Lecture 8. The StreamIt Language IAP 2007 MIT
|
|
|
- Bernadette Dorsey
- 5 years ago
- Views:
Transcription
1 6.189 IAP 2007 Lecture 8 The StreamIt Language IAP 2007 MIT


2 Languages Have Not Kept Up C von-neumann machine Modern architecture Two choices: Develop cool architecture with complicated, ad-hoc language Bend over backwards to support old languages like C/C IAP 2007 MIT
3 Why a New Language? #of cores For uniprocessors, Pi hi PC102 C was: Portable High Performance Raza Composable Raw XLR Malleable Niagara Maintainable a abe Broadcom Picochip Ambric AM Cisco CSR-1 Intel Tflops Cavium Octeon Opteron 4P 4 Xeon MP Xbox360 PA-8800 Opteron Tanglewood Power4 2 PExtreme Power6 Yonah Pentium P2 P3 Itanium 1 P Athlon Itanium 2 Cell ?? IAP 2007 MIT
4 Why a New Language? #of cores 512 Picochip Ambric PC102 AM Uniprocessors: C is the common machine language Raw Cisco CSR-1 Intel Tflops Raza XLR Niagara Cavium Octeon Opteron 4P Broadcom Xeon MP Xbox360 PA-8800 Opteron Tanglewood Power4 2 PExtreme Power6 Yonah Pentium P2 P3 Itanium 1 P Athlon Itanium 2 Cell ?? IAP 2007 MIT
5 Why a New Language? #of cores What is the common Pi hi PC102 machine language for multicores? 512 Picochip Ambric AM Raw Cisco CSR-1 Intel Tflops Raza XLR Niagara Cavium Octeon Opteron 4P Broadcom Xeon MP Xbox360 PA-8800 Opteron Tanglewood Power4 2 PExtreme Power6 Yonah Pentium P2 P3 Itanium 1 P Athlon Itanium 2 Cell ?? IAP 2007 MIT
6 Common Machine Languages Uniprocessors: Common Properties Single flow of control Single memory image Differences: Register File ISA Functional Units von-neumann languages represent the common properties and abstract away the differences Multicores: Common Properties Multiple flows of control Multiple local memories Differences: Number and capabilities of cores Communication Model Synchronization Model Need common machine language(s) for multicores IAP 2007 MIT
7 Streaming as a Common Machine Language For programs based on streams of data Audio, video, DSP, networking, and cryptographic processing kernels Examples: HDTV editing, radar tracking, microphone arrays, cell phone base stations, graphics Several attractive properties Regular and repeating computation Independent filters with explicit communication AtoD FMDemod Scatter LPF 1 LPF 2 LPF 3 HPF 1 HPF 2 HPF 3 Gather Task, data, and pipeline parallelism Adder Speaker IAP 2007 MIT
8 Streaming Models of Computation Many different ways to represent streaming Do senders/receivers block? How much buffering is allowed on channels? Is computation deterministic? Can you avoid deadlock? Three common models: 1. Kahn Process Networks 2. Synchronous Dataflow 3. Communicating Sequential Processes IAP 2007 MIT
9 Streaming Models of Computation Communication Pattern Buffering Notes Kahn process networks (KPN) Synchronous dataflow (SDF) Data-dependent, but deterministic Static Conceptually unbounded Fixed by compiler - UNIX pipes - Ambric (startup) - Static scheduling - Deadlock freedom Communicating Data-dependent, None - Rich synchronization Sequential allows nondeterminism - Occam (Rendesvouz) primitives Processes (CSP) language SDF KPN CSP space of program behaviors IAP 2007 MIT
10 The StreamIt Language A high-level, architecture-independent language for streaming applications Improves programmer productivity (vs. Java, C) Offers scalable performance on multicores Based on synchronous dataflow, with dynamic extensions Compiler determines execution order of filters Many aggressive optimizations possible IAP 2007 MIT
11 The StreamIt Project Applications DES and Serpent [PLDI 05] MPEG-2 [IPDPS 06] SAR, DSP benchmarks, JPEG, Programmability StreamIt Language (CC 02) Teleport Messaging (PPOPP 05) Programming Environment in Eclipse (P-PHEC 05) Domain Specific Optimizations Linear Analysis and Optimization (PLDI 03) Optimizations for bit streaming (PLDI 05) Linear State Space Analysis (CASES 05) Architecture Specific Optimizations Compiling for Communication-Exposed Architectures (ASPLOS 02) Phased Scheduling (LCTES 03) Cache Aware Optimization (LCTES 05) Load-Balanced Rendering (Graphics Hardware 05) Uniprocessor backend Simulator (Java Library) StreamIt Program Front-end Annotated Java Cluster backend Stream-Aware Optimizations Raw backend IBM X10 backend C/C++ MPI-like C per tile + Streaming C/C++ msg code X10 runtime IAP 2007 MIT
12 Example: A Simple Counter void->void pipeline Counter() { add IntSource(); add IntPrinter(); } void->int filter IntSource() { int x; init { x = 0; } work push 1{ push (x++); } } int->void filter IntPrinter() { work pop 1 { print(pop()); } } Counter IntSource IntPrinter % strc Counter.str o counter %./counter i IAP 2007 MIT
13 Representing Streams Conventional wisdom: streams are graphs Graphs have no simple textual representation Graphs are difficult to analyze and optimize Insight: stream programs have structure unstructured structured IAP 2007 MIT
14 Structured Streams filter pipeline splitjoin may be any StreamIt language construct parallel computation Each structure is singleinput, single-output Hierarchical and composable splitter joiner feedback loop joiner splitter IAP 2007 MIT
15 Filter Example: Low Pass Filter float->float filter LowPassFilter (int N, float freq) { float[n] weights; init { weights = calcweights(freq); } N } work peek N push 1 pop 1 { float result = 0; for (int i=0; i<weights.length; i++) { result += weights[i] * peek(i); } push(result); pop(); } filter IAP 2007 MIT
16 Low Pass Filter in C void FIR( int* src, int* dest, int* srcindex, int* destindex, int srcbuffersize, int destbuffersize, int N) { } FIR functionality obscured by buffer management details Programmer must commit to a particular buffer implementation strategy float result = 0.0; for (int i = 0; i < N; i++) { result += weights[i] * src[(*srcindex + i) % srcbuffersize]; } dest[*destindex] = result; *srcindex = (*srcindex + 1) % srcbuffersize; *destindex = (*destindex + 1) % destbuffersize; IAP 2007 MIT
17 Pipeline Example: Band Pass Filter float float pipeline BandPassFilter (int N, float low, float high) { add LowPassFilter(N, low); add HighPassFilter(N, high); LowPassFilter HighPassFilter } IAP 2007 MIT
18 SplitJoin Example: Equalizer float float pipeline Equalizer (int N, float lo, float hi) { Equalizer duplicate add splitjoin { ; for (int i=0; i<n; i++) add BandPassFilter(64, lo + i*(hi - lo)/n); BPF BPF BPF join roundrobin(1); } add Adder(N); roundrobin } Adder IAP 2007 MIT
19 Building Larger Programs: FMRadio void->void pipeline FMRadio(int N, float lo, float hi) { add AtoD(); add FMDemod(); add splitjoin { ; for (int i=0; i<n; i++) { add pipeline { AtoD FMDemod Duplicate add LowPassFilter(lo + i*(hi - lo)/n); LPF 1 LPF 2 LPF 3 add HighPassFilter(lo + i*(hi - lo)/n); } } join roundrobin(); } add Adder(); HPF 1 HPF 2 HPF 3 RoundRobin Adder } add Speaker(); Speaker IAP 2007 MIT


20 The Beauty of Streaming Some programs are elegant, some are exquisite, it some are sparkling. My claim is that it is possible to write grand programs, noble programs, truly magnificient ones! Don Knuth, ACM Turing Award Lecture IAP 2007 MIT
21 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
22 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
23 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
24 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
25 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
