High Speed DAQ with DPDK
|
|
|
- Kathryn Pitts
- 6 years ago
- Views:
Transcription

1 High Speed DAQ with DPDK June - August 2016 Author: Saiyida Noor Fatima Supervisors: Niko Neufeld Sebastian Valat CERN Openlab Summer Student Report 2016
2 Acknowledgment My sincere thanks to my supervisor Niko Neufeld, Sebastien Valat, Balazs Voneki, LHCb Secretariat and the entire LHCb team; without their guidance this project would not be possible. I would like to express my gratitude towards CERN Openlab team, my parents and fellow Openlab summer students for their constant support.
3 Project Specification The experiments at CERN generate mountainous amounts of data. In the first run of the Large Hadron Collider (LHC) [1], 30 petabytes of data was produced annually, and up to 40 Terabits per second amount of data more is expected to be produced during the future run of LHC in To filter the data coming from the LHCb [2] detector, LHCb team is working on a benchmark application called DAQPIPE [3] which emulates the data coming from the detector in a local area network. One of the major challenges faced by DAQPIPE is to prevent any type of data loss by implementing high-speed networks which can bear the load of the data coming in. The aim of the project is to implement a DPDK [4] driver for DAQPIPE to create a high speed packet processing, transfer and communication mechanism for future LHCb upgrades.
4 Abstract DPDK is a new frame-work for very fast software defined networking. It allows multi-stage Ethernet networks for DAQ to be implemented with very cost-effective hardware by offloading all intelligence and most of the buffering into commodity servers. The LHCb data acquisition for Run3 will need a 40 Terabit/s network, where 100 Gigabit Ethernet is one of the interesting candidates. In this project we aim to port the existing DAQ exerciser software of LHCb, DAQPIPE, to DPDK and perform tests on state of the art network hardware.
5 Table of Contents 1 Introduction DAQPIPE Components Supported Networks DPDK Components Problem Statement Problem Desired Throughput Linux Kernel Network Stack - Performance Limitations Solution Kernel Bypass DPDK Driver for DAQPIPE Forwarding Packets with DPDK API Examples Packet Construction Forwarding Example Packet Example Results Bandwidth Issues Future Work Threading in DPDK Packet Size in DPDK Segmentation of Packets Implementation of DPDK Driver for DAQPIPE Exploring DPDK further Conclusion Acronyms and Abbreviations References... 23
6 Table of Figures Figure 1. DAQ System Flowchart... 7 Figure 2. DAQ System Hardware View... 8 Figure 3. DAQ System View... 8 Figure 4. DPDK Components... 9 Figure 5. Readout Units and Builder Units communication chanels Figure 6. Packet Transfer with and without DPDK Figure 7. Received Packet Figure 8. Sent Packets Figure 9. Bandwidth Results... 18
, a benchmark application to test network fabrics for the future LHCb upgrade, for emulating the data input, filtration")

7 1 Introduction The experiments at CERN generate huge amount of data which has to be filtered, processed and stored. The LHCb is working on DAQ Protocol-Independent Performance Evaluator (DAQPIPE), a benchmark application to test network fabrics for the future LHCb upgrade, for emulating the data input, filtration and storage. 1.1 DAQPIPE DAQPIPE emulates reading data from input cards, which in a real DAQ is connected to the detector. Data coming from one event is correlated and needs to be brought together in one place. This event data is spread over multiple nodes (~ 500 to 1000 for the LHCb DAQ upgrade) so DAQPIPE has to aggregate all the parts. The LHCb data acquisition will need a 40 Terabit/s network in Tb/s data coming from the LHCb detector in the DAQ system, which consists of 500 computing nodes, makes the required throughput to be 80 Gb/s Components DAQPIPE has 4 components: i. The Readout Unit reads data from the detector (or input cards in case of emulation) and sends it to the Builder Unit. ii. The Builder Unit aggregates the data of one particular event and sends it to a Filter Unit. iii. The Filter Unit has to decide whether or not the event is to be stored. iv. The Event Manager manages the job of dispatching between the Readout Unit and Builder Unit Supported Networks DAQPIPE supports various network interfaces [5] which can be paired with different technologies to provide user with multiple pair options while keeping the user transparent to the underlying working. Some of the networks supported by the DAQPIPE include: i. MPI ii. LibFabric iii. Infiniband VERBS iv. TCP/IP v. RapidIO vi. PSM2 Figure 1. DAQ System Flowchart Figure 1 Source: 7 P a g e


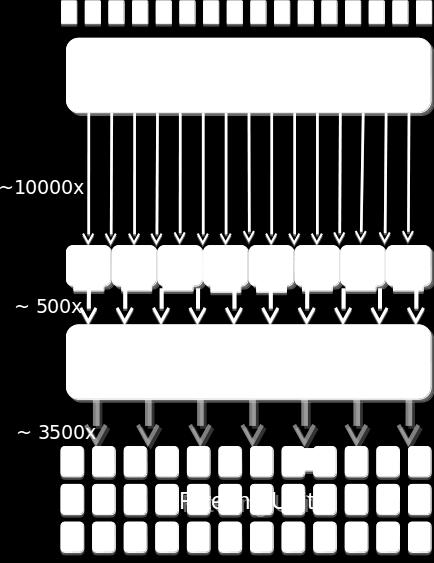
8 2 Figure 2. DAQ System Hardware View Figure 3. DAQ System View Figure 2 and 3 Source: 8 P a g e

9 1.2 DPDK DPDK is a set of libraries and drivers for fast packet processing. It is designed to run on any processor including Intel x86, IBM Power 8, EZchip TILE-Gx and ARM. It is a new frame-work for very fast software defined networking. It allows multi-stage Ethernet networks for DAQ to be implemented with very cost-effective hardware by offloading all intelligence and most of the buffering into commodity servers. It works with Ethernet. DPDK is aimed for switch implementation, however, in this project, it is being used for data transfer and communication Components DPDK consists of the following major modules: i. Environment Abstraction Layer (EAL): It is responsible for gaining access to low level resources such as hardware and memory space. ii. iii. iv. Memory Manager: Responsible for allocating pools of objects in memory space. Buffer Manager: Assigns outgoing and incoming (TX/RX) packet queues. Queue Manager: Manages the queues allocated by the buffer manager. v. Packet Flow Classifier: Implements hash based flow classification to place packets into flows for processing. vi. Poll Mode Drivers: These are designed to work without Interrupt-based signalling, which saves the CPU time. 3 Figure 4. DPDK Components Figure 4 Source: 9 P a g e

10 2 Problem Statement 2.1 Problem As explained earlier in section 1.1, it is estimated that in the 2020 upgrade, Run3, the LHCb data acquisition will need a 40 Terabit/s network, where 100 Gigabit Ethernet is one of the most interesting candidates Desired Throughput 80 Gb/s is the throughput required by the network in DAQPIPE to transfer data among Readout Units and Builder Units. Figure 5. Readout Units and Builder Units communication chanels Linux Kernel Network Stack - Performance Limitations Linux is not designed as a high operation and high throughput for network traffic operating system, but as a general purpose OS. Forwarding process of TCP/IP packets in Linux goes through many layers of the network stack, in both, reception of the packets and transmittance of the packet. These layers of the operating systems don't give the user much control over the hardware features. Therefore, high throughput communication and specialized workloads require methods other than the general purpose methods working with Linux OS which cannot get us very high throughput as desired in the LHCb DAQPIPE. 2.2 Solution Over the years, many attempts have been made to overcome the Linux kernel performance limitations. Specialized APIs have been designed to increase packet reception at high speed in Linux environment. 10 P a g e
11 2.2.1 Kernel Bypass One of the most popularly used techniques used to send and receive more packets from existing hardware is by working around the Linux kernel networking stack. This is known as Kernel Bypassing [6] DPDK Driver for DAQPIPE DPDK is a set of libraries and drivers for high speed packet processing. It allows the user to send and receive packets with the minimum number of CPU cycles. It also allows the development of fast packet capture algorithms. In this project, we are looking to implement a driver of DPDK for DAQPIPE to produce a high speed network for the future LHCb upgrades. Comparisons of the packet send/receive path in Linux and DPDK is shown in the following figures. Applications Applications DPDK Libraries Linux Kernel Network Driver Linux Kernel Network Driver NIC NIC Figure 6. Packet Transfer with and without DPDK 11 P a g e
12 3 Forwarding Packets with DPDK 3.1 API Examples As DPDK is a set of libraries, it has the following major topics in which the headers can be categorized: i. Device ii. Memory iii. Timers iv. Locks v. CPU arch vi. CPU multicore vii. Layers viii. QoS ix. Hashes x. Containers xi. Packet framework xii. Basic xiii. Debug For a simple hello world program: i. The EAL has to be initialized first. ret = rte_eal_init(argc, argv); if (ret < 0) rte_panic("cannot init EAL\n"); ii. A function to print hello world on console. static int lcore_hello( attribute ((unused)) void *arg) { unsigned lcore_id; } lcore_id = rte_lcore_id(); printf("hello from core %u\n", lcore_id); return 0; iii. Call the function on ach available slave node. RTE_LCORE_FOREACH_SLAVE(lcore_id) { rte_eal_remote_launch(lcore_hello, NULL, lcore_id); } iv. Call the function on master (current) node. lcore_hello(null); 12 P a g e
13 3.2 Packet Construction For a more customized communication and packet transfer, DPDK allows us to create a packet of our choice and send/receive it. i. Initialize the EAL. int ret = rte_eal_init(argc, argv); if (ret < 0) rte_panic("cannot init EAL\n"); ii. Create a memory pool for the program. packet_pool = rte_mempool_create("packet_pool", nb_ports, MBUF_SIZE, MBUF_CACHE_SIZE, MBUF_DATA_SIZE, rte_pktmbuf_pool_init, NULL, rte_pktmbuf_init, NULL, rte_socket_id(), 0); iii. iv. Allocate a packet in memory pool. packet = rte_pktmbuf_alloc(packet_pool); Populate the packet with data, source address, destination address, and initialize packet fields. pkt_size = sizeof(struct ether_hdr) + sizeof(struct data); packet->data_len = pkt_size; packet->pkt_len = pkt_size; eth_hdr = rte_pktmbuf_mtod(packet, struct ether_hdr *); rte_eth_macaddr_get(src_port, ð_hdr->s_addr); rte_eth_macaddr_get(dst_port, ð_hdr->d_addr); v. Transmit the packet to the destination port address. rte_eth_tx_burst(dst_port, 0, &packet, 1); vi. vii. The receiver side can receive the incoming packets in a similar way. rte_eth_rx_burst(port, 0, &packet, 1); Free the memory occupied by packet after processing. rte_pktmbuf_free(packet); 13 P a g e
14 3.3 Forwarding Example Following is a basic forwarding example derived from the basicfwd.c example in the DPDK sample applications [7]. The lcore_main function is reads from an input port and writes to an output port. The forwarding loop continues for 10 seconds in this example. /* * The main thread that does the work, reading from * an input port and writing to an output port. */ struct message { char data[data_size]; }; static attribute (()) void lcore_main(void) { const uint8_t nb_ports = rte_eth_dev_count(); uint8_t port; for (port = 0; port < nb_ports; port++) if (rte_eth_dev_socket_id(port) > 0 && rte_eth_dev_socket_id(port)!= (int)rte_socket_id()) printf("warning, port %u is on remote NUMA node to " "polling thread.\n\tperformance will " "not be optimal.\n", port); struct rte_mbuf *pkt; struct ether_hdr *eth_hdr; struct message obj; struct message *msg; int nb_rx = 0, nb_tx = 0, cnt = 0, pkt_size = 0; int count = 0; int k = 0; for (count = 0; count < DATA_SIZE; count++){ obj.data[count] = (char)(97 + (k++)); if (k == 26) k = 0; } time_t endtime = time(null) + 10; port = 0; while (time(null) < endtime) { cnt = rte_eth_rx_burst(port, 0, &pkt, 1); nb_rx += cnt; if (cnt > 0) { eth_hdr = rte_pktmbuf_mtod(pkt, struct ether_hdr *); rte_eth_macaddr_get(port, ð_hdr->s_addr); PRIx8 // printf("port %u MAC: %02" PRIx8 " %02" PRIx8 " %02" 14 P a g e
15 // " %02" PRIx8 " %02" PRIx8 " %02" PRIx8 "\n", // (unsigned)port, // eth_hdr->s_addr.addr_bytes[0], eth_hdr- >s_addr.addr_bytes[1], // eth_hdr->s_addr.addr_bytes[2], eth_hdr- >s_addr.addr_bytes[3], // eth_hdr->s_addr.addr_bytes[4], eth_hdr- >s_addr.addr_bytes[5]); pkt_size = sizeof(struct message) + sizeof(struct ether_hdr); msg = (struct message *) (rte_pktmbuf_mtod(pkt, char*)) + sizeof(struct ether_hdr); rte_pktmbuf_free(pkt); } msg = &obj; pkt = rte_pktmbuf_alloc(mbuf_pool); pkt_size = sizeof(struct message) + sizeof(struct ether_hdr); pkt->data_len = pkt_size; pkt->pkt_len = pkt_size; eth_hdr = rte_pktmbuf_mtod(pkt, struct ether_hdr *); rte_eth_macaddr_get(port, ð_hdr->d_addr); rte_eth_macaddr_get(port ^ 1, ð_hdr->s_addr); eth_hdr->ether_type = htons(ptp_protocol); char* data; data = rte_pktmbuf_append(pkt, sizeof(struct message)); if (data!= NULL) rte_memcpy(data, msg, sizeof(struct message)); nb_tx += rte_eth_tx_burst(port ^ 1, 0, &pkt, 1); } printf("----\ndata size: %d\npacket size: %d\nrx : %d, TX : %d\n\n", DATA_SIZE, pkt_size, nb_rx, nb_tx); } 15 P a g e

16 3.4 Packet Example Following are the packet examples being sent and received on a port Received Figure 7. Received Packet 16 P a g e

17 Sent Figure 8. Sent Packets 17 P a g e
18 4 Results 4.1 Bandwidth The maximum bandwidth achieved is on packet size = Figure 9 shows how the bandwidth is affected by packet size. The graph displays 5 runs each for packet sizes: 64, 128, 256, 512, 1024, 1200 bytes. Figure 9. Bandwidth Results 18 P a g e
19 5 Issues A few issues faced during the project include: I. DPDK requires specialized hardware [8] support to work. Initially, the NIC chosen to work with was Chelsio, but due to the compatibility constraints between the Chelsio driver and the OS used by the test servers, the cards had to be changed to Mellanox. This caused a lag in the timeline estimated for the project. II. DPDK is aimed for switch implementation. However, we are using it as a communication protocol. Hence, it was quite difficult to find any example or previous work regarding our area of interest. III. Currently, there are no DPDK experts in the computing team in LHCb. Therefore, obtaining expert guidance was not possible. IV. The maximum packet sizes that worked initially were not impressive. The maximum packet size being communicated at the moment is 1200 bytes. 19 P a g e
20 6 Future Work 6.1 Threading in DPDK DPDK offers users to write parallel code using its thread-safe libraries. The typical runtime environment of DPDK is a single-threaded process per logical core. However, it can be multithreaded or multi-process in some cases. According to DPDK documentation, there are three threading models: i. One EAL thread per physical core. ii. Multiple EAL threads per physical core. iii. Multiple light-weight threads per EAL thread. In future work for this project, the developers can utilize threading to increase parallelism and throughput of the current system. 6.2 Packet Size in DPDK The current maximum packet size is 1200 bytes. Further optimizations can be made to increase the packet size for the data transfer. 6.3 Segmentation of Packets DPDK allows the developers to create segmented packets. This feature can be tested and utilized to increase the packet size efficiently. 6.4 Implementation of DPDK Driver for DAQPIPE Due to unforeseen complications in the project, the DPDK driver for DAQPIPE could not be completely implemented in time. Therefore, the next step is to implement a complete API for the driver. 6.5 Exploring DPDK further This project, as mentioned before, was a prospective project as no one in the LHCb group had worked with DPDK before. It leaves the team with a chance to further explore and exploit the features by DPDK. 20 P a g e
21 7 Conclusion This project was a prospective step by the LHCb team. The bandwidth results obtained so far (i.e. 32Gb/s approximately) signify that DPDK can be an interesting candidate for the LHCb upgrade in However, there is still a need for further exploration and optimization for the driver implementation in DAQPIPE. Given the specified hardware support, and feature such as threading and segmentation utilized, DPDK might be able to produce close to the desired throughput (80 Gb/s). 21 P a g e
22 8 Acronyms and Abbreviations # Keyword Meaning 1 API Application Programming Interface 2 DAQ Data Acquisition 3 DAQPIPE DAQ Protocol-Independent Performance Evaluator 4 DPDK Data Plane Development Kit 5 EAL Environment Abstraction Layer 6 Gb/s Gigabits per second 7 LHC Large Hadron Collider 8 LHCb Large Hadron Collider beauty 9 NIC Network Interface Card 10 OS Operating System 11 RX Receiver 12 Tb/s Terabits per second 13 TX Transmitter 22 P a g e
23 9 References [1] Large Hadron Collider (LHC). [2] LHCb Detector. [3] DAQPIPE. [4] DPDK. [5] Networks Supported by DAQPIPE. [6] Kernel Bypass. [7] DPDK Sample Applications. [8] NICs supported by DPDK P a g e
Benchmarking message queue libraries and network technologies to transport large data volume in
 Benchmarking message queue libraries and network technologies to transport large data volume in the ALICE O 2 system V. Chibante Barroso, U. Fuchs, A. Wegrzynek for the ALICE Collaboration Abstract ALICE
Benchmarking message queue libraries and network technologies to transport large data volume in the ALICE O 2 system V. Chibante Barroso, U. Fuchs, A. Wegrzynek for the ALICE Collaboration Abstract ALICE
FAQ. Release rc2
 FAQ Release 19.02.0-rc2 January 15, 2019 CONTENTS 1 What does EAL: map_all_hugepages(): open failed: Permission denied Cannot init memory mean? 2 2 If I want to change the number of hugepages allocated,
FAQ Release 19.02.0-rc2 January 15, 2019 CONTENTS 1 What does EAL: map_all_hugepages(): open failed: Permission denied Cannot init memory mean? 2 2 If I want to change the number of hugepages allocated,
Supporting Cloud Native with DPDK and containers KEITH INTEL CORPORATION
 x Supporting Cloud Native with DPDK and containers KEITH WILES @ INTEL CORPORATION Making Applications Cloud Native Friendly How can we make DPDK Cloud Native Friendly? Reduce startup resources for quicker
x Supporting Cloud Native with DPDK and containers KEITH WILES @ INTEL CORPORATION Making Applications Cloud Native Friendly How can we make DPDK Cloud Native Friendly? Reduce startup resources for quicker
An Experimental review on Intel DPDK L2 Forwarding
 An Experimental review on Intel DPDK L2 Forwarding Dharmanshu Johar R.V. College of Engineering, Mysore Road,Bengaluru-560059, Karnataka, India. Orcid Id: 0000-0001- 5733-7219 Dr. Minal Moharir R.V. College
An Experimental review on Intel DPDK L2 Forwarding Dharmanshu Johar R.V. College of Engineering, Mysore Road,Bengaluru-560059, Karnataka, India. Orcid Id: 0000-0001- 5733-7219 Dr. Minal Moharir R.V. College
Advanced Computer Networks. End Host Optimization
 Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
IsoStack Highly Efficient Network Processing on Dedicated Cores
 IsoStack Highly Efficient Network Processing on Dedicated Cores Leah Shalev Eran Borovik, Julian Satran, Muli Ben-Yehuda Outline Motivation IsoStack architecture Prototype TCP/IP over 10GE on a single
IsoStack Highly Efficient Network Processing on Dedicated Cores Leah Shalev Eran Borovik, Julian Satran, Muli Ben-Yehuda Outline Motivation IsoStack architecture Prototype TCP/IP over 10GE on a single
High-Speed Forwarding: A P4 Compiler with a Hardware Abstraction Library for Intel DPDK
 High-Speed Forwarding: A P4 Compiler with a Hardware Abstraction Library for Intel DPDK Sándor Laki Eötvös Loránd University Budapest, Hungary lakis@elte.hu Motivation Programmability of network data plane
High-Speed Forwarding: A P4 Compiler with a Hardware Abstraction Library for Intel DPDK Sándor Laki Eötvös Loránd University Budapest, Hungary lakis@elte.hu Motivation Programmability of network data plane
Work Project Report: Benchmark for 100 Gbps Ethernet network analysis
 Work Project Report: Benchmark for 100 Gbps Ethernet network analysis CERN Summer Student Programme 2016 Student: Iraklis Moutidis imoutidi@cern.ch Main supervisor: Balazs Voneki balazs.voneki@cern.ch
Work Project Report: Benchmark for 100 Gbps Ethernet network analysis CERN Summer Student Programme 2016 Student: Iraklis Moutidis imoutidi@cern.ch Main supervisor: Balazs Voneki balazs.voneki@cern.ch
RAPIDIO USAGE IN A BIG DATA ENVIRONMENT
 RAPIDIO USAGE IN A BIG DATA ENVIRONMENT September 2015 Author: Jorge Costa Supervisor(s): Olof Barring PROJECT SPECIFICATION RapidIO (http://rapidio.org/) technology is a package-switched high-performance
RAPIDIO USAGE IN A BIG DATA ENVIRONMENT September 2015 Author: Jorge Costa Supervisor(s): Olof Barring PROJECT SPECIFICATION RapidIO (http://rapidio.org/) technology is a package-switched high-performance
Fast packet processing in the cloud. Dániel Géhberger Ericsson Research
 Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Supporting Fine-Grained Network Functions through Intel DPDK
 Supporting Fine-Grained Network Functions through Intel DPDK Ivano Cerrato, Mauro Annarumma, Fulvio Risso - Politecnico di Torino, Italy EWSDN 2014, September 1st 2014 This project is co-funded by the
Supporting Fine-Grained Network Functions through Intel DPDK Ivano Cerrato, Mauro Annarumma, Fulvio Risso - Politecnico di Torino, Italy EWSDN 2014, September 1st 2014 This project is co-funded by the
FaRM: Fast Remote Memory
 FaRM: Fast Remote Memory Problem Context DRAM prices have decreased significantly Cost effective to build commodity servers w/hundreds of GBs E.g. - cluster with 100 machines can hold tens of TBs of main
FaRM: Fast Remote Memory Problem Context DRAM prices have decreased significantly Cost effective to build commodity servers w/hundreds of GBs E.g. - cluster with 100 machines can hold tens of TBs of main
Agilio CX 2x40GbE with OVS-TC
 PERFORMANCE REPORT Agilio CX 2x4GbE with OVS-TC OVS-TC WITH AN AGILIO CX SMARTNIC CAN IMPROVE A SIMPLE L2 FORWARDING USE CASE AT LEAST 2X. WHEN SCALED TO REAL LIFE USE CASES WITH COMPLEX RULES TUNNELING
PERFORMANCE REPORT Agilio CX 2x4GbE with OVS-TC OVS-TC WITH AN AGILIO CX SMARTNIC CAN IMPROVE A SIMPLE L2 FORWARDING USE CASE AT LEAST 2X. WHEN SCALED TO REAL LIFE USE CASES WITH COMPLEX RULES TUNNELING
NIC TEAMING IEEE 802.3ad
 WHITE PAPER NIC TEAMING IEEE 802.3ad NIC Teaming IEEE 802.3ad Summary This tech note describes the NIC (Network Interface Card) teaming capabilities of VMware ESX Server 2 including its benefits, performance
WHITE PAPER NIC TEAMING IEEE 802.3ad NIC Teaming IEEE 802.3ad Summary This tech note describes the NIC (Network Interface Card) teaming capabilities of VMware ESX Server 2 including its benefits, performance
A first look at 100 Gbps LAN technologies, with an emphasis on future DAQ applications.
 21st International Conference on Computing in High Energy and Nuclear Physics (CHEP21) IOP Publishing Journal of Physics: Conference Series 664 (21) 23 doi:1.188/1742-696/664//23 A first look at 1 Gbps
21st International Conference on Computing in High Energy and Nuclear Physics (CHEP21) IOP Publishing Journal of Physics: Conference Series 664 (21) 23 doi:1.188/1742-696/664//23 A first look at 1 Gbps
URDMA: RDMA VERBS OVER DPDK
 13 th ANNUAL WORKSHOP 2017 URDMA: RDMA VERBS OVER DPDK Patrick MacArthur, Ph.D. Candidate University of New Hampshire March 28, 2017 ACKNOWLEDGEMENTS urdma was initially developed during an internship
13 th ANNUAL WORKSHOP 2017 URDMA: RDMA VERBS OVER DPDK Patrick MacArthur, Ph.D. Candidate University of New Hampshire March 28, 2017 ACKNOWLEDGEMENTS urdma was initially developed during an internship
Wireless Base Band Device (bbdev) Amr Mokhtar DPDK Summit Userspace - Dublin- 2017
 Amr Mokhtar DPDK Summit Userspace - Dublin- 2017") Wireless Base Band Device (bbdev) Amr Mokhtar DPDK Summit Userspace - Dublin- 2017 why baseband..? MAC Tx Data Downlink * Reference: 3GPP TS 36.211 & 36.212 architecture Common programing framework for
Wireless Base Band Device (bbdev) Amr Mokhtar DPDK Summit Userspace - Dublin- 2017 why baseband..? MAC Tx Data Downlink * Reference: 3GPP TS 36.211 & 36.212 architecture Common programing framework for
IBM Network Processor, Development Environment and LHCb Software
 IBM Network Processor, Development Environment and LHCb Software LHCb Readout Unit Internal Review July 24 th 2001 Niko Neufeld, CERN 1 Outline IBM NP4GS3 Architecture A Readout Unit based on the NP4GS3
IBM Network Processor, Development Environment and LHCb Software LHCb Readout Unit Internal Review July 24 th 2001 Niko Neufeld, CERN 1 Outline IBM NP4GS3 Architecture A Readout Unit based on the NP4GS3
Using DPDK with Go. Takanari Hayama Technology Consulting Company IGEL Co.,Ltd.
 Using DPDK with Go Technology Consulting Company Research, Development & Global Standard Takanari Hayama taki@igel.co.jp Technology Consulting Company IGEL Co.,Ltd. 1 BACKGROUND 2017/9/26,27 DPDK Summit
Using DPDK with Go Technology Consulting Company Research, Development & Global Standard Takanari Hayama taki@igel.co.jp Technology Consulting Company IGEL Co.,Ltd. 1 BACKGROUND 2017/9/26,27 DPDK Summit
Networking for Data Acquisition Systems. Fabrice Le Goff - 14/02/ ISOTDAQ
 Networking for Data Acquisition Systems Fabrice Le Goff - 14/02/2018 - ISOTDAQ Outline Generalities The OSI Model Ethernet and Local Area Networks IP and Routing TCP, UDP and Transport Efficiency Networking
Networking for Data Acquisition Systems Fabrice Le Goff - 14/02/2018 - ISOTDAQ Outline Generalities The OSI Model Ethernet and Local Area Networks IP and Routing TCP, UDP and Transport Efficiency Networking
Next Gen Virtual Switch. CloudNetEngine Founder & CTO Jun Xiao
 Next Gen Virtual Switch CloudNetEngine Founder & CTO Jun Xiao Agenda Thoughts on next generation virtual switch Technical deep dive on CloudNetEngine virtual switch Q & A 2 Major vswitches categorized
Next Gen Virtual Switch CloudNetEngine Founder & CTO Jun Xiao Agenda Thoughts on next generation virtual switch Technical deep dive on CloudNetEngine virtual switch Q & A 2 Major vswitches categorized
An FPGA-Based Optical IOH Architecture for Embedded System
 An FPGA-Based Optical IOH Architecture for Embedded System Saravana.S Assistant Professor, Bharath University, Chennai 600073, India Abstract Data traffic has tremendously increased and is still increasing
An FPGA-Based Optical IOH Architecture for Embedded System Saravana.S Assistant Professor, Bharath University, Chennai 600073, India Abstract Data traffic has tremendously increased and is still increasing
NetFPGA Hardware Architecture
 NetFPGA Hardware Architecture Jeffrey Shafer Some slides adapted from Stanford NetFPGA tutorials NetFPGA http://netfpga.org 2 NetFPGA Components Virtex-II Pro 5 FPGA 53,136 logic cells 4,176 Kbit block
NetFPGA Hardware Architecture Jeffrey Shafer Some slides adapted from Stanford NetFPGA tutorials NetFPGA http://netfpga.org 2 NetFPGA Components Virtex-II Pro 5 FPGA 53,136 logic cells 4,176 Kbit block
Learning with Purpose
 Network Measurement for 100Gbps Links Using Multicore Processors Xiaoban Wu, Dr. Peilong Li, Dr. Yongyi Ran, Prof. Yan Luo Department of Electrical and Computer Engineering University of Massachusetts
Network Measurement for 100Gbps Links Using Multicore Processors Xiaoban Wu, Dr. Peilong Li, Dr. Yongyi Ran, Prof. Yan Luo Department of Electrical and Computer Engineering University of Massachusetts
Reduces latency and buffer overhead. Messaging occurs at a speed close to the processors being directly connected. Less error detection
 Switching Operational modes: Store-and-forward: Each switch receives an entire packet before it forwards it onto the next switch - useful in a general purpose network (I.e. a LAN). usually, there is a
Switching Operational modes: Store-and-forward: Each switch receives an entire packet before it forwards it onto the next switch - useful in a general purpose network (I.e. a LAN). usually, there is a
Optimizing Performance: Intel Network Adapters User Guide
 Optimizing Performance: Intel Network Adapters User Guide Network Optimization Types When optimizing network adapter parameters (NIC), the user typically considers one of the following three conditions
Optimizing Performance: Intel Network Adapters User Guide Network Optimization Types When optimizing network adapter parameters (NIC), the user typically considers one of the following three conditions
IO virtualization. Michael Kagan Mellanox Technologies
 IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
Netronome 25GbE SmartNICs with Open vswitch Hardware Offload Drive Unmatched Cloud and Data Center Infrastructure Performance
 WHITE PAPER Netronome 25GbE SmartNICs with Open vswitch Hardware Offload Drive Unmatched Cloud and NETRONOME AGILIO CX 25GBE SMARTNICS SIGNIFICANTLY OUTPERFORM MELLANOX CONNECTX-5 25GBE NICS UNDER HIGH-STRESS
WHITE PAPER Netronome 25GbE SmartNICs with Open vswitch Hardware Offload Drive Unmatched Cloud and NETRONOME AGILIO CX 25GBE SMARTNICS SIGNIFICANTLY OUTPERFORM MELLANOX CONNECTX-5 25GBE NICS UNDER HIGH-STRESS
Asynchronous Events on Linux
 Asynchronous Events on Linux Frederic.Rossi@Ericsson.CA Open System Lab Systems Research June 25, 2002 Ericsson Research Canada Introduction Linux performs well as a general purpose OS but doesn t satisfy
Asynchronous Events on Linux Frederic.Rossi@Ericsson.CA Open System Lab Systems Research June 25, 2002 Ericsson Research Canada Introduction Linux performs well as a general purpose OS but doesn t satisfy
Improving Packet Processing Performance of a Memory- Bounded Application
 Improving Packet Processing Performance of a Memory- Bounded Application Jörn Schumacher CERN / University of Paderborn, Germany jorn.schumacher@cern.ch On behalf of the ATLAS FELIX Developer Team LHCb
Improving Packet Processing Performance of a Memory- Bounded Application Jörn Schumacher CERN / University of Paderborn, Germany jorn.schumacher@cern.ch On behalf of the ATLAS FELIX Developer Team LHCb
DPDK+eBPF KONSTANTIN ANANYEV INTEL
 x DPDK+eBPF KONSTANTIN ANANYEV INTEL BPF overview BPF (Berkeley Packet Filter) is a VM in the kernel (linux/freebsd/etc.) allowing to execute bytecode at various hook points in a safe manner. It is used
x DPDK+eBPF KONSTANTIN ANANYEV INTEL BPF overview BPF (Berkeley Packet Filter) is a VM in the kernel (linux/freebsd/etc.) allowing to execute bytecode at various hook points in a safe manner. It is used
MiniDAQ1 A COMPACT DATA ACQUISITION SYSTEM FOR GBT READOUT OVER 10G ETHERNET 22/05/2017 TIPP PAOLO DURANTE - MINIDAQ1 1
 MiniDAQ1 A COMPACT DATA ACQUISITION SYSTEM FOR GBT READOUT OVER 10G ETHERNET 22/05/2017 TIPP 2017 - PAOLO DURANTE - MINIDAQ1 1 Overview LHCb upgrade Optical frontend readout Slow control implementation
MiniDAQ1 A COMPACT DATA ACQUISITION SYSTEM FOR GBT READOUT OVER 10G ETHERNET 22/05/2017 TIPP 2017 - PAOLO DURANTE - MINIDAQ1 1 Overview LHCb upgrade Optical frontend readout Slow control implementation
Meltdown and Spectre Interconnect Performance Evaluation Jan Mellanox Technologies
 Meltdown and Spectre Interconnect Evaluation Jan 2018 1 Meltdown and Spectre - Background Most modern processors perform speculative execution This speculation can be measured, disclosing information about
Meltdown and Spectre Interconnect Evaluation Jan 2018 1 Meltdown and Spectre - Background Most modern processors perform speculative execution This speculation can be measured, disclosing information about
Memory Management Strategies for Data Serving with RDMA
 Memory Management Strategies for Data Serving with RDMA Dennis Dalessandro and Pete Wyckoff (presenting) Ohio Supercomputer Center {dennis,pw}@osc.edu HotI'07 23 August 2007 Motivation Increasing demands
Memory Management Strategies for Data Serving with RDMA Dennis Dalessandro and Pete Wyckoff (presenting) Ohio Supercomputer Center {dennis,pw}@osc.edu HotI'07 23 August 2007 Motivation Increasing demands
pthreads CS449 Fall 2017
 pthreads CS449 Fall 2017 POSIX Portable Operating System Interface Standard interface between OS and program UNIX-derived OSes mostly follow POSIX Linux, macos, Android, etc. Windows requires separate
pthreads CS449 Fall 2017 POSIX Portable Operating System Interface Standard interface between OS and program UNIX-derived OSes mostly follow POSIX Linux, macos, Android, etc. Windows requires separate
Much Faster Networking
 Much Faster Networking David Riddoch driddoch@solarflare.com Copyright 2016 Solarflare Communications, Inc. All rights reserved. What is kernel bypass? The standard receive path The standard receive path
Much Faster Networking David Riddoch driddoch@solarflare.com Copyright 2016 Solarflare Communications, Inc. All rights reserved. What is kernel bypass? The standard receive path The standard receive path
HIGH-PERFORMANCE NETWORKING :: USER-LEVEL NETWORKING :: REMOTE DIRECT MEMORY ACCESS
 HIGH-PERFORMANCE NETWORKING :: USER-LEVEL NETWORKING :: REMOTE DIRECT MEMORY ACCESS CS6410 Moontae Lee (Nov 20, 2014) Part 1 Overview 00 Background User-level Networking (U-Net) Remote Direct Memory Access
HIGH-PERFORMANCE NETWORKING :: USER-LEVEL NETWORKING :: REMOTE DIRECT MEMORY ACCESS CS6410 Moontae Lee (Nov 20, 2014) Part 1 Overview 00 Background User-level Networking (U-Net) Remote Direct Memory Access
High-Throughput and Low-Latency Network Communication with NetIO
 High-Throughput and Low-Latency Network Communication with NetIO Jörn Schumacher 1,2, Christian Plessl 2 and Wainer Vandelli 1 1 CERN, Geneva, Switzerland 2 Paderborn University, Germany E-mail: jorn.schumacher@cern.ch
High-Throughput and Low-Latency Network Communication with NetIO Jörn Schumacher 1,2, Christian Plessl 2 and Wainer Vandelli 1 1 CERN, Geneva, Switzerland 2 Paderborn University, Germany E-mail: jorn.schumacher@cern.ch
Session based high bandwidth throughput testing
 Universiteit van Amsterdam System and Network Engineering Research Project 2 Session based high bandwidth throughput testing Bram ter Borch bram.terborch@os3.nl 29 August 2017 Abstract To maximize and
Universiteit van Amsterdam System and Network Engineering Research Project 2 Session based high bandwidth throughput testing Bram ter Borch bram.terborch@os3.nl 29 August 2017 Abstract To maximize and
Virtual Switch Acceleration with OVS-TC
 WHITE PAPER Virtual Switch Acceleration with OVS-TC HARDWARE ACCELERATED OVS-TC PROVIDES BETTER CPU EFFICIENCY, LOWER COMPLEXITY, ENHANCED SCALABILITY AND INCREASED NETWORK PERFORMANCE COMPARED TO KERNEL-
WHITE PAPER Virtual Switch Acceleration with OVS-TC HARDWARE ACCELERATED OVS-TC PROVIDES BETTER CPU EFFICIENCY, LOWER COMPLEXITY, ENHANCED SCALABILITY AND INCREASED NETWORK PERFORMANCE COMPARED TO KERNEL-
QuickSpecs. HP Z 10GbE Dual Port Module. Models
 Overview Models Part Number: 1Ql49AA Introduction The is a 10GBASE-T adapter utilizing the Intel X722 MAC and X557-AT2 PHY pairing to deliver full line-rate performance, utilizing CAT 6A UTP cabling (or
Overview Models Part Number: 1Ql49AA Introduction The is a 10GBASE-T adapter utilizing the Intel X722 MAC and X557-AT2 PHY pairing to deliver full line-rate performance, utilizing CAT 6A UTP cabling (or
A Low Latency Solution Stack for High Frequency Trading. High-Frequency Trading. Solution. White Paper
 A Low Latency Solution Stack for High Frequency Trading White Paper High-Frequency Trading High-frequency trading has gained a strong foothold in financial markets, driven by several factors including
A Low Latency Solution Stack for High Frequency Trading White Paper High-Frequency Trading High-frequency trading has gained a strong foothold in financial markets, driven by several factors including
6.9. Communicating to the Outside World: Cluster Networking
 6.9 Communicating to the Outside World: Cluster Networking This online section describes the networking hardware and software used to connect the nodes of cluster together. As there are whole books and
6.9 Communicating to the Outside World: Cluster Networking This online section describes the networking hardware and software used to connect the nodes of cluster together. As there are whole books and
SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet
 SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet Mao Miao, Fengyuan Ren, Xiaohui Luo, Jing Xie, Qingkai Meng, Wenxue Cheng Dept. of Computer Science and Technology, Tsinghua
SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet Mao Miao, Fengyuan Ren, Xiaohui Luo, Jing Xie, Qingkai Meng, Wenxue Cheng Dept. of Computer Science and Technology, Tsinghua
An Intelligent NIC Design Xin Song
 2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016) An Intelligent NIC Design Xin Song School of Electronic and Information Engineering Tianjin Vocational
2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016) An Intelligent NIC Design Xin Song School of Electronic and Information Engineering Tianjin Vocational
IBM POWER8 100 GigE Adapter Best Practices
 Introduction IBM POWER8 100 GigE Adapter Best Practices With higher network speeds in new network adapters, achieving peak performance requires careful tuning of the adapters and workloads using them.
Introduction IBM POWER8 100 GigE Adapter Best Practices With higher network speeds in new network adapters, achieving peak performance requires careful tuning of the adapters and workloads using them.
DPDK Performance Report Release Test Date: Nov 16 th 2016
 Test Date: Nov 16 th 2016 Revision History Date Revision Comment Nov 16 th, 2016 1.0 Initial document for release 2 Contents Audience and Purpose... 4 Test setup:... 4 Intel Xeon Processor E5-2699 v4 (55M
Test Date: Nov 16 th 2016 Revision History Date Revision Comment Nov 16 th, 2016 1.0 Initial document for release 2 Contents Audience and Purpose... 4 Test setup:... 4 Intel Xeon Processor E5-2699 v4 (55M
1 Copyright 2011, Oracle and/or its affiliates. All rights reserved.
 1 Copyright 2011, Oracle and/or its affiliates. All rights ORACLE PRODUCT LOGO Solaris 11 Networking Overview Sebastien Roy, Senior Principal Engineer Solaris Core OS, Oracle 2 Copyright 2011, Oracle and/or
1 Copyright 2011, Oracle and/or its affiliates. All rights ORACLE PRODUCT LOGO Solaris 11 Networking Overview Sebastien Roy, Senior Principal Engineer Solaris Core OS, Oracle 2 Copyright 2011, Oracle and/or
USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY
 14th ANNUAL WORKSHOP 2018 USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY Michael Chuvelev, Software Architect Intel April 11, 2018 INTEL MPI LIBRARY Optimized MPI application performance Application-specific
14th ANNUAL WORKSHOP 2018 USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY Michael Chuvelev, Software Architect Intel April 11, 2018 INTEL MPI LIBRARY Optimized MPI application performance Application-specific
OpenDataPlane: network packet journey
 OpenDataPlane: network packet journey Maxim Uvarov This presentation describes what is ODP. Touches common data types and APIs to work with network packets. Answers the question why ODP is needed and how
OpenDataPlane: network packet journey Maxim Uvarov This presentation describes what is ODP. Touches common data types and APIs to work with network packets. Answers the question why ODP is needed and how
Implementation and Analysis of Large Receive Offload in a Virtualized System
 Implementation and Analysis of Large Receive Offload in a Virtualized System Takayuki Hatori and Hitoshi Oi The University of Aizu, Aizu Wakamatsu, JAPAN {s1110173,hitoshi}@u-aizu.ac.jp Abstract System
Implementation and Analysis of Large Receive Offload in a Virtualized System Takayuki Hatori and Hitoshi Oi The University of Aizu, Aizu Wakamatsu, JAPAN {s1110173,hitoshi}@u-aizu.ac.jp Abstract System
vnetwork Future Direction Howie Xu, VMware R&D November 4, 2008
 vnetwork Future Direction Howie Xu, VMware R&D November 4, 2008 Virtual Datacenter OS from VMware Infrastructure vservices and Cloud vservices Existing New - roadmap Virtual Datacenter OS from VMware Agenda
vnetwork Future Direction Howie Xu, VMware R&D November 4, 2008 Virtual Datacenter OS from VMware Infrastructure vservices and Cloud vservices Existing New - roadmap Virtual Datacenter OS from VMware Agenda
Light & NOS. Dan Li Tsinghua University
 Light & NOS Dan Li Tsinghua University Performance gain The Power of DPDK As claimed: 80 CPU cycles per packet Significant gain compared with Kernel! What we care more How to leverage the performance gain
Light & NOS Dan Li Tsinghua University Performance gain The Power of DPDK As claimed: 80 CPU cycles per packet Significant gain compared with Kernel! What we care more How to leverage the performance gain
CS 3305 Intro to Threads. Lecture 6
 CS 3305 Intro to Threads Lecture 6 Introduction Multiple applications run concurrently! This means that there are multiple processes running on a computer Introduction Applications often need to perform
CS 3305 Intro to Threads Lecture 6 Introduction Multiple applications run concurrently! This means that there are multiple processes running on a computer Introduction Applications often need to perform
Tungsten Fabric Optimization by DPDK ZHAOYAN CHEN YIPENG WANG
 x Tungsten Fabric Optimization by DPDK ZHAOYAN CHEN YIPENG WANG Agenda Introduce Tungsten Fabric Support More CPU cores MPLS over GRE Optimization Hash Table Optimization Batch RX for VM and Fabric What
x Tungsten Fabric Optimization by DPDK ZHAOYAN CHEN YIPENG WANG Agenda Introduce Tungsten Fabric Support More CPU cores MPLS over GRE Optimization Hash Table Optimization Batch RX for VM and Fabric What
NETWORK SIMULATION USING NCTUns. Ankit Verma* Shashi Singh* Meenakshi Vyas*
 NETWORK SIMULATION USING NCTUns Ankit Verma* Shashi Singh* Meenakshi Vyas* 1. Introduction: Network simulator is software which is very helpful tool to develop, test, and diagnose any network protocol.
NETWORK SIMULATION USING NCTUns Ankit Verma* Shashi Singh* Meenakshi Vyas* 1. Introduction: Network simulator is software which is very helpful tool to develop, test, and diagnose any network protocol.
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
ETHERNET OVER INFINIBAND
 14th ANNUAL WORKSHOP 2018 ETHERNET OVER INFINIBAND Evgenii Smirnov and Mikhail Sennikovsky ProfitBricks GmbH April 10, 2018 ETHERNET OVER INFINIBAND: CURRENT SOLUTIONS mlx4_vnic Currently deprecated Requires
14th ANNUAL WORKSHOP 2018 ETHERNET OVER INFINIBAND Evgenii Smirnov and Mikhail Sennikovsky ProfitBricks GmbH April 10, 2018 ETHERNET OVER INFINIBAND: CURRENT SOLUTIONS mlx4_vnic Currently deprecated Requires
Speeding up Linux TCP/IP with a Fast Packet I/O Framework
 Speeding up Linux TCP/IP with a Fast Packet I/O Framework Michio Honda Advanced Technology Group, NetApp michio@netapp.com With acknowledge to Kenichi Yasukata, Douglas Santry and Lars Eggert 1 Motivation
Speeding up Linux TCP/IP with a Fast Packet I/O Framework Michio Honda Advanced Technology Group, NetApp michio@netapp.com With acknowledge to Kenichi Yasukata, Douglas Santry and Lars Eggert 1 Motivation
Ethernet Networks for the ATLAS Data Collection System: Emulation and Testing
 Ethernet Networks for the ATLAS Data Collection System: Emulation and Testing F. Barnes, R. Beuran, R. W. Dobinson, M. J. LeVine, Member, IEEE, B. Martin, J. Lokier, and C. Meirosu Abstract-- This paper
Ethernet Networks for the ATLAS Data Collection System: Emulation and Testing F. Barnes, R. Beuran, R. W. Dobinson, M. J. LeVine, Member, IEEE, B. Martin, J. Lokier, and C. Meirosu Abstract-- This paper
Data Path acceleration techniques in a NFV world
 Data Path acceleration techniques in a NFV world Mohanraj Venkatachalam, Purnendu Ghosh Abstract NFV is a revolutionary approach offering greater flexibility and scalability in the deployment of virtual
Data Path acceleration techniques in a NFV world Mohanraj Venkatachalam, Purnendu Ghosh Abstract NFV is a revolutionary approach offering greater flexibility and scalability in the deployment of virtual
A Look at Intel s Dataplane Development Kit
 A Look at Intel s Dataplane Development Kit Dominik Scholz Chair for Network Architectures and Services Department for Computer Science Technische Universität München June 13, 2014 Dominik Scholz: A Look
A Look at Intel s Dataplane Development Kit Dominik Scholz Chair for Network Architectures and Services Department for Computer Science Technische Universität München June 13, 2014 Dominik Scholz: A Look
DPDK Intel NIC Performance Report Release 18.02
 DPDK Intel NIC Performance Report Test Date: Mar 14th 2018 Author: Intel DPDK Validation team Revision History Date Revision Comment Mar 15th, 2018 1.0 Initial document for release 2 Contents Audience
DPDK Intel NIC Performance Report Test Date: Mar 14th 2018 Author: Intel DPDK Validation team Revision History Date Revision Comment Mar 15th, 2018 1.0 Initial document for release 2 Contents Audience
L1 and Subsequent Triggers
 April 8, 2003 L1 and Subsequent Triggers Abstract During the last year the scope of the L1 trigger has changed rather drastically compared to the TP. This note aims at summarising the changes, both in
April 8, 2003 L1 and Subsequent Triggers Abstract During the last year the scope of the L1 trigger has changed rather drastically compared to the TP. This note aims at summarising the changes, both in
Demystifying Network Cards
 Demystifying Network Cards Paul Emmerich December 27, 2017 Chair of Network Architectures and Services About me PhD student at Researching performance of software packet processing systems Mostly working
Demystifying Network Cards Paul Emmerich December 27, 2017 Chair of Network Architectures and Services About me PhD student at Researching performance of software packet processing systems Mostly working
May 1, Foundation for Research and Technology - Hellas (FORTH) Institute of Computer Science (ICS) A Sleep-based Communication Mechanism to
 Institute of Computer Science (ICS) A Sleep-based Communication Mechanism to") A Sleep-based Our Akram Foundation for Research and Technology - Hellas (FORTH) Institute of Computer Science (ICS) May 1, 2011 Our 1 2 Our 3 4 5 6 Our Efficiency in Back-end Processing Efficiency in back-end
A Sleep-based Our Akram Foundation for Research and Technology - Hellas (FORTH) Institute of Computer Science (ICS) May 1, 2011 Our 1 2 Our 3 4 5 6 Our Efficiency in Back-end Processing Efficiency in back-end
NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications
 NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications Outline RDMA Motivating trends iwarp NFS over RDMA Overview Chelsio T5 support Performance results 2 Adoption Rate of 40GbE Source: Crehan
NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications Outline RDMA Motivating trends iwarp NFS over RDMA Overview Chelsio T5 support Performance results 2 Adoption Rate of 40GbE Source: Crehan
Achieve Low Latency NFV with Openstack*
 Achieve Low Latency NFV with Openstack* Yunhong Jiang Yunhong.Jiang@intel.com *Other names and brands may be claimed as the property of others. Agenda NFV and network latency Why network latency on NFV
Achieve Low Latency NFV with Openstack* Yunhong Jiang Yunhong.Jiang@intel.com *Other names and brands may be claimed as the property of others. Agenda NFV and network latency Why network latency on NFV
École Polytechnique Fédérale de Lausanne. Porting a driver for the Intel XL710 40GbE NIC to the IX Dataplane Operating System
 École Polytechnique Fédérale de Lausanne Semester Project Porting a driver for the Intel XL710 40GbE NIC to the IX Dataplane Operating System Student: Andy Roulin (216690) Direct Supervisor: George Prekas
École Polytechnique Fédérale de Lausanne Semester Project Porting a driver for the Intel XL710 40GbE NIC to the IX Dataplane Operating System Student: Andy Roulin (216690) Direct Supervisor: George Prekas
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
OpenDataplane project
 OpenDataplane project ENOG15 2018, Russia, Moscow, 4-5 June Maxim Uvarov Senior Software engineer, Linaro Networking Group maxim.uvarov@linaro.org ENOG15, Russia, Moscow Data plane refers to all the
OpenDataplane project ENOG15 2018, Russia, Moscow, 4-5 June Maxim Uvarov Senior Software engineer, Linaro Networking Group maxim.uvarov@linaro.org ENOG15, Russia, Moscow Data plane refers to all the
Exploring mtcp based Single-Threaded and Multi-Threaded Web Server Design
 Exploring mtcp based Single-Threaded and Multi-Threaded Web Server Design A Thesis Submitted in partial fulfillment of the requirements for the degree of Master of Technology by Pijush Chakraborty (153050015)
Exploring mtcp based Single-Threaded and Multi-Threaded Web Server Design A Thesis Submitted in partial fulfillment of the requirements for the degree of Master of Technology by Pijush Chakraborty (153050015)
CERN openlab Summer 2006: Networking Overview
 CERN openlab Summer 2006: Networking Overview Martin Swany, Ph.D. Assistant Professor, Computer and Information Sciences, U. Delaware, USA Visiting Helsinki Institute of Physics (HIP) at CERN swany@cis.udel.edu,
CERN openlab Summer 2006: Networking Overview Martin Swany, Ph.D. Assistant Professor, Computer and Information Sciences, U. Delaware, USA Visiting Helsinki Institute of Physics (HIP) at CERN swany@cis.udel.edu,
The NE010 iwarp Adapter
 The NE010 iwarp Adapter Gary Montry Senior Scientist +1-512-493-3241 GMontry@NetEffect.com Today s Data Center Users Applications networking adapter LAN Ethernet NAS block storage clustering adapter adapter
The NE010 iwarp Adapter Gary Montry Senior Scientist +1-512-493-3241 GMontry@NetEffect.com Today s Data Center Users Applications networking adapter LAN Ethernet NAS block storage clustering adapter adapter
Open Source Traffic Analyzer
 Open Source Traffic Analyzer Daniel Turull June 2010 Outline 1 Introduction 2 Background study 3 Design 4 Implementation 5 Evaluation 6 Conclusions 7 Demo Outline 1 Introduction 2 Background study 3 Design
Open Source Traffic Analyzer Daniel Turull June 2010 Outline 1 Introduction 2 Background study 3 Design 4 Implementation 5 Evaluation 6 Conclusions 7 Demo Outline 1 Introduction 2 Background study 3 Design
Dataflow Monitoring in LHCb
 Journal of Physics: Conference Series Dataflow Monitoring in LHCb To cite this article: D Svantesson et al 2011 J. Phys.: Conf. Ser. 331 022036 View the article online for updates and enhancements. Related
Journal of Physics: Conference Series Dataflow Monitoring in LHCb To cite this article: D Svantesson et al 2011 J. Phys.: Conf. Ser. 331 022036 View the article online for updates and enhancements. Related
10GE network tests with UDP. Janusz Szuba European XFEL
 10GE network tests with UDP Janusz Szuba European XFEL Outline 2 Overview of initial DAQ architecture Slice test hardware specification Initial networking test results DAQ software UDP tests Summary 10GE
10GE network tests with UDP Janusz Szuba European XFEL Outline 2 Overview of initial DAQ architecture Slice test hardware specification Initial networking test results DAQ software UDP tests Summary 10GE
DPDK Intel NIC Performance Report Release 18.05
 DPDK Intel NIC Performance Report Test Date: Jun 1th 2018 Author: Intel DPDK Validation team Revision History Date Revision Comment Jun 4th, 2018 1.0 Initial document for release 2 Contents Audience and
DPDK Intel NIC Performance Report Test Date: Jun 1th 2018 Author: Intel DPDK Validation team Revision History Date Revision Comment Jun 4th, 2018 1.0 Initial document for release 2 Contents Audience and
Networking at the Speed of Light
 Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Overview. About CERN 2 / 11
 Overview CERN wanted to upgrade the data monitoring system of one of its Large Hadron Collider experiments called ALICE (A La rge Ion Collider Experiment) to ensure the experiment s high efficiency. They
Overview CERN wanted to upgrade the data monitoring system of one of its Large Hadron Collider experiments called ALICE (A La rge Ion Collider Experiment) to ensure the experiment s high efficiency. They
OpenFlow Software Switch & Intel DPDK. performance analysis
 OpenFlow Software Switch & Intel DPDK performance analysis Agenda Background Intel DPDK OpenFlow 1.3 implementation sketch Prototype design and setup Results Future work, optimization ideas OF 1.3 prototype
OpenFlow Software Switch & Intel DPDK performance analysis Agenda Background Intel DPDK OpenFlow 1.3 implementation sketch Prototype design and setup Results Future work, optimization ideas OF 1.3 prototype
Evolution of the netmap architecture
 L < > T H local Evolution of the netmap architecture Evolution of the netmap architecture -- Page 1/21 Evolution of the netmap architecture Luigi Rizzo, Università di Pisa http://info.iet.unipi.it/~luigi/vale/
L < > T H local Evolution of the netmap architecture Evolution of the netmap architecture -- Page 1/21 Evolution of the netmap architecture Luigi Rizzo, Università di Pisa http://info.iet.unipi.it/~luigi/vale/
W4118: OS Overview. Junfeng Yang
 W4118: OS Overview Junfeng Yang References: Modern Operating Systems (3 rd edition), Operating Systems Concepts (8 th edition), previous W4118, and OS at MIT, Stanford, and UWisc Outline OS definitions
W4118: OS Overview Junfeng Yang References: Modern Operating Systems (3 rd edition), Operating Systems Concepts (8 th edition), previous W4118, and OS at MIT, Stanford, and UWisc Outline OS definitions
Support for Smart NICs. Ian Pratt
 Support for Smart NICs Ian Pratt Outline Xen I/O Overview Why network I/O is harder than block Smart NIC taxonomy How Xen can exploit them Enhancing Network device channel NetChannel2 proposal I/O Architecture
Support for Smart NICs Ian Pratt Outline Xen I/O Overview Why network I/O is harder than block Smart NIC taxonomy How Xen can exploit them Enhancing Network device channel NetChannel2 proposal I/O Architecture
Virtualization, Xen and Denali
 Virtualization, Xen and Denali Susmit Shannigrahi November 9, 2011 Susmit Shannigrahi () Virtualization, Xen and Denali November 9, 2011 1 / 70 Introduction Virtualization is the technology to allow two
Virtualization, Xen and Denali Susmit Shannigrahi November 9, 2011 Susmit Shannigrahi () Virtualization, Xen and Denali November 9, 2011 1 / 70 Introduction Virtualization is the technology to allow two
10Gbps TCP/IP streams from the FPGA
 TWEPP 2013 10Gbps TCP/IP streams from the FPGA for the CMS DAQ Eventbuilder Network Petr Žejdl, Dominique Gigi on behalf of the CMS DAQ Group 26 September 2013 Outline CMS DAQ Readout System TCP/IP Introduction,
TWEPP 2013 10Gbps TCP/IP streams from the FPGA for the CMS DAQ Eventbuilder Network Petr Žejdl, Dominique Gigi on behalf of the CMS DAQ Group 26 September 2013 Outline CMS DAQ Readout System TCP/IP Introduction,
DPDK Intel NIC Performance Report Release 17.08
 DPDK Intel NIC Performance Report Test Date: Aug 23th 2017 Author: Intel DPDK Validation team Revision History Date Revision Comment Aug 24th, 2017 1.0 Initial document for release 2 Contents Audience
DPDK Intel NIC Performance Report Test Date: Aug 23th 2017 Author: Intel DPDK Validation team Revision History Date Revision Comment Aug 24th, 2017 1.0 Initial document for release 2 Contents Audience
A Study of the Merits of Precision Time Protocol (IEEE-1588) Across High-Speed Data Networks
 Across High-Speed Data Networks") A Study of the Merits of Precision Time Protocol (IEEE-1588) Across High-Speed Data Networks LHCb-PUB-2015-022 18/09/2015 Public Note Issue: 1 Revision: 0 Reference: LHCb-PUB-2015-022 Created: August 17,
A Study of the Merits of Precision Time Protocol (IEEE-1588) Across High-Speed Data Networks LHCb-PUB-2015-022 18/09/2015 Public Note Issue: 1 Revision: 0 Reference: LHCb-PUB-2015-022 Created: August 17,
RDMA-like VirtIO Network Device for Palacios Virtual Machines
 RDMA-like VirtIO Network Device for Palacios Virtual Machines Kevin Pedretti UNM ID: 101511969 CS-591 Special Topics in Virtualization May 10, 2012 Abstract This project developed an RDMA-like VirtIO network
RDMA-like VirtIO Network Device for Palacios Virtual Machines Kevin Pedretti UNM ID: 101511969 CS-591 Special Topics in Virtualization May 10, 2012 Abstract This project developed an RDMA-like VirtIO network
A practical introduction to XDP
 A practical introduction to XDP Jesper Dangaard Brouer (Red Hat) Andy Gospodarek (Broadcom) Linux Plumbers Conference (LPC) Vancouver, Nov 2018 1 What will you learn? Introduction to XDP and relationship
A practical introduction to XDP Jesper Dangaard Brouer (Red Hat) Andy Gospodarek (Broadcom) Linux Plumbers Conference (LPC) Vancouver, Nov 2018 1 What will you learn? Introduction to XDP and relationship
CSC369 Lecture 2. Larry Zhang, September 21, 2015
 CSC369 Lecture 2 Larry Zhang, September 21, 2015 1 Volunteer note-taker needed by accessibility service see announcement on Piazza for details 2 Change to office hour to resolve conflict with CSC373 lecture
CSC369 Lecture 2 Larry Zhang, September 21, 2015 1 Volunteer note-taker needed by accessibility service see announcement on Piazza for details 2 Change to office hour to resolve conflict with CSC373 lecture
Multifunction Networking Adapters
 Ethernet s Extreme Makeover: Multifunction Networking Adapters Chuck Hudson Manager, ProLiant Networking Technology Hewlett-Packard 2004 Hewlett-Packard Development Company, L.P. The information contained
Ethernet s Extreme Makeover: Multifunction Networking Adapters Chuck Hudson Manager, ProLiant Networking Technology Hewlett-Packard 2004 Hewlett-Packard Development Company, L.P. The information contained
Implementing Ultra Low Latency Data Center Services with Programmable Logic
 Implementing Ultra Low Latency Data Center Services with Programmable Logic John W. Lockwood, CEO: Algo-Logic Systems, Inc. http://algo-logic.com Solutions@Algo-Logic.com (408) 707-3740 2255-D Martin Ave.,
Implementing Ultra Low Latency Data Center Services with Programmable Logic John W. Lockwood, CEO: Algo-Logic Systems, Inc. http://algo-logic.com Solutions@Algo-Logic.com (408) 707-3740 2255-D Martin Ave.,
Accelerating Storage with NVM Express SSDs and P2PDMA Stephen Bates, PhD Chief Technology Officer
 Accelerating Storage with NVM Express SSDs and P2PDMA Stephen Bates, PhD Chief Technology Officer 2018 Storage Developer Conference. Eidetic Communications Inc. All Rights Reserved. 1 Outline Motivation
Accelerating Storage with NVM Express SSDs and P2PDMA Stephen Bates, PhD Chief Technology Officer 2018 Storage Developer Conference. Eidetic Communications Inc. All Rights Reserved. 1 Outline Motivation
Accelerating VM networking through XDP. Jason Wang Red Hat
 Accelerating VM networking through XDP Jason Wang Red Hat Agenda Kernel VS userspace Introduction to XDP XDP for VM Use cases Benchmark and TODO Q&A Kernel Networking datapath TAP A driver to transmit
Accelerating VM networking through XDP Jason Wang Red Hat Agenda Kernel VS userspace Introduction to XDP XDP for VM Use cases Benchmark and TODO Q&A Kernel Networking datapath TAP A driver to transmit
Configuring Priority Flow Control
 This chapter contains the following sections: Information About Priority Flow Control, page 1 Guidelines and Limitations, page 2 Default Settings for Priority Flow Control, page 3 Enabling Priority Flow
This chapter contains the following sections: Information About Priority Flow Control, page 1 Guidelines and Limitations, page 2 Default Settings for Priority Flow Control, page 3 Enabling Priority Flow
Generic RDMA Enablement in Linux
 Generic RDMA Enablement in Linux (Why do we need it, and how) Krishna Kumar Linux Technology Center, IBM February 28, 2006 AGENDA RDMA : Definition Why RDMA, and how does it work OpenRDMA history Architectural
Generic RDMA Enablement in Linux (Why do we need it, and how) Krishna Kumar Linux Technology Center, IBM February 28, 2006 AGENDA RDMA : Definition Why RDMA, and how does it work OpenRDMA history Architectural
Processes and Threads
 TDDI04 Concurrent Programming, Operating Systems, and Real-time Operating Systems Processes and Threads [SGG7] Chapters 3 and 4 Copyright Notice: The lecture notes are mainly based on Silberschatz s, Galvin
TDDI04 Concurrent Programming, Operating Systems, and Real-time Operating Systems Processes and Threads [SGG7] Chapters 3 and 4 Copyright Notice: The lecture notes are mainly based on Silberschatz s, Galvin
Tales of the Tail Hardware, OS, and Application-level Sources of Tail Latency
 Tales of the Tail Hardware, OS, and Application-level Sources of Tail Latency Jialin Li, Naveen Kr. Sharma, Dan R. K. Ports and Steven D. Gribble February 2, 2015 1 Introduction What is Tail Latency? What
Tales of the Tail Hardware, OS, and Application-level Sources of Tail Latency Jialin Li, Naveen Kr. Sharma, Dan R. K. Ports and Steven D. Gribble February 2, 2015 1 Introduction What is Tail Latency? What
Maximum Performance. How to get it and how to avoid pitfalls. Christoph Lameter, PhD
 Maximum Performance How to get it and how to avoid pitfalls Christoph Lameter, PhD cl@linux.com Performance Just push a button? Systems are optimized by default for good general performance in all areas.
Maximum Performance How to get it and how to avoid pitfalls Christoph Lameter, PhD cl@linux.com Performance Just push a button? Systems are optimized by default for good general performance in all areas.