bodies and events. In Meltzoff, A., Prinz, W., eds.: The Imitative Mind. Cambridge University Press (00). Laptev, I., Marsza lek, M., Schmid, C., Rozenfeld, B.: Learning realistic human actions from movies. In: Proc. CVPR. (008). Niebles, J.C., Wang, H., Fei-Fei, L.: Unsupervised learning of human action categories using spatial-temporal words. IJCV 9() (008) Schüldt, C., Laptev, I., Caputo, B.: Recognizing human actions: a local svm approach. In: Proc. ICPR. (00). Wang, H., Schmid, C.: Action recognition with improved trajectories. In: Proc. ICCV. (0). Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: Proc. NIPS. (0). Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Proc. NIPS. (0) 8. Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A large-scale hierarchical image database. In: Proc. CVPR. (009) 9. Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., Oliva, A.: Learning deep features for scene recognition using places database. In: Proc. NIPS. (0) 0. Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proc. CVPR. (0). Taigman, Y., Yang, M., Ranzato, M., Wolf, L.: DeepFace: Closing the gap to human-level performance in face verification. In: Proc. CVPR. (0). Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., Fei-Fei, L.: Largescale video classification with convolutional neural networks. In: Proc. CVPR. (0). Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with D convolutional networks. In: Proc. ICCV. (0). Donahue, J., Hendricks, L.A., Guadarrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., Darrell, T.: Long-term recurrent convolutional networks for visual recognition and description. In: Proc. CVPR. (0). Ji, S., Xu, W., Yang, M., Yu, K.: D convolutional neural networks for human action recognition. In: ICML. (00). Taylor, G.W., Fergus, R., LeCun, Y., Bregler, C.: Convolutional learning of spatiotemporal features. In: Proc. ECCV. (00) Csurka, G., Dance, C., Fan, L., Willamowski, J., Bray, C.: Visual categorization with bags of keypoints. In: ECCV Workshop on statistical learning in computer vision. (00) 9. Perronnin, F., Sánchez, J., Mensink, T.: Improving the fisher kernel for large-scale image classification. In: Proc. ECCV. (00) 0. Fernando, B., Gavves, E., Oramas, J., Ghodrati, A., Tuytelaars, T.: Modeling video evolution for action recognition. In: Proc. CVPR. (0). LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R., Hubbard, W., Jackel, L.: Backpropagation applied to handwritten zip code recognition. Neural Computation () (989). Wang, L., Qiao, Y., Tang, X.: Action recognition with trajectory-pooled deepconvolutional descriptors. In: CVPR. (0)
18 8 Varol, Laptev, Schmid. Wang, L., Xiong, Y., Wang, Z., Qiao, Y.: Towards good practices for very deep two-stream convnets. In: arxiv. (0). Kantorov, V., Laptev, I.: Efficient feature extraction, encoding, and classification for action recognition. In: Proc. CVPR. (0). Farnebäck, G.: Two-frame motion estimation based on polynomial expansion. In: Proc. SCIA. (00). Brox, T., Bruhn, A., Papenberg, N., Weickert, J.: High accuracy optical flow estimation based on a theory for warping. In: Proc. ECCV. (00). Soomro, k., Roshan Zamir, A., Shah, M.: UCF0: A dataset of 0 human actions classes from videos in the wild. In: CRCV-TR--0. (0) 8. Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: HMDB: a large video database for human motion recognition. In: Proc. ICCV. (0) 9. Peng, X., Wang, L., Wang, X., Qiao, Y.: Bag of visual words and fusion methods for action recognition: Comprehensive study and good practice. CoRR (0) 0. Lan, Z.Z., Lin, M., Li, X., Hauptmann, A.G., Raj, B.: Beyond gaussian pyramid: Multi-skip feature stacking for action recognition. In: Proc. CVPR. (0). Peng, X., Zou, C., Qiao, Y., Peng, Q.: Action recognition with stacked Fisher vectors. In: Proc. ECCV. (0). Ng, J.Y., Hausknecht, M.J., Vijayanarasimhan, S., Vinyals, O., Monga, R., Toderici, G.: Beyond short snippets: Deep networks for video classification. In: CVPR. (0). Wang, X., Farhadi, A., Gupta, A.: Actions transformations. In: CVPR. (0). Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: ECCV. (0)
Long-term Temporal Convolutions for Action Recognition
 1 Long-term Temporal Convolutions for Action Recognition Gül Varol, Ivan Laptev, and Cordelia Schmid, Fellow, IEEE arxiv:1604.04494v2 [cs.cv] 2 Jun 2017 Abstract Typical human actions last several seconds