26 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
27 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
28 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
29 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
30 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
31 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
32 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
33 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
34 split roundrobin(n) join roundrobin(n) IAP 2007 MIT
35 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
36 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
37 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
38 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
39 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
40 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
41 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
42 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
43 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
44 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
45 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
46 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
47 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
48 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
49 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
50 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
51 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
52 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
53 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
54 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
55 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
56 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
57 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
58 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
59 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
60 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
61 split roundrobin(1) join roundrobin(1) IAP 2007 MIT
62 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
63 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
64 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
65 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
66 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
67 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
68 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
69 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
70 split roundrobin(2) join roundrobin(1) IAP 2007 MIT
71 split roundrobin(2) join roundrobin(1,2,3) IAP 2007 MIT
72 split roundrobin(2) join roundrobin(1,2,3) IAP 2007 MIT
73 split roundrobin(2) join roundrobin(1,2,3) IAP 2007 MIT
74 split roundrobin(2) join roundrobin(1,2,3) IAP 2007 MIT
75 split roundrobin(2) join roundrobin(1,2,3) IAP 2007 MIT
76 split roundrobin(2) join roundrobin(1,2,3) IAP 2007 MIT
77 split roundrobin(2) join roundrobin(1,2,3) IAP 2007 MIT
78 split roundrobin(2) join roundrobin(1,2,3) IAP 2007 MIT
79 Matrix Transpose N M Transpose M N IAP 2007 MIT
80 Matrix Transpose N M roundrobin(?)? roundrobin(?) M N IAP 2007 MIT
81 Matrix Transpose N M roundrobin(?)? roundrobin(?) M N IAP 2007 MIT
82 Matrix Transpose N M roundrobin(1) N roundrobin(m) M N IAP 2007 MIT
83 Matrix Transpose N M roundrobin(1) N roundrobin(m) M N IAP 2007 MIT
84 Matrix Transpose N M M N roundrobin(1) roundrobin(m) float->float splitjoin Transpose (int M, int N) { split roundrobin(1); for (int i = 0; i<n; i++) { add Identity<float>; } join roundrobin(m); } N IAP 2007 MIT
85 Bit-reversed ordering Many FFT algorithms require a bit-reversal stage If item is at index n (with binary digits b 0 b 1 b k ), then it is transferred to reversed index b k b 1 b 0 For 3-digit binary numbers: IAP 2007 MIT
86 Bit-reversed ordering Many FFT algorithms require a bit-reversal stage If item is at index n (with binary digits b 0 b 1 b k ), then it is transferred to reversed index b k b 1 b 0 For 3-digit binary numbers: RR(w 1 ) RR(w 1 ) RR(w 1 ) RR(w 2 ) RR(w 3 ) RR(w 2 ) IAP 2007 MIT
87 Bit-reversed ordering Many FFT algorithms require a bit-reversal stage If item is at index n (with binary digits b 0 b 1 b k ), then it is transferred to reversed index b k b 1 b 0 For 3-digit binary numbers: RR(1) RR(1) RR(1) RR(2) RR(4) RR(2) IAP 2007 MIT
88 Bit-reversed ordering complex->complex pipeline BitReverse (int N) { } if (N==2) { add Identity<complex>; } else { } rr add splitjoin { split roundrobin(1); rr add BitReverse(N/2); 4 4 rr add BitReverse(N/2); join roundrobin(n/2); } rr rr rr rr rr rr rr rr 4 4 rr rr rr IAP 2007 MIT
89 N/8 N/8 N N/2 N/2 N/4 N/4 N/4 Sort Sort Sort N/8 N/8 Sort N/8 N/8 Sort Sort Sort Sort Merge Merge Merge Merge Merge Merge Merge N/8 N/4 N/8 N-Element Merge Sort int->int pipeline MergeSort (int N) { if (N==2) { add Sort(N); } else { add splitjoin { split roundrobin(n/2); add MergeSort(N/2); add MergeSort(N/2); join roundrobin(n/2); } } add Merge(N); } IAP 2007 MIT
90 N-Element Merge Sort (3-level) N N/2 N/2 N/4 N/4 N/4 N/4 N/8 N/8 N/8 N/8 N/8 N/8 N/8 N/8 Sort Sort Sort Sort Sort Sort Sort Sort Merge Merge Merge Merge Merge Merge Merge IAP 2007 MIT





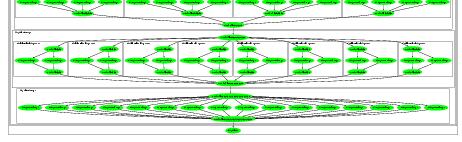
91 Bitonic Sort IAP 2007 MIT


92 FFT IAP 2007 MIT

93 Block Matrix Multiply IAP 2007 MIT
94 Filterbank IAP 2007 MIT
95 FM Radio with Equalizer IAP 2007 MIT
96 Radar-Array Front End IAP 2007 MIT
97 MP3 Decoder IAP 2007 MIT
98 Case Study: MPEG-2 2Decoder in StreamIt IAP 2007 MIT
99 MPEG-2 Decoder in StreamIt MPEG bit stream picture type <QC> <PT1, PT2> quantization coefficients frequency encoded macroblocks <QC> ZigZag IQuantization IDCT Saturation spatially encoded macroblocks VLD macroblocks, motion vectors splitter joiner differentially coded motion vectors Motion Vector Decode Repeat motion vectors splitter Y Cb Cr Motion Compensation Motion Compensation <PT1> reference <PT1> reference picture picture it Channel Upsample Motion Compensation <PT1> reference picture it Channel Upsample add VLD(QC, PT1, PT2); add splitjoin { split roundrobin(n B, (, V); add pipeline { add ZigZag(B); add IQuantization(B) to QC; add IDCT(B); add Saturation(B); } add pipeline { add MotionVectorDecode(); add Repeat(V, N); } join roundrobin(b, V); } add splitjoin { split roundrobin(4 (B+V), B+V, B+V); add MotionCompensation(4 (B+V)) to PT1; for (int i = 0; i < 2; i++) { add pipeline { add MotionCompensation(B+V) to PT1; add ChannelUpsample(B); } } <PT2> joiner recovered picture Picture Reorder } join roundrobin(1, 1, 1); add PictureReorder(3 W H) to PT2; Color Space Conversion output to player add ColorSpaceConversion(3 W H); IAP 2007 MIT
100 Teleport Messaging in MPEG-2 VLD picture type IQ Y splitter Cb Cr Motion Compensation Motion Compensation Motion Compensation MC MC MC Channel Upsample Channel Upsample joiner recovered picture Order IAP 2007 MIT
101 Messaging Equivalent in C The MPEG Bitstream File Parsing Decode Picture Decode Macroblock Decode Block ZigZagUnordering Inverse Quantization Global Variable Space Decode Motion Vectors Motion Compensation Saturate IDCT Motion Compensation For Single Channel Frame Reordering Output Video IAP 2007 MIT
102 MPEG-2 Implementation Fully-functional MPEG-2 decoder and encoder Developed by 1 programmer in 8 weeks 2257 lines of code Vs lines of C code in MPEG-2 reference 48 static streams, 643 instantiated filters IAP 2007 MIT
103 Conclusions StreamIt language preserves program structure Natural for programmers Parallelism and communication naturally exposed Compiler managed buffers, and portable parallelization technology StreamIt increases programmer productivity, enables parallel performance IAP 2007 MIT
MPEG-2 Decoding in a Stream Programming Language
 MPEG-2 Decoding in a Stream Programming Language Matthew Drake, Hank Hoffmann, Rodric Rabbah and Saman Amarasinghe Massachusetts Institute of Technology IPDPS Rhodes, April 2006 1 http://cag.csail.mit.edu/streamit
MPEG-2 Decoding in a Stream Programming Language Matthew Drake, Hank Hoffmann, Rodric Rabbah and Saman Amarasinghe Massachusetts Institute of Technology IPDPS Rhodes, April 2006 1 http://cag.csail.mit.edu/streamit
StreamIt A Programming Language for the Era of Multicores
 StreamIt A Programming Language for the Era of Multicores Saman Amarasinghe http://cag.csail.mit.edu/streamit Moore s Law 100000 From Hennessy and Patterson, Computer Architecture: Itanium 2 A Quantitative
StreamIt A Programming Language for the Era of Multicores Saman Amarasinghe http://cag.csail.mit.edu/streamit Moore s Law 100000 From Hennessy and Patterson, Computer Architecture: Itanium 2 A Quantitative
StreamIt: A Language for Streaming Applications
 StreamIt: A Language for Streaming Applications William Thies, Michal Karczmarek, Michael Gordon, David Maze, Jasper Lin, Ali Meli, Andrew Lamb, Chris Leger and Saman Amarasinghe MIT Laboratory for Computer
StreamIt: A Language for Streaming Applications William Thies, Michal Karczmarek, Michael Gordon, David Maze, Jasper Lin, Ali Meli, Andrew Lamb, Chris Leger and Saman Amarasinghe MIT Laboratory for Computer
Teleport Messaging for. Distributed Stream Programs
 Teleport Messaging for 1 Distributed Stream Programs William Thies, Michal Karczmarek, Janis Sermulins, Rodric Rabbah and Saman Amarasinghe Massachusetts Institute of Technology PPoPP 2005 http://cag.lcs.mit.edu/streamit
Teleport Messaging for 1 Distributed Stream Programs William Thies, Michal Karczmarek, Janis Sermulins, Rodric Rabbah and Saman Amarasinghe Massachusetts Institute of Technology PPoPP 2005 http://cag.lcs.mit.edu/streamit
A Stream Compiler for Communication-Exposed Architectures
 A Stream Compiler for Communication-Exposed Architectures Michael Gordon, William Thies, Michal Karczmarek, Jasper Lin, Ali Meli, Andrew Lamb, Chris Leger, Jeremy Wong, Henry Hoffmann, David Maze, Saman
A Stream Compiler for Communication-Exposed Architectures Michael Gordon, William Thies, Michal Karczmarek, Jasper Lin, Ali Meli, Andrew Lamb, Chris Leger, Jeremy Wong, Henry Hoffmann, David Maze, Saman
Cache Aware Optimization of Stream Programs
 Cache Aware Optimization of Stream Programs Janis Sermulins, William Thies, Rodric Rabbah and Saman Amarasinghe LCTES Chicago, June 2005 Streaming Computing Is Everywhere! Prevalent computing domain with
Cache Aware Optimization of Stream Programs Janis Sermulins, William Thies, Rodric Rabbah and Saman Amarasinghe LCTES Chicago, June 2005 Streaming Computing Is Everywhere! Prevalent computing domain with
CS758: Multicore Programming
 CS758: Multicore Programming Introduction Fall 2009 1 CS758 Credits Material for these slides has been contributed by Prof. Saman Amarasinghe, MIT Prof. Mark Hill, Wisconsin Prof. David Patterson, Berkeley
CS758: Multicore Programming Introduction Fall 2009 1 CS758 Credits Material for these slides has been contributed by Prof. Saman Amarasinghe, MIT Prof. Mark Hill, Wisconsin Prof. David Patterson, Berkeley
6.189 IAP Lecture 12. StreamIt Parallelizing Compiler. Prof. Saman Amarasinghe, MIT IAP 2007 MIT
 6.89 IAP 2007 Lecture 2 StreamIt Parallelizing Compiler 6.89 IAP 2007 MIT Common Machine Language Represent common properties of architectures Necessary for performance Abstract away differences in architectures
6.89 IAP 2007 Lecture 2 StreamIt Parallelizing Compiler 6.89 IAP 2007 MIT Common Machine Language Represent common properties of architectures Necessary for performance Abstract away differences in architectures
Saman Amarasinghe and Rodric Rabbah Massachusetts Institute of Technology
 Saman Amarasinghe and Rodric Rabbah Massachusetts Institute of Technology http://cag.csail.mit.edu/ps3 6.189-chair@mit.edu A new processor design pattern emerges: The Arrival of Multicores MIT Raw 16 Cores
Saman Amarasinghe and Rodric Rabbah Massachusetts Institute of Technology http://cag.csail.mit.edu/ps3 6.189-chair@mit.edu A new processor design pattern emerges: The Arrival of Multicores MIT Raw 16 Cores
Beyond Gaming: Programming the PS3 Cell Architecture for Cost-Effective Parallel Processing. IBM Watson Center. Rodric Rabbah, IBM
 Beyond Gaming: Programming the PS3 Cell Architecture for Cost-Effective Parallel Processing Rodric Rabbah IBM Watson Center 1 Get a PS3, Add Linux The PS3 can boot user installed Operating Systems Dual
Beyond Gaming: Programming the PS3 Cell Architecture for Cost-Effective Parallel Processing Rodric Rabbah IBM Watson Center 1 Get a PS3, Add Linux The PS3 can boot user installed Operating Systems Dual
Parallelization. Saman Amarasinghe. Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Outline. Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities
 Parallelization Outline Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Moore s Law From Hennessy and Patterson, Computer Architecture:
Parallelization Outline Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Moore s Law From Hennessy and Patterson, Computer Architecture:
Blue-Steel Ray Tracer
 MIT 6.189 IAP 2007 Student Project Blue-Steel Ray Tracer Natalia Chernenko Michael D'Ambrosio Scott Fisher Russel Ryan Brian Sweatt Leevar Williams Game Developers Conference March 7 2007 1 Imperative
MIT 6.189 IAP 2007 Student Project Blue-Steel Ray Tracer Natalia Chernenko Michael D'Ambrosio Scott Fisher Russel Ryan Brian Sweatt Leevar Williams Game Developers Conference March 7 2007 1 Imperative
AdaStreams : A Type-based Programming Extension for Stream-Parallelism with Ada 2005
 AdaStreams : A Type-based Programming Extension for Stream-Parallelism with Ada 2005 Gingun Hong*, Kirak Hong*, Bernd Burgstaller* and Johan Blieberger *Yonsei University, Korea Vienna University of Technology,
AdaStreams : A Type-based Programming Extension for Stream-Parallelism with Ada 2005 Gingun Hong*, Kirak Hong*, Bernd Burgstaller* and Johan Blieberger *Yonsei University, Korea Vienna University of Technology,
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Fall 2011 --
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Fall 2011 --
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I") EE382 (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Spring 2015
EE382 (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Spring 2015
StreamIt Cookbook. November 2, 2004
 StreamIt Cookbook streamit@cag.lcs.mit.edu November 2, 2004 1 StreamIt Overview Most data-flow or signal-processing algorithms can be broken down into a number of simple blocks with connections between
StreamIt Cookbook streamit@cag.lcs.mit.edu November 2, 2004 1 StreamIt Overview Most data-flow or signal-processing algorithms can be broken down into a number of simple blocks with connections between
An Empirical Characterization of Stream Programs and its Implications for Language and Compiler Design
 An Empirical Characterization of Stream Programs and its Implications for Language and Compiler Design William Thies Microsoft Research India thies@microsoft.com Saman Amarasinghe Massachusetts Institute
An Empirical Characterization of Stream Programs and its Implications for Language and Compiler Design William Thies Microsoft Research India thies@microsoft.com Saman Amarasinghe Massachusetts Institute
Application-Platform Mapping in Multiprocessor Systems-on-Chip
 Application-Platform Mapping in Multiprocessor Systems-on-Chip Leandro Soares Indrusiak lsi@cs.york.ac.uk http://www-users.cs.york.ac.uk/lsi CREDES Kick-off Meeting Tallinn - June 2009 Application-Platform
Application-Platform Mapping in Multiprocessor Systems-on-Chip Leandro Soares Indrusiak lsi@cs.york.ac.uk http://www-users.cs.york.ac.uk/lsi CREDES Kick-off Meeting Tallinn - June 2009 Application-Platform
EE382N (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I
: Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I") EE382 (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
EE382 (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
StreamIt on Fleet. Amir Kamil Computer Science Division, University of California, Berkeley UCB-AK06.
 StreamIt on Fleet Amir Kamil Computer Science Division, University of California, Berkeley kamil@cs.berkeley.edu UCB-AK06 July 16, 2008 1 Introduction StreamIt [1] is a high-level programming language
StreamIt on Fleet Amir Kamil Computer Science Division, University of California, Berkeley kamil@cs.berkeley.edu UCB-AK06 July 16, 2008 1 Introduction StreamIt [1] is a high-level programming language
Exploiting Coarse-Grained Task, Data, and Pipeline Parallelism in Stream Programs
 Exploiting Coarse-Grained Task, Data, and Pipeline Parallelism in Stream Programs Michael I. Gordon, William Thies, and Saman Amarasinghe Massachusetts Institute of Technology Computer Science and Artificial
Exploiting Coarse-Grained Task, Data, and Pipeline Parallelism in Stream Programs Michael I. Gordon, William Thies, and Saman Amarasinghe Massachusetts Institute of Technology Computer Science and Artificial
FORMLESS: Scalable Utilization of Embedded Manycores in Streaming Applications
 FORMLESS: Scalable Utilization of Embedded Manycores in Streaming Applications Matin Hashemi 1, Mohammad H. Foroozannejad 2, Christoph Etzel 3, Soheil Ghiasi 2 Sharif University of Technology University
FORMLESS: Scalable Utilization of Embedded Manycores in Streaming Applications Matin Hashemi 1, Mohammad H. Foroozannejad 2, Christoph Etzel 3, Soheil Ghiasi 2 Sharif University of Technology University
Implementing bit-intensive programs in StreamIt/StreamBit 1. Writing Bit manipulations using the StreamIt language with StreamBit Compiler
 Implementing bit-intensive programs in StreamIt/StreamBit 1. Writing Bit manipulations using the StreamIt language with StreamBit Compiler The StreamIt language, together with the StreamBit compiler, allows
Implementing bit-intensive programs in StreamIt/StreamBit 1. Writing Bit manipulations using the StreamIt language with StreamBit Compiler The StreamIt language, together with the StreamBit compiler, allows
StreamIt Language Specification Version 2.1
 StreamIt Language Specification Version 2.1 streamit@cag.csail.mit.edu September, 2006 Contents 1 Introduction 2 2 Types 2 2.1 Data Types............................................ 3 2.1.1 Primitive Types.....................................
StreamIt Language Specification Version 2.1 streamit@cag.csail.mit.edu September, 2006 Contents 1 Introduction 2 2 Types 2 2.1 Data Types............................................ 3 2.1.1 Primitive Types.....................................
MPEG-2. And Scalability Support. Nimrod Peleg Update: July.2004
 MPEG-2 And Scalability Support Nimrod Peleg Update: July.2004 MPEG-2 Target...Generic coding method of moving pictures and associated sound for...digital storage, TV broadcasting and communication... Dedicated
MPEG-2 And Scalability Support Nimrod Peleg Update: July.2004 MPEG-2 Target...Generic coding method of moving pictures and associated sound for...digital storage, TV broadcasting and communication... Dedicated
Storage I/O Summary. Lecture 16: Multimedia and DSP Architectures
 Storage I/O Summary Storage devices Storage I/O Performance Measures» Throughput» Response time I/O Benchmarks» Scaling to track technological change» Throughput with restricted response time is normal
Storage I/O Summary Storage devices Storage I/O Performance Measures» Throughput» Response time I/O Benchmarks» Scaling to track technological change» Throughput with restricted response time is normal
Exact and Approximate Task Assignment Algorithms for Pipelined Software Synthesis
 Exact and Approximate Task Assignment Algorithms for Pipelined Software Synthesis Matin Hashemi Soheil Ghiasi Laboratory for Embedded and Programmable Systems http://leps.ece.ucdavis.edu Department of
Exact and Approximate Task Assignment Algorithms for Pipelined Software Synthesis Matin Hashemi Soheil Ghiasi Laboratory for Embedded and Programmable Systems http://leps.ece.ucdavis.edu Department of
EECS 583 Class 20 Research Topic 2: Stream Compilation, GPU Compilation
 EECS 583 Class 20 Research Topic 2: Stream Compilation, GPU Compilation University of Michigan December 3, 2012 Guest Speakers Today: Daya Khudia and Mehrzad Samadi nnouncements & Reading Material Exams
EECS 583 Class 20 Research Topic 2: Stream Compilation, GPU Compilation University of Michigan December 3, 2012 Guest Speakers Today: Daya Khudia and Mehrzad Samadi nnouncements & Reading Material Exams
DIGITAL VS. ANALOG SIGNAL PROCESSING Digital signal processing (DSP) characterized by: OUTLINE APPLICATIONS OF DIGITAL SIGNAL PROCESSING
 characterized by: OUTLINE APPLICATIONS OF DIGITAL SIGNAL PROCESSING") 1 DSP applications DSP platforms The synthesis problem Models of computation OUTLINE 2 DIGITAL VS. ANALOG SIGNAL PROCESSING Digital signal processing (DSP) characterized by: Time-discrete representation
1 DSP applications DSP platforms The synthesis problem Models of computation OUTLINE 2 DIGITAL VS. ANALOG SIGNAL PROCESSING Digital signal processing (DSP) characterized by: Time-discrete representation
EE382N (20): Computer Architecture - Parallelism and Locality Lecture 11 Parallelism in Software II
: Computer Architecture - Parallelism and Locality Lecture 11 Parallelism in Software II") EE382 (20): Computer Architecture - Parallelism and Locality Lecture 11 Parallelism in Software II Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
EE382 (20): Computer Architecture - Parallelism and Locality Lecture 11 Parallelism in Software II Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
Overview of the ECE Computer Software Curriculum. David O Hallaron Associate Professor of ECE and CS Carnegie Mellon University
 Overview of the ECE Computer Software Curriculum David O Hallaron Associate Professor of ECE and CS Carnegie Mellon University The Fundamental Idea of Abstraction Human beings Applications Software systems
Overview of the ECE Computer Software Curriculum David O Hallaron Associate Professor of ECE and CS Carnegie Mellon University The Fundamental Idea of Abstraction Human beings Applications Software systems
Efficient, Deterministic, and Deadlock-free Concurrency
 Efficient, Deterministic Concurrency p. 1/31 Efficient, Deterministic, and Deadlock-free Concurrency Nalini Vasudevan Columbia University Efficient, Deterministic Concurrency p. 2/31 Data Races int x;
Efficient, Deterministic Concurrency p. 1/31 Efficient, Deterministic, and Deadlock-free Concurrency Nalini Vasudevan Columbia University Efficient, Deterministic Concurrency p. 2/31 Data Races int x;
Evaluating MMX Technology Using DSP and Multimedia Applications
 Evaluating MMX Technology Using DSP and Multimedia Applications Ravi Bhargava * Lizy K. John * Brian L. Evans Ramesh Radhakrishnan * November 22, 1999 The University of Texas at Austin Department of Electrical
Evaluating MMX Technology Using DSP and Multimedia Applications Ravi Bhargava * Lizy K. John * Brian L. Evans Ramesh Radhakrishnan * November 22, 1999 The University of Texas at Austin Department of Electrical
Objective. We will study software systems that permit applications programs to exploit the power of modern high-performance computers.
 CS 612 Software Design for High-performance Architectures 1 computers. CS 412 is desirable but not high-performance essential. Course Organization Lecturer:Paul Stodghill, stodghil@cs.cornell.edu, Rhodes
CS 612 Software Design for High-performance Architectures 1 computers. CS 412 is desirable but not high-performance essential. Course Organization Lecturer:Paul Stodghill, stodghil@cs.cornell.edu, Rhodes
ECE 417 Guest Lecture Video Compression in MPEG-1/2/4. Min-Hsuan Tsai Apr 02, 2013
 ECE 417 Guest Lecture Video Compression in MPEG-1/2/4 Min-Hsuan Tsai Apr 2, 213 What is MPEG and its standards MPEG stands for Moving Picture Expert Group Develop standards for video/audio compression
ECE 417 Guest Lecture Video Compression in MPEG-1/2/4 Min-Hsuan Tsai Apr 2, 213 What is MPEG and its standards MPEG stands for Moving Picture Expert Group Develop standards for video/audio compression
Dynamic Expressivity with Static Optimization for Streaming Languages
 Dynamic Expressivity with Static Optimization for Streaming Languages Robert Soulé Michael I. Gordon Saman marasinghe Robert Grimm Martin Hirzel ornell MIT MIT NYU IM DES 2013 1 Stream (FIFO queue) Operator
Dynamic Expressivity with Static Optimization for Streaming Languages Robert Soulé Michael I. Gordon Saman marasinghe Robert Grimm Martin Hirzel ornell MIT MIT NYU IM DES 2013 1 Stream (FIFO queue) Operator
MPEG-2. ISO/IEC (or ITU-T H.262)
") MPEG-2 1 MPEG-2 ISO/IEC 13818-2 (or ITU-T H.262) High quality encoding of interlaced video at 4-15 Mbps for digital video broadcast TV and digital storage media Applications Broadcast TV, Satellite TV,
MPEG-2 1 MPEG-2 ISO/IEC 13818-2 (or ITU-T H.262) High quality encoding of interlaced video at 4-15 Mbps for digital video broadcast TV and digital storage media Applications Broadcast TV, Satellite TV,
Language Support for Stream. Processing. Robert Soulé
 Language Support for Stream Processing Robert Soulé Introduction Proposal Work Plan Outline Formalism Translators & Abstractions Optimizations Related Work Conclusion 2 Introduction Stream processing is
Language Support for Stream Processing Robert Soulé Introduction Proposal Work Plan Outline Formalism Translators & Abstractions Optimizations Related Work Conclusion 2 Introduction Stream processing is
Constrained and Phased Scheduling of Synchronous Data Flow Graphs for StreamIt Language. Michal Karczmarek
 Constrained and Phased Scheduling of Synchronous Data Flow Graphs for StreamIt Language by Michal Karczmarek Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment
Constrained and Phased Scheduling of Synchronous Data Flow Graphs for StreamIt Language by Michal Karczmarek Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment
Shared Memory Parallel Programming. Shared Memory Systems Introduction to OpenMP
 Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Deterministic Concurrency
 Candidacy Exam p. 1/35 Deterministic Concurrency Candidacy Exam Nalini Vasudevan Columbia University Motivation Candidacy Exam p. 2/35 Candidacy Exam p. 3/35 Why Parallelism? Past Vs. Future Power wall:
Candidacy Exam p. 1/35 Deterministic Concurrency Candidacy Exam Nalini Vasudevan Columbia University Motivation Candidacy Exam p. 2/35 Candidacy Exam p. 3/35 Why Parallelism? Past Vs. Future Power wall:
Multimedia Decoder Using the Nios II Processor
 Multimedia Decoder Using the Nios II Processor Third Prize Multimedia Decoder Using the Nios II Processor Institution: Participants: Instructor: Indian Institute of Science Mythri Alle, Naresh K. V., Svatantra
Multimedia Decoder Using the Nios II Processor Third Prize Multimedia Decoder Using the Nios II Processor Institution: Participants: Instructor: Indian Institute of Science Mythri Alle, Naresh K. V., Svatantra
Dataflow Languages. Languages for Embedded Systems. Prof. Stephen A. Edwards. March Columbia University
 Dataflow Languages Languages for Embedded Systems Prof. Stephen A. Edwards Columbia University March 2009 Philosophy of Dataflow Languages Drastically different way of looking at computation Von Neumann
Dataflow Languages Languages for Embedded Systems Prof. Stephen A. Edwards Columbia University March 2009 Philosophy of Dataflow Languages Drastically different way of looking at computation Von Neumann
Programming Models. Contents
 Programming Models Languages and Technologies Contents Advanced languages for multicore systems Programming languages for Non Uniform Cluster Computers IBM X10 Programming languages for embedded systems
Programming Models Languages and Technologies Contents Advanced languages for multicore systems Programming languages for Non Uniform Cluster Computers IBM X10 Programming languages for embedded systems
Lecture 14. Synthesizing Parallel Programs IAP 2007 MIT
 6.189 IAP 2007 Lecture 14 Synthesizing Parallel Programs Prof. Arvind, MIT. 6.189 IAP 2007 MIT Synthesizing parallel programs (or borrowing some ideas from hardware design) Arvind Computer Science & Artificial
6.189 IAP 2007 Lecture 14 Synthesizing Parallel Programs Prof. Arvind, MIT. 6.189 IAP 2007 MIT Synthesizing parallel programs (or borrowing some ideas from hardware design) Arvind Computer Science & Artificial
6.189 IAP Lecture 3. Introduction to Parallel Architectures. Prof. Saman Amarasinghe, MIT IAP 2007 MIT
 6.189 IAP 2007 Lecture 3 Introduction to Parallel Architectures 1 6.189 IAP 2007 MIT Implicit vs. Explicit Parallelism Implicit Explicit Hardware Compiler Superscalar Processors Explicitly Parallel Architectures
6.189 IAP 2007 Lecture 3 Introduction to Parallel Architectures 1 6.189 IAP 2007 MIT Implicit vs. Explicit Parallelism Implicit Explicit Hardware Compiler Superscalar Processors Explicitly Parallel Architectures
Precise Exceptions and Out-of-Order Execution. Samira Khan
 Precise Exceptions and Out-of-Order Execution Samira Khan Multi-Cycle Execution Not all instructions take the same amount of time for execution Idea: Have multiple different functional units that take
Precise Exceptions and Out-of-Order Execution Samira Khan Multi-Cycle Execution Not all instructions take the same amount of time for execution Idea: Have multiple different functional units that take
StreamIt Language Specification Version 2.0
 StreamIt Language Specification Version 2.0 streamit@cag.lcs.mit.edu October 17, 2003 Contents 1 Introduction 3 2 Types 3 2.1 Data Types............................. 3 2.1.1 Primitive Types......................
StreamIt Language Specification Version 2.0 streamit@cag.lcs.mit.edu October 17, 2003 Contents 1 Introduction 3 2 Types 3 2.1 Data Types............................. 3 2.1.1 Primitive Types......................
Modeling of an MPEG Audio Layer-3 Encoder in Ptolemy
 Modeling of an MPEG Audio Layer-3 Encoder in Ptolemy Patrick Brown EE382C Embedded Software Systems May 10, 2000 $EVWUDFW MPEG Audio Layer-3 is a standard for the compression of high-quality digital audio.
Modeling of an MPEG Audio Layer-3 Encoder in Ptolemy Patrick Brown EE382C Embedded Software Systems May 10, 2000 $EVWUDFW MPEG Audio Layer-3 is a standard for the compression of high-quality digital audio.
Automated Space/Time Scaling of Streaming Task Graphs. Hossein Omidian Supervisor: Guy Lemieux
 Automated Space/Time Scaling of Streaming Task Graphs Hossein Omidian Supervisor: Guy Lemieux 1 Contents Introduction KPN-based HLS Tool for MPPA overlay Experimental Results Future Work Conclusion 2 Introduction
Automated Space/Time Scaling of Streaming Task Graphs Hossein Omidian Supervisor: Guy Lemieux 1 Contents Introduction KPN-based HLS Tool for MPPA overlay Experimental Results Future Work Conclusion 2 Introduction
ESE532: System-on-a-Chip Architecture. Today. Process. Message FIFO. Thread. Dataflow Process Model Motivation Issues Abstraction Recommended Approach
 ESE53: System-on-a-Chip Architecture Day 5: January 30, 07 Dataflow Process Model Today Dataflow Process Model Motivation Issues Abstraction Recommended Approach Message Parallelism can be natural Discipline
ESE53: System-on-a-Chip Architecture Day 5: January 30, 07 Dataflow Process Model Today Dataflow Process Model Motivation Issues Abstraction Recommended Approach Message Parallelism can be natural Discipline
A Streaming Multi-Threaded Model
 A Streaming Multi-Threaded Model Extended Abstract Eylon Caspi, André DeHon, John Wawrzynek September 30, 2001 Summary. We present SCORE, a multi-threaded model that relies on streams to expose thread
A Streaming Multi-Threaded Model Extended Abstract Eylon Caspi, André DeHon, John Wawrzynek September 30, 2001 Summary. We present SCORE, a multi-threaded model that relies on streams to expose thread
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
Functional modeling style for efficient SW code generation of video codec applications
 Functional modeling style for efficient SW code generation of video codec applications Sang-Il Han 1)2) Soo-Ik Chae 1) Ahmed. A. Jerraya 2) SD Group 1) SLS Group 2) Seoul National Univ., Korea TIMA laboratory,
Functional modeling style for efficient SW code generation of video codec applications Sang-Il Han 1)2) Soo-Ik Chae 1) Ahmed. A. Jerraya 2) SD Group 1) SLS Group 2) Seoul National Univ., Korea TIMA laboratory,
MPEG-4: Simple Profile (SP)
") MPEG-4: Simple Profile (SP) I-VOP (Intra-coded rectangular VOP, progressive video format) P-VOP (Inter-coded rectangular VOP, progressive video format) Short Header mode (compatibility with H.263 codec)
MPEG-4: Simple Profile (SP) I-VOP (Intra-coded rectangular VOP, progressive video format) P-VOP (Inter-coded rectangular VOP, progressive video format) Short Header mode (compatibility with H.263 codec)
A Streaming Computation Framework for the Cell Processor. Xin David Zhang
 A Streaming Computation Framework for the Cell Processor by Xin David Zhang Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the
A Streaming Computation Framework for the Cell Processor by Xin David Zhang Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Programming Models. Rebecca Schultz Paul Lee Varun Malhotra
 Programming Models Rebecca Schultz Paul Lee Varun Malhotra Outline Motivation Existing sequential languages Discussion about papers Conclusions and things to ponder over Principles of programming language
Programming Models Rebecca Schultz Paul Lee Varun Malhotra Outline Motivation Existing sequential languages Discussion about papers Conclusions and things to ponder over Principles of programming language
Week 14. Video Compression. Ref: Fundamentals of Multimedia
 Week 14 Video Compression Ref: Fundamentals of Multimedia Last lecture review Prediction from the previous frame is called forward prediction Prediction from the next frame is called forward prediction
Week 14 Video Compression Ref: Fundamentals of Multimedia Last lecture review Prediction from the previous frame is called forward prediction Prediction from the next frame is called forward prediction
Halfway! Sequoia. A Point of View. Sequoia. First half of the course is over. Now start the second half. CS315B Lecture 9
 Halfway! Sequoia CS315B Lecture 9 First half of the course is over Overview/Philosophy of Regent Now start the second half Lectures on other programming models Comparing/contrasting with Regent Start with
Halfway! Sequoia CS315B Lecture 9 First half of the course is over Overview/Philosophy of Regent Now start the second half Lectures on other programming models Comparing/contrasting with Regent Start with
The Shift to Multicore Architectures
 Parallel Programming Practice Fall 2011 The Shift to Multicore Architectures Bernd Burgstaller Yonsei University Bernhard Scholz The University of Sydney Why is it important? Now we're into the explicit
Parallel Programming Practice Fall 2011 The Shift to Multicore Architectures Bernd Burgstaller Yonsei University Bernhard Scholz The University of Sydney Why is it important? Now we're into the explicit
MIT OpenCourseWare Multicore Programming Primer, January (IAP) Please use the following citation format:
 Please use the following citation format:") MIT OpenCourseWare http://ocw.mit.edu 6.189 Multicore Programming Primer, January (IAP) 2007 Please use the following citation format: Saman Amarasinghe, 6.189 Multicore Programming Primer, January (IAP)
MIT OpenCourseWare http://ocw.mit.edu 6.189 Multicore Programming Primer, January (IAP) 2007 Please use the following citation format: Saman Amarasinghe, 6.189 Multicore Programming Primer, January (IAP)
CMSC 330: Organization of Programming Languages
 CMSC 330: Organization of Programming Languages Multithreading Multiprocessors Description Multiple processing units (multiprocessor) From single microprocessor to large compute clusters Can perform multiple
CMSC 330: Organization of Programming Languages Multithreading Multiprocessors Description Multiple processing units (multiprocessor) From single microprocessor to large compute clusters Can perform multiple
Computational Process Networks a model and framework for high-throughput signal processing
 Computational Process Networks a model and framework for high-throughput signal processing Gregory E. Allen Ph.D. Defense 25 April 2011 Committee Members: James C. Browne Craig M. Chase Brian L. Evans
Computational Process Networks a model and framework for high-throughput signal processing Gregory E. Allen Ph.D. Defense 25 April 2011 Committee Members: James C. Browne Craig M. Chase Brian L. Evans
10.2 Video Compression with Motion Compensation 10.4 H H.263
 Chapter 10 Basic Video Compression Techniques 10.11 Introduction to Video Compression 10.2 Video Compression with Motion Compensation 10.3 Search for Motion Vectors 10.4 H.261 10.5 H.263 10.6 Further Exploration
Chapter 10 Basic Video Compression Techniques 10.11 Introduction to Video Compression 10.2 Video Compression with Motion Compensation 10.3 Search for Motion Vectors 10.4 H.261 10.5 H.263 10.6 Further Exploration
Static Memory Management for Efficient Mobile Sensing Applications
 Static Memory Management for Efficient Mobile Sensing Applications Farley Lai, Daniel Schmidt, Octav Chipara Department of Computer Science University of Iowa {poyuan-lai, daniel-schmidt, octav-chipara}@uiowa.edu
Static Memory Management for Efficient Mobile Sensing Applications Farley Lai, Daniel Schmidt, Octav Chipara Department of Computer Science University of Iowa {poyuan-lai, daniel-schmidt, octav-chipara}@uiowa.edu
Lab-1: Profiling/Optimizing Video Decoder Using ADS. National Chiao Tung University Chun-Jen Tsai 3/3/2011
 Lab-1: Profiling/Optimizing Video Decoder Using ADS National Chiao Tung University Chun-Jen Tsai 3/3/2011 Profiling MPEG-4 SP Decoder Goal: Profiling and optimizing the MPEG-4 video decoder, m4v_dec Tasks:
Lab-1: Profiling/Optimizing Video Decoder Using ADS National Chiao Tung University Chun-Jen Tsai 3/3/2011 Profiling MPEG-4 SP Decoder Goal: Profiling and optimizing the MPEG-4 video decoder, m4v_dec Tasks:
Chapter 10. Basic Video Compression Techniques Introduction to Video Compression 10.2 Video Compression with Motion Compensation
 Chapter 10 Basic Video Compression Techniques 10.1 Introduction to Video Compression 10.2 Video Compression with Motion Compensation 10.3 Search for Motion Vectors 10.4 H.261 10.5 H.263 10.6 Further Exploration
Chapter 10 Basic Video Compression Techniques 10.1 Introduction to Video Compression 10.2 Video Compression with Motion Compensation 10.3 Search for Motion Vectors 10.4 H.261 10.5 H.263 10.6 Further Exploration
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Computer Architecture Lecture 14: Out-of-Order Execution. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013
 18-447 Computer Architecture Lecture 14: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
18-447 Computer Architecture Lecture 14: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
Control Hazards. Branch Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
CS3350B Computer Architecture CPU Performance and Profiling
 CS3350B Computer Architecture CPU Performance and Profiling Marc Moreno Maza http://www.csd.uwo.ca/~moreno/cs3350_moreno/index.html Department of Computer Science University of Western Ontario, Canada
CS3350B Computer Architecture CPU Performance and Profiling Marc Moreno Maza http://www.csd.uwo.ca/~moreno/cs3350_moreno/index.html Department of Computer Science University of Western Ontario, Canada
ECE 669 Parallel Computer Architecture
 ECE 669 Parallel Computer Architecture Lecture 23 Parallel Compilation Parallel Compilation Two approaches to compilation Parallelize a program manually Sequential code converted to parallel code Develop
ECE 669 Parallel Computer Architecture Lecture 23 Parallel Compilation Parallel Compilation Two approaches to compilation Parallelize a program manually Sequential code converted to parallel code Develop
Branch Prediction & Speculative Execution. Branch Penalties in Modern Pipelines
 6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
5LSE0 - Mod 10 Part 1. MPEG Motion Compensation and Video Coding. MPEG Video / Temporal Prediction (1)
") 1 Multimedia Video Coding & Architectures (5LSE), Module 1 MPEG-1/ Standards: Motioncompensated video coding 5LSE - Mod 1 Part 1 MPEG Motion Compensation and Video Coding Peter H.N. de With (p.h.n.de.with@tue.nl
1 Multimedia Video Coding & Architectures (5LSE), Module 1 MPEG-1/ Standards: Motioncompensated video coding 5LSE - Mod 1 Part 1 MPEG Motion Compensation and Video Coding Peter H.N. de With (p.h.n.de.with@tue.nl
HP PA-8000 RISC CPU. A High Performance Out-of-Order Processor
 The A High Performance Out-of-Order Processor Hot Chips VIII IEEE Computer Society Stanford University August 19, 1996 Hewlett-Packard Company Engineering Systems Lab - Fort Collins, CO - Cupertino, CA
The A High Performance Out-of-Order Processor Hot Chips VIII IEEE Computer Society Stanford University August 19, 1996 Hewlett-Packard Company Engineering Systems Lab - Fort Collins, CO - Cupertino, CA
Sorting. Sorting. Stable Sorting. In-place Sort. Bubble Sort. Bubble Sort. Selection (Tournament) Heapsort (Smoothsort) Mergesort Quicksort Bogosort
 Heapsort (Smoothsort) Mergesort Quicksort Bogosort") Principles of Imperative Computation V. Adamchik CS 15-1 Lecture Carnegie Mellon University Sorting Sorting Sorting is ordering a list of objects. comparison non-comparison Hoare Knuth Bubble (Shell, Gnome)
Principles of Imperative Computation V. Adamchik CS 15-1 Lecture Carnegie Mellon University Sorting Sorting Sorting is ordering a list of objects. comparison non-comparison Hoare Knuth Bubble (Shell, Gnome)
Lightweight Arithmetic for Mobile Multimedia Devices. IEEE Transactions on Multimedia
 Lightweight Arithmetic for Mobile Multimedia Devices Tsuhan Chen Carnegie Mellon University tsuhan@cmu.edu Thanks to Fang Fang and Rob Rutenbar IEEE Transactions on Multimedia EDICS Signal Processing for
Lightweight Arithmetic for Mobile Multimedia Devices Tsuhan Chen Carnegie Mellon University tsuhan@cmu.edu Thanks to Fang Fang and Rob Rutenbar IEEE Transactions on Multimedia EDICS Signal Processing for
Parallel Implementation of Arbitrary-Shaped MPEG-4 Decoder for Multiprocessor Systems
 Parallel Implementation of Arbitrary-Shaped MPEG-4 oder for Multiprocessor Systems Milan Pastrnak *,a,c, Peter H.N. de With a,c, Sander Stuijk c and Jef van Meerbergen b,c a LogicaCMG Nederland B.V., RTSE
Parallel Implementation of Arbitrary-Shaped MPEG-4 oder for Multiprocessor Systems Milan Pastrnak *,a,c, Peter H.N. de With a,c, Sander Stuijk c and Jef van Meerbergen b,c a LogicaCMG Nederland B.V., RTSE
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction
 Stalls with Dynamic Branch Prediction") ISA Support Needed By CPU Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction So far we have dealt with control hazards in instruction pipelines by: 1 2 3 4 Assuming that the branch
ISA Support Needed By CPU Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction So far we have dealt with control hazards in instruction pipelines by: 1 2 3 4 Assuming that the branch
Realization of Replicated Streaming Applications on Multi-Clocked FPGAs
 Realization of Replicated Streaming Applications on Multi-Clocked FPGAs Master Thesis in System-on-Chip Design GUO SHAOCHUN Examiner: Dr. Ingo Sander Supervisor: Zhu Jun Thesis Number: TRITA-ICT-EX-20:70
Realization of Replicated Streaming Applications on Multi-Clocked FPGAs Master Thesis in System-on-Chip Design GUO SHAOCHUN Examiner: Dr. Ingo Sander Supervisor: Zhu Jun Thesis Number: TRITA-ICT-EX-20:70
PetaBricks: A Language and Compiler based on Autotuning
 PetaBricks: A Language and Compiler based on Autotuning Saman Amarasinghe Joint work with Jason Ansel, Marek Olszewski Cy Chan, Yee Lok Wong, Maciej Pacula Una-May O Reilly and Alan Edelman Computer Science
PetaBricks: A Language and Compiler based on Autotuning Saman Amarasinghe Joint work with Jason Ansel, Marek Olszewski Cy Chan, Yee Lok Wong, Maciej Pacula Una-May O Reilly and Alan Edelman Computer Science
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Lossy Coding 2 JPEG. Perceptual Image Coding. Discrete Cosine Transform JPEG. CS559 Lecture 9 JPEG, Raster Algorithms
 CS559 Lecture 9 JPEG, Raster Algorithms These are course notes (not used as slides) Written by Mike Gleicher, Sept. 2005 With some slides adapted from the notes of Stephen Chenney Lossy Coding 2 Suppose
CS559 Lecture 9 JPEG, Raster Algorithms These are course notes (not used as slides) Written by Mike Gleicher, Sept. 2005 With some slides adapted from the notes of Stephen Chenney Lossy Coding 2 Suppose
Compressed-Domain Video Processing and Transcoding
 Compressed-Domain Video Processing and Transcoding Susie Wee, John Apostolopoulos Mobile & Media Systems Lab HP Labs Stanford EE392J Lecture 2006 Hewlett-Packard Development Company, L.P. The information
Compressed-Domain Video Processing and Transcoding Susie Wee, John Apostolopoulos Mobile & Media Systems Lab HP Labs Stanford EE392J Lecture 2006 Hewlett-Packard Development Company, L.P. The information
Complementing Software Pipelining with Software Thread Integration
 Complementing Software Pipelining with Software Thread Integration LCTES 05 - June 16, 2005 Won So and Alexander G. Dean Center for Embedded System Research Dept. of ECE, North Carolina State University
Complementing Software Pipelining with Software Thread Integration LCTES 05 - June 16, 2005 Won So and Alexander G. Dean Center for Embedded System Research Dept. of ECE, North Carolina State University
Compilers and Compiler-based Tools for HPC
 Compilers and Compiler-based Tools for HPC John Mellor-Crummey Department of Computer Science Rice University http://lacsi.rice.edu/review/2004/slides/compilers-tools.pdf High Performance Computing Algorithms
Compilers and Compiler-based Tools for HPC John Mellor-Crummey Department of Computer Science Rice University http://lacsi.rice.edu/review/2004/slides/compilers-tools.pdf High Performance Computing Algorithms
High Performance Computing. University questions with solution
 High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Introduction to Video Compression
 Insight, Analysis, and Advice on Signal Processing Technology Introduction to Video Compression Jeff Bier Berkeley Design Technology, Inc. info@bdti.com http://www.bdti.com Outline Motivation and scope
Insight, Analysis, and Advice on Signal Processing Technology Introduction to Video Compression Jeff Bier Berkeley Design Technology, Inc. info@bdti.com http://www.bdti.com Outline Motivation and scope
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture The Computer Revolution Progress in computer technology Underpinned by Moore s Law Makes novel applications
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture The Computer Revolution Progress in computer technology Underpinned by Moore s Law Makes novel applications
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
2014 Summer School on MPEG/VCEG Video. Video Coding Concept
 2014 Summer School on MPEG/VCEG Video 1 Video Coding Concept Outline 2 Introduction Capture and representation of digital video Fundamentals of video coding Summary Outline 3 Introduction Capture and representation
2014 Summer School on MPEG/VCEG Video 1 Video Coding Concept Outline 2 Introduction Capture and representation of digital video Fundamentals of video coding Summary Outline 3 Introduction Capture and representation
Video coding. Concepts and notations.
 TSBK06 video coding p.1/47 Video coding Concepts and notations. A video signal consists of a time sequence of images. Typical frame rates are 24, 25, 30, 50 and 60 images per seconds. Each image is either
TSBK06 video coding p.1/47 Video coding Concepts and notations. A video signal consists of a time sequence of images. Typical frame rates are 24, 25, 30, 50 and 60 images per seconds. Each image is either
Video Compression An Introduction
 Video Compression An Introduction The increasing demand to incorporate video data into telecommunications services, the corporate environment, the entertainment industry, and even at home has made digital
Video Compression An Introduction The increasing demand to incorporate video data into telecommunications services, the corporate environment, the entertainment industry, and even at home has made digital
ESE532: System-on-a-Chip Architecture. Today. Programmable SoC. Message. Process. Reminder
 ESE532: System-on-a-Chip Architecture Day 5: September 18, 2017 Dataflow Process Model Today Dataflow Process Model Motivation Issues Abstraction Basic Approach Dataflow variants Motivations/demands for
ESE532: System-on-a-Chip Architecture Day 5: September 18, 2017 Dataflow Process Model Today Dataflow Process Model Motivation Issues Abstraction Basic Approach Dataflow variants Motivations/demands for