April 3, 2012 T.C. Havens
|
|
|
- Shana Parks
- 5 years ago
- Views:
Transcription
1 April 3, 2012 T.C. Havens
2 Different training parameters MLP with different weights, number of layers/nodes, etc. Controls instability of classifiers (local minima) Similar strategies can be used to generate different decision trees Different types of classifiers (MLPs, decision trees, NNs, SVMs) can be combined to improve diversity Random feature sets, called random subspace method
3 Two questions: How will the individual classifiers be generated? How will they differ from each other? Answer determines the diversity of classifiers and fusion performance Seek to improve ensemble diversity by some heuristic methods
4 Bagging, short for bootstrap aggregating, is one of the earliest ensemble based algorithms It is also one of the most intuitive and simplest to implement, with a surprisingly good performance Use bootstrapped replicas of the training data; large number of (say 200) training subsets are randomly drawn - with replacement - from the entire training data Each resampled training set is used to train a different classifier of the same type Individual classifiers are combined by taking a majority vote of their decisions Bagging is appealing for small training set; relatively large portion of the samples is included in each subset
5 Algorithm : Bagging input : Training data S with correct labelsω Weak learning algorithm WeakLearn, Integer T specifying number of 1.Take a bootstrapped replica S 2.Call WeakLearn with S 3.Add h 1.Evaluate the ensemble on x. 2.Letυ to the ensemble, E. 1, if ht picks class ω j = 0, otherwise iterations. 3.Obtain total vote received by each classv { ω,,ω } Percent ( of fraction) F to create bootstrapped training data Do t = 1,,T End t Test : Simple Majority Voting t,j t Ω = by randomly drawing percent of S. and receive the hypothesis (classifier) h. - Given unlabled instance be the vote given to class by classifier. t = 1 4.Choose the class that receives the highest total vote as t i j = 1 T υ t,j C representing C classes x, j = 1, C, t the final classification.
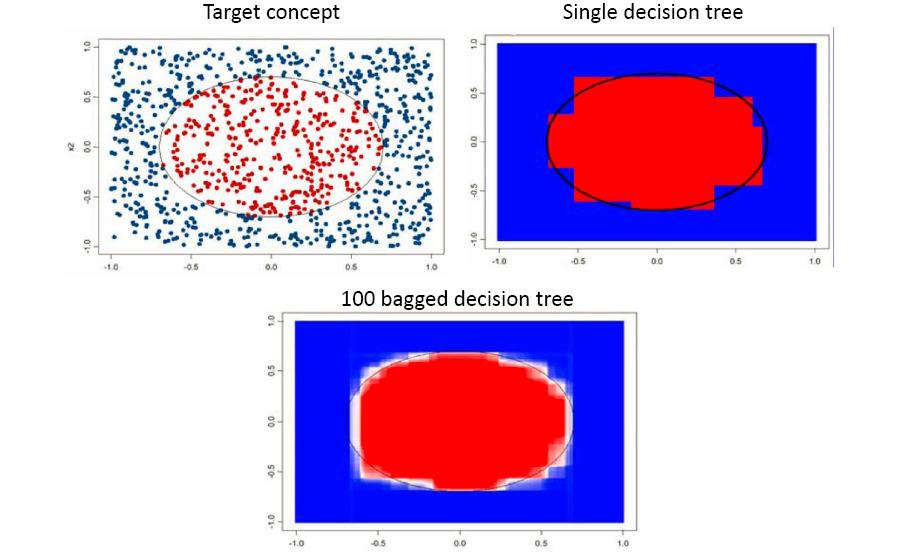
6
7
8
9 Random Forests Constructed from decision trees A random forest is created from individual decision trees, whose training parameters vary randomly Such parameters can be bootstrapped replicas of the training data, as in bagging But they can also be different feature subsets as in random subspace methods
10 Given: N training samples, p variables. Algorithm: 1. For b = 1 to B: a. Draw a bootstrap sample of size N from training data. b. Grow a random-forest tree T b on the bootstrapped data, by recursively repeating the following steps for each terminal node, until the minimum node size n min is reached. i. Select m variables at random from the p variables. ii. Pick the best variable and split-point among the m. iii. Split the node into two child nodes. 2. Output the ensemble of B trees {T b }.
11 Given: N training samples, p variables. Algorithm: 1. For b = 1 to B: a. Draw a bootstrap sample of size N from training data. b. Grow a random-forest tree T b on the bootstrapped data, by recursively repeating the following steps for each terminal node, until the minimum node size n min is reached. i. Select m variables at random from the p variables. ii. Pick the best variable and split-point among the m. iii. Split the node into two child nodes. 2. Output the ensemble of B trees {T b }. Only difference from bagging with decision trees. m typically sqrt( p ) (even as low as 1)
12 Random forests routinely outperform bagged ensembles, and are often competitive with boosting.
13 Random forests provide even more reduction of variance than bagged decision trees. But still do not impact bias. Benefit appears to be from de-correlation of individual trees. Bootstrap samples still have significant correlation. Simpler to train and tune than boosting algorithms.
14 First implemented in FORTRAN by Leo Breiman and Adele Cutler, and the term trademarked by them. Commercial distribution licensed exclusively to Salford Systems. Lots of open-source implementations in various languages and machine learning packages. Available in MATLAB as class TreeBagger (Statistics Toolbox).
15 Boost the performance of a weak learner to the level of a strong one Boosting creates an ensemble of classifiers by resampling the data; classifiers combined by majority voting resampling is strategically geared to provide the most informative training data for each consecutive classifier Boosting creates three weak classifiers: First classifier C1 is trained with a random subset of the available training data Training set for second classifier C2 is chosen as the most informative subset, given C1; half of the training data for C2 is correctly classified by C1, other half is misclassified by C1 Third classifier C3 is trained on instances on which both C1 & C2 disagree
16 Algprithm : Boosting Input : Training data S of the size N with correct labelsω Ω = Weak learning algorithm WeakLearn. Training 1.Select N 2.Call WeakLearn and train with S 3.Create dataset as the most informative dataset S and the other half is misclassified.to do so : a.filp a fair coin. If Add this instance to S b.if tail, select samples from S, and present them to C 4.Train the second classifier C 5.Create by selecting those instances for which C Test - Given a test instance x 1.Classify x by C 1 and C 2.If they disagree, choose the class predicted by C..If with S to create classifier C., given C and C { ω, ω }; < N patterns without replacement from S to create data subset S Head,select samples from S, and present them to C c.continue flipping coins until no more patterns can be added to S i until the first one is correctly classified. Add this instance to disagree.train the third classifier C they agree on the class, this class is the final classification , such that half of S as the ginal classification is correctly classified by C until the first instance is misclassified. 3 with S 3. 2, S 2.
17 Initially, all samples have equal weights. Samples that are wrongly classified have their weights increased. Samples that are classified correctly have their weights decreased. Samples with higher weights have more influence in subsequent training iterations. Adaptively changes training data distribution. Original Data Boosting (Round 1) Boosting (Round 2) Boosting (Round 3) sample 4 is hard to classify its weight is increased
18
19
20
21
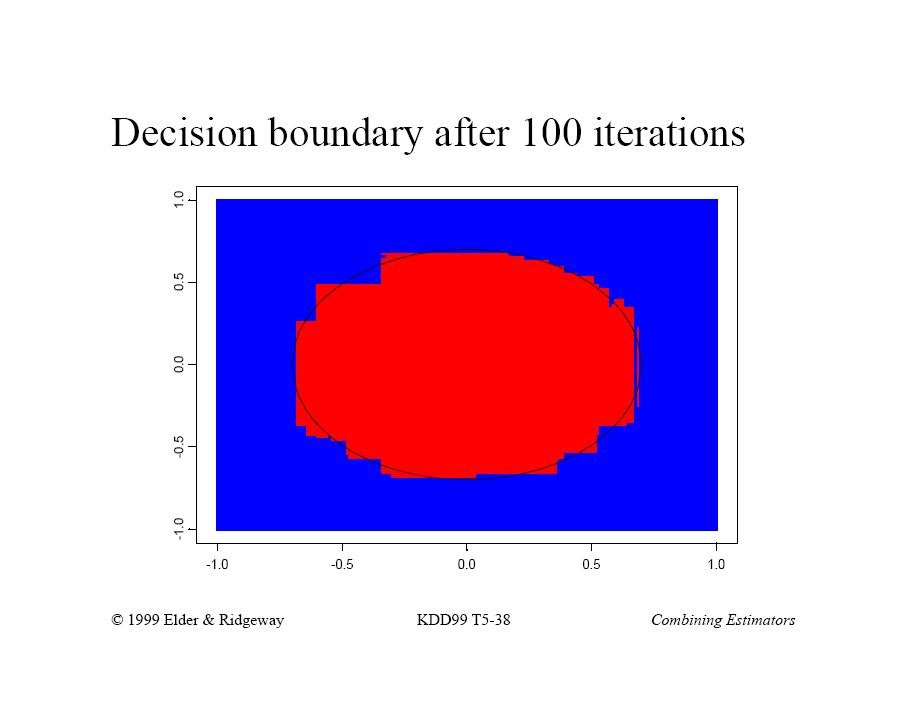
22
23 AdaBoost (1997) is a more general version of the boosting algorithm; AdaBoost.M1 can handle multiclass problems AdaBoost generates a set of hypotheses (classifiers), and combines them through weighted majority voting of the classes predicted by the individual hypotheses Hypotheses are generated by training a weak classifier; samples are drawn from an iteratively updated distribution of the training set This distribution update ensures that instances misclassified by the previous classifier are more likely to be included in the training data of the next classifier Consecutive classifiers are trained on increasingly hard-toclassify samples
24 A weight distribution D t (i) on training instances x i, i=1,,n from which training data subsets S t are chosen for each consecutive classifier (hypothesis) h t A normalized error is then obtained as β t, such that for 0<ε t <1/2, they have 0< β t <1 Distribution update rule: The distribution weights of those instances that are correctly classified by the current hypothesis are reduced by a factor of β t, whereas the weights of the misclassified instances are unchanged. AdaBoost focuses on increasingly difficult instances AdaBoost raises the weights of instanced misclassified by h t, and lowers the weights of correctly classified instances AdaBoost is ready for classifying unlabeled test instances. Unlike bagging or boosting, AdaBoost uses the weighted majority voting 1/β t is therefore a measure of performance, of the t th hypothesis and can be used to weight the classifiers
25 Algorithm AdaBoost.M1 Input : Sequence of N examples S = Weak learning algorithm WeakLearn; Integer T specifying number of iterations. 1 Initialize D1 ( i) =,i = 1,,N N Do for t = 1, 2, T : 1.Select a training data subset S 2.Train WeakLearn with S 3.Calculate the error of h : ε = t Ifε 4.Set β where Z ( i) ( x) ( x ) ( i) > 1/ 2, abort. ( 1 ε ) 5.Update distribution D : D t + 1 ( i) β, if h ( x ) ( i) 1.Obtain total vote received by each class V t j t Test - = t t = ε / D D Z D. [( x,y )],i = 1,,N with labels y Ω, Ω = { ω, ω };, receive hypothesis h t t i = y 1,otherwise, draw from the distribution is a normalization constant chosen so that D Weight Majority Voting : Given an unlabeled instance x. t:h t t i:h t = t = ω j i = t y i i t t t t 1 log, j = 1,,C. β t t t i i 2.Choose the class that receives the highest total vote as the final classification. i t. i D t. t C becomes a proper distribution function.
 is created before")
26 AdaBoost algorithm is sequential; classifier (CK-1) is created before classifier CK

27

28 28
29 Bagging Resample data points Weight of each classifier is same Only reduces variance Robust to noise and outliers Easily parallelized Boosting Reweight data points (modify data distribution) Weight of a classifier depends on its accuracy Reduces both bias and variance Noise and outliers can hurt performance

30 An ensemble of classifiers is first created, whose outputs are used as inputs to a second level meta-classifier to learn the mapping between the ensemble outputs and the actual correct classes C 1,,C T are trained using training parameters θ 1 through θ T to output hypotheses h 1 through h T The outputs of these classifiers and the corresponding true classes are then used as input/output training pairs for the second level classifier, C T+1
31 A conceptually similar technique is the mixture-of-experts model, where a set of classifiers C 1,,C T constitute the ensemble, followed by a second-level classifier C T+1 used for assigning weights for the consecutive combiner The combiner itself is usually not a classifier, but rather a simple combination rule, such as random selection (from a weight distribution), weighted majority, or weighted winner-takes-all the weight distribution used for the combiner is determined by a second level classifier, usually a neural network, called the gating network The inputs to the gating network are the actual training data instances themselves (unlike outputs of first level classifiers for stacked generalization) Mixture-of-experts can, therefore, be seen as a classifier selection algorithm Individual classifiers are experts in some portion of the feature space, and the combination rule selects the most appropriate classifier, or classifiers weighted with respect to their expertise, for each instance x

32 The pooling system may use the weights in several different ways. it may choose a single classifier with the highest weight, or calculate a weighted sum of the classifier outputs for each class, and pick the class that receives the highest weighted sum.
33 How to combine classifiers? Combination rules grouped as (i) trainable vs. non-trainable Trainable rules: parameters of the combiner, called weights determined through a separate training algorithm Weights from trainable rules are usually instance specific, and hence are also called dynamic combination rules Non-trainable rules: combination parameters are available as classifiers are generated; Weighted majority voting is an example (ii) combination rules for class labels vs. class-specific continuous outputs combination rules that apply to class labels only need the classification decision (that is, one of ω j, j=1,,c) Other rules need continuous-valued outputs of individual classifiers
34 Assume that only class labels are available from the classifier outputs Define the decision of the t th classifier as d t,j {0,1}, t=1,,t and j=1,,c, where T is the number of classifiers and C is the number of classes If t th classifier chooses class ω j, then d t,j =1, 0 otherwise a)majority Voting : b)weighted Majority Voting : T d = C max T t,j j= 1 t= 1 t = 1 d c) Behavior Knowledge Space (BKS) : look up Table d)borda Count : each voter (classifier) rank orders the candidates (classes). If there are N candidates, the first-place candidate receives N 1 votes, the secondplace candidate receives N 2, with the candidate in i th place receiving N i votes. The votes are added up across all classifiers, and the class with the most votes is chosen as the ensemble decision t, j T ω d = C max t t,j j= 1 t= 1 t= 1 T ω d t t, j
35 Algebraic combiners a) Mean Rule: µ b) Weighted Average: j ( x) = d ( x) t = 1 c) Minimum/Maximum/Median Rule: { } 1 T T µ j t, j 1 T T ( x) = ω d ( x) t= 1 µ ( x) = max d ( x) µ ( x) = min d ( x) µ j ( x) = median d t, j ( x) j t =1,,T t, j j t =1,,T t, j t, j { } t, j t =1,,T { } d) Product Rule: µ j 1 T T ( x) = d ( x) t = 1 t, j e) Generalized Mean: Many of the above rules are in fact special cases of the generalized mean T 1 α α µ j ( x, α ) = dt, j ( x) T t = 1 α : minimum rule; α :maximum rule; 0: : mean rule α 1 1 T µ j x, α = d t = 1 α ( ) ( ) T t, j x 1
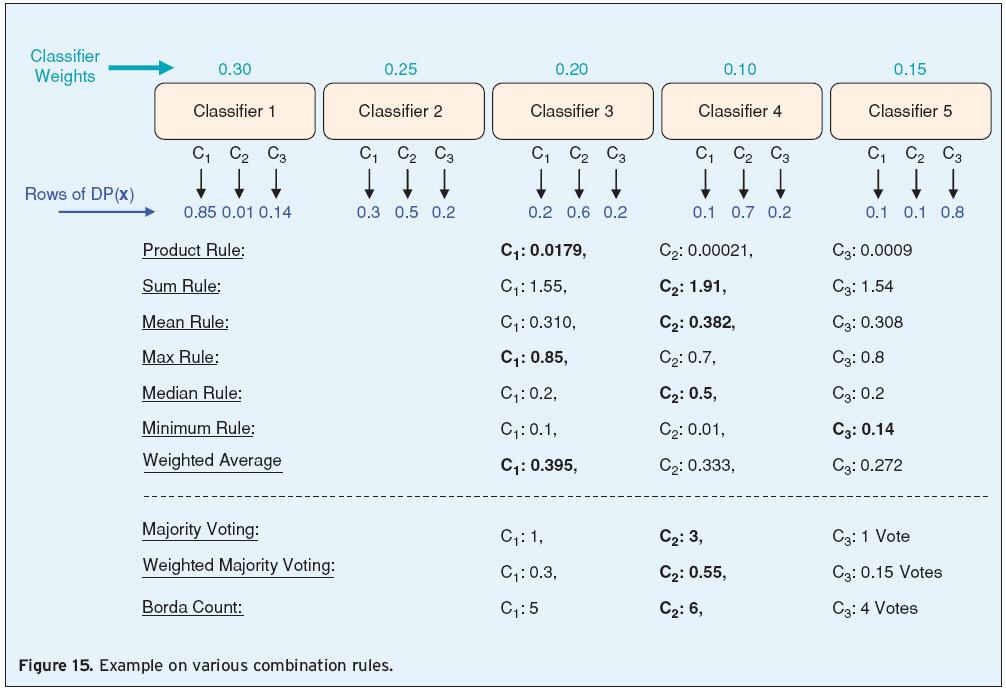
36
37 Ensemble Cloud Army (ECA) A Platform for Parallel Processing of Machine Learning Problems in the Amazon Cloud J. Jeffry Howbert Insilicos LLC May 11, 2011
38 Datasets Name Source Domain Instances Features Feature type(s) Classes satimage UCI soil types from satellite images 4435 train, 2000 test 36 numeric (0-255) 6 covertype UCI forest cover types from cartographic variables numeric, 44 binary qualitative 7 jones Ref. 3 protein secondary structure train, test 315 numeric 3
39 For ensembles, training subsets must deliver diversity, accuracy, and fast computation. For large datasets used with ECA, bootstrap samples are too large for practical computation. Instead, much smaller subsets of records are generated by random sampling without replacement. The key principle for effective sampling is the following: Using a sample will work almost as well as using the entire data set, provided the sample is representative. A sample is representative if it has approximately the same distribution of properties (of interest) as the original set of data
40 Ensembles have better accuracy than individual component classifiers 80 Classification accuracy, % covertype: ensemble of decision trees covertype: average of individual decision trees Jones: ensemble of neural nets Jones: average of individual neural nets Jones: ensemble of decision trees Jones: average of individual decision trees Number of instances per base classifier
41 Accuracy remains high despite large reduction in features Classification accuracy, % Jones neural nets, 315 features neural nets, 157 features neural nets, 78 features decision trees, 315 features decision trees, 157 features decision trees, 78 features Number of instances per base classifier
42 The potential speedup from parallelization is strictly limited by the portion of the computation that cannot be parallelized. Assume proportion P of computation can be parallelized, and proportion (1 P) is necessarily sequential. The speedup from parallelizing on N processors is: 1 (1 P ) + For example, if P = 0.9, maximum possible speedup is 10, no matter how large N is. P N
43 Computational performance: ensembles of decision trees 60 Increase in speed over single node ideal performance Jones instances 5000 instances 2500 instances 1000 instances covertype instances instances 5000 instances 2500 instances 1000 instances Number of nodes in cluster
44 Computational performance: ensembles of neural networks Increase in speed over single node Number of nodes in cluster ideal performance Jones instances instances 5000 instances 2500 instances 1000 instances 500 instances 250 instances 100 instances
45 Large data handling not as critical as expected Best ensemble accuracy associated with smaller partitions (< 5,000 instances) Ensembles with small partitions run much faster than those with larger partitions
46 Ensembles with small partitions run much faster than single classifier trained on all of data, and are more accurate Number of trees Instances per tree Processing mode Number of nodes Node type Runtime Accuracy, % serial 1 64-bit 2:01: serial 1 64-bit 29: parallel bit 5: Jones dataset, ensemble of decision trees
47 RMPI version released on SourceForge ica.sf.net
48 Given two models with similar generalization errors, one should prefer the simpler model over the more complex model. For complex models, there is a greater chance it was fitted accidentally by errors in data. Model complexity should therefore be considered when evaluating a model.

49
50 Ensemble systems are useful in practice Diversity of the base classifiers is important Ensemble generation techniques: bagging, AdaBoost, mixture of experts Classifier combination strategies: algebraic combiners, voting methods, and decision templates. No single ensemble generation algorithm or combination rule is universally better than others Effectiveness on real world data depends on the classifier diversity and characteristics of the data 50
CSC411 Fall 2014 Machine Learning & Data Mining. Ensemble Methods. Slides by Rich Zemel
 CSC411 Fall 2014 Machine Learning & Data Mining Ensemble Methods Slides by Rich Zemel Ensemble methods Typical application: classi.ication Ensemble of classi.iers is a set of classi.iers whose individual
CSC411 Fall 2014 Machine Learning & Data Mining Ensemble Methods Slides by Rich Zemel Ensemble methods Typical application: classi.ication Ensemble of classi.iers is a set of classi.iers whose individual
Ensemble Learning: An Introduction. Adapted from Slides by Tan, Steinbach, Kumar
 Ensemble Learning: An Introduction Adapted from Slides by Tan, Steinbach, Kumar 1 General Idea D Original Training data Step 1: Create Multiple Data Sets... D 1 D 2 D t-1 D t Step 2: Build Multiple Classifiers
Ensemble Learning: An Introduction Adapted from Slides by Tan, Steinbach, Kumar 1 General Idea D Original Training data Step 1: Create Multiple Data Sets... D 1 D 2 D t-1 D t Step 2: Build Multiple Classifiers
Boosting Algorithms for Parallel and Distributed Learning
 Distributed and Parallel Databases, 11, 203 229, 2002 c 2002 Kluwer Academic Publishers. Manufactured in The Netherlands. Boosting Algorithms for Parallel and Distributed Learning ALEKSANDAR LAZAREVIC
Distributed and Parallel Databases, 11, 203 229, 2002 c 2002 Kluwer Academic Publishers. Manufactured in The Netherlands. Boosting Algorithms for Parallel and Distributed Learning ALEKSANDAR LAZAREVIC
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures
 An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures José Ramón Pasillas-Díaz, Sylvie Ratté Presenter: Christoforos Leventis 1 Basic concepts Outlier
An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures José Ramón Pasillas-Díaz, Sylvie Ratté Presenter: Christoforos Leventis 1 Basic concepts Outlier
Ensemble Learning. Another approach is to leverage the algorithms we have via ensemble methods
 Ensemble Learning Ensemble Learning So far we have seen learning algorithms that take a training set and output a classifier What if we want more accuracy than current algorithms afford? Develop new learning
Ensemble Learning Ensemble Learning So far we have seen learning algorithms that take a training set and output a classifier What if we want more accuracy than current algorithms afford? Develop new learning
CS 559: Machine Learning Fundamentals and Applications 10 th Set of Notes
 1 CS 559: Machine Learning Fundamentals and Applications 10 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215
1 CS 559: Machine Learning Fundamentals and Applications 10 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215
Ensemble Methods, Decision Trees
 CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
Semi-supervised learning and active learning
 Semi-supervised learning and active learning Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Combining classifiers Ensemble learning: a machine learning paradigm where multiple learners
Semi-supervised learning and active learning Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Combining classifiers Ensemble learning: a machine learning paradigm where multiple learners
An introduction to random forests
 An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
7. Boosting and Bagging Bagging
 Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Ensemble Methods: Bagging
 Ensemble Methods: Bagging Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Eric Eaton (UPenn), Jenna Wiens (UMich), Tommi Jaakola (MIT), David Kauchak (Pomona), David Sontag
Ensemble Methods: Bagging Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Eric Eaton (UPenn), Jenna Wiens (UMich), Tommi Jaakola (MIT), David Kauchak (Pomona), David Sontag
Adaptive Boosting for Spatial Functions with Unstable Driving Attributes *
 Adaptive Boosting for Spatial Functions with Unstable Driving Attributes * Aleksandar Lazarevic 1, Tim Fiez 2, Zoran Obradovic 1 1 School of Electrical Engineering and Computer Science, Washington State
Adaptive Boosting for Spatial Functions with Unstable Driving Attributes * Aleksandar Lazarevic 1, Tim Fiez 2, Zoran Obradovic 1 1 School of Electrical Engineering and Computer Science, Washington State
Computer Vision Group Prof. Daniel Cremers. 8. Boosting and Bagging
 Prof. Daniel Cremers 8. Boosting and Bagging Repetition: Regression We start with a set of basis functions (x) =( 0 (x), 1(x),..., M 1(x)) x 2 í d The goal is to fit a model into the data y(x, w) =w T
Prof. Daniel Cremers 8. Boosting and Bagging Repetition: Regression We start with a set of basis functions (x) =( 0 (x), 1(x),..., M 1(x)) x 2 í d The goal is to fit a model into the data y(x, w) =w T
Multi-label classification using rule-based classifier systems
 Multi-label classification using rule-based classifier systems Shabnam Nazmi (PhD candidate) Department of electrical and computer engineering North Carolina A&T state university Advisor: Dr. A. Homaifar
Multi-label classification using rule-based classifier systems Shabnam Nazmi (PhD candidate) Department of electrical and computer engineering North Carolina A&T state university Advisor: Dr. A. Homaifar
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Data Mining Lecture 8: Decision Trees
 Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
Naïve Bayes for text classification
 Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Ensemble methods in machine learning. Example. Neural networks. Neural networks
 Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
CS294-1 Final Project. Algorithms Comparison
 CS294-1 Final Project Algorithms Comparison Deep Learning Neural Network AdaBoost Random Forest Prepared By: Shuang Bi (24094630) Wenchang Zhang (24094623) 2013-05-15 1 INTRODUCTION In this project, we
CS294-1 Final Project Algorithms Comparison Deep Learning Neural Network AdaBoost Random Forest Prepared By: Shuang Bi (24094630) Wenchang Zhang (24094623) 2013-05-15 1 INTRODUCTION In this project, we
Data Mining Practical Machine Learning Tools and Techniques
 Engineering the input and output Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 7 of Data Mining by I. H. Witten and E. Frank Attribute selection z Scheme-independent, scheme-specific
Engineering the input and output Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 7 of Data Mining by I. H. Witten and E. Frank Attribute selection z Scheme-independent, scheme-specific
Predictive Analytics: Demystifying Current and Emerging Methodologies. Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA
 Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Bias-Variance Analysis of Ensemble Learning
 Bias-Variance Analysis of Ensemble Learning Thomas G. Dietterich Department of Computer Science Oregon State University Corvallis, Oregon 97331 http://www.cs.orst.edu/~tgd Outline Bias-Variance Decomposition
Bias-Variance Analysis of Ensemble Learning Thomas G. Dietterich Department of Computer Science Oregon State University Corvallis, Oregon 97331 http://www.cs.orst.edu/~tgd Outline Bias-Variance Decomposition
An Empirical Comparison of Ensemble Methods Based on Classification Trees. Mounir Hamza and Denis Larocque. Department of Quantitative Methods
 An Empirical Comparison of Ensemble Methods Based on Classification Trees Mounir Hamza and Denis Larocque Department of Quantitative Methods HEC Montreal Canada Mounir Hamza and Denis Larocque 1 June 2005
An Empirical Comparison of Ensemble Methods Based on Classification Trees Mounir Hamza and Denis Larocque Department of Quantitative Methods HEC Montreal Canada Mounir Hamza and Denis Larocque 1 June 2005
Lecture #17: Autoencoders and Random Forests with R. Mat Kallada Introduction to Data Mining with R
 Lecture #17: Autoencoders and Random Forests with R Mat Kallada Introduction to Data Mining with R Assignment 4 Posted last Sunday Due next Monday! Autoencoders in R Firstly, what is an autoencoder? Autoencoders
Lecture #17: Autoencoders and Random Forests with R Mat Kallada Introduction to Data Mining with R Assignment 4 Posted last Sunday Due next Monday! Autoencoders in R Firstly, what is an autoencoder? Autoencoders
Lecture 2 :: Decision Trees Learning
 Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
CSC 411 Lecture 4: Ensembles I
 CSC 411 Lecture 4: Ensembles I Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 04-Ensembles I 1 / 22 Overview We ve seen two particular classification algorithms:
CSC 411 Lecture 4: Ensembles I Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 04-Ensembles I 1 / 22 Overview We ve seen two particular classification algorithms:
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 20: 10/12/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 20: 10/12/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Oliver Dürr. Statistisches Data Mining (StDM) Woche 12. Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften
 Woche 12. Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften") Statistisches Data Mining (StDM) Woche 12 Oliver Dürr Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften oliver.duerr@zhaw.ch Winterthur, 6 Dezember 2016 1 Multitasking
Statistisches Data Mining (StDM) Woche 12 Oliver Dürr Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften oliver.duerr@zhaw.ch Winterthur, 6 Dezember 2016 1 Multitasking
Classification/Regression Trees and Random Forests
 Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Model combination. Resampling techniques p.1/34
 Model combination The winner-takes-all approach is intuitively the approach which should work the best. However recent results in machine learning show that the performance of the final model can be improved
Model combination The winner-takes-all approach is intuitively the approach which should work the best. However recent results in machine learning show that the performance of the final model can be improved
Soft computing algorithms
 Chapter 1 Soft computing algorithms It is indeed a surprising and fortunate fact that nature can be expressed by relatively low-order mathematical functions. Rudolf Carnap Mitchell [Mitchell, 1997] defines
Chapter 1 Soft computing algorithms It is indeed a surprising and fortunate fact that nature can be expressed by relatively low-order mathematical functions. Rudolf Carnap Mitchell [Mitchell, 1997] defines
Algorithms: Decision Trees
 Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
OPTIMIZATION OF BAGGING CLASSIFIERS BASED ON SBCB ALGORITHM
 OPTIMIZATION OF BAGGING CLASSIFIERS BASED ON SBCB ALGORITHM XIAO-DONG ZENG, SAM CHAO, FAI WONG Faculty of Science and Technology, University of Macau, Macau, China E-MAIL: ma96506@umac.mo, lidiasc@umac.mo,
OPTIMIZATION OF BAGGING CLASSIFIERS BASED ON SBCB ALGORITHM XIAO-DONG ZENG, SAM CHAO, FAI WONG Faculty of Science and Technology, University of Macau, Macau, China E-MAIL: ma96506@umac.mo, lidiasc@umac.mo,
HALF&HALF BAGGING AND HARD BOUNDARY POINTS. Leo Breiman Statistics Department University of California Berkeley, CA
 1 HALF&HALF BAGGING AND HARD BOUNDARY POINTS Leo Breiman Statistics Department University of California Berkeley, CA 94720 leo@stat.berkeley.edu Technical Report 534 Statistics Department September 1998
1 HALF&HALF BAGGING AND HARD BOUNDARY POINTS Leo Breiman Statistics Department University of California Berkeley, CA 94720 leo@stat.berkeley.edu Technical Report 534 Statistics Department September 1998
Bagging for One-Class Learning
 Bagging for One-Class Learning David Kamm December 13, 2008 1 Introduction Consider the following outlier detection problem: suppose you are given an unlabeled data set and make the assumptions that one
Bagging for One-Class Learning David Kamm December 13, 2008 1 Introduction Consider the following outlier detection problem: suppose you are given an unlabeled data set and make the assumptions that one
Outlier Ensembles. Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY Keynote, Outlier Detection and Description Workshop, 2013
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY 10598 Outlier Ensembles Keynote, Outlier Detection and Description Workshop, 2013 Based on the ACM SIGKDD Explorations Position Paper: Outlier
Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY 10598 Outlier Ensembles Keynote, Outlier Detection and Description Workshop, 2013 Based on the ACM SIGKDD Explorations Position Paper: Outlier
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Machine Learning (CS 567)
") Machine Learning (CS 567) Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol Han (cheolhan@usc.edu)
Machine Learning (CS 567) Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol Han (cheolhan@usc.edu)
arxiv: v2 [cs.lg] 11 Sep 2015
![arxiv: v2 [cs.lg] 11 Sep 2015](/thumbs/75/72864154.jpg "arxiv: v2 [cs.lg] 11 Sep 2015") A DEEP analysis of the META-DES framework for dynamic selection of ensemble of classifiers Rafael M. O. Cruz a,, Robert Sabourin a, George D. C. Cavalcanti b a LIVIA, École de Technologie Supérieure, University
A DEEP analysis of the META-DES framework for dynamic selection of ensemble of classifiers Rafael M. O. Cruz a,, Robert Sabourin a, George D. C. Cavalcanti b a LIVIA, École de Technologie Supérieure, University
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Overview. Non-Parametrics Models Definitions KNN. Ensemble Methods Definitions, Examples Random Forests. Clustering. k-means Clustering 2 / 8
 Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
From Ensemble Methods to Comprehensible Models
 From Ensemble Methods to Comprehensible Models Cèsar Ferri, José Hernández-Orallo, M.José Ramírez-Quintana {cferri, jorallo, mramirez}@dsic.upv.es Dep. de Sistemes Informàtics i Computació, Universitat
From Ensemble Methods to Comprehensible Models Cèsar Ferri, José Hernández-Orallo, M.José Ramírez-Quintana {cferri, jorallo, mramirez}@dsic.upv.es Dep. de Sistemes Informàtics i Computació, Universitat
Supervised Learning for Image Segmentation
 Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Probabilistic Approaches
 Probabilistic Approaches Chirayu Wongchokprasitti, PhD University of Pittsburgh Center for Causal Discovery Department of Biomedical Informatics chw20@pitt.edu http://www.pitt.edu/~chw20 Overview Independence
Probabilistic Approaches Chirayu Wongchokprasitti, PhD University of Pittsburgh Center for Causal Discovery Department of Biomedical Informatics chw20@pitt.edu http://www.pitt.edu/~chw20 Overview Independence
MASTER. Random forest visualization. Kuznetsova, N.I. Award date: Link to publication
 MASTER Random forest visualization Kuznetsova, N.I. Award date: 2014 Link to publication Disclaimer This document contains a student thesis (bachelor's or master's), as authored by a student at Eindhoven
MASTER Random forest visualization Kuznetsova, N.I. Award date: 2014 Link to publication Disclaimer This document contains a student thesis (bachelor's or master's), as authored by a student at Eindhoven
Improving the Random Forest Algorithm by Randomly Varying the Size of the Bootstrap Samples for Low Dimensional Data Sets
 Improving the Random Forest Algorithm by Randomly Varying the Size of the Bootstrap Samples for Low Dimensional Data Sets Md Nasim Adnan and Md Zahidul Islam Centre for Research in Complex Systems (CRiCS)
Improving the Random Forest Algorithm by Randomly Varying the Size of the Bootstrap Samples for Low Dimensional Data Sets Md Nasim Adnan and Md Zahidul Islam Centre for Research in Complex Systems (CRiCS)
Logical Rhythm - Class 3. August 27, 2018
 Logical Rhythm - Class 3 August 27, 2018 In this Class Neural Networks (Intro To Deep Learning) Decision Trees Ensemble Methods(Random Forest) Hyperparameter Optimisation and Bias Variance Tradeoff Biological
Logical Rhythm - Class 3 August 27, 2018 In this Class Neural Networks (Intro To Deep Learning) Decision Trees Ensemble Methods(Random Forest) Hyperparameter Optimisation and Bias Variance Tradeoff Biological
Information Fusion Dr. B. K. Panigrahi
 Information Fusion By Dr. B. K. Panigrahi Asst. Professor Department of Electrical Engineering IIT Delhi, New Delhi-110016 01/12/2007 1 Introduction Classification OUTLINE K-fold cross Validation Feature
Information Fusion By Dr. B. K. Panigrahi Asst. Professor Department of Electrical Engineering IIT Delhi, New Delhi-110016 01/12/2007 1 Introduction Classification OUTLINE K-fold cross Validation Feature
The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand).
.") http://researchcommons.waikato.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
http://researchcommons.waikato.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
Cover Page. The handle holds various files of this Leiden University dissertation.
 Cover Page The handle http://hdl.handle.net/1887/22055 holds various files of this Leiden University dissertation. Author: Koch, Patrick Title: Efficient tuning in supervised machine learning Issue Date:
Cover Page The handle http://hdl.handle.net/1887/22055 holds various files of this Leiden University dissertation. Author: Koch, Patrick Title: Efficient tuning in supervised machine learning Issue Date:
Decision Trees. This week: Next week: Algorithms for constructing DT. Pruning DT Ensemble methods. Random Forest. Intro to ML
 Decision Trees This week: Algorithms for constructing DT Next week: Pruning DT Ensemble methods Random Forest 2 Decision Trees - Boolean x 1 0 1 +1 x 6 0 1 +1-1 3 Decision Trees - Continuous Decision stumps
Decision Trees This week: Algorithms for constructing DT Next week: Pruning DT Ensemble methods Random Forest 2 Decision Trees - Boolean x 1 0 1 +1 x 6 0 1 +1-1 3 Decision Trees - Continuous Decision stumps
THE ENSEMBLE CONCEPTUAL CLUSTERING OF SYMBOLIC DATA FOR CUSTOMER LOYALTY ANALYSIS
 THE ENSEMBLE CONCEPTUAL CLUSTERING OF SYMBOLIC DATA FOR CUSTOMER LOYALTY ANALYSIS Marcin Pełka 1 1 Wroclaw University of Economics, Faculty of Economics, Management and Tourism, Department of Econometrics
THE ENSEMBLE CONCEPTUAL CLUSTERING OF SYMBOLIC DATA FOR CUSTOMER LOYALTY ANALYSIS Marcin Pełka 1 1 Wroclaw University of Economics, Faculty of Economics, Management and Tourism, Department of Econometrics
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
Machine Learning Lecture 11
 Machine Learning Lecture 11 Random Forests 23.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 11 Random Forests 23.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Ensemble methods. Ricco RAKOTOMALALA Université Lumière Lyon 2. Ricco Rakotomalala Tutoriels Tanagra -
 Ensemble methods Ricco RAKOTOMALALA Université Lumière Lyon 2 Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 1 Make cooperate several classifiers. Combine the outputs of the individual classifiers
Ensemble methods Ricco RAKOTOMALALA Université Lumière Lyon 2 Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 1 Make cooperate several classifiers. Combine the outputs of the individual classifiers
Classification with Decision Tree Induction
 Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
DESIGN AND EVALUATION OF MACHINE LEARNING MODELS WITH STATISTICAL FEATURES
 EXPERIMENTAL WORK PART I CHAPTER 6 DESIGN AND EVALUATION OF MACHINE LEARNING MODELS WITH STATISTICAL FEATURES The evaluation of models built using statistical in conjunction with various feature subset
EXPERIMENTAL WORK PART I CHAPTER 6 DESIGN AND EVALUATION OF MACHINE LEARNING MODELS WITH STATISTICAL FEATURES The evaluation of models built using statistical in conjunction with various feature subset
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
More Learning. Ensembles Bayes Rule Neural Nets K-means Clustering EM Clustering WEKA
 More Learning Ensembles Bayes Rule Neural Nets K-means Clustering EM Clustering WEKA 1 Ensembles An ensemble is a set of classifiers whose combined results give the final decision. test feature vector
More Learning Ensembles Bayes Rule Neural Nets K-means Clustering EM Clustering WEKA 1 Ensembles An ensemble is a set of classifiers whose combined results give the final decision. test feature vector
Performance Estimation and Regularization. Kasthuri Kannan, PhD. Machine Learning, Spring 2018
 Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
Nonparametric Methods Recap
 Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN
 INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN MOTIVATION FOR RANDOM FOREST Random forest is a great statistical learning model. It works well with small to medium data. Unlike Neural Network which requires
INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN MOTIVATION FOR RANDOM FOREST Random forest is a great statistical learning model. It works well with small to medium data. Unlike Neural Network which requires
CS6716 Pattern Recognition. Ensembles and Boosting (1)
") CS6716 Pattern Recognition Ensembles and Boosting (1) Aaron Bobick School of Interactive Computing Administrivia Chapter 10 of the Hastie book. Slides brought to you by Aarti Singh, Peter Orbanz, and friends.
CS6716 Pattern Recognition Ensembles and Boosting (1) Aaron Bobick School of Interactive Computing Administrivia Chapter 10 of the Hastie book. Slides brought to you by Aarti Singh, Peter Orbanz, and friends.
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Optimal Extension of Error Correcting Output Codes
 Book Title Book Editors IOS Press, 2003 1 Optimal Extension of Error Correcting Output Codes Sergio Escalera a, Oriol Pujol b, and Petia Radeva a a Centre de Visió per Computador, Campus UAB, 08193 Bellaterra
Book Title Book Editors IOS Press, 2003 1 Optimal Extension of Error Correcting Output Codes Sergio Escalera a, Oriol Pujol b, and Petia Radeva a a Centre de Visió per Computador, Campus UAB, 08193 Bellaterra
BIOINF 585: Machine Learning for Systems Biology & Clinical Informatics
 BIOINF 585: Machine Learning for Systems Biology & Clinical Informatics Lecture 12: Ensemble Learning I Jie Wang Department of Computational Medicine & Bioinformatics University of Michigan 1 Outline Bias
BIOINF 585: Machine Learning for Systems Biology & Clinical Informatics Lecture 12: Ensemble Learning I Jie Wang Department of Computational Medicine & Bioinformatics University of Michigan 1 Outline Bias
Cse634 DATA MINING TEST REVIEW. Professor Anita Wasilewska Computer Science Department Stony Brook University
 Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
PV211: Introduction to Information Retrieval
 PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 15-1: Support Vector Machines Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 15-1: Support Vector Machines Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
Advanced and Predictive Analytics with JMP 12 PRO. JMP User Meeting 9. Juni Schwalbach
 Advanced and Predictive Analytics with JMP 12 PRO JMP User Meeting 9. Juni 2016 -Schwalbach Definition Predictive Analytics encompasses a variety of statistical techniques from modeling, machine learning
Advanced and Predictive Analytics with JMP 12 PRO JMP User Meeting 9. Juni 2016 -Schwalbach Definition Predictive Analytics encompasses a variety of statistical techniques from modeling, machine learning
CSE 151 Machine Learning. Instructor: Kamalika Chaudhuri
 CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Announcements Midterm on Monday May 21 (decision trees, kernels, perceptron, and comparison to knns) Review session on Friday (enter time on Piazza)
CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Announcements Midterm on Monday May 21 (decision trees, kernels, perceptron, and comparison to knns) Review session on Friday (enter time on Piazza)
Classification of Hand-Written Numeric Digits
 Classification of Hand-Written Numeric Digits Nyssa Aragon, William Lane, Fan Zhang December 12, 2013 1 Objective The specific hand-written recognition application that this project is emphasizing is reading
Classification of Hand-Written Numeric Digits Nyssa Aragon, William Lane, Fan Zhang December 12, 2013 1 Objective The specific hand-written recognition application that this project is emphasizing is reading
Nonparametric Classification Methods
 Nonparametric Classification Methods We now examine some modern, computationally intensive methods for regression and classification. Recall that the LDA approach constructs a line (or plane or hyperplane)
Nonparametric Classification Methods We now examine some modern, computationally intensive methods for regression and classification. Recall that the LDA approach constructs a line (or plane or hyperplane)
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
The Curse of Dimensionality
 The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
Classifier Case Study: Viola-Jones Face Detector
 Classifier Case Study: Viola-Jones Face Detector P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features. CVPR 2001. P. Viola and M. Jones. Robust real-time face detection.
Classifier Case Study: Viola-Jones Face Detector P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features. CVPR 2001. P. Viola and M. Jones. Robust real-time face detection.
BITS F464: MACHINE LEARNING
 BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
Detecting Faces in Images. Detecting Faces in Images. Finding faces in an image. Finding faces in an image. Finding faces in an image
 Detecting Faces in Images Detecting Faces in Images 37 Finding face like patterns How do we find if a picture has faces in it Where are the faces? A simple solution: Define a typical face Find the typical
Detecting Faces in Images Detecting Faces in Images 37 Finding face like patterns How do we find if a picture has faces in it Where are the faces? A simple solution: Define a typical face Find the typical
Skin and Face Detection
 Skin and Face Detection Linda Shapiro EE/CSE 576 1 What s Coming 1. Review of Bakic flesh detector 2. Fleck and Forsyth flesh detector 3. Details of Rowley face detector 4. Review of the basic AdaBoost
Skin and Face Detection Linda Shapiro EE/CSE 576 1 What s Coming 1. Review of Bakic flesh detector 2. Fleck and Forsyth flesh detector 3. Details of Rowley face detector 4. Review of the basic AdaBoost
Machine Learning for Signal Processing Detecting faces (& other objects) in images
 in images") Machine Learning for Signal Processing Detecting faces (& other objects) in images Class 8. 27 Sep 2016 11755/18979 1 Last Lecture: How to describe a face The typical face A typical face that captures
Machine Learning for Signal Processing Detecting faces (& other objects) in images Class 8. 27 Sep 2016 11755/18979 1 Last Lecture: How to describe a face The typical face A typical face that captures
Globally Induced Forest: A Prepruning Compression Scheme
 Globally Induced Forest: A Prepruning Compression Scheme Jean-Michel Begon, Arnaud Joly, Pierre Geurts Systems and Modeling, Dept. of EE and CS, University of Liege, Belgium ICML 2017 Goal and motivation
Globally Induced Forest: A Prepruning Compression Scheme Jean-Michel Begon, Arnaud Joly, Pierre Geurts Systems and Modeling, Dept. of EE and CS, University of Liege, Belgium ICML 2017 Goal and motivation
The Basics of Decision Trees
 Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
Machine Learning. Chao Lan
 Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Computer Vision Group Prof. Daniel Cremers. 6. Boosting
 Prof. Daniel Cremers 6. Boosting Repetition: Regression We start with a set of basis functions (x) =( 0 (x), 1(x),..., M 1(x)) x 2 í d The goal is to fit a model into the data y(x, w) =w T (x) To do this,
Prof. Daniel Cremers 6. Boosting Repetition: Regression We start with a set of basis functions (x) =( 0 (x), 1(x),..., M 1(x)) x 2 í d The goal is to fit a model into the data y(x, w) =w T (x) To do this,
8. Tree-based approaches
 Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
User Documentation Decision Tree Classification with Bagging
 User Documentation Decision Tree Classification with Bagging A decision tree is a flowchart-like structure in which each internal node represents a "test" on an attribute, each branch represents the outcome
User Documentation Decision Tree Classification with Bagging A decision tree is a flowchart-like structure in which each internal node represents a "test" on an attribute, each branch represents the outcome
A Practical Tour of Ensemble (Machine) Learning
 Learning") A Practical Tour of Ensemble (Machine) Learning Nima Hejazi Evan Muzzall Division of Biostatistics, University of California, Berkeley D-Lab, University of California, Berkeley slides: https://googl/wwaqc
A Practical Tour of Ensemble (Machine) Learning Nima Hejazi Evan Muzzall Division of Biostatistics, University of California, Berkeley D-Lab, University of California, Berkeley slides: https://googl/wwaqc
Classification with PAM and Random Forest
 5/7/2007 Classification with PAM and Random Forest Markus Ruschhaupt Practical Microarray Analysis 2007 - Regensburg Two roads to classification Given: patient profiles already diagnosed by an expert.
5/7/2007 Classification with PAM and Random Forest Markus Ruschhaupt Practical Microarray Analysis 2007 - Regensburg Two roads to classification Given: patient profiles already diagnosed by an expert.
Decision Trees. This week: Next week: constructing DT. Pruning DT. Ensemble methods. Greedy Algorithm Potential Function.
 Decision Trees This week: constructing DT Greedy Algorithm Potential Function upper bounds the error Pruning DT Next week: Ensemble methods Random Forest 2 Decision Trees - Boolean x 0 + x 6 0 + - 3 Decision
Decision Trees This week: constructing DT Greedy Algorithm Potential Function upper bounds the error Pruning DT Next week: Ensemble methods Random Forest 2 Decision Trees - Boolean x 0 + x 6 0 + - 3 Decision
Adaptive Boosting Techniques in Heterogeneous and Spatial Databases
 Adaptive Boosting Techniques in Heterogeneous and Spatial Databases Aleksandar Lazarevic, Zoran Obradovic Center for Information Science and Technology, Temple University, Room 33, Wachman Hall (38-24),
Adaptive Boosting Techniques in Heterogeneous and Spatial Databases Aleksandar Lazarevic, Zoran Obradovic Center for Information Science and Technology, Temple University, Room 33, Wachman Hall (38-24),
Face detection and recognition. Detection Recognition Sally
 Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Binary Hierarchical Classifier for Hyperspectral Data Analysis
 Binary Hierarchical Classifier for Hyperspectral Data Analysis Hafrún Hauksdóttir A intruduction to articles written by Joydeep Gosh and Melba M. Crawford Binary Hierarchical Classifierfor Hyperspectral
Binary Hierarchical Classifier for Hyperspectral Data Analysis Hafrún Hauksdóttir A intruduction to articles written by Joydeep Gosh and Melba M. Crawford Binary Hierarchical Classifierfor Hyperspectral