Chapter 5. Large and Fast: Exploiting Memory Hierarchy
|
|
|
- Angel James
- 6 years ago
- Views:
Transcription

1 Chapter 5 Large and Fast: Exploiting Memory Hierarchy
2 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Access time of SRAM Capacity and cost/gb of disk SSD (Flash technology) 5.1 Introduction 2
3 SRAM DRAM WORD. WORD BIT.. BIT 3
4 Performance Processor-Memory Performance Gap Moore s Law Year µproc 55%/year (2X/1.5yr) Processor-Memory Performance Gap (grows 50%/year) DRAM 7%/year (2X/10yrs) 4
5 The Memory Wall Processor vs DRAM speed disparity continues to grow Clocks per instruction ,1 Core Memory 0,01 VAX/1980 PPro/ Good memory hierarchy (cache) design is increasingly important to overall performance Clocks per DRAM access 5
6 A Typical Memory Hierarchy Take advantage of the principle of locality to present the user with as much memory as is available in the cheapest technology at the speed offered by the fastest technology On-Chip Components Control Datapath RegFile ITLB DTLB Instr Data Cache Cache Second Level Cache (SRAM) Main Memory (DRAM) Secondary Memory (Disk) Speed (%cycles): ½ s 1 s 10 s 100 s 10,000 s Size (bytes): 100 s 10K s M s G s T s Cost: highest lowest 6
7 »Geographical«distances register file on-chip cache on-board cache main memory 1 m 2 m 10 m 100 m on your desk in your desk in your room in the house disk 1000 km abroad 7
8 Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to be accessed again soon e.g., instructions in a loop, induction variables Spatial locality Items near those accessed recently are likely to be accessed soon E.g., sequential instruction access, array data 8
9 Taking Advantage of Locality Memory hierarchy Store everything on disk Copy recently accessed (and nearby) items from disk to smaller DRAM memory Main memory Copy more recently accessed (and nearby) items from DRAM to smaller SRAM memory Cache memory attached to CPU 9

10 Memory Hierarchy Levels Block (aka line): unit of copying May be multiple words If accessed data is present in upper level Hit: access satisfied by upper level Hit ratio: hits/accesses If accessed data is absent Miss: block copied from lower level Time taken: miss penalty Miss ratio: misses/accesses = 1 hit ratio Then accessed data supplied from upper level 10

11 Cache Memory Cache memory The level of the memory hierarchy closest to the CPU 5.2 The Basics of Caches Given accesses X 1,, X n 1, X n How do we know if the data is present? Where do we look? 11


12 Direct Mapped Cache Location determined by address Direct mapped: only one choice (Block address) modulo (#Blocks in cache) #Blocks is a power of 2 Use low-order address bits 12
13 Tags and Valid Bits How do we know which particular block is stored in a cache location? Store block address as well as the data Actually, only need the high-order bits Called the tag What if there is no data in a location? Valid bit: 1 = present, 0 = not present Initially 0 13
14 Cache Example 8-blocks, 1 word/block, direct mapped Initial state Index V Tag Data 000 N 001 N 010 N 011 N 100 N 101 N 110 N 111 N 14
15 Cache Example Word addr Binary addr Hit/miss Cache block Miss 110 Index V Tag Data 000 N 001 N 010 N 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N 15
16 Cache Example Word addr Binary addr Hit/miss Cache block Miss 010 Index V Tag Data 000 N 001 N 010 Y 11 Mem[11010] 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N 16
17 Cache Example Word addr Binary addr Hit/miss Cache block Hit Hit 010 Index V Tag Data 000 N 001 N 010 Y 11 Mem[11010] 011 N 100 N 101 N 110 Y 10 Mem[10110] 111 N 17
18 Cache Example Word addr Binary addr Hit/miss Cache block Miss Miss Hit 000 Index V Tag Data 000 Y 10 Mem[10000] 001 N 010 Y 11 Mem[11010] 011 Y 00 Mem[00011] 100 N 101 N 110 Y 10 Mem[10110] 111 N 18
19 Cache Example Word addr Binary addr Hit/miss Cache block Miss 010 Index V Tag Data 000 Y 10 Mem[10000] 001 N 010 Y 10 Mem[10010] 011 Y 00 Mem[00011] 100 N 101 N 110 Y 10 Mem[10110] 111 N 19
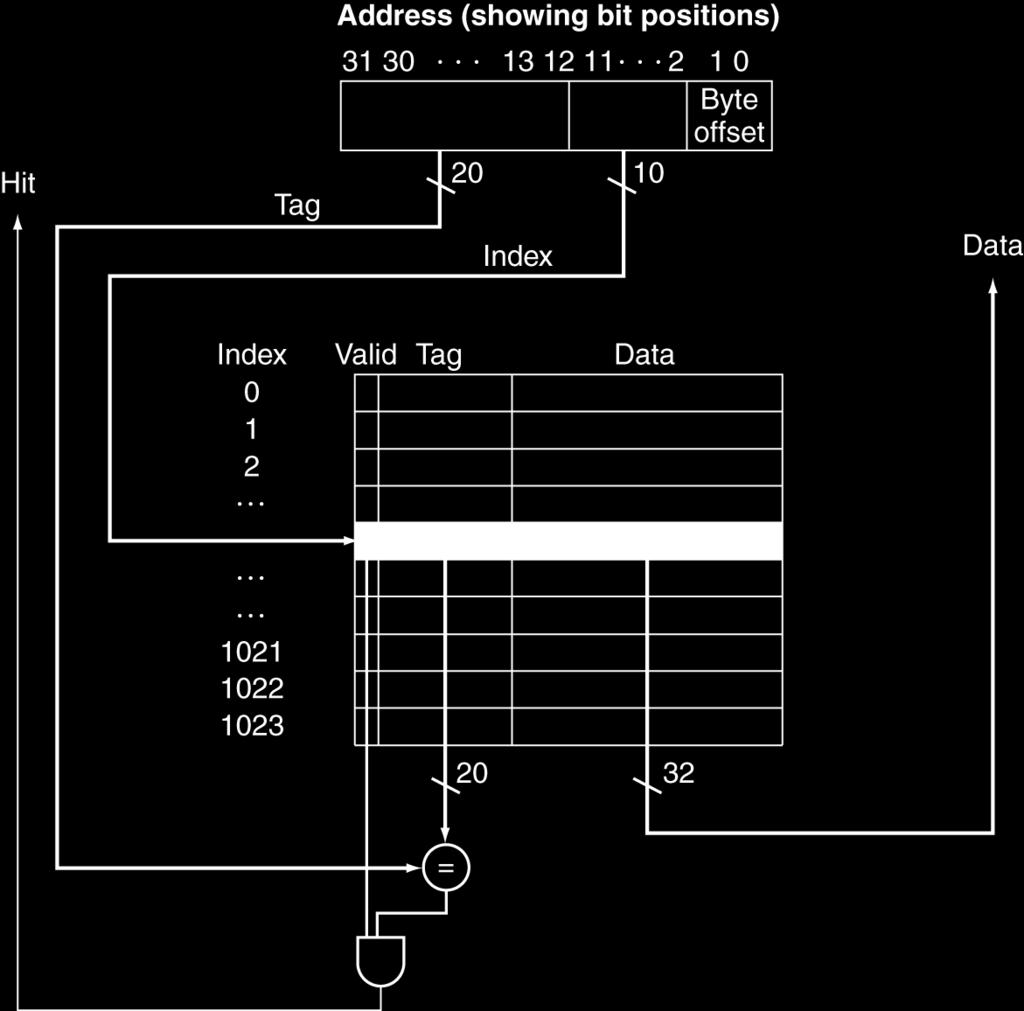
20 Address Subdivision 20
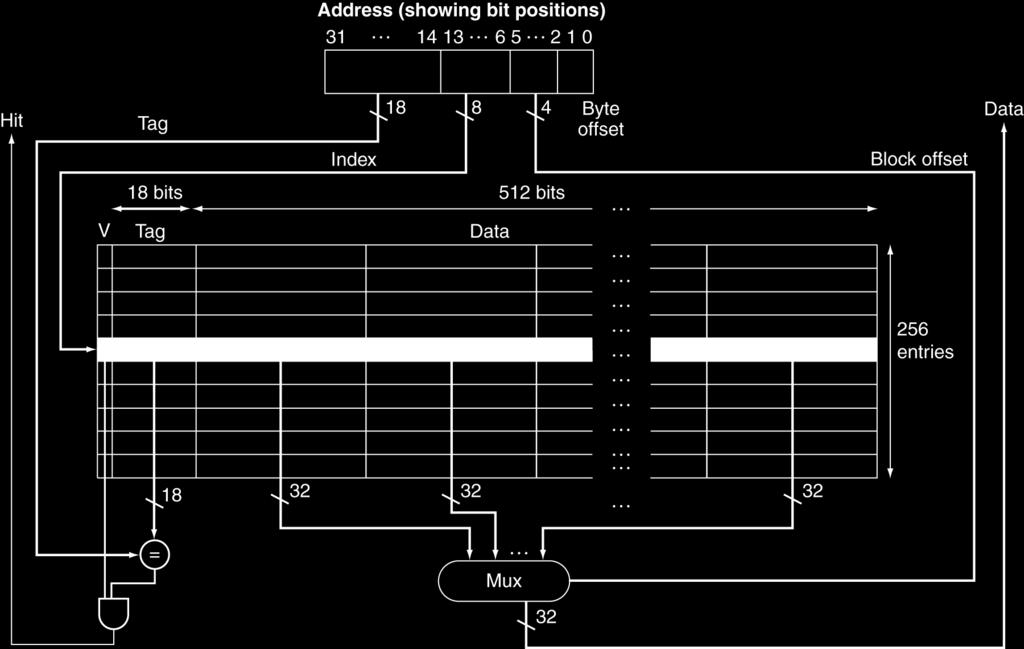
21 Example: Larger Block Size 64 blocks, 16 bytes/block To what block number does address 1200 map? Block address = 1200/16 = 75 Block number = 75 modulo 64 = Tag Index Offset 22 bits 6 bits 4 bits 21
22 Block Size Considerations Larger blocks should reduce miss rate Due to spatial locality But in a fixed-sized cache Larger blocks fewer of them More competition increased miss rate Larger blocks spatial locality decreases Larger miss penalty Can override benefit of reduced miss rate Early restart and critical-word-first can help 22
23 Miss Rate vs Block Size vs Cache Size Miss rate goes up if the block size becomes a significant fraction of the cache size because the number of blocks that can be held in the same size cache is smaller (increasing capacity misses) 10 Miss rate (%) 5 84 KB 16 KB 64 KB 256 KB Block size (bytes) Block size Miss penalty 23
24 Cache Misses On cache hit, CPU proceeds normally On cache miss Stall the CPU pipeline Fetch block from next level of hierarchy Instruction cache miss Restart instruction fetch Data cache miss Complete data access 24
25 Write-Through On data-write hit, could just update the block in cache But then cache and memory would be inconsistent Write through: also update memory But makes writes take longer e.g., if base CPI = 1, 10% of instructions are stores, write to memory takes 100 cycles Effective CPI = = 11 Solution: write buffer Holds data waiting to be written to memory CPU continues immediately Only stalls on write if write buffer is already full 25
26 Write(Copy)-Back Alternative: On data-write hit, just update the block in cache Keep track of whether each block is dirty When a dirty block is replaced Write it back to memory Can use a write buffer to allow replacing block to be read first 26
27 Write Allocation What should happen on a write miss? Alternatives for write-through Allocate on miss: fetch the block Write around: don t fetch the block Since programs often write a whole block before reading it (e.g., initialization) For write-back Usually fetch the block 27
28 Example: Intrinsity FastMATH Embedded MIPS processor 12-stage pipeline Instruction and data access on each cycle Split cache: separate I-cache and D-cache Each 16KB: 256 blocks 16 words/block D-cache: write-through or write-back SPEC2000 miss rates I-cache: 0.4% D-cache: 11.4% Weighted average: 3.2% 28
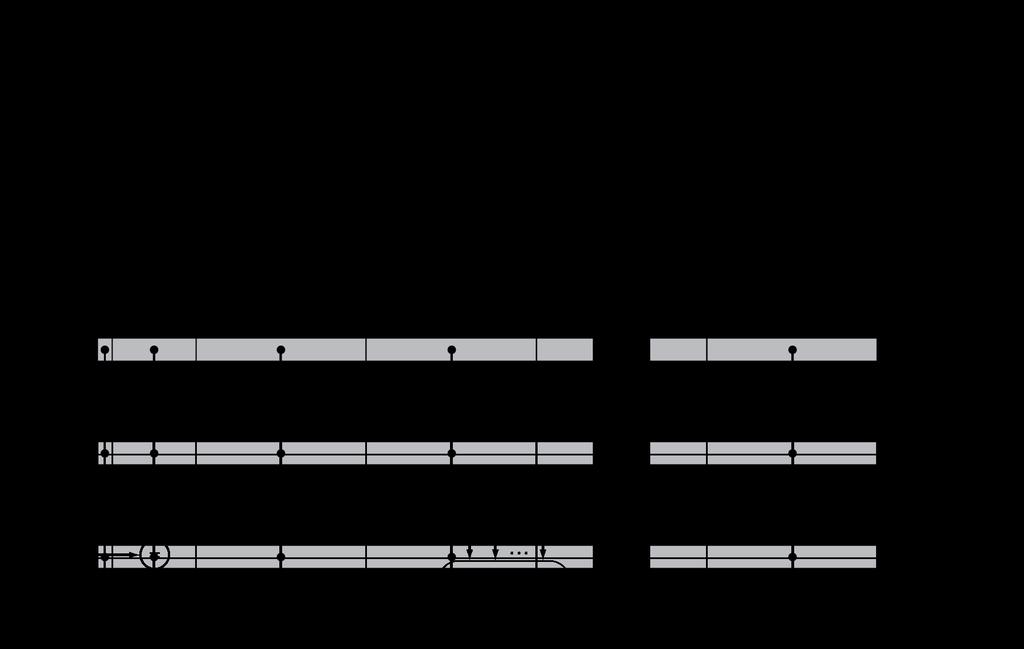
29 Example: Intrinsity FastMATH 29
30 Main Memory Supporting Caches Use DRAMs for main memory Fixed width (e.g., 1 word) Connected by fixed-width clocked bus Bus clock is typically slower than CPU clock Example cache block read 1 bus cycle for address transfer 15 bus cycles per DRAM access 1 bus cycle per data transfer For 4-word block, 1-word-wide DRAM Miss penalty = = 65 bus cycles Bandwidth = 16 bytes / 65 cycles = 0.25 B/cycle 30


31 Increasing Memory Bandwidth 4-word wide memory Miss penalty = = 17 bus cycles Bandwidth = 16 bytes / 17 cycles = 0.94 B/cycle 4-bank interleaved memory Miss penalty = = 20 bus cycles Bandwidth = 16 bytes / 20 cycles = 0.8 B/cycle 31
32 Advanced DRAM Organization Bits in a DRAM are organized as a rectangular array DRAM accesses an entire row Burst mode: supply successive words from a row with reduced latency Double data rate (DDR) DRAM Transfer on rising and falling clock edges Quad data rate (QDR) DRAM Separate DDR inputs and outputs 32
33 DRAM Generations Year Capacity $/GB Kbit $ Kbit $ Mbit $ Mbit $ Mbit $ Mbit $ Mbit $ Mbit $ Mbit $ Gbit $ '80 '83 '85 '89 '92 '96 '98 '00 '04 '07 Trac Tcac 33
34 Measuring Cache Performance Components of CPU time Program execution cycles Includes cache hit time Memory stall cycles Mainly from cache misses With simplifying assumptions: Memory stall cycles = = Memory accesses Program Instructions Program Miss rate Miss penalty Misses Instruction Miss penalty 5.3 Measuring and Improving Cache Performance 34
35 Cache Performance Example Given I-cache miss rate = 2% D-cache miss rate = 4% Miss penalty = 100 cycles Base CPI (ideal cache) = 2 Load & stores are 36% of instructions Miss cycles per instruction I-cache: = 2 D-cache: = 1.44 Actual CPI = = 5.44 Ideal CPU is 5.44/2 = 2.72 times faster 35
36 Average Access Time Hit time is also important for performance Average memory access time (AMAT) AMAT = Hit time + Miss rate Miss penalty Example CPU with 1ns clock, hit time = 1 cycle, miss penalty = 20 cycles, I-cache miss rate = 5% AMAT = = 2ns 2 cycles per instruction 36
37 Performance Summary When CPU performance increased Miss penalty becomes more significant Decreasing base CPI Greater proportion of time spent on memory stalls Increasing clock rate Memory stalls account for more CPU cycles Can t neglect cache behavior when evaluating system performance 37
38 Associative Caches Fully associative Allow a given block to go in any cache entry Requires all entries to be searched at once Comparator per entry (expensive) n-way set associative Each set contains n entries Block number determines which set (Block number) modulo (#Sets in cache) Search all entries in a given set at once n comparators (less expensive) 38

39 Associative Cache Example 39

40 Spectrum of Associativity For a cache with 8 entries 40
41 Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative Block access sequence: 0, 8, 0, 6, 8 Direct mapped Block address Cache index Hit/miss Cache content after access miss Mem[0] 8 0 miss Mem[8] 0 0 miss Mem[0] 6 2 miss Mem[0] Mem[6] 8 0 miss Mem[8] Mem[6] 41
42 Associativity Example 2-way set associative Block address Cache index Hit/miss 0 0 miss Mem[0] 8 0 miss Mem[0] Mem[8] 0 0 hit Mem[0] Mem[8] 6 0 miss Mem[0] Mem[6] 8 0 miss Mem[8] Mem[6] Cache content after access Set 0 Set 1 Fully associative Block address Hit/miss Cache content after access 0 miss Mem[0] 8 miss Mem[0] Mem[8] 0 hit Mem[0] Mem[8] 6 miss Mem[0] Mem[8] Mem[6] 8 hit Mem[0] Mem[8] Mem[6] 42
43 How Much Associativity Increased associativity decreases miss rate But with diminishing returns Simulation of a system with 64KB D-cache, 16-word blocks, SPEC way: 10.3% 2-way: 8.6% 4-way: 8.3% 8-way: 8.1% 43

44 Set Associative Cache Organization 44
45 Replacement Policy Direct mapped: no choice Set associative Prefer non-valid entry, if there is one Otherwise, choose among entries in the set Least-recently used (LRU) Choose the one unused for the longest time Simple for 2-way, manageable for 4-way, too hard beyond that Random Gives approximately the same performance as LRU for high associativity 45
46 Multilevel Caches Primary cache attached to CPU Small, but fast Level-2 cache services misses from primary cache Larger, slower, but still faster than main memory Main memory services L-2 cache misses Some high-end systems include L-3 cache 46
47 Multilevel Cache Example Given CPU base CPI = 1, clock rate = 4GHz Miss rate/instruction = 2% Main memory access time = 100ns With just primary cache Miss penalty = 100ns/0.25ns = 400 cycles Effective CPI = = 9 47
48 Example (cont.) Now add L-2 cache Access time = 5ns Global miss rate to main memory = 0.5% Primary miss with L-2 hit Penalty = 5ns/0.25ns = 20 cycles Primary miss with L-2 miss Extra penalty = 500 cycles CPI = = 3.4 Performance ratio = 9/3.4 =
49 Multilevel Cache Considerations Primary cache Focus on minimal hit time L-2 cache Focus on low miss rate to avoid main memory access Hit time has less overall impact Results L-1 cache usually smaller than a single cache L-1 block size smaller than L-2 block size 49
50 Interactions with Advanced CPUs Out-of-order CPUs can execute instructions during cache miss Pending store stays in load/store unit Dependent instructions wait in reservation stations Independent instructions continue Effect of miss depends on program data flow Much harder to analyse Use system simulation 50
51 Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system (OS) Programs share main memory Each gets a private virtual address space holding its frequently used code and data Protected from other programs CPU and OS translate virtual addresses to physical addresses VM block is called a page VM translation miss is called a page fault 5.4 Virtual Memory 51
52 Two Programs Sharing Physical Memory A program s address space is divided into pages (all one fixed size) or segments (variable sizes) The starting location of each page (either in main memory or in secondary memory) is contained in the program s page table Program 1 virtual address space main memory Program 2 virtual address space 52
53 Address Translation A virtual address is translated to a physical address by a combination of hardware and software Virtual Address (VA) Virtual page number Page offset Translation Physical page number Page offset Physical Address (PA) So each memory request first requires an address translation from the virtual space to the physical space A virtual memory miss (i.e., when the page is not in physical memory) is called a page fault 53
54 Page Fault Penalty On page fault, the page must be fetched from disk Takes millions of clock cycles Handled by OS code Try to minimize page fault rate Fully associative placement in memory Smart replacement algorithms 54
55 Page Tables Stores placement information Array of page table entries, indexed by virtual page number Page table register in CPU points to page table in physical memory If page is present in memory PTE stores the physical page number Plus other status bits (referenced, dirty, ) If page is not present PTE can refer to location in swap space on disk 55
56 Address Translation Mechanisms Virtual page # Offset Physical page # Page table register V Physical page base addr Offset Main memory Page Table (in main memory) Disk storage 56
57 Replacement and Writes To reduce page fault rate, prefer leastrecently used (LRU) replacement Reference bit (aka use bit) in PTE set to 1 on access to page Periodically cleared to 0 by OS A page with reference bit = 0 has not been used recently Disk writes take millions of cycles Block at once, not individual locations Write through is impractical Use write-back Dirty bit in PTE set when page is written 57
58 Fast Translation Using a TLB Address translation would appear to require extra memory references One to access the PTE Then the actual memory access But access to page tables has good locality So use a fast cache of PTEs within the CPU Called a Translation Look-aside Buffer (TLB) Typical: PTEs, cycle for hit, cycles for miss, 0.01% 1% miss rate Misses could be handled by hardware or software 58

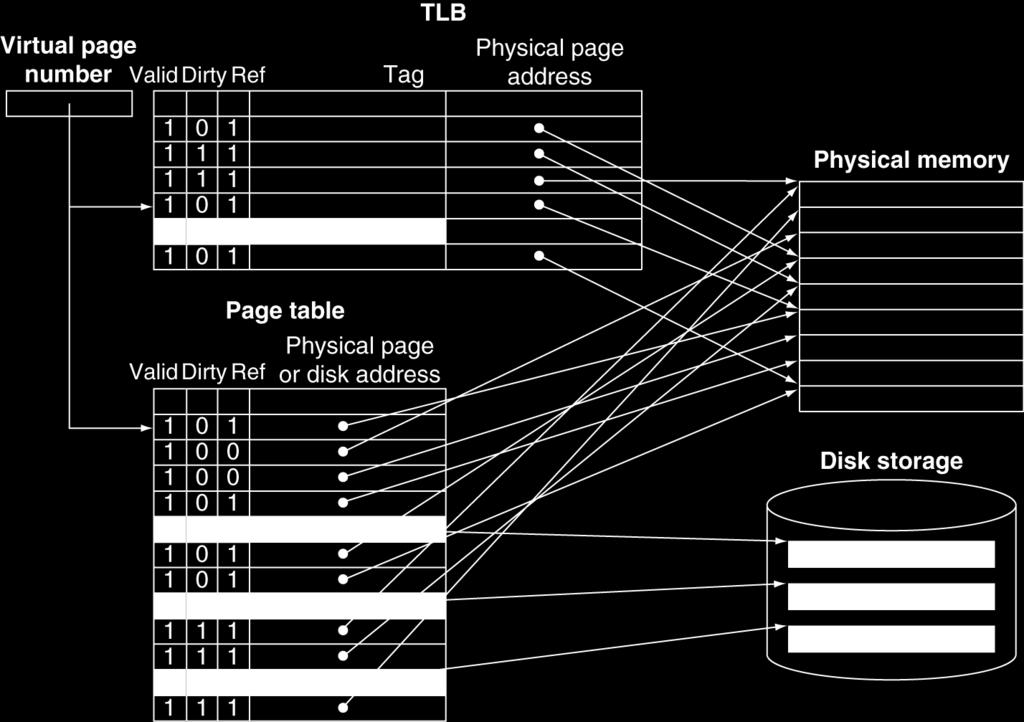
59 Fast Translation Using a TLB 59
60 TLB Misses If page is in memory Load the PTE from memory and retry Could be handled in hardware or in software If page is not in memory (page fault) OS handles fetching the page and updating the page table Then restart the faulting instruction 60
61 Memory Protection Different tasks can share parts of their virtual address spaces But need to protect against errant access Requires OS assistance Hardware support for OS protection Privileged supervisor mode (aka kernel mode) Privileged instructions Page tables and other state information only accessible in supervisor mode System call exception (e.g., syscall in MIPS) 61
62 The Memory Hierarchy The BIG Picture Common principles apply at all levels of the memory hierarchy Based on notions of caching At each level in the hierarchy Block placement Finding a block Replacement on a miss Write policy 5.5 A Common Framework for Memory Hierarchies 62
63 Block Placement Determined by associativity Direct mapped (1-way associative) One choice for placement n-way set associative n choices within a set Fully associative Any location Higher associativity reduces miss rate Increases complexity, cost, and access time 63
64 Finding a Block Associativity Location method Tag comparisons Direct mapped Index 1 n-way set associative Hardware caches Set index, then search entries within the set Fully associative Search all entries #entries Full lookup table 0 Reduce comparisons to reduce cost Virtual memory Full table lookup makes full associativity feasible Benefit in reduced miss rate n 64
65 Replacement Choice of entry to replace on a miss Least recently used (LRU) Complex and costly hardware for high associativity Random Close to LRU, easier to implement Virtual memory LRU approximation with hardware support 65
66 Write Policy Write-through Update both upper and lower levels Simplifies replacement, but may require write buffer Write-back Update upper level only Update lower level when block is replaced Need to keep more state Virtual memory Only write-back is feasible, given disk write latency 66
67 Sources of Misses Compulsory misses (aka cold start misses) First access to a block Capacity misses Due to finite cache size A replaced block is later accessed again Conflict misses (aka collision misses) In a non-fully associative cache Due to competition for entries in a set Would not occur in a fully associative cache of the same total size 67
68 Cache Design Trade-offs Design change Effect on miss rate Negative performance effect Increase cache size Increase associativity Increase block size Decrease capacity misses Decrease conflict misses Decrease compulsory misses May increase access time May increase access time Increases miss penalty. For very large block size, may increase miss rate due to pollution. 68

69 Multilevel On-Chip Caches Intel Nehalem 4-core processor Per core: 32KB L1 I-cache, 32KB L1 D-cache, 512KB L2 cache 5.10 Real Stuff: The AMD Opteron X4 and Intel Nehalem 69
70 2-Level TLB Organization Intel Nehalem AMD Opteron X4 Virtual addr 48 bits 48 bits Physical addr 44 bits 48 bits (256 TB) L1 TLB (per core) L2 TLB (per core) L1 I-TLB: 128 entries for small pages, 7 per thread (2 ) for large pages L1 D-TLB: 64 entries for small pages, 32 for large pages Both 4-way, LRU replacement Single L2 TLB: 512 entries 4-way, LRU replacement L1 I-TLB: 48 entries L1 D-TLB: 48 entries Both fully associative, LRU replacement L2 I-TLB: 512 entries L2 D-TLB: 512 entries Both 4-way, round-robin LRU TLB misses Handled in hardware Handled in hardware 70
71 3-Level Cache Organization L1 caches (per core) L2 unified cache (per core) L3 unified cache (shared) Intel Nehalem L1 I-cache: 32KB, 64-byte blocks, 4-way, approx LRU replacement, hit time n/a L1 D-cache: 32KB, 64-byte blocks, 8-way, approx LRU replacement, writeback/allocate, hit time n/a 256KB, 64-byte blocks, 8-way, approx LRU replacement, writeback/allocate, hit time n/a 8MB, 64-byte blocks, 16-way, replacement n/a, writeback/allocate, hit time n/a AMD Opteron X4 L1 I-cache: 32KB, 64-byte blocks, 2-way, LRU replacement, hit time 3 cycles L1 D-cache: 32KB, 64-byte blocks, 2-way, LRU replacement, writeback/allocate, hit time 9 cycles 512KB, 64-byte blocks, 16-way, approx LRU replacement, writeback/allocate, hit time n/a 2MB, 64-byte blocks, 32-way, replace block shared by fewest cores, write-back/allocate, hit time 32 cycles n/a: data not available 71
72 Pitfalls Byte vs. word addressing Example: 32-byte direct-mapped cache, 4-byte blocks Byte 36 maps to block 1 Word 36 maps to block 4 Ignoring memory system effects when writing or generating code Example: iterating over rows vs. columns of arrays Large strides result in poor locality 5.11 Fallacies and Pitfalls 72
73 Pitfalls In multiprocessor with shared L2 or L3 cache Less associativity than cores results in conflict misses More cores need to increase associativity Using AMAT to evaluate performance of out-of-order processors Evaluate performance by simulation 73
74 Concluding Remarks Fast memories are small, large memories are slow We really want fast, large memories Caching gives this illusion Principle of locality Programs use a small part of their memory space frequently Memory hierarchy L1 cache L2 cache DRAM memory disk Memory system design is critical for multiprocessors 5.12 Concluding Remarks 74
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Computer Architecture Computer Science & Engineering. Chapter 5. Memory Hierachy BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Memory Technology. Chapter 5. Principle of Locality. Chapter 5 Large and Fast: Exploiting Memory Hierarchy 1
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Static RAM (SRAM) Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 0.5ns 2.5ns, $2000 $5000 per GB 5.1 Introduction Memory Technology 5ms
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Static RAM (SRAM) Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 0.5ns 2.5ns, $2000 $5000 per GB 5.1 Introduction Memory Technology 5ms
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY
 LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
The Memory Hierarchy. Cache, Main Memory, and Virtual Memory (Part 2)
") The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Review: Major Components of a Computer Processor Devices Control Memory Input Datapath Output Secondary Memory (Disk) Main Memory Cache Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Review: Major Components of a Computer Processor Devices Control Memory Input Datapath Output Secondary Memory (Disk) Main Memory Cache Performance
Memory Technology. Caches 1. Static RAM (SRAM) Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB
 Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB") Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
Chapter 5A. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Memory Hierarchy Y. K. Malaiya
 Memory Hierarchy Y. K. Malaiya Acknowledgements Computer Architecture, Quantitative Approach - Hennessy, Patterson Vishwani D. Agrawal Review: Major Components of a Computer Processor Control Datapath
Memory Hierarchy Y. K. Malaiya Acknowledgements Computer Architecture, Quantitative Approach - Hennessy, Patterson Vishwani D. Agrawal Review: Major Components of a Computer Processor Control Datapath
Chapter 5. Large and Fast: Exploiting Memory Hierarchy. Jiang Jiang
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 5 Large
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 5 Large
CS/ECE 3330 Computer Architecture. Chapter 5 Memory
 CS/ECE 3330 Computer Architecture Chapter 5 Memory Last Chapter n Focused exclusively on processor itself n Made a lot of simplifying assumptions IF ID EX MEM WB n Reality: The Memory Wall 10 6 Relative
CS/ECE 3330 Computer Architecture Chapter 5 Memory Last Chapter n Focused exclusively on processor itself n Made a lot of simplifying assumptions IF ID EX MEM WB n Reality: The Memory Wall 10 6 Relative
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface COEN-4710 Computer Hardware Lecture 7 Large and Fast: Exploiting Memory Hierarchy (Chapter 5) Cristinel Ababei Marquette University Department
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface COEN-4710 Computer Hardware Lecture 7 Large and Fast: Exploiting Memory Hierarchy (Chapter 5) Cristinel Ababei Marquette University Department
V. Primary & Secondary Memory!
 V. Primary & Secondary Memory! Computer Architecture and Operating Systems & Operating Systems: 725G84 Ahmed Rezine 1 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM)
V. Primary & Secondary Memory! Computer Architecture and Operating Systems & Operating Systems: 725G84 Ahmed Rezine 1 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM)
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-12a Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
CSE 2021: Computer Organization Lecture-12a Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
Main Memory Supporting Caches
 Main Memory Supporting Caches Use DRAMs for main memory Fixed width (e.g., 1 word) Connected by fixed-width clocked bus Bus clock is typically slower than CPU clock Cache Issues 1 Example cache block read
Main Memory Supporting Caches Use DRAMs for main memory Fixed width (e.g., 1 word) Connected by fixed-width clocked bus Bus clock is typically slower than CPU clock Cache Issues 1 Example cache block read
Memory Hierarchy. Reading. Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 (2) Lecture notes from MKP, H. H. Lee and S.
, 5.9 (2) Lecture notes from MKP, H. H. Lee and S.") Memory Hierarchy Lecture notes from MKP, H. H. Lee and S. Yalamanchili Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 Reading (2) 1 SRAM: Value is stored on a pair of inerting gates Very fast but
Memory Hierarchy Lecture notes from MKP, H. H. Lee and S. Yalamanchili Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 Reading (2) 1 SRAM: Value is stored on a pair of inerting gates Very fast but
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Different Storage Memories Chapter 5 Large and Fast: Exploiting Memory
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Different Storage Memories Chapter 5 Large and Fast: Exploiting Memory
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-12 Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
CSE 2021: Computer Organization Lecture-12 Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Movie Rental Store You have a huge warehouse with every movie ever made.
5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Movie Rental Store You have a huge warehouse with every movie ever made.
EN1640: Design of Computing Systems Topic 06: Memory System
 EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
Cache Optimization. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Cache Optimization Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Cache Misses On cache hit CPU proceeds normally On cache miss Stall the CPU pipeline
Cache Optimization Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Cache Misses On cache hit CPU proceeds normally On cache miss Stall the CPU pipeline
Chapter 5. Memory Technology
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Memory. Principle of Locality. It is impossible to have memory that is both. We create an illusion for the programmer. Employ memory hierarchy
 Datorarkitektur och operativsystem Lecture 7 Memory It is impossible to have memory that is both Unlimited (large in capacity) And fast 5.1 Intr roduction We create an illusion for the programmer Before
Datorarkitektur och operativsystem Lecture 7 Memory It is impossible to have memory that is both Unlimited (large in capacity) And fast 5.1 Intr roduction We create an illusion for the programmer Before
Caches. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Chapter 5 (Part II) Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs
 Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs") Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Computer Systems Laboratory Sungkyunkwan University
 Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
CSE 431 Computer Architecture Fall Chapter 5A: Exploiting the Memory Hierarchy, Part 1
 CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
EN1640: Design of Computing Systems Topic 06: Memory System
 EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
Memory Hierarchy. ENG3380 Computer Organization and Architecture Cache Memory Part II. Topics. References. Memory Hierarchy
 ENG338 Computer Organization and Architecture Part II Winter 217 S. Areibi School of Engineering University of Guelph Hierarchy Topics Hierarchy Locality Motivation Principles Elements of Design: Addresses
ENG338 Computer Organization and Architecture Part II Winter 217 S. Areibi School of Engineering University of Guelph Hierarchy Topics Hierarchy Locality Motivation Principles Elements of Design: Addresses
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 6A: Cache Design Avinash Kodi, kodi@ohioedu Agenda 2 Review: Memory Hierarchy Review: Cache Organization Direct-mapped Set- Associative Fully-Associative 1 Major
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 6A: Cache Design Avinash Kodi, kodi@ohioedu Agenda 2 Review: Memory Hierarchy Review: Cache Organization Direct-mapped Set- Associative Fully-Associative 1 Major
Memory Hierarchy. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Memory Hierarchy Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Memory Hierarchy Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Chapter 5. Large and Fast: Exploiting Memory Hierarchy. Part II Virtual Memory
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Part II Virtual Memory Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Part II Virtual Memory Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system
Virtual Memory. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Precise Definition of Virtual Memory Virtual memory is a mechanism for translating logical
Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Precise Definition of Virtual Memory Virtual memory is a mechanism for translating logical
Transistor: Digital Building Blocks
 Final Exam Review Transistor: Digital Building Blocks Logically, each transistor acts as a switch Combined to implement logic functions (gates) AND, OR, NOT Combined to build higher-level structures Multiplexer,
Final Exam Review Transistor: Digital Building Blocks Logically, each transistor acts as a switch Combined to implement logic functions (gates) AND, OR, NOT Combined to build higher-level structures Multiplexer,
COMPUTER ORGANIZATION AND DESIGN ARM
 COMPUTER ORGANIZATION AND DESIGN ARM The Hardware/Software Interface Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Διδάσκων Καθηγητής :Παρασκευάς Ευριπίδου Γραφείο :ΘΕΕ01 115 Τηλέφωνο :22892996
COMPUTER ORGANIZATION AND DESIGN ARM The Hardware/Software Interface Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Διδάσκων Καθηγητής :Παρασκευάς Ευριπίδου Γραφείο :ΘΕΕ01 115 Τηλέφωνο :22892996
COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory
 1 COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Impact of Memory Access 5.1 Introduction Program accesses 7 GB of RAM
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Impact of Memory Access 5.1 Introduction Program accesses 7 GB of RAM
Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, Textbook web site:
 Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, 2003 Textbook web site: www.vrtechnology.org 1 Textbook web site: www.vrtechnology.org Laboratory Hardware 2 Topics 14:332:331
Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, 2003 Textbook web site: www.vrtechnology.org 1 Textbook web site: www.vrtechnology.org Laboratory Hardware 2 Topics 14:332:331
CS161 Design and Architecture of Computer Systems. Cache $$$$$
 CS161 Design and Architecture of Computer Systems Cache $$$$$ Memory Systems! How can we supply the CPU with enough data to keep it busy?! We will focus on memory issues,! which are frequently bottlenecks
CS161 Design and Architecture of Computer Systems Cache $$$$$ Memory Systems! How can we supply the CPU with enough data to keep it busy?! We will focus on memory issues,! which are frequently bottlenecks
Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1)
") Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Course Administration
 Spring 207 EE 363: Computer Organization Chapter 5: Large and Fast: Exploiting Memory Hierarchy - Avinash Kodi Department of Electrical Engineering & Computer Science Ohio University, Athens, Ohio 4570
Spring 207 EE 363: Computer Organization Chapter 5: Large and Fast: Exploiting Memory Hierarchy - Avinash Kodi Department of Electrical Engineering & Computer Science Ohio University, Athens, Ohio 4570
14:332:331. Week 13 Basics of Cache
 14:332:331 Computer Architecture and Assembly Language Spring 2006 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Week131 Spring 2006
14:332:331 Computer Architecture and Assembly Language Spring 2006 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Week131 Spring 2006
Improving Cache Performance
 Improving Cache Performance Computer Organization Architectures for Embedded Computing Tuesday 28 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Improving Cache Performance Computer Organization Architectures for Embedded Computing Tuesday 28 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Virtual Memory. Reading. Sections 5.4, 5.5, 5.6, 5.8, 5.10 (2) Lecture notes from MKP and S. Yalamanchili
 Lecture notes from MKP and S. Yalamanchili") Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
Advanced Memory Organizations
 CSE 3421: Introduction to Computer Architecture Advanced Memory Organizations Study: 5.1, 5.2, 5.3, 5.4 (only parts) Gojko Babić 03-29-2018 1 Growth in Performance of DRAM & CPU Huge mismatch between CPU
CSE 3421: Introduction to Computer Architecture Advanced Memory Organizations Study: 5.1, 5.2, 5.3, 5.4 (only parts) Gojko Babić 03-29-2018 1 Growth in Performance of DRAM & CPU Huge mismatch between CPU
Virtual Memory. Patterson & Hennessey Chapter 5 ELEC 5200/6200 1
 Virtual Memory Patterson & Hennessey Chapter 5 ELEC 5200/6200 1 Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system (OS) Programs
Virtual Memory Patterson & Hennessey Chapter 5 ELEC 5200/6200 1 Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system (OS) Programs
CENG 3420 Computer Organization and Design. Lecture 08: Memory - I. Bei Yu
 CENG 3420 Computer Organization and Design Lecture 08: Memory - I Bei Yu CEG3420 L08.1 Spring 2016 Outline q Why Memory Hierarchy q How Memory Hierarchy? SRAM (Cache) & DRAM (main memory) Memory System
CENG 3420 Computer Organization and Design Lecture 08: Memory - I Bei Yu CEG3420 L08.1 Spring 2016 Outline q Why Memory Hierarchy q How Memory Hierarchy? SRAM (Cache) & DRAM (main memory) Memory System
CS3350B Computer Architecture
 CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
14:332:331. Week 13 Basics of Cache
 14:332:331 Computer Architecture and Assembly Language Fall 2003 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Lec20.1 Fall 2003 Head
14:332:331 Computer Architecture and Assembly Language Fall 2003 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Lec20.1 Fall 2003 Head
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Improving Cache Performance
 Improving Cache Performance Tuesday 27 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary Previous Class Memory hierarchy
Improving Cache Performance Tuesday 27 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary Previous Class Memory hierarchy
Chapter 5 B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 B Large and Fast: Exploiting Memory Hierarchy Dependability 5.5 Dependable Memory Hierarchy Chapter 6 Storage and Other I/O Topics 2 Dependability Service accomplishment Service delivered as
Chapter 5 B Large and Fast: Exploiting Memory Hierarchy Dependability 5.5 Dependable Memory Hierarchy Chapter 6 Storage and Other I/O Topics 2 Dependability Service accomplishment Service delivered as
Page 1. Memory Hierarchies (Part 2)
") Memory Hierarchies (Part ) Outline of Lectures on Memory Systems Memory Hierarchies Cache Memory 3 Virtual Memory 4 The future Increasing distance from the processor in access time Review: The Memory Hierarchy
Memory Hierarchies (Part ) Outline of Lectures on Memory Systems Memory Hierarchies Cache Memory 3 Virtual Memory 4 The future Increasing distance from the processor in access time Review: The Memory Hierarchy
Chapter Seven. Memories: Review. Exploiting Memory Hierarchy CACHE MEMORY AND VIRTUAL MEMORY
 Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
CS 61C: Great Ideas in Computer Architecture. Direct Mapped Caches
 CS 61C: Great Ideas in Computer Architecture Direct Mapped Caches Instructor: Justin Hsia 7/05/2012 Summer 2012 Lecture #11 1 Review of Last Lecture Floating point (single and double precision) approximates
CS 61C: Great Ideas in Computer Architecture Direct Mapped Caches Instructor: Justin Hsia 7/05/2012 Summer 2012 Lecture #11 1 Review of Last Lecture Floating point (single and double precision) approximates
CENG 3420 Computer Organization and Design. Lecture 08: Cache Review. Bei Yu
 CENG 3420 Computer Organization and Design Lecture 08: Cache Review Bei Yu CEG3420 L08.1 Spring 2016 A Typical Memory Hierarchy q Take advantage of the principle of locality to present the user with as
CENG 3420 Computer Organization and Design Lecture 08: Cache Review Bei Yu CEG3420 L08.1 Spring 2016 A Typical Memory Hierarchy q Take advantage of the principle of locality to present the user with as
Lecture 11: Memory Systems -- Cache Organiza9on and Performance CSE 564 Computer Architecture Summer 2017
 Lecture 11: Memory Systems -- Cache Organiza9on and Performance CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
Lecture 11: Memory Systems -- Cache Organiza9on and Performance CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]
![CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]](/thumbs/76/74076691.jpg "CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]") CSF Improving Cache Performance [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user
CSF Improving Cache Performance [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 28: More Virtual Memory Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Virtual memory used to protect applications from
ECE232: Hardware Organization and Design Lecture 28: More Virtual Memory Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Virtual memory used to protect applications from
Computer Architecture Review. Jo, Heeseung
 Computer Architecture Review Jo, Heeseung Computer Abstractions and Technology Jo, Heeseung Below Your Program Application software Written in high-level language System software Compiler: translates HLL
Computer Architecture Review Jo, Heeseung Computer Abstractions and Technology Jo, Heeseung Below Your Program Application software Written in high-level language System software Compiler: translates HLL
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 22: Direct Mapped Cache Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Intel 8-core i7-5960x 3 GHz, 8-core, 20 MB of cache, 140
ECE331: Hardware Organization and Design Lecture 22: Direct Mapped Cache Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Intel 8-core i7-5960x 3 GHz, 8-core, 20 MB of cache, 140
EEC 170 Computer Architecture Fall Cache Introduction Review. Review: The Memory Hierarchy. The Memory Hierarchy: Why Does it Work?
 EEC 17 Computer Architecture Fall 25 Introduction Review Review: The Hierarchy Take advantage of the principle of locality to present the user with as much memory as is available in the cheapest technology
EEC 17 Computer Architecture Fall 25 Introduction Review Review: The Hierarchy Take advantage of the principle of locality to present the user with as much memory as is available in the cheapest technology
4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.
 Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
The Memory Hierarchy Cache, Main Memory, and Virtual Memory
 The Memory Hierarchy Cache, Main Memory, and Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University The Simple View of Memory The simplest view
The Memory Hierarchy Cache, Main Memory, and Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University The Simple View of Memory The simplest view
Modern Computer Architecture
 Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]
![CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]](/thumbs/73/69213006.jpg "CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]") CSF Cache Introduction [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user with as much
CSF Cache Introduction [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user with as much
ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]
![ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]](/thumbs/72/68075397.jpg "ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]") ECE7995 (6) Improving Cache Performance [Adapted from Mary Jane Irwin s slides (PSU)] Measuring Cache Performance Assuming cache hit costs are included as part of the normal CPU execution cycle, then CPU
ECE7995 (6) Improving Cache Performance [Adapted from Mary Jane Irwin s slides (PSU)] Measuring Cache Performance Assuming cache hit costs are included as part of the normal CPU execution cycle, then CPU
Virtual Memory - Objectives
 ECE232: Hardware Organization and Design Part 16: Virtual Memory Chapter 7 http://www.ecs.umass.edu/ece/ece232/ Adapted from Computer Organization and Design, Patterson & Hennessy Virtual Memory - Objectives
ECE232: Hardware Organization and Design Part 16: Virtual Memory Chapter 7 http://www.ecs.umass.edu/ece/ece232/ Adapted from Computer Organization and Design, Patterson & Hennessy Virtual Memory - Objectives
EECS151/251A Spring 2018 Digital Design and Integrated Circuits. Instructors: John Wawrzynek and Nick Weaver. Lecture 19: Caches EE141
 EECS151/251A Spring 2018 Digital Design and Integrated Circuits Instructors: John Wawrzynek and Nick Weaver Lecture 19: Caches Cache Introduction 40% of this ARM CPU is devoted to SRAM cache. But the role
EECS151/251A Spring 2018 Digital Design and Integrated Circuits Instructors: John Wawrzynek and Nick Weaver Lecture 19: Caches Cache Introduction 40% of this ARM CPU is devoted to SRAM cache. But the role
CS3350B Computer Architecture
 CS3350B Computer Architecture Winter 2015 Lecture 3.1: Memory Hierarchy: What and Why? Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and Design, Patterson
CS3350B Computer Architecture Winter 2015 Lecture 3.1: Memory Hierarchy: What and Why? Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and Design, Patterson
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
LECTURE 11. Memory Hierarchy
 LECTURE 11 Memory Hierarchy MEMORY HIERARCHY When it comes to memory, there are two universally desirable properties: Large Size: ideally, we want to never have to worry about running out of memory. Speed
LECTURE 11 Memory Hierarchy MEMORY HIERARCHY When it comes to memory, there are two universally desirable properties: Large Size: ideally, we want to never have to worry about running out of memory. Speed
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350):
:") The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
Locality. Cache. Direct Mapped Cache. Direct Mapped Cache
 Locality A principle that makes having a memory hierarchy a good idea If an item is referenced, temporal locality: it will tend to be referenced again soon spatial locality: nearby items will tend to be
Locality A principle that makes having a memory hierarchy a good idea If an item is referenced, temporal locality: it will tend to be referenced again soon spatial locality: nearby items will tend to be
COSC 6385 Computer Architecture. - Memory Hierarchies (I)
") COSC 6385 Computer Architecture - Hierarchies (I) Fall 2007 Slides are based on a lecture by David Culler, University of California, Berkley http//www.eecs.berkeley.edu/~culler/courses/cs252-s05 Recap
COSC 6385 Computer Architecture - Hierarchies (I) Fall 2007 Slides are based on a lecture by David Culler, University of California, Berkley http//www.eecs.berkeley.edu/~culler/courses/cs252-s05 Recap
Chapter 7-1. Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授. V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor)
 臺大電機系吳安宇教授. V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor)") Chapter 7-1 Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授 V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor) 臺大電機吳安宇教授 - 計算機結構 1 Outline 7.1 Introduction 7.2 The Basics of Caches
Chapter 7-1 Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授 V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor) 臺大電機吳安宇教授 - 計算機結構 1 Outline 7.1 Introduction 7.2 The Basics of Caches
CS 61C: Great Ideas in Computer Architecture. The Memory Hierarchy, Fully Associative Caches
 CS 61C: Great Ideas in Computer Architecture The Memory Hierarchy, Fully Associative Caches Instructor: Alan Christopher 7/09/2014 Summer 2014 -- Lecture #10 1 Review of Last Lecture Floating point (single
CS 61C: Great Ideas in Computer Architecture The Memory Hierarchy, Fully Associative Caches Instructor: Alan Christopher 7/09/2014 Summer 2014 -- Lecture #10 1 Review of Last Lecture Floating point (single
Caches and Memory Hierarchy: Review. UCSB CS240A, Fall 2017
 Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Reducing Hit Times. Critical Influence on cycle-time or CPI. small is always faster and can be put on chip
 Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 1
 Caches Part 1") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 1 Instructors: Nicholas Weaver & Vladimir Stojanovic http://inst.eecs.berkeley.edu/~cs61c/ Components of a Computer Processor
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 1 Instructors: Nicholas Weaver & Vladimir Stojanovic http://inst.eecs.berkeley.edu/~cs61c/ Components of a Computer Processor
Chapter 7 Large and Fast: Exploiting Memory Hierarchy. Memory Hierarchy. Locality. Memories: Review
 Memories: Review Chapter 7 Large and Fast: Exploiting Hierarchy DRAM (Dynamic Random Access ): value is stored as a charge on capacitor that must be periodically refreshed, which is why it is called dynamic
Memories: Review Chapter 7 Large and Fast: Exploiting Hierarchy DRAM (Dynamic Random Access ): value is stored as a charge on capacitor that must be periodically refreshed, which is why it is called dynamic
Caches and Memory Hierarchy: Review. UCSB CS240A, Winter 2016
 Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
CISC 662 Graduate Computer Architecture Lecture 16 - Cache and virtual memory review
 CISC 662 Graduate Computer Architecture Lecture 6 - Cache and virtual memory review Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David
CISC 662 Graduate Computer Architecture Lecture 6 - Cache and virtual memory review Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David
10/19/17. You Are Here! Review: Direct-Mapped Cache. Typical Memory Hierarchy
 CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Krste Asanović & Randy H Katz http://insteecsberkeleyedu/~cs6c/ Parallel Requests Assigned to computer eg, Search
CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Krste Asanović & Randy H Katz http://insteecsberkeleyedu/~cs6c/ Parallel Requests Assigned to computer eg, Search
EITF20: Computer Architecture Part 5.1.1: Virtual Memory
 EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
Lecture 11 Cache. Peng Liu.
 Lecture 11 Cache Peng Liu liupeng@zju.edu.cn 1 Associative Cache Example 2 Associative Cache Example 3 Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative
Lecture 11 Cache Peng Liu liupeng@zju.edu.cn 1 Associative Cache Example 2 Associative Cache Example 3 Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative
Module Outline. CPU Memory interaction Organization of memory modules Cache memory Mapping and replacement policies.
 M6 Memory Hierarchy Module Outline CPU Memory interaction Organization of memory modules Cache memory Mapping and replacement policies. Events on a Cache Miss Events on a Cache Miss Stall the pipeline.
M6 Memory Hierarchy Module Outline CPU Memory interaction Organization of memory modules Cache memory Mapping and replacement policies. Events on a Cache Miss Events on a Cache Miss Stall the pipeline.
Lecture 12. Memory Design & Caches, part 2. Christos Kozyrakis Stanford University
 Lecture 12 Memory Design & Caches, part 2 Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements HW3 is due today PA2 is available on-line today Part 1 is due on 2/27
Lecture 12 Memory Design & Caches, part 2 Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements HW3 is due today PA2 is available on-line today Part 1 is due on 2/27
Memory Hierarchies. Instructor: Dmitri A. Gusev. Fall Lecture 10, October 8, CS 502: Computers and Communications Technology
 Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast