Modeling and Tolerating Heterogeneous Failures in Large Parallel Systems
|
|
|
- Dwayne Russell
- 6 years ago
- Views:
Transcription
1 Modeling and Tolerating Heterogeneous Failures in Large Parallel Systems Eric Heien 1, Derrick Kondo 1, Ana Gainaru 2, Dan LaPine 2, Bill Kramer 2, Franck Cappello 1, 2 1 INRIA, France 2 UIUC, USA
2 Context Increasing failure rates Est. 1 failure / 30 minutes in new PetaFLOP systems Increasing complexity of failures Time and space dynamics Increasing cost of failures Est. $12 million lost in Amazon 4-hour outage in July 2010

3 Motivation Heterogeneity of failures Heterogeneity of components CPU, disk, memory, network Multiple network types, storage, processors in same system Heterogeneity of applications CPU versus memory versus data intensive Current failure models assume onesize-fits all
4 Goal Design application-centric failure model Considering component failure models Considering component usage Implication: improve efficiency and efficacy of fault-tolerance algorithms
5 Approach Analyze 5 years of event logs of production HPC system Develop failure model considering heterogeneous components failures and their correlation Apply model to improve effectiveness of scheduling of checkpoints
 Used for TeraGrid System evolved over time Cluster")
6 Studied System Mercury cluster at the National Center for Supercomputing Applications (NCSA) Used for TeraGrid System evolved over time Cluster specification:


7 Log Collection Nodes logs collected centrally time of message, node, app info Measurement time frames over 5 years Table 2: Event Log Data. Epoch Time Span Days Days Recorded Missing 1 Jul to Jun Jun to Jan Feb to Oct Jul to May Jun to Feb Total







8 Event Processing Summarize messages Classify messages as failures Filter redundant messages Hierarchical Event Log Organizer Worked with sys admin Time thresholds

9 Error Messages

10 Failure Events
11 Failure Analysis and Modeling Heterogeneous failure statistics Per-component failure model Integrated failure model
12 Heterogeneous Failure Statistics Mean and median time to failure Cumulative distribution of failure interarrivals Correlation across nodes


13 Failure Inter-event Statistics (days) Average between failures per day. Mean rate of between days to failure. Wide range in inter-event times.

14 Cumulative Distribution of Inter-event Times Correlated failures Whole Cluster Discount simultaneous failures Best fit
15 Correlation Across nodes 30-40% of the F4 failures on different machines occur within 30 seconds of each other F1, F5, F6 show no correlation Across components Divided each epoch into hour-long periods Value of period is 1 if failure occurred; 0 otherwise Cross-correlation: on average No auto-correlation either
16 Per-Component Failure Model Time to failure Use Maximum Likelihood Estimation (MLE) to fit candidate distributions Consider: Weibull, log-normal, log-gamma and exponential Use p-values to evaluate whether empirical data could not have come from the fitted distribution
 Interevent Time (days) Distribution Epoch 1 Epoch 2 Epoch 3 Epoch 4 Epoch 5 All Weibull λ =0.3166 k =0.7097 λ =0.3868 k =0.6023 λ =0.2613 k =0.6629 λ =0.1624 k =0.6161 λ =0.")
17 Parameters of Time to Failure Model : scale, k: shape Table 5: Failure model parameters. (λ: scale, k: shape) Interevent Time (days) Distribution Epoch 1 Epoch 2 Epoch 3 Epoch 4 Epoch 5 All Weibull λ = k = λ = k = λ = k = λ = k = λ = k = F1 Weibull λ =1.436 k = λ =2.110 k = λ =3.167 k = λ =7.579 k = λ = k = F2 Weibull λ =7.515 k =2.631 λ =1.831 k = λ =13.08 k = λ =8.077 k =1.416 λ =33.16 k =1.994 F3 Log Normal N/A µ = µ = µ = µ = σ =2.361 σ =2.030 σ =2.249 σ =2.125 F4 Weibull λ = k = λ = k = λ = k = λ = k = λ = k = F5 Weibull λ =1.071 k =1.065 λ =4.032 k =1.253 λ =7.181 k = λ =5.506 k = λ =2.274 k = F6 Weibull λ =1.260 k = λ =2.520 k =1.392 λ =2.520 k =1.323 λ =4.788 k =1.455 λ =4.548 k =1.091 Heterogeneous scale and shape parameters F1, F4: hazard rate is decreasing for disk and network failures F5, F6: hazard rate is relatively constant or slightly increasing for memory or processor failures Overall: hazard rate is decreasing
18 Per-Component Failure Model Number of nodes in failure F2, F4 can occur simultaneously on multiple nodes E.g. 91% failures affect just one node, 3% affect two nodes, and 6% affect more than two nodes Fit distributions to number of nodes affected for the combined failures, and for F2 and F5 individually
 can fit distribution of number of nodes involved in")
19 Parameters for Number of Nodes Failed Model : scale, k: shape, : mean, : std dev in log-space Different distributions (some memoryless, others memoryfull) can fit distribution of number of nodes involved in failure

20 Number of Nodes in Failure Combined failure model 91% of failure affect one node 3% affect two nodes 6% affect more than 2 nodes
21 Model Integration Applications types Bag-of-tasks Mainly uses CPU, little memory, disk, network Example: Rosetta Data-intensive Mainly uses disk, memory, and processor Example: CM1 Combined Corresponds to massively parallel applications Uses all resources Example: NAMD
22 Model Integration Holistic failure model Types of components used Number of nodes used Assumptions Checkpoint occurs simultaneously across all nodes Checkpointing does not affect failure rates Failure on one node used by job means all job nodes must restart from checkpoint
23 Probability of Node Failure F i System with 5x5 nodes J! J! J! J! X J! X J! X X X X X X X Calculate probability of a failure on a node used by job J (Probability of 1-node failures) X (Probability it will affect job J) + (Probability of 2-node failures) X (Probability it will affect job J) + (Probability of N-node failures) X (Probability it will affect job J) J: Node occupied by job J! X: Node with component failure
24 Probability of Node Failure F i Weighted sum of the probabilities that the failure affects one of more of the nodes used by the job Assume each node has equal probability of failure (no space correlation) P node (M J )= M tot N=1 Q i(n) 1 N 1 R=0 1 M J M tot R Number of nodes N that fail Probability of N nodes failing Probability that at least one failure affected particular node used by the job 24

25 Job Failure Probability Probability of failure increases drastically even with few nodes Probability of failure increases linearly Heterogeneity in nodes and component failure rates affects probability of job failure

=1 i F J (1 P node (M J )P i (t))")

26 Probability of Job Failure Probability that node did not fail Probability none of the nodes used by the job failed P J (M J,t)=1 i F J (1 P node (M J )P i (t)) Probability that at least one failure affected any one of the nodes used by the job
27 Compute Time to Job Failure via Monte Carlo Simulation For 1:num_experiments! time_to_fail = 0! while(true)! time_to_fail+= Compute time to next failure! Use fitted distribution for failure interarrivals! prob_f = Compute probability failure will affect job! Compute probability of node failing used by job J!» Q i (N): probability of N nodes failing! Used fitted distribution for number of node failures! If (rand(0,1) < prob_f, store time_to_fail and exit while!
28 Simulation Parameters Combinations of Failure types: Combined failures F 5 and F 6 F 1, F 5, and F 6 F all Job sizes: 8, 64, 512 nodes Failure inter-arrival times derived from fitted distributions Failure inter-arrival times derived from traces Total Mercury cluster size: 891

29 Failure Distribution for Different Resource Usage Using fewer components or nodes results in longer time to failure MTBF for F5, F6 8 nodes: 428 days 512 nodes: 7.21 days MTBF with disk failures 8 nodes: 135 days 512 nodes: 2.13 days Model provides upper bound on true failure rate Model overestimates number of nodes affected by F2 and F4 failures

30 Integrated Failure Model Parameters : scale, k: shape Best fitting distribution to model is Weibull Scale changes as number of nodes used by job changes. Shape parameter stays mostly the same Doubling number of job nodes results in halving of
31 Tolerating Heterogeneous Failures with Checkpointing Tradeoff between cost of checkpointing and lost work due to failures Novel problem Checkpoint strategies that account for correlated failures and mixtures of component failure rates Side-effect Show new models are useful
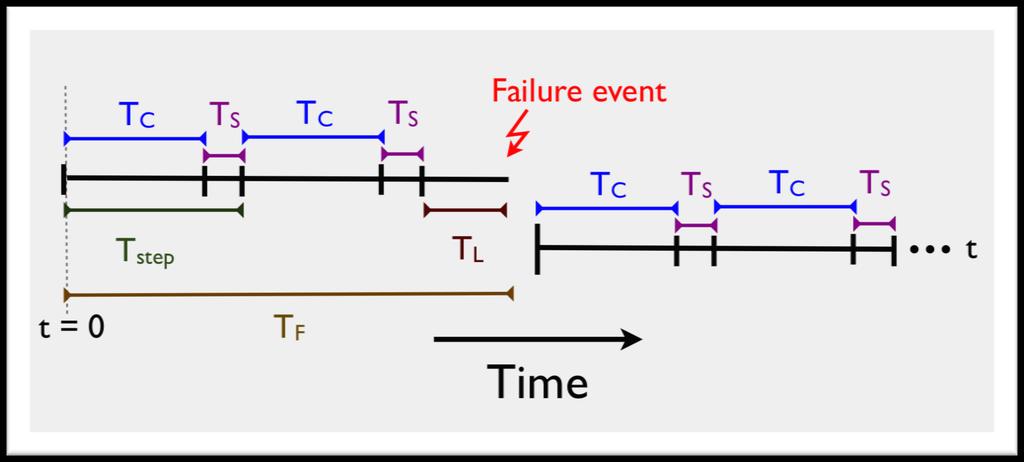

32 Checkpoint Model

tstep")
![nt step [t nt C ] k λ t λ k 1 e ( t λ )k dt Segment](/docs-images/78/76780614/images/33-4.jpg "where failure occurs Failure between time nt step")

33 Expected Wasted Time Compute T W as a weighted average of overhead incurred for all possible times of failure Assume infinite computation time Assume constant checkpoint frequency T W = n=0 (n+1)tstep nt step [t nt C ] k λ t λ k 1 e ( t λ )k dt Segment where failure occurs Failure between time nt step to (n+1)t step Time wasted = total time time computing Weibull density function for failure occurring at time t

34 Optimal Checkpoint Intervals (h) As # of machines increases, optimal checkpoint interval increases: T C 1/ M J As overhead for checkpointing increases, checkpoint period increases: T C T S For a given application profile, checkpoint frequency differs greatly. With 64 node, checkpoint period for F 5, F 6 is ~4 times less frequent for F all
35 Related Work Message log analysis HELO tool shows higher accuracy Analysis of failures in large systems Do not distinguish among component failures nor component usage Or focus exclusively on a particular component type Fault-tolerance for parallel computing Checkpointing assumes homogeneous failure model in terms of components and independence
36 Conclusion Measurement Identified and analyzed five years of event logs from production HPC system Modeling Determine distribution of failure inter-arrival times of different components Formed holistic failure model, given application profile Fault-tolerance Applied model to derive optimal time to checkpoint, considering correlated failures and heterogeneous failure rates per component
37 Future Work Measurement Failure Trace Archive Modeling Development of hierarchical failure models with space correlation Fault-tolerance Closed-form expression for optimal checkpoint period Optimal number of nodes to minimize failure rate




38 Probability of Node Failure F i Probability that none of the N nodes fail Probability a node does not fail Weighted sum of the probabilities that the failure affects one of more of the nodes used by the job P node (M J )= M tot N=1 Q i(n) 1 N 1 R=0 Probability that the node fails 1 M J M tot R Number of nodes N that fail Probability of N nodes failing Probability that at least one failure affected particular node used by the job 38
 [M j /M tot ]+Q i (2) 1 1 M J 1")





39 Example for M tot = 4 P node (M J )=Q i (1) [M j /M tot ]+Q i (2) 1 1 M J 1 M J M tot M tot 1 Probability that one out of the M j nodes will fail. Chance that first failure will affect M J job nodes out of M tot Chance that second failure will affect M J job nodes out of M tot 1remaining Chance first failure did not affect any job nodes Chance that second failure did not affect job nodes Chance that at least one job node affected by 2- node failures
40 BACKUP SLIDES
Towards Ensuring Collective Availability in Volatile Resource Pools via Forecasting
 Towards CloudComputing@home: Ensuring Collective Availability in Volatile Resource Pools via Forecasting Artur Andrzejak Berlin (ZIB) andrzejak[at]zib.de Zuse-Institute Derrick Kondo David P. Anderson
Towards CloudComputing@home: Ensuring Collective Availability in Volatile Resource Pools via Forecasting Artur Andrzejak Berlin (ZIB) andrzejak[at]zib.de Zuse-Institute Derrick Kondo David P. Anderson
Characterizing Result Errors in Internet Desktop Grids
 Characterizing Result Errors in Internet Desktop Grids D. Kondo 1, F. Araujo 2, P. Malecot 1, P. Domingues 2, L. Silva 2, G. Fedak 1, F. Cappello 1 1 INRIA, France 2 University of Coimbra, Portugal Desktop
Characterizing Result Errors in Internet Desktop Grids D. Kondo 1, F. Araujo 2, P. Malecot 1, P. Domingues 2, L. Silva 2, G. Fedak 1, F. Cappello 1 1 INRIA, France 2 University of Coimbra, Portugal Desktop
Discovering Statistical Models of Availability in Large Distributed Systems: An Empirical Study of
 1 Discovering Statistical Models of Availability in Large Distributed Systems: An Empirical Study of SETI@home Bahman Javadi, Member, IEEE, Derrick Kondo, Member, IEEE, Jean-Marc Vincent, Member, IEEE
1 Discovering Statistical Models of Availability in Large Distributed Systems: An Empirical Study of SETI@home Bahman Javadi, Member, IEEE, Derrick Kondo, Member, IEEE, Jean-Marc Vincent, Member, IEEE
REMEM: REmote MEMory as Checkpointing Storage
 REMEM: REmote MEMory as Checkpointing Storage Hui Jin Illinois Institute of Technology Xian-He Sun Illinois Institute of Technology Yong Chen Oak Ridge National Laboratory Tao Ke Illinois Institute of
REMEM: REmote MEMory as Checkpointing Storage Hui Jin Illinois Institute of Technology Xian-He Sun Illinois Institute of Technology Yong Chen Oak Ridge National Laboratory Tao Ke Illinois Institute of
Combing Partial Redundancy and Checkpointing for HPC
 Combing Partial Redundancy and Checkpointing for HPC James Elliott, Kishor Kharbas, David Fiala, Frank Mueller, Kurt Ferreira, and Christian Engelmann North Carolina State University Sandia National Laboratory
Combing Partial Redundancy and Checkpointing for HPC James Elliott, Kishor Kharbas, David Fiala, Frank Mueller, Kurt Ferreira, and Christian Engelmann North Carolina State University Sandia National Laboratory
RELIABILITY IN CLOUD COMPUTING SYSTEMS: SESSION 1
 RELIABILITY IN CLOUD COMPUTING SYSTEMS: SESSION 1 Dr. Bahman Javadi School of Computing, Engineering and Mathematics Western Sydney University, Australia 1 TUTORIAL AGENDA Session 1: Reliability in Cloud
RELIABILITY IN CLOUD COMPUTING SYSTEMS: SESSION 1 Dr. Bahman Javadi School of Computing, Engineering and Mathematics Western Sydney University, Australia 1 TUTORIAL AGENDA Session 1: Reliability in Cloud
A Large-Scale Study of Failures on Petascale Supercomputers
 Liu RT, Chen ZN. A large-scale study of failures on petascale supercomputers. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 33(1): 24 41 Jan. 2018. DOI 10.1007/s11390-018-1806-7 A Large-Scale Study of Failures
Liu RT, Chen ZN. A large-scale study of failures on petascale supercomputers. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 33(1): 24 41 Jan. 2018. DOI 10.1007/s11390-018-1806-7 A Large-Scale Study of Failures
Techniques to improve the scalability of Checkpoint-Restart
 Techniques to improve the scalability of Checkpoint-Restart Bogdan Nicolae Exascale Systems Group IBM Research Ireland 1 Outline A few words about the lab and team Challenges of Exascale A case for Checkpoint-Restart
Techniques to improve the scalability of Checkpoint-Restart Bogdan Nicolae Exascale Systems Group IBM Research Ireland 1 Outline A few words about the lab and team Challenges of Exascale A case for Checkpoint-Restart
CS 470 Spring Fault Tolerance. Mike Lam, Professor. Content taken from the following:
 CS 47 Spring 27 Mike Lam, Professor Fault Tolerance Content taken from the following: "Distributed Systems: Principles and Paradigms" by Andrew S. Tanenbaum and Maarten Van Steen (Chapter 8) Various online
CS 47 Spring 27 Mike Lam, Professor Fault Tolerance Content taken from the following: "Distributed Systems: Principles and Paradigms" by Andrew S. Tanenbaum and Maarten Van Steen (Chapter 8) Various online
A recursive point process model for infectious diseases.
 A recursive point process model for infectious diseases. Frederic Paik Schoenberg, UCLA Statistics Collaborators: Marc Hoffmann, Ryan Harrigan. Also thanks to: Project Tycho, CDC, and WHO datasets. 1 1.
A recursive point process model for infectious diseases. Frederic Paik Schoenberg, UCLA Statistics Collaborators: Marc Hoffmann, Ryan Harrigan. Also thanks to: Project Tycho, CDC, and WHO datasets. 1 1.
An Empirical Study of High Availability in Stream Processing Systems
 An Empirical Study of High Availability in Stream Processing Systems Yu Gu, Zhe Zhang, Fan Ye, Hao Yang, Minkyong Kim, Hui Lei, Zhen Liu Stream Processing Model software operators (PEs) Ω Unexpected machine
An Empirical Study of High Availability in Stream Processing Systems Yu Gu, Zhe Zhang, Fan Ye, Hao Yang, Minkyong Kim, Hui Lei, Zhen Liu Stream Processing Model software operators (PEs) Ω Unexpected machine
Chapter 4:- Introduction to Grid and its Evolution. Prepared By:- NITIN PANDYA Assistant Professor SVBIT.
 Chapter 4:- Introduction to Grid and its Evolution Prepared By:- Assistant Professor SVBIT. Overview Background: What is the Grid? Related technologies Grid applications Communities Grid Tools Case Studies
Chapter 4:- Introduction to Grid and its Evolution Prepared By:- Assistant Professor SVBIT. Overview Background: What is the Grid? Related technologies Grid applications Communities Grid Tools Case Studies
Mean Value Analysis and Related Techniques
 Mean Value Analysis and Related Techniques 34-1 Overview 1. Analysis of Open Queueing Networks 2. Mean-Value Analysis 3. Approximate MVA 4. Balanced Job Bounds 34-2 Analysis of Open Queueing Networks Used
Mean Value Analysis and Related Techniques 34-1 Overview 1. Analysis of Open Queueing Networks 2. Mean-Value Analysis 3. Approximate MVA 4. Balanced Job Bounds 34-2 Analysis of Open Queueing Networks Used
Distributed Operating Systems
 2 Distributed Operating Systems System Models, Processor Allocation, Distributed Scheduling, and Fault Tolerance Steve Goddard goddard@cse.unl.edu http://www.cse.unl.edu/~goddard/courses/csce855 System
2 Distributed Operating Systems System Models, Processor Allocation, Distributed Scheduling, and Fault Tolerance Steve Goddard goddard@cse.unl.edu http://www.cse.unl.edu/~goddard/courses/csce855 System
Are Disks the Dominant Contributor for Storage Failures?
 Are Disks the Dominant Contributor for Storage Failures? A Comprehensive Study of Storage Subsystem Failure Characteristics Weihang Jiang, Chongfeng Hu, Yuanyuan Zhou, and Arkady Kanevsky Department of
Are Disks the Dominant Contributor for Storage Failures? A Comprehensive Study of Storage Subsystem Failure Characteristics Weihang Jiang, Chongfeng Hu, Yuanyuan Zhou, and Arkady Kanevsky Department of
Scheduling Real Time Parallel Structure on Cluster Computing with Possible Processor failures
 Scheduling Real Time Parallel Structure on Cluster Computing with Possible Processor failures Alaa Amin and Reda Ammar Computer Science and Eng. Dept. University of Connecticut Ayman El Dessouly Electronics
Scheduling Real Time Parallel Structure on Cluster Computing with Possible Processor failures Alaa Amin and Reda Ammar Computer Science and Eng. Dept. University of Connecticut Ayman El Dessouly Electronics
Randolph E. Bucklin Catarina Sismeiro The Anderson School at UCLA. Overview. Introduction/Clickstream Research Conceptual Framework
 A Model of Web Site Browsing Behavior Estimated on Clickstream Data Randolph E. Bucklin Catarina Sismeiro The Anderson School at UCLA Overview Introduction/Clickstream Research Conceptual Framework 4 Within-site
A Model of Web Site Browsing Behavior Estimated on Clickstream Data Randolph E. Bucklin Catarina Sismeiro The Anderson School at UCLA Overview Introduction/Clickstream Research Conceptual Framework 4 Within-site
Operating Systems. Deadlock. Lecturer: William Fornaciari Politecnico di Milano Homel.deib.polimi.
 Politecnico di Milano Operating Systems Lecturer: William Fornaciari Politecnico di Milano william.fornaciari@elet.polimi.it Homel.deib.polimi.it/fornacia Summary What is a resource Conditions for deadlock
Politecnico di Milano Operating Systems Lecturer: William Fornaciari Politecnico di Milano william.fornaciari@elet.polimi.it Homel.deib.polimi.it/fornacia Summary What is a resource Conditions for deadlock
Models and Heuristics for Robust Resource Allocation in Parallel and Distributed Computing Systems
 Models and Heuristics for Robust Resource Allocation in Parallel and Distributed Computing Systems D. Janovy, J. Smith, H. J. Siegel, and A. A. Maciejewski Colorado State University Outline n models and
Models and Heuristics for Robust Resource Allocation in Parallel and Distributed Computing Systems D. Janovy, J. Smith, H. J. Siegel, and A. A. Maciejewski Colorado State University Outline n models and
Operating Systems (2INC0) 2017/18
 2017/18") Operating Systems (2INC0) 2017/18 Memory Management (09) Dr. Courtesy of Dr. I. Radovanovic, Dr. R. Mak (figures from Bic & Shaw) System Architecture and Networking Group Agenda Reminder: OS & resources
Operating Systems (2INC0) 2017/18 Memory Management (09) Dr. Courtesy of Dr. I. Radovanovic, Dr. R. Mak (figures from Bic & Shaw) System Architecture and Networking Group Agenda Reminder: OS & resources
Chapter 20: Database System Architectures
 Chapter 20: Database System Architectures Chapter 20: Database System Architectures Centralized and Client-Server Systems Server System Architectures Parallel Systems Distributed Systems Network Types
Chapter 20: Database System Architectures Chapter 20: Database System Architectures Centralized and Client-Server Systems Server System Architectures Parallel Systems Distributed Systems Network Types
Mean Value Analysis and Related Techniques
 Mean Value Analysis and Related Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu Audio/Video recordings of this lecture are available at: 34-1 Overview
Mean Value Analysis and Related Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu Audio/Video recordings of this lecture are available at: 34-1 Overview
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Rollback-Recovery Protocols for Send-Deterministic Applications. Amina Guermouche, Thomas Ropars, Elisabeth Brunet, Marc Snir and Franck Cappello
 Rollback-Recovery Protocols for Send-Deterministic Applications Amina Guermouche, Thomas Ropars, Elisabeth Brunet, Marc Snir and Franck Cappello Fault Tolerance in HPC Systems is Mandatory Resiliency is
Rollback-Recovery Protocols for Send-Deterministic Applications Amina Guermouche, Thomas Ropars, Elisabeth Brunet, Marc Snir and Franck Cappello Fault Tolerance in HPC Systems is Mandatory Resiliency is
Review. EECS 252 Graduate Computer Architecture. Lec 18 Storage. Introduction to Queueing Theory. Deriving Little s Law
 EECS 252 Graduate Computer Architecture Lec 18 Storage David Patterson Electrical Engineering and Computer Sciences University of California, Berkeley Review Disks: Arial Density now 30%/yr vs. 100%/yr
EECS 252 Graduate Computer Architecture Lec 18 Storage David Patterson Electrical Engineering and Computer Sciences University of California, Berkeley Review Disks: Arial Density now 30%/yr vs. 100%/yr
Adaptive Cluster Computing using JavaSpaces
 Adaptive Cluster Computing using JavaSpaces Jyoti Batheja and Manish Parashar The Applied Software Systems Lab. ECE Department, Rutgers University Outline Background Introduction Related Work Summary of
Adaptive Cluster Computing using JavaSpaces Jyoti Batheja and Manish Parashar The Applied Software Systems Lab. ECE Department, Rutgers University Outline Background Introduction Related Work Summary of
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Lecture: Simulation. of Manufacturing Systems. Sivakumar AI. Simulation. SMA6304 M2 ---Factory Planning and scheduling. Simulation - A Predictive Tool
 SMA6304 M2 ---Factory Planning and scheduling Lecture Discrete Event of Manufacturing Systems Simulation Sivakumar AI Lecture: 12 copyright 2002 Sivakumar 1 Simulation Simulation - A Predictive Tool Next
SMA6304 M2 ---Factory Planning and scheduling Lecture Discrete Event of Manufacturing Systems Simulation Sivakumar AI Lecture: 12 copyright 2002 Sivakumar 1 Simulation Simulation - A Predictive Tool Next
Clustering Lecture 5: Mixture Model
 Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
High Availability and Disaster Recovery Solutions for Perforce
 High Availability and Disaster Recovery Solutions for Perforce This paper provides strategies for achieving high Perforce server availability and minimizing data loss in the event of a disaster. Perforce
High Availability and Disaster Recovery Solutions for Perforce This paper provides strategies for achieving high Perforce server availability and minimizing data loss in the event of a disaster. Perforce
Lecture 23 Database System Architectures
 CMSC 461, Database Management Systems Spring 2018 Lecture 23 Database System Architectures These slides are based on Database System Concepts 6 th edition book (whereas some quotes and figures are used
CMSC 461, Database Management Systems Spring 2018 Lecture 23 Database System Architectures These slides are based on Database System Concepts 6 th edition book (whereas some quotes and figures are used
Virtual Memory Design and Implementation
 Virtual Memory Design and Implementation To do q Page replacement algorithms q Design and implementation issues q Next: Last on virtualization VMMs Loading pages When should the OS load pages? On demand
Virtual Memory Design and Implementation To do q Page replacement algorithms q Design and implementation issues q Next: Last on virtualization VMMs Loading pages When should the OS load pages? On demand
BANDWIDTH MODELING IN LARGE DISTRIBUTED SYSTEMS FOR BIG DATA APPLICATIONS
 BANDWIDTH MODELING IN LARGE DISTRIBUTED SYSTEMS FOR BIG DATA APPLICATIONS Bahman Javadi School of Computing, Engineering and Mathematics Western Sydney University, Australia 1 Boyu Zhang and Michela Taufer
BANDWIDTH MODELING IN LARGE DISTRIBUTED SYSTEMS FOR BIG DATA APPLICATIONS Bahman Javadi School of Computing, Engineering and Mathematics Western Sydney University, Australia 1 Boyu Zhang and Michela Taufer
Interactive Analysis of Large Distributed Systems with Scalable Topology-based Visualization
 Interactive Analysis of Large Distributed Systems with Scalable Topology-based Visualization Lucas M. Schnorr, Arnaud Legrand, and Jean-Marc Vincent e-mail : Firstname.Lastname@imag.fr Laboratoire d Informatique
Interactive Analysis of Large Distributed Systems with Scalable Topology-based Visualization Lucas M. Schnorr, Arnaud Legrand, and Jean-Marc Vincent e-mail : Firstname.Lastname@imag.fr Laboratoire d Informatique
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Analysis of WLAN Traffic in the Wild
 Analysis of WLAN Traffic in the Wild Caleb Phillips and Suresh Singh Portland State University, 1900 SW 4th Avenue Portland, Oregon, 97201, USA {calebp,singh}@cs.pdx.edu Abstract. In this paper, we analyze
Analysis of WLAN Traffic in the Wild Caleb Phillips and Suresh Singh Portland State University, 1900 SW 4th Avenue Portland, Oregon, 97201, USA {calebp,singh}@cs.pdx.edu Abstract. In this paper, we analyze
Jobs Resource Utilization as a Metric for Clusters Comparison and Optimization. Slurm User Group Meeting 9-10 October, 2012
 Jobs Resource Utilization as a Metric for Clusters Comparison and Optimization Joseph Emeras Cristian Ruiz Jean-Marc Vincent Olivier Richard Slurm User Group Meeting 9-10 October, 2012 INRIA - MESCAL Jobs
Jobs Resource Utilization as a Metric for Clusters Comparison and Optimization Joseph Emeras Cristian Ruiz Jean-Marc Vincent Olivier Richard Slurm User Group Meeting 9-10 October, 2012 INRIA - MESCAL Jobs
Towards Online Checkpointing Mechanism for Cloud Transient Servers
 Towards Online Checkpointing Mechanism for Cloud Transient Servers Luping Wang, Wei Wang, Bo Li Hong Kong University of Science and Technology {lwangbm, weiwa, bli}@cse.ust.hk Abstract Cloud providers
Towards Online Checkpointing Mechanism for Cloud Transient Servers Luping Wang, Wei Wang, Bo Li Hong Kong University of Science and Technology {lwangbm, weiwa, bli}@cse.ust.hk Abstract Cloud providers
The Effect of Scheduling Discipline on Dynamic Load Sharing in Heterogeneous Distributed Systems
 Appears in Proc. MASCOTS'97, Haifa, Israel, January 1997. The Effect of Scheduling Discipline on Dynamic Load Sharing in Heterogeneous Distributed Systems Sivarama P. Dandamudi School of Computer Science,
Appears in Proc. MASCOTS'97, Haifa, Israel, January 1997. The Effect of Scheduling Discipline on Dynamic Load Sharing in Heterogeneous Distributed Systems Sivarama P. Dandamudi School of Computer Science,
Chapter 18: Database System Architectures.! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems!
 Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Checkpointing HPC Applications
 Checkpointing HC Applications Thomas Ropars thomas.ropars@imag.fr Université Grenoble Alpes 2016 1 Failures in supercomputers Fault tolerance is a serious problem Systems with millions of components Failures
Checkpointing HC Applications Thomas Ropars thomas.ropars@imag.fr Université Grenoble Alpes 2016 1 Failures in supercomputers Fault tolerance is a serious problem Systems with millions of components Failures
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Week 7: Traffic Models and QoS
 Week 7: Traffic Models and QoS Acknowledgement: Some slides are adapted from Computer Networking: A Top Down Approach Featuring the Internet, 2 nd edition, J.F Kurose and K.W. Ross All Rights Reserved,
Week 7: Traffic Models and QoS Acknowledgement: Some slides are adapted from Computer Networking: A Top Down Approach Featuring the Internet, 2 nd edition, J.F Kurose and K.W. Ross All Rights Reserved,
On the Scheduling of Checkpoints in Desktop Grids
 On the Scheduling of Checkpoints in Desktop Grids Mohamed Slim Bouguerra, Derrick Kondo INRIA Rhone-Alpes Grenoble ZIRST, 51, avenue Jean Kuntzmann 3833 MONBONNOT SAINT MARTIN, France mohamed-slim.bouguerra@imag.fr;
On the Scheduling of Checkpoints in Desktop Grids Mohamed Slim Bouguerra, Derrick Kondo INRIA Rhone-Alpes Grenoble ZIRST, 51, avenue Jean Kuntzmann 3833 MONBONNOT SAINT MARTIN, France mohamed-slim.bouguerra@imag.fr;
The Impact of More Accurate Requested Runtimes on Production Job Scheduling Performance
 The Impact of More Accurate Requested Runtimes on Production Job Scheduling Performance Su-Hui Chiang, Andrea Arpaci-Dusseau, and Mary K. Vernon Computer Sciences Department University of Wisconsin 11
The Impact of More Accurate Requested Runtimes on Production Job Scheduling Performance Su-Hui Chiang, Andrea Arpaci-Dusseau, and Mary K. Vernon Computer Sciences Department University of Wisconsin 11
Software Quality Engineering: Testing, Quality Assurance, and Quantifiable Improvement
 Tian: Software Quality Engineering Slide (Ch.22) 1 Software Quality Engineering: Testing, Quality Assurance, and Quantifiable Improvement Jeff Tian, tian@engr.smu.edu www.engr.smu.edu/ tian/sqebook Chapter
Tian: Software Quality Engineering Slide (Ch.22) 1 Software Quality Engineering: Testing, Quality Assurance, and Quantifiable Improvement Jeff Tian, tian@engr.smu.edu www.engr.smu.edu/ tian/sqebook Chapter
Workload Characterization Techniques
 Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Managing CAE Simulation Workloads in Cluster Environments
 Managing CAE Simulation Workloads in Cluster Environments Michael Humphrey V.P. Enterprise Computing Altair Engineering humphrey@altair.com June 2003 Copyright 2003 Altair Engineering, Inc. All rights
Managing CAE Simulation Workloads in Cluster Environments Michael Humphrey V.P. Enterprise Computing Altair Engineering humphrey@altair.com June 2003 Copyright 2003 Altair Engineering, Inc. All rights
5.11 Parallelism and Memory Hierarchy: Redundant Arrays of Inexpensive Disks 485.e1
 5.11 Parallelism and Memory Hierarchy: Redundant Arrays of Inexpensive Disks 485.e1 5.11 Parallelism and Memory Hierarchy: Redundant Arrays of Inexpensive Disks Amdahl s law in Chapter 1 reminds us that
5.11 Parallelism and Memory Hierarchy: Redundant Arrays of Inexpensive Disks 485.e1 5.11 Parallelism and Memory Hierarchy: Redundant Arrays of Inexpensive Disks Amdahl s law in Chapter 1 reminds us that
Introduction to Queueing Theory for Computer Scientists
 Introduction to Queueing Theory for Computer Scientists Raj Jain Washington University in Saint Louis Jain@eecs.berkeley.edu or Jain@wustl.edu A Mini-Course offered at UC Berkeley, Sept-Oct 2012 These
Introduction to Queueing Theory for Computer Scientists Raj Jain Washington University in Saint Louis Jain@eecs.berkeley.edu or Jain@wustl.edu A Mini-Course offered at UC Berkeley, Sept-Oct 2012 These
Simulation Input Data Modeling
 Introduction to Modeling and Simulation Simulation Input Data Modeling OSMAN BALCI Professor Department of Computer Science Virginia Polytechnic Institute and State University (Virginia Tech) Blacksburg,
Introduction to Modeling and Simulation Simulation Input Data Modeling OSMAN BALCI Professor Department of Computer Science Virginia Polytechnic Institute and State University (Virginia Tech) Blacksburg,
POWER SYSTEM RELIABILITY ASSESSMENT CONSIDERING NON-EXPONENTIAL DISTRIBUTIONS AND RESTORATIVE ACTIONS. Gwang Won Kim a and Kwang Y.
 POWER SYSTEM RELIABILITY ASSESSMENT CONSIDERING NON-EXPONENTIAL DISTRIBUTIONS AND RESTORATIVE ACTIONS Gwang Won Kim a and Kwang Y. Lee b a School of Electrical Engineering, University of Ulsan, Ulsan 680-749,
POWER SYSTEM RELIABILITY ASSESSMENT CONSIDERING NON-EXPONENTIAL DISTRIBUTIONS AND RESTORATIVE ACTIONS Gwang Won Kim a and Kwang Y. Lee b a School of Electrical Engineering, University of Ulsan, Ulsan 680-749,
Tackling Latency via Replication in Distributed Systems
 Tackling Latency via Replication in Distributed Systems Zhan Qiu, Imperial College London Juan F. Pe rez, University of Melbourne Peter G. Harrison, Imperial College London ACM/SPEC ICPE 2016 15 th March,
Tackling Latency via Replication in Distributed Systems Zhan Qiu, Imperial College London Juan F. Pe rez, University of Melbourne Peter G. Harrison, Imperial College London ACM/SPEC ICPE 2016 15 th March,
Automating Real-time Seismic Analysis
 Automating Real-time Seismic Analysis Through Streaming and High Throughput Workflows Rafael Ferreira da Silva, Ph.D. http://pegasus.isi.edu Do we need seismic analysis? Pegasus http://pegasus.isi.edu
Automating Real-time Seismic Analysis Through Streaming and High Throughput Workflows Rafael Ferreira da Silva, Ph.D. http://pegasus.isi.edu Do we need seismic analysis? Pegasus http://pegasus.isi.edu
Security and Dependability of Computer Systems. Valentina Casola Domenico Cotroneo
 Security and Dependability of Computer Systems Valentina Casola Domenico Cotroneo Log-Based Field Failure Data Analysis: Exercise Prof. Domenico Cotroneo p. 2 Exercise The students will perform a log-based
Security and Dependability of Computer Systems Valentina Casola Domenico Cotroneo Log-Based Field Failure Data Analysis: Exercise Prof. Domenico Cotroneo p. 2 Exercise The students will perform a log-based
6. Results. This section describes the performance that was achieved using the RAMA file system.
 6. Results This section describes the performance that was achieved using the RAMA file system. The resulting numbers represent actual file data bytes transferred to/from server disks per second, excluding
6. Results This section describes the performance that was achieved using the RAMA file system. The resulting numbers represent actual file data bytes transferred to/from server disks per second, excluding
Lecture 5: Performance Analysis I
 CS 6323 : Modeling and Inference Lecture 5: Performance Analysis I Prof. Gregory Provan Department of Computer Science University College Cork Slides: Based on M. Yin (Performability Analysis) Overview
CS 6323 : Modeling and Inference Lecture 5: Performance Analysis I Prof. Gregory Provan Department of Computer Science University College Cork Slides: Based on M. Yin (Performability Analysis) Overview
Distributed recovery for senddeterministic. Tatiana V. Martsinkevich, Thomas Ropars, Amina Guermouche, Franck Cappello
 Distributed recovery for senddeterministic HPC applications Tatiana V. Martsinkevich, Thomas Ropars, Amina Guermouche, Franck Cappello 1 Fault-tolerance in HPC applications Number of cores on one CPU and
Distributed recovery for senddeterministic HPC applications Tatiana V. Martsinkevich, Thomas Ropars, Amina Guermouche, Franck Cappello 1 Fault-tolerance in HPC applications Number of cores on one CPU and
Simulation Studies of the Basic Packet Routing Problem
 Simulation Studies of the Basic Packet Routing Problem Author: Elena Sirén 48314u Supervisor: Pasi Lassila February 6, 2001 1 Abstract In this paper the simulation of a basic packet routing problem using
Simulation Studies of the Basic Packet Routing Problem Author: Elena Sirén 48314u Supervisor: Pasi Lassila February 6, 2001 1 Abstract In this paper the simulation of a basic packet routing problem using
Review: Identification of cell types from single-cell transcriptom. method
 Review: Identification of cell types from single-cell transcriptomes using a novel clustering method University of North Carolina at Charlotte October 12, 2015 Brief overview Identify clusters by merging
Review: Identification of cell types from single-cell transcriptomes using a novel clustering method University of North Carolina at Charlotte October 12, 2015 Brief overview Identify clusters by merging
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
Are Disks the Dominant Contributor for Storage Failures? A Comprehensive Study of Storage Subsystem Failure Characteristics
 Are Disks the Dominant Contributor for Storage Failures? A Comprehensive Study of Storage Subsystem Failure Characteristics 7 WEIHANG JIANG, CHONGFENG HU, and YUANYUAN ZHOU University of Illinois at Urbana
Are Disks the Dominant Contributor for Storage Failures? A Comprehensive Study of Storage Subsystem Failure Characteristics 7 WEIHANG JIANG, CHONGFENG HU, and YUANYUAN ZHOU University of Illinois at Urbana
CHAPTER 6 ENERGY AWARE SCHEDULING ALGORITHMS IN CLOUD ENVIRONMENT
 CHAPTER 6 ENERGY AWARE SCHEDULING ALGORITHMS IN CLOUD ENVIRONMENT This chapter discusses software based scheduling and testing. DVFS (Dynamic Voltage and Frequency Scaling) [42] based experiments have
CHAPTER 6 ENERGY AWARE SCHEDULING ALGORITHMS IN CLOUD ENVIRONMENT This chapter discusses software based scheduling and testing. DVFS (Dynamic Voltage and Frequency Scaling) [42] based experiments have
Verification and Validation of X-Sim: A Trace-Based Simulator
 http://www.cse.wustl.edu/~jain/cse567-06/ftp/xsim/index.html 1 of 11 Verification and Validation of X-Sim: A Trace-Based Simulator Saurabh Gayen, sg3@wustl.edu Abstract X-Sim is a trace-based simulator
http://www.cse.wustl.edu/~jain/cse567-06/ftp/xsim/index.html 1 of 11 Verification and Validation of X-Sim: A Trace-Based Simulator Saurabh Gayen, sg3@wustl.edu Abstract X-Sim is a trace-based simulator
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Characterizing Result Errors in Internet Desktop Grids
 Characterizing Result Errors in Internet Desktop Grids Derrick Kondo 1, Filipe Araujo 2, Paul Malecot 1, Patricio Domingues 3, Luis Moura Silva 2, Gilles Fedak 1, and Franck Cappello 1 1 INRIA Futurs,
Characterizing Result Errors in Internet Desktop Grids Derrick Kondo 1, Filipe Araujo 2, Paul Malecot 1, Patricio Domingues 3, Luis Moura Silva 2, Gilles Fedak 1, and Franck Cappello 1 1 INRIA Futurs,
Reliability and Dependability in Computer Networks. CS 552 Computer Networks Side Credits: A. Tjang, W. Sanders
 Reliability and Dependability in Computer Networks CS 552 Computer Networks Side Credits: A. Tjang, W. Sanders Outline Overall dependability definitions and concepts Measuring Site dependability Stochastic
Reliability and Dependability in Computer Networks CS 552 Computer Networks Side Credits: A. Tjang, W. Sanders Outline Overall dependability definitions and concepts Measuring Site dependability Stochastic
Dynamic Fault Tolerance and Task Scheduling in Distributed Systems
 Master s Thesis Dynamic Fault Tolerance and Task Scheduling in Distributed Systems Philip Ståhl Jonatan Broberg Department of Electrical and Information Technology, Faculty of Engineering, LTH, Lund University,
Master s Thesis Dynamic Fault Tolerance and Task Scheduling in Distributed Systems Philip Ståhl Jonatan Broberg Department of Electrical and Information Technology, Faculty of Engineering, LTH, Lund University,
Load Balancing with Minimal Flow Remapping for Network Processors
 Load Balancing with Minimal Flow Remapping for Network Processors Imad Khazali and Anjali Agarwal Electrical and Computer Engineering Department Concordia University Montreal, Quebec, Canada Email: {ikhazali,
Load Balancing with Minimal Flow Remapping for Network Processors Imad Khazali and Anjali Agarwal Electrical and Computer Engineering Department Concordia University Montreal, Quebec, Canada Email: {ikhazali,
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
Scheduling. Monday, November 22, 2004
 Scheduling Page 1 Scheduling Monday, November 22, 2004 11:22 AM The scheduling problem (Chapter 9) Decide which processes are allowed to run when. Optimize throughput, response time, etc. Subject to constraints
Scheduling Page 1 Scheduling Monday, November 22, 2004 11:22 AM The scheduling problem (Chapter 9) Decide which processes are allowed to run when. Optimize throughput, response time, etc. Subject to constraints
Module 8 - Fault Tolerance
 Module 8 - Fault Tolerance Dependability Reliability A measure of success with which a system conforms to some authoritative specification of its behavior. Probability that the system has not experienced
Module 8 - Fault Tolerance Dependability Reliability A measure of success with which a system conforms to some authoritative specification of its behavior. Probability that the system has not experienced
A Case Study of Automatically Creating Test Suites from Web Application Field Data. Sara Sprenkle, Emily Gibson, Sreedevi Sampath, and Lori Pollock
 A Case Study of Automatically Creating Test Suites from Web Application Field Data Sara Sprenkle, Emily Gibson, Sreedevi Sampath, and Lori Pollock Evolving Web Applications Code constantly changing Fix
A Case Study of Automatically Creating Test Suites from Web Application Field Data Sara Sprenkle, Emily Gibson, Sreedevi Sampath, and Lori Pollock Evolving Web Applications Code constantly changing Fix
Introduction 1.1 SERVER-CENTRIC IT ARCHITECTURE AND ITS LIMITATIONS
 1 Introduction The purpose of this chapter is to convey the basic idea underlying this book. To this end we will first describe conventional server-centric IT architecture and sketch out its limitations
1 Introduction The purpose of this chapter is to convey the basic idea underlying this book. To this end we will first describe conventional server-centric IT architecture and sketch out its limitations
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
The Impact of More Accurate Requested Runtimes on Production Job Scheduling Performance
 The Impact of More Accurate Requested Runtimes on Production Job Scheduling Performance Su-Hui Chiang Andrea Arpaci-Dusseau Mary K. Vernon Computer Sciences Department University of Wisconsin-Madison {suhui,
The Impact of More Accurate Requested Runtimes on Production Job Scheduling Performance Su-Hui Chiang Andrea Arpaci-Dusseau Mary K. Vernon Computer Sciences Department University of Wisconsin-Madison {suhui,
A Hierarchical Checkpointing Protocol for Parallel Applications in Cluster Federations
 A Hierarchical Checkpointing Protocol for Parallel Applications in Cluster Federations Sébastien Monnet IRISA Sebastien.Monnet@irisa.fr Christine Morin IRISA/INRIA Christine.Morin@irisa.fr Ramamurthy Badrinath
A Hierarchical Checkpointing Protocol for Parallel Applications in Cluster Federations Sébastien Monnet IRISA Sebastien.Monnet@irisa.fr Christine Morin IRISA/INRIA Christine.Morin@irisa.fr Ramamurthy Badrinath
PRESENTATION TITLE GOES HERE
 Performance Basics PRESENTATION TITLE GOES HERE Leah Schoeb, Member of SNIA Technical Council SNIA EmeraldTM Training SNIA Emerald Power Efficiency Measurement Specification, for use in EPA ENERGY STAR
Performance Basics PRESENTATION TITLE GOES HERE Leah Schoeb, Member of SNIA Technical Council SNIA EmeraldTM Training SNIA Emerald Power Efficiency Measurement Specification, for use in EPA ENERGY STAR
Operating systems Architecture
 Operating systems Architecture 1 Operating Systems Low level software system that manages all applications implements an interface between applications and resources manages available resources Resource
Operating systems Architecture 1 Operating Systems Low level software system that manages all applications implements an interface between applications and resources manages available resources Resource
Expressing Fault Tolerant Algorithms with MPI-2. William D. Gropp Ewing Lusk
 Expressing Fault Tolerant Algorithms with MPI-2 William D. Gropp Ewing Lusk www.mcs.anl.gov/~gropp Overview Myths about MPI and Fault Tolerance Error handling and reporting Goal of Fault Tolerance Run
Expressing Fault Tolerant Algorithms with MPI-2 William D. Gropp Ewing Lusk www.mcs.anl.gov/~gropp Overview Myths about MPI and Fault Tolerance Error handling and reporting Goal of Fault Tolerance Run
Spyglass: Fast, Scalable Metadata Search for Large-Scale Storage Systems
 Spyglass: Fast, Scalable Metadata Search for Large-Scale Storage Systems Andrew W Leung Ethan L Miller University of California, Santa Cruz Minglong Shao Timothy Bisson Shankar Pasupathy NetApp 7th USENIX
Spyglass: Fast, Scalable Metadata Search for Large-Scale Storage Systems Andrew W Leung Ethan L Miller University of California, Santa Cruz Minglong Shao Timothy Bisson Shankar Pasupathy NetApp 7th USENIX
Towards Model-based Management of Database Fragmentation
 Towards Model-based Management of Database Fragmentation Asim Ali, Abdelkarim Erradi, Rashid Hadjidj Qatar University Rui Jia, Sherif Abdelwahed Mississippi State University Outline p Introduction p Model-based
Towards Model-based Management of Database Fragmentation Asim Ali, Abdelkarim Erradi, Rashid Hadjidj Qatar University Rui Jia, Sherif Abdelwahed Mississippi State University Outline p Introduction p Model-based
Scalable Fault Tolerance Schemes using Adaptive Runtime Support
 Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Eventual Consistency. Eventual Consistency
 Eventual Consistency Many systems: one or few processes perform updates How frequently should these updates be made available to other read-only processes? Examples: DNS: single naming authority per domain
Eventual Consistency Many systems: one or few processes perform updates How frequently should these updates be made available to other read-only processes? Examples: DNS: single naming authority per domain
Accelerated Life Testing Module Accelerated Life Testing - Overview
 Accelerated Life Testing Module Accelerated Life Testing - Overview The Accelerated Life Testing (ALT) module of AWB provides the functionality to analyze accelerated failure data and predict reliability
Accelerated Life Testing Module Accelerated Life Testing - Overview The Accelerated Life Testing (ALT) module of AWB provides the functionality to analyze accelerated failure data and predict reliability
FAULT TOLERANT SYSTEMS
 FAULT TOLERANT SYSTEMS http://www.ecs.umass.edu/ece/koren/faulttolerantsystems Part 17 - Checkpointing II Chapter 6 - Checkpointing Part.17.1 Coordinated Checkpointing Uncoordinated checkpointing may lead
FAULT TOLERANT SYSTEMS http://www.ecs.umass.edu/ece/koren/faulttolerantsystems Part 17 - Checkpointing II Chapter 6 - Checkpointing Part.17.1 Coordinated Checkpointing Uncoordinated checkpointing may lead
Airside Congestion. Airside Congestion
 Airside Congestion Amedeo R. Odoni T. Wilson Professor Aeronautics and Astronautics Civil and Environmental Engineering Massachusetts Institute of Technology Objectives Airside Congestion _ Introduce fundamental
Airside Congestion Amedeo R. Odoni T. Wilson Professor Aeronautics and Astronautics Civil and Environmental Engineering Massachusetts Institute of Technology Objectives Airside Congestion _ Introduce fundamental
Application-Specific Configuration Selection in the Cloud: Impact of Provider Policy and Potential of Systematic Testing
 Application-Specific Configuration Selection in the Cloud: Impact of Provider Policy and Potential of Systematic Testing Mohammad Hajjat +, Ruiqi Liu*, Yiyang Chang +, T.S. Eugene Ng*, Sanjay Rao + + Purdue
Application-Specific Configuration Selection in the Cloud: Impact of Provider Policy and Potential of Systematic Testing Mohammad Hajjat +, Ruiqi Liu*, Yiyang Chang +, T.S. Eugene Ng*, Sanjay Rao + + Purdue
Multiprocessor Scheduling. Multiprocessor Scheduling
 Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Multiprocessor Scheduling
 Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Cluster Randomization Create Cluster Means Dataset
 Chapter 270 Cluster Randomization Create Cluster Means Dataset Introduction A cluster randomization trial occurs when whole groups or clusters of individuals are treated together. Examples of such clusters
Chapter 270 Cluster Randomization Create Cluster Means Dataset Introduction A cluster randomization trial occurs when whole groups or clusters of individuals are treated together. Examples of such clusters
Use of Extreme Value Statistics in Modeling Biometric Systems
 Use of Extreme Value Statistics in Modeling Biometric Systems Similarity Scores Two types of matching: Genuine sample Imposter sample Matching scores Enrolled sample 0.95 0.32 Probability Density Decision
Use of Extreme Value Statistics in Modeling Biometric Systems Similarity Scores Two types of matching: Genuine sample Imposter sample Matching scores Enrolled sample 0.95 0.32 Probability Density Decision
Chapter 10: Virtual Memory. Background
 Chapter 10: Virtual Memory Background Demand Paging Process Creation Page Replacement Allocation of Frames Thrashing Operating System Examples 10.1 Background Virtual memory separation of user logical
Chapter 10: Virtual Memory Background Demand Paging Process Creation Page Replacement Allocation of Frames Thrashing Operating System Examples 10.1 Background Virtual memory separation of user logical
Performance Impact of I/O on Sender-Initiated and Receiver-Initiated Load Sharing Policies in Distributed Systems
 Appears in Proc. Conf. Parallel and Distributed Computing Systems, Dijon, France, 199. Performance Impact of I/O on Sender-Initiated and Receiver-Initiated Load Sharing Policies in Distributed Systems
Appears in Proc. Conf. Parallel and Distributed Computing Systems, Dijon, France, 199. Performance Impact of I/O on Sender-Initiated and Receiver-Initiated Load Sharing Policies in Distributed Systems
FAILURE AVOIDANCE TECHNIQUES FOR HPC SYSTEMS BASED ON FAILURE PREDICTION ANA GAINARU DISSERTATION
 c 2015 Ana Gainaru FAILURE AVOIDANCE TECHNIQUES FOR HPC SYSTEMS BASED ON FAILURE PREDICTION BY ANA GAINARU DISSERTATION Submitted in partial fulfillment of the requirements for the degree of Doctor of
c 2015 Ana Gainaru FAILURE AVOIDANCE TECHNIQUES FOR HPC SYSTEMS BASED ON FAILURE PREDICTION BY ANA GAINARU DISSERTATION Submitted in partial fulfillment of the requirements for the degree of Doctor of
Shiraz: Exploiting System Reliability and Application Resilience Characteristics to Improve Large Scale System Throughput
 18 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Shiraz: Exploiting System Reliability and Application Resilience Characteristics to Improve Large Scale System Throughput
18 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Shiraz: Exploiting System Reliability and Application Resilience Characteristics to Improve Large Scale System Throughput
Unified Model for Assessing Checkpointing Protocols at Extreme-Scale
 Unified Model for Assessing Checkpointing Protocols at Extreme-Scale George Bosilca 1, Aurélien Bouteiller 1, Elisabeth Brunet 2, Franck Cappello 3, Jack Dongarra 1, Amina Guermouche 4, Thomas Hérault
Unified Model for Assessing Checkpointing Protocols at Extreme-Scale George Bosilca 1, Aurélien Bouteiller 1, Elisabeth Brunet 2, Franck Cappello 3, Jack Dongarra 1, Amina Guermouche 4, Thomas Hérault