1 Long-term Temporal Convolutions for Action Recognition Gül Varol, Ivan Laptev, and Cordelia Schmid, Fellow, IEEE arxiv:1604.04494v2 [cs.cv] 2 Jun 2017 Abstract Typical human actions last several seconds
Long-term Temporal Convolutions for Action Recognition INRIA
 Longterm Temporal Convolutions for Action Recognition Gul Varol Ivan Laptev INRIA Cordelia Schmid 2 Motivation Current CNN methods for action recognition learn representations for short intervals (116
Longterm Temporal Convolutions for Action Recognition Gul Varol Ivan Laptev INRIA Cordelia Schmid 2 Motivation Current CNN methods for action recognition learn representations for short intervals (116
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
 Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
EasyChair Preprint. Real-Time Action Recognition based on Enhanced Motion Vector Temporal Segment Network
 EasyChair Preprint 730 Real-Time Action Recognition based on Enhanced Motion Vector Temporal Segment Network Xue Bai, Enqing Chen and Haron Chweya Tinega EasyChair preprints are intended for rapid dissemination
EasyChair Preprint 730 Real-Time Action Recognition based on Enhanced Motion Vector Temporal Segment Network Xue Bai, Enqing Chen and Haron Chweya Tinega EasyChair preprints are intended for rapid dissemination
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
arxiv: v2 [cs.cv] 2 Apr 2018
![arxiv: v2 [cs.cv] 2 Apr 2018](/thumbs/91/106374014.jpg "arxiv: v2 [cs.cv] 2 Apr 2018") Depth of 3D CNNs Depth of 2D CNNs Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? arxiv:1711.09577v2 [cs.cv] 2 Apr 2018 Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute
Depth of 3D CNNs Depth of 2D CNNs Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? arxiv:1711.09577v2 [cs.cv] 2 Apr 2018 Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute
arxiv: v1 [cs.cv] 29 Apr 2016
![arxiv: v1 [cs.cv] 29 Apr 2016](/thumbs/94/120062841.jpg "arxiv: v1 [cs.cv] 29 Apr 2016") Improved Dense Trajectory with Cross Streams arxiv:1604.08826v1 [cs.cv] 29 Apr 2016 ABSTRACT Katsunori Ohnishi Graduate School of Information Science and Technology University of Tokyo ohnishi@mi.t.utokyo.ac.jp
Improved Dense Trajectory with Cross Streams arxiv:1604.08826v1 [cs.cv] 29 Apr 2016 ABSTRACT Katsunori Ohnishi Graduate School of Information Science and Technology University of Tokyo ohnishi@mi.t.utokyo.ac.jp
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018
 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Large-scale Video Classification with Convolutional Neural Networks
 Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Real-time Action Recognition with Enhanced Motion Vector CNNs
 Real-time Action Recognition with Enhanced Motion Vector CNNs Bowen Zhang 1,2 Limin Wang 1,3 Zhe Wang 1 Yu Qiao 1 Hanli Wang 2 1 Shenzhen key lab of Comp. Vis. & Pat. Rec., Shenzhen Institutes of Advanced
Real-time Action Recognition with Enhanced Motion Vector CNNs Bowen Zhang 1,2 Limin Wang 1,3 Zhe Wang 1 Yu Qiao 1 Hanli Wang 2 1 Shenzhen key lab of Comp. Vis. & Pat. Rec., Shenzhen Institutes of Advanced
Learning Latent Sub-events in Activity Videos Using Temporal Attention Filters
 Learning Latent Sub-events in Activity Videos Using Temporal Attention Filters AJ Piergiovanni, Chenyou Fan, and Michael S Ryoo School of Informatics and Computing, Indiana University, Bloomington, IN
Learning Latent Sub-events in Activity Videos Using Temporal Attention Filters AJ Piergiovanni, Chenyou Fan, and Michael S Ryoo School of Informatics and Computing, Indiana University, Bloomington, IN
Evaluation of Triple-Stream Convolutional Networks for Action Recognition
 Evaluation of Triple-Stream Convolutional Networks for Action Recognition Dichao Liu, Yu Wang and Jien Kato Graduate School of Informatics Nagoya University Nagoya, Japan Email: {liu, ywang, jien} (at)
Evaluation of Triple-Stream Convolutional Networks for Action Recognition Dichao Liu, Yu Wang and Jien Kato Graduate School of Informatics Nagoya University Nagoya, Japan Email: {liu, ywang, jien} (at)
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Deep Local Video Feature for Action Recognition
 Deep Local Video Feature for Action Recognition Zhenzhong Lan 1 Yi Zhu 2 Alexander G. Hauptmann 1 Shawn Newsam 2 1 Carnegie Mellon University 2 University of California, Merced {lanzhzh,alex}@cs.cmu.edu
Deep Local Video Feature for Action Recognition Zhenzhong Lan 1 Yi Zhu 2 Alexander G. Hauptmann 1 Shawn Newsam 2 1 Carnegie Mellon University 2 University of California, Merced {lanzhzh,alex}@cs.cmu.edu
