Open Source Search. Andreas Pesenhofer. max.recall information systems GmbH Künstlergasse 11/1 A-1150 Wien Austria
|
|
|
- Junior Marshall
- 6 years ago
- Views:
Transcription
1 Open Source Search Andreas Pesenhofer max.recall information systems GmbH Künstlergasse 11/1 A-1150 Wien Austria

2 max.recall information systems max.recall is a software and consulting company enabling enterprises to capitalize on the hidden value in the rapidly growing amount of textual data Customized Solutions for Intelligent data analytics Vertical search Products and Services quantalyze: quantity analytics technology smart.coder: open-ended question coding tool for market researchers Founded 2010 and located in Vienna, Austria Operates worldwide with int l customers from sectors such as IP, market research, news and media, IT services 2
3 Recall and precision Recall Percent of relevant documents (items) returned 50 good answers in system, 25 returned = 50% recall Precision Percent of documents returned that are relevant 100 returned, 25 are relevant = 25% precision Ideal is 100% recall and 100% precision: return all relevant documents and only those 100% recall is easy return all documents, but precision is low, relevant documents can t be found Need adequate recall & enough precision for the task - that will vary by application (data & users) 3
4 How to get good recall Collect, index and search all the data Check for missing or corrupt data Index everything Search everything limit results by category AFTER the search (clustering/faceting) Normalize the data Convert to lower case, strip/handle special characters, stemming,... Use spell-checking, synonyms to match users vocabulary with content Adaptive spell-checking, application-specific synonyms Light (or real) natural language processing for abstract concepts 4
5 How to get good precision Term frequency (TF) more occurrences of query terms is better Inverse document frequency (IDF) rarer query terms are more important Phrase boost query terms near each other is better Field boost where the query term is in doc matters (e.g., in 'title' better) Length normalization avoid penalizing short docs Recency all things being equal, recent is better Authority items linked to, clicked on or bought by others may be better Implicit and explicit relevance feedback, more-like-this expand query Clustering/faceting intent is not specific Lots of data 5

6 Every minute 6
7 Groth of patent applications 7


8 Big Data Open Source Tools 8
9 Apache Lucene Apache Lucene TM is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform. Scalable, High-Performance Indexing over 150GB/hour on modern hardware small RAM requirements - only 1MB heap incremental indexing as fast as batch indexing index size roughly 20-30% the size of text indexed 9
10 Apache Lucene (2) Powerful, Accurate and Efficient Search Algorithms ranked searching - best results returned first many powerful query types: phrase queries, wildcard queries, proximity queries, range queries and more fielded searching (e.g. title, author, contents) sorting by any field multiple-index searching with merged results allows simultaneous update and searching flexible faceting, highlighting, joins and result grouping fast, memory-efficient and typo-tolerant suggesters pluggable ranking models, including the Vector Space Model and Okapi BM25 configurable storage engine (codecs) Cross-Platform Solution 10

11 Apache Lucene (3) Cross-Platform Solution Available as Open Source software under the Apache License - Lucene in both commercial and Open Source programs 100%-pure Java Implementations in other programming languages available, the index is compatible Apache Lucene was released on October 5 th,
12 Apache SOLR Apache SOLR is an open source enterprise search platform from the Apache Lucene project. major features: full-text search hit highlighting faceted search dynamic clustering database integration handling of rich documents (e.g., Word, PDF) providing distributed search and index replication, Solr is highly scalable. Apache SOLR was released on October 5 th,
13 elasticsearch elasticsearch is a distributed, RESTful, open source search server based on Apache Lucene. It is developed by Shay Banon and is released under the terms of the Apache License. major features: fully supports the near real-time search of Apache Lucene cluster setup needs no additional software features of Lucene are made available through the JSON and Java API JSON in / JSON out (and YAML) elasticsearch was released on September 17 th, 2013, based on Lucene
14 All Time Top Committers

15 Active Contributors

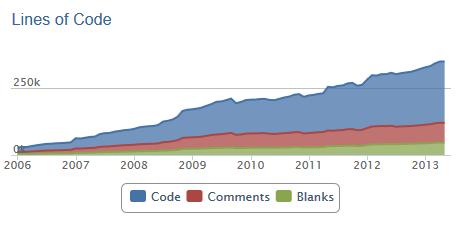

16 Lines of Code

17 The Mailing Lists
18 Interest over time



19 Case study - quantalyze patents.quantalyze.com Runs in your browser Filter and keyword search Physical quantity search Interval search Print view Visualization: Physical quantity distributions Cross-tabulations (e.g. concepts vs. quantity type) Different chart types 19
20 Case study - StumbleUpon Create a world-class customer experience A Stumble provides real-time recommendations to 30 million customers per day Intelligent search is key to providing fast and more informed recommendations Update your searches immediately with newly posted content Develop and scale easily Build in intelligent search to scale with millions of users and interactions Take advantage of powerful and flexible APIs for easy data integration Use easy to use but powerful solutions for your big data search and analytics needs 20
21 Strengths of open source search Best practice segmented index (like Google, Fast) Scalability Best practice, flexible ranking (term/field/doc boosts, function queries, custom scoring ) Best overall query performance and complete query capabilities (unlimited Boolean operations, wildcards, findsimilar, synonyms, spell-check ) Multilingual, query filters, geo search, memory mapped indexes, near real-time search, advanced proximity operators Rapid innovation Extensible architecture, complete control (open source) No license fees (open source) 21
22 Weaknesses of open source search Those typical of open source No formal support Limited access to training, consulting Lack of stringent integrated QA Speed of development and open source environment too complex for some (e.g., what version should I download? What patches? GUI?) Others Lucene/Solr/Elasicsearch development has tended to focus on core capabilities, so missing certain features for enterprise search (e.g., connectors, security, alerts, advanced query operations) 22
