The typical speedup curve - fixed problem size
|
|
|
- Linette Logan
- 5 years ago
- Views:
Transcription
1 Performance analysis Goals are 1. to be able to understand better why your program has the performance it has, and 2. what could be preventing its performance from being better.
2 The typical speedup curve - fixed problem size Speedup Number of processors
3 A typical speedup curve - problem size grows with number of processors Speedup Problem size
4 Speedup Parallel time T P(p) is the time it takes the parallel form of the program to run on p processors Sequential time Ts is more problematic a. Can be TP(1), but this carries the overhead of extra code needed for parallelization. Even with one thread, OpenMP code will call libraries for threading. One way to cheat on benchmarking. b. Should be the best possible sequential implementation: tuned, good or best compiler switches, etc. c. Best possible sequential implementation may not exist for a problem size
5 What is execution time? Execution time can be modeled as the sum of: 1. Inherently sequential computation σ(n) 2. Potentially parallel computation ϕ(n) 3. Communication time κ(n,p)
6 Components of execution time Inherently Sequential Execution time execution time number of processors
7 Components of execution time Parallel time execution time number of processors
8 Components of execution time Communication time and other parallel overheads execution time κ(p) α log2p number of processors
9 Components of execution time Sequential time execution time At some point decrease in parallel execution time of the parallel part is less than increase in communication costs, leading to the knee in the curve speedup < 1 speedup = 1 maximum speedup number of processors
10 Speedup as a function of these components TS - sequential time Sequential time is i. the sequential computation (σ(n)) ii. the parallel computation (Φ(n)) Parallel time is iii. the sequential computation time (σ(n)) iv. the parallel computation time (Φ(n)/p) v. the communication cost (κ(n,p)) TP(p)- parallel time
11 Efficiency 0 < ε(n,p) < 1 all terms > 0, ε(n,p) > 0 numerator denominator 1 Intuitively, efficiency is how effectively the machines are being used by the parallel computation If the number of processors is doubled, for the efficiency to stay the same the parallel execution time Tp must be halved.
12 Efficiency 0 < ε(n,p) < 1 all terms > 0, ε(n,p) denominator > 0 is the total processor time numerator used in parallel denominator execution 1 Intuitively, efficiency is how effectively the machines are being used by the parallel computation If the number of processors is doubled, for the efficiency to stay the same the parallel execution time Tp must be halved.
13 Efficiency by amount of work σ=1, κ = 1 when p = 1; κ increases by log2 P for p < 1 Φ: amount of computation that can be done in parallel 0.50 κ: communication overhead 0.25 σ: sequential computation ϕ=1000 ϕ=10000 ϕ=100000
14 Amdahl s Law Developed by Gene Amdahl Basic idea: the parallel performance of a program is limited by the sequential portion of the program argument for fewer, faster processors Can be used to model performance on various sizes of machines, and to derive other useful relations.
15 Gene Amdahl Worked on IBM 704, 709, Stretch and 7030 machines Stretch was first transistorized computer, fastest from 1961 until CDC 6600 in 1964, 1.2 MIPS Multiprogramming, memory protection, generalized interrupts, the 8-bit byte, Instruction pipelining, prefetch and decoding introduced in this machine Worked on IBM System 360 In technical disagreement with IBM, set up Amdahl Computers to build plug-compatible machines -- later acquired by Hitachi Amdahl's law came from discussions with Dan Slotnick (Illiac IV architect at UIUC) and others about future of parallel processing
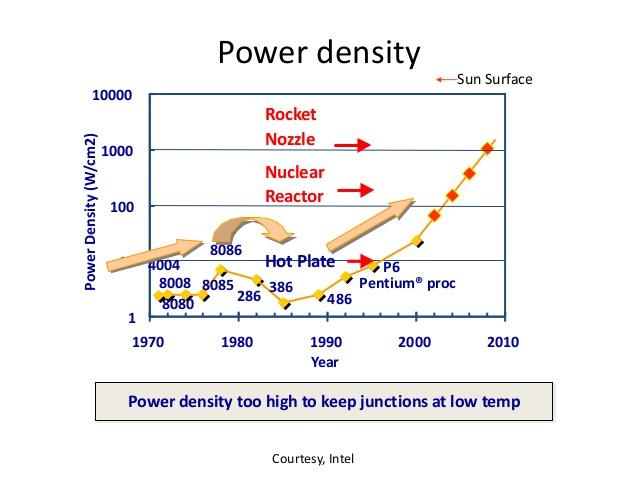
16 16
17 Amdahl s law - key insight With perfect utilization of parallelism on the parallel part of the job, must take at least Tserial time to execute. This observation forms the motivation for Amdahl s law As p, Tparallel 0 and ψ(p): speedup with p processors ψ( ) (Ttotal work)/tserial. Thus, ψ is limited by the serial part of the program.
18 Two measures of speedup Takes into account communication cost. σ(n) and ϕ(n) are arguably fundamental properties of a program κ(n,p) is a property of both the program, the hardware, and the library implementations -- arguably a less fundamental concept. Can formulate a meaningful, but optimistic, approximation to the speedup without κ(n,p)
19 Speedup in terms of the serial fraction of a program Given this formulation, the fraction of the program that is serial in a sequential execution is Speedup can be rewritten in terms of f: This gives us Amdahl s Law.
20 Amdahl's Law speedup
21 Example of using Amdahl s Law A program is 90% parallel. What speedup can be expected when running on four, eight and 16 processors?
22 What is the efficiency of this program? A 2X increase in machine cost gives you a 1.4X increase in performance. And this is optimistic since communication costs are not considered.
23 Another Amdahl s Law example A program is 20% inherently serial. Given 2, 16 and infinite processors, how much speedup can we get?
24 Effect of Amdahl s Law (from Wikipedia, File:AmdahlsLaw.svg)
25 Limitation of Amdahl s Law This result is a limit, not a realistic number. The problem is that communication costs (κ(n,p)) are ignored, and this is an overhead that is worse than fixed (which f is), but actually grows with the number of processors. Amdahl s Law is too optimistic and may target the wrong problem
26 No communication overhead execution time speedup = 1 maximum speedup number of processors
27 O(Log2P) communication costs execution time speedup = 1 maximum speedup number of processors
28 O(P) Communication Costs execution time speedup = 1 maximum speedup number of processors
29 Amdahl Effect Complexity of ϕ(n) usually higher than complexity of κ(n,p) (i.e. computational complexity usually higher than complexity of communication -- same is often true of σ(n) as well.) ϕ(n) usually O(n) or higher κ(n,p) often O(1) or O(log2P) Increasing n allows ϕ(n) to dominate κ(n,p) Thus, increasing the problem size n increases the speedup Ψ for a given number of processors Another cheat to get good results -- make n large Most benchmarks have standard sized inputs to preclude this
30 Amdahl Effect n= Speedup n=10000 n=1000 Number of processors
31 Amdahl Effect both increases speedup and moves the knee of the curve to the right Speedup n= n=10000 n=1000 Number of processors
32 Summary Allows speedup to be computed for fixed problem size n varying number of processes Ignores communication costs Is optimistic, but gives an upper bound
33 Gustafson-Barsis Law How does speedup scale with larger problem sizes? Given a fixed amount of time, how much bigger of a problem can we solve by adding more processors? Large problem sizes often correspond to better resolution and precision on the problem being solved.
34 Basic terms Speedup is Because κ(n,p) > 0 Let s be the fraction of time in a parallel execution of the program that is spent performing sequential operations. Then, (1-s) is the fraction of time spent in a parallel execution of the program performing parallel operations.
35 Note that Amdahl's Law looks at the sequential and parallel parts of the program for a given problem size, and the value of f is the fraction in a sequential execution that is inherently sequential Or stated differently...
36 Speedup in terms of the serial fraction of a program Given this formulation, the fraction of sequential execution that is serial is simply Speedup can be rewritten in terms of f: This gives us Amdahl s Law. Note number of processors not mentioned for definition of f because f is for time in a sequential run
37 Some definitions The sequential part of a parallel computation: The parallel part of a parallel computation: And the speedup
38 Difference between Gustafson- Barsis (G-B) Law and Amdahl s Law The serial portion in Amdahl s law is a fraction of the total execution time of the program. The serial portion in G-B is a fraction of the parallel execution time of the program. To use G-B Law we assume work scales to maintain value of s
39 Deriving G-B Law substitute for (s + (1 - s)p) First, we show that the formula circled in blue leads to our speedup formula. Multiply through simplify, simply
40 Deriving G-B Law Second, we show that the formula circled in blue (that we just showed is equivalent to speedup) leads to the G-B Law formula.
41 An example An application executing on 64 processors requires 220 seconds to run. It is experimentally determined through benchmarking that 5% of the time is spent in the serial code on a single processor. What is the scaled speedup of the application? s = 0.05, thus on 64 processors Ψ = 64 + (1-64)(0.05) = = 60.85
42 An example Another way of looking at this: given P processors, P amount of useful work can be done. However, on P-1 processors there is time wasted due to the sequential part that must be subtracted out from the useful work. s = 0.05, thus on 64 processors Ψ = 64 + (1-64)(0.05) = = 60.85
43 Another example You have money to buy a 16K (16,384) core distributed memory system, but you only want to spend the money if you can get decent performance on your application. Allowing the problem to scale with increasing numbers of processors, what must s be to get a scaled speedup of 15,000 on the machine, i.e. what fraction of the application's parallel execution time can be devoted to inherently serial computation? 15,000 = 16,384-16,383s s = 1,384 / 16,383 s = 0.084
44 Comparison with Amdahl s Law result ψ(n,p) p + (1 - p)s 15,000 = 16,384-16,383s s = 1,384 / 16,383 s = G-B almost 1% can be sequential! Amdahl's law (56 millionths)

45 Comparison with Amdahl s Law result ψ(n,p) p + (1 - p)s 15,000 = 16,384-16,383s s = 1,384 / 16,383 s = But then Amdahl's law doesn't allow the problem size to scale.!
46 Non-scaled performance σ(1) = σ(p); ϕ(1) = ϕ(p) 22 Chart 7 17 Work is constant, 11 speedup levels off 6 at ~256 processors serial par work non-scaled sp non-scaled
47 performance σ(1) = σ(p); p ϕ(1) = ϕ(p) Chart 8 Even though it is hard to see, as the parallel work increases proportionally to the number of processors, the speedup scales proportionally to the number of processors serial par work scaled speedup scaled
48 performance σ(1) = σ(p); p ϕ(1) = ϕ(p) Chart Note that the parallel work may (and usually does) increase faster than the problem size serial par work scaled speedup scaled
49 Scaled speedups, log scales σ(1) = σ(p); p ϕ(1) = ϕ(1) 18 Chart 9 The same chart as 14 before, except log scales for parallel 9 work and speedup. 5 Scaled speedup close to ideal serial log 2 par work scaled log 2 scaled speedup
50 The effect of un-modeled log2p communication This is clearly an important effect that is not being modeled speedup scaled scaled w/communication
51 The Karp-Flatt Metric Takes into account communication costs T(n,p) = σ(n) + ϕ(n)/p + κ(n,p) Serial time T(n,1) = σ(n) + ϕ(n) The experimentally determined serial fraction e of the parallel computation is e = (σ(n) + κ(n,p))/t(n,1)
52 e = (σ(n) + κ(n,p))/t(n,1) Essentially a measure of total work e is the fraction of the one processor execution time that is serial on all p processors Communication cost mandates measuring at a given processor count This is because communication cost is a function of theoretical limits and implementation.
53 Deriving the K-F Metric The experimentally determined serial fraction e of the parallel computation is e = (σ(n) + κ(n,p))/t(n,1) e T(n,1) = σ(n) + κ(n,p) The parallel execution time T(n,p) = σ(n) + ϕ(n)/p + κ(n,p) can now be rewritten as T(n,p) = T(n,1) e + T(n,1)(1 - e)/p Let ψ represent ψ(n,p), and ψ = T(n,1)/T(n,p) fraction of time that then is parallel * total time is parallel time - a good T(n,1) = T(n, p)ψ. approximation of ϕ(n) Therefore T(n,p) = T(n,p)ψe + T(n,p)ψ(1-e)/p
54 The experimentally determined serial fraction e of the parallel computation is e = (σ(n) + κ(n,p))/t(n,1) e T(n,1) = σ(n) + κ(n,p) Deriving the K-F Metric Divide The parallel execution time T(n,p) = σ(n) + ϕ(n)/p + κ(n,p) can now be rewritten as T(n,p) = T(n,1) e + T(n,1)(1 - e)/p Let ψ represent ψ(n,p), and then ψ = T(n,1)/T(n,p) T(n,1) = T(n, p)ψ. The standard formula Therefore T(n,p) = T(n,p)ψe + T(n,p)ψ(1-e)/p
55 Deriving the K-F Metric Total time * serial fraction is the serial time The experimentally determined serial fraction e of the parallel computation is e = (σ(n) + κ(n,p))/t(n,1) Total e T(n,1) = σ(n) + κ(n,p) The parallel execution time T(n,p) = σ(n) + ϕ(n)/p + κ(n,p) can now be rewritten as T(n,p) = T(n,1) e + T(n,1)(1 - e)/p Let ψ represent ψ(n,p), and then ψ = T(n,1)/T(n,p) T(n,1) = T(n, p)ψ. Therefore T(n,p) = T(n,p)ψe + T(n,p)ψ(1-e)/p execution time Experimentally determined serial fraction
56 Deriving the K-F Metric (Total time * parallel part)/p is the parallel The experimentally determined serial fraction e of the parallel computation is e = (σ(n) + κ(n,p))/t(n,1) Total e T(n,1) = σ(n) + κ(n,p) The parallel execution time T(n,p) = σ(n) + ϕ(n)/p + κ(n,p) can now be rewritten as T(n,p) = T(n,1) e + T(n,1)(1 - e)/p Let ψ represent ψ(n,p), and then ψ = T(n,1)/T(n,p) T(n,1) = T(n, p)ψ. Therefore T(n,p) = T(n,p)ψe + T(n,p)ψ(1-e)/p execution time fraction of time that is parallel
57 Karp-Flatt Metric T(n,p) = T(n,p)ψe + T(n,p)ψ(1-e)/p 1 = ψe + ψ(1-e)/p 1/ψ = e + (1-e)/p 1/ψ = e + 1/p - e/p 1/ψ = e(1-1/p) +1/p
58 What is it good for? Takes into account the parallel overhead (κ(n,p)) ignored by Amdahl s Law and Gustafson-Barsis. Helps us to detect other sources of inefficiency ignored in these (sometimes too simple) models of execution time ϕ(n)/p may not be accurate because of load balance issues or work not dividing evenly into c p chunks. other interactions with the system may be causing problems Can determine if the efficiency drop with increasing p for a fixed size problem is a. because of limited parallelism b. because of increases in algorithmic or architectural overhead
59 Example Benchmarking a program on 1, 2,..., 8 processors produces the following speedups: p ψ Why is the speedup only 4.71 on 8 processors? p ψ e e = (1/3.57-1/5)/(1-1/5) = (0.08)/.8 = 0. 1
60 Example 2 Benchmarking a program on 1, 2,..., 8 processors produces the following speedups: p ψ Why is the speedup only 4.71 on 8 processors? p ψ e e is increasing: speedup problem is increasing serial overhead (process startup, communication, algorithmic issues, the architecture of the parallel system, etc.
61 Which has the efficiency problem? 5.00 Chart speedup 1 speedup 2
62 Very easy to see using e Chart e1 e2
63 Isoefficiency Metric Overview Parallel system: parallel program executing on a parallel computer Scalability of a parallel system: measure of its ability to increase performance as number of processors increases A scalable system maintains efficiency as processors are added Isoefficiency: way to measure scalability
64 Isoefficiency Derivation Steps Begin with speedup formula Compute total amount of overhead Assume efficiency remains constant Determine relation between sequential execution time and overhead
65 Deriving Isoefficiency total Relation overhead, problem size of n, p Determine overhead Substitute overhead into speedup equation sequential time, Substitute T(n,1) = σ(n) + ϕ(n). problem size of n Assume efficiency is constant. Isoefficiency Relation
66 Deriving Isoefficiency Relation Determine overhead Substitute overhead into speedup equation Substitute T(n,1) = σ(n) + ϕ(n). Assume efficiency is constant. Isoefficiency Relation
67 Scalability Function Suppose isoefficiency relation is n f(p) Let M(n) denote memory required for problem of size n M(f(p))/p shows how memory usage per processor must increase to maintain same efficiency We call M(f(p))/p the scalability function
68 Meaning of Scalability Function To maintain efficiency when increasing p, we must increase n Maximum problem size limited by available memory, which is linear in p Scalability function shows how memory usage per processor must grow to maintain efficiency Scalability function a constant means parallel system is perfectly scalable
69 Interpreting Scalability Memory needed per processor Function Cplogp Cannot maintain efficiency Cp Memory Size Can maintain efficiency Clogp C Number of processors
70 Example 1: Reduction Sequential algorithm complexity T(n,1) = Θ(n) Parallel algorithm Computational complexity = Θ(n/p) Communication complexity = Θ(log p) Parallel overhead T0(n,p) = Θ(p log p) p term because p processors involved in the reduction for log p time.
71 Reduction (continued) Isoefficiency relation: n C p log p We ask: To maintain same level of efficiency, how must n, the problem size, increase when p increases? M(n) = n The system has good scalability
72 Example 2: Floyd s Algorithm Sequential time complexity: Θ(n 3 ) Parallel computation time: Θ(n 3 /p) Parallel communication time: Θ(n 2 log p) Parallel overhead: T0(n,p) = Θ(pn 2 log p)
73 Floyd s Algorithm (continued) Isoefficiency relation n 3 C(p n 2 log p) n C p log p M(n) = n 2 The parallel system has poor scalability
74 Example 3: Finite Difference Sequential time complexity per iteration: Θ(n 2 ) Parallel communication complexity per iteration: Θ(n/ p) Parallel overhead: Θ(n p)
75 Finite Difference (continued) Isoefficiency relation n2 Cn p n C p M(n) = n2 This algorithm is perfectly scalable
76 Summary (1/3) Performance terms Speedup Efficiency Model of speedup Serial component Parallel component Communication component
77 Summary (2/3) What prevents linear speedup? Serial operations Communication operations Process start-up Imbalanced workloads Architectural limitations
78 Summary (3/3) Analyzing parallel performance Amdahl s Law Gustafson-Barsis Law Karp-Flatt metric Isoefficiency metric
Parallel Programming with MPI and OpenMP
 Parallel Programming with MPI and OpenMP Michael J. Quinn (revised by L.M. Liebrock) Chapter 7 Performance Analysis Learning Objectives Predict performance of parallel programs Understand barriers to higher
Parallel Programming with MPI and OpenMP Michael J. Quinn (revised by L.M. Liebrock) Chapter 7 Performance Analysis Learning Objectives Predict performance of parallel programs Understand barriers to higher
Performance analysis. Performance analysis p. 1
 Performance analysis Performance analysis p. 1 An example of time measurements Dark grey: time spent on computation, decreasing with p White: time spent on communication, increasing with p Performance
Performance analysis Performance analysis p. 1 An example of time measurements Dark grey: time spent on computation, decreasing with p White: time spent on communication, increasing with p Performance
Outline. CSC 447: Parallel Programming for Multi- Core and Cluster Systems
 CSC 447: Parallel Programming for Multi- Core and Cluster Systems Performance Analysis Instructor: Haidar M. Harmanani Spring 2018 Outline Performance scalability Analytical performance measures Amdahl
CSC 447: Parallel Programming for Multi- Core and Cluster Systems Performance Analysis Instructor: Haidar M. Harmanani Spring 2018 Outline Performance scalability Analytical performance measures Amdahl
Parallel Programming with MPI and OpenMP
 Parallel Programming with MPI and OpenMP Michael J. Quinn Chapter 7 Performance Analysis Learning Objectives n Predict performance of parallel programs n Understand barriers to higher performance Outline
Parallel Programming with MPI and OpenMP Michael J. Quinn Chapter 7 Performance Analysis Learning Objectives n Predict performance of parallel programs n Understand barriers to higher performance Outline
Parallel quicksort algorithms with isoefficiency analysis. Parallel quicksort algorithmswith isoefficiency analysis p. 1
 Parallel quicksort algorithms with isoefficiency analysis Parallel quicksort algorithmswith isoefficiency analysis p. 1 Overview Sequential quicksort algorithm Three parallel quicksort algorithms Isoefficiency
Parallel quicksort algorithms with isoefficiency analysis Parallel quicksort algorithmswith isoefficiency analysis p. 1 Overview Sequential quicksort algorithm Three parallel quicksort algorithms Isoefficiency
ECE Spring 2017 Exam 2
 ECE 56300 Spring 2017 Exam 2 All questions are worth 5 points. For isoefficiency questions, do not worry about breaking costs down to t c, t w and t s. Question 1. Innovative Big Machines has developed
ECE 56300 Spring 2017 Exam 2 All questions are worth 5 points. For isoefficiency questions, do not worry about breaking costs down to t c, t w and t s. Question 1. Innovative Big Machines has developed
ECE 563 Second Exam, Spring 2014
 ECE 563 Second Exam, Spring 2014 Don t start working on this until I say so Your exam should have 8 pages total (including this cover sheet) and 11 questions. Each questions is worth 9 points. Please let
ECE 563 Second Exam, Spring 2014 Don t start working on this until I say so Your exam should have 8 pages total (including this cover sheet) and 11 questions. Each questions is worth 9 points. Please let
Chapter 5: Analytical Modelling of Parallel Programs
 Chapter 5: Analytical Modelling of Parallel Programs Introduction to Parallel Computing, Second Edition By Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar Contents 1. Sources of Overhead in Parallel
Chapter 5: Analytical Modelling of Parallel Programs Introduction to Parallel Computing, Second Edition By Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar Contents 1. Sources of Overhead in Parallel
Scalability of Processing on GPUs
 Scalability of Processing on GPUs Keith Kelley, CS6260 Final Project Report April 7, 2009 Research description: I wanted to figure out how useful General Purpose GPU computing (GPGPU) is for speeding up
Scalability of Processing on GPUs Keith Kelley, CS6260 Final Project Report April 7, 2009 Research description: I wanted to figure out how useful General Purpose GPU computing (GPGPU) is for speeding up
CSC630/CSC730 Parallel & Distributed Computing
 CSC630/CSC730 Parallel & Distributed Computing Analytical Modeling of Parallel Programs Chapter 5 1 Contents Sources of Parallel Overhead Performance Metrics Granularity and Data Mapping Scalability 2
CSC630/CSC730 Parallel & Distributed Computing Analytical Modeling of Parallel Programs Chapter 5 1 Contents Sources of Parallel Overhead Performance Metrics Granularity and Data Mapping Scalability 2
PARALLEL AND DISTRIBUTED COMPUTING
 PARALLEL AND DISTRIBUTED COMPUTING 2013/2014 1 st Semester 2 nd Exam January 29, 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc. - Give your answers
PARALLEL AND DISTRIBUTED COMPUTING 2013/2014 1 st Semester 2 nd Exam January 29, 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc. - Give your answers
Lecture 10: Performance Metrics. Shantanu Dutt ECE Dept. UIC
 Lecture 10: Performance Metrics Shantanu Dutt ECE Dept. UIC Acknowledgement Adapted from Chapter 5 slides of the text, by A. Grama w/ a few changes, augmentations and corrections in colored text by Shantanu
Lecture 10: Performance Metrics Shantanu Dutt ECE Dept. UIC Acknowledgement Adapted from Chapter 5 slides of the text, by A. Grama w/ a few changes, augmentations and corrections in colored text by Shantanu
Parallel Systems. Part 7: Evaluation of Computers and Programs. foils by Yang-Suk Kee, X. Sun, T. Fahringer
 Parallel Systems Part 7: Evaluation of Computers and Programs foils by Yang-Suk Kee, X. Sun, T. Fahringer How To Evaluate Computers and Programs? Learning objectives: Predict performance of parallel programs
Parallel Systems Part 7: Evaluation of Computers and Programs foils by Yang-Suk Kee, X. Sun, T. Fahringer How To Evaluate Computers and Programs? Learning objectives: Predict performance of parallel programs
Chapter 13 Strong Scaling
 Chapter 13 Strong Scaling Part I. Preliminaries Part II. Tightly Coupled Multicore Chapter 6. Parallel Loops Chapter 7. Parallel Loop Schedules Chapter 8. Parallel Reduction Chapter 9. Reduction Variables
Chapter 13 Strong Scaling Part I. Preliminaries Part II. Tightly Coupled Multicore Chapter 6. Parallel Loops Chapter 7. Parallel Loop Schedules Chapter 8. Parallel Reduction Chapter 9. Reduction Variables
Performance Metrics. 1 cycle. 1 cycle. Computer B performs more instructions per second, thus it is the fastest for this program.
 Parallel Programming WS6 HOMEWORK (with solutions) Performance Metrics Basic concepts. Performance. Suppose we have two computers A and B. Computer A has a clock cycle of ns and performs on average 2 instructions
Parallel Programming WS6 HOMEWORK (with solutions) Performance Metrics Basic concepts. Performance. Suppose we have two computers A and B. Computer A has a clock cycle of ns and performs on average 2 instructions
Advanced Topics UNIT 2 PERFORMANCE EVALUATIONS
 Advanced Topics UNIT 2 PERFORMANCE EVALUATIONS Structure Page Nos. 2.0 Introduction 4 2. Objectives 5 2.2 Metrics for Performance Evaluation 5 2.2. Running Time 2.2.2 Speed Up 2.2.3 Efficiency 2.3 Factors
Advanced Topics UNIT 2 PERFORMANCE EVALUATIONS Structure Page Nos. 2.0 Introduction 4 2. Objectives 5 2.2 Metrics for Performance Evaluation 5 2.2. Running Time 2.2.2 Speed Up 2.2.3 Efficiency 2.3 Factors
SCALABILITY ANALYSIS
 SCALABILITY ANALYSIS PERFORMANCE AND SCALABILITY OF PARALLEL SYSTEMS Evaluation Sequential: runtime (execution time) Ts =T (InputSize) Parallel: runtime (start-->last PE ends) Tp =T (InputSize,p,architecture)
SCALABILITY ANALYSIS PERFORMANCE AND SCALABILITY OF PARALLEL SYSTEMS Evaluation Sequential: runtime (execution time) Ts =T (InputSize) Parallel: runtime (start-->last PE ends) Tp =T (InputSize,p,architecture)
CSE 613: Parallel Programming. Lecture 2 ( Analytical Modeling of Parallel Algorithms )
") CSE 613: Parallel Programming Lecture 2 ( Analytical Modeling of Parallel Algorithms ) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2017 Parallel Execution Time & Overhead
CSE 613: Parallel Programming Lecture 2 ( Analytical Modeling of Parallel Algorithms ) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2017 Parallel Execution Time & Overhead
Analytical Modeling of Parallel Systems. To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003.
 Analytical Modeling of Parallel Systems To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003. Topic Overview Sources of Overhead in Parallel Programs Performance Metrics for
Analytical Modeling of Parallel Systems To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003. Topic Overview Sources of Overhead in Parallel Programs Performance Metrics for
Design of Parallel Algorithms. Course Introduction
 + Design of Parallel Algorithms Course Introduction + CSE 4163/6163 Parallel Algorithm Analysis & Design! Course Web Site: http://www.cse.msstate.edu/~luke/courses/fl17/cse4163! Instructor: Ed Luke! Office:
+ Design of Parallel Algorithms Course Introduction + CSE 4163/6163 Parallel Algorithm Analysis & Design! Course Web Site: http://www.cse.msstate.edu/~luke/courses/fl17/cse4163! Instructor: Ed Luke! Office:
Understanding Parallelism and the Limitations of Parallel Computing
 Understanding Parallelism and the Limitations of Parallel omputing Understanding Parallelism: Sequential work After 16 time steps: 4 cars Scalability Laws 2 Understanding Parallelism: Parallel work After
Understanding Parallelism and the Limitations of Parallel omputing Understanding Parallelism: Sequential work After 16 time steps: 4 cars Scalability Laws 2 Understanding Parallelism: Parallel work After
ECE 563 Spring 2012 First Exam
 ECE 563 Spring 2012 First Exam version 1 This is a take-home test. You must work, if found cheating you will be failed in the course and you will be turned in to the Dean of Students. To make it easy not
ECE 563 Spring 2012 First Exam version 1 This is a take-home test. You must work, if found cheating you will be failed in the course and you will be turned in to the Dean of Students. To make it easy not
Exercise 1 Advanced Computer Architecture. Exercise 1
 Folie a: Name Advanced Computer Architecture Department of Electrical Engineering and Information Technology Institute for g Dipl.-Ing. M.A. Lebedev Institute for BB 321, Tel: 0203 379-1019 E-mail: michail.lebedev@uni-due.de
Folie a: Name Advanced Computer Architecture Department of Electrical Engineering and Information Technology Institute for g Dipl.-Ing. M.A. Lebedev Institute for BB 321, Tel: 0203 379-1019 E-mail: michail.lebedev@uni-due.de
Analytical Modeling of Parallel Programs
 2014 IJEDR Volume 2, Issue 1 ISSN: 2321-9939 Analytical Modeling of Parallel Programs Hardik K. Molia Master of Computer Engineering, Department of Computer Engineering Atmiya Institute of Technology &
2014 IJEDR Volume 2, Issue 1 ISSN: 2321-9939 Analytical Modeling of Parallel Programs Hardik K. Molia Master of Computer Engineering, Department of Computer Engineering Atmiya Institute of Technology &
Quiz for Chapter 1 Computer Abstractions and Technology 3.10
 Date: 3.10 Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: 1. [15 points] Consider two different implementations, M1 and
Date: 3.10 Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: 1. [15 points] Consider two different implementations, M1 and
Designing for Performance. Patrick Happ Raul Feitosa
 Designing for Performance Patrick Happ Raul Feitosa Objective In this section we examine the most common approach to assessing processor and computer system performance W. Stallings Designing for Performance
Designing for Performance Patrick Happ Raul Feitosa Objective In this section we examine the most common approach to assessing processor and computer system performance W. Stallings Designing for Performance
ECE 563 Spring 2016, Second Exam
 1 ECE 563 Spring 2016, Second Exam DO NOT START WORKING ON THIS UNTIL TOLD TO DO SO. LEAVE IT ON THE DESK. THE LAST PAGE IS THE ANSWER SHEET. TEAR IT OFF AND PUT ALL ANSWERS THERE. TURN IN BOTH PARTS OF
1 ECE 563 Spring 2016, Second Exam DO NOT START WORKING ON THIS UNTIL TOLD TO DO SO. LEAVE IT ON THE DESK. THE LAST PAGE IS THE ANSWER SHEET. TEAR IT OFF AND PUT ALL ANSWERS THERE. TURN IN BOTH PARTS OF
Page 1. Program Performance Metrics. Program Performance Metrics. Amdahl s Law. 1 seq seq 1
 Program Performance Metrics The parallel run time (Tpar) is the time from the moment when computation starts to the moment when the last processor finished his execution The speedup (S) is defined as the
Program Performance Metrics The parallel run time (Tpar) is the time from the moment when computation starts to the moment when the last processor finished his execution The speedup (S) is defined as the
Some aspects of parallel program design. R. Bader (LRZ) G. Hager (RRZE)
 G. Hager (RRZE)") Some aspects of parallel program design R. Bader (LRZ) G. Hager (RRZE) Finding exploitable concurrency Problem analysis 1. Decompose into subproblems perhaps even hierarchy of subproblems that can simultaneously
Some aspects of parallel program design R. Bader (LRZ) G. Hager (RRZE) Finding exploitable concurrency Problem analysis 1. Decompose into subproblems perhaps even hierarchy of subproblems that can simultaneously
Dense Matrix Algorithms
 Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
Measuring Performance. Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks
 Measuring Performance Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks Why Measure Performance? Performance tells you how you are doing and whether things can be improved appreciably When
Measuring Performance Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks Why Measure Performance? Performance tells you how you are doing and whether things can be improved appreciably When
CS560 Lecture Parallelism Review 1
 Prelude CS560 Lecture Parallelism Review 1 Parallelism Review Announcements The readings marked Read: are required. The readings marked Other resources: are NOT required reading but more for your reference.
Prelude CS560 Lecture Parallelism Review 1 Parallelism Review Announcements The readings marked Read: are required. The readings marked Other resources: are NOT required reading but more for your reference.
Outline. Speedup & Efficiency Amdahl s Law Gustafson s Law Sun & Ni s Law. Khoa Khoa học và Kỹ thuật Máy tính - ĐHBK TP.HCM
 Speedup Thoai am Outline Speedup & Efficiency Amdahl s Law Gustafson s Law Sun & i s Law Speedup & Efficiency Speedup: S = T seq T par - T seq : Time(the most efficient sequential algorithm) - T par :
Speedup Thoai am Outline Speedup & Efficiency Amdahl s Law Gustafson s Law Sun & i s Law Speedup & Efficiency Speedup: S = T seq T par - T seq : Time(the most efficient sequential algorithm) - T par :
CSE5351: Parallel Processing Part III
 CSE5351: Parallel Processing Part III -1- Performance Metrics and Benchmarks How should one characterize the performance of applications and systems? What are user s requirements in performance and cost?
CSE5351: Parallel Processing Part III -1- Performance Metrics and Benchmarks How should one characterize the performance of applications and systems? What are user s requirements in performance and cost?
Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era. 11/16/2011 Many-Core Computing 2
 Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era 11/16/2011 Many-Core Computing 2 Gene M. Amdahl, Validity of the Single-Processor Approach to Achieving
Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era 11/16/2011 Many-Core Computing 2 Gene M. Amdahl, Validity of the Single-Processor Approach to Achieving
Parallel Programming Patterns. Overview and Concepts
 Parallel Programming Patterns Overview and Concepts Outline Practical Why parallel programming? Decomposition Geometric decomposition Task farm Pipeline Loop parallelism Performance metrics and scaling
Parallel Programming Patterns Overview and Concepts Outline Practical Why parallel programming? Decomposition Geometric decomposition Task farm Pipeline Loop parallelism Performance metrics and scaling
Evaluation of Parallel Programs by Measurement of Its Granularity
 Evaluation of Parallel Programs by Measurement of Its Granularity Jan Kwiatkowski Computer Science Department, Wroclaw University of Technology 50-370 Wroclaw, Wybrzeze Wyspianskiego 27, Poland kwiatkowski@ci-1.ci.pwr.wroc.pl
Evaluation of Parallel Programs by Measurement of Its Granularity Jan Kwiatkowski Computer Science Department, Wroclaw University of Technology 50-370 Wroclaw, Wybrzeze Wyspianskiego 27, Poland kwiatkowski@ci-1.ci.pwr.wroc.pl
Scalability of Heterogeneous Computing
 Scalability of Heterogeneous Computing Xian-He Sun, Yong Chen, Ming u Department of Computer Science Illinois Institute of Technology {sun, chenyon1, wuming}@iit.edu Abstract Scalability is a key factor
Scalability of Heterogeneous Computing Xian-He Sun, Yong Chen, Ming u Department of Computer Science Illinois Institute of Technology {sun, chenyon1, wuming}@iit.edu Abstract Scalability is a key factor
NAME: Problem Points Score. 7 (bonus) 15. Total
 15. Total") Midterm Exam ECE 741 Advanced Computer Architecture, Spring 2009 Instructor: Onur Mutlu TAs: Michael Papamichael, Theodoros Strigkos, Evangelos Vlachos February 25, 2009 NAME: Problem Points Score 1 40
Midterm Exam ECE 741 Advanced Computer Architecture, Spring 2009 Instructor: Onur Mutlu TAs: Michael Papamichael, Theodoros Strigkos, Evangelos Vlachos February 25, 2009 NAME: Problem Points Score 1 40
Course web site: teaching/courses/car. Piazza discussion forum:
 Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Lecture 4: Parallel Speedup, Efficiency, Amdahl s Law
 COMP 322: Fundamentals of Parallel Programming Lecture 4: Parallel Speedup, Efficiency, Amdahl s Law Vivek Sarkar Department of Computer Science, Rice University vsarkar@rice.edu https://wiki.rice.edu/confluence/display/parprog/comp322
COMP 322: Fundamentals of Parallel Programming Lecture 4: Parallel Speedup, Efficiency, Amdahl s Law Vivek Sarkar Department of Computer Science, Rice University vsarkar@rice.edu https://wiki.rice.edu/confluence/display/parprog/comp322
ECE 669 Parallel Computer Architecture
 ECE 669 Parallel Computer Architecture Lecture 9 Workload Evaluation Outline Evaluation of applications is important Simulation of sample data sets provides important information Working sets indicate
ECE 669 Parallel Computer Architecture Lecture 9 Workload Evaluation Outline Evaluation of applications is important Simulation of sample data sets provides important information Working sets indicate
1 Introduction to Parallel Computing
 1 Introduction to Parallel Computing 1.1 Goals of Parallel vs Distributed Computing Distributed computing, commonly represented by distributed services such as the world wide web, is one form of computational
1 Introduction to Parallel Computing 1.1 Goals of Parallel vs Distributed Computing Distributed computing, commonly represented by distributed services such as the world wide web, is one form of computational
NAME: 1a. (10 pts.) Describe the characteristics of numbers for which this floating-point data type is well-suited. Give an example.
 Describe the characteristics of numbers for which this floating-point data type is well-suited. Give an example.") MSU CSC 285 Spring, 2007 Exam 2 (5 pgs.) NAME: 1. Suppose that a eight-bit floating-point data type is defined with the eight bits divided into fields as follows, where the bits are numbered with zero
MSU CSC 285 Spring, 2007 Exam 2 (5 pgs.) NAME: 1. Suppose that a eight-bit floating-point data type is defined with the eight bits divided into fields as follows, where the bits are numbered with zero
Outline. Speedup & Efficiency Amdahl s Law Gustafson s Law Sun & Ni s Law. Khoa Khoa học và Kỹ thuật Máy tính - ĐHBK TP.HCM
 Speedup Thoai am Outline Speedup & Efficiency Amdahl s Law Gustafson s Law Sun & i s Law Speedup & Efficiency Speedup: S = Time(the most efficient sequential Efficiency: E = S / algorithm) / Time(parallel
Speedup Thoai am Outline Speedup & Efficiency Amdahl s Law Gustafson s Law Sun & i s Law Speedup & Efficiency Speedup: S = Time(the most efficient sequential Efficiency: E = S / algorithm) / Time(parallel
Lecture 8 Parallel Algorithms II
 Lecture 8 Parallel Algorithms II Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Original slides from Introduction to Parallel
Lecture 8 Parallel Algorithms II Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Original slides from Introduction to Parallel
Parallel Constraint Programming (and why it is hard... ) Ciaran McCreesh and Patrick Prosser
 Ciaran McCreesh and Patrick Prosser") Parallel Constraint Programming (and why it is hard... ) This Week s Lectures Search and Discrepancies Parallel Constraint Programming Why? Some failed attempts A little bit of theory and some very simple
Parallel Constraint Programming (and why it is hard... ) This Week s Lectures Search and Discrepancies Parallel Constraint Programming Why? Some failed attempts A little bit of theory and some very simple
What is Performance for Internet/Grid Computation?
 Goals for Internet/Grid Computation? Do things you cannot otherwise do because of: Lack of Capacity Large scale computations Cost SETI Scale/Scope of communication Internet searches All of the above 9/10/2002
Goals for Internet/Grid Computation? Do things you cannot otherwise do because of: Lack of Capacity Large scale computations Cost SETI Scale/Scope of communication Internet searches All of the above 9/10/2002
High Performance Computing Systems
 High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
Performance analysis basics
 Performance analysis basics Christian Iwainsky Iwainsky@rz.rwth-aachen.de 25.3.2010 1 Overview 1. Motivation 2. Performance analysis basics 3. Measurement Techniques 2 Why bother with performance analysis
Performance analysis basics Christian Iwainsky Iwainsky@rz.rwth-aachen.de 25.3.2010 1 Overview 1. Motivation 2. Performance analysis basics 3. Measurement Techniques 2 Why bother with performance analysis
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
1.3 Data processing; data storage; data movement; and control.
 CHAPTER 1 OVERVIEW ANSWERS TO QUESTIONS 1.1 Computer architecture refers to those attributes of a system visible to a programmer or, put another way, those attributes that have a direct impact on the logical
CHAPTER 1 OVERVIEW ANSWERS TO QUESTIONS 1.1 Computer architecture refers to those attributes of a system visible to a programmer or, put another way, those attributes that have a direct impact on the logical
Analytical Modeling of Parallel Programs
 Analytical Modeling of Parallel Programs Alexandre David Introduction to Parallel Computing 1 Topic overview Sources of overhead in parallel programs. Performance metrics for parallel systems. Effect of
Analytical Modeling of Parallel Programs Alexandre David Introduction to Parallel Computing 1 Topic overview Sources of overhead in parallel programs. Performance metrics for parallel systems. Effect of
Multicore Programming
 Multi Programming Parallel Hardware and Performance 8 Nov 00 (Part ) Peter Sewell Jaroslav Ševčík Tim Harris Merge sort 6MB input (-bit integers) Recurse(left) ~98% execution time Recurse(right) Merge
Multi Programming Parallel Hardware and Performance 8 Nov 00 (Part ) Peter Sewell Jaroslav Ševčík Tim Harris Merge sort 6MB input (-bit integers) Recurse(left) ~98% execution time Recurse(right) Merge
A FRAMEWORK ARCHITECTURE FOR SHARED FILE POINTER OPERATIONS IN OPEN MPI
 A FRAMEWORK ARCHITECTURE FOR SHARED FILE POINTER OPERATIONS IN OPEN MPI A Thesis Presented to the Faculty of the Department of Computer Science University of Houston In Partial Fulfillment of the Requirements
A FRAMEWORK ARCHITECTURE FOR SHARED FILE POINTER OPERATIONS IN OPEN MPI A Thesis Presented to the Faculty of the Department of Computer Science University of Houston In Partial Fulfillment of the Requirements
CSL 860: Modern Parallel
 CSL 860: Modern Parallel Computation Course Information www.cse.iitd.ac.in/~subodh/courses/csl860 Grading: Quizes25 Lab Exercise 17 + 8 Project35 (25% design, 25% presentations, 50% Demo) Final Exam 25
CSL 860: Modern Parallel Computation Course Information www.cse.iitd.ac.in/~subodh/courses/csl860 Grading: Quizes25 Lab Exercise 17 + 8 Project35 (25% design, 25% presentations, 50% Demo) Final Exam 25
MPI Optimisation. Advanced Parallel Programming. David Henty, Iain Bethune, Dan Holmes EPCC, University of Edinburgh
 MPI Optimisation Advanced Parallel Programming David Henty, Iain Bethune, Dan Holmes EPCC, University of Edinburgh Overview Can divide overheads up into four main categories: Lack of parallelism Load imbalance
MPI Optimisation Advanced Parallel Programming David Henty, Iain Bethune, Dan Holmes EPCC, University of Edinburgh Overview Can divide overheads up into four main categories: Lack of parallelism Load imbalance
Παράλληλη Επεξεργασία
 Παράλληλη Επεξεργασία Μέτρηση και σύγκριση Παράλληλης Απόδοσης Γιάννος Σαζεϊδης Εαρινό Εξάμηνο 2013 HW 1. Homework #3 due on cuda (summary of Tesla paper on web page) Slides based on Lin and Snyder textbook
Παράλληλη Επεξεργασία Μέτρηση και σύγκριση Παράλληλης Απόδοσης Γιάννος Σαζεϊδης Εαρινό Εξάμηνο 2013 HW 1. Homework #3 due on cuda (summary of Tesla paper on web page) Slides based on Lin and Snyder textbook
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Quiz for Chapter 1 Computer Abstractions and Technology
 Date: Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Date: Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Homework # 2 Due: October 6. Programming Multiprocessors: Parallelism, Communication, and Synchronization
 ECE669: Parallel Computer Architecture Fall 2 Handout #2 Homework # 2 Due: October 6 Programming Multiprocessors: Parallelism, Communication, and Synchronization 1 Introduction When developing multiprocessor
ECE669: Parallel Computer Architecture Fall 2 Handout #2 Homework # 2 Due: October 6 Programming Multiprocessors: Parallelism, Communication, and Synchronization 1 Introduction When developing multiprocessor
Thinking parallel. Decomposition. Thinking parallel. COMP528 Ways of exploiting parallelism, or thinking parallel
 COMP528 Ways of exploiting parallelism, or thinking parallel www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Thinking parallel
COMP528 Ways of exploiting parallelism, or thinking parallel www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Thinking parallel
Homework # 1 Due: Feb 23. Multicore Programming: An Introduction
 C O N D I T I O N S C O N D I T I O N S Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.86: Parallel Computing Spring 21, Agarwal Handout #5 Homework #
C O N D I T I O N S C O N D I T I O N S Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.86: Parallel Computing Spring 21, Agarwal Handout #5 Homework #
Single-Pass List Partitioning
 Single-Pass List Partitioning Leonor Frias 1 Johannes Singler 2 Peter Sanders 2 1 Dep. de Llenguatges i Sistemes Informàtics, Universitat Politècnica de Catalunya 2 Institut für Theoretische Informatik,
Single-Pass List Partitioning Leonor Frias 1 Johannes Singler 2 Peter Sanders 2 1 Dep. de Llenguatges i Sistemes Informàtics, Universitat Politècnica de Catalunya 2 Institut für Theoretische Informatik,
Amdahl s Law in the Datacenter Era! A Market for Fair Processor Allocation!
 Amdahl s Law in the Datacenter Era! A Market for Fair Processor Allocation! Seyed Majid Zahedi* (Duke University), Qiuyun Llull* (VMware/ Duke University), Benjamin C. Lee (Duke University)! *Equal Contributions!
Amdahl s Law in the Datacenter Era! A Market for Fair Processor Allocation! Seyed Majid Zahedi* (Duke University), Qiuyun Llull* (VMware/ Duke University), Benjamin C. Lee (Duke University)! *Equal Contributions!
Performance Metrics. Measuring Performance
 Metrics 12/9/2003 6 Measuring How should the performance of a parallel computation be measured? Traditional measures like MIPS and MFLOPS really don t cut it New ways to measure parallel performance are
Metrics 12/9/2003 6 Measuring How should the performance of a parallel computation be measured? Traditional measures like MIPS and MFLOPS really don t cut it New ways to measure parallel performance are
Lecture 3: Sorting 1
 Lecture 3: Sorting 1 Sorting Arranging an unordered collection of elements into monotonically increasing (or decreasing) order. S = a sequence of n elements in arbitrary order After sorting:
Lecture 3: Sorting 1 Sorting Arranging an unordered collection of elements into monotonically increasing (or decreasing) order. S = a sequence of n elements in arbitrary order After sorting:
High Performance Computing
 The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
Basics of Performance Engineering
 ERLANGEN REGIONAL COMPUTING CENTER Basics of Performance Engineering J. Treibig HiPerCH 3, 23./24.03.2015 Why hardware should not be exposed Such an approach is not portable Hardware issues frequently
ERLANGEN REGIONAL COMPUTING CENTER Basics of Performance Engineering J. Treibig HiPerCH 3, 23./24.03.2015 Why hardware should not be exposed Such an approach is not portable Hardware issues frequently
Sorting Algorithms. Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar
 Sorting Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003. Topic Overview Issues in Sorting on Parallel
Sorting Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003. Topic Overview Issues in Sorting on Parallel
Parallel Implementations of Gaussian Elimination
 s of Western Michigan University vasilije.perovic@wmich.edu January 27, 2012 CS 6260: in Parallel Linear systems of equations General form of a linear system of equations is given by a 11 x 1 + + a 1n
s of Western Michigan University vasilije.perovic@wmich.edu January 27, 2012 CS 6260: in Parallel Linear systems of equations General form of a linear system of equations is given by a 11 x 1 + + a 1n
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #11 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Midterm 1:
EE/CSCI 451: Parallel and Distributed Computation Lecture #11 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Midterm 1:
Review: Creating a Parallel Program. Programming for Performance
 Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
EXAM 1 SOLUTIONS. Midterm Exam. ECE 741 Advanced Computer Architecture, Spring Instructor: Onur Mutlu
 Midterm Exam ECE 741 Advanced Computer Architecture, Spring 2009 Instructor: Onur Mutlu TAs: Michael Papamichael, Theodoros Strigkos, Evangelos Vlachos February 25, 2009 EXAM 1 SOLUTIONS Problem Points
Midterm Exam ECE 741 Advanced Computer Architecture, Spring 2009 Instructor: Onur Mutlu TAs: Michael Papamichael, Theodoros Strigkos, Evangelos Vlachos February 25, 2009 EXAM 1 SOLUTIONS Problem Points
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007
 CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
Search Algorithms for Discrete Optimization Problems
 Search Algorithms for Discrete Optimization Problems Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003. Topic
Search Algorithms for Discrete Optimization Problems Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003. Topic
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
MEASURING COMPUTER TIME. A computer faster than another? Necessity of evaluation computer performance
 Necessity of evaluation computer performance MEASURING COMPUTER PERFORMANCE For comparing different computer performances User: Interested in reducing the execution time (response time) of a task. Computer
Necessity of evaluation computer performance MEASURING COMPUTER PERFORMANCE For comparing different computer performances User: Interested in reducing the execution time (response time) of a task. Computer
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMPSCI 691AD General Purpose Computation on the GPU
 CMPSCI 691AD General Purpose Computation on the GPU Spring 2009 Lecture 5: Quantitative Analysis of Parallel Algorithms Rui Wang (cont. from last lecture) Device Management Context Management Module Management
CMPSCI 691AD General Purpose Computation on the GPU Spring 2009 Lecture 5: Quantitative Analysis of Parallel Algorithms Rui Wang (cont. from last lecture) Device Management Context Management Module Management
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
CPS222 Lecture: Parallel Algorithms Last Revised 4/20/2015. Objectives
 CPS222 Lecture: Parallel Algorithms Last Revised 4/20/2015 Objectives 1. To introduce fundamental concepts of parallel algorithms, including speedup and cost. 2. To introduce some simple parallel algorithms.
CPS222 Lecture: Parallel Algorithms Last Revised 4/20/2015 Objectives 1. To introduce fundamental concepts of parallel algorithms, including speedup and cost. 2. To introduce some simple parallel algorithms.
16/10/2008. Today s menu. PRAM Algorithms. What do you program? What do you expect from a model? Basic ideas for the machine model
 Today s menu 1. What do you program? Parallel complexity and algorithms PRAM Algorithms 2. The PRAM Model Definition Metrics and notations Brent s principle A few simple algorithms & concepts» Parallel
Today s menu 1. What do you program? Parallel complexity and algorithms PRAM Algorithms 2. The PRAM Model Definition Metrics and notations Brent s principle A few simple algorithms & concepts» Parallel
Performance COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Performance COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals What is Performance? How do we measure the performance of
Performance COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals What is Performance? How do we measure the performance of
A Sophomoric Introduction to Shared-Memory Parallelism and Concurrency Lecture 2 Analysis of Fork-Join Parallel Programs
 A Sophomoric Introduction to Shared-Memory Parallelism and Concurrency Lecture 2 Analysis of Fork-Join Parallel Programs Dan Grossman Last Updated: January 2016 For more information, see http://www.cs.washington.edu/homes/djg/teachingmaterials/
A Sophomoric Introduction to Shared-Memory Parallelism and Concurrency Lecture 2 Analysis of Fork-Join Parallel Programs Dan Grossman Last Updated: January 2016 For more information, see http://www.cs.washington.edu/homes/djg/teachingmaterials/
Lecture - 4. Measurement. Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1
 Lecture - 4 Measurement Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1 Acknowledgements David Patterson Dr. Roger Kieckhafer 9/29/2009 2 Computer Architecture is Design and Analysis
Lecture - 4 Measurement Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1 Acknowledgements David Patterson Dr. Roger Kieckhafer 9/29/2009 2 Computer Architecture is Design and Analysis
Solutions for Chapter 4 Exercises
 Solutions for Chapter 4 Exercises Solutions for Chapter 4 Exercises 4. For P, M2 is 4/3 (2 sec/.5 sec) times as fast as M. For P2, M is 2 times as fast (0 sec/5 sec) as M2. 4.2 We know the number of instructions
Solutions for Chapter 4 Exercises Solutions for Chapter 4 Exercises 4. For P, M2 is 4/3 (2 sec/.5 sec) times as fast as M. For P2, M is 2 times as fast (0 sec/5 sec) as M2. 4.2 We know the number of instructions
Parallel Programming. OpenMP Parallel programming for multiprocessors for loops
 Parallel Programming OpenMP Parallel programming for multiprocessors for loops OpenMP OpenMP An application programming interface (API) for parallel programming on multiprocessors Assumes shared memory
Parallel Programming OpenMP Parallel programming for multiprocessors for loops OpenMP OpenMP An application programming interface (API) for parallel programming on multiprocessors Assumes shared memory
Chapter 8 Dense Matrix Algorithms
 Chapter 8 Dense Matrix Algorithms (Selected slides & additional slides) A. Grama, A. Gupta, G. Karypis, and V. Kumar To accompany the text Introduction to arallel Computing, Addison Wesley, 23. Topic Overview
Chapter 8 Dense Matrix Algorithms (Selected slides & additional slides) A. Grama, A. Gupta, G. Karypis, and V. Kumar To accompany the text Introduction to arallel Computing, Addison Wesley, 23. Topic Overview
DPHPC: Performance Recitation session
 SALVATORE DI GIROLAMO DPHPC: Performance Recitation session spcl.inf.ethz.ch Administrativia Reminder: Project presentations next Monday 9min/team (7min talk + 2min questions) Presentations
SALVATORE DI GIROLAMO DPHPC: Performance Recitation session spcl.inf.ethz.ch Administrativia Reminder: Project presentations next Monday 9min/team (7min talk + 2min questions) Presentations
Performance Analysis
 Performance Analysis EE380, Fall 2015 Hank Dietz http://aggregate.org/hankd/ Why Measure Performance? Performance is important Identify HW/SW performance problems Compare & choose wisely Which system configuration
Performance Analysis EE380, Fall 2015 Hank Dietz http://aggregate.org/hankd/ Why Measure Performance? Performance is important Identify HW/SW performance problems Compare & choose wisely Which system configuration
HOW TO WRITE PARALLEL PROGRAMS AND UTILIZE CLUSTERS EFFICIENTLY
 HOW TO WRITE PARALLEL PROGRAMS AND UTILIZE CLUSTERS EFFICIENTLY Sarvani Chadalapaka HPC Administrator University of California Merced, Office of Information Technology schadalapaka@ucmerced.edu it.ucmerced.edu
HOW TO WRITE PARALLEL PROGRAMS AND UTILIZE CLUSTERS EFFICIENTLY Sarvani Chadalapaka HPC Administrator University of California Merced, Office of Information Technology schadalapaka@ucmerced.edu it.ucmerced.edu
Estimating Multimedia Instruction Performance Based on Workload Characterization and Measurement
 Estimating Multimedia Instruction Performance Based on Workload Characterization and Measurement Adil Gheewala*, Jih-Kwon Peir*, Yen-Kuang Chen**, Konrad Lai** *Department of CISE, University of Florida,
Estimating Multimedia Instruction Performance Based on Workload Characterization and Measurement Adil Gheewala*, Jih-Kwon Peir*, Yen-Kuang Chen**, Konrad Lai** *Department of CISE, University of Florida,
Performance of Parallel Programs. Michelle Ku3el
 Performance of Parallel Programs Michelle Ku3el 1 Analyzing algorithms Like all algorithms, parallel algorithms should be: Correct Efficient First we will talk about efficiency 2 Work and Span Let T P
Performance of Parallel Programs Michelle Ku3el 1 Analyzing algorithms Like all algorithms, parallel algorithms should be: Correct Efficient First we will talk about efficiency 2 Work and Span Let T P
Lecture 4: Graph Algorithms
 Lecture 4: Graph Algorithms Definitions Undirected graph: G =(V, E) V finite set of vertices, E finite set of edges any edge e = (u,v) is an unordered pair Directed graph: edges are ordered pairs If e
Lecture 4: Graph Algorithms Definitions Undirected graph: G =(V, E) V finite set of vertices, E finite set of edges any edge e = (u,v) is an unordered pair Directed graph: edges are ordered pairs If e
CSC 447: Parallel Programming for Multi- Core and Cluster Systems
 CSC 447: Parallel Programming for Multi- Core and Cluster Systems Parallel Sorting Algorithms Instructor: Haidar M. Harmanani Spring 2016 Topic Overview Issues in Sorting on Parallel Computers Sorting
CSC 447: Parallel Programming for Multi- Core and Cluster Systems Parallel Sorting Algorithms Instructor: Haidar M. Harmanani Spring 2016 Topic Overview Issues in Sorting on Parallel Computers Sorting
Chapter 9. Pipelining Design Techniques
 Chapter 9 Pipelining Design Techniques 9.1 General Concepts Pipelining refers to the technique in which a given task is divided into a number of subtasks that need to be performed in sequence. Each subtask
Chapter 9 Pipelining Design Techniques 9.1 General Concepts Pipelining refers to the technique in which a given task is divided into a number of subtasks that need to be performed in sequence. Each subtask
Multithreaded Programming
 Multithreaded Programming Arch D. Robison Intel Corporation Copyright 2005 Intel Corporation 1 Overall Goal Acquire mental model of how parallel computers work Learn basic guidelines on designing parallel
Multithreaded Programming Arch D. Robison Intel Corporation Copyright 2005 Intel Corporation 1 Overall Goal Acquire mental model of how parallel computers work Learn basic guidelines on designing parallel
Unit #8: Shared-Memory Parallelism and Concurrency
 Unit #8: Shared-Memory Parallelism and Concurrency CPSC 221: Algorithms and Data Structures Will Evans and Jan Manuch 2016W1 Unit Outline History and Motivation Parallelism versus Concurrency Counting
Unit #8: Shared-Memory Parallelism and Concurrency CPSC 221: Algorithms and Data Structures Will Evans and Jan Manuch 2016W1 Unit Outline History and Motivation Parallelism versus Concurrency Counting
Chapter 05. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 05 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 5.1 Basic structure of a centralized shared-memory multiprocessor based on a multicore chip.
Chapter 05 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 5.1 Basic structure of a centralized shared-memory multiprocessor based on a multicore chip.