Medical Event Extraction using the Swedish FrameNet, a pilot study
|
|
|
- Alexina Dalton
- 5 years ago
- Views:
Transcription
1 Medical Event Extraction using the Swedish FrameNet, a pilot study DIMITRIOS KOKKINAKIS Centre for Language Technology University of Gothenburg Sweden dimitrios.kokkinakis@svenska.gu.se
2 Overview From entities to relations & events Motivation Events Resources Frame selection Methodology Results Summary & Future Plans

3 Motivation Information extraction (IE), a technology with a direct correlation with frame-like structures as described in FN. Templates in the context of IE are frame-like structures with slots representing event information Most event-based IE approaches are designed to identify role fillers that appear as arguments to event verbs or nouns, either explicitly via e.g. syntactic relations
4 Motivation Event-based IE: identifying all entities that play specific roles within an event described in free text (event types specified beforehand) E.g., given text sentences / documents containing descriptions of disease-treatment events, the goal of an IE system could be to extract event role fillers for such event: Thus, specification of events includes fine-grained details about the circumstances under which a textual discourse is said to contain an event description Frame semantics: a framework that can facilitate the development of text understanding and as such can be used as a backbone to NLU systems
5 From entities to relations & events Past: recognizing entities in text and mapping them to unique identifiers in curated databases has been helpful for increasing the specificity of document searches in TM systems. Textual cooccurrence of entities, however, does not necessarily indicate meaningful relationships! For semantic and focused queries to retrieve not just articles, but also facts from the literature, it is essential to recognize entities (e.g. protein) as well as relations or events; characterized by e.g. verbs (regulate) or nominalized verbs (regulation) But entity names are continuous spans in text, relations and events, generally appear as discontinuous spans, and have internal structures: that is, a relation or an event generally involves more than one entity, and the entities involved play distinct roles
6 Events Definition/detection of events have roots in philosophy and linguistics (Davidson 1969; Quine 1985) No 100% consensus on the treatment of events in NLP, in spite of its importance to several areas: topic detection and tracking, information extraction, Q&A Note: comprehensive event detection must encompass the detection of events and their subevents, bridging references (X was murdered yesterday the knife lay nearby; definite descriptions based on previous discourse which require some reasoning in the identification of their textual antecedent) etc.
 Event extraction: the task of extracting structured representations, descriptions of complex combination of relations among one or more entities,")
7 Events Semantic annotation of text with event-level info for mining complex relations and events has gained a growing attention in e.g. biomedicine a valuable source of evidence-based research and text mining (e.g. semantic search; intelligent Question Answering) Event extraction: the task of extracting structured representations, descriptions of complex combination of relations among one or more entities, from e.g. biomed. literature, not contained in structured DBs, that allow associations of arbitrary numbers of participants in specific roles (e.g. Patient) to be captured
8 Events BioNLP Shared Task 2009: n-ary associations of participants (entities or other events), each marked as playing a specific role such as Theme or Cause in the event. Each event is assigned a type from a fixed, taskspecific set Events can further be marked with modifiers identifying additional features (metaknowledge) such as polarity, certainty, knowledge type, manner, (Thompson P. et al (2011). Enriching a biomedical event corpus with meta-knowledge. BMC Bioinf, 12:393)


9 Resources+ All our resources are available on-line: < Number of frames 860 Core elements 2257 Non-Core elements 5476 Lexical units 24718

10
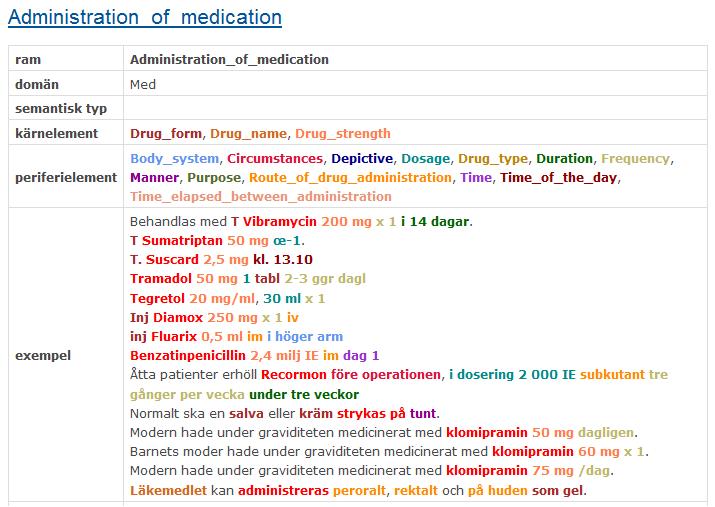
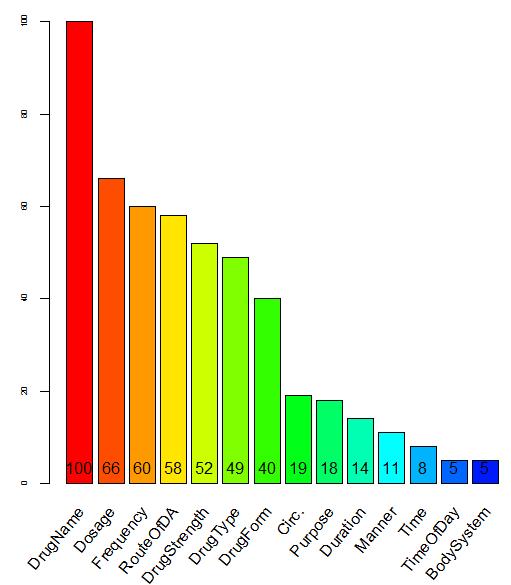
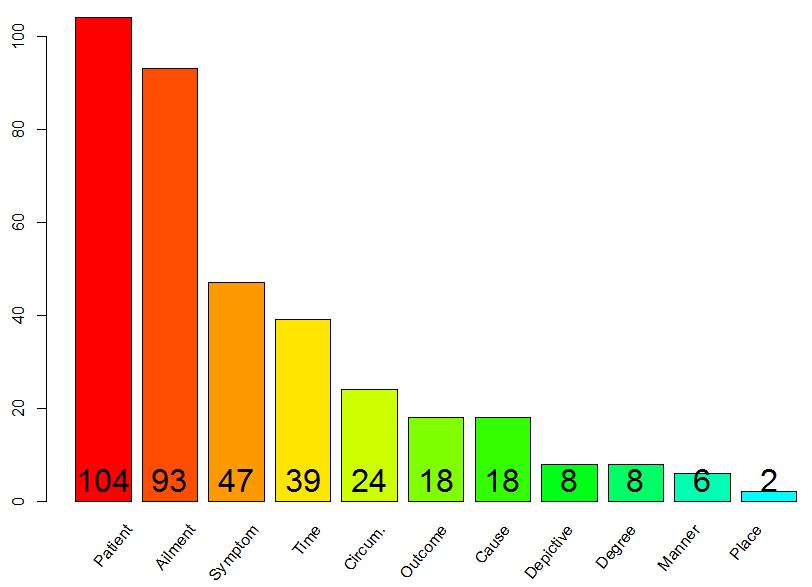
