A Deeply-initialized Coarse-to-fine Ensemble of Regression Trees for Face Alignment
|
|
|
- Julius Lucas
- 5 years ago
- Views:
Transcription
1 A Deeply-initialized Coarse-to-fine Ensemble of Regression Trees for Face Alignment Roberto Valle 1[ ], José M. Buenaposada 2[ ], Antonio Valdés 3, and Luis Baumela 1 1 Univ. Politécnica de Madrid, Spain. {rvalle,lbaumela}@fi.upm.es 2 Univ. Rey Juan Carlos, Spain. josemiguel.buenaposada@urjc.es 3 Univ. Complutense de Madrid, Spain. avaldes@ucm.es Abstract. In this paper we present DCFE, a real-time facial landmark regression method based on a coarse-to-fine Ensemble of Regression Trees (ERT). We use a simple Convolutional Neural Network (CNN) to generate probability maps of landmarks location. These are further refined with the ERT regressor, which is initialized by fitting a 3D face model to the landmark maps. The coarse-to-fine structure of the ERT lets us address the combinatorial explosion of parts deformation. With the 3D model we also tackle other key problems such as robust regressor initialization, self occlusions, and simultaneous frontal and profile face analysis. In the experiments DCFE achieves the best reported result in AFLW, COFW, and 300W private and common public data sets. Keywords: Face alignment, Cascaded Shape Regression, Convolutional Neural Networks, Coarse-to-fine, Occlusions, Real-time 1 Introduction Facial landmarks detection is a preliminary step for many face image analysis problems such as verification and recognition [25], attributes estimation [2], etc. The availability of large annotated data sets has recently encouraged research in this area with important performance improvements. However, it is still a challenging task especially when the faces suffer from large pose variations and partial occlusions. The top performers in the recent 300W benchmark are all based in deep regression models [20, 23, 30, 33] (see Table 1). The most prominent feature of these approaches is their robustness, due to the large receptive fields of deep nets. However, in these models it is not easy to enforce facial shape consistency or estimate self occlusions. ERT-based models [6,7,18,24], on the other hand, are easy to parallelize and implicitly impose shape consistency in their estimations. They are much more efficient than deep models and, as we demonstrate in our experiments (see Fig. 4), with a good initialization, they are also very accurate. In this paper we present a hybrid method, termed Deeply-initialized Coarseto-Fine Ensemble (DCFE). It uses a simple CNN to generate probability maps of
2 2 R. Valle, J.M. Buenaposada, A. Valdés and L. Baumela landmarks location. Hence, obtaining information about the position of individual landmarks without a globally imposed shape. Then we fit a 3D face model, thus enforcing a global face shape prior. This is the starting point of the coarseto-fine ERT regressor. The fitted 3D face model provides the regressor with a valid initial shape and information about landmarks visibility. The coarse-to-fine approach lets the ERT easily address the combinatorial explosion of all possible deformations of non-rigid parts and at the same time impose a part shape prior. The proposed method runs in real-time (32 FPS) and provides the best reported results in AFLW, COFW, and 300W private and common public data sets. 2 Related Work Face alignment has been a topic of intense research for more than twenty years. Initial successful results were based on 2D and 3D generative approaches such as the Active Appearance Models (AAM) [8] or the 3D Morphable Models [4]. More recent discriminative methods are based on two key ideas: indexing image description relative to the current shape estimate [12] and the use of a regressor whose predictions lie on the subspace spanned by the training face shapes[7], this is the so-called Cascade Shape Regressor (CSR) framework. Kazemi et al. [18] improved the original cascade framework by proposing a real-time ensemble of regression trees. Ren et al. [24] used locally binary features to boost the performance up to 3000 FPS. Burgos-Artizzu et al. [6] included occlusion information. Xiong et al. [31,32] use SIFT features and learn a linear regressor dividing the search space into individual regions with similar gradient directions. Overall, the CSR approach is very sensitive to the starting point of the regression process. An important part of recent work revolves around how to find good initialisations [38,37]. In this paper we use the landmark probability maps produced by a CNN to find a robust starting point for the CSR. Current state-of-the-art methods in face alignment are based on CNNs. Sun et al. [26] were pioneers to apply a three-level CNN to obtain accurate landmark estimation. Zhang et al. [36] proposed a multi-task solution to deal with face alignment and attributes classification. Lv et al. s [23] uses global and local face parts regressors for fine-grained facial deformation estimation. Yu et al. [34] transforms the landmarks rather than the input image for the refinement cascade. Trigeorgis et al. [27] and Xiao et al. [30] are the first approaches that fuse the feature extraction and regression steps of CSR into a recurrent neural network trained end-to-end. Kowalski et al. [20] and Yang et al. [33] are among the top performers in the Menpo competition [35]. Both use a global similarity transform to normalize landmark locations followed by a VGG-based and a Stacked Hourglass network respectively to regress the final shape. The large receptive fields of deep neural nets convey these approaches with a high degree of robustness to face rotation, scale and deformation. However, it is not clear how to impose facial shape consistency on the estimated set of landmarks. Moreover, to achieve accuracy they resort to a cascade of deep models that progressively refine the estimation, thus incrementing the computational requirements.



3 A Deeply-initialized Coarse-to-fine Ensemble for Face Alignment 3 There is also an increasing number of works based on 3D face models. In the simplest case they fit a mean model to the estimated image landmarks position [19] or jointly regress the pose and shape of the face [17,29]. These approaches provide 3D pose information that may be used to estimate landmark self-occlusions or to train simpler regressors specialized in a given head orientation. However, building and fitting a 3D face model is a difficult task and the results of the full 3D approaches in current benchmarks are not as good as those described above. Our proposal tries to leverage the best features of the previous approaches. Using a CCN-based initialization we inherit the robustness of deep models. Like the simple 3D approaches we fit a rigid 3D face model to initialize the ERT and estimate global face orientation to address self occlusions. Finally, we use an ERT within a coarse-to-fine framework to achieve accuracy and efficiency. 3 Deeply Initialized Coarse-to-Fine Ensemble In this section, we present the Deeply-initialized Coarse-to-fine Ensemble method (DCFE). It consists of two main steps: CNN-based rigid face pose computation and ERT-based non-rigid face deformation estimation, both shown in Fig. 1. Fig. 1: DCFE framework diagram. GS, Max and POSIT represent the Gaussian smoothing filter, the maximum of each probability map and the 3D pose estimation respectively. 3.1 Rigid pose computation ERT-based regressors require an acceptable initialization to converge to a good solution. We propose the use of face landmark location probability maps like [3,
4 4 R. Valle, J.M. Buenaposada, A. Valdés and L. Baumela 9, 30] to generate plausible shape initialization candidates. We have modified Honari et al. s[16] RCN introducing a loss function to handle missing landmarks, thus enabling semi-supervised training. We train this CNN to obtain a set of probability maps, P(I), indicating the position of each landmark in the input image (see Fig. 1). The maximum of each smoothed probability map determines our initial landmark positions. Note in Fig. 1 that these predictions are sensitive to occlusions and may not be a valid face shape. Compared to typical CNNbased approaches, e.g., [33], our CNN is simpler, since we only require a rough estimation of landmark locations. To start the ERT with a plausible face, we compute the initial shape by fitting a rigid 3D head model to the estimated 2D landmarks locations. To this endweusethesoftpositalgorithmproposedbydavidet al.[10].asaresult,we project the 3D model onto the image using the estimated rigid transformation. This provides the ERT with a rough estimation of the scale, translation and 3D pose of the target face (see Fig. 1). Let x 0 = g 0 (P(I)) be the initial shape, the output of the initialization function g 0 after processing the input image I. In this case x 0 is a L 2 vector with L 2D landmarks coordinates. With our initialization we ensure that x 0 is a valid face shape. This guarantees that the predictions in the next step of the algorithm will also be valid face shapes [7]. 3.2 ERT-based non-rigid shape estimation Let S = {s i } N be the set of train face shapes, where s i = (I i,x g i,vg i,wg i,x0 i ). Each training shape s i has its own: training image, I i ; ground truth shape, x g i ; ground truth visibility label, v g i ; annotated landmark label, wg i (1 annotated and 0 missing) and initial shape for regression training, x 0 i. The ground truth (or target) shape, x g i, is a L 2 vector with the L landmarks coordinates. The L 1 vector v g i holds the visibility binary label of each landmark. If the k-th component of v g, v g (k) = 1 then the k-th landmark is visible. In our implementation we use shape-indexed features [21], φ(p(i i ),x t i,wg i ), that depend on the current shape x t i of the landmarks in image I i and whether they are annotated or not, w t i. We divide the regression process into T stages and learn an ensemble of K regression trees for the t-th stage, C t (f i ) = x t 1 + K k=1 g k(f i ), where f i = φ(p(i),x t 1,w g i ) and xj are the coordinates of the landmarks estimated in j-th stage (or the initialization coordinates, x 0, in the first stage). To train the whole ERT we use the N training samples in S to generate an augmented training set, S A with cardinality N A = S A. From each training shape s i we generate additional training samples by changing their initial shape. To this end we randomly sample new candidate landmark positions from the smoothed probability maps to generate the new initial shapes (see section 3.1). We incorporate the visibility label v with the shape to better handle occlusions (see Fig. 5c) in a way similar to Burgos-Artizzu et al. [6] and naturally handling partially labelled training data like Kazemi et al. [18] using groundtruth annotation labels w {0, 1}. Each initial shape is progressively refined by
.")
