Lecture 11: Memory Systems -- Cache Organiza9on and Performance CSE 564 Computer Architecture Summer 2017
|
|
|
- Morgan McLaughlin
- 6 years ago
- Views:
Transcription
1 Lecture 11: Memory Systems -- Cache Organiza9on and Performance CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan 1
2 Topics for Memory Systems Memory Technology and Metrics SRAM, DRAM, Flash/SSD, 3-D Stack Memory Locality Memory access Hme and banking Cache Cache basics Cache performance and op9miza9on Advanced op9miza9on Mul9ple-level cache, shared and private cache, prefetching Virtual Memory ProtecHon, VirtualizaHon, and RelocaHon Page/segment, protechon Address TranslaHon and TLB 2
3 Technology Challenge: Memory Wall Growing disparity of processor and memory speed DRAM: Slow cheap and dense: Good choice for presenhng the user with a BIG memory system Used for Main memory SRAM: fast, expensive, and not very dense: Good choice for providing the user FAST access Hme. Used for Cache Speed: Latency Bandwidth Memory interleaving 3
4 Program Behavior: Principle of Locality Programs tend to reuse data and instruchons near those they have used recently, or that were recently referenced themselves SpaHal locality: Items with nearby addresses tend to be referenced close together in Hme Temporal locality: Recently referenced items are likely to be referenced in the near future sum = 0; for (i = 0; i < n; i++) sum += a[i]; Data return sum; Locality Example: Reference array elements in succession (stride-1 reference pattern): Spatial locality Reference sum each iteration: Instructions Reference instructions in sequence: Cycle through loop repeatedly: Temporal locality Spatial locality Temporal locality 4
5 Architecture Approach: Memory Hierarchy Keep most recent accessed data and its adjacent data in the smaller/faster caches that are closer to processor Mechanisms for replacing data Processor Datapath Control Registers On-Chip Cache 2 nd /3 rd Level Cache (SRAM) Main Memory (DRAM) Secondary Storage (Disk) Tertiary Storage (Tape) Speed (ns): 1s 10s 100s Size (bytes): 100s Ks Ms 10,000,000s (10s ms) Gs 10,000,000,000s (10s sec) Ts 5



6 Review: Memory Technology and Hierarchy RelaHonships Program Behavior: Principle of Locality Probability of reference 0 Address Space 2^n - 1 Technology challenge: Memory Wall Architecture Approach: Memory Hierarchy 6



7 Memory Hierarchy capacity: Register << SRAM << DRAM latency: Register << SRAM << DRAM bandwidth: on-chip >> off-chip On a data access: if data fast memory low latency access (SRAM) if data fast memory high latency access (DRAM) 7

8 History: Alpha (1994) 8
9 History: Further Back Ideally one would desire an indefinitely large memory capacity such that any word would be immediately available.... We are... forced to recognize the possibility of a hierarchy of memories, each of which has greater capacity than the preceding but which is less quickly accessible. A. W. Burks, H. H. Golds9ne, and J. von Neumann Preliminary Discussion of the Logical Design of an Electronic Compu?ng Instrument,
10 Management of Memory Hierarchy Small/fast storage, e.g., registers Address usually specified in instruchon Generally implemented directly as a register file but hardware might do things behind soeware s back, e.g., stack management, register renaming Larger/slower storage, e.g., main memory Address usually computed from values in register Generally implemented as a hardware-managed cache hierarchy (hardware decides what is kept in fast memory) but soeware may provide hints, e.g., don t cache or prefetch 10

11 Caches exploit both types of predictability: Exploit temporal locality by remembering the contents of recently accessed locahons. Exploit spahal locality by fetching blocks of data around recently accessed locahons. 11

12 Cache Memory Cache memory The level of the memory hierarchy closest to the CPU Given accesses X 1,, X n 1, X n n How do we know if the data is present? n Where do we look? 12
 modulo (#Blocks in cache) n #Blocks is a power of 2 n Use")

13 Direct Mapped Cache Location determined by address Direct mapped: only one choice (Block address) modulo (#Blocks in cache) n #Blocks is a power of 2 n Use low-order address bits as index to the entry 5-bit address space for total 32 bytes. This is simplified and a cache line normally contains more bytes, e.g. 64 or 128 bytes. 13
14 Tags and Valid Bits Which particular block is stored in a cache location? Store block address as well as the data Actually, only need the high-order bits Called the tag: the high-order bits What if there is no data in a location? Valid bit: 1 = present, 0 = not present Initially 0 14
15 Cache Example 8-blocks, 1 word/block, direct mapped Initial state Index V Tag Data 000 N 001 N 010 N 011 N 100 N 101 N 110 N 111 N 15
16 Cache Example Word addr Binary addr Hit/miss Cache block Miss 110 Index V Tag Data 000 N 001 N 010 N 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N 16
17 Cache Example Word addr Binary addr Hit/miss Cache block Miss 010 Index V Tag Data 000 N 001 N 010 Y 11 Mem[11010] 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N 17
18 Cache Example Word addr Binary addr Hit/miss Cache block Hit Hit 010 Index V Tag Data 000 N 001 N 010 Y 11 Mem[11010] 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N 18
19 Cache Example Word addr Binary addr Hit/miss Cache block Miss Miss Hit 000 Index V Tag Data 000 Y 10 Mem[10000] 001 N 010 Y 11 Mem[11010] 011 Y 00 Mem[00011] 100 N 101 N 110 Y 10 Mem[10110] 111 N 19
20 Cache Example Word addr Binary addr Hit/miss Cache block Miss 010 Index V Tag Data 000 Y 10 Mem[10000] 001 N 010 Y 10 Mem[10010] 011 Y 00 Mem[00011] 100 N 101 N 110 Y 10 Mem[10110] 111 N 20

21 Address Subdivision 4-byte data per cache entry: block or line size Cache line Why do we keep mul9ple bytes in one cache line? Spa9al locality 21
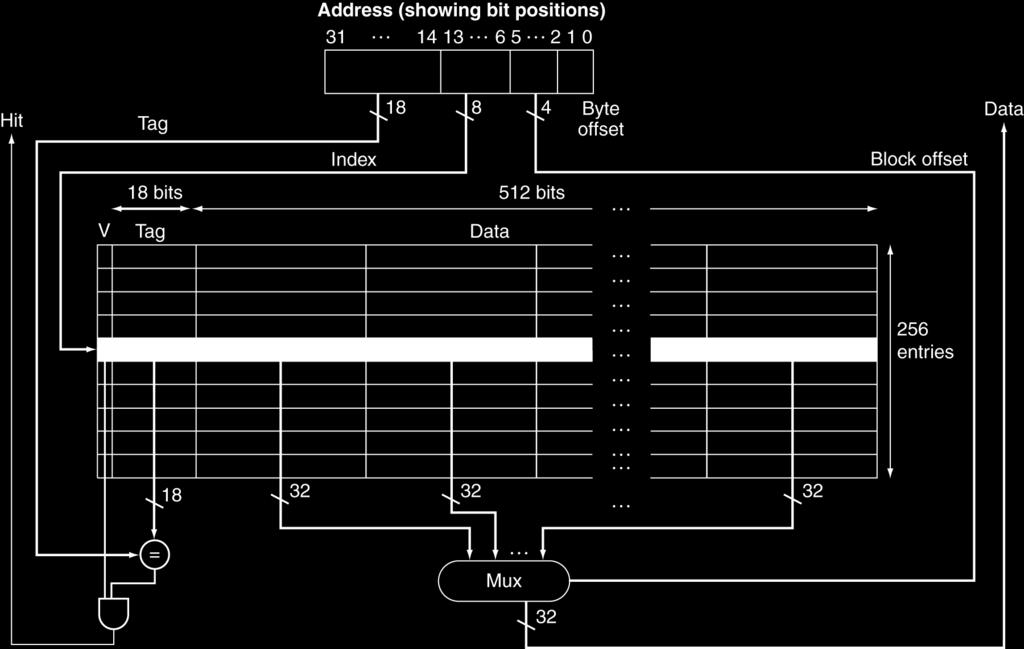
22 Example: Larger Block Size 64 blocks, 16 bytes/block To what block number does address 1200 (decimal) map?: = 0x4B Tag Index Offset 22 bits 6 bits 4 bits Map all addresses between
23 Block Size Considerations Larger blocks should reduce miss rate Due to spatial locality But in a fixed-sized cache Larger blocks fewer of them More competition increased miss rate Larger blocks pollution Larger miss penalty Can override benefit of reduced miss rate Early restart and critical-word-first can help 23
24 Cache Misses On cache hit, CPU proceeds normally IF or MEM stage to access instruction or data memory 1 cycle 100: LW X1 100(X2) On cache miss: à x10 or x100 cycles Stall the CPU pipeline Fetch block from next level of hierarchy Instruction cache miss Restart instruction fetch Data cache miss Complete data access 24
25 Write-Through On data-write hit, could just update the block in cache But then cache and memory would be inconsistent 200: SW X1 100(X2) Write through: also update memory But makes writes take longer e.g., if base CPI = 1, 10% of instructions are stores, write to memory takes 100 cycles Effective CPI = = 11 Solution: write buffer Holds data waiting to be written to memory CPU continues immediately Only stalls on write if write buffer is already full and write multiple bytes a time 25
26 Write-Back Alternative: On data-write hit, just update the block in cache Keep track of whether each block is dirty When a dirty block is replaced Write it back to memory Can use a write buffer to allow replacing block to be read first 26
27 Write Allocation What should happen on a write miss? Alternatives for write-through Allocate on miss: fetch the block Write around: don t fetch the block Since programs often write a whole block before reading it (e.g., initialization) For write-back Usually fetch the block 27
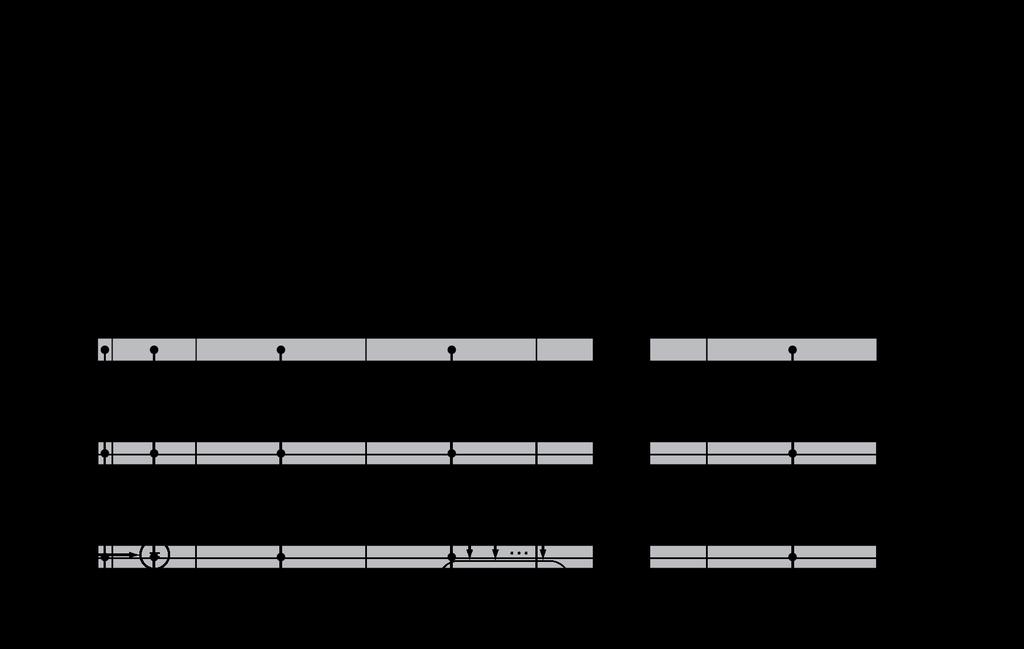
28 Example: Intrinsity FastMATH Embedded MIPS processor 12-stage pipeline Instruction and data access on each cycle Split cache: separate I-cache and D-cache Each 16KB: 256 blocks 16 words/block D-cache: write-through or write-back SPEC2000 miss rates I-cache: 0.4% D-cache: 11.4% Weighted average: 3.2% 28
29 Example: Intrinsity FastMATH 29
30 Main Memory Suppor9ng Caches Use DRAMs for main memory Fixed width (e.g., 1 word) Connected by fixed-width clocked bus Bus clock is typically slower than CPU clock Example cache block read 1 bus cycle for address transfer 15 bus cycles per DRAM access 1 bus cycle per data transfer For 4-word block, 1-word-wide DRAM Miss penalty = = 65 bus cycles Bandwidth = 16 bytes / 65 cycles = 0.25 B/cycle 30
31 Associative Caches Fully associative Allow a given block to go in any cache entry Requires all entries to be searched at once Comparator per entry (expensive) n-way set associative Each set contains n entries Block number determines which set (Block number) modulo (#Sets in cache) Search all entries in a given set at once n comparators (less expensive) 31

32 Associative Cache Example 32

33 Spectrum of Associativity For a cache with 8 entries 33
34 Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative Block access sequence: 0, 8, 0, 6, 8 Direct mapped Access sequence Block address Cache index Hit/miss Cache content after access miss Mem[0] 8 0 miss Mem[8] 0 0 miss Mem[0] 6 2 miss Mem[0] Mem[6] 8 0 miss Mem[8] Mem[6] 34
35 Associativity Example 2-way set associative Block address Cache index Hit/miss 0 0 miss Mem[0] 8 0 miss Mem[0] Mem[8] 0 0 hit Mem[0] Mem[8] 6 0 miss Mem[0] Mem[6] 8 0 miss Mem[8] Mem[6] Cache content after access Set 0 Set 1 n Fully associative Block address Hit/miss Cache content after access 0 miss Mem[0] 8 miss Mem[0] Mem[8] 0 hit Mem[0] Mem[8] 6 miss Mem[0] Mem[8] Mem[6] 8 hit Mem[0] Mem[8] Mem[6] 35
36 How Much Associa9vity Increased associahvity decreases miss rate But with diminishing returns SimulaHon of a system with 64KB D-cache, 16-word blocks, SPEC way: 10.3% 2-way: 8.6% 4-way: 8.3% 8-way: 8.1% 36

37 Set Associa9ve Cache Organiza9on 37
38 Replacement Policy Direct mapped: no choice Set associahve Prefer non-valid entry, if there is one Otherwise, choose among entries in the set Least-recently used (LRU) Choose the one unused for the longest Hme Simple for 2-way, manageable for 4-way, too hard beyond that Random Gives approximately the same performance as LRU for high associahvity 38
39 4 Ques9ons for Cache Organiza9on Review Q1: Where can a block be placed in the upper level? Block placement Q2: How is a block found if it is in the upper level? Block identification Q3: Which block should be replaced on a miss? Block replacement Q4: What happens on a write? Write strategy 39
40 Q1: Where Can a Block be Placed in The Upper Level? Block Placement Direct Mapped, Fully Associative, Set Associative Direct mapped: (Block number) mod (Number of blocks in cache) Set associative: (Block number) mod (Number of sets in cache) # of set # of blocks n-way: n blocks in a set 1-way = direct mapped Fully associative: # of set = 1 Direct mapped: block 12 can go only into block 4 (12 mod 8) Set associative: block 12 can go anywhere in set 0 (12 mod 4) Fully associative: block 12 can go anywhere Block no Block no Block no Block-frame address Set0 Set1 Set2 Set3 Block no
41 1 KB Direct Mapped Cache, 32B blocks For a 2 N byte cache The uppermost (32 - N) bits are always the Cache Tag The lowest M bits are the Byte Select (Block Size = 2 M ) Cache Tag Example: 0x50 Cache Index Byte Select Stored as part of the cache state Ex: 0x01 Ex: 0x00 Valid Bit Cache Tag Cache Data Byte 31 : Byte 1 Byte 0 0 0x50 Byte 63 : Byte 33 Byte : : : Byte 1023 : Byte
42 Set Associa9ve Cache N-way set associative: N entries for each Cache Index N direct mapped caches operates in parallel Example: Two-way set associative cache Cache Index selects a set from the cache; The two tags in the set are compared to the input in parallel; Data is selected based on the tag result. Valid Cache Tag Cache Data Cache Block 0 : : : Cache Index Cache Data Cache Block 0 : Cache Tag : : Valid Adr Tag Compare Sel1 1 Mux 0 Sel0 Compare OR Hit Cache Block 42
43 Disadvantage of Set Associa9ve Cache N-way Set Associative Cache versus Direct Mapped Cache: N comparators vs. 1 Extra MUX delay for the data Data comes AFTER Hit/Miss decision and set selection In a direct mapped cache, Cache Block is available BEFORE Hit/Miss: Possible to assume a hit and continue. Recover later if miss. Valid Cache Tag Cache Data Cache Block 0 : : : Cache Index Cache Data Cache Block 0 : Cache Tag : : Valid Adr Tag Compare Sel1 1 Mux 0 Sel0 Compare OR Hit Cache Block 43
44 Q2: Block Iden9fica9on Tag on each block No need to check index or block offset Increasing associativity shrinks index, expands tag Block Address Tag Index Block Offset Set Select Data Select Cache size = Associativity 2 index_size 2 offest_size 44
 First in, first out (FIFO) Associativity 2-way 4-way 8-way Size LRU Ran. FIFO LRU Ran. FIFO LRU Ran. FIFO 16KB 114.")
45 Q3: Which block should be replaced on a miss? Easy for Direct Mapped Set Associative or Fully Associative Random LRU (Least Recently Used) First in, first out (FIFO) Associativity 2-way 4-way 8-way Size LRU Ran. FIFO LRU Ran. FIFO LRU Ran. FIFO 16KB KB KB
46 Q4: What Happens on a Write? Policy Write-Through Data written to cache block, also written to lowerlevel memory Write-Back 1. Write data only to the cache 2. Update lower level when a block falls out of the cache Debug Easy Hard Do read misses produce writes? No Yes Do repeated writes make it to lower level? Yes No Additional option -- let writes to an un-cached address allocate a new cache line ( write-allocate ). 46
47 Write Buffers for Write-Through Caches Processor Cache DRAM Write Buffer Q. Why a write buffer? A. So CPU doesn t stall Q. Why a buffer, why not just one register? A. Bursts of writes are common. Q. Are Read After Write (RAW) hazards an issue for write buffer? A. Yes! Drain buffer before next read, or send read 1 st after check write buffers. 47
48 Write-Miss Policy Two options on a write miss Write allocate the block is allocated on a write miss, followed by the write hit actions. Write misses act like read misses. No-write allocate write misses do not affect the cache. The block is modified only in the lower-level memory. Block stay out of the cache in no-write allocate until the program tries to read the blocks, but with write allocate even blocks that are only written will still be in the cache. 48
49 Write-Miss Policy Example Example: Assume a fully associative write-back cache with many cache entries that starts empty. Below is sequence of five memory operations (The address is in square brackets): Write Mem[100]; Write Mem[100]; Read Mem[200]; Write Mem[200]; Write Mem[100]. What are the number of hits and misses (inclusive reads and writes) when using nowrite allocate versus write allocate? Answer No-write Allocate: Write allocate: Write Mem[100]; 1 write miss Write Mem[100]; 1 write miss Write Mem[100]; 1 write miss Write Mem[100]; 1 write hit Read Mem[200]; 1 read miss Read Mem[200]; 1 read miss Write Mem[200]; 1 write hit Write Mem[200]; 1 write hit Write Mem[100]. 1 write miss Write Mem[100]; 1 write hit 4 misses; 1 hit 2 misses; 3 hits 49
50 Memory Hierarchy Performance: Terminology Hit: data appears in some block in the upper level (example: Block X) Hit Rate: the frachon of memory access found in the upper level. Hit Time: Time to access the upper level which consists of RAM access Hme + Time to determine hit/miss. Miss: data needs to be retrieve from a block in the lower level (Block Y) Miss Rate = 1 - (Hit Rate). Miss Penalty: Time to replace a block in the upper level + Time to deliver the block the processor. Hit Time << Miss Penalty (500 instruc9ons on 21264!) To Processor From Processor Upper Level Memory Block X Lower Level Memory Block Y 50
51 Cache Measures Hit rate: frachon found in that level So high that usually talk about Miss rate Miss rate fallacy: as MIPS to CPU performance, miss rate to average memory access Hme in memory Average memory-access Hme = Hit Hme + Miss rate x Miss penalty (ns or clocks) Miss penalty: Hme to replace a block from lower level, including Hme to replace in CPU Access Hme: Hme to lower level = f(latency to lower level) Transfer Hme: Hme to transfer block =f(bw between upper & lower levels) 51
52 CPU Performance Revisit CPU performance factors InstrucHon count Determined by ISA and compiler CPI and Cycle Hme Determined by CPU hardware CPU Time = Instructions Program * Cycles Instruction *Time Cycle 52
53 CPU Performance with Memory Factor Components of CPU Hme Program execuhon cycles Includes cache hit Hme Memory stall cycles Mainly from cache misses With simplifying assumphons: Memory stall cycles = Instructions Program Misses Miss penalty Instruction = Memory accesses Program Miss rate Miss penalty 53
54 Cache Performance (1/3) Memory Stall Cycles: the number of cycles during which the processor is stalled waihng for a memory access. RewriHng the CPU performance Hme CPU execution time = (CPUclock cycles + Memory stall cycles) Clock cycle time The number of memory stall cycles depends on both the number of misses and the cost per miss, which is called the miss penalty: Memory stall cycles = Number of misses Miss penalty Misses = IC Miss Penalty Instrution Memory accesses = IC Miss rate Miss Penalty Instrution The advantage of the last form is the component can be easily measured. 54
55 Cache Performance Given I-cache miss rate = 2% D-cache miss rate = 4% Miss penalty = 100 cycles Base CPI (ideal cache) = 2 Load & stores are 36% of instruchons Miss cycles per instruchon I-cache: = 2 D-cache: = 1.44 Actual CPI = = 5.44 Ideal CPU is 5.44/2 =2.72 Hmes faster 55
56 Cache Performance (2/3) Miss penalty depends on Prior memory requests or memory refresh; Different clocks of the processor, bus, and memory; Thus, using miss penalty be a constant is a simplificahon. Miss rate: the frachon of cache access that result in a miss (i.e., number of accesses that miss divided by number of accesses). Extract formula for R/W Memory stall cycles = IC Reads per instruction Read miss rate Read Miss Penalty + IC Writes per instruction Write miss rate Write Miss Penalty Memory accesses Memory stall cycles = IC Miss rate Miss penalty Instrution Simplify the complete formula by combining the R/W. 56
57 Example (C-5) Assume we have a computer where the clocks per instruchon (CPI) is 1.0 when all memory accesses hit in the cache. The only data accesses are loads and stores, and these total 50% of the instruchons. If the miss penalty is 25 clock cycles and the miss rate is 2%, how much faster would the computer be if all instruchons were cache hits? Answer: 1. Compute the performance for the computer that always hits: CPU execution time = (CPU clock cycles + Memory stall cycles) Clock cycle time = (IC CPI + 0) Clock cycle = IC 1.0 Clock cycle 2. For the computer with the real cache, we compute memory stall cycles: Memory accesses Memory stall cycles = IC Miss rate Miss penalty Instruction = IC (1+ 0.5) = IC Compute the total performance CPU execution time = (CPU clock cycles + Memory stall cycles) Clock cycle time =1.75 IC Clock cycle 4. Compute the performance ratio which is the inverse of the execution times CPU execution time cache 1.75 IC Clock cycle = = 1.75 CPU execution time 1.0 IC Clock cycle 1 instruction memory access data memory access 57
58 Cache Performance (3/3) Usually, measuring miss rate as misses per instruchon rather than misses per memory reference. Misses Miss rate Memory accesses Memory accesses = = Miss rate Instrution Instruction count Instruction The latter formula is useful when you know the average number of memory accesses per instruction. For example, in the previous example into misses per instruchon: Misses Instrution Memory accesses = Miss rate Instruction = =
59 Example (C-6) To show equivalency between the two miss rate equations, let s redo the example above, this time assuming a miss rate per 1000 instructions of 30. What is memory stall time in terms of instruction count? Answer Recomputing the memory stall cycles: Memory stall cycles = Number of misses Miss penalty Misses = IC Miss penalty Instruction IC Misses = Miss penalty 1000 Instruction 1000 IC = IC = = IC
60 Improving Cache Performance The next few sections in the text book look at ways to improve cache and memory access times. Average Memory Access Time = Hit Time + Miss Rate * Miss Penalty Memory Accesses CPU Time = IC* ( CPI Execution + Miss Rate Miss Penalty ) Clock Instruction Cycle Time 60
61 Performance Summary When CPU performance increased Miss penalty becomes more significant Decreasing base CPI Greater proporhon of Hme spent on memory stalls Increasing clock rate Memory stalls account for more CPU cycles Can t neglect cache behavior when evalua9ng system performance 61
62 Addi9onal 62

63 Mul9level Caches Primary cache aqached to CPU Small, but fast Level-2 cache services misses from primary cache Larger, slower, but shll faster than main memory Main memory services L-2 cache misses Some high-end systems include L-3 cache 63
64 Mul9level Cache Considera9ons Primary cache Focus on minimal hit time L-2 cache Focus on low miss rate to avoid main memory access Hit time has less overall impact Results L-1 cache usually smaller than a single cache L-1 block size smaller than L-2 block size 64
65 Mul9level Cache Example Given CPU base CPI = 1, clock rate = 4GHz Miss rate/instruction = 2% Main memory access time = 100ns With just primary cache Miss penalty = 100ns/0.25ns = 400 cycles Effective CPI = = 9 65
66 Example (cont.) Now add L-2 cache Access time = 5ns Global miss rate to main memory = 0.5% Primary miss with L-2 hit Penalty = 5ns/0.25ns = 20 cycles Primary miss with L-2 miss Extra penalty = 500 cycles CPI = = 3.4 Performance ratio = 9/3.4 =
67 Memory Hierarchy Performance Two indirect performance measures have waylaid many a computer designer. Instruc@on count is independent of the hardware; Miss rate is independent of the hardware. A beqer measure of memory hierarchy performance is the Average Memory Access Time (AMAT) per instruchons AMAT = Hit time + Mis srate Miss penalty CPU with 1ns clock, hit Hme = 1 cycle, miss penalty = 20 cycles, I-cache miss rate = 5% AMAT = = 2ns 2 cycles per instruchon 67
68 Example (B-16): Separate vs Unified Cache Which has the lower miss rate: a 16 KB instruction cache with a 16KB data or a 32 KB unified cache? Use the miss rates in Figure B.6 to help calculate the correct answer, assuming 36% of the instructions are data transfer instructions. Assume a hit take 1 clock cycle and the miss penalty is 100 clock cycles. A load or store hit takes 1 extra clock cycle on a unified cache if there is only one cache port to satisfy two simultaneous requests. Using the pipelining terminology of Chapter 2, the unified cache leads to a structure hazard. What is the average memory access time in each case? Assume write-through caches with a write buffer and ignore stalls due to the write buffer. Answer: First let s convert misses per 1000 instructions into miss rates. Solving the general formula from above, the miss rate is Miss rate = Misses / Instructions Memory accesses Instruction Since every instruction access has exactly one memory access to fetch the instruction, the instruction miss rate is Miss rate 3.82 / KB instruction = =
69 Example (B-16) Since 36% of the instructions are data transfers, the data miss rate is 40.9 /1000 Miss rate16 KB data = = The unified miss rate needs to account for instruction and data access: Miss rate 43.3/ KB unified = = As stated above, about 74% of the memory accesses are instruction references. Thus, the overall miss rate for the split caches is Thus, a 32 KB unified cache has a slightly lower effective miss rate than two 16 KB caches. The average memory access time formula can be divided into instruction and data accesses: % data Therefore, the time for each organization is ( 74 % 0.004) + ( 26% 0.114) = = % instructions ( Hit time + Instruction miss rate Miss penalty) ( Hit time + Data miss rate Miss penalty) Average memory access time ( ) + 26% ( ) AMAT split = 74% = ( ) + 26% ( ) AMAT unified = 74% = 69
70 Example (B-18) Let s use an in-order execution computer for the first example. Assume the cache miss penalty is 200 clock cycles, and all instructions normally take 1.0 clock cycles (ignoring memory stalls). Assume the average miss rate is 2%, there is an average of 1.5 memory references per instruction, and the average number of cache misses per 1000 instructions is 30. what is the impact on performance when behavior of the cache is included? Calculate the impact using both misses per instruction and miss rate. Answer: The performance, including cache misses, is Memory stall clock cycles CPU time = IC CPI execution + Clock cycle time Instruction Now calculating performance using miss rate: CPU time with cache = IC ( ( 30/ ) ) = IC 7.00 Clock cycle time Clock cycle time Memory accesses CPU time = IC CPI execution + Miss rate Miss penalty Clock cycle time Instruction ( ( % 200) ) Clock cycle time = IC 7.00 Clock cycle time CPU time with cache = IC 70
71 Other Examples (B-19, B-21) 71
Memory Technology. Caches 1. Static RAM (SRAM) Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB
 Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB") Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
Chapter 5A. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Cache Optimization. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Cache Optimization Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Cache Misses On cache hit CPU proceeds normally On cache miss Stall the CPU pipeline
Cache Optimization Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Cache Misses On cache hit CPU proceeds normally On cache miss Stall the CPU pipeline
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Computer Systems Laboratory Sungkyunkwan University
 Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Review: Major Components of a Computer Processor Devices Control Memory Input Datapath Output Secondary Memory (Disk) Main Memory Cache Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Review: Major Components of a Computer Processor Devices Control Memory Input Datapath Output Secondary Memory (Disk) Main Memory Cache Performance
Main Memory Supporting Caches
 Main Memory Supporting Caches Use DRAMs for main memory Fixed width (e.g., 1 word) Connected by fixed-width clocked bus Bus clock is typically slower than CPU clock Cache Issues 1 Example cache block read
Main Memory Supporting Caches Use DRAMs for main memory Fixed width (e.g., 1 word) Connected by fixed-width clocked bus Bus clock is typically slower than CPU clock Cache Issues 1 Example cache block read
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY
 LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
Memory Technology. Chapter 5. Principle of Locality. Chapter 5 Large and Fast: Exploiting Memory Hierarchy 1
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-12a Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
CSE 2021: Computer Organization Lecture-12a Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-12 Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
CSE 2021: Computer Organization Lecture-12 Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
Computer Architecture Computer Science & Engineering. Chapter 5. Memory Hierachy BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
CSE 431 Computer Architecture Fall Chapter 5A: Exploiting the Memory Hierarchy, Part 1
 CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
CS161 Design and Architecture of Computer Systems. Cache $$$$$
 CS161 Design and Architecture of Computer Systems Cache $$$$$ Memory Systems! How can we supply the CPU with enough data to keep it busy?! We will focus on memory issues,! which are frequently bottlenecks
CS161 Design and Architecture of Computer Systems Cache $$$$$ Memory Systems! How can we supply the CPU with enough data to keep it busy?! We will focus on memory issues,! which are frequently bottlenecks
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Static RAM (SRAM) Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 0.5ns 2.5ns, $2000 $5000 per GB 5.1 Introduction Memory Technology 5ms
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Static RAM (SRAM) Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 0.5ns 2.5ns, $2000 $5000 per GB 5.1 Introduction Memory Technology 5ms
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
Caches. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
The Memory Hierarchy. Cache, Main Memory, and Virtual Memory (Part 2)
") The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1)
") Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Memory Hierarchy. Reading. Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 (2) Lecture notes from MKP, H. H. Lee and S.
, 5.9 (2) Lecture notes from MKP, H. H. Lee and S.") Memory Hierarchy Lecture notes from MKP, H. H. Lee and S. Yalamanchili Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 Reading (2) 1 SRAM: Value is stored on a pair of inerting gates Very fast but
Memory Hierarchy Lecture notes from MKP, H. H. Lee and S. Yalamanchili Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 Reading (2) 1 SRAM: Value is stored on a pair of inerting gates Very fast but
Advanced Memory Organizations
 CSE 3421: Introduction to Computer Architecture Advanced Memory Organizations Study: 5.1, 5.2, 5.3, 5.4 (only parts) Gojko Babić 03-29-2018 1 Growth in Performance of DRAM & CPU Huge mismatch between CPU
CSE 3421: Introduction to Computer Architecture Advanced Memory Organizations Study: 5.1, 5.2, 5.3, 5.4 (only parts) Gojko Babić 03-29-2018 1 Growth in Performance of DRAM & CPU Huge mismatch between CPU
Memory Hierarchy. ENG3380 Computer Organization and Architecture Cache Memory Part II. Topics. References. Memory Hierarchy
 ENG338 Computer Organization and Architecture Part II Winter 217 S. Areibi School of Engineering University of Guelph Hierarchy Topics Hierarchy Locality Motivation Principles Elements of Design: Addresses
ENG338 Computer Organization and Architecture Part II Winter 217 S. Areibi School of Engineering University of Guelph Hierarchy Topics Hierarchy Locality Motivation Principles Elements of Design: Addresses
COSC 6385 Computer Architecture - Memory Hierarchies (I)
") COSC 6385 Computer Architecture - Memory Hierarchies (I) Edgar Gabriel Spring 2018 Some slides are based on a lecture by David Culler, University of California, Berkley http//www.eecs.berkeley.edu/~culler/courses/cs252-s05
COSC 6385 Computer Architecture - Memory Hierarchies (I) Edgar Gabriel Spring 2018 Some slides are based on a lecture by David Culler, University of California, Berkley http//www.eecs.berkeley.edu/~culler/courses/cs252-s05
Memory Hierarchy. Maurizio Palesi. Maurizio Palesi 1
 Memory Hierarchy Maurizio Palesi Maurizio Palesi 1 References John L. Hennessy and David A. Patterson, Computer Architecture a Quantitative Approach, second edition, Morgan Kaufmann Chapter 5 Maurizio
Memory Hierarchy Maurizio Palesi Maurizio Palesi 1 References John L. Hennessy and David A. Patterson, Computer Architecture a Quantitative Approach, second edition, Morgan Kaufmann Chapter 5 Maurizio
Modern Computer Architecture
 Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
EECS151/251A Spring 2018 Digital Design and Integrated Circuits. Instructors: John Wawrzynek and Nick Weaver. Lecture 19: Caches EE141
 EECS151/251A Spring 2018 Digital Design and Integrated Circuits Instructors: John Wawrzynek and Nick Weaver Lecture 19: Caches Cache Introduction 40% of this ARM CPU is devoted to SRAM cache. But the role
EECS151/251A Spring 2018 Digital Design and Integrated Circuits Instructors: John Wawrzynek and Nick Weaver Lecture 19: Caches Cache Introduction 40% of this ARM CPU is devoted to SRAM cache. But the role
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
Chapter 7 Large and Fast: Exploiting Memory Hierarchy. Memory Hierarchy. Locality. Memories: Review
 Memories: Review Chapter 7 Large and Fast: Exploiting Hierarchy DRAM (Dynamic Random Access ): value is stored as a charge on capacitor that must be periodically refreshed, which is why it is called dynamic
Memories: Review Chapter 7 Large and Fast: Exploiting Hierarchy DRAM (Dynamic Random Access ): value is stored as a charge on capacitor that must be periodically refreshed, which is why it is called dynamic
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 6A: Cache Design Avinash Kodi, kodi@ohioedu Agenda 2 Review: Memory Hierarchy Review: Cache Organization Direct-mapped Set- Associative Fully-Associative 1 Major
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 6A: Cache Design Avinash Kodi, kodi@ohioedu Agenda 2 Review: Memory Hierarchy Review: Cache Organization Direct-mapped Set- Associative Fully-Associative 1 Major
V. Primary & Secondary Memory!
 V. Primary & Secondary Memory! Computer Architecture and Operating Systems & Operating Systems: 725G84 Ahmed Rezine 1 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM)
V. Primary & Secondary Memory! Computer Architecture and Operating Systems & Operating Systems: 725G84 Ahmed Rezine 1 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM)
CENG 3420 Computer Organization and Design. Lecture 08: Cache Review. Bei Yu
 CENG 3420 Computer Organization and Design Lecture 08: Cache Review Bei Yu CEG3420 L08.1 Spring 2016 A Typical Memory Hierarchy q Take advantage of the principle of locality to present the user with as
CENG 3420 Computer Organization and Design Lecture 08: Cache Review Bei Yu CEG3420 L08.1 Spring 2016 A Typical Memory Hierarchy q Take advantage of the principle of locality to present the user with as
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface COEN-4710 Computer Hardware Lecture 7 Large and Fast: Exploiting Memory Hierarchy (Chapter 5) Cristinel Ababei Marquette University Department
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface COEN-4710 Computer Hardware Lecture 7 Large and Fast: Exploiting Memory Hierarchy (Chapter 5) Cristinel Ababei Marquette University Department
EN1640: Design of Computing Systems Topic 06: Memory System
 EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
Chapter 5. Memory Technology
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
COSC 6385 Computer Architecture. - Memory Hierarchies (I)
") COSC 6385 Computer Architecture - Hierarchies (I) Fall 2007 Slides are based on a lecture by David Culler, University of California, Berkley http//www.eecs.berkeley.edu/~culler/courses/cs252-s05 Recap
COSC 6385 Computer Architecture - Hierarchies (I) Fall 2007 Slides are based on a lecture by David Culler, University of California, Berkley http//www.eecs.berkeley.edu/~culler/courses/cs252-s05 Recap
Course Administration
 Spring 207 EE 363: Computer Organization Chapter 5: Large and Fast: Exploiting Memory Hierarchy - Avinash Kodi Department of Electrical Engineering & Computer Science Ohio University, Athens, Ohio 4570
Spring 207 EE 363: Computer Organization Chapter 5: Large and Fast: Exploiting Memory Hierarchy - Avinash Kodi Department of Electrical Engineering & Computer Science Ohio University, Athens, Ohio 4570
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Chapter Seven. Large & Fast: Exploring Memory Hierarchy
 Chapter Seven Large & Fast: Exploring Memory Hierarchy 1 Memories: Review SRAM (Static Random Access Memory): value is stored on a pair of inverting gates very fast but takes up more space than DRAM DRAM
Chapter Seven Large & Fast: Exploring Memory Hierarchy 1 Memories: Review SRAM (Static Random Access Memory): value is stored on a pair of inverting gates very fast but takes up more space than DRAM DRAM
LECTURE 10: Improving Memory Access: Direct and Spatial caches
 EECS 318 CAD Computer Aided Design LECTURE 10: Improving Memory Access: Direct and Spatial caches Instructor: Francis G. Wolff wolff@eecs.cwru.edu Case Western Reserve University This presentation uses
EECS 318 CAD Computer Aided Design LECTURE 10: Improving Memory Access: Direct and Spatial caches Instructor: Francis G. Wolff wolff@eecs.cwru.edu Case Western Reserve University This presentation uses
EEC 170 Computer Architecture Fall Cache Introduction Review. Review: The Memory Hierarchy. The Memory Hierarchy: Why Does it Work?
 EEC 17 Computer Architecture Fall 25 Introduction Review Review: The Hierarchy Take advantage of the principle of locality to present the user with as much memory as is available in the cheapest technology
EEC 17 Computer Architecture Fall 25 Introduction Review Review: The Hierarchy Take advantage of the principle of locality to present the user with as much memory as is available in the cheapest technology
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 22: Direct Mapped Cache Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Intel 8-core i7-5960x 3 GHz, 8-core, 20 MB of cache, 140
ECE331: Hardware Organization and Design Lecture 22: Direct Mapped Cache Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Intel 8-core i7-5960x 3 GHz, 8-core, 20 MB of cache, 140
COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory
 1 COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Chapter Seven. Memories: Review. Exploiting Memory Hierarchy CACHE MEMORY AND VIRTUAL MEMORY
 Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
CPE 631 Lecture 04: CPU Caches
 Lecture 04 CPU Caches Electrical and Computer Engineering University of Alabama in Huntsville Outline Memory Hierarchy Four Questions for Memory Hierarchy Cache Performance 26/01/2004 UAH- 2 1 Processor-DR
Lecture 04 CPU Caches Electrical and Computer Engineering University of Alabama in Huntsville Outline Memory Hierarchy Four Questions for Memory Hierarchy Cache Performance 26/01/2004 UAH- 2 1 Processor-DR
CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]
![CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]](/thumbs/73/69213006.jpg "CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]") CSF Cache Introduction [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user with as much
CSF Cache Introduction [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user with as much
A Cache Hierarchy in a Computer System
 A Cache Hierarchy in a Computer System Ideally one would desire an indefinitely large memory capacity such that any particular... word would be immediately available... We are... forced to recognize the
A Cache Hierarchy in a Computer System Ideally one would desire an indefinitely large memory capacity such that any particular... word would be immediately available... We are... forced to recognize the
Memory Hierarchies. Instructor: Dmitri A. Gusev. Fall Lecture 10, October 8, CS 502: Computers and Communications Technology
 Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]
![CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]](/thumbs/76/74076691.jpg "CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]") CSF Improving Cache Performance [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user
CSF Improving Cache Performance [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350):
:") The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy & Cache
 Removing The Ideal Memory Assumption: The Memory Hierarchy & Cache The impact of real memory on CPU Performance. Main memory basic properties: Memory Types: DRAM vs. SRAM The Motivation for The Memory
Removing The Ideal Memory Assumption: The Memory Hierarchy & Cache The impact of real memory on CPU Performance. Main memory basic properties: Memory Types: DRAM vs. SRAM The Motivation for The Memory
Improving Cache Performance
 Improving Cache Performance Tuesday 27 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary Previous Class Memory hierarchy
Improving Cache Performance Tuesday 27 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary Previous Class Memory hierarchy
Improving Cache Performance
 Improving Cache Performance Computer Organization Architectures for Embedded Computing Tuesday 28 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Improving Cache Performance Computer Organization Architectures for Embedded Computing Tuesday 28 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Lecture 17 Introduction to Memory Hierarchies" Why it s important " Fundamental lesson(s)" Suggested reading:" (HP Chapter
 Suggested reading: (HP Chapter") Processor components" Multicore processors and programming" Processor comparison" vs." Lecture 17 Introduction to Memory Hierarchies" CSE 30321" Suggested reading:" (HP Chapter 5.1-5.2)" Writing more "
Processor components" Multicore processors and programming" Processor comparison" vs." Lecture 17 Introduction to Memory Hierarchies" CSE 30321" Suggested reading:" (HP Chapter 5.1-5.2)" Writing more "
CS/ECE 3330 Computer Architecture. Chapter 5 Memory
 CS/ECE 3330 Computer Architecture Chapter 5 Memory Last Chapter n Focused exclusively on processor itself n Made a lot of simplifying assumptions IF ID EX MEM WB n Reality: The Memory Wall 10 6 Relative
CS/ECE 3330 Computer Architecture Chapter 5 Memory Last Chapter n Focused exclusively on processor itself n Made a lot of simplifying assumptions IF ID EX MEM WB n Reality: The Memory Wall 10 6 Relative
Locality. Cache. Direct Mapped Cache. Direct Mapped Cache
 Locality A principle that makes having a memory hierarchy a good idea If an item is referenced, temporal locality: it will tend to be referenced again soon spatial locality: nearby items will tend to be
Locality A principle that makes having a memory hierarchy a good idea If an item is referenced, temporal locality: it will tend to be referenced again soon spatial locality: nearby items will tend to be
Page 1. Memory Hierarchies (Part 2)
") Memory Hierarchies (Part ) Outline of Lectures on Memory Systems Memory Hierarchies Cache Memory 3 Virtual Memory 4 The future Increasing distance from the processor in access time Review: The Memory Hierarchy
Memory Hierarchies (Part ) Outline of Lectures on Memory Systems Memory Hierarchies Cache Memory 3 Virtual Memory 4 The future Increasing distance from the processor in access time Review: The Memory Hierarchy
Memory Hierarchy: Caches, Virtual Memory
 Memory Hierarchy: Caches, Virtual Memory Readings: 5.1-5.4, 5.8 Big memories are slow Computer Fast memories are small Processor Memory Devices Control Input Datapath Output Need to get fast, big memories
Memory Hierarchy: Caches, Virtual Memory Readings: 5.1-5.4, 5.8 Big memories are slow Computer Fast memories are small Processor Memory Devices Control Input Datapath Output Need to get fast, big memories
Memory Hierarchy. Maurizio Palesi. Maurizio Palesi 1
 Memory Hierarchy Maurizio Palesi Maurizio Palesi 1 References John L. Hennessy and David A. Patterson, Computer Architecture a Quantitative Approach, second edition, Morgan Kaufmann Chapter 5 Maurizio
Memory Hierarchy Maurizio Palesi Maurizio Palesi 1 References John L. Hennessy and David A. Patterson, Computer Architecture a Quantitative Approach, second edition, Morgan Kaufmann Chapter 5 Maurizio
5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Movie Rental Store You have a huge warehouse with every movie ever made.
5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Movie Rental Store You have a huge warehouse with every movie ever made.
CS3350B Computer Architecture
 CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
Performance! (1/latency)! 1000! 100! 10! Capacity Access Time Cost. CPU Registers 100s Bytes <10s ns. Cache K Bytes ns 1-0.
! 1000! 100! 10! Capacity Access Time Cost. CPU Registers 100s Bytes <10s ns. Cache K Bytes ns 1-0.") Since 1980, CPU has outpaced DRAM... EEL 5764: Graduate Computer Architecture Appendix C Hierarchy Review Ann Gordon-Ross Electrical and Computer Engineering University of Florida http://www.ann.ece.ufl.edu/
Since 1980, CPU has outpaced DRAM... EEL 5764: Graduate Computer Architecture Appendix C Hierarchy Review Ann Gordon-Ross Electrical and Computer Engineering University of Florida http://www.ann.ece.ufl.edu/
Memory Hierarchy: The motivation
 Memory Hierarchy: The motivation The gap between CPU performance and main memory has been widening with higher performance CPUs creating performance bottlenecks for memory access instructions. The memory
Memory Hierarchy: The motivation The gap between CPU performance and main memory has been widening with higher performance CPUs creating performance bottlenecks for memory access instructions. The memory
14:332:331. Week 13 Basics of Cache
 14:332:331 Computer Architecture and Assembly Language Spring 2006 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Week131 Spring 2006
14:332:331 Computer Architecture and Assembly Language Spring 2006 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Week131 Spring 2006
Question?! Processor comparison!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 5.1-5.2!! (Over the next 2 lectures)! Lecture 18" Introduction to Memory Hierarchies! 3! Processor components! Multicore processors and programming! Question?!
1! 2! Suggested Readings!! Readings!! H&P: Chapter 5.1-5.2!! (Over the next 2 lectures)! Lecture 18" Introduction to Memory Hierarchies! 3! Processor components! Multicore processors and programming! Question?!
LECTURE 11. Memory Hierarchy
 LECTURE 11 Memory Hierarchy MEMORY HIERARCHY When it comes to memory, there are two universally desirable properties: Large Size: ideally, we want to never have to worry about running out of memory. Speed
LECTURE 11 Memory Hierarchy MEMORY HIERARCHY When it comes to memory, there are two universally desirable properties: Large Size: ideally, we want to never have to worry about running out of memory. Speed
Chapter Seven. SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors)
") Chapter Seven emories: Review SRA: value is stored on a pair of inverting gates very fast but takes up more space than DRA (4 to transistors) DRA: value is stored as a charge on capacitor (must be refreshed)
Chapter Seven emories: Review SRA: value is stored on a pair of inverting gates very fast but takes up more space than DRA (4 to transistors) DRA: value is stored as a charge on capacitor (must be refreshed)
Chapter 7-1. Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授. V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor)
 臺大電機系吳安宇教授. V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor)") Chapter 7-1 Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授 V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor) 臺大電機吳安宇教授 - 計算機結構 1 Outline 7.1 Introduction 7.2 The Basics of Caches
Chapter 7-1 Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授 V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor) 臺大電機吳安宇教授 - 計算機結構 1 Outline 7.1 Introduction 7.2 The Basics of Caches
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 22: Introduction to Caches Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Caches hold a subset of data from the main
ECE232: Hardware Organization and Design Lecture 22: Introduction to Caches Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Caches hold a subset of data from the main
Let!s go back to a course goal... Let!s go back to a course goal... Question? Lecture 22 Introduction to Memory Hierarchies
 1 Lecture 22 Introduction to Memory Hierarchies Let!s go back to a course goal... At the end of the semester, you should be able to......describe the fundamental components required in a single core of
1 Lecture 22 Introduction to Memory Hierarchies Let!s go back to a course goal... At the end of the semester, you should be able to......describe the fundamental components required in a single core of
Lecture 12. Memory Design & Caches, part 2. Christos Kozyrakis Stanford University
 Lecture 12 Memory Design & Caches, part 2 Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements HW3 is due today PA2 is available on-line today Part 1 is due on 2/27
Lecture 12 Memory Design & Caches, part 2 Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements HW3 is due today PA2 is available on-line today Part 1 is due on 2/27
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Memory Technologies. Technology Trends
 . 5 Technologies Random access technologies Random good access time same for all locations DRAM Dynamic Random Access High density, low power, cheap, but slow Dynamic need to be refreshed regularly SRAM
. 5 Technologies Random access technologies Random good access time same for all locations DRAM Dynamic Random Access High density, low power, cheap, but slow Dynamic need to be refreshed regularly SRAM
Caches and Memory Hierarchy: Review. UCSB CS240A, Fall 2017
 Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
CS 61C: Great Ideas in Computer Architecture. The Memory Hierarchy, Fully Associative Caches
 CS 61C: Great Ideas in Computer Architecture The Memory Hierarchy, Fully Associative Caches Instructor: Alan Christopher 7/09/2014 Summer 2014 -- Lecture #10 1 Review of Last Lecture Floating point (single
CS 61C: Great Ideas in Computer Architecture The Memory Hierarchy, Fully Associative Caches Instructor: Alan Christopher 7/09/2014 Summer 2014 -- Lecture #10 1 Review of Last Lecture Floating point (single
Chapter 5. Large and Fast: Exploiting Memory Hierarchy. Jiang Jiang
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 5 Large
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 5 Large
Memory Hierarchy: Motivation
 Memory Hierarchy: Motivation The gap between CPU performance and main memory speed has been widening with higher performance CPUs creating performance bottlenecks for memory access instructions. The memory
Memory Hierarchy: Motivation The gap between CPU performance and main memory speed has been widening with higher performance CPUs creating performance bottlenecks for memory access instructions. The memory
ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]
![ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]](/thumbs/72/68075397.jpg "ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]") ECE7995 (6) Improving Cache Performance [Adapted from Mary Jane Irwin s slides (PSU)] Measuring Cache Performance Assuming cache hit costs are included as part of the normal CPU execution cycle, then CPU
ECE7995 (6) Improving Cache Performance [Adapted from Mary Jane Irwin s slides (PSU)] Measuring Cache Performance Assuming cache hit costs are included as part of the normal CPU execution cycle, then CPU
Handout 4 Memory Hierarchy
 Handout 4 Memory Hierarchy Outline Memory hierarchy Locality Cache design Virtual address spaces Page table layout TLB design options (MMU Sub-system) Conclusion 2012/11/7 2 Since 1980, CPU has outpaced
Handout 4 Memory Hierarchy Outline Memory hierarchy Locality Cache design Virtual address spaces Page table layout TLB design options (MMU Sub-system) Conclusion 2012/11/7 2 Since 1980, CPU has outpaced
Memory. Principle of Locality. It is impossible to have memory that is both. We create an illusion for the programmer. Employ memory hierarchy
 Datorarkitektur och operativsystem Lecture 7 Memory It is impossible to have memory that is both Unlimited (large in capacity) And fast 5.1 Intr roduction We create an illusion for the programmer Before
Datorarkitektur och operativsystem Lecture 7 Memory It is impossible to have memory that is both Unlimited (large in capacity) And fast 5.1 Intr roduction We create an illusion for the programmer Before
Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, Textbook web site:
 Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, 2003 Textbook web site: www.vrtechnology.org 1 Textbook web site: www.vrtechnology.org Laboratory Hardware 2 Topics 14:332:331
Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, 2003 Textbook web site: www.vrtechnology.org 1 Textbook web site: www.vrtechnology.org Laboratory Hardware 2 Topics 14:332:331
CENG 3420 Computer Organization and Design. Lecture 08: Memory - I. Bei Yu
 CENG 3420 Computer Organization and Design Lecture 08: Memory - I Bei Yu CEG3420 L08.1 Spring 2016 Outline q Why Memory Hierarchy q How Memory Hierarchy? SRAM (Cache) & DRAM (main memory) Memory System
CENG 3420 Computer Organization and Design Lecture 08: Memory - I Bei Yu CEG3420 L08.1 Spring 2016 Outline q Why Memory Hierarchy q How Memory Hierarchy? SRAM (Cache) & DRAM (main memory) Memory System
CS 61C: Great Ideas in Computer Architecture. Direct Mapped Caches
 CS 61C: Great Ideas in Computer Architecture Direct Mapped Caches Instructor: Justin Hsia 7/05/2012 Summer 2012 Lecture #11 1 Review of Last Lecture Floating point (single and double precision) approximates
CS 61C: Great Ideas in Computer Architecture Direct Mapped Caches Instructor: Justin Hsia 7/05/2012 Summer 2012 Lecture #11 1 Review of Last Lecture Floating point (single and double precision) approximates
registers data 1 registers MEMORY ADDRESS on-chip cache off-chip cache main memory: real address space part of virtual addr. sp.
 Cache associativity Cache and performance 12 1 CMPE110 Spring 2005 A. Di Blas 110 Spring 2005 CMPE Cache Direct-mapped cache Reads and writes Textbook Edition: 7.1 to 7.3 Second Third Edition: 7.1 to 7.3
Cache associativity Cache and performance 12 1 CMPE110 Spring 2005 A. Di Blas 110 Spring 2005 CMPE Cache Direct-mapped cache Reads and writes Textbook Edition: 7.1 to 7.3 Second Third Edition: 7.1 to 7.3
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 24: Cache Performance Analysis Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Last time: Associative caches How do we
ECE331: Hardware Organization and Design Lecture 24: Cache Performance Analysis Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Last time: Associative caches How do we
EN1640: Design of Computing Systems Topic 06: Memory System
 EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
Caches and Memory Hierarchy: Review. UCSB CS240A, Winter 2016
 Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
CS3350B Computer Architecture
 CS3350B Computer Architecture Winter 2015 Lecture 3.1: Memory Hierarchy: What and Why? Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and Design, Patterson
CS3350B Computer Architecture Winter 2015 Lecture 3.1: Memory Hierarchy: What and Why? Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and Design, Patterson
Computer Systems Architecture
 Computer Systems Architecture Lecture 12 Mahadevan Gomathisankaran March 4, 2010 03/04/2010 Lecture 12 CSCE 4610/5610 1 Discussion: Assignment 2 03/04/2010 Lecture 12 CSCE 4610/5610 2 Increasing Fetch
Computer Systems Architecture Lecture 12 Mahadevan Gomathisankaran March 4, 2010 03/04/2010 Lecture 12 CSCE 4610/5610 1 Discussion: Assignment 2 03/04/2010 Lecture 12 CSCE 4610/5610 2 Increasing Fetch
CPU issues address (and data for write) Memory returns data (or acknowledgment for write)
 Memory returns data (or acknowledgment for write)") The Main Memory Unit CPU and memory unit interface Address Data Control CPU Memory CPU issues address (and data for write) Memory returns data (or acknowledgment for write) Memories: Design Objectives
The Main Memory Unit CPU and memory unit interface Address Data Control CPU Memory CPU issues address (and data for write) Memory returns data (or acknowledgment for write) Memories: Design Objectives
Lecture 11 Cache. Peng Liu.
 Lecture 11 Cache Peng Liu liupeng@zju.edu.cn 1 Associative Cache Example 2 Associative Cache Example 3 Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative
Lecture 11 Cache Peng Liu liupeng@zju.edu.cn 1 Associative Cache Example 2 Associative Cache Example 3 Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative
3Introduction. Memory Hierarchy. Chapter 2. Memory Hierarchy Design. Computer Architecture A Quantitative Approach, Fifth Edition
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Assignment 1 due Mon (Feb 4pm
 Announcements Assignment 1 due Mon (Feb 19) @ 4pm Next week: no classes Inf3 Computer Architecture - 2017-2018 1 The Memory Gap 1.2x-1.5x 1.07x H&P 5/e, Fig. 2.2 Memory subsystem design increasingly important!
Announcements Assignment 1 due Mon (Feb 19) @ 4pm Next week: no classes Inf3 Computer Architecture - 2017-2018 1 The Memory Gap 1.2x-1.5x 1.07x H&P 5/e, Fig. 2.2 Memory subsystem design increasingly important!