Two-Stream Convolutional Networks for Action Recognition in Videos
 Two-Stream Convolutional Networks for Action Recognition in Videos Karen Simonyan Andrew Zisserman Cemil Zalluhoğlu Introduction Aim Extend deep Convolution Networks to action recognition in video. Motivation
Two-Stream Convolutional Networks for Action Recognition in Videos Karen Simonyan Andrew Zisserman Cemil Zalluhoğlu Introduction Aim Extend deep Convolution Networks to action recognition in video. Motivation
Activity Recognition in Temporally Untrimmed Videos
 Activity Recognition in Temporally Untrimmed Videos Bryan Anenberg Stanford University anenberg@stanford.edu Norman Yu Stanford University normanyu@stanford.edu Abstract We investigate strategies to apply
Activity Recognition in Temporally Untrimmed Videos Bryan Anenberg Stanford University anenberg@stanford.edu Norman Yu Stanford University normanyu@stanford.edu Abstract We investigate strategies to apply
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
arxiv: v2 [cs.cv] 6 May 2018
![arxiv: v2 [cs.cv] 6 May 2018](/thumbs/84/90975684.jpg "arxiv: v2 [cs.cv] 6 May 2018") Appearance-and-Relation Networks for Video Classification Limin Wang 1,2 Wei Li 3 Wen Li 2 Luc Van Gool 2 1 State Key Laboratory for Novel Software Technology, Nanjing University, China 2 Computer Vision
Appearance-and-Relation Networks for Video Classification Limin Wang 1,2 Wei Li 3 Wen Li 2 Luc Van Gool 2 1 State Key Laboratory for Novel Software Technology, Nanjing University, China 2 Computer Vision
Temporal Difference Networks for Video Action Recognition
 Temporal Difference Networks for Video Action Recognition Joe Yue-Hei Ng Larry S. Davis University of Maryland, College Park {yhng,lsd}@umiacs.umd.edu Abstract Deep convolutional neural networks have been
Temporal Difference Networks for Video Action Recognition Joe Yue-Hei Ng Larry S. Davis University of Maryland, College Park {yhng,lsd}@umiacs.umd.edu Abstract Deep convolutional neural networks have been
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Person Action Recognition/Detection
 Person Action Recognition/Detection Fabrício Ceschin Visão Computacional Prof. David Menotti Departamento de Informática - Universidade Federal do Paraná 1 In object recognition: is there a chair in the
Person Action Recognition/Detection Fabrício Ceschin Visão Computacional Prof. David Menotti Departamento de Informática - Universidade Federal do Paraná 1 In object recognition: is there a chair in the
3D CONVOLUTIONAL NEURAL NETWORK WITH MULTI-MODEL FRAMEWORK FOR ACTION RECOGNITION
 3D CONVOLUTIONAL NEURAL NETWORK WITH MULTI-MODEL FRAMEWORK FOR ACTION RECOGNITION Longlong Jing 1, Yuancheng Ye 1, Xiaodong Yang 3, Yingli Tian 1,2 1 The Graduate Center, 2 The City College, City University
3D CONVOLUTIONAL NEURAL NETWORK WITH MULTI-MODEL FRAMEWORK FOR ACTION RECOGNITION Longlong Jing 1, Yuancheng Ye 1, Xiaodong Yang 3, Yingli Tian 1,2 1 The Graduate Center, 2 The City College, City University
Know your data - many types of networks
 Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
arxiv: v1 [cs.cv] 26 Jul 2018
![arxiv: v1 [cs.cv] 26 Jul 2018](/thumbs/88/117269915.jpg "arxiv: v1 [cs.cv] 26 Jul 2018") A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
arxiv: v1 [cs.cv] 22 Nov 2017
![arxiv: v1 [cs.cv] 22 Nov 2017](/thumbs/93/114301500.jpg "arxiv: v1 [cs.cv] 22 Nov 2017") D Nets: New Architecture and Transfer Learning for Video Classification Ali Diba,4,, Mohsen Fayyaz,, Vivek Sharma, Amir Hossein Karami 4, Mohammad Mahdi Arzani 4, Rahman Yousefzadeh 4, Luc Van Gool,4 ESAT-PSI,
D Nets: New Architecture and Transfer Learning for Video Classification Ali Diba,4,, Mohsen Fayyaz,, Vivek Sharma, Amir Hossein Karami 4, Mohammad Mahdi Arzani 4, Rahman Yousefzadeh 4, Luc Van Gool,4 ESAT-PSI,
A Torch Library for Action Recognition and Detection Using CNNs and LSTMs
 A Torch Library for Action Recognition and Detection Using CNNs and LSTMs Gary Thung and Helen Jiang Stanford University {gthung, helennn}@stanford.edu Abstract It is very common now to see deep neural
A Torch Library for Action Recognition and Detection Using CNNs and LSTMs Gary Thung and Helen Jiang Stanford University {gthung, helennn}@stanford.edu Abstract It is very common now to see deep neural
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
arxiv: v1 [cs.cv] 19 May 2015
![arxiv: v1 [cs.cv] 19 May 2015](/thumbs/77/76306535.jpg "arxiv: v1 [cs.cv] 19 May 2015") Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors Limin Wang 1,2 Yu Qiao 2 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University of Hong Kong 2 Shenzhen
Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors Limin Wang 1,2 Yu Qiao 2 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University of Hong Kong 2 Shenzhen
Eigen-Evolution Dense Trajectory Descriptors
 Eigen-Evolution Dense Trajectory Descriptors Yang Wang, Vinh Tran, and Minh Hoai Stony Brook University, Stony Brook, NY 11794-2424, USA {wang33, tquangvinh, minhhoai}@cs.stonybrook.edu Abstract Trajectory-pooled
Eigen-Evolution Dense Trajectory Descriptors Yang Wang, Vinh Tran, and Minh Hoai Stony Brook University, Stony Brook, NY 11794-2424, USA {wang33, tquangvinh, minhhoai}@cs.stonybrook.edu Abstract Trajectory-pooled
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition
 MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition Yizhou Zhou 1 Xiaoyan Sun 2 Zheng-Jun Zha 1 Wenjun Zeng 2 1 University of Science and Technology of China 2 Microsoft Research Asia zyz0205@mail.ustc.edu.cn,
MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition Yizhou Zhou 1 Xiaoyan Sun 2 Zheng-Jun Zha 1 Wenjun Zeng 2 1 University of Science and Technology of China 2 Microsoft Research Asia zyz0205@mail.ustc.edu.cn,
arxiv: v3 [cs.cv] 8 May 2015
![arxiv: v3 [cs.cv] 8 May 2015](/thumbs/81/84567177.jpg "arxiv: v3 [cs.cv] 8 May 2015") Exploiting Image-trained CNN Architectures for Unconstrained Video Classification arxiv:503.0444v3 [cs.cv] 8 May 205 Shengxin Zha Northwestern University Evanston IL USA szha@u.northwestern.edu Abstract
Exploiting Image-trained CNN Architectures for Unconstrained Video Classification arxiv:503.0444v3 [cs.cv] 8 May 205 Shengxin Zha Northwestern University Evanston IL USA szha@u.northwestern.edu Abstract
Multilayer and Multimodal Fusion of Deep Neural Networks for Video Classification
 Multilayer and Multimodal Fusion of Deep Neural Networks for Video Classification Xiaodong Yang, Pavlo Molchanov, Jan Kautz INTELLIGENT VIDEO ANALYTICS Surveillance event detection Human-computer interaction
Multilayer and Multimodal Fusion of Deep Neural Networks for Video Classification Xiaodong Yang, Pavlo Molchanov, Jan Kautz INTELLIGENT VIDEO ANALYTICS Surveillance event detection Human-computer interaction
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
A Unified Method for First and Third Person Action Recognition
 A Unified Method for First and Third Person Action Recognition Ali Javidani Department of Computer Science and Engineering Shahid Beheshti University Tehran, Iran a.javidani@mail.sbu.ac.ir Ahmad Mahmoudi-Aznaveh
A Unified Method for First and Third Person Action Recognition Ali Javidani Department of Computer Science and Engineering Shahid Beheshti University Tehran, Iran a.javidani@mail.sbu.ac.ir Ahmad Mahmoudi-Aznaveh
arxiv: v2 [cs.cv] 26 Apr 2018
![arxiv: v2 [cs.cv] 26 Apr 2018](/thumbs/95/126019772.jpg "arxiv: v2 [cs.cv] 26 Apr 2018") Motion Fused Frames: Data Level Fusion Strategy for Hand Gesture Recognition arxiv:1804.07187v2 [cs.cv] 26 Apr 2018 Okan Köpüklü Neslihan Köse Gerhard Rigoll Institute for Human-Machine Communication Technical
Motion Fused Frames: Data Level Fusion Strategy for Hand Gesture Recognition arxiv:1804.07187v2 [cs.cv] 26 Apr 2018 Okan Köpüklü Neslihan Köse Gerhard Rigoll Institute for Human-Machine Communication Technical
T-C3D: Temporal Convolutional 3D Network for Real-Time Action Recognition
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) T-C3D: Temporal Convolutional 3D Network for Real-Time Action Recognition Kun Liu, 1 Wu Liu, 1 Chuang Gan, 2 Mingkui Tan, 3 Huadong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) T-C3D: Temporal Convolutional 3D Network for Real-Time Action Recognition Kun Liu, 1 Wu Liu, 1 Chuang Gan, 2 Mingkui Tan, 3 Huadong
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
4D Effect Video Classification with Shot-aware Frame Selection and Deep Neural Networks
 4D Effect Video Classification with Shot-aware Frame Selection and Deep Neural Networks Thomhert S. Siadari 1, Mikyong Han 2, and Hyunjin Yoon 1,2 Korea University of Science and Technology, South Korea
4D Effect Video Classification with Shot-aware Frame Selection and Deep Neural Networks Thomhert S. Siadari 1, Mikyong Han 2, and Hyunjin Yoon 1,2 Korea University of Science and Technology, South Korea
