CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
|
|
|
- Isaac Morrison
- 5 years ago
- Views:
Transcription

1 CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z)
2 Status Quo Previously, CPU vendors tried to use special purpose units for targeted performance wins: FPUs, SSEs, Altivec, Now industry explores hybrid models Cell: 1 PowerPC and 8 s AMD Fusion: CPU + GPU Intel Sandy Bridge
3 Classification of Heterogeneous Multicore Different ISAs? Some Systems on Chip multi/manycore & GPUs Same ISA Traditional Multi/Many cores Homogeneous Multicore Cores of Different Capabilities Same cores Different cores
4 How Do We Design Them? by designing a series of cores from scratch by reusing a series of previouslyimplemented processor cores and change the interface The entire family of a microprocessor can be incorporated into a single chip (how about clock frequency?) a combination of the two approaches
5 Why do we need them? Today s microprocessor design should balance high throughput and good singlethread performance Haven t SMT and CMP achieved this? Heterogeneous multicore can do it more efficiently Match each application to the core(s) of its performance demand Provide better area-efficient coverage of workload demands
6 Why do we need them? Different applications have different resource requirements during their execution What are these resource requirements? The best core for execution may vary over time What do we gain from assigning the right thread/process/application to the right core? performance enhancement power consumption reduction
7 Why do we need them? Application with fewer and sophisticated threads -> Traditional multicore with latency optimized cores Application with high concurrency -> large number of throughput optimized cores
8 Two Main Challenges Efficiency Locality Data movement costs more than computation.
9
10 Issues in Heterogeneous Multicore Processors Are they scalable? How is the scheduling done (objective function)? Who does the scheduling? What is the cost of task switching? What is the cost of task migration? When to switch core? Still need shared address space? How about coherence?
11 Examples from real-life

12 XBOX 360

13 22.4 GB/s 10.8 GB/s
14 Specifications 3 CPU cores 4-way SIMD vector units 8-way 1MB L2 cache (3.2 GHz) 2 way SMT In-order 2 Instructions/cycle ATI GPU with embedded EDRAM 3D graphics units 512-Mbyte DRAM main memory
15 Philosophy Value for 5-7 years Big performance increase over last generation Support high-definition video extremely high pixel fill rate (goal: 100+ million pixels/s) Flexible to suit dynamic range of games balance hardware, homogenous resources Programmability (easy to program)
16 Cell Processor
17 Memory Controller Each Cell chip has: One PowerPC core 8 compute cores (s) On-chip Memory controller On-chip I/O On-chip network to connect them all A PS3 has 1 Cell Chip (6 usable s) Overview 25.6GB/s 256MB of DRAM Memory 512MB XDR DRAM I/O PowerPC On-chip Network
18 Memory Controller PowerPC Core (PPE) 3.2GHz Dual issue, in-order 2-way multithreaded 512KB L2 cache No hardware prefetching SIMD (altivec) + FMA 6.4 GFlop/s (double precision) 25.6 GFlop/s (single precision) PowerPC Serves 2 purposes: Compatibility processor; runs legacy code, compilers, libraries, etc. Performs all system level functions including starting the other cores I/O On-chip Network 25.6GB/s 512MB XDR DRAM
19 Memory Controller Synergistic Processing Element () Offload processor Dual issue, in-order, VLIW inspired SIMD processor 128 x 128b register file 256KB local store, no I$, no D$ Runs a small program (placed in LS) Offloads system functions to the PPE MFC (memory flow controller) a programmable DMA engine and onchip network interface Performance 1.83 GFlop/s (double precision) 25.6 GFlop/s (single precision) 51.2GB/s access the local store 25.6GB/s access to the network PowerPC On-chip Network I/O 25.6GB/s 512MB XDR DRAM
20 Threading-Model For each program the PPE must: Create a context Load the program (embedded in the binary) Create a pthread to run it Each pthread can be as simple as: spe_context_run( ); pthread_exit( ); Typically, split the work into 2 phases: Code that runs on the s Code that runs on the PPE with a barrier in between Create pthreads program program program Barrier() Barrier() Barrier() Barrier() Barrier() PPE phase phase phase phase Barrier() Barrier() Barrier() Barrier() Barrier() Barrier() Barrier() Join pthreads
21 Threads-Communication The PPE may communicate with the s via: individual mailboxes (FIFO) HW signals DRAM Direct PPE access to the s local stores PowerPC (PPE) $ Shared off-chip DRAM Local Store Local Store Local Store Local Store
22 AMD S LLANO FUSION APU
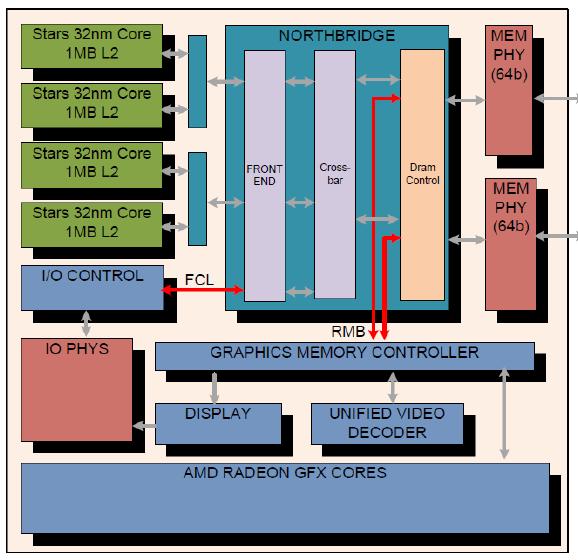
23
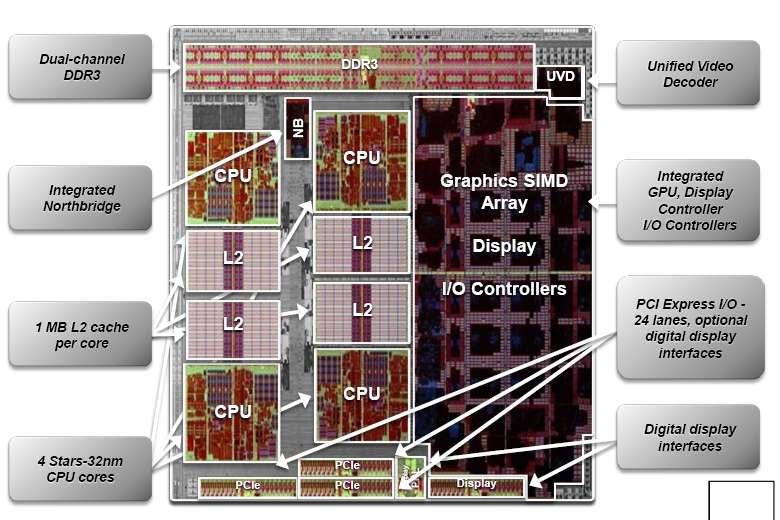
24
25 INTEL: SANDY BRIDGE
26 Sandy Bridge Intel Tock Intel s first processor with GPU on the processor itself. Improvement over its predecessor Nehalem Targeting multimedia applications Introduced Advanced Vector Extensions (AVX) More power-efficient than Westmere
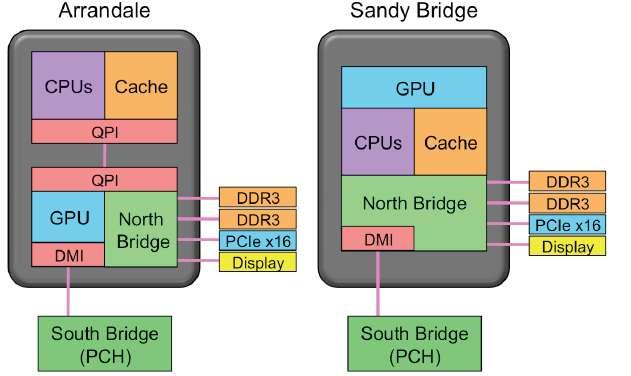
27


28 The GPU can access the large L3 cache Intel s team totally re-designed the GPU
29 Example from research
30 Core Fusion: Accommodating Software Diversity in Chip Multiprocessor A single application can go from highly sequential to highly parallel in different phases This is at odd with traditional multicore, or even tradition heterogeneous multicore Die composition is set at design time and at design time we do not know the different applications that may execute on the chip! What can we do?

31 Core Fusion: Accommodating Software Diversity in Chip Multiprocessor Group of independent cores Cores can dynamically morph into larger CPU or used as distinct CPUs.
32 Core Fusion: Accommodating Software Diversity in Chip Multiprocessor The application requests core fusion/split actions through a pair of FUSE and SPLIT ISA instructions, respectively. FUSE and SPLIT instructions are executed conditionally by hardware, based on the value of an OS-visible control register that indicates which cores within a fusion group are eligible for fusion. To enable core fusion, the OS allocates either two or four of the cores in a fusion group to the application when the applications context-switched in, and annotates the group s control register.
33 Challenges Programs demands vary over time Objective function may vary over time The core capability may vary over time (e.g. if it gets overheated)
34 Some Numbers In paper published in 2005: The Impact of Performance Asymmetry in Multicore Architectures ISCA 05 They experimented with 4 cores Used several configurations and many benchmarks What did they find?
35 all slow 3 slow 2 slow 1 slow all fast Same or Many runs Perf. Metric Perf. Metric Studying impact Scalability Stability (Asymm) 35
36 Workloads evaluated Cjbb CjAppServer Apache Zeus TPC-H COMP H.264 PMake Middle-tier business apps. Throughput parallel Webservers Throughput parallel Task-based parallelization Embarrassingly parallel 36
37 Impact of asymmetry Workloads Cjbb CjAppServer Apache Zeus TPC-H COMP H.264 PMake Scalable P P P O P O P P Stable O P O O O O P P Fix P P O P P 37
38 Programming Heterogeneous Multicore Systems Algorithm, Correctness, Thread Partitioning Programmers Don t reason about asymmetry Asymmetry negatively affects applications -Observed unpredictable workload behavior This can be fixed by - Evaluating threads work partitioning -Scheduling of threads with asymmetry
39 As A Programmer Define your threads As many threads as you can Know your hardware and your system software How many cores? How heterogeneous are they? How does the OS scheduling work? Now combine your threads depending on the core strength You can assign a thread to a core (many languages allow this: pthreads, OpenMP,..) Load imbalance is your enemy!
40 Load Imbalance in Parallel Applications: Main Reasons Poor single processor performance Typically in the memory system Too much parallelism overhead Thread creation, synchronization, communication Different amounts of work across processors Computation and communication Different speeds (or available resources) for the processors
41 How To Recognize Load Imbalance? Hint: Time spent at synchronization is high and is uneven across cores, but not always so simple Imbalance may change over phases! Insufficient parallelism always lead to load imbalance Useful tools: e.php
42 Important Questions When Dealing With Load Imbalance Thread costs Do all threads have equal costs? If not, when are the costs known? Before starting, when created, or only when it ends Thread dependencies Can all threads be run in any order (including parallel)? If not, when are the dependencies known? Before starting, when created, or only when it ends Locality Is it important for some threads to be scheduled on the same processor (or nearby) to reduce communication cost? When is the information about communication known?
43 Important Questions When Dealing With Load Imbalance Thread cost known before starting: matrix multiplication Cost known when thread created: N-Body Cost known when thread ends: search
44 Important Questions When Dealing With Load Imbalance Threads can execute at any order: dependence free loops Threads have a known dependency graph: matrix computations Dependence unknown: search
45 Important Questions When Dealing With Load Imbalance Threads, once created do not communicate: embarrassingly parallel applications Threads communicate in predictable pattern: PDE solver Information about communication is unpredictable: discrete event simulation
46 Many solutions Of Different Flavors Task queue (centralized or distributed) Work stealing Work pushing Off-line scheduling Self-scheduling
47 Question: Are homogeneous cores of different ISAs useful in something? Justify
48 Conclusions Asymmetric systems may be the de facto in the future Good for energy and performance but may introduce unpredictability To reduce unpredictability, loadbalancing is your friend! In multiprogramming environment, the advantage of heterogeneous multicore is obvious!
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Introduction to Computing and Systems Architecture
 Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Core Fusion: Accommodating Software Diversity in Chip Multiprocessors
 Core Fusion: Accommodating Software Diversity in Chip Multiprocessors Authors: Engin Ipek, Meyrem Kırman, Nevin Kırman, and Jose F. Martinez Navreet Virk Dept of Computer & Information Sciences University
Core Fusion: Accommodating Software Diversity in Chip Multiprocessors Authors: Engin Ipek, Meyrem Kırman, Nevin Kırman, and Jose F. Martinez Navreet Virk Dept of Computer & Information Sciences University
CSCI-GA Multicore Processors: Architecture & Programming Lecture 3: The Memory System You Can t Ignore it!
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 3: The Memory System You Can t Ignore it! Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Memory Computer Technology
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 3: The Memory System You Can t Ignore it! Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Memory Computer Technology
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Sony/Toshiba/IBM (STI) CELL Processor. Scientific Computing for Engineers: Spring 2008
 CELL Processor. Scientific Computing for Engineers: Spring 2008") Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Cell Broadband Engine. Spencer Dennis Nicholas Barlow
 Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor Objective: [to bring] supercomputer power to everyday life Bridge the gap between conventional CPU s and high performance GPU s History
Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor Objective: [to bring] supercomputer power to everyday life Bridge the gap between conventional CPU s and high performance GPU s History
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Comparing Memory Systems for Chip Multiprocessors
 Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
Shared Memory Parallel Programming. Shared Memory Systems Introduction to OpenMP
 Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Xbox 360 Architecture. Lennard Streat Samuel Echefu
 Xbox 360 Architecture Lennard Streat Samuel Echefu Overview Introduction Hardware Overview CPU Architecture GPU Architecture Comparison Against Competing Technologies Implications of Technology Introduction
Xbox 360 Architecture Lennard Streat Samuel Echefu Overview Introduction Hardware Overview CPU Architecture GPU Architecture Comparison Against Competing Technologies Implications of Technology Introduction
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Saman Amarasinghe and Rodric Rabbah Massachusetts Institute of Technology
 Saman Amarasinghe and Rodric Rabbah Massachusetts Institute of Technology http://cag.csail.mit.edu/ps3 6.189-chair@mit.edu A new processor design pattern emerges: The Arrival of Multicores MIT Raw 16 Cores
Saman Amarasinghe and Rodric Rabbah Massachusetts Institute of Technology http://cag.csail.mit.edu/ps3 6.189-chair@mit.edu A new processor design pattern emerges: The Arrival of Multicores MIT Raw 16 Cores
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
CSC501 Operating Systems Principles. OS Structure
 CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Performance, Power, Die Yield. CS301 Prof Szajda
 Performance, Power, Die Yield CS301 Prof Szajda Administrative HW #1 assigned w Due Wednesday, 9/3 at 5:00 pm Performance Metrics (How do we compare two machines?) What to Measure? Which airplane has the
Performance, Power, Die Yield CS301 Prof Szajda Administrative HW #1 assigned w Due Wednesday, 9/3 at 5:00 pm Performance Metrics (How do we compare two machines?) What to Measure? Which airplane has the
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
CPU Scheduling. Operating Systems (Fall/Winter 2018) Yajin Zhou ( Zhejiang University
 Yajin Zhou ( Zhejiang University") Operating Systems (Fall/Winter 2018) CPU Scheduling Yajin Zhou (http://yajin.org) Zhejiang University Acknowledgement: some pages are based on the slides from Zhi Wang(fsu). Review Motivation to use threads
Operating Systems (Fall/Winter 2018) CPU Scheduling Yajin Zhou (http://yajin.org) Zhejiang University Acknowledgement: some pages are based on the slides from Zhi Wang(fsu). Review Motivation to use threads
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
THE PROGRAMMER S GUIDE TO THE APU GALAXY. Phil Rogers, Corporate Fellow AMD
 THE PROGRAMMER S GUIDE TO THE APU GALAXY Phil Rogers, Corporate Fellow AMD THE OPPORTUNITY WE ARE SEIZING Make the unprecedented processing capability of the APU as accessible to programmers as the CPU
THE PROGRAMMER S GUIDE TO THE APU GALAXY Phil Rogers, Corporate Fellow AMD THE OPPORTUNITY WE ARE SEIZING Make the unprecedented processing capability of the APU as accessible to programmers as the CPU
Review: Creating a Parallel Program. Programming for Performance
 Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
Microprocessor Trends and Implications for the Future
 Microprocessor Trends and Implications for the Future John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 4 1 September 2016 Context Last two classes: from
Microprocessor Trends and Implications for the Future John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 4 1 September 2016 Context Last two classes: from
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Datacenter application interference
 1 Datacenter application interference CMPs (popular in datacenters) offer increased throughput and reduced power consumption They also increase resource sharing between applications, which can result in
1 Datacenter application interference CMPs (popular in datacenters) offer increased throughput and reduced power consumption They also increase resource sharing between applications, which can result in
Computer Architecture: Parallel Processing Basics. Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Parallel Processing Basics Prof. Onur Mutlu Carnegie Mellon University Readings Required Hill, Jouppi, Sohi, Multiprocessors and Multicomputers, pp. 551-560 in Readings in Computer
Computer Architecture: Parallel Processing Basics Prof. Onur Mutlu Carnegie Mellon University Readings Required Hill, Jouppi, Sohi, Multiprocessors and Multicomputers, pp. 551-560 in Readings in Computer
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
FlexSC. Flexible System Call Scheduling with Exception-Less System Calls. Livio Soares and Michael Stumm. University of Toronto
 FlexSC Flexible System Call Scheduling with Exception-Less System Calls Livio Soares and Michael Stumm University of Toronto Motivation The synchronous system call interface is a legacy from the single
FlexSC Flexible System Call Scheduling with Exception-Less System Calls Livio Soares and Michael Stumm University of Toronto Motivation The synchronous system call interface is a legacy from the single
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Spring 2010 Prof. Hyesoon Kim. Xbox 360 System Architecture, Anderews, Baker
 Spring 2010 Prof. Hyesoon Kim Xbox 360 System Architecture, Anderews, Baker 3 CPU cores 4-way SIMD vector units 8-way 1MB L2 cache (3.2 GHz) 2 way SMT 48 unified shaders 3D graphics units 512-Mbyte DRAM
Spring 2010 Prof. Hyesoon Kim Xbox 360 System Architecture, Anderews, Baker 3 CPU cores 4-way SIMD vector units 8-way 1MB L2 cache (3.2 GHz) 2 way SMT 48 unified shaders 3D graphics units 512-Mbyte DRAM
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Arquitecturas y Modelos de. Multicore
 Arquitecturas y Modelos de rogramacion para Multicore 17 Septiembre 2008 Castellón Eduard Ayguadé Alex Ramírez Opening statements * Some visionaries already predicted multicores 30 years ago And they have
Arquitecturas y Modelos de rogramacion para Multicore 17 Septiembre 2008 Castellón Eduard Ayguadé Alex Ramírez Opening statements * Some visionaries already predicted multicores 30 years ago And they have
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
Re-architecting Virtualization in Heterogeneous Multicore Systems
 Re-architecting Virtualization in Heterogeneous Multicore Systems Himanshu Raj, Sanjay Kumar, Vishakha Gupta, Gregory Diamos, Nawaf Alamoosa, Ada Gavrilovska, Karsten Schwan, Sudhakar Yalamanchili College
Re-architecting Virtualization in Heterogeneous Multicore Systems Himanshu Raj, Sanjay Kumar, Vishakha Gupta, Gregory Diamos, Nawaf Alamoosa, Ada Gavrilovska, Karsten Schwan, Sudhakar Yalamanchili College
A Row Buffer Locality-Aware Caching Policy for Hybrid Memories. HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu
 A Row Buffer Locality-Aware Caching Policy for Hybrid Memories HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu Overview Emerging memories such as PCM offer higher density than
A Row Buffer Locality-Aware Caching Policy for Hybrid Memories HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu Overview Emerging memories such as PCM offer higher density than
Convergence of Parallel Architecture
 Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
An Energy-Efficient Asymmetric Multi-Processor for HPC Virtualization
 An Energy-Efficient Asymmetric Multi-Processor for HP Virtualization hung Lee and Peter Strazdins*, omputer Systems Group, Research School of omputer Science, The Australian National University (slides
An Energy-Efficient Asymmetric Multi-Processor for HP Virtualization hung Lee and Peter Strazdins*, omputer Systems Group, Research School of omputer Science, The Australian National University (slides
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Design Principles for End-to-End Multicore Schedulers
 c Systems Group Department of Computer Science ETH Zürich HotPar 10 Design Principles for End-to-End Multicore Schedulers Simon Peter Adrian Schüpbach Paul Barham Andrew Baumann Rebecca Isaacs Tim Harris
c Systems Group Department of Computer Science ETH Zürich HotPar 10 Design Principles for End-to-End Multicore Schedulers Simon Peter Adrian Schüpbach Paul Barham Andrew Baumann Rebecca Isaacs Tim Harris
Multicore Challenge in Vector Pascal. P Cockshott, Y Gdura
 Multicore Challenge in Vector Pascal P Cockshott, Y Gdura N-body Problem Part 1 (Performance on Intel Nehalem ) Introduction Data Structures (1D and 2D layouts) Performance of single thread code Performance
Multicore Challenge in Vector Pascal P Cockshott, Y Gdura N-body Problem Part 1 (Performance on Intel Nehalem ) Introduction Data Structures (1D and 2D layouts) Performance of single thread code Performance
Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor.
 on a single die. Also called a chip-multiprocessor.") CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
Response Time and Throughput
 Response Time and Throughput Response time How long it takes to do a task Throughput Total work done per unit time e.g., tasks/transactions/ per hour How are response time and throughput affected by Replacing
Response Time and Throughput Response time How long it takes to do a task Throughput Total work done per unit time e.g., tasks/transactions/ per hour How are response time and throughput affected by Replacing
Staged Memory Scheduling
 Staged Memory Scheduling Rachata Ausavarungnirun, Kevin Chang, Lavanya Subramanian, Gabriel H. Loh*, Onur Mutlu Carnegie Mellon University, *AMD Research June 12 th 2012 Executive Summary Observation:
Staged Memory Scheduling Rachata Ausavarungnirun, Kevin Chang, Lavanya Subramanian, Gabriel H. Loh*, Onur Mutlu Carnegie Mellon University, *AMD Research June 12 th 2012 Executive Summary Observation:
Performance of Multicore LUP Decomposition
 Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors
 ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
 ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #2 1/17/2017 Xuehai Qian xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Opportunities
EE/CSCI 451: Parallel and Distributed Computation Lecture #2 1/17/2017 Xuehai Qian xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Opportunities
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Row Buffer Locality Aware Caching Policies for Hybrid Memories. HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu
 Row Buffer Locality Aware Caching Policies for Hybrid Memories HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu Executive Summary Different memory technologies have different
Row Buffer Locality Aware Caching Policies for Hybrid Memories HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu Executive Summary Different memory technologies have different
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Performance & Scalability Testing in Virtual Environment Hemant Gaidhani, Senior Technical Marketing Manager, VMware
 Performance & Scalability Testing in Virtual Environment Hemant Gaidhani, Senior Technical Marketing Manager, VMware 2010 VMware Inc. All rights reserved About the Speaker Hemant Gaidhani Senior Technical
Performance & Scalability Testing in Virtual Environment Hemant Gaidhani, Senior Technical Marketing Manager, VMware 2010 VMware Inc. All rights reserved About the Speaker Hemant Gaidhani Senior Technical
740: Computer Architecture, Fall 2013 SOLUTIONS TO Midterm I
 Instructions: Full Name: Andrew ID (print clearly!): 740: Computer Architecture, Fall 2013 SOLUTIONS TO Midterm I October 23, 2013 Make sure that your exam has 15 pages and is not missing any sheets, then
Instructions: Full Name: Andrew ID (print clearly!): 740: Computer Architecture, Fall 2013 SOLUTIONS TO Midterm I October 23, 2013 Make sure that your exam has 15 pages and is not missing any sheets, then
Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core. Prof. Onur Mutlu Carnegie Mellon University
 18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
The Use of Cloud Computing Resources in an HPC Environment
 The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES TAKAHIRO HARADA, AMD DESTRUCTION FOR GAMES ERWIN COUMANS, AMD
 GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES TAKAHIRO HARADA, AMD DESTRUCTION FOR GAMES ERWIN COUMANS, AMD GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES Jason Yang, Takahiro Harada AMD HYBRID CPU-GPU
GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES TAKAHIRO HARADA, AMD DESTRUCTION FOR GAMES ERWIN COUMANS, AMD GAME PROGRAMMING ON HYBRID CPU-GPU ARCHITECTURES Jason Yang, Takahiro Harada AMD HYBRID CPU-GPU
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop
: Automatic Performance Tuning Workshop") Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Compilation for Heterogeneous Platforms
 Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design
 Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design Based on papers by: A.Fedorova, M.Seltzer, C.Small, and D.Nussbaum Pisa November 6, 2006 Multithreaded Chip
Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design Based on papers by: A.Fedorova, M.Seltzer, C.Small, and D.Nussbaum Pisa November 6, 2006 Multithreaded Chip
Core 2 vs I-series. How Far Have We Really Come?
 Core 2 vs I-series How Far Have We Really Come? Appendix 1. Introduction 2. Road map 3. General specifications 4. Hardware subtleties 5. Technology difference 6. Advantages of the new architecture 7. Conclusion
Core 2 vs I-series How Far Have We Really Come? Appendix 1. Introduction 2. Road map 3. General specifications 4. Hardware subtleties 5. Technology difference 6. Advantages of the new architecture 7. Conclusion
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth: