Application and System Memory Use, Configuration, and Problems on Bassi. Richard Gerber
|
|
|
- Agatha Cook
- 5 years ago
- Views:
Transcription
1 Application and System Memory Use, Configuration, and Problems on Bassi Richard Gerber Lawrence Berkeley National Laboratory NERSC User Services ScicomP 13, Garching, Germany, July 17, 2007 NERSC is supported by the Office of Advanced Scientific Computing Research in the Department of Energy Office of Science under contract number DE-AC02-05CH11231.
2 Overview About Bassi Memory on Bassi Large Page Memory (It s Great!) System Configuration Large Page Gotchas The Plague Workload Characterization

3 Bassi Description NERSC IBM POWER 5 p575: Bassi 111 (114) node single-core 1.9 GHz P5 8-way SMP 32 GB physical memory per node Very diverse workload ~400 active users ~400 jobs per day 28% node-hrs >32 nodes 44% node-hrs < 8 nodes 12% node-hrs = 1 node Fortran, C, C++, mixed-mode MPI, OpenMP, pthreads shmget() MPMD, SPMD, emb. parallel
4 Memory on Bassi NERSC is supported by the Office of Advanced Scientific Computing Research in the Department of Energy Office of Science under contract number DE-AC02-05CH11231.
5 Bassi Memory Overview Each node has 32 GB of memory Memory is partitioned into two types Large Page pool Small Page pool Large pages are required for HPS AIX uses small pages only Applications can use either Small pages only Large and small pages
6 Large Page Memory It s Great! NERSC is supported by the Office of Advanced Scientific Computing Research in the Department of Energy Office of Science under contract number DE-AC02-05CH11231.
7 Large Page Memory Large memory pages are 16 MB Can not be swapped to disk Number of large pages per node is set at boot Large Page memory is backed by Small Pages Small memory pages are 4 KB Can be swapped to disk Large Page memory is good for most scientific applications Enhanced memory bandwidth 16 GB TLB coverage (vs. 4 MB for small) cache lines (vs. 32 for small)

8 Memory Bandwidth
9 LP Memory & NERSC Benchmarks Large page memory improves performance on NERSC Bassi benchmarks NPB MG 2.4 Class C: 38% NPB SP 2.4 Class C: 16% NPB FT 2.4 Class C: 13% GTC (PIC Fusion): 7% PARATEC (Materials): 8% CAM 3.0 (Climate Atms): 1%
10 System Configuration NERSC is supported by the Office of Advanced Scientific Computing Research in the Department of Energy Office of Science under contract number DE-AC02-05CH11231.
11 System Configuration It appears that Large Pages are good for HPC applications Why not configure system for as many large pages as possible, leaving adequate small pages for AIX? After consultation with IBM, NERSC chose to allocate 24 GB to the large page pool
12 System and Application Memory On an idle compute node AIX uses about 4 GB of small page memory; ~4 GB free HPS reserves 69 large pages, or GB; GB free Applications can access the remaining memory 4 GB + 23 GB 27 GB
13 Large Page Gotchas NERSC is supported by the Office of Advanced Scientific Computing Research in the Department of Energy Office of Science under contract number DE-AC02-05CH11231.
14 Large Page Gotchas Users must enable codes to run in Large Pages; it is not the default The application stack must reside in small page memory FORTRAN 90 regular arrays are allocated on the stack by default (? qlargepage) Shared memory segments are allocated in small page memory by default OpenMP PRIVATE data is allocated on the stack (? qsmallstack) Large Page memory allocation is slow (scripts and serial commands should use small pages)
15 Bad Things Happen When Small Page Memory is Exhausted Small Page memory must swap to disk when exhausted When jobs exhaust small-page memory Slows, hangs, or kills the application Makes the node unresponsive GPFS dies Causes other havoc Why? Theory: AIX memory manager can t deal with 8 tasks concurrently trying to allocate/access large chunk of memory that is not physically present and must be paged to disk
16 NERSC Mitigation Efforts Set the mp* compilers to enable large pages by default Serial compiled codes use small pages Set runtime environment variables to force batch jobs into large pages Identify shmget() programmers and tell them to set SHM_LGPAGE and SHM_PIN flags Tell FORTRAN 90 users to use qsave to force normal arrays into static (LP?) memory -qlargepage? WLM ConsumableMemory settings and low paging space kills
17 The Plague NERSC is supported by the Office of Advanced Scientific Computing Research in the Department of Energy Office of Science under contract number DE-AC02-05CH11231.
18 The Memory Exhaustion Plague NERSC has been plagued by users exhausting small page memory and effectively disabling nodes Node becomes unresponsive; services die Users jobs die Node may or may not recover by itself System admins get paged Consultants have to contact users to try to get more information Users get disabled so they won t kill the nodes again
19 System Monitoring We starting monitoring the memory usage on all compute nodes Used LoadLeveler llstatus l utility Free small page memory Free large page memory Sampled every 15 mins since mid April 2007 Recorded user and StepID running on each node
20 Monitoring Results In about 70 days we found Large pages exhausted 3.3% of the time Small pages exhausted 0.87% (1/115) of the time Node paging to disk 0.29% (1/345) of the time Paging with LP use, but free LPs 0.24% (1/417) of the time We identified three common node failure modes Just using too much memory (>27 GB) Running without enabling large page use Using some large pages, but nonetheless exhausting small page memory We contacted users to get more information about their codes and job scripts
21 Causes Users override default programming environment Executables are not large-page enabled Batch environmental variable not set (LDR_CNTRL) bash configuration file issues Using large automatic arrays and OpenMP PRIVATE data (?) Making shared memory calls without LP flags Programming errors Users don t really understand their code s memory requirements Third-party libraries Unknown issues
22 Solutions Work one-on-one with users to resolve known issues Work with third-party developers to incorporate P5-friendly code Global Arrays, NWChem, MOLPRO, GAMESS NERSC reduced Large Page pool to 20 GB on 7/11/2007 to accommodate codes that need a larger stack Possibly set qsave as default for f90 compilers? Or qlargepage? qsmallstack? New system configuration setting promised by IBM to monitor and kill jobs based on small page memory use
23 Workload Characterization NERSC is supported by the Office of Advanced Scientific Computing Research in the Department of Energy Office of Science under contract number DE-AC02-05CH11231.
24 Workload Characterization We have these memory snapshots, so we can ask questions about the NERSC workload How much memory is used on average? What is the maximum memory usage? How many Large Pages should we allocate? Can we help users understand their codes memory use patterns (e.g. find memory leaks) Can we identify classes of jobs based on memory use patterns?

25 Total and Max Memory Used
26 Total Memory Used
27 Large Page Memory Used
28 Small Page Memory Used
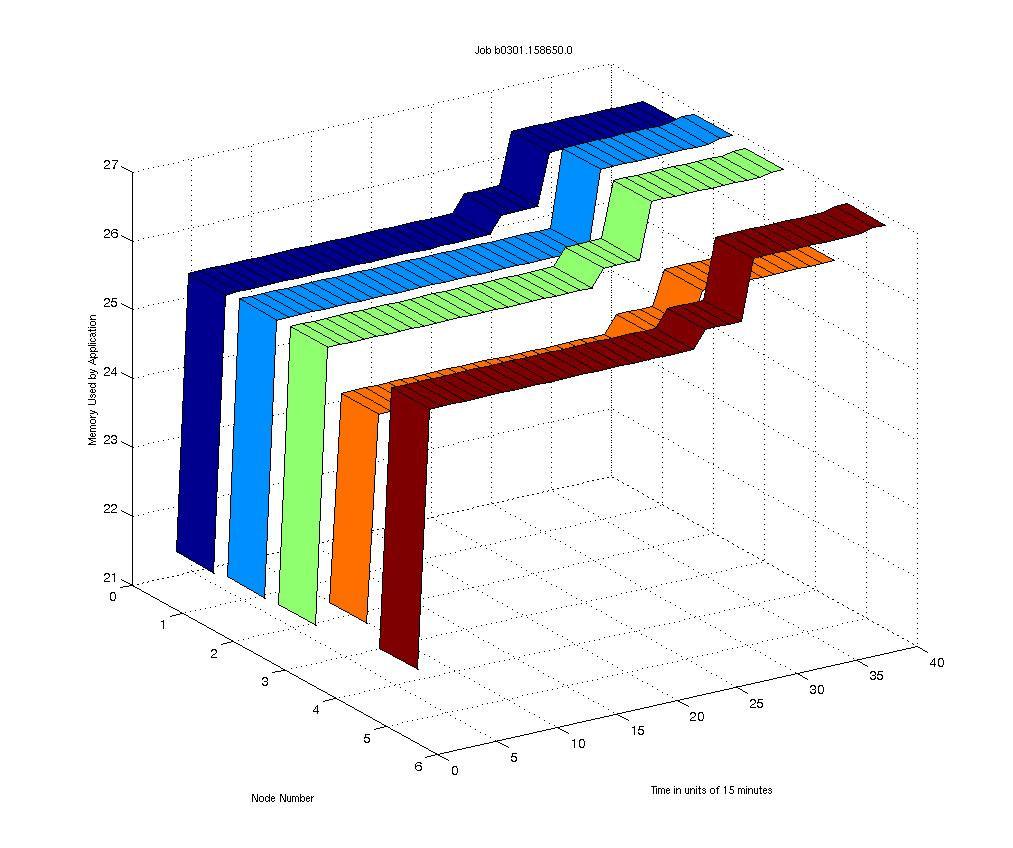
29 Job Characterization
30
The Hopper System: How the Largest* XE6 in the World Went From Requirements to Reality! Katie Antypas, Tina Butler, and Jonathan Carter
 The Hopper System: How the Largest* XE6 in the World Went From Requirements to Reality! Katie Antypas, Tina Butler, and Jonathan Carter CUG 2011, May 25th, 2011 1 Requirements to Reality Develop RFP Select
The Hopper System: How the Largest* XE6 in the World Went From Requirements to Reality! Katie Antypas, Tina Butler, and Jonathan Carter CUG 2011, May 25th, 2011 1 Requirements to Reality Develop RFP Select
Amazon Web Services: Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud
 Amazon Web Services: Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud Summarized by: Michael Riera 9/17/2011 University of Central Florida CDA5532 Agenda
Amazon Web Services: Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud Summarized by: Michael Riera 9/17/2011 University of Central Florida CDA5532 Agenda
Experience with the Jülich HPS Regatta H+ Cluster
 Experience with the Jülich HPS Regatta H+ Cluster K.Wolkersdorfer@fz-juelich.de Jump Architecture IBM RegattaH + SM P Cluster 2 Login Nodes 39 Compute Nodes 2 TSM Partitions Network + HPS (2 Adapter/4links
Experience with the Jülich HPS Regatta H+ Cluster K.Wolkersdorfer@fz-juelich.de Jump Architecture IBM RegattaH + SM P Cluster 2 Login Nodes 39 Compute Nodes 2 TSM Partitions Network + HPS (2 Adapter/4links
CS399 New Beginnings. Jonathan Walpole
 CS399 New Beginnings Jonathan Walpole Memory Management Memory Management Memory a linear array of bytes - Holds O.S. and programs (processes) - Each cell (byte) is named by a unique memory address Recall,
CS399 New Beginnings Jonathan Walpole Memory Management Memory Management Memory a linear array of bytes - Holds O.S. and programs (processes) - Each cell (byte) is named by a unique memory address Recall,
Parallel Performance of the XL Fortran random_number Intrinsic Function on Seaborg
 LBNL-XXXXX Parallel Performance of the XL Fortran random_number Intrinsic Function on Seaborg Richard A. Gerber User Services Group, NERSC Division July 2003 This work was supported by the Director, Office
LBNL-XXXXX Parallel Performance of the XL Fortran random_number Intrinsic Function on Seaborg Richard A. Gerber User Services Group, NERSC Division July 2003 This work was supported by the Director, Office
DVS, GPFS and External Lustre at NERSC How It s Working on Hopper. Tina Butler, Rei Chi Lee, Gregory Butler 05/25/11 CUG 2011
 DVS, GPFS and External Lustre at NERSC How It s Working on Hopper Tina Butler, Rei Chi Lee, Gregory Butler 05/25/11 CUG 2011 1 NERSC is the Primary Computing Center for DOE Office of Science NERSC serves
DVS, GPFS and External Lustre at NERSC How It s Working on Hopper Tina Butler, Rei Chi Lee, Gregory Butler 05/25/11 CUG 2011 1 NERSC is the Primary Computing Center for DOE Office of Science NERSC serves
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
PROCESS VIRTUAL MEMORY. CS124 Operating Systems Winter , Lecture 18
 PROCESS VIRTUAL MEMORY CS124 Operating Systems Winter 2015-2016, Lecture 18 2 Programs and Memory Programs perform many interactions with memory Accessing variables stored at specific memory locations
PROCESS VIRTUAL MEMORY CS124 Operating Systems Winter 2015-2016, Lecture 18 2 Programs and Memory Programs perform many interactions with memory Accessing variables stored at specific memory locations
Introduction to High Performance Parallel I/O
 Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
A Case for High Performance Computing with Virtual Machines
 A Case for High Performance Computing with Virtual Machines Wei Huang*, Jiuxing Liu +, Bulent Abali +, and Dhabaleswar K. Panda* *The Ohio State University +IBM T. J. Waston Research Center Presentation
A Case for High Performance Computing with Virtual Machines Wei Huang*, Jiuxing Liu +, Bulent Abali +, and Dhabaleswar K. Panda* *The Ohio State University +IBM T. J. Waston Research Center Presentation
Lecture 3: Intro to parallel machines and models
 Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Process. One or more threads of execution Resources required for execution. Memory (RAM) Others
 Others") Memory Management 1 Learning Outcomes Appreciate the need for memory management in operating systems, understand the limits of fixed memory allocation schemes. Understand fragmentation in dynamic memory
Memory Management 1 Learning Outcomes Appreciate the need for memory management in operating systems, understand the limits of fixed memory allocation schemes. Understand fragmentation in dynamic memory
Effects of Hyper-Threading on the NERSC workload on Edison
 Effects of Hyper-Threading on the NERSC workload on Edison Zhengji Zhao, Nicholas J. Wright and Katie Antypas National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory
Effects of Hyper-Threading on the NERSC workload on Edison Zhengji Zhao, Nicholas J. Wright and Katie Antypas National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory
A Characterization of Shared Data Access Patterns in UPC Programs
 IBM T.J. Watson Research Center A Characterization of Shared Data Access Patterns in UPC Programs Christopher Barton, Calin Cascaval, Jose Nelson Amaral LCPC `06 November 2, 2006 Outline Motivation Overview
IBM T.J. Watson Research Center A Characterization of Shared Data Access Patterns in UPC Programs Christopher Barton, Calin Cascaval, Jose Nelson Amaral LCPC `06 November 2, 2006 Outline Motivation Overview
Taming Parallel I/O Complexity with Auto-Tuning
 Taming Parallel I/O Complexity with Auto-Tuning Babak Behzad 1, Huong Vu Thanh Luu 1, Joseph Huchette 2, Surendra Byna 3, Prabhat 3, Ruth Aydt 4, Quincey Koziol 4, Marc Snir 1,5 1 University of Illinois
Taming Parallel I/O Complexity with Auto-Tuning Babak Behzad 1, Huong Vu Thanh Luu 1, Joseph Huchette 2, Surendra Byna 3, Prabhat 3, Ruth Aydt 4, Quincey Koziol 4, Marc Snir 1,5 1 University of Illinois
Performance Analysis and Optimization of Parallel Scientific Applications on CMP Cluster Systems
 Performance Analysis and Optimization of Parallel Scientific Applications on CMP Cluster Systems Xingfu Wu, Valerie Taylor, Charles Lively, and Sameh Sharkawi Department of Computer Science, Texas A&M
Performance Analysis and Optimization of Parallel Scientific Applications on CMP Cluster Systems Xingfu Wu, Valerie Taylor, Charles Lively, and Sameh Sharkawi Department of Computer Science, Texas A&M
Content. MPIRUN Command Environment Variables LoadLeveler SUBMIT Command IBM Simple Scheduler. IBM PSSC Montpellier Customer Center
 Content IBM PSSC Montpellier Customer Center MPIRUN Command Environment Variables LoadLeveler SUBMIT Command IBM Simple Scheduler Control System Service Node (SN) An IBM system-p 64-bit system Control
Content IBM PSSC Montpellier Customer Center MPIRUN Command Environment Variables LoadLeveler SUBMIT Command IBM Simple Scheduler Control System Service Node (SN) An IBM system-p 64-bit system Control
Memory Management. Goals of Memory Management. Mechanism. Policies
 Memory Management Design, Spring 2011 Department of Computer Science Rutgers Sakai: 01:198:416 Sp11 (https://sakai.rutgers.edu) Memory Management Goals of Memory Management Convenient abstraction for programming
Memory Management Design, Spring 2011 Department of Computer Science Rutgers Sakai: 01:198:416 Sp11 (https://sakai.rutgers.edu) Memory Management Goals of Memory Management Convenient abstraction for programming
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
High Performance Computing Systems
 High Performance Computing Systems Multikernels Doug Shook Multikernels Two predominant approaches to OS: Full weight kernel Lightweight kernel Why not both? How does implementation affect usage and performance?
High Performance Computing Systems Multikernels Doug Shook Multikernels Two predominant approaches to OS: Full weight kernel Lightweight kernel Why not both? How does implementation affect usage and performance?
 1 of 8 14/12/2013 11:51 Tuning long-running processes Contents 1. Reduce the database size 2. Balancing the hardware resources 3. Specifying initial DB2 database settings 4. Specifying initial Oracle database
1 of 8 14/12/2013 11:51 Tuning long-running processes Contents 1. Reduce the database size 2. Balancing the hardware resources 3. Specifying initial DB2 database settings 4. Specifying initial Oracle database
What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout
 What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout Goals for the OS Interface More convenient abstractions than hardware interface Manage shared resources Provide near-hardware
What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout Goals for the OS Interface More convenient abstractions than hardware interface Manage shared resources Provide near-hardware
GPFS on a Cray XT. Shane Canon Data Systems Group Leader Lawrence Berkeley National Laboratory CUG 2009 Atlanta, GA May 4, 2009
 GPFS on a Cray XT Shane Canon Data Systems Group Leader Lawrence Berkeley National Laboratory CUG 2009 Atlanta, GA May 4, 2009 Outline NERSC Global File System GPFS Overview Comparison of Lustre and GPFS
GPFS on a Cray XT Shane Canon Data Systems Group Leader Lawrence Berkeley National Laboratory CUG 2009 Atlanta, GA May 4, 2009 Outline NERSC Global File System GPFS Overview Comparison of Lustre and GPFS
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
IBM Tivoli Storage Manager for AIX Version Installation Guide IBM
 IBM Tivoli Storage Manager for AIX Version 7.1.3 Installation Guide IBM IBM Tivoli Storage Manager for AIX Version 7.1.3 Installation Guide IBM Note: Before you use this information and the product it
IBM Tivoli Storage Manager for AIX Version 7.1.3 Installation Guide IBM IBM Tivoli Storage Manager for AIX Version 7.1.3 Installation Guide IBM Note: Before you use this information and the product it
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Sami Saarinen Peter Towers. 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1
 Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
The Hopper System: How the Largest XE6 in the World Went From Requirements to Reality
 The Hopper System: How the Largest XE6 in the World Went From Requirements to Reality Katie Antypas, Tina Butler, and Jonathan Carter NERSC Division, Lawrence Berkeley National Laboratory ABSTRACT: This
The Hopper System: How the Largest XE6 in the World Went From Requirements to Reality Katie Antypas, Tina Butler, and Jonathan Carter NERSC Division, Lawrence Berkeley National Laboratory ABSTRACT: This
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Agenda
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Experience the GRID Today with Oracle9i RAC
 1 Experience the GRID Today with Oracle9i RAC Shig Hiura Pre-Sales Engineer Shig_Hiura@etagon.com 2 Agenda Introduction What is the Grid The Database Grid Oracle9i RAC Technology 10g vs. 9iR2 Comparison
1 Experience the GRID Today with Oracle9i RAC Shig Hiura Pre-Sales Engineer Shig_Hiura@etagon.com 2 Agenda Introduction What is the Grid The Database Grid Oracle9i RAC Technology 10g vs. 9iR2 Comparison
Designing Parallel Programs. This review was developed from Introduction to Parallel Computing
 Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Performance Study of the MPI and MPI-CH Communication Libraries on the IBM SP
 Performance Study of the MPI and MPI-CH Communication Libraries on the IBM SP Ewa Deelman and Rajive Bagrodia UCLA Computer Science Department deelman@cs.ucla.edu, rajive@cs.ucla.edu http://pcl.cs.ucla.edu
Performance Study of the MPI and MPI-CH Communication Libraries on the IBM SP Ewa Deelman and Rajive Bagrodia UCLA Computer Science Department deelman@cs.ucla.edu, rajive@cs.ucla.edu http://pcl.cs.ucla.edu
MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization
 SCV Staff Boston University Scientific Computing and Visualization") MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization 2 Glenn Bresnahan Director, SCV MGHPCC Buy-in Program Kadin Tseng HPC Programmer/Consultant
MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization 2 Glenn Bresnahan Director, SCV MGHPCC Buy-in Program Kadin Tseng HPC Programmer/Consultant
Analytics in the cloud
 Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
Analytics in the cloud Dow we really need to reinvent the storage stack? R. Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha, Prasenjit Sarkar, Mansi Shah, Renu Tewari Image courtesy NASA
Introduction to OpenMP
 Introduction to OpenMP p. 1/?? Introduction to OpenMP More Syntax and SIMD Nick Maclaren Computing Service nmm1@cam.ac.uk, ext. 34761 June 2011 Introduction to OpenMP p. 2/?? C/C++ Parallel for (1) I said
Introduction to OpenMP p. 1/?? Introduction to OpenMP More Syntax and SIMD Nick Maclaren Computing Service nmm1@cam.ac.uk, ext. 34761 June 2011 Introduction to OpenMP p. 2/?? C/C++ Parallel for (1) I said
This Unit: Main Memory. Building a Memory System. First Memory System Design. An Example Memory System
 This Unit: Main Memory Building a Memory System Application OS Compiler Firmware CPU I/O Memory Digital Circuits Gates & Transistors Memory hierarchy review DRAM technology A few more transistors Organization:
This Unit: Main Memory Building a Memory System Application OS Compiler Firmware CPU I/O Memory Digital Circuits Gates & Transistors Memory hierarchy review DRAM technology A few more transistors Organization:
NERSC Site Update. National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory. Richard Gerber
 NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
CS 333 Introduction to Operating Systems Class 2 OS-Related Hardware & Software The Process Concept
 CS 333 Introduction to Operating Systems Class 2 OS-Related Hardware & Software The Process Concept Jonathan Walpole Computer Science Portland State University 1 Lecture 2 overview OS-Related Hardware
CS 333 Introduction to Operating Systems Class 2 OS-Related Hardware & Software The Process Concept Jonathan Walpole Computer Science Portland State University 1 Lecture 2 overview OS-Related Hardware
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
CS 390 Chapter 8 Homework Solutions
 CS 390 Chapter 8 Homework Solutions 8.3 Why are page sizes always... Page sizes that are a power of two make it computationally fast for the kernel to determine the page number and offset of a logical
CS 390 Chapter 8 Homework Solutions 8.3 Why are page sizes always... Page sizes that are a power of two make it computationally fast for the kernel to determine the page number and offset of a logical
Introduction to Parallel Programming. Tuesday, April 17, 12
 Introduction to Parallel Programming 1 Overview Parallel programming allows the user to use multiple cpus concurrently Reasons for parallel execution: shorten execution time by spreading the computational
Introduction to Parallel Programming 1 Overview Parallel programming allows the user to use multiple cpus concurrently Reasons for parallel execution: shorten execution time by spreading the computational
Bei Wang, Dmitry Prohorov and Carlos Rosales
 Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Early Evaluation of the Cray X1 at Oak Ridge National Laboratory
 Early Evaluation of the Cray X1 at Oak Ridge National Laboratory Patrick H. Worley Thomas H. Dunigan, Jr. Oak Ridge National Laboratory 45th Cray User Group Conference May 13, 2003 Hyatt on Capital Square
Early Evaluation of the Cray X1 at Oak Ridge National Laboratory Patrick H. Worley Thomas H. Dunigan, Jr. Oak Ridge National Laboratory 45th Cray User Group Conference May 13, 2003 Hyatt on Capital Square
Introduction to PICO Parallel & Production Enviroment
 Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
HP OpenVMS Alpha and Integrity Performance Comparison
 HP OpenVMS Alpha and Integrity Performance Comparison Session 1225 Gregory Jordan OpenVMS Engineering Hewlett-Packard 25 Hewlett-Packard Development Company, L.P. The information contained herein is subject
HP OpenVMS Alpha and Integrity Performance Comparison Session 1225 Gregory Jordan OpenVMS Engineering Hewlett-Packard 25 Hewlett-Packard Development Company, L.P. The information contained herein is subject
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 L17 Main Memory Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Was Great Dijkstra a magician?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 L17 Main Memory Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Was Great Dijkstra a magician?
Improved Solutions for I/O Provisioning and Application Acceleration
 1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories
 Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories Adrian M. Caulfield Arup De, Joel Coburn, Todor I. Mollov, Rajesh K. Gupta, Steven Swanson Non-Volatile Systems
Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories Adrian M. Caulfield Arup De, Joel Coburn, Todor I. Mollov, Rajesh K. Gupta, Steven Swanson Non-Volatile Systems
Chapter 1: Introduction
 Chapter 1: Introduction What is an operating system? Simple Batch Systems Multiprogramming Batched Systems Time-Sharing Systems Personal-Computer Systems Parallel Systems Distributed Systems Real -Time
Chapter 1: Introduction What is an operating system? Simple Batch Systems Multiprogramming Batched Systems Time-Sharing Systems Personal-Computer Systems Parallel Systems Distributed Systems Real -Time
AMD: WebBench Virtualization Performance Study
 March 2005 www.veritest.com info@veritest.com AMD: WebBench Virtualization Performance Study Test report prepared under contract from Advanced Micro Devices, Inc. Executive summary Advanced Micro Devices,
March 2005 www.veritest.com info@veritest.com AMD: WebBench Virtualization Performance Study Test report prepared under contract from Advanced Micro Devices, Inc. Executive summary Advanced Micro Devices,
IBM Tivoli Storage Manager for HP-UX Version Installation Guide IBM
 IBM Tivoli Storage Manager for HP-UX Version 7.1.4 Installation Guide IBM IBM Tivoli Storage Manager for HP-UX Version 7.1.4 Installation Guide IBM Note: Before you use this information and the product
IBM Tivoli Storage Manager for HP-UX Version 7.1.4 Installation Guide IBM IBM Tivoli Storage Manager for HP-UX Version 7.1.4 Installation Guide IBM Note: Before you use this information and the product
Monitoring Agent for Unix OS Version Reference IBM
 Monitoring Agent for Unix OS Version 6.3.5 Reference IBM Monitoring Agent for Unix OS Version 6.3.5 Reference IBM Note Before using this information and the product it supports, read the information in
Monitoring Agent for Unix OS Version 6.3.5 Reference IBM Monitoring Agent for Unix OS Version 6.3.5 Reference IBM Note Before using this information and the product it supports, read the information in
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Operation and Use, Volume 1 Using the Parallel Operating Environment
 IBM Parallel Environment for AIX 5L Operation and Use, Volume 1 Using the Parallel Operating Environment Version 4 Release 2, Modification 2 SA22-7948-04 IBM Parallel Environment for AIX 5L Operation
IBM Parallel Environment for AIX 5L Operation and Use, Volume 1 Using the Parallel Operating Environment Version 4 Release 2, Modification 2 SA22-7948-04 IBM Parallel Environment for AIX 5L Operation
Parallel Programming Models. Parallel Programming Models. Threads Model. Implementations 3/24/2014. Shared Memory Model (without threads)
") Parallel Programming Models Parallel Programming Models Shared Memory (without threads) Threads Distributed Memory / Message Passing Data Parallel Hybrid Single Program Multiple Data (SPMD) Multiple Program
Parallel Programming Models Parallel Programming Models Shared Memory (without threads) Threads Distributed Memory / Message Passing Data Parallel Hybrid Single Program Multiple Data (SPMD) Multiple Program
arxiv: v2 [cs.dc] 2 May 2017
![arxiv: v2 [cs.dc] 2 May 2017](/thumbs/74/71389175.jpg "arxiv: v2 [cs.dc] 2 May 2017") Unimem: Runtime Data Management on Non-Volatile Memory-based Heterogeneous Main Memory Kai Wu University of California, Merced kwu42@ucmerced.edu Yingchao Huang University of California, Merced yhuang46@ucmerced.edu
Unimem: Runtime Data Management on Non-Volatile Memory-based Heterogeneous Main Memory Kai Wu University of California, Merced kwu42@ucmerced.edu Yingchao Huang University of California, Merced yhuang46@ucmerced.edu
Compute Node Linux: Overview, Progress to Date & Roadmap
 Compute Node Linux: Overview, Progress to Date & Roadmap David Wallace Cray Inc ABSTRACT: : This presentation will provide an overview of Compute Node Linux(CNL) for the CRAY XT machine series. Compute
Compute Node Linux: Overview, Progress to Date & Roadmap David Wallace Cray Inc ABSTRACT: : This presentation will provide an overview of Compute Node Linux(CNL) for the CRAY XT machine series. Compute
A More Realistic Way of Stressing the End-to-end I/O System
 A More Realistic Way of Stressing the End-to-end I/O System Verónica G. Vergara Larrea Sarp Oral Dustin Leverman Hai Ah Nam Feiyi Wang James Simmons CUG 2015 April 29, 2015 Chicago, IL ORNL is managed
A More Realistic Way of Stressing the End-to-end I/O System Verónica G. Vergara Larrea Sarp Oral Dustin Leverman Hai Ah Nam Feiyi Wang James Simmons CUG 2015 April 29, 2015 Chicago, IL ORNL is managed
Memory Management. An expensive way to run multiple processes: Swapping. CPSC 410/611 : Operating Systems. Memory Management: Paging / Segmentation 1
 Memory Management Logical vs. physical address space Fragmentation Paging Segmentation An expensive way to run multiple processes: Swapping swap_out OS swap_in start swapping store memory ready_sw ready
Memory Management Logical vs. physical address space Fragmentation Paging Segmentation An expensive way to run multiple processes: Swapping swap_out OS swap_in start swapping store memory ready_sw ready
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters
 Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Objectives and Functions Convenience. William Stallings Computer Organization and Architecture 7 th Edition. Efficiency
 William Stallings Computer Organization and Architecture 7 th Edition Chapter 8 Operating System Support Objectives and Functions Convenience Making the computer easier to use Efficiency Allowing better
William Stallings Computer Organization and Architecture 7 th Edition Chapter 8 Operating System Support Objectives and Functions Convenience Making the computer easier to use Efficiency Allowing better
Memory Management (Chaper 4, Tanenbaum)
") Memory Management (Chaper 4, Tanenbaum) Memory Mgmt Introduction The CPU fetches instructions and data of a program from memory; therefore, both the program and its data must reside in the main (RAM and
Memory Management (Chaper 4, Tanenbaum) Memory Mgmt Introduction The CPU fetches instructions and data of a program from memory; therefore, both the program and its data must reside in the main (RAM and
Memory. From Chapter 3 of High Performance Computing. c R. Leduc
 Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
DB2 Optimized for SAP
 DB2 Optimized for SAP Konstantin Pabst Technical Sales Specialist Information Managment March 26, 2012 Strategic requirements for SAP customers in today s world How do I better manage the current investments
DB2 Optimized for SAP Konstantin Pabst Technical Sales Specialist Information Managment March 26, 2012 Strategic requirements for SAP customers in today s world How do I better manage the current investments
Power Systems with POWER8 Scale-out Technical Sales Skills V1
 Power Systems with POWER8 Scale-out Technical Sales Skills V1 1. An ISV develops Linux based applications in their heterogeneous environment consisting of both IBM Power Systems and x86 servers. They are
Power Systems with POWER8 Scale-out Technical Sales Skills V1 1. An ISV develops Linux based applications in their heterogeneous environment consisting of both IBM Power Systems and x86 servers. They are
Operating systems. Part 1. Module 11 Main memory introduction. Tami Sorgente 1
 Operating systems Module 11 Main memory introduction Part 1 Tami Sorgente 1 MODULE 11 MAIN MEMORY INTRODUCTION Background Swapping Contiguous Memory Allocation Noncontiguous Memory Allocation o Segmentation
Operating systems Module 11 Main memory introduction Part 1 Tami Sorgente 1 MODULE 11 MAIN MEMORY INTRODUCTION Background Swapping Contiguous Memory Allocation Noncontiguous Memory Allocation o Segmentation
Storage Management 1
 Storage Management Goals of this Lecture Help you learn about: Locality and caching Typical storage hierarchy Virtual memory How the hardware and OS give applications the illusion of a large, contiguous,
Storage Management Goals of this Lecture Help you learn about: Locality and caching Typical storage hierarchy Virtual memory How the hardware and OS give applications the illusion of a large, contiguous,
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers
 Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
Research on the Implementation of MPI on Multicore Architectures
 Research on the Implementation of MPI on Multicore Architectures Pengqi Cheng Department of Computer Science & Technology, Tshinghua University, Beijing, China chengpq@gmail.com Yan Gu Department of Computer
Research on the Implementation of MPI on Multicore Architectures Pengqi Cheng Department of Computer Science & Technology, Tshinghua University, Beijing, China chengpq@gmail.com Yan Gu Department of Computer
Enhancements to Linux I/O Scheduling
 Enhancements to Linux I/O Scheduling Seetharami R. Seelam, UTEP Rodrigo Romero, UTEP Patricia J. Teller, UTEP William Buros, IBM-Austin 21 July 2005 Linux Symposium 2005 1 Introduction Dynamic Adaptability
Enhancements to Linux I/O Scheduling Seetharami R. Seelam, UTEP Rodrigo Romero, UTEP Patricia J. Teller, UTEP William Buros, IBM-Austin 21 July 2005 Linux Symposium 2005 1 Introduction Dynamic Adaptability
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
Operating System Support
 Operating System Support Objectives and Functions Convenience Making the computer easier to use Efficiency Allowing better use of computer resources Layers and Views of a Computer System Operating System
Operating System Support Objectives and Functions Convenience Making the computer easier to use Efficiency Allowing better use of computer resources Layers and Views of a Computer System Operating System
Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright. lbl.gov
 Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright njwright @ lbl.gov NERSC- National Energy Research Scientific Computing Center Mission: Accelerate the pace of scientific discovery
Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright njwright @ lbl.gov NERSC- National Energy Research Scientific Computing Center Mission: Accelerate the pace of scientific discovery
Performance comparison between a massive SMP machine and clusters
 Performance comparison between a massive SMP machine and clusters Martin Scarcia, Stefano Alberto Russo Sissa/eLab joint Democritos/Sissa Laboratory for e-science Via Beirut 2/4 34151 Trieste, Italy Stefano
Performance comparison between a massive SMP machine and clusters Martin Scarcia, Stefano Alberto Russo Sissa/eLab joint Democritos/Sissa Laboratory for e-science Via Beirut 2/4 34151 Trieste, Italy Stefano
FUSION1200 Scalable x86 SMP System
 FUSION1200 Scalable x86 SMP System Introduction Life Sciences Departmental System Manufacturing (CAE) Departmental System Competitive Analysis: IBM x3950 Competitive Analysis: SUN x4600 / SUN x4600 M2
FUSION1200 Scalable x86 SMP System Introduction Life Sciences Departmental System Manufacturing (CAE) Departmental System Competitive Analysis: IBM x3950 Competitive Analysis: SUN x4600 / SUN x4600 M2
Virtual Memory. Reading. Sections 5.4, 5.5, 5.6, 5.8, 5.10 (2) Lecture notes from MKP and S. Yalamanchili
 Lecture notes from MKP and S. Yalamanchili") Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
16 Sharing Main Memory Segmentation and Paging
 Operating Systems 64 16 Sharing Main Memory Segmentation and Paging Readings for this topic: Anderson/Dahlin Chapter 8 9; Siberschatz/Galvin Chapter 8 9 Simple uniprogramming with a single segment per
Operating Systems 64 16 Sharing Main Memory Segmentation and Paging Readings for this topic: Anderson/Dahlin Chapter 8 9; Siberschatz/Galvin Chapter 8 9 Simple uniprogramming with a single segment per
The Modern Virtualized Data Center
 WHITEPAPER The Modern Virtualized Data Center Data center resources have traditionally been underutilized while drawing enormous amounts of power and taking up valuable floorspace. Storage virtualization
WHITEPAPER The Modern Virtualized Data Center Data center resources have traditionally been underutilized while drawing enormous amounts of power and taking up valuable floorspace. Storage virtualization
IBM HPC Development MPI update
 IBM HPC Development MPI update Chulho Kim Scicomp 2007 Enhancements in PE 4.3.0 & 4.3.1 MPI 1-sided improvements (October 2006) Selective collective enhancements (October 2006) AIX IB US enablement (July
IBM HPC Development MPI update Chulho Kim Scicomp 2007 Enhancements in PE 4.3.0 & 4.3.1 MPI 1-sided improvements (October 2006) Selective collective enhancements (October 2006) AIX IB US enablement (July
CIS Operating Systems Memory Management Address Translation for Paging. Professor Qiang Zeng Spring 2018
 CIS 3207 - Operating Systems Memory Management Address Translation for Paging Professor Qiang Zeng Spring 2018 Previous class What is logical address? Who use it? Describes a location in the logical memory
CIS 3207 - Operating Systems Memory Management Address Translation for Paging Professor Qiang Zeng Spring 2018 Previous class What is logical address? Who use it? Describes a location in the logical memory
NotesBench Disclosure Report for IBM PC Server 330 with Lotus Domino 4.51 for Windows NT 4.0
 NotesBench Disclosure Report for IBM PC Server 330 with Lotus Domino 4.51 for Windows NT 4.0 Audited September 19, 1997 IBM Corporation NotesBench Disclosure Report Table of Contents Section 1: Executive
NotesBench Disclosure Report for IBM PC Server 330 with Lotus Domino 4.51 for Windows NT 4.0 Audited September 19, 1997 IBM Corporation NotesBench Disclosure Report Table of Contents Section 1: Executive
Readme for Platform Open Cluster Stack (OCS)
") Readme for Platform Open Cluster Stack (OCS) Version 4.1.1-2.0 October 25 2006 Platform Computing Contents What is Platform OCS? What's New in Platform OCS 4.1.1-2.0? Supported Architecture Distribution
Readme for Platform Open Cluster Stack (OCS) Version 4.1.1-2.0 October 25 2006 Platform Computing Contents What is Platform OCS? What's New in Platform OCS 4.1.1-2.0? Supported Architecture Distribution
CS162 - Operating Systems and Systems Programming. Address Translation => Paging"
 CS162 - Operating Systems and Systems Programming Address Translation => Paging" David E. Culler! http://cs162.eecs.berkeley.edu/! Lecture #15! Oct 3, 2014!! Reading: A&D 8.1-2, 8.3.1. 9.7 HW 3 out (due
CS162 - Operating Systems and Systems Programming Address Translation => Paging" David E. Culler! http://cs162.eecs.berkeley.edu/! Lecture #15! Oct 3, 2014!! Reading: A&D 8.1-2, 8.3.1. 9.7 HW 3 out (due
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Transparent Throughput Elas0city for IaaS Cloud Storage Using Guest- Side Block- Level Caching
 Transparent Throughput Elas0city for IaaS Cloud Storage Using Guest- Side Block- Level Caching Bogdan Nicolae (IBM Research, Ireland) Pierre Riteau (University of Chicago, USA) Kate Keahey (Argonne National
Transparent Throughput Elas0city for IaaS Cloud Storage Using Guest- Side Block- Level Caching Bogdan Nicolae (IBM Research, Ireland) Pierre Riteau (University of Chicago, USA) Kate Keahey (Argonne National
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective. Part I: Operating system overview: Memory Management
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part I: Operating system overview: Memory Management 1 Hardware background The role of primary memory Program
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part I: Operating system overview: Memory Management 1 Hardware background The role of primary memory Program
Chapter 9 Memory Management
 Contents 1. Introduction 2. Computer-System Structures 3. Operating-System Structures 4. Processes 5. Threads 6. CPU Scheduling 7. Process Synchronization 8. Deadlocks 9. Memory Management 10. Virtual
Contents 1. Introduction 2. Computer-System Structures 3. Operating-System Structures 4. Processes 5. Threads 6. CPU Scheduling 7. Process Synchronization 8. Deadlocks 9. Memory Management 10. Virtual
Execution Models for the Exascale Era
 Execution Models for the Exascale Era Nicholas J. Wright Advanced Technology Group, NERSC/LBNL njwright@lbl.gov Programming weather, climate, and earth- system models on heterogeneous muli- core plajorms
Execution Models for the Exascale Era Nicholas J. Wright Advanced Technology Group, NERSC/LBNL njwright@lbl.gov Programming weather, climate, and earth- system models on heterogeneous muli- core plajorms
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
arxiv: v2 [cs.dc] 2 May 2017
![arxiv: v2 [cs.dc] 2 May 2017](/thumbs/74/70261364.jpg "arxiv: v2 [cs.dc] 2 May 2017") High Performance Data Persistence in Non-Volatile Memory for Resilient High Performance Computing Yingchao Huang University of California, Merced yhuang46@ucmerced.edu Kai Wu University of California,
High Performance Data Persistence in Non-Volatile Memory for Resilient High Performance Computing Yingchao Huang University of California, Merced yhuang46@ucmerced.edu Kai Wu University of California,
June IBM Power Academy. IBM PowerVM memory virtualization. Luca Comparini STG Lab Services Europe IBM FR. June,13 th Dubai
 June 2012 @Dubai IBM Power Academy IBM PowerVM memory virtualization Luca Comparini STG Lab Services Europe IBM FR June,13 th 2012 @IBM Dubai Agenda How paging works Active Memory Sharing Active Memory
June 2012 @Dubai IBM Power Academy IBM PowerVM memory virtualization Luca Comparini STG Lab Services Europe IBM FR June,13 th 2012 @IBM Dubai Agenda How paging works Active Memory Sharing Active Memory
Monitoring and Trouble Shooting on BioHPC
 Monitoring and Trouble Shooting on BioHPC [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2017-03-15 Why Monitoring & Troubleshooting data code Monitoring jobs running
Monitoring and Trouble Shooting on BioHPC [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2017-03-15 Why Monitoring & Troubleshooting data code Monitoring jobs running
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
POWER4 Systems: Design for Reliability. Douglas Bossen, Joel Tendler, Kevin Reick IBM Server Group, Austin, TX
 Systems: Design for Reliability Douglas Bossen, Joel Tendler, Kevin Reick IBM Server Group, Austin, TX Microprocessor 2-way SMP system on a chip > 1 GHz processor frequency >1GHz Core Shared L2 >1GHz Core
Systems: Design for Reliability Douglas Bossen, Joel Tendler, Kevin Reick IBM Server Group, Austin, TX Microprocessor 2-way SMP system on a chip > 1 GHz processor frequency >1GHz Core Shared L2 >1GHz Core
CS252 S05. CMSC 411 Computer Systems Architecture Lecture 18 Storage Systems 2. I/O performance measures. I/O performance measures
 CMSC 411 Computer Systems Architecture Lecture 18 Storage Systems 2 I/O performance measures I/O performance measures diversity: which I/O devices can connect to the system? capacity: how many I/O devices
CMSC 411 Computer Systems Architecture Lecture 18 Storage Systems 2 I/O performance measures I/O performance measures diversity: which I/O devices can connect to the system? capacity: how many I/O devices
Learning Outcomes. An understanding of page-based virtual memory in depth. Including the R3000 s support for virtual memory.
 Virtual Memory 1 Learning Outcomes An understanding of page-based virtual memory in depth. Including the R3000 s support for virtual memory. 2 Memory Management Unit (or TLB) The position and function
Virtual Memory 1 Learning Outcomes An understanding of page-based virtual memory in depth. Including the R3000 s support for virtual memory. 2 Memory Management Unit (or TLB) The position and function