GPU Accelerated Sequence Learning for Action Recognition. Yemin Shi
 GPU Accelerated Sequence Learning for Action Recognition Yemin Shi shiyemin@pku.edu.cn 2018-03 1 Background Object Recognition (Image Classification) Action Recognition (Video Classification) Action Recognition
GPU Accelerated Sequence Learning for Action Recognition Yemin Shi shiyemin@pku.edu.cn 2018-03 1 Background Object Recognition (Image Classification) Action Recognition (Video Classification) Action Recognition
arxiv: v3 [cs.cv] 2 Aug 2017
![arxiv: v3 [cs.cv] 2 Aug 2017](/thumbs/72/66392286.jpg "arxiv: v3 [cs.cv] 2 Aug 2017") Action Detection ( 4.3) Tube Proposal Network ( 4.1) Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos Rui Hou, Chen Chen, Mubarak Shah Center for Research in Computer Vision (CRCV),
Action Detection ( 4.3) Tube Proposal Network ( 4.1) Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos Rui Hou, Chen Chen, Mubarak Shah Center for Research in Computer Vision (CRCV),
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Large-scale gesture recognition based on Multimodal data with C3D and TSN
 Large-scale gesture recognition based on Multimodal data with C3D and TSN July 6, 2017 1 Team details Team name ASU Team leader name Yunan Li Team leader address, phone number and email address: Xidian
Large-scale gesture recognition based on Multimodal data with C3D and TSN July 6, 2017 1 Team details Team name ASU Team leader name Yunan Li Team leader address, phone number and email address: Xidian
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
arxiv: v1 [cs.cv] 11 Jun 2015
![arxiv: v1 [cs.cv] 11 Jun 2015](/thumbs/76/73120193.jpg "arxiv: v1 [cs.cv] 11 Jun 2015") P-CNN: Pose-based CNN Features for Action Recognition Guilhem Chéron Ivan Laptev Inria firstname.lastname@inria.fr Cordelia Schmid arxiv:1506.03607v1 [cs.cv] 11 Jun 2015 Abstract This work targets human
P-CNN: Pose-based CNN Features for Action Recognition Guilhem Chéron Ivan Laptev Inria firstname.lastname@inria.fr Cordelia Schmid arxiv:1506.03607v1 [cs.cv] 11 Jun 2015 Abstract This work targets human
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
arxiv: v7 [cs.cv] 21 Apr 2018
![arxiv: v7 [cs.cv] 21 Apr 2018](/thumbs/90/103677812.jpg "arxiv: v7 [cs.cv] 21 Apr 2018") End-to-end Video-level Representation Learning for Action Recognition Jiagang Zhu 1,2, Wei Zou 1, Zheng Zhu 1,2 1 Institute of Automation, Chinese Academy of Sciences (CASIA) 2 University of Chinese Academy
End-to-end Video-level Representation Learning for Action Recognition Jiagang Zhu 1,2, Wei Zou 1, Zheng Zhu 1,2 1 Institute of Automation, Chinese Academy of Sciences (CASIA) 2 University of Chinese Academy
Deep Alternative Neural Network: Exploring Contexts as Early as Possible for Action Recognition
 Deep Alternative Neural Network: Exploring Contexts as Early as Possible for Action Recognition Jinzhuo Wang, Wenmin Wang, Xiongtao Chen, Ronggang Wang, Wen Gao School of Electronics and Computer Engineering,
Deep Alternative Neural Network: Exploring Contexts as Early as Possible for Action Recognition Jinzhuo Wang, Wenmin Wang, Xiongtao Chen, Ronggang Wang, Wen Gao School of Electronics and Computer Engineering,
Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos
 for Action Detection in Videos") Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos Rui Hou, Chen Chen, Mubarak Shah Center for Research in Computer Vision (CRCV), University of Central Florida (UCF) houray@gmail.com,
Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos Rui Hou, Chen Chen, Mubarak Shah Center for Research in Computer Vision (CRCV), University of Central Florida (UCF) houray@gmail.com,
YouTube-8M Video Classification
 YouTube-8M Video Classification Alexandre Gauthier and Haiyu Lu Stanford University 450 Serra Mall Stanford, CA 94305 agau@stanford.edu hylu@stanford.edu Abstract Convolutional Neural Networks (CNNs) have
YouTube-8M Video Classification Alexandre Gauthier and Haiyu Lu Stanford University 450 Serra Mall Stanford, CA 94305 agau@stanford.edu hylu@stanford.edu Abstract Convolutional Neural Networks (CNNs) have
CS231N Section. Video Understanding 6/1/2018
 CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
arxiv: v3 [cs.cv] 12 Apr 2018
![arxiv: v3 [cs.cv] 12 Apr 2018](/thumbs/80/81437554.jpg "arxiv: v3 [cs.cv] 12 Apr 2018") A Closer Look at Spatiotemporal Convolutions for Action Recognition Du Tran 1, Heng Wang 1, Lorenzo Torresani 1,2, Jamie Ray 1, Yann LeCun 1, Manohar Paluri 1 1 Facebook Research 2 Dartmouth College {trandu,hengwang,torresani,jamieray,yann,mano}@fb.com
A Closer Look at Spatiotemporal Convolutions for Action Recognition Du Tran 1, Heng Wang 1, Lorenzo Torresani 1,2, Jamie Ray 1, Yann LeCun 1, Manohar Paluri 1 1 Facebook Research 2 Dartmouth College {trandu,hengwang,torresani,jamieray,yann,mano}@fb.com
COMPRESSED-DOMAIN VIDEO CLASSIFICATION WITH DEEP NEURAL NETWORKS: THERE S WAY TOO MUCH INFORMATION TO DECODE THE MATRIX
 COMPRESSED-DOMAIN VIDEO CLASSIFICATION WITH DEEP NEURAL NETWORKS: THERE S WAY TOO MUCH INFORMATION TO DECODE THE MATRIX Aaron Chadha, Alhabib Abbas University College London (UCL) Electronic and Electrical
COMPRESSED-DOMAIN VIDEO CLASSIFICATION WITH DEEP NEURAL NETWORKS: THERE S WAY TOO MUCH INFORMATION TO DECODE THE MATRIX Aaron Chadha, Alhabib Abbas University College London (UCL) Electronic and Electrical
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
arxiv: v1 [cs.cv] 2 May 2015
![arxiv: v1 [cs.cv] 2 May 2015](/thumbs/75/72350299.jpg "arxiv: v1 [cs.cv] 2 May 2015") Dense Optical Flow Prediction from a Static Image Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu arxiv:1505.00295v1
Dense Optical Flow Prediction from a Static Image Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu arxiv:1505.00295v1
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
P-CNN: Pose-based CNN Features for Action Recognition
 P-CNN: Pose-based CNN Features for Action Recognition Guilhem Chéron, Ivan Laptev, Cordelia Schmid To cite this version: Guilhem Chéron, Ivan Laptev, Cordelia Schmid. P-CNN: Pose-based CNN Features for
P-CNN: Pose-based CNN Features for Action Recognition Guilhem Chéron, Ivan Laptev, Cordelia Schmid To cite this version: Guilhem Chéron, Ivan Laptev, Cordelia Schmid. P-CNN: Pose-based CNN Features for
arxiv: v2 [cs.cv] 13 Apr 2015
![arxiv: v2 [cs.cv] 13 Apr 2015](/thumbs/79/79745111.jpg "arxiv: v2 [cs.cv] 13 Apr 2015") Beyond Short Snippets: Deep Networks for Video Classification arxiv:1503.08909v2 [cs.cv] 13 Apr 2015 Joe Yue-Hei Ng 1 yhng@umiacs.umd.edu Oriol Vinyals 3 vinyals@google.com Matthew Hausknecht 2 mhauskn@cs.utexas.edu
Beyond Short Snippets: Deep Networks for Video Classification arxiv:1503.08909v2 [cs.cv] 13 Apr 2015 Joe Yue-Hei Ng 1 yhng@umiacs.umd.edu Oriol Vinyals 3 vinyals@google.com Matthew Hausknecht 2 mhauskn@cs.utexas.edu
arxiv: v1 [cs.cv] 13 Aug 2017
![arxiv: v1 [cs.cv] 13 Aug 2017](/thumbs/81/84196368.jpg "arxiv: v1 [cs.cv] 13 Aug 2017") Lattice Long Short-Term Memory for Human Action Recognition Lin Sun 1,2, Kui Jia 3, Kevin Chen 2, Dit Yan Yeung 1, Bertram E. Shi 1, and Silvio Savarese 2 arxiv:1708.03958v1 [cs.cv] 13 Aug 2017 1 The Hong
Lattice Long Short-Term Memory for Human Action Recognition Lin Sun 1,2, Kui Jia 3, Kevin Chen 2, Dit Yan Yeung 1, Bertram E. Shi 1, and Silvio Savarese 2 arxiv:1708.03958v1 [cs.cv] 13 Aug 2017 1 The Hong
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Robust Scene Classification with Cross-level LLC Coding on CNN Features
 Robust Scene Classification with Cross-level LLC Coding on CNN Features Zequn Jie 1, Shuicheng Yan 2 1 Keio-NUS CUTE Center, National University of Singapore, Singapore 2 Department of Electrical and Computer
Robust Scene Classification with Cross-level LLC Coding on CNN Features Zequn Jie 1, Shuicheng Yan 2 1 Keio-NUS CUTE Center, National University of Singapore, Singapore 2 Department of Electrical and Computer
arxiv: v1 [cs.cv] 23 Jan 2018
![arxiv: v1 [cs.cv] 23 Jan 2018](/thumbs/75/72740712.jpg "arxiv: v1 [cs.cv] 23 Jan 2018") Let s Dance: Learning From Online Dance Videos Daniel Castro Georgia Institute of Technology Steven Hickson Patsorn Sangkloy shickson@gatech.edu patsorn sangkloy@gatech.edu arxiv:1801.07388v1 [cs.cv] 23
Let s Dance: Learning From Online Dance Videos Daniel Castro Georgia Institute of Technology Steven Hickson Patsorn Sangkloy shickson@gatech.edu patsorn sangkloy@gatech.edu arxiv:1801.07388v1 [cs.cv] 23
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/78/78100143.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:1607.01794v1 [cs.cv] 6 Jul 2016 VideoLSTM Convolves, Attends and Flows for Action Recognition Zhenyang Li, Efstratios Gavves, Mihir Jain, and Cees G. M. Snoek QUVA Lab, University of Amsterdam Abstract.
arxiv:1607.01794v1 [cs.cv] 6 Jul 2016 VideoLSTM Convolves, Attends and Flows for Action Recognition Zhenyang Li, Efstratios Gavves, Mihir Jain, and Cees G. M. Snoek QUVA Lab, University of Amsterdam Abstract.
Dynamic Image Networks for Action Recognition
 Dynamic Image Networks for Action Recognition Hakan Bilen Basura Fernando Efstratios Gavves Andrea Vedaldi Stephen Gould University of Oxford The Australian National University QUVA Lab, University of
Dynamic Image Networks for Action Recognition Hakan Bilen Basura Fernando Efstratios Gavves Andrea Vedaldi Stephen Gould University of Oxford The Australian National University QUVA Lab, University of
arxiv: v1 [cs.cv] 4 Dec 2014
![arxiv: v1 [cs.cv] 4 Dec 2014](/thumbs/83/87999872.jpg "arxiv: v1 [cs.cv] 4 Dec 2014") Convolutional Neural Networks at Constrained Time Cost Kaiming He Jian Sun Microsoft Research {kahe,jiansun}@microsoft.com arxiv:1412.1710v1 [cs.cv] 4 Dec 2014 Abstract Though recent advanced convolutional
Convolutional Neural Networks at Constrained Time Cost Kaiming He Jian Sun Microsoft Research {kahe,jiansun}@microsoft.com arxiv:1412.1710v1 [cs.cv] 4 Dec 2014 Abstract Though recent advanced convolutional
Dense Optical Flow Prediction from a Static Image
 Dense Optical Flow Prediction from a Static Image Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu Abstract Given a
Dense Optical Flow Prediction from a Static Image Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu Abstract Given a
Return of the Devil in the Details: Delving Deep into Convolutional Nets
 Return of the Devil in the Details: Delving Deep into Convolutional Nets Ken Chatfield - Karen Simonyan - Andrea Vedaldi - Andrew Zisserman University of Oxford The Devil is still in the Details 2011 2014
Return of the Devil in the Details: Delving Deep into Convolutional Nets Ken Chatfield - Karen Simonyan - Andrea Vedaldi - Andrew Zisserman University of Oxford The Devil is still in the Details 2011 2014
Cultural Event Recognition by Subregion Classification with Convolutional Neural Network
 Cultural Event Recognition by Subregion Classification with Convolutional Neural Network Sungheon Park and Nojun Kwak Graduate School of CST, Seoul National University Seoul, Korea {sungheonpark,nojunk}@snu.ac.kr
Cultural Event Recognition by Subregion Classification with Convolutional Neural Network Sungheon Park and Nojun Kwak Graduate School of CST, Seoul National University Seoul, Korea {sungheonpark,nojunk}@snu.ac.kr
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks
 Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks August 16, 2016 1 Team details Team name FLiXT Team leader name Yunan Li Team leader address, phone number and email address:
Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks August 16, 2016 1 Team details Team name FLiXT Team leader name Yunan Li Team leader address, phone number and email address:
Attention-based Temporal Weighted Convolutional Neural Network for Action Recognition
 Attention-based Temporal Weighted Convolutional Neural Network for Action Recognition Jinliang Zang 1, Le Wang 1, Ziyi Liu 1, Qilin Zhang 2, Zhenxing Niu 3, Gang Hua 4, and Nanning Zheng 1 1 Xi an Jiaotong
Attention-based Temporal Weighted Convolutional Neural Network for Action Recognition Jinliang Zang 1, Le Wang 1, Ziyi Liu 1, Qilin Zhang 2, Zhenxing Niu 3, Gang Hua 4, and Nanning Zheng 1 1 Xi an Jiaotong
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015
 CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
arxiv: v1 [cs.cv] 19 Jun 2018
![arxiv: v1 [cs.cv] 19 Jun 2018](/thumbs/95/125862818.jpg "arxiv: v1 [cs.cv] 19 Jun 2018") Multimodal feature fusion for CNN-based gait recognition: an empirical comparison F.M. Castro a,, M.J. Marín-Jiménez b, N. Guil a, N. Pérez de la Blanca c a Department of Computer Architecture, University
Multimodal feature fusion for CNN-based gait recognition: an empirical comparison F.M. Castro a,, M.J. Marín-Jiménez b, N. Guil a, N. Pérez de la Blanca c a Department of Computer Architecture, University
Learning to track for spatio-temporal action localization
 Learning to track for spatio-temporal action localization Philippe Weinzaepfel a Zaid Harchaoui a,b Cordelia Schmid a a Inria b NYU firstname.lastname@inria.fr Abstract We propose an effective approach
Learning to track for spatio-temporal action localization Philippe Weinzaepfel a Zaid Harchaoui a,b Cordelia Schmid a a Inria b NYU firstname.lastname@inria.fr Abstract We propose an effective approach
Attention-Based Temporal Weighted Convolutional Neural Network for Action Recognition
 Attention-Based Temporal Weighted Convolutional Neural Network for Action Recognition Jinliang Zang 1, Le Wang 1(&), Ziyi Liu 1, Qilin Zhang 2, Gang Hua 3, and Nanning Zheng 1 1 Xi an Jiaotong University,
Attention-Based Temporal Weighted Convolutional Neural Network for Action Recognition Jinliang Zang 1, Le Wang 1(&), Ziyi Liu 1, Qilin Zhang 2, Gang Hua 3, and Nanning Zheng 1 1 Xi an Jiaotong University,
Image and Video Understanding
 Image and Video Understanding 2VO 70.095 WS Christoph Feichtenhofer, Axel Pinz Slide credits: Many thanks to all the great computer vision researchers on which this presentation relies on. Most material
Image and Video Understanding 2VO 70.095 WS Christoph Feichtenhofer, Axel Pinz Slide credits: Many thanks to all the great computer vision researchers on which this presentation relies on. Most material
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions
 Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Spatiotemporal Residual Networks for Video Action Recognition
 Spatiotemporal Residual Networks for Video Action Recognition Christoph Feichtenhofer Graz University of Technology feichtenhofer@tugraz.at Axel Pinz Graz University of Technology axel.pinz@tugraz.at Richard
Spatiotemporal Residual Networks for Video Action Recognition Christoph Feichtenhofer Graz University of Technology feichtenhofer@tugraz.at Axel Pinz Graz University of Technology axel.pinz@tugraz.at Richard
Recurrent Neural Networks and Transfer Learning for Action Recognition
 Recurrent Neural Networks and Transfer Learning for Action Recognition Andrew Giel Stanford University agiel@stanford.edu Ryan Diaz Stanford University ryandiaz@stanford.edu Abstract We have taken on the
Recurrent Neural Networks and Transfer Learning for Action Recognition Andrew Giel Stanford University agiel@stanford.edu Ryan Diaz Stanford University ryandiaz@stanford.edu Abstract We have taken on the
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos
 Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos Tomas Pfister 1, Karen Simonyan 1, James Charles 2 and Andrew Zisserman 1 1 Visual Geometry Group, Department of Engineering
Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos Tomas Pfister 1, Karen Simonyan 1, James Charles 2 and Andrew Zisserman 1 1 Visual Geometry Group, Department of Engineering
P-CNN: Pose-based CNN Features for Action Recognition. Iman Rezazadeh
 P-CNN: Pose-based CNN Features for Action Recognition Iman Rezazadeh Introduction automatic understanding of dynamic scenes strong variations of people and scenes in motion and appearance Fine-grained
P-CNN: Pose-based CNN Features for Action Recognition Iman Rezazadeh Introduction automatic understanding of dynamic scenes strong variations of people and scenes in motion and appearance Fine-grained
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Deep Face Recognition. Nathan Sun
 Deep Face Recognition Nathan Sun Why Facial Recognition? Picture ID or video tracking Higher Security for Facial Recognition Software Immensely useful to police in tracking suspects Your face will be an
Deep Face Recognition Nathan Sun Why Facial Recognition? Picture ID or video tracking Higher Security for Facial Recognition Software Immensely useful to police in tracking suspects Your face will be an
Learning visual odometry with a convolutional network
 Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Spatio-Temporal Vector of Locally Max Pooled Features for Action Recognition in Videos
 Spatio-Temporal Vector of Locally Max Pooled Features for Action Recognition in Videos Ionut Cosmin Duta 1 Bogdan Ionescu 2 Kiyoharu Aizawa 3 Nicu Sebe 1 1 University of Trento, Italy 2 University Politehnica
Spatio-Temporal Vector of Locally Max Pooled Features for Action Recognition in Videos Ionut Cosmin Duta 1 Bogdan Ionescu 2 Kiyoharu Aizawa 3 Nicu Sebe 1 1 University of Trento, Italy 2 University Politehnica
arxiv: v2 [cs.cv] 23 May 2016
![arxiv: v2 [cs.cv] 23 May 2016](/thumbs/88/115196824.jpg "arxiv: v2 [cs.cv] 23 May 2016") Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research