11 Methodology: Frame Selection Identify domain specific medical frames: Administration_of_medication, with core frame elements e.g. Drug, Patient and Medic (112) Medical_Treatment, with core frame elements e.g. Treatment, Affliction and Patient (102) Cure, with core frame elements e.g. Healer, Affliction and Body_Part (115) Falling_Ill, with core frame elements e.g. Patient, Symptom and Ailment (116) # number of manually annotated sentences, extracted from a Swedish biomedical corpus
12 Methodology: Samples&Resources Sentences selected using trigger words and manual inspection from the MEDLEX corpus (a variety of textdocuments related to various medical text genres) Domain resources: FASS, the Swedish national formulary; SNOMED CT s hierarchies; drug and disease lexicon extensions, e.g. generic drug expressions, misspellings; List of abbreviations: iv, i.v., im, i.m. sc, ; List of drug forms: pill, tablet, capsule, cream, gel, ; List of drug administration paths: intranasal, intravenous, Named Entities: for time, frequency and other relevant numerical information recognition,
13 Methodology Rule-based approach all steps are applied at the sentence level, i.e. no coherent, larger text fragments used 1. pre-processing: selecting a relevant sample of sentences for med. frames using trigger words (constraint: relevant LUs and medical NEs) for both manual annotation and pattern development and also evaluation 2. main processing: includes terminology, named entity and key word/text segment identification 3. post-processing: modeling observed frame element patterns as rules (regular expressions over annotations and text fragments)
14
15 Event Recognition Workflow 21-årig man vars lungtuberkulos <TRIGGER>läkte ut</trigger> med streptomycin. 21-year old man whose pulmonary tuberculosis healed out by streptomycin. TERM: 21-årig man vars <SNOMED>lungtuberkulos</SNOMED> läkte ut med <FASS>streptomycin</FASS>. NER: <PERSON>21-årig man</person> vars lungtuberkulos läkte ut med streptomycin. Normalization, merging and modeling observed patterns in rules: <PERSON> <TERM> [trigger-word] <FASS> <PATIENT> <AFFLICTION> <CURE> <MEDICATION> Manual analysis of the annotated examples gave an approximation of how the examined medical events are expressed Created rules (regular expressions) for the task and also some annotated data for future supervised ML
16 Results Evaluation sample: 30x4 sentences; P: # elements correctly labeled, out of the total number of all elements labeled; R: # elements correctly labeled given all of the possible elements
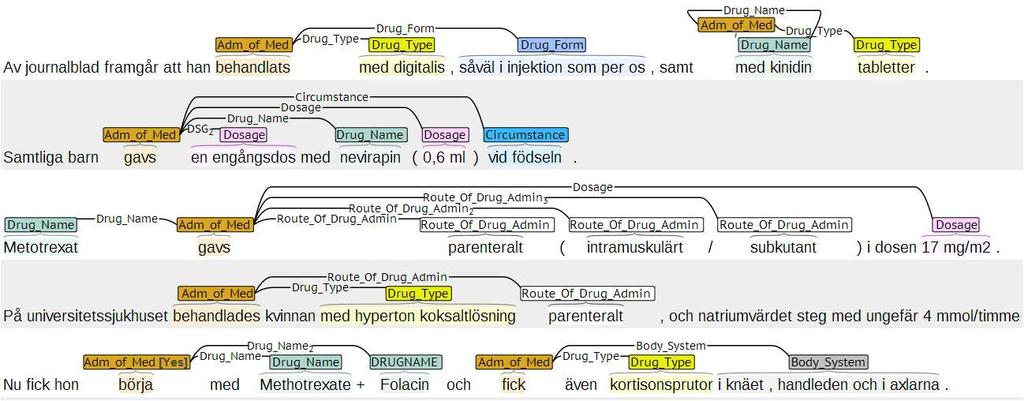
17 Problems Certain elements are difficult to capture using regular expressions: <Purpose>, <Outcome> and <Circumstance>, due to great variability, expressed by lengthy language patterns - syntactic parsing needs to be exploited (chunking): complex NPs or PPs and clauses. E.g., a prepositional phrase complex with four prepositions (in bold face): <Circumstance>Vid klart skyldig blindtarmsinflammation av varierande grad upp till kraftigare inflammation med tecken på vävnadsdöd i blindtarmen</circumstance> administreras antibiotika Tienam 0,5 g x 3 (litt. 'In clear-cut case appendicitis of varying degree up to stronger inflammation with signs of necrosis in the cecum antibiotic Tienam 0.5 g x 3 administered').
18 Problems Ellipsis: clauses where an overt trigger word is missing (often a predicate belonging to the frame) For instance, the following retrieved example lacks an overt trigger, a verb, in the last clause marked in italic that we would like to have an annotation for: Av journalblad framgår att han behandlats med digitalis, såväl i injektion som per os, samt med kinidin tabletter. (litt. Of the record sheet it is shown that he has been treated with digitalis, both as injection and per os, and with quinidine tablets)
19 More Issues Some frame elements could not be found in the annotated samples; some had very few occurrences and were not formally evaluated, e.g. the element Place in the Falling_Ill frame The manual annotation resulted to revision of some frames, some domain frames are divided in two, obtaining more accurate and precise semantics and more specialization. E.g., the Administration_of_medication was divided into Administration_of_medication_conveyance (where the procedures that describe the administration of medicine is the focus; e.g. Normalt ska en salva eller kräm strykas på tunt; litt. "Normally, an ointment or cream will be thinly applied") and Administration_of_medication_specification (where the focus is on the specifications concerning administration of medicines; e.g. Tegretol 20 mg/ml, 30 ml x 1).
20 Summary Simple rule-based, lexical knowledge oriented SRL Findings from a study into how a semantic resource, FrameNet (FN), can be applied for event extraction in the Swedish biomedical domain The Swedish FN ( ) is based on the Berkeley FN, which provides the appropriate conceptual structure that describes various events along with their participants and properties Combining the lexical semantic content of FN with domain specific knowledge provides a modeling mechanism that can be utilized for event extraction and other text mining activities
21 Future Plans Use the annotated sentences as gold standard and look for new sentences in corpora using the triggers and match to the gold standard in order to augment with new sentences using e.g. sequence alignment (identify regions of similarity) More annotated samples for all medical frames Syntactic analysis of the sentences; sufficient with chunking? Automatic pattern learning Rely less on the presence of trigger words event detection as a classification task
22 Future Plans Compare which technique is most appropriate for which type of frame machine learning vs. rulebased/knowledge-based For some frames, e.g. Adm_of_Medication, simple means - regular expressions - are enough for accurate identification of frame elements (numerical info, domain-specific abbreviations and acronyms). In other cases, such as in the Cure frame, other means seem more appropriate, such as parsing
Text mining tools for semantically enriching the scientific literature
 Text mining tools for semantically enriching the scientific literature Sophia Ananiadou Director National Centre for Text Mining School of Computer Science University of Manchester Need for enriching the
Text mining tools for semantically enriching the scientific literature Sophia Ananiadou Director National Centre for Text Mining School of Computer Science University of Manchester Need for enriching the
Text Mining for Software Engineering
 Text Mining for Software Engineering Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe (TH), Germany Department of Computer Science and Software
Text Mining for Software Engineering Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe (TH), Germany Department of Computer Science and Software
Customisable Curation Workflows in Argo
 Customisable Curation Workflows in Argo Rafal Rak*, Riza Batista-Navarro, Andrew Rowley, Jacob Carter and Sophia Ananiadou National Centre for Text Mining, University of Manchester, UK *Corresponding author:
Customisable Curation Workflows in Argo Rafal Rak*, Riza Batista-Navarro, Andrew Rowley, Jacob Carter and Sophia Ananiadou National Centre for Text Mining, University of Manchester, UK *Corresponding author:
structure of the presentation Frame Semantics knowledge-representation in larger-scale structures the concept of frame
 structure of the presentation Frame Semantics semantic characterisation of situations or states of affairs 1. introduction (partially taken from a presentation of Markus Egg): i. what is a frame supposed
structure of the presentation Frame Semantics semantic characterisation of situations or states of affairs 1. introduction (partially taken from a presentation of Markus Egg): i. what is a frame supposed
Using Relations for Identification and Normalization of Disorders: Team CLEAR in the ShARe/CLEF 2013 ehealth Evaluation Lab
 Using Relations for Identification and Normalization of Disorders: Team CLEAR in the ShARe/CLEF 2013 ehealth Evaluation Lab James Gung University of Colorado, Department of Computer Science Boulder, CO
Using Relations for Identification and Normalization of Disorders: Team CLEAR in the ShARe/CLEF 2013 ehealth Evaluation Lab James Gung University of Colorado, Department of Computer Science Boulder, CO
Natural Language Processing. SoSe Question Answering
 Natural Language Processing SoSe 2017 Question Answering Dr. Mariana Neves July 5th, 2017 Motivation Find small segments of text which answer users questions (http://start.csail.mit.edu/) 2 3 Motivation
Natural Language Processing SoSe 2017 Question Answering Dr. Mariana Neves July 5th, 2017 Motivation Find small segments of text which answer users questions (http://start.csail.mit.edu/) 2 3 Motivation
University of Sheffield, NLP. Chunking Practical Exercise
 Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
University of Sheffield, NLP. Chunking Practical Exercise
 Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Text Mining. Representation of Text Documents
 Data Mining is typically concerned with the detection of patterns in numeric data, but very often important (e.g., critical to business) information is stored in the form of text. Unlike numeric data,
Data Mining is typically concerned with the detection of patterns in numeric data, but very often important (e.g., critical to business) information is stored in the form of text. Unlike numeric data,
Question Answering Using XML-Tagged Documents
 Question Answering Using XML-Tagged Documents Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/trec11/index.html XML QA System P Full text processing of TREC top 20 documents Sentence
Question Answering Using XML-Tagged Documents Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/trec11/index.html XML QA System P Full text processing of TREC top 20 documents Sentence
Document Retrieval using Predication Similarity
 Document Retrieval using Predication Similarity Kalpa Gunaratna 1 Kno.e.sis Center, Wright State University, Dayton, OH 45435 USA kalpa@knoesis.org Abstract. Document retrieval has been an important research
Document Retrieval using Predication Similarity Kalpa Gunaratna 1 Kno.e.sis Center, Wright State University, Dayton, OH 45435 USA kalpa@knoesis.org Abstract. Document retrieval has been an important research
Maximizing the Value of STM Content through Semantic Enrichment. Frank Stumpf December 1, 2009
 Maximizing the Value of STM Content through Semantic Enrichment Frank Stumpf December 1, 2009 What is Semantics and Semantic Processing? Content Knowledge Framework Technology Framework Search Text Images
Maximizing the Value of STM Content through Semantic Enrichment Frank Stumpf December 1, 2009 What is Semantics and Semantic Processing? Content Knowledge Framework Technology Framework Search Text Images
Question Answering Systems
 Question Answering Systems An Introduction Potsdam, Germany, 14 July 2011 Saeedeh Momtazi Information Systems Group Outline 2 1 Introduction Outline 2 1 Introduction 2 History Outline 2 1 Introduction
Question Answering Systems An Introduction Potsdam, Germany, 14 July 2011 Saeedeh Momtazi Information Systems Group Outline 2 1 Introduction Outline 2 1 Introduction 2 History Outline 2 1 Introduction
Semantics Isn t Easy Thoughts on the Way Forward
 Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
UML data models from an ORM perspective: Part 4
 data models from an ORM perspective: Part 4 by Dr. Terry Halpin Director of Database Strategy, Visio Corporation This article first appeared in the August 1998 issue of the Journal of Conceptual Modeling,
data models from an ORM perspective: Part 4 by Dr. Terry Halpin Director of Database Strategy, Visio Corporation This article first appeared in the August 1998 issue of the Journal of Conceptual Modeling,
Natural Language Processing SoSe Question Answering. (based on the slides of Dr. Saeedeh Momtazi)
") Natural Language Processing SoSe 2015 Question Answering Dr. Mariana Neves July 6th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Introduction History QA Architecture Outline 3 Introduction
Natural Language Processing SoSe 2015 Question Answering Dr. Mariana Neves July 6th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Introduction History QA Architecture Outline 3 Introduction
Precise Medication Extraction using Agile Text Mining
 Precise Medication Extraction using Agile Text Mining Chaitanya Shivade *, James Cormack, David Milward * The Ohio State University, Columbus, Ohio, USA Linguamatics Ltd, Cambridge, UK shivade@cse.ohio-state.edu,
Precise Medication Extraction using Agile Text Mining Chaitanya Shivade *, James Cormack, David Milward * The Ohio State University, Columbus, Ohio, USA Linguamatics Ltd, Cambridge, UK shivade@cse.ohio-state.edu,
A bit of theory: Algorithms
 A bit of theory: Algorithms There are different kinds of algorithms Vector space models. e.g. support vector machines Decision trees, e.g. C45 Probabilistic models, e.g. Naive Bayes Neural networks, e.g.
A bit of theory: Algorithms There are different kinds of algorithms Vector space models. e.g. support vector machines Decision trees, e.g. C45 Probabilistic models, e.g. Naive Bayes Neural networks, e.g.
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Parmenides. Semi-automatic. Ontology. construction and maintenance. Ontology. Document convertor/basic processing. Linguistic. Background knowledge
 Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
An UIMA based Tool Suite for Semantic Text Processing
 An UIMA based Tool Suite for Semantic Text Processing Katrin Tomanek, Ekaterina Buyko, Udo Hahn Jena University Language & Information Engineering Lab StemNet Knowledge Management for Immunology in life
An UIMA based Tool Suite for Semantic Text Processing Katrin Tomanek, Ekaterina Buyko, Udo Hahn Jena University Language & Information Engineering Lab StemNet Knowledge Management for Immunology in life
Chapter 8: Enhanced ER Model
 Chapter 8: Enhanced ER Model Subclasses, Superclasses, and Inheritance Specialization and Generalization Constraints and Characteristics of Specialization and Generalization Hierarchies Modeling of UNION
Chapter 8: Enhanced ER Model Subclasses, Superclasses, and Inheritance Specialization and Generalization Constraints and Characteristics of Specialization and Generalization Hierarchies Modeling of UNION
Natural Language Processing SoSe Question Answering. (based on the slides of Dr. Saeedeh Momtazi) )
 )") Natural Language Processing SoSe 2014 Question Answering Dr. Mariana Neves June 25th, 2014 (based on the slides of Dr. Saeedeh Momtazi) ) Outline 2 Introduction History QA Architecture Natural Language
Natural Language Processing SoSe 2014 Question Answering Dr. Mariana Neves June 25th, 2014 (based on the slides of Dr. Saeedeh Momtazi) ) Outline 2 Introduction History QA Architecture Natural Language
@Note2 tutorial. Hugo Costa Ruben Rodrigues Miguel Rocha
 @Note2 tutorial Hugo Costa (hcosta@silicolife.com) Ruben Rodrigues (pg25227@alunos.uminho.pt) Miguel Rocha (mrocha@di.uminho.pt) 23-01-2018 The document presents a typical workflow using @Note2 platform
@Note2 tutorial Hugo Costa (hcosta@silicolife.com) Ruben Rodrigues (pg25227@alunos.uminho.pt) Miguel Rocha (mrocha@di.uminho.pt) 23-01-2018 The document presents a typical workflow using @Note2 platform
High Accuracy Information Retrieval and Information Extraction System for Electronic Clinical Notes
 High Accuracy Information Retrieval and Information Extraction System for Electronic Clinical Notes Jon Patrick and Min Li Health Information Technology Research Laboratory, School of IT The University
High Accuracy Information Retrieval and Information Extraction System for Electronic Clinical Notes Jon Patrick and Min Li Health Information Technology Research Laboratory, School of IT The University
INFORMATION EXTRACTION
 COMP90042 LECTURE 13 INFORMATION EXTRACTION INTRODUCTION Given this: Brasilia, the Brazilian capital, was founded in 1960. Obtain this: capital(brazil, Brasilia) founded(brasilia, 1960) Main goal: turn
COMP90042 LECTURE 13 INFORMATION EXTRACTION INTRODUCTION Given this: Brasilia, the Brazilian capital, was founded in 1960. Obtain this: capital(brazil, Brasilia) founded(brasilia, 1960) Main goal: turn
Argument Structures and Semantic Roles: Actual State in ISO TC37/SC4 TDG 3
 ISO/TC 37/SC 4 N280 Argument Structures and Semantic Roles: Actual State in ISO TC37/SC4 TDG 3 Thierry Declerck (DFKI), joined work with Mandy Schiffrin (Tilburg) Possible Definition of Semantic Roles
ISO/TC 37/SC 4 N280 Argument Structures and Semantic Roles: Actual State in ISO TC37/SC4 TDG 3 Thierry Declerck (DFKI), joined work with Mandy Schiffrin (Tilburg) Possible Definition of Semantic Roles
A Multilingual Social Media Linguistic Corpus
 A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th
A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th
Genescene: Biomedical Text and Data Mining
 Claremont Colleges Scholarship @ Claremont CGU Faculty Publications and Research CGU Faculty Scholarship 5-1-2003 Genescene: Biomedical Text and Data Mining Gondy Leroy Claremont Graduate University Hsinchun
Claremont Colleges Scholarship @ Claremont CGU Faculty Publications and Research CGU Faculty Scholarship 5-1-2003 Genescene: Biomedical Text and Data Mining Gondy Leroy Claremont Graduate University Hsinchun
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
Australian Journal of Basic and Applied Sciences. Named Entity Recognition from Biomedical Abstracts An Information Extraction Task
 ISSN:1991-8178 Australian Journal of Basic and Applied Sciences Journal home page: www.ajbasweb.com Named Entity Recognition from Biomedical Abstracts An Information Extraction Task 1 N. Kanya and 2 Dr.
ISSN:1991-8178 Australian Journal of Basic and Applied Sciences Journal home page: www.ajbasweb.com Named Entity Recognition from Biomedical Abstracts An Information Extraction Task 1 N. Kanya and 2 Dr.
Knowledge Engineering with Semantic Web Technologies
 This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
Frame Semantic Structure Extraction
 Frame Semantic Structure Extraction Organizing team: Collin Baker, Michael Ellsworth (International Computer Science Institute, Berkeley), Katrin Erk(U Texas, Austin) October 4, 2006 1 Description of task
Frame Semantic Structure Extraction Organizing team: Collin Baker, Michael Ellsworth (International Computer Science Institute, Berkeley), Katrin Erk(U Texas, Austin) October 4, 2006 1 Description of task
English Understanding: From Annotations to AMRs
 English Understanding: From Annotations to AMRs Nathan Schneider August 28, 2012 :: ISI NLP Group :: Summer Internship Project Presentation 1 Current state of the art: syntax-based MT Hierarchical/syntactic
English Understanding: From Annotations to AMRs Nathan Schneider August 28, 2012 :: ISI NLP Group :: Summer Internship Project Presentation 1 Current state of the art: syntax-based MT Hierarchical/syntactic
What is this Song About?: Identification of Keywords in Bollywood Lyrics
 What is this Song About?: Identification of Keywords in Bollywood Lyrics by Drushti Apoorva G, Kritik Mathur, Priyansh Agrawal, Radhika Mamidi in 19th International Conference on Computational Linguistics
What is this Song About?: Identification of Keywords in Bollywood Lyrics by Drushti Apoorva G, Kritik Mathur, Priyansh Agrawal, Radhika Mamidi in 19th International Conference on Computational Linguistics
Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus
 Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus Donald C. Comeau *, Haibin Liu, Rezarta Islamaj Doğan and W. John Wilbur National Center
Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus Donald C. Comeau *, Haibin Liu, Rezarta Islamaj Doğan and W. John Wilbur National Center
Generating FrameNets of various granularities: The FrameNet Transformer
 Generating FrameNets of various granularities: The FrameNet Transformer Josef Ruppenhofer, Jonas Sunde, & Manfred Pinkal Saarland University LREC, May 2010 Ruppenhofer, Sunde, Pinkal (Saarland U.) Generating
Generating FrameNets of various granularities: The FrameNet Transformer Josef Ruppenhofer, Jonas Sunde, & Manfred Pinkal Saarland University LREC, May 2010 Ruppenhofer, Sunde, Pinkal (Saarland U.) Generating
Proseminar on Semantic Theory Fall 2013 Ling 720 An Algebraic Perspective on the Syntax of First Order Logic (Without Quantification) 1
 1") An Algebraic Perspective on the Syntax of First Order Logic (Without Quantification) 1 1. Statement of the Problem, Outline of the Solution to Come (1) The Key Problem There is much to recommend an algebraic
An Algebraic Perspective on the Syntax of First Order Logic (Without Quantification) 1 1. Statement of the Problem, Outline of the Solution to Come (1) The Key Problem There is much to recommend an algebraic
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2
 A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
Introduction to Lexical Functional Grammar. Wellformedness conditions on f- structures. Constraints on f-structures
 Introduction to Lexical Functional Grammar Session 8 f(unctional)-structure & c-structure/f-structure Mapping II & Wrap-up Summary of last week s lecture LFG-specific grammar rules (i.e. PS-rules annotated
Introduction to Lexical Functional Grammar Session 8 f(unctional)-structure & c-structure/f-structure Mapping II & Wrap-up Summary of last week s lecture LFG-specific grammar rules (i.e. PS-rules annotated
Context-Free Grammars. Carl Pollard Ohio State University. Linguistics 680 Formal Foundations Tuesday, November 10, 2009
 Context-Free Grammars Carl Pollard Ohio State University Linguistics 680 Formal Foundations Tuesday, November 10, 2009 These slides are available at: http://www.ling.osu.edu/ scott/680 1 (1) Context-Free
Context-Free Grammars Carl Pollard Ohio State University Linguistics 680 Formal Foundations Tuesday, November 10, 2009 These slides are available at: http://www.ling.osu.edu/ scott/680 1 (1) Context-Free
A Semantic Multi-Field Clinical Search for Patient Medical Records
 BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 18, No 1 Sofia 2018 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.2478/cait-2018-0014 A Semantic Multi-Field Clinical
BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 18, No 1 Sofia 2018 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.2478/cait-2018-0014 A Semantic Multi-Field Clinical
A hybrid method to categorize HTML documents
 Data Mining VI 331 A hybrid method to categorize HTML documents M. Khordad, M. Shamsfard & F. Kazemeyni Electrical & Computer Engineering Department, Shahid Beheshti University, Iran Abstract In this paper
Data Mining VI 331 A hybrid method to categorize HTML documents M. Khordad, M. Shamsfard & F. Kazemeyni Electrical & Computer Engineering Department, Shahid Beheshti University, Iran Abstract In this paper
TIPSTER Text Phase II Architecture Requirements
 1.0 INTRODUCTION TIPSTER Text Phase II Architecture Requirements 1.1 Requirements Traceability Version 2.0p 3 June 1996 Architecture Commitee tipster @ tipster.org The requirements herein are derived from
1.0 INTRODUCTION TIPSTER Text Phase II Architecture Requirements 1.1 Requirements Traceability Version 2.0p 3 June 1996 Architecture Commitee tipster @ tipster.org The requirements herein are derived from
Graphical Notation for Topic Maps (GTM)
") Graphical Notation for Topic Maps (GTM) 2005.11.12 Jaeho Lee University of Seoul jaeho@uos.ac.kr 1 Outline 2 Motivation Requirements for GTM Goals, Scope, Constraints, and Issues Survey on existing approaches
Graphical Notation for Topic Maps (GTM) 2005.11.12 Jaeho Lee University of Seoul jaeho@uos.ac.kr 1 Outline 2 Motivation Requirements for GTM Goals, Scope, Constraints, and Issues Survey on existing approaches
Annotation by category - ELAN and ISO DCR
 Annotation by category - ELAN and ISO DCR Han Sloetjes, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500 AH Nijmegen, The Netherlands E-mail: Han.Sloetjes@mpi.nl, Peter.Wittenburg@mpi.nl
Annotation by category - ELAN and ISO DCR Han Sloetjes, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500 AH Nijmegen, The Netherlands E-mail: Han.Sloetjes@mpi.nl, Peter.Wittenburg@mpi.nl
Semantic and Multimodal Annotation. CLARA University of Copenhagen August 2011 Susan Windisch Brown
 Semantic and Multimodal Annotation CLARA University of Copenhagen 15-26 August 2011 Susan Windisch Brown 2 Program: Monday Big picture Coffee break Lexical ambiguity and word sense annotation Lunch break
Semantic and Multimodal Annotation CLARA University of Copenhagen 15-26 August 2011 Susan Windisch Brown 2 Program: Monday Big picture Coffee break Lexical ambiguity and word sense annotation Lunch break
Domain Independent Knowledge Base Population From Structured and Unstructured Data Sources
 Domain Independent Knowledge Base Population From Structured and Unstructured Data Sources Michelle Gregory, Liam McGrath, Eric Bell, Kelly O Hara, and Kelly Domico Pacific Northwest National Laboratory
Domain Independent Knowledge Base Population From Structured and Unstructured Data Sources Michelle Gregory, Liam McGrath, Eric Bell, Kelly O Hara, and Kelly Domico Pacific Northwest National Laboratory
Let s get parsing! Each component processes the Doc object, then passes it on. doc.is_parsed attribute checks whether a Doc object has been parsed
 Let s get parsing! SpaCy default model includes tagger, parser and entity recognizer nlp = spacy.load('en ) tells spacy to use "en" with ["tagger", "parser", "ner"] Each component processes the Doc object,
Let s get parsing! SpaCy default model includes tagger, parser and entity recognizer nlp = spacy.load('en ) tells spacy to use "en" with ["tagger", "parser", "ner"] Each component processes the Doc object,
A Method for Semi-Automatic Ontology Acquisition from a Corporate Intranet
 A Method for Semi-Automatic Ontology Acquisition from a Corporate Intranet Joerg-Uwe Kietz, Alexander Maedche, Raphael Volz Swisslife Information Systems Research Lab, Zuerich, Switzerland fkietz, volzg@swisslife.ch
A Method for Semi-Automatic Ontology Acquisition from a Corporate Intranet Joerg-Uwe Kietz, Alexander Maedche, Raphael Volz Swisslife Information Systems Research Lab, Zuerich, Switzerland fkietz, volzg@swisslife.ch
Natural Language Requirements
 Natural Language Requirements Software Verification and Validation Laboratory Requirement Elaboration Heuristic Domain Model» Requirement Relationship Natural Language is elaborated via Requirement application
Natural Language Requirements Software Verification and Validation Laboratory Requirement Elaboration Heuristic Domain Model» Requirement Relationship Natural Language is elaborated via Requirement application
What is Text Mining? Sophia Ananiadou National Centre for Text Mining University of Manchester
 National Centre for Text Mining www.nactem.ac.uk University of Manchester Outline Aims of text mining Text Mining steps Text Mining uses Applications 2 Aims Extract and discover knowledge hidden in text
National Centre for Text Mining www.nactem.ac.uk University of Manchester Outline Aims of text mining Text Mining steps Text Mining uses Applications 2 Aims Extract and discover knowledge hidden in text
I Know Your Name: Named Entity Recognition and Structural Parsing
 I Know Your Name: Named Entity Recognition and Structural Parsing David Philipson and Nikil Viswanathan {pdavid2, nikil}@stanford.edu CS224N Fall 2011 Introduction In this project, we explore a Maximum
I Know Your Name: Named Entity Recognition and Structural Parsing David Philipson and Nikil Viswanathan {pdavid2, nikil}@stanford.edu CS224N Fall 2011 Introduction In this project, we explore a Maximum
Context-Free Grammars
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 3, 2012 (CFGs) A CFG is an ordered quadruple T, N, D, P where a. T is a finite set called the terminals; b. N is a
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 3, 2012 (CFGs) A CFG is an ordered quadruple T, N, D, P where a. T is a finite set called the terminals; b. N is a
Knowledge Retrieval. Franz J. Kurfess. Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A.
 Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Ontology Development. Qing He
 A tutorial report for SENG 609.22 Agent Based Software Engineering Course Instructor: Dr. Behrouz H. Far Ontology Development Qing He 1 Why develop an ontology? In recent years the development of ontologies
A tutorial report for SENG 609.22 Agent Based Software Engineering Course Instructor: Dr. Behrouz H. Far Ontology Development Qing He 1 Why develop an ontology? In recent years the development of ontologies
Information Retrieval CS Lecture 01. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Tokenization and Sentence Segmentation. Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017
 Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Data and Information Integration: Information Extraction
 International OPEN ACCESS Journal Of Modern Engineering Research (IJMER) Data and Information Integration: Information Extraction Varnica Verma 1 1 (Department of Computer Science Engineering, Guru Nanak
International OPEN ACCESS Journal Of Modern Engineering Research (IJMER) Data and Information Integration: Information Extraction Varnica Verma 1 1 (Department of Computer Science Engineering, Guru Nanak
Getting Started With Syntax October 15, 2015
 Getting Started With Syntax October 15, 2015 Introduction The Accordance Syntax feature allows both viewing and searching of certain original language texts that have both morphological tagging along with
Getting Started With Syntax October 15, 2015 Introduction The Accordance Syntax feature allows both viewing and searching of certain original language texts that have both morphological tagging along with
Semi-Supervised Abstraction-Augmented String Kernel for bio-relationship Extraction
 Semi-Supervised Abstraction-Augmented String Kernel for bio-relationship Extraction Pavel P. Kuksa, Rutgers University Yanjun Qi, Bing Bai, Ronan Collobert, NEC Labs Jason Weston, Google Research NY Vladimir
Semi-Supervised Abstraction-Augmented String Kernel for bio-relationship Extraction Pavel P. Kuksa, Rutgers University Yanjun Qi, Bing Bai, Ronan Collobert, NEC Labs Jason Weston, Google Research NY Vladimir
TEXT PREPROCESSING FOR TEXT MINING USING SIDE INFORMATION
 TEXT PREPROCESSING FOR TEXT MINING USING SIDE INFORMATION Ms. Nikita P.Katariya 1, Prof. M. S. Chaudhari 2 1 Dept. of Computer Science & Engg, P.B.C.E., Nagpur, India, nikitakatariya@yahoo.com 2 Dept.
TEXT PREPROCESSING FOR TEXT MINING USING SIDE INFORMATION Ms. Nikita P.Katariya 1, Prof. M. S. Chaudhari 2 1 Dept. of Computer Science & Engg, P.B.C.E., Nagpur, India, nikitakatariya@yahoo.com 2 Dept.
Introduction to Lexical Analysis
 Introduction to Lexical Analysis Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexers Regular expressions Examples
Introduction to Lexical Analysis Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexers Regular expressions Examples
Activity Report at SYSTRAN S.A.
 Activity Report at SYSTRAN S.A. Pierre Senellart September 2003 September 2004 1 Introduction I present here work I have done as a software engineer with SYSTRAN. SYSTRAN is a leading company in machine
Activity Report at SYSTRAN S.A. Pierre Senellart September 2003 September 2004 1 Introduction I present here work I have done as a software engineer with SYSTRAN. SYSTRAN is a leading company in machine
SEMANTIC SUPPORT FOR MEDICAL IMAGE SEARCH AND RETRIEVAL
 SEMANTIC SUPPORT FOR MEDICAL IMAGE SEARCH AND RETRIEVAL Wang Wei, Payam M. Barnaghi School of Computer Science and Information Technology The University of Nottingham Malaysia Campus {Kcy3ww, payam.barnaghi}@nottingham.edu.my
SEMANTIC SUPPORT FOR MEDICAL IMAGE SEARCH AND RETRIEVAL Wang Wei, Payam M. Barnaghi School of Computer Science and Information Technology The University of Nottingham Malaysia Campus {Kcy3ww, payam.barnaghi}@nottingham.edu.my
ANNIS3 Multiple Segmentation Corpora Guide
 ANNIS3 Multiple Segmentation Corpora Guide (For the latest documentation see also: http://korpling.github.io/annis) title: version: ANNIS3 Multiple Segmentation Corpora Guide 2013-6-15a author: Amir Zeldes
ANNIS3 Multiple Segmentation Corpora Guide (For the latest documentation see also: http://korpling.github.io/annis) title: version: ANNIS3 Multiple Segmentation Corpora Guide 2013-6-15a author: Amir Zeldes
Chapter 6 Architectural Design. Lecture 1. Chapter 6 Architectural design
 Chapter 6 Architectural Design Lecture 1 1 Topics covered ² Architectural design decisions ² Architectural views ² Architectural patterns ² Application architectures 2 Software architecture ² The design
Chapter 6 Architectural Design Lecture 1 1 Topics covered ² Architectural design decisions ² Architectural views ² Architectural patterns ² Application architectures 2 Software architecture ² The design
INFO216: Advanced Modelling
 INFO216: Advanced Modelling Theme, spring 2018: Modelling and Programming the Web of Data Andreas L. Opdahl Session S13: Development and quality Themes: ontology (and vocabulary)
INFO216: Advanced Modelling Theme, spring 2018: Modelling and Programming the Web of Data Andreas L. Opdahl Session S13: Development and quality Themes: ontology (and vocabulary)
Annotating Spatio-Temporal Information in Documents
 Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Text Mining: A Burgeoning technology for knowledge extraction
 Text Mining: A Burgeoning technology for knowledge extraction 1 Anshika Singh, 2 Dr. Udayan Ghosh 1 HCL Technologies Ltd., Noida, 2 University School of Information &Communication Technology, Dwarka, Delhi.
Text Mining: A Burgeoning technology for knowledge extraction 1 Anshika Singh, 2 Dr. Udayan Ghosh 1 HCL Technologies Ltd., Noida, 2 University School of Information &Communication Technology, Dwarka, Delhi.
Information Extraction
 Information Extraction A Survey Katharina Kaiser and Silvia Miksch Vienna University of Technology Institute of Software Technology & Interactive Systems Asgaard-TR-2005-6 May 2005 Authors: Katharina Kaiser
Information Extraction A Survey Katharina Kaiser and Silvia Miksch Vienna University of Technology Institute of Software Technology & Interactive Systems Asgaard-TR-2005-6 May 2005 Authors: Katharina Kaiser
SAPIENT Automation project
 Dr Maria Liakata Leverhulme Trust Early Career fellow Department of Computer Science, Aberystwyth University Visitor at EBI, Cambridge mal@aber.ac.uk 25 May 2010, London Motivation SAPIENT Automation Project
Dr Maria Liakata Leverhulme Trust Early Career fellow Department of Computer Science, Aberystwyth University Visitor at EBI, Cambridge mal@aber.ac.uk 25 May 2010, London Motivation SAPIENT Automation Project
The Text Analytics Challenge BioCreative V - Extraction of causal network information in BEL
 The Text Analytics Challenge BioCreative V - Extraction of causal network information in BEL http://tinyurl.com/beltask Fabio Rinaldi Outline Biomedical text mining, motivation Competitive evaluations:
The Text Analytics Challenge BioCreative V - Extraction of causal network information in BEL http://tinyurl.com/beltask Fabio Rinaldi Outline Biomedical text mining, motivation Competitive evaluations:
MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion
 MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion Sara Lana-Serrano 1,3, Julio Villena-Román 2,3, José C. González-Cristóbal 1,3 1 Universidad Politécnica de Madrid 2 Universidad
MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion Sara Lana-Serrano 1,3, Julio Villena-Román 2,3, José C. González-Cristóbal 1,3 1 Universidad Politécnica de Madrid 2 Universidad
The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation
 The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/dppdemo/index.html Dictionary Parsing Project Purpose: to
The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/dppdemo/index.html Dictionary Parsing Project Purpose: to
KNOWLEDGE GRAPH: FROM METADATA TO INFORMATION VISUALIZATION AND BACK. Xia Lin College of Computing and Informatics Drexel University Philadelphia, PA
 KNOWLEDGE GRAPH: FROM METADATA TO INFORMATION VISUALIZATION AND BACK Xia Lin College of Computing and Informatics Drexel University Philadelphia, PA 1 A little background of me Teach at Drexel University
KNOWLEDGE GRAPH: FROM METADATA TO INFORMATION VISUALIZATION AND BACK Xia Lin College of Computing and Informatics Drexel University Philadelphia, PA 1 A little background of me Teach at Drexel University
The CKY algorithm part 2: Probabilistic parsing
 The CKY algorithm part 2: Probabilistic parsing Syntactic analysis/parsing 2017-11-14 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Recap: The CKY algorithm The
The CKY algorithm part 2: Probabilistic parsing Syntactic analysis/parsing 2017-11-14 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Recap: The CKY algorithm The
A Framework for BioCuration (part II)
") A Framework for BioCuration (part II) Text Mining for the BioCuration Workflow Workshop, 3rd International Biocuration Conference Friday, April 17, 2009 (Berlin) Martin Krallinger Spanish National Cancer
A Framework for BioCuration (part II) Text Mining for the BioCuration Workflow Workshop, 3rd International Biocuration Conference Friday, April 17, 2009 (Berlin) Martin Krallinger Spanish National Cancer
Sustainability of Text-Technological Resources
 Sustainability of Text-Technological Resources Maik Stührenberg, Michael Beißwenger, Kai-Uwe Kühnberger, Harald Lüngen, Alexander Mehler, Dieter Metzing, Uwe Mönnich Research Group Text-Technological Overview
Sustainability of Text-Technological Resources Maik Stührenberg, Michael Beißwenger, Kai-Uwe Kühnberger, Harald Lüngen, Alexander Mehler, Dieter Metzing, Uwe Mönnich Research Group Text-Technological Overview
Projects Tools BLAH proposal Conclusion. OntoGene/BioMeXT
 OntoGene/BioMeXT The Bio Term Hub and OGER Lenz Furrer, Nico Colic, Fabio Rinaldi University of Zurich and Swiss Institute of Bioinformatics January 10, 2018 Outline Projects Tools BLAH proposal Conclusion
OntoGene/BioMeXT The Bio Term Hub and OGER Lenz Furrer, Nico Colic, Fabio Rinaldi University of Zurich and Swiss Institute of Bioinformatics January 10, 2018 Outline Projects Tools BLAH proposal Conclusion
National Centre for Text Mining NaCTeM. e-science and data mining workshop
 National Centre for Text Mining NaCTeM e-science and data mining workshop John Keane Co-Director, NaCTeM john.keane@manchester.ac.uk School of Informatics, University of Manchester What is text mining?
National Centre for Text Mining NaCTeM e-science and data mining workshop John Keane Co-Director, NaCTeM john.keane@manchester.ac.uk School of Informatics, University of Manchester What is text mining?
Extracting Conceptual Relationships from Specialized Documents
 Extracting Conceptual Relationships from Specialized Documents Bowen Hui Dept of Computer Science University of Toronto Eric Yu Fac of Information Studies University of Toronto Motivation much of human
Extracting Conceptual Relationships from Specialized Documents Bowen Hui Dept of Computer Science University of Toronto Eric Yu Fac of Information Studies University of Toronto Motivation much of human
Watson & WMR2017. (slides mostly derived from Jim Hendler and Simon Ellis, Rensselaer Polytechnic Institute, or from IBM itself)
") Watson & WMR2017 (slides mostly derived from Jim Hendler and Simon Ellis, Rensselaer Polytechnic Institute, or from IBM itself) R. BASILI A.A. 2016-17 Overview Motivations Watson Jeopardy NLU in Watson
Watson & WMR2017 (slides mostly derived from Jim Hendler and Simon Ellis, Rensselaer Polytechnic Institute, or from IBM itself) R. BASILI A.A. 2016-17 Overview Motivations Watson Jeopardy NLU in Watson
Schema Quality Improving Tasks in the Schema Integration Process
 468 Schema Quality Improving Tasks in the Schema Integration Process Peter Bellström Information Systems Karlstad University Karlstad, Sweden e-mail: peter.bellstrom@kau.se Christian Kop Institute for
468 Schema Quality Improving Tasks in the Schema Integration Process Peter Bellström Information Systems Karlstad University Karlstad, Sweden e-mail: peter.bellstrom@kau.se Christian Kop Institute for
Humboldt-University of Berlin
 Humboldt-University of Berlin Exploiting Link Structure to Discover Meaningful Associations between Controlled Vocabulary Terms exposé of diploma thesis of Andrej Masula 13th October 2008 supervisor: Louiqa
Humboldt-University of Berlin Exploiting Link Structure to Discover Meaningful Associations between Controlled Vocabulary Terms exposé of diploma thesis of Andrej Masula 13th October 2008 supervisor: Louiqa
Chapter 8 The Enhanced Entity- Relationship (EER) Model
 Model") Chapter 8 The Enhanced Entity- Relationship (EER) Model Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 8 Outline Subclasses, Superclasses, and Inheritance Specialization
Chapter 8 The Enhanced Entity- Relationship (EER) Model Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 8 Outline Subclasses, Superclasses, and Inheritance Specialization
Topics for Today. The Last (i.e. Final) Class. Weakly Supervised Approaches. Weakly supervised learning algorithms (for NP coreference resolution)
 Class. Weakly Supervised Approaches. Weakly supervised learning algorithms (for NP coreference resolution)") Topics for Today The Last (i.e. Final) Class Weakly supervised learning algorithms (for NP coreference resolution) Co-training Self-training A look at the semester and related courses Submit the teaching
Topics for Today The Last (i.e. Final) Class Weakly supervised learning algorithms (for NP coreference resolution) Co-training Self-training A look at the semester and related courses Submit the teaching
Ontology Based Prediction of Difficult Keyword Queries
 Ontology Based Prediction of Difficult Keyword Queries Lubna.C*, Kasim K Pursuing M.Tech (CSE)*, Associate Professor (CSE) MEA Engineering College, Perinthalmanna Kerala, India lubna9990@gmail.com, kasim_mlp@gmail.com
Ontology Based Prediction of Difficult Keyword Queries Lubna.C*, Kasim K Pursuing M.Tech (CSE)*, Associate Professor (CSE) MEA Engineering College, Perinthalmanna Kerala, India lubna9990@gmail.com, kasim_mlp@gmail.com
Background and Context for CLASP. Nancy Ide, Vassar College
 Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Diagnosticating and Propagating Health Maintenance Information Using Machine Learning Based Methodology
 Diagnosticating and Propagating Health Maintenance Information Using Machine Learning Based Methodology P.Deepa, M.Baskar Abstract:-The Machine Learning field has gained its thrust in almost any domain
Diagnosticating and Propagating Health Maintenance Information Using Machine Learning Based Methodology P.Deepa, M.Baskar Abstract:-The Machine Learning field has gained its thrust in almost any domain
Web Search: Techniques, algorithms and Aplications. Basic Techniques for Web Search
 Web Search: Techniques, algorithms and Aplications Basic Techniques for Web Search German Rigau [Based on slides by Eneko Agirre and Christopher Manning and Prabhakar Raghavan] 1
Web Search: Techniques, algorithms and Aplications Basic Techniques for Web Search German Rigau [Based on slides by Eneko Agirre and Christopher Manning and Prabhakar Raghavan] 1
Machine Learning in GATE
 Machine Learning in GATE Angus Roberts, Horacio Saggion, Genevieve Gorrell Recap Previous two days looked at knowledge engineered IE This session looks at machine learned IE Supervised learning Effort
Machine Learning in GATE Angus Roberts, Horacio Saggion, Genevieve Gorrell Recap Previous two days looked at knowledge engineered IE This session looks at machine learned IE Supervised learning Effort
Powering Knowledge Discovery. Insights from big data with Linguamatics I2E
 Powering Knowledge Discovery Insights from big data with Linguamatics I2E Gain actionable insights from unstructured data The world now generates an overwhelming amount of data, most of it written in natural
Powering Knowledge Discovery Insights from big data with Linguamatics I2E Gain actionable insights from unstructured data The world now generates an overwhelming amount of data, most of it written in natural
Unsupervised Semantic Parsing
 Unsupervised Semantic Parsing Hoifung Poon Dept. Computer Science & Eng. University of Washington (Joint work with Pedro Domingos) 1 Outline Motivation Unsupervised semantic parsing Learning and inference
Unsupervised Semantic Parsing Hoifung Poon Dept. Computer Science & Eng. University of Washington (Joint work with Pedro Domingos) 1 Outline Motivation Unsupervised semantic parsing Learning and inference
Describe The Differences In Meaning Between The Terms Relation And Relation Schema
 Describe The Differences In Meaning Between The Terms Relation And Relation Schema describe the differences in meaning between the terms relation and relation schema. consider the bank database of figure
Describe The Differences In Meaning Between The Terms Relation And Relation Schema describe the differences in meaning between the terms relation and relation schema. consider the bank database of figure
SEMINAR: RECENT ADVANCES IN PARSING TECHNOLOGY. Parser Evaluation Approaches
 SEMINAR: RECENT ADVANCES IN PARSING TECHNOLOGY Parser Evaluation Approaches NATURE OF PARSER EVALUATION Return accurate syntactic structure of sentence. Which representation? Robustness of parsing. Quick
SEMINAR: RECENT ADVANCES IN PARSING TECHNOLOGY Parser Evaluation Approaches NATURE OF PARSER EVALUATION Return accurate syntactic structure of sentence. Which representation? Robustness of parsing. Quick
Text Mining. Munawar, PhD. Text Mining - Munawar, PhD
 10 Text Mining Munawar, PhD Definition Text mining also is known as Text Data Mining (TDM) and Knowledge Discovery in Textual Database (KDT).[1] A process of identifying novel information from a collection
10 Text Mining Munawar, PhD Definition Text mining also is known as Text Data Mining (TDM) and Knowledge Discovery in Textual Database (KDT).[1] A process of identifying novel information from a collection
ICT for Health Care and Life Sciences
 School of Information Engineering Laurea Magistrale in Information Engineering Dipartimento di Elettronica e Informazione ICT for Health Care and Life Sciences 7 th November 2012 Davide Chicco davide.chicco@gmail.com
School of Information Engineering Laurea Magistrale in Information Engineering Dipartimento di Elettronica e Informazione ICT for Health Care and Life Sciences 7 th November 2012 Davide Chicco davide.chicco@gmail.com
It s time for a semantic engine!
 It s time for a semantic engine! Ido Dagan Bar-Ilan University, Israel 1 Semantic Knowledge is not the goal it s a primary mean to achieve semantic inference! Knowledge design should be derived from its
It s time for a semantic engine! Ido Dagan Bar-Ilan University, Israel 1 Semantic Knowledge is not the goal it s a primary mean to achieve semantic inference! Knowledge design should be derived from its
Extracting patient data from tables in clinical literature Case study on extraction of BMI, weight and number of patients
 Extracting patient data from tables in clinical literature Case study on extraction of BMI, weight and number of patients Nikola Milosevic 1, Cassie Gregson 2, Robert Hernandez 2 and Goran Nenadic 1,3
Extracting patient data from tables in clinical literature Case study on extraction of BMI, weight and number of patients Nikola Milosevic 1, Cassie Gregson 2, Robert Hernandez 2 and Goran Nenadic 1,3