} N A all current shapes and corresponding visibility vectors for all training data.")
,xt 1 i,w g i )}N A,v t 1 i )} N A )+Ct v (f i)} N A Learn coarse-to-fine regressor, C v t, from S A, F A and U t 1 = {(x t 1 i Update current shapes and")



5 A Deeply-initialized Coarse-to-fine Ensemble for Face Alignment 5 estimating a shape and visibility increments C v t (φ(p(i i ),x t 1 i,w g i )) where xt 1 i represents the current shape of the i-th sample (see Algorithm 1). Ct v is trained to minimize only the landmark position errors but on each tree leaf, in addition to the mean shape, we also output the mean of all training shapes visibilities, as the set of v g i, that belong to that node. We define U t 1 = {(x t 1 i,v t 1 i )} N A all current shapes and corresponding visibility vectors for all training data. Algorithm 1 Training an Ensemble of Regression Trees Input: Training data S, T Generate augmented training samples set, S A for t=1 to T do Extract features for all samples, F A = {f i} N A = {φ(p(ii),xt 1 i,w g i )}N A,v t 1 i )} N A )+Ct v (f i)} N A Learn coarse-to-fine regressor, C v t, from S A, F A and U t 1 = {(x t 1 i Update current shapes and visibilities, {(x t i,v t i) = (x t 1 i end for Output: {C v t } T t=1,v t 1 i Compared with conventional ERT approaches, our ensemble is simpler. It will require fewer trees because we only have to estimate the non-rigid face shape deformation, since the 3D rigid component has been estimated in the previous step. In the following, we describe the details of our ERT. Initial shapes for regression. The selection of the starting point in the ERT is fundamental to reach a good solution. The simplest choice is the mean of the ground truth training shapes, x 0 = N xg i /N. However, such a poor initialization leads to wrong alignment results in test images with large pose variations. Alternative strategies are running the ERT several times with different initializations and taking the median [6], initializing with other ground truth shapes x 0 i xg j where i j [18] or randomly deforming the initial shape [20]. In our approach we initialize the ERT using the algorithm described in section 3.1, that provides a robust and approximate shape for initialization (see Fig. 2). Hence, the ERT only needs to estimate the non-rigid component of face pose. Fig. 2: Worst initial shapes for the 300W training subset.
6 6 R. Valle, J.M. Buenaposada, A. Valdés and L. Baumela Feature Extraction. ERT efficiency depends on the feature extraction step. In general, descriptor features such as SIFT used by [31, 38] improve face alignment results, but have higher computational cost compared to simpler features such as plain pixel value differences [7,6,18,24]. In our case, a simple feature suffices, since shape landmarks are close to their ground truth location. In DCFE we use the probability maps P(I) to extract features for the cascade. To this end, we select a landmark l and its associated probability map P l (I). The feature is computed as the difference between two pixels values in P l (I) from a FREAK descriptor pattern [1] around l. Our features are similar to those in Lee et al. s [21]. However, ours are defined on the probability maps, P(I), instead of the image, I. We let the training algorithm select the most informative landmark and pair of pixels in each iteration. Learn a coarse-to-fine regressor. To train the t-th stage regressor, C v t, we fit an ERT. Thus, the goal is to sequentially learn a series of weak learners to greedily minimize the regression loss function: N A L t (S A,F A,U t 1 ) = w g i (xg i xt 1 i K g k (f i )) 2, (1) where is the Hadamard product. There are different ways of minimizing Equation 1. Kazemi et al.[18] present a general framework based on Gradient Boosting for learning an ensemble of regression trees. Lee et al. [21] establish an optimization method based on Gaussian Processes also learning an ensemble of regression trees but outperforming previous literature by reducing the overfitting. A crucial problem when training a global face landmark regressor is the lack of examples showing all possible combinations of face parts deformations. Hence, these regressors quickly overfit and generalize poorly to combinations of part deformations not present in the training set. To address this problem we introduce the coarse-to-fine ERT architecture. Thegoalistobeabletocopewithcombinationsoffacepartdeformationsnot seen during training. A single monolithic regressor is not able to estimate these local deformations (see difference between Fig. 3b and Fig. 3c). Our algorithm is agnostic in the number of parts or levels of the coarse-to-fine estimation. Algorithm 2 details the training of P face parts regressors (each one with a subset of the landmarks) to build a coarse-to-fine regressor. Note that x 0 i and v 0 i in this context are the shape and visibility vectors from the last regressor output (e.g., the previous part regressor or a previous full stage regressor). In ourimplementationweusep = 1(alllandmarks)withthefirstK 1 regressorsand in the last K 2 regressors the number of parts is increased to P = 10 (left/right eyebrow, left/right eye, nose, top/bottom mouth, left/right ear and chin), see all the parts connected by lines in Fig. 3c. k=1 Fit a regression tree. The training objective for the k-th regression tree is to minimize the sum of squared residuals, taking into account the annotated
7 A Deeply-initialized Coarse-to-fine Ensemble for Face Alignment 7 Algorithm 2 Training P parts regressors Input: S A, F A,{(x 0 i,v 0 i)} N A,ν,K,P for k=1 to K do for p=1 to P do // is the Hadamard product, (p) selects elements of a vector in that part Compute shape residuals {r k i(p) = w g i (p) (xg i (p) xk 1 i (p)} N A Fit a regression tree g p k using the residuals {rk i(p)} and F A(p) // ν is the shrinkage factor to scale the contribution of each tree Update samples {(x k i(p),v k i(p)) = (x k 1 i (p),v k 1 i (p))+ν g p k (fi(p))}n A end for end for Output: P part regressors {C p } P p=1, with K weak learners each C p = {g p k }K k=1 landmark labels: N A N A E k = r k i 2 = w g i (xg i xk 1 i ) 2. (2) We learn each regression binary tree by recursively splitting the training set into the left (l) and right (r) child nodes. The tree node split function is designed to minimize E k from Equation 2 in the selected landmark. To train a regression tree node we randomly generate a set of candidate split functions, each of them involving four parameters θ = (τ,p 1,p 2,l), where p 1 and p 2 are pixels coordinates on a fixed FREAK structure around the l-th landmark coordinates in x k 1 i. The feature value corresponding to θ for the i-th training sample is f i (θ) = P l (I i )[p 1 ] P l (I i )[p 2 ], the difference of probability values in the maps for the given landmark. Finally, we compute the split function thresholding the feature value, f i (θ) > τ. Given N S A the set of training samples at a node, fitting a tree node for the k-th tree, consists of finding the parameter θ that minimizes E k (N,θ) arg mine k (N,θ) = argmin θ θ b {l,r} s N θ,b r k s µ θ,b 2 (3) where N θ,l and N θ,r are, respectively, the samples sent to the left and right child nodes due to the decision induced by θ. The mean residual µ θ,b for a candidate split function and a subset of training data is given by µ θ,b = 1 N θ,b s N θ,b r k s (4) Once we know the optimal split each leaf node stores the mean residual, µ θ,b, as the output of the regression for any example reaching that leaf.
