Matrix-Vector Multiplication by MapReduce. From Rajaraman / Ullman- Ch.2 Part 1
|
|
|
- Alexia Bradley
- 6 years ago
- Views:
Transcription
1 Matrix-Vector Multiplication by MapReduce From Rajaraman / Ullman- Ch.2 Part 1
2 Google implementation of MapReduce created to execute very large matrix-vector multiplications When ranking of Web pages that goes on at search engines, n is in the tens of billions. Page Rank- iterative algorithm Also, useful for simple (memory-based) recommender systems
3 Problem Statement Given, n n matrix M, whose element in row i and column j will be denoted m ij. a vector v of length n. x i = σ 1 n m ij. v j Assume that the row-column coordinates of each matrix element will be discoverable, either from its position in the file, or because it is stored with explicit coordinates, as a triple (i, j, m ij ). the position of element v j in the vector v will be discoverable in the analogous way.
4 Case 1: n is large, but not so large that vector v cannot fit in main memory The Map Function: Map function is written to apply to one element of M v is first read to computing node executing a Map task and is available for all applications of the Map function at this compute node. Each Map task will operate on a chunk of the matrix M. From each matrix element m ij it produces the keyvalue pair (i, ( m ij. v j ) ). Thus, all terms of the sum that make up the component x i of the matrix-vector product will get the same key, i.
5 Case 1 Continued The Reduce Function: The Reduce function simply sums all the values associated with a given key i. The result will be a pair (i,x i ).
6 Case 2: n is large to fit into main memory v should be stored in computing nodes used for the Map task Divide the matrix into vertical stripes of equal width and divide the vector into an equal number of horizontal stripes, of the same height. Our goal is to use enough stripes so that the portion of the vector in one stripe can fit conveniently into main memory at a compute node.
7 Matrix M vector v Figure 2.4: Division of a matrix and vector into five stripes The ith stripe of the matrix multiplies only components from the ith stripe of the vector. Divide the matrix into one file for each stripe, and do the same for the vector. Each Map task is assigned a chunk from one of the stripes of the matrix and gets the entire corresponding stripe of the vector. The Map and Reduce tasks can then act exactly as was described, as case 1.
8 Recommender is one of the most popular large-scale machine learning techniques. Amazon ebay Facebook Netflix
9 Two types of recommender techniques Collaborative Filtering Content Based Recommendation Collaborative Filtering Model based Memory based User similarity based Item similarity based
10 Item-based collaborative filtering Basic idea: Use the similarity between items (and not users) to make predictions Example: Look Item1 for items Item2that Item3 are similar Item4 to Item5 Alice ? Take Alice's ratings for these items to predict the rating for Item5 User User User User

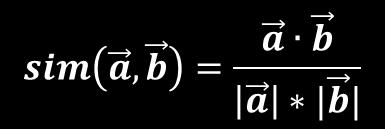
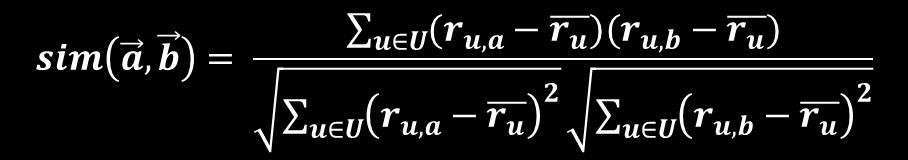
11 The cosine similarity measure



12 Making predictions A common prediction function: u > user; i,p -> items; user has not rated item p. Neighborhood size is typically also limited to a specific size Not all neighbors are taken into account for the prediction An analysis of the MovieLens dataset indicates that "in most real-world situations, a neighborhood of 20 to 50 neighbors seems reasonable" (Herlocker et al. 2002)
13 Pre-processing for item-based filtering Item-based filtering does not solve the scalability problem itself Pre-processing approach by Amazon.com (in 2003) Calculate all pair-wise item similarities in advance The neighborhood to be used at run-time is typically rather small, because only items are taken into account which the user has rated Item similarities are supposed to be more stable than user similarities Memory requirements Up to N 2 pair-wise similarities to be memorized (N = number of items) in theory In practice, this is significantly lower (items with no co-ratings) Further reductions possible Minimum threshold for co-ratings Limit the neighborhood size (might affect recommendation accuracy)
14 Mahout s Item-Based RS Apache Mahout is an open source Apache Foundation project for scalable machine learning. Mahout uses Map-Reduce paradigm for scalable recommendation 14
15 Mahout s RS Matrix Multiplication for Preference Prediction Item-Item Similarity Matrix Active User s Preference Vector 15
16 As matrix math, again Inside-out method
17 Page Rank Algorithm One iteration of the PageRank algorithm involves taking an estimated Page-Rank vector v and computing the next estimate v by v = βmv + (1 β)e/n β is a constant slightly less than 1, e is a vector of all 1 s, and n is the number of nodes in the graph that transition matrix M represents.
18 Vectors v and v are too large for Main Memory If using the stripe method to partition a matrix and vector that do not fit in main memory, then a vertical stripe from the matrix M and a horizontal stripe from the vector v will contribute to all components of the result vector v. Since that vector is the same length as v, it will not fit in main memory either. M is stored column-by-column for efficiency reasons, a column can affect any of the components of v. As a result, it is unlikely that when we need to add a term to some component v i, that component will already be in main memory. Thrashing
19 Square Blocks, instead of Slices An additional constraint is that the result vector should be partitioned in the same way as the input vector, so the output may become the input for another iteration of the matrix-vector multiplication. An alternative strategy is based on partitioning the matrix into k 2 blocks, while the vectors are still partitioned into k stripes.

20 Figure from Rajaraman, Ullmann
21 Iterative Computation- Square Blocks Method In this method, we use k 2 Map tasks. Each task gets one square of the matrix M, say M ij, and one stripe of the vector v, which must be v j. Notice that each stripe of the vector is sent to k different Map tasks; v j is sent to the task handling M ij for each of the k possible values of i. Thus, v is transmitted over the network k times. However, each piece of the matrix is sent only once. The advantage of this approach is that we can keep both the jth stripe of v and the ith stripe of v in main memory as we process M ij. Note that all terms generated from M ij and v j contribute to v i and no other stripe of v.
22 Matrix-Matrix Multiplication using MapReduce Like Natural Join Operation
 Recommender")
23 The Alternating Least Squares (ALS) Recommender Algorithm
24 Matrix A represents a typical user-product-rating model The algorithm tries to derive a set of latent factors (like tastes) from the user-product-rating matrix from matrix A. So matrix X can be viewed as user-taste matrix And matrix Y can be viewed as a product-taste matrix
25 Objective Function minimize 1 2 A XYT 2 Only check observed ratings minimize 1 2 (i,j) Ω (a i,j x i T yj ) 2 If we fix X, the objective function becomes a convex. Then we can calculate the gradient to find Y If we fix Y, we can calculate the gradient to find X
26 Iterative Training Algorithm Given Y, you can Solve X X i = AY i 1 (Y i 1T Y i 1 ) -1 The algorithm works in the following way: Y 0 -> X 1 -> Y 1 -> X 2 -> Y 2 -> Till the squared difference is small enough
2.3 Algorithms Using Map-Reduce
 28 CHAPTER 2. MAP-REDUCE AND THE NEW SOFTWARE STACK one becomes available. The Master must also inform each Reduce task that the location of its input from that Map task has changed. Dealing with a failure
28 CHAPTER 2. MAP-REDUCE AND THE NEW SOFTWARE STACK one becomes available. The Master must also inform each Reduce task that the location of its input from that Map task has changed. Dealing with a failure
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
CS435 Introduction to Big Data FALL 2018 Colorado State University. 9/24/2018 Week 6-A Sangmi Lee Pallickara. Topics. This material is built based on,
 FLL 218 olorado State University 9/24/218 Week 6-9/24/218 S435 Introduction to ig ata - FLL 218 W6... PRT 1. LRGE SLE T NLYTIS WE-SLE LINK N SOIL NETWORK NLYSIS omputer Science, olorado State University
FLL 218 olorado State University 9/24/218 Week 6-9/24/218 S435 Introduction to ig ata - FLL 218 W6... PRT 1. LRGE SLE T NLYTIS WE-SLE LINK N SOIL NETWORK NLYSIS omputer Science, olorado State University
Data Partitioning and MapReduce
 Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Generalizing Map- Reduce
 Generalizing Map- Reduce 1 Example: A Map- Reduce Graph map reduce map... reduce reduce map 2 Map- reduce is not a solu;on to every problem, not even every problem that profitably can use many compute
Generalizing Map- Reduce 1 Example: A Map- Reduce Graph map reduce map... reduce reduce map 2 Map- reduce is not a solu;on to every problem, not even every problem that profitably can use many compute
CS535 Big Data Fall 2017 Colorado State University 9/5/2017. Week 3 - A. FAQs. This material is built based on,
 S535 ig ata Fall 217 olorado State University 9/5/217 Week 3-9/5/217 S535 ig ata - Fall 217 Week 3--1 S535 IG T FQs Programming ssignment 1 We will discuss link analysis in week3 Installation/configuration
S535 ig ata Fall 217 olorado State University 9/5/217 Week 3-9/5/217 S535 ig ata - Fall 217 Week 3--1 S535 IG T FQs Programming ssignment 1 We will discuss link analysis in week3 Installation/configuration
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman
 Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Distributed Itembased Collaborative Filtering with Apache Mahout. Sebastian Schelter twitter.com/sscdotopen. 7.
 Distributed Itembased Collaborative Filtering with Apache Mahout Sebastian Schelter ssc@apache.org twitter.com/sscdotopen 7. October 2010 Overview 1. What is Apache Mahout? 2. Introduction to Collaborative
Distributed Itembased Collaborative Filtering with Apache Mahout Sebastian Schelter ssc@apache.org twitter.com/sscdotopen 7. October 2010 Overview 1. What is Apache Mahout? 2. Introduction to Collaborative
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU
 Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University Infinite data. Filtering data streams
 /9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
/9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Databases 2 (VU) ( )
 ( )") Databases 2 (VU) (707.030) Map-Reduce Denis Helic KMI, TU Graz Nov 4, 2013 Denis Helic (KMI, TU Graz) Map-Reduce Nov 4, 2013 1 / 90 Outline 1 Motivation 2 Large Scale Computation 3 Map-Reduce 4 Environment
Databases 2 (VU) (707.030) Map-Reduce Denis Helic KMI, TU Graz Nov 4, 2013 Denis Helic (KMI, TU Graz) Map-Reduce Nov 4, 2013 1 / 90 Outline 1 Motivation 2 Large Scale Computation 3 Map-Reduce 4 Environment
An Introduction to Double Integrals Math Insight
 An Introduction to Double Integrals Math Insight Suppose that you knew the hair density at each point on your head and you wanted to calculate the total number of hairs on your head. In other words, let
An Introduction to Double Integrals Math Insight Suppose that you knew the hair density at each point on your head and you wanted to calculate the total number of hairs on your head. In other words, let
Recommender Systems 6CCS3WSN-7CCSMWAL
 Recommender Systems 6CCS3WSN-7CCSMWAL http://insidebigdata.com/wp-content/uploads/2014/06/humorrecommender.jpg Some basic methods of recommendation Recommend popular items Collaborative Filtering Item-to-Item:
Recommender Systems 6CCS3WSN-7CCSMWAL http://insidebigdata.com/wp-content/uploads/2014/06/humorrecommender.jpg Some basic methods of recommendation Recommend popular items Collaborative Filtering Item-to-Item:
Multi-domain Predictive AI. Correlated Cross-Occurrence with Apache Mahout and GPUs
 Multi-domain Predictive AI Correlated Cross-Occurrence with Apache Mahout and GPUs Pat Ferrel ActionML, Chief Consultant Apache Mahout, PMC & Committer Apache PredictionIO, PMC & Committer pat@apache.org
Multi-domain Predictive AI Correlated Cross-Occurrence with Apache Mahout and GPUs Pat Ferrel ActionML, Chief Consultant Apache Mahout, PMC & Committer Apache PredictionIO, PMC & Committer pat@apache.org
CS535 Big Data Fall 2017 Colorado State University 10/10/2017 Sangmi Lee Pallickara Week 8- A.
 CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
Recommender Systems New Approaches with Netflix Dataset
 Recommender Systems New Approaches with Netflix Dataset Robert Bell Yehuda Koren AT&T Labs ICDM 2007 Presented by Matt Rodriguez Outline Overview of Recommender System Approaches which are Content based
Recommender Systems New Approaches with Netflix Dataset Robert Bell Yehuda Koren AT&T Labs ICDM 2007 Presented by Matt Rodriguez Outline Overview of Recommender System Approaches which are Content based
Lecture Map-Reduce. Algorithms. By Marina Barsky Winter 2017, University of Toronto
 Lecture 04.02 Map-Reduce Algorithms By Marina Barsky Winter 2017, University of Toronto Example 1: Language Model Statistical machine translation: Need to count number of times every 5-word sequence occurs
Lecture 04.02 Map-Reduce Algorithms By Marina Barsky Winter 2017, University of Toronto Example 1: Language Model Statistical machine translation: Need to count number of times every 5-word sequence occurs
A Parallel Algorithm for Finding Sub-graph Isomorphism
 CS420: Parallel Programming, Fall 2008 Final Project A Parallel Algorithm for Finding Sub-graph Isomorphism Ashish Sharma, Santosh Bahir, Sushant Narsale, Unmil Tambe Department of Computer Science, Johns
CS420: Parallel Programming, Fall 2008 Final Project A Parallel Algorithm for Finding Sub-graph Isomorphism Ashish Sharma, Santosh Bahir, Sushant Narsale, Unmil Tambe Department of Computer Science, Johns
B490 Mining the Big Data. 5. Models for Big Data
 B490 Mining the Big Data 5. Models for Big Data Qin Zhang 1-1 2-1 MapReduce MapReduce The MapReduce model (Dean & Ghemawat 2004) Input Output Goal Map Shuffle Reduce Standard model in industry for massive
B490 Mining the Big Data 5. Models for Big Data Qin Zhang 1-1 2-1 MapReduce MapReduce The MapReduce model (Dean & Ghemawat 2004) Input Output Goal Map Shuffle Reduce Standard model in industry for massive
A Comparative study of Clustering Algorithms using MapReduce in Hadoop
 A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
MapReduce and the New Software Stack
 20 Chapter 2 MapReduce and the New Software Stack Modern data-mining applications, often called big-data analysis, require us to manage immense amounts of data quickly. In many of these applications, the
20 Chapter 2 MapReduce and the New Software Stack Modern data-mining applications, often called big-data analysis, require us to manage immense amounts of data quickly. In many of these applications, the
CS224W Project: Recommendation System Models in Product Rating Predictions
 CS224W Project: Recommendation System Models in Product Rating Predictions Xiaoye Liu xiaoye@stanford.edu Abstract A product recommender system based on product-review information and metadata history
CS224W Project: Recommendation System Models in Product Rating Predictions Xiaoye Liu xiaoye@stanford.edu Abstract A product recommender system based on product-review information and metadata history
Recommender System. What is it? How to build it? Challenges. R package: recommenderlab
 Recommender System What is it? How to build it? Challenges R package: recommenderlab 1 What is a recommender system Wiki definition: A recommender system or a recommendation system (sometimes replacing
Recommender System What is it? How to build it? Challenges R package: recommenderlab 1 What is a recommender system Wiki definition: A recommender system or a recommendation system (sometimes replacing
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
INTRODUCTION TO DATA SCIENCE. Link Analysis (MMDS5)
") INTRODUCTION TO DATA SCIENCE Link Analysis (MMDS5) Introduction Motivation: accurate web search Spammers: want you to land on their pages Google s PageRank and variants TrustRank Hubs and Authorities (HITS)
INTRODUCTION TO DATA SCIENCE Link Analysis (MMDS5) Introduction Motivation: accurate web search Spammers: want you to land on their pages Google s PageRank and variants TrustRank Hubs and Authorities (HITS)
Link Analysis. Chapter PageRank
 Chapter 5 Link Analysis One of the biggest changes in our lives in the decade following the turn of the century was the availability of efficient and accurate Web search, through search engines such as
Chapter 5 Link Analysis One of the biggest changes in our lives in the decade following the turn of the century was the availability of efficient and accurate Web search, through search engines such as
Evaluating Private Information Retrieval on the Cloud
 Evaluating Private Information Retrieval on the Cloud Casey Devet University ofwaterloo cjdevet@cs.uwaterloo.ca Abstract The goal of Private Information Retrieval (PIR) is for a client to query a database
Evaluating Private Information Retrieval on the Cloud Casey Devet University ofwaterloo cjdevet@cs.uwaterloo.ca Abstract The goal of Private Information Retrieval (PIR) is for a client to query a database
Reduce and Aggregate: Similarity Ranking in Multi-Categorical Bipartite Graphs
 Reduce and Aggregate: Similarity Ranking in Multi-Categorical Bipartite Graphs Alessandro Epasto J. Feldman*, S. Lattanzi*, S. Leonardi, V. Mirrokni*. *Google Research Sapienza U. Rome Motivation Recommendation
Reduce and Aggregate: Similarity Ranking in Multi-Categorical Bipartite Graphs Alessandro Epasto J. Feldman*, S. Lattanzi*, S. Leonardi, V. Mirrokni*. *Google Research Sapienza U. Rome Motivation Recommendation
CS30 - Neural Nets in Python
 CS30 - Neural Nets in Python We will experiment with neural networks using a simple software package written in Python. You can find the package at: http://www.cs.pomona.edu/~dkauchak/classes/cs30/assignments/assign6/cs30neural.txt
CS30 - Neural Nets in Python We will experiment with neural networks using a simple software package written in Python. You can find the package at: http://www.cs.pomona.edu/~dkauchak/classes/cs30/assignments/assign6/cs30neural.txt
1 2 (3 + x 3) x 2 = 1 3 (3 + x 1 2x 3 ) 1. 3 ( 1 x 2) (3 + x(0) 3 ) = 1 2 (3 + 0) = 3. 2 (3 + x(0) 1 2x (0) ( ) = 1 ( 1 x(0) 2 ) = 1 3 ) = 1 3
 x 2 = 1 3 (3 + x 1 2x 3 ) 1. 3 ( 1 x 2) (3 + x(0) 3 ) = 1 2 (3 + 0) = 3. 2 (3 + x(0) 1 2x (0) ( ) = 1 ( 1 x(0) 2 ) = 1 3 ) = 1 3") 6 Iterative Solvers Lab Objective: Many real-world problems of the form Ax = b have tens of thousands of parameters Solving such systems with Gaussian elimination or matrix factorizations could require
6 Iterative Solvers Lab Objective: Many real-world problems of the form Ax = b have tens of thousands of parameters Solving such systems with Gaussian elimination or matrix factorizations could require
The Matrix-Tree Theorem and Its Applications to Complete and Complete Bipartite Graphs
 The Matrix-Tree Theorem and Its Applications to Complete and Complete Bipartite Graphs Frankie Smith Nebraska Wesleyan University fsmith@nebrwesleyan.edu May 11, 2015 Abstract We will look at how to represent
The Matrix-Tree Theorem and Its Applications to Complete and Complete Bipartite Graphs Frankie Smith Nebraska Wesleyan University fsmith@nebrwesleyan.edu May 11, 2015 Abstract We will look at how to represent
Unit #13 : Integration to Find Areas and Volumes, Volumes of Revolution
 Unit #13 : Integration to Find Areas and Volumes, Volumes of Revolution Goals: Beabletoapplyaslicingapproachtoconstructintegralsforareasandvolumes. Be able to visualize surfaces generated by rotating functions
Unit #13 : Integration to Find Areas and Volumes, Volumes of Revolution Goals: Beabletoapplyaslicingapproachtoconstructintegralsforareasandvolumes. Be able to visualize surfaces generated by rotating functions
Collaborative Filtering using Euclidean Distance in Recommendation Engine
 Indian Journal of Science and Technology, Vol 9(37), DOI: 10.17485/ijst/2016/v9i37/102074, October 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Collaborative Filtering using Euclidean Distance
Indian Journal of Science and Technology, Vol 9(37), DOI: 10.17485/ijst/2016/v9i37/102074, October 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Collaborative Filtering using Euclidean Distance
CSE152 Introduction to Computer Vision Assignment 3 (SP15) Instructor: Ben Ochoa Maximum Points : 85 Deadline : 11:59 p.m., Friday, 29-May-2015
 Instructor: Ben Ochoa Maximum Points : 85 Deadline : 11:59 p.m., Friday, 29-May-2015") Instructions: CSE15 Introduction to Computer Vision Assignment 3 (SP15) Instructor: Ben Ochoa Maximum Points : 85 Deadline : 11:59 p.m., Friday, 9-May-015 This assignment should be solved, and written
Instructions: CSE15 Introduction to Computer Vision Assignment 3 (SP15) Instructor: Ben Ochoa Maximum Points : 85 Deadline : 11:59 p.m., Friday, 9-May-015 This assignment should be solved, and written
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
CS425: Algorithms for Web Scale Data
 CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
Apache Giraph. for applications in Machine Learning & Recommendation Systems. Maria Novartis
 Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
STAT STATISTICAL METHODS. Statistics: The science of using data to make decisions and draw conclusions
 STAT 515 --- STATISTICAL METHODS Statistics: The science of using data to make decisions and draw conclusions Two branches: Descriptive Statistics: The collection and presentation (through graphical and
STAT 515 --- STATISTICAL METHODS Statistics: The science of using data to make decisions and draw conclusions Two branches: Descriptive Statistics: The collection and presentation (through graphical and
Using Social Networks to Improve Movie Rating Predictions
 Introduction Using Social Networks to Improve Movie Rating Predictions Suhaas Prasad Recommender systems based on collaborative filtering techniques have become a large area of interest ever since the
Introduction Using Social Networks to Improve Movie Rating Predictions Suhaas Prasad Recommender systems based on collaborative filtering techniques have become a large area of interest ever since the
Jeff Howbert Introduction to Machine Learning Winter
 Collaborative Filtering Nearest es Neighbor Approach Jeff Howbert Introduction to Machine Learning Winter 2012 1 Bad news Netflix Prize data no longer available to public. Just after contest t ended d
Collaborative Filtering Nearest es Neighbor Approach Jeff Howbert Introduction to Machine Learning Winter 2012 1 Bad news Netflix Prize data no longer available to public. Just after contest t ended d
Similarity Ranking in Large- Scale Bipartite Graphs
 Similarity Ranking in Large- Scale Bipartite Graphs Alessandro Epasto Brown University - 20 th March 2014 1 Joint work with J. Feldman, S. Lattanzi, S. Leonardi, V. Mirrokni [WWW, 2014] 2 AdWords Ads Ads
Similarity Ranking in Large- Scale Bipartite Graphs Alessandro Epasto Brown University - 20 th March 2014 1 Joint work with J. Feldman, S. Lattanzi, S. Leonardi, V. Mirrokni [WWW, 2014] 2 AdWords Ads Ads
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Part 11: Collaborative Filtering. Francesco Ricci
 Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Non-exhaustive, Overlapping k-means
 Non-exhaustive, Overlapping k-means J. J. Whang, I. S. Dhilon, and D. F. Gleich Teresa Lebair University of Maryland, Baltimore County October 29th, 2015 Teresa Lebair UMBC 1/38 Outline Introduction NEO-K-Means
Non-exhaustive, Overlapping k-means J. J. Whang, I. S. Dhilon, and D. F. Gleich Teresa Lebair University of Maryland, Baltimore County October 29th, 2015 Teresa Lebair UMBC 1/38 Outline Introduction NEO-K-Means
Opening the Black Box Data Driven Visualizaion of Neural N
 Opening the Black Box Data Driven Visualizaion of Neural Networks September 20, 2006 Aritificial Neural Networks Limitations of ANNs Use of Visualization (ANNs) mimic the processes found in biological
Opening the Black Box Data Driven Visualizaion of Neural Networks September 20, 2006 Aritificial Neural Networks Limitations of ANNs Use of Visualization (ANNs) mimic the processes found in biological
Graph Data Management
 Graph Data Management Analysis and Optimization of Graph Data Frameworks presented by Fynn Leitow Overview 1) Introduction a) Motivation b) Application for big data 2) Choice of algorithms 3) Choice of
Graph Data Management Analysis and Optimization of Graph Data Frameworks presented by Fynn Leitow Overview 1) Introduction a) Motivation b) Application for big data 2) Choice of algorithms 3) Choice of
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
MapReduce Design Patterns
 MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
HW 4: PageRank & MapReduce. 1 Warmup with PageRank and stationary distributions [10 points], collaboration
![HW 4: PageRank & MapReduce. 1 Warmup with PageRank and stationary distributions [10 points], collaboration](/thumbs/86/94153784.jpg "HW 4: PageRank & MapReduce. 1 Warmup with PageRank and stationary distributions [10 points], collaboration") CMS/CS/EE 144 Assigned: 1/25/2018 HW 4: PageRank & MapReduce Guru: Joon/Cathy Due: 2/1/2018 at 10:30am We encourage you to discuss these problems with others, but you need to write up the actual solutions
CMS/CS/EE 144 Assigned: 1/25/2018 HW 4: PageRank & MapReduce Guru: Joon/Cathy Due: 2/1/2018 at 10:30am We encourage you to discuss these problems with others, but you need to write up the actual solutions
Part 11: Collaborative Filtering. Francesco Ricci
 Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
AI Dining Suggestion App. CS 297 Report Bao Pham ( ) Advisor: Dr. Chris Pollett
 Advisor: Dr. Chris Pollett") AI Dining Suggestion App CS 297 Report Bao Pham (009621001) Advisor: Dr. Chris Pollett Abstract Trying to decide what to eat can be challenging and time-consuming. Google or Yelp are two popular search
AI Dining Suggestion App CS 297 Report Bao Pham (009621001) Advisor: Dr. Chris Pollett Abstract Trying to decide what to eat can be challenging and time-consuming. Google or Yelp are two popular search
CSE 547: Machine Learning for Big Data Spring Problem Set 2. Please read the homework submission policies.
 CSE 547: Machine Learning for Big Data Spring 2019 Problem Set 2 Please read the homework submission policies. 1 Principal Component Analysis and Reconstruction (25 points) Let s do PCA and reconstruct
CSE 547: Machine Learning for Big Data Spring 2019 Problem Set 2 Please read the homework submission policies. 1 Principal Component Analysis and Reconstruction (25 points) Let s do PCA and reconstruct
REGULAR GRAPHS OF GIVEN GIRTH. Contents
 REGULAR GRAPHS OF GIVEN GIRTH BROOKE ULLERY Contents 1. Introduction This paper gives an introduction to the area of graph theory dealing with properties of regular graphs of given girth. A large portion
REGULAR GRAPHS OF GIVEN GIRTH BROOKE ULLERY Contents 1. Introduction This paper gives an introduction to the area of graph theory dealing with properties of regular graphs of given girth. A large portion
Exploring the Hidden Dimension in Graph Processing
 Exploring the Hidden Dimension in Graph Processing Mingxing Zhang, Yongwei Wu, Kang Chen, *Xuehai Qian, Xue Li, and Weimin Zheng Tsinghua University *University of Shouthern California Graph is Ubiquitous
Exploring the Hidden Dimension in Graph Processing Mingxing Zhang, Yongwei Wu, Kang Chen, *Xuehai Qian, Xue Li, and Weimin Zheng Tsinghua University *University of Shouthern California Graph is Ubiquitous
Sparse Estimation of Movie Preferences via Constrained Optimization
 Sparse Estimation of Movie Preferences via Constrained Optimization Alexander Anemogiannis, Ajay Mandlekar, Matt Tsao December 17, 2016 Abstract We propose extensions to traditional low-rank matrix completion
Sparse Estimation of Movie Preferences via Constrained Optimization Alexander Anemogiannis, Ajay Mandlekar, Matt Tsao December 17, 2016 Abstract We propose extensions to traditional low-rank matrix completion
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 3 Mutually recursive definition: A hub links to many authorities; An authority is linked to by many hubs. Authorities turn out to be places where information can
Jeffrey D. Ullman Stanford University 3 Mutually recursive definition: A hub links to many authorities; An authority is linked to by many hubs. Authorities turn out to be places where information can
Introduction to Programming in C Department of Computer Science and Engineering. Lecture No. #43. Multidimensional Arrays
 Introduction to Programming in C Department of Computer Science and Engineering Lecture No. #43 Multidimensional Arrays In this video will look at multi-dimensional arrays. (Refer Slide Time: 00:03) In
Introduction to Programming in C Department of Computer Science and Engineering Lecture No. #43 Multidimensional Arrays In this video will look at multi-dimensional arrays. (Refer Slide Time: 00:03) In
PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets
 2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
Personalized Web Search
 Personalized Web Search Dhanraj Mavilodan (dhanrajm@stanford.edu), Kapil Jaisinghani (kjaising@stanford.edu), Radhika Bansal (radhika3@stanford.edu) Abstract: With the increase in the diversity of contents
Personalized Web Search Dhanraj Mavilodan (dhanrajm@stanford.edu), Kapil Jaisinghani (kjaising@stanford.edu), Radhika Bansal (radhika3@stanford.edu) Abstract: With the increase in the diversity of contents
For example, the system. 22 may be represented by the augmented matrix
 Matrix Solutions to Linear Systems A matrix is a rectangular array of elements. o An array is a systematic arrangement of numbers or symbols in rows and columns. Matrices (the plural of matrix) may be
Matrix Solutions to Linear Systems A matrix is a rectangular array of elements. o An array is a systematic arrangement of numbers or symbols in rows and columns. Matrices (the plural of matrix) may be
HaLoop Efficient Iterative Data Processing on Large Clusters
 HaLoop Efficient Iterative Data Processing on Large Clusters Yingyi Bu, Bill Howe, Magdalena Balazinska, and Michael D. Ernst University of Washington Department of Computer Science & Engineering Presented
HaLoop Efficient Iterative Data Processing on Large Clusters Yingyi Bu, Bill Howe, Magdalena Balazinska, and Michael D. Ernst University of Washington Department of Computer Science & Engineering Presented
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Unit VIII. Chapter 9. Link Analysis
 Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
A probabilistic model to resolve diversity-accuracy challenge of recommendation systems
 A probabilistic model to resolve diversity-accuracy challenge of recommendation systems AMIN JAVARI MAHDI JALILI 1 Received: 17 Mar 2013 / Revised: 19 May 2014 / Accepted: 30 Jun 2014 Recommendation systems
A probabilistic model to resolve diversity-accuracy challenge of recommendation systems AMIN JAVARI MAHDI JALILI 1 Received: 17 Mar 2013 / Revised: 19 May 2014 / Accepted: 30 Jun 2014 Recommendation systems
Part 12: Advanced Topics in Collaborative Filtering. Francesco Ricci
 Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Diffusion Wavelets for Natural Image Analysis
 Diffusion Wavelets for Natural Image Analysis Tyrus Berry December 16, 2011 Contents 1 Project Description 2 2 Introduction to Diffusion Wavelets 2 2.1 Diffusion Multiresolution............................
Diffusion Wavelets for Natural Image Analysis Tyrus Berry December 16, 2011 Contents 1 Project Description 2 2 Introduction to Diffusion Wavelets 2 2.1 Diffusion Multiresolution............................
MATE-EC2: A Middleware for Processing Data with Amazon Web Services
 MATE-EC2: A Middleware for Processing Data with Amazon Web Services Tekin Bicer David Chiu* and Gagan Agrawal Department of Compute Science and Engineering Ohio State University * School of Engineering
MATE-EC2: A Middleware for Processing Data with Amazon Web Services Tekin Bicer David Chiu* and Gagan Agrawal Department of Compute Science and Engineering Ohio State University * School of Engineering
Data Mining Lecture 2: Recommender Systems
 Data Mining Lecture 2: Recommender Systems Jo Houghton ECS Southampton February 19, 2019 1 / 32 Recommender Systems - Introduction Making recommendations: Big Money 35% of Amazons income from recommendations
Data Mining Lecture 2: Recommender Systems Jo Houghton ECS Southampton February 19, 2019 1 / 32 Recommender Systems - Introduction Making recommendations: Big Money 35% of Amazons income from recommendations
Antonio Fernández Anta
 Antonio Fernández Anta Joint work with Luis F. Chiroque, Héctor Cordobés, Rafael A. García Leiva, Philippe Morere, Lorenzo Ornella, Fernando Pérez, and Agustín Santos Recommendation Engines (RE) suggest
Antonio Fernández Anta Joint work with Luis F. Chiroque, Héctor Cordobés, Rafael A. García Leiva, Philippe Morere, Lorenzo Ornella, Fernando Pérez, and Agustín Santos Recommendation Engines (RE) suggest
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Recommender Systems. Techniques of AI
 Recommender Systems Techniques of AI Recommender Systems User ratings Collect user preferences (scores, likes, purchases, views...) Find similarities between items and/or users Predict user scores for
Recommender Systems Techniques of AI Recommender Systems User ratings Collect user preferences (scores, likes, purchases, views...) Find similarities between items and/or users Predict user scores for
General Instructions. Questions
 CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
Hybrid Recommendation System Using Clustering and Collaborative Filtering
 Hybrid Recommendation System Using Clustering and Collaborative Filtering Roshni Padate Assistant Professor roshni@frcrce.ac.in Priyanka Bane B.E. Student priyankabane56@gmail.com Jayesh Kudase B.E. Student
Hybrid Recommendation System Using Clustering and Collaborative Filtering Roshni Padate Assistant Professor roshni@frcrce.ac.in Priyanka Bane B.E. Student priyankabane56@gmail.com Jayesh Kudase B.E. Student
Recommender Systems - Introduction. Data Mining Lecture 2: Recommender Systems
 Recommender Systems - Introduction Making recommendations: Big Money 35% of amazons income from recommendations Netflix recommendation engine worth $ Billion per year And yet, Amazon seems to be able to
Recommender Systems - Introduction Making recommendations: Big Money 35% of amazons income from recommendations Netflix recommendation engine worth $ Billion per year And yet, Amazon seems to be able to
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Web Personalization & Recommender Systems
 Web Personalization & Recommender Systems COSC 488 Slides are based on: - Bamshad Mobasher, Depaul University - Recent publications: see the last page (Reference section) Web Personalization & Recommender
Web Personalization & Recommender Systems COSC 488 Slides are based on: - Bamshad Mobasher, Depaul University - Recent publications: see the last page (Reference section) Web Personalization & Recommender
Neural Network Weight Selection Using Genetic Algorithms
 Neural Network Weight Selection Using Genetic Algorithms David Montana presented by: Carl Fink, Hongyi Chen, Jack Cheng, Xinglong Li, Bruce Lin, Chongjie Zhang April 12, 2005 1 Neural Networks Neural networks
Neural Network Weight Selection Using Genetic Algorithms David Montana presented by: Carl Fink, Hongyi Chen, Jack Cheng, Xinglong Li, Bruce Lin, Chongjie Zhang April 12, 2005 1 Neural Networks Neural networks
Building a Recommendation System for EverQuest Landmark s Marketplace
 Building a Recommendation System for EverQuest Landmark s Marketplace Ben G. Weber Director of BI & Analytics, Daybreak Game Company Motivation Content discovery is becoming a challenge for players Questions
Building a Recommendation System for EverQuest Landmark s Marketplace Ben G. Weber Director of BI & Analytics, Daybreak Game Company Motivation Content discovery is becoming a challenge for players Questions
Rapid growth of massive datasets
 Overview Rapid growth of massive datasets E.g., Online activity, Science, Sensor networks Data Distributed Clusters are Pervasive Data Distributed Computing Mature Methods for Common Problems e.g., classification,
Overview Rapid growth of massive datasets E.g., Online activity, Science, Sensor networks Data Distributed Clusters are Pervasive Data Distributed Computing Mature Methods for Common Problems e.g., classification,
Lecture #3: PageRank Algorithm The Mathematics of Google Search
 Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Collaborative Filtering for Netflix
 Collaborative Filtering for Netflix Michael Percy Dec 10, 2009 Abstract The Netflix movie-recommendation problem was investigated and the incremental Singular Value Decomposition (SVD) algorithm was implemented
Collaborative Filtering for Netflix Michael Percy Dec 10, 2009 Abstract The Netflix movie-recommendation problem was investigated and the incremental Singular Value Decomposition (SVD) algorithm was implemented
Extracting Information from Complex Networks
 Extracting Information from Complex Networks 1 Complex Networks Networks that arise from modeling complex systems: relationships Social networks Biological networks Distinguish from random networks uniform
Extracting Information from Complex Networks 1 Complex Networks Networks that arise from modeling complex systems: relationships Social networks Biological networks Distinguish from random networks uniform
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference
 Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference Minh Dao 1, Xiang Xiang 1, Bulent Ayhan 2, Chiman Kwan 2, Trac D. Tran 1 Johns Hopkins Univeristy, 3400
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference Minh Dao 1, Xiang Xiang 1, Bulent Ayhan 2, Chiman Kwan 2, Trac D. Tran 1 Johns Hopkins Univeristy, 3400
Demystifying movie ratings 224W Project Report. Amritha Raghunath Vignesh Ganapathi Subramanian
 Demystifying movie ratings 224W Project Report Amritha Raghunath (amrithar@stanford.edu) Vignesh Ganapathi Subramanian (vigansub@stanford.edu) 9 December, 2014 Introduction The past decade or so has seen
Demystifying movie ratings 224W Project Report Amritha Raghunath (amrithar@stanford.edu) Vignesh Ganapathi Subramanian (vigansub@stanford.edu) 9 December, 2014 Introduction The past decade or so has seen
Convex Optimization / Homework 2, due Oct 3
 Convex Optimization 0-725/36-725 Homework 2, due Oct 3 Instructions: You must complete Problems 3 and either Problem 4 or Problem 5 (your choice between the two) When you submit the homework, upload a
Convex Optimization 0-725/36-725 Homework 2, due Oct 3 Instructions: You must complete Problems 3 and either Problem 4 or Problem 5 (your choice between the two) When you submit the homework, upload a
Graphs (Part II) Shannon Quinn
 Shannon Quinn") Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
[3-5] Consider a Combiner that tracks local counts of followers and emits only the local top10 users with their number of followers.
![[3-5] Consider a Combiner that tracks local counts of followers and emits only the local top10 users with their number of followers.](/thumbs/78/78610712.jpg "[3-5] Consider a Combiner that tracks local counts of followers and emits only the local top10 users with their number of followers.") Quiz 6 We design of a MapReduce application that generates the top-10 most popular Twitter users (based on the number of followers) of a month based on the number of followers. Suppose that you have the
Quiz 6 We design of a MapReduce application that generates the top-10 most popular Twitter users (based on the number of followers) of a month based on the number of followers. Suppose that you have the
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Joint Entity Resolution
 Joint Entity Resolution Steven Euijong Whang, Hector Garcia-Molina Computer Science Department, Stanford University 353 Serra Mall, Stanford, CA 94305, USA {swhang, hector}@cs.stanford.edu No Institute
Joint Entity Resolution Steven Euijong Whang, Hector Garcia-Molina Computer Science Department, Stanford University 353 Serra Mall, Stanford, CA 94305, USA {swhang, hector}@cs.stanford.edu No Institute
Music Recommendation with Implicit Feedback and Side Information
 Music Recommendation with Implicit Feedback and Side Information Shengbo Guo Yahoo! Labs shengbo@yahoo-inc.com Behrouz Behmardi Criteo b.behmardi@criteo.com Gary Chen Vobile gary.chen@vobileinc.com Abstract
Music Recommendation with Implicit Feedback and Side Information Shengbo Guo Yahoo! Labs shengbo@yahoo-inc.com Behrouz Behmardi Criteo b.behmardi@criteo.com Gary Chen Vobile gary.chen@vobileinc.com Abstract
STREAMING RANKING BASED RECOMMENDER SYSTEMS
 STREAMING RANKING BASED RECOMMENDER SYSTEMS Weiqing Wang, Hongzhi Yin, Zi Huang, Qinyong Wang, Xingzhong Du, Quoc Viet Hung Nguyen University of Queensland, Australia & Griffith University, Australia July
STREAMING RANKING BASED RECOMMENDER SYSTEMS Weiqing Wang, Hongzhi Yin, Zi Huang, Qinyong Wang, Xingzhong Du, Quoc Viet Hung Nguyen University of Queensland, Australia & Griffith University, Australia July
Indexing Large-Scale Data
 Indexing Large-Scale Data Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook November 16, 2010
Indexing Large-Scale Data Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook November 16, 2010
MATH 423 Linear Algebra II Lecture 17: Reduced row echelon form (continued). Determinant of a matrix.
. Determinant of a matrix.") MATH 423 Linear Algebra II Lecture 17: Reduced row echelon form (continued). Determinant of a matrix. Row echelon form A matrix is said to be in the row echelon form if the leading entries shift to the
MATH 423 Linear Algebra II Lecture 17: Reduced row echelon form (continued). Determinant of a matrix. Row echelon form A matrix is said to be in the row echelon form if the leading entries shift to the
Edge and local feature detection - 2. Importance of edge detection in computer vision
 Edge and local feature detection Gradient based edge detection Edge detection by function fitting Second derivative edge detectors Edge linking and the construction of the chain graph Edge and local feature
Edge and local feature detection Gradient based edge detection Edge detection by function fitting Second derivative edge detectors Edge linking and the construction of the chain graph Edge and local feature
Parallel learning of content recommendations using map- reduce
 Parallel learning of content recommendations using map- reduce Michael Percy Stanford University Abstract In this paper, machine learning within the map- reduce paradigm for ranking
Parallel learning of content recommendations using map- reduce Michael Percy Stanford University Abstract In this paper, machine learning within the map- reduce paradigm for ranking
Advanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, Madras
 Advanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, Madras Lecture - 35 Quadratic Programming In this lecture, we continue our discussion on
Advanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, Madras Lecture - 35 Quadratic Programming In this lecture, we continue our discussion on