Machine Learning for Large-Scale Data Analysis and Decision Making A. Distributed Machine Learning Week #9
|
|
|
- Garey O’Connor’
- 5 years ago
- Views:
Transcription
1 Machine Learning for Large-Scale Data Analysis and Decision Making A Distributed Machine Learning Week #9
2 Today Distributed computing for machine learning Background MapReduce/Hadoop & Spark Theory & Practice Note: Most lectures so far used stats concepts Today we ll turn to computer science 2
3 Modern view of ML Understand massive quantities of data Google (4K searches/s), Twitter: (6K tweets/s), Amazon: (100s sold products/s) (source: internetlifestatscom) Banks, insurance companies, etc Modestly-sized websites Both large n and large p Computation will scale up with the data n p X Often fitting an ML models requires one or multiple operations that looks at the whole dataset 3
4 Modern view of ML Understand massive quantities of data Google (4K searches/s), Twitter: (6K tweets/s), Amazon: (100s sold products/s) (source: internetlifestatscom) Banks, insurance companies, etc Modestly-sized websites Both large n and large p Computation will scale up with the data n p X Often fitting an ML models requires one or multiple operations that looks at the whole dataset Linear regression w =(X X) 1 X Y 3
5 Issues with massive datasets 1 Storage 2 Computation 4


6 Moore s Law [
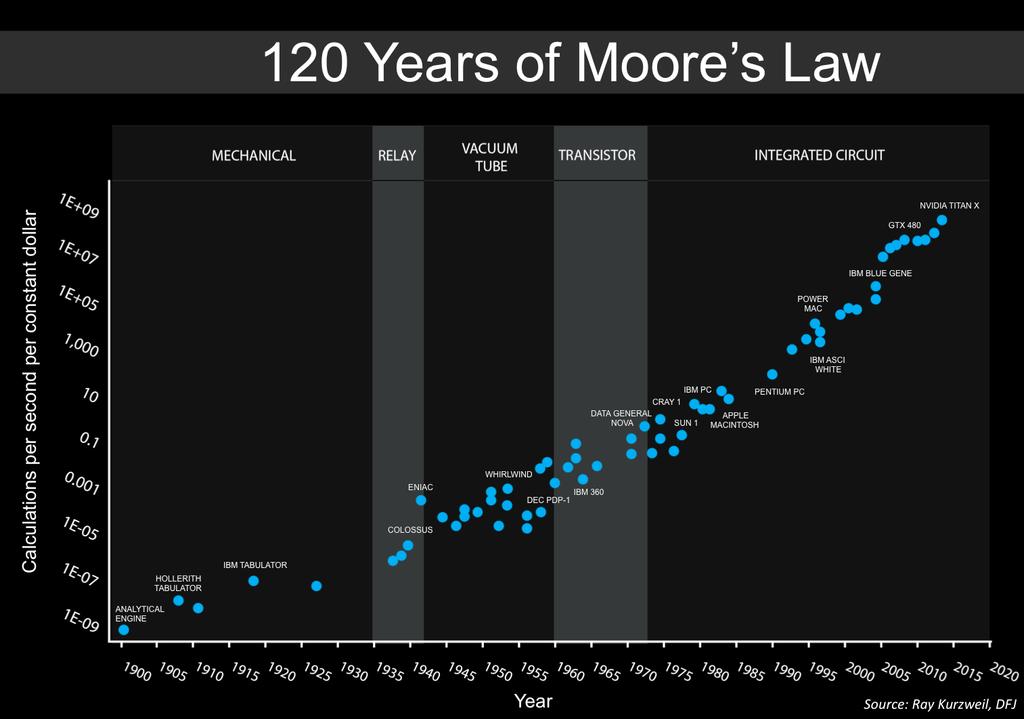
7 [
8 Modern Computation paradigms 7
9 Modern Computation Floating point operations per second (Flop) Smart phone ~ 0005 TFlops paradigms 1 Tera: 1,000 Giga 7
10 Modern Computation Floating point operations per second (Flop) Smart phone ~ 0005 TFlops paradigms 1 Tera: 1,000 Giga 1 Single computers Large Computers TFlops 7
11 Modern Computation Floating point operations per second (Flop) Smart phone ~ 0005 TFlops paradigms 1 Tera: 1,000 Giga 1 Single computers 2 Specialized hardware Large Computers TFlops Focusses on subset of operations Graphical Processing Unit (GPU), Field Programmable Gated Array (FPGA) 75 TFlops 7
12 Modern Computation Floating point operations per second (Flop) Smart phone ~ 0005 TFlops paradigms 1 Tera: 1,000 Giga 1 Single computers Large Computers TFlops 2 Specialized hardware Focusses on subset of operations Graphical Processing Unit (GPU), Field Programmable Gated Array (FPGA) 2 Distributed computation ~ TFlops (Folding@home) 75 TFlops 7

 2 Distributed computation ~100 000 TFlops")
13 Modern Computation Floating point operations per second (Flop) Smart phone ~ 0005 TFlops paradigms 1 Tera: 1,000 Giga 1 Single computers Large Computers TFlops 2 Specialized hardware Focusses on subset of operations Graphical Processing Unit (GPU), Field Programmable Gated Array (FPGA) 2 Distributed computation ~ TFlops (Folding@home) 75 TFlops 7
14 Distributed Computing 8
15 Distributed Computing Faster computers can help 8
16 Distributed Computing Faster computers can help What about a large of slow computers working together? Divide the computation into small problems 1 All (slow) computers solve a small problem at the same time 2 Combine the solution of small problems into initial solution 8
17 Distributed Computing Faster computers can help What about a large of slow computers working together? Divide the computation into small problems 1 All (slow) computers solve a small problem at the same time 2 Combine the solution of small problems into initial solution 8
18 Simple example You are tasked with counting the number of houses in Montreal 1 Centralized (single computer): Ask a marathon runner to jog around the city and count Build a system to count houses from satellite imagery 9
19 Simple example You are tasked with counting the number of houses in Montreal 1 Centralized (single computer): Ask a marathon runner to jog around the city and count Build a system to count houses from satellite imagery 2 Distributed (many computers): Ask 1,000 people to each count houses from a small geographical area Once they are done they report their result at your HQ 9
20 Tool for distributed computing (for machine learning) Apache Spark ( Builds on MapReduce ideas More flexible computation graphs High-level APIs MLlib 10
21 Outline MapReduce Fundamentals and bag-of-words example Spark Fundamentals & MLlib Live examples 11
22 MapReduce From Google engineers MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean and Sanjay Ghemawat, 2004 Now also known as (Apache) Hadoop Google built large-scale computation from commodity hardware Specific distributed interface Useful for algorithms that can be expressed using this interface 12
23 MapReduce Two types of tasks: A Map: Solve a subproblem B Reduce: Combine the results of map workers Map Reduce Initial Problem Solution 13
24 TASK: Create a document s bag-of-word representation A Map B Reduce The black dog A black cat The blue cat
25 TASK: Create a document s bag-of-word representation A Map The black dog B Reduce The black dog A black cat The blue cat A black cat The blue cat
26 TASK: Create a document s bag-of-word representation A Map The, 1 black, 1 dog, 1 The black dog A, 1 black, 1 cat, 1 B Reduce The black dog A black cat The blue cat A black cat The blue cat The, 1 blue, 1 cat, 1
27 TASK: Create a document s bag-of-word representation A Map The, 1 black, 1 dog, 1 Sort by key The black dog A black cat The blue cat The black dog A black cat The blue cat A, 1 black, 1 cat, 1 The, 1 blue, 1 cat, 1 The, 1 The, 1 black, 1 black, 1 dog, 1 cat, 1 cat, 1 B Reduce
28 TASK: Create a document s bag-of-word representation A Map The, 1 black, 1 dog, 1 Sort by key The black dog A black cat The blue cat The black dog A black cat The blue cat A, 1 black, 1 cat, 1 The, 1 blue, 1 cat, 1 The, 1 The, 1 black, 1 black, 1 dog, 1 cat, 1 cat, 1 B Reduce The, 2 black, 2 dog, 1 cat, 2
29 Some details Typically the number of subproblems is higher than the number of available machines ~linear speed-up wrt to the number of machines If a node crashes, need to recompute its subproblem Input/Output Data is read from disk when beginning Data is written to disk at the end 15
30 MapReduce is quite versatile When I was at Google the saying was: If your problem cannot be framed as MapReduce you haven t thought hard enough about it A few examples of map-reduceable problems: Sorting, filtering, distinct values, basic statistics Finding common friends, sql-like queries, sentiment analysis 16
31 MapReduce for machine learning Training linear regression Reminder: there is a closed form solution w =(X X) 1 X Y 17
32 MapReduce for machine learning Training linear regression Reminder: there is a closed form solution w =(X X) 1 X Y w =( X i X j ) 1 ( X i Y i ) ij i 17
33 MapReduce for machine learning Training linear regression Reminder: there is a closed form solution w =(X X) 1 X Y w =( X i X j ) 1 ( X i Y i ) Each term in the sums can be computer independently ij i 17
34 MapReduce for machine learning Training linear regression Reminder: there is a closed form solution w =(X X) 1 X Y w =( X i X j ) 1 ( X i Y i ) Each term in the sums can be computer independently A Map ij i X 0 X 1 17
35 MapReduce for machine learning Training linear regression Reminder: there is a closed form solution w =(X X) 1 X Y w =( X i X j ) 1 ( X i Y i ) Each term in the sums can be computer independently A Map ij i X 0 X 1 Other models we studies have a closed form solution (eg, Naive Bayes and LDA) 17
36 MapReduce for machine learning Training linear regression Reminder: there is a closed form solution w =(X X) 1 X Y w =( X i X j ) 1 ( X i Y i ) Each term in the sums can be computer independently A Map ij i X 0 X 1 Other models we studies have a closed form solution (eg, Naive Bayes and LDA) Hyper-parameter search A neural network with 2 hidden layers and 5 hidden units per layer and another with 3 hidden layers and 10 hidden units 17
37 Shortcomings of MapReduce Many models are fitted with iterative algorithms Gradient descent: 1 Find the gradient for the current set parameters 2 Update the parameters with the gradient Not ideal for MapReduce Would require several iterations of MapReduce Each time the data is read/written from/to the disk 18
38 (Apache) Spark Advantages over MapReduce Solution 1 Less restrictive computations graph (DAG instead of Map then Reduce) Initial Problem Doesn t have to write to disk in-between operations 2 Richer set of transformations map, filter, cartesian, union, intersection, distinct, etc 3 In-memory processing 19
39 Spark History Started in Berkeley s AMPLab (2009) Version Based on Resilient Distributed Datasets (RDDs) Version 20 June 2016 Version 23 February 2018 We will be using pyspark Best (current) documentation: 1 Advanced Analytics with Spark, 2nd edition (2017) 2 Project docs: 20

40 [
41 Resilient Distributed Datasets (RDDs) A data abstraction Collection of partitions Partitions are the distribution unit Operations on RDDs are (automatically) distributed RDDs support two types of operations: 1 Transformations Transform a dataset and return it 2 Actions Compute a result based on an RDD These operations can then be chained into complex execution flows 22
42 DataFrames An extra abstraction on top of RDDs Encodes rows as a set of columns Each column has a defined type Useful for (pre-processed) machine learning datasets Same name as dataframe (R) or pandasdataframe Similar type of abstraction but for distributed datasets Two types of actions (for our needs): transformers, estimators 23
43 Spark s Hello World data = sparkreadformat("libsvm")load("hdfs://") model = LogisticRegression(regParam=001)fit(data)
44 Spark s Hello World DataFrame data = sparkreadformat("libsvm")load("hdfs://") model = LogisticRegression(regParam=001)fit(data)
45 Spark s Hello World DataFrame data = sparkreadformat("libsvm")load("hdfs://") model = LogisticRegression(regParam=001)fit(data) Estimator
46 Parallel gradient descent Logistic Regression y = 1 1 +exp( w 0 w 1 x 1 w 2 x 2 w p x p ) 25
47 Parallel gradient descent Logistic Regression y = 1 1 +exp( w 0 w 1 x 1 w 2 x 2 w p x p ) No closed-form solution, can use gradients Loss(Y, X, w) w i 25
48 Parallel gradient descent Logistic Regression y = 1 1 +exp( w 0 w 1 x 1 w 2 x 2 w p x p ) No closed-form solution, can use gradients Loss(Y, X, w) w i Loss functions are often decomposable j Loss(Y j, X j, w) w i 25
49 Parallel gradient descent Logistic Regression y = 1 1 +exp( w 0 w 1 x 1 w 2 x 2 w p x p ) No closed-form solution, can use gradients Loss(Y, X, w) w i Loss functions are often decomposable j Loss(Y j, X j, w) w i Loss(Y 0, X 0, w) w i Loss(Y 1, X 1, w) w i Loss(Y 2, X 2, w) w i Loss(Y n, X n, w) w i 25
50 Demo Fitting Logistic Regression [ Dataset: Ad clicks given ad and user features 45M observations, 39 features (13 continuous, 26 categorical) [Spark: ] 26
51 Resources for (think of your project) Ask me for a account Notebook access Available kernels: python2, python3, pyspark Your account is on a google cloud cluster 27
52 Takeaways Distributed computing is useful: for large-scale data for faster computing Current frameworks (eg, spark) offer easy access to popular ML models + algorithms Useful speedups by decomposing the computation into a number of identical smaller pieces Still requires some engineering/coding 28
53 Administrative matters Final presentation In front of class or poster session? Final exam With or without documentation? 29
Distributed Machine Learning" on Spark
 Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science
 Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing
Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Scaled Machine Learning at Matroid
 Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Bringing Data to Life
 Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Rapid growth of massive datasets
 Overview Rapid growth of massive datasets E.g., Online activity, Science, Sensor networks Data Distributed Clusters are Pervasive Data Distributed Computing Mature Methods for Common Problems e.g., classification,
Overview Rapid growth of massive datasets E.g., Online activity, Science, Sensor networks Data Distributed Clusters are Pervasive Data Distributed Computing Mature Methods for Common Problems e.g., classification,
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Matrix Computations and " Neural Networks in Spark
 Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
732A54/TDDE31 Big Data Analytics
 732A54/TDDE31 Big Data Analytics Lecture 10: Machine Learning with MapReduce Jose M. Peña IDA, Linköping University, Sweden 1/27 Contents MapReduce Framework Machine Learning with MapReduce Neural Networks
732A54/TDDE31 Big Data Analytics Lecture 10: Machine Learning with MapReduce Jose M. Peña IDA, Linköping University, Sweden 1/27 Contents MapReduce Framework Machine Learning with MapReduce Neural Networks
Deep Learning Frameworks with Spark and GPUs
 Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
MLlib and Distributing the " Singular Value Decomposition. Reza Zadeh
 MLlib and Distributing the " Singular Value Decomposition Reza Zadeh Outline Example Invocations Benefits of Iterations Singular Value Decomposition All-pairs Similarity Computation MLlib + {Streaming,
MLlib and Distributing the " Singular Value Decomposition Reza Zadeh Outline Example Invocations Benefits of Iterations Singular Value Decomposition All-pairs Similarity Computation MLlib + {Streaming,
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
CS 245: Principles of Data-Intensive Systems. Instructor: Matei Zaharia cs245.stanford.edu
 CS 245: Principles of Data-Intensive Systems Instructor: Matei Zaharia cs245.stanford.edu Outline Why study data-intensive systems? Course logistics Key issues and themes A bit of history CS 245 2 My Background
CS 245: Principles of Data-Intensive Systems Instructor: Matei Zaharia cs245.stanford.edu Outline Why study data-intensive systems? Course logistics Key issues and themes A bit of history CS 245 2 My Background
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
Lecture 22 : Distributed Systems for ML
 10-708: Probabilistic Graphical Models, Spring 2017 Lecture 22 : Distributed Systems for ML Lecturer: Qirong Ho Scribes: Zihang Dai, Fan Yang 1 Introduction Big data has been very popular in recent years.
10-708: Probabilistic Graphical Models, Spring 2017 Lecture 22 : Distributed Systems for ML Lecturer: Qirong Ho Scribes: Zihang Dai, Fan Yang 1 Introduction Big data has been very popular in recent years.
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Chapter 1 - The Spark Machine Learning Library
 Chapter 1 - The Spark Machine Learning Library Objectives Key objectives of this chapter: The Spark Machine Learning Library (MLlib) MLlib dense and sparse vectors and matrices Types of distributed matrices
Chapter 1 - The Spark Machine Learning Library Objectives Key objectives of this chapter: The Spark Machine Learning Library (MLlib) MLlib dense and sparse vectors and matrices Types of distributed matrices
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
COMP6237 Data Mining Data Mining & Machine Learning with Big Data. Jonathon Hare
 COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Machine Learning With Spark
 Ons Dridi R&D Engineer 13 Novembre 2015 Centre d Excellence en Technologies de l Information et de la Communication CETIC Presentation - An applied research centre in the field of ICT - The knowledge developed
Ons Dridi R&D Engineer 13 Novembre 2015 Centre d Excellence en Technologies de l Information et de la Communication CETIC Presentation - An applied research centre in the field of ICT - The knowledge developed
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition
 Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition What s the BIG deal?! 2011 2011 2008 2010 2012 What s the BIG deal?! (Gartner Hype Cycle) What s the
Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition What s the BIG deal?! 2011 2011 2008 2010 2012 What s the BIG deal?! (Gartner Hype Cycle) What s the
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Spark & Spark SQL. High- Speed In- Memory Analytics over Hadoop and Hive Data. Instructor: Duen Horng (Polo) Chau
 Chau") CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
Python Certification Training
 Introduction To Python Python Certification Training Goal : Give brief idea of what Python is and touch on basics. Define Python Know why Python is popular Setup Python environment Discuss flow control
Introduction To Python Python Certification Training Goal : Give brief idea of what Python is and touch on basics. Define Python Know why Python is popular Setup Python environment Discuss flow control
Introduction to MapReduce
 Introduction to MapReduce April 19, 2012 Jinoh Kim, Ph.D. Computer Science Department Lock Haven University of Pennsylvania Research Areas Datacenter Energy Management Exa-scale Computing Network Performance
Introduction to MapReduce April 19, 2012 Jinoh Kim, Ph.D. Computer Science Department Lock Haven University of Pennsylvania Research Areas Datacenter Energy Management Exa-scale Computing Network Performance
Blurring the Line Between Developer and Data Scientist
 Blurring the Line Between Developer and Data Scientist Notebooks with PixieDust va barbosa va@us.ibm.com Developer Advocacy IBM Watson Data Platform WHY ARE YOU HERE? More companies making bet-the-business
Blurring the Line Between Developer and Data Scientist Notebooks with PixieDust va barbosa va@us.ibm.com Developer Advocacy IBM Watson Data Platform WHY ARE YOU HERE? More companies making bet-the-business
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Using Existing Numerical Libraries on Spark
 Using Existing Numerical Libraries on Spark Brian Spector Chicago Spark Users Meetup June 24 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm
Using Existing Numerical Libraries on Spark Brian Spector Chicago Spark Users Meetup June 24 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm
15-388/688 - Practical Data Science: Big data and MapReduce. J. Zico Kolter Carnegie Mellon University Spring 2018
 15-388/688 - Practical Data Science: Big data and MapReduce J. Zico Kolter Carnegie Mellon University Spring 2018 1 Outline Big data Some context in distributed computing map + reduce MapReduce MapReduce
15-388/688 - Practical Data Science: Big data and MapReduce J. Zico Kolter Carnegie Mellon University Spring 2018 1 Outline Big data Some context in distributed computing map + reduce MapReduce MapReduce
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
Always start off with a joke, to lighten the mood. Workflows 3: Graphs, PageRank, Loops, Spark
 Always start off with a joke, to lighten the mood Workflows 3: Graphs, PageRank, Loops, Spark 1 The course so far Cost of operations Streaming learning algorithms Parallel streaming with map-reduce Building
Always start off with a joke, to lighten the mood Workflows 3: Graphs, PageRank, Loops, Spark 1 The course so far Cost of operations Streaming learning algorithms Parallel streaming with map-reduce Building
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
2.3 Algorithms Using Map-Reduce
 28 CHAPTER 2. MAP-REDUCE AND THE NEW SOFTWARE STACK one becomes available. The Master must also inform each Reduce task that the location of its input from that Map task has changed. Dealing with a failure
28 CHAPTER 2. MAP-REDUCE AND THE NEW SOFTWARE STACK one becomes available. The Master must also inform each Reduce task that the location of its input from that Map task has changed. Dealing with a failure
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
Data Analytics on RAMCloud
 Data Analytics on RAMCloud Jonathan Ellithorpe jdellit@stanford.edu Abstract MapReduce [1] has already become the canonical method for doing large scale data processing. However, for many algorithms including
Data Analytics on RAMCloud Jonathan Ellithorpe jdellit@stanford.edu Abstract MapReduce [1] has already become the canonical method for doing large scale data processing. However, for many algorithms including
ELTMaestro for Spark: Data integration on clusters
 Introduction Spark represents an important milestone in the effort to make computing on clusters practical and generally available. Hadoop / MapReduce, introduced the early 2000s, allows clusters to be
Introduction Spark represents an important milestone in the effort to make computing on clusters practical and generally available. Hadoop / MapReduce, introduced the early 2000s, allows clusters to be
Apache SystemML Declarative Machine Learning
 Apache Big Data Seville 2016 Apache SystemML Declarative Machine Learning Luciano Resende About Me Luciano Resende (lresende@apache.org) Architect and community liaison at Have been contributing to open
Apache Big Data Seville 2016 Apache SystemML Declarative Machine Learning Luciano Resende About Me Luciano Resende (lresende@apache.org) Architect and community liaison at Have been contributing to open
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Scalable Machine Learning in R. with H2O
 Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
COMP 322: Fundamentals of Parallel Programming. Lecture 37: Distributed Computing, Apache Spark
 COMP 322: Fundamentals of Parallel Programming Lecture 37: Distributed Computing, Apache Spark Vivek Sarkar, Shams Imam Department of Computer Science, Rice University vsarkar@rice.edu, shams@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: Distributed Computing, Apache Spark Vivek Sarkar, Shams Imam Department of Computer Science, Rice University vsarkar@rice.edu, shams@rice.edu
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Python, PySpark and Riak TS. Stephen Etheridge Lead Solution Architect, EMEA
 Python, PySpark and Riak TS Stephen Etheridge Lead Solution Architect, EMEA Agenda Introduction to Riak TS The Riak Python client The Riak Spark connector and PySpark CONFIDENTIAL Basho Technologies 3
Python, PySpark and Riak TS Stephen Etheridge Lead Solution Architect, EMEA Agenda Introduction to Riak TS The Riak Python client The Riak Spark connector and PySpark CONFIDENTIAL Basho Technologies 3
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Data Analytics and Machine Learning: From Node to Cluster
 Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
MLI - An API for Distributed Machine Learning. Sarang Dev
 MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
Introduction to Apache Spark
 1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Linear Regression Optimization
 Gradient Descent Linear Regression Optimization Goal: Find w that minimizes f(w) f(w) = Xw y 2 2 Closed form solution exists Gradient Descent is iterative (Intuition: go downhill!) n w * w Scalar objective:
Gradient Descent Linear Regression Optimization Goal: Find w that minimizes f(w) f(w) = Xw y 2 2 Closed form solution exists Gradient Descent is iterative (Intuition: go downhill!) n w * w Scalar objective:
Map-Reduce. John Hughes
 Map-Reduce John Hughes The Problem 850TB in 2006 The Solution? Thousands of commodity computers networked together 1,000 computers 850GB each How to make them work together? Early Days Hundreds of ad-hoc
Map-Reduce John Hughes The Problem 850TB in 2006 The Solution? Thousands of commodity computers networked together 1,000 computers 850GB each How to make them work together? Early Days Hundreds of ad-hoc
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Why do we need graph processing?
 Why do we need graph processing? Community detection: suggest followers? Determine what products people will like Count how many people are in different communities (polling?) Graphs are Everywhere Group
Why do we need graph processing? Community detection: suggest followers? Determine what products people will like Count how many people are in different communities (polling?) Graphs are Everywhere Group
Machine learning library for Apache Flink
 Machine learning library for Apache Flink MTP Mid Term Report submitted to Indian Institute of Technology Mandi for partial fulfillment of the degree of B. Tech. by Devang Bacharwar (B2059) under the guidance
Machine learning library for Apache Flink MTP Mid Term Report submitted to Indian Institute of Technology Mandi for partial fulfillment of the degree of B. Tech. by Devang Bacharwar (B2059) under the guidance
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
We consider the general additive objective function that we saw in previous lectures: n F (w; x i, y i ) i=1
 i=1") CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
Center for Information Services and High Performance Computing (ZIH) Current trends in big data analysis: second generation data processing
 Current trends in big data analysis: second generation data processing") Center for Information Services and High Performance Computing (ZIH) Current trends in big data analysis: second generation data processing Course overview Part 1 Challenges Fundamentals and challenges
Center for Information Services and High Performance Computing (ZIH) Current trends in big data analysis: second generation data processing Course overview Part 1 Challenges Fundamentals and challenges
Data Science Bootcamp Curriculum. NYC Data Science Academy
 Data Science Bootcamp Curriculum NYC Data Science Academy 100+ hours free, self-paced online course. Access to part-time in-person courses hosted at NYC campus Machine Learning with R and Python Foundations
Data Science Bootcamp Curriculum NYC Data Science Academy 100+ hours free, self-paced online course. Access to part-time in-person courses hosted at NYC campus Machine Learning with R and Python Foundations
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
A Cloud System for Machine Learning Exploiting a Parallel Array DBMS
 2017 28th International Workshop on Database and Expert Systems Applications A Cloud System for Machine Learning Exploiting a Parallel Array DBMS Yiqun Zhang, Carlos Ordonez, Lennart Johnsson Department
2017 28th International Workshop on Database and Expert Systems Applications A Cloud System for Machine Learning Exploiting a Parallel Array DBMS Yiqun Zhang, Carlos Ordonez, Lennart Johnsson Department