4 Chip Multiprocessors (I) Chip Multiprocessors (ACS MPhil) Robert Mullins
|
|
|
- Alisha Hutchinson
- 6 years ago
- Views:
Transcription
1 4 Chip Multiprocessors (I) Robert Mullins
2 Overview Coherent memory systems Introduction to cache coherency protocols Advanced cache coherency protocols, memory systems and synchronization covered in the next seminar Memory consistency models Discuss tutorial paper in reading group 2
3 Memory We expect memory to provide a set of locations that hold the values we write to them In a uniprocessor system we boost performance by buffering and reordering memory operations and introducing caches These optimisations rarely affect our intuitive view of how memory should behave 3
4 Multiprocessor memory systems How do we expect memory to behave in a multiprocessor system? How can we provide a high-performance memory system? What are the implications of supporting caches and other memory system optimisations? What are the different ways we may organise our memory hierarchy? What impact does the choice of interconnection network have on the memory system? How do we build memory systems that can support hundreds of processors? Seminar 5 4
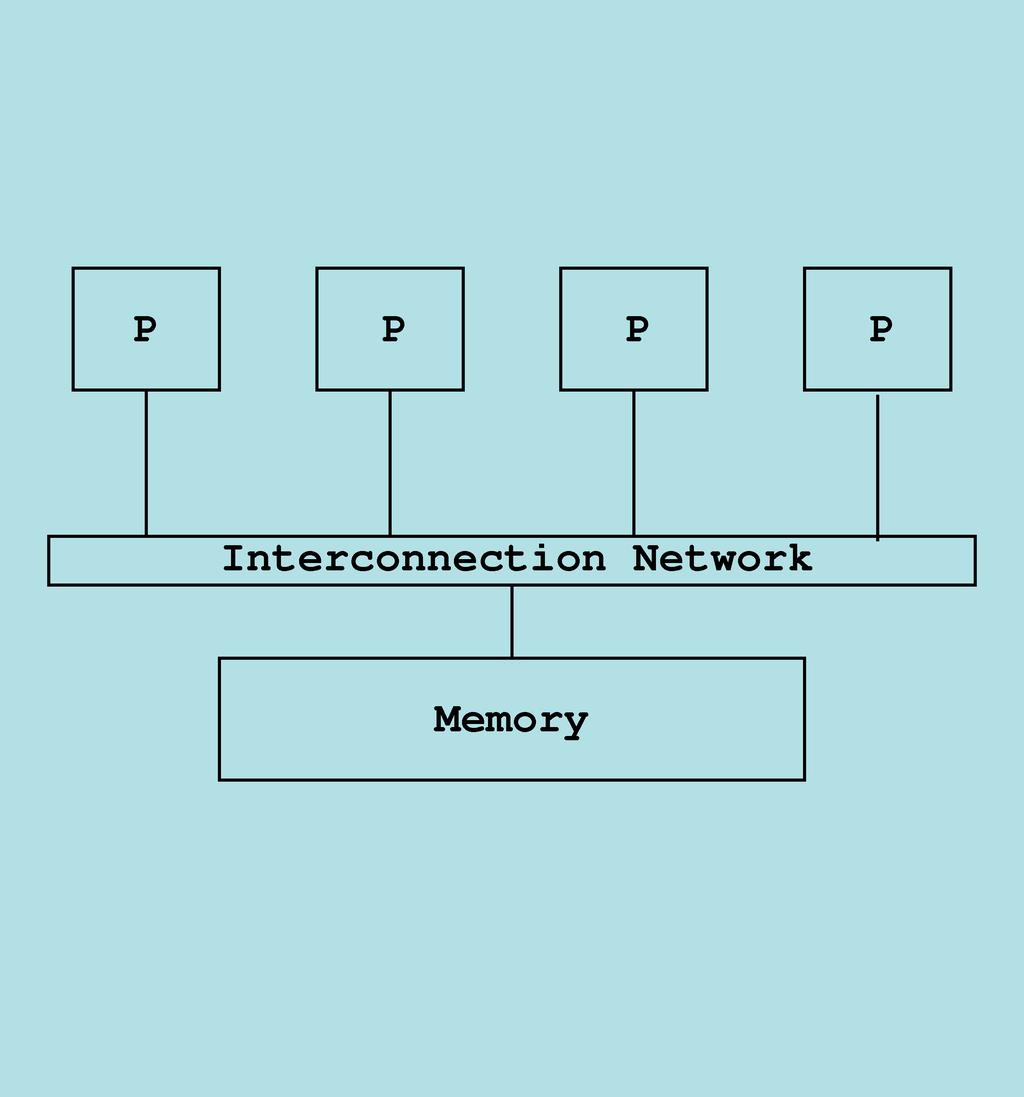
5 Shared-memory 5
6 A coherent memory How might we expect a single memory location to behave when accessed by multiple processors? Informally, we would expect (it would at least appear that) the read/write operations from each processor are interleaved and that the memory location will respond to this combined stream of operations as if it came from a single processor We have no reason to believe that the memory should interleave the accesses from different processors in a particular way (only that individual program orders should be preserved) For any interleaving the memory does permit, it should maintain our expected view of how a memory location should behave 6
7 A coherent memory A memory system is coherent if, for each location, it can serialise all operations such that: 1) Operations issued by each process occur in the order they we issued 2) The value returned by a read operation is the value written by the last write ( last is the most recent operation in the apparent serial order that a coherent memory imposes) Implicit properties: Write propagation writes become visible to other processes Write serialisation all writes to a location are seen in the same order by all processes See Culler book p
8 Coherence invariants Consistency-like definitions of coherence (as presented on the previous slide) are sometimes criticized as not being particularly insightful to the architect. Sorin, Hill and Wood offer an alternative definition: Single-Writer, Multiple-Read (SWMR) invariant: For any memory location A, at any given (logical) time, there exists only a single core that may write to A (and can also read it) or some number of cores that may only read A Data-Value Invariant: The value of the memory location at the start of an epoch is the same as the value of the memory location at the end of its last read-write epoch A primer on memory consistency and cache coherence, Sorin, Hill and Wood 8
9 Is coherence all that we expect? Coherence is concerned with the behaviour of individual memory locations The memory system illustrated (containing locations X and Y) is coherent but does not guarantee anything about when writes become visible to other processors Consider this program: P1 P2 Y=5 X=1 while (X=0) read Y 9
10 Is coherence all that we expect? The operation Y=5 does not need to have completed (as we might expect) before X=1 is performed and X is read by P2 Perhaps surprisingly, this allows P2 to exit from the while loop and read the value 10 from memory location Y, clearly not the intent of the programmer In reality, there are many reasons why the Y=5 write operation may be delayed in this way (e.g. due to congestion in the interconnection network) 10
11 Sequential consistency An intuitive model of an ordering (or consistency model) for a shared address space is Lamport's sequential consistency (SC) A multiprocessor is sequentially consistent if the result of any execution is the same as if the operations of all processors were executed in some sequential order, and the operations of each individual processor occur in this sequence in the order specified by its program 11
12 Sequential consistency Unfortunately, sequential consistency restricts the use of many common memory system optimisations e.g. write buffers, overlapping write operations, non-blocking read operations, use of caches and even compiler optimisations The majority (if not all) modern multiprocessors instead adopt a relaxed memory consistency model We will discuss this in detail in the reading group 12
13 Summary Memory consistency model If we consider a single processor, the memory consistency model determines what reads and writes to memory the compiler or hardware is allowed to reorder. Cache coherency If we consider a single memory location, cache coherence maintains the illusion that data is stored in a single shared memory. This is possible even when the system is actually designed to duplicate data in multiple caches private to each processor. 13
14 Cache coherency Let's examine the problem of providing a coherent memory system in a multiprocessor where each processor has a private cache In general, we consider coherency issues at the boundary between private caches and shared memory (be it main memory or a shared cache) 14
15 Cache coherency X: 14 X: 14 Step 1. Step 2. X: 14 15
16 Cache coherency Step 3. P3 writes 5 to X X: 14 X: 5 X: 14 16
17 Cache coherency Step 4. X=??? Step 5. X=??? X: 14 X: 5 X: 14 17
18 Cache coherency Clearly this memory system can violate our definition of a coherent memory It doesn't even guarantee that writes are propagated This is a result of the ability of the caches to duplicate data 18
19 Cache coherency The most common solution is to add support for cache coherency in hardware reading and writing shared variables is a frequent event, we don't want to restrict caching (to private data) or handle these common events in software We'll look at some alternatives to full coherence Caches automatically replicate and migrate data closer to the processor, they help reduce communication (energy/power/congestion) and memory latency Cache coherent shared memory provides a flexible general-purpose platform Although efficient hardware implementations can quickly become complex 19
20 Cache coherency protocols Let's examine some examples: Simple 2-state write-through invalidate protocol 3-state (MSI) write-back invalidate protocol 4-state MESI (or Illinois) invalidate protocol Dragon (update) protocol 20
21 Cache coherency protocols The simple protocols we will examine today all assume that the processors are connected to main memory via a single shared bus Access to the bus is arbitrated at most one transaction takes place at a time All bus transactions are broadcast and can be observed by all processors (in the same order) Coherence is maintained by having all cache controllers snoop (snoopy protocol) on the bus and monitor the transactions The controller takes action if the bus transaction involves a memory block of which it has a copy 21
22 A bus-based system 22
23 2-state invalidate protocol Let's examine a simple write-through invalidation protocol Write-through caches Every write operation (even if the block is in the cache) causes a write transaction on the bus and main memory to be updated Invalidate or invalidation-based protocols The snooping cache monitors the bus for writes. If it detects that another processor has written to a block it is caching, it invalidates its copy. This requires each cache controller to perform a tag match operation Cache tags can be made dual-ported 23
24 2-state invalidate protocol X: 14 X: 14 Step 1. Step 2. X: 14 24

25 2-state invalidate protocol P3 writes 5 to X Update or invalidate Bus snoop X: 14 X: 5 Write Transaction X: 14 X: 5 In practice coherency is maintained at the granularity of a cache block 25
26 2-state invalidate protocol The protocol is defined by a collection of cooperating finite state machines Each cache controller receives Processor memory requests Information from snooping the bus In response the controller may Update the state of a particular cache block Initiate a new bus transaction The state transitions shown using dotted lines are in response to bus transactions 26
27 MSI write-back invalidate protocol Write-through caches simplify cache coherence as all writes are broadcast over the bus and we can always read the most recent value of a data item from main memory Unfortunately they require additional memory bandwidth. For this reason write-back caches are used in most multiprocessors, as they can support more/faster processors. 27
28 MSI write-back invalidate protocol Cache line states: (S)hared The block is present in an unmodified state in this cache Main memory is up-todate Zero or more up-to-date copies exist in other caches (M)odified Only this cache has a valid copy, the copy in memory is stale Only copy of block 28
29 MSI write-back invalidate protocol Let's build the protocol up in stages... If another cache needs the block that we have in state M (the block is dirty/modified), we must flush the block to memory and provide the data to the requesting cache (over the bus) On a read miss, we get the data in state S (clean unmodified, other copies may exist). Data may come from main memory or be provided by another cache 29
30 MSI write-back invalidate protocol BusRdX ask for a particular block and permission to write to it. If we are holding the requested block and receive a BusRdX, we must transition to the I(nvalid) state 30
31 MSI write-back invalidate protocol The complete protocol 31
32 MSI write-back invalidate protocol The data produced by this BusRdX is ignored as the data is already present in the cache. A common optimisation is to use a BusUpgr (upgrade) transaction instead, to save main memory responding with data. 32
33 MESI protocol Let's consider what happens if we read a block and then subsequently wish to modify it This will require two bus transactions using the 3state MSI protocol But if we know that we have the only copy of the block, the transaction (BusUpgr) required to transition from state S to M is really unnecessary We could safely, and silently, transition from S to M This will be a common event in parallel programs and especially in sequential applications Very common to see sequential apps. running on CMP 33
34 MESI protocol 34
35 MESI protocol If we are in state E and need to write, we require no bus transaction to take place The shared signal (S) is used to determine if any caches currently hold the requested data on a PrRd. BusRd(S) means the bus read transaction caused the shared signal to be asserted (another cache has a copy of the data). BusRd(Not S) means no cache has the data. This signal is used to decide if we transition from state I to S or E 35
36 MESI protocol BusRd/Flush' To enable cache-to-cache sharing we must be sure to select only one cache to provide the required block. Flush' is used to indicate that only one cache will flush the data (in order to supply it to the requesting cache). This is easy in a bus-based system of course as only one transaction can take place at a time. Of course a cache will normally be able to provide the block faster than main memory. 36
37 MESI protocol BusRd/Flush If we are in state M or E and other cache requests the block, we provide the data (we have the only copy) and move to state S (clean & zero or more copies) 37
38 MESI protocol BusRdX/Flush If we are in states M, E or S and receive a BusRdX we simply flush our data and move to state I 38
39 MOESI protocol 39
40 MOESI protocol O(wner) state Other shared copies of this block exist, but memory is stale. This cache (the owner) is responsible for supplying the data when it observes the relevant bus transaction. This avoids the need to write modified data back to memory when another processor wants to read it Look at the M to S transition in the MSI protocol A summary of the cache states and an annotated transition diagram for the MSI protocol (hopefully useful cheat sheets) are available from the course wiki 40
41 MOESI protocol AMD MOESI protocol state transition diagram Reproduced from AMD64 Architecture Programmer's Manual, Volume 2: System Programming p.168 You can think of probe write hit as BusRdX probe read hit as BusRd (the actions taken are omitted from the transitions in this diagram) 41
42 Exercise Processor Action P1 read x P1 state P2 state P3 state S Bus Action Data supplied from BusRd Memory P2 read x P1 write x P1 read x... Add some more processor actions of your own and complete this table for the MSI and MESI protocols we have discussed. 42
43 Update protocols On a write we have two options (1) Invalidate cache copies We have looked at invalidate-based protocols so far (2) Update the cache copies with the new data These are unsurprisingly called update protocols 43
44 Update protocols Update protocols keep the cached copies of the block up to date. Low-latency communication Conserve bandwidth, we only need one update transaction to keep multiple sharers up to date Unnecessary traffic when a single processor writes repeatedly to a block (and no other processor accesses the block) 44
45 Dragon update protocol Dragon protocol (4-state update protocol) Dragon multiprocessor, Xerox, Thacker et al, '84 Culler book p.301 Note: there is no (I) state, blocks are kept up-to-date (E) Exclusive-Clean clean, only-copy of data (Sc) Shared-clean two or more caches potentially have a copy of this block main-memory main or may not be up-to-date The block may be in state Sm in one other cache 45
46 Dragon update protocol (Sm) Shared-modified two or more caches potentially have a copy of this block main-memory is not up-to-date it is this cache's responsibility to update memory (when block is replaced) A block can only be in state Sm in one cache at a time (M) modified (dirty) Only this cache has a copy, the block is dirty (mainmemory's copy is stale) 46
47 Dragon update protocol Since we no longer have an (I)nvalid state we distinguish between a cache miss and cache hit: PrRdMiss and PrRd PrWrMiss and PrWr We also need to support BusUpd (Bus Update transactions) and Update (update block with new data) actions 47
48 Simple update protocol Simple 2-state update protocol We just need to remember who owns the data (the writer) Superfluous bus transactions can be removed by adding states for when we hold the only copy of the data E Exclusive (clean) M Modified (dirty) 48
49 Dragon update protocol 49
50 Update protocols Update vs. invalidate Depends on sharing patterns e.g. producer-consumer pattern favours update Update produces more traffic (scalability and energy cost worries) Could dynamically choose best protocol at run-time or be assisted by compiler hints Recent work In-network cache coherency work from Princeton Analysis of sharing patterns and exploitation of direct cache-to-cache accesses (Cambridge) 50
51 Transient (intermediate) states Nonatomic state transitions Bus transactions are atomic, but a processor's actions are often more complex and must be granted access to bus before they can complete What happens if we snoop a transaction that we must respond to while we are waiting for an outstanding request to be acted upon? e.g. we are waiting for access to the bus 51
52 Transient (intermediate) states Processor Action P1 state P2 state... S S P1/P2 write x (both need to perform a BusUpgr slide 27) P2 wins bus arb. P2 issues a BusUpgr P1 needs to downgrade state of X to I(nvalid) P1 must now issue a BusRdX (not a BusUpgr as orginally planned) Doesn't require a new BusReq I M... BusRdX... Bus Action 52
53 Transient (intermediate) states Note: This figure omits the transitions between the normal states (see Culler book, p.388 for complete state diagram) 53
54 Split-transaction buses An atomic bus remains idle between each request and response (e.g. while data is read from main memory) Split-transaction buses allow multiple outstanding requests in order to make better use of the bus This introduces the possibility of receiving a response to a request after you have snooped a transaction that has resulted in a transition to another state Culler Section
55 Split-transaction buses Example: P1: I->S Issued BusRd and awaiting response (in state IS) The IS state records the fact that the request has been sent P2: S->M Issued an invalidate, P1 sees this before the response to its BusRd P1: P1 can't simply move to state I, it needs to service the outstanding load. Don't want to reissue BusRd either as this may prevent forward progress being made Answer move to another intermediate state (ISI) wait for original response, service load, then move to state I 55
56 Split-transaction buses ISI state: Wait for data from original BusRd Service the outstanding load instruction Move to the I(nvalid) state 56
57 Bus-based cache coherency protocols In a real system it is common to see 4 stable states and perhaps 10 transient states Design and verification is complex Basic concept is relatively simple Optimisations introduce complexity Bugs do slip through the net Problematic for correctness and security Intel Core 2 Duo A139: Cache data access request from one core hitting a modified line in the L1 data cache of the other core may cause unpredictable system behaviour 57
Processor Architecture
 Processor Architecture Shared Memory Multiprocessors M. Schölzel The Coherence Problem s may contain local copies of the same memory address without proper coordination they work independently on their
Processor Architecture Shared Memory Multiprocessors M. Schölzel The Coherence Problem s may contain local copies of the same memory address without proper coordination they work independently on their
Lecture 11: Snooping Cache Coherence: Part II. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Lecture 11: Snooping Cache Coherence: Part II CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 2 due tonight 11:59 PM - Recall 3-late day policy Assignment
Lecture 11: Snooping Cache Coherence: Part II CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 2 due tonight 11:59 PM - Recall 3-late day policy Assignment
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Module 10: "Design of Shared Memory Multiprocessors" Lecture 20: "Performance of Coherence Protocols" MOESI protocol.
 MOESI protocol Dragon protocol State transition Dragon example Design issues General issues Evaluating protocols Protocol optimizations Cache size Cache line size Impact on bus traffic Large cache line
MOESI protocol Dragon protocol State transition Dragon example Design issues General issues Evaluating protocols Protocol optimizations Cache size Cache line size Impact on bus traffic Large cache line
Page 1. SMP Review. Multiprocessors. Bus Based Coherence. Bus Based Coherence. Characteristics. Cache coherence. Cache coherence
 SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
Computer Architecture
 18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
Cache Coherence in Bus-Based Shared Memory Multiprocessors
 Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5)
 Symmetric Multiprocessors Part 1 (Chapter 5)") CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
Cache Coherence. (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri
 Mainak Chaudhuri") Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Lecture 3: Snooping Protocols. Topics: snooping-based cache coherence implementations
 Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Shared Memory Multiprocessors
 Parallel Computing Shared Memory Multiprocessors Hwansoo Han Cache Coherence Problem P 0 P 1 P 2 cache load r1 (100) load r1 (100) r1 =? r1 =? 4 cache 5 cache store b (100) 3 100: a 100: a 1 Memory 2 I/O
Parallel Computing Shared Memory Multiprocessors Hwansoo Han Cache Coherence Problem P 0 P 1 P 2 cache load r1 (100) load r1 (100) r1 =? r1 =? 4 cache 5 cache store b (100) 3 100: a 100: a 1 Memory 2 I/O
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Lecture 11: Cache Coherence: Part II. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 11: Cache Coherence: Part II Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Bang Bang (My Baby Shot Me Down) Nancy Sinatra (Kill Bill Volume 1 Soundtrack) It
Lecture 11: Cache Coherence: Part II Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Bang Bang (My Baby Shot Me Down) Nancy Sinatra (Kill Bill Volume 1 Soundtrack) It
Parallel Computer Architecture Lecture 5: Cache Coherence. Chris Craik (TA) Carnegie Mellon University
 Carnegie Mellon University") 18-742 Parallel Computer Architecture Lecture 5: Cache Coherence Chris Craik (TA) Carnegie Mellon University Readings: Coherence Required for Review Papamarcos and Patel, A low-overhead coherence solution
18-742 Parallel Computer Architecture Lecture 5: Cache Coherence Chris Craik (TA) Carnegie Mellon University Readings: Coherence Required for Review Papamarcos and Patel, A low-overhead coherence solution
Lecture 24: Multiprocessing Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley
 Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols CA SMP and cache coherence
 Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy
 EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University
 EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
A Basic Snooping-Based Multi-Processor Implementation
 Lecture 11: A Basic Snooping-Based Multi-Processor Implementation Parallel Computer Architecture and Programming Tsinghua has its own ice cream! Wow! CMU / 清华 大学, Summer 2017 Review: MSI state transition
Lecture 11: A Basic Snooping-Based Multi-Processor Implementation Parallel Computer Architecture and Programming Tsinghua has its own ice cream! Wow! CMU / 清华 大学, Summer 2017 Review: MSI state transition
Snooping-Based Cache Coherence
 Lecture 10: Snooping-Based Cache Coherence Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Tunes Elle King Ex s & Oh s (Love Stuff) Once word about my code profiling skills
Lecture 10: Snooping-Based Cache Coherence Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Tunes Elle King Ex s & Oh s (Love Stuff) Once word about my code profiling skills
Advanced OpenMP. Lecture 3: Cache Coherency
 Advanced OpenMP Lecture 3: Cache Coherency Cache coherency Main difficulty in building multiprocessor systems is the cache coherency problem. The shared memory programming model assumes that a shared variable
Advanced OpenMP Lecture 3: Cache Coherency Cache coherency Main difficulty in building multiprocessor systems is the cache coherency problem. The shared memory programming model assumes that a shared variable
Multicore Workshop. Cache Coherency. Mark Bull David Henty. EPCC, University of Edinburgh
 Multicore Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh Symmetric MultiProcessing 2 Each processor in an SMP has equal access to all parts of memory same latency and bandwidth
Multicore Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh Symmetric MultiProcessing 2 Each processor in an SMP has equal access to all parts of memory same latency and bandwidth
CS252 Spring 2017 Graduate Computer Architecture. Lecture 12: Cache Coherence
 CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
Cache Coherence. Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T.
 Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L25-1 Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L25-1 Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Memory Hierarchy in a Multiprocessor
 EEC 581 Computer Architecture Multiprocessor and Coherence Department of Electrical Engineering and Computer Science Cleveland State University Hierarchy in a Multiprocessor Shared cache Fully-connected
EEC 581 Computer Architecture Multiprocessor and Coherence Department of Electrical Engineering and Computer Science Cleveland State University Hierarchy in a Multiprocessor Shared cache Fully-connected
Cache Coherence. Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T.
 Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L5- Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L5- Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Switch Gear to Memory Consistency
 Outline Memory consistency equential consistency Invalidation vs. update coherence protocols MI protocol tate diagrams imulation Gehringer, based on slides by Yan olihin 1 witch Gear to Memory Consistency
Outline Memory consistency equential consistency Invalidation vs. update coherence protocols MI protocol tate diagrams imulation Gehringer, based on slides by Yan olihin 1 witch Gear to Memory Consistency
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
NOW Handout Page 1. Recap. Protocol Design Space of Snooping Cache Coherent Multiprocessors. Sequential Consistency.
 Recap Protocol Design Space of Snooping Cache Coherent ultiprocessors CS 28, Spring 99 David E. Culler Computer Science Division U.C. Berkeley Snooping cache coherence solve difficult problem by applying
Recap Protocol Design Space of Snooping Cache Coherent ultiprocessors CS 28, Spring 99 David E. Culler Computer Science Division U.C. Berkeley Snooping cache coherence solve difficult problem by applying
Lecture-22 (Cache Coherence Protocols) CS422-Spring
 CS422-Spring") Lecture-22 (Cache Coherence Protocols) CS422-Spring 2018 Biswa@CSE-IITK Single Core Core 0 Private L1 Cache Bus (Packet Scheduling) Private L2 DRAM CS422: Spring 2018 Biswabandan Panda, CSE@IITK 2 Multicore
Lecture-22 (Cache Coherence Protocols) CS422-Spring 2018 Biswa@CSE-IITK Single Core Core 0 Private L1 Cache Bus (Packet Scheduling) Private L2 DRAM CS422: Spring 2018 Biswabandan Panda, CSE@IITK 2 Multicore
Shared Memory Architectures. Shared Memory Multiprocessors. Caches and Cache Coherence. Cache Memories. Cache Memories Write Operation
 hared Architectures hared Multiprocessors ngo ander ngo@imit.kth.se hared Multiprocessor are often used pecial Class: ymmetric Multiprocessors (MP) o ymmetric access to all of main from any processor A
hared Architectures hared Multiprocessors ngo ander ngo@imit.kth.se hared Multiprocessor are often used pecial Class: ymmetric Multiprocessors (MP) o ymmetric access to all of main from any processor A
Snooping coherence protocols (cont.)
") Snooping coherence protocols (cont.) A four-state update protocol [ 5.3.3] When there is a high degree of sharing, invalidation-based protocols perform poorly. Blocks are often invalidated, and then have
Snooping coherence protocols (cont.) A four-state update protocol [ 5.3.3] When there is a high degree of sharing, invalidation-based protocols perform poorly. Blocks are often invalidated, and then have
Approaches to Building Parallel Machines. Shared Memory Architectures. Example Cache Coherence Problem. Shared Cache Architectures
 Approaches to Building arallel achines Switch/Bus n Scale Shared ory Architectures (nterleaved) First-level (nterleaved) ain memory n Arvind Krishnamurthy Fall 2004 (nterleaved) ain memory Shared Cache
Approaches to Building arallel achines Switch/Bus n Scale Shared ory Architectures (nterleaved) First-level (nterleaved) ain memory n Arvind Krishnamurthy Fall 2004 (nterleaved) ain memory Shared Cache
Portland State University ECE 588/688. Cache Coherence Protocols
 Portland State University ECE 588/688 Cache Coherence Protocols Copyright by Alaa Alameldeen 2018 Conditions for Cache Coherence Program Order. A read by processor P to location A that follows a write
Portland State University ECE 588/688 Cache Coherence Protocols Copyright by Alaa Alameldeen 2018 Conditions for Cache Coherence Program Order. A read by processor P to location A that follows a write
Module 9: Addendum to Module 6: Shared Memory Multiprocessors Lecture 17: Multiprocessor Organizations and Cache Coherence. The Lecture Contains:
 The Lecture Contains: Shared Memory Multiprocessors Shared Cache Private Cache/Dancehall Distributed Shared Memory Shared vs. Private in CMPs Cache Coherence Cache Coherence: Example What Went Wrong? Implementations
The Lecture Contains: Shared Memory Multiprocessors Shared Cache Private Cache/Dancehall Distributed Shared Memory Shared vs. Private in CMPs Cache Coherence Cache Coherence: Example What Went Wrong? Implementations
Module 9: "Introduction to Shared Memory Multiprocessors" Lecture 16: "Multiprocessor Organizations and Cache Coherence" Shared Memory Multiprocessors
 Shared Memory Multiprocessors Shared memory multiprocessors Shared cache Private cache/dancehall Distributed shared memory Shared vs. private in CMPs Cache coherence Cache coherence: Example What went
Shared Memory Multiprocessors Shared memory multiprocessors Shared cache Private cache/dancehall Distributed shared memory Shared vs. private in CMPs Cache coherence Cache coherence: Example What went
Shared Memory Architectures. Approaches to Building Parallel Machines
 Shared Memory Architectures Arvind Krishnamurthy Fall 2004 Approaches to Building Parallel Machines P 1 Switch/Bus P n Scale (Interleaved) First-level $ P 1 P n $ $ (Interleaved) Main memory Shared Cache
Shared Memory Architectures Arvind Krishnamurthy Fall 2004 Approaches to Building Parallel Machines P 1 Switch/Bus P n Scale (Interleaved) First-level $ P 1 P n $ $ (Interleaved) Main memory Shared Cache
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Shared Memory Multiprocessors
 Shared Memory Multiprocessors Jesús Labarta Index 1 Shared Memory architectures............... Memory Interconnect Cache Processor Concepts? Memory Time 2 Concepts? Memory Load/store (@) Containers Time
Shared Memory Multiprocessors Jesús Labarta Index 1 Shared Memory architectures............... Memory Interconnect Cache Processor Concepts? Memory Time 2 Concepts? Memory Load/store (@) Containers Time
Overview: Shared Memory Hardware. Shared Address Space Systems. Shared Address Space and Shared Memory Computers. Shared Memory Hardware
 Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware
 Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
L7 Shared Memory Multiprocessors. Shared Memory Multiprocessors
 L7 Shared Memory Multiprocessors Logical design and software interactions 1 Shared Memory Multiprocessors Symmetric Multiprocessors (SMPs) Symmetric access to all of main memory from any processor Dominate
L7 Shared Memory Multiprocessors Logical design and software interactions 1 Shared Memory Multiprocessors Symmetric Multiprocessors (SMPs) Symmetric access to all of main memory from any processor Dominate
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Foundations of Computer Systems
 18-600 Foundations of Computer Systems Lecture 21: Multicore Cache Coherence John P. Shen & Zhiyi Yu November 14, 2016 Prevalence of multicore processors: 2006: 75% for desktops, 85% for servers 2007:
18-600 Foundations of Computer Systems Lecture 21: Multicore Cache Coherence John P. Shen & Zhiyi Yu November 14, 2016 Prevalence of multicore processors: 2006: 75% for desktops, 85% for servers 2007:
EC 513 Computer Architecture
 EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
Lecture 24: Board Notes: Cache Coherency
 Lecture 24: Board Notes: Cache Coherency Part A: What makes a memory system coherent? Generally, 3 qualities that must be preserved (SUGGESTIONS?) (1) Preserve program order: - A read of A by P 1 will
Lecture 24: Board Notes: Cache Coherency Part A: What makes a memory system coherent? Generally, 3 qualities that must be preserved (SUGGESTIONS?) (1) Preserve program order: - A read of A by P 1 will
Multiprocessors 1. Outline
 Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
1. Memory technology & Hierarchy
 1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
CS315A Midterm Solutions
 K. Olukotun Spring 05/06 Handout #14 CS315a CS315A Midterm Solutions Open Book, Open Notes, Calculator okay NO computer. (Total time = 120 minutes) Name (please print): Solutions I agree to abide by the
K. Olukotun Spring 05/06 Handout #14 CS315a CS315A Midterm Solutions Open Book, Open Notes, Calculator okay NO computer. (Total time = 120 minutes) Name (please print): Solutions I agree to abide by the
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Recall: Sequential Consistency. CS 258 Parallel Computer Architecture Lecture 15. Sequential Consistency and Snoopy Protocols
 CS 258 Parallel Computer Architecture Lecture 15 Sequential Consistency and Snoopy Protocols arch 17, 2008 Prof John D. Kubiatowicz http://www.cs.berkeley.edu/~kubitron/cs258 ecall: Sequential Consistency
CS 258 Parallel Computer Architecture Lecture 15 Sequential Consistency and Snoopy Protocols arch 17, 2008 Prof John D. Kubiatowicz http://www.cs.berkeley.edu/~kubitron/cs258 ecall: Sequential Consistency
Physical Design of Snoop-Based Cache Coherence on Multiprocessors
 Physical Design of Snoop-Based Cache Coherence on Multiprocessors Muge Guher University Of Ottawa Abstract This report focuses on the hardware design issues associated with the physical implementation
Physical Design of Snoop-Based Cache Coherence on Multiprocessors Muge Guher University Of Ottawa Abstract This report focuses on the hardware design issues associated with the physical implementation
5 Chip Multiprocessors (II) Chip Multiprocessors (ACS MPhil) Robert Mullins
 Chip Multiprocessors (ACS MPhil) Robert Mullins") 5 Chip Multiprocessors (II) Chip Multiprocessors (ACS MPhil) Robert Mullins Overview Synchronization hardware primitives Cache Coherency Issues Coherence misses, false sharing Cache coherence and interconnects
5 Chip Multiprocessors (II) Chip Multiprocessors (ACS MPhil) Robert Mullins Overview Synchronization hardware primitives Cache Coherency Issues Coherence misses, false sharing Cache coherence and interconnects
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano
 Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Cache Coherence. Bryan Mills, PhD. Slides provided by Rami Melhem
 Cache Coherence Bryan Mills, PhD Slides provided by Rami Melhem Cache coherence Programmers have no control over caches and when they get updated. x = 2; /* initially */ y0 eventually ends up = 2 y1 eventually
Cache Coherence Bryan Mills, PhD Slides provided by Rami Melhem Cache coherence Programmers have no control over caches and when they get updated. x = 2; /* initially */ y0 eventually ends up = 2 y1 eventually
A Basic Snooping-Based Multi-Processor Implementation
 Lecture 15: A Basic Snooping-Based Multi-Processor Implementation Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Pushing On (Oliver $ & Jimi Jules) Time for the second
Lecture 15: A Basic Snooping-Based Multi-Processor Implementation Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Pushing On (Oliver $ & Jimi Jules) Time for the second
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Snooping coherence protocols (cont.)
") Snooping coherence protocols (cont.) A four-state update protocol [ 5.3.3] When there is a high degree of sharing, invalidation-based protocols perform poorly. Blocks are often invalidated, and then have
Snooping coherence protocols (cont.) A four-state update protocol [ 5.3.3] When there is a high degree of sharing, invalidation-based protocols perform poorly. Blocks are often invalidated, and then have
Alewife Messaging. Sharing of Network Interface. Alewife User-level event mechanism. CS252 Graduate Computer Architecture.
 CS252 Graduate Computer Architecture Lecture 18 April 5 th, 2010 ory Consistency Models and Snoopy Bus Protocols Alewife Messaging Send message write words to special network interface registers Execute
CS252 Graduate Computer Architecture Lecture 18 April 5 th, 2010 ory Consistency Models and Snoopy Bus Protocols Alewife Messaging Send message write words to special network interface registers Execute
Computer Architecture and Engineering CS152 Quiz #5 April 27th, 2016 Professor George Michelogiannakis Name: <ANSWER KEY>
 Computer Architecture and Engineering CS152 Quiz #5 April 27th, 2016 Professor George Michelogiannakis Name: This is a closed book, closed notes exam. 80 Minutes 19 pages Notes: Not all questions
Computer Architecture and Engineering CS152 Quiz #5 April 27th, 2016 Professor George Michelogiannakis Name: This is a closed book, closed notes exam. 80 Minutes 19 pages Notes: Not all questions
CMSC 611: Advanced. Distributed & Shared Memory
 CMSC 611: Advanced Computer Architecture Distributed & Shared Memory Centralized Shared Memory MIMD Processors share a single centralized memory through a bus interconnect Feasible for small processor
CMSC 611: Advanced Computer Architecture Distributed & Shared Memory Centralized Shared Memory MIMD Processors share a single centralized memory through a bus interconnect Feasible for small processor
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
Page 1. Cache Coherence
 Page 1 Cache Coherence 1 Page 2 Memory Consistency in SMPs CPU-1 CPU-2 A 100 cache-1 A 100 cache-2 CPU-Memory bus A 100 memory Suppose CPU-1 updates A to 200. write-back: memory and cache-2 have stale
Page 1 Cache Coherence 1 Page 2 Memory Consistency in SMPs CPU-1 CPU-2 A 100 cache-1 A 100 cache-2 CPU-Memory bus A 100 memory Suppose CPU-1 updates A to 200. write-back: memory and cache-2 have stale
Cray XE6 Performance Workshop
 Cray XE6 Performance Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh ymmetric MultiProcessing Each processor in an MP has equal access to all parts of memory same latency and
Cray XE6 Performance Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh ymmetric MultiProcessing Each processor in an MP has equal access to all parts of memory same latency and
Scalable Cache Coherence
 Scalable Cache Coherence [ 8.1] All of the cache-coherent systems we have talked about until now have had a bus. Not only does the bus guarantee serialization of transactions; it also serves as convenient
Scalable Cache Coherence [ 8.1] All of the cache-coherent systems we have talked about until now have had a bus. Not only does the bus guarantee serialization of transactions; it also serves as convenient
CMSC Computer Architecture Lecture 15: Memory Consistency and Synchronization. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 15: Memory Consistency and Synchronization Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Basic requirements: out later today
CMSC 22200 Computer Architecture Lecture 15: Memory Consistency and Synchronization Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Basic requirements: out later today
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
A More Sophisticated Snooping-Based Multi-Processor
 Lecture 16: A More Sophisticated Snooping-Based Multi-Processor Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes The Projects Handsome Boy Modeling School (So... How
Lecture 16: A More Sophisticated Snooping-Based Multi-Processor Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes The Projects Handsome Boy Modeling School (So... How
Lecture 7: Implementing Cache Coherence. Topics: implementation details
 Lecture 7: Implementing Cache Coherence Topics: implementation details 1 Implementing Coherence Protocols Correctness and performance are not the only metrics Deadlock: a cycle of resource dependencies,
Lecture 7: Implementing Cache Coherence Topics: implementation details 1 Implementing Coherence Protocols Correctness and performance are not the only metrics Deadlock: a cycle of resource dependencies,
Bus-Based Coherent Multiprocessors
 Bus-Based Coherent Multiprocessors Lecture 13 (Chapter 7) 1 Outline Bus-based coherence Memory consistency Sequential consistency Invalidation vs. update coherence protocols Several Configurations for
Bus-Based Coherent Multiprocessors Lecture 13 (Chapter 7) 1 Outline Bus-based coherence Memory consistency Sequential consistency Invalidation vs. update coherence protocols Several Configurations for
Lecture 25: Multiprocessors. Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization
 Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
The Cache Write Problem
 Cache Coherency A multiprocessor and a multicomputer each comprise a number of independent processors connected by a communications medium, either a bus or more advanced switching system, such as a crossbar
Cache Coherency A multiprocessor and a multicomputer each comprise a number of independent processors connected by a communications medium, either a bus or more advanced switching system, such as a crossbar
Shared Symmetric Memory Systems
 Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Shared-Memory Multi-Processors Shared-Memory Multiprocessors Multiple threads use shared memory (address space) SysV Shared Memory or Threads in software Communication implicit
CSE 502: Computer Architecture Shared-Memory Multi-Processors Shared-Memory Multiprocessors Multiple threads use shared memory (address space) SysV Shared Memory or Threads in software Communication implicit
Review: Symmetric Multiprocesors (SMP)
") CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 2 Copyright 2005 Mark D. Hill University of Wisconsin-Madison Slides are derived from work
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 2 Copyright 2005 Mark D. Hill University of Wisconsin-Madison Slides are derived from work
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Shared Memory Most slides adapted from David Patterson. Some from Mohomed Younis Interconnection Networks Massively processor networks (MPP) Thousands of nodes
CMSC 611: Advanced Computer Architecture Shared Memory Most slides adapted from David Patterson. Some from Mohomed Younis Interconnection Networks Massively processor networks (MPP) Thousands of nodes
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
Lecture 1: Introduction
 Lecture 1: Introduction ourse organization: 4 lectures on cache coherence and consistency 2 lectures on transactional memory 2 lectures on interconnection networks 4 lectures on caches 4 lectures on memory
Lecture 1: Introduction ourse organization: 4 lectures on cache coherence and consistency 2 lectures on transactional memory 2 lectures on interconnection networks 4 lectures on caches 4 lectures on memory
Lecture 7: PCM Wrap-Up, Cache coherence. Topics: handling PCM errors and writes, cache coherence intro
 Lecture 7: M Wrap-Up, ache coherence Topics: handling M errors and writes, cache coherence intro 1 Optimizations for Writes (Energy, Lifetime) Read a line before writing and only write the modified bits
Lecture 7: M Wrap-Up, ache coherence Topics: handling M errors and writes, cache coherence intro 1 Optimizations for Writes (Energy, Lifetime) Read a line before writing and only write the modified bits
5 Chip Multiprocessors (II) Robert Mullins
 Robert Mullins") 5 Chip Multiprocessors (II) ( MPhil Chip Multiprocessors (ACS Robert Mullins Overview Synchronization hardware primitives Cache Coherency Issues Coherence misses Cache coherence and interconnects Directory-based
5 Chip Multiprocessors (II) ( MPhil Chip Multiprocessors (ACS Robert Mullins Overview Synchronization hardware primitives Cache Coherency Issues Coherence misses Cache coherence and interconnects Directory-based
Module 5: Performance Issues in Shared Memory and Introduction to Coherence Lecture 10: Introduction to Coherence. The Lecture Contains:
 The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
Aleksandar Milenkovich 1
 Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
A Basic Snooping-Based Multi-processor
 Lecture 15: A Basic Snooping-Based Multi-processor Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes Stompa (Serena Ryder) I wrote Stompa because I just get so excited
Lecture 15: A Basic Snooping-Based Multi-processor Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes Stompa (Serena Ryder) I wrote Stompa because I just get so excited
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Suggested Readings! What makes a memory system coherent?! Lecture 27" Cache Coherency! ! Readings! ! Program order!! Sequential writes!! Causality!
 1! 2! Suggested Readings! Readings!! H&P: Chapter 5.8! Could also look at material on CD referenced on p. 538 of your text! Lecture 27" Cache Coherency! 3! Processor components! Multicore processors and
1! 2! Suggested Readings! Readings!! H&P: Chapter 5.8! Could also look at material on CD referenced on p. 538 of your text! Lecture 27" Cache Coherency! 3! Processor components! Multicore processors and
Chapter-4 Multiprocessors and Thread-Level Parallelism
 Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Wenisch Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar. Prof. Thomas Wenisch. Lecture 23 EECS 470.
 Multiprocessors Fall 2007 Prof. Thomas Wenisch www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth Shen, Smith, Sohi, and Vijaykumar of Carnegie
Multiprocessors Fall 2007 Prof. Thomas Wenisch www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth Shen, Smith, Sohi, and Vijaykumar of Carnegie
CMSC 411 Computer Systems Architecture Lecture 21 Multiprocessors 3
 MS 411 omputer Systems rchitecture Lecture 21 Multiprocessors 3 Outline Review oherence Write onsistency dministrivia Snooping Building Blocks Snooping protocols and examples oherence traffic and performance
MS 411 omputer Systems rchitecture Lecture 21 Multiprocessors 3 Outline Review oherence Write onsistency dministrivia Snooping Building Blocks Snooping protocols and examples oherence traffic and performance
Cache Coherence: Part 1
 Cache Coherence: art 1 Todd C. Mowry CS 74 October 5, Topics The Cache Coherence roblem Snoopy rotocols The Cache Coherence roblem 1 3 u =? u =? $ 4 $ 5 $ u:5 u:5 1 I/O devices u:5 u = 7 3 Memory A Coherent
Cache Coherence: art 1 Todd C. Mowry CS 74 October 5, Topics The Cache Coherence roblem Snoopy rotocols The Cache Coherence roblem 1 3 u =? u =? $ 4 $ 5 $ u:5 u:5 1 I/O devices u:5 u = 7 3 Memory A Coherent
Limitations of parallel processing
 Your professor du jour: Steve Gribble gribble@cs.washington.edu 323B Sieg Hall all material in this lecture in Henessey and Patterson, Chapter 8 635-640 645, 646 654-665 11/8/00 CSE 471 Multiprocessors
Your professor du jour: Steve Gribble gribble@cs.washington.edu 323B Sieg Hall all material in this lecture in Henessey and Patterson, Chapter 8 635-640 645, 646 654-665 11/8/00 CSE 471 Multiprocessors
Cache Coherence Protocols for Chip Multiprocessors - I
 Cache Coherence Protocols for Chip Multiprocessors - I John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 5 6 September 2016 Context Thus far chip multiprocessors
Cache Coherence Protocols for Chip Multiprocessors - I John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 5 6 September 2016 Context Thus far chip multiprocessors
Review: Multiprocessor. CPE 631 Session 21: Multiprocessors (Part 2) Potential HW Coherency Solutions. Bus Snooping Topology
 Potential HW Coherency Solutions. Bus Snooping Topology") Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
CSE 5306 Distributed Systems
 CSE 5306 Distributed Systems Consistency and Replication Jia Rao http://ranger.uta.edu/~jrao/ 1 Reasons for Replication Data is replicated for the reliability of the system Servers are replicated for performance
CSE 5306 Distributed Systems Consistency and Replication Jia Rao http://ranger.uta.edu/~jrao/ 1 Reasons for Replication Data is replicated for the reliability of the system Servers are replicated for performance