UNIT 8 1. Explain in detail the hardware support for preserving exception behavior during Speculation.
|
|
|
- Madison Bates
- 6 years ago
- Views:
Transcription
1 UNIT 8 1. Explain in detail the hardware support for preserving exception behavior during Speculation. July 14) (June 2013) (June 2015)(Jan 2016)(June 2016) H/W Support : Conditional Execution Also known as Predicated Execution Enhancement to instruction set Can be used to eliminate branches All control dependences are converted to data dependences Instruction refers to a condition Evaluated as part of the execution True? Executed normally False? Execution continues as if the instruction were a no-op Example : Conditional move between registers Example if (A==0) S = T; Straightforward Code BNEZ R1, L; ADDU R2, R3, R0 L: Conditional Code CMOVZ R2, R3, R1 Annulled if R1 is not 0 Conditional Instruction Can convert control to data dependence In vector computing, it s called if conversion. Traditionally, in a pipelined system Dependence has to be resolved closer to front of pipeline For conditional execution Dependence is resolved at end of pipeline, closer to the register write Another example A = abs(b) if (B < 0) A = -B; else A = B; Two conditional moves
2 One unconditional and one conditional move The branch condition has moved into the instruction Control dependence becomes data dependence Limitations of Conditional Moves Conditional moves are the simplest form of predicated instructions Useful for short sequences For large code, this can be inefficient Introduces many conditional moves Some architectures support full predication All instructions, not just moves Very useful in global scheduling Can handle nonloop branches nicely Eg : The whole if portion can be predicated if the frequent path is not taken Assume : Two issues, one to ALU and one to memory; or branch by itself Wastes a memory operation slot in second cycle Can incur a data dependence stall if branch is not taken R9 depends on R8 Predicated Execution Assume : LWC is predicated load and loads if third operand is not 0 One instruction issue slot is eliminated On mispredicted branch, predicated instruction will not have any effect If sequence following the branch is short, the entire block of the code can be predicated
3 Some Complications Exception Behavior Must not generate exception if the predicate is false If R10 is zero in the previous example LW R8, 0(R10) can cause a protection fault If condition is satisfied A page fault can still occur Biggest Issue Decide when to annul an instruction Can be done during issue Early in pipeline Value of condition must be known early, can induce stalls Can be done before commit Modern processors do this Annulled instructions will use functional resources Register forwarding and such can complicate implementation 2. Explain the prediction and Speculation support provided in IA64? (Dec 2013) (June 2014) IA-64 Pipeline Features Branch Prediction Predicate Registers allow branches to be turned on or off Compiler can provide branch prediction hints Register Rotation Allows faster loop execution in parallel Predication Controls Pipeline Stages Cache Features L1 Cache 4 way associative 16Kb Instruction 16Kb Data L2 Cache Itanium 6 way associative 96 Kb Itanium2 8 way associative 256 Kb Initially 256Kb Data and 1Mb Instruction on Montvale! Cache Features L3 Cache Itanium 4 way associative Accessible through FSB 2-4Mb

4 Itanium2 2 4 way associative On Die 3Mb Up to 24Mb on Montvale chips(12mb/core)! Register Specification _128, 65-bit General Purpose Registers _128, 82-bit Floating Point Registers _128, 64-bit Application Registers _8, 64-bit Branch Registers _64, 1-bit Predicate Registers Register Model _128 General and Floating Point Registers _32 always available, 96 on stack _As functions are called, compiler allocates a specific number of local and output registers to use in the function by using register allocation instruction Alloc. _Programs renames registers to start from 32 to 127. _Register Stack Engine (RSE) automatically saves/restores stack to memory when needed _RSE may be designed to utilize unused memory bandwidth to perform register spill and fill operations in the background Dept of CSE,SJBIT,Bangalore 94
5 On function call, machine shifts register window such that previous output registers become new locals starting at r32
6

 and memory operations (in what level of the memory hierarchy to cache")
7 Instruction Encoding Each instruction includes the opcode and three operands Each instructions holds the identifier for a corresponding Predicate Register Each bundle contains 3 independent instructions Each instruction is 41 bits wide Each bundle also holds a 5 bit template field Distributing Responsibility _ILP Instruction Groups _Control flow parallelism Parallel comparison Multiway branches _Influencing dynamic events Provides an extensive set of hints that the compiler uses to tell the hardware about likely branch behavior (taken or not taken, amount to fetch at branch target) and memory operations (in what level of the memory hierarchy to cache data).

8 _Use predicates to eliminate branches, move instructions across branches _Conditional execution of an instruction based on predicate register (64 1-bit predicate registers) _Predicates are set by compare instructions _Most instructions can be predicated each instruction code contains predicate field _If predicate is true, the instruction updates the computation state; otherwise, it behaves like a nop Scheduling and Speculation Basic block: code with single entry and exit, exit point can be multiway branch Control Improve ILP by statically move ahead long latency code blocks. path is a frequent execution path Schedule for control paths Because of branches and loops, only small percentage of code is executed regularly Analyze dependences in blocks and paths Compiler can analyze more efficiently - more time, memory, larger view of the program Compiler can locate and optimize the commonly executed blocks
9 Control speculation _ Not all the branches can be removed using predication. _ Loads have longer latency than most instructions and tend to start timecritical chains of instructions _ Constraints on code motion on loads limit parallelism _ Non-EPIC architectures constrain motion of load instruction _ IA-64: Speculative loads, can safely schedule load instruction before one or more prior branches Control Speculation _Exceptions are handled by setting NaT (Not a Thing) in target register _Check instruction-branch to fix-up code if NaT flag set _Fix-up code: generated by compiler, handles exceptions _NaT bit propagates in execution (almost all IA-64 instructions) _NaT propagation reduces required check points Speculative Load _ Load instruction (ld.s) can be moved outside of a basic block even if branch target is not known
 will jump to fix-up code if NaT is set Data Speculation _ The compiler may not be able to determine the location in memory being referenced (pointers) _ Want to move calculations ahead of a")
10 _ Speculative loads does not produce exception - it sets the NaT _ Check instruction (chk.s) will jump to fix-up code if NaT is set Data Speculation _ The compiler may not be able to determine the location in memory being referenced (pointers) _ Want to move calculations ahead of a possible memory dependency _ Traditionally, given a store followed by a load, if the compiler cannot determine if the addresses will be equal, the load cannot be moved ahead of the store. _ IA-64: allows compiler to schedule a load before one or more stores _ Use advance load (ld.a) and check (chk.a) to implement _ ALAT (Advanced Load Address Table) records target register, memory address accessed, and access size Data Speculation 1. Allows for loads to be moved ahead of stores even if the compiler is unsure if addresses are the same 2. A speculative load generates an entry in the ALAT 3. A store removes every entry in the ALAT that have the same address 4. Check instruction will branch to fix-up if the given address is not in the ALAT Use address field as the key for comparison If an address cannot be found, run recovery code ALAT are smaller and simpler implementation than equivalent structures for superscalars 3.Explain in detail the hardware support for preserving exception behavior during speculation. (July 2014) (June2013) (June 2016) H/W Support : Conditional Execution Also known as Predicated Execution Enhancement to instruction set Can be used to eliminate branches All control dependences are converted to data dependences Instruction refers to a condition Evaluated as part of the execution
11 True? Executed normally False? Execution continues as if the instruction were a no-op Example : Conditional move between registers Example if (A==0) S = T; Straightforward Code BNEZ R1, L; ADDU R2, R3, R0 L: Conditional Code CMOVZ R2, R3, R1 Annulled if R1 is not 0 Conditional Instruction Can convert control to data dependence In vector computing, it s called if conversion. Traditionally, in a pipelined system Dependence has to be resolved closer to front of pipeline For conditional execution Dependence is resolved at end of pipeline, closer to the register write Another example A = abs(b) if (B < 0) A = -B; else A = B; Two conditional moves One unconditional and one conditional move The branch condition has moved into the instruction Control dependence becomes data dependence Limitations of Conditional Moves Conditional moves are the simplest form of predicated instructions Useful for short sequences For large code, this can be inefficient Introduces many conditional moves
12 Some architectures support full predication All instructions, not just moves Very useful in global scheduling Can handle nonloop branches nicely Eg : The whole if portion can be predicated if the frequent path is not taken Assume : Two issues, one to ALU and one to memory; or branch by itself Wastes a memory operation slot in second cycle Can incur a data dependence stall if branch is not taken R9 depends on R8 Predicated Execution Assume : LWC is predicated load and loads if third operand is not 0 One instruction issue slot is eliminated On mispredicted branch, predicated instruction will not have any effect If sequence following the branch is short, the entire block of the code can be predicated Some Complications Exception Behavior Must not generate exception if the predicate is false If R10 is zero in the previous example
13 LW R8, 0(R10) can cause a protection fault If condition is satisfied A page fault can still occur Biggest Issue Decide when to annul an instruction Can be done during issue Early in pipeline Value of condition must be known early, can induce stalls Can be done before commit Modern processors do this Annulled instructions will use functional resources Register forwarding and such can complicate implementation 4. Explain the architecture of IA64 Intel processor and also the prediction and speculation support provided. (June 2013) (Jan 2014) (Jan 2015) (June 2015)(Jan 2016) IA-64 and Itanium Processor Introducing The IA-64 Architecture Itanium and Itanium2 Processor Slide Sources: Based on Computer Architecture by Hennessy/Patterson. Supplemented from various freely downloadable sources IA-64 is an EPIC IA-64 largely depends on software for parallelism VLIW Very Long Instruction Word EPIC Explicitly Parallel Instruction Computer VLIW points VLIW Overview RISC technique Bundles of instructions to be run in parallel Similar to superscaling Uses compiler instead of branch prediction hardware EPIC EPIC Overview Builds on VLIW Redefines instruction format Instruction coding tells CPU how to process data Very compiler dependent Predicated execution


14 EPIC pros and cons EPIC Pros: Compiler has more time to spend with code Time spent by compiler is a one-time cost Reduces circuit complexity Chip Layout Itanium Architecture Diagram
þ 800Mhz Clock Intel Itanium 800 MHz 10 stage pipeline Can issue 6 instructions (2 bundles) per cycle 4 Integer, 4 Floating Point, 4 Multimedia, 2 Memory, 3 Branch Units 32 KB L1, 96")
15 Itanium Specs 4 Integer ALU's 4 multimedia ALU's 2 Extended Precision FP Units 2 Single Precision FP units 2 Load or Store Units 3 Branch Units 10 Stage 6 Wide Pipeline 32k L1 Cache 96K L2 Cache 4MB L3 Cache(extern)þ 800Mhz Clock Intel Itanium 800 MHz 10 stage pipeline Can issue 6 instructions (2 bundles) per cycle 4 Integer, 4 Floating Point, 4 Multimedia, 2 Memory, 3 Branch Units 32 KB L1, 96 KB L2, 4 MB L3 caches 2.1 GB/s memory bandwidth Itanium2 Specs 6 Integer ALU's
16 6 multimedia ALU's 2 Extended Precision FP Units 2 Single Precision FP units 2 Load and Store Units 3 Branch Units 8 Stage 6 Wide Pipeline 32k L1 Cache 256K L2 Cache 3MB L3 Cache(on die)þ 1Ghz Clock initially Up to 1.66Ghz on Montvale Itanium2 Improvements Initially a 180nm process Increased to 130nm in 2003 Further increased to 90nm in 2007 Improved Thermal Management Clock Speed increased to 1.0Ghz Bus Speed Increase from 266Mhz to 400Mhz L3 cache moved on die Faster access rate IA-64 Pipeline Features Branch Prediction Predicate Registers allow branches to be turned on or off Compiler can provide branch prediction hints Register Rotation Allows faster loop execution in parallel Predication Controls Pipeline Stages Cache Features L1 Cache 4 way associative 16Kb Instruction 16Kb Data L2 Cache Itanium 6 way associative 96 Kb Itanium2 8 way associative 256 Kb Initially 256Kb Data and 1Mb Instruction on Montvale! Cache Features
17 L3 Cache Itanium 4 way associative Accessible through FSB 2-4Mb Itanium2 2 4 way associative On Die 3Mb Up to 24Mb on Montvale chips(12mb/core)! Register Specification _128, 65-bit General Purpose Registers _128, 82-bit Floating Point Registers _128, 64-bit Application Registers _8, 64-bit Branch Registers _64, 1-bit Predicate Registers Register Model _128 General and Floating Point Registers _32 always available, 96 on stack _As functions are called, compiler allocates a specific number of local and output registers to use in the function by using register allocation instruction Alloc. _Programs renames registers to start from 32 to 127. _Register Stack Engine (RSE) automatically saves/restores stack to memory when needed _RSE may be designed to utilize unused memory bandwidth to perform register spill and fill operations in the background On function call, machine shifts register window such that previous output registers become new locals starting at
18 5. Consider the loop below: For ( i = 1;i 100 ; i = i+1 { A[ i ]= A[i] + B[i] ; 1 * S1 *1 B[ i+1]= C[i] + D[i] ; 1 * S2 *1 } What are the dependencies between S1 and S2? Is the loop parallel? If not show how to make it parallel. (Dec 2013) (Jan 2015)(June 2016) For the loop: for (i=1; i<=100; i=i+1) { A[i+1] = A[i] + C[i]; /* S1 */ B[i+1] = B[i] + A[i+1]; /* S2 */ } what are the dependences? There are two different dependences:
19 loop-carried: (prevents parallel operation of iterations) S1 computes A[i+1] using value of A[i] computed in previous iteration S2 computes B[i+1] using value of B[i] computed in previous iteration not loop-carried: (parallel operation of iterations is ok) S2 uses the value A[i+1] computed by S1 in the same iteration The loop-carried dependences in this case force successive iterations of the loop to execute in series. Why? S1 of iteration i depends on S1 of iteration i-1 which in turn depends on, etc. Another Loop with Dependences Generally, loop-carried dependences hinder ILP if there are no loop-carried dependences all iterations could be executed in parallel even if there are loop-carried dependences it may be possible to parallelize the loop an analysis of the dependences is required For the loop: for (i=1; i<=100; i=i+1) { A[i] = A[i] + B[i]; /* S1 */ B[i+1] = C[i] + D[i]; /* S2 */ } what are the dependences? There is one loop-carried dependence: S1 uses the value of B[i] computed in a previous iteration by S2 but this does not force iterations to execute in series. Why? because S1 of iteration i depends on S2 of iteration i-1, and the chain of dependences stops here! Parallelizing Loops with Short Chains of Dependences Parallelize the loop: for (i=1; i<=100; i=i+1) { A[i] = A[i] + B[i]; /* S1 */ B[i+1] = C[i] + D[i]; /* S2 */ } Parallelized code: A[1] = A[1] + B[1]; for (i=1; i<=99; i=i+1) { B[i+1] = C[i] + D[i]; A[i+1] = A[i+1] + B[i+1]; } B[101] = C[100] + D[100]; the dependence between the two statements in the loop is no longer loop-carried and iterations of the loop may be executed in parallel
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Several Common Compiler Strategies. Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining
 Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 10 Compiler Techniques / VLIW Israel Koren ECE568/Koren Part.10.1 FP Loop Example Add a scalar
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 10 Compiler Techniques / VLIW Israel Koren ECE568/Koren Part.10.1 FP Loop Example Add a scalar
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
Advanced Computer Architecture
 ECE 563 Advanced Computer Architecture Fall 2010 Lecture 6: VLIW 563 L06.1 Fall 2010 Little s Law Number of Instructions in the pipeline (parallelism) = Throughput * Latency or N T L Throughput per Cycle
ECE 563 Advanced Computer Architecture Fall 2010 Lecture 6: VLIW 563 L06.1 Fall 2010 Little s Law Number of Instructions in the pipeline (parallelism) = Throughput * Latency or N T L Throughput per Cycle
Agenda. What is the Itanium Architecture? Terminology What is the Itanium Architecture? Thomas Siebold Technology Consultant Alpha Systems Division
 What is the Itanium Architecture? Thomas Siebold Technology Consultant Alpha Systems Division thomas.siebold@hp.com Agenda Terminology What is the Itanium Architecture? 1 Terminology Processor Architectures
What is the Itanium Architecture? Thomas Siebold Technology Consultant Alpha Systems Division thomas.siebold@hp.com Agenda Terminology What is the Itanium Architecture? 1 Terminology Processor Architectures
Computer Science 146. Computer Architecture
 Computer Architecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 12: Hardware Assisted Software ILP and IA64/Itanium Case Study Lecture Outline Review of Global Scheduling,
Computer Architecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 12: Hardware Assisted Software ILP and IA64/Itanium Case Study Lecture Outline Review of Global Scheduling,
HY425 Lecture 09: Software to exploit ILP
 HY425 Lecture 09: Software to exploit ILP Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 4, 2010 ILP techniques Hardware Dimitrios S. Nikolopoulos HY425 Lecture 09: Software to exploit
HY425 Lecture 09: Software to exploit ILP Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 4, 2010 ILP techniques Hardware Dimitrios S. Nikolopoulos HY425 Lecture 09: Software to exploit
HY425 Lecture 09: Software to exploit ILP
 HY425 Lecture 09: Software to exploit ILP Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 4, 2010 Dimitrios S. Nikolopoulos HY425 Lecture 09: Software to exploit ILP 1 / 44 ILP techniques
HY425 Lecture 09: Software to exploit ILP Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 4, 2010 Dimitrios S. Nikolopoulos HY425 Lecture 09: Software to exploit ILP 1 / 44 ILP techniques
The IA-64 Architecture. Salient Points
 The IA-64 Architecture Department of Electrical Engineering at College Park OUTLINE: Architecture overview Background Architecture Specifics UNIVERSITY OF MARYLAND AT COLLEGE PARK Salient Points 128 Registers
The IA-64 Architecture Department of Electrical Engineering at College Park OUTLINE: Architecture overview Background Architecture Specifics UNIVERSITY OF MARYLAND AT COLLEGE PARK Salient Points 128 Registers
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Lecture 6: Static ILP
 Lecture 6: Static ILP Topics: loop analysis, SW pipelining, predication, speculation (Section 2.2, Appendix G) Assignment 2 posted; due in a week 1 Loop Dependences If a loop only has dependences within
Lecture 6: Static ILP Topics: loop analysis, SW pipelining, predication, speculation (Section 2.2, Appendix G) Assignment 2 posted; due in a week 1 Loop Dependences If a loop only has dependences within
Page # Let the Compiler Do it Pros and Cons Pros. Exploiting ILP through Software Approaches. Cons. Perhaps a mixture of the two?
 Exploiting ILP through Software Approaches Venkatesh Akella EEC 270 Winter 2005 Based on Slides from Prof. Al. Davis @ cs.utah.edu Let the Compiler Do it Pros and Cons Pros No window size limitation, the
Exploiting ILP through Software Approaches Venkatesh Akella EEC 270 Winter 2005 Based on Slides from Prof. Al. Davis @ cs.utah.edu Let the Compiler Do it Pros and Cons Pros No window size limitation, the
UCI. Intel Itanium Line Processor Efforts. Xiaobin Li. PASCAL EECS Dept. UC, Irvine. University of California, Irvine
 Intel Itanium Line Processor Efforts Xiaobin Li PASCAL EECS Dept. UC, Irvine Outline Intel Itanium Line Roadmap IA-64 Architecture Itanium Processor Microarchitecture Case Study of Exploiting TLP at VLIW
Intel Itanium Line Processor Efforts Xiaobin Li PASCAL EECS Dept. UC, Irvine Outline Intel Itanium Line Roadmap IA-64 Architecture Itanium Processor Microarchitecture Case Study of Exploiting TLP at VLIW
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
ECE 552 / CPS 550 Advanced Computer Architecture I. Lecture 15 Very Long Instruction Word Machines
 ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 15 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 15 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Hiroaki Kobayashi 12/21/2004
 Hiroaki Kobayashi 12/21/2004 1 Loop Unrolling Static Branch Prediction Static Multiple Issue: The VLIW Approach Software Pipelining Global Code Scheduling Trace Scheduling Superblock Scheduling Conditional
Hiroaki Kobayashi 12/21/2004 1 Loop Unrolling Static Branch Prediction Static Multiple Issue: The VLIW Approach Software Pipelining Global Code Scheduling Trace Scheduling Superblock Scheduling Conditional
Lecture 13 - VLIW Machines and Statically Scheduled ILP
 CS 152 Computer Architecture and Engineering Lecture 13 - VLIW Machines and Statically Scheduled ILP John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 13 - VLIW Machines and Statically Scheduled ILP John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Lecture 7: Static ILP, Branch prediction. Topics: static ILP wrap-up, bimodal, global, local branch prediction (Sections )
") Lecture 7: Static ILP, Branch prediction Topics: static ILP wrap-up, bimodal, global, local branch prediction (Sections 2.2-2.6) 1 Predication A branch within a loop can be problematic to schedule Control
Lecture 7: Static ILP, Branch prediction Topics: static ILP wrap-up, bimodal, global, local branch prediction (Sections 2.2-2.6) 1 Predication A branch within a loop can be problematic to schedule Control
ECE 252 / CPS 220 Advanced Computer Architecture I. Lecture 14 Very Long Instruction Word Machines
 ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 14 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 14 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
VLIW/EPIC: Statically Scheduled ILP
 6.823, L21-1 VLIW/EPIC: Statically Scheduled ILP Computer Science & Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind
6.823, L21-1 VLIW/EPIC: Statically Scheduled ILP Computer Science & Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Lecture: Static ILP. Topics: predication, speculation (Sections C.5, 3.2)
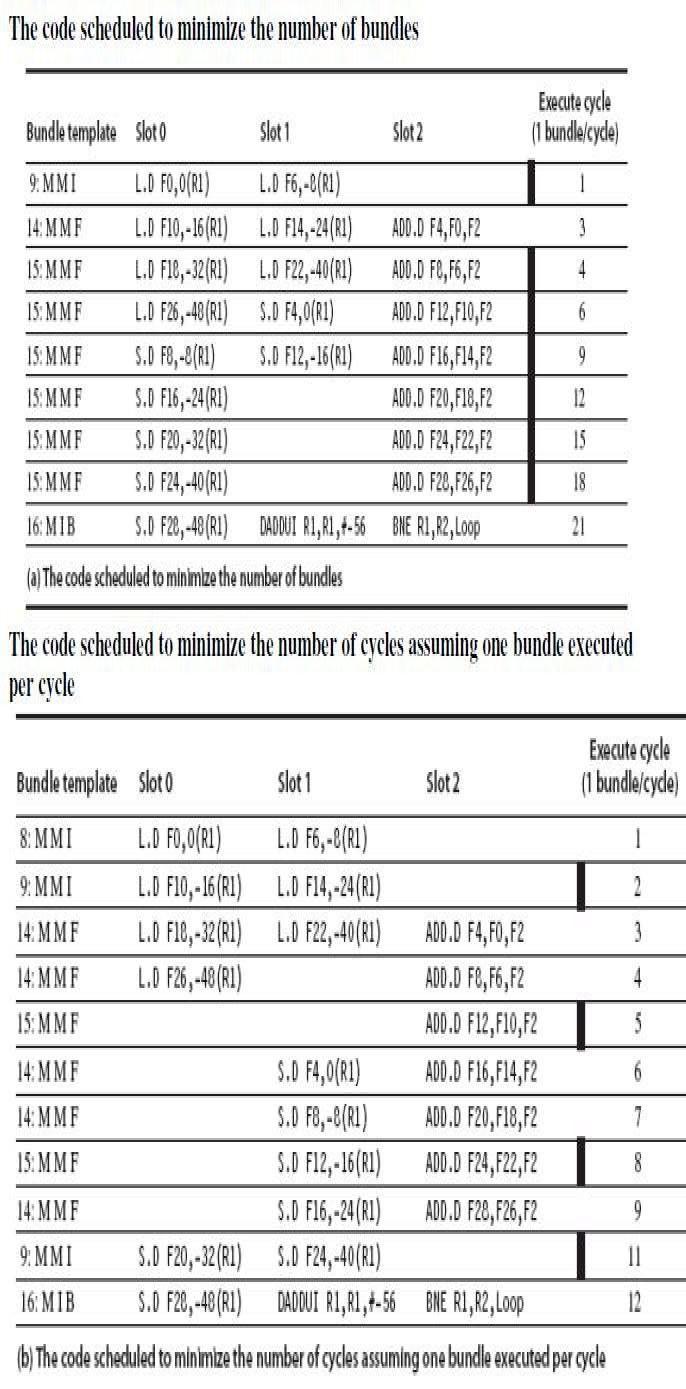
") Lecture: Static ILP Topics: predication, speculation (Sections C.5, 3.2) 1 Scheduled and Unrolled Loop Loop: L.D F0, 0(R1) L.D F6, -8(R1) L.D F10,-16(R1) L.D F14, -24(R1) ADD.D F4, F0, F2 ADD.D F8, F6,
Lecture: Static ILP Topics: predication, speculation (Sections C.5, 3.2) 1 Scheduled and Unrolled Loop Loop: L.D F0, 0(R1) L.D F6, -8(R1) L.D F10,-16(R1) L.D F14, -24(R1) ADD.D F4, F0, F2 ADD.D F8, F6,
The CPU IA-64: Key Features to Improve Performance
 The CPU IA-64: Key Features to Improve Performance Ricardo Freitas Departamento de Informática, Universidade do Minho 4710-057 Braga, Portugal freitas@fam.ulusiada.pt Abstract. The IA-64 architecture is
The CPU IA-64: Key Features to Improve Performance Ricardo Freitas Departamento de Informática, Universidade do Minho 4710-057 Braga, Portugal freitas@fam.ulusiada.pt Abstract. The IA-64 architecture is
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
CS 152 Computer Architecture and Engineering. Lecture 13 - VLIW Machines and Statically Scheduled ILP
 CS 152 Computer Architecture and Engineering Lecture 13 - VLIW Machines and Statically Scheduled ILP Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 13 - VLIW Machines and Statically Scheduled ILP Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Chapter 4 The Processor (Part 4)
") Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
INSTRUCTION LEVEL PARALLELISM
 INSTRUCTION LEVEL PARALLELISM Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix H, John L. Hennessy and David A. Patterson,
INSTRUCTION LEVEL PARALLELISM Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix H, John L. Hennessy and David A. Patterson,
Computer Science 146. Computer Architecture
 Computer rchitecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 11: Software Pipelining and Global Scheduling Lecture Outline Review of Loop Unrolling Software Pipelining
Computer rchitecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 11: Software Pipelining and Global Scheduling Lecture Outline Review of Loop Unrolling Software Pipelining
Computer Science 246 Computer Architecture
 Computer Architecture Spring 2009 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Compiler ILP Static ILP Overview Have discussed methods to extract ILP from hardware Why can t some of these
Computer Architecture Spring 2009 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Compiler ILP Static ILP Overview Have discussed methods to extract ILP from hardware Why can t some of these
Advanced Instruction-Level Parallelism
 Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Intel released new technology call P6P
 P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
Itanium 2 Processor Microarchitecture Overview
 Itanium 2 Processor Microarchitecture Overview Don Soltis, Mark Gibson Cameron McNairy, August 2002 Block Diagram F 16KB L1 I-cache Instr 2 Instr 1 Instr 0 M/A M/A M/A M/A I/A Template I/A B B 2 FMACs
Itanium 2 Processor Microarchitecture Overview Don Soltis, Mark Gibson Cameron McNairy, August 2002 Block Diagram F 16KB L1 I-cache Instr 2 Instr 1 Instr 0 M/A M/A M/A M/A I/A Template I/A B B 2 FMACs
Lecture 9: Multiple Issue (Superscalar and VLIW)
") Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
IA-64, P4 HT and Crusoe Architectures Ch 15
 IA-64, P4 HT and Crusoe Architectures Ch 15 IA-64 General Organization Predication, Speculation Software Pipelining Example: Itanium Pentium 4 HT Crusoe General Architecture Emulated Precise Exceptions
IA-64, P4 HT and Crusoe Architectures Ch 15 IA-64 General Organization Predication, Speculation Software Pipelining Example: Itanium Pentium 4 HT Crusoe General Architecture Emulated Precise Exceptions
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
計算機結構 Chapter 4 Exploiting Instruction-Level Parallelism with Software Approaches
 4.1 Basic Compiler Techniques for Exposing ILP 計算機結構 Chapter 4 Exploiting Instruction-Level Parallelism with Software Approaches 吳俊興高雄大學資訊工程學系 To avoid a pipeline stall, a dependent instruction must be
4.1 Basic Compiler Techniques for Exposing ILP 計算機結構 Chapter 4 Exploiting Instruction-Level Parallelism with Software Approaches 吳俊興高雄大學資訊工程學系 To avoid a pipeline stall, a dependent instruction must be
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Superscalar Processors Ch 14
 Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processing (5) Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?
 Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?") Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Advanced processor designs
 Advanced processor designs We ve only scratched the surface of CPU design. Today we ll briefly introduce some of the big ideas and big words behind modern processors by looking at two example CPUs. The
Advanced processor designs We ve only scratched the surface of CPU design. Today we ll briefly introduce some of the big ideas and big words behind modern processors by looking at two example CPUs. The
Dynamic Control Hazard Avoidance
 Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Exploiting ILP with SW Approaches. Aleksandar Milenković, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Multiple Issue ILP Processors. Summary of discussions
 Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
Last time: forwarding/stalls. CS 6354: Branch Prediction (con t) / Multiple Issue. Why bimodal: loops. Last time: scheduling to avoid stalls
 / Multiple Issue. Why bimodal: loops. Last time: scheduling to avoid stalls") CS 6354: Branch Prediction (con t) / Multiple Issue 14 September 2016 Last time: scheduling to avoid stalls 1 Last time: forwarding/stalls add $a0, $a2, $a3 ; zero or more instructions sub $t0, $a0, $a1
CS 6354: Branch Prediction (con t) / Multiple Issue 14 September 2016 Last time: scheduling to avoid stalls 1 Last time: forwarding/stalls add $a0, $a2, $a3 ; zero or more instructions sub $t0, $a0, $a1
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Super Scalar. Kalyan Basu March 21,
 Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Lecture 7: Static ILP and branch prediction. Topics: static speculation and branch prediction (Appendix G, Section 2.3)
") Lecture 7: Static ILP and branch prediction Topics: static speculation and branch prediction (Appendix G, Section 2.3) 1 Support for Speculation In general, when we re-order instructions, register renaming
Lecture 7: Static ILP and branch prediction Topics: static speculation and branch prediction (Appendix G, Section 2.3) 1 Support for Speculation In general, when we re-order instructions, register renaming
Architectures & instruction sets R_B_T_C_. von Neumann architecture. Computer architecture taxonomy. Assembly language.
 Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Pipelined Processor Design. EE/ECE 4305: Computer Architecture University of Minnesota Duluth By Dr. Taek M. Kwon
 Pipelined Processor Design EE/ECE 4305: Computer Architecture University of Minnesota Duluth By Dr. Taek M. Kwon Concept Identification of Pipeline Segments Add Pipeline Registers Pipeline Stage Control
Pipelined Processor Design EE/ECE 4305: Computer Architecture University of Minnesota Duluth By Dr. Taek M. Kwon Concept Identification of Pipeline Segments Add Pipeline Registers Pipeline Stage Control
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
Processing Unit CS206T
 Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS 152 Computer Architecture and Engineering. Lecture 16 - VLIW Machines and Statically Scheduled ILP
 CS 152 Computer Architecture and Engineering Lecture 16 - VLIW Machines and Statically Scheduled ILP Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16 - VLIW Machines and Statically Scheduled ILP Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
c. What are the machine cycle times (in nanoseconds) of the non-pipelined and the pipelined implementations?
 of the non-pipelined and the pipelined implementations?") Brown University School of Engineering ENGN 164 Design of Computing Systems Professor Sherief Reda Homework 07. 140 points. Due Date: Monday May 12th in B&H 349 1. [30 points] Consider the non-pipelined
Brown University School of Engineering ENGN 164 Design of Computing Systems Professor Sherief Reda Homework 07. 140 points. Due Date: Monday May 12th in B&H 349 1. [30 points] Consider the non-pipelined
CMSC411 Fall 2013 Midterm 2 Solutions
 CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Review: Evaluating Branch Alternatives. Lecture 3: Introduction to Advanced Pipelining. Review: Evaluating Branch Prediction
 Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Latches. IT 3123 Hardware and Software Concepts. Registers. The Little Man has Registers. Data Registers. Program Counter
 IT 3123 Hardware and Software Concepts Notice: This session is being recorded. CPU and Memory June 11 Copyright 2005 by Bob Brown Latches Can store one bit of data Can be ganged together to store more
IT 3123 Hardware and Software Concepts Notice: This session is being recorded. CPU and Memory June 11 Copyright 2005 by Bob Brown Latches Can store one bit of data Can be ganged together to store more
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects
 Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Lecture 6 MIPS R4000 and Instruction Level Parallelism. Computer Architectures S
 Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
These slides do not give detailed coverage of the material. See class notes and solved problems (last page) for more information.
 for more information.") 11-1 This Set 11-1 These slides do not give detailed coverage of the material. See class notes and solved problems (last page) for more information. Text covers multiple-issue machines in Chapter 4, but
11-1 This Set 11-1 These slides do not give detailed coverage of the material. See class notes and solved problems (last page) for more information. Text covers multiple-issue machines in Chapter 4, but
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4
![IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4](/thumbs/74/71306691.jpg "IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4") 12 1 CMPE110 Fall 2006 A. Di Blas 110 Fall 2006 CMPE pipeline concepts Advanced ffl ILP ffl Deep pipeline ffl Static multiple issue ffl Loop unrolling ffl VLIW ffl Dynamic multiple issue Textbook Edition:
12 1 CMPE110 Fall 2006 A. Di Blas 110 Fall 2006 CMPE pipeline concepts Advanced ffl ILP ffl Deep pipeline ffl Static multiple issue ffl Loop unrolling ffl VLIW ffl Dynamic multiple issue Textbook Edition:
COMPUTER ORGANIZATION AND DESIGN. The Hardware/Software Interface. Chapter 4. The Processor: C Multiple Issue Based on P&H
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: C Multiple Issue Based on P&H Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: C Multiple Issue Based on P&H Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in
CS433 Midterm. Prof Josep Torrellas. October 19, Time: 1 hour + 15 minutes
 CS433 Midterm Prof Josep Torrellas October 19, 2017 Time: 1 hour + 15 minutes Name: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your time.
CS433 Midterm Prof Josep Torrellas October 19, 2017 Time: 1 hour + 15 minutes Name: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your time.
Superscalar Processors
 Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Processors, Performance, and Profiling
 Processors, Performance, and Profiling Architecture 101: 5-Stage Pipeline Fetch Decode Execute Memory Write-Back Registers PC FP ALU Memory Architecture 101 1. Fetch instruction from memory. 2. Decode
Processors, Performance, and Profiling Architecture 101: 5-Stage Pipeline Fetch Decode Execute Memory Write-Back Registers PC FP ALU Memory Architecture 101 1. Fetch instruction from memory. 2. Decode
EEC 581 Computer Architecture. Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW)
") 1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Dynamic Scheduling. CSE471 Susan Eggers 1
 Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Homework 5. Start date: March 24 Due date: 11:59PM on April 10, Monday night. CSCI 402: Computer Architectures
 Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Superscalar Machines. Characteristics of superscalar processors
 Superscalar Machines Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any performance
Superscalar Machines Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any performance
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW. Computer Architectures S
 Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Control Hazards. Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Sam Naffziger. Gary Hammond. Next Generation Itanium Processor Overview. Lead Circuit Architect Microprocessor Technology Lab HP Corporation
 Next Generation Itanium Processor Overview Gary Hammond Principal Architect Enterprise Platform Group Corporation August 27-30, 2001 Sam Naffziger Lead Circuit Architect Microprocessor Technology Lab HP
Next Generation Itanium Processor Overview Gary Hammond Principal Architect Enterprise Platform Group Corporation August 27-30, 2001 Sam Naffziger Lead Circuit Architect Microprocessor Technology Lab HP
CS311 Lecture: Pipelining and Superscalar Architectures
 Objectives: CS311 Lecture: Pipelining and Superscalar Architectures Last revised July 10, 2013 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as a result
Objectives: CS311 Lecture: Pipelining and Superscalar Architectures Last revised July 10, 2013 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as a result