23 Addressing open source weaknesses Community Community has a wealth of information on web sites, wikis and mailing lists Community members usually respond quickly to questions Consultants May be especially helpful for systems integration or addressing gaps Commercialization Companies commercializing open source provide commercial support, certified versions, training and consulting Internal resources 23
24 Product strengths of commercial competitors Well established players tend to be full-featured Some organizations have focused on a particular application or domain (e.g., ecommerce, publishing, legal, help desk) Some competitors have focused on appliance 24
25 Weaknesses of top commercial competitors Usually expensive, especially at scale Platform or portability limitations Limited transparency Limited flexibility, especially for other than intended application or domain Limited customization, especially for appliance-like products Sometimes limited scalability Technical debt and/or lack of rapid innovation Customers are dependent on the company s continued business success 25
26 Competitive landscape Last years commercial companies have felt increasing competition from Lucene/Solr/Elasticsearch because of the combination of its capability and price Some competitors have responded with diversification Some have been acquired Need for good, affordable, flexible search remains 26

27 Questions
28 Credits 28
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Hibernate Search Googling your persistence domain model. Emmanuel Bernard Doer JBoss, a division of Red Hat
 Hibernate Search Googling your persistence domain model Emmanuel Bernard Doer JBoss, a division of Red Hat Search: left over of today s applications Add search dimension to the domain model Frankly, search
Hibernate Search Googling your persistence domain model Emmanuel Bernard Doer JBoss, a division of Red Hat Search: left over of today s applications Add search dimension to the domain model Frankly, search
EPL660: Information Retrieval and Search Engines Lab 2
 EPL660: Information Retrieval and Search Engines Lab 2 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Apache Lucene Extremely rich and powerful full-text search
EPL660: Information Retrieval and Search Engines Lab 2 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Apache Lucene Extremely rich and powerful full-text search
A short introduction to the development and evaluation of Indexing systems
 A short introduction to the development and evaluation of Indexing systems Danilo Croce croce@info.uniroma2.it Master of Big Data in Business SMARS LAB 3 June 2016 Outline An introduction to Lucene Main
A short introduction to the development and evaluation of Indexing systems Danilo Croce croce@info.uniroma2.it Master of Big Data in Business SMARS LAB 3 June 2016 Outline An introduction to Lucene Main
ElasticSearch in Production
 ElasticSearch in Production lessons learned Anne Veling, ApacheCon EU, November 6, 2012 agenda! Introduction! ElasticSearch! Udini! Upcoming Tool! Lessons Learned introduction! Anne Veling, @anneveling!
ElasticSearch in Production lessons learned Anne Veling, ApacheCon EU, November 6, 2012 agenda! Introduction! ElasticSearch! Udini! Upcoming Tool! Lessons Learned introduction! Anne Veling, @anneveling!
Battle of the Giants Apache Solr 4.0 vs ElasticSearch 0.20 Rafał Kuć sematext.com
 Battle of the Giants Apache Solr 4.0 vs ElasticSearch 0.20 Rafał Kuć Sematext International @kucrafal @sematext sematext.com Who Am I Solr 3.1 Cookbook author (4.0 inc) Sematext consultant & engineer Solr.pl
Battle of the Giants Apache Solr 4.0 vs ElasticSearch 0.20 Rafał Kuć Sematext International @kucrafal @sematext sematext.com Who Am I Solr 3.1 Cookbook author (4.0 inc) Sematext consultant & engineer Solr.pl
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Improving Drupal search experience with Apache Solr and Elasticsearch
 Improving Drupal search experience with Apache Solr and Elasticsearch Milos Pumpalovic Web Front-end Developer Gene Mohr Web Back-end Developer About Us Milos Pumpalovic Front End Developer Drupal theming
Improving Drupal search experience with Apache Solr and Elasticsearch Milos Pumpalovic Web Front-end Developer Gene Mohr Web Back-end Developer About Us Milos Pumpalovic Front End Developer Drupal theming
LAB 7: Search engine: Apache Nutch + Solr + Lucene
 LAB 7: Search engine: Apache Nutch + Solr + Lucene Apache Nutch Apache Lucene Apache Solr Crawler + indexer (mainly crawler) indexer + searcher indexer + searcher Lucene vs. Solr? Lucene = library, more
LAB 7: Search engine: Apache Nutch + Solr + Lucene Apache Nutch Apache Lucene Apache Solr Crawler + indexer (mainly crawler) indexer + searcher indexer + searcher Lucene vs. Solr? Lucene = library, more
Technical Deep Dive: Cassandra + Solr. Copyright 2012, Think Big Analy7cs, All Rights Reserved
 Technical Deep Dive: Cassandra + Solr Confiden7al Business case 2 Super scalable realtime analytics Hadoop is fantastic at performing batch analytics Cassandra is an advanced column family oriented system
Technical Deep Dive: Cassandra + Solr Confiden7al Business case 2 Super scalable realtime analytics Hadoop is fantastic at performing batch analytics Cassandra is an advanced column family oriented system
Search Engine Architecture II
 Search Engine Architecture II Primary Goals of Search Engines Effectiveness (quality): to retrieve the most relevant set of documents for a query Process text and store text statistics to improve relevance
Search Engine Architecture II Primary Goals of Search Engines Effectiveness (quality): to retrieve the most relevant set of documents for a query Process text and store text statistics to improve relevance
A Scotas white paper September Scotas Push Connector
 A Scotas white paper September 2013 Scotas Push Connector Introduction When you have to perform searches over big data, you need specialized solutions that can deal with the velocity, variety and volume
A Scotas white paper September 2013 Scotas Push Connector Introduction When you have to perform searches over big data, you need specialized solutions that can deal with the velocity, variety and volume
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Apache Lucene 7 What s coming next?
 Apache Lucene 7 What s coming next? Uwe Schindler Apache Software Foundation SD DataSolutions GmbH PANGAEA @thetaph1 uschindler@apache.org My Background Committer and PMC member of Apache Lucene and Solr
Apache Lucene 7 What s coming next? Uwe Schindler Apache Software Foundation SD DataSolutions GmbH PANGAEA @thetaph1 uschindler@apache.org My Background Committer and PMC member of Apache Lucene and Solr
Creating a Recommender System. An Elasticsearch & Apache Spark approach
 Creating a Recommender System An Elasticsearch & Apache Spark approach My Profile SKILLS Álvaro Santos Andrés Big Data & Analytics Solution Architect in Ericsson with more than 12 years of experience focused
Creating a Recommender System An Elasticsearch & Apache Spark approach My Profile SKILLS Álvaro Santos Andrés Big Data & Analytics Solution Architect in Ericsson with more than 12 years of experience focused
VK Multimedia Information Systems
 VK Multimedia Information Systems Mathias Lux, mlux@itec.uni-klu.ac.at This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Results Exercise 01 Exercise 02 Retrieval
VK Multimedia Information Systems Mathias Lux, mlux@itec.uni-klu.ac.at This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Results Exercise 01 Exercise 02 Retrieval
Building a Scalable Recommender System with Apache Spark, Apache Kafka and Elasticsearch
 Nick Pentreath Nov / 14 / 16 Building a Scalable Recommender System with Apache Spark, Apache Kafka and Elasticsearch About @MLnick Principal Engineer, IBM Apache Spark PMC Focused on machine learning
Nick Pentreath Nov / 14 / 16 Building a Scalable Recommender System with Apache Spark, Apache Kafka and Elasticsearch About @MLnick Principal Engineer, IBM Apache Spark PMC Focused on machine learning
LucidWorks: Searching with curl October 1, 2012
 LucidWorks: Searching with curl October 1, 2012 1. Module name: LucidWorks: Searching with curl 2. Scope: Utilizing curl and the Query admin to search documents 3. Learning objectives Students will be
LucidWorks: Searching with curl October 1, 2012 1. Module name: LucidWorks: Searching with curl 2. Scope: Utilizing curl and the Query admin to search documents 3. Learning objectives Students will be
Session 10: Information Retrieval
 INFM 63: Information Technology and Organizational Context Session : Information Retrieval Jimmy Lin The ischool University of Maryland Thursday, November 7, 23 Information Retrieval What you search for!
INFM 63: Information Technology and Organizational Context Session : Information Retrieval Jimmy Lin The ischool University of Maryland Thursday, November 7, 23 Information Retrieval What you search for!
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Information Retrieval
 Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Parallel SQL and Streaming Expressions in Apache Solr 6. Shalin Shekhar Lucidworks Inc.
 Parallel SQL and Streaming Expressions in Apache Solr 6 Shalin Shekhar Mangar @shalinmangar Lucidworks Inc. Introduction Shalin Shekhar Mangar Lucene/Solr Committer PMC Member Senior Solr Consultant with
Parallel SQL and Streaming Expressions in Apache Solr 6 Shalin Shekhar Mangar @shalinmangar Lucidworks Inc. Introduction Shalin Shekhar Mangar Lucene/Solr Committer PMC Member Senior Solr Consultant with
DotNetNuke. Easy to Use Extensible Highly Scalable
 DotNetNuke is the leading Web Content Management Platform for Microsoft.NET. It enables your organization to leverage your existing Microsoft investments to create rich, highly interactive web sites and
DotNetNuke is the leading Web Content Management Platform for Microsoft.NET. It enables your organization to leverage your existing Microsoft investments to create rich, highly interactive web sites and
Information Retrieval. CS630 Representing and Accessing Digital Information. What is a Retrieval Model? Basic IR Processes
 CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
Turbocharge your MySQL analytics with ElasticSearch. Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017
 Turbocharge your MySQL analytics with ElasticSearch Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017 About the Speaker Guillaume Lefranc Data Architect at Productsup
Turbocharge your MySQL analytics with ElasticSearch Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017 About the Speaker Guillaume Lefranc Data Architect at Productsup
RINGTAIL A COMPETITIVE ADVANTAGE FOR LAW FIRMS. Award-winning visual e-discovery software delivers faster insights and superior case strategies.
 RINGTAIL A COMPETITIVE ADVANTAGE FOR LAW FIRMS Award-winning visual e-discovery software delivers faster insights and superior case strategies. Key reasons Ringtail should be the choice. The latest technology
RINGTAIL A COMPETITIVE ADVANTAGE FOR LAW FIRMS Award-winning visual e-discovery software delivers faster insights and superior case strategies. Key reasons Ringtail should be the choice. The latest technology
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source
 Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Realtime visitor analysis with Couchbase and Elasticsearch
 Realtime visitor analysis with Couchbase and Elasticsearch Jeroen Reijn @jreijn #nosql13 About me Jeroen Reijn Software engineer Hippo @jreijn http://blog.jeroenreijn.com About Hippo Visitor Analysis OneHippo
Realtime visitor analysis with Couchbase and Elasticsearch Jeroen Reijn @jreijn #nosql13 About me Jeroen Reijn Software engineer Hippo @jreijn http://blog.jeroenreijn.com About Hippo Visitor Analysis OneHippo
modern database systems lecture 4 : information retrieval
 modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
Semantic Search at Bloomberg
 Semantic Search at Bloomberg Search Solutions 2017 Edgar Meij Team lead, R&D AI emeij@bloomberg.net @edgarmeij Bloomberg Professional Service Bloomberg at a glance Bloomberg Professional Service Trading
Semantic Search at Bloomberg Search Solutions 2017 Edgar Meij Team lead, R&D AI emeij@bloomberg.net @edgarmeij Bloomberg Professional Service Bloomberg at a glance Bloomberg Professional Service Trading
EPL660: Information Retrieval and Search Engines Lab 3
 EPL660: Information Retrieval and Search Engines Lab 3 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Apache Solr Popular, fast, open-source search platform built
EPL660: Information Retrieval and Search Engines Lab 3 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Apache Solr Popular, fast, open-source search platform built
I'm Charlie Hull, co-founder and Managing Director of Flax. We've been building open source search applications since 2001
 Open Source Search I'm Charlie Hull, co-founder and Managing Director of Flax We've been building open source search applications since 2001 I'm going to tell you why and how you should use open source
Open Source Search I'm Charlie Hull, co-founder and Managing Director of Flax We've been building open source search applications since 2001 I'm going to tell you why and how you should use open source
The Billion Object Platform (BOP): a system to lower barriers to support big, streaming, spatio-temporal data sources
: a system to lower barriers to support big, streaming, spatio-temporal data sources") FOSS4G 2017 Boston The Billion Object Platform (BOP): a system to lower barriers to support big, streaming, spatio-temporal data sources Devika Kakkar and Ben Lewis Harvard Center for Geographic Analysis
FOSS4G 2017 Boston The Billion Object Platform (BOP): a system to lower barriers to support big, streaming, spatio-temporal data sources Devika Kakkar and Ben Lewis Harvard Center for Geographic Analysis
Natural Language Processing
 Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
COMP6237 Data Mining Searching and Ranking
 COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
Apache Lucene Eurocon: Preview
 Apache Lucene Eurocon: Preview www.lucene-eurocon.org Overview Introduction Near Real Time Search: Yonik Seeley A link to download these slides will be available after the webcast is complete. An on-demand
Apache Lucene Eurocon: Preview www.lucene-eurocon.org Overview Introduction Near Real Time Search: Yonik Seeley A link to download these slides will be available after the webcast is complete. An on-demand
BM25 is so Yesterday. Modern Techniques for Better Search Relevance in Solr. Grant Ingersoll CTO Lucidworks Lucene/Solr/Mahout Committer
 BM25 is so Yesterday Modern Techniques for Better Search Relevance in Solr Grant Ingersoll CTO Lucidworks Lucene/Solr/Mahout Committer ipad case ipad case "ipad accessory"~3 OR "ipad case"~5 1. 15. So,
BM25 is so Yesterday Modern Techniques for Better Search Relevance in Solr Grant Ingersoll CTO Lucidworks Lucene/Solr/Mahout Committer ipad case ipad case "ipad accessory"~3 OR "ipad case"~5 1. 15. So,
Searching the Web for Information
 Search Xin Liu Searching the Web for Information How a Search Engine Works Basic parts: 1. Crawler: Visits sites on the Internet, discovering Web pages 2. Indexer: building an index to the Web's content
Search Xin Liu Searching the Web for Information How a Search Engine Works Basic parts: 1. Crawler: Visits sites on the Internet, discovering Web pages 2. Indexer: building an index to the Web's content
Viewpoint Review & Analytics
 The Viewpoint all-in-one e-discovery platform enables law firms, corporations and service providers to manage every phase of the e-discovery lifecycle with the power of a single product. The Viewpoint
The Viewpoint all-in-one e-discovery platform enables law firms, corporations and service providers to manage every phase of the e-discovery lifecycle with the power of a single product. The Viewpoint
BA Insight Federator. How the BA Insight Federator Extends SharePoint Search
 How the BA Insight Federator Extends SharePoint Search 20 Park Plaza, Suite 1115 Boston, MA 02116, USA 1.339.368.7234 info@bainsight.com www.bainsight.com BA Insight Federator The BA Insight Federator
How the BA Insight Federator Extends SharePoint Search 20 Park Plaza, Suite 1115 Boston, MA 02116, USA 1.339.368.7234 info@bainsight.com www.bainsight.com BA Insight Federator The BA Insight Federator
Using Elastic with Magento
 Using Elastic with Magento Stefan Willkommer CTO and CO-Founder @ TechDivision GmbH Comparison License Apache License Apache License Index Lucene Lucene API RESTful Webservice RESTful Webservice Scheme
Using Elastic with Magento Stefan Willkommer CTO and CO-Founder @ TechDivision GmbH Comparison License Apache License Apache License Index Lucene Lucene API RESTful Webservice RESTful Webservice Scheme
Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT
 Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT 1. Overview This assignment picks up where the last one left off. You will take your JSON
Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT 1. Overview This assignment picks up where the last one left off. You will take your JSON
Starting a Search Application. Mark Krellenstein CTO Lucid Imagination
 Starting a Search Application Mark Krellenstein CTO Lucid Imagination Abstract If you think you need a search application, there are some useful first steps to take: validating that full-text search is
Starting a Search Application Mark Krellenstein CTO Lucid Imagination Abstract If you think you need a search application, there are some useful first steps to take: validating that full-text search is
Apache Solr Learning to Rank FTW!
 Apache Solr Learning to Rank FTW! Berlin Buzzwords 2017 June 12, 2017 Diego Ceccarelli Software Engineer, News Search dceccarelli4@bloomberg.net Michael Nilsson Software Engineer, Unified Search mnilsson23@bloomberg.net
Apache Solr Learning to Rank FTW! Berlin Buzzwords 2017 June 12, 2017 Diego Ceccarelli Software Engineer, News Search dceccarelli4@bloomberg.net Michael Nilsson Software Engineer, Unified Search mnilsson23@bloomberg.net
Ninja Level Infrastructure Monitoring. Defensive Approach to Security Monitoring and Automation
 Ninja Level Infrastructure Monitoring Defensive Approach to Security Monitoring and Automation 1 DEFCON 24 06 th August 2016, Saturday 10:00-14:00 Madhu Akula & Riyaz Walikar Appsecco.com 2 About Automation
Ninja Level Infrastructure Monitoring Defensive Approach to Security Monitoring and Automation 1 DEFCON 24 06 th August 2016, Saturday 10:00-14:00 Madhu Akula & Riyaz Walikar Appsecco.com 2 About Automation
Elementary IR: Scalable Boolean Text Search. (Compare with R & G )
") Elementary IR: Scalable Boolean Text Search (Compare with R & G 27.1-3) Information Retrieval: History A research field traditionally separate from Databases Hans P. Luhn, IBM, 1959: Keyword in Context
Elementary IR: Scalable Boolean Text Search (Compare with R & G 27.1-3) Information Retrieval: History A research field traditionally separate from Databases Hans P. Luhn, IBM, 1959: Keyword in Context
60-538: Information Retrieval
 60-538: Information Retrieval September 7, 2017 1 / 48 Outline 1 what is IR 2 3 2 / 48 Outline 1 what is IR 2 3 3 / 48 IR not long time ago 4 / 48 5 / 48 now IR is mostly about search engines there are
60-538: Information Retrieval September 7, 2017 1 / 48 Outline 1 what is IR 2 3 2 / 48 Outline 1 what is IR 2 3 3 / 48 IR not long time ago 4 / 48 5 / 48 now IR is mostly about search engines there are
ΕΠΛ660. Ανάκτηση µε το µοντέλο διανυσµατικού χώρου
 Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
Information Retrieval
 Introduction Information Retrieval Information retrieval is a field concerned with the structure, analysis, organization, storage, searching and retrieval of information Gerard Salton, 1968 J. Pei: Information
Introduction Information Retrieval Information retrieval is a field concerned with the structure, analysis, organization, storage, searching and retrieval of information Gerard Salton, 1968 J. Pei: Information
Evaluating Cloud Databases for ecommerce Applications. What you need to grow your ecommerce business
 Evaluating Cloud Databases for ecommerce Applications What you need to grow your ecommerce business EXECUTIVE SUMMARY ecommerce is the future of not just retail but myriad industries from telecommunications
Evaluating Cloud Databases for ecommerce Applications What you need to grow your ecommerce business EXECUTIVE SUMMARY ecommerce is the future of not just retail but myriad industries from telecommunications
Midterm Exam Search Engines ( / ) October 20, 2015
 October 20, 2015") Student Name: Andrew ID: Seat Number: Midterm Exam Search Engines (11-442 / 11-642) October 20, 2015 Answer all of the following questions. Each answer should be thorough, complete, and relevant. Points
Student Name: Andrew ID: Seat Number: Midterm Exam Search Engines (11-442 / 11-642) October 20, 2015 Answer all of the following questions. Each answer should be thorough, complete, and relevant. Points
Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies
 Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies Giulio Barcaroli 1 (barcarol@istat.it), Monica Scannapieco 1 (scannapi@istat.it), Donato Summa
Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies Giulio Barcaroli 1 (barcarol@istat.it), Monica Scannapieco 1 (scannapi@istat.it), Donato Summa
Using ElasticSearch to Enable Stronger Query Support in Cassandra
 Using ElasticSearch to Enable Stronger Query Support in Cassandra www.impetus.com Introduction Relational Databases have been in use for decades, but with the advent of big data, there is a need to use
Using ElasticSearch to Enable Stronger Query Support in Cassandra www.impetus.com Introduction Relational Databases have been in use for decades, but with the advent of big data, there is a need to use
Information Retrieval
 Information Retrieval WS 2016 / 2017 Lecture 2, Tuesday October 25 th, 2016 (Ranking, Evaluation) Prof. Dr. Hannah Bast Chair of Algorithms and Data Structures Department of Computer Science University
Information Retrieval WS 2016 / 2017 Lecture 2, Tuesday October 25 th, 2016 (Ranking, Evaluation) Prof. Dr. Hannah Bast Chair of Algorithms and Data Structures Department of Computer Science University
Soir 1.4 Enterprise Search Server
 Soir 1.4 Enterprise Search Server Enhance your search with faceted navigation, result highlighting, fuzzy queries, ranked scoring, and more David Smiley Eric Pugh *- PUBLISHING -J BIRMINGHAM - MUMBAI Preface
Soir 1.4 Enterprise Search Server Enhance your search with faceted navigation, result highlighting, fuzzy queries, ranked scoring, and more David Smiley Eric Pugh *- PUBLISHING -J BIRMINGHAM - MUMBAI Preface
Istat s Pilot Use Case 1
 Istat s Pilot Use Case 1 Pilot identification 1 IT 1 Reference Use case X 1) URL Inventory of enterprises 2) E-commerce from enterprises websites 3) Job advertisements on enterprises websites 4) Social
Istat s Pilot Use Case 1 Pilot identification 1 IT 1 Reference Use case X 1) URL Inventory of enterprises 2) E-commerce from enterprises websites 3) Job advertisements on enterprises websites 4) Social
extensible Text Framework (XTF): Building a Digital Publishing Framework
: Building a Digital Publishing Framework") extensible Text Framework (XTF): Building a Digital Publishing Framework California Digital Library Kirk Hastings Martin Haye XTF Topics Digital publishing at CDL What XTF is (and isn't) Design and Features
extensible Text Framework (XTF): Building a Digital Publishing Framework California Digital Library Kirk Hastings Martin Haye XTF Topics Digital publishing at CDL What XTF is (and isn't) Design and Features
CS54701: Information Retrieval
 CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016
 Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016 Nikita Ivanov CTO and Co-Founder GridGain Systems Peter Zaitsev CEO and Co-Founder Percona About the Presentation
Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016 Nikita Ivanov CTO and Co-Founder GridGain Systems Peter Zaitsev CEO and Co-Founder Percona About the Presentation
JBoss Enterprise Middleware
 JBoss Enterprise Middleware Making software from the open source community ready for the enterprise DLT Solutions 2411 Dulles Corner Park, Suite 800 Herndon, VA 20171 Web: www.dlt.com Phone: 703-709-7172
JBoss Enterprise Middleware Making software from the open source community ready for the enterprise DLT Solutions 2411 Dulles Corner Park, Suite 800 Herndon, VA 20171 Web: www.dlt.com Phone: 703-709-7172
Fusing Corporate Thesaurus Management with Linked Data using PoolParty
 Fusing Corporate Thesaurus Management with Linked Data using PoolParty Thomas Schandl PoolParty at a glance Developed by punkt. netservices Current release: PoolParty 2.8 Main focus on three application
Fusing Corporate Thesaurus Management with Linked Data using PoolParty Thomas Schandl PoolParty at a glance Developed by punkt. netservices Current release: PoolParty 2.8 Main focus on three application
Search Engines and Time Series Databases
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Search Engines and Time Series Databases Corso di Sistemi e Architetture per Big Data A.A. 2017/18
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Search Engines and Time Series Databases Corso di Sistemi e Architetture per Big Data A.A. 2017/18
Web scraping. Donato Summa. 3 WP1 face to face meeting September 2017 Thessaloniki (EL)
") Web scraping Donato Summa Summary Web scraping : Specific vs Generic Web scraping phases Web scraping tools Istat Web scraping chain Summary Web scraping : Specific vs Generic Web scraping phases Web scraping
Web scraping Donato Summa Summary Web scraping : Specific vs Generic Web scraping phases Web scraping tools Istat Web scraping chain Summary Web scraping : Specific vs Generic Web scraping phases Web scraping
Building the News Search Engine
 Building the News Search Engine Ramkumar Aiyengar Team Leader, R&D News Search, Bloomberg L.P. andyetitmoves@apache.org A technology company Our strength and focus is data The Terminal, vertical portals
Building the News Search Engine Ramkumar Aiyengar Team Leader, R&D News Search, Bloomberg L.P. andyetitmoves@apache.org A technology company Our strength and focus is data The Terminal, vertical portals
vector space retrieval many slides courtesy James Amherst
 vector space retrieval many slides courtesy James Allan@umass Amherst 1 what is a retrieval model? Model is an idealization or abstraction of an actual process Mathematical models are used to study the
vector space retrieval many slides courtesy James Allan@umass Amherst 1 what is a retrieval model? Model is an idealization or abstraction of an actual process Mathematical models are used to study the
Multi-domain Predictive AI. Correlated Cross-Occurrence with Apache Mahout and GPUs
 Multi-domain Predictive AI Correlated Cross-Occurrence with Apache Mahout and GPUs Pat Ferrel ActionML, Chief Consultant Apache Mahout, PMC & Committer Apache PredictionIO, PMC & Committer pat@apache.org
Multi-domain Predictive AI Correlated Cross-Occurrence with Apache Mahout and GPUs Pat Ferrel ActionML, Chief Consultant Apache Mahout, PMC & Committer Apache PredictionIO, PMC & Committer pat@apache.org
Information Retrieval: Retrieval Models
 CS473: Web Information Retrieval & Management CS-473 Web Information Retrieval & Management Information Retrieval: Retrieval Models Luo Si Department of Computer Science Purdue University Retrieval Models
CS473: Web Information Retrieval & Management CS-473 Web Information Retrieval & Management Information Retrieval: Retrieval Models Luo Si Department of Computer Science Purdue University Retrieval Models
Goal of this document: A simple yet effective
 INTRODUCTION TO ELK STACK Goal of this document: A simple yet effective document for folks who want to learn basics of ELK (Elasticsearch, Logstash and Kibana) without any prior knowledge. Introduction:
INTRODUCTION TO ELK STACK Goal of this document: A simple yet effective document for folks who want to learn basics of ELK (Elasticsearch, Logstash and Kibana) without any prior knowledge. Introduction:
Apache Lucene 4. Robert Muir
 Apache Lucene 4 Robert Muir Agenda Overview of Lucene Conclusion Resources Q & A Download of Lucene: core/ analysis/ queryparser/ highlighter/ suggest/ expressions/ join/ memory/ codecs/... core/ Lucene
Apache Lucene 4 Robert Muir Agenda Overview of Lucene Conclusion Resources Q & A Download of Lucene: core/ analysis/ queryparser/ highlighter/ suggest/ expressions/ join/ memory/ codecs/... core/ Lucene
rpaf ktl Pen Apache Solr 3 Enterprise Search Server J community exp<= highlighting, relevancy ranked sorting, and more source publishing""
 Apache Solr 3 Enterprise Search Server Enhance your search with faceted navigation, result highlighting, relevancy ranked sorting, and more David Smiley Eric Pugh rpaf ktl Pen I I riv IV I J community
Apache Solr 3 Enterprise Search Server Enhance your search with faceted navigation, result highlighting, relevancy ranked sorting, and more David Smiley Eric Pugh rpaf ktl Pen I I riv IV I J community
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
MEAP Edition Manning Early Access Program Solr in Action version 1
 MEAP Edition Manning Early Access Program Solr in Action version 1 Copyright 2012 Manning Publications For more information on this and other Manning titles go to www.manning.com brief contents PART 1:
MEAP Edition Manning Early Access Program Solr in Action version 1 Copyright 2012 Manning Publications For more information on this and other Manning titles go to www.manning.com brief contents PART 1:
Building A Billion Spatio-Temporal Object Search and Visualization Platform
 2017 2 nd International Symposium on Spatiotemporal Computing Harvard University Building A Billion Spatio-Temporal Object Search and Visualization Platform Devika Kakkar, Benjamin Lewis Goal Develop a
2017 2 nd International Symposium on Spatiotemporal Computing Harvard University Building A Billion Spatio-Temporal Object Search and Visualization Platform Devika Kakkar, Benjamin Lewis Goal Develop a
Information Retrieval
 Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Search and Time Series Databases
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Search and Time Series Databases Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Search and Time Series Databases Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria
Indexing and Query Processing. What will we cover?
 Indexing and Query Processing CS 510 Winter 2007 1 What will we cover? Key concepts and terminology Inverted index structures Organization, creation, maintenance Compression Distribution Answering queries
Indexing and Query Processing CS 510 Winter 2007 1 What will we cover? Key concepts and terminology Inverted index structures Organization, creation, maintenance Compression Distribution Answering queries
CS377: Database Systems Text data and information. Li Xiong Department of Mathematics and Computer Science Emory University
 CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval
 Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
MuseKnowledge Hybrid Search
 MuseKnowledge Hybrid Search MuseGlobal, Inc. One Embarcadero Suite 500 San Francisco, CA 94111 415 896-6873 www.museglobal.com MuseGlobal S.A Calea Bucuresti Bl. 27B, Sc. 1, Ap. 10 Craiova, România 40
MuseKnowledge Hybrid Search MuseGlobal, Inc. One Embarcadero Suite 500 San Francisco, CA 94111 415 896-6873 www.museglobal.com MuseGlobal S.A Calea Bucuresti Bl. 27B, Sc. 1, Ap. 10 Craiova, România 40
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 7: Information Retrieval II. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 7: Information Retrieval II Aidan Hogan aidhog@gmail.com How does Google know about the Web? Inverted Index: Example 1 Fruitvale Station is a 2013
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 7: Information Retrieval II Aidan Hogan aidhog@gmail.com How does Google know about the Web? Inverted Index: Example 1 Fruitvale Station is a 2013
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CHAPTER 6 PROPOSED HYBRID MEDICAL IMAGE RETRIEVAL SYSTEM USING SEMANTIC AND VISUAL FEATURES
 188 CHAPTER 6 PROPOSED HYBRID MEDICAL IMAGE RETRIEVAL SYSTEM USING SEMANTIC AND VISUAL FEATURES 6.1 INTRODUCTION Image representation schemes designed for image retrieval systems are categorized into two