8 8 R. Valle, J.M. Buenaposada, A. Valdés and L. Baumela 4 Experiments To train and evaluate our proposal, we perform experiments with 300W, COFW and AFLW that are considered the most challenging public data sets. In addition, we also show qualitative face alignment results with the Menpo competition images. 300W. It provides bounding boxes and 68 manually annotated landmarks. We follow the most established approach and divide the 300W annotations into 3148 training and 689 testing images (public competition). Evaluation is also performed on the newly updated 300W private competition. Menpo. Consist of 8979 training and testing faces containing semi-frontal and 4253 profile images. The images were annotated with the previous set of 68 landmarks but without facial bounding boxes. COFW. It focuses on occlusion. Commonly, there are 1345 training faces in total. The testing set is made of 507 images. The annotations include the landmark positions and the binary occlusion labels for 29 points. AFLW. Provides an extensive collection of in-the-wild faces, with 21 facial landmarks annotated depending on their visibility. We have found several annotations errors and, consequently, removed these faces from our experiments. From the remaining faces we randomly choose images for training/validation and 4828 instances for testing. 4.1 Evaluation We use the Normalized Mean Error (NME) as a metric to measure the shape estimation error ( NME = 100 N 1 L ( w g N w g i (l) x i(l) x g i (l) ) ) i. (5) 1 d i l=1 It computes the euclidean distance between the ground-truth and estimated landmark positions normalized by d i. We report our results using different values of d i : the distance between the eye centres (pupils), the distance between the outer eye corners (corners) and the bounding box size (height). In addition, we also compare our results using Cumulative Error Distribution (CED) curves. We calculate AUC ε as the area under the CED curve for images with an NME smaller than ε and FR ε as the failure rate representing the percentage of testing faces with NME greater than ε. We use precision/recall percentages to compare occlusion prediction. To train our algorithm we shuffle the training set and split it into 90% trainset and 10% validation-set. 4.2 Implementation All experiments have been carried out with the settings described in this section. We train from scratch the CNN selecting the model parameters with lowest


9 A Deeply-initialized Coarse-to-fine Ensemble for Face Alignment 9 validation error. We crop faces using the original bounding boxes annotations enlarged by 30%. We generate different training samples in each epoch by applying random in plane rotations between ±30, scale changes by ±15% and translations by ±5% of bounding box size, randomly mirroring images horizontally and generating random rectangular occlusions. We use Adam stochastic optimization with β 1 = 0.9, β 2 = and ǫ = 1e 8 parameters. We train during 400 epochs with an initial learning rate α = 0.001, without decay and a batch size of 35 images. In the CNN the cropped input face is reduced from to 1 1 pixels gradually dividing by half their size across B = 8 branches applying a 2 2 pooling 4. All layers contain 64 channels to describe the required landmark features. We train the coarse-to-fine ERT with the Gradient Boosting algorithm [15]. It requires T = 20 stages of K = 50 regression trees per stage. The depth of trees is set to 5. The number of tests to choose the best split parameters, θ, is set to 200. We resize each image to set the face size to 160 pixels. For feature extraction, the FREAK pattern diameter is reduced gradually in each stage (i.e., in the last stages the pixel pairs for each feature are closer). We generate several initializations for each face training image to create a set of at least N A = samples to train the cascade. To avoid overfitting we use a shrinkage factor ν = 0.1 in the ERT. Our regressor triggers the coarse-to-fine strategy once the cascade has gone through 40% of the stages (see Fig. 3a). (a) NME evolution (b) Monolithic (c) Coarse-to-fine Fig. 3: Example of a monolithic ERT regressor vs our coarse-to-fine approach. (a) Evolution of the error through the different stages in the cascade (dashed line represents the algorithm without the coarse-to-fine improvement); (b) predicted shape with a monolithic regressor; (c) predicted shape with our coarse-to-fine approach. For the Mempo data set training the CNN and the coarse-to-fine ensemble of trees takes 48 hours using a NVidia GeForce GTX 1080 (8GB) GPU and an Intel Xeon E at 3.50GHz (6 cores/12 threads, 32 GB of RAM). At runtime our method process test images on average at a rate of 32 FPS, where the CNN takes 25 ms and the ERT 6.25 ms per face image using C++, Tensorflow and OpenCV libraries. 4 Except when the 5 5 images are reduced to 2 2 where we apply a 3 3 pooling
10 10 R. Valle, J.M. Buenaposada, A. Valdés and L. Baumela 4.3 Results Here we compare our algorithm, DCFE, with the best reported results for each dataset.tothisendwehavetrainedourmodelandthoseindan[20],rcn[16], cgprt [21], RCPR [6] and ERT [18] with the code provided by the authors and the same settings including same training, validation and bounding boxes. In Fig. 4 we plot the CED curves and we provide AUC 8 and FR 8 values for each algorithm. Also, for comparison with other methods in Tables 1, 2, 3, 4 we show the original results published in the literature Images proportion DCFE (45.71) (7.26) cgprt (39.08) (14.08) Images proportion DCFE (52.43) (1.83) DAN (46.96) (2.67) RCN (43.71) (2.50) 0.2 DAN (39.00) (8.27) RCN (38.56) (11.61) 0.2 cgprt (41.32) (12.83) Fan (38.31) (16.33) ERT (31.20) (22.21) Deng (35.79) (12.17) RCPR (28.91) (21.48) ERT (32.35) (19.33) NME (%) NME (%) (a) 300W public (b) 300W private Images proportion Images proportion DCFE (35.86) (7.30) 0.2 DCFE (47.17) (3.38) RCN (28.89) (13.61) RCN (44.70) (4.04) ERT (21.42) (29.19) ERT (27.96) (17.85) NME (%) NME (%) (c) COFW (d) AFLW Fig. 4: Cumulative error distributions sorted by AUC. In Tables 1 and 2 we provide the results of the state-of-the-art methods in the 300W public and private data sets. Our approach obtains the best performance in the private (see Table 2) and in the common and full subsets of the 300W competition public test set (see Table 1). This is due to the excellent accuracy achieved by the coarse-to-fine ERT scheme enforcing valid face shapes. In the challenging subset of the 300W competition public test set SHN [33] achieves better results. This is caused by errors in initializing the ERT in a few images with very large scale and pose variations, that are not present in the training set. Our method exhibits superior capability in handling cases with low error since we achieve the best NME results in the 300W common subset by the largest margin. The CED curves in Figs. 4a and 4b show that DCFE is better than all
11 A Deeply-initialized Coarse-to-fine Ensemble for Face Alignment 11 its competitors that provide code in all types of images in both data sets. In the 300W private challenge we obtain the best results outperforming Deng et al. [11] and Fan et al. [13] that were the academia and industry winners of the competition (see Fig. 4b). Method Common Challenging Full pupils corners pupils corners pupils corners NME NME NME NME NME NME AUC 8 FR 8 RCPR [6] ESR [7] SDM [31] ERT [18] LBF [24] cgprt [21] CFSS [38] DDN [34] TCDCN [36] MDM [27] RCN [16] DAN [20] TSR [23] RAR [30] SHN [33] DCFE Table 1: Error of face alignment methods on the 300W public test set. We may appreciate the improvement achieved by the ERT by comparing the results of DCFE in the full subset of 300W, 4.55, with Honari s baseline RCN [16], It represents an 16% improvement. The coarse-to-fine strategy in our ERT only affects difficult cases, with rare facial part combinations. Zoomingin Figs. 3b and 3c you may appreciate how it improves the adjustment of the cheek and mouth. Although it is a crucial step to align local parts properly, the global NME is only marginally affected. Table 3 and Fig. 4c compare the performance of our model and baselines using the COFW data set. We obtain the best results (i.e., NME 5.27) establishing a new state-of-the-art without requiring a sophisticated network, which demonstrates the importance of preserving the facial shape and the robustness of our framework to severe occlusions. In terms of landmark visibility, we have obtained comparable performance with previous methods. In Table 4 and Fig. 4d we show the results with AFLW. This is a challenging data set not only because of its size, but also because of the number of samples with self-occluded landmarks that are not annotated. This is the reason for the small number of competitors in Fig. 4d, very few approaches allow training with
12 12 R. Valle, J.M. Buenaposada, A. Valdés and L. Baumela Method Indoor Outdoor Full corners corners corners NME AUC 8 FR 8 NME AUC 8 FR 8 NME AUC 8 FR 8 ESR [7] cgprt [21] CFSS [38] MDM [27] DAN [20] SHN [33] DCFE Table 2: Error of face alignment methods on the 300W private test set. missing data. Although the results in Table 4 are not strictly comparable because each paper uses its own train and test subsets, we get a NME of 2.17 that again establishes a new state-of-the-art, considering that [37, 14, 23] do not use the two most difficult landmarks, the ones in the ears. Method pupils occlusion NME AUC 8 FR 8 precision/recall ESR [7] RCPR [6] /40 TCDCN [36] RAR [30] DAC-CSR [14] Wu et al. [28] /49.11 SHN [33] DCFE /49.57 Table 3: COFW results. Method height NME ESR [7] 4.35 CFSS [38] 3.92 RCPR [6] 3.73 Bulat et al. [5] 2.85 CCL [37] 2.72 DAC-CSR [14] 2.27 TSR [23] 2.17 DCFE 2.17 Table 4: AFLW results. Menpo test annotations have not been released, but we have processed their testing images to visually perform an analysis of the errors. In comparison with many other approaches our algorithm evaluates in both subsets training a unique semi-supervised model through the 68 (semi-frontal) and 39 (profile) landmark annotations all together. We detect test faces using the public Single Shot Detector [22] from OpenCV. We manually filter the detected face bounding boxes to reduce false positives and improve the accuracy. In Fig. 5 we present some qualitative results for all data sets, including Menpo.
