arxiv: v2 [cs.cv] 10 Sep 2018
|
|
|
- Jewel Black
- 5 years ago
- Views:
Transcription
1 Feature Agglomeration Networks for Single Stage Face Detection Jialiang Zhang, Xiongwei Wu, Jianke Zhu, Steven C.H. Hoi School of Information Systems, Singapore Management University, Singapore College of Computer Science and Technology, Zhejiang University, Hangzhou, China DeepIR Inc., Beijing, China arxiv: v2 [cs.cv] 0 Sep 208 {chhoi,xwwu.205@phdis}@smu.edu.sg;{zjialiang,jkzhu}@zju.edu.cn Abstract Recent years have witnessed promising results of face detection using deep learning. Despite making remarkable progresses, face detection in the wild remains an open research challenge especially when detecting faces at vastly different scales and characteristics. In this paper, we propose a novel simple yet effective framework of Feature Agglomeration Networks (FANet) to build a new single stage face detector, which not only achieves state-of-the-art performance but also runs efficiently. As inspired by Feature Pyramid Networks (FPN) [], the key idea of our framework is to exploit inherent multi-scale features of a single convolutional neural network by aggregating higher-level semantic feature maps of different scales as contextual cues to augment lower-level feature maps via a hierarchical agglomeration manner at marginal extra computation cost. We further propose a Hierarchical Loss to effectively train the FANet model. We evaluate the proposed FANet detector on several public face detection benchmarks, including PASCAL face, FDDB and WIDER FACE datasets and achieved state-of-the-art results. Our detector can run in real time for VGA-resolution images on GPU. Keywords Feature Agglomeration, Context-aware, Hierarchical Loss, Single-stage Detectors. Introduction Face detection is generally the first key step towards face related applications, such as face alignment, face recognition and facial expression analysis, etc. Despite being studied extensively, detecting faces in the wild remains an open research problem due to various challenges with real-world faces. Early works of face detection mainly focused on crafting effective features manually and then building powerful classifiers [20], which are often sub-optimal and may not always achieve satisfactory results. Recent years have The first two authors contributed equally to this work. witnessed the successful applications of deep learning techniques for face detection tasks [7, 2]. Despite being extensively studied, it remains an open challenge for building a fast face detector with high accuracy in any real-world scenario. In general, face detection can be viewed as a special case of generic object detection [7, 2]. Many previous state-of-the-art face detectors inherited a lot of successful techniques from generic object detection, especially for the family of region-based CNN (R-CNN) methods. Among the family of R-CNN based face detectors, there are two major categories of detection frameworks: (i) two-stage detectors (a.k.a. proposal-based ), such as Fast R-CNN [6], Faster R-CNN [7], etc; and (ii) single-stage detectors (a.k.a. proposal-free ), such as Region Proposal Networks (RPN) [7], Single-Shot Multibox Detector (SSD) [2], etc. The single-stage detection framework enjoys higher inference efficiency, and thus has attracted increasing attention recently due to the high demand of real-time face detectors in real applications. Despite enjoying computational advantages, single-stage detectors performance can may dramaticaly when handling small faces. In order to build a robust detector, there exist two major routes for improvement. One way is to train multi-shot single-scale detectors by using the idea of image pyramid to train multiple separate single-scale detectors each for one specific scale (e.g., the HR detector in [8]). However, such approach is computationally expensive since it has to pass a very deep network multiple times during inference. Another way is to train a single-shot multi-scale detector by exploiting multi-scale feature representations of a deep convolutional network, requiring only a single pass to the network during inference. For example, S3FD [28] follows the second approach by extending SSD [2] for face detection. Though achieving promising performance, S3FD shares the similar drawback of SSD-style detection frameworks, where each of multi-scale feature maps is used alone for prediction and thus a high-resolution semantically weak
2 feature map may fail to perform accurate predictions. Inspired by the recent success of Feature Pyramid Networks (FPN) [] for generic object detection, we propose a novel simple yet effective detection framework of Feature Agglomeration Networks (FANet) to overcome this by combining low-resolution semantically strong features with high-resolution semantically weak features. In particular, FANet aims to create a hierarchical feature pyramid with rich semantics at all scales to boost the prediction performance of high-resolution feature maps using rich contextual cues from low-resolution semantically strong features. Unlike FPN that creates feature pyramid using the skip connection module, we propose a novel Agglomeration Connection module to create a new hierarchical feature pyramid for FANet. Besides, a new Hierarchical Loss (HL) is presented to train the FANet model effectively in an end-toend manner. We conduct extensive experiments on several public face detection benchmarks to validate the efficacy of our proposed FANet structure as well as the HL training scheme. As a summary, the main contributions of this paper include the following We introduce Agglomeration Connection module to enhance the feature representation power in highresolution shallow layers. We propose a simple yet effective framework of Feature Agglomeration Networks (FANet) for single stage face detection, which creates a new hierarchical effective feature pyramid with rich semantics at all scales; An effective Hierarchical Loss based training scheme is presented to train the proposed FANet model in an end-to-end manner, which guids a more stable and better training for discriminative features; Comprehensive experiments are carried out on several public Face Detection benchmarks to demonstrate the superiority of the proposed FANet framework. 2. Related Work Generic Object Detection. As a special case of generic object detection, many face detectors inherit successful techniques for generic object detection [28, 2, 8]. There are two major categories of Region-based CNN variants for object detection: (i) two-stage detection systems where proposals are generated in the first stage and further classified in the second stage; and (ii) single-stage detection systems where the object detection and classification are performed simultaneously from the feature maps without a separate proposal generation stage. The two-stage detection systems include Fast R-CNN [6], Faster R-CNN [7] and their variants, and the single-stage detection systems include YOLO [6], RPN [7], SSD [2], etc. Our detector essentially belongs to the single-stage detection framework. Multi-shot single-scale Face Detector. To detect faces with a large range of scales, one way is to train multiple detectors each of which targets for a specific scale. Hu et al. [8] trained multiple separate RPN detectors for different scales and made inference using image pyramids. However, their method is very time-consuming since images are required to pass a very deep network multiple times during inference. Hao et al. [7] learned a Scale Aware Network by estimating face scales in images and built image pyramids according to the estimated values. Although avoiding computation cost to some extent, multiple passes are still required if faces of varied ranges of scales presented in one image. Due to high computational cost, such paradigm is not suitable for real-time applications. Single-shot multi-scale Face Detector. Single-shot multi-box detector (SSD) [2] applies multi-scale feature representations for detecting different scales and thus only a single pass is required. S3FD [28] inherits SSD framework with carefully designed scale-aware anchors. However, S3FD shares the same limitation of SSD, where each feature is used alone for prediction and as a consequence, high-resolution features may fail to provide robust prediction due to the weak semantics. As inspired by FPN [], we propose a new framework of FANet to effectively address the limitation of S3FD by aggregating low-resolution semantically strong features with high-resolution semantically weak features using the proposed Agglomeration Connection module. Context Modeling Contextual information is important to improve face detection. In [26], context is modeled by enlarging the window around proposals. For face detection, CMS-RCNN [30] utilizes a larger window with the cost of duplicating the classification head. This increases the memory requirement as well as detection time. SSH [3] uses the idea of inception module to create context module. While in our Agglomeration Connection module, other than an inception-like context module, we also incorporate the semantics from a deeper feature maps through agglomeration manner. Feature Pyramid. Feature pyramid is a structure which combines semantically weak features with semantically strong features using skip-connection. IoN [] extracts RoI features from different feature maps and concatenates them together. HyperNet [0] makes prediction on a Hyper Feature Map produced by aggregating multi-scale feature maps. DSSD [5] and RON [9] also apply the idea of lateral skip connection to create feature pyramids and achieve promising performance. In this paper, we propose a new Agglomerate Connection module which can aggregate multi-scale features more effectively than the skip connection module. Besides, we also introduce a novel Hierarchi-
3 cal Loss on the proposed FANet framework which enables us to train this powerful detector effectively and robustly in an end-to-end approach. 3. Feature Agglomeration Networks In this section, we present the Feature Agglomeration Networks (FANet) framework for face detection. First, we present the overall architecture of FANet. Then we propose the core agglomeration connection module for building FANet. The third part is the detailed configuration of our detector. Finally, the Hierarchical loss will be introduced to guide a more stable and better training in our designed network structure. 3.. Overall Architecture Our goal is to create an effective feature hierarchy with rich semantics at all levels to achieve robust multi-feature detection. Figure. shows our proposed Feature Agglomeration Network (FANet) with 3-level feature hierarchies. The proposed FANet framework is general-purpose. Without loss of generality, in this paper, we consider the widely used VGG6 model as the backbone CNN architecture and SSD as the single stage detector. As shown in Figure., the detection is performed on n = 6 layers of feature maps (ranging from index to 6). The existing SSD-like detector simply runs detections on the the six feature maps of the first level of feature hierarchy for face detection. By contract, we create the multi-level feature hierarchy with feature agglomeration, and run face detection on the enhanced feature maps (The 3 rd level, highlighted as blue feature maps in Figure. ). Specifically, the proposed Feature Agglomeration operation for an m-level FANet (m n) can be mathematically defined as follows: φ l = F l (φ l ) () φ k l = A l (φ k l, φ k ) k = 2,.., m (2) l+ where φ k l denotes the feature maps in the l-th layer and the k-th hierarchy. Specifically, for k =, i.e., the first-level hierarchy, φ k l is the original feature maps in vanilla S3FD, and F l ( ) is the non-linear function to transform the feature maps from l-th layer to (l + )-th layer, which consists of Convolution, ReLU and Pooling layers, etc. For k >, Eq.(2) denotes that φ k l is generated through a feature agglomeration function A l to agglomerate two adjacent-layer feature maps in the same hierarchy (φ k l, φ k l+ ). The agglomeration function A l is critical to the performance of the proposed detector. In the following, we propose a novel Agglomeration Connection block for the agglomeration function Agglomeration Connection Figure. 2 illustrates the idea of the proposed Agglomeration Connection building block, called A-block for short. It consists of two input feature maps, a shallower feature map φ and a deeper one φ 2. First of all, we notice that feature maps in the shallower layers generally lack of semantics. We thus apply an inception-like module on the shallower feature φ to enhance its feature representation and at the meantime change the output channel to a fixed number X (e.g., 256). Specifically, as shown in the left diagram of Figure. 2, we use 4 branches with 4 kinds of filters in the shallow feature enhancement block, e.g.,, 3 together with 3 and 3 3. The proportion (output channels) of each branch is : : :, respectively. To ensure the high efficiency of this module, we first apply a convolution layer to reduce the dimension to X = 256 channels, and thus our shallow feature enhancement module uses fewer parameters compared with those directly using 3 3 filters. For the deeper feature map φ 2, we first reduce the dimensionality using a convolution layer by reducing the channel size to 8 of N (e.g., 32), and then we apply a 2 bilinear upsampling in order to match the same size as φ. The final feature of the Agglomeration Connection block is obtained by concating these two features followed with a 3 3 convolution smooth layer Final Detector with Detailed Configurations The final detection exploits the m-th (m=3) hierarchy of feature maps, including a total of six detection layers {conv3 3 (3), conv4 3 (3), conv5 3 (3), conv fc7 (3), conv6 2 (2), conv7 2 () }. The final detection result can be expressed as follows: R = D(φ m, φ m 2,..., φ m n ) (3) where D denotes the final detection process including bounding box regression and class prediction followed by Non-Maximum Suppression to obtain the final detection results. As shown in Figure., the red dotted line denotes the connected 2 blobs share the memory, eg. conv7 2 (3) and conv7 2 (2) are identical to conv7 2 (), etc. We also discuss the details of configuring our proposed 3-level FANet for single-stage face detector. In Figure., six detection layers have strides of {4, 8, 6, 32, 64, 28}, respectively. We follow the settings of [28], each of the six feature maps is associated with a specific scale anchor {6, 32, 64, 28, 256, 52} with aspect ratio : to detect corresponding scale s faces. Since the shallow feature with high resolution plays a key role in detecting small faces, while deep feature is already with sufficient semantics, we build our FANet structure starting aggregating the feature maps from the 4-th layer conv fc7 () instead of


4 Input image st level 2 nd level 3 rd level Share memory A A A A A A A A A HL HL3 HL2 HL3 HL3 D e t e c t i o n Figure. The network architecture of the proposed Feature Agglomeration Networks (FANet). This is a three-level FANet architecture with VGG-6 variant as the backbone CNN network. Hierarchical Loss(HL i) accounts for all level feature maps while detection is performed on the last level feature maps. X/4 x X Channels x x3 3x3 3x3 3x X/4 X/4 X/4 x X Channels 3x3 Context Concat Smooth Reduce Figure 2. The Agglomeration Connection block (A-block), where the left diagram is a context-aware extraction module. conv7 2 (). We found it does not hurt the performance while reducing the model complexity. For anchor-based detectors, we need to match each anchor as a positive or negative according to the ground truth bounding boxes. We adopt the following matching strategy: (i) for each face, the anchor with the best Jaccard overlap is matched; and (ii) each anchor is matched to the face that has Jaccard overlap larger than Remark. The insight behind hierarchical agglomeration design is that in vanilla SSD, shallower features which are important to detect small faces are semantically weak in feature representation. The A-block hierarchically aggregates semantics information from deeper layers to form a stronger set of hierarchical multi-feature maps. The ratio 2x up A of deeper and shallower feature in one A-block is set to 8, which ensures that the deeper feature generally plays a role of providing extra contextual cues. Besides, we notice that the receptive field largely impacts the performance of detecting small faces. As shown in [8], either too large or too small receptive field can hurt the performance. The superiority of our structure is that the A-block only incorporates semantics from one deeper layer, and thus we can easily control the receptive field of each feature map through our hierarchical design. This is in contrast to FPN [], where a feature map incorporates information from all the deeper layers Hierarchical Loss In order to train the proposed FANet effectively, we propose a new loss function called hierarchical loss defined on the proposed FANet structure. The key idea is to define a loss function that accounts for all hierarchies of feature maps, and meanwhile allows to train the entire network effectively in an end-to-end manner. See Figure. for more details. To this end, we propose the hierarchical loss as follows m m HL(φ m,..., φ m n ) = ω i HL i = ω i L(φ i,..., φ i n) (4) i= i=
5 where ω i is a weight parameter for the loss of the i-th hierarchy. L(φ i,..., φ i n) accounts for the loss on the i-th hierarchy, which is SSD [2] multibox loss. L(φ i,..., φ i n)= N i N i j= ( ) λl cls (y j, yj ) + L loc (p j, p j ) Using the hierarchical loss, we can train the FANet detector end-to-end. Specifically, during training, all the losses are simultaneously computed, and the gradients are back propagated to each hierarchy of feature maps, respectively. In contrast to the standard loss, the proposed hierarchical loss enjoys some key advantages. On one hand, hierarchical loss plays a crucial role in training the FANet model robustly and effectively. This is because FANet has more newly added parameters than vanilla SSD for optimization, which is not easy to be directly trained with the existing loss in vanilla SSD training. With multiple hierarchies, hierarchical loss guides a better training process which gradually increases the power of feature maps representation. This allows us to supervise the training process hierarchically to obtain more robust features. On the other hand, compared with the standard single loss, the use of hierarchical loss does not incur extra computation cost during inference after the model has been trained Other Training Strategies In this section, we introduce our data augmentation, hard negative mining and other implementation details. Data augmentation. We use similar data augmentation strategies as in SSD[2], like random flip, color distortion, expansion, etc. Besides, we follow the setting of S3FD[28], instead of directly resizing the whole image to a squared patch (e.g., we use as input size for training), we first crop a squared patch from original image whose scale ranges from 0.3 to of the short size of original image. After random cropping, the final patch is resized to Hard negative mining. After anchor matching, most of the anchors are assigned as negatives, which results in a significant imbalance between positive and negative samples. We use an online hard negative mining strategy [2] during training. The ratio of negative and positive anchors is at most 3 :. Other implementation details. We choose λ = 3 in Eq.(5) and ω i in Eq.(4) as uniform for simplicity. The training starts from fine-tuning VGG6 backbone network using SGD with momentum of, weight decay of , and a total batch size of 2 on two GPUs. The newly added layers are initialized with xavier. We train our FANet for 20 epochs and a learning rate of for first 80 epochs and continue training for 20 epochs with and Our implementation is based on Pytorch [5], and our source code will be made publicly available. (5) 4. Experiments In this section, we conduct extensive experiments and ablation studies to evaluate the effectiveness of the proposed FANet framework in two folds. Firstly, we examine the impact of several key components including Agglomeration Connection module, the layer-wise Hierarchical Loss, and other techniques used in our solution. Secondly, we compare the proposed FANet face detector with the state-of-theart face detectors on popular face detection benchmarks and finally evaluate the inference speed of the proposed face detector. 4.. Results on WIDER FACE Datasets Dataset. We conduct model analysis on the WIDER FACE dataset [24], which has 32,203 images with about 400k faces for a large range of scales. It consists of three subsets: 40% for training, 0% for validation, and 50% for testing. The annotations of training and validation sets are online available. According to the difficulty of detection tasks, it has three splits: Easy, Medium and Hard. The evaluation metric is mean average precision (map) with Interception-of-Union (IoU) threshold as. We train FANet on the training set of WIDER Face, and evaluate it on the validation and testing set. If not specified, the results in Table and 2 are obtained by single scale testing in which the shorter size of image is resized to 640 while keeping image aspect ratio. Table. Evaluation of our FANet for learning discriminative features in contrast to vanilla S3FD and a simple FPN. For fair comparison, we only use 2-level hierarchy without context module. Loss Easy Medium Hard S3FD vanilla w/ FPN FANet w/ 2-level w/ 2-level w/ HL Baseline. We adopt the closely related detector S3FD [28] as the baseline to validate the effectiveness of our technique. S3FD achieved the state-of-the-art results on several well-known face detection benchmarks. It inherited the standard SSD framework with carefully designed scaleaware anchors according to effective receptive fields. We follow the same experimental setup in S3FD. Agglomeration Connection. We validate the contribution of Agglomeration Connection module with different hierarchies. First, we validate the efficacy of our hierarchical structure design without HL and inception-like context extraction module. In Table 2, with increasing number of hier-
6 Table 2. Evaluation Results on WIDER FACE validation set. Shorter-768 indicates the single scale testing that the shorter size of image is resized to 768 while keeping image aspect ratio. We use this to compare the performance with different input size. FANet (ours) -Level 2-Level 3-Level Context HL Shorter-768 Multi-scale map (Easy) map (Medium) map (Hard) archies, the performance of FANet significantly improves, especially for hard cases which our design mainly aims for. Specifically, the performance gains in hard task are +.6%, +2.0% for 2-level and 3-level, respectively. See column, 2, 4. With the context module, the performance further improved, +.0% in hard tasks, shown in column 6, 7. Next we will show that Hierarchical Loss is necessary in guiding a better and more effective training with high hierarchicallevel Agglomeration Connection. Hierarchical Loss. In this part, we compared the performance of our FANet optimized with and without Hierarchical Loss. In Table 2, the performance of both 2-level and 3-level FANet with Hierarchical Loss gains significant improvement compared with its single loss setting in hard levels (+% for 2-level, and +% for 3-level). Besides, 3- level FANet outperforms 2-level FANet consistently, which indicates high level Agglomeration Connection is crucial to improve detection accuracy with Hierarchical Loss optimization method. Robust Feature Learning. We build S3FD w/ FPN based on S3FD with skip-connection in top-down structure as FPN[]. In Table, compared with S3FD, S3FD w/ FPN gains improvement +.0% in hard level, which validates the efficacy of feature pyramid for improving feature representation. Our FANet with 2-level HL outperforms S3FD w/ FPN with large margin, +.5% in hard task, which demonstrates the superiority of our agglomeration connection over the skip connection. Multi-scale Inference. Multi-scale testing is a widely used technique in object detection, which can further boost the detection accuracy especially for small objects. In Table 2, We show that with larger input size eg. 768 compared with 640, it can significantly improve the performance in hard task. The final multi-scale testing result of our FANet is shown in the last column. Comparisons with the State of the Art. Our Final FANet model is trained with 3-level HL. Figure. 4 and Figure. 5 show the precision-recall curves on WIDER Face evaluation and test set and Table 3 summarizes the state-of- Table 3. Evaluation on WIDER FACE validation set (map). Algorithms Backbone Easy Med Hard MTCNN [27] LDCF+ [4] ScaleFace [25] ResNet HR [8] ResNet Face R-FCN [22] ResNet Zhu[29] ResNet CMS-RCNN [30] VGG MSCNN [2] VGG Face R-CNN [2] VGG SSH [3] VGG S3FD[28] VGG FANet(ours) VGG the-art results on the WIDER Face validation and test set. Our FANet reaches the state-of-the-art result among all detectors. WIDER FACE is a very challenging face benchmark and the results strongly prove the effectiveness of FANet in handling high scale variances, especially for small faces Evaluation on Other Public Face Benchmarks. In addition to the WIDER FACE data set, we also want to examine the generalization performance of the proposed face detector for other data sets. We thus test the pre-trained FANet face detector on another two popular face detection benchmarks. FDDB. The Face Detection Data set and Benchmark (FDDB)[9] is a well-known face detection benchmark with 5,7 faces in 2,845 images. We compare our FANet detector trained on the WIDER FACE training set with other published results on FDDB. Figure. 6 shows the evaluation results, in which our FANet detector achieves the state-ofthe-art performance on both discrete and continuous ROC curves. PASCAL FACE. This dataset was collected from PAS- CAL person layout test set [4], with,335 labeled faces in 85 images. Figure. 3 shows the evaluation results of the precision-recall curves. Among all the existing meth-
7 ods, the proposed FANet achieved the best map (98.78%), which outperforms the previous state-of-the-art detectors S3FD (98.45%), and significantly beats the other submitted methods. [23, 3]..0 Ours FAN (AP 98.78) S3FD (AP 98.49) DPM (AP 90.29) Headhunter (AP 89.63) 0.4 SquaresChnFtrs-5 (AP 85.57) Structured Models (AP 83.87) TSM (AP 76.35) Sky Biometry (AP 68.57) 0.2 OpenCV (AP 6.09) W.S. Boosting (AP 59.72) Picasa Face Figure 3. Benchmark evaluation on PASCAL FACE dataset Inference Speed Our FANet detector is a single-stage detector and thus enjoys high inference speed. It runs in real-time inference speed with 35.6 FPS for VGA-resolution input images on a computing environment with NVIDIA GPU GTX 080ti and CuDNN-v6. 5. Conclusion This paper proposed a novel framework of Feature Agglomeration Networks (FANet) for building single stage face detectors. The proposed FANet based face detector achieves the state-of-the-art performance on several wellknown face detection benchmarks, yet still enjoys real-time inference speed on GPU due to the nature of the single-stage detection framework. FANet introduces two key novel components: (i) the Agglomeration Connection module for context aware feature enhancing and multi-scale features agglomeration with hierarchical structure, which effectively handles scale variance in face detection; and (ii) the Hierarchical Loss to guide a more stable and better training in an end-to-end manner. We noted that the general idea of the Feature Agglomeration Networks is perhaps not restricted to face detection tasks, and might also be beneficial to other types of object detection tasks. For future work, we will explore the extension of the Feature Agglomeration Networks (FANet) framework for more other object detection tasks in computer vision, including generic object detection or specialized object detection tasks in other domains, such as pedestrian detection, vehicle detection, etc. Acknowledgements The authors would like to acknowledge the assistance and collaboration from colleagues of DeepIR Inc. References [] S. Bell, C. Lawrence Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), [2] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos. A unified multi-scale deep convolutional neural network for fast object detection. In European Conference on Computer Vision, [3] D. Chen, G. Hua, F. Wen, and J. Sun. Supervised transformer network for efficient face detection. In European Conference on Computer Vision, [4] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. Intl. Journal of Computer Vision (IJCV), [5] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg. Dssd: Deconvolutional single shot detector. arxiv preprint arxiv: , [6] R. Girshick. Fast r-cnn. In The IEEE International Conference on Computer Vision (ICCV), 205., 2 [7] Z. Hao, Y. Liu, H. Qin, J. Yan, X. Li, and X. Hu. Scaleaware face detection. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), [8] P. Hu and D. Ramanan. Finding tiny faces. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 207., 2, 4, 6 [9] V. Jain and E. Learned-Miller. Fddb: A benchmark for face detection in unconstrained settings. Technical Report UM-CS , University of Massachusetts, Amherst, , 0 [0] T. Kong, A. Yao, Y. Chen, and F. Sun. Hypernet: Towards accurate region proposal generation and joint object detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), [] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 207., 2, 4, 6, 0 [2] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. SSD: Single shot multi-
8 5 FANet(ours)-6 Zhu et al.-49 Face R-FCN-47 SFD-37 Face R-CNN-37 SSH-3 HR-25 MSCNN-6 CMS-RCNN-99 ScaleFace-68 Multitask Cascade CNN-48 LDCF+-90 Faceness-WIDER-3 Multiscale Cascade CNN-9 Two-stage CNN-8 5 FANet(ours)-47 Face R-FCN-35 Zhu et al.-33 SFD-25 Face R-CNN-2 SSH-2 HR-0 MSCNN-03 CMS-RCNN-74 ScaleFace-67 Multitask Cascade CNN-25 LDCF+-69 Multiscale Cascade CNN-64 Faceness-WIDER-34 Two-stage CNN-8 5 FANet(ours)-95 Face R-FCN-74 Zhu et al.-6 SFD-59 SSH-45 Face R-CNN-3 HR-06 MSCNN-02 ScaleFace-72 CMS-RCNN-24 Multitask Cascade CNN-98 LDCF+-22 Multiscale Cascade CNN Faceness-WIDER Two-stage CNN (a) Easy (b) Medium (c) Hard Figure 4. Evaluation of various state-of-the-art methods on the validation set of WIDER FACE 5 Zhu et al.-49 FANet(ours)-47 Face R-FCN-43 SFD-35 Face R-CNN-32 SSH-27 HR-23 MSCNN-7 CMS-RCNN-02 ScaleFace-67 Multitask Cascade CNN-5 LDCF+-97 Faceness-WIDER-6 Multiscale Cascade CNN- Two-stage CNN-7 5 FANet(ours)-39 Zhu et al.-35 Face R-FCN-3 SFD-2 Face R-CNN-6 SSH- HR-0 MSCNN-03 CMS-RCNN-74 ScaleFace-66 Multitask Cascade CNN-20 LDCF+-72 Multiscale Cascade CNN-36 Faceness-WIDER-04 Two-stage CNN-89 5 FANet(ours)-87 Face R-FCN-76 Zhu et al.-65 SFD-58 SSH-44 Face R-CNN-27 HR-9 MSCNN-09 ScaleFace-64 CMS-RCNN-43 Multitask Cascade CNN-07 LDCF+-64 Multiscale Cascade CNN Faceness-WIDER-0.35 Two-stage CNN (a) Easy (b) Medium Figure 5. Evaluation of various state-of-the-art methods on the test set of WIDER FACE (c) Hard.0.0 True positive rate Ours_FANet (90) SFD (84) HR- (76) RSA dis (74) ICC-CNN- (7) DeepIR (7) FaceBoxes (70) ScaleFace- (60) MTCNN- (0) LDCF (34) FD-CNN (26) Conv3d (2) Faceness- (0) JointCascade (67) CasCNN- (57) DDFD (48) dr40 (74) False positives True positive rate Ours_FANet (60) SFD (57) RSA con (49) DeepIR (47) FaceBoxes (36) Conv3d (67) Face R-CNN (60) JointCascade (2) Faceness- (32) ICC-CNN- (25) FDDB FSA4 2 (98) FD-CNN (94) HR- (93) LDCF (9) ScaleFace- (89) CasCNN- (68) dr40 (96) False positives (a) FDDB Discrete ROC Curves (b) FDDB Continuous ROC Curves Figure 6. Evaluation on FDDB face detection box detector. In European Conference on Computer Vision, 206., 2, 5 [3] M. Najibi, P. Samangouei, R. Chellappa, and L. Davis. Ssh: Single stage headless face detector. In The IEEE International Conference on Computer Vision (ICCV), , 6
9 [4] E. Ohn-Bar and M. M. Trivedi. To boost or not to boost? on the limits of boosted trees for object detection. In Pattern Recognition (ICPR), [5] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in pytorch [6] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), [7] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems, 205., 2 [8] X. Sun, P. Wu, and S. C. Hoi. Face detection using deep learning: An improved faster rcnn approach. Neurocomputing, 299:42 50, [9] A. Y. H. L. M. L. Y. C. Tao Kong, Fuchun Sun. Ron: Reverse connection with objectness prior networks for object detection. In IEEE Conference on Computer Vision and Pattern Recognition, [20] P. Viola and M. J. Jones. Robust real-time face detection. International Journal of Computer Vision, [2] H. Wang, Z. Li, X. Ji, and Y. Wang. Face r-cnn. arxiv preprint arxiv: , [22] Y. Wang, X. Ji, Z. Zhou, H. Wang, and Z. Li. Detecting faces using region-based fully convolutional networks. CoRR, abs/ , [23] S. Yang, P. Luo, C.-C. Loy, and X. Tang. From facial parts responses to face detection: A deep learning approach. In IEEE Intl. Conference on Computer Vision (ICCV), [24] S. Yang, P. Luo, C.-C. Loy, and X. Tang. Wwider face: A face detection benchmark. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), , 0 [25] S. Yang, Y. Xiong, C. C. Loy, and X. Tang. Face detection through scale-friendly deep convolutional networks. CoRR, abs/ , [26] S. Zagoruyko, A. Lerer, T.-Y. Lin, P. O. Pinheiro, S. Gross, S. Chintala, and P. Dollár. A multipath network for object detection. In BMVC, [27] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao. Jjoint face detection and alignment using multi-task cascaded convolutional networks. IEEE Signal Processing Letters, [28] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. S3fd: Single shot scale-invariant face detector. In IEEE Intl. Conference on Computer Vision (ICCV), 207., 2, 3, 5, 6, 0 [29] C. Zhu, R. Tao, K. Luu, and M. Savvides. Seeing small faces from robust anchors perspective. 6 [30] C. Zhu, Y. Zheng, K. Luu, and M. Savvides. Cmsrcnn: Contextual multi-scale region-based cnn for unconstrained face detection. In Deep Learning for Biometrics , 6
10 map map Appendix We first showed the precision-recall curves of our ablation experiments, Figure. 8. Then the Speed Accuracy tradeoff and the Model-Size Accuracy tradeoff of our FANet are analyzed. Finally, we demonstrate some qualitative results of our detector. In Figure. 7, the result is obtained on the hard task of WIDER face [24] evaluation set 8(c) by single scale testing in which the shorter size of image is resized to 640 while keeping image aspect ratio. We test the result under a computing environment with NVIDIA GPU GTX 080ti and CuDNN-v recall curves Figure. 8 showed the precision-recall curves of our ablation experiments level FPN 2-level 3-level 3-level w/ context 7. Speed Accuracy Tradeoff In this section, we compared the Speed Accuracy tradeoff between vanilla S3FD [28] structure, FPN [] and our FANet. As shown in Figure. 7(a), our 2-level is a good tradeoff between speed and accuracy. Specifically, it achieves comparable speed as FPN structure (45.4 fps vs 45.9 fps), while getting much better result than FPN (85.3 vs 83.8). Our final FANet improved +3.9% over vanilla S3FD while still reaching the real-time speed. 8. Model-Size Accuracy Tradeoff In this section, we showed the Model Size Accuracy tradeoff of our FANet. As shown in Figure. 7(b), our 2-level structure achieves better results than FPN while still having less parameters than it. Compared with vanilla S3FD, our 2-level has only % more parameters while reaching much better results (85.3 vs 82.8). The final FANet gets significant improved results +3.9% with tolerable increased parameters. 9. Qualitative Analysis In this section, we demonstrate some qualitative results of our FANet, including World s Largest Selfie, Figure. 9, in which our FANet can find 858 faces out of 000 facial images present, results on FDDB [9] dataset, Figure. 0 and results under various conditions, Figure.. With hierarchical loss training scheme, our FANet is very stable, the variance is within 0.2% Speed(fps) (a) Speed accuracy tradeoff. -level FPN 2-level 3-level 3-level w/ context # parameters #0 7 (b) ModelSize accuracy tradeoff. Figure 7. Model performance analysis. -level is of the same structure as S3FD and 3-level w/ context is our final FANet.
 Easy (b) Medium (c) Hard Figure 8.")
11 level-HL-context-0 2-level-48 2-level-HL-48 3-level-HL-48 3-level-47 -level-45 FPN-43 3-level-HL-context-39 2-level-HL-36 3-level-HL-36 2-level-36 3-level-33 FPN-3 -level-29 3-level-HL-context-67 3-level-HL-57 2-level-HL-53 3-level-48 2-level-44 FPN-38 -level-28 (a) Easy (b) Medium (c) Hard Figure 8. -recall curves of ablation experiments on the validation set of WIDER Face Figure 9. Example of face detection with the proposed method. In the above image, the proposed method can find 858 faces out of 000 facial images present. The detection confidence scores are also given by the color bar as shown on the right. Best viewed in color.








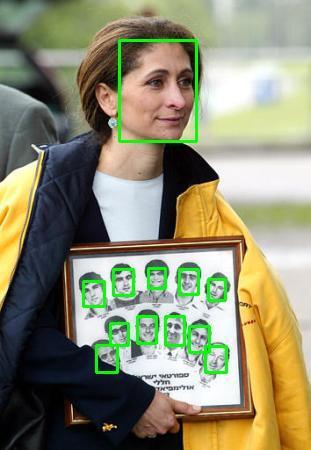
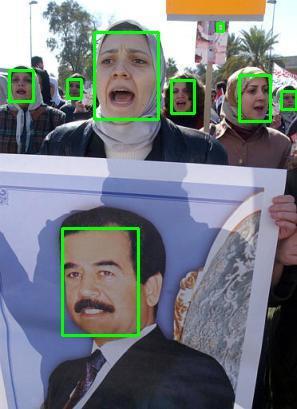


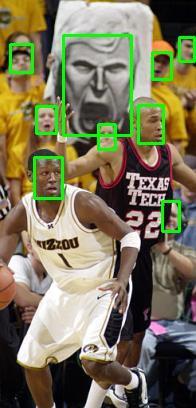








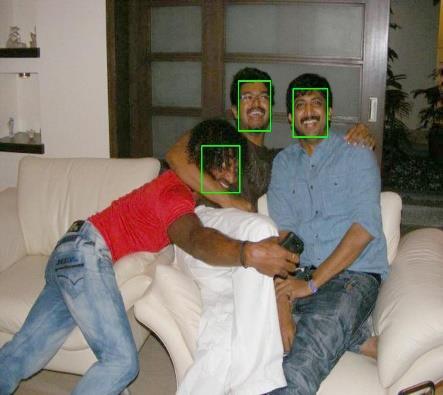









12 Figure 0. Qualitative results on FDDB. Our model is robust to occlusion and scale variance Blur Occlution Pose Expression Makeup Illumination Figure. Qualitative results of our FANet. Our model is robust to blur, occlusion, pose, expression, makeup, illumination, etc.
arxiv: v3 [cs.cv] 18 Oct 2017
![arxiv: v3 [cs.cv] 18 Oct 2017](/thumbs/75/72627087.jpg "arxiv: v3 [cs.cv] 18 Oct 2017") SSH: Single Stage Headless Face Detector Mahyar Najibi* Pouya Samangouei* Rama Chellappa University of Maryland arxiv:78.3979v3 [cs.cv] 8 Oct 27 najibi@cs.umd.edu Larry S. Davis {pouya,rama,lsd}@umiacs.umd.edu
SSH: Single Stage Headless Face Detector Mahyar Najibi* Pouya Samangouei* Rama Chellappa University of Maryland arxiv:78.3979v3 [cs.cv] 8 Oct 27 najibi@cs.umd.edu Larry S. Davis {pouya,rama,lsd}@umiacs.umd.edu
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
arxiv: v2 [cs.cv] 22 Nov 2017
![arxiv: v2 [cs.cv] 22 Nov 2017](/thumbs/86/93068521.jpg "arxiv: v2 [cs.cv] 22 Nov 2017") Face Attention Network: An Effective Face Detector for the Occluded Faces Jianfeng Wang College of Software, Beihang University Beijing, China wjfwzzc@buaa.edu.cn Ye Yuan Megvii Inc. (Face++) Beijing,
Face Attention Network: An Effective Face Detector for the Occluded Faces Jianfeng Wang College of Software, Beihang University Beijing, China wjfwzzc@buaa.edu.cn Ye Yuan Megvii Inc. (Face++) Beijing,
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
arxiv: v1 [cs.cv] 25 Feb 2018
![arxiv: v1 [cs.cv] 25 Feb 2018](/thumbs/79/79921598.jpg "arxiv: v1 [cs.cv] 25 Feb 2018") Seeing Small Faces from Robust Anchor s Perspective Chenchen Zhu Ran Tao Khoa Luu Marios Savvides Carnegie Mellon University 5 Forbes Avenue, Pittsburgh, PA 523, USA {chenchez, rant, kluu, marioss}@andrew.cmu.edu
Seeing Small Faces from Robust Anchor s Perspective Chenchen Zhu Ran Tao Khoa Luu Marios Savvides Carnegie Mellon University 5 Forbes Avenue, Pittsburgh, PA 523, USA {chenchez, rant, kluu, marioss}@andrew.cmu.edu
arxiv: v1 [cs.cv] 19 Feb 2019
![arxiv: v1 [cs.cv] 19 Feb 2019](/thumbs/88/117177831.jpg "arxiv: v1 [cs.cv] 19 Feb 2019") Detector-in-Detector: Multi-Level Analysis for Human-Parts Xiaojie Li 1[0000 0001 6449 2727], Lu Yang 2[0000 0003 3857 3982], Qing Song 2[0000000346162200], and Fuqiang Zhou 1[0000 0001 9341 9342] arxiv:1902.07017v1
Detector-in-Detector: Multi-Level Analysis for Human-Parts Xiaojie Li 1[0000 0001 6449 2727], Lu Yang 2[0000 0003 3857 3982], Qing Song 2[0000000346162200], and Fuqiang Zhou 1[0000 0001 9341 9342] arxiv:1902.07017v1
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
arxiv: v1 [cs.cv] 22 Mar 2018
![arxiv: v1 [cs.cv] 22 Mar 2018](/thumbs/89/99243655.jpg "arxiv: v1 [cs.cv] 22 Mar 2018") Single-Shot Bidirectional Pyramid Networks for High-Quality Object Detection Xiongwei Wu, Daoxin Zhang, Jianke Zhu, Steven C.H. Hoi School of Information Systems, Singapore Management University, Singapore
Single-Shot Bidirectional Pyramid Networks for High-Quality Object Detection Xiongwei Wu, Daoxin Zhang, Jianke Zhu, Steven C.H. Hoi School of Information Systems, Singapore Management University, Singapore
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks
 Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks Xuepeng Shi 1,2 Shiguang Shan 1,3 Meina Kan 1,3 Shuzhe Wu 1,2 Xilin Chen 1 1 Key Lab of Intelligent Information Processing
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks Xuepeng Shi 1,2 Shiguang Shan 1,3 Meina Kan 1,3 Shuzhe Wu 1,2 Xilin Chen 1 1 Key Lab of Intelligent Information Processing
A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications
 A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications Le Thanh Nguyen-Meidine 1, Eric Granger 1, Madhu Kiran 1 and Louis-Antoine Blais-Morin 2 1 École de technologie
A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications Le Thanh Nguyen-Meidine 1, Eric Granger 1, Madhu Kiran 1 and Louis-Antoine Blais-Morin 2 1 École de technologie
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
arxiv: v2 [cs.cv] 2 Jun 2018
![arxiv: v2 [cs.cv] 2 Jun 2018](/thumbs/87/95225561.jpg "arxiv: v2 [cs.cv] 2 Jun 2018") Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy Guanglu Song, Yu Liu 2, Ming Jiang, Yujie Wang, Junjie Yan 3, Biao Leng Beihang University, 2 The Chinese University of Hong Kong,
Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy Guanglu Song, Yu Liu 2, Ming Jiang, Yujie Wang, Junjie Yan 3, Biao Leng Beihang University, 2 The Chinese University of Hong Kong,
arxiv: v1 [cs.cv] 31 Mar 2017
![arxiv: v1 [cs.cv] 31 Mar 2017](/thumbs/80/81467687.jpg "arxiv: v1 [cs.cv] 31 Mar 2017") End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL
 PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
arxiv: v2 [cs.cv] 23 Jan 2019
![arxiv: v2 [cs.cv] 23 Jan 2019](/thumbs/88/114974572.jpg "arxiv: v2 [cs.cv] 23 Jan 2019") COCO AP Consistent Optimization for Single-Shot Object Detection Tao Kong 1 Fuchun Sun 1 Huaping Liu 1 Yuning Jiang 2 Jianbo Shi 3 1 Department of Computer Science and Technology, Tsinghua University,
COCO AP Consistent Optimization for Single-Shot Object Detection Tao Kong 1 Fuchun Sun 1 Huaping Liu 1 Yuning Jiang 2 Jianbo Shi 3 1 Department of Computer Science and Technology, Tsinghua University,
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
An Analysis of Scale Invariance in Object Detection SNIP
 An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
arxiv: v3 [cs.cv] 17 May 2018
![arxiv: v3 [cs.cv] 17 May 2018](/thumbs/79/79331767.jpg "arxiv: v3 [cs.cv] 17 May 2018") FSSD: Feature Fusion Single Shot Multibox Detector Zuo-Xin Li Fu-Qiang Zhou Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, Beihang University, Beijing 100191, China {lizuoxin,
FSSD: Feature Fusion Single Shot Multibox Detector Zuo-Xin Li Fu-Qiang Zhou Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, Beihang University, Beijing 100191, China {lizuoxin,
An Analysis of Scale Invariance in Object Detection SNIP
 An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
Multi-Path Region-Based Convolutional Neural Network for Accurate Detection of Unconstrained Hard Faces
 Multi-Path Region-Based Convolutional Neural Network for Accurate Detection of Unconstrained Hard Faces Yuguang Liu, Martin D. Levine Department of Electrical and Computer Engineering Center for Intelligent
Multi-Path Region-Based Convolutional Neural Network for Accurate Detection of Unconstrained Hard Faces Yuguang Liu, Martin D. Levine Department of Electrical and Computer Engineering Center for Intelligent
arxiv: v3 [cs.cv] 29 Mar 2017
![arxiv: v3 [cs.cv] 29 Mar 2017](/thumbs/89/98535829.jpg "arxiv: v3 [cs.cv] 29 Mar 2017") EVOLVING BOXES FOR FAST VEHICLE DETECTION Li Wang 1,2, Yao Lu 3, Hong Wang 2, Yingbin Zheng 2, Hao Ye 2, Xiangyang Xue 1 arxiv:1702.00254v3 [cs.cv] 29 Mar 2017 1 Shanghai Key Lab of Intelligent Information
EVOLVING BOXES FOR FAST VEHICLE DETECTION Li Wang 1,2, Yao Lu 3, Hong Wang 2, Yingbin Zheng 2, Hao Ye 2, Xiangyang Xue 1 arxiv:1702.00254v3 [cs.cv] 29 Mar 2017 1 Shanghai Key Lab of Intelligent Information
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
 Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
FCHD: A fast and accurate head detector
 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
arxiv: v2 [cs.cv] 10 Oct 2018
![arxiv: v2 [cs.cv] 10 Oct 2018](/thumbs/92/109817158.jpg "arxiv: v2 [cs.cv] 10 Oct 2018") Net: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving Qijie Zhao 1, Tao Sheng 1, Yongtao Wang 1, Feng Ni 1, Ling Cai 2 1 Institute of Computer Science and Technology, Peking
Net: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving Qijie Zhao 1, Tao Sheng 1, Yongtao Wang 1, Feng Ni 1, Ling Cai 2 1 Institute of Computer Science and Technology, Peking
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
 M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network Qijie Zhao 1, Tao Sheng 1,Yongtao Wang 1, Zhi Tang 1, Ying Chen 2, Ling Cai 2 and Haibin Ling 3 1 Institute of Computer
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network Qijie Zhao 1, Tao Sheng 1,Yongtao Wang 1, Zhi Tang 1, Ying Chen 2, Ling Cai 2 and Haibin Ling 3 1 Institute of Computer
Detecting Faces Using Inside Cascaded Contextual CNN
 Detecting Faces Using Inside Cascaded Contextual CNN Kaipeng Zhang 1, Zhanpeng Zhang 2, Hao Wang 1, Zhifeng Li 1, Yu Qiao 3, Wei Liu 1 1 Tencent AI Lab 2 SenseTime Group Limited 3 Guangdong Provincial
Detecting Faces Using Inside Cascaded Contextual CNN Kaipeng Zhang 1, Zhanpeng Zhang 2, Hao Wang 1, Zhifeng Li 1, Yu Qiao 3, Wei Liu 1 1 Tencent AI Lab 2 SenseTime Group Limited 3 Guangdong Provincial
Final Report: Smart Trash Net: Waste Localization and Classification
 Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
DAFE-FD: Density Aware Feature Enrichment for Face Detection
 DAFE-FD: Density Aware Feature Enrichment for Face Detection Vishwanath A. Sindagi Vishal M. Patel Department of Electrical and Computer Engineering, Johns Hopkins University, 3400 N. Charles St, Baltimore,
DAFE-FD: Density Aware Feature Enrichment for Face Detection Vishwanath A. Sindagi Vishal M. Patel Department of Electrical and Computer Engineering, Johns Hopkins University, 3400 N. Charles St, Baltimore,
Pedestrian Detection based on Deep Fusion Network using Feature Correlation
 Pedestrian Detection based on Deep Fusion Network using Feature Correlation Yongwoo Lee, Toan Duc Bui and Jitae Shin School of Electronic and Electrical Engineering, Sungkyunkwan University, Suwon, South
Pedestrian Detection based on Deep Fusion Network using Feature Correlation Yongwoo Lee, Toan Duc Bui and Jitae Shin School of Electronic and Electrical Engineering, Sungkyunkwan University, Suwon, South
R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS
 R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS JIFENG DAI YI LI KAIMING HE JIAN SUN MICROSOFT RESEARCH TSINGHUA UNIVERSITY MICROSOFT RESEARCH MICROSOFT RESEARCH SPEED/ACCURACY TRADE-OFFS
R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS JIFENG DAI YI LI KAIMING HE JIAN SUN MICROSOFT RESEARCH TSINGHUA UNIVERSITY MICROSOFT RESEARCH MICROSOFT RESEARCH SPEED/ACCURACY TRADE-OFFS
arxiv: v2 [cs.cv] 24 Mar 2018
![arxiv: v2 [cs.cv] 24 Mar 2018](/thumbs/80/82184067.jpg "arxiv: v2 [cs.cv] 24 Mar 2018") 2018 IEEE Winter Conference on Applications of Computer Vision Context-Aware Single-Shot Detector Wei Xiang 2 Dong-Qing Zhang 1 Heather Yu 1 Vassilis Athitsos 2 1 Media Lab, Futurewei Technologies 2 University
2018 IEEE Winter Conference on Applications of Computer Vision Context-Aware Single-Shot Detector Wei Xiang 2 Dong-Qing Zhang 1 Heather Yu 1 Vassilis Athitsos 2 1 Media Lab, Futurewei Technologies 2 University
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
arxiv: v1 [cs.cv] 26 Jul 2018
![arxiv: v1 [cs.cv] 26 Jul 2018](/thumbs/88/117269915.jpg "arxiv: v1 [cs.cv] 26 Jul 2018") A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Learning Efficient Single-stage Pedestrian Detectors by Asymptotic Localization Fitting
 Learning Efficient Single-stage Pedestrian Detectors by Asymptotic Localization Fitting Wei Liu 1,3, Shengcai Liao 1,2, Weidong Hu 3, Xuezhi Liang 1,2, Xiao Chen 3 1 Center for Biometrics and Security
Learning Efficient Single-stage Pedestrian Detectors by Asymptotic Localization Fitting Wei Liu 1,3, Shengcai Liao 1,2, Weidong Hu 3, Xuezhi Liang 1,2, Xiao Chen 3 1 Center for Biometrics and Security
arxiv: v1 [cs.cv] 26 May 2017
![arxiv: v1 [cs.cv] 26 May 2017](/thumbs/78/78157133.jpg "arxiv: v1 [cs.cv] 26 May 2017") arxiv:1705.09587v1 [cs.cv] 26 May 2017 J. JEONG, H. PARK AND N. KWAK: UNDER REVIEW IN BMVC 2017 1 Enhancement of SSD by concatenating feature maps for object detection Jisoo Jeong soo3553@snu.ac.kr Hyojin
arxiv:1705.09587v1 [cs.cv] 26 May 2017 J. JEONG, H. PARK AND N. KWAK: UNDER REVIEW IN BMVC 2017 1 Enhancement of SSD by concatenating feature maps for object detection Jisoo Jeong soo3553@snu.ac.kr Hyojin
arxiv: v3 [cs.cv] 15 Nov 2017 Abstract
![arxiv: v3 [cs.cv] 15 Nov 2017 Abstract](/thumbs/79/79551866.jpg "arxiv: v3 [cs.cv] 15 Nov 2017 Abstract") S 3 FD: Single Shot Scale-invariant Face Detector Shifeng Zhang Xiangyu Zhu Zhen Lei * Hailin Shi Xiaobo Wang Stan Z. Li CBSR & NLPR, Institute of Automation, Chinese Academy of Sciences, Beijing, China
S 3 FD: Single Shot Scale-invariant Face Detector Shifeng Zhang Xiangyu Zhu Zhen Lei * Hailin Shi Xiaobo Wang Stan Z. Li CBSR & NLPR, Institute of Automation, Chinese Academy of Sciences, Beijing, China
Traffic Multiple Target Detection on YOLOv2
 Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
R-FCN: Object Detection with Really - Friggin Convolutional Networks
 R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
Finding Tiny Faces. Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University Abstract. 1.
 Finding Tiny Faces Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu Figure 1: We describe a detector that can find around 800 faces out of the reportedly
Finding Tiny Faces Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu Figure 1: We describe a detector that can find around 800 faces out of the reportedly
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
arxiv: v2 [cs.cv] 8 Apr 2018
![arxiv: v2 [cs.cv] 8 Apr 2018](/thumbs/86/94330536.jpg "arxiv: v2 [cs.cv] 8 Apr 2018") Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Automatic detection of books based on Faster R-CNN
 Automatic detection of books based on Faster R-CNN Beibei Zhu, Xiaoyu Wu, Lei Yang, Yinghua Shen School of Information Engineering, Communication University of China Beijing, China e-mail: zhubeibei@cuc.edu.cn,
Automatic detection of books based on Faster R-CNN Beibei Zhu, Xiaoyu Wu, Lei Yang, Yinghua Shen School of Information Engineering, Communication University of China Beijing, China e-mail: zhubeibei@cuc.edu.cn,
Parallel Feature Pyramid Network for Object Detection
 Parallel Feature Pyramid Network for Object Detection Seung-Wook Kim [0000 0002 6004 4086], Hyong-Keun Kook, Jee-Young Sun, Mun-Cheon Kang, and Sung-Jea Ko School of Electrical Engineering, Korea University,
Parallel Feature Pyramid Network for Object Detection Seung-Wook Kim [0000 0002 6004 4086], Hyong-Keun Kook, Jee-Young Sun, Mun-Cheon Kang, and Sung-Jea Ko School of Electrical Engineering, Korea University,
Supplementary Material: Unconstrained Salient Object Detection via Proposal Subset Optimization
 Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
Photo OCR ( )
") Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
arxiv: v3 [cs.cv] 12 Mar 2018
![arxiv: v3 [cs.cv] 12 Mar 2018](/thumbs/86/94163176.jpg "arxiv: v3 [cs.cv] 12 Mar 2018") Improving Object Localization with Fitness NMS and Bounded IoU Loss Lachlan Tychsen-Smith, Lars Petersson CSIRO (Data6) CSIRO-Synergy Building, Acton, ACT, 26 Lachlan.Tychsen-Smith@data6.csiro.au, Lars.Petersson@data6.csiro.au
Improving Object Localization with Fitness NMS and Bounded IoU Loss Lachlan Tychsen-Smith, Lars Petersson CSIRO (Data6) CSIRO-Synergy Building, Acton, ACT, 26 Lachlan.Tychsen-Smith@data6.csiro.au, Lars.Petersson@data6.csiro.au
arxiv: v1 [cs.cv] 10 Jan 2019
![arxiv: v1 [cs.cv] 10 Jan 2019](/thumbs/93/113326709.jpg "arxiv: v1 [cs.cv] 10 Jan 2019") Region Proposal by Guided Anchoring Jiaqi Wang 1 Kai Chen 1 Shuo Yang 2 Chen Change Loy 3 Dahua Lin 1 1 CUHK - SenseTime Joint Lab, The Chinese University of Hong Kong 2 Amazon Rekognition 3 Nanyang Technological
Region Proposal by Guided Anchoring Jiaqi Wang 1 Kai Chen 1 Shuo Yang 2 Chen Change Loy 3 Dahua Lin 1 1 CUHK - SenseTime Joint Lab, The Chinese University of Hong Kong 2 Amazon Rekognition 3 Nanyang Technological
Context Refinement for Object Detection
 Context Refinement for Object Detection Zhe Chen, Shaoli Huang, and Dacheng Tao UBTECH Sydney AI Centre, SIT, FEIT, University of Sydney, Australia {zche4307}@uni.sydney.edu.au {shaoli.huang, dacheng.tao}@sydney.edu.au
Context Refinement for Object Detection Zhe Chen, Shaoli Huang, and Dacheng Tao UBTECH Sydney AI Centre, SIT, FEIT, University of Sydney, Australia {zche4307}@uni.sydney.edu.au {shaoli.huang, dacheng.tao}@sydney.edu.au
ScratchDet: Exploring to Train Single-Shot Object Detectors from Scratch
 ScratchDet: Exploring to Train Single-Shot Object Detectors from Scratch Rui Zhu 1,4, Shifeng Zhang 3, Xiaobo Wang 1, Longyin Wen 2, Hailin Shi 1, Liefeng Bo 2, Tao Mei 1 1 JD AI Research, China. 2 JD
ScratchDet: Exploring to Train Single-Shot Object Detectors from Scratch Rui Zhu 1,4, Shifeng Zhang 3, Xiaobo Wang 1, Longyin Wen 2, Hailin Shi 1, Liefeng Bo 2, Tao Mei 1 1 JD AI Research, China. 2 JD
RON: Reverse Connection with Objectness Prior Networks for Object Detection
 RON: Reverse Connection with Objectness Prior Networks for Object Detection Tao Kong 1, Fuchun Sun 1, Anbang Yao 2, Huaping Liu 1, Ming Lu 3, Yurong Chen 2 1 Department of CST, Tsinghua University, 2 Intel
RON: Reverse Connection with Objectness Prior Networks for Object Detection Tao Kong 1, Fuchun Sun 1, Anbang Yao 2, Huaping Liu 1, Ming Lu 3, Yurong Chen 2 1 Department of CST, Tsinghua University, 2 Intel
Modern Convolutional Object Detectors
 Modern Convolutional Object Detectors Faster R-CNN, R-FCN, SSD 29 September 2017 Presented by: Kevin Liang Papers Presented Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Modern Convolutional Object Detectors Faster R-CNN, R-FCN, SSD 29 September 2017 Presented by: Kevin Liang Papers Presented Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
arxiv: v1 [cs.cv] 19 Mar 2018
![arxiv: v1 [cs.cv] 19 Mar 2018](/thumbs/78/77646221.jpg "arxiv: v1 [cs.cv] 19 Mar 2018") arxiv:1803.07066v1 [cs.cv] 19 Mar 2018 Learning Region Features for Object Detection Jiayuan Gu 1, Han Hu 2, Liwei Wang 1, Yichen Wei 2 and Jifeng Dai 2 1 Key Laboratory of Machine Perception, School of
arxiv:1803.07066v1 [cs.cv] 19 Mar 2018 Learning Region Features for Object Detection Jiayuan Gu 1, Han Hu 2, Liwei Wang 1, Yichen Wei 2 and Jifeng Dai 2 1 Key Laboratory of Machine Perception, School of
Detecting Heads using Feature Refine Net and Cascaded Multi-scale Architecture
 Detecting Heads using Feature Refine Net and Cascaded Multi-scale Architecture Dezhi Peng, Zikai Sun, Zirong Chen, Zirui Cai, Lele Xie, Lianwen Jin School of Electronic and Information Engineering South
Detecting Heads using Feature Refine Net and Cascaded Multi-scale Architecture Dezhi Peng, Zikai Sun, Zirong Chen, Zirui Cai, Lele Xie, Lianwen Jin School of Electronic and Information Engineering South
Improving Small Object Detection
 Improving Small Object Detection Harish Krishna, C.V. Jawahar CVIT, KCIS International Institute of Information Technology Hyderabad, India Abstract While the problem of detecting generic objects in natural
Improving Small Object Detection Harish Krishna, C.V. Jawahar CVIT, KCIS International Institute of Information Technology Hyderabad, India Abstract While the problem of detecting generic objects in natural
Face Detection with the Faster R-CNN
 Face Detection with the Huaizu Jiang University of Massachusetts Amherst Amherst MA 3 hzjiang@cs.umass.edu Erik Learned-Miller University of Massachusetts Amherst Amherst MA 3 elm@cs.umass.edu Abstract
Face Detection with the Huaizu Jiang University of Massachusetts Amherst Amherst MA 3 hzjiang@cs.umass.edu Erik Learned-Miller University of Massachusetts Amherst Amherst MA 3 elm@cs.umass.edu Abstract
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Mask R-CNN. Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018
 Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Multi-Scale Fully Convolutional Network for Face Detection in the Wild
 Multi-Scale Fully Convolutional Network for Face Detection in the Wild Yancheng Bai 1,2 and Bernard Ghanem 1 1 King Abdullah University of Science and Technology (KAUST), Saudi Arabia 2 Institute of Software,
Multi-Scale Fully Convolutional Network for Face Detection in the Wild Yancheng Bai 1,2 and Bernard Ghanem 1 1 King Abdullah University of Science and Technology (KAUST), Saudi Arabia 2 Institute of Software,
CornerNet: Detecting Objects as Paired Keypoints
 CornerNet: Detecting Objects as Paired Keypoints Hei Law Jia Deng more efficient. One-stage detectors place anchor boxes densely over an image and generate final box predictions by scoring anchor boxes
CornerNet: Detecting Objects as Paired Keypoints Hei Law Jia Deng more efficient. One-stage detectors place anchor boxes densely over an image and generate final box predictions by scoring anchor boxes
Pixel Offset Regression (POR) for Single-shot Instance Segmentation
 for Single-shot Instance Segmentation") Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
Instance-aware Semantic Segmentation via Multi-task Network Cascades
 Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
arxiv: v1 [cs.cv] 9 Aug 2017
![arxiv: v1 [cs.cv] 9 Aug 2017](/thumbs/78/78708739.jpg "arxiv: v1 [cs.cv] 9 Aug 2017") BlitzNet: A Real-Time Deep Network for Scene Understanding Nikita Dvornik Konstantin Shmelkov Julien Mairal Cordelia Schmid Inria arxiv:1708.02813v1 [cs.cv] 9 Aug 2017 Abstract Real-time scene understanding
BlitzNet: A Real-Time Deep Network for Scene Understanding Nikita Dvornik Konstantin Shmelkov Julien Mairal Cordelia Schmid Inria arxiv:1708.02813v1 [cs.cv] 9 Aug 2017 Abstract Real-time scene understanding
CS6501: Deep Learning for Visual Recognition. Object Detection I: RCNN, Fast-RCNN, Faster-RCNN
 CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Hand Detection For Grab-and-Go Groceries
 Hand Detection For Grab-and-Go Groceries Xianlei Qiu Stanford University xianlei@stanford.edu Shuying Zhang Stanford University shuyingz@stanford.edu Abstract Hands detection system is a very critical
Hand Detection For Grab-and-Go Groceries Xianlei Qiu Stanford University xianlei@stanford.edu Shuying Zhang Stanford University shuyingz@stanford.edu Abstract Hands detection system is a very critical
Comprehensive Feature Enhancement Module for Single-Shot Object Detector
 Comprehensive Feature Enhancement Module for Single-Shot Object Detector Qijie Zhao, Yongtao Wang, Tao Sheng, and Zhi Tang Institute of Computer Science and Technology, Peking University, Beijing, China
Comprehensive Feature Enhancement Module for Single-Shot Object Detector Qijie Zhao, Yongtao Wang, Tao Sheng, and Zhi Tang Institute of Computer Science and Technology, Peking University, Beijing, China
Recognizing people. Deva Ramanan
 Recognizing people Deva Ramanan The goal Why focus on people? How many person-pixels are in a video? 35% 34% Movies TV 40% YouTube Let s start our discussion with a loaded question: why is visual recognition
Recognizing people Deva Ramanan The goal Why focus on people? How many person-pixels are in a video? 35% 34% Movies TV 40% YouTube Let s start our discussion with a loaded question: why is visual recognition
A Novel Representation and Pipeline for Object Detection
 A Novel Representation and Pipeline for Object Detection Vishakh Hegde Stanford University vishakh@stanford.edu Manik Dhar Stanford University dmanik@stanford.edu Abstract Object detection is an important
A Novel Representation and Pipeline for Object Detection Vishakh Hegde Stanford University vishakh@stanford.edu Manik Dhar Stanford University dmanik@stanford.edu Abstract Object detection is an important