Face Detection with the Faster R-CNN
|
|
|
- Cory Hill
- 6 years ago
- Views:
Transcription
1 Face Detection with the Huaizu Jiang University of Massachusetts Amherst Amherst MA 3 hzjiang@cs.umass.edu Erik Learned-Miller University of Massachusetts Amherst Amherst MA 3 elm@cs.umass.edu Abstract While deep learning based methods for generic object detection have improved rapidly in the last two years, most approaches to face detection are still based on the R-CNN framework [], leading to limited accuracy and processing speed. In this paper, we investigate applying the Faster R- CNN [26], which has recently demonstrated impressive results on various object detection benchmarks, to face detection. By training a model on the large scale WIDER face dataset [34], we report state-of-the-art results on the WIDER test set as well as two other widely used face detection benchmarks, FDDB and the recently released IJB-A. I. INTRODUCTION Deep convolutional neural networks (CNNs) have dominated many tasks in computer vision. For object detection, region-based CNN detection methods are now the main paradigm. It is such a rapidly developing area that three generations of region-based CNN detection models, from the R-CNN [], to the Fast R-CNN [], and finally the Faster R-CNN [26], have been proposed in the last few years, with increasingly better accuracy and faster processing speed. Although generic object detection methods have seen large advances in the last two years, the methodology of face detection has lagged behind somewhat. Most of the approaches are still based on the R-CNN framework, leading to limited accuracy and processing speed, reflected in the results on the de facto FDDB [4] benchmark. In this paper, we investigate how to apply state-of-the art object detection methods to face detection and motivate more advanced methods for the future. Unlike generic object detection, there has been no largescale face detection dataset that allowed training a very deep CNN until the recent release of the WIDER dataset [34]. The first contribution of this paper is to evaluate the stateof-the-art on this large database of faces. In addition, it is natural to ask if we could get an off-the-shelf face detector to perform well when it is trained on one data set and tested on another. Our paper answers this question by training on WIDER and testing on FDDB. The [26], as the latest generation of regionbased generic object detection methods, demonstrates impressive results on various object detection benchmarks. It is also the foundational framework for the winning entry of the COCO detection challenge 25. In this paper, we demonstrate state-of-the-art face detection results using the /7/$3. c 27 IEEE on three popular face detection benchmarks, the widely used Face Detection Dataset and Benchmark (FDDB) [4], the more recent IJB-A benchmark [5], and the WIDER face dataset [34]. We also compare different generations of region-based CNN object detection models, and compare to a variety of other recent high-performing detectors. Our code and pre-trained face detection models can be found at II. RELATED WORK In this section, we briefly introduce previous work on face detection. Considering the remarkable performance of deep learning methods for face detection, we simply categorize previous work as non-neural based and neural based methods. Non-Neural Based Methods. Since the well-known work of Viola and Jones [32], real-time face detection in unconstrained environments has been an active topic of study in computer vision. The success of the Viola-Jones detector [32] stems from two factors: fast evaluation of the Haar features and the cascaded structure which allows early pruning of false positives. In recent work, Chen et al. [3] demonstrate better face detection performance with a joint cascade for face detection and alignment, where shape-index features are used. A lot of other hand-designed features, including SURF [2], LBP [], and HOG [5], have also been applied to face detection, achieving remarkable progress in the last two decades. One of the significant advances was in using HOG features with the Deformable Parts Model (DPM) [8], in which the face was represented as a single root and a set of deformable (semantic) parts (e.g., eyes, mouth, etc.). A tree-structured deformable model is presented in [37], which jointly addresses face detection and alignment. In [9], it is shown that partial face occlusions can be dealt with using a hierarchical deformable model. Mathias et al. [2] demonstrate top face detection performance with a vanilla DPM and rigid templates. In addition to the feature plus model paradigm, Shen et al. [28] utilize image retrieval techniques for face detection and alignment. In [8], an efficient exemplar-based face detection method is proposed, where exemplars are discriminatively trained as weak learners in a boosting framework. Neural Based Methods. There has been a long history of training neural networks for face detection. In [3], two
2 CNNs are trained: the first one classifies each pixel according to whether it is part of a face, and the second one determines the exact face position given the output of the first step. Rowley et al. [27] present a retinally connected neural network for face detection, which determines whether each sliding window contains a face. In [22], a CNN is trained to perform joint face detection and pose estimation. Since 22, deeply trained neural networks, especially CNNs, have revolutionized many computer vision tasks, including face detection, as witnessed by the increasingly higher performance on the Face Detection Database and Benchmark (FDDB) [4]. Ranjan et al. [24] introduced a deformable part model based on normalized features extracted from a deep CNN. A CNN cascade is presented in [9] which operates at multiple resolutions and quickly rejects false positives. Following the Region CNN [], Yang et al. [33] proposed a two-stage approach for face detection. The first stage generates a set of face proposals base on facial part responses, which are then fed into a CNN in the second stage for refinement. Farfade et al. [7] propose a fully convolutional neural network to detect faces at different resolutions. In a recent paper [2], a convolutional neural network and a 3D face model are integrated in an end-toend multi-task discriminative learning framework. Compared with non-neural based methods, which usually rely on hand-crafted features, the can automatically learn a feature representation from data. Compared with other neural based methods, the allows end-to-end learning of all layers, increasing its robustness. Using the for face detection have been studied in [2], [23]. In this paper, we don t explicity address the occlusion as in [2]. Instead, it turns out the Faster R- CNN model can learn to deal with occlusions purely form data. Compared with [23], we show it is possible to train an off-the-shelf face detector and achieve state-of-the-art performance on several benchmark datasets. III. OVERVIEW OF THE FASTER R-CNN After the remarkable success of a deep CNN [6] in image classification on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 22, it was asked whether the same success could be achieved for object detection. The short answer is yes. A. Evolution of Region-based CNNs for Object Detection Girshick et al. [] introduced a region-based CNN (R- CNN) for object detection. The pipeline consists of two stages. In the first, a set of category-independent object proposals are generated, using selective search [3]. In the second refinement stage, the image region within each proposal is warped to a fixed size (e.g., for the AlexNet [6]) and then mapped to a 496-dimensional feature vector. This feature vector is then fed into a classifier and also into a regressor that refines the position of the detection. The significance of the R-CNN is that it brings the high accuracy of CNNs on classification tasks to the problem of object detection. Its success is largely due to transferring the supervised pre-trained image representation for image classification to object detection. The R-CNN, however, requires a forward pass through the convolutional network for each object proposal in order to extract features, leading to a heavy computational burden. To mitigate this problem, two approaches, the SPPnet [3] and the Fast R-CNN [] have been proposed. Instead of feeding each warped proposal image region to the CNN, the SPPnet and the Fast R-CNN run through the CNN exactly once for the entire input image. After projecting the proposals to convolutional feature maps, a fixed length feature vector can be extracted for each proposal in a manner similar to spatial pyramid pooling. The Fast R-CNN is a special case of the SPPnet, which uses a single spatial pyramid pooling layer, i.e., the region of interest (RoI) pooling layer, and thus allows end-to-end fine-tuning of a pre-trained ImageNet model. This is the key to its better performance relative to the original R-CNN. Both the R-CNN and the Fast R-CNN (and the SPPNet) rely on the input generic object proposals, which usually come from a hand-crafted model such as selective search [3] or EdgeBox [6]. There are two main issues with this approach. The first, as shown in image classification and object detection, is that (deeply) learned representations often generalize better than hand-crafted ones. The second is that the computational burden of proposal generation dominate the processing time of the entire pipeline (e.g., 2.73 seconds for EdgeBox in our experiments). Although there are now deeply trained models for proposal generation, e.g.deepbox [7] (based on the Fast R-CNN framework), its processing time is still not negligible. To reduce the computational burden of proposal generation, the was proposed. It consists of two modules. The first, called the Regional Proposal Network (RPN), is a fully convolutional network for generating object proposals that will be fed into the second module. The second module is the Fast R-CNN detector whose purpose is to refine the proposals. The key idea is to share the same convolutional layers for the RPN and Fast R-CNN detector up to their own fully connected layers. Now the image only passes through the CNN once to produce and then refine object proposals. More importantly, thanks to the sharing of convolutional layers, it is possible to use a very deep network (e.g., VGG6 [29]) to generate high-quality object proposals. The key differences of the R-CNN, the Fast R-CNN, and the are summarized in Table I. The running time of different modules are reported on the FDDB dataset [4], where the typical resolution of an image is about The code was run on a server equipped with an Intel Xeon CPU E of 2.6GHz and an NVIDIA Tesla K4c GPU with 2GB memory. We can clearly see that the entire running time of the is significantly lower than for both the R-CNN and the Fast R-CNN.
![TABLE I C OMPARISONS OF THE entire PIPELINE OF DIFFERENT REGION - BASED OBJECT DETECTION METHODS. (B OTH FACENESS [33] AND D EEP B OX [7] RELY ON THE OUTPUT OF E DGE B OX.](/docs-images/79/79911267/images/3-0.jpg "T HEREFORE THEIR ENTIRE RUNNING TIME SHOULD INCLUDE THE PROCESSING TIME OF E DGE B OX.) R-CNN proposal stage time refinement stage input to CNN #forward thru.")

![The In this section, we briefy introduce the key aspects of the. We refer readers to the original paper [26] for more technical details.](/docs-images/79/79911267/images/3-2.jpg "In the RPN, the convolution layers of a pre-trained network are followed by a 3 3 convolutional layer. This corresponds to mapping")


![Following the default setting of [26], we use 3 scales (282, 2562, and 522 pixels) and 3 aspect ratios ( :, : 2, and 2 : ), leading to k = 9 anchors at each location.](/docs-images/79/79911267/images/3-5.jpg "Each proposal is parameterized relative to an anchor. Therefore, for a convolutional feature map of size W H, we have at most W Hk possible proposals.")
3 TABLE I C OMPARISONS OF THE entire PIPELINE OF DIFFERENT REGION - BASED OBJECT DETECTION METHODS. (B OTH FACENESS [33] AND D EEP B OX [7] RELY ON THE OUTPUT OF E DGE B OX. T HEREFORE THEIR ENTIRE RUNNING TIME SHOULD INCLUDE THE PROCESSING TIME OF E DGE B OX.) R-CNN proposal stage time refinement stage input to CNN #forward thru. CNN time total time Fast R-CNN EdgeBox: 2.73s : 9.9s (+ 2.73s = 2.64s) DeepBox:.27s (+ 2.73s = 3.s) cropped proposal image input image & proposals #proposals 4.8s.2s R-CNN + EdgeBox: 4.8s Fast R-CNN + EdgeBox: 2.94s R-CNN + : 26.72s Fast R-CNN + : 2.85s R-CNN + DeepBox: 7.8s Fast R-CNN + DeepBox: 3.2s.32s input image.6s.38s B. The In this section, we briefy introduce the key aspects of the. We refer readers to the original paper [26] for more technical details. In the RPN, the convolution layers of a pre-trained network are followed by a 3 3 convolutional layer. This corresponds to mapping a large spatial window or receptive field (e.g., for VGG6) in the input image to a low-dimensional feature vector at a center stride (e.g., 6 for VGG6). Two convolutional layers are then added for classification and regression branches of all spatial windows. To deal with different scales and aspect ratios of objects, anchors are introduced in the RPN. An anchor is at each sliding location of the convolutional maps and thus at the center of each spatial window. Each anchor is associated with a scale and an aspect ratio. Following the default setting of [26], we use 3 scales (282, 2562, and 522 pixels) and 3 aspect ratios ( :, : 2, and 2 : ), leading to k = 9 anchors at each location. Each proposal is parameterized relative to an anchor. Therefore, for a convolutional feature map of size W H, we have at most W Hk possible proposals. We note that the same features of each sliding location are used to regress k = 9 proposals, instead of extracting k sets of features and training a single regressor.t Training of the RPN can be done in an end-to-end manner using stochastic gradient descent (SGD) for both classification and regression branches. For the entire system, we have to take care of both the RPN and Fast R-CNN modules since they share convolutional layers. In this paper, we adopt the approximate joint learning strategy proposed in [25]. The RPN and Fast R-CNN are trained end-to-end as they are independent. Note that the input of the Fast R-CNN is actually dependent on the output of the RPN. For the exact joint training, the SGD solver should also consider the derivatives of the RoI pooling layer in the Fast R-CNN with respect to the coordinates of the proposals predicted by the RPN. However, as pointed out by [25], it is not a trivial optimization problem. IV. E XPERIMENTS In this section, we report experiments on comparisons of region proposals and also on end-to-end performance of top face detectors. Fig.. Sample images in the WIDER face dataset, where green bounding boxes are ground-truth annotations. A. Setup We train a face detection model on the recently released WIDER face dataset [34]. There are 2,88 images and 59,424 faces in the training set. In Fig., we demonstrate some randomly sampled images of the WIDER dataset. We can see that there exist great variations in scale, pose, and the number of faces in each image, making this dataset challenging. We train the face detection model based on a pre-trained ImageNet model, VGG6 [29]. We randomly sample one image per batch for training. In order to fit it in the GPU memory, it is resized based on the ratio 24/ max(w, h), where w and h are the width and height of the image, respectively. We run the stochastic gradient descent (SGD) solver for 5, iterations with a base learning rate of. and run another 3, iterations reducing the base learning
4 Detection Rate EdgeBox DeepBox RPN Detection Rate EdgeBox DeepBox RPN we can generate a set of true positives and false positives and report the ROC curve. For the more restrictive continuous scores, the true positives are weighted by the IoU scores. On IJB-A, we use the discrete score setting and report the true positive rate based on the normalized false positive rate per image instead of the total number of false positives. Detection Rate IoU threshold (a) Proposals EdgeBox DeepBox RPN IoU threshold Fig. 2. True Positive Rate (c) 5 proposals Detection Rate IoU threshold (b) 3 Proposals EdgeBox DeepBox RPN IoU threshold (d) proposals Comparisons of face proposals on FDDB using different methods. R-CNN Fast R-CNN Total False Positives Fig. 3. Comparisons of region-based CNN object detection methods for face detection on FDDB. rate to.. 2 In addition to the extemely challenging WIDER testing set, we also test the trained face detection model on two benchmark datasets, FDDB [4] and IJB-A [5]. There are splits in both FDDB and IJB-A. For testing, we resize the input image based on the ratio min(6/ min(w, h), 24/ max(w, h)). For the RPN, we use only the top 3 face proposals to balance efficiency and accuracy. There are two criteria for quantatitive comparison for the FDDB benchmark. For the discrete scores, each detection is considered to be positive if its intersection-over-union (IoU) ratioe with its one-one matched ground-truth annotation is greater than.5. By varying the threshold of detection scores, 2 We use the author released Python implementation B. Comparison of Face Proposals We compare the RPN with other approaches including EdgeBox [6], [33], and DeepBox [7] on FDDB. EdgeBox evaluates the objectness score of each proposal based on the distribution of edge responses within it in a sliding window fashion. Both and DeepBox rerank other object proposals, e.g., EdgeBox. In, five CNNs are trained based on attribute annotations of facial parts including hair, eyes, nose, mouth, and beard. The score of each proposal is then computed based on the response maps of different networks. DeepBox, which is based on the Fast R-CNN framework, re-ranks each proposal based on the region-pooled features. We re-train a DeepBox model for face proposals on the WIDER training set. We follow [6] to measure the detection rate of the top N proposals by varying the Intersection-over-Union (IoU) threshold. The larger the threshold is, the fewer the proposals that are considered to be true objects. Quantitative comparisons of proposals are displayed in Fig. 2. As can be seen, the RPN and DeepBox are significantly better than the other two. It is perhaps not surprising that learningbased approaches perform better than the heuristic one, EdgeBox. Although is also based on deeply trained convolutional networks (fine-tuned from AlexNet), the rule to compute the faceness score of each proposal is handcrafted in contrast to the end-to-end learning of the RPN and DeepBox. The RPN performs slightly better than DeepBox, perhaps since it uses a deeper CNN. Due to the sharing of convolutional layers between the RPN and the Fast R- CNN detector, the process time of the entire system is lower. Moreover, the RPN does not rely on other object proposal methods, e.g., EdgeBox. C. Comparison of Region-based CNN Methods We also compare face detection performance of the R- CNN, the Fast R-CNN, and the on FDDB. For both the R-CNN and Fast R-CNN, we use the top 2 proposals generated by the method [33]. For the R- CNN, we fine-tune the pre-trained VGG-M model. Different from the original R-CNN implementation [], we train a CNN with both classification and regression branches endto-end following [33]. For both the Fast R-CNN and Faster R-CNN, we fine-tune the pre-trained VGG6 model. As can be observed from Fig. 3, the significantly outperforms the other two. Since the also contains the Fast R-CNN detector module, the performance boost mostly comes from the RPN module, which is based on a deeply trained CNN. Note that the also runs much faster than both the R-CNN and Fast R-CNN, as summarized in Table I.
 5 5 2 Total False Positives (b) True Positive Rate.7.6.5.4.3.2. headhunter MTCNN hyperface DP2MFD CCF NPDFace MultiresHPM FD3DM DDFD CascadeCNN Conv3D 5 5 2 Total False Positives (c) (d) Fig. 4.")
 ROC curves on FDDB with discrete scores, (b) ROC curves on FDDB with discrete scores using less false positives, (c) ROC curves on FDDB with continuous scores, and (d) results on IJB-A dataset..8.")
5 Precision Precision Precision.9.9 True Positive Rate headhunter MTCNN hyperface DP2MFD CCF NPDFace MultiresHPM FD3DM DDFD CascadeCNN Conv3D True Positive Rate headhunter MTCNN hyperface DP2MFD CCF NPDFace MultiresHPM FD3DM DDFD CascadeCNN Conv3D Total False Positives.8 (a) Total False Positives (b) True Positive Rate headhunter MTCNN hyperface DP2MFD CCF NPDFace MultiresHPM FD3DM DDFD CascadeCNN Conv3D Total False Positives (c) (d) Fig. 4. Comparisons of face detection with state-of-the-art methods. (a) ROC curves on FDDB with discrete scores, (b) ROC curves on FDDB with discrete scores using less false positives, (c) ROC curves on FDDB with continuous scores, and (d) results on IJB-A dataset ACF-WIDER WIDER-.76 Multiscale Cascade CNN-.7 Two-stage CNN Multitask Cascade CNN-.85 CMS-RCNN Recall.6 ACF-WIDER WIDER-.64 Multiscale Cascade CNN-.636 Two-stage CNN Multitask Cascade CNN-.82 CMS-RCNN Recall (a) (b) (c).6 ACF-WIDER WIDER-.35 Multiscale Cascade CNN-.4 Two-stage CNN Multitask Cascade CNN-.67 CMS-RCNN Recall Fig. 5. Comparisons of face detection with state-of-the-art methods on the WIDER testing set. From left to right: (a) on the easy set, (b) on the medium set, and (c) on the hard set. D. Comparison with State-of-the-art Methods We compare the model trained on WIDER with other top detectors on FDDB, all published since 25. ROC curves of the different methods, obtained from the FDDB results page, are shown in Fig. 4. For discrete scores on FDDB, the performs better than all others when there are more than around 2 false positives for the entire test set, as shown in Fig. 4(a) and (b). With the more restrictive continuous scores, the is better than most of other state-of-the-art methods but poorer


6 (a) (b) Fig. 6. Illustrations of different annotation styles of (a) WIDER dataset and (b) IJB-A dataset. Notice that the annotation on the left does not include the top of the head and is narrowly cropped around the face. The annotation on the right includes the entire head. than MultiresHPM [9]. This discrepancy can be attributed to the fact that the detection results of the are not always exactly around the annotated face regions, as can be seen in Fig. 7. For 5 false positives, the true positive rates with discrete and continuous scores are.952 and.78 respectively. One possible reason for the relatively poor performance on the continuous scoring might be the difference of face annotations between WIDER and FDDB. The testing set of WIDER is divided into easy, medium, and hard according to the detection scores of EdgeBox. From easy to hard, the faces get smaller and more crowded. There are also more extreme poses and illuminations, making it extremely challenging. Comparison of our model with other published methods are presented in Fig. 5. Not surprisingly, the performance of our model decreases from the easy set to the hard set. Compared with two concurrent work [35], [36], the performance of our model drops more. One possible reason might be that they consider more cues, such as alignment supervision in [35] and multiscale convolution features and body cues in [36]. But in the easy set, our model performs the best. We further demonstrate qualitative face detection results in Fig. 7 and Fig. 9. It can be observed that the Faster RCNN model can deal with challenging cases with multiple overlapping faces and faces with extreme poses and scales. In the right bottom of Fig. 9, we also show some failure cases of the model on the WIDER testing set. In addition to false positives, there are some false negatives (i.e., faces are not detected) in the extremely crowded images, this suggests trying to integrate more cues, e.g., the context of the scene, to better detect the missing faces. E. Face Annotation Style Adaptation In addition to FDDB and WIDER, we also report quantitative comparisons on IJB-A, which is a relatively new face detection benchmark dataset published at CVPR 25, and thus not too many results have been reported on it yet. As the face annotation styles on IJB-A are quite different from WIDER, when applying the face detection model trained on the WIDER dataset to the IJB-A dataset, the results are very poor, suggesting the necessity of doing annotation style adaptation. As shown in Fig 6, in WIDER, the face annotations are specified tightly around the facial region while annotations in IJB-A include larger areas (e.g., hair). First, we use supervised annotation style adaptation. Specifically, we fine-tune the face detection model on the training images of each split of IJB-A using only, iterations. In the first 5, iterations, the base learning rate is. and it is reduced to. in the last 5,. Note that there are more then 5, training images in each split. We run only, iterations of fine-tuning to adapt the regression branches of the model trained on WIDER to the annotation styles of IJB-A. The comparison is shown in Fig. 4(d). We borrow results of other methods from [4], [5]. As we can see, the performs better than all of the others by a large margin. More qualitative face detection results on IJB-A can be found at Fig. 8. However, in a private superset of IJB-A (denote as sijba), all annotated samples are reserved for testing, which means we can not used any single annotation of the testing set to do supervised annotation style adaptation. Here we propose a simple yet effective unsupervised annotation style adaptation method. In specific, we fine-tune the model trained on WIDER on sijb-a, as what we do in the supervised annotation style adaptation. We then run face detections on training images of WIDER. For each training image, we replace the original WIDER-style annotation with its detection coming from the fine-tuned model if their IoU score is greater than.5. We finally re-train the Faster R-CNN model on WIDER training set with annotations borrowed from sijb-a. With this cycle training, we can obtain similar performance to the supervised annotation style adaptation. V. C ONCLUSION In this report, we have demonstrated state-of-the-art face detection performance on three benchmark datasets using the. Experimental results suggest that its effectiveness comes from the region proposal network (RPN) module. Due to the sharing of convolutional layers between the RPN and Fast R-CNN detector module, it is possible to use multiple convolutional layers within an RPN without extra computational burden. Although the is designed for generic object detection, it demonstrates impressive face detection performance when retrained on a suitable face detection training set. It may be possible to further boost its performance by considering the special patterns of human faces. ACKNOWLEDGEMENT This research is based upon work supported by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via contract number The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of ODNI, IARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purpose notwithstanding any copyright annotation thereon.










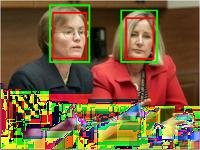





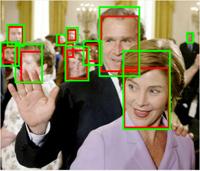
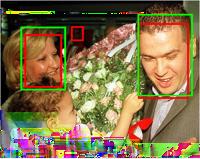
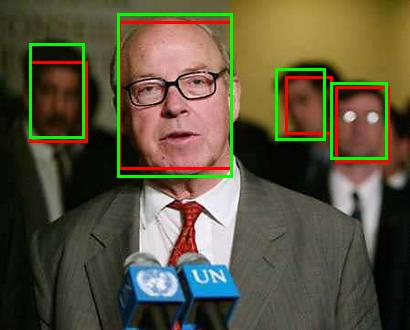
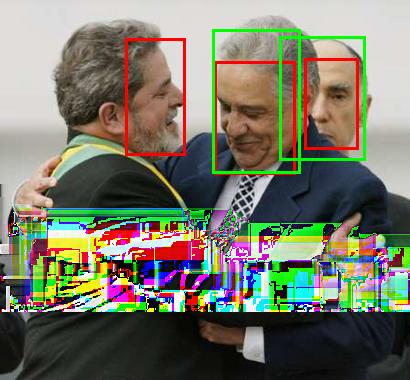


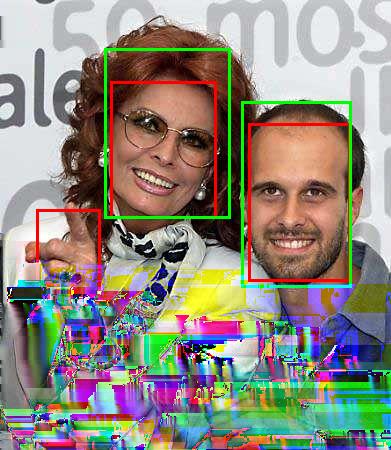


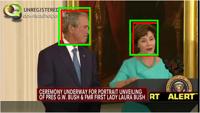
















7 Fig. 7. Sample detection results on the FDDB dataset, where green bounding boxes are ground-truth annotations and red bounding boxes are detection results of the. Fig. 8. Sample detection results on the IJB-A dataset, where green bounding boxes are ground-truth annotations and red bounding boxes are detection results of the.
![Fig. 9. Sample detection results on the WIDER testing set. R EFERENCES [] T. Ahonen, A. Hadid, and M. Pietik ainen.](/docs-images/79/79911267/images/8-0.jpg "Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell., 28(2):237 24, 26. [2] H. Bay, A.")
![Ess, T. Tuytelaars, and L. J. V. Gool. Speeded-up robust features (SURF). Computer Vision and Image Understanding, (3):346 359, 28. [3] D. Chen, S.](/docs-images/79/79911267/images/8-1.jpg "Ren, Y. Wei, X. Cao, and J. Sun. Joint cascade face detection and alignment. In ECCV, pages 9 22, 24. [4] J. Cheney, B. Klein, A. K. Jain, and B. F.")
![Klare. Unconstrained face detection: State of the art baseline and challenges. In ICB, pages 229 236, 25. [5] N. Dalal and B. Triggs.](/docs-images/79/79911267/images/8-2.jpg "Histograms of oriented gradients for human detection. In CVPR, pages 886 893, 25. [6] P. Doll ar and C. L. Zitnick.")
![Fast edge detection using structured forests. IEEE Trans. Pattern Anal. Mach. Intell., 37(8):558 57, 25. [7] S. S. Farfade, M. J. Saberian, and L. Li.](/docs-images/79/79911267/images/8-3.jpg "Multi-view face detection using deep convolutional neural networks. In ICMR, pages 643 65, 25. [8] P. F. Felzenszwalb, R. B. Girshick, D. A.")

![[] R. B. Girshick. Fast R-CNN. In ICCV, pages 44 448, 25. [] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik.](/docs-images/79/79911267/images/8-5.jpg "Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, pages 58 587, 24. [2] J. Guo, J. Xu, S. Liu, D. Huang, and Y.")
![Wang. Occlusion-Robust Face Detection Using Shallow and Deep Proposal Based Faster RCNN, pages 3 2. Springer International Publishing, Cham, 26. [3] K.](/docs-images/79/79911267/images/8-6.jpg "He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, pages 346 36, 24. [4] V.")


![In NIPS, pages 6 4, 22. [7] W. Kuo, B. Hariharan, and J. Malik. Deepbox: Learning objectness with convolutional networks. In ICCV, pages 2479 2487, 25.](/docs-images/79/79911267/images/8-9.jpg "[8] H. Li, Z. Lin, J. Brandt, X. Shen, and G. Hua. Efficient boosted exemplar-based face detection. In CVPR, pages 843 85, 24. [9] H. Li, Z. Lin, X.")
![Shen, J. Brandt, and G. Hua. A convolutional neural network cascade for face detection. In CVPR, pages 5325 5334, 25. [2] Y. Li, B. Sun, T. Wu, Y.](/docs-images/79/79911267/images/8-10.jpg "Wang, and W. Gao. Face detection with end-to-end integration of a convnet and a 3d model. ECCV, abs/66.85, 26. [2] M. Mathias, R. Benenson, M.")
![Pedersoli, and L. J. V. Gool. Face detection without bells and whistles. In ECCV, pages 72 735, 24. [22] M. Osadchy, Y. LeCun, and M. L. Miller.](/docs-images/79/79911267/images/8-11.jpg "Synergistic face detection and pose estimation with energy-based models. Journal of Machine Learning Research, 8:97 25, 27. [23] H. Qin, J. Yan, X.")
![Li, and X. Hu. Joint training of cascaded cnn for face detection. In CVPR, June 26. [24] R. Ranjan, V. M. Patel, and R. Chellappa.](/docs-images/79/79911267/images/8-12.jpg "A deep pyramid deformable part model for face detection. In BTAS, pages 8. IEEE, 25. [25] S. Ren, K. He, R. Girshick, and J. Sun.")
![: Towards realtime object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell., 26. [26] S. Ren, K. He, R. B.](/docs-images/79/79911267/images/8-13.jpg "Girshick, and J. Sun. : towards real-time object detection with region proposal networks. In NIPS, pages 9 99, 25. [27] H. A. Rowley, S. Baluja, and T.")
![Kanade. Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell., 2():23 38, 998. [28] X. Shen, Z. Lin, J. Brandt, and Y. Wu.](/docs-images/79/79911267/images/8-14.jpg "Detecting and aligning faces by image retrieval. In CVPR, pages 346 3467, 23. [29] K. Simonyan and A. Zisserman.")
![Very deep convolutional networks for large-scale image recognition. CoRR, abs/49.556, 24. [3] J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, and A.](/docs-images/79/79911267/images/8-15.jpg "W. M. Smeulders. Selective search for object recognition. International Journal of Computer Vision, 4(2):54 7, 23. [3] R. Vaillant, C. Monrocq, and Y.")
![LeCun. Original approach for the localisation of objects in images. IEE Proc on Vision, Image, and Signal Processing, 4(4):245 25, August 994. [32] P. A. Viola and M.](/docs-images/79/79911267/images/8-16.jpg "J. Jones. Robust real-time face detection. International Journal of Computer Vision, 57(2):37 54, 24. [33] S. Yang, P. Luo, C. C. Loy, and X. Tang.")
![From facial parts responses to face detection: A deep learning approach. In ICCV, pages 3676 3684, 25. [34] S. Yang, P. Luo, C. C. Loy, and X. Tang.](/docs-images/79/79911267/images/8-17.jpg "WIDER FACE: A face detection benchmark. In CVPR, 26. [35] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao.")
8 Fig. 9. Sample detection results on the WIDER testing set. R EFERENCES [] T. Ahonen, A. Hadid, and M. Pietik ainen. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell., 28(2):237 24, 26. [2] H. Bay, A. Ess, T. Tuytelaars, and L. J. V. Gool. Speeded-up robust features (SURF). Computer Vision and Image Understanding, (3): , 28. [3] D. Chen, S. Ren, Y. Wei, X. Cao, and J. Sun. Joint cascade face detection and alignment. In ECCV, pages 9 22, 24. [4] J. Cheney, B. Klein, A. K. Jain, and B. F. Klare. Unconstrained face detection: State of the art baseline and challenges. In ICB, pages , 25. [5] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, pages , 25. [6] P. Doll ar and C. L. Zitnick. Fast edge detection using structured forests. IEEE Trans. Pattern Anal. Mach. Intell., 37(8):558 57, 25. [7] S. S. Farfade, M. J. Saberian, and L. Li. Multi-view face detection using deep convolutional neural networks. In ICMR, pages , 25. [8] P. F. Felzenszwalb, R. B. Girshick, D. A. McAllester, and D. Ramanan. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell., 32(9): , 2. [9] G. Ghiasi and C. C. Fowlkes. Occlusion coherence: Localizing occluded faces with a hierarchical deformable part model. In CVPR, pages , 24. [] R. B. Girshick. Fast R-CNN. In ICCV, pages , 25. [] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, pages , 24. [2] J. Guo, J. Xu, S. Liu, D. Huang, and Y. Wang. Occlusion-Robust Face Detection Using Shallow and Deep Proposal Based Faster RCNN, pages 3 2. Springer International Publishing, Cham, 26. [3] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, pages , 24. [4] V. Jain and E. Learned-Miller. FDDB: A benchmark for face detection in unconstrained settings. Technical Report UM-CS-29, University of Massachusetts, Amherst, 2. [5] B. F. Klare, B. Klein, E. Taborsky, A. Blanton, J. Cheney, K. Allen, P. Grother, A. Mah, M. Burge, and A. K. Jain. Pushing the frontiers of unconstrained face detection and recognition: IARPA Janus benchmark A. In CVPR, pages , 25. [6] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, pages 6 4, 22. [7] W. Kuo, B. Hariharan, and J. Malik. Deepbox: Learning objectness with convolutional networks. In ICCV, pages , 25. [8] H. Li, Z. Lin, J. Brandt, X. Shen, and G. Hua. Efficient boosted exemplar-based face detection. In CVPR, pages , 24. [9] H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua. A convolutional neural network cascade for face detection. In CVPR, pages , 25. [2] Y. Li, B. Sun, T. Wu, Y. Wang, and W. Gao. Face detection with end-to-end integration of a convnet and a 3d model. ECCV, abs/66.85, 26. [2] M. Mathias, R. Benenson, M. Pedersoli, and L. J. V. Gool. Face detection without bells and whistles. In ECCV, pages , 24. [22] M. Osadchy, Y. LeCun, and M. L. Miller. Synergistic face detection and pose estimation with energy-based models. Journal of Machine Learning Research, 8:97 25, 27. [23] H. Qin, J. Yan, X. Li, and X. Hu. Joint training of cascaded cnn for face detection. In CVPR, June 26. [24] R. Ranjan, V. M. Patel, and R. Chellappa. A deep pyramid deformable part model for face detection. In BTAS, pages 8. IEEE, 25. [25] S. Ren, K. He, R. Girshick, and J. Sun. : Towards realtime object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell., 26. [26] S. Ren, K. He, R. B. Girshick, and J. Sun. : towards real-time object detection with region proposal networks. In NIPS, pages 9 99, 25. [27] H. A. Rowley, S. Baluja, and T. Kanade. Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell., 2():23 38, 998. [28] X. Shen, Z. Lin, J. Brandt, and Y. Wu. Detecting and aligning faces by image retrieval. In CVPR, pages , 23. [29] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/49.556, 24. [3] J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, and A. W. M. Smeulders. Selective search for object recognition. International Journal of Computer Vision, 4(2):54 7, 23. [3] R. Vaillant, C. Monrocq, and Y. LeCun. Original approach for the localisation of objects in images. IEE Proc on Vision, Image, and Signal Processing, 4(4):245 25, August 994. [32] P. A. Viola and M. J. Jones. Robust real-time face detection. International Journal of Computer Vision, 57(2):37 54, 24. [33] S. Yang, P. Luo, C. C. Loy, and X. Tang. From facial parts responses to face detection: A deep learning approach. In ICCV, pages , 25. [34] S. Yang, P. Luo, C. C. Loy, and X. Tang. WIDER FACE: A face detection benchmark. In CVPR, 26. [35] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23():499 53, Oct 26. [36] C. Zhu, Y. Zheng, K. Luu, and M. Savvides. CMS-RCNN: contextual multi-scale region-based CNN for unconstrained face detection. CoRR, abs/66.543, 26. [37] X. Zhu and D. Ramanan. Face detection, pose estimation, and landmark localization in the wild. In CVPR, pages , 22.
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
arxiv: v3 [cs.cv] 18 Oct 2017
![arxiv: v3 [cs.cv] 18 Oct 2017](/thumbs/75/72627087.jpg "arxiv: v3 [cs.cv] 18 Oct 2017") SSH: Single Stage Headless Face Detector Mahyar Najibi* Pouya Samangouei* Rama Chellappa University of Maryland arxiv:78.3979v3 [cs.cv] 8 Oct 27 najibi@cs.umd.edu Larry S. Davis {pouya,rama,lsd}@umiacs.umd.edu
SSH: Single Stage Headless Face Detector Mahyar Najibi* Pouya Samangouei* Rama Chellappa University of Maryland arxiv:78.3979v3 [cs.cv] 8 Oct 27 najibi@cs.umd.edu Larry S. Davis {pouya,rama,lsd}@umiacs.umd.edu
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Detecting Faces Using Inside Cascaded Contextual CNN
 Detecting Faces Using Inside Cascaded Contextual CNN Kaipeng Zhang 1, Zhanpeng Zhang 2, Hao Wang 1, Zhifeng Li 1, Yu Qiao 3, Wei Liu 1 1 Tencent AI Lab 2 SenseTime Group Limited 3 Guangdong Provincial
Detecting Faces Using Inside Cascaded Contextual CNN Kaipeng Zhang 1, Zhanpeng Zhang 2, Hao Wang 1, Zhifeng Li 1, Yu Qiao 3, Wei Liu 1 1 Tencent AI Lab 2 SenseTime Group Limited 3 Guangdong Provincial
arxiv: v1 [cs.cv] 18 Aug 2015 Abstract
![arxiv: v1 [cs.cv] 18 Aug 2015 Abstract](/thumbs/74/69754074.jpg "arxiv: v1 [cs.cv] 18 Aug 2015 Abstract") A Deep Pyramid Deformable Part Model for Face Detection Rajeev Ranjan, Vishal M. Patel, Rama Chellappa Center for Automation Research University of Maryland, College Park, MD 20742 {rranjan1, pvishalm,
A Deep Pyramid Deformable Part Model for Face Detection Rajeev Ranjan, Vishal M. Patel, Rama Chellappa Center for Automation Research University of Maryland, College Park, MD 20742 {rranjan1, pvishalm,
Lightweight Two-Stream Convolutional Face Detection
 Lightweight Two-Stream Convolutional Face Detection Danai Triantafyllidou, Paraskevi Nousi and Anastasios Tefas Department of Informatics, Aristotle University of Thessaloniki, Thessaloniki, Greece danaitri22@gmail.com,
Lightweight Two-Stream Convolutional Face Detection Danai Triantafyllidou, Paraskevi Nousi and Anastasios Tefas Department of Informatics, Aristotle University of Thessaloniki, Thessaloniki, Greece danaitri22@gmail.com,
Multi-Path Region-Based Convolutional Neural Network for Accurate Detection of Unconstrained Hard Faces
 Multi-Path Region-Based Convolutional Neural Network for Accurate Detection of Unconstrained Hard Faces Yuguang Liu, Martin D. Levine Department of Electrical and Computer Engineering Center for Intelligent
Multi-Path Region-Based Convolutional Neural Network for Accurate Detection of Unconstrained Hard Faces Yuguang Liu, Martin D. Levine Department of Electrical and Computer Engineering Center for Intelligent
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Detecting Masked Faces in the Wild with LLE-CNNs
 Detecting Masked Faces in the Wild with LLE-CNNs Shiming Ge 1, Jia Li 2, Qiting Ye 1,3, Zhao Luo 1,3 1 Beijing Key Laboratory of IOT information Security, Institute of Information Engineering, Chinese
Detecting Masked Faces in the Wild with LLE-CNNs Shiming Ge 1, Jia Li 2, Qiting Ye 1,3, Zhao Luo 1,3 1 Beijing Key Laboratory of IOT information Security, Institute of Information Engineering, Chinese
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Deep Convolutional Neural Network in Deformable Part Models for Face Detection
 Deep Convolutional Neural Network in Deformable Part Models for Face Detection Dinh-Luan Nguyen 1, Vinh-Tiep Nguyen 2, Minh-Triet Tran 2, Atsuo Yoshitaka 3 1,2 University of Science, Vietnam National University,
Deep Convolutional Neural Network in Deformable Part Models for Face Detection Dinh-Luan Nguyen 1, Vinh-Tiep Nguyen 2, Minh-Triet Tran 2, Atsuo Yoshitaka 3 1,2 University of Science, Vietnam National University,
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
 Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
arxiv: v1 [cs.cv] 31 Mar 2017
![arxiv: v1 [cs.cv] 31 Mar 2017](/thumbs/80/81467687.jpg "arxiv: v1 [cs.cv] 31 Mar 2017") End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL
 PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
Project 3 Q&A. Jonathan Krause
 Project 3 Q&A Jonathan Krause 1 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations 2 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations
Project 3 Q&A Jonathan Krause 1 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations 2 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations
arxiv: v1 [cs.cv] 25 Feb 2018
![arxiv: v1 [cs.cv] 25 Feb 2018](/thumbs/79/79921598.jpg "arxiv: v1 [cs.cv] 25 Feb 2018") Seeing Small Faces from Robust Anchor s Perspective Chenchen Zhu Ran Tao Khoa Luu Marios Savvides Carnegie Mellon University 5 Forbes Avenue, Pittsburgh, PA 523, USA {chenchez, rant, kluu, marioss}@andrew.cmu.edu
Seeing Small Faces from Robust Anchor s Perspective Chenchen Zhu Ran Tao Khoa Luu Marios Savvides Carnegie Mellon University 5 Forbes Avenue, Pittsburgh, PA 523, USA {chenchez, rant, kluu, marioss}@andrew.cmu.edu
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Hybrid Cascade Model for Face Detection in the Wild Based on Normalized Pixel Difference and a Deep Convolutional Neural Network
 Hybrid Cascade Model for Face Detection in the Wild Based on Normalized Pixel Difference and a Deep Convolutional Neural Network Darijan Marčetić [-2-6556-665X], Martin Soldić [-2-431-44] and Slobodan
Hybrid Cascade Model for Face Detection in the Wild Based on Normalized Pixel Difference and a Deep Convolutional Neural Network Darijan Marčetić [-2-6556-665X], Martin Soldić [-2-431-44] and Slobodan
A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications
 A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications Le Thanh Nguyen-Meidine 1, Eric Granger 1, Madhu Kiran 1 and Louis-Antoine Blais-Morin 2 1 École de technologie
A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications Le Thanh Nguyen-Meidine 1, Eric Granger 1, Madhu Kiran 1 and Louis-Antoine Blais-Morin 2 1 École de technologie
arxiv: v2 [cs.cv] 22 Nov 2017
![arxiv: v2 [cs.cv] 22 Nov 2017](/thumbs/86/93068521.jpg "arxiv: v2 [cs.cv] 22 Nov 2017") Face Attention Network: An Effective Face Detector for the Occluded Faces Jianfeng Wang College of Software, Beihang University Beijing, China wjfwzzc@buaa.edu.cn Ye Yuan Megvii Inc. (Face++) Beijing,
Face Attention Network: An Effective Face Detector for the Occluded Faces Jianfeng Wang College of Software, Beihang University Beijing, China wjfwzzc@buaa.edu.cn Ye Yuan Megvii Inc. (Face++) Beijing,
PEDESTRIAN detection based on Convolutional Neural. Learning Multilayer Channel Features for Pedestrian Detection
 Learning Multilayer Channel Features for Pedestrian Detection Jiale Cao, Yanwei Pang, and Xuelong Li arxiv:603.0024v [cs.cv] Mar 206 Abstract Pedestrian detection based on the combination of Convolutional
Learning Multilayer Channel Features for Pedestrian Detection Jiale Cao, Yanwei Pang, and Xuelong Li arxiv:603.0024v [cs.cv] Mar 206 Abstract Pedestrian detection based on the combination of Convolutional
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Recognizing people. Deva Ramanan
 Recognizing people Deva Ramanan The goal Why focus on people? How many person-pixels are in a video? 35% 34% Movies TV 40% YouTube Let s start our discussion with a loaded question: why is visual recognition
Recognizing people Deva Ramanan The goal Why focus on people? How many person-pixels are in a video? 35% 34% Movies TV 40% YouTube Let s start our discussion with a loaded question: why is visual recognition
Deep Learning for Object detection & localization
 Deep Learning for Object detection & localization RCNN, Fast RCNN, Faster RCNN, YOLO, GAP, CAM, MSROI Aaditya Prakash Sep 25, 2018 Image classification Image classification Whole of image is classified
Deep Learning for Object detection & localization RCNN, Fast RCNN, Faster RCNN, YOLO, GAP, CAM, MSROI Aaditya Prakash Sep 25, 2018 Image classification Image classification Whole of image is classified
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Finding Tiny Faces. Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University Abstract. 1.
 Finding Tiny Faces Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu Figure 1: We describe a detector that can find around 800 faces out of the reportedly
Finding Tiny Faces Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu Figure 1: We describe a detector that can find around 800 faces out of the reportedly
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Automatic detection of books based on Faster R-CNN
 Automatic detection of books based on Faster R-CNN Beibei Zhu, Xiaoyu Wu, Lei Yang, Yinghua Shen School of Information Engineering, Communication University of China Beijing, China e-mail: zhubeibei@cuc.edu.cn,
Automatic detection of books based on Faster R-CNN Beibei Zhu, Xiaoyu Wu, Lei Yang, Yinghua Shen School of Information Engineering, Communication University of China Beijing, China e-mail: zhubeibei@cuc.edu.cn,
Industrial Technology Research Institute, Hsinchu, Taiwan, R.O.C ǂ
 Stop Line Detection and Distance Measurement for Road Intersection based on Deep Learning Neural Network Guan-Ting Lin 1, Patrisia Sherryl Santoso *1, Che-Tsung Lin *ǂ, Chia-Chi Tsai and Jiun-In Guo National
Stop Line Detection and Distance Measurement for Road Intersection based on Deep Learning Neural Network Guan-Ting Lin 1, Patrisia Sherryl Santoso *1, Che-Tsung Lin *ǂ, Chia-Chi Tsai and Jiun-In Guo National
Multi-Scale Fully Convolutional Network for Face Detection in the Wild
 Multi-Scale Fully Convolutional Network for Face Detection in the Wild Yancheng Bai 1,2 and Bernard Ghanem 1 1 King Abdullah University of Science and Technology (KAUST), Saudi Arabia 2 Institute of Software,
Multi-Scale Fully Convolutional Network for Face Detection in the Wild Yancheng Bai 1,2 and Bernard Ghanem 1 1 King Abdullah University of Science and Technology (KAUST), Saudi Arabia 2 Institute of Software,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks
 Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks Xuepeng Shi 1,2 Shiguang Shan 1,3 Meina Kan 1,3 Shuzhe Wu 1,2 Xilin Chen 1 1 Key Lab of Intelligent Information Processing
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks Xuepeng Shi 1,2 Shiguang Shan 1,3 Meina Kan 1,3 Shuzhe Wu 1,2 Xilin Chen 1 1 Key Lab of Intelligent Information Processing
Pedestrian Detection with Deep Convolutional Neural Network
 Pedestrian Detection with Deep Convolutional Neural Network Xiaogang Chen, Pengxu Wei, Wei Ke, Qixiang Ye, Jianbin Jiao School of Electronic,Electrical and Communication Engineering, University of Chinese
Pedestrian Detection with Deep Convolutional Neural Network Xiaogang Chen, Pengxu Wei, Wei Ke, Qixiang Ye, Jianbin Jiao School of Electronic,Electrical and Communication Engineering, University of Chinese
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
arxiv: v1 [cs.cv] 6 Sep 2016
![arxiv: v1 [cs.cv] 6 Sep 2016](/thumbs/74/70191346.jpg "arxiv: v1 [cs.cv] 6 Sep 2016") Object Specific Deep Learning Feature and Its Application to Face Detection arxiv:1609.01366v1 [cs.cv] 6 Sep 2016 Xianxu Hou University of Nottingham, Ningbo, China xianxu.hou@nottingham.edu.cn Linlin
Object Specific Deep Learning Feature and Its Application to Face Detection arxiv:1609.01366v1 [cs.cv] 6 Sep 2016 Xianxu Hou University of Nottingham, Ningbo, China xianxu.hou@nottingham.edu.cn Linlin
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
arxiv: v1 [cs.cv] 23 Sep 2016
![arxiv: v1 [cs.cv] 23 Sep 2016](/thumbs/78/77488783.jpg "arxiv: v1 [cs.cv] 23 Sep 2016") Funnel-Structured Cascade for Multi-View Face Detection with Alignment-Awareness arxiv:1609.07304v1 [cs.cv] 23 Sep 2016 Shuzhe Wu 1 Meina Kan 1,2 Zhenliang He 1 Shiguang Shan 1,2 Xilin Chen 1 1 Key Laboratory
Funnel-Structured Cascade for Multi-View Face Detection with Alignment-Awareness arxiv:1609.07304v1 [cs.cv] 23 Sep 2016 Shuzhe Wu 1 Meina Kan 1,2 Zhenliang He 1 Shiguang Shan 1,2 Xilin Chen 1 1 Key Laboratory
Visual features detection based on deep neural network in autonomous driving tasks
 430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model
 Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Face Detection by Aggregating Visible Components
 Face Detection by Aggregating Visible Components Jiali Duan 1, Shengcai Liao 2, Xiaoyuan Guo 3, and Stan Z. Li 2 1 School of Electronic, Electrical and Communication Engineering University of Chinese Academy
Face Detection by Aggregating Visible Components Jiali Duan 1, Shengcai Liao 2, Xiaoyuan Guo 3, and Stan Z. Li 2 1 School of Electronic, Electrical and Communication Engineering University of Chinese Academy
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Improving Small Object Detection
 Improving Small Object Detection Harish Krishna, C.V. Jawahar CVIT, KCIS International Institute of Information Technology Hyderabad, India Abstract While the problem of detecting generic objects in natural
Improving Small Object Detection Harish Krishna, C.V. Jawahar CVIT, KCIS International Institute of Information Technology Hyderabad, India Abstract While the problem of detecting generic objects in natural
FAce detection is an important and long-standing problem in
 1 Faceness-Net: Face Detection through Deep Facial Part Responses Shuo Yang, Ping Luo, Chen Change Loy, Senior Member, IEEE and Xiaoou Tang, Fellow, IEEE arxiv:11.08393v3 [cs.cv] 25 Aug 2017 Abstract We
1 Faceness-Net: Face Detection through Deep Facial Part Responses Shuo Yang, Ping Luo, Chen Change Loy, Senior Member, IEEE and Xiaoou Tang, Fellow, IEEE arxiv:11.08393v3 [cs.cv] 25 Aug 2017 Abstract We
FACE DETECTION USING LOCAL HYBRID PATTERNS. Chulhee Yun, Donghoon Lee, and Chang D. Yoo
 FACE DETECTION USING LOCAL HYBRID PATTERNS Chulhee Yun, Donghoon Lee, and Chang D. Yoo Department of Electrical Engineering, Korea Advanced Institute of Science and Technology chyun90@kaist.ac.kr, iamdh@kaist.ac.kr,
FACE DETECTION USING LOCAL HYBRID PATTERNS Chulhee Yun, Donghoon Lee, and Chang D. Yoo Department of Electrical Engineering, Korea Advanced Institute of Science and Technology chyun90@kaist.ac.kr, iamdh@kaist.ac.kr,
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Yield Estimation using faster R-CNN
 Yield Estimation using faster R-CNN 1 Vidhya Sagar, 2 Sailesh J.Jain and 2 Arjun P. 1 Assistant Professor, 2 UG Scholar, Department of Computer Engineering and Science SRM Institute of Science and Technology,Chennai,
Yield Estimation using faster R-CNN 1 Vidhya Sagar, 2 Sailesh J.Jain and 2 Arjun P. 1 Assistant Professor, 2 UG Scholar, Department of Computer Engineering and Science SRM Institute of Science and Technology,Chennai,
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK
 FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
arxiv: v1 [cs.cv] 19 Feb 2019
![arxiv: v1 [cs.cv] 19 Feb 2019](/thumbs/88/117177831.jpg "arxiv: v1 [cs.cv] 19 Feb 2019") Detector-in-Detector: Multi-Level Analysis for Human-Parts Xiaojie Li 1[0000 0001 6449 2727], Lu Yang 2[0000 0003 3857 3982], Qing Song 2[0000000346162200], and Fuqiang Zhou 1[0000 0001 9341 9342] arxiv:1902.07017v1
Detector-in-Detector: Multi-Level Analysis for Human-Parts Xiaojie Li 1[0000 0001 6449 2727], Lu Yang 2[0000 0003 3857 3982], Qing Song 2[0000000346162200], and Fuqiang Zhou 1[0000 0001 9341 9342] arxiv:1902.07017v1
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE. Chubu University 1200, Matsumoto-cho, Kasugai, AICHI
 FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Development in Object Detection. Junyuan Lin May 4th
 Development in Object Detection Junyuan Lin May 4th Line of Research [1] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection, CVPR 2005. HOG Feature template [2] P. Felzenszwalb,
Development in Object Detection Junyuan Lin May 4th Line of Research [1] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection, CVPR 2005. HOG Feature template [2] P. Felzenszwalb,
Rich feature hierarchies for accurate object detection and semant
 Rich feature hierarchies for accurate object detection and semantic segmentation Speaker: Yucong Shen 4/5/2018 Develop of Object Detection 1 DPM (Deformable parts models) 2 R-CNN 3 Fast R-CNN 4 Faster
Rich feature hierarchies for accurate object detection and semantic segmentation Speaker: Yucong Shen 4/5/2018 Develop of Object Detection 1 DPM (Deformable parts models) 2 R-CNN 3 Fast R-CNN 4 Faster
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
A Study of Vehicle Detector Generalization on U.S. Highway
 26 IEEE 9th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November -4, 26 A Study of Vehicle Generalization on U.S. Highway Rakesh
26 IEEE 9th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November -4, 26 A Study of Vehicle Generalization on U.S. Highway Rakesh
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Joint Object Detection and Viewpoint Estimation using CNN features
 Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
arxiv: v2 [cs.cv] 2 Jun 2018
![arxiv: v2 [cs.cv] 2 Jun 2018](/thumbs/87/95225561.jpg "arxiv: v2 [cs.cv] 2 Jun 2018") Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy Guanglu Song, Yu Liu 2, Ming Jiang, Yujie Wang, Junjie Yan 3, Biao Leng Beihang University, 2 The Chinese University of Hong Kong,
Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy Guanglu Song, Yu Liu 2, Ming Jiang, Yujie Wang, Junjie Yan 3, Biao Leng Beihang University, 2 The Chinese University of Hong Kong,
OBJECT DETECTION HYUNG IL KOO
 OBJECT DETECTION HYUNG IL KOO INTRODUCTION Computer Vision Tasks Classification + Localization Classification: C-classes Input: image Output: class label Evaluation metric: accuracy Localization Input:
OBJECT DETECTION HYUNG IL KOO INTRODUCTION Computer Vision Tasks Classification + Localization Classification: C-classes Input: image Output: class label Evaluation metric: accuracy Localization Input:
Detection and Localization with Multi-scale Models
 Detection and Localization with Multi-scale Models Eshed Ohn-Bar and Mohan M. Trivedi Computer Vision and Robotics Research Laboratory University of California San Diego {eohnbar, mtrivedi}@ucsd.edu Abstract
Detection and Localization with Multi-scale Models Eshed Ohn-Bar and Mohan M. Trivedi Computer Vision and Robotics Research Laboratory University of California San Diego {eohnbar, mtrivedi}@ucsd.edu Abstract
Pedestrian Detection via Mixture of CNN Experts and thresholded Aggregated Channel Features
 Pedestrian Detection via Mixture of CNN Experts and thresholded Aggregated Channel Features Ankit Verma, Ramya Hebbalaguppe, Lovekesh Vig, Swagat Kumar, and Ehtesham Hassan TCS Innovation Labs, New Delhi
Pedestrian Detection via Mixture of CNN Experts and thresholded Aggregated Channel Features Ankit Verma, Ramya Hebbalaguppe, Lovekesh Vig, Swagat Kumar, and Ehtesham Hassan TCS Innovation Labs, New Delhi
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm
 CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
 https://en.wikipedia.org/wiki/the_dress Recap: Viola-Jones sliding window detector Fast detection through two mechanisms Quickly eliminate unlikely windows Use features that are fast to compute Viola
https://en.wikipedia.org/wiki/the_dress Recap: Viola-Jones sliding window detector Fast detection through two mechanisms Quickly eliminate unlikely windows Use features that are fast to compute Viola
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
G-CNN: an Iterative Grid Based Object Detector
 G-CNN: an Iterative Grid Based Object Detector Mahyar Najibi 1, Mohammad Rastegari 1,2, Larry S. Davis 1 1 University of Maryland, College Park 2 Allen Institute for Artificial Intelligence najibi@cs.umd.edu
G-CNN: an Iterative Grid Based Object Detector Mahyar Najibi 1, Mohammad Rastegari 1,2, Larry S. Davis 1 1 University of Maryland, College Park 2 Allen Institute for Artificial Intelligence najibi@cs.umd.edu
DAFE-FD: Density Aware Feature Enrichment for Face Detection
 DAFE-FD: Density Aware Feature Enrichment for Face Detection Vishwanath A. Sindagi Vishal M. Patel Department of Electrical and Computer Engineering, Johns Hopkins University, 3400 N. Charles St, Baltimore,
DAFE-FD: Density Aware Feature Enrichment for Face Detection Vishwanath A. Sindagi Vishal M. Patel Department of Electrical and Computer Engineering, Johns Hopkins University, 3400 N. Charles St, Baltimore,
arxiv: v1 [cs.cv] 4 Nov 2016
![arxiv: v1 [cs.cv] 4 Nov 2016](/thumbs/94/119492781.jpg "arxiv: v1 [cs.cv] 4 Nov 2016") UMDFaces: An Annotated Face Dataset for Training Deep Networks Ankan Bansal Anirudh Nanduri Rajeev Ranjan Carlos D. Castillo Rama Chellappa University of Maryland, College Park {ankan,snanduri,rranjan1,carlos,rama}@umiacs.umd.edu
UMDFaces: An Annotated Face Dataset for Training Deep Networks Ankan Bansal Anirudh Nanduri Rajeev Ranjan Carlos D. Castillo Rama Chellappa University of Maryland, College Park {ankan,snanduri,rranjan1,carlos,rama}@umiacs.umd.edu
arxiv: v3 [cs.cv] 29 Mar 2017
![arxiv: v3 [cs.cv] 29 Mar 2017](/thumbs/89/98535829.jpg "arxiv: v3 [cs.cv] 29 Mar 2017") EVOLVING BOXES FOR FAST VEHICLE DETECTION Li Wang 1,2, Yao Lu 3, Hong Wang 2, Yingbin Zheng 2, Hao Ye 2, Xiangyang Xue 1 arxiv:1702.00254v3 [cs.cv] 29 Mar 2017 1 Shanghai Key Lab of Intelligent Information
EVOLVING BOXES FOR FAST VEHICLE DETECTION Li Wang 1,2, Yao Lu 3, Hong Wang 2, Yingbin Zheng 2, Hao Ye 2, Xiangyang Xue 1 arxiv:1702.00254v3 [cs.cv] 29 Mar 2017 1 Shanghai Key Lab of Intelligent Information
arxiv: v2 [cs.cv] 10 Sep 2018
![arxiv: v2 [cs.cv] 10 Sep 2018](/thumbs/95/126354862.jpg "arxiv: v2 [cs.cv] 10 Sep 2018") Feature Agglomeration Networks for Single Stage Face Detection Jialiang Zhang, Xiongwei Wu, Jianke Zhu, Steven C.H. Hoi School of Information Systems, Singapore Management University, Singapore College
Feature Agglomeration Networks for Single Stage Face Detection Jialiang Zhang, Xiongwei Wu, Jianke Zhu, Steven C.H. Hoi School of Information Systems, Singapore Management University, Singapore College
Robust Face Recognition Based on Convolutional Neural Network
 2017 2nd International Conference on Manufacturing Science and Information Engineering (ICMSIE 2017) ISBN: 978-1-60595-516-2 Robust Face Recognition Based on Convolutional Neural Network Ying Xu, Hui Ma,
2017 2nd International Conference on Manufacturing Science and Information Engineering (ICMSIE 2017) ISBN: 978-1-60595-516-2 Robust Face Recognition Based on Convolutional Neural Network Ying Xu, Hui Ma,
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Towards Real-Time Automatic Number Plate. Detection: Dots in the Search Space
 Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Deeply Cascaded Networks
 Deeply Cascaded Networks Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu 1 Introduction After the seminal work of Viola-Jones[15] fast object
Deeply Cascaded Networks Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu 1 Introduction After the seminal work of Viola-Jones[15] fast object
CS6501: Deep Learning for Visual Recognition. Object Detection I: RCNN, Fast-RCNN, Faster-RCNN
 CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
Improving Face Recognition by Exploring Local Features with Visual Attention
 Improving Face Recognition by Exploring Local Features with Visual Attention Yichun Shi and Anil K. Jain Michigan State University East Lansing, Michigan, USA shiyichu@msu.edu, jain@cse.msu.edu Abstract
Improving Face Recognition by Exploring Local Features with Visual Attention Yichun Shi and Anil K. Jain Michigan State University East Lansing, Michigan, USA shiyichu@msu.edu, jain@cse.msu.edu Abstract