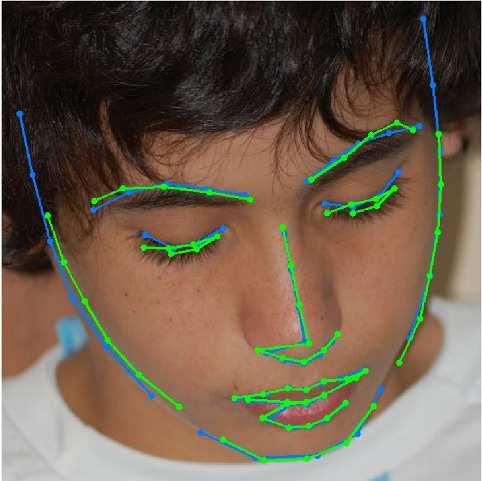




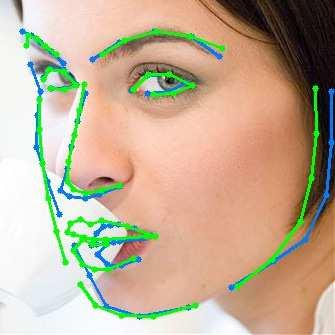




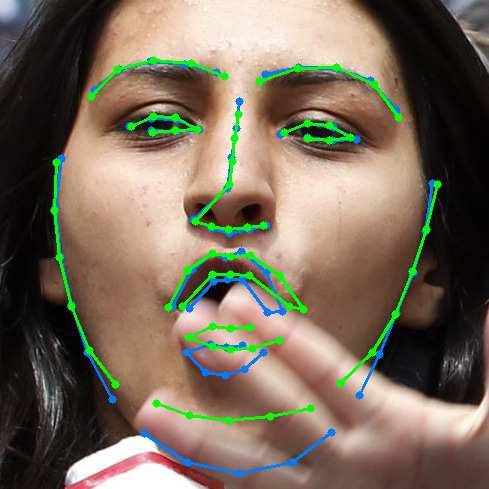















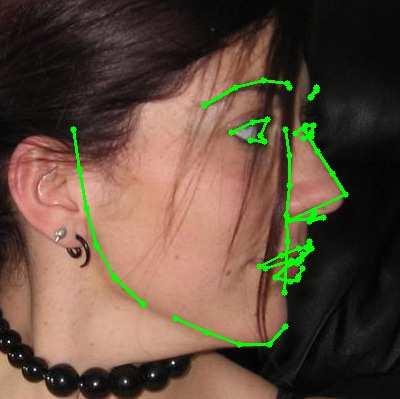

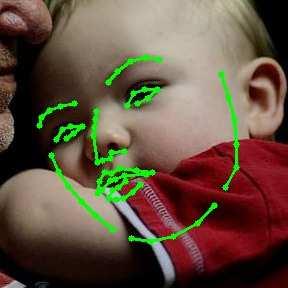

13 A Deeply-initialized Coarse-to-fine Ensemble for Face Alignment 13 (a) 300W public (b) 300W private (c) COFW (d) AFLW (e) Menpo Fig. 5: Representative results using DCFE in 300W, COFW, AFLW and Menpo testing subsets. Blue colour represents ground truth, green and red colours point out visible and non-visible shape predictions respectively.
14 14 R. Valle, J.M. Buenaposada, A. Valdés and L. Baumela 5 Conclusions In this paper we have introduced DCFE, a robust face alignment method that leverages on the best features of the three main approaches in the literature: 3D face models, CNNs and ERT. The CNN provides robust landmark estimations with no face shape enforcement. The ERT is able to enforce face shape and achieve better accuracy in landmark detection, but it only converges when properly initialized. Finally, 3D models exploit face orientation information to improve self-occlusion estimation. DCFE combines CNNs and ERT by fitting a 3D model to the initial CNN prediction and using it as initial shape of the ERT. Moreover, the 3D reasoning capability allows DCFE to easily handle self occlusions and deal with both frontal and profile faces. Once we have solved the problem of ERT initialization, we can exploit its benefits. Namely, we are able to train it in a semi-supervised way with missing landmarks. We can also estimate landmark visibility due to occlusions and we can parallelize the execution of the regression trees in each stage. We have additionally introduced a coarse-to-fine ERT that is able to deal with the combinatorial explosion of local parts deformation. In this case, the usual monolithic ERT will perform poorly when fitting faces with combinations of facial part deformations not present in the training set. In the experiments we have shown that DCFE runs in real-time improving, as far as we know, the state-of-the-art performance in 300W, COFW and AFLW data sets. Our approach is able to deal with missing and occluded landmarks allowing us to train a single regressor for both full profile and semi-frontal images in the Mempo and AFLW data sets. Acknowledgments: The authors thank Pedro López Maroto for his help implementing the CNN. They also gratefully acknowledge computing resources provided by the Super-computing and Visualization Center of Madrid (CeSViMa) and funding from the Spanish Ministry of Economy and Competitiveness under project TIN C2-2-R. José M. Buenaposada acknowledges the support of Computer Vision and Image Processing research group (CVIP) from Universidad Rey Juan Carlos.
15 References A Deeply-initialized Coarse-to-fine Ensemble for Face Alignment Alahi, A., Ortiz, R., Vandergheynst, P.: FREAK: fast retina keypoint. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2012) 2. Bekios-Calfa, J., Buenaposada, J.M., Baumela, L.: Robust gender recognition by exploiting facial attributes dependencies. Pattern Recognition Letters (PRL) 36, (2014) 3. Belhumeur, P.N., Jacobs, D.W., Kriegman, D.J., Kumar, N.: Localizing parts of faces using a consensus of exemplars. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2011) 4. Blanz, V., Vetter, T.: Face recognition based on fitting a 3d morphable model. IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI) (2003) 5. Bulat, A., Tzimiropoulos, G.: Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources. In: Proc. International Conference on Computer Vision (ICCV) (2017) 6. Burgos-Artizzu, X.P., Perona, P., Dollar, P.: Robust face landmark estimation under occlusion. In: Proc. International Conference on Computer Vision (ICCV) (2013) 7. Cao, X., Wei, Y., Wen, F., Sun, J.: Face alignment by explicit shape regression. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2012) 8. Cootes, T.F., Edwards, G.J., Taylor, C.J.: Active appearance models. In: Proc. European Conference on Computer Vision (ECCV) (1998) 9. Dantone, M., Gall, J., Fanelli, G., Gool, L.V.: Real-time facial feature detection using conditional regression forests. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2012) 10. David, P., DeMenthon, D., Duraiswami, R., Samet, H.: Softposit: Simultaneous pose and correspondence determination. International Journal of Computer Vision (IJCV) 59(3), (2004) 11. Deng, J., Liu, Q., Yang, J., Tao, D.: CSR: multi-view, multi-scale and multicomponent cascade shape regression. Image and Vision Computing (IVC) 47, (2016) 12. Dollar, P., Welinder, P., Perona, P.: Cascaded pose regression. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2010) 13. Fan, H., Zhou, E.: Approaching human level facial landmark localization by deep learning. Image and Vision Computing (IVC) 47, (2016) 14. Feng, Z., Kittler, J., Christmas, W.J., Huber, P., Wu, X.: Dynamic attentioncontrolled cascaded shape regression exploiting training data augmentation and fuzzy-set sample weighting. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017) 15. Hastie, T., Tibshirani, R., Friedman, J.H.: The Elements of Statistical Learning. Springer (2009) 16. Honari, S., Yosinski, J., Vincent, P., Pal, C.J.: Recombinator networks: Learning coarse-to-fine feature aggregation. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016) 17. Jourabloo, A., Ye, M., Liu, X., Ren, L.: Pose-invariant face alignment with a single CNN. In: Proc. International Conference on Computer Vision (ICCV) (2017) 18. Kazemi, V., Sullivan, J.: One millisecond face alignment with an ensemble of regression trees. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2014)
16 16 R. Valle, J.M. Buenaposada, A. Valdés and L. Baumela 19. Kowalski, M., Naruniec, J.: Face alignment using k-cluster regression forests with weighted splitting. IEEE Signal Processing Letters 23(11), (2016) 20. Kowalski, M., Naruniec, J., Trzcinski, T.: Deep alignment network: A convolutional neural network for robust face alignment. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2017) 21. Lee, D., Park, H., Yoo, C.D.: Face alignment using cascade gaussian process regression trees. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015) 22. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.E., Fu, C., Berg, A.C.: SSD: single shot multibox detector. In: Proc. European Conference on Computer Vision (ECCV) (2016) 23. Lv, J., Shao, X., Xing, J., Cheng, C., Zhou, X.: A deep regression architecture with two-stage re-initialization for high performance facial landmark detection. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017) 24. Ren, S., Cao, X., Wei, Y., Sun, J.: Face alignment at 3000 fps via regressing local binary features. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2014) 25. Soltanpour, S., Boufama, B., Wu, Q.M.J.: A survey of local feature methods for 3D face recognition. Pattern Recognition (PR) 72, (2017) 26. Sun, Y., Wang, X., Tang, X.: Deep convolutional network cascade for facial point detection. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2013) 27. Trigeorgis, G., Snape, P., Nicolaou, M.A., Antonakos, E., Zafeiriou, S.: Mnemonic descent method: A recurrent process applied for end-to-end face alignment. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016) 28. Wu, Y., Ji, Q.: Robust facial landmark detection under significant head poses and occlusion. In: Proc. International Conference on Computer Vision (ICCV) (2015) 29. Xiao, S., Feng, J., Liu, L., Nie, X., Wang, W., Yan, S., Kassim, A.A.: Recurrent 3d- 2d dual learning for large-pose facial landmark detection. In: Proc. International Conference on Computer Vision (ICCV) (2017) 30. Xiao, S., Feng, J., Xing, J., Lai, H., Yan, S., Kassim, A.A.: Robust facial landmark detection via recurrent attentive-refinement networks. In: Proc. European Conference on Computer Vision (ECCV) (2016) 31. Xiong, X., la Torre, F.D.: Supervised descent method and its applications to face alignment. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2013) 32. Xiong, X., la Torre, F.D.: Global supervised descent method. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015) 33. Yang, J., Liu, Q., Zhang, K.: Stacked hourglass network for robust facial landmark localisation. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2017) 34. Yu, X., Zhou, F., Chandraker, M.: Deep deformation network for object landmark localization. In: Proc. European Conference on Computer Vision (ECCV) (2016) 35. Zafeiriou, S., Trigeorgis, G., Chrysos, G., Deng, J., Shen, J.: The menpo facial landmark localisation challenge: A step towards the solution. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2017) 36. Zhang, Z., Luo, P., Loy, C.C., Tang, X.: Facial landmark detection by deep multitask learning. In: Proc. European Conference on Computer Vision (ECCV) (2014)
17 A Deeply-initialized Coarse-to-fine Ensemble for Face Alignment Zhu, S., Li, C., Change, C., Tang, X.: Unconstrained face alignment via cascaded compositional learning. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016) 38. Zhu, S., Li, C., Loy, C.C., Tang, X.: Face alignment by coarse-to-fine shape searching. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Robust FEC-CNN: A High Accuracy Facial Landmark Detection System
 Robust FEC-CNN: A High Accuracy Facial Landmark Detection System Zhenliang He 1,2 Jie Zhang 1,2 Meina Kan 1,3 Shiguang Shan 1,3 Xilin Chen 1 1 Key Lab of Intelligent Information Processing of Chinese Academy
Robust FEC-CNN: A High Accuracy Facial Landmark Detection System Zhenliang He 1,2 Jie Zhang 1,2 Meina Kan 1,3 Shiguang Shan 1,3 Xilin Chen 1 1 Key Lab of Intelligent Information Processing of Chinese Academy
Locating Facial Landmarks Using Probabilistic Random Forest
 2324 IEEE SIGNAL PROCESSING LETTERS, VOL. 22, NO. 12, DECEMBER 2015 Locating Facial Landmarks Using Probabilistic Random Forest Changwei Luo, Zengfu Wang, Shaobiao Wang, Juyong Zhang, and Jun Yu Abstract
2324 IEEE SIGNAL PROCESSING LETTERS, VOL. 22, NO. 12, DECEMBER 2015 Locating Facial Landmarks Using Probabilistic Random Forest Changwei Luo, Zengfu Wang, Shaobiao Wang, Juyong Zhang, and Jun Yu Abstract
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Intensity-Depth Face Alignment Using Cascade Shape Regression
 Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
OVer the last few years, cascaded-regression (CR) based
 based") 1 Random Cascaded-Regression Copse for Robust Facial Landmark Detection Zhen-Hua Feng 1,2, Student Member, IEEE, Patrik Huber 2, Josef Kittler 2, Life Member, IEEE, William Christmas 2, and Xiao-Jun Wu
1 Random Cascaded-Regression Copse for Robust Facial Landmark Detection Zhen-Hua Feng 1,2, Student Member, IEEE, Patrik Huber 2, Josef Kittler 2, Life Member, IEEE, William Christmas 2, and Xiao-Jun Wu
A Fully End-to-End Cascaded CNN for Facial Landmark Detection
 2017 IEEE 12th International Conference on Automatic Face & Gesture Recognition A Fully End-to-End Cascaded CNN for Facial Landmark Detection Zhenliang He 1,2 Meina Kan 1,3 Jie Zhang 1,2 Xilin Chen 1 Shiguang
2017 IEEE 12th International Conference on Automatic Face & Gesture Recognition A Fully End-to-End Cascaded CNN for Facial Landmark Detection Zhenliang He 1,2 Meina Kan 1,3 Jie Zhang 1,2 Xilin Chen 1 Shiguang
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE. Chubu University 1200, Matsumoto-cho, Kasugai, AICHI
 FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
One Millisecond Face Alignment with an Ensemble of Regression Trees
 One Millisecond Face Alignment with an Ensemble of Regression Trees Vahid Kazemi and Josephine Sullivan KTH, Royal Institute of Technology Computer Vision and Active Perception Lab Teknikringen 14, Stockholm,
One Millisecond Face Alignment with an Ensemble of Regression Trees Vahid Kazemi and Josephine Sullivan KTH, Royal Institute of Technology Computer Vision and Active Perception Lab Teknikringen 14, Stockholm,
Deep Alignment Network: A convolutional neural network for robust face alignment
 Deep Alignment Network: A convolutional neural network for robust face alignment Marek Kowalski, Jacek Naruniec, and Tomasz Trzcinski Warsaw University of Technology m.kowalski@ire.pw.edu.pl, j.naruniec@ire.pw.edu.pl,
Deep Alignment Network: A convolutional neural network for robust face alignment Marek Kowalski, Jacek Naruniec, and Tomasz Trzcinski Warsaw University of Technology m.kowalski@ire.pw.edu.pl, j.naruniec@ire.pw.edu.pl,
arxiv: v2 [cs.cv] 10 Aug 2017
![arxiv: v2 [cs.cv] 10 Aug 2017](/thumbs/74/69722894.jpg "arxiv: v2 [cs.cv] 10 Aug 2017") Deep Alignment Network: A convolutional neural network for robust face alignment Marek Kowalski, Jacek Naruniec, and Tomasz Trzcinski arxiv:1706.01789v2 [cs.cv] 10 Aug 2017 Warsaw University of Technology
Deep Alignment Network: A convolutional neural network for robust face alignment Marek Kowalski, Jacek Naruniec, and Tomasz Trzcinski arxiv:1706.01789v2 [cs.cv] 10 Aug 2017 Warsaw University of Technology
Unconstrained Face Alignment without Face Detection
 Unconstrained Face Alignment without Face Detection Xiaohu Shao 1,2, Junliang Xing 3, Jiangjing Lv 1,2, Chunlin Xiao 4, Pengcheng Liu 1, Youji Feng 1, Cheng Cheng 1 1 Chongqing Institute of Green and Intelligent
Unconstrained Face Alignment without Face Detection Xiaohu Shao 1,2, Junliang Xing 3, Jiangjing Lv 1,2, Chunlin Xiao 4, Pengcheng Liu 1, Youji Feng 1, Cheng Cheng 1 1 Chongqing Institute of Green and Intelligent
Deep Multi-Center Learning for Face Alignment
 1 Deep Multi-Center Learning for Face Alignment Zhiwen Shao 1, Hengliang Zhu 1, Xin Tan 1, Yangyang Hao 1, and Lizhuang Ma 2,1 1 Department of Computer Science and Engineering, Shanghai Jiao Tong University,
1 Deep Multi-Center Learning for Face Alignment Zhiwen Shao 1, Hengliang Zhu 1, Xin Tan 1, Yangyang Hao 1, and Lizhuang Ma 2,1 1 Department of Computer Science and Engineering, Shanghai Jiao Tong University,
Robust Facial Landmark Detection under Significant Head Poses and Occlusion
 Robust Facial Landmark Detection under Significant Head Poses and Occlusion Yue Wu Qiang Ji ECSE Department, Rensselaer Polytechnic Institute 110 8th street, Troy, NY, USA {wuy9,jiq}@rpi.edu Abstract There
Robust Facial Landmark Detection under Significant Head Poses and Occlusion Yue Wu Qiang Ji ECSE Department, Rensselaer Polytechnic Institute 110 8th street, Troy, NY, USA {wuy9,jiq}@rpi.edu Abstract There
Tweaked residual convolutional network for face alignment
 Journal of Physics: Conference Series PAPER OPEN ACCESS Tweaked residual convolutional network for face alignment To cite this article: Wenchao Du et al 2017 J. Phys.: Conf. Ser. 887 012077 Related content
Journal of Physics: Conference Series PAPER OPEN ACCESS Tweaked residual convolutional network for face alignment To cite this article: Wenchao Du et al 2017 J. Phys.: Conf. Ser. 887 012077 Related content
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK
 FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
Facial Landmark Detection via Progressive Initialization
 Facial Landmark Detection via Progressive Initialization Shengtao Xiao Shuicheng Yan Ashraf A. Kassim Department of Electrical and Computer Engineering, National University of Singapore Singapore 117576
Facial Landmark Detection via Progressive Initialization Shengtao Xiao Shuicheng Yan Ashraf A. Kassim Department of Electrical and Computer Engineering, National University of Singapore Singapore 117576
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
 Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks Zhen-Hua Feng 1 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre for Vision, Speech and Signal
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks Zhen-Hua Feng 1 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre for Vision, Speech and Signal
Joint Head Pose Estimation and Face Alignment Framework Using Global and Local CNN Features
 2017 IEEE 12th International Conference on Automatic Face & Gesture Recognition Joint Head Pose Estimation and Face Alignment Framework Using Global and Local CNN Features Xiang Xu and Ioannis A. Kakadiaris
2017 IEEE 12th International Conference on Automatic Face & Gesture Recognition Joint Head Pose Estimation and Face Alignment Framework Using Global and Local CNN Features Xiang Xu and Ioannis A. Kakadiaris
Extended Supervised Descent Method for Robust Face Alignment
 Extended Supervised Descent Method for Robust Face Alignment Liu Liu, Jiani Hu, Shuo Zhang, Weihong Deng Beijing University of Posts and Telecommunications, Beijing, China Abstract. Supervised Descent
Extended Supervised Descent Method for Robust Face Alignment Liu Liu, Jiani Hu, Shuo Zhang, Weihong Deng Beijing University of Posts and Telecommunications, Beijing, China Abstract. Supervised Descent
Look at Boundary: A Boundary-Aware Face Alignment Algorithm
 Look at Boundary: A Boundary-Aware Face Alignment Algorithm Wayne Wu 1,2, Chen Qian2, Shuo Yang3, Quan Wang2, Yici Cai1, Qiang Zhou1 1 Tsinghua National Laboratory for Information Science and Technology
Look at Boundary: A Boundary-Aware Face Alignment Algorithm Wayne Wu 1,2, Chen Qian2, Shuo Yang3, Quan Wang2, Yici Cai1, Qiang Zhou1 1 Tsinghua National Laboratory for Information Science and Technology
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
 Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Simultaneous Facial Landmark Detection, Pose and Deformation Estimation under Facial Occlusion
 Simultaneous Facial Landmark Detection, Pose and Deformation Estimation under Facial Occlusion Yue Wu Chao Gou Qiang Ji ECSE Department Institute of Automation ECSE Department Rensselaer Polytechnic Institute
Simultaneous Facial Landmark Detection, Pose and Deformation Estimation under Facial Occlusion Yue Wu Chao Gou Qiang Ji ECSE Department Institute of Automation ECSE Department Rensselaer Polytechnic Institute
Facial shape tracking via spatio-temporal cascade shape regression
 Facial shape tracking via spatio-temporal cascade shape regression Jing Yang nuist yj@126.com Jiankang Deng jiankangdeng@gmail.com Qingshan Liu Kaihua Zhang zhkhua@gmail.com qsliu@nuist.edu.cn Nanjing
Facial shape tracking via spatio-temporal cascade shape regression Jing Yang nuist yj@126.com Jiankang Deng jiankangdeng@gmail.com Qingshan Liu Kaihua Zhang zhkhua@gmail.com qsliu@nuist.edu.cn Nanjing
arxiv: v1 [cs.cv] 12 Sep 2018
![arxiv: v1 [cs.cv] 12 Sep 2018](/thumbs/93/112746977.jpg "arxiv: v1 [cs.cv] 12 Sep 2018") In Proceedings of the 2018 IEEE International Conference on Image Processing (ICIP) The final publication is available at: http://dx.doi.org/10.1109/icip.2018.8451026 A TWO-STEP LEARNING METHOD FOR DETECTING
In Proceedings of the 2018 IEEE International Conference on Image Processing (ICIP) The final publication is available at: http://dx.doi.org/10.1109/icip.2018.8451026 A TWO-STEP LEARNING METHOD FOR DETECTING
Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network
 MAHPOD et al.: CCNN 1 Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network arxiv:1805.01760v2 [cs.cv] 17 Jan 2019 Shahar Mahpod, Rig Das, Emanuele Maiorana, Yosi Keller,
MAHPOD et al.: CCNN 1 Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network arxiv:1805.01760v2 [cs.cv] 17 Jan 2019 Shahar Mahpod, Rig Das, Emanuele Maiorana, Yosi Keller,
Robust Facial Landmark Localization Based on Texture and Pose Correlated Initialization
 1 Robust Facial Landmark Localization Based on Texture and Pose Correlated Initialization Yiyun Pan, Junwei Zhou, Member, IEEE, Yongsheng Gao, Senior Member, IEEE, Shengwu Xiong arxiv:1805.05612v1 [cs.cv]
1 Robust Facial Landmark Localization Based on Texture and Pose Correlated Initialization Yiyun Pan, Junwei Zhou, Member, IEEE, Yongsheng Gao, Senior Member, IEEE, Shengwu Xiong arxiv:1805.05612v1 [cs.cv]
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
") How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) Adrian Bulat and Georgios Tzimiropoulos Computer Vision Laboratory, The University of Nottingham
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) Adrian Bulat and Georgios Tzimiropoulos Computer Vision Laboratory, The University of Nottingham
Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild
 Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild Zhen-Hua Feng 1,2 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre
Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild Zhen-Hua Feng 1,2 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre
SUPPLEMENTARY MATERIAL FOR: ADAPTIVE CASCADED REGRESSION
 SUPPLEMENTARY MATERIAL FOR: ADAPTIVE CASCADED REGRESSION Epameinondas Antonakos,, Patrick Snape,, George Trigeorgis, Stefanos Zafeiriou, Department of Computing, Imperial College London, U.K. Center for
SUPPLEMENTARY MATERIAL FOR: ADAPTIVE CASCADED REGRESSION Epameinondas Antonakos,, Patrick Snape,, George Trigeorgis, Stefanos Zafeiriou, Department of Computing, Imperial College London, U.K. Center for
Combining Local and Global Features for 3D Face Tracking
 Combining Local and Global Features for 3D Face Tracking Pengfei Xiong, Guoqing Li, Yuhang Sun Megvii (face++) Research {xiongpengfei, liguoqing, sunyuhang}@megvii.com Abstract In this paper, we propose
Combining Local and Global Features for 3D Face Tracking Pengfei Xiong, Guoqing Li, Yuhang Sun Megvii (face++) Research {xiongpengfei, liguoqing, sunyuhang}@megvii.com Abstract In this paper, we propose
LEARNING A MULTI-CENTER CONVOLUTIONAL NETWORK FOR UNCONSTRAINED FACE ALIGNMENT. Zhiwen Shao, Hengliang Zhu, Yangyang Hao, Min Wang, and Lizhuang Ma
 LEARNING A MULTI-CENTER CONVOLUTIONAL NETWORK FOR UNCONSTRAINED FACE ALIGNMENT Zhiwen Shao, Hengliang Zhu, Yangyang Hao, Min Wang, and Lizhuang Ma Department of Computer Science and Engineering, Shanghai
LEARNING A MULTI-CENTER CONVOLUTIONAL NETWORK FOR UNCONSTRAINED FACE ALIGNMENT Zhiwen Shao, Hengliang Zhu, Yangyang Hao, Min Wang, and Lizhuang Ma Department of Computer Science and Engineering, Shanghai
arxiv:submit/ [cs.cv] 7 Sep 2017
![arxiv:submit/ [cs.cv] 7 Sep 2017](/thumbs/82/85530844.jpg "arxiv:submit/ [cs.cv] 7 Sep 2017") How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) arxiv:submit/2000193 [cs.cv] 7 Sep 2017 Adrian Bulat and Georgios Tzimiropoulos Computer Vision
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) arxiv:submit/2000193 [cs.cv] 7 Sep 2017 Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Nonlinear Hierarchical Part-Based Regression for Unconstrained Face Alignment
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Nonlinear Hierarchical Part-Based Regression for Unconstrained Face Alignment Xiang Yu, Zhe Lin, Shaoting
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Nonlinear Hierarchical Part-Based Regression for Unconstrained Face Alignment Xiang Yu, Zhe Lin, Shaoting
Face Alignment Under Various Poses and Expressions
 Face Alignment Under Various Poses and Expressions Shengjun Xin and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn Abstract.
Face Alignment Under Various Poses and Expressions Shengjun Xin and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn Abstract.
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
arxiv: v1 [cs.cv] 16 Feb 2017
![arxiv: v1 [cs.cv] 16 Feb 2017](/thumbs/88/114857056.jpg "arxiv: v1 [cs.cv] 16 Feb 2017") KEPLER: Keypoint and Pose Estimation of Unconstrained Faces by Learning Efficient H-CNN Regressors Amit Kumar, Azadeh Alavi and Rama Chellappa Department of Electrical and Computer Engineering, CFAR and
KEPLER: Keypoint and Pose Estimation of Unconstrained Faces by Learning Efficient H-CNN Regressors Amit Kumar, Azadeh Alavi and Rama Chellappa Department of Electrical and Computer Engineering, CFAR and
Topic-aware Deep Auto-encoders (TDA) for Face Alignment
 for Face Alignment") Topic-aware Deep Auto-encoders (TDA) for Face Alignment Jie Zhang 1,2, Meina Kan 1, Shiguang Shan 1, Xiaowei Zhao 3, and Xilin Chen 1 1 Key Lab of Intelligent Information Processing of Chinese Academy
Topic-aware Deep Auto-encoders (TDA) for Face Alignment Jie Zhang 1,2, Meina Kan 1, Shiguang Shan 1, Xiaowei Zhao 3, and Xilin Chen 1 1 Key Lab of Intelligent Information Processing of Chinese Academy
Dynamic Attention-controlled Cascaded Shape Regression Exploiting Training Data Augmentation and Fuzzy-set Sample Weighting
 Dynamic Attention-controlled Cascaded Shape Regression Exploiting Training Data Augmentation and Fuzzy-set Sample Weighting Zhen-Hua Feng 1 Josef Kittler 1 William Christmas 1 Patrik Huber 1 Xiao-Jun Wu
Dynamic Attention-controlled Cascaded Shape Regression Exploiting Training Data Augmentation and Fuzzy-set Sample Weighting Zhen-Hua Feng 1 Josef Kittler 1 William Christmas 1 Patrik Huber 1 Xiao-Jun Wu
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild
 Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild Zhen-Hua Feng 1,2 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre
Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild Zhen-Hua Feng 1,2 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
 MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
Learn to Combine Multiple Hypotheses for Accurate Face Alignment
 2013 IEEE International Conference on Computer Vision Workshops Learn to Combine Multiple Hypotheses for Accurate Face Alignment Junjie Yan Zhen Lei Dong Yi Stan Z. Li Center for Biometrics and Security
2013 IEEE International Conference on Computer Vision Workshops Learn to Combine Multiple Hypotheses for Accurate Face Alignment Junjie Yan Zhen Lei Dong Yi Stan Z. Li Center for Biometrics and Security
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Face Alignment across Large Pose via MT-CNN based 3D Shape Reconstruction
 Face Alignment across Large Pose via MT-CNN based 3D Shape Reconstruction Gang Zhang 1,2, Hu Han 1, Shiguang Shan 1,2,3, Xingguang Song 4, Xilin Chen 1,2 1 Key Laboratory of Intelligent Information Processing
Face Alignment across Large Pose via MT-CNN based 3D Shape Reconstruction Gang Zhang 1,2, Hu Han 1, Shiguang Shan 1,2,3, Xingguang Song 4, Xilin Chen 1,2 1 Key Laboratory of Intelligent Information Processing
Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet
 1 Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet Naimish Agarwal, IIIT-Allahabad (irm2013013@iiita.ac.in) Artus Krohn-Grimberghe, University of Paderborn (artus@aisbi.de)
1 Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet Naimish Agarwal, IIIT-Allahabad (irm2013013@iiita.ac.in) Artus Krohn-Grimberghe, University of Paderborn (artus@aisbi.de)
arxiv: v1 [cs.cv] 8 Nov 2018
![arxiv: v1 [cs.cv] 8 Nov 2018](/thumbs/90/101618928.jpg "arxiv: v1 [cs.cv] 8 Nov 2018") Noname manuscript No. (will be inserted by the editor) Facial Landmark Detection for Manga Images Marco Stricker Olivier Augereau Koichi Kise Motoi Iwata Received: date / Accepted: date arxiv:1811.03214v1
Noname manuscript No. (will be inserted by the editor) Facial Landmark Detection for Manga Images Marco Stricker Olivier Augereau Koichi Kise Motoi Iwata Received: date / Accepted: date arxiv:1811.03214v1
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
FROM VIDEO STREAMS IN THE WILD
 SEMANTIC FACE SEGMENTATION FROM VIDEO STREAMS IN THE WILD Student: Deividas Skiparis Supervisors: Pascal Landry (Imersivo) and Sergio Escalera (UB) In Collaboration With Imersivo SL 7/5/2017 2 Problem
SEMANTIC FACE SEGMENTATION FROM VIDEO STREAMS IN THE WILD Student: Deividas Skiparis Supervisors: Pascal Landry (Imersivo) and Sergio Escalera (UB) In Collaboration With Imersivo SL 7/5/2017 2 Problem
arxiv: v1 [cs.cv] 11 Jun 2015
![arxiv: v1 [cs.cv] 11 Jun 2015](/thumbs/92/109137547.jpg "arxiv: v1 [cs.cv] 11 Jun 2015") Pose-Invariant 3D Face Alignment Amin Jourabloo, Xiaoming Liu Department of Computer Science and Engineering Michigan State University, East Lansing MI 48824 {jourablo, liuxm}@msu.edu arxiv:506.03799v
Pose-Invariant 3D Face Alignment Amin Jourabloo, Xiaoming Liu Department of Computer Science and Engineering Michigan State University, East Lansing MI 48824 {jourablo, liuxm}@msu.edu arxiv:506.03799v
Convolutional Experts Constrained Local Model for 3D Facial Landmark Detection
 Correction Network FC200 FC200 Final Prediction Convolutional Experts Constrained Local Model for 3D Facial Landmark Detection Amir Zadeh, Yao Chong Lim, Tadas Baltrušaitis, Louis-Philippe Morency Carnegie
Correction Network FC200 FC200 Final Prediction Convolutional Experts Constrained Local Model for 3D Facial Landmark Detection Amir Zadeh, Yao Chong Lim, Tadas Baltrušaitis, Louis-Philippe Morency Carnegie
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
FaceNet. Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana
 FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade
 2013 IEEE International Conference on Computer Vision Workshops Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade Erjin Zhou Haoqiang Fan Zhimin Cao Yuning Jiang
2013 IEEE International Conference on Computer Vision Workshops Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade Erjin Zhou Haoqiang Fan Zhimin Cao Yuning Jiang
Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection
 Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection Yue Wu Qiang Ji ECSE Department, Rensselaer Polytechnic Institute 110 8th street,
Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection Yue Wu Qiang Ji ECSE Department, Rensselaer Polytechnic Institute 110 8th street,
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Generic Face Alignment Using an Improved Active Shape Model
 Generic Face Alignment Using an Improved Active Shape Model Liting Wang, Xiaoqing Ding, Chi Fang Electronic Engineering Department, Tsinghua University, Beijing, China {wanglt, dxq, fangchi} @ocrserv.ee.tsinghua.edu.cn
Generic Face Alignment Using an Improved Active Shape Model Liting Wang, Xiaoqing Ding, Chi Fang Electronic Engineering Department, Tsinghua University, Beijing, China {wanglt, dxq, fangchi} @ocrserv.ee.tsinghua.edu.cn
GoDP: Globally Optimized Dual Pathway deep network architecture for facial landmark localization in-the-wild
 GoDP: Globally Optimized Dual Pathway deep network architecture for facial landmark localization in-the-wild Yuhang Wu, Shishir K. Shah, Ioannis A. Kakadiaris 1 {ywu35,sshah,ikakadia}@central.uh.edu Computational
GoDP: Globally Optimized Dual Pathway deep network architecture for facial landmark localization in-the-wild Yuhang Wu, Shishir K. Shah, Ioannis A. Kakadiaris 1 {ywu35,sshah,ikakadia}@central.uh.edu Computational
A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection
 A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection Jiangjing Lv 1,2, Xiaohu Shao 1,2, Junliang Xing 3, Cheng Cheng 1, Xi Zhou 1 1 Chongqing Institute
A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection Jiangjing Lv 1,2, Xiaohu Shao 1,2, Junliang Xing 3, Cheng Cheng 1, Xi Zhou 1 1 Chongqing Institute
Leveraging Intra and Inter-Dataset Variations for Robust Face Alignment
 Leveraging Intra and Inter-Dataset Variations for Robust Face Alignment Wenyan Wu Department of Computer Science and Technology Tsinghua University wwy5@mails.tsinghua.edu.cn Shuo Yang Department of Information
Leveraging Intra and Inter-Dataset Variations for Robust Face Alignment Wenyan Wu Department of Computer Science and Technology Tsinghua University wwy5@mails.tsinghua.edu.cn Shuo Yang Department of Information
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Face detection and recognition. Detection Recognition Sally
 Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Occlusion-free Face Alignment: Deep Regression Networks Coupled with De-corrupt AutoEncoders
 Occlusion-free Face Alignment: Deep Regression Networks Coupled with De-corrupt AutoEncoders Jie Zhang 1,2 Meina Kan 1,3 Shiguang Shan 1,3 Xilin Chen 1 1 Key Lab of Intelligent Information Processing of
Occlusion-free Face Alignment: Deep Regression Networks Coupled with De-corrupt AutoEncoders Jie Zhang 1,2 Meina Kan 1,3 Shiguang Shan 1,3 Xilin Chen 1 1 Key Lab of Intelligent Information Processing of
THE study of face alignment, or facial
 1 An Empirical Study of Recent Face Alignment Methods Heng Yang, Xuhui Jia, Chen Change Loy and Peter Robinson arxiv:1511.05049v1 [cs.cv] 16 Nov 2015 Abstract The problem of face alignment has been intensively
1 An Empirical Study of Recent Face Alignment Methods Heng Yang, Xuhui Jia, Chen Change Loy and Peter Robinson arxiv:1511.05049v1 [cs.cv] 16 Nov 2015 Abstract The problem of face alignment has been intensively
Integral Channel Features with Random Forest for 3D Facial Landmark Detection
 MSc Artificial Intelligence Track: Computer Vision Master Thesis Integral Channel Features with Random Forest for 3D Facial Landmark Detection by Arif Qodari 10711996 February 2016 42 EC Supervisor/Examiner:
MSc Artificial Intelligence Track: Computer Vision Master Thesis Integral Channel Features with Random Forest for 3D Facial Landmark Detection by Arif Qodari 10711996 February 2016 42 EC Supervisor/Examiner:
Human and Sheep Facial Landmarks Localisation by Triplet Interpolated Features
 Human and Sheep Facial Landmarks Localisation by Triplet Interpolated Features Heng Yang*, Renqiao Zhang* and Peter Robinson University of Cambridge {hy36,rz264, pr1}@cam.ac.uk Abstract In this paper we
Human and Sheep Facial Landmarks Localisation by Triplet Interpolated Features Heng Yang*, Renqiao Zhang* and Peter Robinson University of Cambridge {hy36,rz264, pr1}@cam.ac.uk Abstract In this paper we
Detecting facial landmarks in the video based on a hybrid framework
 Detecting facial landmarks in the video based on a hybrid framework Nian Cai 1, *, Zhineng Lin 1, Fu Zhang 1, Guandong Cen 1, Han Wang 2 1 School of Information Engineering, Guangdong University of Technology,
Detecting facial landmarks in the video based on a hybrid framework Nian Cai 1, *, Zhineng Lin 1, Fu Zhang 1, Guandong Cen 1, Han Wang 2 1 School of Information Engineering, Guangdong University of Technology,
Pose-Robust 3D Facial Landmark Estimation from a Single 2D Image
 SMITH & DYER: 3D FACIAL LANDMARK ESTIMATION 1 Pose-Robust 3D Facial Landmark Estimation from a Single 2D Image Brandon M. Smith http://www.cs.wisc.edu/~bmsmith Charles R. Dyer http://www.cs.wisc.edu/~dyer
SMITH & DYER: 3D FACIAL LANDMARK ESTIMATION 1 Pose-Robust 3D Facial Landmark Estimation from a Single 2D Image Brandon M. Smith http://www.cs.wisc.edu/~bmsmith Charles R. Dyer http://www.cs.wisc.edu/~dyer
Supplementary Material for Ensemble Diffusion for Retrieval
 Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
Memory-efficient Global Refinement of Decision-Tree Ensembles and its Application to Face Alignment
 MARKUŠ, GOGIĆ, PANDŽIĆ, AHLBERG: MEMORY-EFFICIENT GLOBAL REFINEMENT 1 Memory-efficient Global Refinement of Decision-Tree Ensembles and its Application to Face Alignment Nenad Markuš 1 nenad.markus@fer.hr
MARKUŠ, GOGIĆ, PANDŽIĆ, AHLBERG: MEMORY-EFFICIENT GLOBAL REFINEMENT 1 Memory-efficient Global Refinement of Decision-Tree Ensembles and its Application to Face Alignment Nenad Markuš 1 nenad.markus@fer.hr
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Pose-Invariant Face Alignment via CNN-Based Dense 3D Model Fitting
 DOI 10.1007/s11263-017-1012-z Pose-Invariant Face Alignment via CNN-Based Dense 3D Model Fitting Amin Jourabloo 1 Xiaoming Liu 1 Received: 12 June 2016 / Accepted: 6 April 2017 Springer Science+Business
DOI 10.1007/s11263-017-1012-z Pose-Invariant Face Alignment via CNN-Based Dense 3D Model Fitting Amin Jourabloo 1 Xiaoming Liu 1 Received: 12 June 2016 / Accepted: 6 April 2017 Springer Science+Business
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks
 Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks Xuepeng Shi 1,2 Shiguang Shan 1,3 Meina Kan 1,3 Shuzhe Wu 1,2 Xilin Chen 1 1 Key Lab of Intelligent Information Processing
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks Xuepeng Shi 1,2 Shiguang Shan 1,3 Meina Kan 1,3 Shuzhe Wu 1,2 Xilin Chen 1 1 Key Lab of Intelligent Information Processing
Extending Explicit Shape Regression with Mixed Feature Channels and Pose Priors
 Extending Explicit Shape Regression with Mixed Feature Channels and Pose Priors Matthias Richter Karlsruhe Institute of Technology (KIT) Karlsruhe, Germany matthias.richter@kit.edu Hua Gao École Polytechnique
Extending Explicit Shape Regression with Mixed Feature Channels and Pose Priors Matthias Richter Karlsruhe Institute of Technology (KIT) Karlsruhe, Germany matthias.richter@kit.edu Hua Gao École Polytechnique
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Joint Estimation of Pose and Face Landmark
 Joint Estimation of Pose and Face Landmark Donghoon Lee (B), Junyoung Chung, and Chang D. Yoo Department of Electrical Engineering, KAIST, Daejeon, Korea iamdh@kaist.ac.kr Abstract. This paper proposes
Joint Estimation of Pose and Face Landmark Donghoon Lee (B), Junyoung Chung, and Chang D. Yoo Department of Electrical Engineering, KAIST, Daejeon, Korea iamdh@kaist.ac.kr Abstract. This paper proposes
Facial Landmark Localization A Literature Survey
 International Journal of Current Engineering and Technology E-ISSN 2277 4106, P-ISSN 2347-5161 2014 INPRESSCO, All Rights Reserved Available at http://inpressco.com/category/ijcet Review Article Dhananjay
International Journal of Current Engineering and Technology E-ISSN 2277 4106, P-ISSN 2347-5161 2014 INPRESSCO, All Rights Reserved Available at http://inpressco.com/category/ijcet Review Article Dhananjay
Detecting Faces Using Inside Cascaded Contextual CNN
 Detecting Faces Using Inside Cascaded Contextual CNN Kaipeng Zhang 1, Zhanpeng Zhang 2, Hao Wang 1, Zhifeng Li 1, Yu Qiao 3, Wei Liu 1 1 Tencent AI Lab 2 SenseTime Group Limited 3 Guangdong Provincial
Detecting Faces Using Inside Cascaded Contextual CNN Kaipeng Zhang 1, Zhanpeng Zhang 2, Hao Wang 1, Zhifeng Li 1, Yu Qiao 3, Wei Liu 1 1 Tencent AI Lab 2 SenseTime Group Limited 3 Guangdong Provincial
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Feature Detection and Tracking with Constrained Local Models
 Feature Detection and Tracking with Constrained Local Models David Cristinacce and Tim Cootes Dept. Imaging Science and Biomedical Engineering University of Manchester, Manchester, M3 9PT, U.K. david.cristinacce@manchester.ac.uk
Feature Detection and Tracking with Constrained Local Models David Cristinacce and Tim Cootes Dept. Imaging Science and Biomedical Engineering University of Manchester, Manchester, M3 9PT, U.K. david.cristinacce@manchester.ac.uk
A survey of deep facial landmark detection
 A survey of deep facial landmark detection Yongzhe Yan 1,2 Xavier Naturel 2 Thierry Chateau 1 Stefan Duffner 3 Christophe Garcia 3 Christophe Blanc 1 1 Université Clermont Auvergne, France 2 Wisimage,
A survey of deep facial landmark detection Yongzhe Yan 1,2 Xavier Naturel 2 Thierry Chateau 1 Stefan Duffner 3 Christophe Garcia 3 Christophe Blanc 1 1 Université Clermont Auvergne, France 2 Wisimage,
Cross-pose Facial Expression Recognition
 Cross-pose Facial Expression Recognition Abstract In real world facial expression recognition (FER) applications, it is not practical for a user to enroll his/her facial expressions under different pose
Cross-pose Facial Expression Recognition Abstract In real world facial expression recognition (FER) applications, it is not practical for a user to enroll his/her facial expressions under different pose
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Cascade Multi-view Hourglass Model for Robust 3D Face Alignment
 Cascade Multi-view Hourglass Model for Robust 3D Face Alignment Jiankang Deng 1, Yuxiang Zhou 1, Shiyang Cheng 1, and Stefanos Zaferiou 1,2 1 Department of Computing, Imperial College London, UK 2 Centre
Cascade Multi-view Hourglass Model for Robust 3D Face Alignment Jiankang Deng 1, Yuxiang Zhou 1, Shiyang Cheng 1, and Stefanos Zaferiou 1,2 1 Department of Computing, Imperial College London, UK 2 Centre
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Face Detection and Tracking Control with Omni Car
 Face Detection and Tracking Control with Omni Car Jheng-Hao Chen, Tung-Yu Wu CS 231A Final Report June 31, 2016 Abstract We present a combination of frontal and side face detection approach, using deep
Face Detection and Tracking Control with Omni Car Jheng-Hao Chen, Tung-Yu Wu CS 231A Final Report June 31, 2016 Abstract We present a combination of frontal and side face detection approach, using deep
Deep Evolutionary 3D Diffusion Heat Maps for Large-pose Face Alignment
 SUN, SHAO, XIA, FU: DEEP EVOLUTIONARY 3D DHM FOR FACE ALIGNMENT 1 Deep Evolutionary 3D Diffusion Heat Maps for Large-pose Face Alignment Bin Sun 1 sun.bi@husky.neu.edu Ming Shao 2 mshao@umassd.edu Siyu
SUN, SHAO, XIA, FU: DEEP EVOLUTIONARY 3D DHM FOR FACE ALIGNMENT 1 Deep Evolutionary 3D Diffusion Heat Maps for Large-pose Face Alignment Bin Sun 1 sun.bi@husky.neu.edu Ming Shao 2 mshao@umassd.edu Siyu
Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction
 Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali University of Louisville Louisville, KY {hmrara01,syelha01,amali003}@louisville.edu Mike Miller,
Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali University of Louisville Louisville, KY {hmrara01,syelha01,amali003}@louisville.edu Mike Miller,
A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications
 A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications Le Thanh Nguyen-Meidine 1, Eric Granger 1, Madhu Kiran 1 and Louis-Antoine Blais-Morin 2 1 École de technologie
A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications Le Thanh Nguyen-Meidine 1, Eric Granger 1, Madhu Kiran 1 and Louis-Antoine Blais-Morin 2 1 École de technologie
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
arxiv: v1 [cs.cv] 13 Jul 2015
![arxiv: v1 [cs.cv] 13 Jul 2015](/thumbs/92/110223043.jpg "arxiv: v1 [cs.cv] 13 Jul 2015") Unconstrained Facial Landmark Localization with Backbone-Branches Fully-Convolutional Networks arxiv:7.349v [cs.cv] 3 Jul 2 Zhujin Liang, Shengyong Ding, Liang Lin Sun Yat-Sen University Guangzhou Higher
Unconstrained Facial Landmark Localization with Backbone-Branches Fully-Convolutional Networks arxiv:7.349v [cs.cv] 3 Jul 2 Zhujin Liang, Shengyong Ding, Liang Lin Sun Yat-Sen University Guangzhou Higher
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological