Lightning Talks. Platform Lab Students Stanford University
|
|
|
- Donald Cole
- 6 years ago
- Views:
Transcription

1 Lightning Talks Platform Lab Students Stanford University
2 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
3 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
4 MC Switch: Application-Layer Load Balancing on a Switch
5 MC Switch: Application-Layer Load Balancing on a Switch
6 MC Switch: Application-Layer Load Balancing on a Switch
7 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
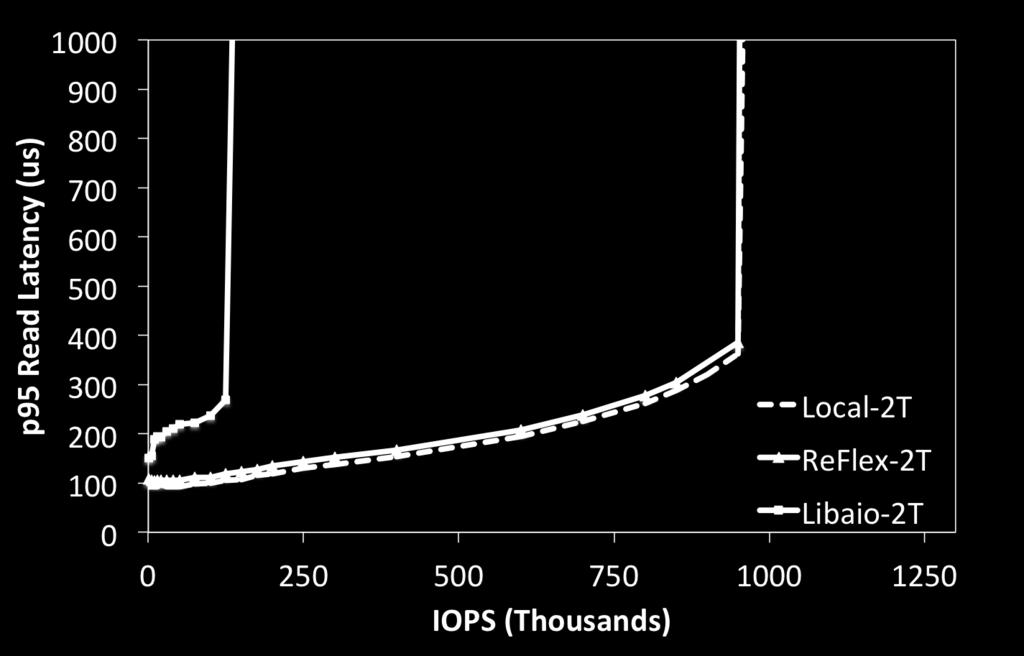
8
9 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
10
11 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
12 Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Goals: Round-trip latency < 10µs for short messages Support high network load Simulation results: 99th percentile tail latency for short messages within 2x of ideal, at 80% load Can support 90% bandwidth utilization for variety of workloads Outperforms both pfabric and phost
13 Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Key ideas: Manage congestion from receiver: receiver schedules incoming packets Minimize buffer occupancy Small amount of unscheduled packets per message Use a few network priorities to prioritize small messages and resolve bipartite matching problem
14 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez

15 Distributing Simulations on Adaptive Grids OpenVDB is a hierarchical, sparse, geometric data structure, for representing 3D volumes with varying levels of details. Resembles B+ trees. Store data at multiple levels. Uses geometric information for fast accessors. Partitioning dynamic geometric structures and computations over them is challenging: Varying topology Varying partition sizes
16 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
17 Building Blocks of a Modular Notification System Collin Lee and John Ousterhout Motivation Popular notification systems are full-featured but that means applications pay for features they don t need. New notification system focused on modularity, flexibility, and composability. Avoids unnecessary overhead in a unified system to improve performance for today s applications or enable granular computing. Want to chat? Notifications, Applications, Granular Computing, Drones, and much much more!
18 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
19 Parallelizing Computational Applications Requires High Task Throughput Parallelize an application to more cores: More tasks to keep cores busy. Individual tasks are shorter. More than 1 task per core gives scheduling flexibility. A limited task throughput hurts parallelization.
20 Existing Solutions Spark (centralized) TensorFlow (distributed, but static)
21 Our Solution A scheduling abstraction that enables nodes to spawn and executed tasks in parallel. A lightweight control plane which pushes scheduling decisions to nodes, while nodes redistribute tasks accordingly.
22 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez

23 NumFabric: Fast and Flexible Bandwidth Allocation in Datacenters Several proposals for bandwidth allocation frameworks in last 5 years Each to achieve a specific flow-level objective Which one does the operator chose if he wants flexibility? NUMFabric provides a flexible data center fabric that is also fast

24 NumFabric: Flexibility Network Utility Maximization (NUM) NUMFabric can flexibly implement several operator objective functions like minimize average flow completion time, weighted max-min, MPTCP objective, etc.

25 Why are existing NUM approaches not fast?

26 NUMFabric : Fast
27 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
28 Grazelle Hardware-Optimized In-Memory Graph Processing
29 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez
30 Don't Wait for Sync to Achieve Strong Consistency! Primary-backup is widely used because of its simplicity For strong consistency, updates had to wait for replication to backup Primary-Backup Async Replication (eg. Redis, TAO) Ø? Strong consistency (eg. MySQL,RAMCloud) Use RPC retry + async backup for consistent recovery Result: Consistency Strongest (linearizability) RAMCloud write Durability Same as synchronous backup Latency No delay by backup 14.6 µs 7.8 µs Throughput Maximum batching for backup 138 kops 500 kops (~3x)
31 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez



32 NanoLog: A Nanosecond Scale Logging System x faster than its competitors such as Log4j2 or spdlog Key Concept: Shift work out of Runtime Achieves a throughput of over 60M log messages/second at a 12.5ns median latency Extract static log information at Compile-Time Only log dynamic information in binary format at Runtime Postpone message formatting until Post-Execution Talk later today
33 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez

34 TorcDB: TinkerPop on RAMCloud
35 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez

36 Arachne: Make Multi-Core Great Again It is time for applications to take scheduling back from the kernel! Schedule threads in user land. Allocate cores in user land.
37 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez



38 Self Driving Networks SILC: a System for Sensing, Inference, Learning and Control for the Cloud Infrastructure
39 Lightning Talks 1. MC Switch: Application-Layer Load Balancing on a Switch Eyal Cidon and Sean Choi 2. ReFlex: Remote Flash == Local Flash Ana Klimovic 3. Flashield: a key-value cache that minimizes write to flash Assaf Eisenman 4. Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri 5. Distributing Simulations on Adaptive Grids Chinmayee Shah 6. Building Blocks of a Modular Notification System Collin Lee 7. Dynamic, High-throughput Task Scheduling with Task Recipes Hang Qu 8. NumFabric - Fast and Flexible Bandwidth Allocation in Datacenters Kanthi Nagaraj 9. Grazelle: Hardware-Optimized In-Memory Graph Processing Samuel Robert Grossman 10. Don't wait for sync to achieve strong consistency Seo Jin Park 11. NanoLog: A Nanosecond Scale Logging System Stephen Yang 12. TorcDB: TinkerPop on RAMCloud Jonathan Ellithorpe 13. Arachne: Make Multi-Core Great Again Henry Qin and Jacqueline Speiser 14. SILC: A Sensing, Inference, Learning and Control System for a Self Driving Network Zi Yin and Shiyu Liu 15. High Speed Networks Need Proactive Congestion Control Lavanya Jose and Steve Ibanez

40 High Speed Networks Need Proactive Congestion Control


41 High Speed Networks Need Proactive Congestion Control Synchronous Scheme in NetFPGA SUME No Per Flow State. Static Flows. Holy Grail?? - Asynchronous Scheme - Simple to implement - No Per Flow State - Dynamic Flows.
