Apache Hadoop Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.
|
|
|
- Evelyn Day
- 5 years ago
- Views:
Transcription
1 SDJ INFOSOFT PVT. LTD Apache Hadoop Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.x Table of Contents Topic Software Requirements Hardware Requirements. Introduction 1. Setting up the Ubuntu Desktop 1.1 Creating an Ubuntu VM Player instance Download the VMware image Page Open the image file Play the Virtual Machine Update the OS packages and their dependencies Install the Java and openssh server for Hadoop Download the Apache Hadoop binaries Download the Hadoop package 2. Configure the Apache Hadoop Single Node Server 2.1 Update the Configuration files Update.bashrc file for user ubuntu SDJINFOSOFT PVT. LTD 1
2 2.2 Setup the Hadoop Cluster Configure JAVA_HOME Create NameNode and DataNode directory Configure the Default File system Configure the HDFS Configure YARN framework Configure MapReduce framework Edit /etc/hosts file Creating ssh Moving the key to authorized key: Start the DFS services Perform the Health Check 2015 SDJINFOSOFT PVT. LTD 2
3 Introduction This setup and configuration document is a guide to setup a Single-Node Apache Hadoop 2.0 cluster on an Ubuntu virtual machine on your PC. If you are new to both Ubuntu and Hadoop, this guide comes handy to quickly setup a Single-Node Apache Hadoop 2.0 Cluster on Ubuntu and start your Big Data and Hadoop learning journey. The guide describes the whole process in two parts: Section 1: Setting up the Ubuntu OS for Hadoop 2.0 This section describes step by step guide to download, configure an Ubuntu Virtual Machine image in VMPlayer, and provides steps to install pre-requisites for Hadoop Installation on Ubuntu. Section 2: Installing Apache Hadoop 2.0 and Setting up the Single Node Cluster This section explains primary Hadoop 2.0 configuration files, Single-Node cluster configuration and Hadoop daemons start and stop process in detail. 1. Setting up the Ubuntu Desktop This section describes the steps to download and create an Ubuntu image on VMware Player. 1.1 Creating an Ubuntu VM Player instance The first step is to download an Ubuntu image and create an Ubuntu VMPlayer instance Download the VMware image 2015 SDJINFOSOFT PVT. LTD 3


4 Access the following link and download the Ubuntu image: l Open the image file Extract the Ubuntu VM image and Open it in VMware Workstation. Click open virtual machine and select path where you have extracted the image 2015 SDJINFOSOFT PVT. LTD 4

5 1.1.3 Play the Virtual Machine You would see the below screen in VMware Workstation after the VM image creation completes SDJINFOSOFT PVT. LTD 5

6 You will get the home screen with the following image SDJINFOSOFT PVT. LTD 6

 short cut key to open terminal.")
7 The user details for the Virtual instance is: Username : user Password : password Open the terminal to access the file system. (CTRL+ALT+T) short cut key to open terminal SDJINFOSOFT PVT. LTD 7



8 1.1.4 Update the OS packages and their dependencies The first task is to run apt-get update to download the package lists from the repositories and "update" them to get information on the newest versions of packages and their dependencies. Type command on terminal. $sudo apt - get update Problem Note : sudo apt-get update not working error related to lock file than $sudo rm /var/lib/apt/lists/lock $sudo rm /var/cache/apt/archives/lock Install the Java and openssh server for Hadoop Check java version installation. $java version 2015 SDJINFOSOFT PVT. LTD 8


9 Use apt-get to install the JDK 7. $sudo apt-get install openjdk-7-jdk $java version Check the location of java folder where java install. $cd usr/lib/jvm 2015 SDJINFOSOFT PVT. LTD 9


10 $sudo apt-get install openssh-server 1.2 Download the Apache Hadoop binaries Download the Hadoop package Download the binaries to your home directory. Use the default user user for the installation SDJINFOSOFT PVT. LTD 10

11 In Live production instances a dedicated Hadoop user account for running Hadoop is used. Though, it s not mandatory to use a dedicated Hadoop user account but is recommended because this helps to separate the Hadoop installation from other software applications and user accounts running on the same machine (separating for security, permissions, backups, etc.). Click on following link to download hadoop tar.gz file SDJINFOSOFT PVT. LTD 11

12 Unzip the files and review the package content and configuration files. $tar xvf hadoop tar.gz 2015 SDJINFOSOFT PVT. LTD 12

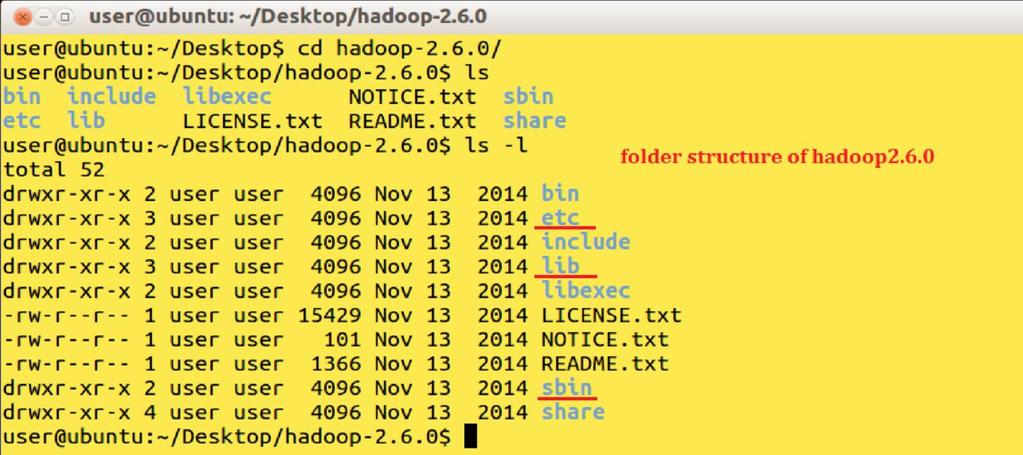
13 2015 SDJINFOSOFT PVT. LTD 13

14 Review the Hadoop configurations files. After creating and configuring your virtual servers, the Ubuntu instance is now ready to start installation and configuration of Apache Hadoop Single Node Cluster. This section describes the steps in details to install Apache Hadoop and configure a Single Node Apache Hadoop cluster. 2. Configure the Apache Hadoop Single Node Server This section explains the steps to configure the Single Node Apache Hadoop Server on Ubuntu. 2.1 Update the Configuration files Update.bashrc file for user ubuntu. Must be move to user $HOME directory and edit.bashrc file SDJINFOSOFT PVT. LTD 14


15 Update the.bashrc file to add important Apache Hadoop environment variables for user. a) Change directory to home. $ cd b) Edit the file $ sudo gedit.bashrc Add below lines in the.bashrc file. # Set Hadoop-related environment variables export HADOOP_HOME=$HOME/hadoop export HADOOP_CONF_DIR=$HOME/hadoop-2.6.0/etc/hadoop export HADOOP_MAPRED_HOME=$HOME/hadoop export HADOOP_COMMON_HOME=$HOME/hadoop export HADOOP_HDFS_HOME=$HOME/hadoop export YARN_HOME=$HOME/hadoop # Set JAVA_HOME export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386 # Add Hadoop bin/ directory to PATH export PATH=$PATH:$HOME/hadoop-2.6.0/bin 2015 SDJINFOSOFT PVT. LTD 15


