Parallel Programming in C with MPI and OpenMP
|
|
|
- Valerie Hoover
- 6 years ago
- Views:
Transcription


1 Parallel Programming in C with MPI and OpenMP Michael J. Quinn
2 Chapter 8 Matrix-vector Multiplication
3 Chapter Objectives Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
4 Outline Sequential algorithm and its complexity Design, analysis, and implementation of three parallel programs Rowwise block striped Columnwise block striped Checkerboard block
5 Sequential Algorithm =
6 Storing Vectors Divide vector elements among processes Replicate vector elements Vector replication acceptable because vectors have only n elements, versus n2 elements in matrices
7 Rowwise Block Striped Matrix Partitioning through domain decomposition Primitive task associated with Row of matrix Entire vector
8 Phases of Parallel Algorithm Inner product computation b Row i of A b Row i of A b Row i of A ci c All-gather communication
9 Agglomeration and Mapping Static number of tasks Regular communication pattern (all-gather) Computation time per task is constant Strategy: Agglomerate groups of rows Create one task per MPI process
10 Complexity Analysis Sequential algorithm complexity: (n2) Parallel algorithm computational complexity: (n2/p) Communication complexity of all-gather: (log p + n) Overall complexity: (n2/p + log p)
11 Isoefficiency Analysis Sequential time complexity: (n2) Only parallel overhead is all-gather When n is large, message transmission time dominates message latency Parallel communication time: (n) n2 Cpn n Cp and M(n) = n M (Cp ) / p C p / p C p System is not highly scalable
12 Block-to-replicated Transformation
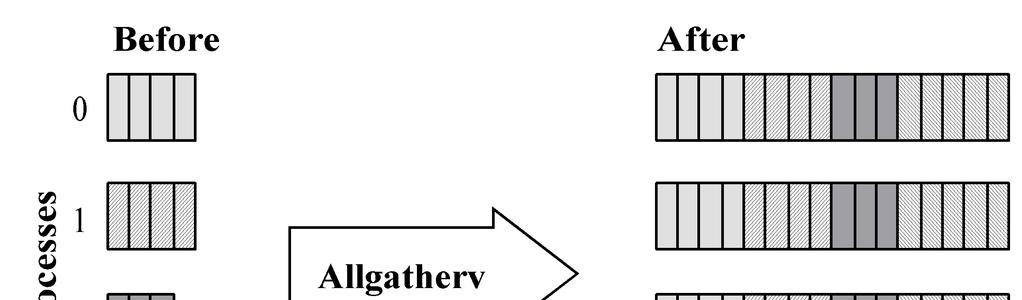

13 MPI_Allgatherv
14 MPI_Allgatherv int MPI_Allgatherv ( void *send_buffer, int send_cnt, MPI_Datatype send_type, void *receive_buffer, int *receive_cnt, int *receive_disp, MPI_Datatype receive_type, MPI_Comm communicator)
15 MPI_Allgatherv in Action
16 Function create_mixed_xfer_arrays First array How many elements contributed by each process Uses utility macro BLOCK_SIZE Second array Starting position of each process block Assume blocks in process rank order
17 Function replicate_block_vector Create space for entire vector Create mixed transfer arrays Call MPI_Allgatherv
18 Function read_replicated_vector Process p-1 Opens file Reads vector length Broadcast vector length (root process = p-1) Allocate space for vector Process p-1 reads vector, closes file Broadcast vector
19 Function print_replicated_vector Process 0 prints vector Exact call to printf depends on value of parameter datatype
20 Run-time Expression : inner product loop iteration time Computational time: n n/p All-gather requires log p messages with latency Total vector elements transmitted: (2 log p -1) / 2 log p Total execution time: n n/p + log p + (2 log p -1) / (2 log p )
21 Benchmarking Results Execution Time (msec) p Predicted Actual Speedup Mflops
22 Columnwise Block Striped Matrix Partitioning through domain decomposition Task associated with Column of matrix Vector element
23 Matrix-Vector Multiplication c0 = a0,0 b0 + a0,1 b1 + a0,2 b2 + a0,3 b3 + a4,4 b4 c1 = a1,0 b0 + a1,1 b1 + a1,2 b2 + a1,3 b3 + a1,4 b4 c2 = a2,0 b0 + a2,1 b1 + a2,2 b2 + a2,3 b3 + a2,4 b4 c3 = a3,0 b0 + a3,1 b1 + a3,2 b2 + a3,3 b3 + b3,4 b4 c4 = a4,0 b0 + a4,1 b1 + a4,2 b2 + a4,3 b3 + a4,4 b4 Proc 4 Proc 3 Proc 2 Processor 1 s initial computation Processor 0 s initial computation
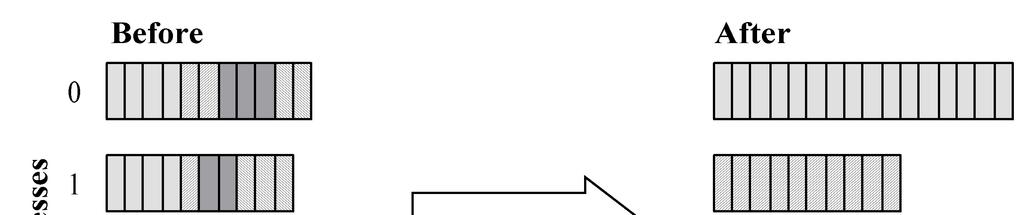
24 All-to-all Exchange (Before) P0 P1 P2 P3 P4
25 All-to-all Exchange (After) P0 P1 P2 P3 P4
26 Multiplications b Column i of A Column i of A Phases of Parallel Algorithm b ~c b c Reduction Column i of A Column i of A All-to-all exchange b ~c
27 Agglomeration and Mapping Static number of tasks Regular communication pattern (all-to-all) Computation time per task is constant Strategy: Agglomerate groups of columns Create one task per MPI process
28 Complexity Analysis Sequential algorithm complexity: (n2) Parallel algorithm computational complexity: (n2/p) Communication complexity of all-to-all: (p + n/p) Overall complexity: (n2/p + log p)
29 Isoefficiency Analysis Sequential time complexity: (n2) Only parallel overhead is all-to-all When n is large, message transmission time dominates message latency Parallel communication time: (n) n2 Cpn n Cp Scalability function same as rowwise algorithm: C2p
30 Reading a Block-Column Matrix File
31 MPI_Scatterv
32 Header for MPI_Scatterv int MPI_Scatterv ( void *send_buffer, int *send_cnt, int *send_disp, MPI_Datatype send_type, void *receive_buffer, int receive_cnt, MPI_Datatype receive_type, int root, MPI_Comm communicator)
33 Printing a Block-Column Matrix Data motion opposite to that we did when reading the matrix Replace scatter with gather Use v variant because different processes contribute different numbers of elements

34 Function MPI_Gatherv
35 Header for MPI_Gatherv int MPI_Gatherv void int MPI_Datatype void int int MPI_Datatype int MPI_Comm ( *send_buffer, send_cnt, send_type, *receive_buffer, *receive_cnt, *receive_disp, receive_type, root, communicator)

36 Function MPI_Alltoallv
37 Header for MPI_Alltoallv int MPI_Gatherv void int int MPI_Datatype void int int MPI_Datatype MPI_Comm ( *send_buffer, *send_cnt, *send_disp, send_type, *receive_buffer, *receive_cnt, *receive_disp, receive_type, communicator)
38 Count/Displacement Arrays MPI_Alltoallv requirescreate_mixed_xfer_arrays two pairs of builds these count/displacement arrays First pair for values being sent send_cnt: number of elements send_disp: index of first element Second pair for values being received recv_cnt: number of elements recv_disp: index of first element
39 Function create_uniform_xfer_arrays First array How many elements received from each process (always same value) Uses ID and utility macro block_size Second array Starting position of each process block Assume blocks in process rank order
40 Run-time Expression : inner product loop iteration time Computational time: n n/p All-gather requires p-1 messages, each of length about n/p 8 bytes per element Total execution time: n n/p + (p-1)( + (8n/p)/ )
41 Benchmarking Results Execution Time (msec) p Predicted Actual Speedup Mflops
42 Checkerboard Block Decomposition Associate primitive task with each element of the matrix A Each primitive task performs one multiply Agglomerate primitive tasks into rectangular blocks Processes form a 2-D grid Vector b distributed by blocks among processes in first column of grid
43 Tasks after Agglomeration
44 Algorithm s Phases
45 Redistributing Vector b Step 1: Move b from processes in first row to processes in first column If p square First column/first row processes send/receive portions of b If p not square Gather b on process 0, 0 Process 0, 0 broadcasts to first row procs Step 2: First row processes scatter b within columns
46 Redistributing Vector b When p is a square number When p is not a square number
47 Complexity Analysis Assume p is a square number If grid is 1 p, devolves into columnwise block striped If grid is p 1, devolves into rowwise block striped
48 Complexity Analysis (continued) Each process does its share of computation: (n2/p) Redistribute b: (n / p + log p(n / p )) = (n log p / p) Reduction of partial results vectors: (n log p / p) Overall parallel complexity: (n3/p + n log p / p)
49 Isoefficiency Analysis Sequential complexity: (n2) Parallel communication complexity: (n log p / p) Isoefficiency function: n2 Cn p log p n C p log p M (C p log p ) / p C p log p / p C log p This system is much more scalable than the previous two implementations
50 Creating Communicators Want processes in a virtual 2-D grid Create a custom communicator to do this Collective communications involve all processes in a communicator We need to do broadcasts, reductions among subsets of processes We will create communicators for processes in same row or same column
51 What s in a Communicator? Process group Context Attributes Topology (lets us address processes another way) Others we won t consider
52 Creating 2-D Virtual Grid of Processes MPI_Dims_create Input parameters Total number of processes in desired grid Number of grid dimensions Returns number of processes in each dim MPI_Cart_create Creates communicator with cartesian topology
53 MPI_Dims_create int MPI_Dims_create ( int nodes, /* Input - Procs in grid */ int dims, /* Input - Number of dims */ int *size) /* Input/Output - Size of each grid dimension */
54 MPI_Cart_create int MPI_Cart_create ( MPI_Comm old_comm, /* Input - old communicator */ int dims, /* Input - grid dimensions */ int *size, /* Input - # procs in each dim */ int *periodic, /* Input - periodic[j] is 1 if dimension j wraps around; 0 otherwise */ int reorder, /* 1 if process ranks can be reordered */ MPI_Comm *cart_comm) /* Output - new communicator */
55 Using MPI_Dims_create and MPI_Cart_create MPI_Comm cart_comm; int p; int periodic[2]; int size[2];... size[0] = size[1] = 0; MPI_Dims_create (p, 2, size); periodic[0] = periodic[1] = 0; MPI_Cart_create (MPI_COMM_WORLD, 2, size, 1, &cart_comm);
56 Useful Grid-related Functions MPI_Cart_rank Given coordinates of process in Cartesian communicator, returns process rank MPI_Cart_coords Given rank of process in Cartesian communicator, returns process coordinates
57 Header for MPI_Cart_rank int MPI_Cart_rank ( MPI_Comm comm, /* In - Communicator */ int *coords, /* In - Array containing process grid location */ int *rank) /* Out - Rank of process at specified coords */
58 Header for MPI_Cart_coords int MPI_Cart_coords ( MPI_Comm comm, /* In - Communicator */ int rank, /* In - Rank of process */ int dims, /* In - Dimensions in virtual grid */ int *coords) /* Out - Coordinates of specified process in virtual grid */
59 MPI_Comm_split Partitions the processes of a communicator into one or more subgroups Constructs a communicator for each subgroup Allows processes in each subgroup to perform their own collective communications Needed for columnwise scatter and rowwise reduce
60 Header for MPI_Comm_split int MPI_Comm_split ( MPI_Comm old_comm, /* In - Existing communicator */ int partition, /* In - Partition number */ int new_rank, /* In - Ranking order of processes in new communicator */ MPI_Comm *new_comm) /* Out - New communicator shared by processes in same partition */
61 Example: Create Communicators for Process Rows MPI_Comm grid_comm; /* 2-D process grid */ MPI_Comm grid_coords[2]; /* Location of process in grid */ MPI_Comm row_comm; /* Processes in same row */ MPI_Comm_split (grid_comm, grid_coords[0], grid_coords[1], &row_comm);
62 Run-time Expression Computational time: n/ p n/ p Suppose p a square number Redistribute b Send/recv: + 8 n/ p / Broadcast: log p ( + 8 n/ p / ) Reduce partial results: log p ( + 8 n/ p / )
63 Benchmarking Procs Predicted (msec) Actual (msec) Speedup Megaflops
64 Speedup Comparison of Three Algorithms Rowwise Block Striped Columnwise Block Striped Checkerboard Block Processors 15 20
65 Summary (1/3) Matrix decomposition communications needed Rowwise block striped: all-gather Columnwise block striped: all-to-all exchange Checkerboard block: gather, scatter, broadcast, reduce All three algorithms: roughly same number of messages Elements transmitted per process varies First two algorithms: (n) elements per process Checkerboard algorithm: (n/ p) elements Checkerboard block algorithm has better scalability
66 Summary (2/3) Communicators with Cartesian topology Creation Identifying processes by rank or coords Subdividing communicators Allows collective operations among subsets of processes
67 Summary (3/3) Parallel programs and supporting functions much longer than C counterparts Extra code devoted to reading, distributing, printing matrices and vectors Developing and debugging these functions is tedious and difficult Makes sense to generalize functions and put them in libraries for reuse
68 MPI Application Development Application Application-specific Library MPI Library C and Standard Libraries
Parallel Programming. Matrix Decomposition Options (Matrix-Vector Product)
") Parallel Programming Matrix Decomposition Options (Matrix-Vector Product) Matrix Decomposition Sequential algorithm and its complexity Design, analysis, and implementation of three parallel programs using
Parallel Programming Matrix Decomposition Options (Matrix-Vector Product) Matrix Decomposition Sequential algorithm and its complexity Design, analysis, and implementation of three parallel programs using
Copyright The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Chapter 8
 Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplicaiton Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplicaiton Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
Matrix-vector Multiplication
 Matrix-vector Multiplication Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition Outline Sequential algorithm
Matrix-vector Multiplication Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition Outline Sequential algorithm
Copyright The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Chapter 8
 Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
Project C/MPI: Matrix-Vector Multiplication
 Master MICS: Parallel Computing Lecture Project C/MPI: Matrix-Vector Multiplication Sebastien Varrette Matrix-vector multiplication is embedded in many algorithms for solving
Master MICS: Parallel Computing Lecture Project C/MPI: Matrix-Vector Multiplication Sebastien Varrette Matrix-vector multiplication is embedded in many algorithms for solving
Parallel Programming with MPI and OpenMP
 Parallel Programming with MPI and OpenMP Michael J. Quinn Chapter 6 Floyd s Algorithm Chapter Objectives Creating 2-D arrays Thinking about grain size Introducing point-to-point communications Reading
Parallel Programming with MPI and OpenMP Michael J. Quinn Chapter 6 Floyd s Algorithm Chapter Objectives Creating 2-D arrays Thinking about grain size Introducing point-to-point communications Reading
More Communication (cont d)
") Data types and the use of communicators can simplify parallel program development and improve code readability Sometimes, however, simply treating the processors as an unstructured collection is less than
Data types and the use of communicators can simplify parallel program development and improve code readability Sometimes, however, simply treating the processors as an unstructured collection is less than
Chapter 8 Matrix-Vector Multiplication
 Chapter 8 Matrix-Vector Multiplication We can't solve problems by using the same kind of thinking we used when we created them. - Albert Einstein 8. Introduction The purpose of this chapter is two-fold:
Chapter 8 Matrix-Vector Multiplication We can't solve problems by using the same kind of thinking we used when we created them. - Albert Einstein 8. Introduction The purpose of this chapter is two-fold:
Learning Lab 2: Parallel Algorithms of Matrix Multiplication
 Learning Lab 2: Parallel Algorithms of Matrix Multiplication Lab Objective... Exercise Stating the Matrix Multiplication Problem... 2 Task 2 Code the Seriial Matrix Multiplication Program... 2 Task Open
Learning Lab 2: Parallel Algorithms of Matrix Multiplication Lab Objective... Exercise Stating the Matrix Multiplication Problem... 2 Task 2 Code the Seriial Matrix Multiplication Program... 2 Task Open
All-Pairs Shortest Paths - Floyd s Algorithm
 All-Pairs Shortest Paths - Floyd s Algorithm Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 31, 2011 CPD (DEI / IST) Parallel
All-Pairs Shortest Paths - Floyd s Algorithm Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 31, 2011 CPD (DEI / IST) Parallel
High-Performance Computing: MPI (ctd)
") High-Performance Computing: MPI (ctd) Adrian F. Clark: alien@essex.ac.uk 2015 16 Adrian F. Clark: alien@essex.ac.uk High-Performance Computing: MPI (ctd) 2015 16 1 / 22 A reminder Last time, we started
High-Performance Computing: MPI (ctd) Adrian F. Clark: alien@essex.ac.uk 2015 16 Adrian F. Clark: alien@essex.ac.uk High-Performance Computing: MPI (ctd) 2015 16 1 / 22 A reminder Last time, we started
Introduction to MPI part II. Fabio AFFINITO
 Introduction to MPI part II Fabio AFFINITO (f.affinito@cineca.it) Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or
Introduction to MPI part II Fabio AFFINITO (f.affinito@cineca.it) Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or
Practical Scientific Computing: Performanceoptimized
 Practical Scientific Computing: Performanceoptimized Programming Advanced MPI Programming December 13, 2006 Dr. Ralf-Peter Mundani Department of Computer Science Chair V Technische Universität München,
Practical Scientific Computing: Performanceoptimized Programming Advanced MPI Programming December 13, 2006 Dr. Ralf-Peter Mundani Department of Computer Science Chair V Technische Universität München,
MPI Programming Techniques
 MPI Programming Techniques Copyright (c) 2012 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any
MPI Programming Techniques Copyright (c) 2012 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any
HPC Parallel Programing Multi-node Computation with MPI - I
 HPC Parallel Programing Multi-node Computation with MPI - I Parallelization and Optimization Group TATA Consultancy Services, Sahyadri Park Pune, India TCS all rights reserved April 29, 2013 Copyright
HPC Parallel Programing Multi-node Computation with MPI - I Parallelization and Optimization Group TATA Consultancy Services, Sahyadri Park Pune, India TCS all rights reserved April 29, 2013 Copyright
Topics. Lecture 7. Review. Other MPI collective functions. Collective Communication (cont d) MPI Programming (III)
 MPI Programming (III)") Topics Lecture 7 MPI Programming (III) Collective communication (cont d) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking
Topics Lecture 7 MPI Programming (III) Collective communication (cont d) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking
Review of MPI Part 2
 Review of MPI Part Russian-German School on High Performance Computer Systems, June, 7 th until July, 6 th 005, Novosibirsk 3. Day, 9 th of June, 005 HLRS, University of Stuttgart Slide Chap. 5 Virtual
Review of MPI Part Russian-German School on High Performance Computer Systems, June, 7 th until July, 6 th 005, Novosibirsk 3. Day, 9 th of June, 005 HLRS, University of Stuttgart Slide Chap. 5 Virtual
MPI 8. CSCI 4850/5850 High-Performance Computing Spring 2018
 MPI 8 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
MPI 8 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Intermediate MPI features
 Intermediate MPI features Advanced message passing Collective communication Topologies Group communication Forms of message passing (1) Communication modes: Standard: system decides whether message is
Intermediate MPI features Advanced message passing Collective communication Topologies Group communication Forms of message passing (1) Communication modes: Standard: system decides whether message is
Linear systems of equations
 Linear systems of equations Michael Quinn Parallel Programming with MPI and OpenMP material do autor Terminology Back substitution Gaussian elimination Outline Problem System of linear equations Solve
Linear systems of equations Michael Quinn Parallel Programming with MPI and OpenMP material do autor Terminology Back substitution Gaussian elimination Outline Problem System of linear equations Solve
Introduction to Parallel. Programming
 University of Nizhni Novgorod Faculty of Computational Mathematics & Cybernetics Introduction to Parallel Section 4. Part 3. Programming Parallel Programming with MPI Gergel V.P., Professor, D.Sc., Software
University of Nizhni Novgorod Faculty of Computational Mathematics & Cybernetics Introduction to Parallel Section 4. Part 3. Programming Parallel Programming with MPI Gergel V.P., Professor, D.Sc., Software
CME 213 SPRING Eric Darve
 CME 213 SPRING 2017 Eric Darve LINEAR ALGEBRA MATRIX-VECTOR PRODUCTS Application example: matrix-vector product We are going to use that example to illustrate additional MPI functionalities. This will
CME 213 SPRING 2017 Eric Darve LINEAR ALGEBRA MATRIX-VECTOR PRODUCTS Application example: matrix-vector product We are going to use that example to illustrate additional MPI functionalities. This will
MPI Workshop - III. Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3
 MPI Workshop - III Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3 Schedule 4Course Map 4Fix environments to run MPI codes 4CartesianTopology! MPI_Cart_create! MPI_
MPI Workshop - III Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3 Schedule 4Course Map 4Fix environments to run MPI codes 4CartesianTopology! MPI_Cart_create! MPI_
CME 194 Introduc0on to MPI
 CME 194 Introduc0on to MPI Coe0bus Opus h8p://cme194.stanford.edu Recap Last class: Collec0ve Opera0ons communica0on protocols (algorithms) such as reduce, broadcast, etc.. Naïve implementa0ons of them
CME 194 Introduc0on to MPI Coe0bus Opus h8p://cme194.stanford.edu Recap Last class: Collec0ve Opera0ons communica0on protocols (algorithms) such as reduce, broadcast, etc.. Naïve implementa0ons of them
MPI Collective communication
 MPI Collective communication CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) MPI Collective communication Spring 2018 1 / 43 Outline 1 MPI Collective communication
MPI Collective communication CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) MPI Collective communication Spring 2018 1 / 43 Outline 1 MPI Collective communication
CPS 303 High Performance Computing
 CPS 303 High Performance Computing Wensheng Shen Department of Computational Science SUNY Brockport Chapter 7: Communicators and topologies Communicators: a communicator is a collection of processes that
CPS 303 High Performance Computing Wensheng Shen Department of Computational Science SUNY Brockport Chapter 7: Communicators and topologies Communicators: a communicator is a collection of processes that
CSE 160 Lecture 23. Matrix Multiplication Continued Managing communicators Gather and Scatter (Collectives)
") CS 160 Lecture 23 Matrix Multiplication Continued Managing communicators Gather and Scatter (Collectives) Today s lecture All to all communication Application to Parallel Sorting Blocking for cache 2013
CS 160 Lecture 23 Matrix Multiplication Continued Managing communicators Gather and Scatter (Collectives) Today s lecture All to all communication Application to Parallel Sorting Blocking for cache 2013
PARALLEL AND DISTRIBUTED COMPUTING
 PARALLEL AND DISTRIBUTED COMPUTING 2013/2014 1 st Semester 1 st Exam January 7, 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc. - Give your answers
PARALLEL AND DISTRIBUTED COMPUTING 2013/2014 1 st Semester 1 st Exam January 7, 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc. - Give your answers
Introduction to MPI Part II Collective Communications and communicators
 Introduction to MPI Part II Collective Communications and communicators Andrew Emerson, Fabio Affinito {a.emerson,f.affinito}@cineca.it SuperComputing Applications and Innovation Department Collective
Introduction to MPI Part II Collective Communications and communicators Andrew Emerson, Fabio Affinito {a.emerson,f.affinito}@cineca.it SuperComputing Applications and Innovation Department Collective
Message Passing with MPI
 Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 9 Document Classification Chapter Objectives Complete introduction of MPI functions Show how to implement manager-worker programs
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 9 Document Classification Chapter Objectives Complete introduction of MPI functions Show how to implement manager-worker programs
Lecture 16. Parallel Matrix Multiplication
 Lecture 16 Parallel Matrix Multiplication Assignment #5 Announcements Message passing on Triton GPU programming on Lincoln Calendar No class on Tuesday/Thursday Nov 16th/18 th TA Evaluation, Professor
Lecture 16 Parallel Matrix Multiplication Assignment #5 Announcements Message passing on Triton GPU programming on Lincoln Calendar No class on Tuesday/Thursday Nov 16th/18 th TA Evaluation, Professor
Introduction to TDDC78 Lab Series. Lu Li Linköping University Parts of Slides developed by Usman Dastgeer
 Introduction to TDDC78 Lab Series Lu Li Linköping University Parts of Slides developed by Usman Dastgeer Goals Shared- and Distributed-memory systems Programming parallelism (typical problems) Goals Shared-
Introduction to TDDC78 Lab Series Lu Li Linköping University Parts of Slides developed by Usman Dastgeer Goals Shared- and Distributed-memory systems Programming parallelism (typical problems) Goals Shared-
Programming with MPI Collectives
 Programming with MPI Collectives Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Collectives Classes Communication types exercise: BroadcastBarrier Gather Scatter exercise:
Programming with MPI Collectives Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Collectives Classes Communication types exercise: BroadcastBarrier Gather Scatter exercise:
Basic MPI Communications. Basic MPI Communications (cont d)
") Basic MPI Communications MPI provides two non-blocking routines: MPI_Isend(buf,cnt,type,dst,tag,comm,reqHandle) buf: source of data to be sent cnt: number of data elements to be sent type: type of each
Basic MPI Communications MPI provides two non-blocking routines: MPI_Isend(buf,cnt,type,dst,tag,comm,reqHandle) buf: source of data to be sent cnt: number of data elements to be sent type: type of each
INTRODUCTION TO MPI VIRTUAL TOPOLOGIES
 INTRODUCTION TO MPI VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 18-19-20 november 2013 a.marani@cineca.it g.muscianisi@cineca.it l.ferraro@cineca.it VIRTUAL TOPOLOGY Topology:
INTRODUCTION TO MPI VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 18-19-20 november 2013 a.marani@cineca.it g.muscianisi@cineca.it l.ferraro@cineca.it VIRTUAL TOPOLOGY Topology:
Topologies in MPI. Instructor: Dr. M. Taufer
 Topologies in MPI Instructor: Dr. M. Taufer WS2004/2005 Topology We can associate additional information (beyond the group and the context) to a communicator. A linear ranking of processes may not adequately
Topologies in MPI Instructor: Dr. M. Taufer WS2004/2005 Topology We can associate additional information (beyond the group and the context) to a communicator. A linear ranking of processes may not adequately
Document Classification
 Document Classification Introduction Search engine on web Search directories, subdirectories for documents Search for documents with extensions.html,.txt, and.tex Using a dictionary of key words, create
Document Classification Introduction Search engine on web Search directories, subdirectories for documents Search for documents with extensions.html,.txt, and.tex Using a dictionary of key words, create
L15: Putting it together: N-body (Ch. 6)!
!") Outline L15: Putting it together: N-body (Ch. 6)! October 30, 2012! Review MPI Communication - Blocking - Non-Blocking - One-Sided - Point-to-Point vs. Collective Chapter 6 shows two algorithms (N-body
Outline L15: Putting it together: N-body (Ch. 6)! October 30, 2012! Review MPI Communication - Blocking - Non-Blocking - One-Sided - Point-to-Point vs. Collective Chapter 6 shows two algorithms (N-body
INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES
 INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 24 november 2017 a.marani@cineca.it WHAT ARE COMMUNICATORS? Many users are familiar with
INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 24 november 2017 a.marani@cineca.it WHAT ARE COMMUNICATORS? Many users are familiar with
MA471. Lecture 5. Collective MPI Communication
 MA471 Lecture 5 Collective MPI Communication Today: When all the processes want to send, receive or both Excellent website for MPI command syntax available at: http://www-unix.mcs.anl.gov/mpi/www/ 9/10/2003
MA471 Lecture 5 Collective MPI Communication Today: When all the processes want to send, receive or both Excellent website for MPI command syntax available at: http://www-unix.mcs.anl.gov/mpi/www/ 9/10/2003
Department of Informatics V. HPC-Lab. Session 4: MPI, CG M. Bader, A. Breuer. Alex Breuer
 HPC-Lab Session 4: MPI, CG M. Bader, A. Breuer Meetings Date Schedule 10/13/14 Kickoff 10/20/14 Q&A 10/27/14 Presentation 1 11/03/14 H. Bast, Intel 11/10/14 Presentation 2 12/01/14 Presentation 3 12/08/14
HPC-Lab Session 4: MPI, CG M. Bader, A. Breuer Meetings Date Schedule 10/13/14 Kickoff 10/20/14 Q&A 10/27/14 Presentation 1 11/03/14 H. Bast, Intel 11/10/14 Presentation 2 12/01/14 Presentation 3 12/08/14
Reusing this material
 Virtual Topologies Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Virtual Topologies Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
a. Assuming a perfect balance of FMUL and FADD instructions and no pipeline stalls, what would be the FLOPS rate of the FPU?
 CPS 540 Fall 204 Shirley Moore, Instructor Test November 9, 204 Answers Please show all your work.. Draw a sketch of the extended von Neumann architecture for a 4-core multicore processor with three levels
CPS 540 Fall 204 Shirley Moore, Instructor Test November 9, 204 Answers Please show all your work.. Draw a sketch of the extended von Neumann architecture for a 4-core multicore processor with three levels
Advanced Message-Passing Interface (MPI)
") Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
COSC 4397 Parallel Computation. Introduction to MPI (III) Process Grouping. Terminology (I)
 Process Grouping. Terminology (I)") COSC 4397 Introduction to MPI (III) Process Grouping Spring 2010 Terminology (I) an MPI_Group is the object describing the list of processes forming a logical entity a group has a size MPI_Group_size every
COSC 4397 Introduction to MPI (III) Process Grouping Spring 2010 Terminology (I) an MPI_Group is the object describing the list of processes forming a logical entity a group has a size MPI_Group_size every
Standard MPI - Message Passing Interface
 c Ewa Szynkiewicz, 2007 1 Standard MPI - Message Passing Interface The message-passing paradigm is one of the oldest and most widely used approaches for programming parallel machines, especially those
c Ewa Szynkiewicz, 2007 1 Standard MPI - Message Passing Interface The message-passing paradigm is one of the oldest and most widely used approaches for programming parallel machines, especially those
Masterpraktikum - Scientific Computing, High Performance Computing
 Masterpraktikum - Scientific Computing, High Performance Computing Message Passing Interface (MPI) and CG-method Michael Bader Alexander Heinecke Technische Universität München, Germany Outline MPI Hello
Masterpraktikum - Scientific Computing, High Performance Computing Message Passing Interface (MPI) and CG-method Michael Bader Alexander Heinecke Technische Universität München, Germany Outline MPI Hello
Optimization of MPI Applications Rolf Rabenseifner
 Optimization of MPI Applications Rolf Rabenseifner University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Optimization of MPI Applications Slide 1 Optimization and Standardization
Optimization of MPI Applications Rolf Rabenseifner University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Optimization of MPI Applications Slide 1 Optimization and Standardization
Buffering in MPI communications
 Buffering in MPI communications Application buffer: specified by the first parameter in MPI_Send/Recv functions System buffer: Hidden from the programmer and managed by the MPI library Is limitted and
Buffering in MPI communications Application buffer: specified by the first parameter in MPI_Send/Recv functions System buffer: Hidden from the programmer and managed by the MPI library Is limitted and
Matrix multiplication
 Matrix multiplication Standard serial algorithm: procedure MAT_VECT (A, x, y) begin for i := 0 to n - 1 do begin y[i] := 0 for j := 0 to n - 1 do y[i] := y[i] + A[i, j] * x [j] end end MAT_VECT Complexity:
Matrix multiplication Standard serial algorithm: procedure MAT_VECT (A, x, y) begin for i := 0 to n - 1 do begin y[i] := 0 for j := 0 to n - 1 do y[i] := y[i] + A[i, j] * x [j] end end MAT_VECT Complexity:
Topics. Lecture 6. Point-to-point Communication. Point-to-point Communication. Broadcast. Basic Point-to-point communication. MPI Programming (III)
") Topics Lecture 6 MPI Programming (III) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking communication Manager-Worker Programming
Topics Lecture 6 MPI Programming (III) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking communication Manager-Worker Programming
Distributed Memory Systems: Part IV
 Chapter 5 Distributed Memory Systems: Part IV Max Planck Institute Magdeburg Jens Saak, Scientific Computing II 293/342 The Message Passing Interface is a standard for creation of parallel programs using
Chapter 5 Distributed Memory Systems: Part IV Max Planck Institute Magdeburg Jens Saak, Scientific Computing II 293/342 The Message Passing Interface is a standard for creation of parallel programs using
Masterpraktikum - Scientific Computing, High Performance Computing
 Masterpraktikum - Scientific Computing, High Performance Computing Message Passing Interface (MPI) Thomas Auckenthaler Wolfgang Eckhardt Technische Universität München, Germany Outline Hello World P2P
Masterpraktikum - Scientific Computing, High Performance Computing Message Passing Interface (MPI) Thomas Auckenthaler Wolfgang Eckhardt Technische Universität München, Germany Outline Hello World P2P
Introduzione al Message Passing Interface (MPI) Andrea Clematis IMATI CNR
 Andrea Clematis IMATI CNR") Introduzione al Message Passing Interface (MPI) Andrea Clematis IMATI CNR clematis@ge.imati.cnr.it Ack. & riferimenti An Introduction to MPI Parallel Programming with the Message Passing InterfaceWilliam
Introduzione al Message Passing Interface (MPI) Andrea Clematis IMATI CNR clematis@ge.imati.cnr.it Ack. & riferimenti An Introduction to MPI Parallel Programming with the Message Passing InterfaceWilliam
Foster s Methodology: Application Examples
 Foster s Methodology: Application Examples Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 19, 2011 CPD (DEI / IST) Parallel and
Foster s Methodology: Application Examples Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 19, 2011 CPD (DEI / IST) Parallel and
The MPI Message-passing Standard Practical use and implementation (V) SPD Course 6/03/2017 Massimo Coppola
 SPD Course 6/03/2017 Massimo Coppola") The MPI Message-passing Standard Practical use and implementation (V) SPD Course 6/03/2017 Massimo Coppola Intracommunicators COLLECTIVE COMMUNICATIONS SPD - MPI Standard Use and Implementation (5) 2 Collectives
The MPI Message-passing Standard Practical use and implementation (V) SPD Course 6/03/2017 Massimo Coppola Intracommunicators COLLECTIVE COMMUNICATIONS SPD - MPI Standard Use and Implementation (5) 2 Collectives
Cornell Theory Center. Discussion: MPI Collective Communication I. Table of Contents. 1. Introduction
 1 of 18 11/1/2006 3:59 PM Cornell Theory Center Discussion: MPI Collective Communication I This is the in-depth discussion layer of a two-part module. For an explanation of the layers and how to navigate
1 of 18 11/1/2006 3:59 PM Cornell Theory Center Discussion: MPI Collective Communication I This is the in-depth discussion layer of a two-part module. For an explanation of the layers and how to navigate
Parallel Programming with MPI and OpenMP
 Parallel Programming with MPI and OpenMP Michael J. Quinn (revised by L.M. Liebrock) Chapter 7 Performance Analysis Learning Objectives Predict performance of parallel programs Understand barriers to higher
Parallel Programming with MPI and OpenMP Michael J. Quinn (revised by L.M. Liebrock) Chapter 7 Performance Analysis Learning Objectives Predict performance of parallel programs Understand barriers to higher
Parallel Programming. Functional Decomposition (Document Classification)
") Parallel Programming Functional Decomposition (Document Classification) Document Classification Problem Search directories, subdirectories for text documents (look for.html,.txt,.tex, etc.) Using a dictionary
Parallel Programming Functional Decomposition (Document Classification) Document Classification Problem Search directories, subdirectories for text documents (look for.html,.txt,.tex, etc.) Using a dictionary
Copyright The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Chapter 9
 Chapter 9 Document Classification Document Classification Problem Search directories, subdirectories for documents (look for.html,.txt,.tex, etc.) Using a dictionary of key words, create a profile vector
Chapter 9 Document Classification Document Classification Problem Search directories, subdirectories for documents (look for.html,.txt,.tex, etc.) Using a dictionary of key words, create a profile vector
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives n Understanding how MPI programs execute n Familiarity with fundamental MPI functions
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives n Understanding how MPI programs execute n Familiarity with fundamental MPI functions
Recap of Parallelism & MPI
 Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
Last Time. Intro to Parallel Algorithms. Parallel Search Parallel Sorting. Merge sort Sample sort
 Intro to MPI Last Time Intro to Parallel Algorithms Parallel Search Parallel Sorting Merge sort Sample sort Today Network Topology Communication Primitives Message Passing Interface (MPI) Randomized Algorithms
Intro to MPI Last Time Intro to Parallel Algorithms Parallel Search Parallel Sorting Merge sort Sample sort Today Network Topology Communication Primitives Message Passing Interface (MPI) Randomized Algorithms
CS 426. Building and Running a Parallel Application
 CS 426 Building and Running a Parallel Application 1 Task/Channel Model Design Efficient Parallel Programs (or Algorithms) Mainly for distributed memory systems (e.g. Clusters) Break Parallel Computations
CS 426 Building and Running a Parallel Application 1 Task/Channel Model Design Efficient Parallel Programs (or Algorithms) Mainly for distributed memory systems (e.g. Clusters) Break Parallel Computations
Collective Communication: Gatherv. MPI v Operations. root
 Collective Communication: Gather MPI v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Collective Communication: Gather MPI v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Parallel Computing: Parallel Algorithm Design Examples Jin, Hai
 Parallel Computing: Parallel Algorithm Design Examples Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! Given associative operator!! a 0! a 1! a 2!! a
Parallel Computing: Parallel Algorithm Design Examples Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! Given associative operator!! a 0! a 1! a 2!! a
Message Passing Interface
 Message Passing Interface DPHPC15 TA: Salvatore Di Girolamo DSM (Distributed Shared Memory) Message Passing MPI (Message Passing Interface) A message passing specification implemented
Message Passing Interface DPHPC15 TA: Salvatore Di Girolamo DSM (Distributed Shared Memory) Message Passing MPI (Message Passing Interface) A message passing specification implemented
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives Understanding how MPI programs execute Familiarity with fundamental MPI functions
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives Understanding how MPI programs execute Familiarity with fundamental MPI functions
Lecture 6: Parallel Matrix Algorithms (part 3)
") Lecture 6: Parallel Matrix Algorithms (part 3) 1 A Simple Parallel Dense Matrix-Matrix Multiplication Let A = [a ij ] n n and B = [b ij ] n n be n n matrices. Compute C = AB Computational complexity of
Lecture 6: Parallel Matrix Algorithms (part 3) 1 A Simple Parallel Dense Matrix-Matrix Multiplication Let A = [a ij ] n n and B = [b ij ] n n be n n matrices. Compute C = AB Computational complexity of
MPI. (message passing, MIMD)
") MPI (message passing, MIMD) What is MPI? a message-passing library specification extension of C/C++ (and Fortran) message passing for distributed memory parallel programming Features of MPI Point-to-point
MPI (message passing, MIMD) What is MPI? a message-passing library specification extension of C/C++ (and Fortran) message passing for distributed memory parallel programming Features of MPI Point-to-point
Parallel Algorithm Design. Parallel Algorithm Design p. 1
 Parallel Algorithm Design Parallel Algorithm Design p. 1 Overview Chapter 3 from Michael J. Quinn, Parallel Programming in C with MPI and OpenMP Another resource: http://www.mcs.anl.gov/ itf/dbpp/text/node14.html
Parallel Algorithm Design Parallel Algorithm Design p. 1 Overview Chapter 3 from Michael J. Quinn, Parallel Programming in C with MPI and OpenMP Another resource: http://www.mcs.anl.gov/ itf/dbpp/text/node14.html
Programming SoHPC Course June-July 2015 Vladimir Subotic MPI - Message Passing Interface
 www.bsc.es Programming with Message-Passing Libraries SoHPC Course June-July 2015 Vladimir Subotic 1 Data Transfer Blocking: Function does not return, before message can be accessed again Process is blocked
www.bsc.es Programming with Message-Passing Libraries SoHPC Course June-July 2015 Vladimir Subotic 1 Data Transfer Blocking: Function does not return, before message can be accessed again Process is blocked
Lecture 7. Revisiting MPI performance & semantics Strategies for parallelizing an application Word Problems
 Lecture 7 Revisiting MPI performance & semantics Strategies for parallelizing an application Word Problems Announcements Quiz #1 in section on Friday Midterm Room: SSB 106 Monday 10/30, 7:00 to 8:20 PM
Lecture 7 Revisiting MPI performance & semantics Strategies for parallelizing an application Word Problems Announcements Quiz #1 in section on Friday Midterm Room: SSB 106 Monday 10/30, 7:00 to 8:20 PM
Lecture 13. Writing parallel programs with MPI Matrix Multiplication Basic Collectives Managing communicators
 Lecture 13 Writing parallel programs with MPI Matrix Multiplication Basic Collectives Managing communicators Announcements Extra lecture Friday 4p to 5.20p, room 2154 A4 posted u Cannon s matrix multiplication
Lecture 13 Writing parallel programs with MPI Matrix Multiplication Basic Collectives Managing communicators Announcements Extra lecture Friday 4p to 5.20p, room 2154 A4 posted u Cannon s matrix multiplication
Distributed Memory Programming with MPI
 Distributed Memory Programming with MPI Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna moreno.marzolla@unibo.it Algoritmi Avanzati--modulo 2 2 Credits Peter Pacheco,
Distributed Memory Programming with MPI Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna moreno.marzolla@unibo.it Algoritmi Avanzati--modulo 2 2 Credits Peter Pacheco,
Lecture 17: Array Algorithms
 Lecture 17: Array Algorithms CS178: Programming Parallel and Distributed Systems April 4, 2001 Steven P. Reiss I. Overview A. We talking about constructing parallel programs 1. Last time we discussed sorting
Lecture 17: Array Algorithms CS178: Programming Parallel and Distributed Systems April 4, 2001 Steven P. Reiss I. Overview A. We talking about constructing parallel programs 1. Last time we discussed sorting
Parallel Computing. Parallel Algorithm Design
 Parallel Computing Parallel Algorithm Design Task/Channel Model Parallel computation = set of tasks Task Program Local memory Collection of I/O ports Tasks interact by sending messages through channels
Parallel Computing Parallel Algorithm Design Task/Channel Model Parallel computation = set of tasks Task Program Local memory Collection of I/O ports Tasks interact by sending messages through channels
In the simplest sense, parallel computing is the simultaneous use of multiple computing resources to solve a problem.
 1. Introduction to Parallel Processing In the simplest sense, parallel computing is the simultaneous use of multiple computing resources to solve a problem. a) Types of machines and computation. A conventional
1. Introduction to Parallel Processing In the simplest sense, parallel computing is the simultaneous use of multiple computing resources to solve a problem. a) Types of machines and computation. A conventional
Hybrid MPI+UPC parallel programming paradigm on an SMP cluster
 Turk J Elec Eng & Comp Sci, Vol.20, No.Sup.2, 2012, c TÜBİTAK doi:10.3906/elk-1103-11 Hybrid MPI+UPC parallel programming paradigm on an SMP cluster Zeki BOZKUŞ Department of Computer Engineering, Kadir
Turk J Elec Eng & Comp Sci, Vol.20, No.Sup.2, 2012, c TÜBİTAK doi:10.3906/elk-1103-11 Hybrid MPI+UPC parallel programming paradigm on an SMP cluster Zeki BOZKUŞ Department of Computer Engineering, Kadir
Cluster Computing MPI. Industrial Standard Message Passing
 MPI Industrial Standard Message Passing MPI Features Industrial Standard Highly portable Widely available SPMD programming model Synchronous execution MPI Outer scope int MPI_Init( int *argc, char ** argv)
MPI Industrial Standard Message Passing MPI Features Industrial Standard Highly portable Widely available SPMD programming model Synchronous execution MPI Outer scope int MPI_Init( int *argc, char ** argv)
Collective Communication: Gather. MPI - v Operations. Collective Communication: Gather. MPI_Gather. root WORKS A OK
 Collective Communication: Gather MPI - v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Collective Communication: Gather MPI - v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Parallel I/O. and split communicators. David Henty, Fiona Ried, Gavin J. Pringle
 Parallel I/O and split communicators David Henty, Fiona Ried, Gavin J. Pringle Dr Gavin J. Pringle Applications Consultant gavin@epcc.ed.ac.uk +44 131 650 6709 4x4 array on 2x2 Process Grid Parallel IO
Parallel I/O and split communicators David Henty, Fiona Ried, Gavin J. Pringle Dr Gavin J. Pringle Applications Consultant gavin@epcc.ed.ac.uk +44 131 650 6709 4x4 array on 2x2 Process Grid Parallel IO
MPI - v Operations. Collective Communication: Gather
 MPI - v Operations Based on notes by Dr. David Cronk Innovative Computing Lab University of Tennessee Cluster Computing 1 Collective Communication: Gather A Gather operation has data from all processes
MPI - v Operations Based on notes by Dr. David Cronk Innovative Computing Lab University of Tennessee Cluster Computing 1 Collective Communication: Gather A Gather operation has data from all processes
Week 3: MPI. Day 03 :: Data types, groups, topologies, error handling, parallel debugging
 Week 3: MPI Day 03 :: Data types, groups, topologies, error handling, parallel debugging Other MPI-1 features Timing REAL(8) :: t t = MPI_Wtime() -- not a sub, no ierror! Get the current wall-clock time
Week 3: MPI Day 03 :: Data types, groups, topologies, error handling, parallel debugging Other MPI-1 features Timing REAL(8) :: t t = MPI_Wtime() -- not a sub, no ierror! Get the current wall-clock time
COSC 462. Parallel Algorithms. The Design Basics. Piotr Luszczek
 COSC 462 Parallel Algorithms The Design Basics Piotr Luszczek September 18, 2017 1/16 Levels of Abstraction 2/16 Concepts Tools Algorithms: partitioning, communication, agglomeration, mapping Domain, channel,
COSC 462 Parallel Algorithms The Design Basics Piotr Luszczek September 18, 2017 1/16 Levels of Abstraction 2/16 Concepts Tools Algorithms: partitioning, communication, agglomeration, mapping Domain, channel,
L19: Putting it together: N-body (Ch. 6)!
!") Administrative L19: Putting it together: N-body (Ch. 6)! November 22, 2011! Project sign off due today, about a third of you are done (will accept it tomorrow, otherwise 5% loss on project grade) Next
Administrative L19: Putting it together: N-body (Ch. 6)! November 22, 2011! Project sign off due today, about a third of you are done (will accept it tomorrow, otherwise 5% loss on project grade) Next
Outline. Communication modes MPI Message Passing Interface Standard
 MPI THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
MPI THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
Topologies. Ned Nedialkov. McMaster University Canada. SE 4F03 March 2016
 Topologies Ned Nedialkov McMaster University Canada SE 4F03 March 2016 Outline Introduction Cartesian topology Some Cartesian topology functions Some graph topology functions c 2013 16 Ned Nedialkov 2/11
Topologies Ned Nedialkov McMaster University Canada SE 4F03 March 2016 Outline Introduction Cartesian topology Some Cartesian topology functions Some graph topology functions c 2013 16 Ned Nedialkov 2/11
Collective Communications II
 Collective Communications II Ned Nedialkov McMaster University Canada SE/CS 4F03 January 2014 Outline Scatter Example: parallel A b Distributing a matrix Gather Serial A b Parallel A b Allocating memory
Collective Communications II Ned Nedialkov McMaster University Canada SE/CS 4F03 January 2014 Outline Scatter Example: parallel A b Distributing a matrix Gather Serial A b Parallel A b Allocating memory
Distributed Memory Parallel Programming
 COSC Big Data Analytics Parallel Programming using MPI Edgar Gabriel Spring 201 Distributed Memory Parallel Programming Vast majority of clusters are homogeneous Necessitated by the complexity of maintaining
COSC Big Data Analytics Parallel Programming using MPI Edgar Gabriel Spring 201 Distributed Memory Parallel Programming Vast majority of clusters are homogeneous Necessitated by the complexity of maintaining
Dense Matrix Algorithms
 Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
Introduction to Lab Series DMS & MPI
 TDDC 78 Labs: Memory-based Taxonomy Introduction to Lab Series DMS & Mikhail Chalabine Linköping University Memory Lab(s) Use Distributed 1 Shared 2 3 Posix threads OpenMP Distributed 4 2011 LAB 5 (tools)
TDDC 78 Labs: Memory-based Taxonomy Introduction to Lab Series DMS & Mikhail Chalabine Linköping University Memory Lab(s) Use Distributed 1 Shared 2 3 Posix threads OpenMP Distributed 4 2011 LAB 5 (tools)
Message Passing Interface
 MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
Document Classification Problem
 Document Classification Problem Search directories, subdirectories for documents (look for.html,.txt,.tex, etc.) Using a dictionary of key words, create a profile vector for each document Store profile
Document Classification Problem Search directories, subdirectories for documents (look for.html,.txt,.tex, etc.) Using a dictionary of key words, create a profile vector for each document Store profile
CSCE 5610 Midterm-2 (Krishna Kavi)
") CSCE 5610 Midterm-2 (Krishna Kavi) OPEN BOOKS OPEN NOTES Wednesday April 2, 2019: 2:30-4:00pm Your Name: State any (and all) assumptions you are making in answering the following questions. I may give
CSCE 5610 Midterm-2 (Krishna Kavi) OPEN BOOKS OPEN NOTES Wednesday April 2, 2019: 2:30-4:00pm Your Name: State any (and all) assumptions you are making in answering the following questions. I may give
Message Passing Interface. most of the slides taken from Hanjun Kim
 Message Passing Interface most of the slides taken from Hanjun Kim Message Passing Pros Scalable, Flexible Cons Someone says it s more difficult than DSM MPI (Message Passing Interface) A standard message
Message Passing Interface most of the slides taken from Hanjun Kim Message Passing Pros Scalable, Flexible Cons Someone says it s more difficult than DSM MPI (Message Passing Interface) A standard message
CS 6230: High-Performance Computing and Parallelization Introduction to MPI
 CS 6230: High-Performance Computing and Parallelization Introduction to MPI Dr. Mike Kirby School of Computing and Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT, USA
CS 6230: High-Performance Computing and Parallelization Introduction to MPI Dr. Mike Kirby School of Computing and Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT, USA
Collective Communications
 Collective Communications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Collective Communications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us