Platform Lab Overview and Update. John Ousterhout Faculty Director
 Platform Lab Overview and Update John Ousterhout Faculty Director Thank You, Sponsors! June 2, 2016 Platform Lab Overview and Update Slide 2 Special Thanks To... June 2, 2016 Platform Lab Overview and
Platform Lab Overview and Update John Ousterhout Faculty Director Thank You, Sponsors! June 2, 2016 Platform Lab Overview and Update Slide 2 Special Thanks To... June 2, 2016 Platform Lab Overview and
CGAR: Strong Consistency without Synchronous Replication. Seo Jin Park Advised by: John Ousterhout
 CGAR: Strong Consistency without Synchronous Replication Seo Jin Park Advised by: John Ousterhout Improved update performance of storage systems with master-back replication Fast: updates complete before
CGAR: Strong Consistency without Synchronous Replication Seo Jin Park Advised by: John Ousterhout Improved update performance of storage systems with master-back replication Fast: updates complete before
Exploiting Commutativity For Practical Fast Replication. Seo Jin Park and John Ousterhout
 Exploiting Commutativity For Practical Fast Replication Seo Jin Park and John Ousterhout Overview Problem: replication adds latency and throughput overheads CURP: Consistent Unordered Replication Protocol
Exploiting Commutativity For Practical Fast Replication Seo Jin Park and John Ousterhout Overview Problem: replication adds latency and throughput overheads CURP: Consistent Unordered Replication Protocol
Low-Latency Datacenters. John Ousterhout Platform Lab Retreat May 29, 2015
 Low-Latency Datacenters John Ousterhout Platform Lab Retreat May 29, 2015 Datacenters: Scale and Latency Scale: 1M+ cores 1-10 PB memory 200 PB disk storage Latency: < 0.5 µs speed-of-light delay Most
Low-Latency Datacenters John Ousterhout Platform Lab Retreat May 29, 2015 Datacenters: Scale and Latency Scale: 1M+ cores 1-10 PB memory 200 PB disk storage Latency: < 0.5 µs speed-of-light delay Most
Low-Latency Datacenters. John Ousterhout
 Low-Latency Datacenters John Ousterhout The Datacenter Revolution Phase 1: Scale How to use 10,000 servers for a single application? New storage systems: Bigtable, HDFS,... New models of computation: MapReduce,
Low-Latency Datacenters John Ousterhout The Datacenter Revolution Phase 1: Scale How to use 10,000 servers for a single application? New storage systems: Bigtable, HDFS,... New models of computation: MapReduce,
Making RAMCloud Writes Even Faster
 Making RAMCloud Writes Even Faster (Bring Asynchrony to Distributed Systems) Seo Jin Park John Ousterhout Overview Goal: make writes asynchronous with consistency. Approach: rely on client Server returns
Making RAMCloud Writes Even Faster (Bring Asynchrony to Distributed Systems) Seo Jin Park John Ousterhout Overview Goal: make writes asynchronous with consistency. Approach: rely on client Server returns
An Implementation of the Homa Transport Protocol in RAMCloud. Yilong Li, Behnam Montazeri, John Ousterhout
 An Implementation of the Homa Transport Protocol in RAMCloud Yilong Li, Behnam Montazeri, John Ousterhout Introduction Homa: receiver-driven low-latency transport protocol using network priorities HomaTransport
An Implementation of the Homa Transport Protocol in RAMCloud Yilong Li, Behnam Montazeri, John Ousterhout Introduction Homa: receiver-driven low-latency transport protocol using network priorities HomaTransport
Exploiting Commutativity For Practical Fast Replication. Seo Jin Park and John Ousterhout
 Exploiting Commutativity For Practical Fast Replication Seo Jin Park and John Ousterhout Overview Problem: consistent replication adds latency and throughput overheads Why? Replication happens after ordering
Exploiting Commutativity For Practical Fast Replication Seo Jin Park and John Ousterhout Overview Problem: consistent replication adds latency and throughput overheads Why? Replication happens after ordering
Arachne. Core Aware Thread Management Henry Qin Jacqueline Speiser John Ousterhout
 Arachne Core Aware Thread Management Henry Qin Jacqueline Speiser John Ousterhout Granular Computing Platform Zaharia Winstein Levis Applications Kozyrakis Cluster Scheduling Ousterhout Low-Latency RPC
Arachne Core Aware Thread Management Henry Qin Jacqueline Speiser John Ousterhout Granular Computing Platform Zaharia Winstein Levis Applications Kozyrakis Cluster Scheduling Ousterhout Low-Latency RPC
2018 Spring Retreat: Lab Overview and Update. John Ousterhout Faculty Director
 2018 Spring Retreat 2018 Spring Retreat: Lab Overview and Update John Ousterhout Faculty Director Thank You, Sponsors! June 7, 2018 Platform Lab Overview and Update Slide 3 Platform Lab Faculty Bill Dally
2018 Spring Retreat 2018 Spring Retreat: Lab Overview and Update John Ousterhout Faculty Director Thank You, Sponsors! June 7, 2018 Platform Lab Overview and Update Slide 3 Platform Lab Faculty Bill Dally
RAMCloud and the Low- Latency Datacenter. John Ousterhout Stanford University
 RAMCloud and the Low- Latency Datacenter John Ousterhout Stanford University Most important driver for innovation in computer systems: Rise of the datacenter Phase 1: large scale Phase 2: low latency Introduction
RAMCloud and the Low- Latency Datacenter John Ousterhout Stanford University Most important driver for innovation in computer systems: Rise of the datacenter Phase 1: large scale Phase 2: low latency Introduction
What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout
 What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout Goals for the OS Interface More convenient abstractions than hardware interface Manage shared resources Provide near-hardware
What s Wrong with the Operating System Interface? Collin Lee and John Ousterhout Goals for the OS Interface More convenient abstractions than hardware interface Manage shared resources Provide near-hardware
2017 Winter Review: Lab Overview and Update. John Ousterhout Faculty Director
 2017 Winter Review 2017 Winter Review: Lab Overview and Update John Ousterhout Faculty Director Thank You, Sponsors! February 9, 2017 Platform Lab Overview and Update Slide 3 Special Thanks To... February
2017 Winter Review 2017 Winter Review: Lab Overview and Update John Ousterhout Faculty Director Thank You, Sponsors! February 9, 2017 Platform Lab Overview and Update Slide 3 Special Thanks To... February
High-Level Data Models on RAMCloud
 High-Level Data Models on RAMCloud An early status report Jonathan Ellithorpe, Mendel Rosenblum EE & CS Departments, Stanford University Talk Outline The Idea Data models today Graph databases Experience
High-Level Data Models on RAMCloud An early status report Jonathan Ellithorpe, Mendel Rosenblum EE & CS Departments, Stanford University Talk Outline The Idea Data models today Graph databases Experience
COLLIN LEE INITIAL DESIGN THOUGHTS FOR A GRANULAR COMPUTING PLATFORM
 COLLIN LEE INITIAL DESIGN THOUGHTS FOR A GRANULAR COMPUTING PLATFORM INITIAL DESIGN THOUGHTS FOR A GRANULAR COMPUTING PLATFORM GOAL OF THIS TALK Introduce design ideas and issues for a granular computing
COLLIN LEE INITIAL DESIGN THOUGHTS FOR A GRANULAR COMPUTING PLATFORM INITIAL DESIGN THOUGHTS FOR A GRANULAR COMPUTING PLATFORM GOAL OF THIS TALK Introduce design ideas and issues for a granular computing
RAMCloud: A Low-Latency Datacenter Storage System Ankita Kejriwal Stanford University
 RAMCloud: A Low-Latency Datacenter Storage System Ankita Kejriwal Stanford University (Joint work with Diego Ongaro, Ryan Stutsman, Steve Rumble, Mendel Rosenblum and John Ousterhout) a Storage System
RAMCloud: A Low-Latency Datacenter Storage System Ankita Kejriwal Stanford University (Joint work with Diego Ongaro, Ryan Stutsman, Steve Rumble, Mendel Rosenblum and John Ousterhout) a Storage System
Hello, my name is Stephen Yang and I m a PhD Candidate from Stanford University. Today, I ll be giving a talk on NanoLog, a nanosecond scale logging
 Hello, my name is Stephen Yang and I m a PhD Candidate from Stanford University. Today, I ll be giving a talk on NanoLog, a nanosecond scale logging system that we developed for C++ to help debug the low
Hello, my name is Stephen Yang and I m a PhD Candidate from Stanford University. Today, I ll be giving a talk on NanoLog, a nanosecond scale logging system that we developed for C++ to help debug the low
DeTail Reducing the Tail of Flow Completion Times in Datacenter Networks. David Zats, Tathagata Das, Prashanth Mohan, Dhruba Borthakur, Randy Katz
 DeTail Reducing the Tail of Flow Completion Times in Datacenter Networks David Zats, Tathagata Das, Prashanth Mohan, Dhruba Borthakur, Randy Katz 1 A Typical Facebook Page Modern pages have many components
DeTail Reducing the Tail of Flow Completion Times in Datacenter Networks David Zats, Tathagata Das, Prashanth Mohan, Dhruba Borthakur, Randy Katz 1 A Typical Facebook Page Modern pages have many components
RAMCloud: Scalable High-Performance Storage Entirely in DRAM John Ousterhout Stanford University
 RAMCloud: Scalable High-Performance Storage Entirely in DRAM John Ousterhout Stanford University (with Nandu Jayakumar, Diego Ongaro, Mendel Rosenblum, Stephen Rumble, and Ryan Stutsman) DRAM in Storage
RAMCloud: Scalable High-Performance Storage Entirely in DRAM John Ousterhout Stanford University (with Nandu Jayakumar, Diego Ongaro, Mendel Rosenblum, Stephen Rumble, and Ryan Stutsman) DRAM in Storage
Distributed Geometric Data Structures. Philip Levis Stanford Platform Lab Review Feb 9, 2017
 Distributed Geometric Data Structures Philip Levis Stanford Platform Lab Review Feb 9, 2017 Big Control The Physical World Big control applications collect data on, and take action in, the physical world
Distributed Geometric Data Structures Philip Levis Stanford Platform Lab Review Feb 9, 2017 Big Control The Physical World Big control applications collect data on, and take action in, the physical world
DAL: A Locality-Optimizing Distributed Shared Memory System
 DAL: A Locality-Optimizing Distributed Shared Memory System Gábor Németh, Dániel Géhbeger and Péter Mátray Ericsson Research {gabor.a.nemeth, daniel.gehberger, peter.matray}@ericsson.com HotCloud '17 2017-07-10
DAL: A Locality-Optimizing Distributed Shared Memory System Gábor Németh, Dániel Géhbeger and Péter Mátray Ericsson Research {gabor.a.nemeth, daniel.gehberger, peter.matray}@ericsson.com HotCloud '17 2017-07-10
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay, A. et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Reviewed by Chun-Yu and Xinghao Li Summary In this
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay, A. et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Reviewed by Chun-Yu and Xinghao Li Summary In this
Fastpass A Centralized Zero-Queue Datacenter Network
 Fastpass A Centralized Zero-Queue Datacenter Network Jonathan Perry Amy Ousterhout Hari Balakrishnan Devavrat Shah Hans Fugal Ideal datacenter network properties No current design satisfies all these properties
Fastpass A Centralized Zero-Queue Datacenter Network Jonathan Perry Amy Ousterhout Hari Balakrishnan Devavrat Shah Hans Fugal Ideal datacenter network properties No current design satisfies all these properties
Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities
 : A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri, Yilong Li, Mohammad Alizadeh, and John Ousterhout Stanford University, MIT ABSTRACT is a new transport protocol
: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities Behnam Montazeri, Yilong Li, Mohammad Alizadeh, and John Ousterhout Stanford University, MIT ABSTRACT is a new transport protocol
Arachne: Core-Aware Thread Management
 Henry Qin Stanford University hq6@cs.stanford.edu Arachne: Core-Aware Thread Management Peter Kraft Stanford University kraftp@stanford.edu Qian Li Stanford University qianli@cs.stanford.edu John Ousterhout
Henry Qin Stanford University hq6@cs.stanford.edu Arachne: Core-Aware Thread Management Peter Kraft Stanford University kraftp@stanford.edu Qian Li Stanford University qianli@cs.stanford.edu John Ousterhout
Toward a Reliable Data Transport Architecture for Optical Burst-Switched Networks
 Toward a Reliable Data Transport Architecture for Optical Burst-Switched Networks Dr. Vinod Vokkarane Assistant Professor, Computer and Information Science Co-Director, Advanced Computer Networks Lab University
Toward a Reliable Data Transport Architecture for Optical Burst-Switched Networks Dr. Vinod Vokkarane Assistant Professor, Computer and Information Science Co-Director, Advanced Computer Networks Lab University
Exploiting Commutativity For Practical Fast Replication
 Exploiting Commutativity For Practical Fast Replication Seo Jin Park Stanford University John Ousterhout Stanford University Abstract Traditional approaches to replication require client requests to be
Exploiting Commutativity For Practical Fast Replication Seo Jin Park Stanford University John Ousterhout Stanford University Abstract Traditional approaches to replication require client requests to be
Millisort: An Experiment in Granular Computing. Seo Jin Park with Yilong Li, Collin Lee and John Ousterhout
 Millisort: An Experiment in Granular Computing Seo Jin Park with Yilong Li, Collin Lee and John Ousterhout Massively Parallel Granular Computing Massively parallel computing as an application of granular
Millisort: An Experiment in Granular Computing Seo Jin Park with Yilong Li, Collin Lee and John Ousterhout Massively Parallel Granular Computing Massively parallel computing as an application of granular
Application of SDN: Load Balancing & Traffic Engineering
 Application of SDN: Load Balancing & Traffic Engineering Outline 1 OpenFlow-Based Server Load Balancing Gone Wild Introduction OpenFlow Solution Partitioning the Client Traffic Transitioning With Connection
Application of SDN: Load Balancing & Traffic Engineering Outline 1 OpenFlow-Based Server Load Balancing Gone Wild Introduction OpenFlow Solution Partitioning the Client Traffic Transitioning With Connection
At-most-once Algorithm for Linearizable RPC in Distributed Systems
 At-most-once Algorithm for Linearizable RPC in Distributed Systems Seo Jin Park 1 1 Stanford University Abstract In a distributed system, like RAM- Cloud, supporting automatic retry of RPC, it is tricky
At-most-once Algorithm for Linearizable RPC in Distributed Systems Seo Jin Park 1 1 Stanford University Abstract In a distributed system, like RAM- Cloud, supporting automatic retry of RPC, it is tricky
A Generalized Blind Scheduling Policy
 A Generalized Blind Scheduling Policy Hanhua Feng 1, Vishal Misra 2,3 and Dan Rubenstein 2 1 Infinio Systems 2 Columbia University in the City of New York 3 Google TTIC SUMMER WORKSHOP: DATA CENTER SCHEDULING
A Generalized Blind Scheduling Policy Hanhua Feng 1, Vishal Misra 2,3 and Dan Rubenstein 2 1 Infinio Systems 2 Columbia University in the City of New York 3 Google TTIC SUMMER WORKSHOP: DATA CENTER SCHEDULING
Pocket: Elastic Ephemeral Storage for Serverless Analytics
 Pocket: Elastic Ephemeral Storage for Serverless Analytics Ana Klimovic*, Yawen Wang*, Patrick Stuedi +, Animesh Trivedi +, Jonas Pfefferle +, Christos Kozyrakis* *Stanford University, + IBM Research 1
Pocket: Elastic Ephemeral Storage for Serverless Analytics Ana Klimovic*, Yawen Wang*, Patrick Stuedi +, Animesh Trivedi +, Jonas Pfefferle +, Christos Kozyrakis* *Stanford University, + IBM Research 1
Memory-Based Cloud Architectures
 Memory-Based Cloud Architectures ( Or: Technical Challenges for OnDemand Business Software) Jan Schaffner Enterprise Platform and Integration Concepts Group Example: Enterprise Benchmarking -) *%'+,#$)
Memory-Based Cloud Architectures ( Or: Technical Challenges for OnDemand Business Software) Jan Schaffner Enterprise Platform and Integration Concepts Group Example: Enterprise Benchmarking -) *%'+,#$)
Towards Deadline Guaranteed Cloud Storage Services Guoxin Liu, Haiying Shen, and Lei Yu
 Towards Deadline Guaranteed Cloud Storage Services Guoxin Liu, Haiying Shen, and Lei Yu Presenter: Guoxin Liu Ph.D. Department of Electrical and Computer Engineering, Clemson University, Clemson, USA Computer
Towards Deadline Guaranteed Cloud Storage Services Guoxin Liu, Haiying Shen, and Lei Yu Presenter: Guoxin Liu Ph.D. Department of Electrical and Computer Engineering, Clemson University, Clemson, USA Computer
Packet Scheduling in Data Centers. Lecture 17, Computer Networks (198:552)
") Packet Scheduling in Data Centers Lecture 17, Computer Networks (198:552) Datacenter transport Goal: Complete flows quickly / meet deadlines Short flows (e.g., query, coordination) Large flows (e.g., data
Packet Scheduling in Data Centers Lecture 17, Computer Networks (198:552) Datacenter transport Goal: Complete flows quickly / meet deadlines Short flows (e.g., query, coordination) Large flows (e.g., data
Tailwind: Fast and Atomic RDMA-based Replication. Yacine Taleb, Ryan Stutsman, Gabriel Antoniu, Toni Cortes
 Tailwind: Fast and Atomic RDMA-based Replication Yacine Taleb, Ryan Stutsman, Gabriel Antoniu, Toni Cortes In-Memory Key-Value Stores General purpose in-memory key-value stores are widely used nowadays
Tailwind: Fast and Atomic RDMA-based Replication Yacine Taleb, Ryan Stutsman, Gabriel Antoniu, Toni Cortes In-Memory Key-Value Stores General purpose in-memory key-value stores are widely used nowadays
FaRM: Fast Remote Memory
 FaRM: Fast Remote Memory Problem Context DRAM prices have decreased significantly Cost effective to build commodity servers w/hundreds of GBs E.g. - cluster with 100 machines can hold tens of TBs of main
FaRM: Fast Remote Memory Problem Context DRAM prices have decreased significantly Cost effective to build commodity servers w/hundreds of GBs E.g. - cluster with 100 machines can hold tens of TBs of main
CPS 512 midterm exam #1, 10/7/2016
 CPS 512 midterm exam #1, 10/7/2016 Your name please: NetID: Answer all questions. Please attempt to confine your answers to the boxes provided. If you don t know the answer to a question, then just say
CPS 512 midterm exam #1, 10/7/2016 Your name please: NetID: Answer all questions. Please attempt to confine your answers to the boxes provided. If you don t know the answer to a question, then just say
Using the SDACK Architecture to Build a Big Data Product. Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver
 Apache Big Data NA 2016 Vancouver") Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
Tales of the Tail Hardware, OS, and Application-level Sources of Tail Latency
 Tales of the Tail Hardware, OS, and Application-level Sources of Tail Latency Jialin Li, Naveen Kr. Sharma, Dan R. K. Ports and Steven D. Gribble February 2, 2015 1 Introduction What is Tail Latency? What
Tales of the Tail Hardware, OS, and Application-level Sources of Tail Latency Jialin Li, Naveen Kr. Sharma, Dan R. K. Ports and Steven D. Gribble February 2, 2015 1 Introduction What is Tail Latency? What
Designing Distributed Systems using Approximate Synchrony in Data Center Networks
 Designing Distributed Systems using Approximate Synchrony in Data Center Networks Dan R. K. Ports Jialin Li Naveen Kr. Sharma Vincent Liu Arvind Krishnamurthy University of Washington CSE Today s most
Designing Distributed Systems using Approximate Synchrony in Data Center Networks Dan R. K. Ports Jialin Li Naveen Kr. Sharma Vincent Liu Arvind Krishnamurthy University of Washington CSE Today s most
Kernel Bypass. Sujay Jayakar (dsj36) 11/17/2016
 11/17/2016") Kernel Bypass Sujay Jayakar (dsj36) 11/17/2016 Kernel Bypass Background Why networking? Status quo: Linux Papers Arrakis: The Operating System is the Control Plane. Simon Peter, Jialin Li, Irene Zhang,
Kernel Bypass Sujay Jayakar (dsj36) 11/17/2016 Kernel Bypass Background Why networking? Status quo: Linux Papers Arrakis: The Operating System is the Control Plane. Simon Peter, Jialin Li, Irene Zhang,
Starling: A Scheduler Architecture for High Performance Cloud Computing
 Starling: A Scheduler Architecture for High Performance Cloud Computing Hang Qu, Omid Mashayekhi, David Terei, Philip Levis Stanford Platform Lab Seminar May 17, 2016 1 High Performance Computing (HPC)
Starling: A Scheduler Architecture for High Performance Cloud Computing Hang Qu, Omid Mashayekhi, David Terei, Philip Levis Stanford Platform Lab Seminar May 17, 2016 1 High Performance Computing (HPC)
ReFlex: Remote Flash Local Flash
 ReFlex: Remote Flash Local Flash Ana Klimovic Heiner Litz Christos Kozyrakis October 28, 216 IAP Cloud Workshop Flash in Datacenters Flash provides 1 higher throughput and 2 lower latency than disk PCIe
ReFlex: Remote Flash Local Flash Ana Klimovic Heiner Litz Christos Kozyrakis October 28, 216 IAP Cloud Workshop Flash in Datacenters Flash provides 1 higher throughput and 2 lower latency than disk PCIe
Scalable Low-Latency Indexes for a Key-Value Store Ankita Kejriwal
 Scalable Low-Latency Indexes for a Key-Value Store Ankita Kejriwal With Arjun Gopalan, Ashish Gupta, Zhihao Jia, Stephen Yang and John Ousterhout Conjecture Can a key value store support strongly consistent
Scalable Low-Latency Indexes for a Key-Value Store Ankita Kejriwal With Arjun Gopalan, Ashish Gupta, Zhihao Jia, Stephen Yang and John Ousterhout Conjecture Can a key value store support strongly consistent
Indexing in RAMCloud. Ankita Kejriwal, Ashish Gupta, Arjun Gopalan, John Ousterhout. Stanford University
 Indexing in RAMCloud Ankita Kejriwal, Ashish Gupta, Arjun Gopalan, John Ousterhout Stanford University RAMCloud 1.0 Introduction Higher-level data models Without sacrificing latency and scalability Secondary
Indexing in RAMCloud Ankita Kejriwal, Ashish Gupta, Arjun Gopalan, John Ousterhout Stanford University RAMCloud 1.0 Introduction Higher-level data models Without sacrificing latency and scalability Secondary
VoltDB vs. Redis Benchmark
 Volt vs. Redis Benchmark Motivation and Goals of this Evaluation Compare the performance of several distributed databases that can be used for state storage in some of our applications Low latency is expected
Volt vs. Redis Benchmark Motivation and Goals of this Evaluation Compare the performance of several distributed databases that can be used for state storage in some of our applications Low latency is expected
High-Performance Data Loading and Augmentation for Deep Neural Network Training
 High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
Rocksteady: Fast Migration for Low-Latency In-memory Storage. Chinmay Kulkarni, Aniraj Kesavan, Tian Zhang, Robert Ricci, Ryan Stutsman
 Rocksteady: Fast Migration for Low-Latency In-memory Storage Chinmay Kulkarni, niraj Kesavan, Tian Zhang, Robert Ricci, Ryan Stutsman 1 Introduction Distributed low-latency in-memory key-value stores are
Rocksteady: Fast Migration for Low-Latency In-memory Storage Chinmay Kulkarni, niraj Kesavan, Tian Zhang, Robert Ricci, Ryan Stutsman 1 Introduction Distributed low-latency in-memory key-value stores are
HPX. High Performance ParalleX CCT Tech Talk Series. Hartmut Kaiser
 HPX High Performance CCT Tech Talk Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 What s HPX? Exemplar runtime system implementation Targeting conventional architectures (Linux based SMPs and clusters) Currently,
HPX High Performance CCT Tech Talk Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 What s HPX? Exemplar runtime system implementation Targeting conventional architectures (Linux based SMPs and clusters) Currently,
Execu&on Templates: Caching Control Plane Decisions for Strong Scaling of Data Analy&cs
 Execu&on Templates: Caching Control Plane Decisions for Strong Scaling of Data Analy&cs Omid Mashayekhi Hang Qu Chinmayee Shah Philip Levis July 13, 2017 2 Cloud Frameworks SQL Streaming Machine Learning
Execu&on Templates: Caching Control Plane Decisions for Strong Scaling of Data Analy&cs Omid Mashayekhi Hang Qu Chinmayee Shah Philip Levis July 13, 2017 2 Cloud Frameworks SQL Streaming Machine Learning
Asymmetry-aware execution placement on manycore chips
 Asymmetry-aware execution placement on manycore chips Alexey Tumanov Joshua Wise, Onur Mutlu, Greg Ganger CARNEGIE MELLON UNIVERSITY Introduction: Core Scaling? Moore s Law continues: can still fit more
Asymmetry-aware execution placement on manycore chips Alexey Tumanov Joshua Wise, Onur Mutlu, Greg Ganger CARNEGIE MELLON UNIVERSITY Introduction: Core Scaling? Moore s Law continues: can still fit more
Implementing Linearizability at Large Scale and Low Latency
 Implementing Linearizability at Large Scale and Low Latency Collin Lee, Seo Jin Park, Ankita Kejriwal, Satoshi Matsushita, and John Ousterhout Stanford University, NEC Abstract Linearizability is the strongest
Implementing Linearizability at Large Scale and Low Latency Collin Lee, Seo Jin Park, Ankita Kejriwal, Satoshi Matsushita, and John Ousterhout Stanford University, NEC Abstract Linearizability is the strongest
DIBS: Just-in-time congestion mitigation for Data Centers
 DIBS: Just-in-time congestion mitigation for Data Centers Kyriakos Zarifis, Rui Miao, Matt Calder, Ethan Katz-Bassett, Minlan Yu, Jitendra Padhye University of Southern California Microsoft Research Summary
DIBS: Just-in-time congestion mitigation for Data Centers Kyriakos Zarifis, Rui Miao, Matt Calder, Ethan Katz-Bassett, Minlan Yu, Jitendra Padhye University of Southern California Microsoft Research Summary
Data Analytics on RAMCloud
 Data Analytics on RAMCloud Jonathan Ellithorpe jdellit@stanford.edu Abstract MapReduce [1] has already become the canonical method for doing large scale data processing. However, for many algorithms including
Data Analytics on RAMCloud Jonathan Ellithorpe jdellit@stanford.edu Abstract MapReduce [1] has already become the canonical method for doing large scale data processing. However, for many algorithms including
RAMCloud. Scalable High-Performance Storage Entirely in DRAM. by John Ousterhout et al. Stanford University. presented by Slavik Derevyanko
 RAMCloud Scalable High-Performance Storage Entirely in DRAM 2009 by John Ousterhout et al. Stanford University presented by Slavik Derevyanko Outline RAMCloud project overview Motivation for RAMCloud storage:
RAMCloud Scalable High-Performance Storage Entirely in DRAM 2009 by John Ousterhout et al. Stanford University presented by Slavik Derevyanko Outline RAMCloud project overview Motivation for RAMCloud storage:
Datacenter replication solution with quasardb
 Datacenter replication solution with quasardb Technical positioning paper April 2017 Release v1.3 www.quasardb.net Contact: sales@quasardb.net Quasardb A datacenter survival guide quasardb INTRODUCTION
Datacenter replication solution with quasardb Technical positioning paper April 2017 Release v1.3 www.quasardb.net Contact: sales@quasardb.net Quasardb A datacenter survival guide quasardb INTRODUCTION
Real-Time Internet of Things
 Real-Time Internet of Things Chenyang Lu Cyber-Physical Systems Laboratory h7p://www.cse.wustl.edu/~lu/ Internet of Things Ø Convergence of q Miniaturized devices: integrate processor, sensors and radios.
Real-Time Internet of Things Chenyang Lu Cyber-Physical Systems Laboratory h7p://www.cse.wustl.edu/~lu/ Internet of Things Ø Convergence of q Miniaturized devices: integrate processor, sensors and radios.
Making Non-Distributed Databases, Distributed. Ioannis Papapanagiotou, PhD Shailesh Birari
 Making Non-Distributed Databases, Distributed Ioannis Papapanagiotou, PhD Shailesh Birari Dynomite Ecosystem Dynomite - Proxy layer Dyno - Client Dynomite-manager - Ecosystem orchestrator Dynomite-explorer
Making Non-Distributed Databases, Distributed Ioannis Papapanagiotou, PhD Shailesh Birari Dynomite Ecosystem Dynomite - Proxy layer Dyno - Client Dynomite-manager - Ecosystem orchestrator Dynomite-explorer
TCP Nice: A Mechanism for Background Transfers
 Improving Internet Availability and Reliability TCP : A Mechanism for Background Transfers Z. Morley Mao Lecture 7 Feb 2, 2004 Arun Venkataramani, Ravi Kokku, Mike Dahlin Laboratory of Advanced Systems
Improving Internet Availability and Reliability TCP : A Mechanism for Background Transfers Z. Morley Mao Lecture 7 Feb 2, 2004 Arun Venkataramani, Ravi Kokku, Mike Dahlin Laboratory of Advanced Systems
Automatic Scaling Iterative Computations. Aug. 7 th, 2012
 Automatic Scaling Iterative Computations Guozhang Wang Cornell University Aug. 7 th, 2012 1 What are Non-Iterative Computations? Non-iterative computation flow Directed Acyclic Examples Batch style analytics
Automatic Scaling Iterative Computations Guozhang Wang Cornell University Aug. 7 th, 2012 1 What are Non-Iterative Computations? Non-iterative computation flow Directed Acyclic Examples Batch style analytics
SOFTWARE DEFINED NETWORKS. Jonathan Chu Muhammad Salman Malik
 SOFTWARE DEFINED NETWORKS Jonathan Chu Muhammad Salman Malik Credits Material Derived from: Rob Sherwood, Saurav Das, Yiannis Yiakoumis AT&T Tech Talks October 2010 (available at:www.openflow.org/wk/images/1/17/openflow_in_spnetworks.ppt)
SOFTWARE DEFINED NETWORKS Jonathan Chu Muhammad Salman Malik Credits Material Derived from: Rob Sherwood, Saurav Das, Yiannis Yiakoumis AT&T Tech Talks October 2010 (available at:www.openflow.org/wk/images/1/17/openflow_in_spnetworks.ppt)
I/O Buffering and Streaming
 I/O Buffering and Streaming I/O Buffering and Caching I/O accesses are reads or writes (e.g., to files) Application access is arbitary (offset, len) Convert accesses to read/write of fixed-size blocks
I/O Buffering and Streaming I/O Buffering and Caching I/O accesses are reads or writes (e.g., to files) Application access is arbitary (offset, len) Convert accesses to read/write of fixed-size blocks
Variable Step Fluid Simulation for Communication Network
 Variable Step Fluid Simulation for Communication Network Hongjoong Kim 1 and Junsoo Lee 2 1 Korea University, Seoul, Korea, hongjoong@korea.ac.kr 2 Sookmyung Women s University, Seoul, Korea, jslee@sookmyung.ac.kr
Variable Step Fluid Simulation for Communication Network Hongjoong Kim 1 and Junsoo Lee 2 1 Korea University, Seoul, Korea, hongjoong@korea.ac.kr 2 Sookmyung Women s University, Seoul, Korea, jslee@sookmyung.ac.kr
Designing Next Generation Data-Centers with Advanced Communication Protocols and Systems Services
 Designing Next Generation Data-Centers with Advanced Communication Protocols and Systems Services P. Balaji, K. Vaidyanathan, S. Narravula, H. W. Jin and D. K. Panda Network Based Computing Laboratory
Designing Next Generation Data-Centers with Advanced Communication Protocols and Systems Services P. Balaji, K. Vaidyanathan, S. Narravula, H. W. Jin and D. K. Panda Network Based Computing Laboratory
ParalleX. A Cure for Scaling Impaired Parallel Applications. Hartmut Kaiser
 ParalleX A Cure for Scaling Impaired Parallel Applications Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 Tianhe-1A 2.566 Petaflops Rmax Heterogeneous Architecture: 14,336 Intel Xeon CPUs 7,168 Nvidia Tesla M2050
ParalleX A Cure for Scaling Impaired Parallel Applications Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 Tianhe-1A 2.566 Petaflops Rmax Heterogeneous Architecture: 14,336 Intel Xeon CPUs 7,168 Nvidia Tesla M2050
No Tradeoff Low Latency + High Efficiency
 No Tradeoff Low Latency + High Efficiency Christos Kozyrakis http://mast.stanford.edu Latency-critical Applications A growing class of online workloads Search, social networking, software-as-service (SaaS),
No Tradeoff Low Latency + High Efficiency Christos Kozyrakis http://mast.stanford.edu Latency-critical Applications A growing class of online workloads Search, social networking, software-as-service (SaaS),
DCRoute: Speeding up Inter-Datacenter Traffic Allocation while Guaranteeing Deadlines
 DCRoute: Speeding up Inter-Datacenter Traffic Allocation while Guaranteeing Deadlines Mohammad Noormohammadpour, Cauligi S. Raghavendra Ming Hsieh Department of Electrical Engineering University of Southern
DCRoute: Speeding up Inter-Datacenter Traffic Allocation while Guaranteeing Deadlines Mohammad Noormohammadpour, Cauligi S. Raghavendra Ming Hsieh Department of Electrical Engineering University of Southern
Ambry: LinkedIn s Scalable Geo- Distributed Object Store
 Ambry: LinkedIn s Scalable Geo- Distributed Object Store Shadi A. Noghabi *, Sriram Subramanian +, Priyesh Narayanan +, Sivabalan Narayanan +, Gopalakrishna Holla +, Mammad Zadeh +, Tianwei Li +, Indranil
Ambry: LinkedIn s Scalable Geo- Distributed Object Store Shadi A. Noghabi *, Sriram Subramanian +, Priyesh Narayanan +, Sivabalan Narayanan +, Gopalakrishna Holla +, Mammad Zadeh +, Tianwei Li +, Indranil
Open-Channel SSDs Offer the Flexibility Required by Hyperscale Infrastructure Matias Bjørling CNEX Labs
 Open-Channel SSDs Offer the Flexibility Required by Hyperscale Infrastructure Matias Bjørling CNEX Labs 1 Public and Private Cloud Providers 2 Workloads and Applications Multi-Tenancy Databases Instance
Open-Channel SSDs Offer the Flexibility Required by Hyperscale Infrastructure Matias Bjørling CNEX Labs 1 Public and Private Cloud Providers 2 Workloads and Applications Multi-Tenancy Databases Instance
Essential Features of an Integration Solution
 Essential Features of an Integration Solution September 2017 WHITE PAPER Essential Features of an Integration Solution When an enterprise uses multiple applications, it needs to connect them for a variety
Essential Features of an Integration Solution September 2017 WHITE PAPER Essential Features of an Integration Solution When an enterprise uses multiple applications, it needs to connect them for a variety
Goals. Facebook s Scaling Problem. Scaling Strategy. Facebook Three Layer Architecture. Workload. Memcache as a Service.