188 CHAPTER 6 PROPOSED HYBRID MEDICAL IMAGE RETRIEVAL SYSTEM USING SEMANTIC AND VISUAL FEATURES 6.1 INTRODUCTION Image representation schemes designed for image retrieval systems are categorized into two
REAL TIME BOM EXPLOSIONS WITH APACHE SOLR AND SPARK. Andreas Zitzelsberger
 REAL TIME BOM EXPLOSIONS WITH APACHE SOLR AND SPARK Andreas Zitzelsberger BILLS OF MATERIAL (BOMS) EXPLAINED BOMS ARE NEEDED FOR Production Planning Forecasting Demand Scenario-Based Planning Running Simulations
REAL TIME BOM EXPLOSIONS WITH APACHE SOLR AND SPARK Andreas Zitzelsberger BILLS OF MATERIAL (BOMS) EXPLAINED BOMS ARE NEEDED FOR Production Planning Forecasting Demand Scenario-Based Planning Running Simulations
Information Retrieval CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Boolean Retrieval vs. Ranked Retrieval Many users (professionals) prefer
Information Retrieval CS 6900 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Boolean Retrieval vs. Ranked Retrieval Many users (professionals) prefer
Today we show how a search engine works
 How Search Engines Work Today we show how a search engine works What happens when a searcher enters keywords What was performed well in advance Also explain (briefly) how paid results are chosen If we
How Search Engines Work Today we show how a search engine works What happens when a searcher enters keywords What was performed well in advance Also explain (briefly) how paid results are chosen If we
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most
 In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
Apache Lucene - Overview
 Table of contents 1 Apache Lucene...2 2 The Apache Software Foundation... 2 3 Lucene News...2 3.1 27 November 2011 - Lucene Core 3.5.0... 2 3.2 26 October 2011 - Java 7u1 fixes index corruption and crash
Table of contents 1 Apache Lucene...2 2 The Apache Software Foundation... 2 3 Lucene News...2 3.1 27 November 2011 - Lucene Core 3.5.0... 2 3.2 26 October 2011 - Java 7u1 fixes index corruption and crash
The Performance Study of Hyper Textual Medium Size Web Search Engine
 The Performance Study of Hyper Textual Medium Size Web Search Engine Tarek S. Sobh and M. Elemam Shehab Information System Department, Egyptian Armed Forces tarekbox2000@gmail.com melemam@hotmail.com Abstract
The Performance Study of Hyper Textual Medium Size Web Search Engine Tarek S. Sobh and M. Elemam Shehab Information System Department, Egyptian Armed Forces tarekbox2000@gmail.com melemam@hotmail.com Abstract
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Multimedia Information Extraction and Retrieval Term Frequency Inverse Document Frequency
 Multimedia Information Extraction and Retrieval Term Frequency Inverse Document Frequency Ralf Moeller Hamburg Univ. of Technology Acknowledgement Slides taken from presentation material for the following
Multimedia Information Extraction and Retrieval Term Frequency Inverse Document Frequency Ralf Moeller Hamburg Univ. of Technology Acknowledgement Slides taken from presentation material for the following
Efficiency vs. Effectiveness in Terabyte-Scale IR
 Efficiency vs. Effectiveness in Terabyte-Scale Information Retrieval Stefan Büttcher Charles L. A. Clarke University of Waterloo, Canada November 17, 2005 1 2 3 4 5 6 What is Wumpus? Multi-user file system
Efficiency vs. Effectiveness in Terabyte-Scale Information Retrieval Stefan Büttcher Charles L. A. Clarke University of Waterloo, Canada November 17, 2005 1 2 3 4 5 6 What is Wumpus? Multi-user file system
The official TYPO3 partner program
 The official TYPO3 partner program Table of contents Partner Program... 4 Separate Yourself From The Competition... 4 Be Successful - Together... 4 Unique Benefits... 6 Partner Ranking In A Nutshell...
The official TYPO3 partner program Table of contents Partner Program... 4 Separate Yourself From The Competition... 4 Be Successful - Together... 4 Unique Benefits... 6 Partner Ranking In A Nutshell...
Information Retrieval CS Lecture 01. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
CISC689/ Information Retrieval Midterm Exam
 CISC689/489-010 Information Retrieval Midterm Exam You have 2 hours to complete the following four questions. You may use notes and slides. You can use a calculator, but nothing that connects to the internet
CISC689/489-010 Information Retrieval Midterm Exam You have 2 hours to complete the following four questions. You may use notes and slides. You can use a calculator, but nothing that connects to the internet
Optimal Query. Assume that the relevant set of documents C r. 1 N C r d j. d j. Where N is the total number of documents.
 Optimal Query Assume that the relevant set of documents C r are known. Then the best query is: q opt 1 C r d j C r d j 1 N C r d j C r d j Where N is the total number of documents. Note that even this
Optimal Query Assume that the relevant set of documents C r are known. Then the best query is: q opt 1 C r d j C r d j 1 N C r d j C r d j Where N is the total number of documents. Note that even this
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput