Instruction-Level Parallelism and Its Exploitation
|
|
|
- Julian Wilfrid Jordan
- 6 years ago
- Views:
Transcription
1 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1
2 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic Hardware Prediction Basic Branch Prediction and Branch-Prediction Buffers Branch Target Buffers Overview of Superscalar and VLIW processors 2
3 CPI Equation Pipeline CPI = Ideal pipeline CPI + Structural stalls + RAW stalls + WAR stalls + WAW stalls + Control stalls Technique Loop unrolling Basic pipeline scheduling Dynamic scheduling with scoreboarding Dynamic scheduling with register renaming Dynamic branch prediction Issuing multiple instructions per cycle Compiler dependence analysis Software pipelining and trace scheduling Speculation Dynamic memory disambiguation Reduces Control stalls RAW stalls RAW stalls WAR and WAW stalls Control stalls Ideal CPI Ideal CPI and data stalls Ideal CPI and data stalls All data and control stalls RAW stalls involving memory 3
4 Instruction Level Parallelism Potential overlap among instructions Few possibilities in a basic block Blocks are small (6-7 instructions) Instructions are dependent Exploit ILP across multiple basic blocks Iterations of a loop for (i = 1000; i > 0; i=i-1) x[i] = x[i] + s; Alternative to vector instructions 4
5 Basic Pipeline Scheduling Find sequences of unrelated instructions Compiler s ability to schedule Amount of ILP available in the program Latencies of the functional units Latency assumptions for the examples Standard MIPS integer pipeline No structural hazards (fully pipelined or duplicated units Latencies of FP operations: Instruction producing result Instruction using result Latency FP ALU op FP ALU op 3 FP ALU op SD 2 LD FP ALU op 1 LD SD 0 5
6 Sample Pipeline EX IF ID FP1 FP2 FP3 FP4 DM WB FP1 FP2 FP3 FP4... FP ALU IF ID FP1 FP2 FP3 FP4 DM WB FP ALU IF ID stall stall stall FP1 FP2 FP3 FP ALU SD IF ID FP1 FP2 FP3 FP4 DM WB IF ID EX stall stall DM WB 6
7 Basic Scheduling for (i = 1000; i > 0; i=i-1) Sequential MIPS Assembly Code Loop: LD F0, 0(R1) ADDD F4 F0 F2 SD 0(R1), F4 SUBI R1, R1, #8 BNEZ R1, Loop x[i] = x[i] + s; ADDD F4, F0, F2 Pipelined execution: Loop: LD F0, 0(R1) 1 stall 2 ADDD F4, F0, F2 3 stall 4 stall 5 SD 0(R1), F4 6 SUBI R1, R1, #8 7 stall 8 BNEZ R1, Loop 9 stall 10 Scheduled pipelined execution: Loop: LD F0, 0(R1) 1 SUBI R1, R1, #8 2 ADDD F4, F0, F2 3 stall 4 BNEZ R1, Loop 5 SD 8(R1), F4 6 7
8 Loop Unrolling Unrolled loop (four copies): Loop: LD F0, 0(R1) ADDD F4, F0, F2 SD 0(R1), F4 LD F6, -8(R1) ADDD F8, F6, F2 SD -8(R1), F8 LD F10, -16(R1) ADDD F12, F10, F2 SD -16(R1), F12 LD F14, -24(R1) ADDD F16, F14, F2 SD -24(R1), F16 SUBI R1, R1, #32 BNEZ R1, Loop Scheduled Unrolled loop: Loop: LD F0, 0(R1) LD F6, -8(R1) LD F10, -16(R1) LD F14, -24(R1) ADDD F4, F0, F2 ADDD F8, F6, F2 ADDD F12, F10, F2 ADDD F16, F14, F2 SD 0(R1), F4 SD -8(R1), F8 SUBI R1, R1, #32 SD 16(R1), F12 BNEZ R1, Loop SD 8(R1), F16 8
9 Dynamic Scheduling Scheduling separates dependent instructions Static performed by the compiler Dynamic performed by the hardware Advantages of dynamic scheduling Handles dependences unknown at compile time Simplifies the compiler Optimization is done at run time Disadvantages Can not eliminate true data dependences 9
10 Out-of-order execution (1/2) Central idea of dynamic scheduling In-order execution: DIVD F0, F2, F4 IF ID DIV.. ADDD F10, F0, F8 IF ID stall stall stall SUBD F12, F8, F14 IF stall stall.. Out-of-order order execution: DIVD F0, F2, F4 IF ID DIV.. SUBD F12, F8, F14 IF ID A1 A2 A3 A4 ADDD F10, F0, F8 IF ID stall.. 10
11 Out-of-Order Execution (2/2) Separate issue process in ID: Issue decode instruction check structural hazards in-order execution Read operands Wait until no data hazards Read operands Out-of-order execution/completion i Exception handling problems WAR hazards 11
12 Dynamic Scheduling with a Scoreboard Details in Appendix A.7 Allows out-of-order execution Sufficient resources No data dependenciesd Responsible for issue, execution and hazards Functional units with long delays Duplicated Fully pipelined CDC functional units 12

13 MIPS with Scoreboard 13
14 Scoreboard Operation Scoreboard centralizes hazard management Every instruction goes through the scoreboard Scoreboard determines when the instruction can read its operands and begin execution Monitors changes in hardware and decides when an stalled instruction i can execute Controls when instructions can write results New pipeline ID EX WB Issue Read Regs Execution Write 14
15 Issue Execution Process Functional unit is free (structural) Active instructions do not have same Rd (WAW) Read Operands Checks availability of source operands Resolves RAW hazards dynamically (out-of-order execution) Execution Functional unit begins execution when operands arrive Notifies the scoreboard when it has completed execution Write result Scoreboard checks WAR hazards Stalls the completing instruction if necessary 15
16 Scoreboard Data Structure Instruction status indicates pipeline stage Functional unit status t Busy functional unit is busy or not Op operation to perform in the unit (+, -, etc.) Fi destination register Fj, Fk source register numbers Qj, Qk functional unit producing Fj, Fk Rj, Rk flags indicating when Fj, Fk are ready Register result status FU that will write registers 16
17 Scoreboard Data Structure (1/3) Instruction Issue Read operands Execution completed Write LD F6, 34(R2) Y Y Y Y LD F2, 45(R3) Y Y Y MULTD F0, F2, F4 Y SUBD F8, F6, F2 Y DIVD F10, F0, F6 Y ADDD F6, F8, F2 Name Integer Mult1 Mult2 Add Divide Busy Op Fi Fj Fk Qj Qk Rj Rk Y Load F2 R3 N Y Mult F0 F2 F4 Integer N Y N Y Sub F8 F6 F2 Integer Y N Y Div F10 F0 F6 Mult1 N Y Functional Unit F0 F2 F4 F6 F8 F10 F12... F30 Mult1 Int Add Div 17
18 Scoreboard Data Structure (2/3) 18
19 Scoreboard Data Structure (3/3) 19
20 Scoreboard Algorithm 20
21 Scoreboard Limitations Amount of available ILP Number of scoreboard entries Limited to a basic block Extended beyond a branch Number and types of functional units Structural hazards can increase with DS Presence of anti- and output- dependences Lead to WAR and WAW stalls 21
22 Tomasulo Approach Another approach to eliminate stalls Combines scoreboard with Register renaming (to avoid WAR and WAW) Designed for the IBM 360/91 High FP performance for the whole 360 family Four double precision FP registers Long memory access and long FP delays Can support overlapped execution of multiple iterations of a loop 22
23 Tomasulo Approach 23
24 Issue Stages Empty reservation station or buffer Send operands to the reservation station Use name of reservation station for operands Execute Execute operation if operands are available Monitor CDB for availability of operands Write result When result is available, write it to the CDB 24
25 Example (1/2) 25
26 Example (2/2) 26
27 Tomasulo s Algorithm An enhanced and detailed design in Fig of the textbook 27





28 Loop Iterations Loop: LD F0, 0(R1) MULTD F4,F0,F2 SD 0(R1), F4 SUBI R1, R1, #8 BNEZ R1, Loop 28
29 Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the pipeline) Predict-not-taken taken and predict-takentaken Delayed branch and canceling branch Dynamic predictors Effectiveness of dynamic prediction i schemes Accuracy Cost 29
30 Basic Branch Prediction Buffers a.k.a. Branch History Table (BHT) - Small direct-mapped cache of T/NT bits IR: Branch Instruction PC: + Branch Target BHT T (predict taken) NT (predict not- taken) PC


31 N-bit Branch Prediction Buffers Use an n-bit saturating counter Only the loop exit causes a misprediction 2-bit predictor almost as good as any general n-bit predictor 31



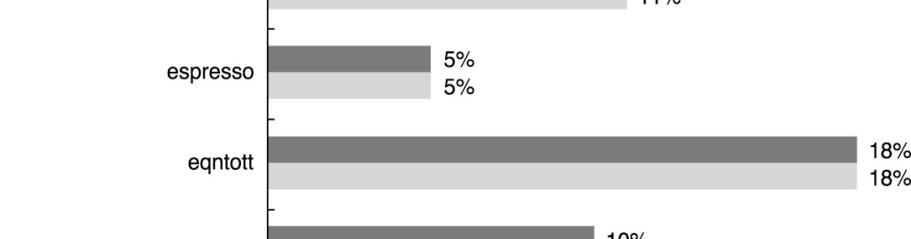
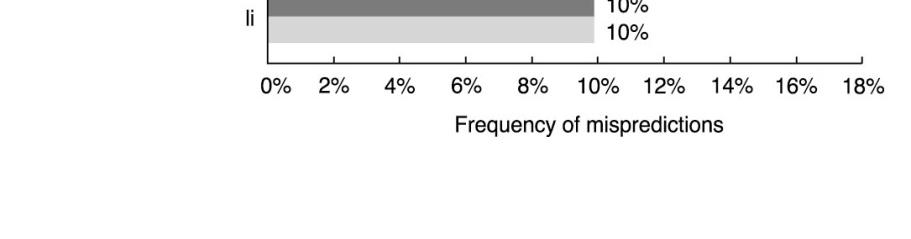
32 Prediction Accuracy of a 4K-entry 2-bit Prediction Buffer 32


33 Branch-Target Buffers Further reduce control stalls (hopefully to 0) Store the predicted address in the buffer Access the buffer during IF 33

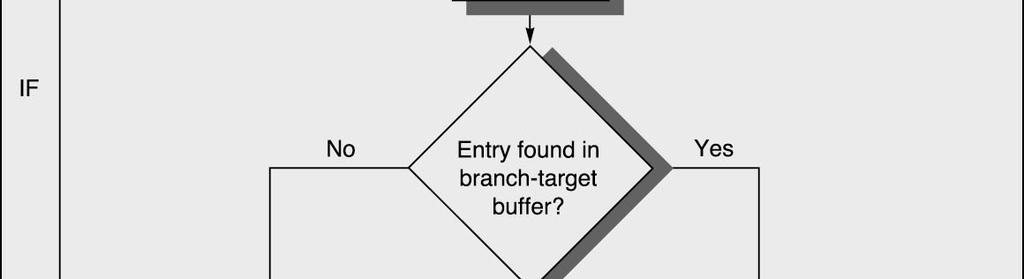
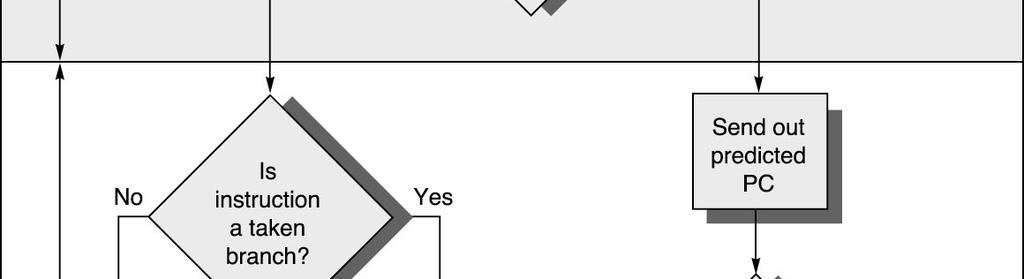
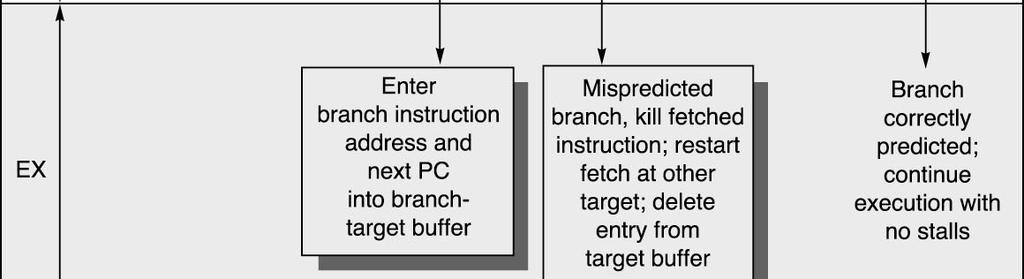

34 Prediction with BTF 34
35 Performance Issues Limitations of branch prediction schemes Prediction accuracy (80% - 95%) Type of program Size of buffer Penalty of misprediction Fetch from both directions to reduce penalty Memory system should: Dual-ported Have an interleaved cache Fetch from one path and then from the other 35
36 Five Primary Approaches in use for Multiple-issue issue Processors 36
What is ILP? Instruction Level Parallelism. Where do we find ILP? How do we expose ILP?
 What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
Scoreboard information (3 tables) Four stages of scoreboard control
 Four stages of scoreboard control") Scoreboard information (3 tables) Instruction : issued, read operands and started execution (dispatched), completed execution or wrote result, Functional unit (assuming non-pipelined units) busy/not busy
Scoreboard information (3 tables) Instruction : issued, read operands and started execution (dispatched), completed execution or wrote result, Functional unit (assuming non-pipelined units) busy/not busy
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Processor: Superscalars Dynamic Scheduling
 Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by:
 Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CPE 631 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
CISC 662 Graduate Computer Architecture. Lecture 10 - ILP 3
 CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction Level Parallelism (ILP)
") Instruction Level Parallelism (ILP) Pipelining supports a limited sense of ILP e.g. overlapped instructions, out of order completion and issue, bypass logic, etc. Remember Pipeline CPI = Ideal Pipeline
Instruction Level Parallelism (ILP) Pipelining supports a limited sense of ILP e.g. overlapped instructions, out of order completion and issue, bypass logic, etc. Remember Pipeline CPI = Ideal Pipeline
Website for Students VTU NOTES QUESTION PAPERS NEWS RESULTS
 Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation. Types of dependences
 and its exploitation. Types of dependences") Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
CPE 631 Lecture 09: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 09: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 09: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Graduate Computer Architecture. Chapter 3. Instruction Level Parallelism and Its Dynamic Exploitation
 Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
Review: Compiler techniques for parallelism Loop unrolling Ÿ Multiple iterations of loop in software:
 CS152 Computer Architecture and Engineering Lecture 17 Dynamic Scheduling: Tomasulo March 20, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
CS152 Computer Architecture and Engineering Lecture 17 Dynamic Scheduling: Tomasulo March 20, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Pipelining: Issue instructions in every cycle (CPI 1) Compiler scheduling (static scheduling) reduces impact of dependences
 Compiler scheduling (static scheduling) reduces impact of dependences") Dynamic Scheduling Pipelining: Issue instructions in every cycle (CPI 1) Compiler scheduling (static scheduling) reduces impact of dependences Increased compiler complexity, especially when attempting
Dynamic Scheduling Pipelining: Issue instructions in every cycle (CPI 1) Compiler scheduling (static scheduling) reduces impact of dependences Increased compiler complexity, especially when attempting
Page 1. Recall from Pipelining Review. Lecture 15: Instruction Level Parallelism and Dynamic Execution
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
Advantages of Dynamic Scheduling
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 5 Dynamic scheduling with Scoreboards Israel Koren ECE568/Koren Part.5.1 Advantages of Dynamic
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 5 Dynamic scheduling with Scoreboards Israel Koren ECE568/Koren Part.5.1 Advantages of Dynamic
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Good luck and have fun!
 Midterm Exam October 13, 2014 Name: Problem 1 2 3 4 total Points Exam rules: Time: 90 minutes. Individual test: No team work! Open book, open notes. No electronic devices, except an unprogrammed calculator.
Midterm Exam October 13, 2014 Name: Problem 1 2 3 4 total Points Exam rules: Time: 90 minutes. Individual test: No team work! Open book, open notes. No electronic devices, except an unprogrammed calculator.
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism
 ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
Lecture 4: Introduction to Advanced Pipelining
 Lecture 4: Introduction to Advanced Pipelining Prepared by: Professor David A. Patterson Computer Science 252, Fall 1996 Edited and presented by : Prof. Kurt Keutzer Computer Science 252, Spring 2000 KK
Lecture 4: Introduction to Advanced Pipelining Prepared by: Professor David A. Patterson Computer Science 252, Fall 1996 Edited and presented by : Prof. Kurt Keutzer Computer Science 252, Spring 2000 KK
Review: Evaluating Branch Alternatives. Lecture 3: Introduction to Advanced Pipelining. Review: Evaluating Branch Prediction
 Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Detailed Scoreboard Pipeline Control. Three Parts of the Scoreboard. Scoreboard Example Cycle 1. Scoreboard Example. Scoreboard Example Cycle 3
 1 From MIPS pipeline to Scoreboard Lecture 5 Scoreboarding: Enforce Register Data Dependence Scoreboard design, big example Out-of-order execution divides ID stage: 1.Issue decode instructions, check for
1 From MIPS pipeline to Scoreboard Lecture 5 Scoreboarding: Enforce Register Data Dependence Scoreboard design, big example Out-of-order execution divides ID stage: 1.Issue decode instructions, check for
COSC4201 Instruction Level Parallelism Dynamic Scheduling
 COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Dynamic Scheduling. Better than static scheduling Scoreboarding: Tomasulo algorithm:
 LECTURE - 13 Dynamic Scheduling Better than static scheduling Scoreboarding: Used by the CDC 6600 Useful only within basic block WAW and WAR stalls Tomasulo algorithm: Used in IBM 360/91 for the FP unit
LECTURE - 13 Dynamic Scheduling Better than static scheduling Scoreboarding: Used by the CDC 6600 Useful only within basic block WAW and WAR stalls Tomasulo algorithm: Used in IBM 360/91 for the FP unit
COSC 6385 Computer Architecture - Pipelining (II)
") COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
Compiler Optimizations. Lecture 7 Overview of Superscalar Techniques. Memory Allocation by Compilers. Compiler Structure. Register allocation
 Lecture 7 Overview of Superscalar Techniques CprE 581 Computer Systems Architecture, Fall 2013 Reading: Textbook, Ch. 3 Complexity-Effective Superscalar Processors, PhD Thesis by Subbarao Palacharla, Ch.1
Lecture 7 Overview of Superscalar Techniques CprE 581 Computer Systems Architecture, Fall 2013 Reading: Textbook, Ch. 3 Complexity-Effective Superscalar Processors, PhD Thesis by Subbarao Palacharla, Ch.1
CS252 Graduate Computer Architecture Lecture 6. Recall: Software Pipelining Example
 CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Instruction Frequency CPI. Load-store 55% 5. Arithmetic 30% 4. Branch 15% 4
 PROBLEM 1: An application running on a 1GHz pipelined processor has the following instruction mix: Instruction Frequency CPI Load-store 55% 5 Arithmetic 30% 4 Branch 15% 4 a) Determine the overall CPI
PROBLEM 1: An application running on a 1GHz pipelined processor has the following instruction mix: Instruction Frequency CPI Load-store 55% 5 Arithmetic 30% 4 Branch 15% 4 a) Determine the overall CPI
Latencies of FP operations used in chapter 4.
 Instruction-Level Parallelism (ILP) ILP: refers to the overlap execution of instructions. Pipelined CPI = Ideal pipeline CPI + structural stalls + RAW stalls + WAR stalls + WAW stalls + Control stalls.
Instruction-Level Parallelism (ILP) ILP: refers to the overlap execution of instructions. Pipelined CPI = Ideal pipeline CPI + structural stalls + RAW stalls + WAR stalls + WAW stalls + Control stalls.
Instruction Level Parallelism
 Instruction Level Parallelism Dynamic scheduling Scoreboard Technique Tomasulo Algorithm Speculation Reorder Buffer Superscalar Processors 1 Definition of ILP ILP=Potential overlap of execution among unrelated
Instruction Level Parallelism Dynamic scheduling Scoreboard Technique Tomasulo Algorithm Speculation Reorder Buffer Superscalar Processors 1 Definition of ILP ILP=Potential overlap of execution among unrelated
Instruction Level Parallelism. Taken from
 Instruction Level Parallelism Taken from http://www.cs.utsa.edu/~dj/cs3853/lecture5.ppt Outline ILP Compiler techniques to increase ILP Loop Unrolling Static Branch Prediction Dynamic Branch Prediction
Instruction Level Parallelism Taken from http://www.cs.utsa.edu/~dj/cs3853/lecture5.ppt Outline ILP Compiler techniques to increase ILP Loop Unrolling Static Branch Prediction Dynamic Branch Prediction
Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1
![Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1](/thumbs/92/108067849.jpg "Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1") Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
吳俊興高雄大學資訊工程學系. October Example to eleminate WAR and WAW by register renaming. Tomasulo Algorithm. A Dynamic Algorithm: Tomasulo s Algorithm
 EEF011 Computer Architecture 計算機結構 吳俊興高雄大學資訊工程學系 October 2004 Example to eleminate WAR and WAW by register renaming Original DIV.D ADD.D S.D SUB.D MUL.D F0, F2, F4 F6, F0, F8 F6, 0(R1) F8, F10, F14 F6,
EEF011 Computer Architecture 計算機結構 吳俊興高雄大學資訊工程學系 October 2004 Example to eleminate WAR and WAW by register renaming Original DIV.D ADD.D S.D SUB.D MUL.D F0, F2, F4 F6, F0, F8 F6, 0(R1) F8, F10, F14 F6,
DYNAMIC INSTRUCTION SCHEDULING WITH SCOREBOARD
 DYNAMIC INSTRUCTION SCHEDULING WITH SCOREBOARD Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson,
DYNAMIC INSTRUCTION SCHEDULING WITH SCOREBOARD Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson,
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions
 CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CMSC411 Fall 2013 Midterm 2 Solutions
 CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
Advanced Computer Architecture CMSC 611 Homework 3. Due in class Oct 17 th, 2012
 Advanced Computer Architecture CMSC 611 Homework 3 Due in class Oct 17 th, 2012 (Show your work to receive partial credit) 1) For the following code snippet list the data dependencies and rewrite the code
Advanced Computer Architecture CMSC 611 Homework 3 Due in class Oct 17 th, 2012 (Show your work to receive partial credit) 1) For the following code snippet list the data dependencies and rewrite the code
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Pipelining and Exploiting Instruction-Level Parallelism (ILP)
") Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Dynamic Hardware Prediction. Basic Branch Prediction Buffers. N-bit Branch Prediction Buffers
 Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the
Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 09
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 09
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Multicycle ALU Operations 2/28/2011. Diversified Pipelines The Path Toward Superscalar Processors. Limitations of Our Simple 5 stage Pipeline
 //11 Limitations of Our Simple stage Pipeline Diversified Pipelines The Path Toward Superscalar Processors HPCA, Spring 11 Assumes single cycle EX stage for all instructions This is not feasible for Complex
//11 Limitations of Our Simple stage Pipeline Diversified Pipelines The Path Toward Superscalar Processors HPCA, Spring 11 Assumes single cycle EX stage for all instructions This is not feasible for Complex
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW. Computer Architectures S
 Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Chapter 3 & Appendix C Part B: ILP and Its Exploitation
 CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
EECC551 Review. Dynamic Hardware-Based Speculation
 EECC551 Review Recent Trends in Computer Design. Computer Performance Measures. Instruction Pipelining. Branch Prediction. Instruction-Level Parallelism (ILP). Loop-Level Parallelism (LLP). Dynamic Pipeline
EECC551 Review Recent Trends in Computer Design. Computer Performance Measures. Instruction Pipelining. Branch Prediction. Instruction-Level Parallelism (ILP). Loop-Level Parallelism (LLP). Dynamic Pipeline
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2018 Static Instruction Scheduling 1 Techniques to reduce stalls CPI = Ideal CPI + Structural stalls per instruction + RAW stalls per instruction + WAR stalls per
CS425 Computer Systems Architecture Fall 2018 Static Instruction Scheduling 1 Techniques to reduce stalls CPI = Ideal CPI + Structural stalls per instruction + RAW stalls per instruction + WAR stalls per
Preventing Stalls: 1
 Preventing Stalls: 1 2 PipeLine Pipeline efficiency Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls Ideal pipeline CPI: best possible (1 as n ) Structural hazards:
Preventing Stalls: 1 2 PipeLine Pipeline efficiency Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls Ideal pipeline CPI: best possible (1 as n ) Structural hazards:
Tomasulo s Algorithm
 Tomasulo s Algorithm Architecture to increase ILP Removes WAR and WAW dependencies during issue WAR and WAW Name Dependencies Artifact of using the same storage location (variable name) Can be avoided
Tomasulo s Algorithm Architecture to increase ILP Removes WAR and WAW dependencies during issue WAR and WAW Name Dependencies Artifact of using the same storage location (variable name) Can be avoided
ELE 818 * ADVANCED COMPUTER ARCHITECTURES * MIDTERM TEST *
 ELE 818 * ADVANCED COMPUTER ARCHITECTURES * MIDTERM TEST * SAMPLE 1 Section: Simple pipeline for integer operations For all following questions we assume that: a) Pipeline contains 5 stages: IF, ID, EX,
ELE 818 * ADVANCED COMPUTER ARCHITECTURES * MIDTERM TEST * SAMPLE 1 Section: Simple pipeline for integer operations For all following questions we assume that: a) Pipeline contains 5 stages: IF, ID, EX,
ILP: Instruction Level Parallelism
 ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
CS252 Graduate Computer Architecture Lecture 8. Review: Scoreboard (CDC 6600) Explicit Renaming Precise Interrupts February 13 th, 2010
 Explicit Renaming Precise Interrupts February 13 th, 2010") CS252 Graduate Computer Architecture Lecture 8 Explicit Renaming Precise Interrupts February 13 th, 2010 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley
CS252 Graduate Computer Architecture Lecture 8 Explicit Renaming Precise Interrupts February 13 th, 2010 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley
CS433 Homework 2 (Chapter 3)
") CS433 Homework 2 (Chapter 3) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
CS433 Homework 2 (Chapter 3) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Exploiting ILP with SW Approaches. Aleksandar Milenković, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Functional Units. Registers. The Big Picture: Where are We Now? The Five Classic Components of a Computer Processor Input Control Memory
 The Big Picture: Where are We Now? CS152 Computer Architecture and Engineering Lecture 18 The Five Classic Components of a Computer Processor Input Control Dynamic Scheduling (Cont), Speculation, and ILP
The Big Picture: Where are We Now? CS152 Computer Architecture and Engineering Lecture 18 The Five Classic Components of a Computer Processor Input Control Dynamic Scheduling (Cont), Speculation, and ILP
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,
 Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,") Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Topics. Digital Systems Architecture EECE EECE Predication, Prediction, and Speculation
 Digital Systems Architecture EECE 343-01 EECE 292-02 Predication, Prediction, and Speculation Dr. William H. Robinson February 25, 2004 http://eecs.vanderbilt.edu/courses/eece343/ Topics Aha, now I see,
Digital Systems Architecture EECE 343-01 EECE 292-02 Predication, Prediction, and Speculation Dr. William H. Robinson February 25, 2004 http://eecs.vanderbilt.edu/courses/eece343/ Topics Aha, now I see,
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Hardware-based Speculation
 Hardware-based Speculation M. Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica 1 Introduction Hardware-based speculation is a technique for reducing the effects of control dependences
Hardware-based Speculation M. Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica 1 Introduction Hardware-based speculation is a technique for reducing the effects of control dependences
Superscalar Architectures: Part 2
 Superscalar Architectures: Part 2 Dynamic (Out-of-Order) Scheduling Lecture 3.2 August 23 rd, 2017 Jae W. Lee (jaewlee@snu.ac.kr) Computer Science and Engineering Seoul NaMonal University Download this
Superscalar Architectures: Part 2 Dynamic (Out-of-Order) Scheduling Lecture 3.2 August 23 rd, 2017 Jae W. Lee (jaewlee@snu.ac.kr) Computer Science and Engineering Seoul NaMonal University Download this
DYNAMIC SPECULATIVE EXECUTION
 DYNAMIC SPECULATIVE EXECUTION Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
DYNAMIC SPECULATIVE EXECUTION Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CS433 Homework 2 (Chapter 3)
") CS Homework 2 (Chapter ) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies on collaboration..
CS Homework 2 (Chapter ) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies on collaboration..
What is instruction level parallelism?
 Instruction Level Parallelism Sangyeun Cho Computer Science Department What is instruction level parallelism? Execute independent instructions in parallel Provide more hardware function units (e.g., adders,
Instruction Level Parallelism Sangyeun Cho Computer Science Department What is instruction level parallelism? Execute independent instructions in parallel Provide more hardware function units (e.g., adders,
NOW Handout Page 1. Review from Last Time. CSE 820 Graduate Computer Architecture. Lec 7 Instruction Level Parallelism. Recall from Pipelining Review
 Review from Last Time CSE 820 Graduate Computer Architecture Lec 7 Instruction Level Parallelism Based on slides by David Patterson 4 papers: All about where to draw line between HW and SW IBM set foundations
Review from Last Time CSE 820 Graduate Computer Architecture Lec 7 Instruction Level Parallelism Based on slides by David Patterson 4 papers: All about where to draw line between HW and SW IBM set foundations
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
Computer Architecture Homework Set # 3 COVER SHEET Please turn in with your own solution
 CSCE 6 (Fall 07) Computer Architecture Homework Set # COVER SHEET Please turn in with your own solution Eun Jung Kim Write your answers on the sheets provided. Submit with the COVER SHEET. If you need
CSCE 6 (Fall 07) Computer Architecture Homework Set # COVER SHEET Please turn in with your own solution Eun Jung Kim Write your answers on the sheets provided. Submit with the COVER SHEET. If you need
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
The basic structure of a MIPS floating-point unit
 Tomasulo s scheme The algorithm based on the idea of reservation station The reservation station fetches and buffers an operand as soon as it is available, eliminating the need to get the operand from
Tomasulo s scheme The algorithm based on the idea of reservation station The reservation station fetches and buffers an operand as soon as it is available, eliminating the need to get the operand from
Course on Advanced Computer Architectures
 Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
NOW Handout Page 1. Outline. Csci 211 Computer System Architecture. Lec 4 Instruction Level Parallelism. Instruction Level Parallelism
 Outline Csci 211 Computer System Architecture Lec 4 Instruction Level Parallelism Xiuzhen Cheng Department of Computer Sciences The George Washington University ILP Compiler techniques to increase ILP
Outline Csci 211 Computer System Architecture Lec 4 Instruction Level Parallelism Xiuzhen Cheng Department of Computer Sciences The George Washington University ILP Compiler techniques to increase ILP
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
CSE 502 Graduate Computer Architecture. Lec 8-10 Instruction Level Parallelism
 CSE 502 Graduate Computer Architecture Lec 8-10 Instruction Level Parallelism Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
CSE 502 Graduate Computer Architecture Lec 8-10 Instruction Level Parallelism Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Computer Architectures. Chapter 4. Tien-Fu Chen. National Chung Cheng Univ.
 Computer Architectures Chapter 4 Tien-Fu Chen National Chung Cheng Univ. chap4-0 Advance Pipelining! Static Scheduling Have compiler to minimize the effect of structural, data, and control dependence "
Computer Architectures Chapter 4 Tien-Fu Chen National Chung Cheng Univ. chap4-0 Advance Pipelining! Static Scheduling Have compiler to minimize the effect of structural, data, and control dependence "
CS433 Midterm. Prof Josep Torrellas. October 19, Time: 1 hour + 15 minutes
 CS433 Midterm Prof Josep Torrellas October 19, 2017 Time: 1 hour + 15 minutes Name: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your time.
CS433 Midterm Prof Josep Torrellas October 19, 2017 Time: 1 hour + 15 minutes Name: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your time.
Branch prediction ( 3.3) Dynamic Branch Prediction
 Dynamic Branch Prediction") prediction ( 3.3) Static branch prediction (built into the architecture) The default is to assume that branches are not taken May have a design which predicts that branches are taken It is reasonable to
prediction ( 3.3) Static branch prediction (built into the architecture) The default is to assume that branches are not taken May have a design which predicts that branches are taken It is reasonable to