Lecture 3: Sorting 1
|
|
|
- Ernest Oliver
- 5 years ago
- Views:
Transcription
1 Lecture 3: Sorting 1
2 Sorting Arranging an unordered collection of elements into monotonically increasing (or decreasing) order. S = <a 1, a 2,, a n > a sequence of n elements in arbitrary order After sorting: S is transformed into a permutation of S: S = <a 1, a 2,, a n > such that a i <= a j for 1 <= i <= j <= n Internal vs. external sorting: Internal sorting: elements to be sorted fit into the processor s main memory. External sorting: huge number of elements stored into auxiliary storage (hard disks). 2
3 Comparison-based vs. Noncomparison-based Sorting Comparison-based sorting: Repeatedly compare pairs of elements and if they are out of order exchange them => compare-exchange operation Theorem: The lower bound of any comparison-based sorting algorithm is Ω(n log n). i.e. no comparison-based algorithm can possibly be faster than Ω(n log n) in the worst case. Noncomparison-based sorting: Use certain known properties of the elements (e.g. distribution) Lower bound: Ω(n) 3
4 Issues in Parallel Sorting Where the input and output sequences are stored? Stored on only one process. Distributed among the processes => assumed here How comparison are performed? One element per process: 4
5 Compare-Split: More than One Element Per Process Each process is assigned a block of n/p elements. Block A i assigned to P i A i <= A j if every element of A i is less than or equal to every element in A j. After sorting each P i holds a set A i such that A i <= A j for i <= j Compare-split operation: (assume blocks already sorted at each process) 1. Each process sends its block to the other process. 2. Each process merges the two sorted blocks and retains only the appropriate half of the merged block. Communication cost: t s +t w (n/p) Total time: Θ(n/p) 5
6 Compare-Split 6
7 Comparators: Sorting Networks Increasing comparator Decreasing comparator 7
8 Sorting Networks Depth of a network = number of columns The speed of a network is determined by its depth. 8
9 Bitonic Sort Bitonic sequence: a sequence of elements <a 0, a 1,, a n-1 > with the property that either: 1. There exists i, 0<=i<=n-1, such that <a 0,a 1,,a i > is monotonically increasing and <a i+1, a i+2,, a n-1 > is monotonically decreasing, or 2. There exists a cyclic shift of indices so that (1) is satisfied. Examples: <1, 2, 4, 7, 6, 0> <8, 9, 2, 1, 0, 4> cyclic shift of <0, 4, 8, 9, 2, 1> 9
10 Bitonic Split s = <a 0, a 1,, a n-1 > a bitonic sequence such that a 0 <=a 1 <= <= a n/2-1 and a n/2 =>a n/2+1 => =>a n-1 Bitonic split: s 1 = <min{a 0,a n/2 }, min{a 1,a n/2+1 },, min{a n/2-1,a n-1 },> s 2 = <max{a 0,a n/2 }, max{a 1,a n/2+1 },, max{a n/2-1,a n-1 },> There exists b i from s 1 such that all the elements before b i are from the increasing part of s and all the elements after b i are from the decreasing part of s. There exists b i from s 2 such that all the elements before b i are from the decreasing part of s and all the elements after b i are from the increasing part of s. => s 1 and s 2 are bitonic Every element of s 1 is smaller than every element of s 2 10
11 Bitonic Split a 5 s 2 a 6 a 7 a 8 =b 2 a 3 a 4 a 2 =b 2 a 9 a 10 a 0 a 1 s 1 a 11 11
12 Bitonic Merge Reduce the problem of rearranging a bitonic sequence of size n to that of rearranging two smaller bitonic sequences and concatenating the result. Bitonic merge: Apply recursively the procedure until the length of the sequences is 1 => sorted sequence Takes log n bitonic splits. Can be implemented on a network of comparators => bitonic merging network 12
13 Bitonic Merge: Example 13
14 Bitonic Merging Network ΘBM[16] log n columns of n/2 comparators 14
15 Bitonic Sorting Network 15
16 Bitonic Sorting Network First three stages detailed 16
17 Bitonic Sorting Network: Complexity Depth d(n): d(n) = d(n/2) + log n d(n) = log n = (log 2 n + log n)/2 d(n) = Θ(log 2 n) On a serial computer => Θ(n log 2 n) 17
18 Mapping Bitonic Sort on Parallel Computers Bitonic sort is communication intensive => we need to take into account the topology of the interconnection network. One element per process: Each wire of the bitonic sorting network represents a distinct process The compare-exchange operations are performed by n/2 pairs of processes Good mapping: minimizes the distance that the elements travel during a compare-exchange operation. Observation: wires whose labels differ in the i-th leastsignificant bit perform a compare-exchange operation (log n i +1) times. 18
19 Bitonic Sort on a Hypercube Bitonic sort property: Compare-exchange operations only between wires that differ in only one bit. Hypercube property: processes whose labels differ in only one bit are neighbors. Optimal mapping: wire l to process l, l =0, 1, n-1 In i-th step of the final stage processes communicate along the (d - (i - 1)) -th dimension. 19
20 Bitonic Sort on a Hypercube Communication during the last stage of bitonic sort 20
21 Bitonic Sort on a Hypercube Communication during the last stage of bitonic sort 21
22 Bitonic Sort on a Hypercube Hypercube dimensions involved in bitonic sort communication 22
23 Bitonic Sort on a Hypercube T p = log n = (log 2 n + log n)/2 T p = Θ(log 2 n) Cost =Θ(n log 2 n) => cost optimal with respect to the sequential bitonic sort => not cost optimal with respect to the best comparison based algorithm 23
24 Bitonic Sort on a Mesh A mesh has a lower connectivity than that of a hypercube It is impossible to map wires to processes such that each compare-exchange operation occurs only between neighboring processes. Map wires such that the most frequent compare-exchange operations occur between neighbors. 24
25 Bitonic Sort on a Mesh row-major row-major snakelike row-major shuffled 25
26 Bitonic Sort on a Mesh row-major shuffled 26
27 Bitonic Sort on a Mesh Property: Wires that differ in the i-th least significant bit are mapped onto mesh processes that are 2 [(i-1)/2] links away. Assuming Store-and-Forward routing: t comm = Θ(n 1/2 ) logn i [( j 2] 2 1) / i= 1 j= 1 Parallel run time = Θ(log 2 n) + Θ(n 1/2 ) Cost = Θ(n 1.5 ) => not cost optimal 7 n 27
28 More than One Element Per Process Simple way: n/p virtual processes on each processor and on hypercube: T p = Θ((n/p) log 2 n) => not cost-optimal system Another way: use compare and split operations The problem reduces to bitonic sorting of p blocks using compare-split operations and local sorting of n/p elements. Total number of steps required: (1+log p)(log p)/2 28
29 Bitonic Sort on a Hypercube (p<n) Compare-split operation takesθ(n/p) computation time andθ(n/p) communication time Analysis: Initial local sort Θ((n/p) log (n/p)) Comparisons Θ((n/p) log 2 p) Communication Θ((n/p) log 2 p) T p = Θ((n/p) log (n/p)) + Θ((n/p) log 2 p) Cost optimal if: log 2 p = Θ(log n) => p = Θ(2 log1/2 n ) Isoefficiency function: W = Θ(p log p log 2 p) Θ(2 log2 p log 2 p) => for large p is worse than polynomial => poor scalability 29
30 Bitonic Sort on a Mesh (p<n) Compare-split operation takesθ(n/p) computation time andθ(n/p) communication time Analysis: Initial local sort Θ((n/p) log (n/p)) Comparisons Θ((n/p) log 2 p) Communication Θ((n/p) p 1/2 ) T p = Θ((n/p) log (n/p)) + Θ((n/p) log 2 p) + Θ(n/p 1/2 ) Cost optimal if: p 1/2 = Θ(log n) => p = Θ(log 2 n) Isoefficiency function: W = Θ(2 p1/2 p 1/2 ) => exponential function => very poor scalability! 30
31 Bubble Sort and its Variants Sequential bubble sort: (n-1) compare-exchange operations: (a 1, a 2 ), (a 2, a 3 ),, (a n-1, a n ) => it moves the largest element at the end (n-2) compare-exchange operations to the first n-1 elements of the resulting sequence. After n-1 iterations the sequence is sorted. 31
32 Sequential Bubble Sort T s = Θ(n 2 ) It compares all adjacent pairs in order => Inherently sequential => Difficult to parallelize! 32
33 Odd-Even Transposition Sorts n elements in n phases (n even) using n/2 compare-exchange operations Odd phase: compare-exchange between the elements with odd indices and their right neighbors. (a 1, a 2 ), (a 3, a 4 ),, (a n-1, a n ) Even phase: compare-exchange between the elements with odd indices and their right neighbors. (a 2, a 3 ), (a 4, a 5 ),, (a n-2, a n-1 ) 33
34 Sequential Odd-Even Transposition T s = Θ(n 2 ) 34
35 Parallel Odd-Even Transposition Assumes a n processor ring and one element per process. During each phase compare-exchange operations are performed simultaneously => Θ(1) T p = Θ(n) Cost = Θ(n 2 ) => not cost-optimal 35
36 Parallel Odd-Even Transposition More than one element per process (p<n): Initial local sort of n/p elements => Θ((n/p)log(n/p)) p phases (p/2 odd, p/2 even) using compare-split operations. Each phase: computation Θ(n/p), communication Θ(n/p) => Total for p phases: computation Θ(n), communication Θ(n) T p = Θ((n/p)log(n/p)) + Θ(n) + Θ(n) Cost optimal when p = Θ(log n) Isoefficiency function: Θ(p2 p ) => exponential It is poorly scalable! 36
37 Parallel Shellsort Compare-exchange between nonadjacent elements. First stage: processes that are far away from each other in the array compare-split their elements. Second stage: odd-even transposition in which the odd and even phases are performed only if the blocks on the processes are changing. In the first stage the elements are moved close to their final destination => fewer odd and even phases on the second stage. 37
38 Parallel Shellsort first phase 38
39 Parallel Shellsort: Analysis Initially: Local sort of n/p elements: Θ((n/p)log (n/p)) First stage: each process performs log p compare-split operations Assuming a bisection bandwidth of Θ(p) then each compare-split operation is Θ(n/p). => first stage takes Θ((n/p) log p) Second stage: l < p odd and even phases are performed each taking Θ(n/p) => second stage takes Θ(l(n/p)) T p = Θ((n/p)log (n/p)) + Θ((n/p) log p) + Θ(l(n/p)) If l small => better than odd-even transposition If l = Θ(p) => similar to odd-even transposition 39
40 Sequential Quicksort Complexity in the average case: Θ(n log n) Divide-and-conquer algorithm First step => divide A[q r] is partitioned into two nonempty subsequences A[q s] and A[s+1 r] such that elements of the first are smaller than or equal to each element of the second subsequence. Second step => conquer Sort the two subsequences by recursively applying quicksort. 40
")
41 Sequential Quicksort Algorithm Pivot (assumed to be the first element of the subsequence) 41
42 Sequential Quicksort: Analysis Complexity of partitioning a sequence of size k: Θ(k) Worst case: always partition into a sequence of one element and one of k-1 elements => T(n) = T(n-1) + Θ(n) => T(n) = Θ(n 2 ) Best case: always partition into two roughly equal size subsequences => T(n) = 2T(n/2) + Θ(n) => T(n) = Θ(n log n) Average case: equally likely to break the sequence into partitions of size 0 and n-1, 1 and n-2, etc. => T(n) = (1/n) n-1 k=0 (T(k) + T(n-1-k)) + Θ(n) => T(n) = Θ(n log n) 42
43 Parallelizing Quicksort Naïve parallelization: execute it initially on a single process then assign one of the subproblems to another process and so on. Upon termination each process contains one element Major drawback: one process must partition the initial array of size n => runtime is bounded below by Ω(n) => not cost optimal Efficient parallelization: do the partitioning steps in parallel! 43
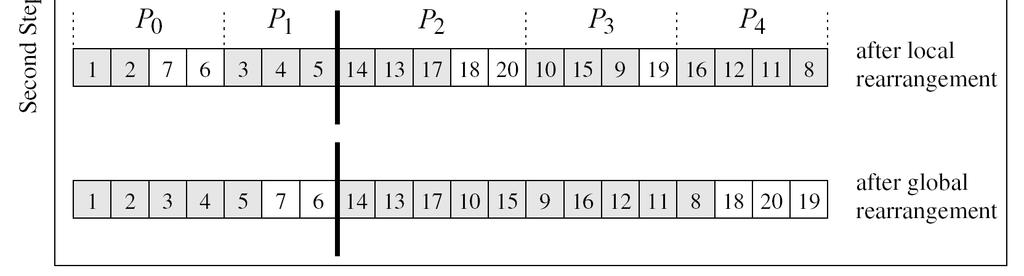
44 Parallelizing Quicksort 44
45 Parallelizing Quicksort 45
46 Efficient Global Rearrangement 46
47 Parallelizing Quicksort Four steps for splitting: 1. Determine and broadcast the pivot => Θ(log p) 2. Locally rearrange the array assigned to each process => Θ(n/p) 3. Determine the locations in the globally rearranged array that the local elements will go to => two prefix sum operations => Θ(log p) 4. Perform the global rearrangement => Θ(n/p) (lower bound) Each of these four steps are executed log p times => Total time for splitting: Θ((n/p)log p) + Θ(log 2 p) The last phase is to sort locally the elements => Θ((n/p)log (n/p)) T p = Θ((n/p)log (n/p)) + Θ((n/p)log p) + Θ(log 2 p) Isoefficiency: Θ(p log 2 p) 47
48 Pivot Selection The split should be done such that each partition has a non-trivial fraction of the original array. Random: During the i-th split one process in each group randomly selects one of its elements to be the pivot. Bad for the parallel implementation Median: Assumes a uniform distribution of the elements in the initial array. n/p elements stored at each process form a representative sample of all n elements. Distribution of elements at each process is the same as the overall distribution. The median at each process approximates the overall median. Pivot = local median Maintains balanced subsequences throughout the execution of the algorithm. 48
49 Bucket Sort Sorts an array of n elements whose values are uniformly distributed over an interval [a,b] Sequential Bucket Sort: Divide [a,b] into m equal-sized subintervals => buckets Place the elements in the appropriate bucket => approximately n/m elements per bucket Sort the elements in each bucket. T s = Θ(n log(n/m)) If m = Θ(n) => T s = Θ(n) linear time! 49
50 Parallel Bucket Sort Each process represents a bucket (m = p) Parallel Bucket Sort: Each process partitions its block into p processes. Each process sorts its bucket. The uniform distribution assumption is not realistic If the distribution is not uniform sub-blocks => buckets have a significantly different number of elements => degrading the performance 50
51 Sample Sort Does not assume uniform distribution. A sample of size s is selected from the n element sequence Sort the sample and select m-1 elements (splitters). Splitters determine the range of the buckets After the buckets are determined the algorithm proceeds as in bucket sort. 51
52 Parallel Sample Sort 52
53 Parallel Sample Sort: Analysis p processes message-passing computer and O(p) bisection bandwidth. Parallel Sample Sort Internal sort => Θ((n/p)log (n/p)) Selection of p-1 samples =>Θ(p) Send p-1 elements to P 0 (gather) =>Θ(p 2 ) Internal sort of p(p-1) elements at P 0 => Θ(p 2 log p) Select p-1 splitters at P 0 => Θ(p) Broadcast p-1 splitters =>Θ(p log p) Each process partitions its blocks into p sub-blocks, one for each bucket => p-1 binary searches => Θ(p log (n/p)) What s the algorithm? Each process sends sub-blocks to the appropriate processes (if distribution is close to uniform then size of sub-blocks is approx n/p 2 and assume Hypercube) (t s + t w mp/2)log p => Θ((n/p)log p) T p = Θ((n/p)log (n/p)) + Θ(p 2 log p) + Θ(p log (n/p)) + Θ((n/p)log p) Isoefficiency function:θ(p 3 log p) 53
Lecture 8 Parallel Algorithms II
 Lecture 8 Parallel Algorithms II Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Original slides from Introduction to Parallel
Lecture 8 Parallel Algorithms II Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Original slides from Introduction to Parallel
Sorting Algorithms. Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar
 Sorting Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003. Topic Overview Issues in Sorting on Parallel
Sorting Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel Computing'', Addison Wesley, 2003. Topic Overview Issues in Sorting on Parallel
CSC 447: Parallel Programming for Multi- Core and Cluster Systems
 CSC 447: Parallel Programming for Multi- Core and Cluster Systems Parallel Sorting Algorithms Instructor: Haidar M. Harmanani Spring 2016 Topic Overview Issues in Sorting on Parallel Computers Sorting
CSC 447: Parallel Programming for Multi- Core and Cluster Systems Parallel Sorting Algorithms Instructor: Haidar M. Harmanani Spring 2016 Topic Overview Issues in Sorting on Parallel Computers Sorting
Sorting (Chapter 9) Alexandre David B2-206
 Alexandre David B2-206") Sorting (Chapter 9) Alexandre David B2-206 Sorting Problem Arrange an unordered collection of elements into monotonically increasing (or decreasing) order. Let S = . Sort S into S =
Sorting (Chapter 9) Alexandre David B2-206 Sorting Problem Arrange an unordered collection of elements into monotonically increasing (or decreasing) order. Let S = . Sort S into S =
Sorting (Chapter 9) Alexandre David B2-206
 Alexandre David B2-206") Sorting (Chapter 9) Alexandre David B2-206 1 Sorting Problem Arrange an unordered collection of elements into monotonically increasing (or decreasing) order. Let S = . Sort S into S =
Sorting (Chapter 9) Alexandre David B2-206 1 Sorting Problem Arrange an unordered collection of elements into monotonically increasing (or decreasing) order. Let S = . Sort S into S =
Parallel Systems Course: Chapter VIII. Sorting Algorithms. Kumar Chapter 9. Jan Lemeire ETRO Dept. Fall Parallel Sorting
 Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. Fall 2017 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. Fall 2017 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Parallel Systems Course: Chapter VIII. Sorting Algorithms. Kumar Chapter 9. Jan Lemeire ETRO Dept. November Parallel Sorting
 Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. November 2014 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. November 2014 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
CSC630/CSC730 Parallel & Distributed Computing
 CSC630/CSC730 Parallel & Distributed Computing Parallel Sorting Chapter 9 1 Contents General issues Sorting network Bitonic sort Bubble sort and its variants Odd-even transposition Quicksort Other Sorting
CSC630/CSC730 Parallel & Distributed Computing Parallel Sorting Chapter 9 1 Contents General issues Sorting network Bitonic sort Bubble sort and its variants Odd-even transposition Quicksort Other Sorting
Introduction to Parallel Computing
 Introduction to Parallel Computing George Karypis Sorting Outline Background Sorting Networks Quicksort Bucket-Sort & Sample-Sort Background Input Specification Each processor has n/p elements A ordering
Introduction to Parallel Computing George Karypis Sorting Outline Background Sorting Networks Quicksort Bucket-Sort & Sample-Sort Background Input Specification Each processor has n/p elements A ordering
Sorting Algorithms. Slides used during lecture of 8/11/2013 (D. Roose) Adapted from slides by
 Adapted from slides by") Sorting Algorithms Slides used during lecture of 8/11/2013 (D. Roose) Adapted from slides by Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel
Sorting Algorithms Slides used during lecture of 8/11/2013 (D. Roose) Adapted from slides by Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text ``Introduction to Parallel
Algorithms and Applications
 Algorithms and Applications 1 Areas done in textbook: Sorting Algorithms Numerical Algorithms Image Processing Searching and Optimization 2 Chapter 10 Sorting Algorithms - rearranging a list of numbers
Algorithms and Applications 1 Areas done in textbook: Sorting Algorithms Numerical Algorithms Image Processing Searching and Optimization 2 Chapter 10 Sorting Algorithms - rearranging a list of numbers
CS475 Parallel Programming
 CS475 Parallel Programming Sorting Wim Bohm, Colorado State University Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 license. Sorting
CS475 Parallel Programming Sorting Wim Bohm, Colorado State University Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 license. Sorting
With regards to bitonic sorts, everything boils down to doing bitonic sorts efficiently.
 Lesson 2 5 Distributed Memory Sorting Bitonic Sort The pseudo code for generating a bitonic sequence: 1. create two bitonic subsequences 2. Make one an increasing sequence 3. Make one into a decreasing
Lesson 2 5 Distributed Memory Sorting Bitonic Sort The pseudo code for generating a bitonic sequence: 1. create two bitonic subsequences 2. Make one an increasing sequence 3. Make one into a decreasing
Sorting Algorithms. - rearranging a list of numbers into increasing (or decreasing) order. Potential Speedup
 order. Potential Speedup") Sorting Algorithms - rearranging a list of numbers into increasing (or decreasing) order. Potential Speedup The worst-case time complexity of mergesort and the average time complexity of quicksort are
Sorting Algorithms - rearranging a list of numbers into increasing (or decreasing) order. Potential Speedup The worst-case time complexity of mergesort and the average time complexity of quicksort are
Information Coding / Computer Graphics, ISY, LiTH
 Sorting on GPUs Revisiting some algorithms from lecture 6: Some not-so-good sorting approaches Bitonic sort QuickSort Concurrent kernels and recursion Adapt to parallel algorithms Many sorting algorithms
Sorting on GPUs Revisiting some algorithms from lecture 6: Some not-so-good sorting approaches Bitonic sort QuickSort Concurrent kernels and recursion Adapt to parallel algorithms Many sorting algorithms
John Mellor-Crummey Department of Computer Science Rice University
 Parallel Sorting John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 23 6 April 2017 Topics for Today Introduction Sorting networks and Batcher s bitonic
Parallel Sorting John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 23 6 April 2017 Topics for Today Introduction Sorting networks and Batcher s bitonic
Parallel Sorting Algorithms
 Parallel Sorting Algorithms Ricardo Rocha and Fernando Silva Computer Science Department Faculty of Sciences University of Porto Parallel Computing 2016/2017 (Slides based on the book Parallel Programming:
Parallel Sorting Algorithms Ricardo Rocha and Fernando Silva Computer Science Department Faculty of Sciences University of Porto Parallel Computing 2016/2017 (Slides based on the book Parallel Programming:
08 A: Sorting III. CS1102S: Data Structures and Algorithms. Martin Henz. March 10, Generated on Tuesday 9 th March, 2010, 09:58
 08 A: Sorting III CS1102S: Data Structures and Algorithms Martin Henz March 10, 2010 Generated on Tuesday 9 th March, 2010, 09:58 CS1102S: Data Structures and Algorithms 08 A: Sorting III 1 1 Recap: Sorting
08 A: Sorting III CS1102S: Data Structures and Algorithms Martin Henz March 10, 2010 Generated on Tuesday 9 th March, 2010, 09:58 CS1102S: Data Structures and Algorithms 08 A: Sorting III 1 1 Recap: Sorting
Parallel Sorting. Sathish Vadhiyar
 Parallel Sorting Sathish Vadhiyar Parallel Sorting Problem The input sequence of size N is distributed across P processors The output is such that elements in each processor P i is sorted elements in P
Parallel Sorting Sathish Vadhiyar Parallel Sorting Problem The input sequence of size N is distributed across P processors The output is such that elements in each processor P i is sorted elements in P
How many leaves on the decision tree? There are n! leaves, because every permutation appears at least once.
 Chapter 8. Sorting in Linear Time Types of Sort Algorithms The only operation that may be used to gain order information about a sequence is comparison of pairs of elements. Quick Sort -- comparison-based
Chapter 8. Sorting in Linear Time Types of Sort Algorithms The only operation that may be used to gain order information about a sequence is comparison of pairs of elements. Quick Sort -- comparison-based
Sorting and Selection
 Sorting and Selection Introduction Divide and Conquer Merge-Sort Quick-Sort Radix-Sort Bucket-Sort 10-1 Introduction Assuming we have a sequence S storing a list of keyelement entries. The key of the element
Sorting and Selection Introduction Divide and Conquer Merge-Sort Quick-Sort Radix-Sort Bucket-Sort 10-1 Introduction Assuming we have a sequence S storing a list of keyelement entries. The key of the element
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Problem. Input: An array A = (A[1],..., A[n]) with length n. Output: a permutation A of A, that is sorted: A [i] A [j] for all. 1 i j n.
![Problem. Input: An array A = (A[1],..., A[n]) with length n. Output: a permutation A of A, that is sorted: A [i] A [j] for all. 1 i j n.](/thumbs/84/89326706.jpg "Problem. Input: An array A = (A[1],..., A[n]) with length n. Output: a permutation A of A, that is sorted: A [i] A [j] for all. 1 i j n.") Problem 5. Sorting Simple Sorting, Quicksort, Mergesort Input: An array A = (A[1],..., A[n]) with length n. Output: a permutation A of A, that is sorted: A [i] A [j] for all 1 i j n. 98 99 Selection Sort
Problem 5. Sorting Simple Sorting, Quicksort, Mergesort Input: An array A = (A[1],..., A[n]) with length n. Output: a permutation A of A, that is sorted: A [i] A [j] for all 1 i j n. 98 99 Selection Sort
Lesson 1 4. Prefix Sum Definitions. Scans. Parallel Scans. A Naive Parallel Scans
 Lesson 1 4 Prefix Sum Definitions Prefix sum given an array...the prefix sum is the sum of all the elements in the array from the beginning to the position, including the value at the position. The sequential
Lesson 1 4 Prefix Sum Definitions Prefix sum given an array...the prefix sum is the sum of all the elements in the array from the beginning to the position, including the value at the position. The sequential
Unit 6 Chapter 15 EXAMPLES OF COMPLEXITY CALCULATION
 DESIGN AND ANALYSIS OF ALGORITHMS Unit 6 Chapter 15 EXAMPLES OF COMPLEXITY CALCULATION http://milanvachhani.blogspot.in EXAMPLES FROM THE SORTING WORLD Sorting provides a good set of examples for analyzing
DESIGN AND ANALYSIS OF ALGORITHMS Unit 6 Chapter 15 EXAMPLES OF COMPLEXITY CALCULATION http://milanvachhani.blogspot.in EXAMPLES FROM THE SORTING WORLD Sorting provides a good set of examples for analyzing
COMP Data Structures
 COMP 2140 - Data Structures Shahin Kamali Topic 5 - Sorting University of Manitoba Based on notes by S. Durocher. COMP 2140 - Data Structures 1 / 55 Overview Review: Insertion Sort Merge Sort Quicksort
COMP 2140 - Data Structures Shahin Kamali Topic 5 - Sorting University of Manitoba Based on notes by S. Durocher. COMP 2140 - Data Structures 1 / 55 Overview Review: Insertion Sort Merge Sort Quicksort
Lecture 4: Graph Algorithms
 Lecture 4: Graph Algorithms Definitions Undirected graph: G =(V, E) V finite set of vertices, E finite set of edges any edge e = (u,v) is an unordered pair Directed graph: edges are ordered pairs If e
Lecture 4: Graph Algorithms Definitions Undirected graph: G =(V, E) V finite set of vertices, E finite set of edges any edge e = (u,v) is an unordered pair Directed graph: edges are ordered pairs If e
CS256 Applied Theory of Computation
 CS256 Applied Theory of Computation Parallel Computation II John E Savage Overview Mesh-based architectures Hypercubes Embedding meshes in hypercubes Normal algorithms on hypercubes Summing and broadcasting
CS256 Applied Theory of Computation Parallel Computation II John E Savage Overview Mesh-based architectures Hypercubes Embedding meshes in hypercubes Normal algorithms on hypercubes Summing and broadcasting
Design and Analysis of Algorithms
 Design and Analysis of Algorithms CSE 5311 Lecture 8 Sorting in Linear Time Junzhou Huang, Ph.D. Department of Computer Science and Engineering CSE5311 Design and Analysis of Algorithms 1 Sorting So Far
Design and Analysis of Algorithms CSE 5311 Lecture 8 Sorting in Linear Time Junzhou Huang, Ph.D. Department of Computer Science and Engineering CSE5311 Design and Analysis of Algorithms 1 Sorting So Far
Parallel Sorting Algorithms
 CSC 391/691: GPU Programming Fall 015 Parallel Sorting Algorithms Copyright 015 Samuel S. Cho Sorting Algorithms Review Bubble Sort: O(n ) Insertion Sort: O(n ) Quick Sort: O(n log n) Heap Sort: O(n log
CSC 391/691: GPU Programming Fall 015 Parallel Sorting Algorithms Copyright 015 Samuel S. Cho Sorting Algorithms Review Bubble Sort: O(n ) Insertion Sort: O(n ) Quick Sort: O(n log n) Heap Sort: O(n log
Jana Kosecka. Linear Time Sorting, Median, Order Statistics. Many slides here are based on E. Demaine, D. Luebke slides
 Jana Kosecka Linear Time Sorting, Median, Order Statistics Many slides here are based on E. Demaine, D. Luebke slides Insertion sort: Easy to code Fast on small inputs (less than ~50 elements) Fast on
Jana Kosecka Linear Time Sorting, Median, Order Statistics Many slides here are based on E. Demaine, D. Luebke slides Insertion sort: Easy to code Fast on small inputs (less than ~50 elements) Fast on
Dense Matrix Algorithms
 Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
DIVIDE AND CONQUER ALGORITHMS ANALYSIS WITH RECURRENCE EQUATIONS
 CHAPTER 11 SORTING ACKNOWLEDGEMENT: THESE SLIDES ARE ADAPTED FROM SLIDES PROVIDED WITH DATA STRUCTURES AND ALGORITHMS IN C++, GOODRICH, TAMASSIA AND MOUNT (WILEY 2004) AND SLIDES FROM NANCY M. AMATO AND
CHAPTER 11 SORTING ACKNOWLEDGEMENT: THESE SLIDES ARE ADAPTED FROM SLIDES PROVIDED WITH DATA STRUCTURES AND ALGORITHMS IN C++, GOODRICH, TAMASSIA AND MOUNT (WILEY 2004) AND SLIDES FROM NANCY M. AMATO AND
CPSC 311 Lecture Notes. Sorting and Order Statistics (Chapters 6-9)
") CPSC 311 Lecture Notes Sorting and Order Statistics (Chapters 6-9) Acknowledgement: These notes are compiled by Nancy Amato at Texas A&M University. Parts of these course notes are based on notes from
CPSC 311 Lecture Notes Sorting and Order Statistics (Chapters 6-9) Acknowledgement: These notes are compiled by Nancy Amato at Texas A&M University. Parts of these course notes are based on notes from
Lecture 16: Sorting. CS178: Programming Parallel and Distributed Systems. April 2, 2001 Steven P. Reiss
 Lecture 16: Sorting CS178: Programming Parallel and Distributed Systems April 2, 2001 Steven P. Reiss I. Overview A. Before break we started talking about parallel computing and MPI 1. Basic idea of a
Lecture 16: Sorting CS178: Programming Parallel and Distributed Systems April 2, 2001 Steven P. Reiss I. Overview A. Before break we started talking about parallel computing and MPI 1. Basic idea of a
Data Structures and Algorithms CSE 465
 Data Structures and Algorithms CSE 465 LECTURE 4 More Divide and Conquer Binary Search Exponentiation Multiplication Sofya Raskhodnikova and Adam Smith Review questions How long does Merge Sort take on
Data Structures and Algorithms CSE 465 LECTURE 4 More Divide and Conquer Binary Search Exponentiation Multiplication Sofya Raskhodnikova and Adam Smith Review questions How long does Merge Sort take on
SORTING AND SELECTION
 2 < > 1 4 8 6 = 9 CHAPTER 12 SORTING AND SELECTION ACKNOWLEDGEMENT: THESE SLIDES ARE ADAPTED FROM SLIDES PROVIDED WITH DATA STRUCTURES AND ALGORITHMS IN JAVA, GOODRICH, TAMASSIA AND GOLDWASSER (WILEY 2016)
2 < > 1 4 8 6 = 9 CHAPTER 12 SORTING AND SELECTION ACKNOWLEDGEMENT: THESE SLIDES ARE ADAPTED FROM SLIDES PROVIDED WITH DATA STRUCTURES AND ALGORITHMS IN JAVA, GOODRICH, TAMASSIA AND GOLDWASSER (WILEY 2016)
O(n): printing a list of n items to the screen, looking at each item once.
: printing a list of n items to the screen, looking at each item once.") UNIT IV Sorting: O notation efficiency of sorting bubble sort quick sort selection sort heap sort insertion sort shell sort merge sort radix sort. O NOTATION BIG OH (O) NOTATION Big oh : the function f(n)=o(g(n))
UNIT IV Sorting: O notation efficiency of sorting bubble sort quick sort selection sort heap sort insertion sort shell sort merge sort radix sort. O NOTATION BIG OH (O) NOTATION Big oh : the function f(n)=o(g(n))
CSL 860: Modern Parallel
 CSL 860: Modern Parallel Computation PARALLEL SORTING BitonicMerge and Sort Bitonicsequence: {a 0, a 1,, a n-1 }: A sequence with a monotonically increasing part and a monotonically decreasing part For
CSL 860: Modern Parallel Computation PARALLEL SORTING BitonicMerge and Sort Bitonicsequence: {a 0, a 1,, a n-1 }: A sequence with a monotonically increasing part and a monotonically decreasing part For
II (Sorting and) Order Statistics
 Order Statistics") II (Sorting and) Order Statistics Heapsort Quicksort Sorting in Linear Time Medians and Order Statistics 8 Sorting in Linear Time The sorting algorithms introduced thus far are comparison sorts Any comparison
II (Sorting and) Order Statistics Heapsort Quicksort Sorting in Linear Time Medians and Order Statistics 8 Sorting in Linear Time The sorting algorithms introduced thus far are comparison sorts Any comparison
Lower Bound on Comparison-based Sorting
 Lower Bound on Comparison-based Sorting Different sorting algorithms may have different time complexity, how to know whether the running time of an algorithm is best possible? We know of several sorting
Lower Bound on Comparison-based Sorting Different sorting algorithms may have different time complexity, how to know whether the running time of an algorithm is best possible? We know of several sorting
COMP 352 FALL Tutorial 10
 1 COMP 352 FALL 2016 Tutorial 10 SESSION OUTLINE Divide-and-Conquer Method Sort Algorithm Properties Quick Overview on Sorting Algorithms Merge Sort Quick Sort Bucket Sort Radix Sort Problem Solving 2
1 COMP 352 FALL 2016 Tutorial 10 SESSION OUTLINE Divide-and-Conquer Method Sort Algorithm Properties Quick Overview on Sorting Algorithms Merge Sort Quick Sort Bucket Sort Radix Sort Problem Solving 2
Module 3: Sorting and Randomized Algorithms
 Module 3: Sorting and Randomized Algorithms CS 240 - Data Structures and Data Management Sajed Haque Veronika Irvine Taylor Smith Based on lecture notes by many previous cs240 instructors David R. Cheriton
Module 3: Sorting and Randomized Algorithms CS 240 - Data Structures and Data Management Sajed Haque Veronika Irvine Taylor Smith Based on lecture notes by many previous cs240 instructors David R. Cheriton
Module 3: Sorting and Randomized Algorithms
 Module 3: Sorting and Randomized Algorithms CS 240 - Data Structures and Data Management Reza Dorrigiv, Daniel Roche School of Computer Science, University of Waterloo Winter 2010 Reza Dorrigiv, Daniel
Module 3: Sorting and Randomized Algorithms CS 240 - Data Structures and Data Management Reza Dorrigiv, Daniel Roche School of Computer Science, University of Waterloo Winter 2010 Reza Dorrigiv, Daniel
High Performance Computing Programming Paradigms and Scalability Part 6: Examples of Parallel Algorithms
 High Performance Computing Programming Paradigms and Scalability Part 6: Examples of Parallel Algorithms PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering (CiE) Scientific Computing
High Performance Computing Programming Paradigms and Scalability Part 6: Examples of Parallel Algorithms PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering (CiE) Scientific Computing
Module 3: Sorting and Randomized Algorithms. Selection vs. Sorting. Crucial Subroutines. CS Data Structures and Data Management
 Module 3: Sorting and Randomized Algorithms CS 240 - Data Structures and Data Management Sajed Haque Veronika Irvine Taylor Smith Based on lecture notes by many previous cs240 instructors David R. Cheriton
Module 3: Sorting and Randomized Algorithms CS 240 - Data Structures and Data Management Sajed Haque Veronika Irvine Taylor Smith Based on lecture notes by many previous cs240 instructors David R. Cheriton
COMP Analysis of Algorithms & Data Structures
 COMP 3170 - Analysis of Algorithms & Data Structures Shahin Kamali Lecture 6 - Jan. 15, 2018 CLRS 7.1, 7-4, 9.1, 9.3 University of Manitoba COMP 3170 - Analysis of Algorithms & Data Structures 1 / 12 Quick-sort
COMP 3170 - Analysis of Algorithms & Data Structures Shahin Kamali Lecture 6 - Jan. 15, 2018 CLRS 7.1, 7-4, 9.1, 9.3 University of Manitoba COMP 3170 - Analysis of Algorithms & Data Structures 1 / 12 Quick-sort
Introduction. e.g., the item could be an entire block of information about a student, while the search key might be only the student's name
 Chapter 7 Sorting 2 Introduction sorting fundamental task in data management well-studied problem in computer science basic problem given an of items where each item contains a key, rearrange the items
Chapter 7 Sorting 2 Introduction sorting fundamental task in data management well-studied problem in computer science basic problem given an of items where each item contains a key, rearrange the items
Interconnection networks
 Interconnection networks When more than one processor needs to access a memory structure, interconnection networks are needed to route data from processors to memories (concurrent access to a shared memory
Interconnection networks When more than one processor needs to access a memory structure, interconnection networks are needed to route data from processors to memories (concurrent access to a shared memory
CS61BL. Lecture 5: Graphs Sorting
 CS61BL Lecture 5: Graphs Sorting Graphs Graphs Edge Vertex Graphs (Undirected) Graphs (Directed) Graphs (Multigraph) Graphs (Acyclic) Graphs (Cyclic) Graphs (Connected) Graphs (Disconnected) Graphs (Unweighted)
CS61BL Lecture 5: Graphs Sorting Graphs Graphs Edge Vertex Graphs (Undirected) Graphs (Directed) Graphs (Multigraph) Graphs (Acyclic) Graphs (Cyclic) Graphs (Connected) Graphs (Disconnected) Graphs (Unweighted)
Examination Questions Midterm 2
 CS1102s Data Structures and Algorithms 12/3/2010 Examination Questions Midterm 2 This examination question booklet has 6 pages, including this cover page, and contains 12 questions. You have 30 minutes
CS1102s Data Structures and Algorithms 12/3/2010 Examination Questions Midterm 2 This examination question booklet has 6 pages, including this cover page, and contains 12 questions. You have 30 minutes
7. Sorting I. 7.1 Simple Sorting. Problem. Algorithm: IsSorted(A) 1 i j n. Simple Sorting
 1 i j n. Simple Sorting") Simple Sorting 7. Sorting I 7.1 Simple Sorting Selection Sort, Insertion Sort, Bubblesort [Ottman/Widmayer, Kap. 2.1, Cormen et al, Kap. 2.1, 2.2, Exercise 2.2-2, Problem 2-2 19 197 Problem Algorithm:
Simple Sorting 7. Sorting I 7.1 Simple Sorting Selection Sort, Insertion Sort, Bubblesort [Ottman/Widmayer, Kap. 2.1, Cormen et al, Kap. 2.1, 2.2, Exercise 2.2-2, Problem 2-2 19 197 Problem Algorithm:
Presentation for use with the textbook, Algorithm Design and Applications, by M. T. Goodrich and R. Tamassia, Wiley, Merge Sort & Quick Sort
 Presentation for use with the textbook, Algorithm Design and Applications, by M. T. Goodrich and R. Tamassia, Wiley, 2015 Merge Sort & Quick Sort 1 Divide-and-Conquer Divide-and conquer is a general algorithm
Presentation for use with the textbook, Algorithm Design and Applications, by M. T. Goodrich and R. Tamassia, Wiley, 2015 Merge Sort & Quick Sort 1 Divide-and-Conquer Divide-and conquer is a general algorithm
SAMPLE OF THE STUDY MATERIAL PART OF CHAPTER 6. Sorting Algorithms
 SAMPLE OF THE STUDY MATERIAL PART OF CHAPTER 6 6.0 Introduction Sorting algorithms used in computer science are often classified by: Computational complexity (worst, average and best behavior) of element
SAMPLE OF THE STUDY MATERIAL PART OF CHAPTER 6 6.0 Introduction Sorting algorithms used in computer science are often classified by: Computational complexity (worst, average and best behavior) of element
Copyright 2009, Artur Czumaj 1
 CS 244 Algorithm Design Instructor: Artur Czumaj Lecture 2 Sorting You already know sorting algorithms Now you will see more We will want to understand generic techniques used for sorting! Lectures: Monday
CS 244 Algorithm Design Instructor: Artur Czumaj Lecture 2 Sorting You already know sorting algorithms Now you will see more We will want to understand generic techniques used for sorting! Lectures: Monday
The divide and conquer strategy has three basic parts. For a given problem of size n,
 1 Divide & Conquer One strategy for designing efficient algorithms is the divide and conquer approach, which is also called, more simply, a recursive approach. The analysis of recursive algorithms often
1 Divide & Conquer One strategy for designing efficient algorithms is the divide and conquer approach, which is also called, more simply, a recursive approach. The analysis of recursive algorithms often
Sorting Algorithms. + Analysis of the Sorting Algorithms
 Sorting Algorithms + Analysis of the Sorting Algorithms Insertion Sort What if first k elements of array are already sorted? 4, 7, 12, 5, 19, 16 We can shift the tail of the sorted elements list down and
Sorting Algorithms + Analysis of the Sorting Algorithms Insertion Sort What if first k elements of array are already sorted? 4, 7, 12, 5, 19, 16 We can shift the tail of the sorted elements list down and
Parallel quicksort algorithms with isoefficiency analysis. Parallel quicksort algorithmswith isoefficiency analysis p. 1
 Parallel quicksort algorithms with isoefficiency analysis Parallel quicksort algorithmswith isoefficiency analysis p. 1 Overview Sequential quicksort algorithm Three parallel quicksort algorithms Isoefficiency
Parallel quicksort algorithms with isoefficiency analysis Parallel quicksort algorithmswith isoefficiency analysis p. 1 Overview Sequential quicksort algorithm Three parallel quicksort algorithms Isoefficiency
Introduction to Computers and Programming. Today
 Introduction to Computers and Programming Prof. I. K. Lundqvist Lecture 10 April 8 2004 Today How to determine Big-O Compare data structures and algorithms Sorting algorithms 2 How to determine Big-O Partition
Introduction to Computers and Programming Prof. I. K. Lundqvist Lecture 10 April 8 2004 Today How to determine Big-O Compare data structures and algorithms Sorting algorithms 2 How to determine Big-O Partition
Randomized Algorithms: Selection
 Randomized Algorithms: Selection CSE21 Winter 2017, Day 25 (B00), Day 16 (A00) March 15, 2017 http://vlsicad.ucsd.edu/courses/cse21-w17 Selection Problem: WHAT Given list of distinct integers a 1, a 2,,
Randomized Algorithms: Selection CSE21 Winter 2017, Day 25 (B00), Day 16 (A00) March 15, 2017 http://vlsicad.ucsd.edu/courses/cse21-w17 Selection Problem: WHAT Given list of distinct integers a 1, a 2,,
Data Partitioning. Figure 1-31: Communication Topologies. Regular Partitions
 Data In single-program multiple-data (SPMD) parallel programs, global data is partitioned, with a portion of the data assigned to each processing node. Issues relevant to choosing a partitioning strategy
Data In single-program multiple-data (SPMD) parallel programs, global data is partitioned, with a portion of the data assigned to each processing node. Issues relevant to choosing a partitioning strategy
Sorting Shabsi Walfish NYU - Fundamental Algorithms Summer 2006
 Sorting The Sorting Problem Input is a sequence of n items (a 1, a 2,, a n ) The mapping we want is determined by a comparison operation, denoted by Output is a sequence (b 1, b 2,, b n ) such that: {
Sorting The Sorting Problem Input is a sequence of n items (a 1, a 2,, a n ) The mapping we want is determined by a comparison operation, denoted by Output is a sequence (b 1, b 2,, b n ) such that: {
I/O Model. Cache-Oblivious Algorithms : Algorithms in the Real World. Advantages of Cache-Oblivious Algorithms 4/9/13
 I/O Model 15-853: Algorithms in the Real World Locality II: Cache-oblivious algorithms Matrix multiplication Distribution sort Static searching Abstracts a single level of the memory hierarchy Fast memory
I/O Model 15-853: Algorithms in the Real World Locality II: Cache-oblivious algorithms Matrix multiplication Distribution sort Static searching Abstracts a single level of the memory hierarchy Fast memory
CSE373: Data Structure & Algorithms Lecture 21: More Comparison Sorting. Aaron Bauer Winter 2014
 CSE373: Data Structure & Algorithms Lecture 21: More Comparison Sorting Aaron Bauer Winter 2014 The main problem, stated carefully For now, assume we have n comparable elements in an array and we want
CSE373: Data Structure & Algorithms Lecture 21: More Comparison Sorting Aaron Bauer Winter 2014 The main problem, stated carefully For now, assume we have n comparable elements in an array and we want
11/8/2016. Chapter 7 Sorting. Introduction. Introduction. Sorting Algorithms. Sorting. Sorting
 Introduction Chapter 7 Sorting sorting fundamental task in data management well-studied problem in computer science basic problem given an array of items where each item contains a key, rearrange the items
Introduction Chapter 7 Sorting sorting fundamental task in data management well-studied problem in computer science basic problem given an array of items where each item contains a key, rearrange the items
SORTING, SETS, AND SELECTION
 CHAPTER 11 SORTING, SETS, AND SELECTION ACKNOWLEDGEMENT: THESE SLIDES ARE ADAPTED FROM SLIDES PROVIDED WITH DATA STRUCTURES AND ALGORITHMS IN C++, GOODRICH, TAMASSIA AND MOUNT (WILEY 2004) AND SLIDES FROM
CHAPTER 11 SORTING, SETS, AND SELECTION ACKNOWLEDGEMENT: THESE SLIDES ARE ADAPTED FROM SLIDES PROVIDED WITH DATA STRUCTURES AND ALGORITHMS IN C++, GOODRICH, TAMASSIA AND MOUNT (WILEY 2004) AND SLIDES FROM
Chapter 3: The Efficiency of Algorithms. Invitation to Computer Science, C++ Version, Third Edition
 Chapter 3: The Efficiency of Algorithms Invitation to Computer Science, C++ Version, Third Edition Objectives In this chapter, you will learn about: Attributes of algorithms Measuring efficiency Analysis
Chapter 3: The Efficiency of Algorithms Invitation to Computer Science, C++ Version, Third Edition Objectives In this chapter, you will learn about: Attributes of algorithms Measuring efficiency Analysis
Chapter 7 Sorting. Terminology. Selection Sort
 Chapter 7 Sorting Terminology Internal done totally in main memory. External uses auxiliary storage (disk). Stable retains original order if keys are the same. Oblivious performs the same amount of work
Chapter 7 Sorting Terminology Internal done totally in main memory. External uses auxiliary storage (disk). Stable retains original order if keys are the same. Oblivious performs the same amount of work
Lecture 5: Sorting Part A
 Lecture 5: Sorting Part A Heapsort Running time O(n lg n), like merge sort Sorts in place (as insertion sort), only constant number of array elements are stored outside the input array at any time Combines
Lecture 5: Sorting Part A Heapsort Running time O(n lg n), like merge sort Sorts in place (as insertion sort), only constant number of array elements are stored outside the input array at any time Combines
Partitioning. Partition the problem into parts such that each part can be solved separately. 1/22
 Partitioning Partition the problem into parts such that each part can be solved separately. 1/22 Partitioning Partition the problem into parts such that each part can be solved separately. At the end the
Partitioning Partition the problem into parts such that each part can be solved separately. 1/22 Partitioning Partition the problem into parts such that each part can be solved separately. At the end the
The Limits of Sorting Divide-and-Conquer Comparison Sorts II
 The Limits of Sorting Divide-and-Conquer Comparison Sorts II CS 311 Data Structures and Algorithms Lecture Slides Monday, October 12, 2009 Glenn G. Chappell Department of Computer Science University of
The Limits of Sorting Divide-and-Conquer Comparison Sorts II CS 311 Data Structures and Algorithms Lecture Slides Monday, October 12, 2009 Glenn G. Chappell Department of Computer Science University of
University of the Western Cape Department of Computer Science
 University of the Western Cape Department of Computer Science Algorithms and Complexity CSC212 Paper II Final Examination 13 November 2015 Time: 90 Minutes. Marks: 100. UWC number Surname, first name Mark
University of the Western Cape Department of Computer Science Algorithms and Complexity CSC212 Paper II Final Examination 13 November 2015 Time: 90 Minutes. Marks: 100. UWC number Surname, first name Mark
CS2223: Algorithms Sorting Algorithms, Heap Sort, Linear-time sort, Median and Order Statistics
 CS2223: Algorithms Sorting Algorithms, Heap Sort, Linear-time sort, Median and Order Statistics 1 Sorting 1.1 Problem Statement You are given a sequence of n numbers < a 1, a 2,..., a n >. You need to
CS2223: Algorithms Sorting Algorithms, Heap Sort, Linear-time sort, Median and Order Statistics 1 Sorting 1.1 Problem Statement You are given a sequence of n numbers < a 1, a 2,..., a n >. You need to
CS240 Fall Mike Lam, Professor. Quick Sort
 ??!!!!! CS240 Fall 2015 Mike Lam, Professor Quick Sort Merge Sort Merge sort Sort sublists (divide & conquer) Merge sorted sublists (combine) All the "hard work" is done after recursing Hard to do "in-place"
??!!!!! CS240 Fall 2015 Mike Lam, Professor Quick Sort Merge Sort Merge sort Sort sublists (divide & conquer) Merge sorted sublists (combine) All the "hard work" is done after recursing Hard to do "in-place"
The complexity of Sorting and sorting in linear-time. Median and Order Statistics. Chapter 8 and Chapter 9
 Subject 6 Spring 2017 The complexity of Sorting and sorting in linear-time Median and Order Statistics Chapter 8 and Chapter 9 Disclaimer: These abbreviated notes DO NOT substitute the textbook for this
Subject 6 Spring 2017 The complexity of Sorting and sorting in linear-time Median and Order Statistics Chapter 8 and Chapter 9 Disclaimer: These abbreviated notes DO NOT substitute the textbook for this
CS61B Lectures # Purposes of Sorting. Some Definitions. Classifications. Sorting supports searching Binary search standard example
 Announcements: CS6B Lectures #27 28 We ll be runningapreliminarytestingrun for Project #2 on Tuesday night. Today: Sorting algorithms: why? Insertion, Shell s, Heap, Merge sorts Quicksort Selection Distribution
Announcements: CS6B Lectures #27 28 We ll be runningapreliminarytestingrun for Project #2 on Tuesday night. Today: Sorting algorithms: why? Insertion, Shell s, Heap, Merge sorts Quicksort Selection Distribution
IS 709/809: Computational Methods in IS Research. Algorithm Analysis (Sorting)
") IS 709/809: Computational Methods in IS Research Algorithm Analysis (Sorting) Nirmalya Roy Department of Information Systems University of Maryland Baltimore County www.umbc.edu Sorting Problem Given an
IS 709/809: Computational Methods in IS Research Algorithm Analysis (Sorting) Nirmalya Roy Department of Information Systems University of Maryland Baltimore County www.umbc.edu Sorting Problem Given an
Lower bound for comparison-based sorting
 COMP3600/6466 Algorithms 2018 Lecture 8 1 Lower bound for comparison-based sorting Reading: Cormen et al, Section 8.1 and 8.2 Different sorting algorithms may have different running-time complexities.
COMP3600/6466 Algorithms 2018 Lecture 8 1 Lower bound for comparison-based sorting Reading: Cormen et al, Section 8.1 and 8.2 Different sorting algorithms may have different running-time complexities.
Shell s sort. CS61B Lecture #25. Sorting by Selection: Heapsort. Example of Shell s Sort
 CS6B Lecture #5 Today: Sorting, t. Standard methods Properties of standard methods Selection Readings for Today: DS(IJ), Chapter 8; Readings for Next Topic: Balanced searches, DS(IJ), Chapter ; Shell s
CS6B Lecture #5 Today: Sorting, t. Standard methods Properties of standard methods Selection Readings for Today: DS(IJ), Chapter 8; Readings for Next Topic: Balanced searches, DS(IJ), Chapter ; Shell s
Chapter 3: The Efficiency of Algorithms
 Chapter 3: The Efficiency of Algorithms Invitation to Computer Science, Java Version, Third Edition Objectives In this chapter, you will learn about Attributes of algorithms Measuring efficiency Analysis
Chapter 3: The Efficiency of Algorithms Invitation to Computer Science, Java Version, Third Edition Objectives In this chapter, you will learn about Attributes of algorithms Measuring efficiency Analysis
4. Sorting and Order-Statistics
 4. Sorting and Order-Statistics 4. Sorting and Order-Statistics The sorting problem consists in the following : Input : a sequence of n elements (a 1, a 2,..., a n ). Output : a permutation (a 1, a 2,...,
4. Sorting and Order-Statistics 4. Sorting and Order-Statistics The sorting problem consists in the following : Input : a sequence of n elements (a 1, a 2,..., a n ). Output : a permutation (a 1, a 2,...,
CS 171: Introduction to Computer Science II. Quicksort
 CS 171: Introduction to Computer Science II Quicksort Roadmap MergeSort Recursive Algorithm (top-down) Practical Improvements Non-recursive algorithm (bottom-up) Analysis QuickSort Algorithm Analysis Practical
CS 171: Introduction to Computer Science II Quicksort Roadmap MergeSort Recursive Algorithm (top-down) Practical Improvements Non-recursive algorithm (bottom-up) Analysis QuickSort Algorithm Analysis Practical
Chapter 5. Quicksort. Copyright Oliver Serang, 2018 University of Montana Department of Computer Science
 Chapter 5 Quicsort Copyright Oliver Serang, 08 University of Montana Department of Computer Science Quicsort is famous because of its ability to sort in-place. I.e., it directly modifies the contents of
Chapter 5 Quicsort Copyright Oliver Serang, 08 University of Montana Department of Computer Science Quicsort is famous because of its ability to sort in-place. I.e., it directly modifies the contents of
Divide and Conquer Sorting Algorithms and Noncomparison-based
 Divide and Conquer Sorting Algorithms and Noncomparison-based Sorting Algorithms COMP1927 16x1 Sedgewick Chapters 7 and 8 Sedgewick Chapter 6.10, Chapter 10 DIVIDE AND CONQUER SORTING ALGORITHMS Step 1
Divide and Conquer Sorting Algorithms and Noncomparison-based Sorting Algorithms COMP1927 16x1 Sedgewick Chapters 7 and 8 Sedgewick Chapter 6.10, Chapter 10 DIVIDE AND CONQUER SORTING ALGORITHMS Step 1
Chapter 4. Divide-and-Conquer. Copyright 2007 Pearson Addison-Wesley. All rights reserved.
 Chapter 4 Divide-and-Conquer Copyright 2007 Pearson Addison-Wesley. All rights reserved. Divide-and-Conquer The most-well known algorithm design strategy: 2. Divide instance of problem into two or more
Chapter 4 Divide-and-Conquer Copyright 2007 Pearson Addison-Wesley. All rights reserved. Divide-and-Conquer The most-well known algorithm design strategy: 2. Divide instance of problem into two or more
Chapter 3: The Efficiency of Algorithms Invitation to Computer Science,
 Chapter 3: The Efficiency of Algorithms Invitation to Computer Science, Objectives In this chapter, you will learn about Attributes of algorithms Measuring efficiency Analysis of algorithms When things
Chapter 3: The Efficiency of Algorithms Invitation to Computer Science, Objectives In this chapter, you will learn about Attributes of algorithms Measuring efficiency Analysis of algorithms When things
Week 10. Sorting. 1 Binary heaps. 2 Heapification. 3 Building a heap 4 HEAP-SORT. 5 Priority queues 6 QUICK-SORT. 7 Analysing QUICK-SORT.
 Week 10 1 2 3 4 5 6 Sorting 7 8 General remarks We return to sorting, considering and. Reading from CLRS for week 7 1 Chapter 6, Sections 6.1-6.5. 2 Chapter 7, Sections 7.1, 7.2. Discover the properties
Week 10 1 2 3 4 5 6 Sorting 7 8 General remarks We return to sorting, considering and. Reading from CLRS for week 7 1 Chapter 6, Sections 6.1-6.5. 2 Chapter 7, Sections 7.1, 7.2. Discover the properties
Quicksort. Repeat the process recursively for the left- and rightsub-blocks.
 Quicksort As the name implies, this is the fastest known sorting algorithm in practice. It is excellent for average input but bad for the worst-case input. (you will see later). Basic idea: (another divide-and-conquer
Quicksort As the name implies, this is the fastest known sorting algorithm in practice. It is excellent for average input but bad for the worst-case input. (you will see later). Basic idea: (another divide-and-conquer
PRAM Divide and Conquer Algorithms
 PRAM Divide and Conquer Algorithms (Chapter Five) Introduction: Really three fundamental operations: Divide is the partitioning process Conquer the the process of (eventually) solving the eventual base
PRAM Divide and Conquer Algorithms (Chapter Five) Introduction: Really three fundamental operations: Divide is the partitioning process Conquer the the process of (eventually) solving the eventual base
5. DIVIDE AND CONQUER I
 5. DIVIDE AND CONQUER I mergesort counting inversions closest pair of points randomized quicksort median and selection Lecture slides by Kevin Wayne Copyright 2005 Pearson-Addison Wesley Copyright 2013
5. DIVIDE AND CONQUER I mergesort counting inversions closest pair of points randomized quicksort median and selection Lecture slides by Kevin Wayne Copyright 2005 Pearson-Addison Wesley Copyright 2013
Computer Science & Engineering 423/823 Design and Analysis of Algorithms
 Computer Science & Engineering 423/823 Design and Analysis of s Lecture 01 Medians and s (Chapter 9) Stephen Scott (Adapted from Vinodchandran N. Variyam) 1 / 24 Spring 2010 Given an array A of n distinct
Computer Science & Engineering 423/823 Design and Analysis of s Lecture 01 Medians and s (Chapter 9) Stephen Scott (Adapted from Vinodchandran N. Variyam) 1 / 24 Spring 2010 Given an array A of n distinct
Quick Sort. CSE Data Structures May 15, 2002
 Quick Sort CSE 373 - Data Structures May 15, 2002 Readings and References Reading Section 7.7, Data Structures and Algorithm Analysis in C, Weiss Other References C LR 15-May-02 CSE 373 - Data Structures
Quick Sort CSE 373 - Data Structures May 15, 2002 Readings and References Reading Section 7.7, Data Structures and Algorithm Analysis in C, Weiss Other References C LR 15-May-02 CSE 373 - Data Structures
CSC Design and Analysis of Algorithms
 CSC 8301- Design and Analysis of Algorithms Lecture 6 Divide and Conquer Algorithm Design Technique Divide-and-Conquer The most-well known algorithm design strategy: 1. Divide a problem instance into two
CSC 8301- Design and Analysis of Algorithms Lecture 6 Divide and Conquer Algorithm Design Technique Divide-and-Conquer The most-well known algorithm design strategy: 1. Divide a problem instance into two
Fundamental mathematical techniques reviewed: Mathematical induction Recursion. Typically taught in courses such as Calculus and Discrete Mathematics.
 Fundamental mathematical techniques reviewed: Mathematical induction Recursion Typically taught in courses such as Calculus and Discrete Mathematics. Techniques introduced: Divide-and-Conquer Algorithms
Fundamental mathematical techniques reviewed: Mathematical induction Recursion Typically taught in courses such as Calculus and Discrete Mathematics. Techniques introduced: Divide-and-Conquer Algorithms
Basic Communication Operations (Chapter 4)
") Basic Communication Operations (Chapter 4) Vivek Sarkar Department of Computer Science Rice University vsarkar@cs.rice.edu COMP 422 Lecture 17 13 March 2008 Review of Midterm Exam Outline MPI Example Program:
Basic Communication Operations (Chapter 4) Vivek Sarkar Department of Computer Science Rice University vsarkar@cs.rice.edu COMP 422 Lecture 17 13 March 2008 Review of Midterm Exam Outline MPI Example Program:
Parallel Computing: Parallel Algorithm Design Examples Jin, Hai
 Parallel Computing: Parallel Algorithm Design Examples Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! Given associative operator!! a 0! a 1! a 2!! a
Parallel Computing: Parallel Algorithm Design Examples Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! Given associative operator!! a 0! a 1! a 2!! a
Sorting. Bubble Sort. Pseudo Code for Bubble Sorting: Sorting is ordering a list of elements.
 Sorting Sorting is ordering a list of elements. Types of sorting: There are many types of algorithms exist based on the following criteria: Based on Complexity Based on Memory usage (Internal & External
Sorting Sorting is ordering a list of elements. Types of sorting: There are many types of algorithms exist based on the following criteria: Based on Complexity Based on Memory usage (Internal & External
CS 561, Lecture 1. Jared Saia University of New Mexico
 CS 561, Lecture 1 Jared Saia University of New Mexico Quicksort Based on divide and conquer strategy Worst case is Θ(n 2 ) Expected running time is Θ(n log n) An In-place sorting algorithm Almost always
CS 561, Lecture 1 Jared Saia University of New Mexico Quicksort Based on divide and conquer strategy Worst case is Θ(n 2 ) Expected running time is Θ(n log n) An In-place sorting algorithm Almost always
CSC Design and Analysis of Algorithms. Lecture 6. Divide and Conquer Algorithm Design Technique. Divide-and-Conquer
 CSC 8301- Design and Analysis of Algorithms Lecture 6 Divide and Conquer Algorithm Design Technique Divide-and-Conquer The most-well known algorithm design strategy: 1. Divide a problem instance into two
CSC 8301- Design and Analysis of Algorithms Lecture 6 Divide and Conquer Algorithm Design Technique Divide-and-Conquer The most-well known algorithm design strategy: 1. Divide a problem instance into two
Week 10. Sorting. 1 Binary heaps. 2 Heapification. 3 Building a heap 4 HEAP-SORT. 5 Priority queues 6 QUICK-SORT. 7 Analysing QUICK-SORT.
 Week 10 1 Binary s 2 3 4 5 6 Sorting Binary s 7 8 General remarks Binary s We return to sorting, considering and. Reading from CLRS for week 7 1 Chapter 6, Sections 6.1-6.5. 2 Chapter 7, Sections 7.1,
Week 10 1 Binary s 2 3 4 5 6 Sorting Binary s 7 8 General remarks Binary s We return to sorting, considering and. Reading from CLRS for week 7 1 Chapter 6, Sections 6.1-6.5. 2 Chapter 7, Sections 7.1,