 Goals Memcache as a Service Tom Anderson Rapid application development - Speed of adding new features is paramount Scale Billions of users Every user on FB all the time Performance Low latency for every
Goals Memcache as a Service Tom Anderson Rapid application development - Speed of adding new features is paramount Scale Billions of users Every user on FB all the time Performance Low latency for every
FlexNIC: Rethinking Network DMA
 FlexNIC: Rethinking Network DMA Antoine Kaufmann Simon Peter Tom Anderson Arvind Krishnamurthy University of Washington HotOS 2015 Networks: Fast and Growing Faster 1 T 400 GbE Ethernet Bandwidth [bits/s]
FlexNIC: Rethinking Network DMA Antoine Kaufmann Simon Peter Tom Anderson Arvind Krishnamurthy University of Washington HotOS 2015 Networks: Fast and Growing Faster 1 T 400 GbE Ethernet Bandwidth [bits/s]
Developing Enterprise Cloud Solutions with Azure
 Developing Enterprise Cloud Solutions with Azure Java Focused 5 Day Course AUDIENCE FORMAT Developers and Software Architects Instructor-led with hands-on labs LEVEL 300 COURSE DESCRIPTION This course
Developing Enterprise Cloud Solutions with Azure Java Focused 5 Day Course AUDIENCE FORMAT Developers and Software Architects Instructor-led with hands-on labs LEVEL 300 COURSE DESCRIPTION This course
ReFlex: Remote Flash Local Flash
 ReFlex: Remote Flash Local Flash Ana Klimovic Heiner Litz Christos Kozyrakis NVMW 18 Memorable Paper Award Finalist 1 Flash in Datacenters Flash provides 1000 higher throughput and 100 lower latency than
ReFlex: Remote Flash Local Flash Ana Klimovic Heiner Litz Christos Kozyrakis NVMW 18 Memorable Paper Award Finalist 1 Flash in Datacenters Flash provides 1000 higher throughput and 100 lower latency than
Mobile Edge Computing for 5G: The Communication Perspective
 Mobile Edge Computing for 5G: The Communication Perspective Kaibin Huang Dept. of Electrical & Electronic Engineering The University of Hong Kong Hong Kong Joint Work with Yuyi Mao (HKUST), Changsheng
Mobile Edge Computing for 5G: The Communication Perspective Kaibin Huang Dept. of Electrical & Electronic Engineering The University of Hong Kong Hong Kong Joint Work with Yuyi Mao (HKUST), Changsheng
Advanced Computer Networks. Datacenter TCP
 Advanced Computer Networks 263 3501 00 Datacenter TCP Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Today Problems with TCP in the Data Center TCP Incast TPC timeouts Improvements
Advanced Computer Networks 263 3501 00 Datacenter TCP Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Today Problems with TCP in the Data Center TCP Incast TPC timeouts Improvements
Storage Networking Strategy for the Next Five Years
 White Paper Storage Networking Strategy for the Next Five Years 2018 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public Information. Page 1 of 8 Top considerations for storage
White Paper Storage Networking Strategy for the Next Five Years 2018 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public Information. Page 1 of 8 Top considerations for storage
Wedge A New Frontier for Pull-based Graph Processing. Samuel Grossman and Christos Kozyrakis Platform Lab Retreat June 8, 2018
 Wedge A New Frontier for Pull-based Graph Processing Samuel Grossman and Christos Kozyrakis Platform Lab Retreat June 8, 2018 Graph Processing Problems modelled as objects (vertices) and connections between
Wedge A New Frontier for Pull-based Graph Processing Samuel Grossman and Christos Kozyrakis Platform Lab Retreat June 8, 2018 Graph Processing Problems modelled as objects (vertices) and connections between
Networking Recap Storage Intro. CSE-291 (Cloud Computing), Fall 2016 Gregory Kesden
, Fall 2016 Gregory Kesden") Networking Recap Storage Intro CSE-291 (Cloud Computing), Fall 2016 Gregory Kesden Networking Recap Storage Intro Long Haul/Global Networking Speed of light is limiting; Latency has a lower bound (.) Throughput
Networking Recap Storage Intro CSE-291 (Cloud Computing), Fall 2016 Gregory Kesden Networking Recap Storage Intro Long Haul/Global Networking Speed of light is limiting; Latency has a lower bound (.) Throughput
Diffusing Your Mobile Apps: Extending In-Network Function Virtualisation to Mobile Function Offloading
 Diffusing Your Mobile Apps: Extending In-Network Function Virtualisation to Mobile Function Offloading Mario Almeida, Liang Wang*, Jeremy Blackburn, Konstantina Papagiannaki, Jon Crowcroft* Telefonica
Diffusing Your Mobile Apps: Extending In-Network Function Virtualisation to Mobile Function Offloading Mario Almeida, Liang Wang*, Jeremy Blackburn, Konstantina Papagiannaki, Jon Crowcroft* Telefonica
WAN Application Infrastructure Fueling Storage Networks
 WAN Application Infrastructure Fueling Storage Networks Andrea Chiaffitelli, AT&T Ian Perez-Ponce, Cisco SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies
WAN Application Infrastructure Fueling Storage Networks Andrea Chiaffitelli, AT&T Ian Perez-Ponce, Cisco SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies
TDT Appendix E Interconnection Networks
 TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
Module 17: "Interconnection Networks" Lecture 37: "Introduction to Routers" Interconnection Networks. Fundamentals. Latency and bandwidth
 Interconnection Networks Fundamentals Latency and bandwidth Router architecture Coherence protocol and routing [From Chapter 10 of Culler, Singh, Gupta] file:///e /parallel_com_arch/lecture37/37_1.htm[6/13/2012
Interconnection Networks Fundamentals Latency and bandwidth Router architecture Coherence protocol and routing [From Chapter 10 of Culler, Singh, Gupta] file:///e /parallel_com_arch/lecture37/37_1.htm[6/13/2012
Application-defined Multipath TCP Scheduling
 Application-defined Multipath TCP Scheduling Frühjahrstreffen der GI Fachgruppen BS und KuVS Amr Rizk Userland Kernel Application Send Data Load MPTCP Scheduler Sending Queue Network Stack Programmable
Application-defined Multipath TCP Scheduling Frühjahrstreffen der GI Fachgruppen BS und KuVS Amr Rizk Userland Kernel Application Send Data Load MPTCP Scheduler Sending Queue Network Stack Programmable
Data Center Networks and Switching and Queueing and Covert Timing Channels
 Data Center Networks and Switching and Queueing and Covert Timing Channels Hakim Weatherspoon Associate Professor, Dept of Computer Science CS 5413: High Performance Computing and Networking March 10,
Data Center Networks and Switching and Queueing and Covert Timing Channels Hakim Weatherspoon Associate Professor, Dept of Computer Science CS 5413: High Performance Computing and Networking March 10,
EbbRT: A Framework for Building Per-Application Library Operating Systems
 EbbRT: A Framework for Building Per-Application Library Operating Systems Overview Motivation Objectives System design Implementation Evaluation Conclusion Motivation Emphasis on CPU performance and software
EbbRT: A Framework for Building Per-Application Library Operating Systems Overview Motivation Objectives System design Implementation Evaluation Conclusion Motivation Emphasis on CPU performance and software
How Cisco IT Deployed Enterprise Messaging on Cisco UCS
 Cisco IT Case Study July 2012 Enterprise Messaging on Cisco UCS How Cisco IT Deployed Enterprise Messaging on Cisco UCS Messaging platform upgrade and new servers reduce costs and improve management, availability,
Cisco IT Case Study July 2012 Enterprise Messaging on Cisco UCS How Cisco IT Deployed Enterprise Messaging on Cisco UCS Messaging platform upgrade and new servers reduce costs and improve management, availability,
P51: High Performance Networking
 P51: High Performance Networking Lecture 6: Programmable network devices Dr Noa Zilberman noa.zilberman@cl.cam.ac.uk Lent 2017/18 High Throughput Interfaces Performance Limitations So far we discussed
P51: High Performance Networking Lecture 6: Programmable network devices Dr Noa Zilberman noa.zilberman@cl.cam.ac.uk Lent 2017/18 High Throughput Interfaces Performance Limitations So far we discussed
Memshare: a Dynamic Multi-tenant Key-value Cache
 Memshare: a Dynamic Multi-tenant Key-value Cache ASAF CIDON*, DANIEL RUSHTON, STEPHEN M. RUMBLE, RYAN STUTSMAN *STANFORD UNIVERSITY, UNIVERSITY OF UTAH, GOOGLE INC. 1 Cache is 100X Faster Than Database
Memshare: a Dynamic Multi-tenant Key-value Cache ASAF CIDON*, DANIEL RUSHTON, STEPHEN M. RUMBLE, RYAN STUTSMAN *STANFORD UNIVERSITY, UNIVERSITY OF UTAH, GOOGLE INC. 1 Cache is 100X Faster Than Database
Performance and Scalability with Griddable.io
 Performance and Scalability with Griddable.io Executive summary Griddable.io is an industry-leading timeline-consistent synchronized data integration grid across a range of source and target data systems.
Performance and Scalability with Griddable.io Executive summary Griddable.io is an industry-leading timeline-consistent synchronized data integration grid across a range of source and target data systems.
Topic 6: SDN in practice: Microsoft's SWAN. Student: Miladinovic Djordje Date:
 Topic 6: SDN in practice: Microsoft's SWAN Student: Miladinovic Djordje Date: 17.04.2015 1 SWAN at a glance Goal: Boost the utilization of inter-dc networks Overcome the problems of current traffic engineering
Topic 6: SDN in practice: Microsoft's SWAN Student: Miladinovic Djordje Date: 17.04.2015 1 SWAN at a glance Goal: Boost the utilization of inter-dc networks Overcome the problems of current traffic engineering
Router s Queue Management
 Router s Queue Management Manages sharing of (i) buffer space (ii) bandwidth Q1: Which packet to drop when queue is full? Q2: Which packet to send next? FIFO + Drop Tail Keep a single queue Answer to Q1:
Router s Queue Management Manages sharing of (i) buffer space (ii) bandwidth Q1: Which packet to drop when queue is full? Q2: Which packet to send next? FIFO + Drop Tail Keep a single queue Answer to Q1:
Advanced Computer Networks. Flow Control
 Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi, Qin Yin, Timothy Roscoe Spring Semester 2015 Oriana Riva, Department of Computer Science ETH Zürich 1 Today Flow Control Store-and-forward,
Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi, Qin Yin, Timothy Roscoe Spring Semester 2015 Oriana Riva, Department of Computer Science ETH Zürich 1 Today Flow Control Store-and-forward,
Cisco I/O Accelerator Deployment Guide
 Cisco I/O Accelerator Deployment Guide Introduction This document provides design and configuration guidance for deploying the Cisco MDS 9000 Family I/O Accelerator (IOA) feature, which significantly improves
Cisco I/O Accelerator Deployment Guide Introduction This document provides design and configuration guidance for deploying the Cisco MDS 9000 Family I/O Accelerator (IOA) feature, which significantly improves
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
Disks and their Cloudy Future
 1x every 5 years Disks and their Cloudy uture ric Brewer VP Infrastructure, Google 4 hours uploaded every minute (Nov 215) @eric_brewer AST 216 Keynote ebruary 23, 216 1GB per hour 1 PB new storage every
1x every 5 years Disks and their Cloudy uture ric Brewer VP Infrastructure, Google 4 hours uploaded every minute (Nov 215) @eric_brewer AST 216 Keynote ebruary 23, 216 1GB per hour 1 PB new storage every
Infiniswap. Efficient Memory Disaggregation. Mosharaf Chowdhury. with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin
 Infiniswap Efficient Memory Disaggregation Mosharaf Chowdhury with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow
Infiniswap Efficient Memory Disaggregation Mosharaf Chowdhury with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow
Xen and the Art of Virtualization. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") Xen and the Art of Virtualization CSE-291 (Cloud Computing) Fall 2016 Why Virtualization? Share resources among many uses Allow heterogeneity in environments Allow differences in host and guest Provide
Xen and the Art of Virtualization CSE-291 (Cloud Computing) Fall 2016 Why Virtualization? Share resources among many uses Allow heterogeneity in environments Allow differences in host and guest Provide
Venugopal Ramasubramanian Emin Gün Sirer SIGCOMM 04
 The Design and Implementation of a Next Generation Name Service for the Internet Venugopal Ramasubramanian Emin Gün Sirer SIGCOMM 04 Presenter: Saurabh Kadekodi Agenda DNS overview Current DNS Problems
The Design and Implementation of a Next Generation Name Service for the Internet Venugopal Ramasubramanian Emin Gün Sirer SIGCOMM 04 Presenter: Saurabh Kadekodi Agenda DNS overview Current DNS Problems