Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
|
|
|
- Austen Ramsey
- 6 years ago
- Views:
Transcription
1 Minnesota Supercomputing Institute
2 Parallel Computation Overview Andrew Gustafson Brent Swartz David Porter
3 Parallel Computation Parallel Computation means dividing up calculations into independent parts, and computing the independent parts simultaneously. Most CPU processors are not much faster than what you can buy in a Desktop PC. To perform faster computations you must parallelize. There are different forms of parallel computation. What form to use depends both on the type of problem, and on the type of compute system available.
4 Shared Memory System Source:
5 Strategies for a Shared Memory System Simple Parallelization: Collect Serial Calculations Thread parallelization A single program uses multiple threads which can communicate using shared memory. Coding for thread parallelization often means using OpenMP (which in turn is based on POSIX threads). Message Passing Message passing frameworks such as MPI may be used, but are often not needed because thread parallel methods are sufficient.

6 Distributed Memory System: Cluster Source:
7 Mesabi About 17,700 total cores, on Intel Haswell processors. 24 cores and 62 GB per node in the large primary queues. Special queues with large memory (up to 1TB), and GPUs. Allows node sharing: good for both small and large jobs. mesabi.msi.umn.edu Itasca Clusters at MSI About 9,000 total cores, on Intel Nehalem processors. 8 cores and 22 GB per node in the large primary queue. Special queues with larger memory and 16 cores per node. itasca.msi.umn.edu Interactive (Lab) Server About 500 total cores, on older hardware. For interactive, or small single node jobs. 8 cores and 15 GB per node in the primary queue. lab.msi.umn.edu
8 Strategies for a Distributed Memory System Simple Parallelization: Collect Serial Calculations Message Passing Message passing frameworks such as MPI may be used to pass messages between nodes. Message Passing + Threads within node Possible to combine message passing between nodes, with thread communication within a node. Often involves using both MPI and OpenMP.
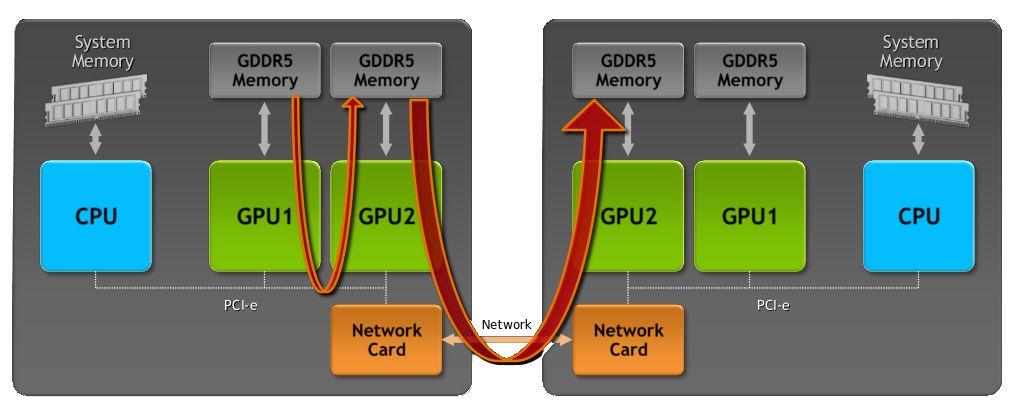
9 Heterogeneous Systems Source:
10 Heterogeneous Systems at MSI Mesabi (k40 queue) 40 nodes with 2 NVidia k40 GPUs per node k40 queue on mesabi.msi.umn.edu Intel PHI coprocessor nodes 3 nodes with 1 PHI coprocessor per node. In MSI Beta, send to help@msi.umm.edu to get access.
11 Coding for Heterogenous Systems NVIDIA GPUS Coding can be done in a sub-language called CUDA, which is supported by the PGI Fortran/C compilers (module pgi/15.7). Can also use OpenACC ( which is a C/C++/Fortran standard similar to OpenMP (openmp.org), implemented on PGI and (future) GNU compilers. OpenACC is an experimental feature of GCC 5.1 (module gcc/5.1.0). MPI may need to be used if multiple CPU nodes are used. Intel PHI Coprocessors Coding is done with compiler directives. The OpenMP 4.0 standard (supported by the intel/cluster/2015 module) introduced the target compiler directive, which supports offloading data and computations to the Intel PHI.
12 Programming Difficulty The general view of programming difficulty is that programming becomes more complicated in this order: Simple Parallelization: Collect Serial Calculations OpenMP (thread parallel) MPI (message passing) MPI + OpenMP (hybrid message passing + threads) Accelerators (GPUs using CUDA or OpenACC, Phis) (Note that GPUs can more easily be used via the nvidia supplied libraries, e.g. cufft, cublas, cusparse, etc. See: ). The more difficult strategies can also yield larger speed increases, but it is important to examine the calculation type.

13 Job Scheduling Parallel jobs are scheduled using a queueing system so that the hardware is fairly shared.
14 Job Scheduling Jobs are scheduled using the Portable Batch System (PBS) queueing system To schedule a job first make a PBS job script: #!/bin/bash -l #PBS -l walltime=8:00:00,nodes=3:ppn=8,pmem=1000mb #PBS -m abe #PBS -M sample_ @umn.edu cd ~/program_directory module load intel module load ompi/intel mpirun -np 24 program_name < inputfile > outputfile
15 Interactive Jobs Nodes may be requested for interactive use: qsub -I -l walltime=1:00:00,nodes=2:ppn=8,mem=4gb The terminal will hang until the job starts, and then it will return control. You can then use the nodes interactively for the job duration.
16 Simple Parallelization: Backgrounding Most easily done with single node jobs. #!/bin/bash -l #PBS -l walltime=8:00:00,nodes=1:ppn=8,pmem=1000mb #PBS -m abe #PBS -M cd ~/job_directory module load example/1.0./program1.exe < input1 > output1 &./program2.exe < input2 > output2 &./program3.exe < input3 > output3 &./program4.exe < input4 > output4 &./program5.exe < input5 > output5 &./program6.exe < input6 > output6 &./program7.exe < input7 > output7 &./program8.exe < input8 > output8 & wait
17 Simple Parallelization: Job Arrays Works best on Mesabi. Template Job Script, template.pbs: #!/bin/bash -l #PBS -l walltime=8:00:00,nodes=1:ppn=1,mem=2gb #PBS -m abe #PBS -M cd ~/job_directory module load example/1.0./program.exe < input$pbs_arrayid > output$pbs_arrayid Submit an array of 10 jobs: qsub -t 1-10 template.pbs
18 Simple Parallelization: GNU Parallel A way to spawn multiple threads to perform a shell task. Example: cat command_list.txt parallel -j 24 This will take a list of command in command_list.txt, and then have GNU Parallel execute them simultaneously on one node using up to 24 concurrent threads. Example: find. -name '*.txt' parallel -j 48 -sshloginfile $PBS_NODEFILE wc {} This will find files ending in.txt, and then will use 48 threads to word count (wc) each of the files. Specifying sshloginfile makes it aware of all nodes being used.
19 Simple Parallelization: pdsh A way to run multiple independent processes on multiple hosts. Example: pdsh -R ssh -w node0123,node0123,node0124./program.exe This would start two copies of program.exe on node0123, and one copy of program.exe on node0124, using ssh to connect. Example: pdsh -R ssh -w^ $PBS_NODEFILE./program.exe This run one copy of program.exe on each of the cores assigned to the job.
20 OpenMP OpenMP is for parallelization on shared memory systems (at MSI, usually one node, composed of 2 sockets). OpenMP is an abbreviation for: Open Multi-Processing OpenMP is a specification for a set of compiler directives, library routines, and environment variables that can be used to specify high-level parallelism in Fortran and C/C++ programs. OpenMP Compiler Directives Interpreted when OpenMP compiler option is turned on. Each directive applies to the succeeding structured block.
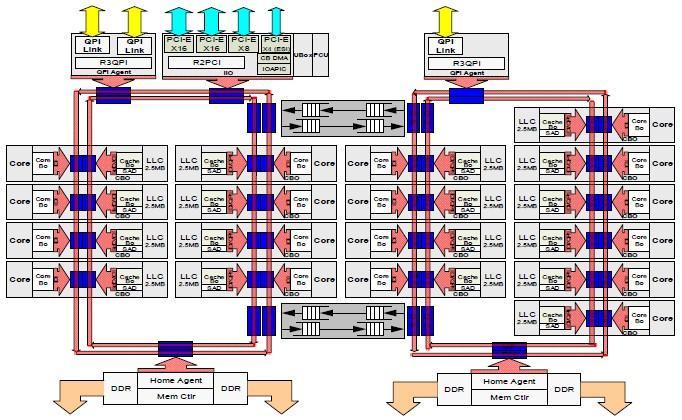
21 Intel Haswell Xeon Architecture Source:
22 Haswell Architecture Details (lscpu) ln0005 % lscpu Architecture: x86_64 Stepping: 2 CPU op-mode(s): 32-bit, 64-bit CPU MHz: Byte Order: Little Endian BogoMIPS: CPU(s): 24 Virtualization: VT-x On-line CPU(s) list: 0-23 L1d cache: 32K Thread(s) per core: 1 L1i cache: 32K Core(s) per socket: 12 L2 cache: 256K Socket(s): 2 L3 cache: 30720K NUMA node(s): 2 NUMA node0 CPU(s): 0-5,12-17 Vendor ID: GenuineIntel NUMA node1 CPU(s): 6-11,18-23 CPU family: 6 Model: 63
23 OpenMP: Arguments For & Against Pros: Programmability - Easier to program/debug than MPI. Allows incremental introduction of OpenMP, one loop at a time. Maintainability - Code is easier to understand, so it may be more easily maintained. Allows for a single source version of code. Minimal code modification - Serial code usually doesn t require modification. Can still run the program as a serial code. Performance - Most nodes on Itasca have 8 cores, and most nodes on Mesabi have 24 cores. An OpenMP application can use all cores on a node, giving a theoretical 24 fold performance improvement. Most modern laptops/servers have multi core CPUs. Portability- OpenMP is a standard not an implementation. SIMD directive is the only portable way to force a loop to be vector.
24 OpenMP: Arguments For & Against Cons: Memory - Can only run on shared memory (usually one node). So can only use the memory on one node. Compiler Support - Requires a compiler that supports OpenMP. All MSI compilers (Intel, GNU, PGI) support OpenMP. False sharing - Possible data placement problem. Can be a problem if loops are not coded optimally. First touch - Should try to initialize the memory in the same way you use it during computation. Discussed later.


25 OpenMP Terminology Shared Memory Model: OpenMP is designed for multi-processor/core, shared memory machines. The underlying architecture can be shared memory UMA or NUMA. Uniform Memory Access Access Source: Non-Uniform Memory
26 OpenMP Terminology Thread Based Parallelism: OpenMP programs accomplish parallelism exclusively through the use of threads. A thread of execution is the smallest unit of processing that can be scheduled by an operating system. The idea of a subroutine that can be scheduled to run autonomously might help explain what a thread is. Threads exist within the resources of a single process. Without the process, they cease to exist. Typically, the number of threads match the number of machine processors/cores. However, the actual use of threads is up to the application. Source:
27 OpenMP Terminology Explicit Parallelism: OpenMP is an explicit (not automatic) programming model, offering the programmer full control over parallelization. Parallelization can be as simple as taking a serial program and inserting compiler directives... Or as complex as inserting subroutines to set multiple levels of parallelism, locks and even nested locks. Source:
28 OpenMP For parallelization on shared memory systems. Source:
29 OpenMP Terminology OpenMP uses the fork-join model of parallel execution: All OpenMP programs begin as a single process: the master thread. The master thread executes sequentially until the first parallel region construct is encountered. FORK: the master thread then creates a team of parallel threads. The statements in the program that are enclosed by the parallel region construct are then executed in parallel among the various team threads. JOIN: When the team threads complete the statements in the parallel region construct, they synchronize and terminate, leaving only the master thread. The number of parallel regions and the threads that comprise them are arbitrary. Source:
30 OpenMP Terminology Compiler Directive Based: Most OpenMP parallelism is specified through the use of compiler directives which are imbedded in C/C++ or Fortran source code. Nested Parallelism: The API provides for the placement of parallel regions inside other parallel regions. Implementations may or may not support this feature. Dynamic Threads: The API provides for the runtime environment to dynamically alter the number of threads used to execute parallel regions. Intended to promote more efficient use of resources, if possible. Implementations may or may not support this feature. Source:
31 I/O: OpenMP Terminology OpenMP specifies nothing about parallel I/O. This is particularly important if multiple threads attempt to write/read from the same file. If every thread conducts I/O to a different file, the issues are not as significant. It is entirely up to the programmer to ensure that I/O is conducted correctly within the context of a multi-threaded program. Memory Model: FLUSH Often? OpenMP provides a "relaxed-consistency" and "temporary" view of thread memory (in their words). In other words, threads can "cache" their data and are not required to maintain exact consistency with real memory all of the time. When it is critical that all threads view a shared variable identically, the programmer is responsible for insuring that the variable is FLUSHed by all threads as needed. Source:
32 OpenMP API Overview Three Components: The OpenMP API is comprised of three distinct components. As of version 4.0: Compiler Directives (44) Runtime Library Routines (35) Environment Variables (13) The application developer decides how to employ these components. In the simplest case, only a few of them are needed. Implementations differ in their support of all API components. For example, an implementation may state that it supports nested parallelism, but the API makes it clear that may be limited to a single thread - the master thread. Not exactly what the developer might expect? Source:
33 OpenMP API Overview Compiler Directives: Compiler directives appear as comments in your source code and are ignored by compilers unless you tell them otherwise - usually by specifying the appropriate compiler flag, as discussed in the Compiling section later. OpenMP compiler directives are used for various purposes: Spawning a parallel region Dividing blocks of code among threads Distributing loop iterations between threads Serializing sections of code Synchronization of work among threads Compiler directives have the following syntax: sentinel directive-name [clause,...] For example: Fortran:!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(BETA,PI) C/C++: #pragma omp parallel default(shared) private(beta,pi) Source:
34 OpenMP API Overview Run-time Library Routines: The OpenMP API includes an ever-growing number of run-time library routines. These routines are used for a variety of purposes: Setting and querying the number of threads Querying a thread's unique identifier (thread ID), a thread's ancestor's identifier, the thread team size Setting and querying the dynamic threads feature Querying if in a parallel region, and at what level Setting and querying nested parallelism Setting, initializing and terminating locks and nested locks Querying wall clock time and resolution For C/C++, all of the run-time library routines are actual subroutines. For Fortran, some are actually functions, and some are subroutines. For example: Fortran: INTEGER FUNCTION OMP_GET_NUM_THREADS() C/C++: #include <omp.h> int omp_get_num_threads(void) Source:
35 OpenMP API Overview Run-time Library Routines: Note that for C/C++, you usually need to include the <omp.h> header file. Fortran routines are not case sensitive, but C/C++ routines are. The run-time library routines are briefly discussed as an overview in the Run-Time Library Routines section, and in more detail in Appendix A. Source:
36 OpenMP API Overview Environment Variables: OpenMP provides several environment variables for controlling the execution of parallel code at run-time. These environment variables can be used to control such things as: Setting the number of threads Specifying how loop iterations are divided Binding threads to processors Enabling/disabling nested parallelism; setting the maximum levels of nested parallelism Enabling/disabling dynamic threads Setting thread stack size Setting thread wait policy Source:
37 OpenMP API Overview Environment Variables: - Setting OpenMP environment variables is done the same way you set any other environment variables, and depends upon which shell you use. For example: csh/tcsh: setenv OMP_NUM_THREADS 8 sh/bash: export OMP_NUM_THREADS=8 OpenMP environment variables are discussed in the Environment Variables section. Source:
38 OpenMP Syntax Fortran: case insensitive Add: use omp_lib or include omp_lib.h Fixed format Sentinel directive [clauses] Sentinel could be:!$omp, *$OMP, c$omp Free format!$omp directive [clauses] C/C++: case sensitive Add: #include omp.h #pragma omp directive [clauses] newline Source:
39 OpenMP Simple Example Simple OpenMP example (code.c): #include <omp.h> #include <stdio.h> int main() { #pragma omp parallel printf("hello World from thread = %d, nthreads = %d\n", omp_get_thread_num(), omp_get_num_threads()); } Source:
40 OpenMP Compilation OpenMP compilation examples: Intel (icc,ifort): icc -openmp -o omp_helloc code.c GNU (gcc, g++, gfortran): gcc -fopenmp -o omp_helloc code.c PGI(pgcc, pgcc, pgf77, pgf90): pgcc -mp -o omp_helloc code.c Default behavior for number of threads (when OMP_NUM_THREADS not set): - One thread for PGI. - For Intel/GNU, as many threads as available cores. Source:
41 OpenMP Execution Example OpenMP execution example: $ export OMP_NUM_THREADS=3 $./omp_helloc Hello World from thread = 0, nthreads = 3 Hello World from thread = 2, nthreads = 3 Hello World from thread = 1, nthreads = 3 Source:
42 OpenMP C/C++ Directives PARALLEL Region Construct Purpose: A parallel region is a block of code that will be executed by multiple threads. This is the fundamental OpenMP parallel construct. #pragma omp parallel [clause...] newline if (scalar_expression) private (list) shared (list) default (shared none) firstprivate (list) reduction (operator: list) copyin (list) num_threads (integer-expression) structured_block Source:
43 Notes: OpenMP C/C++ Directives When a thread reaches a PARALLEL directive, it creates a team of threads and becomes the master of the team. The master is a member of that team and has thread number 0 within that team. Starting from the beginning of this parallel region, the code is duplicated and all threads will execute that code. There is an implied barrier at the end of a parallel section. Only the master thread continues execution past this point. If any thread terminates within a parallel region, all threads in the team will terminate, and the work done up until that point is undefined. Source:
44 OpenMP C/C++ Directives ow Many Threads? The number of threads in a parallel region is determined by the following factors, in order of precedence: 1. Evaluation of the IF clause 2. Setting of the NUM_THREADS clause 3. Use of the omp_set_num_threads() library function 4. Setting of the OMP_NUM_THREADS environment variable 5. Implementation default - usually the number of CPUs on a node, though it could be dynamic (see next bullet). Threads are numbered from 0 (master thread) to N-1 ynamic Threads: Use the omp_get_dynamic() function to determine if dynamic threads are enabled. If supported, the two methods available for enabling dynamic threads are: 1. The omp_set_dynamic() library routine 2. Setting of the OMP_DYNAMIC environment variable to TRUE Source:
45 OpenMP C/C++ Directives lauses: IF clause: If present, it must evaluate to.true. (Fortran) or non-zero (C/C++) in order for a team of threads to be created. Otherwise, the region is executed serially by the master thread. The remaining clauses are described in detail later, in the Data Scope Attribute Clauses section. estrictions: A parallel region must be a structured block that does not span multiple routines or code files It is illegal to branch (goto) into or out of a parallel region Only a single IF clause is permitted Only a single NUM_THREADS clause is permitted A program must not depend upon the ordering of the clauses Source:
46 OpenMP C/C++ Directives ork-sharing Constructs A work-sharing construct divides the execution of the enclosed code region among the members of the team that encounter it. Work-sharing constructs do not launch new threads There is no implied barrier upon entry to a work-sharing construct, however there is an implied barrier at the end of a work sharing construct. Source:

47 OpenMP C/C++ Directives ork-sharing Constructs ypes of Work-Sharing Constructs: SECTIONS - breaks work into separate, discrete DO / for - shares iterations of a loop across the team. sections. Each section is executed by a thread. Can be Represents a type of "data parallelism". used to implement a type of "functional parallelism". SINGLE - serializes a section of code Source:
48 OpenMP C/C++ Directives Work-Sharing Constructs Restrictions: A work-sharing construct must be enclosed dynamically within a parallel region in order for the directive to execute in parallel. Work-sharing constructs must be encountered by all members of a team or none at all Successive work-sharing constructs must be encountered in the same order by all members of a team Source:
49 OpenMP C/C++ Directives Work-Sharing Constructs DO / for Directive Purpose: The DO / for directive specifies that the iterations of the loop immediately following it must be executed in parallel by the team. This assumes a parallel region has already been initiated, otherwise it executes in serial on a single processor. Source:
50 DO / for Directive OpenMP C/C++ Directives Format: #pragma omp for [clause...] newline schedule (type [,chunk]) ordered private (list) firstprivate (list) lastprivate (list) shared (list) reduction (operator: list) collapse (n) nowait for_loop Source:
51 OpenMP C/C++ Directives DO / for Directive Clauses: SCHEDULE: Describes how iterations of the loop are divided among the threads in the team. The default schedule is implementation dependent. For a discussion on how one type of scheduling may be more optimal than others, see org/forum/viewtopic.php?f=3&t=83. STATIC: Loop iterations are divided into pieces of size chunk and then statically assigned to threads. If chunk is not specified, the iterations are evenly (if possible) divided contiguously among the threads. DYNAMIC: Loop iterations are divided into pieces of size chunk, and dynamically scheduled among the threads; when a thread finishes one chunk, it is dynamically assigned another. The default chunk size is 1. Source:
52 OpenMP C/C++ Directives DO / for Directive Clauses: SCHEDULE (cont.): GUIDED: Iterations are dynamically assigned to threads in blocks as threads request them until no blocks remain to be assigned. Similar to DYNAMIC except that the block size decreases each time a parcel of work is given to a thread. The size of the initial block is proportional to: - number_of_iterations / number_of_threads Subsequent blocks are proportional to: - number_of_iterations_remaining / number_of_threads The chunk parameter defines the minimum block size. The default chunk size is 1. RUNTIME: The scheduling decision is deferred until runtime by the environment variable OMP_SCHEDULE. It is illegal to specify a chunk size for this clause. AUTO: The scheduling decision is delegated to the compiler and/or runtime system. Source:
53 OpenMP C/C++ Directives DO / for Directive Clauses: SCHEDULE (cont.): NO WAIT / nowait: If specified, then threads do not synchronize at the end of the parallel loop. ORDERED: Specifies that the iterations of the loop must be executed as they would be in a serial program. COLLAPSE: Specifies how many loops in a nested loop should be collapsed into one large iteration space and divided according to the schedule clause. The sequential execution of the iterations in all associated loops determines the order of the iterations in the collapsed iteration space. Other clauses are described in detail later, in the Data Scope Attribute Clauses section. Source:
54 OpenMP C/C++ Directives C / C++ - for Directive Example #include <omp.h> #define CHUNKSIZE 100 #define N 1000 main () { int i, chunk; float a[n], b[n], c[n]; /* Some initializations */ for (i=0; i < N; i++) a[i] = b[i] = i * 1.0; chunk = CHUNKSIZE; #pragma omp parallel shared(a,b,c,chunk) private(i) { #pragma omp for schedule(dynamic,chunk) nowait for (i=0; i < N; i++) c[i] = a[i] + b[i]; } /* end of parallel section */ } Source:
55 OpenMP C/C++ Directives Combined Parallel Work-Sharing Constructs OpenMP provides three directives that are merely conveniences: PARALLEL DO / parallel for PARALLEL SECTIONS PARALLEL WORKSHARE (fortran only) For the most part, these directives behave identically to an individual PARALLEL directive being immediately followed by a separate work-sharing directive. Most of the rules, clauses and restrictions that apply to both directives are in effect. See the OpenMP API for details. Source:
56 MSI Hardware (MAXCORES) The number of cores per node varies with the type of Xeon on that node. We define: MAXCORES=number of cores/node e.g. Nehalem=8 (Itasca), Westmere=12, SandyBridge=16, IvyBridge=20, Haswell=24 (Mesabi). Since MAXCORES will not vary within the PBS job (the Itasca and Mesabi queues are split by Xeon type), you can determine this at the start of the PBS job (in bash): MAXCORES=`grep "core id" /proc/cpuinfo wc -l` export OMP_NUM_THREADS=$MAXCORES
57 OpenMP Parallel Loop The following example demonstrates how to parallelize a simple loop using the parallel loop construct. The loop iteration variable is private by default, so it is not necessary to specify it explicitly in a private clause. void simple(int n, float *a, float *b) { int i; #pragma omp parallel for for (i=1; i<n; i++) /* i is private by default */ b[i] = (a[i] + a[i-1]) / 2.0; } Source:
58 OpenMP Parallel Loop Threads share the work in loop parallelism. For example, using 8 threads with n=800 under the default static scheduling: - thread 0 has i= thread 1 has i= , etc. void simple(int n, float *a, float *b) { int i; #pragma omp parallel for for (i=1; i<n; i++) /* i is private by default */ b[i] = (a[i] + a[i-1]) / 4.0; } Source:
59 OpenMP Parallel Loop _OPENMP is defined if the code is compiled with the openmp flag. #ifdef _OPENMP #include <omp.h> #endif Source:
60 OpenMP 4.0 SIMD Directive For best efficiency in all cases (serial, OpenMP, MPI, etc.), you should use SIMD (vectors) on the innermost loops. On Haswell, each core is able to retrieve 256 bits per clock in vector mode, but only 64 bits per clock without vectorization. So memory bandwidth (which limits most applications performance) is up to 4 times slower without vectorization. Here is Intel s video describing how to use the OpenMP 4.0 SIMD directive:
61 OpenMP Reduction Example #include <stdio.h> #include <stdlib.h> #include <omp.h> #define SUM_INIT 0 int main() { int i, n = 250; int sum, a[n]; int ref = SUM_INIT + (n-1)*n/2; for (i=0; i<n; i++) a[i] = i; Source:
62 Reduction Example (cont.) #pragma omp parallel { #pragma omp single printf("number of threads is %d\n",omp_get_num_threads()); } sum = SUM_INIT; printf("value of sum prior to parallel region: %d\n",sum); #pragma omp parallel for default(none) shared(n,a) reduction(+:sum) for (i=0; i<n; i++) sum += a[i]; /*-- End of parallel reduction --*/ } printf("value of sum after parallel region: %d\n",sum); printf("check results: sum = %d (should be %d)\n",sum,ref); return(0); Source:
63 OpenMP Optimization Tips - Avoid thread migration for better data locality. All scripts on MSI systems should set env var OMP_PROC_BIND=true although the current system gcc (4.4.6) does not use it, gcc versions 4.7 and above do use it (Intel compiled apps, too). Setting OMP_PROC_BIND=true will eliminate cache invalidations due to processes switching to different cores. It will not necessarily force OPTIMAL thread to core binding (to do this you need to set KMP_AFFINITY for Intel compiled apps, GOMP_CPU_AFFINITY for gcc compiled apps). OMP_PROC_BIND was added in OpenMP 3.1.
64 OpenMP Optimization Tips Memory Affinity: First Touch Memory Memory affinity: Allocate memory as close as possible to the core on which the task that requested the memory is running. Memory affinity is not decided by the memory allocation, but by the initialization. Memory will be local to the thread which initializes it. This is called first touch policy. Hard to do perfect touch for real applications. Instead, use a number of threads fewer than number of cores per NUMA domain. Source:
65 OpenMP Optimization Tips Memory Affinity: First Touch Memory Example Initialization #pragma omp parallel for for (j=0; j<vectorsize; j++) { a[j] = 1.0; b[j] = 2.0; c[j] = 0.0;} Compute #pragma omp parallel for for (j=0; j<vectorsize; j++) { a[j]=b[j]+d*c[j];}
66 OpenMP Optimization Tips - False sharing can cause significant performance degradation. See: - In general it should be fastest to parallelize the outer loop only, provided there is sufficient parallelism to keep the threads busy and load balanced. Parallelizing the inner loop only adds an overhead for every parallel region encountered which (although dependent on the implementation and the number of threads) is typically of the order of tens of microseconds.
67 OpenMP References OpenMP standard, summary cards, examples: Recommended tutorial: gov/tutorials/openmp/ MSI hardware descriptions: MSI queue descriptions: Source:
68 MPI
69 MPI: Message Passing Interface MPI is a message passing library specification. It includes a standard set of commands to be used in parallel communication. Programmers write MPI commands in program code (C,C++,Fortran) to perform inter-process communication. The code is then compiled and linked with an MPI library. MPI Libraries available at MSI: Intel MPI (impi), OpenMPI (ompi), Platform MPI (pmpi, Itasca only)
70 MPI: Motivation & Examples Distributed memory Hardware Parallel Software Parallel Applications & Message Passing Source code A short list of MPI routines is all you need to remember A simple example MPI: pros & Cons
71 Mesabi: Hardware Hierarchy core 2.5 GHz clock; up to 16 +s & *s per clock Processor Node 12 cores; 30 MB Cache memory 2 processors & 64+ GB shared memory Level 1 Switch: Leaf 24 nodes (or fewer) 1x EDR to each node Level 2 Switch: Island 8 Leafs 6x FDR to each leaf Level 3 Switch: Cluster 4 Islands 12x FDR to each island
72 MPI: Software Hierarchy Thread Scheduled work in time slices Process Application 1 MPI rank: variables arrays, IO streams, one or more threads 1 or more Ranks (processes) MPI communicators Workflow 1 or more applications, scripts,...
73 Distributed Memory Systems Network Memory node 44 node 45 node N Each node can only directly access it s own memory Nodes communicate through the network
74 MPI & Distributed Memory Network... Rank Rank 0 1 Rank 2 Rank 3 Rank m node 44 node 45 node N Each rank is an instance of your code Each rank can only see its own variables All the ranks working together are an MPI application.
75 MPI: Hardware vs. Software A process is NOT a processor A processor has physical cores & cache memory. A process has time slices and process address space. 1 MPI Rank = 1 process An MPI rank may have many cores or share a core. An MPI rank usually is confined to a shared memory node. An MPI rank ALWAYS has a process address space. MPI ranks are visible in the process table. Different MPI ranks have different address spaces. #PBS -l ppn=... Really means: Processes Per Node
76 MPI: What It Does Start run copies of your program on a list of nodes mpirun -np 8 -hostfile $PBS_NODEFILE program Coordinate the operation of all these copies of your program MPI_Init Initialize MPI within each rank MPI_Comm_size Get the total number of ranks MPI_Comm_rank Get the local rank MPI_Finalize Shut down MPI framework Enable these copies of your program to communicate MPI_Send(buffer, ) Rank i sends a message MPI_Recv(buffer, ) Rank j receives the message
77 MPI Starts Copies of Your App Network Memory Rank i Rank j mpirun starts ranks (instances of your app) on nodes
78 Your Application Generates Data Network... Data Memory Rank i Rank j Rank i generates some Data This Data is needed on Rank j
79 Message Passing Network... Data Memory Rank i Send Rank i sends a buffer of data to rank j Ranks MAY be on different nodes Ranks WILL be different processes Martial Bits Data Rank j Receives
80 MPI Syntax MPI_Init(&argc,&argv) MPI_Comm_size(comm, &nranks) MI_Comm_rank(comm, &myrank) MPI_Finalize() MPI_Send(data, length, type, destination,tag, com) MPI_Recv(data, length, type, origin, tag, comm, status) MPI_Barrier(comm) MPI_Bcast(data, length, type, origin, comm) MPI_Reduce(data_in, data_out, length, type, operation, destination, comm)
81 MPI Commands C / C++: int ierror = MPI_Xxxx(...) - Case sensitive - All MPI calls are functions - Program must include mpi.h - Most parameters passed by reference Fortran: Call MPI_XXXX(...,ierror) - Case insensitive - All MPI calls are subroutines - ierror is always the last parameter - Program must include mpif.h

82 Structure of an MPI Program
83 Structure of an MPI Program #include "mpi.h"... int main (int argc, char** argv){ int ierror, myrank;... ierror = MPI_Init(&argc,&argv); ierror = MPI_Comm_rank(MPI_COMM_WORLD, &myrank);... if(myrank > 4){... }... ierror = MPI_Finalize(); return(0); }
84 #include "mpi.h" #include <cstdlib> #include <iostream> int main(int argc,char** argv){ using namespace std; int ierror, myrank; MPI_Status status; Example: Send and Receive } ierror = MPI_Init(&argc, &argv); ierror = MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if(myrank == 0){ int value_to_send = 5; ierror = MPI_Send(&value_to_send, 1, MPI_INT, 1, 123, MPI_COMM_WORLD); cout << "Process " << MPI_rank << " sent value " << value_to_send << endl; } else if(myrank == 1){ int value_received(0); ierror = MPI_Recv(&value_received, 1, MPI_INT, 0, 123, MPI_COMM_WORLD, &status); cout << "Process " << MPI_rank << " received value " << value_received << endl; } ierror = MPI_Finalize(); return(0);
85 MPI: Arguments For & Against Pros: Performance scalability flexibility portability - Strong Scaling & Cache Coherency - more cores AND more memory - hardware topology & heterogeneity - MPI is a standard not an implementation Cons: Need to restructure your code However: possibly not by much May need to restructure IO & data formats However: may lead to much faster (parallel) IO Can fall back to Rank 0 doing all IO
86 Current Architecture Trends - Multi- socket nodes with rapidly increasing core counts. - Memory per core decreases. - Memory bandwidth per core decreases. - Network bandwidth per core decreases. Need a hybrid programming model with three levels of parallelism MPI between nodes or sockets. Shared memory (such as OpenMP) on the nodes/sockets. Increase vectorization (SIMD) for lower level loops.
87 Hybrid MPI/OpenMP Applications gov/assets/pubs_presos/hybridmpiopenmp pdf Application Optimization Strategy: 1. Serial Optimization: Compiler options, profile code, etc. 2. Increase vectorization (SIMD) for lower level loops. 3. Implement shared memory threading (using OpenMP or pthreads) on a node/socket. 4. Implement MPI between nodes or sockets.
88 Minnesota Supercomputing Institute Web: Telephone: (612) The University of Minnesota is an equal opportunity educator and employer. This PowerPoint is available in alternative formats upon request. Direct requests to Minnesota Supercomputing Institute, 599 Walter library, 117 Pleasant St. SE, Minneapolis, Minnesota, 55455,
EE/CSCI 451 Introduction to Parallel and Distributed Computation. Discussion #4 2/3/2017 University of Southern California
 EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
OpenMP Algoritmi e Calcolo Parallelo. Daniele Loiacono
 OpenMP Algoritmi e Calcolo Parallelo References Useful references Using OpenMP: Portable Shared Memory Parallel Programming, Barbara Chapman, Gabriele Jost and Ruud van der Pas OpenMP.org http://openmp.org/
OpenMP Algoritmi e Calcolo Parallelo References Useful references Using OpenMP: Portable Shared Memory Parallel Programming, Barbara Chapman, Gabriele Jost and Ruud van der Pas OpenMP.org http://openmp.org/
OpenMP 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 OpenMP 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
OpenMP 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
ECE 574 Cluster Computing Lecture 10
 ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
An Introduction to OpenMP
 An Introduction to OpenMP U N C L A S S I F I E D Slide 1 What Is OpenMP? OpenMP Is: An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism
An Introduction to OpenMP U N C L A S S I F I E D Slide 1 What Is OpenMP? OpenMP Is: An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism
Lecture 4: OpenMP Open Multi-Processing
 CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
OpenMP. António Abreu. Instituto Politécnico de Setúbal. 1 de Março de 2013
 OpenMP António Abreu Instituto Politécnico de Setúbal 1 de Março de 2013 António Abreu (Instituto Politécnico de Setúbal) OpenMP 1 de Março de 2013 1 / 37 openmp what? It s an Application Program Interface
OpenMP António Abreu Instituto Politécnico de Setúbal 1 de Março de 2013 António Abreu (Instituto Politécnico de Setúbal) OpenMP 1 de Março de 2013 1 / 37 openmp what? It s an Application Program Interface
OpenMP examples. Sergeev Efim. Singularis Lab, Ltd. Senior software engineer
 OpenMP examples Sergeev Efim Senior software engineer Singularis Lab, Ltd. OpenMP Is: An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism.
OpenMP examples Sergeev Efim Senior software engineer Singularis Lab, Ltd. OpenMP Is: An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism.
Distributed Systems + Middleware Concurrent Programming with OpenMP
 Distributed Systems + Middleware Concurrent Programming with OpenMP Gianpaolo Cugola Dipartimento di Elettronica e Informazione Politecnico, Italy cugola@elet.polimi.it http://home.dei.polimi.it/cugola
Distributed Systems + Middleware Concurrent Programming with OpenMP Gianpaolo Cugola Dipartimento di Elettronica e Informazione Politecnico, Italy cugola@elet.polimi.it http://home.dei.polimi.it/cugola
Shared Memory Parallelism - OpenMP
 Shared Memory Parallelism - OpenMP Sathish Vadhiyar Credits/Sources: OpenMP C/C++ standard (openmp.org) OpenMP tutorial (http://www.llnl.gov/computing/tutorials/openmp/#introduction) OpenMP sc99 tutorial
Shared Memory Parallelism - OpenMP Sathish Vadhiyar Credits/Sources: OpenMP C/C++ standard (openmp.org) OpenMP tutorial (http://www.llnl.gov/computing/tutorials/openmp/#introduction) OpenMP sc99 tutorial
OpenMP - Introduction
 OpenMP - Introduction Süha TUNA Bilişim Enstitüsü UHeM Yaz Çalıştayı - 21.06.2012 Outline What is OpenMP? Introduction (Code Structure, Directives, Threads etc.) Limitations Data Scope Clauses Shared,
OpenMP - Introduction Süha TUNA Bilişim Enstitüsü UHeM Yaz Çalıştayı - 21.06.2012 Outline What is OpenMP? Introduction (Code Structure, Directives, Threads etc.) Limitations Data Scope Clauses Shared,
Introduction to OpenMP
 Introduction to OpenMP Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Shared Memory Programming OpenMP Fork-Join Model Compiler Directives / Run time library routines Compiling and
Introduction to OpenMP Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Shared Memory Programming OpenMP Fork-Join Model Compiler Directives / Run time library routines Compiling and
15-418, Spring 2008 OpenMP: A Short Introduction
 15-418, Spring 2008 OpenMP: A Short Introduction This is a short introduction to OpenMP, an API (Application Program Interface) that supports multithreaded, shared address space (aka shared memory) parallelism.
15-418, Spring 2008 OpenMP: A Short Introduction This is a short introduction to OpenMP, an API (Application Program Interface) that supports multithreaded, shared address space (aka shared memory) parallelism.
Module 10: Open Multi-Processing Lecture 19: What is Parallelization? The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program
 The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
Introduction to. Slides prepared by : Farzana Rahman 1
 Introduction to OpenMP Slides prepared by : Farzana Rahman 1 Definition of OpenMP Application Program Interface (API) for Shared Memory Parallel Programming Directive based approach with library support
Introduction to OpenMP Slides prepared by : Farzana Rahman 1 Definition of OpenMP Application Program Interface (API) for Shared Memory Parallel Programming Directive based approach with library support
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Shared Memory programming paradigm: openmp
 IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to Job Submission and Scheduling Andrew Gustafson Interacting with MSI Systems Connecting to MSI SSH is the most reliable connection method Linux and Mac
Minnesota Supercomputing Institute Introduction to Job Submission and Scheduling Andrew Gustafson Interacting with MSI Systems Connecting to MSI SSH is the most reliable connection method Linux and Mac
COMP4510 Introduction to Parallel Computation. Shared Memory and OpenMP. Outline (cont d) Shared Memory and OpenMP
 Shared Memory and OpenMP") COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
EPL372 Lab Exercise 5: Introduction to OpenMP
 EPL372 Lab Exercise 5: Introduction to OpenMP References: https://computing.llnl.gov/tutorials/openmp/ http://openmp.org/wp/openmp-specifications/ http://openmp.org/mp-documents/openmp-4.0-c.pdf http://openmp.org/mp-documents/openmp4.0.0.examples.pdf
EPL372 Lab Exercise 5: Introduction to OpenMP References: https://computing.llnl.gov/tutorials/openmp/ http://openmp.org/wp/openmp-specifications/ http://openmp.org/mp-documents/openmp-4.0-c.pdf http://openmp.org/mp-documents/openmp4.0.0.examples.pdf
OpenMP Programming. Prof. Thomas Sterling. High Performance Computing: Concepts, Methods & Means
 High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
Parallelising Scientific Codes Using OpenMP. Wadud Miah Research Computing Group
 Parallelising Scientific Codes Using OpenMP Wadud Miah Research Computing Group Software Performance Lifecycle Scientific Programming Early scientific codes were mainly sequential and were executed on
Parallelising Scientific Codes Using OpenMP Wadud Miah Research Computing Group Software Performance Lifecycle Scientific Programming Early scientific codes were mainly sequential and were executed on
Shared Memory Parallelism using OpenMP
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Shared Memory Parallelism using OpenMP Yogesh Simmhan Adapted from: o
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Shared Memory Parallelism using OpenMP Yogesh Simmhan Adapted from: o
Introduction to OpenMP
 Introduction to OpenMP Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 A little about me! PhD Computer Engineering Texas A&M University Computer Science
Introduction to OpenMP Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 A little about me! PhD Computer Engineering Texas A&M University Computer Science
Overview: The OpenMP Programming Model
 Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing
 Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Topics. Introduction. Shared Memory Parallelization. Example. Lecture 11. OpenMP Execution Model Fork-Join model 5/15/2012. Introduction OpenMP
 Topics Lecture 11 Introduction OpenMP Some Examples Library functions Environment variables 1 2 Introduction Shared Memory Parallelization OpenMP is: a standard for parallel programming in C, C++, and
Topics Lecture 11 Introduction OpenMP Some Examples Library functions Environment variables 1 2 Introduction Shared Memory Parallelization OpenMP is: a standard for parallel programming in C, C++, and
OpenMP threading: parallel regions. Paolo Burgio
 OpenMP threading: parallel regions Paolo Burgio paolo.burgio@unimore.it Outline Expressing parallelism Understanding parallel threads Memory Data management Data clauses Synchronization Barriers, locks,
OpenMP threading: parallel regions Paolo Burgio paolo.burgio@unimore.it Outline Expressing parallelism Understanding parallel threads Memory Data management Data clauses Synchronization Barriers, locks,
Parallel Computing: Overview
 Parallel Computing: Overview Jemmy Hu SHARCNET University of Waterloo March 1, 2007 Contents What is Parallel Computing? Why use Parallel Computing? Flynn's Classical Taxonomy Parallel Computer Memory
Parallel Computing: Overview Jemmy Hu SHARCNET University of Waterloo March 1, 2007 Contents What is Parallel Computing? Why use Parallel Computing? Flynn's Classical Taxonomy Parallel Computer Memory
[Potentially] Your first parallel application
![[Potentially] Your first parallel application](/thumbs/71/65941908.jpg "[Potentially] Your first parallel application") [Potentially] Your first parallel application Compute the smallest element in an array as fast as possible small = array[0]; for( i = 0; i < N; i++) if( array[i] < small ) ) small = array[i] 64-bit Intel
[Potentially] Your first parallel application Compute the smallest element in an array as fast as possible small = array[0]; for( i = 0; i < N; i++) if( array[i] < small ) ) small = array[i] 64-bit Intel
Session 4: Parallel Programming with OpenMP
 Session 4: Parallel Programming with OpenMP Xavier Martorell Barcelona Supercomputing Center Agenda Agenda 10:00-11:00 OpenMP fundamentals, parallel regions 11:00-11:30 Worksharing constructs 11:30-12:00
Session 4: Parallel Programming with OpenMP Xavier Martorell Barcelona Supercomputing Center Agenda Agenda 10:00-11:00 OpenMP fundamentals, parallel regions 11:00-11:30 Worksharing constructs 11:30-12:00
Introduction to Standard OpenMP 3.1
 Introduction to Standard OpenMP 3.1 Massimiliano Culpo - m.culpo@cineca.it Gian Franco Marras - g.marras@cineca.it CINECA - SuperComputing Applications and Innovation Department 1 / 59 Outline 1 Introduction
Introduction to Standard OpenMP 3.1 Massimiliano Culpo - m.culpo@cineca.it Gian Franco Marras - g.marras@cineca.it CINECA - SuperComputing Applications and Innovation Department 1 / 59 Outline 1 Introduction
Parallel Computing Using OpenMP/MPI. Presented by - Jyotsna 29/01/2008
 Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Alfio Lazzaro: Introduction to OpenMP
 First INFN International School on Architectures, tools and methodologies for developing efficient large scale scientific computing applications Ce.U.B. Bertinoro Italy, 12 17 October 2009 Alfio Lazzaro:
First INFN International School on Architectures, tools and methodologies for developing efficient large scale scientific computing applications Ce.U.B. Bertinoro Italy, 12 17 October 2009 Alfio Lazzaro:
A brief introduction to OpenMP
 A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
Introduction to OpenMP
 Introduction to OpenMP Le Yan Scientific computing consultant User services group High Performance Computing @ LSU Goals Acquaint users with the concept of shared memory parallelism Acquaint users with
Introduction to OpenMP Le Yan Scientific computing consultant User services group High Performance Computing @ LSU Goals Acquaint users with the concept of shared memory parallelism Acquaint users with
High Performance Computing: Tools and Applications
 High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 2 OpenMP Shared address space programming High-level
High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 2 OpenMP Shared address space programming High-level
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 2 Part I Programming
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 2 Part I Programming
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016
 Ion Stoica, UC Berkeley November 19, 2016") MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
OpenMP 4. CSCI 4850/5850 High-Performance Computing Spring 2018
 OpenMP 4 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
OpenMP 4 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Multithreading in C with OpenMP
 Multithreading in C with OpenMP ICS432 - Spring 2017 Concurrent and High-Performance Programming Henri Casanova (henric@hawaii.edu) Pthreads are good and bad! Multi-threaded programming in C with Pthreads
Multithreading in C with OpenMP ICS432 - Spring 2017 Concurrent and High-Performance Programming Henri Casanova (henric@hawaii.edu) Pthreads are good and bad! Multi-threaded programming in C with Pthreads
HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP)
") HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP) V. Akishina, I. Kisel, G. Kozlov, I. Kulakov, M. Pugach, M. Zyzak Goethe University of Frankfurt am Main 2015 Task Parallelism Parallelization
HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP) V. Akishina, I. Kisel, G. Kozlov, I. Kulakov, M. Pugach, M. Zyzak Goethe University of Frankfurt am Main 2015 Task Parallelism Parallelization
Shared Memory Programming with OpenMP
 Shared Memory Programming with OpenMP (An UHeM Training) Süha Tuna Informatics Institute, Istanbul Technical University February 12th, 2016 2 Outline - I Shared Memory Systems Threaded Programming Model
Shared Memory Programming with OpenMP (An UHeM Training) Süha Tuna Informatics Institute, Istanbul Technical University February 12th, 2016 2 Outline - I Shared Memory Systems Threaded Programming Model
Shared memory parallel computing
 Shared memory parallel computing OpenMP Sean Stijven Przemyslaw Klosiewicz Shared-mem. programming API for SMP machines Introduced in 1997 by the OpenMP Architecture Review Board! More high-level than
Shared memory parallel computing OpenMP Sean Stijven Przemyslaw Klosiewicz Shared-mem. programming API for SMP machines Introduced in 1997 by the OpenMP Architecture Review Board! More high-level than
Mango DSP Top manufacturer of multiprocessing video & imaging solutions.
 1 of 11 3/3/2005 10:50 AM Linux Magazine February 2004 C++ Parallel Increase application performance without changing your source code. Mango DSP Top manufacturer of multiprocessing video & imaging solutions.
1 of 11 3/3/2005 10:50 AM Linux Magazine February 2004 C++ Parallel Increase application performance without changing your source code. Mango DSP Top manufacturer of multiprocessing video & imaging solutions.
HPC Workshop University of Kentucky May 9, 2007 May 10, 2007
 HPC Workshop University of Kentucky May 9, 2007 May 10, 2007 Part 3 Parallel Programming Parallel Programming Concepts Amdahl s Law Parallel Programming Models Tools Compiler (Intel) Math Libraries (Intel)
HPC Workshop University of Kentucky May 9, 2007 May 10, 2007 Part 3 Parallel Programming Parallel Programming Concepts Amdahl s Law Parallel Programming Models Tools Compiler (Intel) Math Libraries (Intel)
Parallel Programming with OpenMP. CS240A, T. Yang
 Parallel Programming with OpenMP CS240A, T. Yang 1 A Programmer s View of OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for defining multi-threaded shared-memory programs
Parallel Programming with OpenMP CS240A, T. Yang 1 A Programmer s View of OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for defining multi-threaded shared-memory programs
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
CS 470 Spring Mike Lam, Professor. OpenMP
 CS 470 Spring 2017 Mike Lam, Professor OpenMP OpenMP Programming language extension Compiler support required "Open Multi-Processing" (open standard; latest version is 4.5) Automatic thread-level parallelism
CS 470 Spring 2017 Mike Lam, Professor OpenMP OpenMP Programming language extension Compiler support required "Open Multi-Processing" (open standard; latest version is 4.5) Automatic thread-level parallelism
OpenMP. Application Program Interface. CINECA, 14 May 2012 OpenMP Marco Comparato
 OpenMP Application Program Interface Introduction Shared-memory parallelism in C, C++ and Fortran compiler directives library routines environment variables Directives single program multiple data (SPMD)
OpenMP Application Program Interface Introduction Shared-memory parallelism in C, C++ and Fortran compiler directives library routines environment variables Directives single program multiple data (SPMD)
CS 470 Spring Mike Lam, Professor. OpenMP
 CS 470 Spring 2018 Mike Lam, Professor OpenMP OpenMP Programming language extension Compiler support required "Open Multi-Processing" (open standard; latest version is 4.5) Automatic thread-level parallelism
CS 470 Spring 2018 Mike Lam, Professor OpenMP OpenMP Programming language extension Compiler support required "Open Multi-Processing" (open standard; latest version is 4.5) Automatic thread-level parallelism
Using OpenMP. Rebecca Hartman-Baker Oak Ridge National Laboratory
 Using OpenMP Rebecca Hartman-Baker Oak Ridge National Laboratory hartmanbakrj@ornl.gov 2004-2009 Rebecca Hartman-Baker. Reproduction permitted for non-commercial, educational use only. Outline I. About
Using OpenMP Rebecca Hartman-Baker Oak Ridge National Laboratory hartmanbakrj@ornl.gov 2004-2009 Rebecca Hartman-Baker. Reproduction permitted for non-commercial, educational use only. Outline I. About
Chip Multiprocessors COMP Lecture 9 - OpenMP & MPI
 Chip Multiprocessors COMP35112 Lecture 9 - OpenMP & MPI Graham Riley 14 February 2018 1 Today s Lecture Dividing work to be done in parallel between threads in Java (as you are doing in the labs) is rather
Chip Multiprocessors COMP35112 Lecture 9 - OpenMP & MPI Graham Riley 14 February 2018 1 Today s Lecture Dividing work to be done in parallel between threads in Java (as you are doing in the labs) is rather
A Short Introduction to OpenMP. Mark Bull, EPCC, University of Edinburgh
 A Short Introduction to OpenMP Mark Bull, EPCC, University of Edinburgh Overview Shared memory systems Basic Concepts in Threaded Programming Basics of OpenMP Parallel regions Parallel loops 2 Shared memory
A Short Introduction to OpenMP Mark Bull, EPCC, University of Edinburgh Overview Shared memory systems Basic Concepts in Threaded Programming Basics of OpenMP Parallel regions Parallel loops 2 Shared memory
Introduction to OpenMP
 Introduction to OpenMP Le Yan HPC Consultant User Services Goals Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Discuss briefly the
Introduction to OpenMP Le Yan HPC Consultant User Services Goals Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Discuss briefly the
Data Environment: Default storage attributes
 COSC 6374 Parallel Computation Introduction to OpenMP(II) Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel) Edgar Gabriel Fall 2014 Data Environment: Default storage attributes
COSC 6374 Parallel Computation Introduction to OpenMP(II) Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel) Edgar Gabriel Fall 2014 Data Environment: Default storage attributes
Introduction to OpenMP
 Introduction to OpenMP Xiaoxu Guan High Performance Computing, LSU April 6, 2016 LSU HPC Training Series, Spring 2016 p. 1/44 Overview Overview of Parallel Computing LSU HPC Training Series, Spring 2016
Introduction to OpenMP Xiaoxu Guan High Performance Computing, LSU April 6, 2016 LSU HPC Training Series, Spring 2016 p. 1/44 Overview Overview of Parallel Computing LSU HPC Training Series, Spring 2016
OpenMP: Open Multiprocessing
 OpenMP: Open Multiprocessing Erik Schnetter June 7, 2012, IHPC 2012, Iowa City Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to parallelise an existing code 4. Advanced
OpenMP: Open Multiprocessing Erik Schnetter June 7, 2012, IHPC 2012, Iowa City Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to parallelise an existing code 4. Advanced
MPI 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
OpenMP - II. Diego Fabregat-Traver and Prof. Paolo Bientinesi WS15/16. HPAC, RWTH Aachen
 OpenMP - II Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 OpenMP References Using OpenMP: Portable Shared Memory Parallel Programming. The MIT
OpenMP - II Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 OpenMP References Using OpenMP: Portable Shared Memory Parallel Programming. The MIT
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
Parallel Programming. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Programming Shared Memory Systems with OpenMP Part I. Book
 Programming Shared Memory Systems with OpenMP Part I Instructor Dr. Taufer Book Parallel Programming in OpenMP by Rohit Chandra, Leo Dagum, Dave Kohr, Dror Maydan, Jeff McDonald, Ramesh Menon 2 1 Machine
Programming Shared Memory Systems with OpenMP Part I Instructor Dr. Taufer Book Parallel Programming in OpenMP by Rohit Chandra, Leo Dagum, Dave Kohr, Dror Maydan, Jeff McDonald, Ramesh Menon 2 1 Machine
OpenMP programming. Thomas Hauser Director Research Computing Research CU-Boulder
 OpenMP programming Thomas Hauser Director Research Computing thomas.hauser@colorado.edu CU meetup 1 Outline OpenMP Shared-memory model Parallel for loops Declaring private variables Critical sections Reductions
OpenMP programming Thomas Hauser Director Research Computing thomas.hauser@colorado.edu CU meetup 1 Outline OpenMP Shared-memory model Parallel for loops Declaring private variables Critical sections Reductions
Advanced C Programming Winter Term 2008/09. Guest Lecture by Markus Thiele
 Advanced C Programming Winter Term 2008/09 Guest Lecture by Markus Thiele Lecture 14: Parallel Programming with OpenMP Motivation: Why parallelize? The free lunch is over. Herb
Advanced C Programming Winter Term 2008/09 Guest Lecture by Markus Thiele Lecture 14: Parallel Programming with OpenMP Motivation: Why parallelize? The free lunch is over. Herb
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Elementary Parallel Programming with Examples. Reinhold Bader (LRZ) Georg Hager (RRZE)
 Georg Hager (RRZE)") Elementary Parallel Programming with Examples Reinhold Bader (LRZ) Georg Hager (RRZE) Two Paradigms for Parallel Programming Hardware Designs Distributed Memory M Message Passing explicit programming required
Elementary Parallel Programming with Examples Reinhold Bader (LRZ) Georg Hager (RRZE) Two Paradigms for Parallel Programming Hardware Designs Distributed Memory M Message Passing explicit programming required
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
OpenMP on Ranger and Stampede (with Labs)
") OpenMP on Ranger and Stampede (with Labs) Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition November 6, 2012 Based on materials developed by Kent
OpenMP on Ranger and Stampede (with Labs) Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition November 6, 2012 Based on materials developed by Kent
CS691/SC791: Parallel & Distributed Computing
 CS691/SC791: Parallel & Distributed Computing Introduction to OpenMP 1 Contents Introduction OpenMP Programming Model and Examples OpenMP programming examples Task parallelism. Explicit thread synchronization.
CS691/SC791: Parallel & Distributed Computing Introduction to OpenMP 1 Contents Introduction OpenMP Programming Model and Examples OpenMP programming examples Task parallelism. Explicit thread synchronization.
Practical stuff! ü OpenMP. Ways of actually get stuff done in HPC:
 Ways of actually get stuff done in HPC: Practical stuff! Ø Message Passing (send, receive, broadcast,...) Ø Shared memory (load, store, lock, unlock) ü MPI Ø Transparent (compiler works magic) Ø Directive-based
Ways of actually get stuff done in HPC: Practical stuff! Ø Message Passing (send, receive, broadcast,...) Ø Shared memory (load, store, lock, unlock) ü MPI Ø Transparent (compiler works magic) Ø Directive-based
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 17 Shared-memory Programming 1 Outline n OpenMP n Shared-memory model n Parallel for loops n Declaring private variables n Critical
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 17 Shared-memory Programming 1 Outline n OpenMP n Shared-memory model n Parallel for loops n Declaring private variables n Critical
by system default usually a thread per CPU or core using the environment variable OMP_NUM_THREADS from within the program by using function call
 OpenMP Syntax The OpenMP Programming Model Number of threads are determined by system default usually a thread per CPU or core using the environment variable OMP_NUM_THREADS from within the program by
OpenMP Syntax The OpenMP Programming Model Number of threads are determined by system default usually a thread per CPU or core using the environment variable OMP_NUM_THREADS from within the program by
OpenMP Shared Memory Programming
 OpenMP Shared Memory Programming John Burkardt, Information Technology Department, Virginia Tech.... Mathematics Department, Ajou University, Suwon, Korea, 13 May 2009.... http://people.sc.fsu.edu/ jburkardt/presentations/
OpenMP Shared Memory Programming John Burkardt, Information Technology Department, Virginia Tech.... Mathematics Department, Ajou University, Suwon, Korea, 13 May 2009.... http://people.sc.fsu.edu/ jburkardt/presentations/
COSC 6374 Parallel Computation. Introduction to OpenMP. Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel)
 and Tim Mattson (Intel)") COSC 6374 Parallel Computation Introduction to OpenMP Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel) Edgar Gabriel Fall 2015 OpenMP Provides thread programming model at a
COSC 6374 Parallel Computation Introduction to OpenMP Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel) Edgar Gabriel Fall 2015 OpenMP Provides thread programming model at a
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to MSI Systems Andrew Gustafson The Machines at MSI Machine Type: Cluster Source: http://en.wikipedia.org/wiki/cluster_%28computing%29 Machine Type: Cluster
Minnesota Supercomputing Institute Introduction to MSI Systems Andrew Gustafson The Machines at MSI Machine Type: Cluster Source: http://en.wikipedia.org/wiki/cluster_%28computing%29 Machine Type: Cluster
Parallel Programming
 Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
Parallel programming using OpenMP
 Parallel programming using OpenMP Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department
Parallel programming using OpenMP Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department
OpenMP Introduction. CS 590: High Performance Computing. OpenMP. A standard for shared-memory parallel programming. MP = multiprocessing
 CS 590: High Performance Computing OpenMP Introduction Fengguang Song Department of Computer Science IUPUI OpenMP A standard for shared-memory parallel programming. MP = multiprocessing Designed for systems
CS 590: High Performance Computing OpenMP Introduction Fengguang Song Department of Computer Science IUPUI OpenMP A standard for shared-memory parallel programming. MP = multiprocessing Designed for systems
COMP4300/8300: The OpenMP Programming Model. Alistair Rendell. Specifications maintained by OpenMP Architecture Review Board (ARB)
") COMP4300/8300: The OpenMP Programming Model Alistair Rendell See: www.openmp.org Introduction to High Performance Computing for Scientists and Engineers, Hager and Wellein, Chapter 6 & 7 High Performance
COMP4300/8300: The OpenMP Programming Model Alistair Rendell See: www.openmp.org Introduction to High Performance Computing for Scientists and Engineers, Hager and Wellein, Chapter 6 & 7 High Performance
COMP4300/8300: The OpenMP Programming Model. Alistair Rendell
 COMP4300/8300: The OpenMP Programming Model Alistair Rendell See: www.openmp.org Introduction to High Performance Computing for Scientists and Engineers, Hager and Wellein, Chapter 6 & 7 High Performance
COMP4300/8300: The OpenMP Programming Model Alistair Rendell See: www.openmp.org Introduction to High Performance Computing for Scientists and Engineers, Hager and Wellein, Chapter 6 & 7 High Performance
https://www.youtube.com/playlist?list=pllx- Q6B8xqZ8n8bwjGdzBJ25X2utwnoEG
 https://www.youtube.com/playlist?list=pllx- Q6B8xqZ8n8bwjGdzBJ25X2utwnoEG OpenMP Basic Defs: Solution Stack HW System layer Prog. User layer Layer Directives, Compiler End User Application OpenMP library
https://www.youtube.com/playlist?list=pllx- Q6B8xqZ8n8bwjGdzBJ25X2utwnoEG OpenMP Basic Defs: Solution Stack HW System layer Prog. User layer Layer Directives, Compiler End User Application OpenMP library
OpenMP I. Diego Fabregat-Traver and Prof. Paolo Bientinesi WS16/17. HPAC, RWTH Aachen
 OpenMP I Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS16/17 OpenMP References Using OpenMP: Portable Shared Memory Parallel Programming. The MIT Press,
OpenMP I Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS16/17 OpenMP References Using OpenMP: Portable Shared Memory Parallel Programming. The MIT Press,
Parallel Programming with OpenMP. CS240A, T. Yang, 2013 Modified from Demmel/Yelick s and Mary Hall s Slides
 Parallel Programming with OpenMP CS240A, T. Yang, 203 Modified from Demmel/Yelick s and Mary Hall s Slides Introduction to OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for
Parallel Programming with OpenMP CS240A, T. Yang, 203 Modified from Demmel/Yelick s and Mary Hall s Slides Introduction to OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for
OpenMP C and C++ Application Program Interface Version 1.0 October Document Number
 OpenMP C and C++ Application Program Interface Version 1.0 October 1998 Document Number 004 2229 001 Contents Page v Introduction [1] 1 Scope............................. 1 Definition of Terms.........................
OpenMP C and C++ Application Program Interface Version 1.0 October 1998 Document Number 004 2229 001 Contents Page v Introduction [1] 1 Scope............................. 1 Definition of Terms.........................
Introduction to OpenMP
 Introduction to OpenMP Le Yan Objectives of Training Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Memory System: Shared Memory
Introduction to OpenMP Le Yan Objectives of Training Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Memory System: Shared Memory
OpenMP 4.0/4.5. Mark Bull, EPCC
 OpenMP 4.0/4.5 Mark Bull, EPCC OpenMP 4.0/4.5 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all
OpenMP 4.0/4.5 Mark Bull, EPCC OpenMP 4.0/4.5 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all
OpenMP 4.0. Mark Bull, EPCC
 OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
OpenMP Application Program Interface
 OpenMP Application Program Interface DRAFT Version.1.0-00a THIS IS A DRAFT AND NOT FOR PUBLICATION Copyright 1-0 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material
OpenMP Application Program Interface DRAFT Version.1.0-00a THIS IS A DRAFT AND NOT FOR PUBLICATION Copyright 1-0 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Introduction to OpenMP. Martin Čuma Center for High Performance Computing University of Utah
 Introduction to OpenMP Martin Čuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu Overview Quick introduction. Parallel loops. Parallel loop directives. Parallel sections.
Introduction to OpenMP Martin Čuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu Overview Quick introduction. Parallel loops. Parallel loop directives. Parallel sections.
OpenMP, Part 2. EAS 520 High Performance Scientific Computing. University of Massachusetts Dartmouth. Spring 2015
 OpenMP, Part 2 EAS 520 High Performance Scientific Computing University of Massachusetts Dartmouth Spring 2015 References This presentation is almost an exact copy of Dartmouth College's openmp tutorial.
OpenMP, Part 2 EAS 520 High Performance Scientific Computing University of Massachusetts Dartmouth Spring 2015 References This presentation is almost an exact copy of Dartmouth College's openmp tutorial.
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 17 Shared-memory Programming 1 Outline n OpenMP n Shared-memory model n Parallel for loops n Declaring private variables n Critical
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 17 Shared-memory Programming 1 Outline n OpenMP n Shared-memory model n Parallel for loops n Declaring private variables n Critical
Multi-core Architecture and Programming
 Multi-core Architecture and Programming Yang Quansheng( 杨全胜 ) http://www.njyangqs.com School of Computer Science & Engineering 1 http://www.njyangqs.com Programming with OpenMP Content What is PpenMP Parallel
Multi-core Architecture and Programming Yang Quansheng( 杨全胜 ) http://www.njyangqs.com School of Computer Science & Engineering 1 http://www.njyangqs.com Programming with OpenMP Content What is PpenMP Parallel
Programming with Shared Memory PART II. HPC Fall 2012 Prof. Robert van Engelen
 Programming with Shared Memory PART II HPC Fall 2012 Prof. Robert van Engelen Overview Sequential consistency Parallel programming constructs Dependence analysis OpenMP Autoparallelization Further reading
Programming with Shared Memory PART II HPC Fall 2012 Prof. Robert van Engelen Overview Sequential consistency Parallel programming constructs Dependence analysis OpenMP Autoparallelization Further reading
Programming with Shared Memory PART II. HPC Fall 2007 Prof. Robert van Engelen
 Programming with Shared Memory PART II HPC Fall 2007 Prof. Robert van Engelen Overview Parallel programming constructs Dependence analysis OpenMP Autoparallelization Further reading HPC Fall 2007 2 Parallel
Programming with Shared Memory PART II HPC Fall 2007 Prof. Robert van Engelen Overview Parallel programming constructs Dependence analysis OpenMP Autoparallelization Further reading HPC Fall 2007 2 Parallel
OpenMP Fundamentals Fork-join model and data environment
 www.bsc.es OpenMP Fundamentals Fork-join model and data environment Xavier Teruel and Xavier Martorell Agenda: OpenMP Fundamentals OpenMP brief introduction The fork-join model Data environment OpenMP
www.bsc.es OpenMP Fundamentals Fork-join model and data environment Xavier Teruel and Xavier Martorell Agenda: OpenMP Fundamentals OpenMP brief introduction The fork-join model Data environment OpenMP