16 c) Source the.bashrc file to set the hadoop environment variables without having to invoke a new shell: 2.2 Setup the Hadoop Cluster This section describes the detail steps needed for setting up the Hadoop Cluster and configuring the core Hadoop configuration files Configure JAVA_HOME Configure JAVA_HOME in hadoop-env.sh. This file specifies environment variables that affect the JDK used by Apache Hadoop daemons started by the Hadoop start-up scripts: /hadoop-2.6.0/etc/hadoop$sudo gedit hadood-env.sh Copy this line in haoop-env.sh 2015 SDJINFOSOFT PVT. LTD 16


17 export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i Create NameNode and DataNode directory Check the $HADOOP_HOME value. Create DataNode and NameNode directories to store HDFS data. $sudo mkdir p $HADOOP_HOME/hadoop2_data/hdfs/namenode $sudo mkdir p $HADOOP_HOME/hadoop2_data/hdfs/datanode 2015 SDJINFOSOFT PVT. LTD 17
 used by clients in core-site.")
18 Check by hadoop2_data folder create inside /home/user/hadoop Configure the Default File system The core-site.xml file contains the configuration settings for Apache Hadoop Core such as I/O settings that are common to HDFS, YARN and MapReduce. Configure default files-system (Parameter: fs.default.name) used by clients in core-site.xml Note : copy <configuration> tag to </configuration> and replace same tag in core-site.xml file <!-- core-site.xml --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> Where hostname and port are the machine and port on which Name Node daemon runs and listens. It also informs the Name Node as to which IP and port it should bind. The commonly used port is 9000 and you can also specify IP address rather than hostname SDJINFOSOFT PVT. LTD 18
19 2.2.4 Configure the HDFS This file contains the configuration settings for HDFS daemons; the Name Node and the data nodes. Configure hdfs-site.xml and specify default block replication, and NameNode and DataNode directories for HDFS. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/user/hadoop-2.6.0/hadoop2_data/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/user/hadoop-2.6.0/hadoop2_data/hdfs/datanode</value> </property> </configuration> 2015 SDJINFOSOFT PVT. LTD 19
20 2.2.5 Configure YARN framework This file contains the configuration settings for YARN the NodeManager. <!-- yarn-site.xml --> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.shufflehandler</value> </property> </configuration> 2.6 Configure MapReduce framework This file contains the configuration settings for MapReduce. Configure mapred-site.xml and specify framework details. /hadoop-2.6.0/etc/hadoop$cp mapred-site.xml.template mapred-site.xml /hadoop-2.6.0/etc/hadoop$sudo gedit mapred-site.xml 2015 SDJINFOSOFT PVT. LTD 20

21 <!-- mapread-site.xml --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> Edit /etc/hosts file Give ifconfig in the terminal and note down the ip address. Then put this ip address in /etc/hosts file as mentioned in below snapshots, save the file and then close it. $cd $ifconfig The ip address in this file, localhost and ubuntu are separated by tab SDJINFOSOFT PVT. LTD 21

22 $sudo gedit /etc/hosts Note: if not change anything in this etc/hosts file only first two line mention than also correct. etc/hosts File generally use in Multimode cluster Creating ssh $ssh-keygen -t rsa -P "" 2015 SDJINFOSOFT PVT. LTD 22

23 Moving the key to authorized key: $cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys start the DFS services The first step in starting up your Hadoop installation is formatting the Hadoop file-system, which is implemented on top of the local file-systems of your cluster. This is required on the first time Hadoop installation. Do not format a running Hadoop file-system, this will cause all your data to be erased. To format the file-system, run the command: 2015 SDJINFOSOFT PVT. LTD 23
24 $cd $hadoop namenode -format Reboot the system You are now all set to start the HDFS services i.e. Name Node, Resource Manager, Node Manager and Data Nodes on your Apache Hadoop Cluster. $cd hadoop-2.6.0/sbin/ $./hadoop-daemon.sh start namenode $./hadoop-daemon.sh start datanode 2015 SDJINFOSOFT PVT. LTD 24
. $./yarn-daemon.")
25 Start the YARN daemons i.e. Resource Manager and Node Manager. Cross check the service start-up using JPS (Java Process Monitoring Tool). $./yarn-daemon.sh start resourcemanager $./yarn-daemon.sh start nodemanager 2015 SDJINFOSOFT PVT. LTD 25



26 Start the History server. $./mr-jobhistory-daemon.sh start historyserver Note: Always suspend your VMware Workstation, do not shut it down. So that when you open your VM again, your cluster will be up. In case you shut it down, so when you start your VM all your daemons will be down (not running). So again start all your daeons starting from namenode, do not format the namenode again Perform the Health Check a) Check the NameNode status: 2015 SDJINFOSOFT PVT. LTD 26
 JobHistory status: http://localhost:19888/jobhistory 2015")
27 b) JobHistory status: SDJINFOSOFT PVT. LTD 27


28 c) Browse HDFS input and output file and log informaton SDJINFOSOFT PVT. LTD 28
Installing Hadoop. You need a *nix system (Linux, Mac OS X, ) with a working installation of Java 1.7, either OpenJDK or the Oracle JDK. See, e.g.
 with a working installation of Java 1.7, either OpenJDK or the Oracle JDK. See, e.g.") Big Data Computing Instructor: Prof. Irene Finocchi Master's Degree in Computer Science Academic Year 2013-2014, spring semester Installing Hadoop Emanuele Fusco (fusco@di.uniroma1.it) Prerequisites You
Big Data Computing Instructor: Prof. Irene Finocchi Master's Degree in Computer Science Academic Year 2013-2014, spring semester Installing Hadoop Emanuele Fusco (fusco@di.uniroma1.it) Prerequisites You
Installation of Hadoop on Ubuntu
 Installation of Hadoop on Ubuntu Various software and settings are required for Hadoop. This section is mainly developed based on rsqrl.com tutorial. 1- Install Java Software Java Version* Openjdk version
Installation of Hadoop on Ubuntu Various software and settings are required for Hadoop. This section is mainly developed based on rsqrl.com tutorial. 1- Install Java Software Java Version* Openjdk version
Part II (c) Desktop Installation. Net Serpents LLC, USA
 Desktop Installation. Net Serpents LLC, USA") Part II (c) Desktop ation Desktop ation ation Supported Platforms Required Software Releases &Mirror Sites Configure Format Start/ Stop Verify Supported Platforms ation GNU Linux supported for Development
Part II (c) Desktop ation Desktop ation ation Supported Platforms Required Software Releases &Mirror Sites Configure Format Start/ Stop Verify Supported Platforms ation GNU Linux supported for Development
UNIT II HADOOP FRAMEWORK
 UNIT II HADOOP FRAMEWORK Hadoop Hadoop is an Apache open source framework written in java that allows distributed processing of large datasets across clusters of computers using simple programming models.
UNIT II HADOOP FRAMEWORK Hadoop Hadoop is an Apache open source framework written in java that allows distributed processing of large datasets across clusters of computers using simple programming models.
3 Hadoop Installation: Pseudo-distributed mode
 Laboratory 3 Hadoop Installation: Pseudo-distributed mode Obecjective Hadoop can be run in 3 different modes. Different modes of Hadoop are 1. Standalone Mode Default mode of Hadoop HDFS is not utilized
Laboratory 3 Hadoop Installation: Pseudo-distributed mode Obecjective Hadoop can be run in 3 different modes. Different modes of Hadoop are 1. Standalone Mode Default mode of Hadoop HDFS is not utilized
About the Tutorial. Audience. Prerequisites. Copyright & Disclaimer. HCatalog
 About the Tutorial HCatalog is a table storage management tool for Hadoop that exposes the tabular data of Hive metastore to other Hadoop applications. It enables users with different data processing tools
About the Tutorial HCatalog is a table storage management tool for Hadoop that exposes the tabular data of Hive metastore to other Hadoop applications. It enables users with different data processing tools
Multi-Node Cluster Setup on Hadoop. Tushar B. Kute,
 Multi-Node Cluster Setup on Hadoop Tushar B. Kute, http://tusharkute.com What is Multi-node? Multi-node cluster Multinode Hadoop cluster as composed of Master- Slave Architecture to accomplishment of BigData
Multi-Node Cluster Setup on Hadoop Tushar B. Kute, http://tusharkute.com What is Multi-node? Multi-node cluster Multinode Hadoop cluster as composed of Master- Slave Architecture to accomplishment of BigData
Hadoop Setup on OpenStack Windows Azure Guide
 CSCI4180 Tutorial- 2 Hadoop Setup on OpenStack Windows Azure Guide ZHANG, Mi mzhang@cse.cuhk.edu.hk Sep. 24, 2015 Outline Hadoop setup on OpenStack Ø Set up Hadoop cluster Ø Manage Hadoop cluster Ø WordCount
CSCI4180 Tutorial- 2 Hadoop Setup on OpenStack Windows Azure Guide ZHANG, Mi mzhang@cse.cuhk.edu.hk Sep. 24, 2015 Outline Hadoop setup on OpenStack Ø Set up Hadoop cluster Ø Manage Hadoop cluster Ø WordCount
Installing Hadoop / Yarn, Hive 2.1.0, Scala , and Spark 2.0 on Raspberry Pi Cluster of 3 Nodes. By: Nicholas Propes 2016
 Installing Hadoop 2.7.3 / Yarn, Hive 2.1.0, Scala 2.11.8, and Spark 2.0 on Raspberry Pi Cluster of 3 Nodes By: Nicholas Propes 2016 1 NOTES Please follow instructions PARTS in order because the results
Installing Hadoop 2.7.3 / Yarn, Hive 2.1.0, Scala 2.11.8, and Spark 2.0 on Raspberry Pi Cluster of 3 Nodes By: Nicholas Propes 2016 1 NOTES Please follow instructions PARTS in order because the results
BIG DATA TRAINING PRESENTATION
 BIG DATA TRAINING PRESENTATION TOPICS TO BE COVERED HADOOP YARN MAP REDUCE SPARK FLUME SQOOP OOZIE AMBARI TOPICS TO BE COVERED FALCON RANGER KNOX SENTRY MASTER IMAGE INSTALLATION 1 JAVA INSTALLATION: 1.
BIG DATA TRAINING PRESENTATION TOPICS TO BE COVERED HADOOP YARN MAP REDUCE SPARK FLUME SQOOP OOZIE AMBARI TOPICS TO BE COVERED FALCON RANGER KNOX SENTRY MASTER IMAGE INSTALLATION 1 JAVA INSTALLATION: 1.
Hadoop Quickstart. Table of contents
 Table of contents 1 Purpose...2 2 Pre-requisites...2 2.1 Supported Platforms... 2 2.2 Required Software... 2 2.3 Installing Software...2 3 Download...2 4 Prepare to Start the Hadoop Cluster...3 5 Standalone
Table of contents 1 Purpose...2 2 Pre-requisites...2 2.1 Supported Platforms... 2 2.2 Required Software... 2 2.3 Installing Software...2 3 Download...2 4 Prepare to Start the Hadoop Cluster...3 5 Standalone
Big Data Retrieving Required Information From Text Files Desmond Hill Yenumula B Reddy (Advisor)
") Big Data Retrieving Required Information From Text Files Desmond Hill Yenumula B Reddy (Advisor) 1 OUTLINE Objective What is Big data Characteristics of Big Data Setup Requirements Hadoop Setup Word Count
Big Data Retrieving Required Information From Text Files Desmond Hill Yenumula B Reddy (Advisor) 1 OUTLINE Objective What is Big data Characteristics of Big Data Setup Requirements Hadoop Setup Word Count
Installation and Configuration Documentation
 Installation and Configuration Documentation Release 1.0.1 Oshin Prem Sep 27, 2017 Contents 1 HADOOP INSTALLATION 3 1.1 SINGLE-NODE INSTALLATION................................... 3 1.2 MULTI-NODE INSTALLATION....................................
Installation and Configuration Documentation Release 1.0.1 Oshin Prem Sep 27, 2017 Contents 1 HADOOP INSTALLATION 3 1.1 SINGLE-NODE INSTALLATION................................... 3 1.2 MULTI-NODE INSTALLATION....................................
Getting Started with Hadoop/YARN
 Getting Started with Hadoop/YARN Michael Völske 1 April 28, 2016 1 michael.voelske@uni-weimar.de Michael Völske Getting Started with Hadoop/YARN April 28, 2016 1 / 66 Outline Part One: Hadoop, HDFS, and
Getting Started with Hadoop/YARN Michael Völske 1 April 28, 2016 1 michael.voelske@uni-weimar.de Michael Völske Getting Started with Hadoop/YARN April 28, 2016 1 / 66 Outline Part One: Hadoop, HDFS, and
Hadoop is essentially an operating system for distributed processing. Its primary subsystems are HDFS and MapReduce (and Yarn).
.") 1 Hadoop Primer Hadoop is essentially an operating system for distributed processing. Its primary subsystems are HDFS and MapReduce (and Yarn). 2 Passwordless SSH Before setting up Hadoop, setup passwordless
1 Hadoop Primer Hadoop is essentially an operating system for distributed processing. Its primary subsystems are HDFS and MapReduce (and Yarn). 2 Passwordless SSH Before setting up Hadoop, setup passwordless
Inria, Rennes Bretagne Atlantique Research Center
 Hadoop TP 1 Shadi Ibrahim Inria, Rennes Bretagne Atlantique Research Center Getting started with Hadoop Prerequisites Basic Configuration Starting Hadoop Verifying cluster operation Hadoop INRIA S.IBRAHIM
Hadoop TP 1 Shadi Ibrahim Inria, Rennes Bretagne Atlantique Research Center Getting started with Hadoop Prerequisites Basic Configuration Starting Hadoop Verifying cluster operation Hadoop INRIA S.IBRAHIM
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem. Janusz Szwabiński
 Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Outline Introduction Big Data Sources of Big Data Tools HDFS Installation Configuration Starting & Stopping Map Reduc.
 D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
Hadoop Cluster Implementation
 Hadoop Cluster Implementation By Aysha Binta Sayed ID:2013-1-60-068 Supervised By Dr. Md. Shamim Akhter Assistant Professor Department of Computer Science and Engineering East West University A project
Hadoop Cluster Implementation By Aysha Binta Sayed ID:2013-1-60-068 Supervised By Dr. Md. Shamim Akhter Assistant Professor Department of Computer Science and Engineering East West University A project
Hadoop Lab 2 Exploring the Hadoop Environment
 Programming for Big Data Hadoop Lab 2 Exploring the Hadoop Environment Video A short video guide for some of what is covered in this lab. Link for this video is on my module webpage 1 Open a Terminal window
Programming for Big Data Hadoop Lab 2 Exploring the Hadoop Environment Video A short video guide for some of what is covered in this lab. Link for this video is on my module webpage 1 Open a Terminal window
Installation Guide. Community release
 Installation Guide Community 151 release This document details step-by-step deployment procedures, system and environment requirements to assist Jumbune deployment 1 P a g e Table of Contents Introduction
Installation Guide Community 151 release This document details step-by-step deployment procedures, system and environment requirements to assist Jumbune deployment 1 P a g e Table of Contents Introduction
Big Data Analytics by Using Hadoop
 Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Big Data Analytics by Using Hadoop Chaitanya Arava Governors State University
Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Big Data Analytics by Using Hadoop Chaitanya Arava Governors State University
Cloud Computing II. Exercises
 Cloud Computing II Exercises Exercise 1 Creating a Private Cloud Overview In this exercise, you will install and configure a private cloud using OpenStack. This will be accomplished using a singlenode
Cloud Computing II Exercises Exercise 1 Creating a Private Cloud Overview In this exercise, you will install and configure a private cloud using OpenStack. This will be accomplished using a singlenode
Hadoop Setup Walkthrough
 Hadoop 2.7.3 Setup Walkthrough This document provides information about working with Hadoop 2.7.3. 1 Setting Up Configuration Files... 2 2 Setting Up The Environment... 2 3 Additional Notes... 3 4 Selecting
Hadoop 2.7.3 Setup Walkthrough This document provides information about working with Hadoop 2.7.3. 1 Setting Up Configuration Files... 2 2 Setting Up The Environment... 2 3 Additional Notes... 3 4 Selecting
halvade Documentation
 halvade Documentation Release 1.1.0 Dries Decap Mar 12, 2018 Contents 1 Introduction 3 1.1 Recipes.................................................. 3 2 Installation 5 2.1 Build from source............................................
halvade Documentation Release 1.1.0 Dries Decap Mar 12, 2018 Contents 1 Introduction 3 1.1 Recipes.................................................. 3 2 Installation 5 2.1 Build from source............................................
Developer s Manual. Version May, Computer Science Department, Texas Christian University
 Developer s Manual Version 4.0 2 May, 2016 2015-2016 Computer Science Department, Texas Christian University Revision Signatures By signing the following document, the team member is acknowledging that
Developer s Manual Version 4.0 2 May, 2016 2015-2016 Computer Science Department, Texas Christian University Revision Signatures By signing the following document, the team member is acknowledging that
RDMA for Apache Hadoop 2.x User Guide
 1.3.0 User Guide HIGH-PERFORMANCE BIG DATA TEAM http://hibd.cse.ohio-state.edu NETWORK-BASED COMPUTING LABORATORY DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING THE OHIO STATE UNIVERSITY Copyright (c)
1.3.0 User Guide HIGH-PERFORMANCE BIG DATA TEAM http://hibd.cse.ohio-state.edu NETWORK-BASED COMPUTING LABORATORY DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING THE OHIO STATE UNIVERSITY Copyright (c)
Guidelines - Configuring PDI, MapReduce, and MapR
 Guidelines - Configuring PDI, MapReduce, and MapR This page intentionally left blank. Contents Overview... 1 Set Up Your Environment... 2 Get MapR Server Information... 2 Set Up Your Host Environment...
Guidelines - Configuring PDI, MapReduce, and MapR This page intentionally left blank. Contents Overview... 1 Set Up Your Environment... 2 Get MapR Server Information... 2 Set Up Your Host Environment...
Getting Started with Hadoop
 Getting Started with Hadoop May 28, 2018 Michael Völske, Shahbaz Syed Web Technology & Information Systems Bauhaus-Universität Weimar 1 webis 2018 What is Hadoop Started in 2004 by Yahoo Open-Source implementation
Getting Started with Hadoop May 28, 2018 Michael Völske, Shahbaz Syed Web Technology & Information Systems Bauhaus-Universität Weimar 1 webis 2018 What is Hadoop Started in 2004 by Yahoo Open-Source implementation
Create Test Environment
 Create Test Environment Describes how to set up the Trafodion test environment used by developers and testers Prerequisites Python Passwordless ssh If you already have an existing set of ssh keys If you
Create Test Environment Describes how to set up the Trafodion test environment used by developers and testers Prerequisites Python Passwordless ssh If you already have an existing set of ssh keys If you
How to Install and Configure EBF16193 for Hortonworks HDP 2.3 and HotFix 3 Update 2
 How to Install and Configure EBF16193 for Hortonworks HDP 2.3 and 9.6.1 HotFix 3 Update 2 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any
How to Install and Configure EBF16193 for Hortonworks HDP 2.3 and 9.6.1 HotFix 3 Update 2 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any
DATA MIGRATION METHODOLOGY FROM SQL TO COLUMN ORIENTED DATABASES (HBase)
") 1 DATA MIGRATION METHODOLOGY FROM SQL TO COLUMN ORIENTED DATABASES (HBase) Nosql No predefined schema/ less rigid schema Unstructured and constantly evolving data No Declarative Query Language Weaker Transactional
1 DATA MIGRATION METHODOLOGY FROM SQL TO COLUMN ORIENTED DATABASES (HBase) Nosql No predefined schema/ less rigid schema Unstructured and constantly evolving data No Declarative Query Language Weaker Transactional
Hadoop Tutorial. General Instructions
 CS246H: Mining Massive Datasets Hadoop Lab Winter 2018 Hadoop Tutorial General Instructions The purpose of this tutorial is to get you started with Hadoop. Completing the tutorial is optional. Here you
CS246H: Mining Massive Datasets Hadoop Lab Winter 2018 Hadoop Tutorial General Instructions The purpose of this tutorial is to get you started with Hadoop. Completing the tutorial is optional. Here you
docs.hortonworks.com
 docs.hortonworks.com Hortonworks Data Platform : Security Administration Tools Guide Copyright 2012-2014 Hortonworks, Inc. Some rights reserved. The Hortonworks Data Platform, powered by Apache Hadoop,
docs.hortonworks.com Hortonworks Data Platform : Security Administration Tools Guide Copyright 2012-2014 Hortonworks, Inc. Some rights reserved. The Hortonworks Data Platform, powered by Apache Hadoop,
Dell EMC ME4 Series vsphere Client Plug-in
 Dell EMC ME4 Series vsphere Client Plug-in User's Guide Regulatory Model: E09J, E10J, E11J Regulatory Type: E09J001, E10J001, E11J001 Notes, cautions, and warnings NOTE: A NOTE indicates important information
Dell EMC ME4 Series vsphere Client Plug-in User's Guide Regulatory Model: E09J, E10J, E11J Regulatory Type: E09J001, E10J001, E11J001 Notes, cautions, and warnings NOTE: A NOTE indicates important information
Installation and Configuration Document
 Installation and Configuration Document Table of Contents 1 Introduction... 3 1.1 Purpose... 3 1.2 Scope... 3 2 Installation... 3 2.1 Pre-requisites... 3 2.2 Installation Steps... 3 2.3 User Management...
Installation and Configuration Document Table of Contents 1 Introduction... 3 1.1 Purpose... 3 1.2 Scope... 3 2 Installation... 3 2.1 Pre-requisites... 3 2.2 Installation Steps... 3 2.3 User Management...
Running Kmeans Spark on EC2 Documentation
 Running Kmeans Spark on EC2 Documentation Pseudo code Input: Dataset D, Number of clusters k Output: Data points with cluster memberships Step1: Read D from HDFS as RDD Step 2: Initialize first k data
Running Kmeans Spark on EC2 Documentation Pseudo code Input: Dataset D, Number of clusters k Output: Data points with cluster memberships Step1: Read D from HDFS as RDD Step 2: Initialize first k data
MapReduce for Parallel Computing
 MapReduce for Parallel Computing Amit Jain 1/44 Big Data, Big Disks, Cheap Computers In pioneer days they used oxen for heavy pulling, and when one ox couldn t budge a log, they didn t try to grow a larger
MapReduce for Parallel Computing Amit Jain 1/44 Big Data, Big Disks, Cheap Computers In pioneer days they used oxen for heavy pulling, and when one ox couldn t budge a log, they didn t try to grow a larger
SQL Server vnext on Linux Ubuntu - Part 1
 SQL Server vnext on Linux Ubuntu - Part 1 Built on SQL Server 2016, SQL Server vnext represents a major step towards making SQL Server a cross operating systems and bringing the power of SQL Server to
SQL Server vnext on Linux Ubuntu - Part 1 Built on SQL Server 2016, SQL Server vnext represents a major step towards making SQL Server a cross operating systems and bringing the power of SQL Server to
Getting Started with Pentaho and Cloudera QuickStart VM
 Getting Started with Pentaho and Cloudera QuickStart VM This page intentionally left blank. Contents Overview... 1 Before You Begin... 1 Prerequisites... 1 Use Case: Development Sandbox for Pentaho and
Getting Started with Pentaho and Cloudera QuickStart VM This page intentionally left blank. Contents Overview... 1 Before You Begin... 1 Prerequisites... 1 Use Case: Development Sandbox for Pentaho and
Session 1 Big Data and Hadoop - Overview. - Dr. M. R. Sanghavi
 Session 1 Big Data and Hadoop - Overview - Dr. M. R. Sanghavi Acknowledgement Prof. Kainjan M. Sanghavi For preparing this prsentation This presentation is available on my blog https://maheshsanghavi.wordpress.com/expert-talk-fdp-workshop/
Session 1 Big Data and Hadoop - Overview - Dr. M. R. Sanghavi Acknowledgement Prof. Kainjan M. Sanghavi For preparing this prsentation This presentation is available on my blog https://maheshsanghavi.wordpress.com/expert-talk-fdp-workshop/
Quick Deployment Step-by-step instructions to deploy Oracle Big Data Lite Virtual Machine
 Quick Deployment Step-by-step instructions to deploy Oracle Big Data Lite Virtual Machine Version 4.11 Last Updated: 1/10/2018 Please note: This appliance is for testing and educational purposes only;
Quick Deployment Step-by-step instructions to deploy Oracle Big Data Lite Virtual Machine Version 4.11 Last Updated: 1/10/2018 Please note: This appliance is for testing and educational purposes only;
Implementation of Randomized Hydrodynamic Load Balancing Algorithm using Map Reduce framework on Open Source Platform of Hadoop
 ISSN: 2393-8528 Contents lists available at www.ijicse.in International Journal of Innovative Computer Science & Engineering Volume 2 Issue 3; July-August-2015; Page No. 44-51 Implementation of Randomized
ISSN: 2393-8528 Contents lists available at www.ijicse.in International Journal of Innovative Computer Science & Engineering Volume 2 Issue 3; July-August-2015; Page No. 44-51 Implementation of Randomized
Pre-Installation Tasks Before you apply the update, shut down the Informatica domain and perform the pre-installation tasks.
 Informatica LLC Big Data Edition Version 9.6.1 HotFix 3 Update 3 Release Notes January 2016 Copyright (c) 1993-2016 Informatica LLC. All rights reserved. Contents Pre-Installation Tasks... 1 Prepare the
Informatica LLC Big Data Edition Version 9.6.1 HotFix 3 Update 3 Release Notes January 2016 Copyright (c) 1993-2016 Informatica LLC. All rights reserved. Contents Pre-Installation Tasks... 1 Prepare the
Part 1: Installing MongoDB
 Samantha Orogvany-Charpentier CSU ID: 2570586 Installing NoSQL Systems Part 1: Installing MongoDB For my lab, I installed MongoDB version 3.2.12 on Ubuntu 16.04. I followed the instructions detailed at
Samantha Orogvany-Charpentier CSU ID: 2570586 Installing NoSQL Systems Part 1: Installing MongoDB For my lab, I installed MongoDB version 3.2.12 on Ubuntu 16.04. I followed the instructions detailed at
The Analysis and Implementation of the K - Means Algorithm Based on Hadoop Platform
 Computer and Information Science; Vol. 11, No. 1; 2018 ISSN 1913-8989 E-ISSN 1913-8997 Published by Canadian Center of Science and Education The Analysis and Implementation of the K - Means Algorithm Based
Computer and Information Science; Vol. 11, No. 1; 2018 ISSN 1913-8989 E-ISSN 1913-8997 Published by Canadian Center of Science and Education The Analysis and Implementation of the K - Means Algorithm Based
Apache Tomcat Installation Guide [ Application : IVMS Base, Rich and Core Version ] [ Platform : 64 Bit Linux ] Tomcat Version: 6.0.
![Apache Tomcat Installation Guide [ Application : IVMS Base, Rich and Core Version ] [ Platform : 64 Bit Linux ] Tomcat Version: 6.0.](/thumbs/74/69871816.jpg "Apache Tomcat Installation Guide [ Application : IVMS Base, Rich and Core Version ] [ Platform : 64 Bit Linux ] Tomcat Version: 6.0.") Apache Tomcat Installation Guide [ Application : IVMS Base, Rich and Core Version ] [ Platform : 64 Bit Linux ] Tomcat Version: 6.0.44 Introduction Apache Tomcat is an open source software implementation
Apache Tomcat Installation Guide [ Application : IVMS Base, Rich and Core Version ] [ Platform : 64 Bit Linux ] Tomcat Version: 6.0.44 Introduction Apache Tomcat is an open source software implementation
Vendor: Cloudera. Exam Code: CCA-505. Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam.
 CDH5 Upgrade Exam.") Vendor: Cloudera Exam Code: CCA-505 Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam Version: Demo QUESTION 1 You have installed a cluster running HDFS and MapReduce
Vendor: Cloudera Exam Code: CCA-505 Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam Version: Demo QUESTION 1 You have installed a cluster running HDFS and MapReduce
Build your own Lightweight Webserver - Hands-on I - Information Network I. Marius Georgescu. Internet Engineering Laboratory. 17 Apr
 Build your own Lightweight Webserver - Hands-on I - Information Network I Marius Georgescu Internet Engineering Laboratory 17 Apr. 2015 iplab Prerequisites Prerequisites Download and Install VirtualBox
Build your own Lightweight Webserver - Hands-on I - Information Network I Marius Georgescu Internet Engineering Laboratory 17 Apr. 2015 iplab Prerequisites Prerequisites Download and Install VirtualBox
How to Install and Configure Big Data Edition for Hortonworks
 How to Install and Configure Big Data Edition for Hortonworks 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying,
How to Install and Configure Big Data Edition for Hortonworks 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying,
Aims. Background. This exercise aims to get you to:
 Aims This exercise aims to get you to: Import data into HBase using bulk load Read MapReduce input from HBase and write MapReduce output to HBase Manage data using Hive Manage data using Pig Background
Aims This exercise aims to get you to: Import data into HBase using bulk load Read MapReduce input from HBase and write MapReduce output to HBase Manage data using Hive Manage data using Pig Background
Top 25 Big Data Interview Questions And Answers
 Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Hadoop On Demand: Configuration Guide
 Hadoop On Demand: Configuration Guide Table of contents 1 1. Introduction...2 2 2. Sections... 2 3 3. HOD Configuration Options...2 3.1 3.1 Common configuration options...2 3.2 3.2 hod options... 3 3.3
Hadoop On Demand: Configuration Guide Table of contents 1 1. Introduction...2 2 2. Sections... 2 3 3. HOD Configuration Options...2 3.1 3.1 Common configuration options...2 3.2 3.2 hod options... 3 3.3
SQOOP - QUICK GUIDE SQOOP - INTRODUCTION
 SQOOP - QUICK GUIDE http://www.tutorialspoint.com/sqoop/sqoop_quick_guide.htm Copyright tutorialspoint.com SQOOP - INTRODUCTION The traditional application management system, that is, the interaction of
SQOOP - QUICK GUIDE http://www.tutorialspoint.com/sqoop/sqoop_quick_guide.htm Copyright tutorialspoint.com SQOOP - INTRODUCTION The traditional application management system, that is, the interaction of
Implementation and performance test of cloud platform based on Hadoop
 IOP Conference Series: Earth and Environmental Science PAPER OPEN ACCESS Implementation and performance test of cloud platform based on Hadoop To cite this article: Jingxian Xu et al 2018 IOP Conf. Ser.:
IOP Conference Series: Earth and Environmental Science PAPER OPEN ACCESS Implementation and performance test of cloud platform based on Hadoop To cite this article: Jingxian Xu et al 2018 IOP Conf. Ser.:
Talend Big Data Sandbox. Big Data Insights Cookbook
 Overview Pre-requisites Setup & Configuration Hadoop Distribution Download Demo (Scenario) Overview Pre-requisites Setup & Configuration Hadoop Distribution Demo (Scenario) About this cookbook What is
Overview Pre-requisites Setup & Configuration Hadoop Distribution Download Demo (Scenario) Overview Pre-requisites Setup & Configuration Hadoop Distribution Demo (Scenario) About this cookbook What is
This brief tutorial provides a quick introduction to Big Data, MapReduce algorithm, and Hadoop Distributed File System.
 About this tutorial Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models. It is designed
About this tutorial Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models. It is designed
Running various Bigtop components
 Running various Bigtop components Running Hadoop Components One of the advantages of Bigtop is the ease of installation of the different Hadoop Components without having to hunt for a specific Hadoop Component
Running various Bigtop components Running Hadoop Components One of the advantages of Bigtop is the ease of installation of the different Hadoop Components without having to hunt for a specific Hadoop Component
Beta. VMware vsphere Big Data Extensions Administrator's and User's Guide. vsphere Big Data Extensions 1.0 EN
 VMware vsphere Big Data Extensions Administrator's and User's Guide vsphere Big Data Extensions 1.0 This document supports the version of each product listed and supports all subsequent versions until
VMware vsphere Big Data Extensions Administrator's and User's Guide vsphere Big Data Extensions 1.0 This document supports the version of each product listed and supports all subsequent versions until
LENS Server Maintenance Guide JZ 2017/07/28
 LENS Server Maintenance Guide JZ 2017/07/28 Duty Maintain LENS server with minimum downtime Patch critical vulnerabilities Assist LAB member for using the LENS services Evaluate for custom requirements
LENS Server Maintenance Guide JZ 2017/07/28 Duty Maintain LENS server with minimum downtime Patch critical vulnerabilities Assist LAB member for using the LENS services Evaluate for custom requirements
HADOOP PERFORMANCE EVALUATION IN CLUSTER ENVIRONMENT
 HADOOP PERFORMANCE EVALUATION IN CLUSTER ENVIRONMENT LAHTI UNIVERSITY OF APPLIED SCIENCES Master s Degree Programme in Information and Communications Technology Master s Thesis Autumn 2017 Fitsum Belay
HADOOP PERFORMANCE EVALUATION IN CLUSTER ENVIRONMENT LAHTI UNIVERSITY OF APPLIED SCIENCES Master s Degree Programme in Information and Communications Technology Master s Thesis Autumn 2017 Fitsum Belay
About 1. Chapter 1: Getting started with oozie 2. Remarks 2. Versions 2. Examples 2. Installation or Setup 2. Chapter 2: Oozie
 oozie #oozie Table of Contents About 1 Chapter 1: Getting started with oozie 2 Remarks 2 Versions 2 Examples 2 Installation or Setup 2 Chapter 2: Oozie 101 7 Examples 7 Oozie Architecture 7 Oozie Application
oozie #oozie Table of Contents About 1 Chapter 1: Getting started with oozie 2 Remarks 2 Versions 2 Examples 2 Installation or Setup 2 Chapter 2: Oozie 101 7 Examples 7 Oozie Architecture 7 Oozie Application
SE256 : Scalable Systems for Data Science
 SE256 : Scalable Systems for Data Science Lab Session: 2 Maven setup: Run the following commands to download and extract maven. wget http://www.eu.apache.org/dist/maven/maven 3/3.3.9/binaries/apache maven
SE256 : Scalable Systems for Data Science Lab Session: 2 Maven setup: Run the following commands to download and extract maven. wget http://www.eu.apache.org/dist/maven/maven 3/3.3.9/binaries/apache maven
Configuring Sqoop Connectivity for Big Data Management
 Configuring Sqoop Connectivity for Big Data Management Copyright Informatica LLC 2017. Informatica, the Informatica logo, and Big Data Management are trademarks or registered trademarks of Informatica
Configuring Sqoop Connectivity for Big Data Management Copyright Informatica LLC 2017. Informatica, the Informatica logo, and Big Data Management are trademarks or registered trademarks of Informatica
Hadoop Integration User Guide. Functional Area: Hadoop Integration. Geneos Release: v4.9. Document Version: v1.0.0
 Hadoop Integration User Guide Functional Area: Hadoop Integration Geneos Release: v4.9 Document Version: v1.0.0 Date Published: 25 October 2018 Copyright 2018. ITRS Group Ltd. All rights reserved. Information
Hadoop Integration User Guide Functional Area: Hadoop Integration Geneos Release: v4.9 Document Version: v1.0.0 Date Published: 25 October 2018 Copyright 2018. ITRS Group Ltd. All rights reserved. Information
EE516: Embedded Software Project 1. Setting Up Environment for Projects
 EE516: Embedded Software Project 1. Setting Up Environment for Projects By Dong Jae Shin 2015. 09. 01. Contents Introduction to Projects of EE516 Tasks Setting Up Environment Virtual Machine Environment
EE516: Embedded Software Project 1. Setting Up Environment for Projects By Dong Jae Shin 2015. 09. 01. Contents Introduction to Projects of EE516 Tasks Setting Up Environment Virtual Machine Environment
Parallel Programming
 Parallel Programming Installing Eclipse Parallel Tools Platform (PTP) (Linux Distributions) Preliminaries - Install Java Author B. Wilkinson - Modification date May 29, 2015 Java is needed for the Eclipse
Parallel Programming Installing Eclipse Parallel Tools Platform (PTP) (Linux Distributions) Preliminaries - Install Java Author B. Wilkinson - Modification date May 29, 2015 Java is needed for the Eclipse
Initial setting up of VPN Java version.
 VPN Linux 64 bit To access work documents from home you will need to create a VPN connection. This will allow you to securely connect to Exeter University network from other location such as your home.
VPN Linux 64 bit To access work documents from home you will need to create a VPN connection. This will allow you to securely connect to Exeter University network from other location such as your home.
Pentaho MapReduce with MapR Client
 Pentaho MapReduce with MapR Client Change log (if you want to use it): Date Version Author Changes Contents Overview... 1 Before You Begin... 1 Use Case: Run MapReduce Jobs on Cluster... 1 Set Up Your
Pentaho MapReduce with MapR Client Change log (if you want to use it): Date Version Author Changes Contents Overview... 1 Before You Begin... 1 Use Case: Run MapReduce Jobs on Cluster... 1 Set Up Your
Linux Operating System Environment Computadors Grau en Ciència i Enginyeria de Dades Q2
 Linux Operating System Environment Computadors Grau en Ciència i Enginyeria de Dades 2017-2018 Q2 Facultat d Informàtica de Barcelona This first lab session is focused on getting experience in working
Linux Operating System Environment Computadors Grau en Ciència i Enginyeria de Dades 2017-2018 Q2 Facultat d Informàtica de Barcelona This first lab session is focused on getting experience in working
How to Configure Informatica HotFix 2 for Cloudera CDH 5.3
 How to Configure Informatica 9.6.1 HotFix 2 for Cloudera CDH 5.3 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying,
How to Configure Informatica 9.6.1 HotFix 2 for Cloudera CDH 5.3 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying,
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
About the Tutorial. Audience. Prerequisites. Copyright and Disclaimer. PySpark
 About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
Ranger installation in Kerberized Environment
 Ranger installation in Kerberized Environment Summary Creating Keytab and principals For Ranger Admin For Ranger Lookup For Ranger Usersync For Ranger Tagsync Installation Steps for Ranger-Admin Installation
Ranger installation in Kerberized Environment Summary Creating Keytab and principals For Ranger Admin For Ranger Lookup For Ranger Usersync For Ranger Tagsync Installation Steps for Ranger-Admin Installation
How to Install and Configure EBF15545 for MapR with MapReduce 2
 How to Install and Configure EBF15545 for MapR 4.0.2 with MapReduce 2 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
How to Install and Configure EBF15545 for MapR 4.0.2 with MapReduce 2 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
OpenStack Havana All-in-One lab on VMware Workstation
 OpenStack Havana All-in-One lab on VMware Workstation With all of the popularity of OpenStack in general, and specifically with my other posts on deploying the Rackspace Private Cloud lab on VMware Workstation,
OpenStack Havana All-in-One lab on VMware Workstation With all of the popularity of OpenStack in general, and specifically with my other posts on deploying the Rackspace Private Cloud lab on VMware Workstation,
Jackson State University Department of Computer Science CSC / Computer Security Fall 2013 Instructor: Dr. Natarajan Meghanathan
 Jackson State University Department of Computer Science CSC 437-01/539-01 Computer Security Fall 2013 Instructor: Dr. Natarajan Meghanathan Lab Project # 2: Running Secure Shell (SSH) Server in a Virtual
Jackson State University Department of Computer Science CSC 437-01/539-01 Computer Security Fall 2013 Instructor: Dr. Natarajan Meghanathan Lab Project # 2: Running Secure Shell (SSH) Server in a Virtual
Greenplum Data Loader Installation and User Guide
 Greenplum DataLoader 1.2 Installation and User Guide Rev: A01 1 Copyright 2012 EMC Corporation. All rights reserved. EMC believes the information in this publication is accurate as of its publication date.
Greenplum DataLoader 1.2 Installation and User Guide Rev: A01 1 Copyright 2012 EMC Corporation. All rights reserved. EMC believes the information in this publication is accurate as of its publication date.
Exam Questions CCA-500
 Exam Questions CCA-500 Cloudera Certified Administrator for Apache Hadoop (CCAH) https://www.2passeasy.com/dumps/cca-500/ Question No : 1 Your cluster s mapred-start.xml includes the following parameters
Exam Questions CCA-500 Cloudera Certified Administrator for Apache Hadoop (CCAH) https://www.2passeasy.com/dumps/cca-500/ Question No : 1 Your cluster s mapred-start.xml includes the following parameters
Tizen TCT User Guide
 Tizen 2.3.1 TCT User Guide Table of Contents 1. Environment setup... 3 1.1. Symbols and abbreviations... 3 1.2. Hardware Requirements... 3 1.3. Software Requirements... 3 2. Getting TCT-source and TCT-manager...
Tizen 2.3.1 TCT User Guide Table of Contents 1. Environment setup... 3 1.1. Symbols and abbreviations... 3 1.2. Hardware Requirements... 3 1.3. Software Requirements... 3 2. Getting TCT-source and TCT-manager...
How to Run the Big Data Management Utility Update for 10.1
 How to Run the Big Data Management Utility Update for 10.1 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording
How to Run the Big Data Management Utility Update for 10.1 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording
Developer Training for Apache Spark and Hadoop: Hands-On Exercises
 201709c Developer Training for Apache Spark and Hadoop: Hands-On Exercises Table of Contents General Notes... 1 Hands-On Exercise: Starting the Exercise Environment (Local VM)... 5 Hands-On Exercise: Starting
201709c Developer Training for Apache Spark and Hadoop: Hands-On Exercises Table of Contents General Notes... 1 Hands-On Exercise: Starting the Exercise Environment (Local VM)... 5 Hands-On Exercise: Starting
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2011 Slides based on last years tutorial by Florian Klien and Chris Körner 1 IMPORTANT The presented information has been tested on the
Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2011 Slides based on last years tutorial by Florian Klien and Chris Körner 1 IMPORTANT The presented information has been tested on the
Android Studio Setup Procedure
 Android Studio Setup Procedure System Requirements : Windows OS Linux OS Mac OS Microsoft Windows 7/8/10 (32- or 64-bit) 3 GB RAM minimum, 8 GB RAM recommended; plus 1 GB for the Android Emulator 2 GB
Android Studio Setup Procedure System Requirements : Windows OS Linux OS Mac OS Microsoft Windows 7/8/10 (32- or 64-bit) 3 GB RAM minimum, 8 GB RAM recommended; plus 1 GB for the Android Emulator 2 GB
Hortonworks Technical Preview for Apache Falcon
 Architecting the Future of Big Data Hortonworks Technical Preview for Apache Falcon Released: 11/20/2013 Architecting the Future of Big Data 2013 Hortonworks Inc. All Rights Reserved. Welcome to Hortonworks
Architecting the Future of Big Data Hortonworks Technical Preview for Apache Falcon Released: 11/20/2013 Architecting the Future of Big Data 2013 Hortonworks Inc. All Rights Reserved. Welcome to Hortonworks
HOD User Guide. Table of contents
 Table of contents 1 Introduction...3 2 Getting Started Using HOD... 3 2.1 A typical HOD session... 3 2.2 Running hadoop scripts using HOD...5 3 HOD Features... 6 3.1 Provisioning and Managing Hadoop Clusters...6
Table of contents 1 Introduction...3 2 Getting Started Using HOD... 3 2.1 A typical HOD session... 3 2.2 Running hadoop scripts using HOD...5 3 HOD Features... 6 3.1 Provisioning and Managing Hadoop Clusters...6
GIT. A free and open source distributed version control system. User Guide. January, Department of Computer Science and Engineering
 GIT A free and open source distributed version control system User Guide January, 2018 Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Table of Contents What is
GIT A free and open source distributed version control system User Guide January, 2018 Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Table of Contents What is
How to Configure Big Data Management 10.1 for MapR 5.1 Security Features
 How to Configure Big Data Management 10.1 for MapR 5.1 Security Features 2014, 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying,
How to Configure Big Data Management 10.1 for MapR 5.1 Security Features 2014, 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying,
VMware vsphere Big Data Extensions Administrator's and User's Guide
 VMware vsphere Big Data Extensions Administrator's and User's Guide vsphere Big Data Extensions 1.1 This document supports the version of each product listed and supports all subsequent versions until
VMware vsphere Big Data Extensions Administrator's and User's Guide vsphere Big Data Extensions 1.1 This document supports the version of each product listed and supports all subsequent versions until
Hands-on Exercise Hadoop
 Department of Economics and Business Administration Chair of Business Information Systems I Prof. Dr. Barbara Dinter Big Data Management Hands-on Exercise Hadoop Building and Testing a Hadoop Cluster by
Department of Economics and Business Administration Chair of Business Information Systems I Prof. Dr. Barbara Dinter Big Data Management Hands-on Exercise Hadoop Building and Testing a Hadoop Cluster by
CMU MSP Intro to Hadoop
 CMU MSP 36602 Intro to Hadoop H. Seltman, April 3 and 5 2017 1) Carl had created an MSP virtual machine that you can download as an appliance for VirtualBox (also used for SAS University Edition). See
CMU MSP 36602 Intro to Hadoop H. Seltman, April 3 and 5 2017 1) Carl had created an MSP virtual machine that you can download as an appliance for VirtualBox (also used for SAS University Edition). See
Hortonworks Data Platform
 Hortonworks Data Platform Command Line Upgrade (May 17, 2018) docs.hortonworks.com Hortonworks Data Platform: Command Line Upgrade Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Command Line Upgrade (May 17, 2018) docs.hortonworks.com Hortonworks Data Platform: Command Line Upgrade Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hadoop-PR Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer)
") Hortonworks Hadoop-PR000007 Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer) http://killexams.com/pass4sure/exam-detail/hadoop-pr000007 QUESTION: 99 Which one of the following
Hortonworks Hadoop-PR000007 Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer) http://killexams.com/pass4sure/exam-detail/hadoop-pr000007 QUESTION: 99 Which one of the following
Using The Hortonworks Virtual Sandbox Powered By Apache Hadoop
 Using The Hortonworks Virtual Sandbox Powered By Apache Hadoop This work by Hortonworks, Inc. is licensed under a Creative Commons Attribution ShareAlike3.0 Unported License. Legal Notice Copyright 2012
Using The Hortonworks Virtual Sandbox Powered By Apache Hadoop This work by Hortonworks, Inc. is licensed under a Creative Commons Attribution ShareAlike3.0 Unported License. Legal Notice Copyright 2012
Cluster Setup. Table of contents
 Table of contents 1 Purpose...2 2 Pre-requisites...2 3 Installation...2 4 Configuration... 2 4.1 Configuration Files...2 4.2 Site Configuration... 3 5 Cluster Restartability... 10 5.1 Map/Reduce...10 6
Table of contents 1 Purpose...2 2 Pre-requisites...2 3 Installation...2 4 Configuration... 2 4.1 Configuration Files...2 4.2 Site Configuration... 3 5 Cluster Restartability... 10 5.1 Map/Reduce...10 6
Performing Maintenance Operations
 This chapter describes how to back up and restore Cisco Mobility Services Engine (MSE) data and how to update the MSE software. It also describes other maintenance operations. Guidelines and Limitations,
This chapter describes how to back up and restore Cisco Mobility Services Engine (MSE) data and how to update the MSE software. It also describes other maintenance operations. Guidelines and Limitations,
IBM Spectrum Scale. HDFS Transparency Guide. IBM Spectrum Scale. March 9, 2017
 IBM Spectrum Scale HDFS Transparency Guide IBM Spectrum Scale March 9, 2017 1 Contents Contents... 2 1. Overview... 4 2. Supported IBM Spectrum Scale Storage modes... 5 2.1. Local storage mode... 5 2.2.
IBM Spectrum Scale HDFS Transparency Guide IBM Spectrum Scale March 9, 2017 1 Contents Contents... 2 1. Overview... 4 2. Supported IBM Spectrum Scale Storage modes... 5 2.1. Local storage mode... 5 2.2.
TDDE31/732A54 - Big Data Analytics Lab compendium
 TDDE31/732A54 - Big Data Analytics Lab compendium For relational databases lab, please refer to http://www.ida.liu.se/~732a54/lab/rdb/index.en.shtml. Description and Aim In the lab exercises you will work
TDDE31/732A54 - Big Data Analytics Lab compendium For relational databases lab, please refer to http://www.ida.liu.se/~732a54/lab/rdb/index.en.shtml. Description and Aim In the lab exercises you will work
Exam Questions CCA-505
 Exam Questions CCA-505 Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam https://www.2passeasy.com/dumps/cca-505/ 1.You want to understand more about how users browse you public
Exam Questions CCA-505 Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam https://www.2passeasy.com/dumps/cca-505/ 1.You want to understand more about how users browse you public
HBase Installation and Configuration
 Aims This exercise aims to get you to: Install and configure HBase Manage data using HBase Shell Install and configure Hive Manage data using Hive HBase Installation and Configuration 1. Download HBase
Aims This exercise aims to get you to: Install and configure HBase Manage data using HBase Shell Install and configure Hive Manage data using Hive HBase Installation and Configuration 1. Download HBase